3.2. Study of NSGA-III Variants
The original NSGA-III used simulated binary crossover (SBX) [
23] to generate individual offspring. This section calls this method the NSGA-III-SBX to distinguish it from other NSGA-III variants studied in this section. In this paper, we introduce cycle crossover (CX) [
24], order-based crossover (OBX) [
25], order-crossover (OX) [
26], partially mapped crossover (PMX) [
27], and position-based crossover (PBX) [
25] into the NSGA-III, replacing the original SBX operator and forming 5 NSGA-III variants, namely, NSGA-III-CX, NSGA-III-OBX, NSGA-III-OX, NSGA-III-PBX, and NSGA-III-PMX.
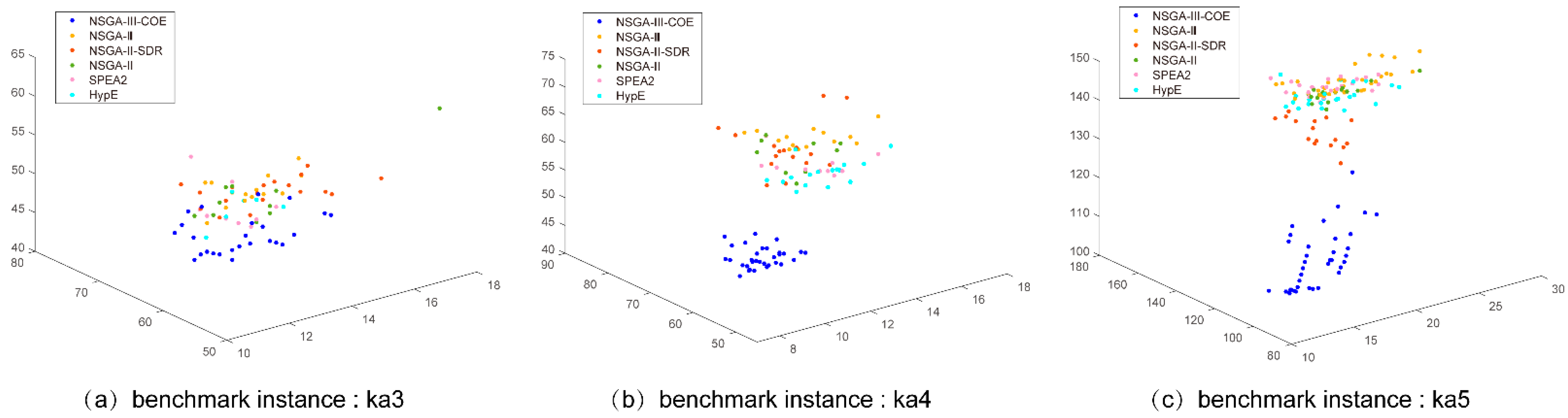
In order to study the search performance of all NSGA-III variant algorithms in the decision space, we use part of three sets of well-known FJSP benchmark instances, including ka3, ka4, and ka5 in the Kacem instance [
22] and mk4, mk5, and mk7 in the BRdata instance [
21], to conduct exploration and testing. These six instances are representative from simple to complex. In the experiments in this section, we use these six benchmark instances to explore the NSGA-III variants mentioned in this section and propose a modified NSGA-III based on the research results.
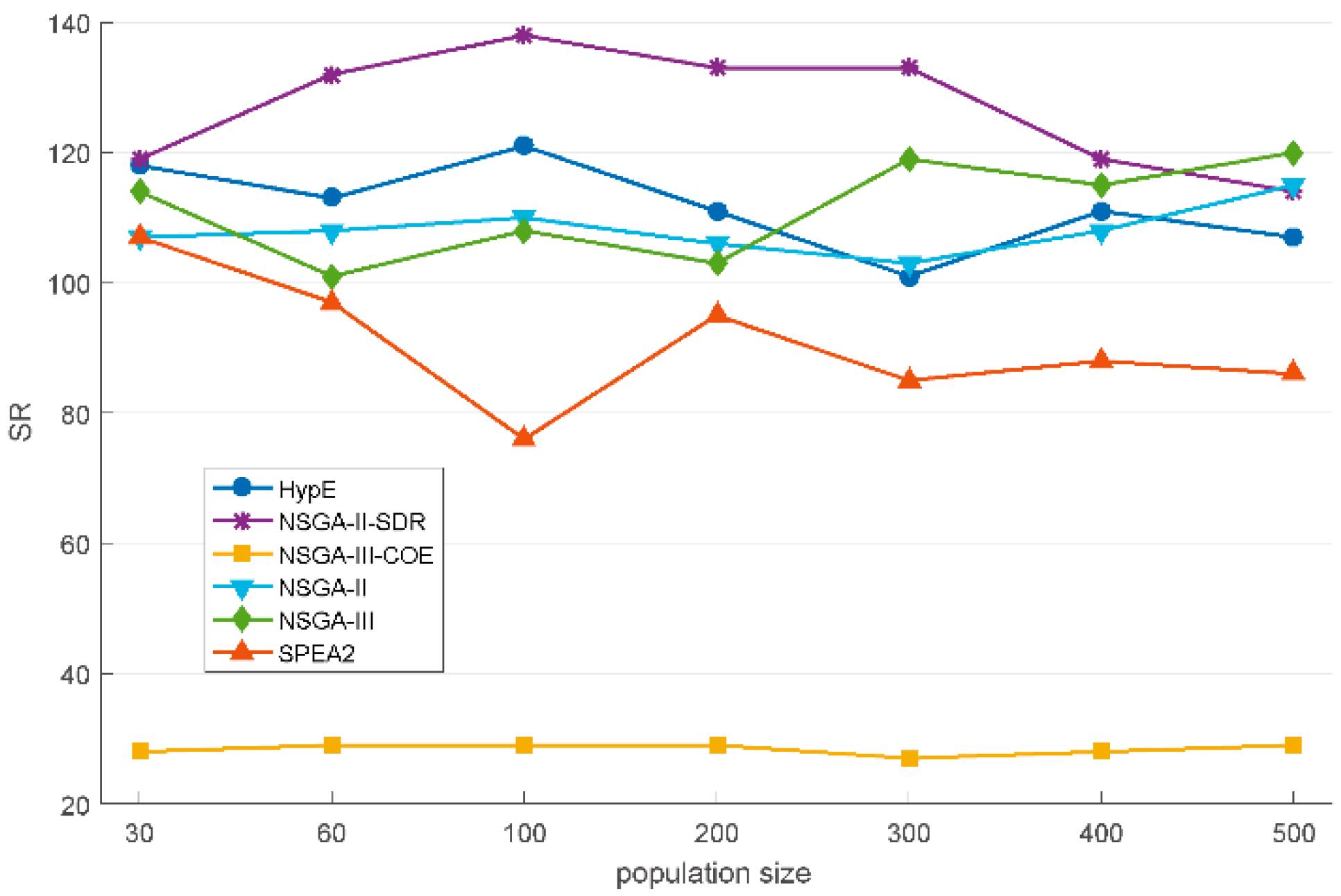
Table 3 lists the parameters used in this section to study the different variants of NSGA-III, and we use uniform parameter values for all variants. In preliminary research, we found that the widely used MOEAs are prone to fall into local optimum on FJSP. Some studies in the literature have found that a larger mutation probability can effectively help the population jump out of the local optimum [
10]. Thus, we use a high mutation probability. In order to explore whether the performance of different variants is related to population size, we use two population sizes in our research, 200 and 300. When the number of iterations reaches the set maximum number of iterations, the algorithm is terminated. To ensure a fair comparison, for each benchmark instance, all variants are run independently with the same initial population 30 times, and the average of 30 experiments is taken for comparison.
In our experiments, we use the generational distance (GD) [
28] and the inverted generational distance (IGD) [
29] as evaluation indicators to evaluate the convergence of the non-dominated solution set and the comprehensive performance of the algorithm. They can be expressed as follows.
GD: Assuming that
is the solution set obtained by the algorithm and
is a set of uniformly distributed reference points sampled from the Pareto front (PF), the
GD of solution set
is defined as follows:
represents the Euclidean distance between point in solution set and point in reference set . GD only evaluates the convergence of the solution set. The smaller the GD value is, the better the convergence of the algorithm is.
IGD: Assuming that
is the solution set obtained by the algorithm and
is a set of uniformly distributed reference points sampled from the Pareto front (PF), then the IGD value of solution set
is defined as follows:
represents the Euclidean distance between point in reference set and point in solution set . If is large enough to fully represent the Pareto front, then the IGD can comprehensively measure the convergence and the diversity of the solution set. If we want to obtain a smaller IGD, the solution set must be close enough to the Pareto front in the target space.
When calculating the GD and the IGD, a reference set is needed. Since the actual Pareto front of the benchmark instance is unknown, the reference set used in the calculation of the GD and the IGD in this paper is formed by collecting all the non-dominated solutions found during the runtime of all implemented algorithms.
Next, we compare the search behavior of different NSGA-III variants on the MO-FJSP. Simply put, we want to understand the algorithm search process for solution sets in the decision space as well as which algorithm is better at exploration and which algorithm is better at development. Knowing these can help us design more effective evolutionary mechanisms. First, we randomly initialize a population for each instance and then perform 200 and 300 iterations.
Figure 2 and
Figure 3 depicts the trajectories of the GDs obtained from the six NSGA-III variants as the number of iterations increases when the population sizes are 200 and 300, respectively.
Figure 2 and
Figure 3 show that, although the population sizes are different, the same NSGA-III variant shows very similar convergence trends on these benchmark instances, and the convergence of different NSGA-III variants is significantly different due to the different complexities of the benchmark instances. As the complexity of the benchmark instance increases, NSGA-III-CX, NSGA-III-OBX, and NSGA-III-PBX show better convergence, and the GDs of these three algorithms decrease in a similar way during the evolutionary process. This phenomenon indicates that the initial population is a randomly distributed solution in the decision space, and then the optimal solution is searched continuously. NSGA-III-CX, NSGA-III-OBX, and NSGA-III-PBX can search for better solutions faster than other algorithms. The above experimental results show that the three NSGA-III variants, NSGA-III-CX, NSGA-III-OBX, and NSGA-III-PBX, can explore more optimal solutions more effectively in the decision space.
In order to study the development capabilities of different NSGA-III variants, we conduct a similar experiment. The difference from the previous experiment is that we replace the initial population with a population that is already closer to the Pareto front, which can be obtained through iteration by any multi-objective evolutionary algorithm. In this experiment, only the three NSGA-III variants with better exploration capabilities are used. The purpose is to study the abilities of NSGA-III-CX, NSGA-III-OBX, and NSGA-III-PBX to develop better solutions. The three NSGA-III variant algorithms use the population close to the Pareto front as the initial population to perform 100 iterations. As before, use two population sizes, 200 and 300.
Figure 4 and
Figure 5 depicts the trajectories of IGDs obtained from the three NSGA-III variants as the number of iterations increases when the initial population is close to the Pareto front when the population size is 200 and 300 respectively. We compare
Figure 4 and
Figure 5 first. Similar to the previous experiment, the same NSGA-III variant showed very similar ability to develop better solutions when the population size was different. However, the situation in
Figure 4 and
Figure 5 is very different from that in
Figure 2 and
Figure 3. In
Figure 4 and
Figure 5, from the beginning, as the number of iterations increases, a certain algorithm will reduce IGD faster, while the IGD of other algorithms will decrease more slowly. Since the initial population is a population closer to the Pareto frontier, an algorithm with a faster IGD decline has a better ability to develop better solutions in the decision space. In
Figure 4e and
Figure 5e, on the instance mk5, the NSGA-III-CX has the best ability to develop better solutions. NSGA-III-OBX has the best development capability on other instances. It is speculated from this that when faced with different decision spaces, the crossover operator with better development capabilities may change. The research in this section can help us design more effective evolutionary mechanisms to solve low carbon FJSP.
3.3. The NSGA-III-COE Proposal
The research in the previous two sections shows that the NSGA-III variant using the three crossover operators CX, OBX, and PBX has better exploration capabilities than others in the decision space. When the initial population is close to the Pareto frontier, in most instances, NSGA-III-OBX has the best ability to develop better solutions in the decision space. However, in a few instances, NSGA-III-OBX does not have the best development capabilities. Therefore, which cross-operator has the best development capability is still uncertain. The above research aims to help us design a more effective evolutionary mechanism when solving the MO-FJSP.
Many studies have shown that exploring and developing strategies at the same time can find more useful information from the decision space in the process of finding a better solution. If we make full use of the three crossover operators of CX, OBX, and PBX, we can expect the algorithm to achieve better performance. This is the motivation for proposing the NSGA-III-COE algorithm. The effects of three different crossover operators are naturally integrated to improve the search ability of the decision space and maintain the diversity of the population. This is the main purpose of the NSGA-III-COE.
The NSGA-III-COE is the result of the combination of Pareto dominance and indicator-based thought. In order to achieve our purpose, we decided to coevolve three subpopulations using CX, OBX, and PBX crossover operators. In the process of evolution, natural selection is carried out by simulating the evolution of biological populations to achieve the purpose of survival of the fittest. To achieve natural selection, a certain parameter is necessary to guide the evolution of the population. Therefore, we combine the indicator-based idea with NSGA-III and add the concept of indicator into NSGA-III to guide the natural selection of the population.
In order to propose the NSGA-III-COE algorithm, we introduce the set coverage (SC) [
30]. Assuming that both set
A and set
B are obtained approximate solution sets, the numerator of formula (10) represents the number of solutions in which the solution in
B is dominated by at least one solution in
A, and the denominator represents the total number of solutions contained in
B. The SC is the probability that the solutions in
B is dominated by at least one solution in
A.
Each subpopulation in the initial population has the same number of individuals. In the evolution process, the evolution of biological populations is simulated, and a small number of individuals are randomly exchanged in each iteration to increase the diversity of chromosomes in the decision space and to increase the amount of useful information in the decision space.
When the evolution reaches half of the maximum number of iterations, the SC indicator intervenes. The subpopulation size is adjusted every 10 generations according to the SC indicator. The SC indicator makes natural selection of the subpopulation based on the exploration and the development ability of the subpopulation in the decision space. Natural selection in the evolutionary process means increasing the size of superior subpopulations and reducing the size of disadvantaged subpopulations in order to achieve the survival of the fittest. Algorithm 1 describes the evolutionary mechanism of the NSGA-III-COE.
| Algorithm 1: Evolutionary mechanism of the NSGA-III-COE. |
| 1. function Evolution(PopCX, PopOBX, PopPBX, genNow, gen) |
| 2. if genNow > gen/2 and mod(genNow, gen/10) == 0 then |
| 3. PopCX, PopOBX, PopPBX AdjustPopSzie(PopCX, PopOBX, PopPBX) |
| 4. end if |
| 5. PopCX, PopOBX, PopPBX RandomExchange(PopCX, PopOBX, PopPBX) |
| 6. PopCX OperatorCX(PopCX) |
| 7. PopCX OperatorCX(PopCX) |
| 8. PopCX OperatorCX(PopCX) |
| 9. return PopCX, PopOBX, PopPBX |
| 10. end function |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}