
Lightweight Helmet-Wearing Detection Algorithm Based on StarNet-YOLOv10


Abstract
1. Introduction
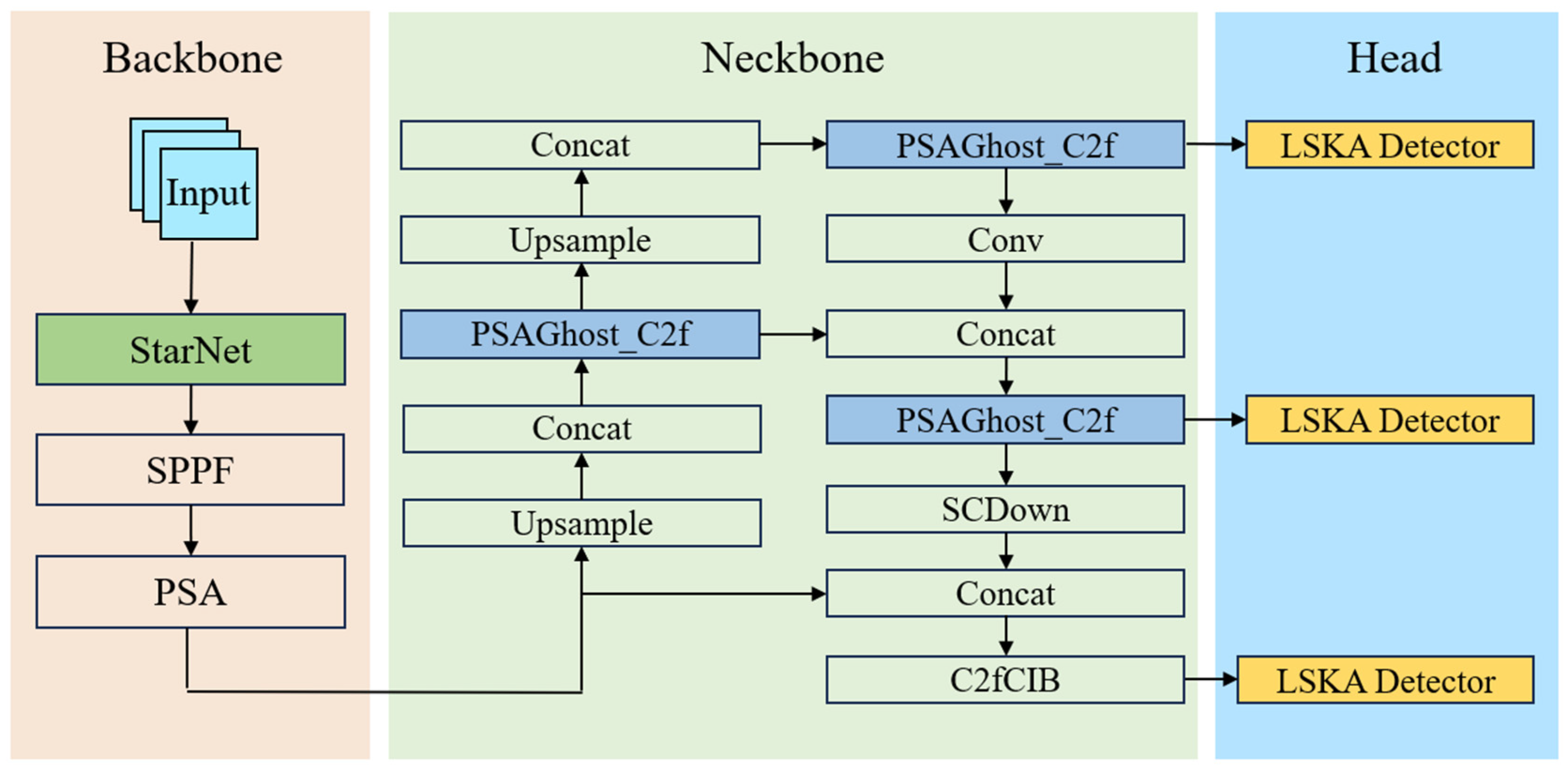
2. StarNet-YOLOv10 Model
2.1. Overall Model Design
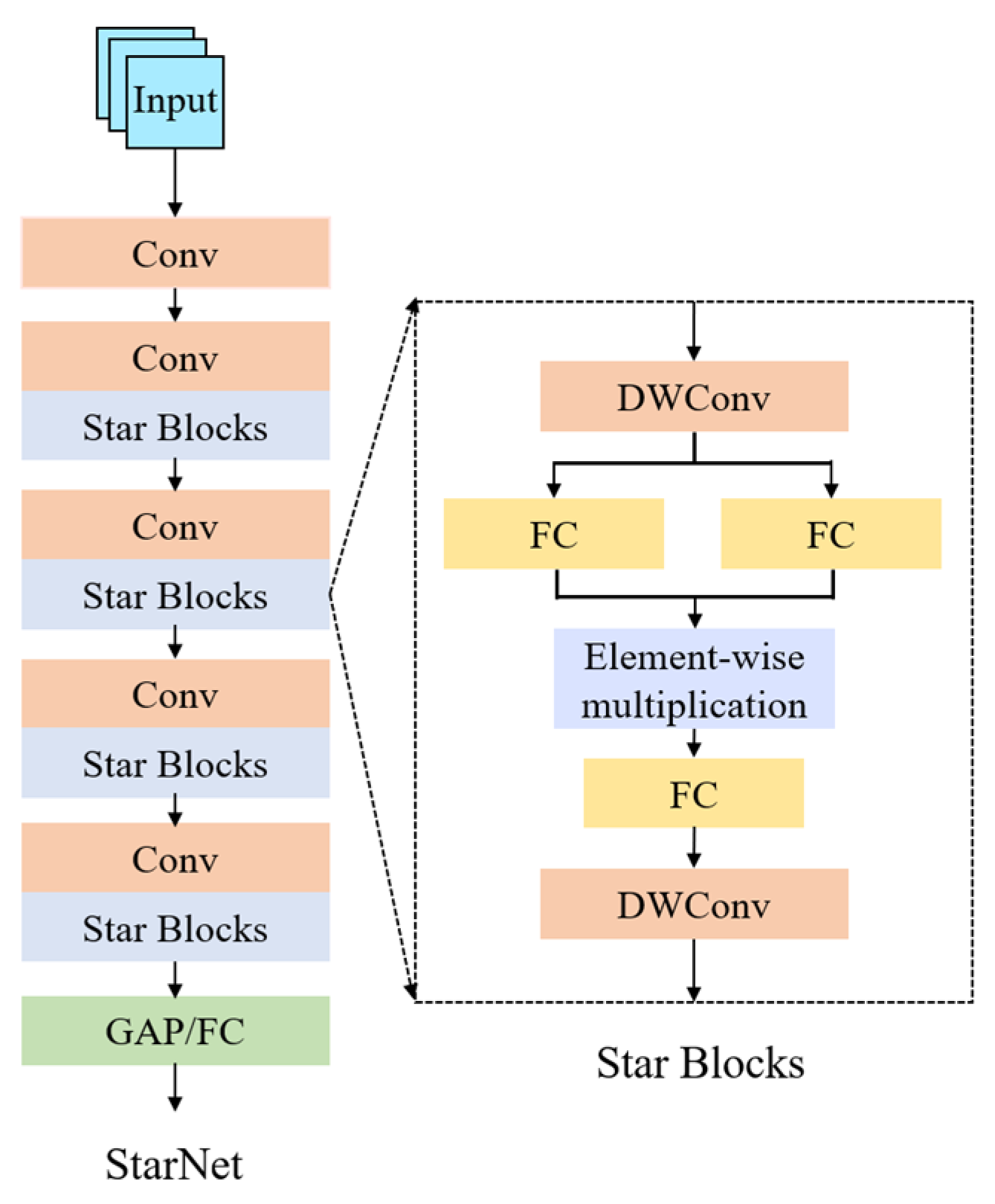
2.2. StarNet-Based Backbone Network
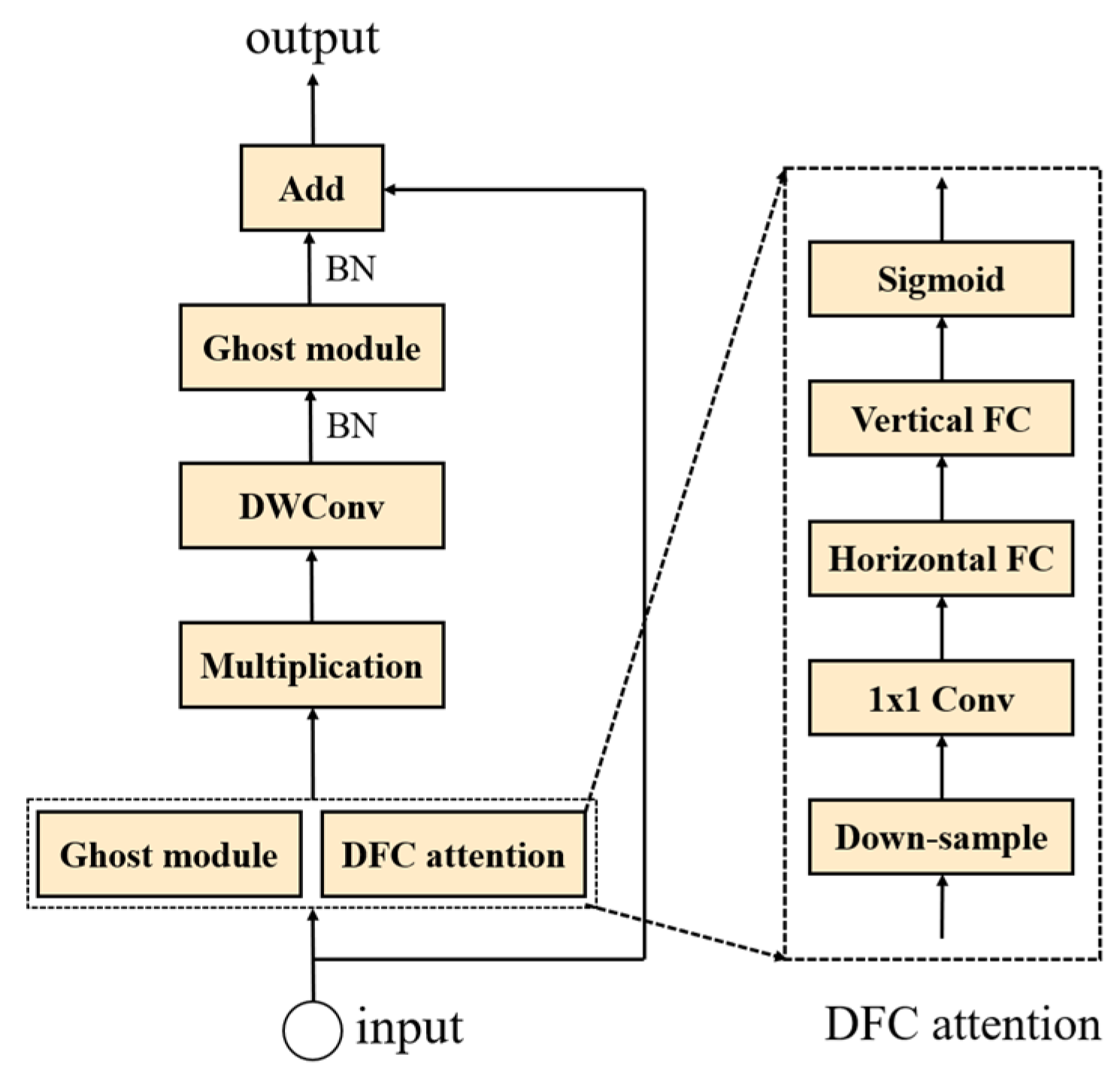
2.3. PSAGhost_C2f Module Design
2.4. LSKA Detection Head Design
3. Experiment and Analysis of Results
3.1. Experimental Environment and Data Preparation
3.2. Performance Indicators Selection
3.3. Analysis of Indicator Results
3.4. Ablation Experiment
3.5. Image Analysis Results
4. Summary and Future Work
4.1. Summary
4.2. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X. Research on Analysis of Influencing Factors of Building Construction Safety Management and Intelligent Control. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2021. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. YOLOv10: Real-Time End-to-End Object Detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Zhou, X.; Wang, K.; Zhou, X.; Han, J. Electric Vehicle Helmet Wearing Detection Algorithm Based on Improved YOLOv10n. Electron. Meas. Technol. 2025, 1–12. Available online: http://kns.cnki.net/kcms/detail/11.2175.tn.20250206.1353.030.html (accessed on 17 February 2025).
- Shen, J.; Zeng, Q.; Gao, Y.; Deng, N. Vehicle and Pedestrian Detection Method Based on YOLOv10s. Comput. Knowl. Technol. 2024, 20, 25–27,39. [Google Scholar]
- Jin, X.; Liang, X.; Deng, P. A Lightweight Yellow Cauliflower Grading Detection Model Based on Improved YOLOv10. Intell. Agric. 2024, 6, 108–118. [Google Scholar]
- Chen, M.; Wang, J.; Wang, L.; Zhang, Q.; Xu, W.; Chen, W. Multi-Focus Cell Image Fusion Method Based on Target Recognition. Adv. Lasers Optoelectron. 2025, 1–19. Available online: http://kns.cnki.net/kcms/detail/31.1690.TN.20250213.1003.006.html (accessed on 17 February 2025).
- Gao, L.P.; Zhou, M.R.; Hu, F.; Bian, K.; Chen, Y. Small Target Detection Algorithm for Underground Helmet Based on REIW-YOLOv10n. Coal Sci. Technol. 2025, 1–13. Available online: http://kns.cnki.net/kcms/detail/11.2402.td.20240919.1902.003.html (accessed on 17 February 2025).
- Wang, J.; Sang, B.; Zhang, B.; Liu, W. A Safety Helmet Detection Model Based on YOLOv8-ADSC in Complex Working Environments. Electronics 2024, 13, 4589. [Google Scholar] [CrossRef]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the Stars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2024; pp. 5694–5703. [Google Scholar]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network. arXiv 2021, arXiv:2105.14447. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetV2: Enhance Cheap Operation with Long-Range Attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- Lau, K.W.; Po, L.M.; Rehman, Y.A.U. Large Separable Kernel Attention: Rethinking the Large Kernel Attention Design in CNN. Expert Syst. Appl. 2024, 236, 121352. [Google Scholar]
- Zhang, G.; Zhou, J.; Ma, G.; He, H. Lightweight Safety Helmet Wearing Detection Algorithm of Improved YOLOv8. Electron. Meas. Technol. 2024, 45, 147–154. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [PubMed]
- Hu, Y.; Hu, S.; Liu, S.; Song, X. Helmet Wear Detection Based on YOLOv5s Algorithm. Inf. Technol. 2025, 1, 61–67. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 10–12 March 2024; pp. 1–6. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2024; pp. 1–21. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device and Parameters | Value |
|---|---|
| operation system | Windows11 |
| CPU | Intel i5-12600KF |
| memory | 16 GB |
| display card | NVIDIA RTX 4060ti |
| deep learning frameworks | Pytorch 2.6 |
| epochs | 200 |
| patience | 50 |
| batch | 32 |
| iou | 0.5 |
| imgsz | 640 |
| degrees | 25 |
| lr0 | 0.0001 |
| optimiser | Adam |
| Precession | Recall | mAP | GFLOPs | FPS | |
|---|---|---|---|---|---|
| Faster R-CNN [15] | 74.21% | 72.63% | 69.52% | 32.8 | 76.5 |
| YOLOv5s [16] | 71.21% | 71.68% | 66.95% | 14.6 | 72.3 |
| YOLOv7-tiny [17] | 76.36% | 74.12% | 70.33% | 18 | 78 |
| YOLOv8 [18] | 80.23% | 78.34% | 71.18% | 34.2 | 80.1 |
| YOLOv9 [19] | 80.68% | 76.41% | 70.86% | 56.7 | 78.3 |
| YOLOv10 [3] | 81.66% | 79.55% | 74.23% | 24.1 | 87.9 |
| StarNet-YOLOv10 | 83.36% | 81.17% | 78.66% | 10.6 | 96.4 |
| StarNet | PSA_C2f | LSKA | Precession | Recall | mAP |
|---|---|---|---|---|---|
| √ | — | — | 82.78% | 80.43% | 76.34% |
| — | √ | — | 82.32% | 80.16% | 75.49% |
| — | — | √ | 82.15% | 80.10% | 75.38% |
| √ | √ | — | 82.97% | 80.89% | 77.41% |
| — | √ | √ | 82.18% | 80.26% | 76.13% |
| √ | — | √ | 82.77% | 80.86% | 77.25% |
| √ | √ | √ | 83.36% | 81.17% | 78.66% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Zong, Q.; Liao, Y.; Luo, X.; Gong, M.; Liang, Z.; Gu, B.; Liao, Y. Lightweight Helmet-Wearing Detection Algorithm Based on StarNet-YOLOv10. Processes 2025, 13, 946. https://doi.org/10.3390/pr13040946
Wang H, Zong Q, Liao Y, Luo X, Gong M, Liang Z, Gu B, Liao Y. Lightweight Helmet-Wearing Detection Algorithm Based on StarNet-YOLOv10. Processes. 2025; 13(4):946. https://doi.org/10.3390/pr13040946
Chicago/Turabian StyleWang, Hongli, Qiangwen Zong, Yang Liao, Xiao Luo, Mingzhi Gong, Zhenyao Liang, Bin Gu, and Yong Liao. 2025. "Lightweight Helmet-Wearing Detection Algorithm Based on StarNet-YOLOv10" Processes 13, no. 4: 946. https://doi.org/10.3390/pr13040946
APA StyleWang, H., Zong, Q., Liao, Y., Luo, X., Gong, M., Liang, Z., Gu, B., & Liao, Y. (2025). Lightweight Helmet-Wearing Detection Algorithm Based on StarNet-YOLOv10. Processes, 13(4), 946. https://doi.org/10.3390/pr13040946