1. Introduction
The pharmaceutical industry is a highly research and development (R&D)-intensive sector. Since the 1970s, R&D activity in the pharmaceutical industry has increased rapidly. In addition to the intensive use of R&D, the challenges faced in pharmaceutical R&D have increased considerably. Consequently, developments in the pharmaceutical industry have taken place as a result of the increased difficulties encountered in the pharmaceutical R&D [
1,
2].
Pharmaceutical companies have attempted to find novel materials that are different from incumbent and traditional materials, such as small molecules and the so-called new molecular entities (NMEs), through the use of biologics and biological entities. Changes in the type of pharmaceutical R&D companies have also taken place; more recently, small companies have increased and, from 2004, these exceeded the productivity of the R&D departments of bigger companies [
2].
In the early 2000s, pharmaceutical innovation was science-based, i.e., the innovation was highly dependent on scientific researchers, their network, and the collaborations among scientists and scientific institutes [
3,
4,
5].
In the last 10 years, rapid changes in innovation have occurred as a result of improvements in data availability and computational ability. This innovation is a part of the “fourth industrial revolution,” which combines technologies and blends advanced services based on data science [
6,
7,
8,
9,
10,
11,
12,
13,
14]. In detail, data science shows many possibilities of improving productivity and adopting new business models with promising technologies, such as wireless sensor networking, big data, artificial intelligence, cloud-based services, and so forth. Data science plays a role in enabling automation, optimization of production, data-driven innovation, variety of personalized services, and so forth in various industries [
12,
13].
The pharmaceutical industry has also used data sciences for innovation and attempted to overcome the drawbacks of business models that require tremendous amounts of budget for innovation. Hence, pharmaceutical innovators or companies have tried to find ways to reduce R&D cost and initiate less risky business models. Pharmaceutical innovation players have attempted to apply data-driven models to assist innovation in the pharmaceutical industry and achieve a lower failure rate in the drug approval process [
9]. The pharmaceutical industry could attempt to develop a new business model supplying personalized services that are less risky and less profitable by applying data science with medical health information [
6,
7,
12,
14].
The pharmaceutical industry has been adopting data science-based innovation. These changes in pharmaceutical innovation can be identified through the examination of patent activities. The authors hypothesized that the technological innovation regime differed according to period, and the patent data could reflect the changes in the technological innovation regime. Thus, this study aimed to find innovation trends in the patent information that could provide a deeper and more specific understanding of data-science-based pharmaceutical innovation.
Section 2 of this paper highlights previous studies discussing trends in innovation in the pharmaceutical industries that have moved from science-based to a data science-based innovation.
Section 3 of this paper explains the empirical methodology, showing the relationship between technology classification codes and the data retrieval process.
Section 4 of this paper includes the descriptive statistics of data, empirical results, and a discussion on the implications of the empirical results. In
Section 5 of the paper, the authors suggest conclusive results and offer an in-depth discussion on pharmaceutical innovation trends from the patent analysis.
2. Literature Review
Innovation is the process that refers to the development and application of a new product, process, or service, as assessed by the United States (US) Office of Technology [
15]. Innovation is driven by social situations, and the trends can be monitored.
The pharmaceutical industry is under immense pressure to innovate. This pressure has increased exponentially owing to the vast increase in R&D assets and scientific and engineering personnel. The pharmaceutical industry has spent enormous amounts of money on R&D since the early 1960s. The extent of R&D expenditure was approximately twice that of all other industries in the 1980s, and it had increased by approximately three times that of all other industries by the late of 1990s, despite the decrease in the approval of new drug applications (NDAs) for new molecular entities (NMEs) and non-new molecular entities (non-NME) since 1996 [
1].
Given the increasing complexity in pharmaceutical innovation, companies have attempted to find new ways to survive. The production of biopharmaceuticals compounds began in 1982. Between 1980 and 2004, the number of discovery projects in small companies slightly exceeded those in large companies. This resulted in a few small companies succeeding in their discovery projects, which, in turn, led to an increase in the mergers and acquisitions (M&A) of small companies [
2].
In view of the increased computing ability and genomic knowledge, pharmaceutical innovation adopted science-based innovation in the early 2000s. The changes in innovation in the pharmaceutical industry have resulted in changes in the process of innovation and, subsequently, presented new possibilities. The key requirements for the successful management of science-based innovation in the pharmaceutical industry are a new international market strategy and internationalization and collaboration strategies in the R&D management [
3]. The collaboration strategy should be used at the level of the national innovation system. Korea has a national innovation system using horizontal and vertical collaboration among government-sponsored research institutes to promote innovation within the pharmaceutical industry [
4,
5].
Since the late 2000s, most science has been impacted by the rapid increase in availability of information. As a result of this impact, traditional methodologies are re-adopted and re-applied with the largely increased size of available data. This phenomenon is known as data science, which has rebuilt traditional science based on this largely increased size of data. Data science has induced changes in many industries, as well as in science and academia. The healthcare industry has adopted data science to provide developed, qualified, and personalized services [
6,
7,
12]. The strength of data science is that it merges various technologies; in particular, it combines pharmaceutical technology with digital and physical technologies [
8,
12].
Before the emergence of data science, science-based innovation was limited by productivity and dependent on previous research [
16,
17,
18,
19]. For example, in other R&D intensive industries, such as the energy industry, upstream companies insisted on the continued production of shale gas and oil from the early to the middle 2010s [
20]. However, these companies needed to develop new production technologies by using data science [
21,
22]. Moreover, they attempted to change their business routine by horizontally and vertically expanding their business area [
23].
In case of the pharmaceutical industry, some incumbent pharmaceutical innovators have applied modeling and simulating to reduce development costs. In addition, some companies have used data to perform a qualitative risk assessment [
9].
However, recently, data-driven methods have emerged to reduce the high cost of extensive experimentation through the replacement of traditional simulation-based analysis with a quality by design (QbD) system [
10]. The manufacturing system can be made more productive and efficient through the adoption of data science analysis methods. In the recent years, the continuous tablet manufacturing system is one of the most notable applications of data science-driven innovation [
11]. The genomic data analysis-based development of drugs is used in clinical practice to reduce the cost of gathering the three billion human DNA [
24].
A data science-based approach to the medical or pharmaceutical industry starts with the generation of data (electronic medical records (EMR) and electronic health records (HER)) related to medical, health, or clinical use and the transmission and storage of the data in the medical information system. The stored data are integrated and analyzed by a comprehensive clinical research approach dealing with data regarding genes, transcripts, proteins, and metabolites, known as omics. Interestingly, the omics-based services are also provided by traditional information technology companies as well as traditional medical care company [
25].
The data science-based innovation or R&D begins with the measurement of highly utilizable data suitable for data science. Recent data science environments require high-performance hardware and time, to develop data science-based analytical models. However, for analysis and measurement, it is possible to operate even if the hardware is small and has a low performance capability. With the universalization of the wireless internet and the use of cloud-based services, small devices are now able to measure, analyze, store, and manage data and results for users, through network communications without the necessity for separate storage. In addition, with the popularization of the smartphone, most people have access to high-performance computing and wireless network equipment. Thus, the development of measuring equipment in such a technological environment, can be used as a means to secure competitiveness by lowering users’ entry barriers in healthcare services. Additionally, the development of multi-purpose health care measurement equipment has the advantage of applicability across various methods of service [
13,
14].
Personalized pharmaceutical services have also been developed by the application of 3-dimensional printing tools. The first approval of a 3D printed drug was announced in August 2015. As 3D-printed drugs are in the early stages of innovation, additional time will be required before they are suitable for clinical and general use by the customer. However, the 3D-printed drug technology has an enormous potential for innovation [
26,
27].
A role for data science in the pharmaceutical industry has been suggested in various forms within the integrated value chain. It begins with the generation of patient data, followed by the application of the generated and measured patient data in the conduction of large-scale clinical trials, and, finally, the production and distribution of personally optimized drugs based on the results of clinical research. The administration of an optimized drug generates clinical trial data, and the data subsequently obtained from the dose can be further utilized as clinical research, resulting in a virtuous cycle that improves the accuracy of the optimized drug [
13,
14].
4. Results and Discussion
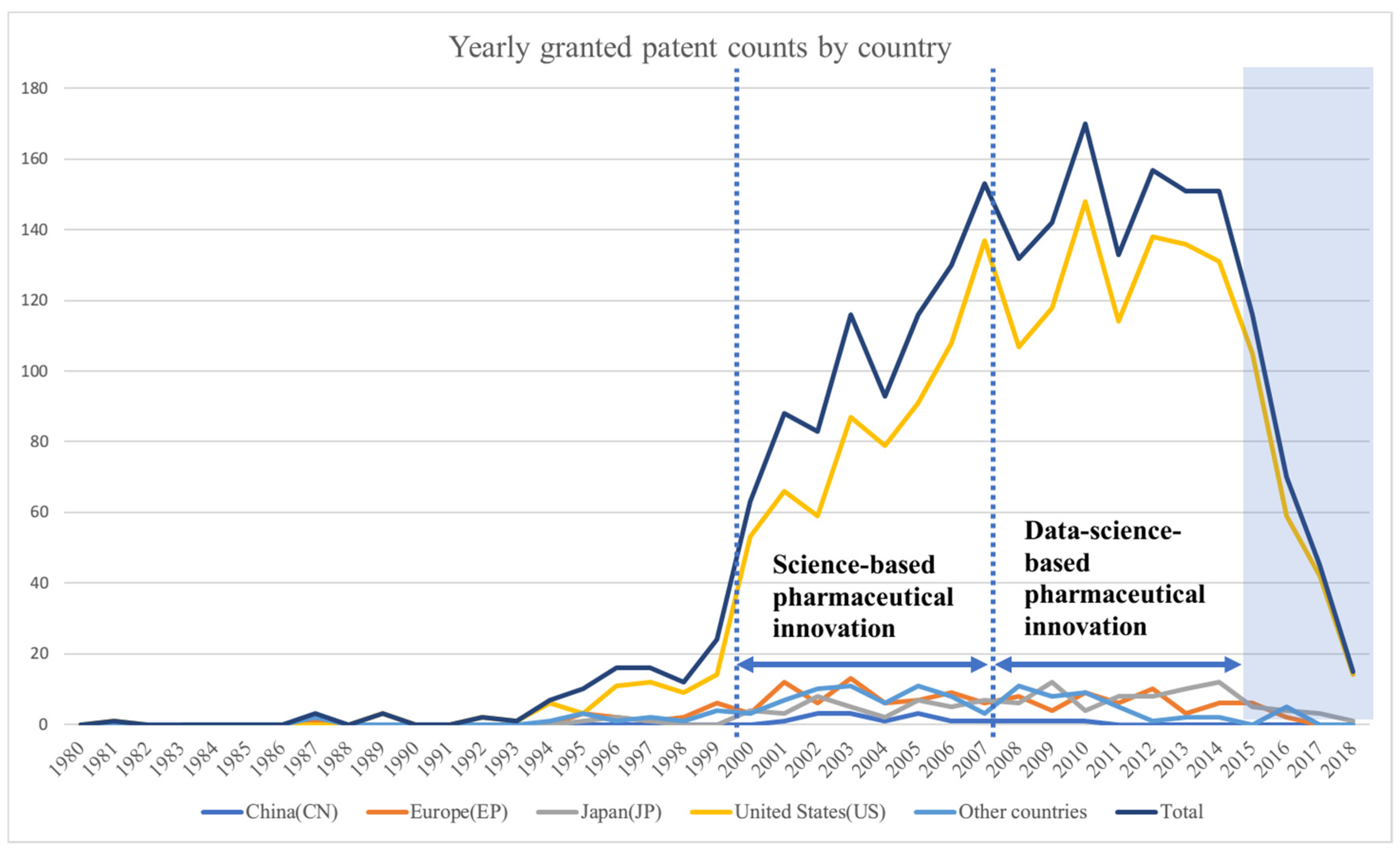
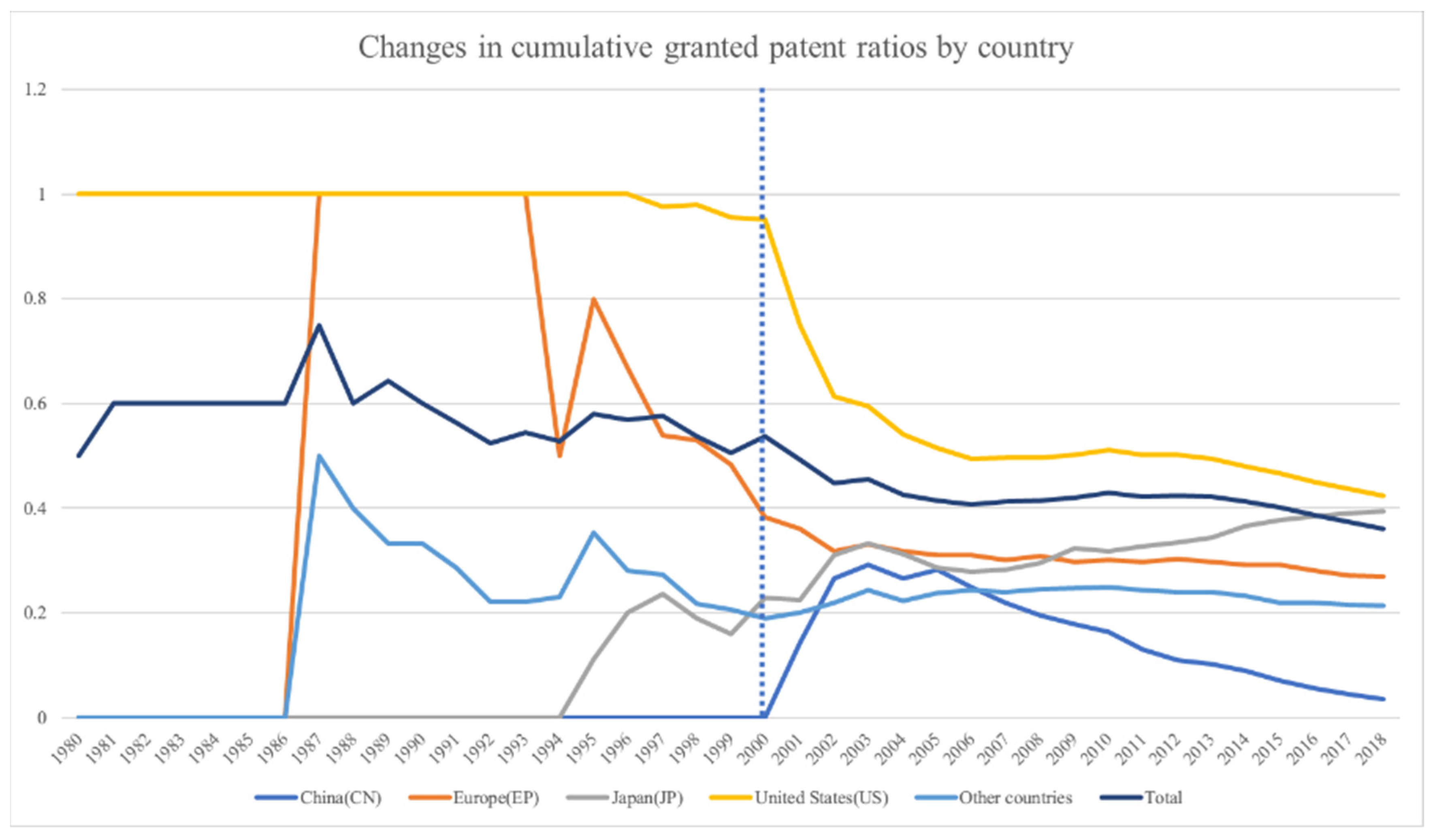
In this section, this study will present the association rules and maps representing the relationship of technologies for a specific innovation regime. The period between 2000 and 2007 was assumed to represent science-based innovation in the pharmaceutical industry. Data science-based innovation in the pharmaceutical industry has been represented by the period between 2008 and 2015. Moreover, this study has provided an in-depth discussion of the results from the perspective of the technological innovation theory.
This study set the minimum value of 0.01 for confidence and support. Therefore, the results showed only the association rules when the confidence and support exceed the minimum value.
4.1. Association Rule and Map of Science Based Pharmaceutical Technology
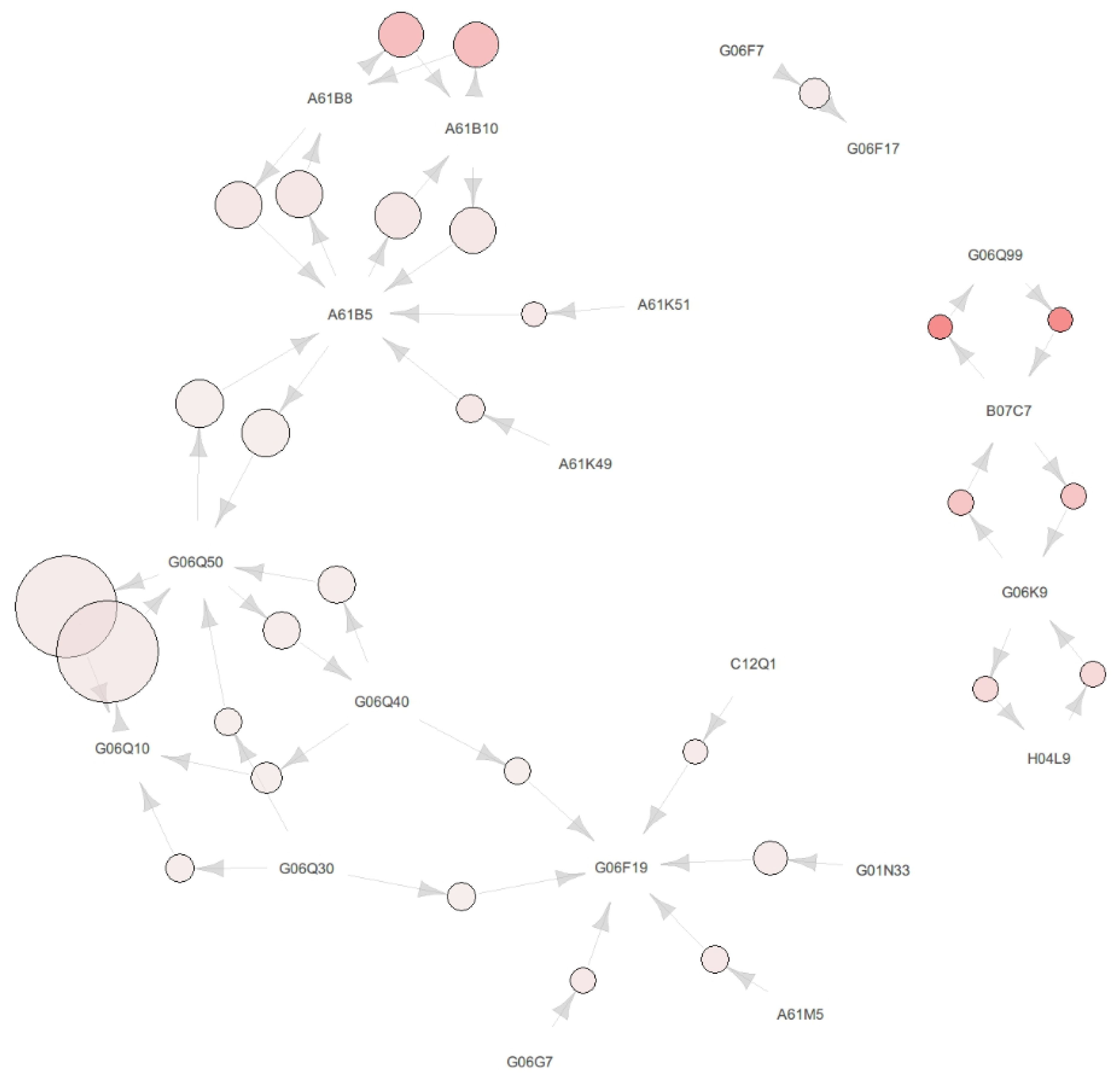
This section shows the association rules and map of the pharmaceutical patent data from 2000 to 2007. As shown in
Figure 3, we found three big clusters with certain IPC codes as the centroid. The IPC codes located as the centroid were A61B5, G06Q50, and G06F19. First,
Figure 3 showed some IPC codes surrounding A61B5 and the codes A61B8, A61B10, A61K49, A61K52, and G06Q50, which have a relationship with A61B5. Second, the IPC codes surrounding G06Q50, that is A61B5, G06Q10, Q06Q30, and G06Q40, which have a relationship with G06Q50, are shown in
Figure 3. Third, the IPC codes surrounding G06F19, that is A61M5, C12Q1, G01N33, G06G7, G06Q30, and G06Q40, which have a relationship with G06F19, are shown in
Figure 3. Detailed information of
Figure 3 is shown in
Table A1,
Table A2 and
Table A3 of
Appendix A.
The IPC code located as the centroid has a relationship from some surrounding codes and a relationship towards some other surrounding codes. The feature of the centroid IPC code is that the relationship from surrounding IPC code to centroid IPC code has a higher confidence than the confidence of relationship from the centroid to the surrounding IPC code. This characteristic means that the technology corresponding to the centroid IPC code dispreads and is more commonly used when new patents or technology are invented. Furthermore, it would imply that the technology corresponding to the centroid IPC code is adopted, together with technologies corresponding to surrounding IPC code, but that the precedence of technology corresponding to the centroid IPC code would be an efficient way to invent technology and receive patents.
As another characteristic of the centroid IPC code, the centroid IPC code has a relationship with other centroid IPC codes. For example, the IPC code G06Q50 has a relationship with A61B5, and also the G06Q50 has a relationship with G06F19 through intermediate IPC codes, as shown in
Figure 3. The code A61B5 has a relationship with G06Q50 and no relationship with G06F19. Actually, there is a direct relationship between the centroid IPC codes, but it is not weighty enough to be shown in
Figure 3. The less weighty and directly connected relationships between the centroid IPC codes are presented in
Table 4.
Table 4 shows the relationships of G06Q10 with G06F19, A61B5 with G06F19, and A61B5 with G06Q50. The feature of panel A in
Table 4 is that all relationships are substitutive, because every value of lift is less than one. However, the substitutive extent was different. The relationship between A61B5 and G06Q10 was 0.903. As that was close to one, most of the last substitutive relationships were in panel A of
Table 4. G06Q50 has a relationship with G06F19 and A61B5. The relationships involving G06Q50 show a lower lift value than the relationship between A61B5 and G06F19. The lift value of the relationship between G06Q50 and G06F19 is 0.693, which is the most substitutive and lowest lift value in panel A of
Table 4. The lift value of the relationship between A61B5 and G06Q50 was 0.739. Interestingly, the multi-component, which is the combination of centroid IPC codes and other IPC codes, always showed a complementary relationship toward the centroid IPC codes, as shown in panel B of
Table 4. This had two implications. The first is that there was a need to develop combined technology in addition to single and independent technologies. The second is that the technologies of each cluster were developed simultaneously and were then developed independently by cluster. Moreover, the relationship from the triple component to the centroid of clusters showed the highest lift value, other than the relationship of multi-component cases, as shown in panel B of
Table 4.
4.2. Association Rule and Map of Data-Science Based Pharmaceutical Technology
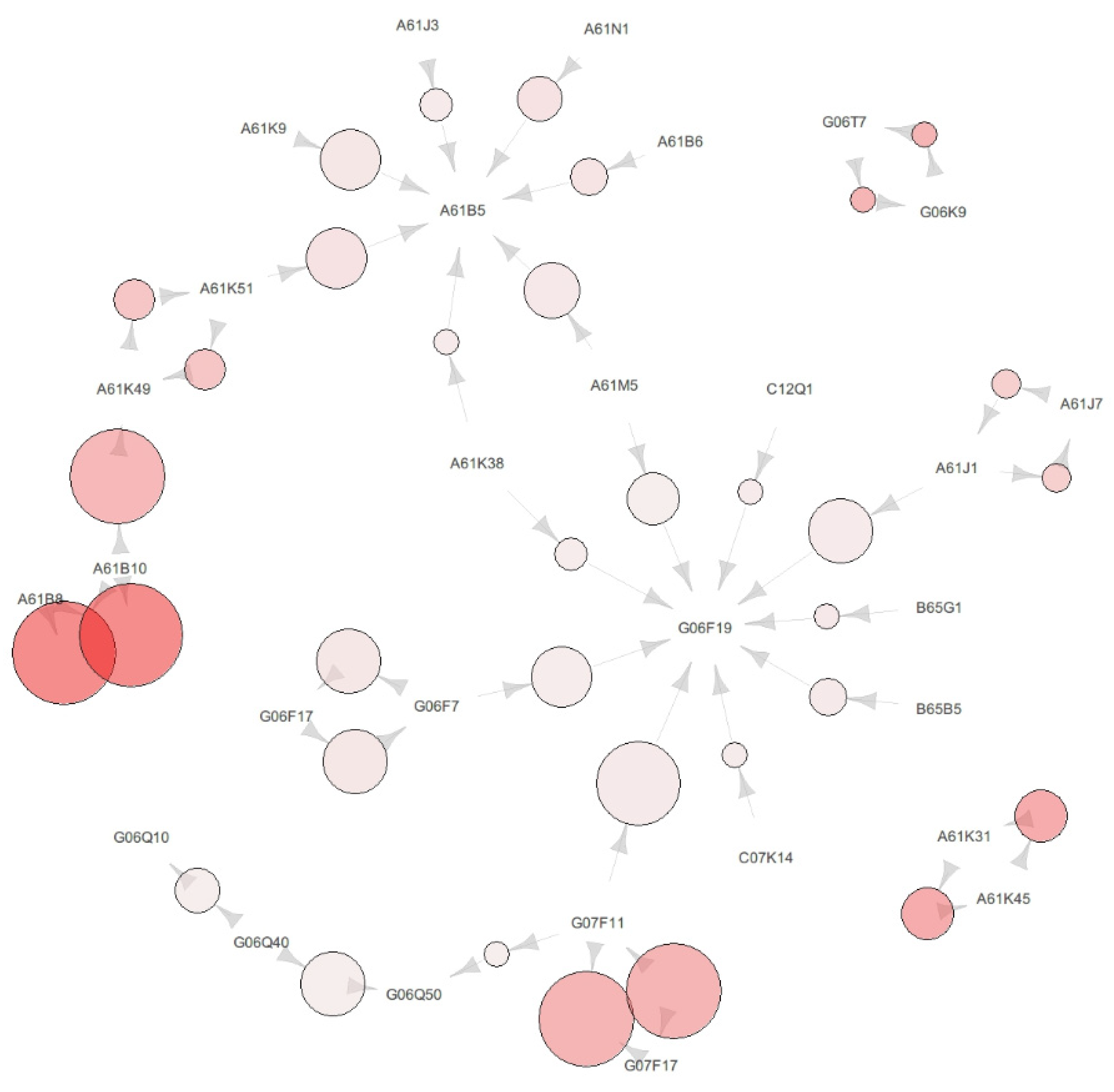
This section shows the association rules and map of pharmaceutical patent data from 2008 to 2015. There were two clusters encircled by different IPC codes, as shown in
Figure 4. The IPC codes located as the centroid are A61B5 and G06F19. First, A61B5 is surrounded by A61K9, A61J3, A61N1, A61B6, A61M5, A61K38, and A61K51. Secondly, G06F19 is surrounded by C12Q1, A61J1, B65G1, B65B5, C07K14, G07F11, G06F7, A61K38, and A61M5. Detailed information of
Figure 4 is shown in
Table A4 and
Table A5 of
Appendix A.
Broadly, the IPC codes are divided into two group in
Figure 4. The majority of IPC codes starting with A61 are linked with the A61B5 cluster and the majority of IPC codes starting with G06 are linked with the G06F19 cluster. In particular, there are intermediate IPC codes between A61B5 and G06F19, that is, A61K38 and A61M5.
The relationship between A61B5 and G06F19 is shown in
Table 5. The relationship between centroid cluster A61B5 and G06F19 was substitutive and the lift value of the relationship was 0.549. The interesting point was that the multi-component’s relationship was different according to object IPC code. The relationship toward G06F19 was complementary, but the relationship toward A61B5 was substitutive in panel B of
Table 5. Every relationship from multi-component to centroid IPC code (A61B5) was complementary except the case involving G06F19, as shown in
Table A4 of
Appendix A. Moreover, every relationship from the multi-component to centroid IPC code (G06F19) was complementary, as shown in
Table A5 of
Appendix A. This implied that there was a need to develop combined technology compared with single and independent technologies when the purpose of developing the technology was represented by G06F19. Further, it implied that technology represented by A61B5 was developed as a precedent technology for the technology represented by G06F19.
Table 6 shows the relationships between intermediate IPC codes (A61M5 and A61K38), and between A61B5 and G06F19. The lift value from A61M5 to A61B5 was 2.740, and the lift value from A61M5 to G06F19 was 1.470. The relationship from A61M5 to A61B5 was more complementary, higher than 1.270, than the relationship from A61M5 to G06F19. The lift value from A61K38 to A61B5 was 2.314, and the lift value from A61K38 to G06F19 was 1.524. The relationship from A61K38 to A61B5 was more complementary, higher than 0.79, compared to the relationship from A61K38 to G06F19. This implied that there was a need for the precedent development of technologies represented by A61M5 and A61K38.
4.3. Discussion
In this section, we will focus on the differences between the science-based period and the data science-based period to illuminate data-driven technological innovation in the pharmaceutical industry. The differences are summarized in
Table 7.
First, the most remarkable difference existed in the intermediate IPC code between two periods. In the science-based innovation period, the centroid IPC codes were A61B5, G06Q50, and G06F19, and the intermediate IPC code between A61B5 and G06F19 was G06Q50. In the data science-based innovation period, the centroid IPC codes were A61B5 and G06F19, and the intermediate IPC code between A61B5 and G06F19 was A61M5 and A61K38. The most remarkable difference was that the intermediate technology changed from G06Q50 to A61K38 and A61M5.
A61M5 has no relationship with A61B5; it only has a relationship with G06F19 from 2000 to 2007. However, A61M5 has a complementary relationship with both A61B5 and G06F19. A61M5 represents “devices for bringing media into the body in a subcutaneous, intra-vascular or intramuscular way,” as shown in
Table A6 of
Appendix A. This implied that the technology represented by A61M5 was more necessary and was invented during the development of clinical testing in the data science-based innovation period.
A61K38 represents “medical preparations containing peptides,” as shown in
Table A7 of
Appendix A. The appearance of technology that used peptides in the data science-based innovation period may reflect the increase in the use of omics-based technologies [
25]. In addition, we found similar cases showing directly connected and complementary relationships for digital computing (G06F19) and chemical materials (C07K14).
The direct relationship of A61B5 and G06F19 has changed. The lift value of A61B5 and G06F19 has decreased, and the difference was 0.354. This implied that the independent development of technology A61B5 and G06F19 occurred less frequently in the science-based innovation period than in the data science-based innovation period. Moreover, as described in
Section 4.2, the precedence for development has been established. Thus, it may be implied that the relationship of technology has become more strict and concrete owing to the accumulation of technological development.
Differences also existed in surrounding IPC codes. A61J3 represented “devices or methods specially adapted for bringing pharmaceutical products into particular physical or administering forms.” The appearance of A61J3 may have indicated the invention for personalized drug forms, such as tablets printed by 3D printers [
27]. The appearance of B65B5, representing “packaging individual articles in containers or receptacles,” and B65G1, representing “storing articles, individually or in orderly arrangement, in warehouses or magazines,” implied the occurrence of inventions for data processing technology dealing with personalized information [
6,
7,
25] as shown in
Table A7 of
Appendix A.
Overall, the empirical results showed some agreement with the literature reviews. Specifically, some results indicated the invention of personalized and qualified services, and some results indicated the features of data science-based pharmaceutical characteristics in the discipline (omics). As summarized in
Table 7, the suggested results and implications of data science-based pharmaceutical innovations are expected to bring about changes in the pharmaceutical industry to reduce risk and obtain medium return compared with the science-based innovation period.
We proposed an in-depth discussion about the most noteworthy IPC code ‘A61B5′ that refers to “measuring for diagnostic purposes.” The following interpretation of the observations of ‘A61B5′ were presented. Development of a measuring device may be relatively easier than the development of an analytical algorithm. Pharmaceutical companies have been competing through the development of measuring instruments. Traditional measuring equipment lacked sufficient potential to provide numerous and frequent measurements suitable for data science-based research. In addition, A61B5 may be included in patents to reflect the corresponding technical features as secondary or incidental technical components, rather than as a major component of the patent. Nevertheless, A61B5 has been included in many patents owing to the pharmacological industry’s data science-based innovation or business model generally including measurement and diagnostic technology as one of the technical features.
5. Conclusions
This paper presents an analysis of patent data distinguished by the period according to the technological innovation regime. The first period, that is science-based innovation, in which pharmaceutical innovation activity was based on simulation, focused on ways to find new NMEs, which involved high return but also high risk. During the second period, that is data science-based innovation, pharmaceutical innovation activity attempted to apply new ways to use data involving personal characteristics and information to identify services and products.
This study attempted to find macro evidence and trends in pharmaceutical innovation activity by using patent data. The empirical results characterized data science-based innovation technology and the points of accordance with the literature review. Despite these efforts to find macro trends, this study has limitations; thus, the accordance of empirical results with the literature review should be developed further to identify a more direct association.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



