
Named Entity Recognition in Mechanical Fault Diagnosis: A Template-Free Prompt Learning Approach


Abstract
1. Introduction
- To overcome the limitations of traditional template-dependent prompt learning methods with limited sample data, a template-free prompt NER (TFP-NER) model is proposed, eliminating the need for template construction. This approach reduces template dependency and enhances the model’s adaptability and generalization ability across domains, particularly in low-resource domains such as mechanical equipment fault diagnosis.
- The TFP-NER model leverages the prompt learning technique to effectively recognize new entities even with limited labeled data by mining the implicit representations within the model.
- Transforming the NER task into a language model (LM) problem further improves the model’s performance and flexibility. This approach reduces the dependence on a large amount of labeled data and lowers the cost and difficulty of manual labeling.
2. Related Work
2.1. Traditional NER Methods
2.2. Machine Learning-Based NER Methods
2.3. Deep Learning-Based NER Methods
2.4. Pre-Trained Model-Based NER Methods
2.5. Prompt Learning-Based NER Methods
3. Materials and Methods
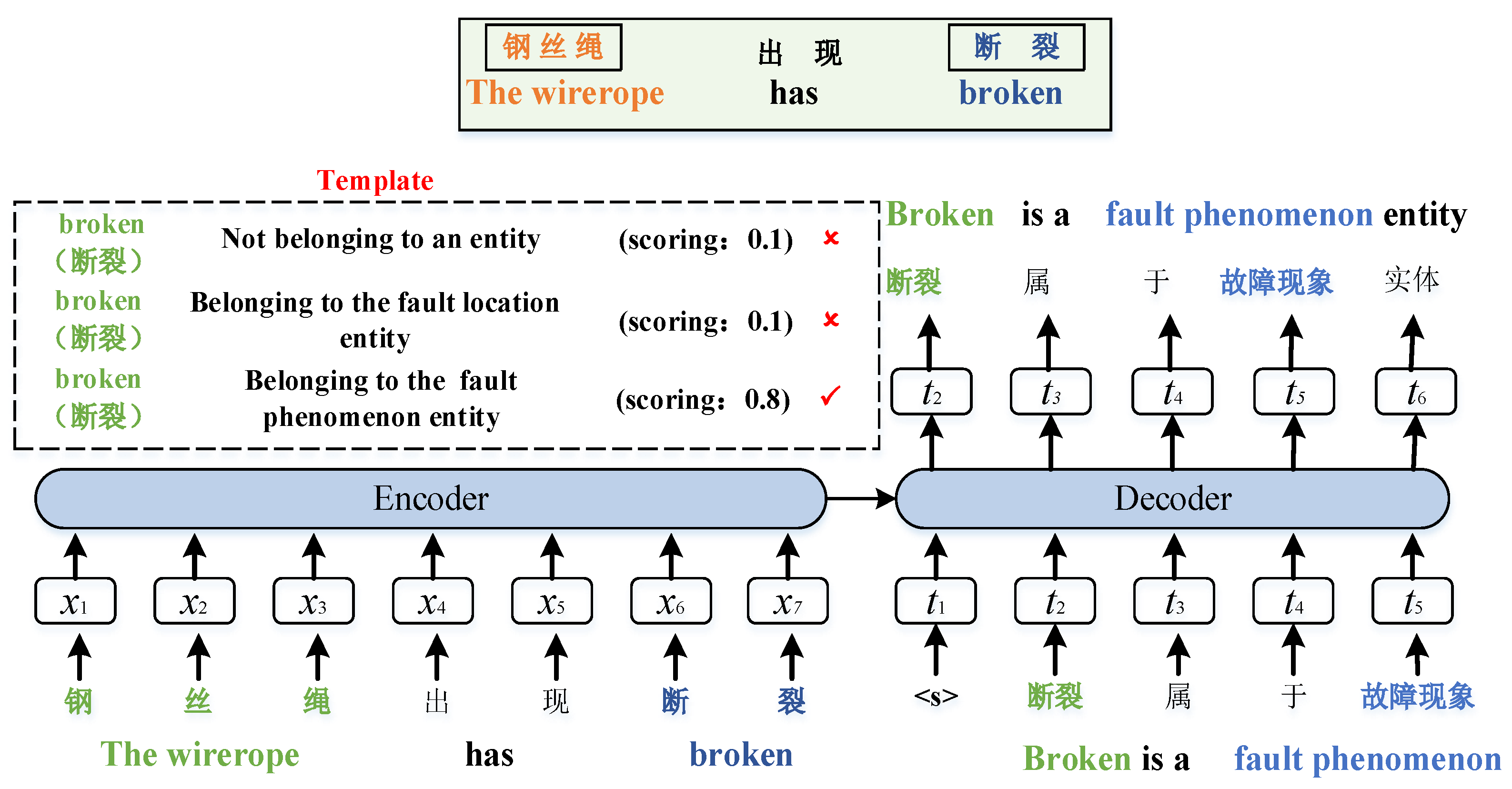
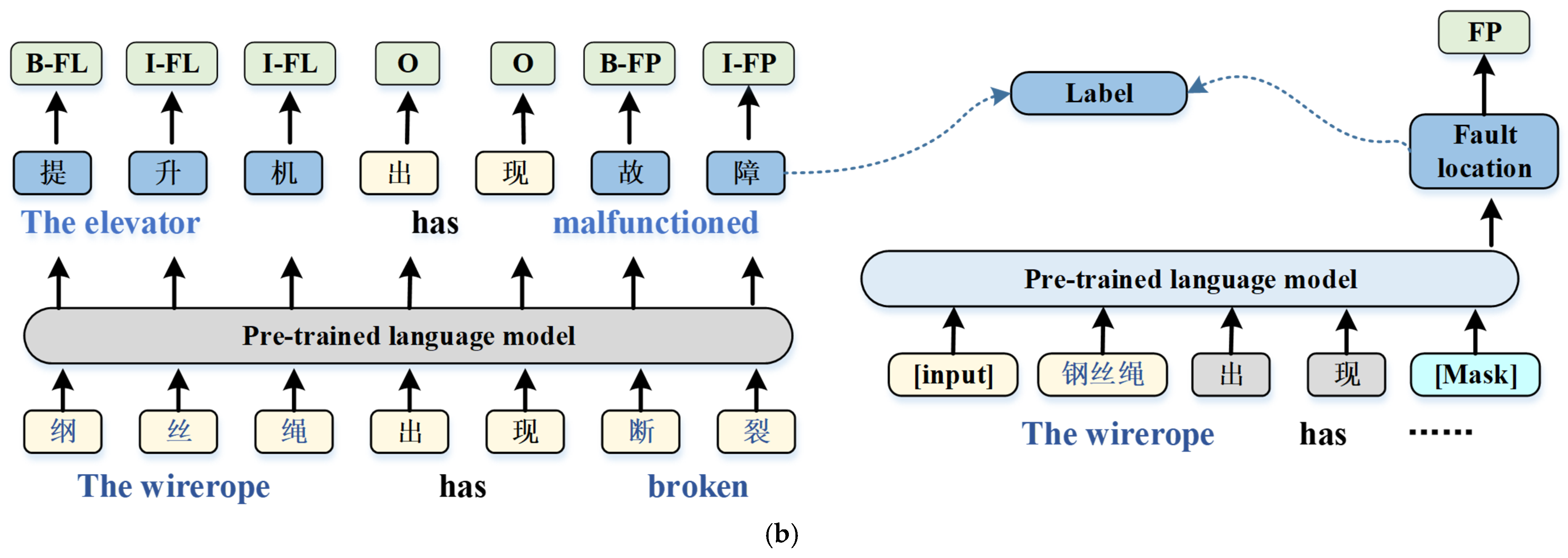
3.1. Model Structure
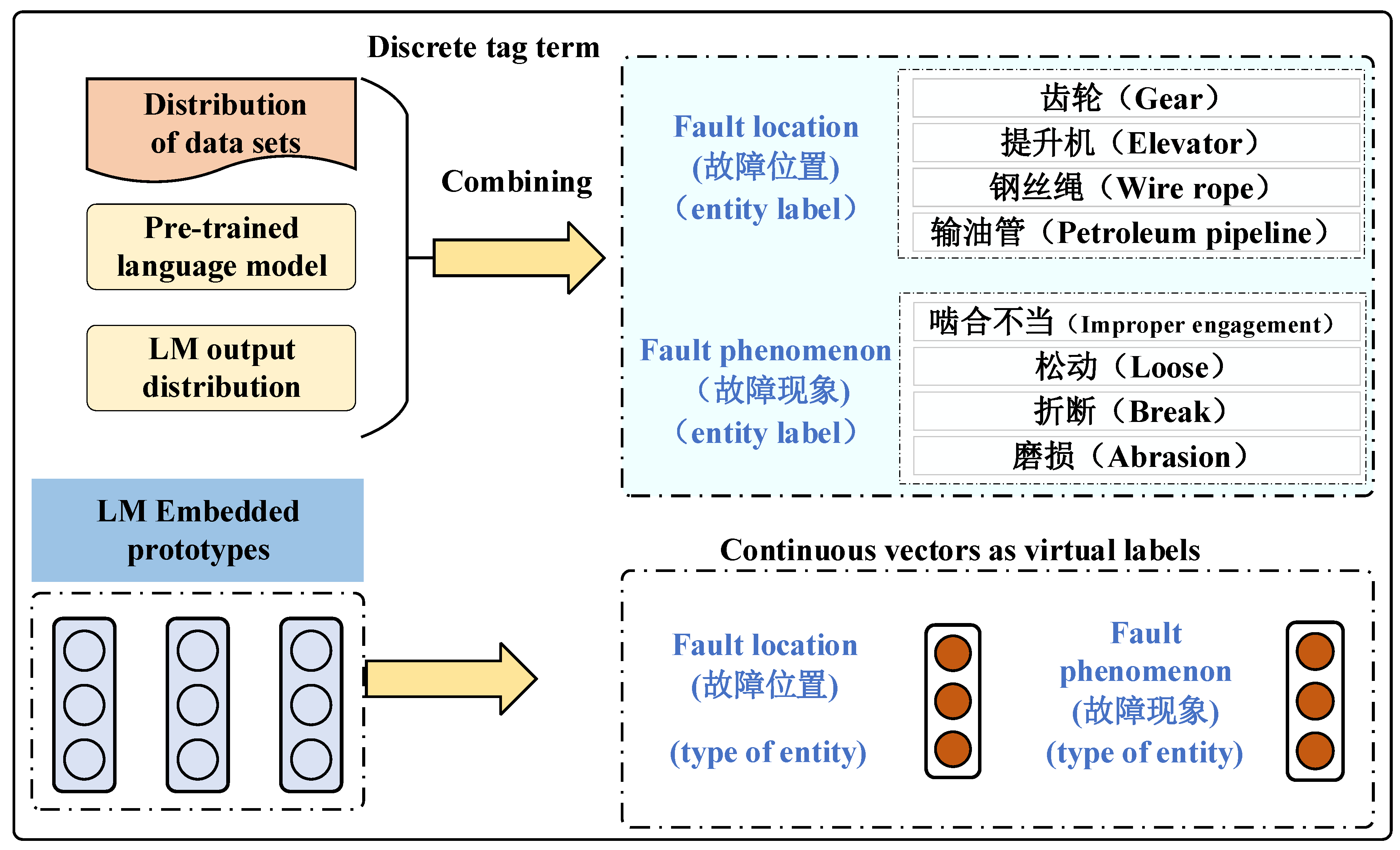
3.2. NER Based on Template-Free Prompt Learning
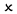 ” indicates that the score is too low and will not be used as a classification result, while “✓” indicates that the score is the highest and will be used as a classification result. In that case, it indicates that the sentence is correct, and “broken” can be extracted as an entity corresponding to the failure phenomenon.
” indicates that the score is too low and will not be used as a classification result, while “✓” indicates that the score is the highest and will be used as a classification result. In that case, it indicates that the sentence is correct, and “broken” can be extracted as an entity corresponding to the failure phenomenon.3.3. Labeling Word Selection
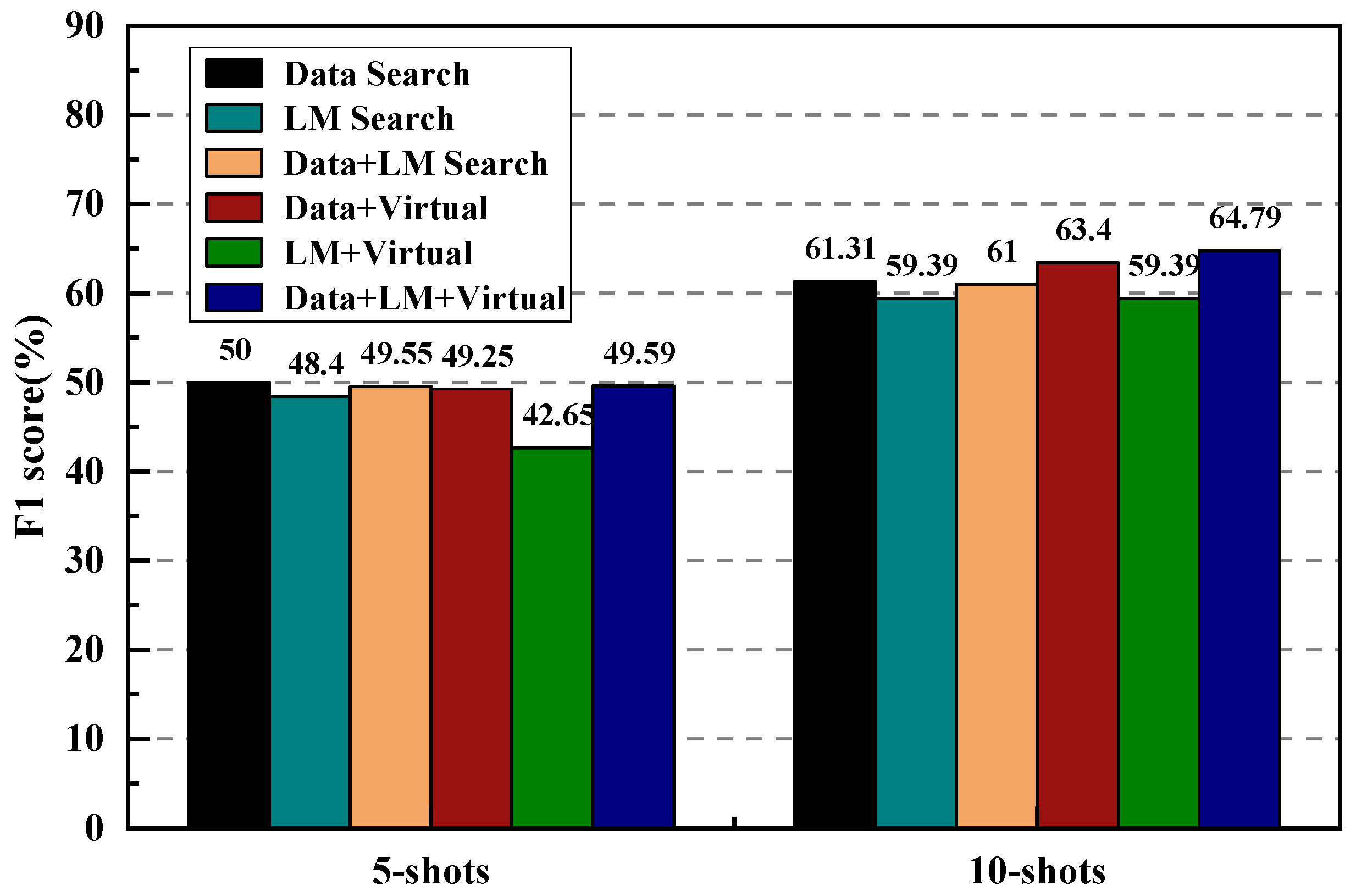
3.3.1. Data Distribution Search
3.3.2. Tag Term Selection Using Pre-Trained Language Models
3.3.3. Tag Term Selection for Fusing Data Distribution Search and Language Model Search
3.3.4. Using Virtual Vectors as Labeling Words
4. Experimental Results and Analysis
4.1. Experimental Environment and Parameter Settings

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Dimension of the word vector | 200 |
| Learning rate | 1 × 10−5 |
| Batch size | 16 |
| Dropout | 0.1 |
| Hidden layer | 768 |
| Number of attention heads | 12 |
| Maximum sentence length | 128 |
| Maximum fused vocabulary information per word | 3 |
4.2. Experimental Data and Evaluation Index
4.3. Analysis of Experimental Results
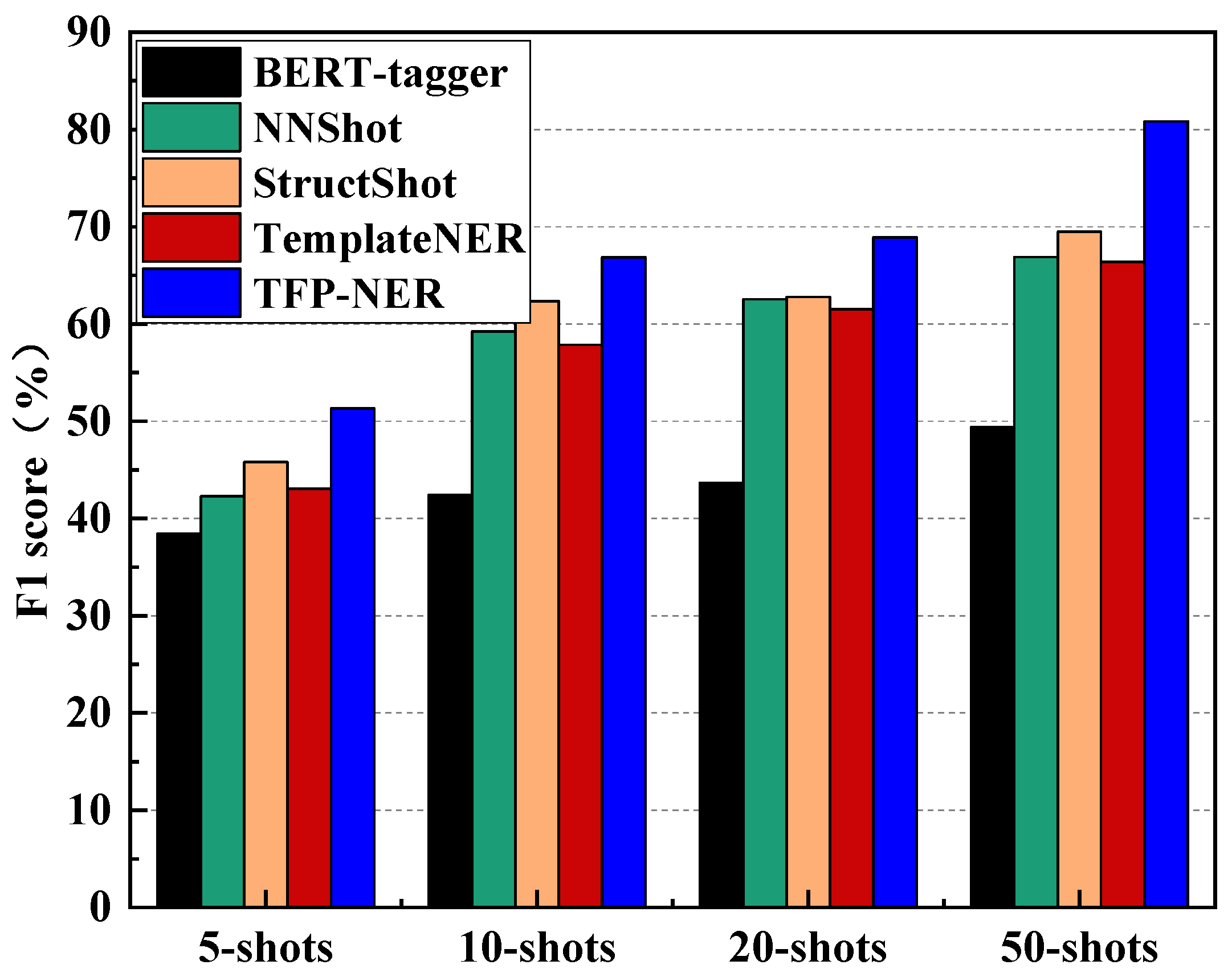
4.3.1. Baseline Model Experiments
4.3.2. Influence of Tag Word Selection on Recognition Effect
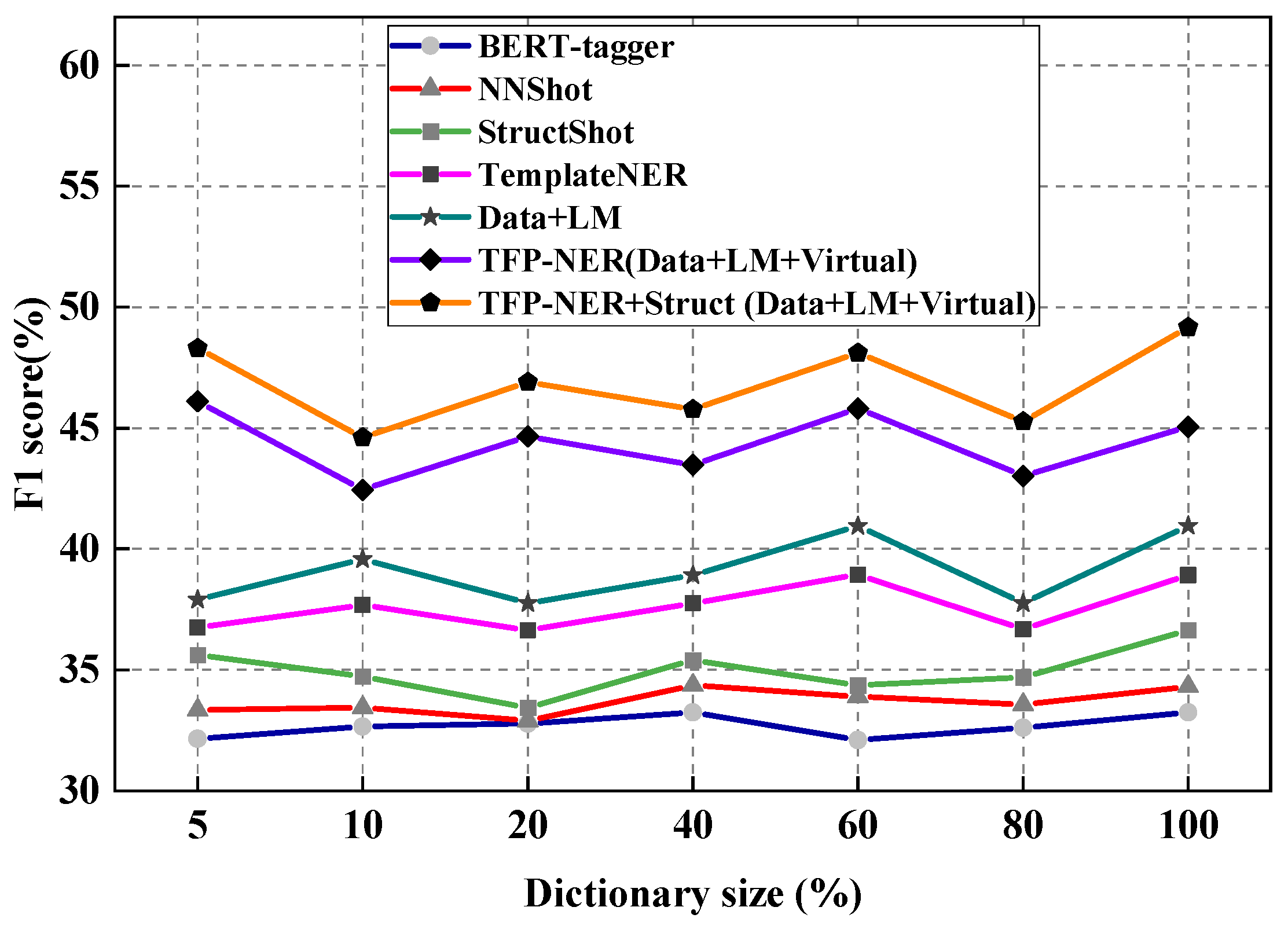
4.3.3. Lexicon Sampling Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lei, Y.G.; Jia, F.; Kong, D.T.; Lin, J. Opportunities and challenges of intelligent fault diagnosis of machinery under big data. J. Mech. Eng. 2018, 54, 94–104. [Google Scholar] [CrossRef]
- Li, C. Exploration of safety management problems and countermeasures of mining electromechanical machinery and equipment. China Met. Bull. 2023, 80–82. [Google Scholar]
- Wu, N. Design and Implementation of Fault Diagnosis System Based on Deep Learning. Master’s Thesis, University of Chinese Academy of Sciences (Shenyang Institute of Computing Technology, Chinese Academy of Sciences), Shenyang, China, 2021. [Google Scholar]
- Basra, J.; Saravanan, R.; Rahul, A. A survey on named entity recognition—Datasets, tools, and methodologies. Nat. Lang. Process. J. 2023, 3, 100017. [Google Scholar]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Ansari, S.; Raut, R.; Shah, K.B. A review of question answering systems: Approaches, challenges, and applications. Int. J. Comput. 2023, 46, 25–33. [Google Scholar]
- Zhang, Q.T.; Wang, Y.C.; Wang, H.X.; Wang, J.X.; Chen, H. A research review on fine-tuning techniques for large language models. Comput. Eng. Appl. 2024, 60, 17–33. [Google Scholar]
- Li, H.P.; Ma, B.; Yang, Y.T.; Wang, L.; Wang, Z.; Li, X. A chapter-level event extraction method based on slot semantic augmented cue learning. Comput. Eng. 2023, 49, 23–31. [Google Scholar]
- Rau, L.F. Extracting company names from text. In Proceedings of the Seventh IEEE Conference on Artificial Intelligence Application, Miami Beach, FL, USA, 24–28 February 1991; pp. 29–32. [Google Scholar]
- Grishman, R.; Sundheim, B. Message understanding conference-6: A brief history. In Proceedings of the 16th International Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996; pp. 466–471. [Google Scholar]
- Etzioni, O.; Cafarella, M.; Downey, D.; Popescu, A.-M.; Shaked, T.; Soderland, S.; Weld, D.S.; Yates, A. Unsupervised named-entity extraction from the Web: An experimental study. Artif. Intell. 2005, 165, 91–134. [Google Scholar] [CrossRef]
- Zhang, S.; Elhadad, N. Unsupervised biomedical named entity recognition: Experiments with clinical and biological texts. J. Biomed. Inform. 2013, 46, 1088–1089. [Google Scholar] [CrossRef] [PubMed]
- Grishman, R. The NYU system for MUC-6 or where’s the syntax? In Proceedings of the Sixth Message Understanding Conference (MUC-6), Columbia, MD, USA, 6–8 November 1995. [Google Scholar]
- Humphreys, K.; Gaizauskas, R.; Azzam, S.; Huyck, C.; Mitchell, B.; Cunningham, H.; Wilks, Y. University of Sheffield: Description of the LaSIE-II system as used for MUC-7. In Proceedings of the Seventh Message Understanding Conference (MUC-7), Fairfax, VA, USA, 29 April–1 May 1998. [Google Scholar]
- Black, W.J.; Rinaldi, F.; Mowatt, D. FACILE: Description of the NE system used for MUC-7. In Proceedings of the Seventh Message Understanding Conference (MUC-7), Fairfax, VA, USA, 29 April–1 May 1998. [Google Scholar]
- Chopra, D.; Joshi, N.; Mathur, I. Named entity recognition in Hindi using hidden Markov model. In Proceedings of the 2016 Second International Conference on Computational Intelligence & Communication Technology (CICT), Ghaziabad, India, 12–13 February 2016; IEEE: New York, NY, USA, 2016; pp. 581–586. [Google Scholar]
- Sun, C.; Guan, Y.; Wang, X.; Lin, L. Biomedical named entities recognition using conditional random fields model. In Proceedings of the International Conference on Fuzzy Systems and Knowledge Discovery, Xi’an, China, 24–28 September 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1279–1288. [Google Scholar]
- Wang, D.; Li, Y.G.; Zhang, X.; Pu, X.Z. Chinese named entity recognition based on quasi-recurrent neural network. Comput. Eng. Des. 2020, 41, 2038–2043. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Zhang, J.; Zong, C.; Hattori, M.; Hui, D. Character-based LSTM-CRF with radical-level features for Chinese named entity recognition. In Natural Language Understanding and Intelligent Applications; Springer: Berlin/Heidelberg, Germany, 2016; pp. 239–250. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; ACL: Stroudsburg, PA, USA, 2014; pp. 1746–1751. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via Bi-directional LSTM-CNNs-CRF. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; ACL: Stroudsburg, PA, USA, 2016; pp. 1064–1074. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional Transformers for language understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 16–21 June 2024; ACL: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar]
- Yu, Y.; Wang, Y.; Mu, J.; Li, W. Chinese mineral named entity recognition based on BERT model. Expert Syst. Appl. 2022, 206, 117727. [Google Scholar] [CrossRef]
- Tong, Z.; Wang, L.D.; Zhu, X.J.; Du, Y. Research on named entity recognition in military domain based on pre-training model. Front. Data Comput. Dev. 2022, 4, 120–128. [Google Scholar]
- Song, Y.; Wang, T.; Cai, P.; Mondal, S.K.; Sahoo, J.P. A comprehensive survey of few-shot learning: Evolution, applications, challenges, and opportunities. ACM Comput. Surv. 2023, 55 (Suppl. S13), 1–40. [Google Scholar] [CrossRef]
- Pourpanah, F.; Abdar, M.; Luo, Y.; Zhou, X.; Wang, R.; Lim, C.P.; Wang, X.Z.; Wu, Q.M.J. A review of generalized zero-shot learning methods. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4051–4070. [Google Scholar] [CrossRef] [PubMed]
- Cui, L.; Wu, Y.; Liu, J.; Yang, S.; Zhang, Y. Template-based named entity recognition using BART. In Findings of the Association for Computational Linguistics; ACL: Stroudsburg, PA, USA, 2021; pp. 1835–1845. [Google Scholar]
- Shen, J.Y.; Tan, Z.Q.; Wu, S.H.; Zhang, W.; Zhang, R.; Xi, Y.; Lu, W.; Zhuang, Y. PromptNER: Prompt Locating and Typing for Named Entity Recognition. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 1, pp. 12492–12507. [Google Scholar]
- Ashok, D.; Lipton, Z.C. Promptner: Prompting for named entity recognition. arXiv 2023, arXiv:2305.15444. [Google Scholar]
- Layegh, A.; Payberah, A.H.; Soylu, A.; Roman, D.; Matskin, M. ContrastNER: Contrastive-based prompt tuning for few-shot NER. In Proceedings of the 2023 IEEE 47th Annual Computers, Software, and Applications Conference (COMPSAC), Torino, Italy, 26–30 June 2023; IEEE: New York, NY, USA, 2023; pp. 241–249. [Google Scholar]
- Shao, J.X.; Huang, Q.; Xiao, C.; Liu, J.; Luo, W.B.; Wang, M.W. Two-Stage Prompt Learning for Few-Shot Named Entity Recognition. In Proceedings of the 23rd Chinese National Conference on Computational Linguistics, Taiyuan, China, 25–28 July 2024; Chinese Information Processing Society of China: Beijing, China, 2024; Volume 1, pp. 394–405. [Google Scholar]
- Sang, E.F.; De Meulder, F. Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL, Edmonton, AB, Canada, 31 May–1 June 2003; pp. 142–147. [Google Scholar]
- Liu, J.; Pasupat, P.; Cyphers, S.; Glass, J. ASGARD: A Portable Architecture for Multilingual Dialogue Systems. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: New York, NY, USA, 2013; pp. 8386–8390. [Google Scholar]
- Yang, Y.; Katiyar, A. Simple and effective few-shot named entity recognition with structured nearest neighbor learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 6365–6375. [Google Scholar]

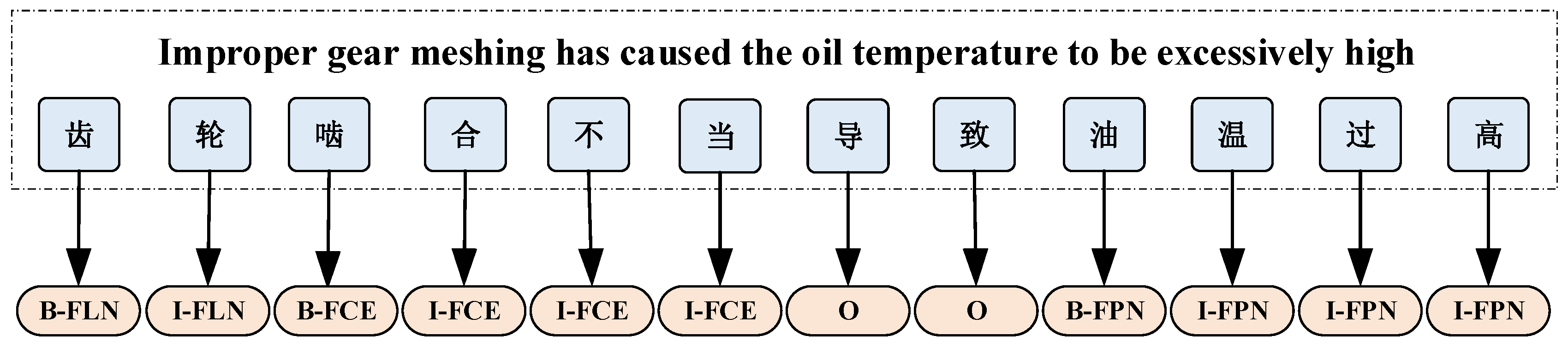
| Abbreviation | Entity Category | Start of Entity | Within Entity | Example | Quantity | Ratio |
|---|---|---|---|---|---|---|
| FLN | Fault Location (故障位置) | B-FLN | I-FLN | Screws, oil pumps, wire rope, hoist drums (螺钉、油泵、钢丝绳、提升机卷筒) | 3749 | 48.5% |
| FET | Fault Effects (故障影响) | B-FET | I-FET | Alarm light flashing, lighted alarm (报警灯闪烁、亮灯报警) | 110 | 1.4% |
| RMS | Repair Measures (修护措施) | B-RMS | I-RMS | Check reconnection, optimize lubrication station cooling system (检查重新连接、优化润滑站冷却系统) | 801 | 10.4% |
| FCE | Fault Cause (故障原因) | B-FCE | I-FCE | High oil temperature, overuse (油温过高、超期使用) | 791 | 10.2% |
| FPN | Failure Phenomenon (故障现象) | B-FPN | I-FPN | Improper engagement, wrong winding connection (啮合不当、绕组连接错误) | 2282 | 29.5% |
| Type of Entity | Number of Entities |
|---|---|
| PER | 1685 |
| LOG | 1968 |
| ORG | 978 |
| Other | 705 |
| K-Shots | K = 5 | K = 10 | K = 20 | K = 50 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT-tagger | 38.89 | 38.26 | 38.45 | 42.56 | 42.32 | 42.4 | 44.18 | 43.56 | 43.68 | 49.35 | 49.56 | 49.37 |
| NNShot | 42.98 | 41.65 | 42.31 | 59.63 | 58.98 | 59.24 | 63.76 | 62.16 | 62.55 | 66.38 | 67.54 | 66.89 |
| StructShot | 44.63 | 46.63 | 45.82 | 62.33 | 62.36 | 62.37 | 63.54 | 62.45 | 62.79 | 68.71 | 69.89 | 69.51 |
| TemplateNER | 43.01 | 43.15 | 43.04 | 57.63 | 58.12 | 57.86 | 62.27 | 61.74 | 61.52 | 66.47 | 66.23 | 66.38 |
| TFP-NER | 51.23 | 51.46 | 51.32 | 66.90 | 66.78 | 66.86 | 69.45 | 68.74 | 68.92 | 80.63 | 80.89 | 80.86 |
| K-Shots | K = 5 | K = 10 | K = 20 | K = 50 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT-tagger | 41.35 | 42.23 | 41.87 | 58.65 | 60.23 | 59.91 | 69.37 | 68.51 | 68.66 | 72.65 | 74.32 | 73.20 |
| NNShot | 42.58 | 42.21 | 42.31 | 58.79 | 60.32 | 59.24 | 67.52 | 66.74 | 66.89 | 71.36 | 72.88 | 72.63 |
| StructShot | 45.63 | 46.96 | 45.82 | 61.63 | 63.35 | 62.37 | 68.45 | 70.23 | 69.51 | 74.89 | 74.36 | 74.73 |
| TemplateNER | 43.62 | 42.63 | 43.04 | 58.36 | 57.54 | 57.86 | 67.32 | 66.57 | 66.38 | 72.68 | 72.76 | 72.71 |
| TFP-NER | 53.68 | 51.17 | 51.32 | 66.45 | 67.54 | 66.86 | 71.65 | 70.89 | 71.23 | 72.89 | 73.10 | 73.66 |
| K-Shots | K = 5 | K = 10 | K = 20 | K = 50 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT-tagger | 37.94 | 37.76 | 37.77 | 50.23 | 49.61 | 49.85 | 58.67 | 57.31 | 57.89 | 71.35 | 70.58 | 70.72 |
| NNShot | 39.56 | 38.54 | 38.76 | 51.34 | 49.76 | 50.42 | 59.44 | 58.72 | 58.63 | 71.55 | 70.32 | 70.43 |
| StructShot | 41.57 | 40.96 | 41.25 | 51.88 | 51.24 | 51.39 | 59.45 | 58.88 | 59.07 | 71.77 | 71.02 | 70.58 |
| TemplateNER | 44.76 | 44.21 | 44.34 | 48.16 | 47.53 | 47.58 | 58.48 | 56.57 | 57.62 | 72.54 | 71.53 | 71.69 |
| TFP-NER | 55.18 | 53.64 | 54.23 | 61.23 | 59.78 | 60.55 | 67.78 | 66.92 | 67.13 | 74.55 | 73.67 | 73.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, F.; Luo, P.; Luo, J.; Qin, G.; Ma, H. Named Entity Recognition in Mechanical Fault Diagnosis: A Template-Free Prompt Learning Approach. Processes 2025, 13, 1242. https://doi.org/10.3390/pr13041242
Li F, Luo P, Luo J, Qin G, Ma H. Named Entity Recognition in Mechanical Fault Diagnosis: A Template-Free Prompt Learning Approach. Processes. 2025; 13(4):1242. https://doi.org/10.3390/pr13041242
Chicago/Turabian StyleLi, Fenfang, Ping Luo, Junjun Luo, Guoyu Qin, and Haijun Ma. 2025. "Named Entity Recognition in Mechanical Fault Diagnosis: A Template-Free Prompt Learning Approach" Processes 13, no. 4: 1242. https://doi.org/10.3390/pr13041242
APA StyleLi, F., Luo, P., Luo, J., Qin, G., & Ma, H. (2025). Named Entity Recognition in Mechanical Fault Diagnosis: A Template-Free Prompt Learning Approach. Processes, 13(4), 1242. https://doi.org/10.3390/pr13041242