1. Introduction
The increase in road traffic due to urbanization has led to several transportation and traffic management issues, such as frequent traffic congestions and traffic accidents etc. [
1,
2,
3]. Related research conducted under Intelligent Transportation System (ITS) helps deal with such issues and provide solutions for efficient traffic infrastructure planning and reduction in road congestions and road accidents etc. Similarly, road congestions in a city traffic require smart solutions like estimation of vehicle queue length in a traffic lane and prediction of traffic etc. [
4,
5,
6,
7,
8,
9].
Technological advancement in wireless communication and computing power has transformed ITS. For example, development towards connected vehicles is contributing to the implementation of next generation ITS. The connectivity in vehicles enable collection of necessary data for better traffic management and control [
10]. Recent advances in computer vision and deep learning have also enabled improved vehicle annotation, detection and classification in traffic surveillance application. Moreover, large-scale deployment of surveillance cameras all over the world has shown a great potential in the collection of vehicular data. Similarly, ITS technologies such as smart roadside sensors and surveillance cameras with enhanced analytics functionalities are widely adapted around the world [
3]. These traffic cameras can be used independently or if required can also augment the functionality of other smart roadside sensors to effectively estimate queue length at prescribed traffic lanes.
Vehicle queue length on the signalized intersection is defined as the distance from the stop line to the tail of the last vehicle stopped in any traffic lane while the signal is red during one signal cycle. Vehicle queue length is an important parameter to determine traffic density in traffic lanes so that possible congestion in any lane can be minimized. It is also important for traffic optimization on a signal in terms of prediction of traffic, intersection delay and travel time etc. [
11].
Figure 1 shows a random vehicle queue at a traffic intersection. Vehicle queue length information is generally extracted by using fixed roadside sensors like loop detectors, pneumatic road tubes, radars and in-vehicle sensors like GPS etc. The roadside sensors such as loop detectors are promising, however, their installation and maintenance costs are comparatively higher. Their installation also requires a lot of traffic disruption. Similarly, magnetic sensors can easily get affected by temperature and humidity. Radar sensors are very accurate but their main disadvantage is high exposure to electromagnetic interferences. Compared to these sensors, traffic surveillance cameras can be used effectively to determine the presence and location of vehicles, queue length, flow rate and occupancy across several traffic lanes etc.
In this research work, a state-of-the-art CNN-based vehicle detection model is used to estimate the queue lengths of vehicles (particularly cars) in signalized traffic lanes. Using the proposed model, a fairly accurate estimation of vehicle queues for dense urban traffic can be made without any on-site camera calibration. The major contributions of the paper are highlighted as follows:
A detailed comparison of deep learning architectures including YOLOv3, YOLOv4, YOLOv5, SSD, ResNet101, and InceptionV3 with inexpensive training dynamics for vehicle detection.
Proposed method for estimation of vehicle count-based queue length using images obtained from low-resolution traffic surveillance cameras.
Selection of an application specific dataset with a fixed far-field camera view for better estimation of queue lengths while also considering the depth of a queue and camera angles.
The remainder of the paper is organized as follows:
Section 2 provides literature review regarding queue length estimation.
Section 3 describes the methodology adopted to estimate the queue length.
Section 4 provides the implementation of the proposed model in detail.
Section 5 discusses and demonstrates the effectiveness of the proposed method. Finally,
Section 6 concludes the paper and presents a future research direction related to the proposed research.
2. Literature Review
Several works in the literature are available which present efficient models for queue length estimation. A common approach is to develop a mathematical model using data collected from roadside or in-vehicle sensors. Based on the methodology and type of sensors used, the literature on queue length estimation and related tasks can be categorized broadly into three groups.
Estimation using Fixed Location Sensors. These include fixed sensors such as loop detectors etc.
Estimation using Mobile Sensors. These include sensors installed in vehicles such as Global Positioning System (GPS) etc.
Estimation using Vision based Sensors. These include processing of traffic camera feeds using Computer vision tools.
Lee et al. determined the number of queued vehicles in each lane with the help of loop detectors [
12]. The simulations used Kalman filter to find traffic volume in each lane. Wu et al. presented an approach for queue length detection using roadside LiDAR data [
13]. The proposed approach achieved an average of 98% accuracy at various sites. Ki An et al. devised a numerical model for queue length estimation at a metering roundabout [
14]. The framework used two roadside detectors and traffic signal for estimation of queue lengths. The ground-truth queue length information was obtained from two different drones. The ground truth was then used to calibrate and validate the model. The model performance was analyzed using the R
test and achieved an 83% value. Skabardonis et al. proposed an intersection queue length estimation method using loop detector and traffic signal data with 30 s intervals. Using this approach accurate results were reported for travel time estimation [
15].
Li et al. proposed a cycle-by-cycle queue length estimation approach using probe data obtained from vehicles participating in traffic flow [
16]. The results were benchmarked compared to paper from Ramezani et al. [
17] and reported improved accuracy under low penetration rate. Blokpoel et al. compared different queue length estimation approaches based on Cooperative Awareness Messages (CAM) received from vehicles [
18]. The GPS information from these vehicles is easily obtained through CAM instead of relying on expensive equipment. The overall approach showed methods to improve queue length detections with this obtained data. Wu et al. proposed queue length estimation based on data obtained from RFID detectors [
19]. Instead of relying on incoming traffic flow, the authors exploited the queue delay of individual vehicles to measure queue length at an intersection. Authors reported satisfactory results using this approach. Rompis et al. performed lane identification and queue length estimation using probe vehicle data [
20]. Using the optimal Bayes Rule model, promising results were obtained for lane identification which was then used for queue length estimation.
Okaishi et al. proposed a real-time vehicular queue length measurement system for intersections based on camera feeds [
21]. The proposed system used frame differencing to analyze motion in focused areas. When no motion is observed, vehicles in that area are detected using CNN based SSD networks. The system works with video feeds obtained from stationary cameras. Similarly, Zanin et al. proposed a system for real-time measurement of vehicle queue parameters [
22]. It is based on vehicle presence detection and movement analysis in a set of videos acquired from stationary traffic cameras. The system can then detect queues in lanes of interest. Albiol et al. presented an approach to estimate traffic queue lengths in real time by collecting and evaluating low-level features such as corners to detect the presence of vehicles [
23]. After that, features are classified as either moving or static. The algorithm only requires locations of lane masks and starting point of queues etc. Shirazi et al. has also presented a tracking method for estimation of queue lengths and waiting time of vehicles at junctions [
11]. Background subtraction technique was used to detect all the moving vehicles in the prescribed motion area. The vehicles were continuously tracked until stopped. The total number of vehicles that cross the motion area helps with estimation of queue length. Though the proposed system is unable to detect queue lengths beyond this motion area. Li et al. collected traffic images from custom-installed cameras, which constitute the training and testing sets for YOLO-based models [
24]. The training was performed using transfer learning with initial parameters loaded from a pretrained model followed by fine-tuning on the obtained traffic images. The authors reported network improvements by converting an 80-classes classifier into a binary classifier. The final improved model achieved an average accuracy of 90% in detecting vehicles from traffic flows of different densities.
In summary, there is limited research on deep learning and vision-based queue length estimation at signalized intersections. The reviewed literature presents satisfactory results on a single intersection and is not applicable on large network of intersections. Similarly, vehicle detection and tracking in different conditions such as low-resolution traffic feeds, varying illumination conditions, or loss of tracks for long waiting vehicles still need enhancement.
4. Implementation
4.1. Hardware and Software Configuration
The experimentation is performed on a laptop with core i5-6300hq CPU, 8 GB of RAM and GTX960M GPU with 2 GB VRAM. The versions of Python and the software framework used are Python 3.5.2, TensorFlow 2.2.0, and OpenCV 3.4.2. Training of YOLO model is done using Google Colab computing platform with Intel Xeon 2 Cores CPU, 12 GB of RAM and Nvidia Tesla K80 GPU with 12 GB of VRAM. The versions of Python and the software framework used are Python 3.6.7 and TensorFlow 2.2.0 respectively.
4.2. Code Implementation
The queue length inference and model training software pipelines are built on top of an open-source YOLOv4 implementation with TensorFlow. To perform the queue length inference, videos are processed using the OpenCV library and are fed to the object detection model frame by frame. Later, these videos are passed through Deep SORT for identification of stopped vehicles on stop lines. Subsequently, queue length for every traffic lane is calculated based on the detection model output and set rules regarding queue length definition. While doing inference using the pre-trained 80-classes YOLOv4 model, the output classes are restricted to show only vehicle classes (i.e car, truck and bus etc). Calculated queue lengths are then exported to Excel.
4.3. Training of a New Object Detection Model
Fine-tuning allows latest object detection models to train new object categories with reduced training data. In this research, the 524 images are used to train a single “vehicle” class. To perform fine-tuning, firstly, the 80-classes COCO pretrained YOLOv4 model was selected as the base model. The fine-tuning process makes use of the features that are already extracted in the pre-trained model. It then modifies the original fully-connected output layers to reflect the result intended for the new network. The training process of a new YOLOv4-based single class object detection model is to unfreeze the weights of all model layers and fine-tune all the weights in the entire YOLOv4 model. After early stopping conditions for training are met, the final model can be obtained and used to perform queue length inference for traffic videos.
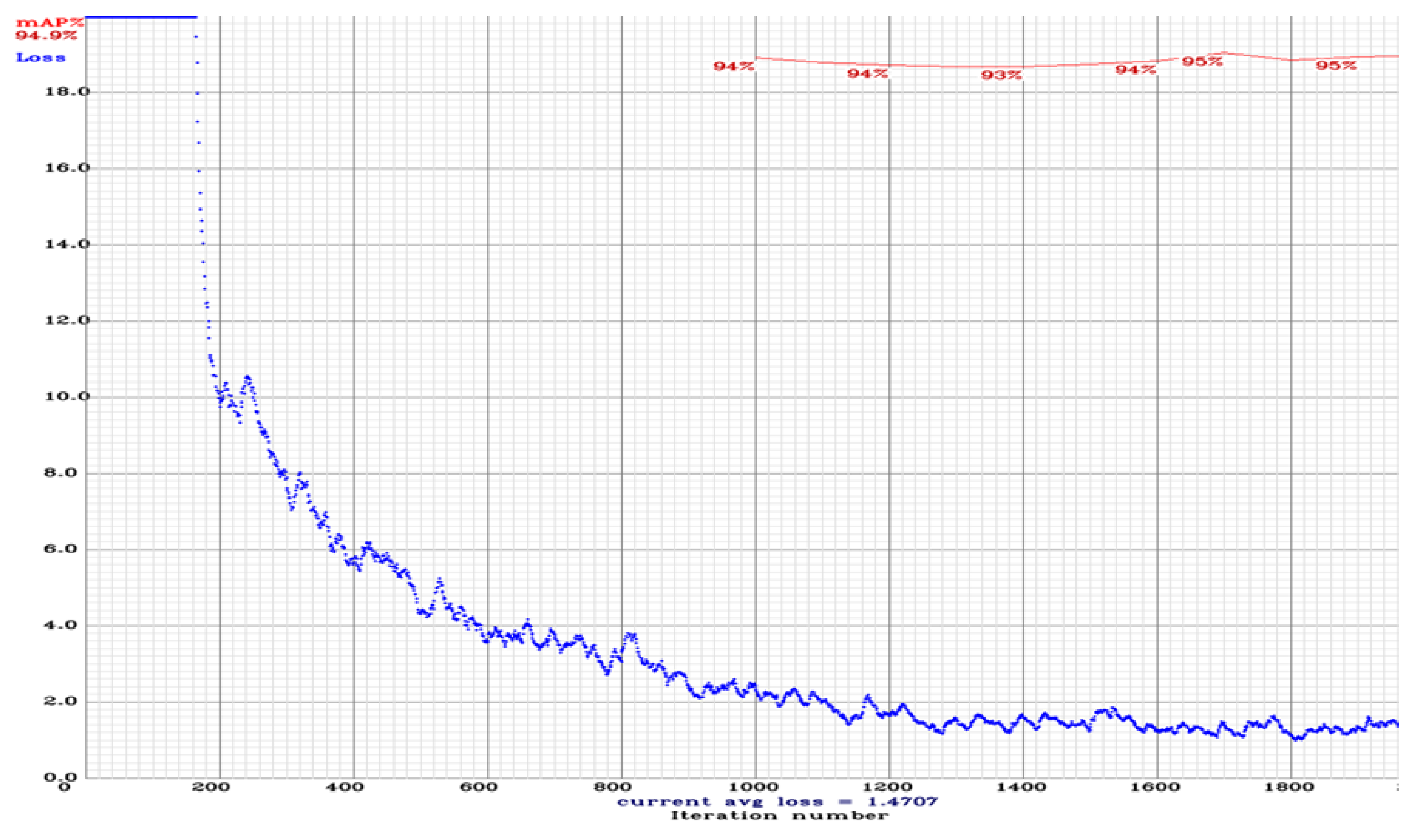
Training records are logged and visualized with a custom python code. The training loss (graph shown at
Figure 8) reduced from 20.0 to 1.9 after fine-tuning 1000 iterations of weights. The loss stabilizes at 1400 iterations with slight fluctuations. The Mean Average Precision (mAP) starts at 1000 iterations from 94%. The mAP falls to 93% at 1400 iterations, while achieving the highest mAP of 95% at 1700 iterations. Though the train and test sets are randomly sampled, a slight increase in training loss near the end indicates a possibility for overfitting. However, the object detection model still outperforms the original vehicle detector, as shown in
Section 5. Due to no major change in loss or accuracy after 1700 iterations, the model was stopped to avoid further overfitting. The final model used for queue length inference had around 1900 iterations of fine-tuning on all weights of the model, with the mAP fixed around 93% to 95% while the training loss remained at 1.47 on average.
5. Results and Discussion
The accuracies were compared for selected videos both before and after applying fine-tuning. As discussed in
Section 3.5, there are three different performance evaluation methods for queue length estimation. The method 1 calculates individual queue length at each frame. While method 2 and 3 takes the average and maximum queue lengths obtained from all frames in a second, respectively. The method 3 is preferred for cases where there is a chance of vehicle misdetection.
Figure 9 shows an accuracy comparison (for each selected video ) between three different performance evaluation methods discussed in
Section 3. The comparatively low performance can be seen in B34M video. The possible reason could be that the pretrained YOLOv4 model sometimes fails to detect vehicles in the far end of a lane or when the vehicles are stacked together. The B20M video has frames where most vehicles are at the far end, which made vehicle recognition harder because of blurry vehicle appearance and background occlusions. Since these vehicles are not always detected, therefore, maximum queue length evaluated using method 3 performed comparatively better than method 1 and 2.
Table 2 and
Table 3 show the improvement of queue length accuracies in terms of vehicle count and vehicle count-based queue length estimation. Using a pre-trained 80-classes YOLOv4 model, an overall accuracy of 73% and 88% was achieved for vehicle count and vehicle count-based queue length estimation, respectively. After fine-tuning of model and narrowing the output classes to vehicle class only, an average accuracy of 83% and 93% was achieved, respectively. The results for each video have been averaged across all lanes and all queue length measuring methods. The greatest improvements are seen at 30% after applying fine-tuning implementation on sampled videos. Most of the videos are significantly improved, except for the vehicle count accuracies in B20M video. The improvements are result of enhanced vehicle detection in the traffic videos. Fine-tuning enabled the YOLOv4 network to recognize vehicles which were small or had an appearance which could easily blend into part of the road, as shown in
Figure 10. Similarly, the improved model also detects cars stacked in queues that were not picked up by the original network, particularly in B34M and B30S videos. Confidence scores assigned to detected vehicles are also observed to be much higher than before. Nevertheless, there is still room for improvement as the vehicle count accuracies for the B20M video are much lower than the other two videos. If video frames that have the same stacked vehicle density are used in fine-tuning labels, the recognition result can improve.
6. Conclusions and Future Work
In this paper a CNN-based approach for estimation of vehicle queue length in an urban traffic scenario using low-resolution traffic videos is proposed. Queue length is the distance from the stop line to the tail of the last vehicle stopped in any traffic lane while the signal is red during one signal cycle. The queue length is calculated by multiplying the detected vehicle count with an average vehicle length of approximately 5 m. This estimation is done while keeping in view the different type of vehicles such as cars, trucks, and buses etc. The results have shown a decent performance for estimation of vehicle count and queue length based on vehicle count. Identification of the stopped vehicles is performed using Deep SORT which defines the start of a lane. A detailed comparative analysis of different vehicle detection models including YOLOv3, YOLOv4, YOLOv5, SSD, ResNet101, and InceptionV3 was performed. Based on this analysis, YOLOv4 was selected for queue length estimations. It is shown with experimentation that CNN-based architectures are effective in improving vehicle detection accuracies. It is also proved that fine-tuning is highly effective in improving the accuracies even for low-resolution images.
As part of future work, the research can be further improved by development of advanced deep learning architecture capable of performing faster and better inferences using the same low-resolution videos. Super-resolution techniques can also be utilized to improve the image resolution and overall detection accuracies. This will further improve the estimation of vehicle queue lengths at signalized intersections.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













































































