
Application of Hybrid Model Based on LASSO-SMOTE-BO-SVM to Lithology Identification During Drilling

Abstract
1. Introduction
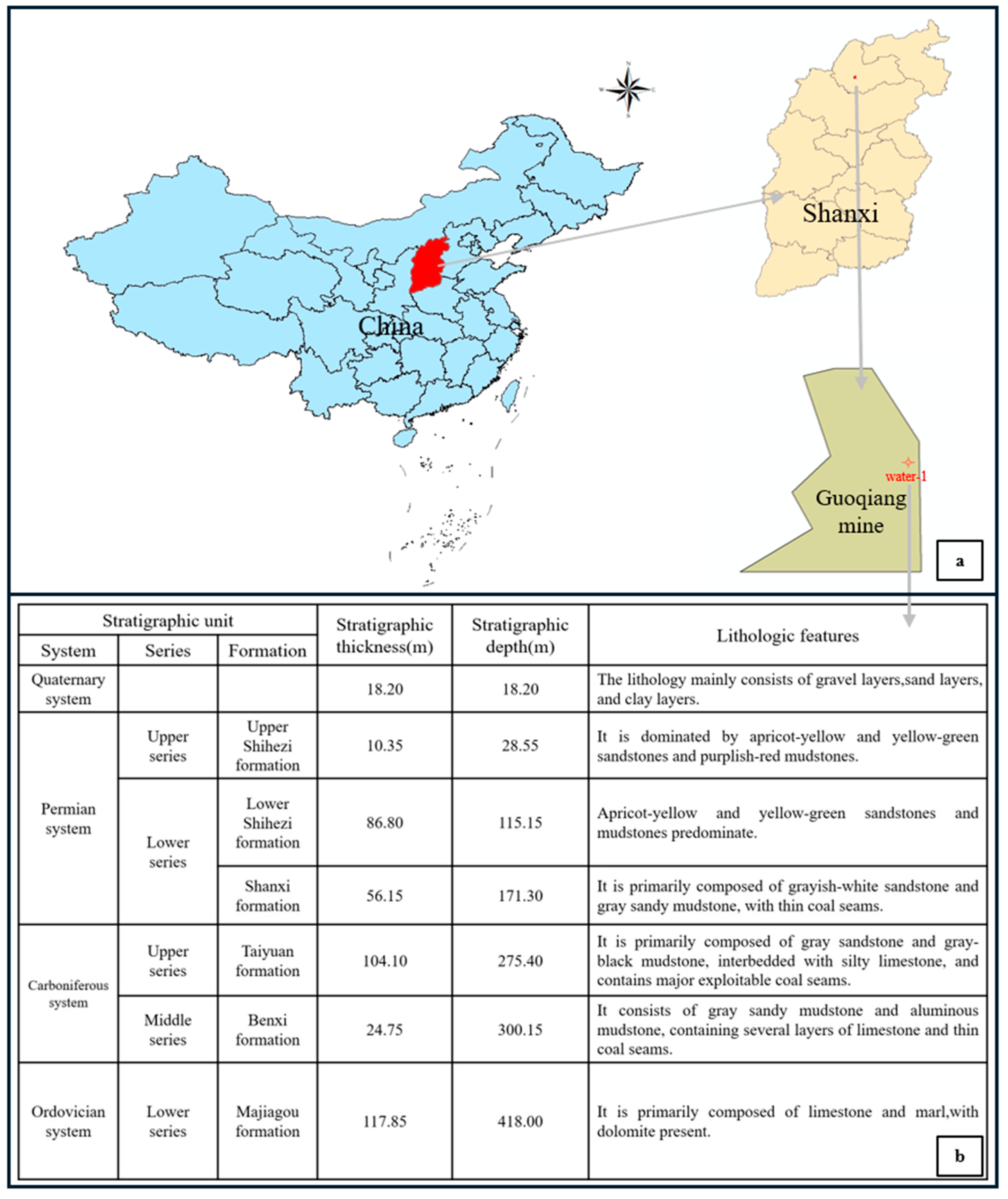
2. Overview of the Study Area
3. Basic Theory
3.1. LASSO Algorithm
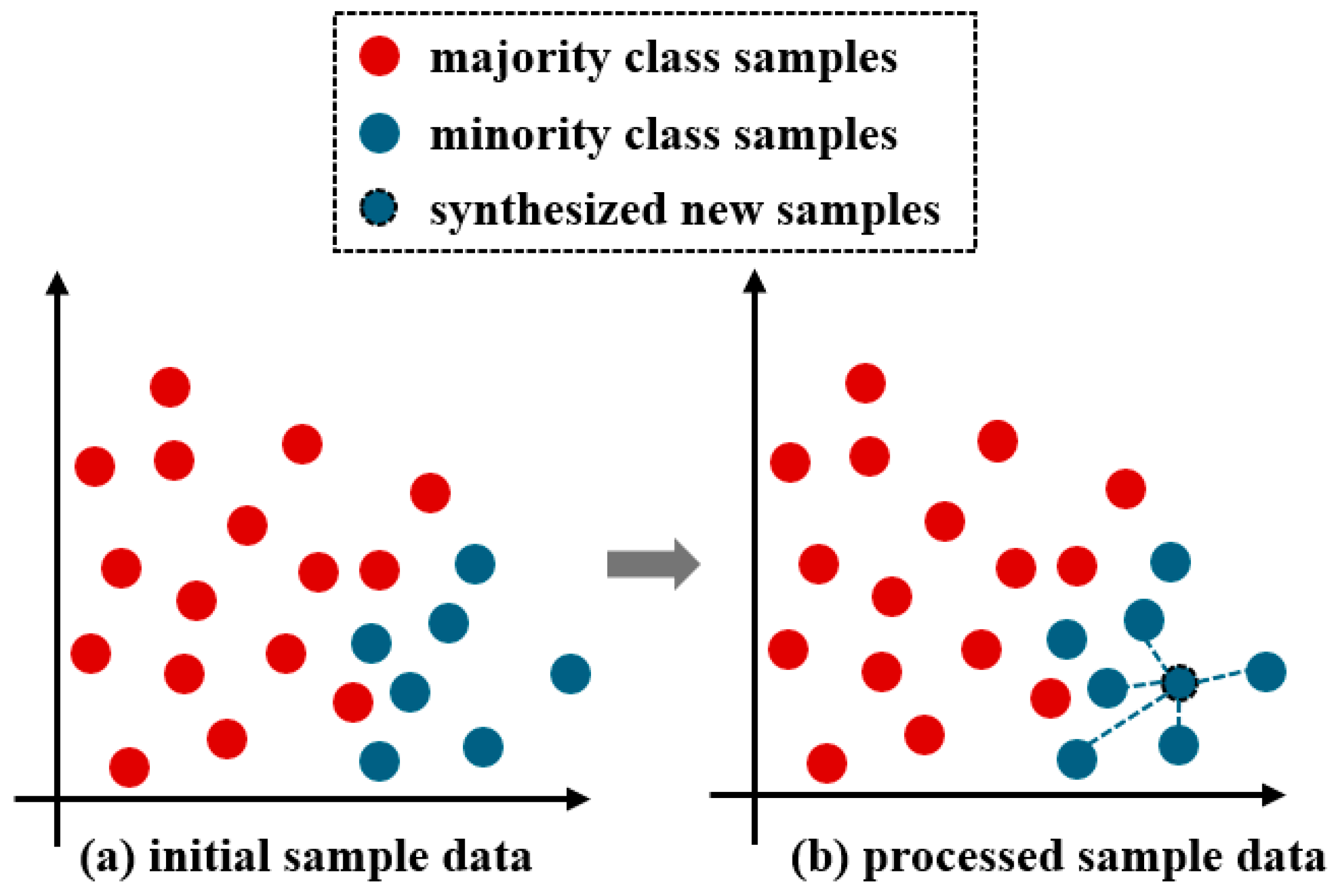
3.2. SMOTE Algorithm
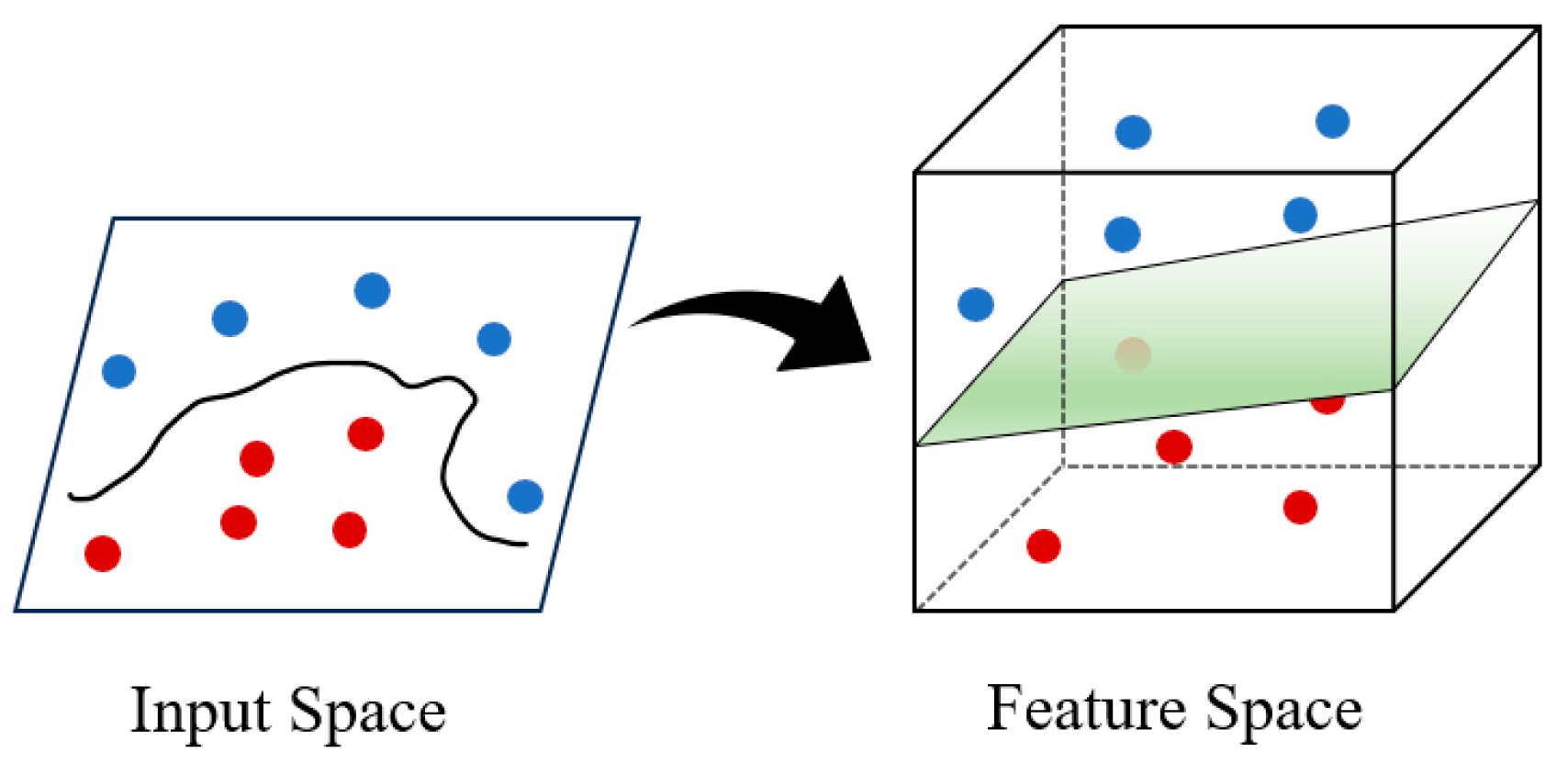
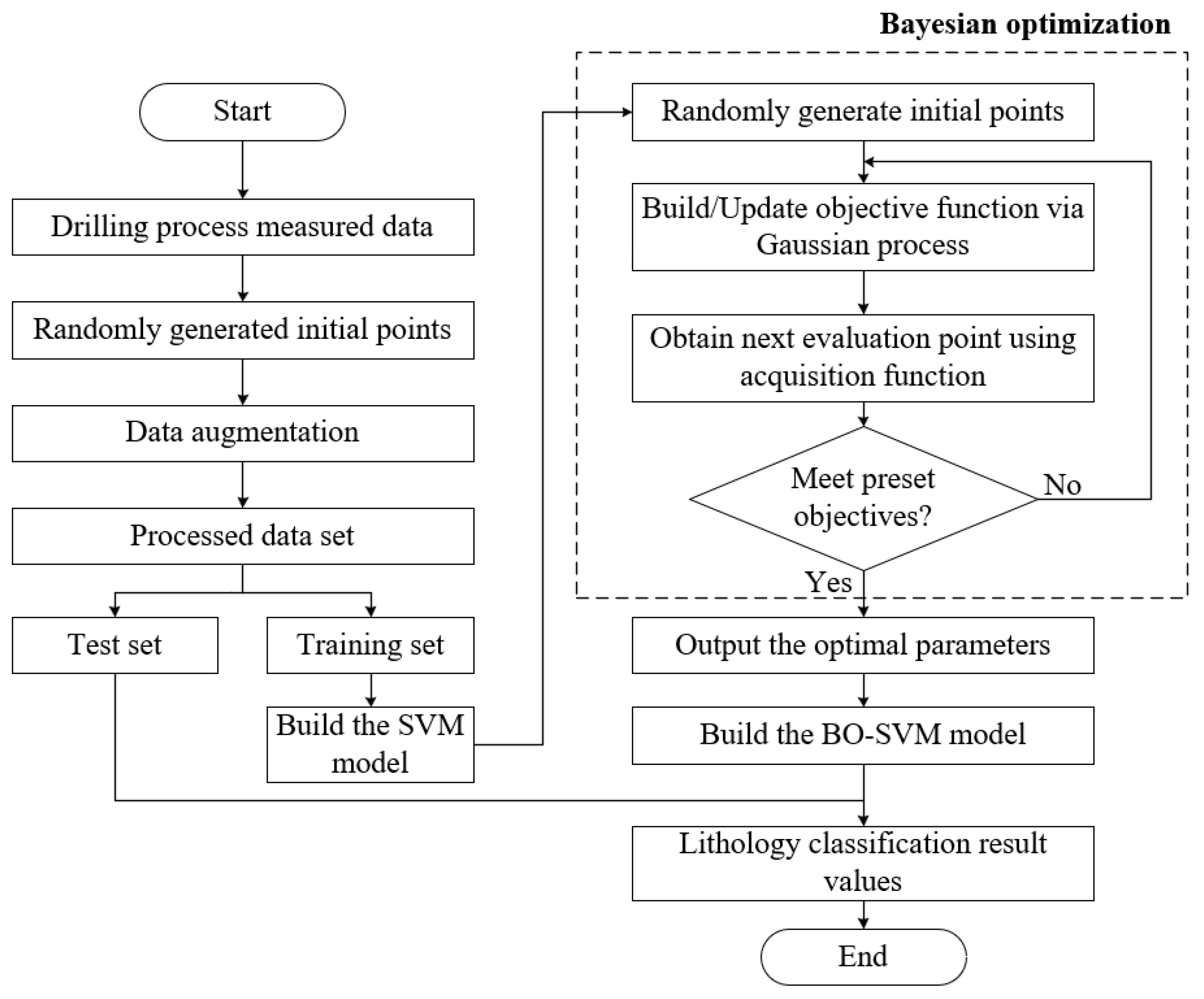
3.3. BO-SVM Algorithm
- (1)
- Set the parameter setting range to be optimized for the SVM model;
- (2)
- Input randomly generated initialization sample points into the Gaussian process and obtain the mean and standard deviation of the points to be determined based on the determined points;
- (3)
- Select the point with the best probability and calculate the corresponding true value of this point;
- (4)
- When the optimization condition is not met, the Gaussian model is updated, and the next optimal point with the best probability is selected and input into the modified Gaussian model. Iterations are repeated until the optimal parameter value of the support vector machine suitable for lithology identification is found.
4. Model Building and Data Processing
4.1. Raw Data
4.2. Model Building
4.3. Effect Evaluation
5. Results Analysis
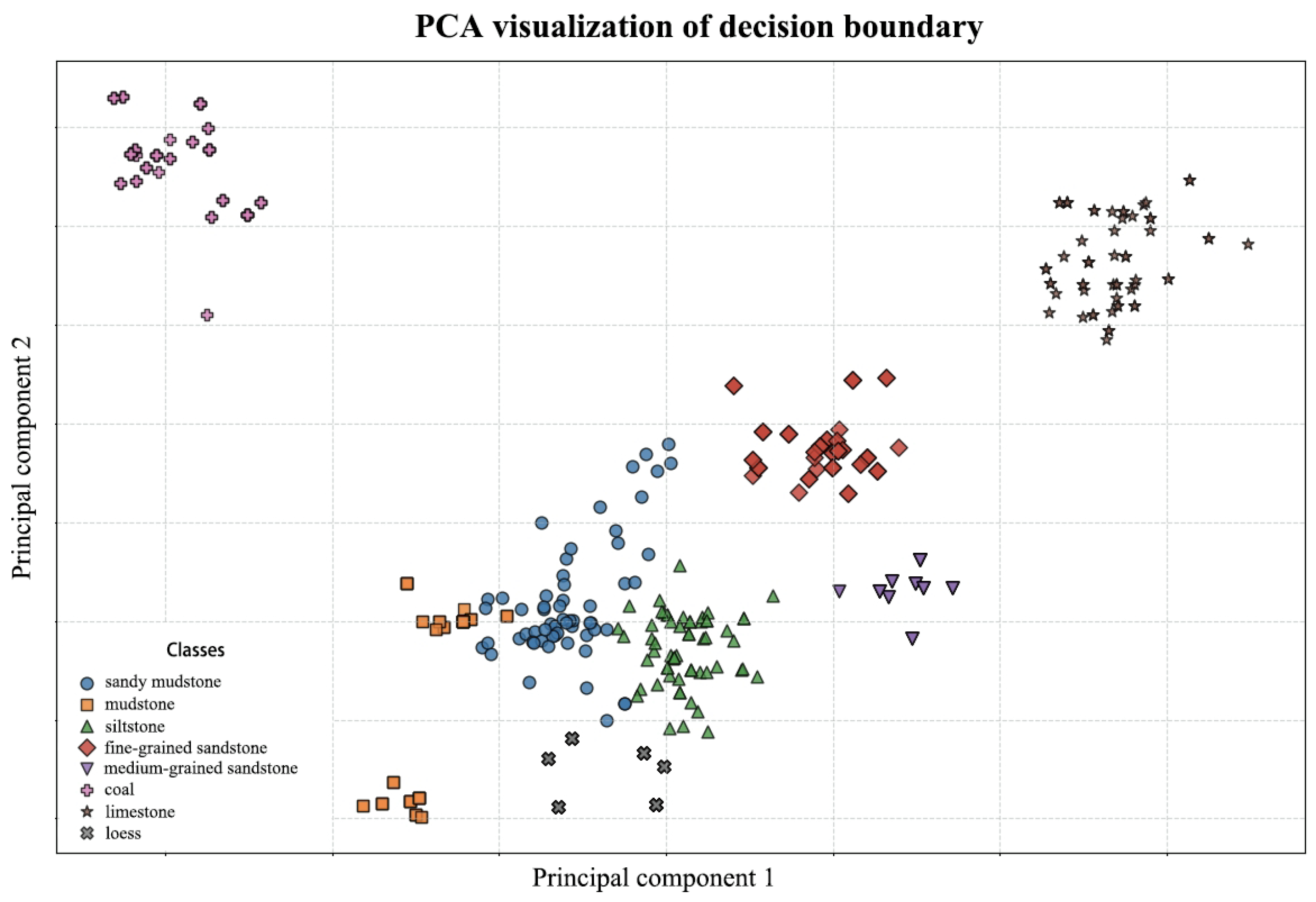
5.1. Indicator Feature Screening
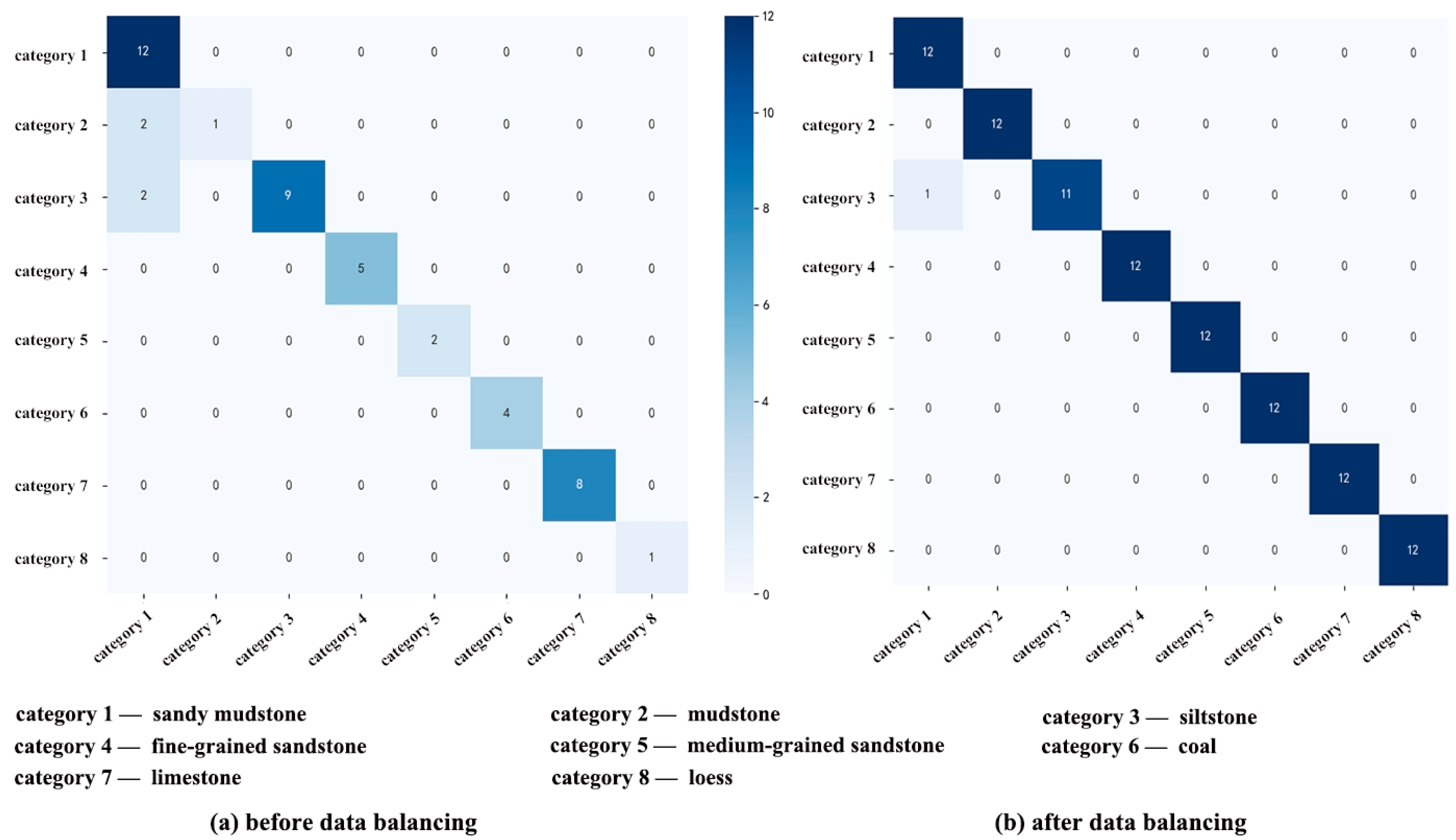
5.2. Sample Balance Processing
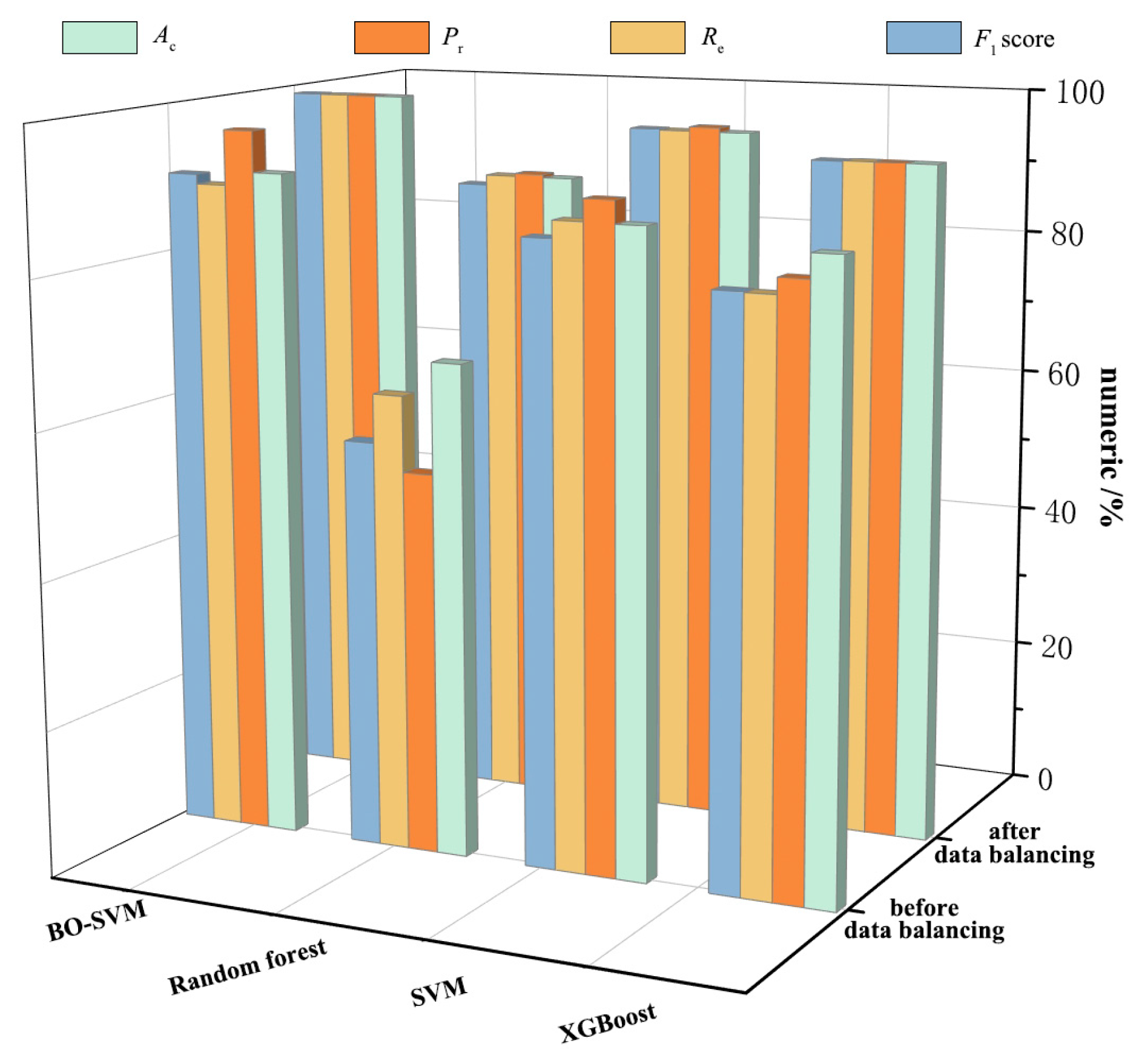
5.3. Results Comparison
6. Conclusions
- The four drilling parameters, namely drilling speed, mud pressure, slurry flow rate and torque, show high correlation with lithology identification, and there is no multicollinearity among the indicators, so they can be used as effective feature variables for the lithology identification classification task.
- The SMOTE oversampling algorithm is introduced to perform sample balancing on the training data. This expands the number of samples without affecting the sample quality and balances the sample categories. This effectively improves the classification performance of various models under imbalanced data conditions, especially for models that originally performed poorly. This method can be used as a solution to the sample imbalance problem.
- The Bayesian optimization algorithm is used to find the optimal parameters of the SVM model, and it is combined with the feature screening and sample balance algorithm to establish a combined model. Compared with the traditional lithology identification model, the results of this study are more in line with the actual engineering situation and can correctly identify 95 groups of data out of 96 test samples, indicating that the identification method after data optimization and model optimization has a good effect in lithology identification while drilling.
- With the rapid development of machine learning methods, deep learning models with higher accuracy and generalization performance such as convolutional neural networks and recurrent neural networks can be explored for application in lithology identification to further enhance the actual identification effect in engineering.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Asante-Okyere, S.; Shen, C.; Ziggah, Y.; Rulegeta, M.; Zhu, X. A Novel Hybrid Technique of Integrating Gradient-Boosted Machine and Clustering Algorithms for Lithology Classification. Nat. Resour. Res. 2020, 29, 2257–2273. [Google Scholar] [CrossRef]
- Chen, L.; Ma, M.; Wang, H.; Liu, X.; Wu, M.; Hirota, K. Lithology Identification of Coal-Bearing Strata Based on Data-Driven Dual-Channel Relevance Networks in Coal Mine Roadway Drilling Process. Inf. Sci. 2025, 690, 121339. [Google Scholar] [CrossRef]
- Yue, Z.; Yue, X.; Yang, R.; Wang, X.; Li, W.; Dai, S.; Li, Y. Research Progress of Lithology Identification Technology While Drilling. J. Min. Sci. Technol. 2022, 7, 389–402. [Google Scholar] [CrossRef]
- Huang, J.; Ci, Y.; Liu, X. Research Status and Prospects of Intelligent Logging Lithology Identification. Meas. Sci. Technol. 2024, 36, 012010. [Google Scholar] [CrossRef]
- Kahraman, S. Rotary and Percussive Drilling Prediction Using Regression Analysis. Int. J. Rock Mech. Min. Sci. 1999, 36, 981–989. [Google Scholar] [CrossRef]
- Mostofi, M.; Rasouli, V.; Mawuli, E. An Estimation of Rock Strength Using a Drilling Performance Model: A Case Study in Blacktip Field, Australia. Rock Mech. Rock Eng. 2011, 44, 305–316. [Google Scholar] [CrossRef]
- Shreedharan, S.; Hegde, C.; Sharma, S.; Vardhan, H. Acoustic Fingerprinting for Rock Identification During Drilling. Int. J. Miner. Eng. 2014, 5, 89–105. [Google Scholar] [CrossRef]
- Kumar, B.; Vardhan, H.; Govindaraj, M. Prediction of Uniaxial Compressive Strength, Tensile Strength, and Porosity of Sedimentary Rocks Using Sound Level Produced During Rotary Drilling. Rock Mech. Rock Eng. 2011, 44, 613–620. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, B.; Ma, J. Deep Convolutional Auto-Encoder Based Lithologic Classification and Recognition. J. Signal Process. 2023, 39, 11–19. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Z.; Chen, Q.; Zeng, W.; Bai, J.; Yin, S.; Chen, M. Lithology Identification Method Based on Deep Learning of Vibration and Sound Signals. Sci. Technol. Eng. 2023, 23, 2759–2767. [Google Scholar] [CrossRef]
- Guan, Y.; Wang, Q.; Feng, J.; Yang, Q.; Shi, L. Comprehensive Lithology Recognition of Altered Igneous Reservoirs Based on Machine Learning for Wireline and Cutting Logs in Huizhou Depression, Pearl River Mouth Basin, Northern South China Sea. J. Jilin Univ. (Earth Sci. Ed.) 2024, 54, 345–358. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. B Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zhong, H.; Hu, H.; Hou, N.; Fan, Z. Study on Abnormal Pattern Detection Method for In-Service Bridge Based on Lasso Regression. Appl. Sci. 2024, 14, 2829. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef]
- Chawla, N.; Bowyer, K.; Hall, L.; Kegelmeyer, W. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Shi, H.; Chen, Y.; Chen, X. Summary of Research on SMOTE Oversampling and Its Improved Algorithms. CAAI Trans. Intell. Syst. 2019, 14, 1073–1083. [Google Scholar] [CrossRef]
- Sayegh, H.; Dong, W.; Al-madani, A. Enhanced Intrusion Detection with LSTM-Based Model, Feature Selection, and SMOTE for Imbalanced Data. Appl. Sci. 2024, 14, 479. [Google Scholar] [CrossRef]
- Huang, A.; Cai, W.; Wei, X.; Li, Y.; Duan, G.; Liu, D. Lithology Identification of Volcanic Rock Logging Based on Improved Random Forest. Sci. Technol. Eng. 2023, 23, 3696–3704. [Google Scholar] [CrossRef]
- Mou, D.; Wang, Z.; Huang, Y.; Xu, S.; Zhou, D. Lithology Identification of Volcanic Rocks Based on SVM Logging Data: A Case Study of the Eastern Depression of Liaohe Basin. Chin. J. Geophys. 2015, 58, 1785–1793. [Google Scholar] [CrossRef]
- Huang, F.; Wu, D.; Chang, Z.; Chen, Q.; Tao, J.; Jiang, S.; Zhou, C. Landslide Susceptibility Pattern and Potential Landslide Identification under Sample Deficiency: A Susceptibility–InSAR Multi-Source Information Method. J. Rock Mech. Eng. 2025, 44, 584–601. [Google Scholar] [CrossRef]
- Weng, Y.; Zhang, W.; Gao, L. Risk Assessment of Rainfall-Induced Landslides Based on SHALSTAB-SVM Model: A Case Study of Daguan County, Yunnan Province. Sediment. Geol. Tethyan Geol. 2024, 44, 523–533. [Google Scholar] [CrossRef]
- Mukhamediev, R.; Kuchin, Y.; Yunicheva, N.; Kalpeyeva, Z.; Muhamedijeva, E.; Gopejenko, V.; Rystygulov, P. Classification of Logging Data Using Machine Learning Algorithms. Appl. Sci. 2024, 14, 7779. [Google Scholar] [CrossRef]
- Zhang, X. Evaluation of Landslide Susceptibility Based on Bayesian Algorithm Optimized Machine Learning Model—Example of Liliu Coal Mining Area. Master’s Thesis, Taiyuan University of Technology, Taiyuan, China, 2023. [Google Scholar] [CrossRef]
- Feng, R.; Chen, Z.; Yi, S. Study on Maize Variety Identification Based on Bayesian Optimization of SVM. Spectrosc. Spectr. Anal. 2022, 42, 1698–1703. [Google Scholar] [CrossRef]
- Yang, M.; Tian, H. Short-Term Wind Power Forecasting Based on Bayesian Optimized XGBoost. Electron. Devices 2024, 47, 1389–1395. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, C.; Liu, X.; Liu, J.; Chen, S.; Huang, S. Application of Machine Learning-Based Lithology Identification Analysis for Tunnel Geological Survey. Tunnel Constr. 2023, 43, 1549. [Google Scholar] [CrossRef]
- Yang, W.; Yue, Z.; Tham, L. Automatic Monitoring of Inserting or Retrieving SPT Sampler in Drillhole. Geotech. Test. J. 2012, 35, 103450. [Google Scholar] [CrossRef]
- Song, L.; Li, N.; Li, Q. Study on the Intrinsic Relationship between Rotary Penetration Parameters and Mechanical Parameters of Soft Rock. Rock Soil Mech. Eng. J. 2011, 30, 1274–1282. [Google Scholar]
- Yue, Z. Improvement and Enhancement of Engineering Rock Mass Quality Evaluation Method Based on Drilling Process Monitoring (DPM). Rock Soil Mech. Eng. J. 2014, 33, 1977–1996. [Google Scholar] [CrossRef]
- Chen, J.; Yue, Z.Q. Hole Collapse Detection Based on Full Drill Analysis of DPM System. Eng. Geotech. Investig. 2010, 38, 26–31. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Advantages | Limitations | Comparison with SVM |
|---|---|---|---|
| Neural network | good fitting effect for big data | requires large number of samples, difficult to train | SVM model is more stable with smaller sample sizes |
| Random forest (RF) | good stability and high robustness | models are slow to train and difficult to interpret | SVM performs well on high-dimensional data [20] |
| K-nearest neighbors | simple model, fast training | more sensitive to outliers | SVM is more robust and has clearer decision boundaries [21] |
| XGBoost | simple model, good interpretability | inability to deal with nonlinearities | SVM can handle nonlinear problems |
| Number | Figure | Lithology | |||||
|---|---|---|---|---|---|---|---|
| Drilling Speed /(m·h−1) | Bottom Hole Pressure/MPa | Mud Pressure /MPa | Slurry Flow Rate /(L·min−1) | Torque /(N·m) | Hole Depth /m | ||
| 1 | 0.41 | 3.36 | 1.99 | 5.01 | 3830 | 3 | loess |
| 2 | 0.45 | 3.37 | 1.99 | 4.84 | 3922 | 6 | loess |
| 3 | 0.45 | 3.40 | 1.99 | 4.84 | 3238 | 9 | loess |
| 4 | 0.39 | 3.45 | 1.97 | 5.18 | 3342 | 12 | loess |
| … | … | … | … | … | … | … | … |
| 78 | 0.45 | 3.66 | 2.01 | 5.18 | 4628 | 113 | sandy mudstone |
| 79 | 0.45 | 3.67 | 2.02 | 5.18 | 4822 | 114 | sandy mudstone |
| 80 | 0.47 | 3.25 | 1.89 | 6.18 | 2899 | 115 | mudstone |
| 81 | 0.48 | 3.27 | 1.89 | 6.35 | 2788 | 116 | mudstone |
| … | … | … | … | … | … | … | … |
| 226 | 0.35 | 4.89 | 2.45 | 3.84 | 8905 | 406 | limestone |
| 227 | 0.35 | 4.87 | 2.45 | 3.84 | 8164 | 409 | limestone |
| 228 | 0.36 | 4.86 | 2.32 | 3.84 | 8263 | 412 | limestone |
| 229 | 0.37 | 4.86 | 2.32 | 3.67 | 8723 | 415 | limestone |
| Drilling Speed | Bottom Hole Pressure | Mud Pressure | Slurry Flow Rate | Torque | Hole Depth | |
|---|---|---|---|---|---|---|
| LASSO regression coefficients | −1.803 | 0 | 1.387 | 2.482 | −0.119 | 0 |
| R2 values | 0.683 | 0.733 | 0.703 | 0.661 | 0.713 | 0.489 |
| VIF coefficients | 6.69 | 22.02 | 10.26 | 14.67 | 4.02 | / |
| VIF coefficients of various indicators after removing the “bottom hole pressure” | 6.53 | / | 7.56 | 6.31 | 4.02 | / |
| Model | Evaluation Index | |||
|---|---|---|---|---|
| Ac | Pr | Re | F1 Score | |
| Random forest | 0.674 | 0.522 | 0.625 | 0.558 |
| XGBoost | 0.848 | 0.815 | 0.793 | 0.794 |
| SVM | 0.870 | 0.901 | 0.871 | 0.847 |
| BO-SVM | 0.913 | 0.969 | 0.894 | 0.907 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, H.; Liang, M.; Yin, S.; Zhang, Q.; Tian, Y.; Wang, G.; Hou, E.; Lian, H.; Zhang, J.; Wu, C. Application of Hybrid Model Based on LASSO-SMOTE-BO-SVM to Lithology Identification During Drilling. Processes 2025, 13, 2038. https://doi.org/10.3390/pr13072038
Yao H, Liang M, Yin S, Zhang Q, Tian Y, Wang G, Hou E, Lian H, Zhang J, Wu C. Application of Hybrid Model Based on LASSO-SMOTE-BO-SVM to Lithology Identification During Drilling. Processes. 2025; 13(7):2038. https://doi.org/10.3390/pr13072038
Chicago/Turabian StyleYao, Hui, Manyu Liang, Shangxian Yin, Qing Zhang, Yunlei Tian, Guoan Wang, Enke Hou, Huiqing Lian, Jinfu Zhang, and Chuanshi Wu. 2025. "Application of Hybrid Model Based on LASSO-SMOTE-BO-SVM to Lithology Identification During Drilling" Processes 13, no. 7: 2038. https://doi.org/10.3390/pr13072038
APA StyleYao, H., Liang, M., Yin, S., Zhang, Q., Tian, Y., Wang, G., Hou, E., Lian, H., Zhang, J., & Wu, C. (2025). Application of Hybrid Model Based on LASSO-SMOTE-BO-SVM to Lithology Identification During Drilling. Processes, 13(7), 2038. https://doi.org/10.3390/pr13072038