1. Introduction
Prediction technology is a comprehensive data analysis method, which aims to reveal and model the underlying patterns of events and make scientific inferences about future trends by carefully exploring historical data, current trends, established patterns, and domain knowledge. Currently, prediction technology is widely used in the fields of stock prices, traffic flow, air temperature, and power loads [
1,
2,
3,
4].
Time-series data play a crucial role in current forecasting tasks. This type of data is typically represented as an ordered sequence that records the results of observations or measurements of a process at fixed time intervals [
5]. Additionally, cross-sectional data also play a key role in predictive analytics. Traditional statistical forecasting methods, such as autoregressive integrated moving average (ARIMA) [
6], exponential smoothing (ES) [
7], and Holt–Winters methods [
8], primarily rely on difference operations and moving averages to capture the trends in time-series data. However, their linear assumptions often struggle to model the nonlinear coupling relationships that are common in industrial data. In contrast, machine learning techniques, especially deep learning algorithms, are capable of delving into the complex structures and dynamic characteristics of the data, thus addressing nonlinear modeling issues more effectively.
Currently, the mainstream deep prediction models are primarily based on recurrent neural networks (RNN) and long short-term memory networks (LSTM) as their core. These model temporal dependencies through the recursive updating mechanism of hidden state vectors; however, when dealing with long input sequences, the RNN is affected by the chain rule and prone to problems such as gradient explosion or vanishing [
9,
10]. LSTM mitigates this situation by introducing a gating mechanism and cellular states [
11], but a single LSTM still suffers from problems such as solidification of hidden state dimensions, insufficient local feature capture, and low computational efficiency.
In order to overcome the representation bottleneck of single models, Lu et al. [
12] proposed a CNN-LSTM cascaded model, which first utilizes convolutional kernels to extract local feature information from the data and then inputs this into the LSTM to capture temporal dynamics, achieving relatively outstanding performance, although there is still potential for improvement. Rai et al. [
13] built upon this by introducing a bidirectional long short-term memory (BiLSTM) in place of LSTM, allowing the model to consider both the forward evolutionary characteristics and reverse dependencies of the data, thereby achieving a more comprehensive information analysis. Kavianpour et al. [
14] further integrated the attention mechanism (AM) to dynamically focus on key time steps, further enhancing the model’s information recognition capabilities. However, there are still problems such as insufficient generalization ability and difficulty in parameter selection.
On the other hand, Wu et al. [
15] attempted to combine the AdaBoost algorithm with LSTM by integrating the prediction results of each base learner through weighted integration, allowing the model to take a multi-perspective view of the problem, enhancing the comprehensiveness of the analysis. Yaprakdal [
16] and Busari et al. [
17] further confirmed the effectiveness of the ensemble learning strategy through experiments. However, it cannot be ignored that using a single model as the base learner results in a significant consumption of computational resources.
Given the existing research and challenges, we attempt to fuse the deep composite model with the concept of ensemble learning. Meanwhile, we introduce a dual-channel convolutional neural network, a mistake correction mechanism, and the gold rush optimizer to further optimize the model’s information processing capabilities, thereby achieving superior generalization performance. It should be noted that this paper is an expansion of our already accepted conference paper titled “The GAC-BiLSTM-AM Method and Its Application to the Prediction of Cracking Outlet Temperature in Ethylene Cracking Furnaces” [
18], with the expanded content accounting for no less than thirty percent.
2. Background Knowledge and Methods
2.1. Convolution Neural Network (CNN)
CNN is a kind of feed forward neural network proposed by Lecun et al. [
19] in 1989. The network simulates the way the human visual system processes visual information. The core idea is to extract and represent the multi-level features of the input data through the organic combination of internal functional modules, which is currently widely applied in the fields of face recognition, autonomous driving, bioinformatics, among others [
20], and it mainly consists of three parts: a convolutional layer, pooling layer, and fully connected layer [
21]. Among them, the convolutional layer is responsible for feature extraction, and each convolutional layer contains a set of learnable filters, which follow the principles of local connectivity and weight sharing; the pooling layer is responsible for feature selection, which reduces the dimension of the data; and the fully connected layer, which is usually located at the end of the neural network, is responsible for the integration of features. Since the convolution operation of CNN can effectively deal with the local correlation of the data, the use of one-dimensional convolution to extract data features in prediction tasks can help neural networks with a memory mechanism to better address long-term dependency issues.
2.2. Bidirectional Long Short-Term Memory (BiLSTM)
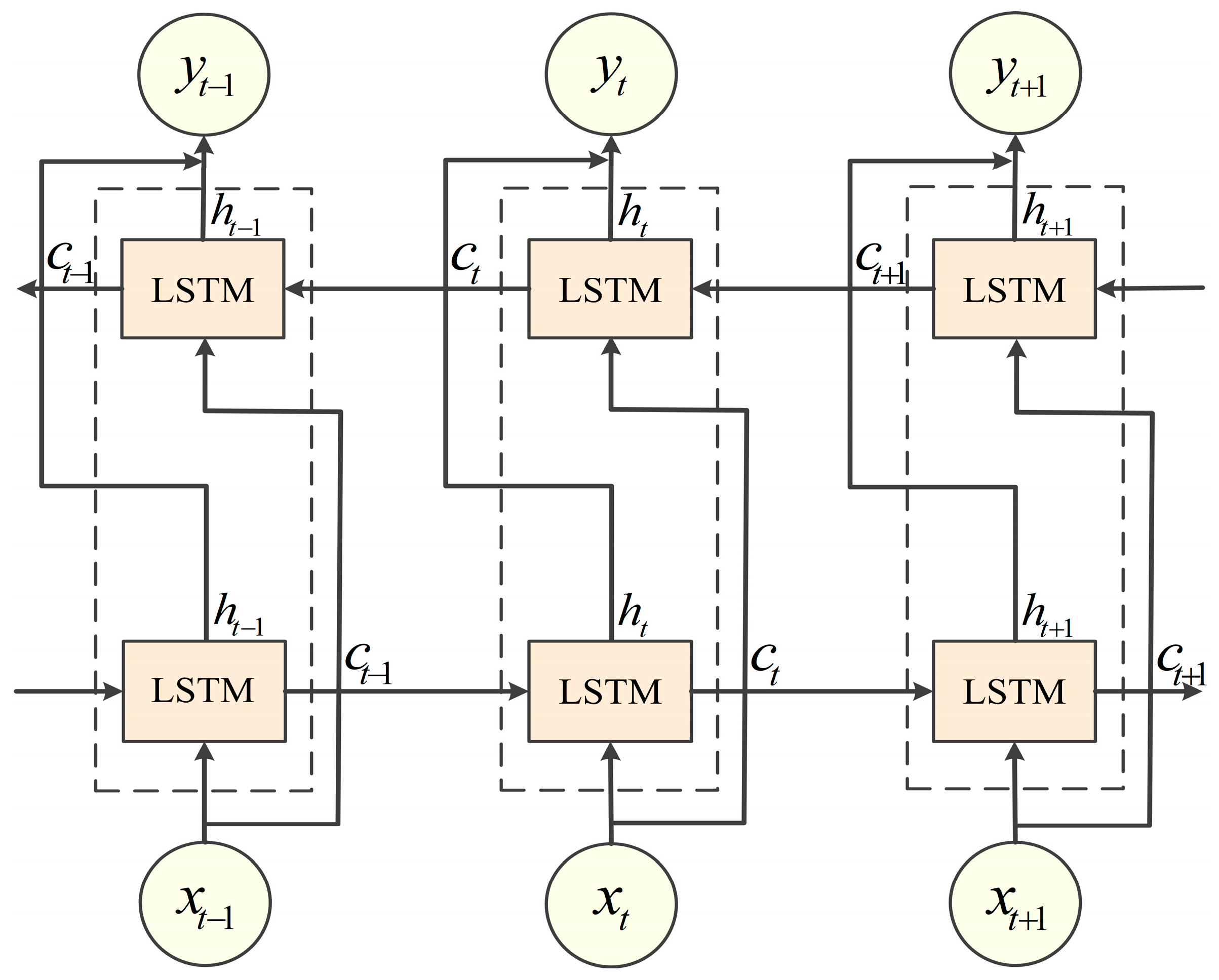
In order to alleviate the long-term dependency problem of traditional recurrent neural networks, Sepp Hochreiter and Jürgen Schmidhuber [
22] proposed LSTM in 1997. LSTM realizes the effective processing of sequence data through cell states and three types of gate structures. Building on this, BiLSTM was subsequently proposed, consisting of two LSTM layers running in parallel with opposite directions of information transfer. This allows BiLSTM to process data in both directions simultaneously, thereby enhancing its ability to understand and interpret sequences. The structure of BiLSTM is shown in
Figure 1. Siami-Namini et al. [
23] conducted a comparison across multiple datasets and found that the prediction accuracy of BiLSTM was improved. It was enhanced by an average of 37.78% compared to LSTM. Given the advantages of BiLSTM in handling sequential data, we employ this technique in our study to obtain better prediction performance. For example, we utilize BiLSTM’s bidirectional information flow to jointly model the historical time-series characteristics of multiple variables (e.g., temperature, humidity, and wind speed) and their inter-temporal dependencies, thereby accurately capturing the dynamic interaction patterns among the variables. In terms of stock price prediction, we analyze the influence of historical data on current prices using BiLSTM’s forward layer and reveal the market sentiment implied by current price fluctuations with the reverse layer, thereby gaining a more comprehensive understanding of the long-range dependencies within the price series.
2.3. Attention Mechanism (AM)
The attention mechanism is inspired by a human’s visual perception of the environment. When people make visual observations, the visual system will focus on the local area (key area) and, with the large amount of attention resources invested in this area, quickly obtain the required high-value information. Similarly, the attention mechanism will pay more attention to the important information, and the unimportant information is ignored, which is implemented through a weighted processing approach, typically divided into the following three stages [
24]:
- (1)
Calculate the correlation between Query (output feature) and Key (input feature) as shown in Equation (1):
where
is the weight of the attention mechanism,
is the bias of the attention mechanism, and
is the input vector.
- (2)
Normalize the obtained
scores to maintain the value range between 0 and 1, as shown in Equation (2):
where
is the attention value.
- (3)
Based on the weighting coefficients
, perform a weighted summation to arrive at the final attention value, as shown in Equation (3):
By assigning different weights to information, the attention mechanism allows the model to focus on the important parts of the data. This mechanism has been applied in various fields such as image captioning, behavioral analysis, earthquake forecasting, etc. [
25,
26,
27]. In this paper, we assign weights and sum the output of BiLSTM in the time dimension with the help of the attention mechanism to effectively highlight the key time steps that have a significant impact on the final prediction results to help the model accurately identify and process the core information, and further improve the accuracy of the prediction.
2.4. Gold Rush Optimizer (GRO)
The gold rush optimizer is a meta-heuristic algorithm proposed by Kamran Zolf [
28] in 2023. The algorithm simulates the gold panning process carried out by gold miners during the gold rush era, which mainly consists of three parts: migration, mining, and collaboration. The algorithm starts by first generating a batch of gold miners randomly, and each of them has the corresponding fitness value (the total amount of gold that can be mined under the current location). When the gold miners find other gold mines, they will change the location. At the same time, because the location of the best gold mine belongs to an unknown state, the algorithm approximates the location of the best gold miner as the location of the best gold mine, and the formula of the migration process is as follows:
where
is the location of the best gold mine,
is the location of the
-th gold miner,
is the current iteration number,
is the new position of the
-th gold miner,
are random vectors with values ranging from 0 to 1,
is defined by equation (8),
is the maximum number of iterations, and
is the current number of iterations.
During the gold panning process, each gold miner tries to mine as much gold as possible from their own panning area. The formula for the mining process is as follows:
where
is the location information of a gold miner randomly selected among the remaining gold miners after removing the
-th gold miner, and
is also defined by Equation (8).
In order to improve the efficiency of the search for gold in a limited time, sometimes, it is necessary for more than one person to work as a team, and the formula of the cooperation process between members is as follows:
where
are the location information of the two gold miners randomly selected among the remaining gold miners after removing the
-th gold miner.
For all the above processes, the gold miner updates the position only if the gold content (fitness value) of the new position is better than the previous position; otherwise, the original position is kept unchanged, and the modeling formulation of the minimization problem is as follows:
The gold rush optimizer offers advantages such as fast convergence speed and the capability of achieving global optimization. Optimizing the key structural parameters of the model with this algorithm can yield superior results.
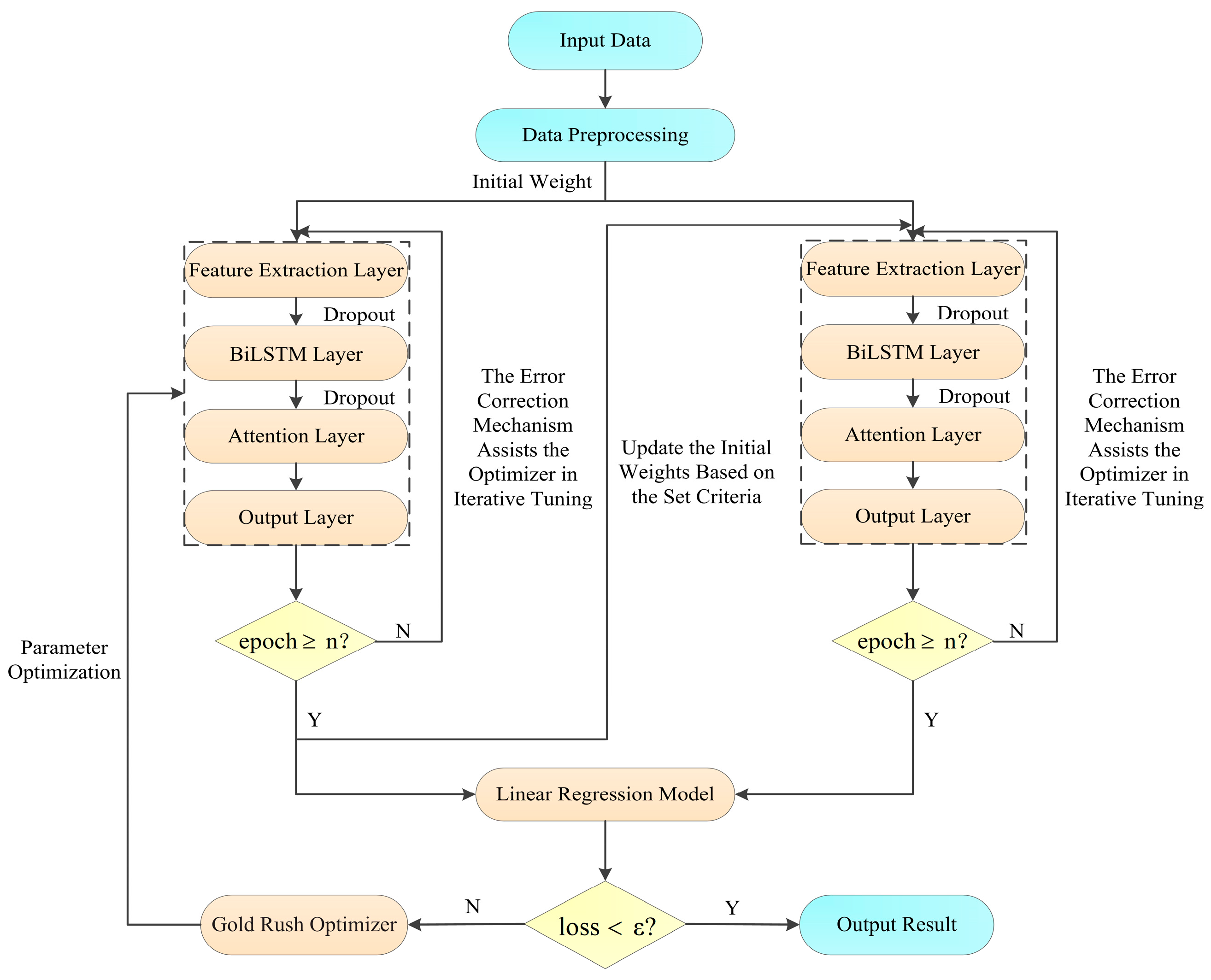
2.5. Model Framework
The overall architecture of the GAC-BiLSTM-AM model is shown in
Figure 2.
Before training commences, the input data is preprocessed as follows: First, an appropriate imputation strategy is selected to handle missing values based on the data characteristics. Second, using the Pearson correlation coefficient, features that have a correlation coefficient of at least 0.19 with the target variable are selected as input features. Lastly, the input features are normalized with z-score normalization, retaining the mean and standard deviation. These preprocessing operations aim to improve data quality, reduce the impact of noise and outliers, and unify feature scales. The comparison of effects is shown in
Figure 3. In the figure, the left side depicts the original feature data, while the right side shows the feature data after preprocessing.
The data are then transformed into a three-dimensional tensor using the sliding window technique where is the batch size, is the time step, and is the feature dimension. The sample weights are initialized and fed into a dual-channel convolutional neural network to capture sample features, the bidirectional long short-term memory network, attention mechanism, and fully connected layers for further analysis and processing. Finally, the real results are obtained through inverse normalization. To prevent overfitting, Dropout is added after the convolutional module and the bidirectional long short-term memory network to achieve random inactivation of neurons.
During the iterative optimization process, the mistake correction mechanism assists the adaptive optimization algorithm in adjusting model parameters. The linear regression model maps the aggregated outputs of all base learners to the final result. The gold rush optimizer is used to search for the optimal values of four key structural parameters: the number of neurons in the BiLSTM hidden layer, the two independent Dropout discard rates, and the weight update interval value. The main reason for this is that having too many hidden layer neurons may cause the model to overfit, while too few may fail to adequately capture the complexity of the time series. If the Dropout discard rate is set too low, it will not effectively prevent overfitting; conversely, if set too high, it may lead to underfitting of the model. Similarly, if the weight update interval is too small, it will not effectively contribute to the model’s correction; if too large, it may introduce new attention biases. Only with appropriate parameter settings can the model be ensured to have good predictive performance. The search ranges are [20, 136], [0, 0.3], [0, 0.3], and [5, 20], respectively. These ranges were based on the parameter settings in multiple papers in related fields and were finalized with the specific needs of this study. The optimization goal of the gold rush optimizer in the experiment is to find the minimum cumulative sum of the four evaluation metrics. Throughout the optimization process, the number of neurons in the BiLSTM hidden layer and the weight update interval are rounded to integers when input into the model.
2.6. Dual-Channel Convolutional Neural Network
In the feature mining process, the model’s deep representation learning capability plays a crucial role in the accuracy of prediction results. Traditional single-layer one-dimensional convolutional neural networks have limitations in deep feature representation, making it difficult to fully capture the global information of the data. Especially when dealing with industrial data characterized by non-stationarity and strong coupling, it can easily lead to the loss of key information and degradation of representation capabilities. To address this issue, we propose a dual-channel convolutional neural network architecture, as shown in
Figure 4. In this architecture, the single-layer one-dimensional convolution is responsible for capturing shallow feature information, while the three-layer stacked one-dimensional convolution focuses on mining deep abstract feature information. The two convolution modules work in collaboration to ensure the comprehensiveness and consistency of feature extraction. Furthermore, to overcome issues such as vanishing gradients, the ReLU activation function is used to introduce nonlinearity, ensuring that gradients can propagate effectively through the network. Finally, a fully connected layer is employed to integrate the extracted information, improving the computational efficiency of the model.
2.7. Mistake Correction Mechanism
During the process of iterative optimization of model parameters, adaptive optimization algorithms such as Adam can easily lead to implicit preference optimization issues due to the heterogeneity of sample prediction difficulty. This manifests as follows: the optimization process tends to quickly converge to local optima composed of easy-to-learn samples, while the gradient response to difficult-to-predict samples gradually diminishes. This phenomenon will result in two key deficiencies: 1. The model’s decision boundary is dominated by easy-to-learn samples, making it difficult to capture the tail characteristics of the data distribution. 2. The parameter update direction deviates from the global optimal trajectory, thereby weakening the model’s generalization ability. To address this optimization bias, we propose a mechanism for dynamically adjusting sample weights, with the following specific implementation details:
In the initial phase of training, which is the first 60% of the total number of iterations, all training samples are assigned equal weights. At this point, the adjustment of model parameters relies entirely on the action of the adaptive optimization algorithm, with the aim of quickly reducing the training loss. When the number of iterations reaches 60% of the total, in this and subsequent iterations, an additional judgment is made to determine if the current iteration count is divisible by a predefined weight update interval value. If the integer division condition is met, the weights of the samples with an absolute prediction error exceeding the dividing value for that round are increased, while the weights of other samples are decreased for use in the next iteration. The weight update formula is as follows:
where
is the base learning model used,
is the training dataset,
is sample weights for the
iteration,
is the prediction results,
is the initial value,
is the current iteration number, the value of
is sixty,
is the decrement,
is the dividing value, subscript
is the
-th sample,
is the weight of the
-th sample in the
iteration,
is the sample label, and
is the weight of
after updating.
If the integer division condition is not met, the sample weights from the previous iteration continue to be used, thereby assisting the adaptive optimization algorithm in adjusting the model parameters, ensuring that the model can give appropriate attention to samples that were not fully considered previously.
It is worth noting that, to ensure the denominator in Formula (18) is not zero, the initial value is set relatively small for all tasks. The denominator in Formula (19), being the sum of all weights after the sample weights are updated, will always be greater than zero.
3. Experiments and Results
The experimental process is divided into two stages: comparison and application. First, a comparative analysis of single-step and multi-step (five-step) prediction results is conducted on public and simulated data. In the experiment, the appropriateness of the chosen time step size directly affects the accuracy of the final results. When the time step is small, it is beneficial for the model to capture instantaneous changes in information, thus better reflecting the dynamic characteristics of the system. When the time step is large, it helps the model focus on the long-term trends and overall patterns in the data. After multiple experimental tests, we finally set the time step size as follows: for single-step prediction, the step size is 5, and for multi-step prediction, the step size is 20. In the experiments, the number of iterations for the model is 100, the loss function is MSE, the activation function is RELU, the optimizer is Adam, and the learning rate is 0.01. In the comparison stage, the average of ten evaluation metrics is used as the basis for measuring the performance of the model, with the standard deviation serving as auxiliary information. Furthermore, since the data used in the experiments may be subject to measurement errors, signal interference, and operational changes, leading to uncertainty and inaccuracy, fuzzy similarity or the Pearson correlation coefficient might be an effective solution [
29,
30]. In this paper, we choose to combine the Pearson correlation coefficient to filter out the features.
In the comparison phase, the model parameters for the other four compared methods are derived from the literature [
24], as shown in
Table 1. Some of the parameters in our method are obtained through the gold rush optimizer, which seeks optimal values during a single-step prediction experiment on the first 10,000 data points of the Jena Climate Dataset, while other parameters are determined through multiple experimental tests.
3.1. Evaluation Metrics
We use four evaluation metrics, namely, mean absolute error (MAE), root-mean-square error (RMSE), coefficient of determination (R
2), and symmetric mean absolute percentage error (SMAPE), to comprehensively assess the performance of the model. The reason for choosing these metrics is that they are widely recognized in the field of prediction and are able to evaluate the model’s performance from different perspectives, ensuring the comprehensiveness and accuracy of the assessment. In the model, the smaller the values of MAE, RMSE, and SMAPE, the smaller the deviation of the model-predicted value from the real one, and the higher the model fitting accuracy. The closer the R
2 value is to 1, the stronger the explanatory ability of the independent variables to the dependent variable in the regression analysis, and the better the model prediction effect. The formulas for the four evaluation indexes are shown below [
31]:
where
is model prediction value,
is sample true value,
is sample mean, and
is number of prediction samples.
3.2. Public Data
3.2.1. Dataset Introduction and Model Parameter Settings
We used three different types of time series data as public datasets. Among them, the temperature dataset uses the Jena Climate Dataset and takes the first 10,000 pieces of data as well as the 51,264th piece of data to the 61,263th piece of data to form the T1 and T2 datasets. The oil temperature dataset uses the ETT-small-h1 under the Electric Transformer Dataset and takes the first 10,000 pieces of data to form the ETTh1 dataset, and the price dataset uses the two stocks indexed as 000001 and 000002 in the Shenzhen index in the Tushare financial data interface package, which are referred to as the S1 and S2 datasets. For single-step prediction, the ratio of training to testing data is 7:3 for all datasets, and for multi-step prediction, the ratio of training to testing data is still 7:3 for the T1, T2, and ETTh1 datasets, whereas for the S1 and S2 datasets, the last 3 pieces of data of the S1 dataset are removed first, and then the first 5500 pieces of data are taken for training and the last 2355 pieces of data are taken for testing, respectively. The GAC-BiLSTM-AM model parameter settings in the public dataset are shown in
Table 2.
3.2.2. Result Analysis
RNN, LSTM, CNN-LSTM, CNN-BiLSTM-AM and GAC-BiLSTM-AM models were built, respectively, to predict the one-step and five-steps-ahead results of the key variables in each public dataset, and the resulting evaluation indexes are shown in
Table 3.
As can be seen from
Table 3, on average, the prediction abilities of RNN and LSTM were very close to each other and did not present a situation where a certain model had an absolute advantage. However, the prediction accuracy of CNN-LSTM was improved compared to LSTM in some tasks, indicating that LSTM could handle complex patterns in the data more efficiently with the help of features extracted from CNN, but its generalization ability and stability were relatively weak. To address this, the CNN-BiLSTM-AM model was further optimized to enhance its versatility. As indicated in the table, the mean indexes of CNN-BiLSTM-AM were better than those of the other three comparative methods in most cases. Our model, when compared to CNN-BiLSTM-AM, achieved a maximum additional improvement in R
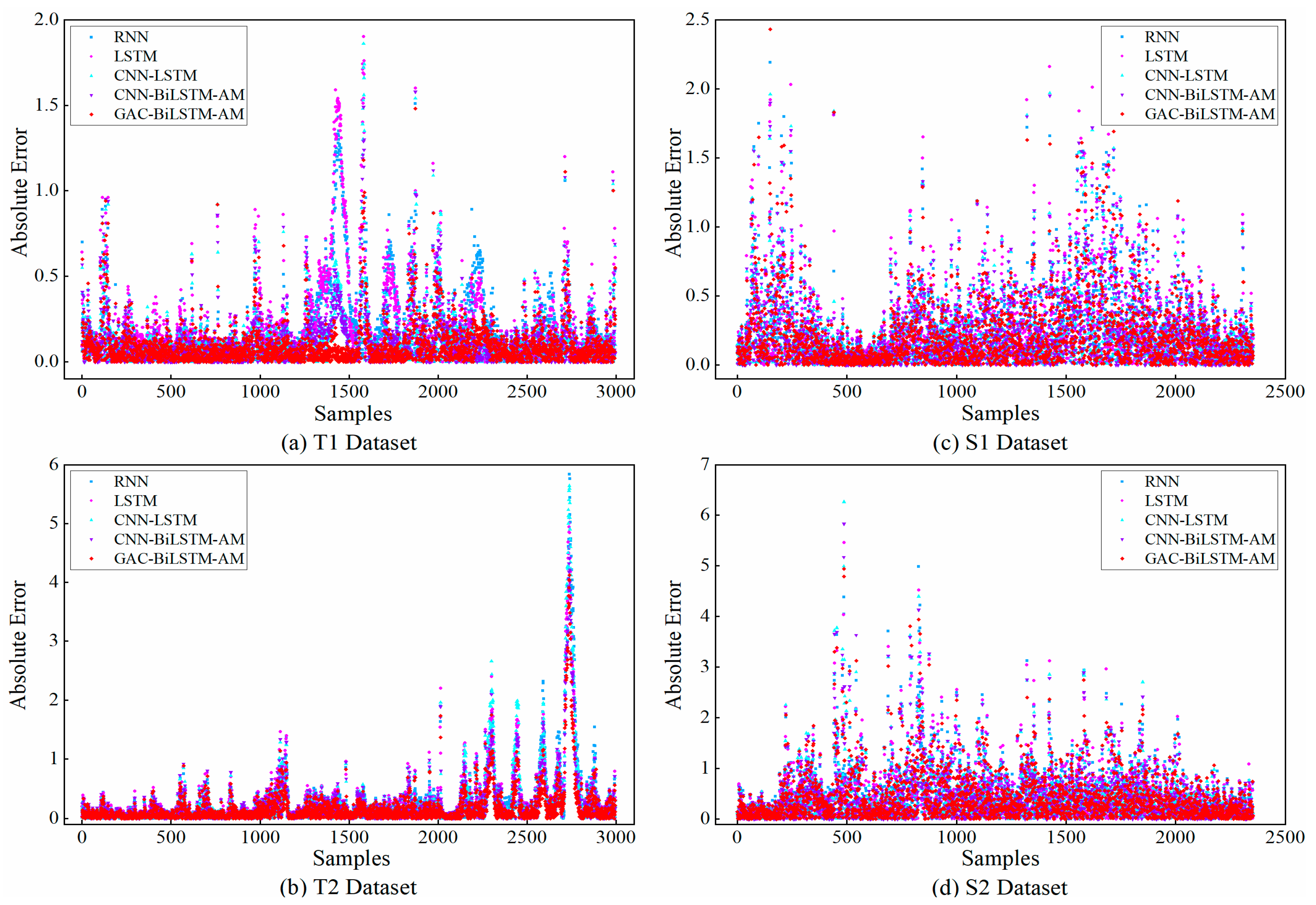
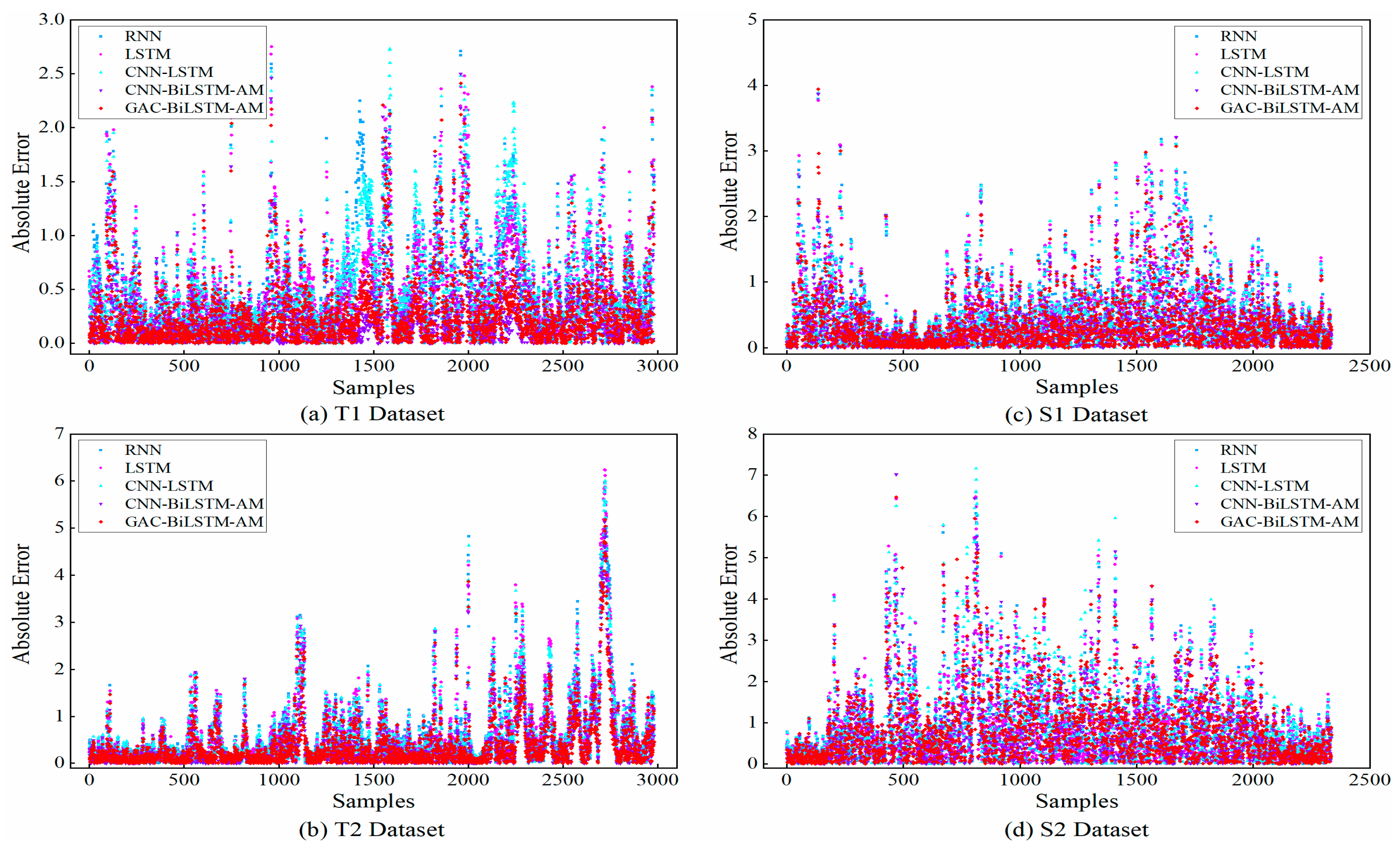
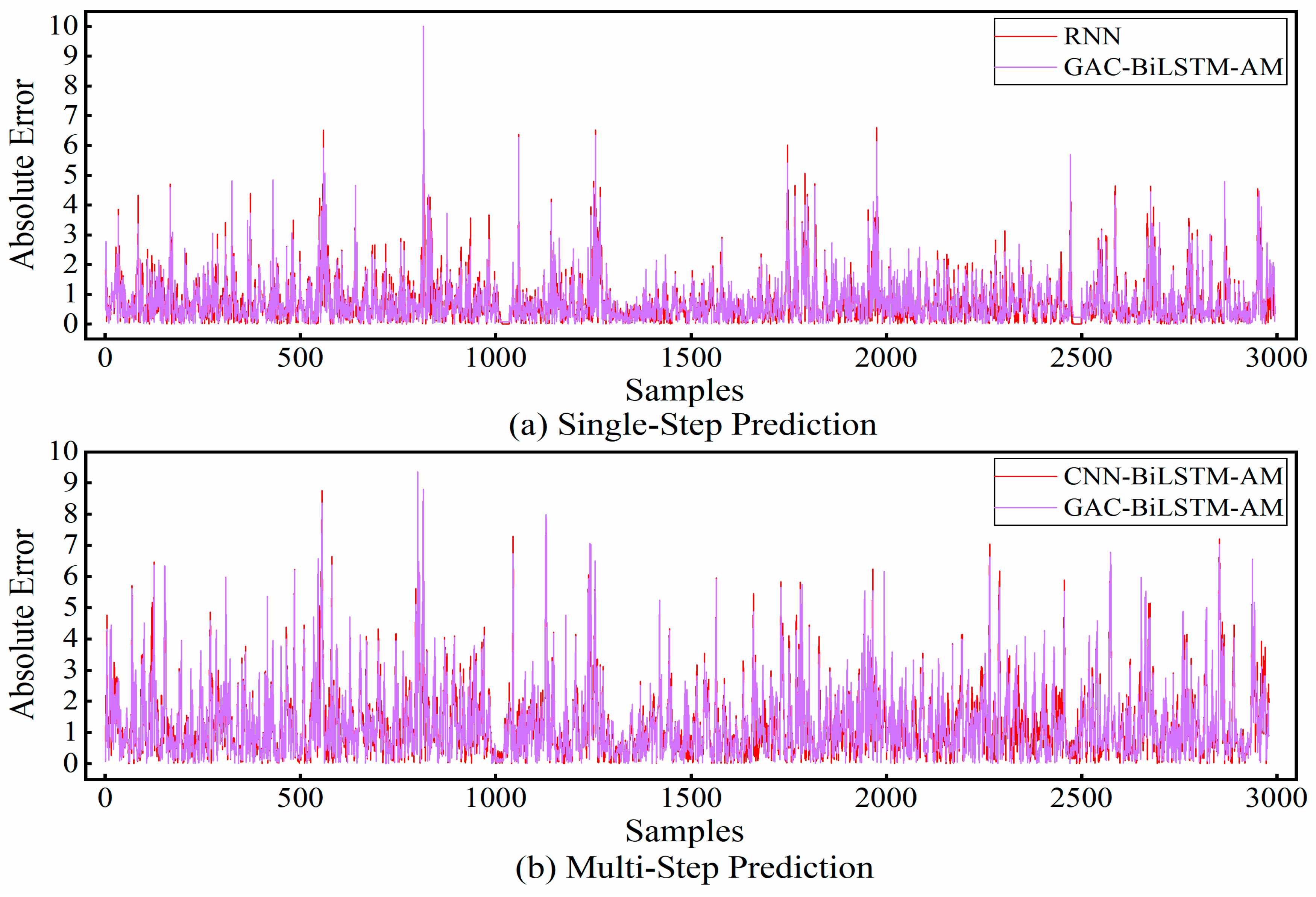
2 of 0.018, with corresponding reductions in MAE, RMSE, and SMAPE by 0.0499, 0.0552, and 0.2409, respectively, demonstrating superior predictive performance. When shifting from single-step prediction to multi-step prediction, although the prediction accuracy and stability of all models generally decrease, our model exhibits a relatively low decrease, which further validates its advantages in dealing with the long-term dependencies of time series data. The scatter plots of the absolute prediction errors of the models in the single-step and multi-step prediction tasks for the T1, T2, S1, and S2 datasets are shown in
Figure 5 and
Figure 6, respectively. As shown in these figures, the prediction values of our model were closest to the real values. The comparison of the absolute prediction error curves for the two models with the best performance in single-step and multi-step forecasting tasks on the ETTh1 dataset is shown in
Figure 7. This figure shows that the prediction error of our model was still the lowest in most cases, which is consistent with the results in
Table 3.
Overall, the GAC-BiLSTM-AM model achieves the highest R2 and the lowest MAE, RMSE, and SMAPE across all public datasets, and it also demonstrates excellent stability in most cases. This fully showcases the superior performance of the GAC-BiLSTM-AM model.
3.3. Fluent Simulation Data
3.3.1. Dataset Introduction and Model Parameter Settings
Fluent simulation data are a cross-section dataset obtained by building a furnace combustion model, a turbulence model, and an ethylene cracking reaction model to simulate the process of ethylene cracking on fluent [
32] simulation software, respectively. The dataset has a total of 50,025 pieces of data and 18 features, among which, t_ p represents the furnace tube temperature, which is the prediction target of this experiment, and its first 10,000 pieces of data are taken to form the F1 dataset in the experiment, and the ratio of the training and test data is set to 7:3. The model parameters of GAC-BiLSTM-AM are shown in
Table 4.
3.3.2. Result Analysis
The GAC-BiLSTM-AM model is compared and analyzed with the RNN, LSTM, CNN-LSTM, and CNN-BiLSTM-AM models, and the evaluation indexes obtained are shown in
Table 5.
As shown in
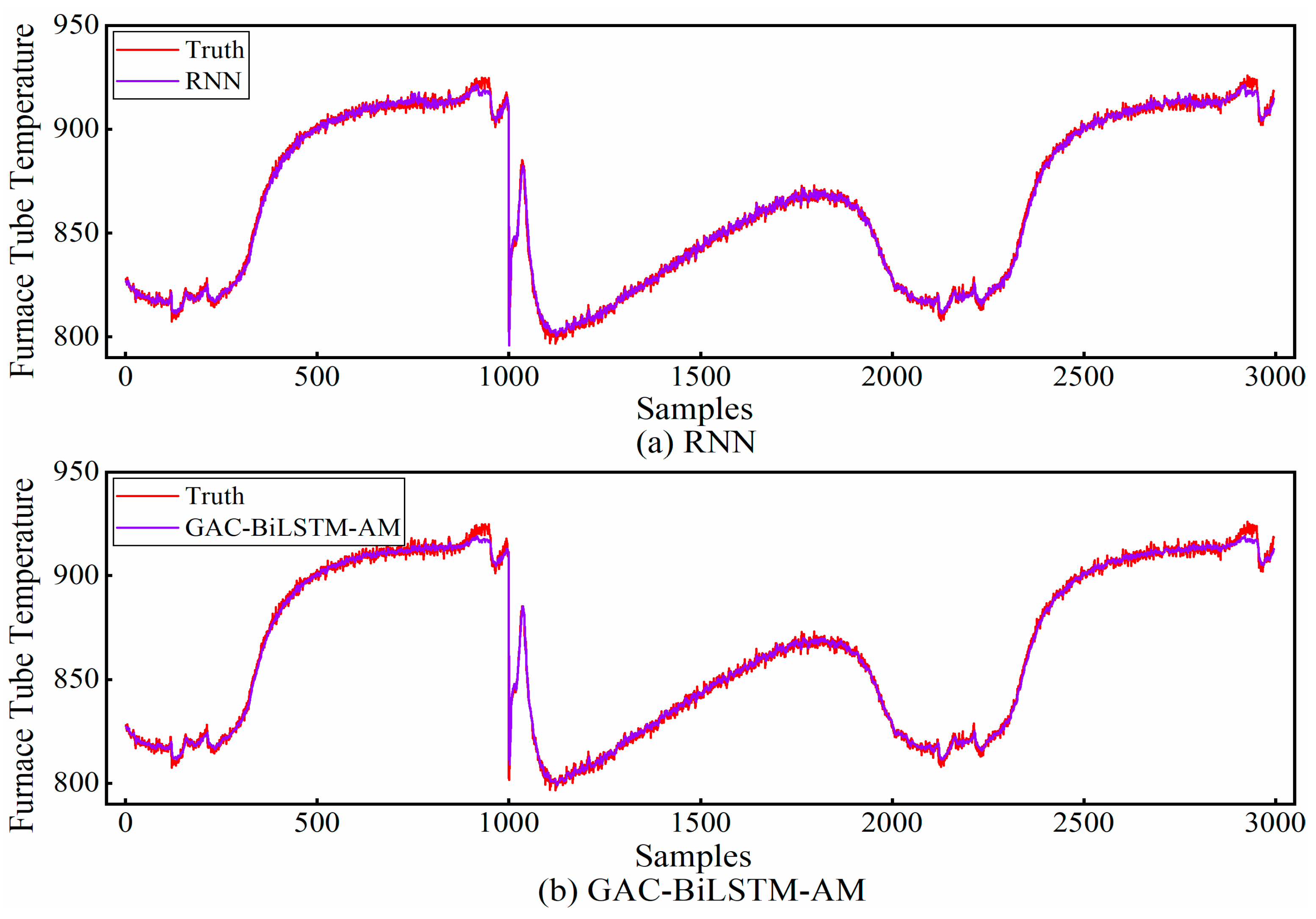
Table 5, the CNN-BiLSTM-AM model exhibits the worst prediction performance among the five models in single-step forecasting. By observing the standard deviation of the results from ten runs, it is found that the highest value is attributed to the CNN-BiLSTM-AM, indicating poor stability in this model, which leads to less-than-ideal prediction outcomes. In contrast, both the RNN and GAC-BiLSTM-AM models demonstrate superior prediction performance. A comparison of their single-step forecasting results is presented in
Figure 8. From the figure, it can be observed that in non-transitional regions, the GAC-BiLSTM-AM model has a smaller deviation between the predicted values and the actual values, which is the reason for its higher accuracy.
With multi-step prediction, the prediction accuracy of RNN decreases more significantly compared to single-step prediction, and its MAE, RMSE, and SMAPE are improved by 38.1%, 67.96%, and 37.72%, respectively, and R
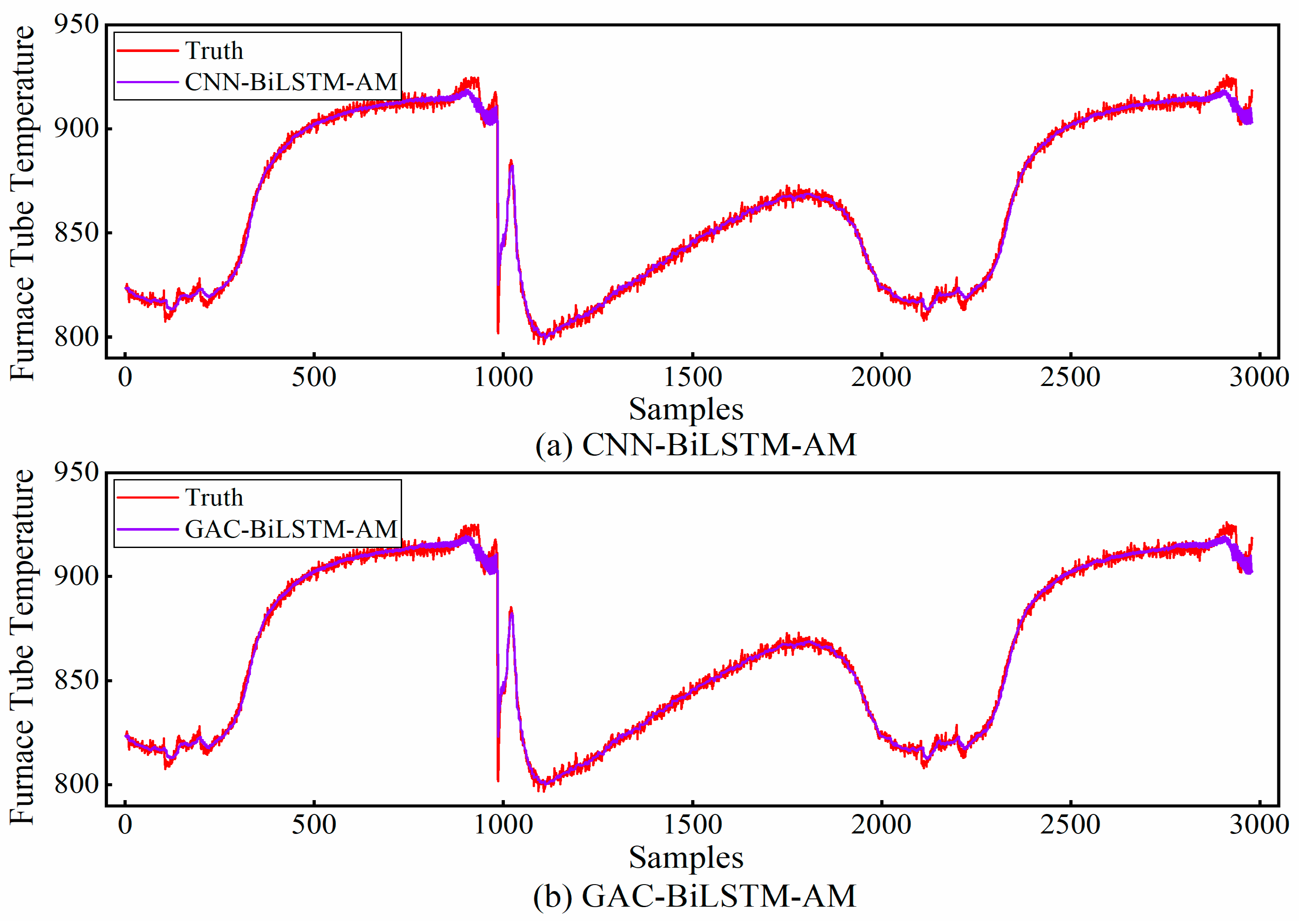
2 is reduced by 1.06%. This situation arises because RNN gradually encounters the long sequence dependence issue as the input step size increases. In contrast, CNN-BiLSTM-AM and GAC-BiLSTM-AM have demonstrated better performance than RNN. Primarily, these model alleviates long-sequence dependence and information overload issues. This is achieved by leveraging the synergy between the attention mechanism and the information stored in the cell state. A comparison of the two models’ multi-step prediction results is depicted in
Figure 9. As seen in the figure, the latter model exhibits a superior fitting effect, which is mainly attributable to GAC-BiLSTM-AM’s ability to perform more comprehensive information analysis, thereby ensuring the model achieves higher prediction accuracy.
The above results show that our model is more applicable in the prediction task, and it possesses higher robustness and stronger generalization.
3.4. Parameter Comparison and Ablation Analysis
In the comparison stage above, the structural parameters used in our model are not the optimal parameters for all tasks. In order to understand the optimal performance of the model in each dataset and, at the same time, grasp the true effect of our model when using the comparison method parameters, the following parametric contrast experiments were conducted and the results obtained are shown in
Table 6. In the table, 1 indicates the use of the same parameters as the comparison method, 2 indicates the use of the experimental parameters above, 3 indicates the use of the respective optimized structural parameters, and * indicates that the graphics card model used is the T400 (all experiments mentioned above were conducted using the T400), and ′ indicates that the graphics card model is the A10.
By comparing the results in the table with the above, we find that the performance of our model remains optimal in most of the datasets when using the same parameters, which further confirms the superiority of our model’s performance. Meanwhile, from
Table 6, it can be seen that the structural parameters obtained from the optimization are more effective in improving the multi-step prediction accuracy. If the model uses the respective optimization structural parameters in all of the above datasets, the R
2 value can be further increased by a maximum of 0.0146 over the existing optimal results. The MAE, RMSE, and SMAPE, correspondingly, decrease by 0.0325, 0.045, and 0.1728, respectively, and prediction errors are further minimized. This also confirms the effectiveness of the optimization algorithm used.
Our model is an improvement on the CNN-BiLSTM-AM model. Specifically, we made the following three changes: 1) added a mistake correction mechanism; 2) optimized the feature extraction module; and 3) added the Adaboost algorithm and linear regression model. To understand the impact of these improvements on the final results, we conducted ablation analysis using the T2 and S2 datasets. The reason for choosing these two datasets is that the T2 dataset retains more features after the feature selection, while the S2 dataset retains fewer features after the feature selection. The number of features input into the network for both basically represents the current feature status of all the data, making the experimental results more persuasive. In the experiment, we only changed the structure of the model, and the results are shown in
Table 7. In the table, a represents the current model, b has the error correction mechanism removed, c replaces the feature extraction module on the basis of b, and d is the CNN-BiLSTM-AM model. By comparing the results in the table, we can draw the following conclusions:
- (1)
During the iterative optimization of model parameters, the mistake correction mechanism can dynamically adjust the weights of samples, effectively correcting the model’s focus and promoting a more balanced learning process, which, in turn, enhances the model’s generalization performance.
- (2)
The dual-channel convolutional neural network excels in processing complex data with rich features, and the deep semantic information it extracts markedly improves the model’s comprehension capabilities.
- (3)
By integrating the Adaboost algorithm and linear regression model and synthesizing the different focuses of these two base learners, the model’s ability to analyze information comprehensively is enhanced.
3.5. Real Industrial Data
When the cracking outlet temperature (COT) is too high, it accelerates the coking rate on the inner wall of the cracking furnace tubes. When the temperature is too low, it affects the cracking efficiency [
33]. Therefore, in the ethylene production process, regulating the COT is critical. The current real-time monitoring and control methods require a certain amount of time to adjust the temperature, subject to lag. If the future temperature trend can be known in advance, measures can be taken as early as possible to further optimize the production process. Therefore, we apply the methodology of this paper to COT prediction. It is worth mentioning that our method is also suitable for solving complex industrial prediction problems that need to consider the spatial distribution, time-series dynamics, and multivariate interactions at the same time—for example, the prediction of energy loads and the prediction of equipment failures. The real data used are sourced from the 1# ethylene cracking unit of a large state-owned petrochemical company in China. The unit consists of 11 USC-type cracking furnaces, numbered from H-110 to H-120 [
34]. We randomly select two furnace tubes from the H-115 cracking furnace as the validation objects, named tube a and tube b, respectively. Then, we collect 5760 pieces of data as the experimental data for single-step prediction. Of these, the first 5000 pieces of data are used as training data, and the remaining 760 pieces of data are used as test data. The parameters of the GAC-BiLSTM-AM model are set as shown in
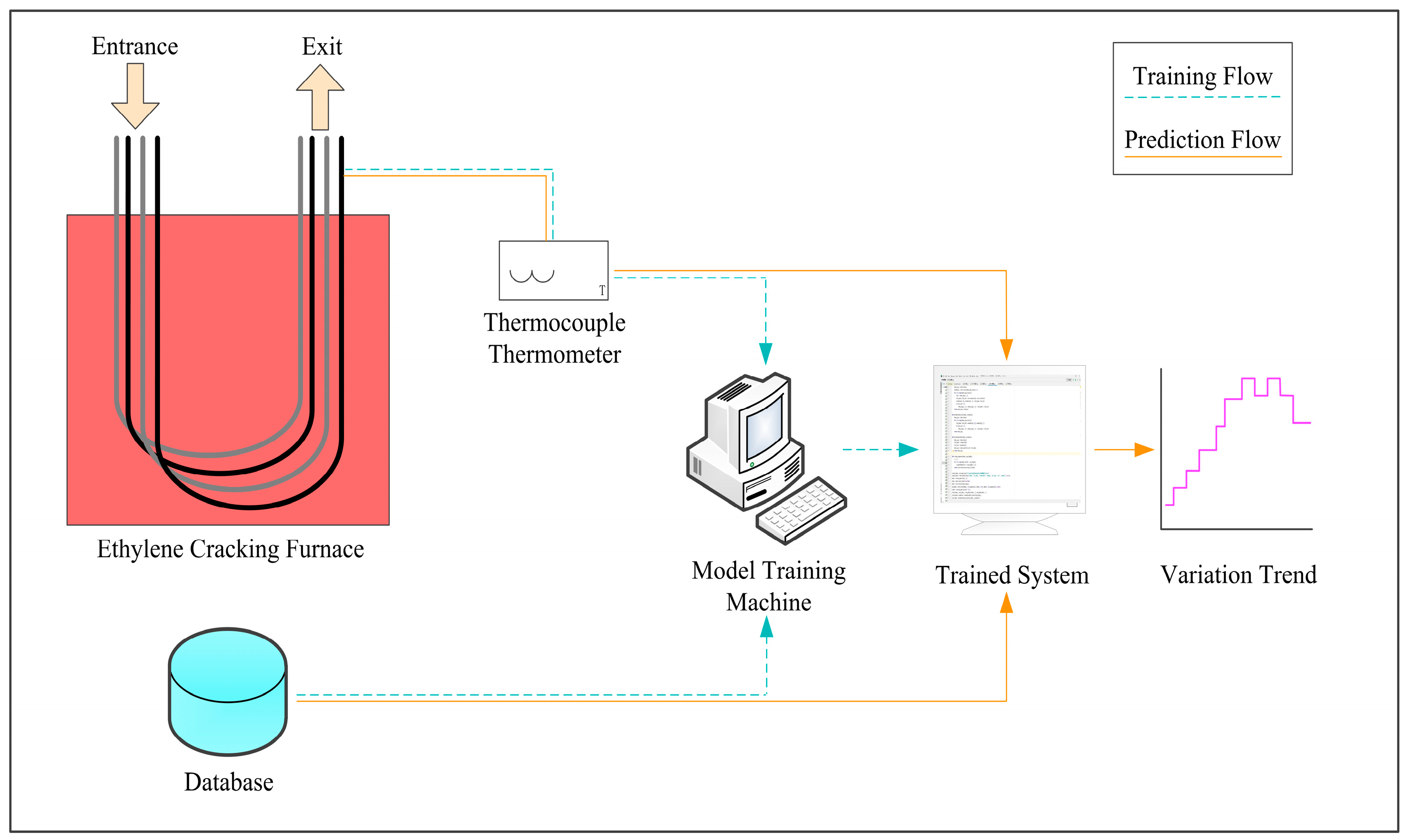
Table 8. The overall framework of the prediction system is shown in
Figure 10.
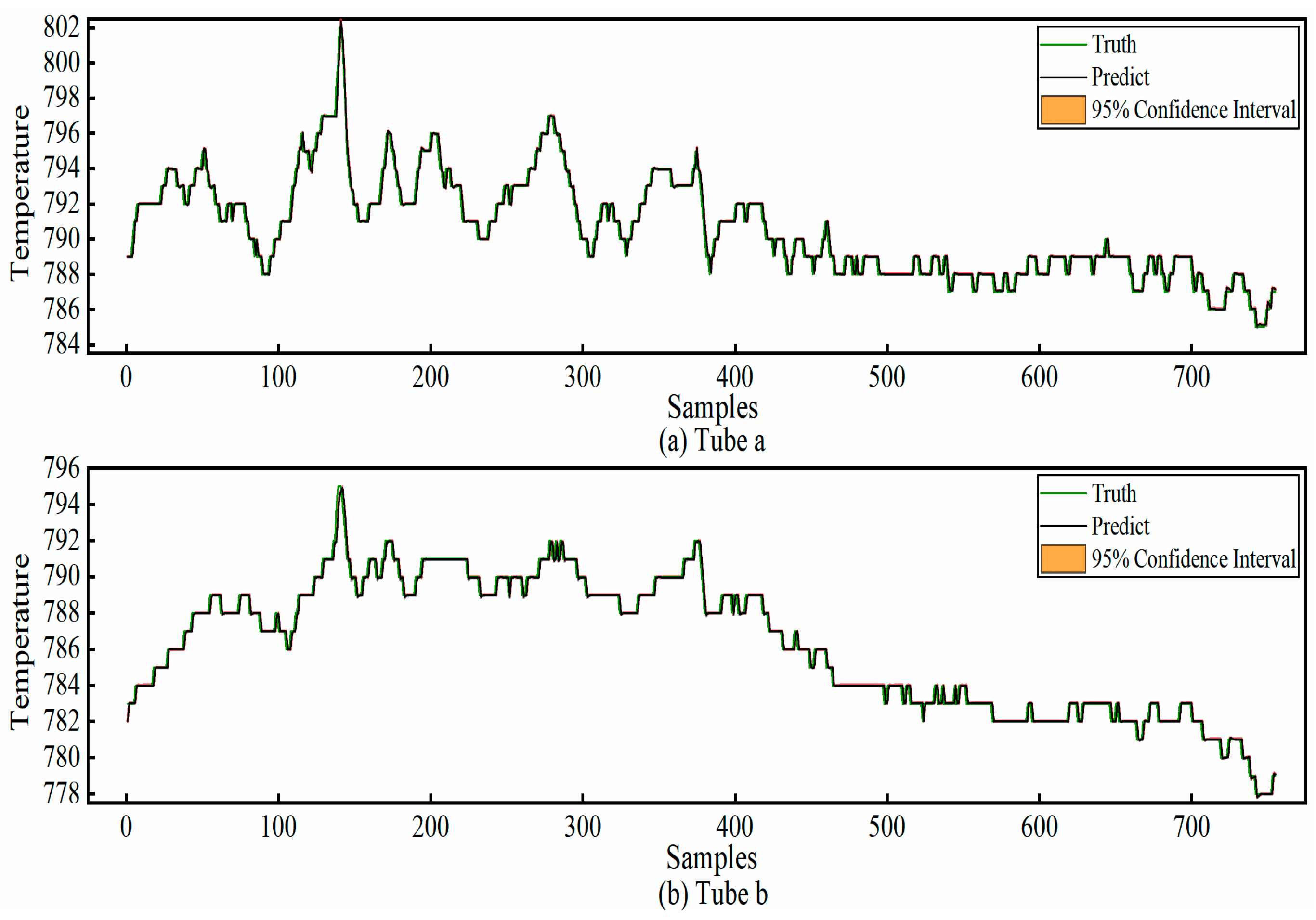
The experimental results show that for tube a, the MAE is 0.2629, the RMSE is 0.4895, the R
2 is 0.9702, and the SMAPE is 0.0332; for tube b, the MAE is 0.1761, the RMSE is 0.3978, the R
2 is 0.9882, and the SMAPE is 0.0223. The required running times for each are 11.53 s and 10.96 s, respectively. The prediction results are presented in
Figure 11. As can be seen from the figure, the model’s predicted values closely match the actual values, with the maximum prediction error being within 2 °C. This can provide a reliable reference for the relevant staff to grasp the changes in temperature in advance. Furthermore, the time expenditure also satisfies the requirements of practical applications. Consequently, applying our method to predict the cracking outlet temperature in ethylene cracking furnaces holds significant practical relevance.
4. Conclusions
To address the common problem of insufficient generalization capability in prediction models, we have proposed a novel GAC-BiLSTM-AM prediction method. This method, by means of dual-channel feature extraction and dynamic attention modification, further improves the generalization ability of the composite model and strengthens its robustness in prediction tasks. Additionally, to overcome the limitations of empirical parameter setting, we utilize the gold rush optimizer for the adaptive optimization of parameters. By establishing a multi-objective optimization mechanism to ensure the rationalization of structural parameters. Experimental results from multiple prediction tasks indicate that our method exhibits outstanding generalization performance. In the application of predicting the cracking furnace outlet temperature, the prediction error consistently remains within ±2 °C, fully capable of providing reliable technical support for actual industrial production. However, since our method is based on the integration of composite models, it has, to some extent, increased the time complexity of the model. How to simplify the model while maintaining the prediction accuracy will be a key research direction for the future.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}