
A Novel Hybrid Model Based on an Improved Seagull Optimization Algorithm for Short-Term Wind Speed Forecasting




Abstract
1. Introduction
2. Methods
2.1. Variational Mode Decomposition (VMD)
2.2. Kernel Extreme Learning Machine
2.3. The Proposed ISOA Algorithm
2.3.1. Seagull Optimization Algorithm
- Avoid collision: To avoid collisions with other seagulls, variable A is employed to calculate the new position of the search seagull.where represents a new position that does not conflict with other search seagulls, represents the current position of the search seagull, t represents the current iteration and A represents the motion behavior of the search seagull in a given search space.where , can control the frequency of the variable, and its value drops from 2 to 0.
- Best position: After avoiding overlapping with other seagulls, seagulls will move in the direction of the best position.where represents the positions of the search seagull. is the random number responsible for balancing the global and local search seagull.where is a random number that lies in the range of .
- Close to the best search seagull: After the seagull moves to a position where it does not collide with other seagulls, it moves in the direction of the best position to reach its new position.where represents the best fit search seagull.
2.3.2. Improved Seagull Optimization Algorithm (ISOA)
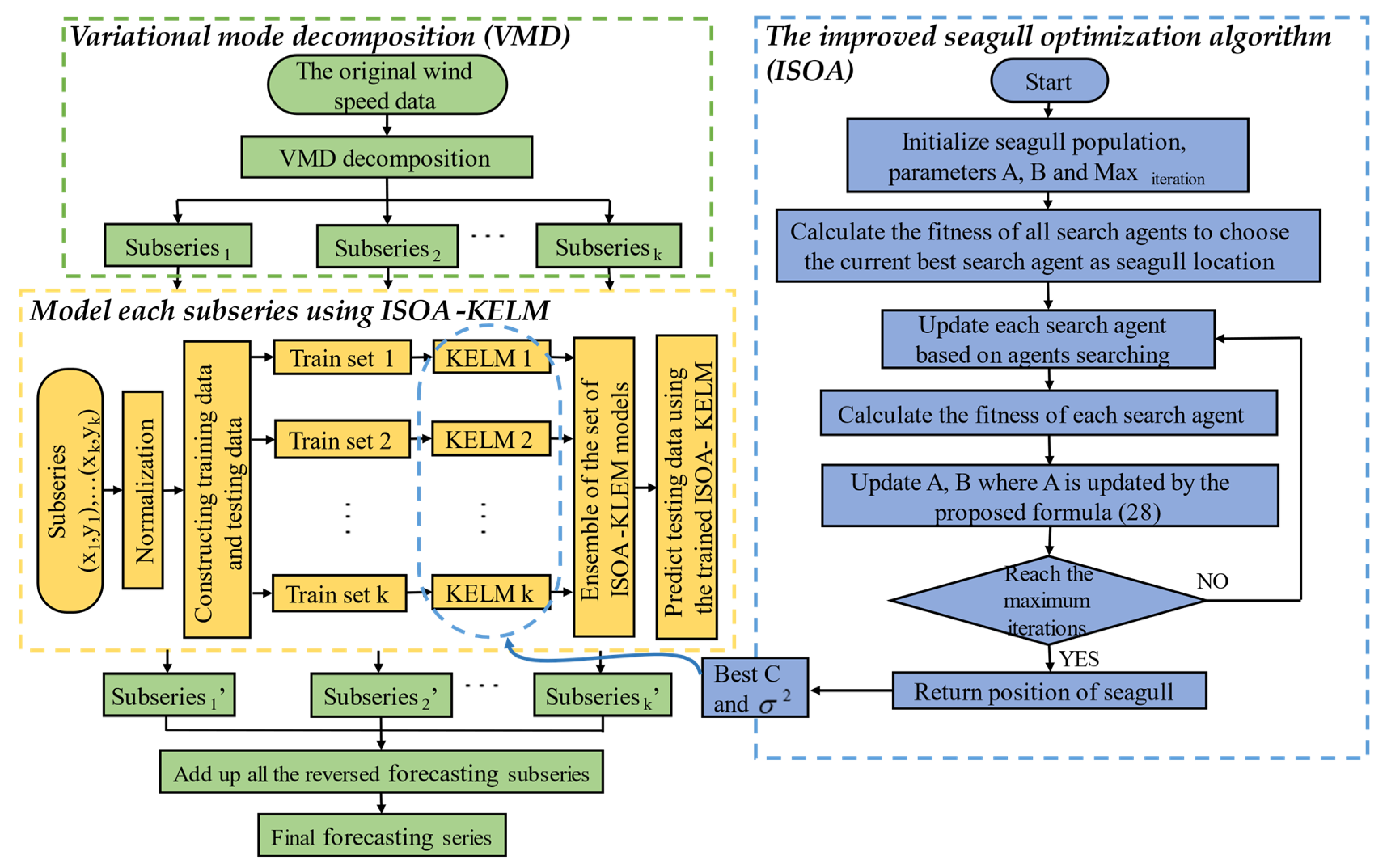
2.4. Workflow of the Hybrid Model
2.4.1. Data Preprocessing
2.4.2. Hybrid Models Forecasting
2.4.3. Multi-Step ahead Forecasting
3. Experimental Design
3.1. Data Description
3.2. Performance Metrics
4. Different Experiments and Relative Analysis
4.1. Experimental Setup
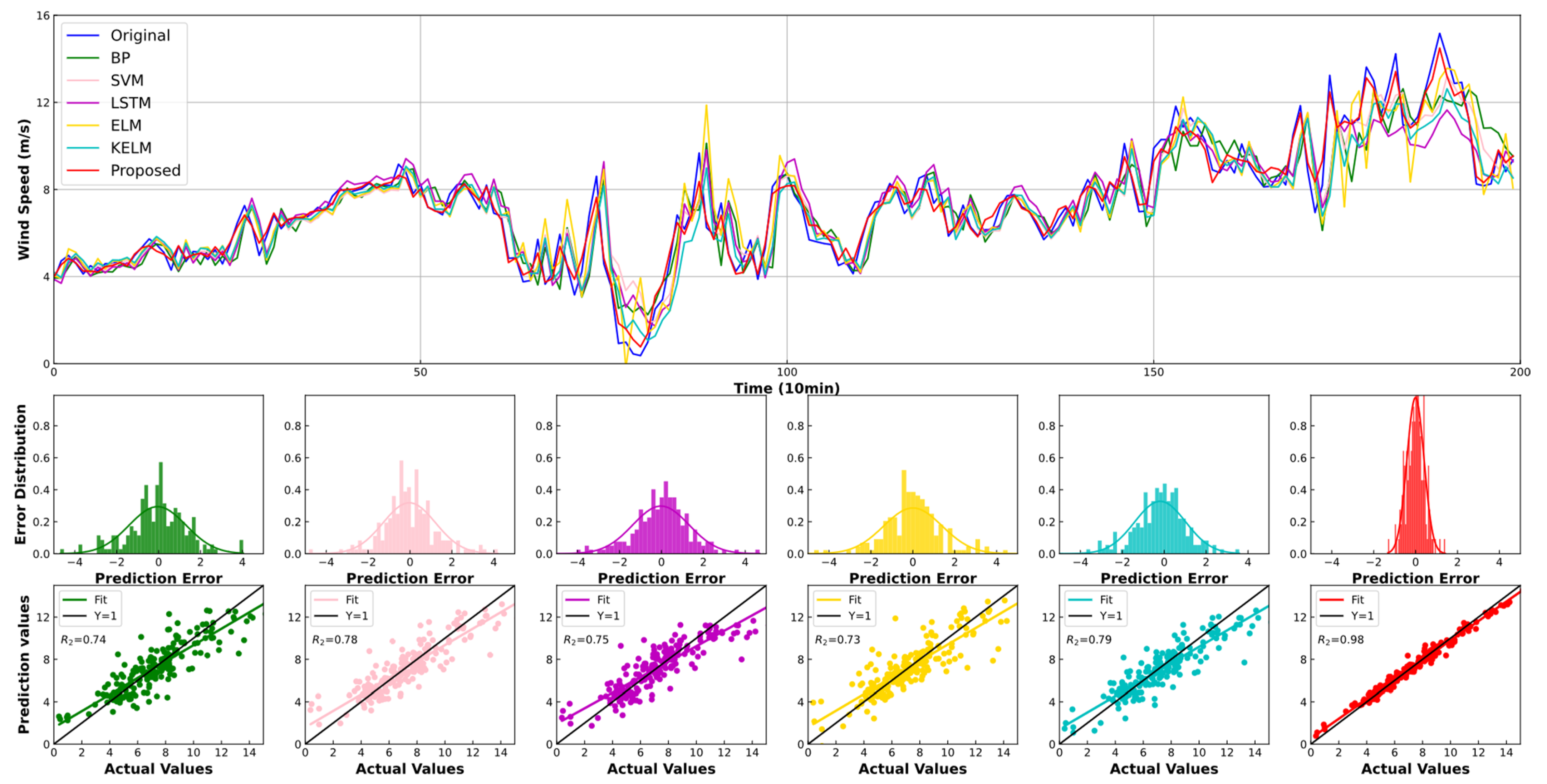
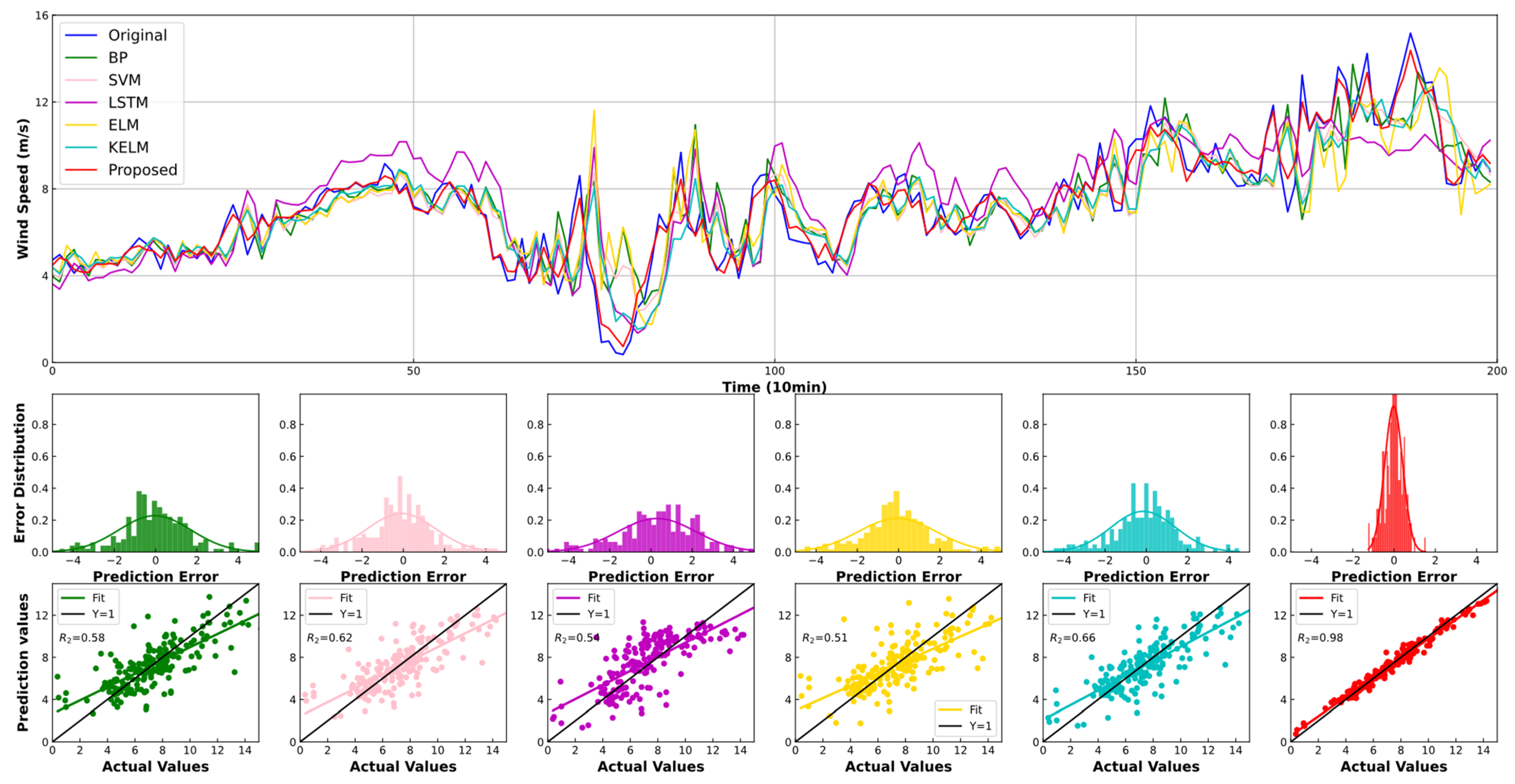
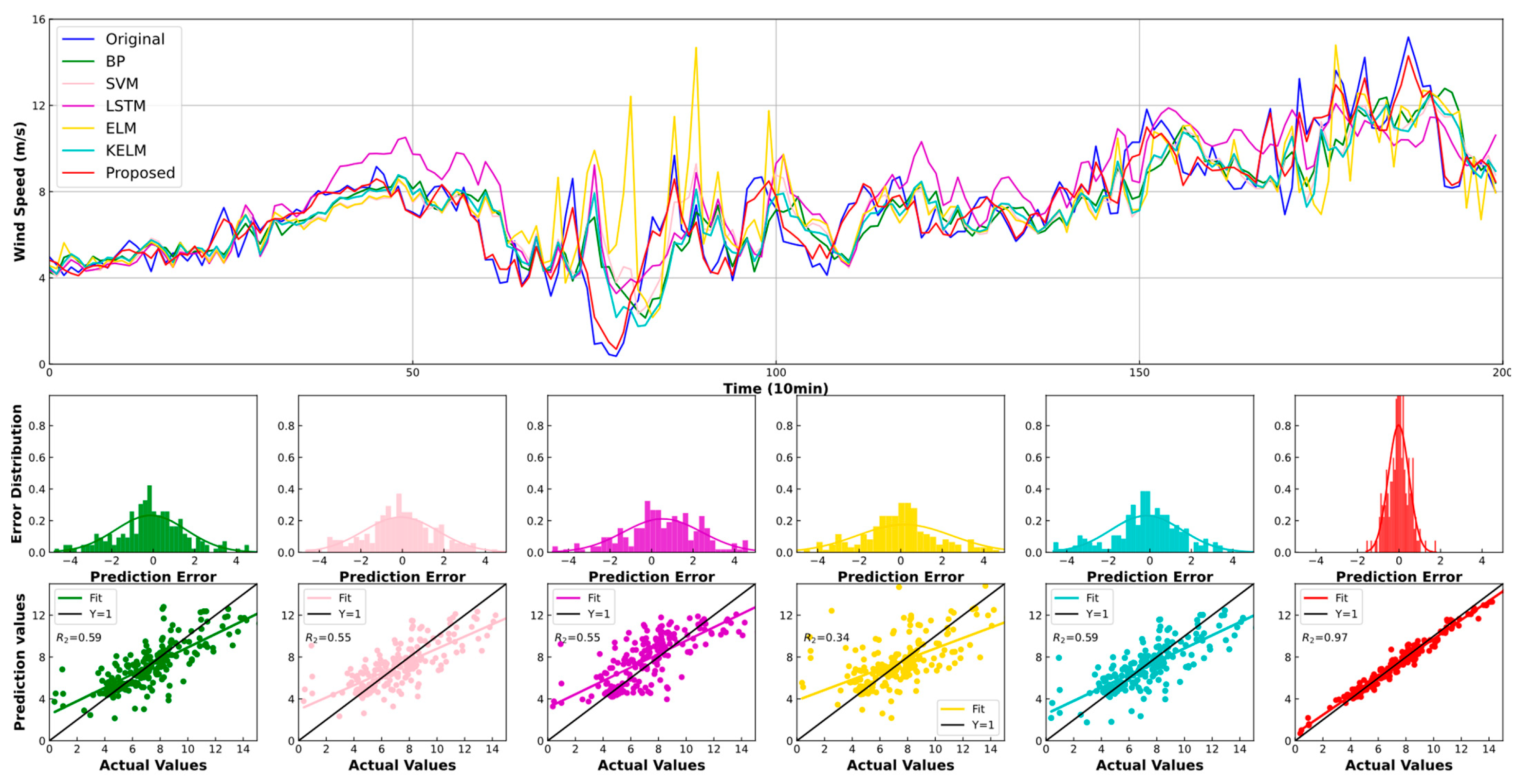
4.2. Experiment I: Comparison with Other Individual Models
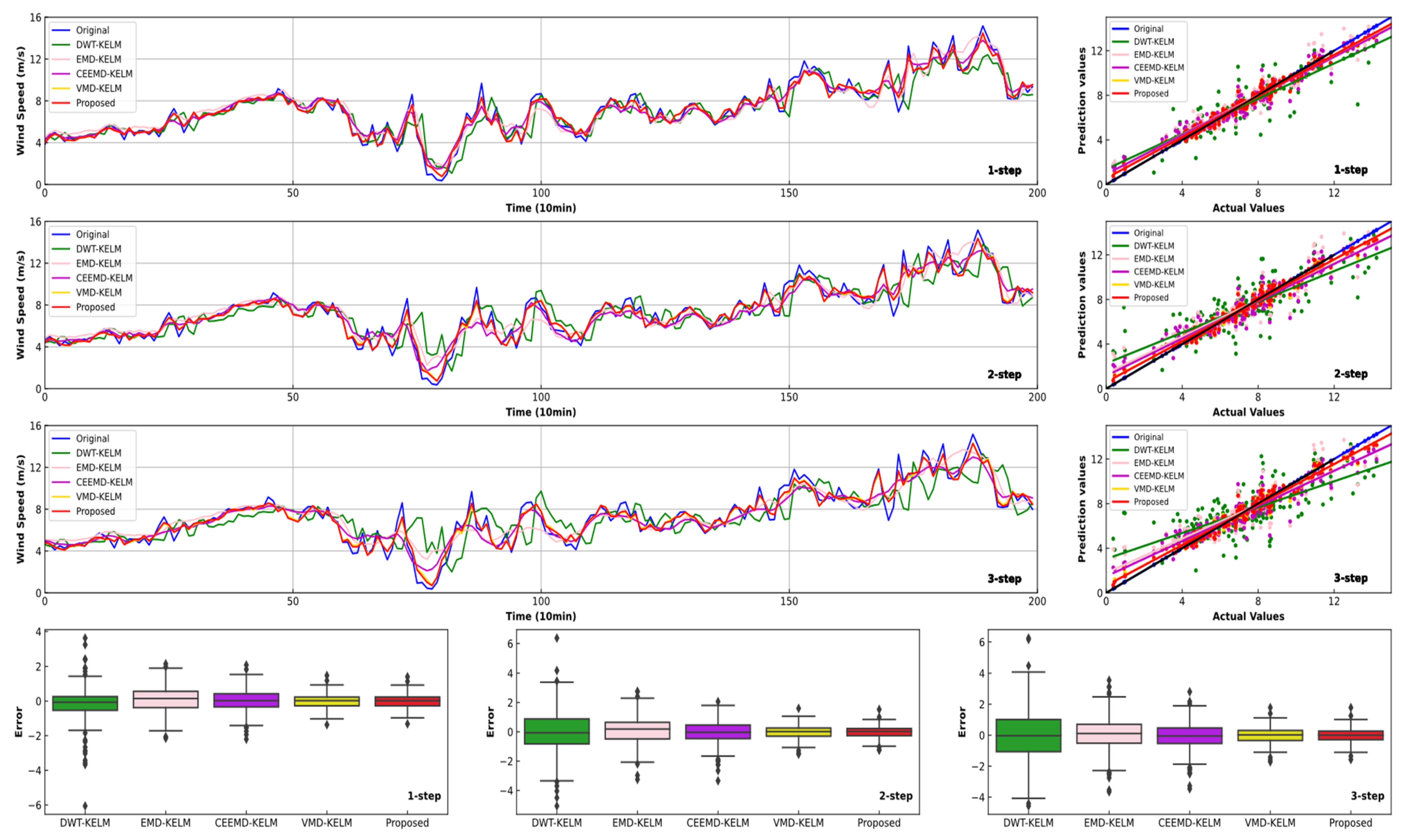
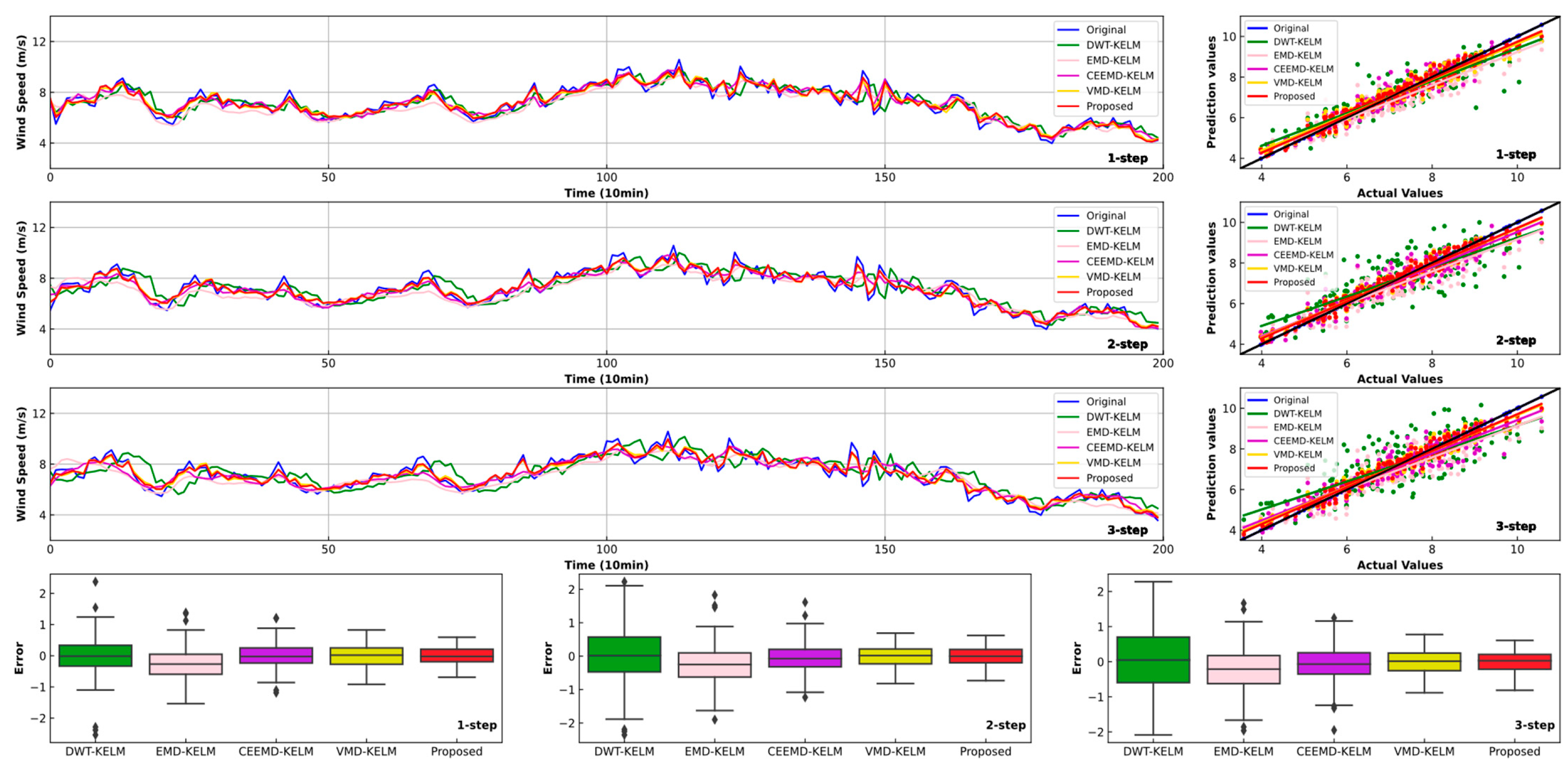
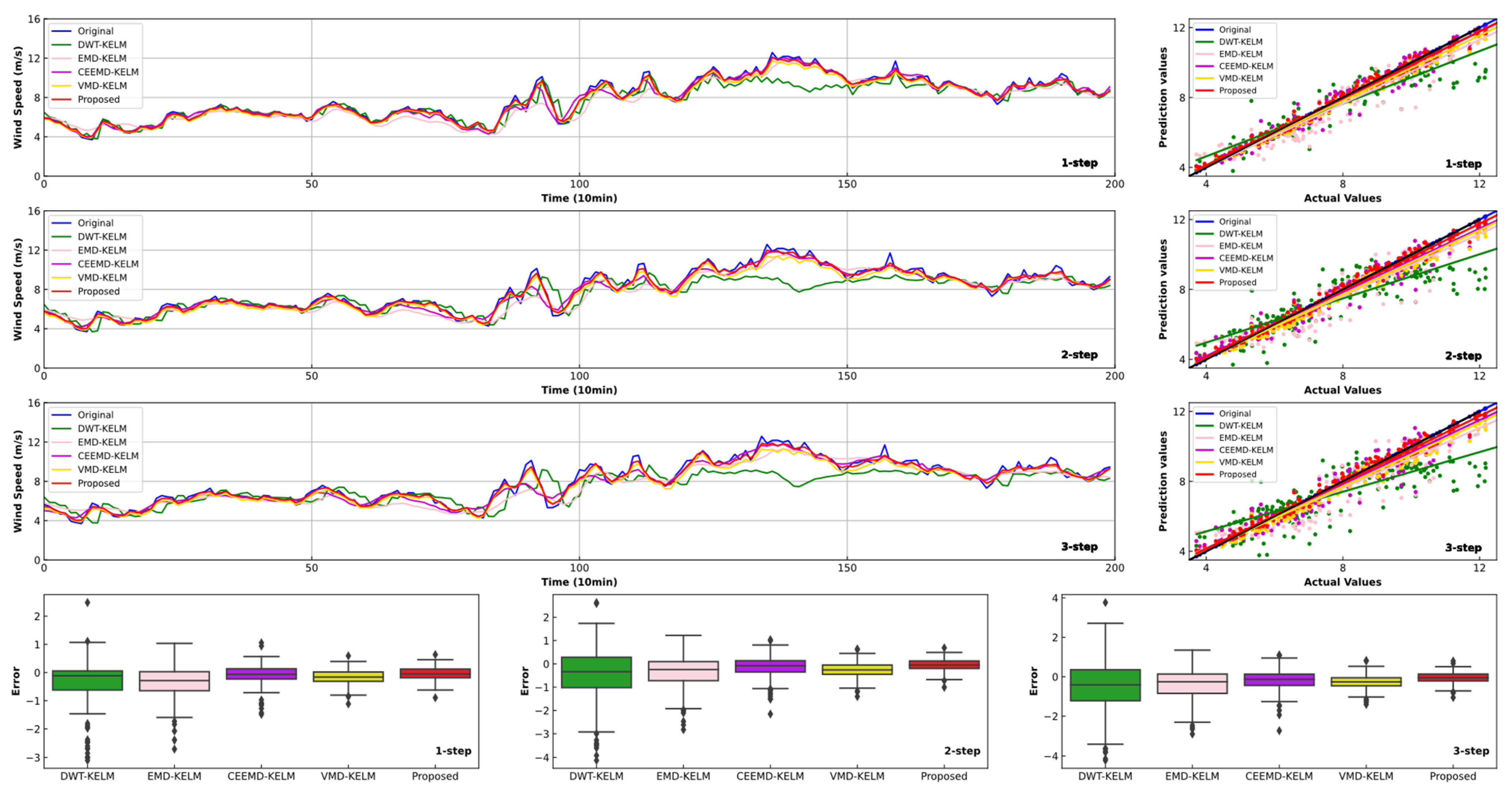
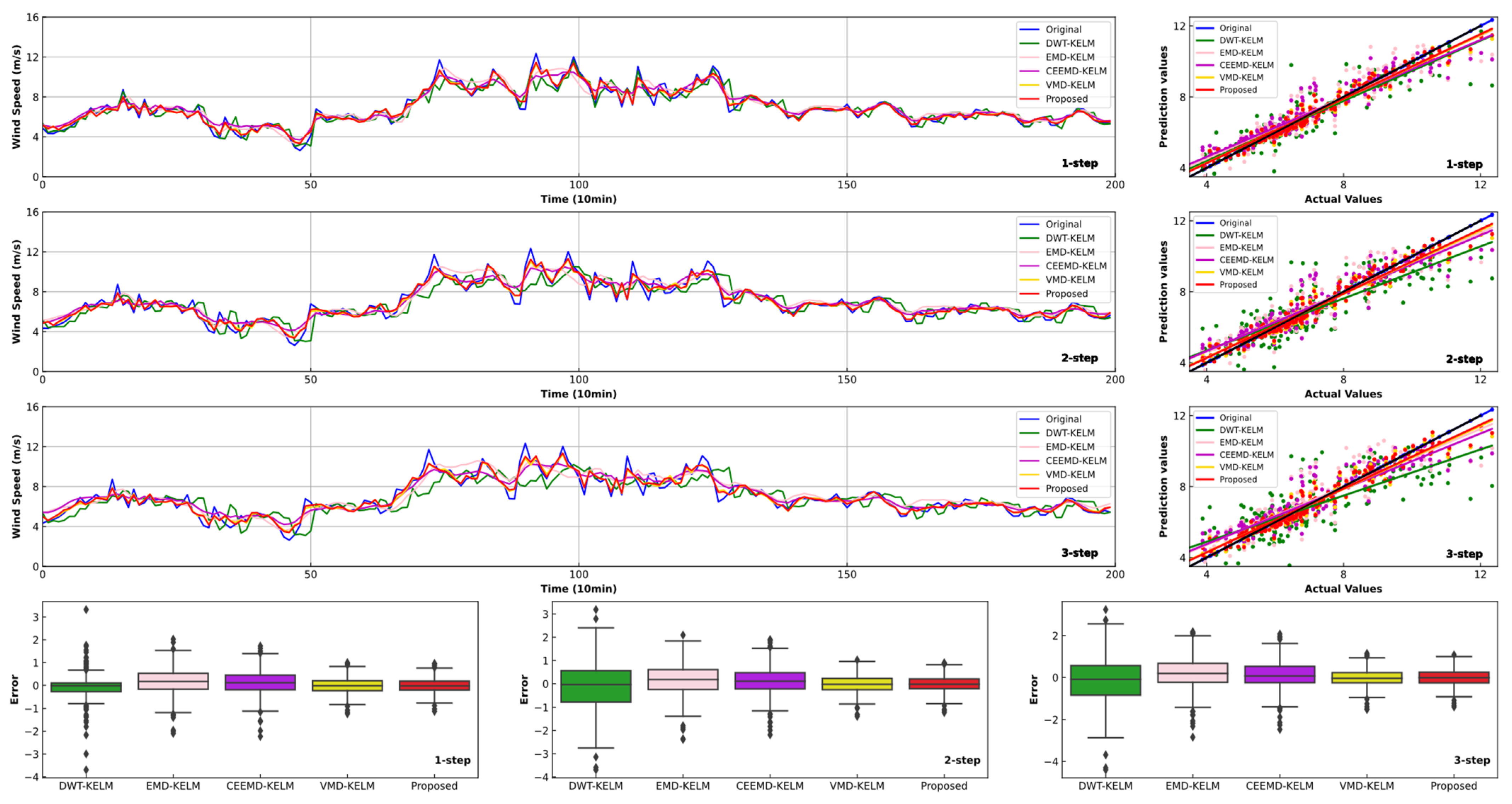
4.3. Experiment II: Comparsion with Other Models Using Different Data Preprocessing Methods
5. Discussion
5.1. Main Achievements and Results
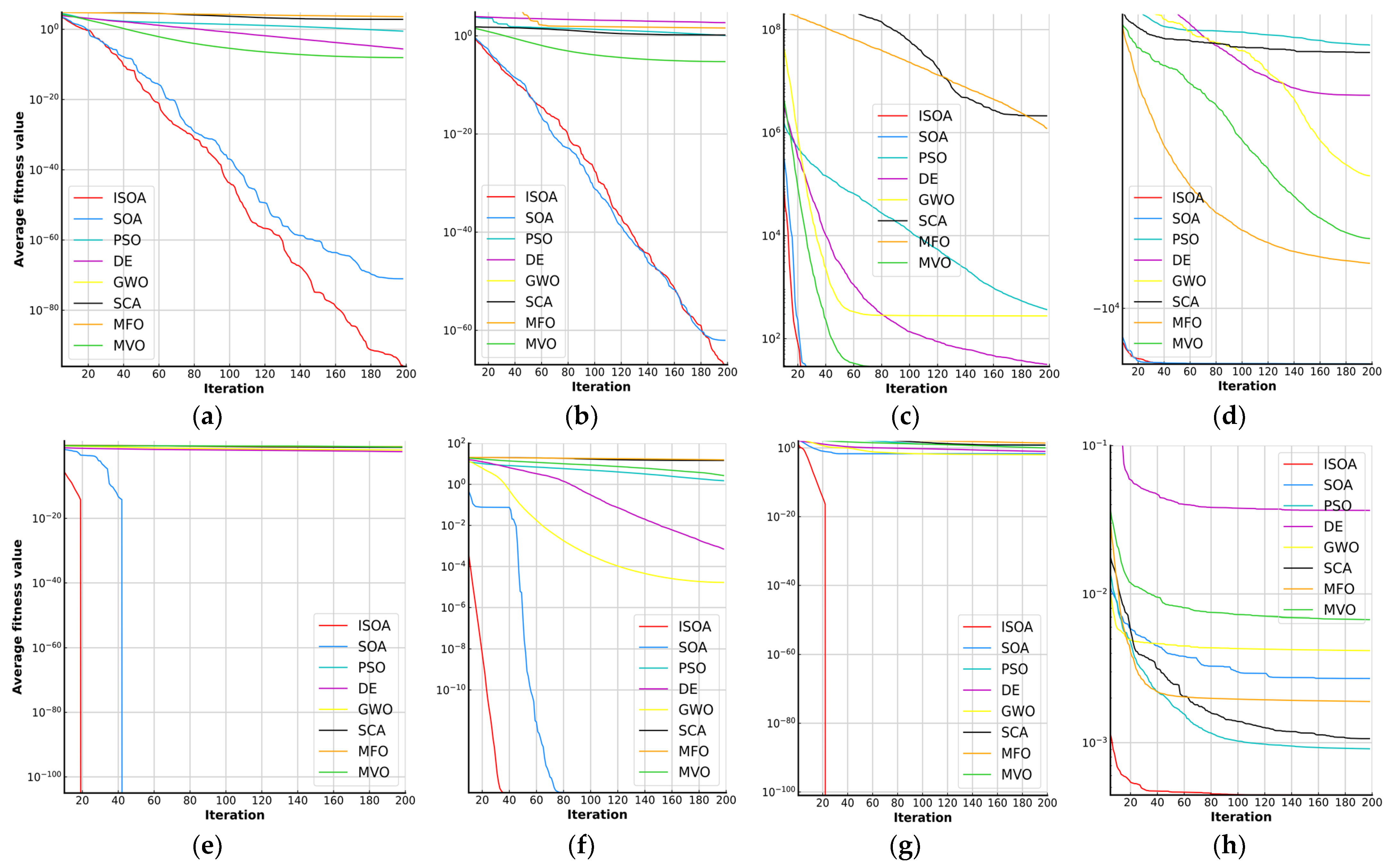
5.2. Performance of the Employed Optimization Algorithm
5.3. Effectiveness of the Developed Strategy
5.4. Improvements of the Proposed Model
- The improvement ratios of the evaluation indicators of the proposed strategy compared with individual models are greater than 50%. Among the classic individual models, the maximum improvement percentages of MAPE for the three steps forecasting are 78.01% (SH Apr, one-step), 81.49% (SH Oct, two-step) and 83.69% (SH Jan, three-step), which shows the developed model’s significant improvements to multi-step forecasting.
- Similar to previous research, when compared with other models using different data preprocessing technologies, the improvements in the forecasting effectiveness of the proposed model are fairly evident. For instance, in comparison with DWT-KELM, EMD-KELM, CEEMD-KELM and VMD-KELM, the proposed model leads to 63.54%, 52.06%, 53.83% and 6.81% reductions for one-step forecasting, respectively. Thus, the developed combined model can obtain satisfactory forecasting effectiveness.
- These results show that there is still much room for individual models to improve forecasting accuracy. Adding a data preprocessing technique can significantly improve the forecast precision. However, the use of optimization algorithms can further improve the accuracy and stability of short-term wind speed forecasting.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Anoune, K.; Bouya, M.; Astito, A.; Abdellah, A.B. Sizing methods and optimization techniques for PV-wind based hybrid renewable energy system: A review. Renew. Sustain. Energy Rev. 2018, 93, 652–673. [Google Scholar] [CrossRef]
- Duan, J.; Zuo, H.; Bai, Y.; Duan, J.; Chang, M.; Chen, B. Short-term wind speed forecasting using recurrent neural networks with error correction. Energy 2021, 217, 119397. [Google Scholar] [CrossRef]
- Lee, J.; Zhao, F.; Dutton, A.; Lathigara, A. Global wind Report 2019; Global Wind Energy Council (GWEC): Brussels, Belgium, 2020; Available online: https://gwec.net/global-wind-report-2019/ (accessed on 25 March 2020).
- Jiang, P.; Liu, Z.; Niu, X.; Zhang, L. A combined forecasting system based on statistical method, artificial neural networks, and deep learning methods for short-term wind speed forecasting. Energy 2020, 217, 119361. [Google Scholar] [CrossRef]
- Peng, T.; Zhang, C.; Zhou, J.; Nazir, M.S. Negative correlation learning-based RELM ensemble model integrated with OVMD for multi-step ahead wind speed forecasting. Renew. Energy 2020, 156, 804–819. [Google Scholar] [CrossRef]
- Song, J.; Wang, J.; Lu, H. A novel combined model based on advanced optimization algorithm for short-term wind speed forecasting. Appl. Energy 2018, 215, 643–658. [Google Scholar] [CrossRef]
- Landberg, L. Short-term prediction of the power production from wind farms. J. Wind. Eng. Ind. Aerodyn. 1999, 80, 207–220. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Perez-Bellido, Á.M.; Ortiz-García, E.G.; Portilla-Figueras, A.; Prieto, L.; Correoso, F. Accurate short-term wind speed prediction by exploiting diversity in input data using banks of artificial neural networks. Neurocomputing 2009, 72, 1336–1341. [Google Scholar] [CrossRef]
- Prósper, M.A.; Otero-Casal, C.; Fernández, F.C.; Miguez-Macho, G. Wind power forecasting for a real onshore wind farm on complex terrain using WRF high resolution simulations. Renew. Energy 2019, 135, 674–686. [Google Scholar] [CrossRef]
- Wang, K.; Fu, W.; Chen, T.; Zhang, B.; Xiong, D.; Fang, P. A compound framework for wind speed forecasting based on comprehensive feature selection, quantile regression incorporated into convolutional simplified long short-term memory network and residual error correction. Energy Convers. Manag. 2020, 222, 113234. [Google Scholar] [CrossRef]
- Firat, U.; Engin, S.N.; Saraclar, M.; Ertuzun, A.B. Wind Speed Forecasting Based on Second Order Blind Identification and Autoregressive Model. In Proceedings of the 2010 Ninth International Conference on Machine Learning and Applications, Washington, DA, USA, 12–14 December 2010; pp. 686–691. [Google Scholar] [CrossRef]
- Erdem, E.; Shi, J. ARMA based approaches for forecasting the tuple of wind speed and direction. Appl. Energy 2011, 88, 1405–1414. [Google Scholar] [CrossRef]
- Zhang, J.; Wei, Y.; Tan, Z. An adaptive hybrid model for short term wind speed forecasting. Energy 2020, 190, 115615. [Google Scholar] [CrossRef]
- Kavasseri, R.G.; Seetharaman, K. Day-ahead wind speed forecasting using f-ARIMA models. Renew. Energy 2009, 34, 1388–1393. [Google Scholar] [CrossRef]
- Samalot, A.; Astitha, M.; Yang, J.; Galanis, G. Combined Kalman filter and universal kriging to improve storm wind speed predictions for the northeastern United States. Weather. Forecast. 2019, 34, 587–601. [Google Scholar] [CrossRef]
- Wang, J.; Li, Y. An innovative hybrid approach for multi-step ahead wind speed prediction. Appl. Soft Comput. 2019, 78, 296–309. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.-Q.; Pan, D.-F.; Li, Y.-F. Forecasting models for wind speed using wavelet, wavelet packet, time series and Artificial Neural Networks. Appl. Energy 2013, 107, 191–208. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, J.; Li, G. Fine tuning support vector machines for short-term wind speed forecasting. Energy Convers. Manag. 2011, 52, 1990–1998. [Google Scholar] [CrossRef]
- Liu, D.; Niu, D.; Wang, H.; Fan, L. Short-term wind speed forecasting using wavelet transform and support vector machines optimized by genetic algorithm. Renew. Energy 2014, 62, 592–597. [Google Scholar] [CrossRef]
- Yang, H.; Jiang, Z.; Lu, H. A hybrid wind speed forecasting system based on a ‘decomposition and ensemble’strategy and fuzzy time series. Energies 2017, 10, 1422. [Google Scholar] [CrossRef]
- Li, C.; Zhu, Z.; Yang, H.; Li, R. An innovative hybrid system for wind speed forecasting based on fuzzy preprocessing scheme and multi-objective optimization. Energy 2019, 174, 1219–1237. [Google Scholar] [CrossRef]
- Monfared, M.; Rastegar, H.; Kojabadi, H.M. A new strategy for wind speed forecasting using artificial intelligent methods. Renew. Energy 2009, 34, 845–848. [Google Scholar] [CrossRef]
- Li, G.; Shi, J. On comparing three artificial neural networks for wind speed forecasting. Appl. Energy 2010, 87, 2313–2320. [Google Scholar] [CrossRef]
- Guo, Z.-H.; Wu, J.; Lu, H.-Y.; Wang, J.-Z. A case study on a hybrid wind speed forecasting method using BP neural network. Knowl.-Based Syst. 2011, 24, 1048–1056. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, H.; Xie, L.; Shen, Y.; Zhang, K. Direct interval forecasting of wind speed using radial basis function neural networks in a multi-objective optimization framework. Neurocomputing 2016, 205, 53–63. [Google Scholar] [CrossRef]
- Sun, W.; Liu, M. Wind speed forecasting using FEEMD echo state networks with RELM in Hebei, China. Energy Convers. Manag. 2016, 114, 197–208. [Google Scholar] [CrossRef]
- Liu, D.; Wang, J.; Wang, H. Short-term wind speed forecasting based on spectral clustering and optimised echo state networks. Renew. Energy 2015, 78, 599–608. [Google Scholar] [CrossRef]
- Niu, D.; Liang, Y.; Hong, W.-C. Wind speed forecasting based on EMD and GRNN optimized by FOA. Energies 2017, 10, 2001. [Google Scholar] [CrossRef]
- Ren, Y.; Suganthan, P.; Srikanth, N. A comparative study of empirical mode decomposition-based short-term wind speed forecasting methods. IEEE Trans. Sustain. Energy 2014, 6, 236–244. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, H.; Xu, Y.; Jiang, W. A hybrid framework for short term multi-step wind speed forecasting based on variational model decomposition and convolutional neural network. Energies 2018, 11, 2292. [Google Scholar] [CrossRef]
- Jiang, P.; Wang, B.; Li, H.; Lu, H. Modeling for chaotic time series based on linear and nonlinear framework: Application to wind speed forecasting. Energy 2019, 173, 468–482. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Dhiman, G.; Kumar, V. Seagull optimization algorithm: Theory and its applications for large-scale industrial engineering problems. Knowl.-Based Syst. 2019, 165, 169–196. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Period | Statistics Indicator | |||||
|---|---|---|---|---|---|---|---|
| Max. (m/s) | Min. (m/s) | Mean (m/s) | SD (m/s) | Skew. | Kurt. | ||
| Spring | 8–14 April | 15.17 | 0.37 | 6.97 | 2.79 | 0.19 | 2.31 |
| Summer | 4–10 July | 21.39 | 0.12 | 7.36 | 4.32 | 1.27 | 4.14 |
| Autumn | 20–26 October | 12.58 | 0.76 | 5.63 | 2.14 | 0.25 | 2.77 |
| Winter | 15–21 January | 12.34 | 0.93 | 6.45 | 1.97 | −0.11 | 3.07 |
| Metrics | Definition | Equation |
|---|---|---|
| MAE | Mean absolute error | |
| RMSE | Root-mean-square error | |
| MAPE | Absolute percentage error |
| Datasets | Models | One-Step | Two-Step | Three-Step | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | ||
| (m/s) | (m/s) | (%) | (m/s) | (m/s) | (%) | (m/s) | (m/s) | (%) | ||
| SH Apr | BP | 1.247 | 1.642 | 30.167 | 1.273 | 1.747 | 33.836 | 1.274 | 1.713 | 31.622 |
| SVM | 0.919 | 1.248 | 23.690 | 1.202 | 1.648 | 31.104 | 1.338 | 1.796 | 35.701 | |
| LSTM | 1.014 | 1.331 | 21.583 | 1.496 | 1.919 | 29.888 | 1.516 | 1.961 | 36.335 | |
| ELM | 0.954 | 1.303 | 21.051 | 1.340 | 1.890 | 35.802 | 1.576 | 2.281 | 46.062 | |
| KELM | 0.888 | 1.190 | 17.373 | 1.156 | 1.568 | 23.916 | 1.270 | 1.731 | 29.056 | |
| Proposed | 0.315 | 0.408 | 6.606 | 0.330 | 0.436 | 6.837 | 0.378 | 0.496 | 7.512 | |
| SH Jul | BP | 0.677 | 0.864 | 9.792 | 0.770 | 0.961 | 11.105 | 1.002 | 1.228 | 14.638 |
| SVM | 0.519 | 0.678 | 7.434 | 0.687 | 0.858 | 9.956 | 0.767 | 0.931 | 11.197 | |
| LSTM | 0.638 | 0.819 | 8.561 | 0.761 | 0.946 | 11.168 | 0.765 | 0.952 | 10.830 | |
| ELM | 0.521 | 0.684 | 7.355 | 0.693 | 0.856 | 9.931 | 0.787 | 0.969 | 11.431 | |
| KELM | 0.515 | 0.672 | 7.342 | 0.680 | 0.839 | 9.883 | 0.739 | 0.900 | 10.853 | |
| Proposed | 0.221 | 0.270 | 3.140 | 0.226 | 0.276 | 3.205 | 0.237 | 0.288 | 3.361 | |
| SH Oct | BP | 0.676 | 0.886 | 8.966 | 1.055 | 1.326 | 13.731 | 0.853 | 1.120 | 11.471 |
| SVM | 0.749 | 1.079 | 8.763 | 0.937 | 1.243 | 11.468 | 1.070 | 1.393 | 13.285 | |
| LSTM | 0.616 | 0.823 | 7.731 | 0.823 | 1.073 | 10.557 | 0.937 | 1.221 | 11.753 | |
| ELM | 0.671 | 0.947 | 8.184 | 0.897 | 1.219 | 11.145 | 1.045 | 1.396 | 12.996 | |
| KELM | 0.750 | 1.018 | 8.981 | 0.941 | 1.210 | 11.672 | 1.056 | 1.348 | 13.268 | |
| Proposed | 0.182 | 0.235 | 2.367 | 0.198 | 0.257 | 2.541 | 0.223 | 0.287 | 2.844 | |
| SH Jan | BP | 0.809 | 1.095 | 11.848 | 0.880 | 1.179 | 13.159 | 0.985 | 1.347 | 14.676 |
| SVM | 0.629 | 0.903 | 9.066 | 0.828 | 1.112 | 12.333 | 0.942 | 1.262 | 14.244 | |
| LSTM | 0.655 | 0.940 | 9.485 | 0.875 | 1.161 | 12.714 | 0.902 | 1.223 | 13.556 | |
| ELM | 0.739 | 1.120 | 10.279 | 0.970 | 1.374 | 14.066 | 1.092 | 1.539 | 15.869 | |
| KELM | 0.632 | 0.891 | 9.179 | 0.823 | 1.104 | 12.239 | 0.916 | 1.239 | 13.783 | |
| Proposed | 0.252 | 0.333 | 3.894 | 0.280 | 0.372 | 4.276 | 0.314 | 0.418 | 4.737 | |
| Datasets | Models | One-Step | Two-Step | Three-Step | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | ||
| (m/s) | (m/s) | (%) | (m/s) | (m/s) | (%) | (m/s) | (m/s) | (%) | ||
| SH Apr | DWT | 0.639 | 1.074 | 18.12 | 1.121 | 1.532 | 28.585 | 1.377 | 1.808 | 36.064 |
| EMD | 0.606 | 0.768 | 13.779 | 0.764 | 0.999 | 19.892 | 0.856 | 1.156 | 23.910 | |
| CEEMD | 0.552 | 0.731 | 14.308 | 0.634 | 0.860 | 14.796 | 0.699 | 0.951 | 16.466 | |
| VMD | 0.331 | 0.437 | 7.089 | 0.353 | 0.471 | 7.412 | 0.404 | 0.528 | 8.340 | |
| Proposed | 0.315 | 0.408 | 6.606 | 0.330 | 0.436 | 6.837 | 0.378 | 0.496 | 7.512 | |
| SH Jul | DWT | 0.427 | 0.589 | 6.116 | 0.649 | 0.825 | 9.301 | 0.759 | 0.917 | 11.002 |
| EMD | 0.441 | 0.555 | 6.031 | 0.494 | 0.630 | 6.817 | 0.531 | 0.671 | 7.346 | |
| CEEMD | 0.288 | 0.374 | 4.114 | 0.334 | 0.436 | 4.682 | 0.388 | 0.503 | 5.464 | |
| VMD | 0.289 | 0.353 | 4.098 | 0.248 | 0.302 | 3.533 | 0.279 | 0.340 | 4.002 | |
| Proposed | 0.221 | 0.270 | 3.140 | 0.226 | 0.276 | 3.205 | 0.237 | 0.288 | 3.361 | |
| SH Oct | DWT | 0.521 | 0.848 | 5.981 | 0.875 | 1.206 | 10.587 | 1.043 | 1.388 | 12.927 |
| EMD | 0.505 | 0.677 | 6.744 | 0.565 | 0.768 | 7.452 | 0.635 | 0.844 | 8.293 | |
| CEEMD | 0.266 | 0.372 | 3.452 | 0.350 | 0.485 | 4.559 | 0.410 | 0.561 | 5.412 | |
| VMD | 0.251 | 0.316 | 3.114 | 0.337 | 0.423 | 4.154 | 0.365 | 0.458 | 4.529 | |
| Proposed | 0.182 | 0.235 | 2.367 | 0.198 | 0.257 | 2.541 | 0.223 | 0.287 | 2.844 | |
| SH Jan | DWT | 0.416 | 0.701 | 6.016 | 0.780 | 1.042 | 11.552 | 0.917 | 1.216 | 13.738 |
| EMD | 0.51 | 0.672 | 7.569 | 0.579 | 0.764 | 8.661 | 0.634 | 0.838 | 9.448 | |
| CEEMD | 0.442 | 0.596 | 6.807 | 0.489 | 0.669 | 7.610 | 0.531 | 0.727 | 8.246 | |
| VMD | 0.273 | 0.364 | 4.200 | 0.308 | 0.410 | 4.690 | 0.336 | 0.445 | 5.077 | |
| Proposed | 0.252 | 0.333 | 3.894 | 0.280 | 0.372 | 4.276 | 0.314 | 0.418 | 4.737 | |
| Function | Peak | Dim | Range | |
|---|---|---|---|---|
| Unimodal | 30 | [−100, 100] | 0 | |
| Unimodal | 30 | [−10, 10] | 0 | |
| Unimodal | 30 | [−30, 30] | 0 | |
| Multimodal | 30 | [−500, 500] | −12,569.5 | |
| Multimodal | 30 | [−5.12, 5.12] | 0 | |
| Multimodal | 30 | [−32, 32] | 0 | |
| Multimodal | 30 | [−600, 600] | 0 | |
| Fixed-dimension | 4 | [−5, 5] | 0.0003 |
| ID | Metric | ISOA | SOA | PSO | DE | GWO | SCA | MFO | MVO |
|---|---|---|---|---|---|---|---|---|---|
| F1 | AVG | 1.80 × 10−96 | 9.18 × 10−72 | 3.90 × 10−1 | 2.64 × 10−6 | 8.70 × 10−9 | 6.87 × 102 | 3.98 × 104 | 8.41 × 100 |
| STD | 1.27 × 10−95 | 6.49 × 10−71 | 2.75 × 10−1 | 2.15 × 10−6 | 8.14 × 10−9 | 7.40 × 102 | 5.13 × 103 | 2.60 × 100 | |
| F2 | AVG | 9.45 × 10−68 | 9.40 × 10−63 | 1.23 × 100 | 1.05 × 10−4 | 5.61 × 10−6 | 1.50 × 100 | 3.95 × 101 | 4.28 × 101 |
| STD | 4.51 × 10−67 | 3.97 × 10−62 | 4.62 × 10−1 | 3.42 × 10−5 | 2.91 × 10−6 | 1.41 × 100 | 1.90 × 101 | 8.35 × 101 | |
| F5 | AVG | 2.88 × 101 | 2.88 × 101 | 4.17 × 102 | 3.17 × 101 | 2.78 × 102 | 2.05 × 106 | 5.54 × 106 | 1.07 × 103 |
| STD | 2.95 × 10−2 | 4.62 × 10−2 | 5.17 × 102 | 1.84 × 101 | 7.76 × 101 | 4.70 × 106 | 1.91 × 107 | 1.59 × 103 | |
| F8 | AVG | −1.25 × 104 | −1.25 × 104 | −3.40 × 103 | −4.18 × 103 | −5.81 × 103 | −3.51 × 103 | −8.31 × 103 | −7.51 × 103 |
| STD | 5.07 × 101 | 7.95 × 101 | 5.23 × 102 | 3.57 × 101 | 1.16 × 103 | 2.71 × 102 | 8.04 × 102 | 5.74 × 102 | |
| F9 | AVG | 0.00 × 100 | 0.00 × 100 | 1.08 × 102 | 4.72 × 100 | 1.47 × 101 | 1.03 × 102 | 1.73 × 102 | 1.35 × 102 |
| STD | 0.00 × 100 | 0.00 × 100 | 3.25 × 101 | 2.11 × 100 | 8.63 × 100 | 4.94 × 101 | 2.72 × 101 | 3.23 × 101 | |
| F10 | AVG | 8.89 × 10−16 | 8.89 × 10−16 | 1.51 × 100 | 7.09 × 10−4 | 1.67 × 10−6 | 1.47 × 101 | 1.57 × 101 | 2.70 × 100 |
| STD | 0.00 × 100 | 0.00 × 100 | 5.16 × 10−1 | 3.08 × 10−4 | 9.73 × 10−6 | 7.21 × 100 | 4.69 × 100 | 5.79 × 10−1 | |
| F11 | AVG | 0.00 × 100 | 2.02 × 10−2 | 5.96 × 100 | 9.69 × 10−2 | 1.03 × 10−2 | 6.89 × 100 | 2.55 × 101 | 1.07 × 100 |
| STD | 0.00 × 100 | 1.43 × 10−1 | 3.09 × 100 | 5.57 × 10−2 | 1.48 × 10−2 | 5.44 × 100 | 3.35 × 101 | 1.98 × 10−2 | |
| F15 | AVG | 3.70 × 10−4 | 4.40 × 10−3 | 9.10 × 10−4 | 3.67 × 10−2 | 4.20 × 10−3 | 1.10 × 10−3 | 1.90 × 10−3 | 6.70 × 10−3 |
| STD | 2.90 × 10−4 | 4.80 × 10−3 | 2.19 × 104 | 4.24 × 10−2 | 7.71 × 10−3 | 3.96 × 10−4 | 4.00 × 10−3 | 8.81 × 10−3 |
| Model | 1-Step | 2-Step | 3-Step |
|---|---|---|---|
| BP | 7.9252 | 8.6438 | 8.6631 |
| SVM | 6.3969 | 7.9864 | 8.4509 |
| LSTM | 7.0239 | 8.2106 | 8.6123 |
| ELM | 6.9602 | 7.0022 | 7.3714 |
| KELM | 6.6534 | 8.1960 | 8.7345 |
| DWT | 6.3367 | 6.6578 | 7.5850 |
| EMD | 4.2412 | 6.6594 | 6.8246 |
| CEEMD | 5.5755 | 5.4812 | 5.6415 |
| VMD | 3.6386 | 4.6848 | 4.1407 |
| Model | SH April | SH July | SH October | SH January | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | |
| BP | 78.10 | 79.79 | 76.24 | 67.93 | 71.14 | 77.04 | 73.60 | 81.49 | 75.21 | 67.13 | 67.51 | 67.72 |
| SVM | 72.11 | 78.02 | 78.96 | 57.76 | 67.81 | 69.98 | 72.99 | 77.84 | 78.59 | 57.05 | 65.33 | 66.74 |
| LSTM | 69.39 | 77.12 | 79.33 | 63.32 | 71.30 | 68.97 | 69.38 | 75.93 | 75.80 | 58.95 | 66.37 | 65.06 |
| ELM | 68.62 | 80.90 | 83.69 | 57.31 | 67.73 | 70.60 | 71.08 | 77.20 | 78.12 | 62.12 | 69.60 | 70.15 |
| KELM | 61.98 | 71.41 | 74.15 | 57.23 | 67.57 | 69.03 | 73.64 | 78.23 | 78.56 | 57.58 | 65.06 | 65.63 |
| DWT | 63.54 | 76.08 | 79.17 | 48.66 | 65.54 | 69.45 | 60.42 | 76.00 | 78.00 | 35.27 | 62.98 | 65.52 |
| EMD | 52.06 | 65.63 | 68.58 | 47.94 | 52.99 | 54.25 | 64.90 | 65.90 | 65.71 | 48.55 | 50.63 | 49.86 |
| CEEMD | 53.83 | 53.79 | 54.38 | 23.68 | 31.55 | 38.49 | 31.43 | 44.26 | 47.45 | 42.79 | 43.81 | 42.55 |
| VMD | 6.81 | 7.76 | 9.93 | 23.38 | 9.28 | 16.02 | 23.99 | 38.83 | 37.20 | 7.29 | 8.83 | 6.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Li, Y.; Zhang, Y.; Ye, X.; Xiong, X.; Zhang, F. A Novel Hybrid Model Based on an Improved Seagull Optimization Algorithm for Short-Term Wind Speed Forecasting. Processes 2021, 9, 387. https://doi.org/10.3390/pr9020387
Chen X, Li Y, Zhang Y, Ye X, Xiong X, Zhang F. A Novel Hybrid Model Based on an Improved Seagull Optimization Algorithm for Short-Term Wind Speed Forecasting. Processes. 2021; 9(2):387. https://doi.org/10.3390/pr9020387
Chicago/Turabian StyleChen, Xin, Yuanlu Li, Yingchao Zhang, Xiaoling Ye, Xiong Xiong, and Fanghong Zhang. 2021. "A Novel Hybrid Model Based on an Improved Seagull Optimization Algorithm for Short-Term Wind Speed Forecasting" Processes 9, no. 2: 387. https://doi.org/10.3390/pr9020387
APA StyleChen, X., Li, Y., Zhang, Y., Ye, X., Xiong, X., & Zhang, F. (2021). A Novel Hybrid Model Based on an Improved Seagull Optimization Algorithm for Short-Term Wind Speed Forecasting. Processes, 9(2), 387. https://doi.org/10.3390/pr9020387