Algorithmic Approaches to Inventory Management Optimization


Abstract
1. Introduction
- A deterministic linear programming model (DLP) that uses either the rolling horizon or shrinking horizon technique in order to determine optimal re-order quantities for each time period at each node in the supply network. Customer demand is modeled at its expectation value throughout the rolling/shrinking horizon time window.
- A multi-stage stochastic program (MSSP) with a simplified scenario tree, as described in Section 2.7. Shrinking and rolling horizon for the MSSP model are both implemented to decide the reorder quantity at each time period.
- A reinforcement learning model (RL) that makes re-order decisions based on the current state of the entire network.
2. Materials and Methods
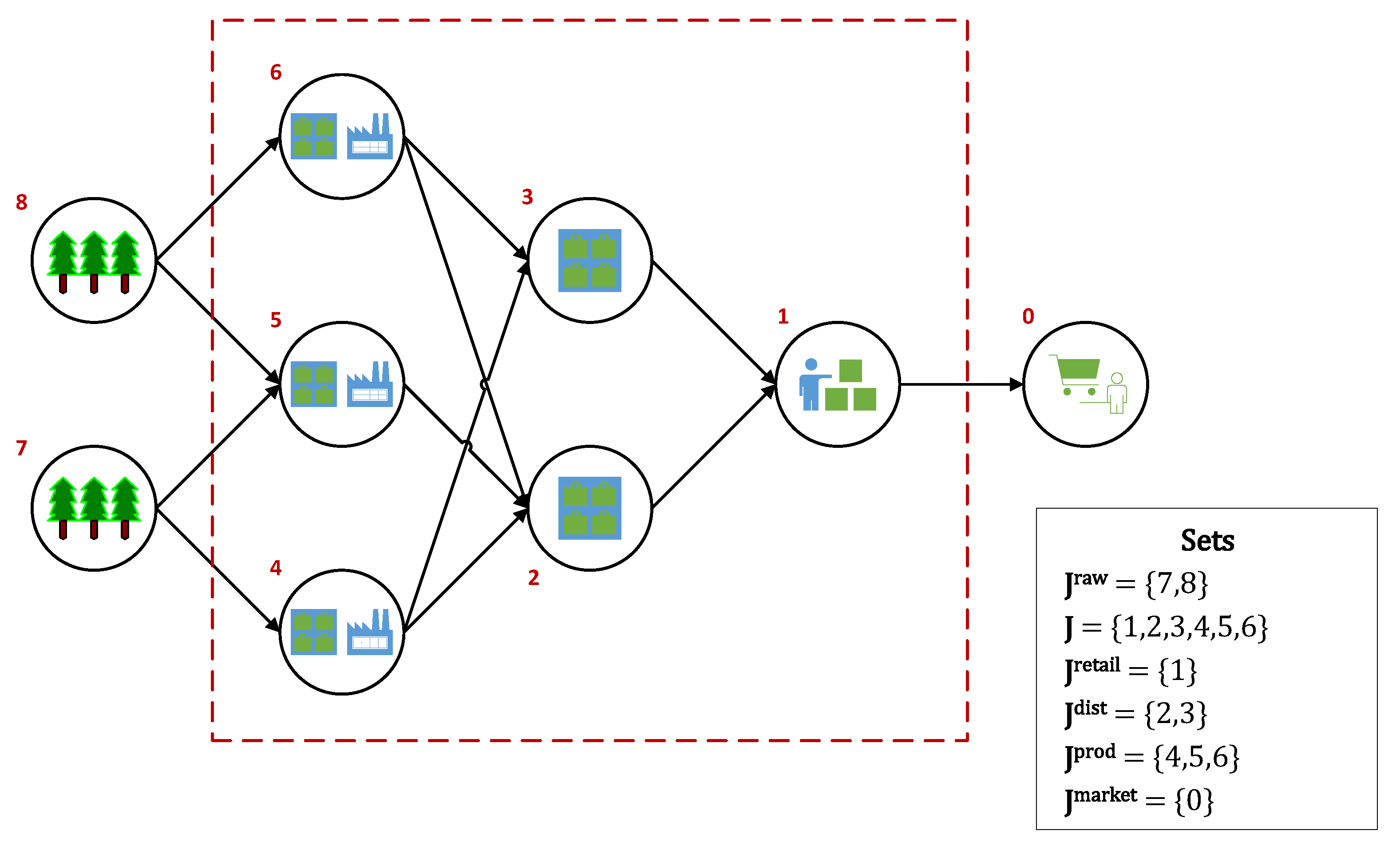
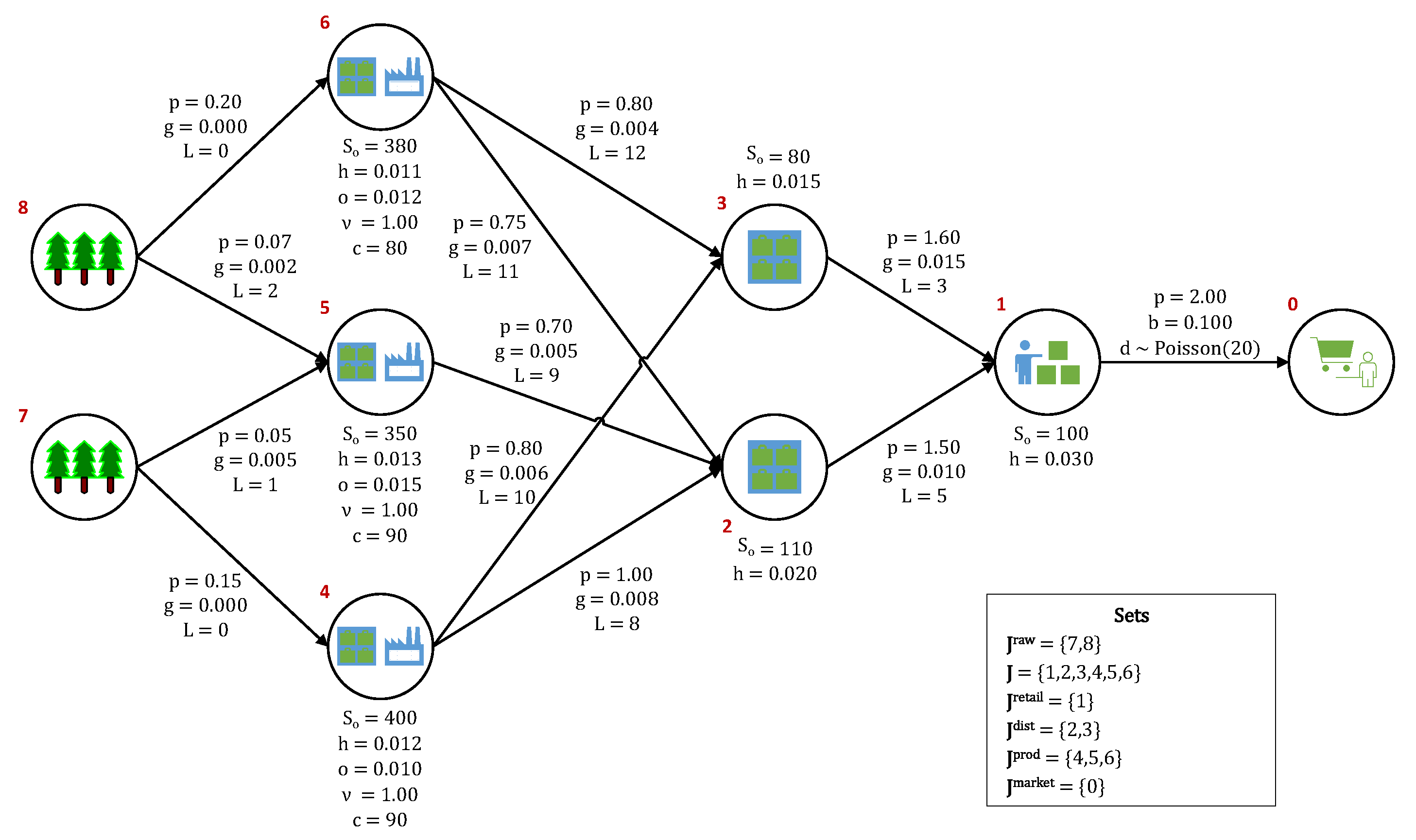
2.1. Problem Statement
2.2. Sequence of Events
- Main network nodes (retailer, distributors, and producers) place replenishment orders to their respective suppliers. Replenishment orders are filled according to available production capacity and available feedstock inventory at the respective suppliers. The supply network is assumed to be centralized, such that replenishment orders never exceed what can be provided by the suppliers to each node.
- The main network nodes receive incoming feedstock inventory replenishment shipments that have made it down the product pipeline (after the associated lead times have transpired). The lead times between stages include both production times and transportation times.
- Single-product customer demand occurs at the retail node and it is filled according to the available inventory at that stage.
- One of the following occurs at the retailer node,
- (a)
- Unfulfilled sales are backlogged at a penalty. Backlogged sales take priority in the following period.
- (b)
- Unfulfilled sales are lost and a goodwill loss penalty is levied.
- Surplus inventory is held at each node at a holding cost. Inventory holding capacity limits are not included in the present formulation, but they can be easily added to the model, if needed. The IMP that is presented here is capacitated in the sense that manufacturing at production nodes is limited by both the production capacity and the availability of feedstock inventory at each node. Because the supply network operates as a make-to-order system, only feedstock inventories are held at the nodes. All of the product inventory is immediately shipped to the downstream nodes upon request, becoming feedstock inventory to those nodes (or simply inventory if the downstream node is a distributor/retailer). A holding (e.g., transportation) cost is also placed on any pipeline inventory (in-transit inventory).
- Any inventory remaining at the end of the last period (period 30 in the base case) is lost, which means that it has no salvage value.
2.3. Key Variables
2.4. Objective Function
2.5. IMP Model
2.5.1. Network Profit
2.5.2. Inventory Balances
2.5.3. Inventory Requests
2.5.4. Market Sales
2.5.5. Variable Domains
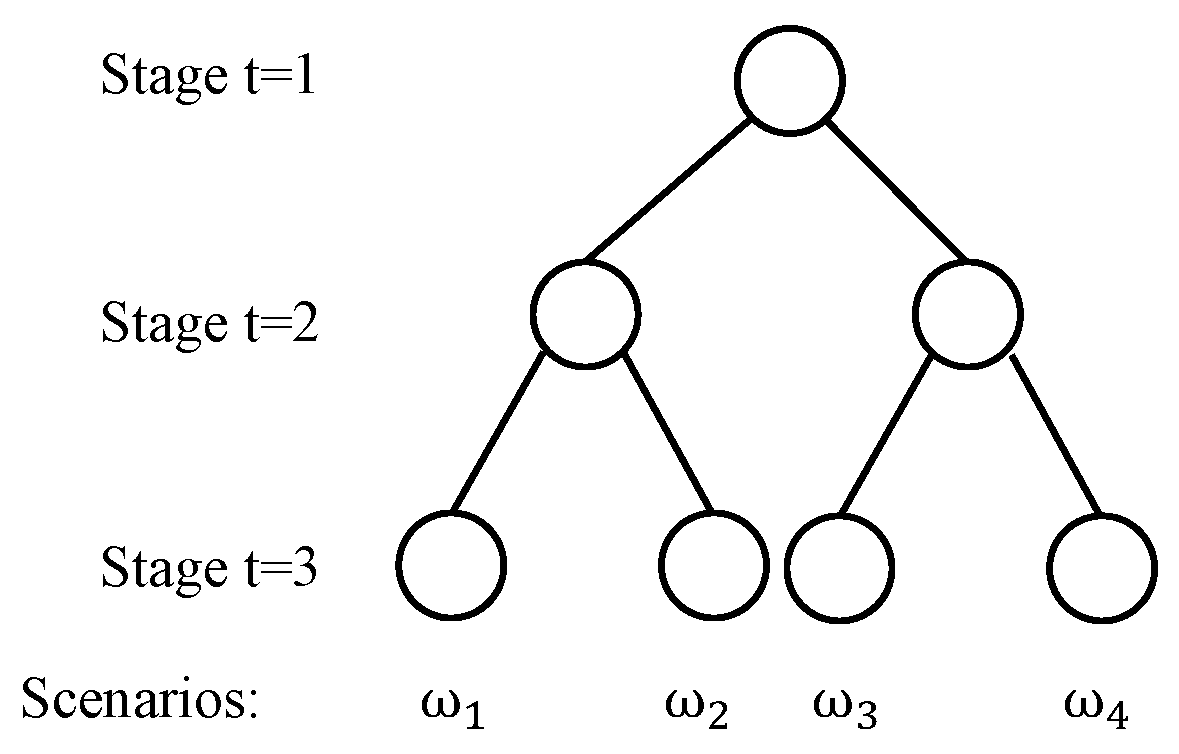
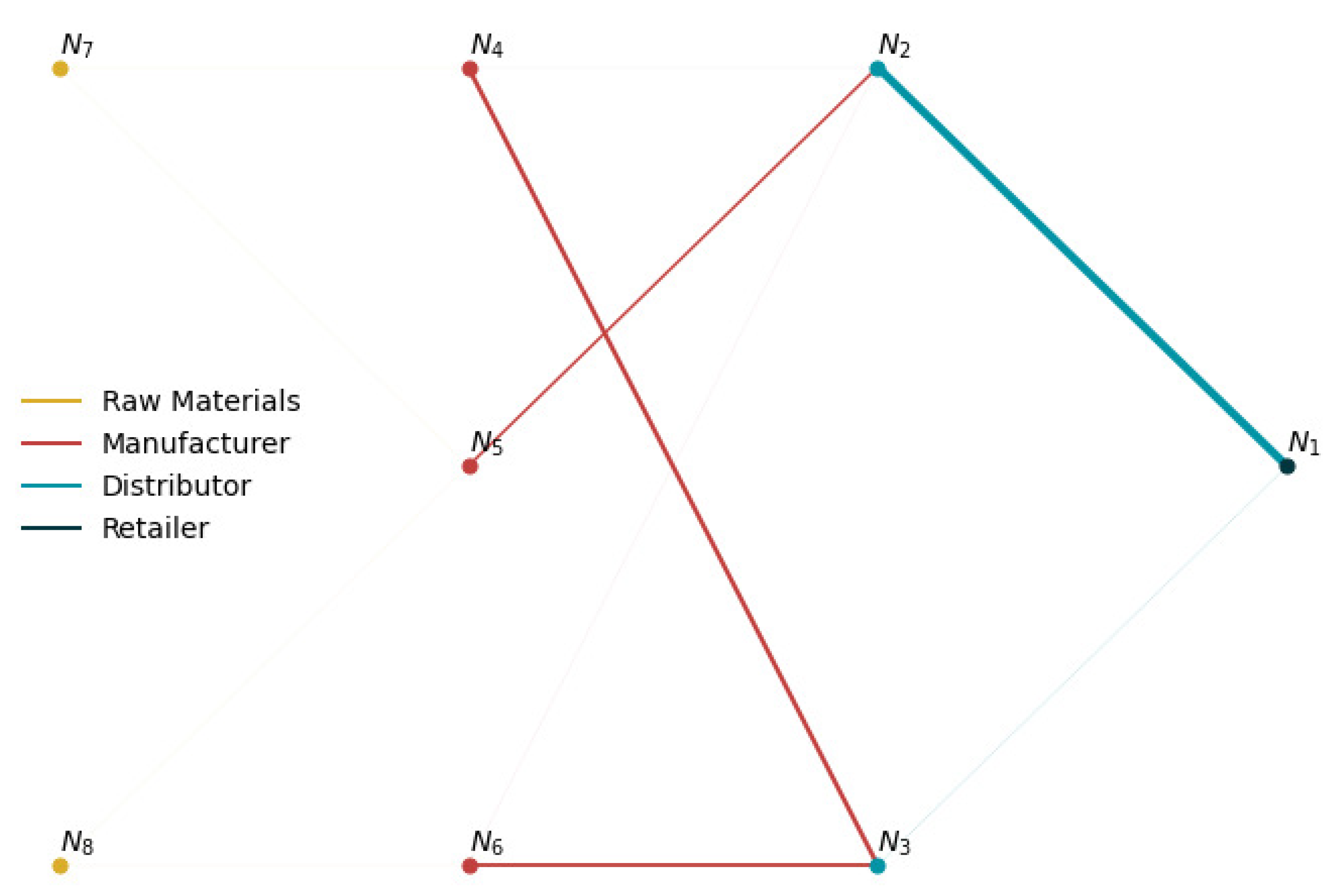
2.6. Scenario Tree for Multistage Stochastic Programming
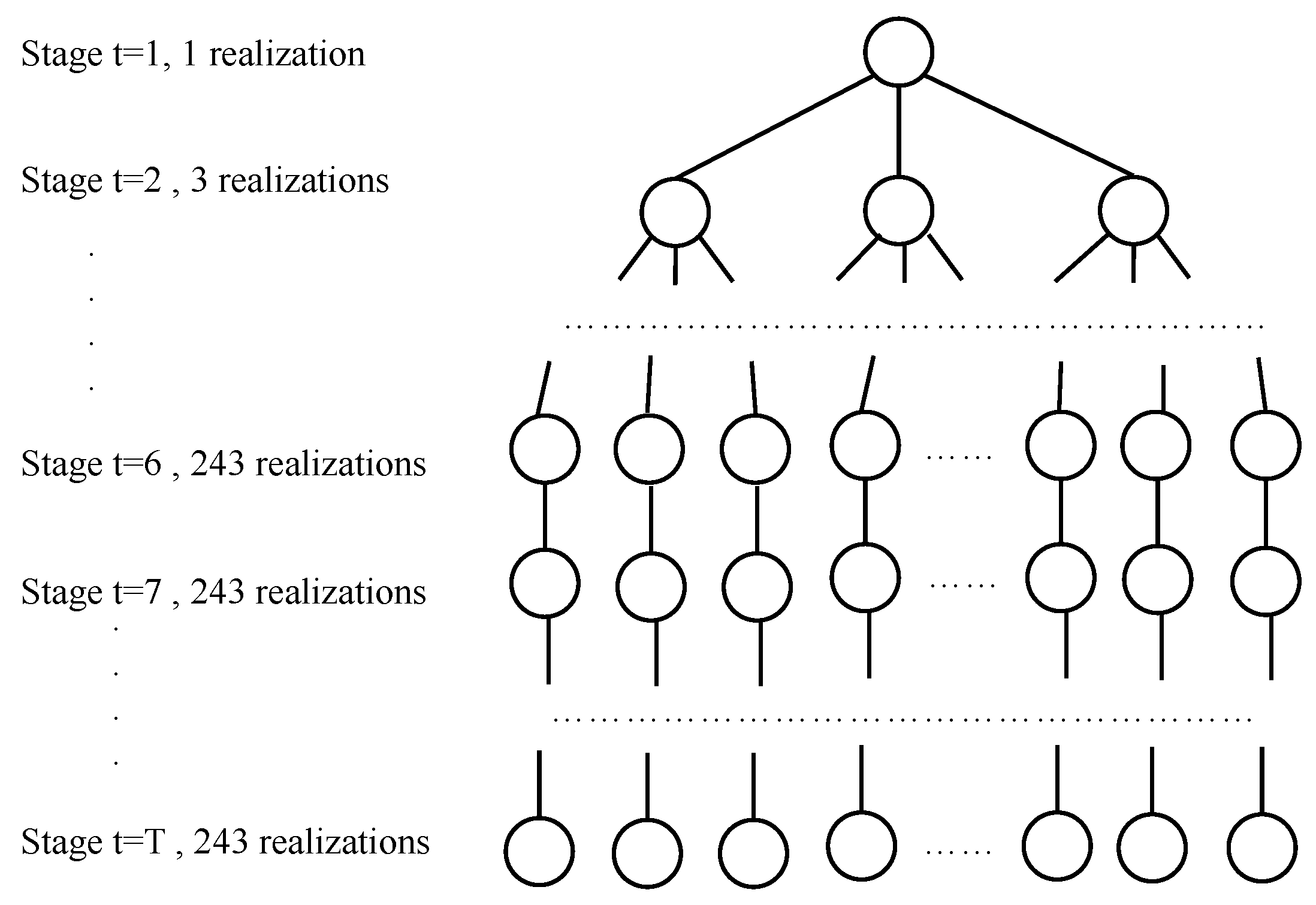
2.7. Approximation for the Multistage Scenario Tree
2.8. Perfect Information and Deterministic Model
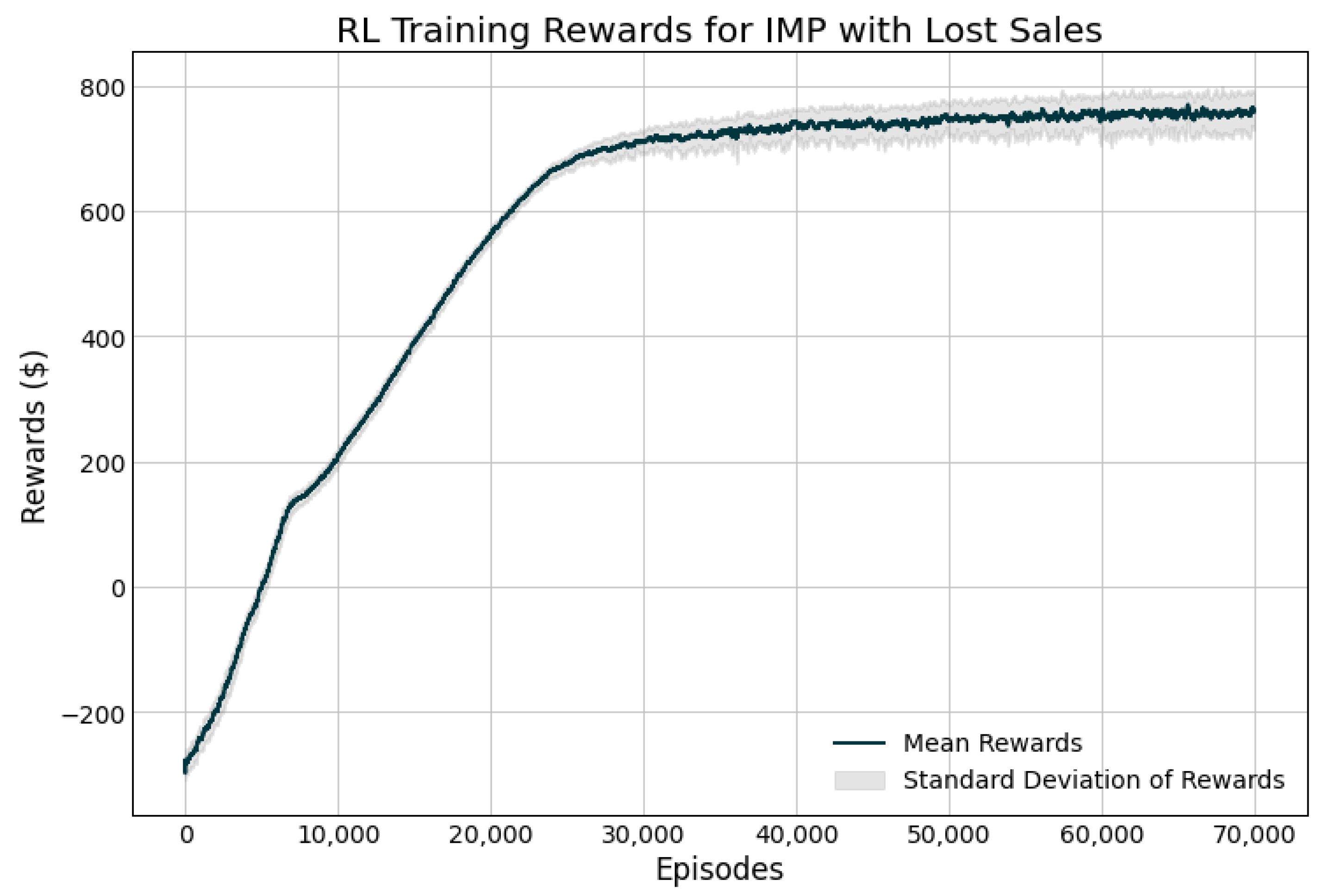
2.9. Reinforcement Learning Model
2.10. Case Study
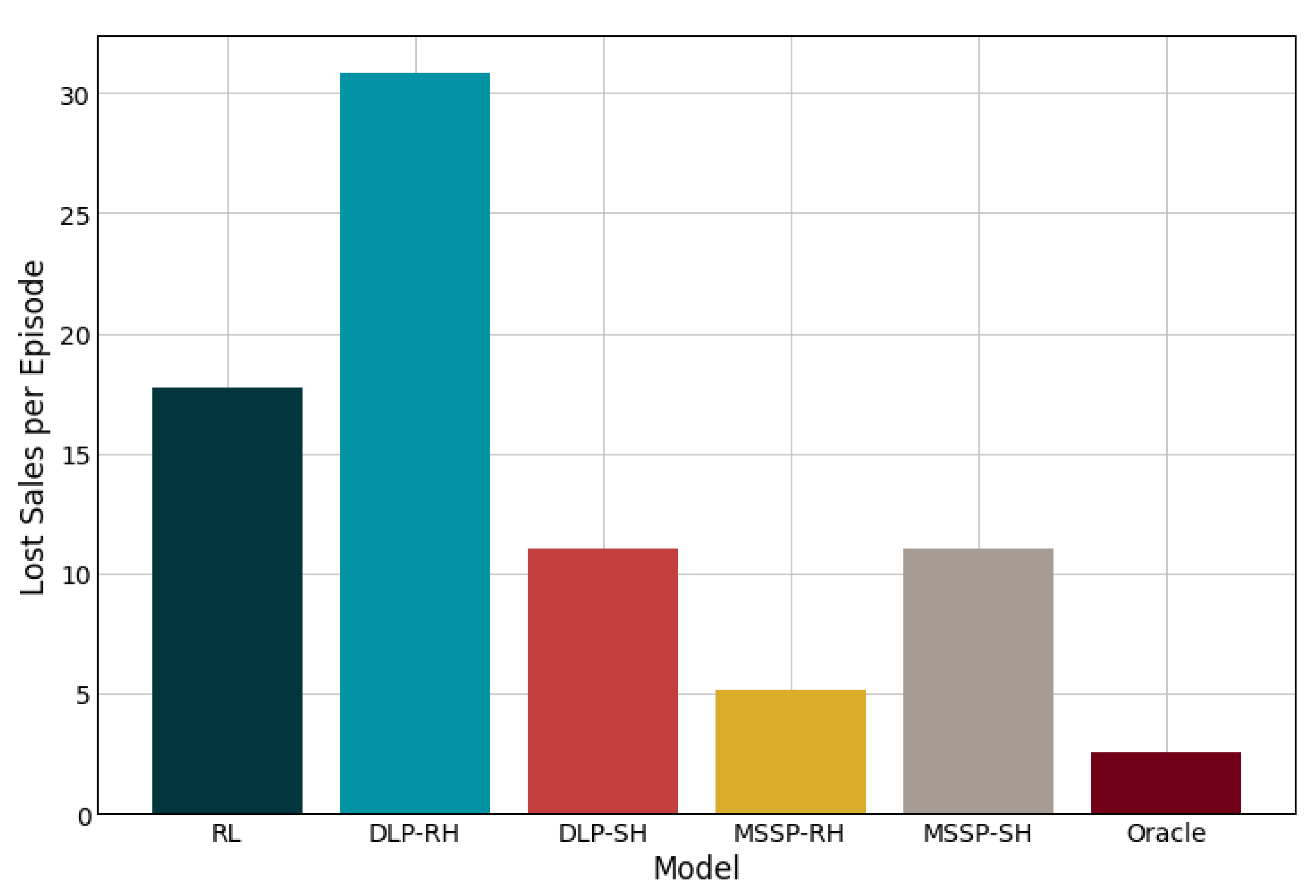
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| LP | Linear Programming |
| DLP | Deterministic Linear Programming |
| MILP | Mixed-integer Linear Programming |
| 2SSP | Two-stage Stochastic Programming |
| MSSP | Multi-stage Stochastic Programming |
| RL | Reinforcement Learning |
| AI | Artificial Intelligence |
| PPO | Proximal Policy Optimization |
| MDP | Markov Decision Process |
| IMP | Inventory Management Problem |
References
- Lee, H.L.; Padmanabhan, V.; Whang, S. Information distortion in a supply chain: The bullwhip effect. Manag. Sci. 1997, 43, 546–558. [Google Scholar] [CrossRef]
- Eruguz, A.S.; Sahin, E.; Jemai, Z.; Dallery, Y. A comprehensive survey of guaranteed-service models for multi-echelon inventory optimization. Int. J. Prod. Econ. 2016, 172, 110–125. [Google Scholar] [CrossRef]
- Simchi-Levi, D.; Zhao, Y. Performance Evaluation of Stochastic Multi-Echelon Inventory Systems: A Survey. Adv. Oper. Res. 2012, 2012, 126254. [Google Scholar] [CrossRef]
- Glasserman, P.; Tayur, S. Sensitivity analysis for base-stock levels in multiechelon production-inventory systems. Manag. Sci. 1995, 41, 263–281. [Google Scholar] [CrossRef]
- Chu, Y.; You, F.; Wassick, J.M.; Agarwal, A. Simulation-based optimization framework for multi-echelon inventory systems under uncertainty. Comput. Chem. Eng. 2015, 73, 1–16. [Google Scholar] [CrossRef]
- Dillon, M.; Oliveira, F.; Abbasi, B. A two-stage stochastic programming model for inventory management in the blood supply chain. Int. J. Prod. Econ. 2017, 187, 27–41. [Google Scholar] [CrossRef]
- Fattahi, M.; Mahootchi, M.; Moattar Husseini, S.M.; Keyvanshokooh, E.; Alborzi, F. Investigating replenishment policies for centralised and decentralised supply chains using stochastic programming approach. Int. J. Prod. Res. 2015, 53, 41–69. [Google Scholar] [CrossRef]
- Pauls-Worm, K.G.; Hendrix, E.M.; Haijema, R.; Van Der Vorst, J.G. An MILP approximation for ordering perishable products with non-stationary demand and service level constraints. Int. J. Prod. Econ. 2014, 157, 133–146. [Google Scholar] [CrossRef]
- Zahiri, B.; Torabi, S.A.; Mohammadi, M.; Aghabegloo, M. A multi-stage stochastic programming approach for blood supply chain planning. Comput. Ind. Eng. 2018, 122, 1–14. [Google Scholar] [CrossRef]
- Bertsimas, D.; Thiele, A. A robust optimization approach to inventory theory. Oper. Res. 2006, 54, 150–168. [Google Scholar] [CrossRef]
- Govindan, K.; Cheng, T.C. Advances in stochastic programming and robust optimization for supply chain planning. Comput. Oper. Res. 2018, 100, 262–269. [Google Scholar] [CrossRef]
- Roy, B.V.; Bertsekas, D.P.; North, L. A neuro-dynamic programming approach to admission control in ATM networks. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997. [Google Scholar]
- Kleywegt, A.J.; Non, V.S.; Savelsbergh, M.W. Dynamic Programming Approximations for a Stochastic Inventory Routing Problem. Transport. Sci. 2004, 38, 42–70. [Google Scholar] [CrossRef]
- Topaloglu, H.; Kunnumkal, S. Approximate dynamic programming methods for an inventory allocation problem under uncertainty. Naval Res. Logist. 2006, 53, 822–841. [Google Scholar] [CrossRef]
- Kunnumkal, S.; Topaloglu, H. Using stochastic approximation methods to compute optimal base-stock levels in inventory control problems. Oper. Res. 2008, 56, 646–664. [Google Scholar] [CrossRef]
- Cimen, M.; Kirkbride, C. Approximate dynamic programming algorithms for multidimensional inventory optimization problems. In Proceedings of the 7th IFAC Conference on Manufacturing, Modeling, Management, and Control, Saint Petersburg, Russia, 19–21 June 2013; Volume 46, pp. 2015–2020. [Google Scholar] [CrossRef]
- Sarimveis, H.; Patrinos, P.; Tarantilis, C.D.; Kiranoudis, C.T. Dynamic modeling and control of supply chain systems: A review. Comput. Oper. Res. 2008, 35, 3530–3561. [Google Scholar] [CrossRef]
- Mortazavi, A.; Arshadi Khamseh, A.; Azimi, P. Designing of an intelligent self-adaptive model for supply chain ordering management system. Eng. Appl. Artif. Intell. 2015, 37, 207–220. [Google Scholar] [CrossRef]
- Oroojlooyjadid, A.; Nazari, M.; Snyder, L.; Takáč, M. A Deep Q-Network for the Beer Game: A Reinforcement Learning algorithm to Solve Inventory Optimization Problems. arXiv 2017, arXiv:1708.05924. [Google Scholar]
- Kara, A.; Dogan, I. Reinforcement learning approaches for specifying ordering policies of perishable inventory systems. Expert Syst. Appl. 2018, 91, 150–158. [Google Scholar] [CrossRef]
- Sultana, N.N.; Meisheri, H.; Baniwal, V.; Nath, S.; Ravindran, B.; Khadilkar, H. Reinforcement Learning for Multi-Product Multi-Node Inventory Management in Supply Chains. arXiv 2020, arXiv:2006.04037. [Google Scholar]
- Hubbs, C.D.; Perez, H.D.; Sarwar, O.; Sahinidis, N.V.; Grossmann, I.E.; Wassick, J.M. OR-Gym: A Reinforcement Learning Library for Operations Research Problems. arXiv 2020, arXiv:2008.06319. [Google Scholar]
- Hochreiter, R.; Pflug, G.C. Financial scenario generation for stochastic multi-stage decision processes as facility location problems. Ann. Oper. Res. 2007, 152, 257–272. [Google Scholar] [CrossRef]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.I.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2016, arXiv:1506.02438. [Google Scholar]
- Moritz, P.; Nishihara, R.; Wang, S.; Tumanov, A.; Liaw, R.; Liang, E.; Elibol, M.; Yang, Z.; Paul, W.; Jordan, M.I.; et al. Ray: A Distributed Framework for Emerging AI Applications. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018. [Google Scholar]
- Lima, R.M.; Grossmann, I.E.; Jiao, Y. Long-term scheduling of a single-unit multi-product continuous process to manufacture high performance glass. Comput. Chem. Eng. 2011, 35, 554–574. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| The reorder quantity requested to supplier node j by node k at the beginning of period t (the amount of material sent from node j to node k) | |
| The amount retailer j sells to market k in period . Note: Retail sales are indexed at the next period since these occur after demand in the current period is realized. | |
| The on-hand inventory at node j just prior to when the demand is realized in period t. | |
| The in-transit (pipeline) inventory between node j and node k just prior to when the demand is realized in period t. | |
| The unfulfilled demand at retailer j associated with market k in period . Note: indexing is also shifted since any unfulfilled demand occurs after the uncertain demand is realized. | |
| The profit (reward) in node j for period t. |
| DLP-RH | DLP-SH | MSSP-RH | MSSP-SH | RL | Oracle | |
|---|---|---|---|---|---|---|
| Backlog | ||||||
| Mean Profit | 791.6 | 825.3 | 802.7 | 847.7 | 737.2 | 861.3 |
| Standard Deviation | 52.5 | 37.0 | 56.3 | 49.4 | 24.8 | 56.4 |
| Performance Ratio | 1.09 | 1.04 | 1.07 | 1.02 | 1.17 | 1.00 |
| Lost Sales | ||||||
| Mean Profit | 735.8 | 786.9 | 790.6 | 830.6 | 757.8 | 854.9 |
| Standard Deviation | 31.2 | 30.8 | 47.8 | 37.7 | 33.1 | 49.9 |
| Performance Ratio | 1.16 | 1.09 | 1.08 | 1.03 | 1.13 | 1.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perez, H.D.; Hubbs, C.D.; Li, C.; Grossmann, I.E. Algorithmic Approaches to Inventory Management Optimization. Processes 2021, 9, 102. https://doi.org/10.3390/pr9010102
Perez HD, Hubbs CD, Li C, Grossmann IE. Algorithmic Approaches to Inventory Management Optimization. Processes. 2021; 9(1):102. https://doi.org/10.3390/pr9010102
Chicago/Turabian StylePerez, Hector D., Christian D. Hubbs, Can Li, and Ignacio E. Grossmann. 2021. "Algorithmic Approaches to Inventory Management Optimization" Processes 9, no. 1: 102. https://doi.org/10.3390/pr9010102
APA StylePerez, H. D., Hubbs, C. D., Li, C., & Grossmann, I. E. (2021). Algorithmic Approaches to Inventory Management Optimization. Processes, 9(1), 102. https://doi.org/10.3390/pr9010102