
Industrial Compressor-Monitoring Data Prediction Based on LSTM and Self-Attention Model

Abstract
1. Introduction
2. Research Methodology
2.1. Basic Theory
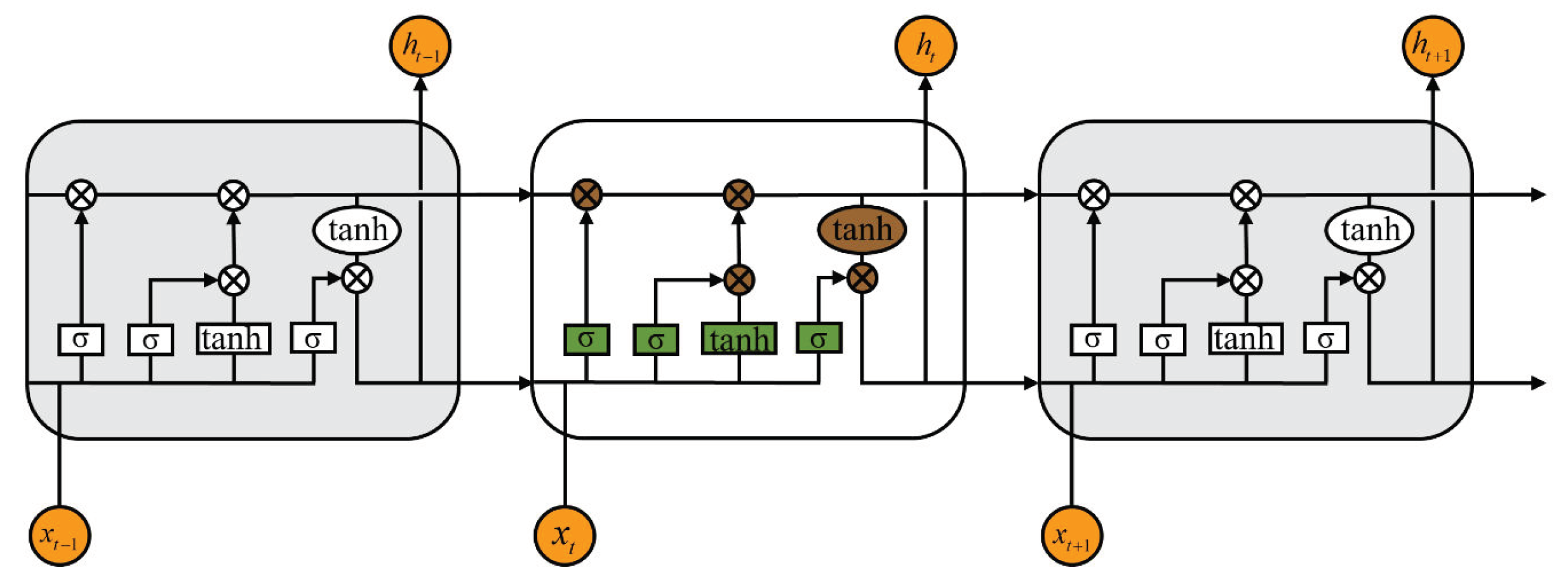
2.1.1. LSTM
- 1.
- Forget gate:The forget gate determines whether the information from the previous time step should be retained or discarded. Based on the current time step input and the previous hidden state, the forget gate outputs a value between 0 and 1, which dictates how much of the past information should be forgotten. A value closer to 0 means that more information will be discarded, while a value closer to 1 indicates that more information will be retained. This mechanism allows the LSTM to selectively forget irrelevant information and focus on relevant patterns. The mathematical expression of the forget gate can be expressed as follows:where is the output of the forget gate, is the hidden state from the previous time step, is the input at time t, is the weight matrix, is the bias matrix, and denotes the sigmoid activation function, which can be expressed aswhere x represents any input variable.
- 2.
- Input gate:The input gate quantifies the importance of the new information carried by the input and selectively records it in the memory cell. First, a “how much to retain” coefficient is calculated using the sigmoid function, and then a candidate memory state is generated using the tanh function. The two are multiplied to obtain the new information to be added to the memory cell. This process can be divided into two steps: First, how much of the new information to keep is determined via the sigmoid gate, as shown below:where represents the output of the input gate, and and are the weight and bias matrices of the input gate, respectively. Second, the candidate memory content is generated based on the current input and previous hidden state through the tanh function:where represents the candidate memory state, and and are the weight and bias matrices, respectively.
- 3.
- Output gate:
2.1.2. Self-Attention Mechanism
- Query (Q): Used to match with the keys of other elements to identify which elements are related to the current one.
- Key (K): Paired with the query to measure the similarity between different elements.
- Value (V): Once matching is complete, it determines how the information of this element will influence the final output based on the similarity weights.
2.2. The Proposed Model
2.2.1. Forward Propagation
2.2.2. Loss Function
2.2.3. Backpropagation
- 1.
- Gradient of loss with respect to hidden statePerform backpropagation through time from the last time step T to the first time step 1. For each time step, calculate the gradient of the output, forget, and input gates:where represents the gradient at the current time step.
- 2.
- Updating cell stateThe cell sate can be updated based on the following equation:
- 3.
- Gradient of the weights and biases of LSTMThe gradients for the weight and bias for each time step can be determined using the chain rule:Following the above equations, each gradient expression uses summation over time steps t to accumulate the contributions from all time steps
- 4.
- Gradients of the self-attentionThe gradient of matrices Q, K, and V in self-attention can be calculated based on the following equation:
2.2.4. Parameter Updating
3. Results
3.1. Industrial System Introduction
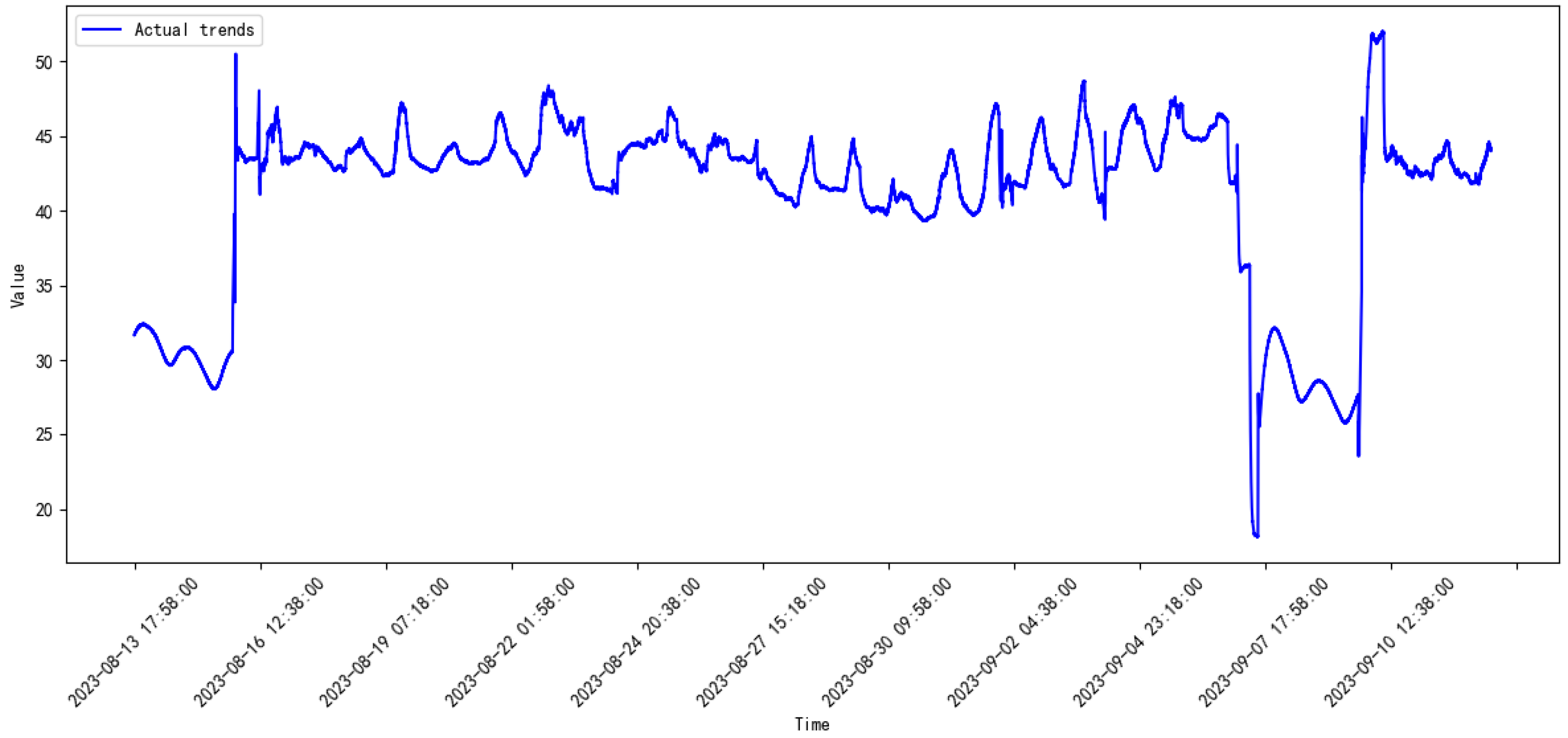
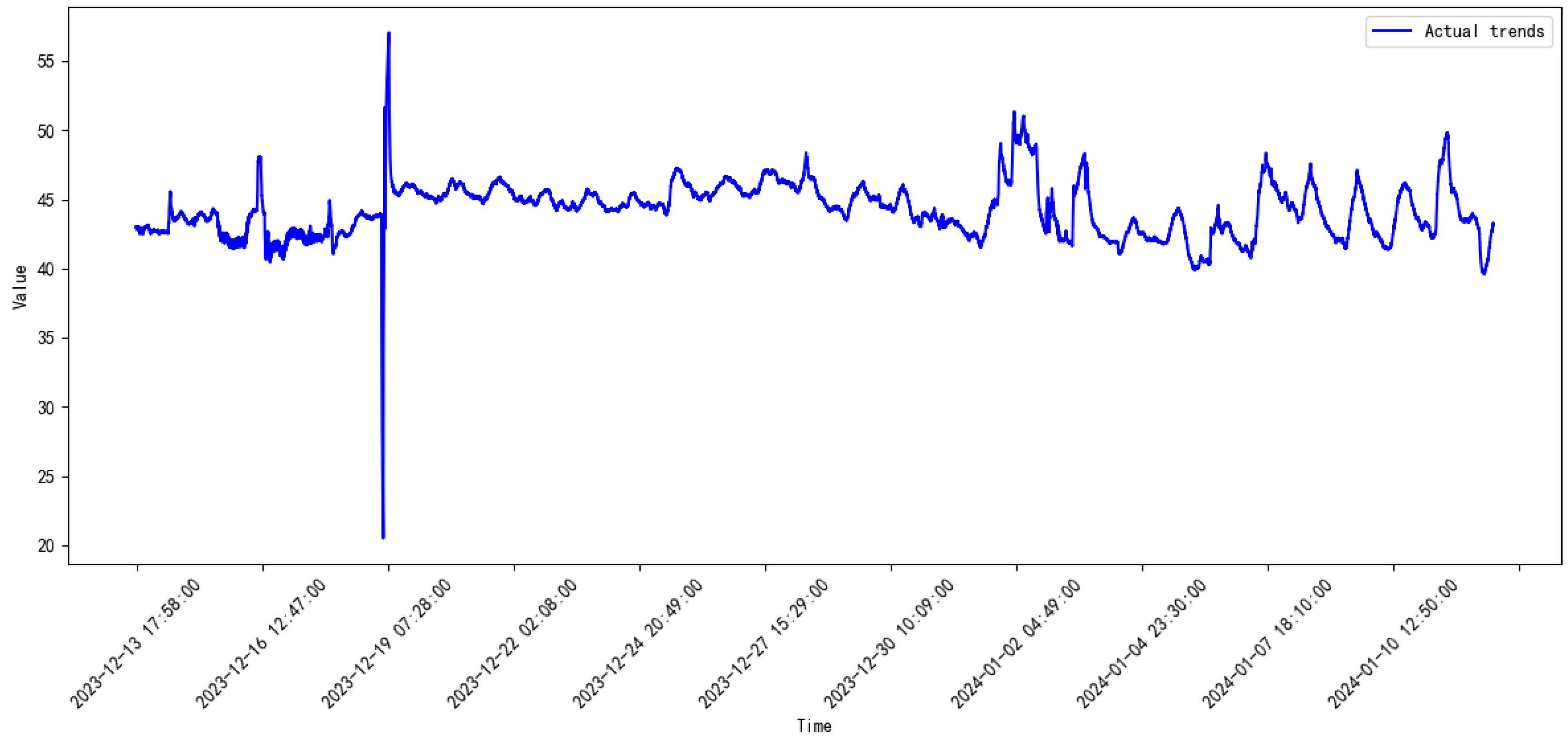
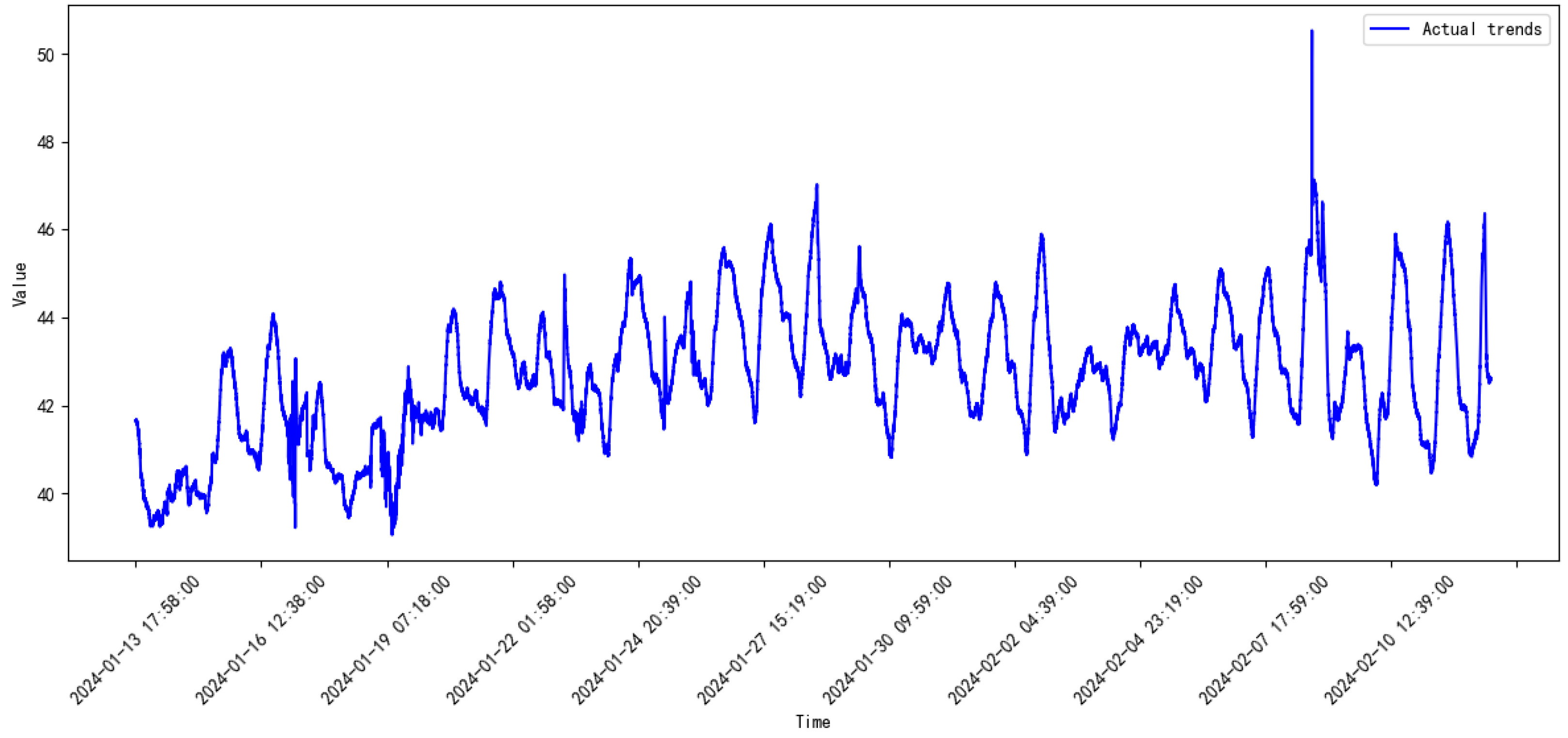
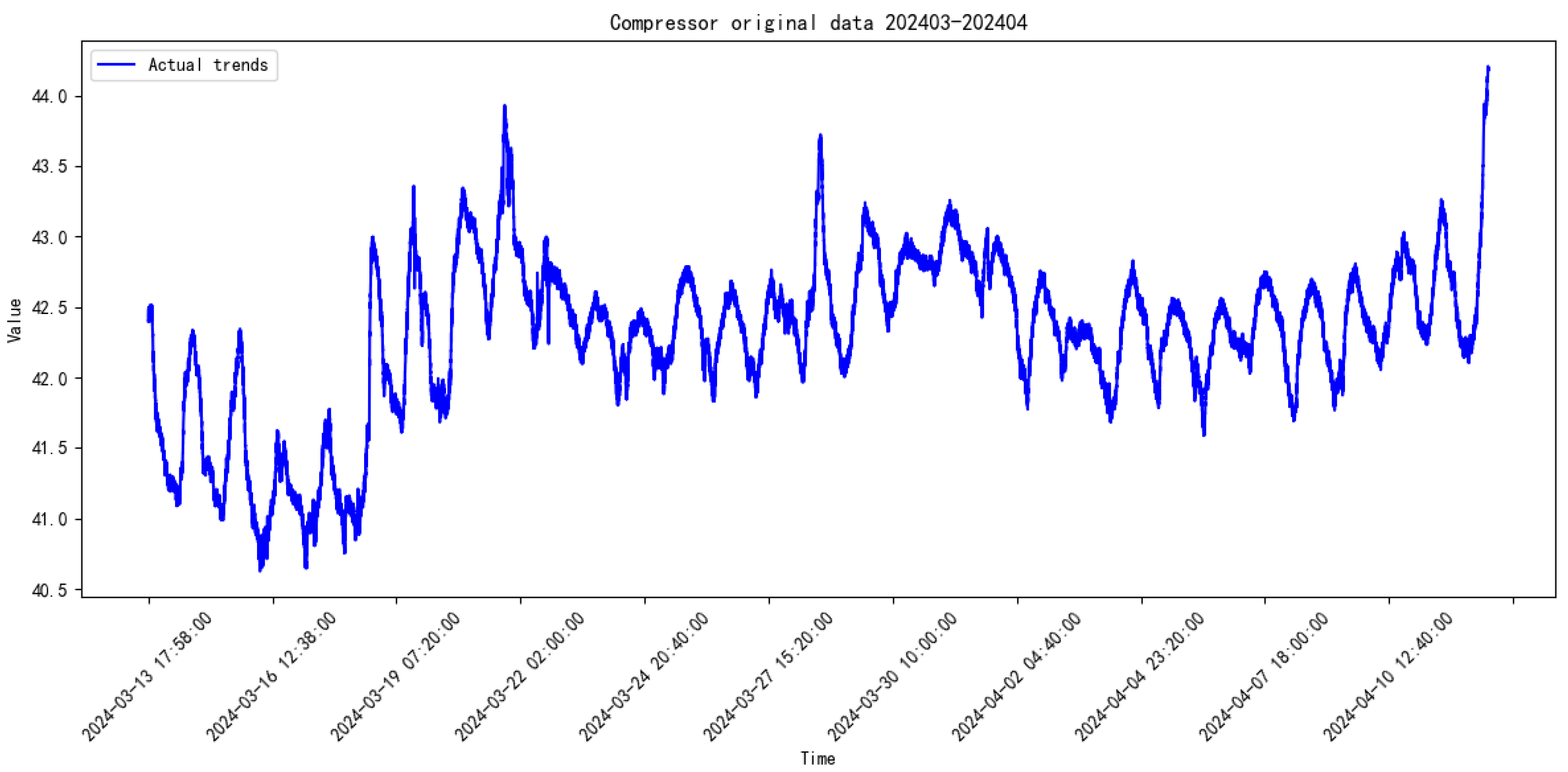
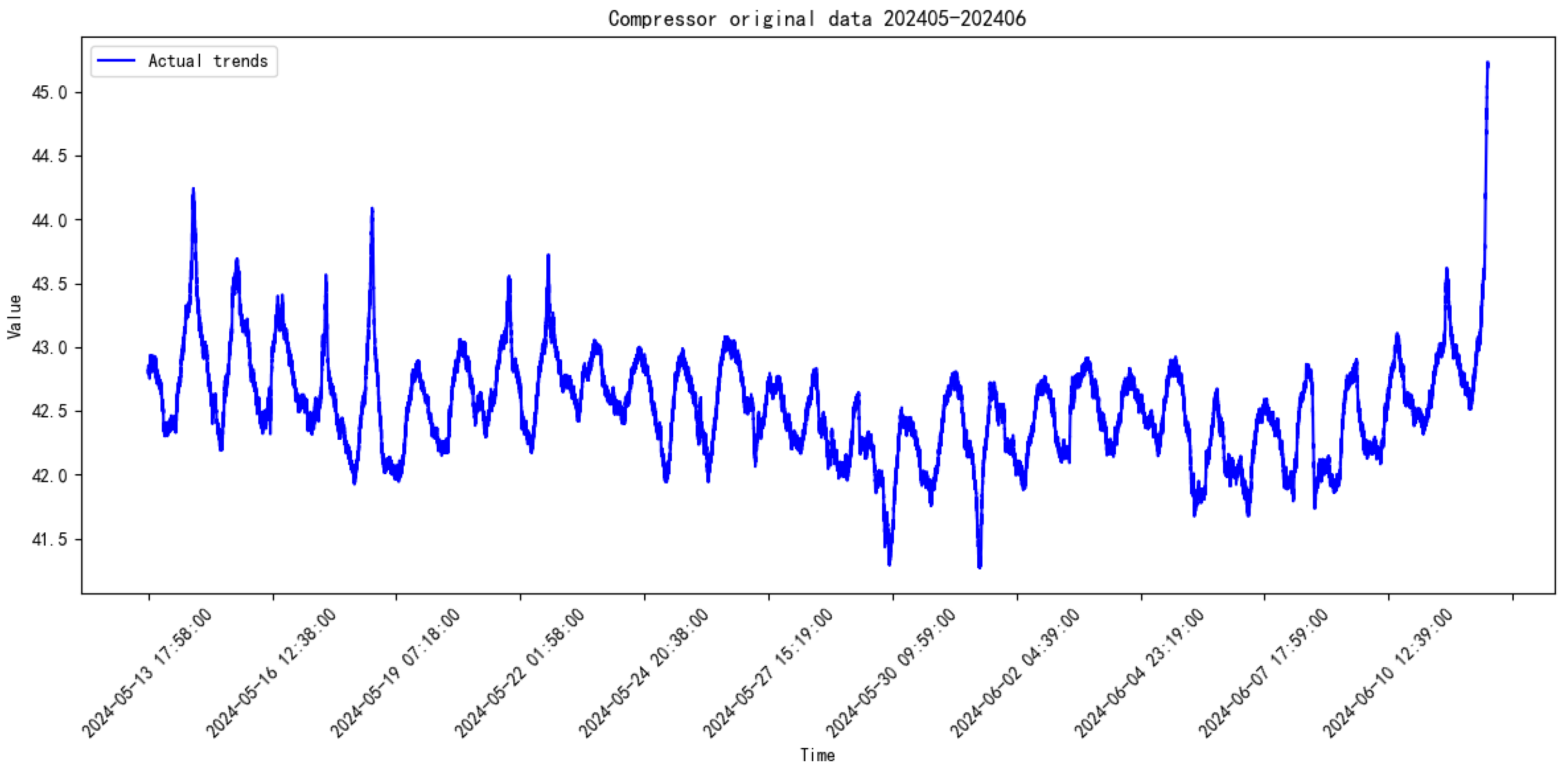
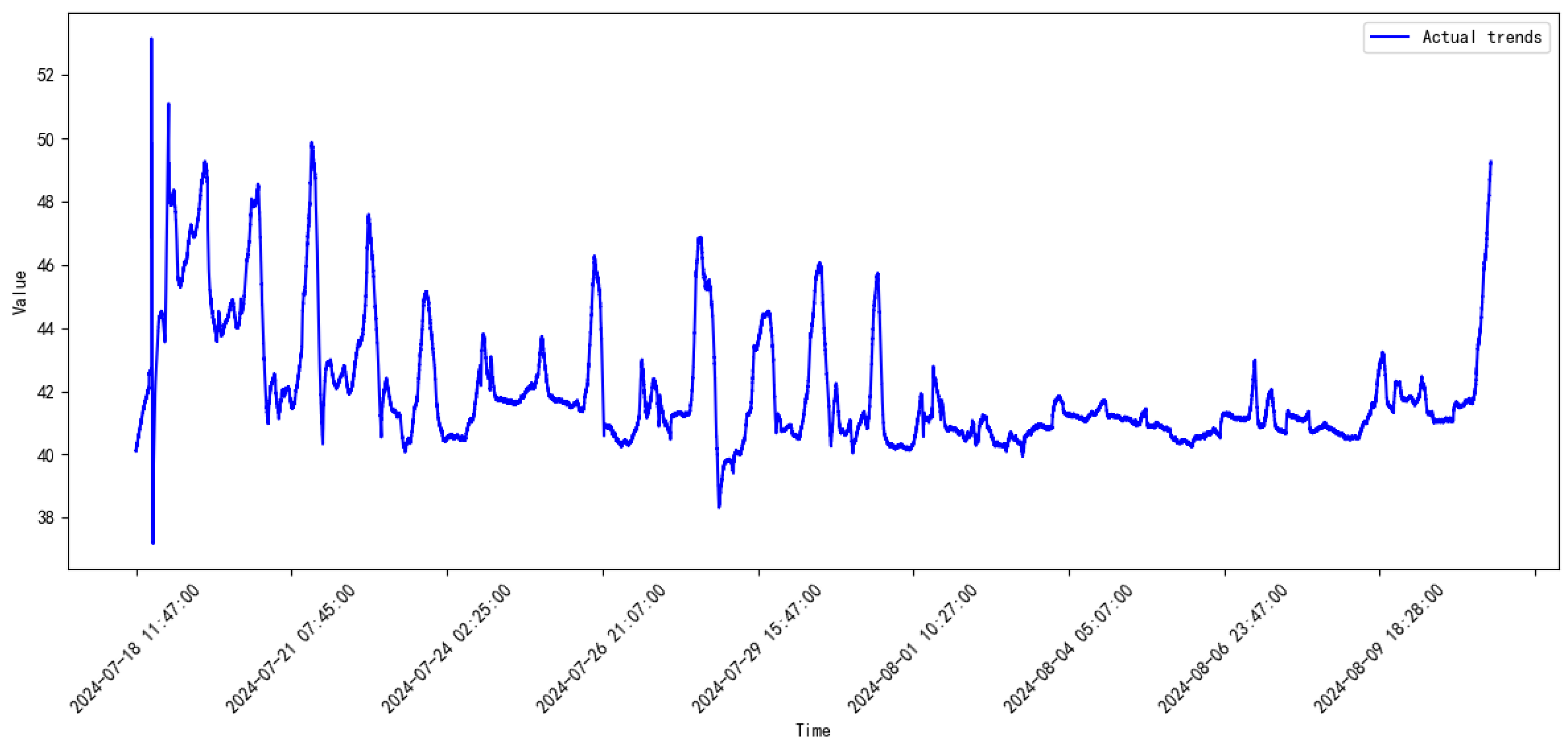
3.2. Data Introduction
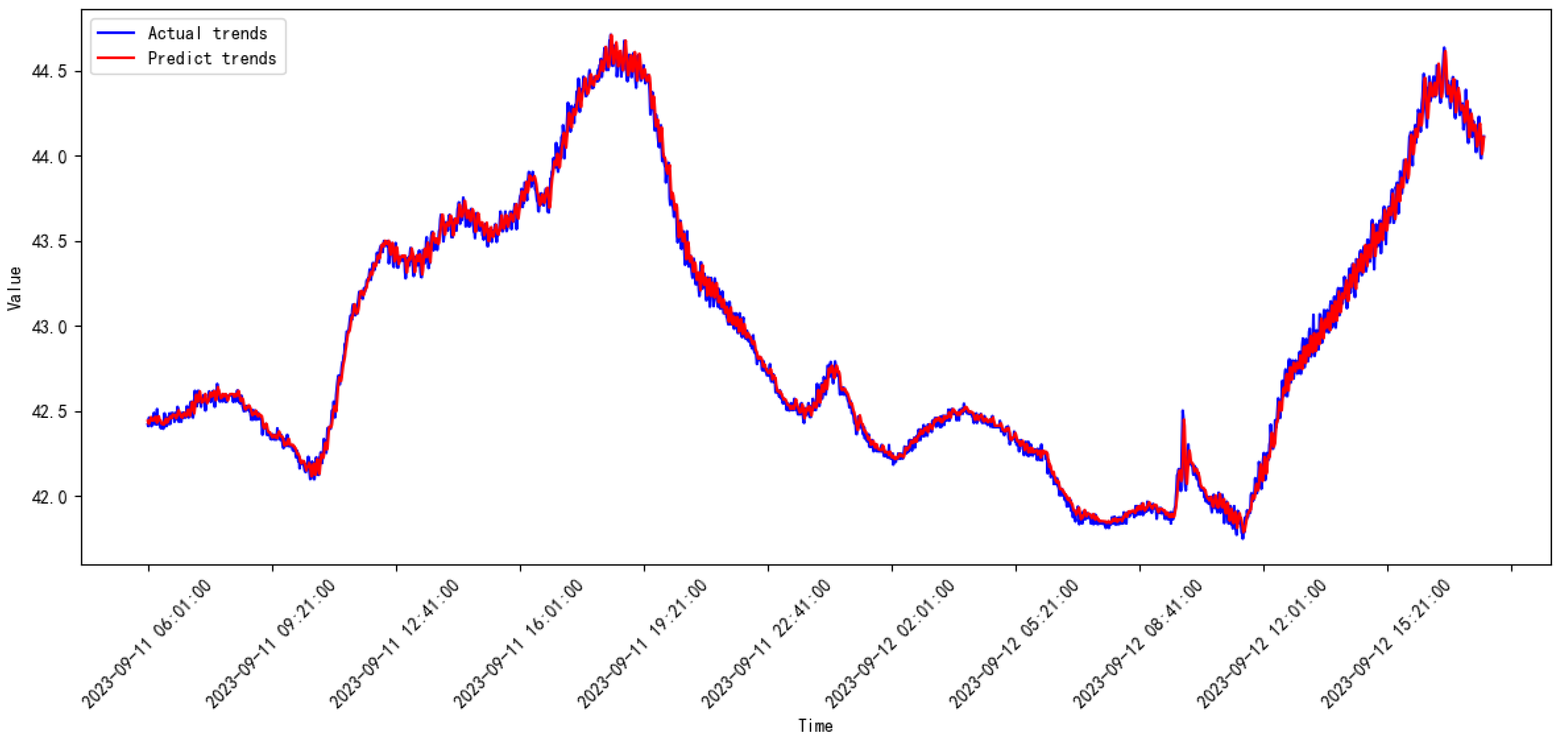
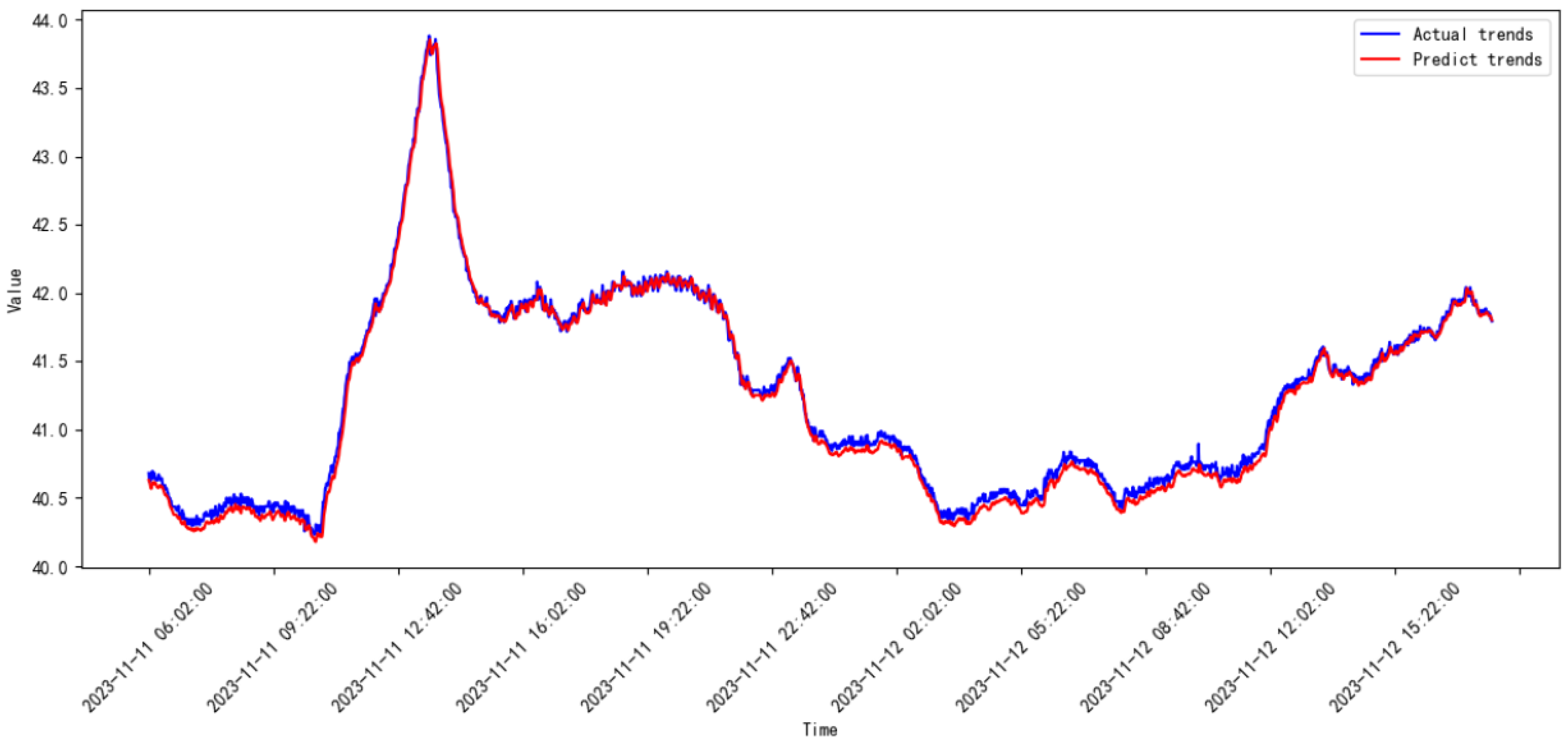
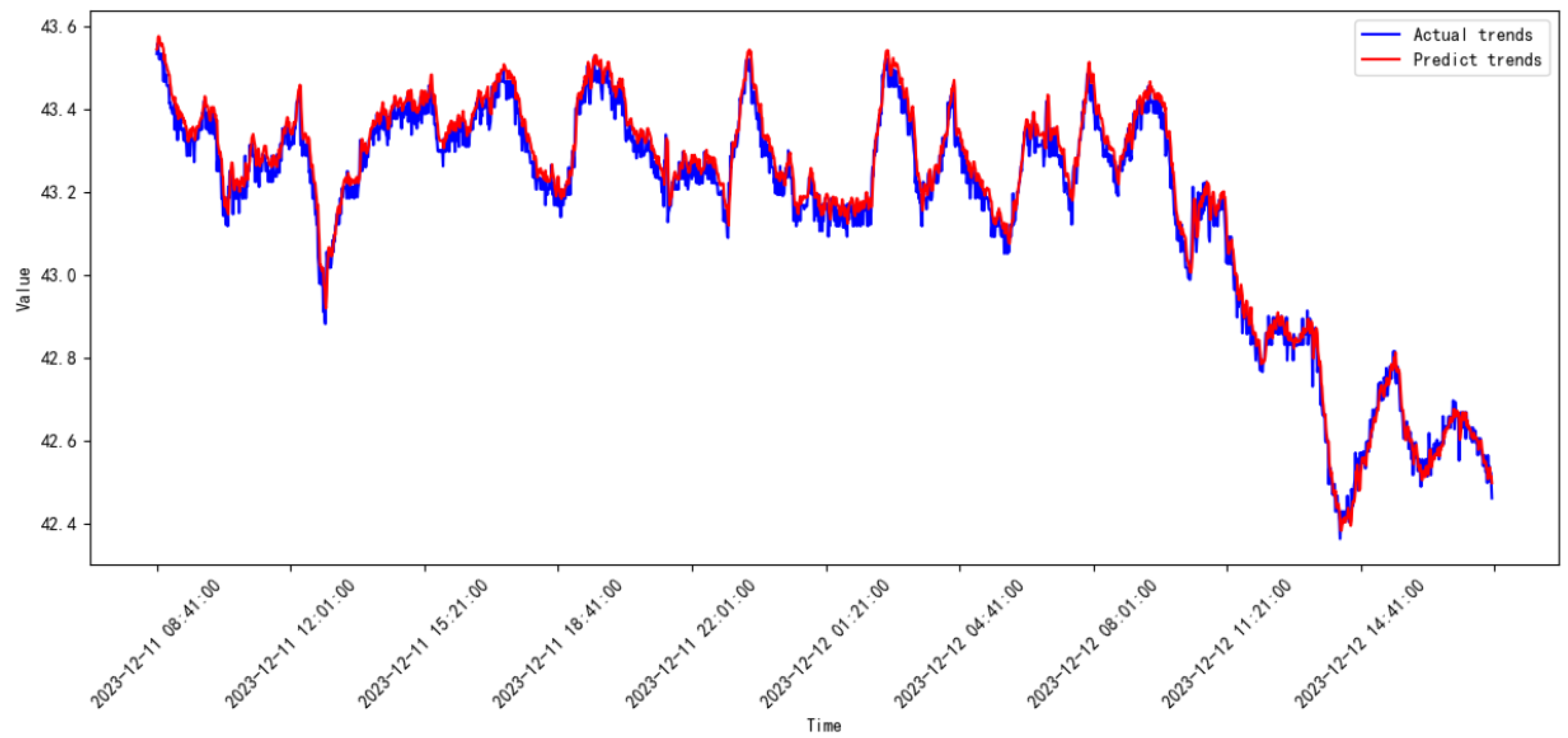
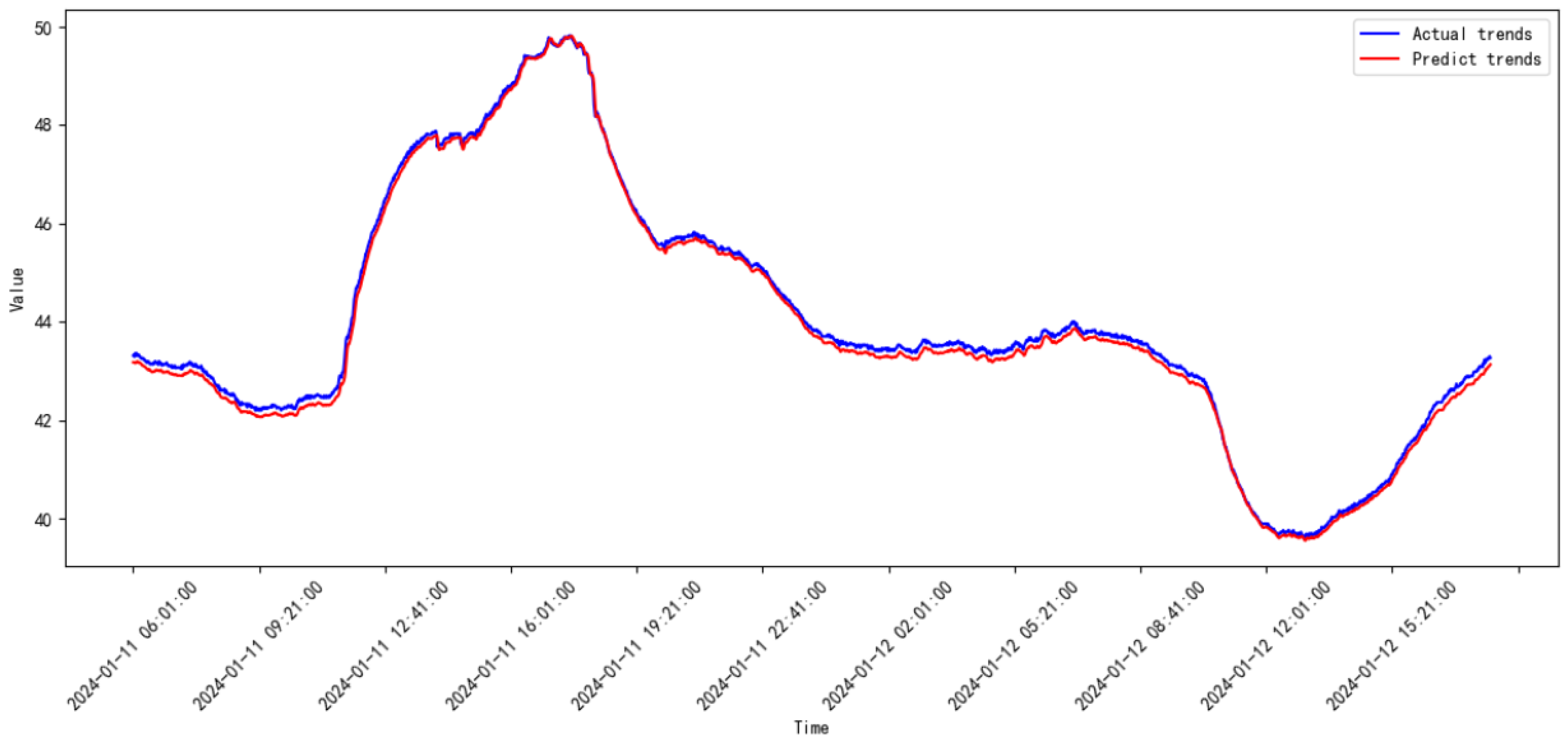
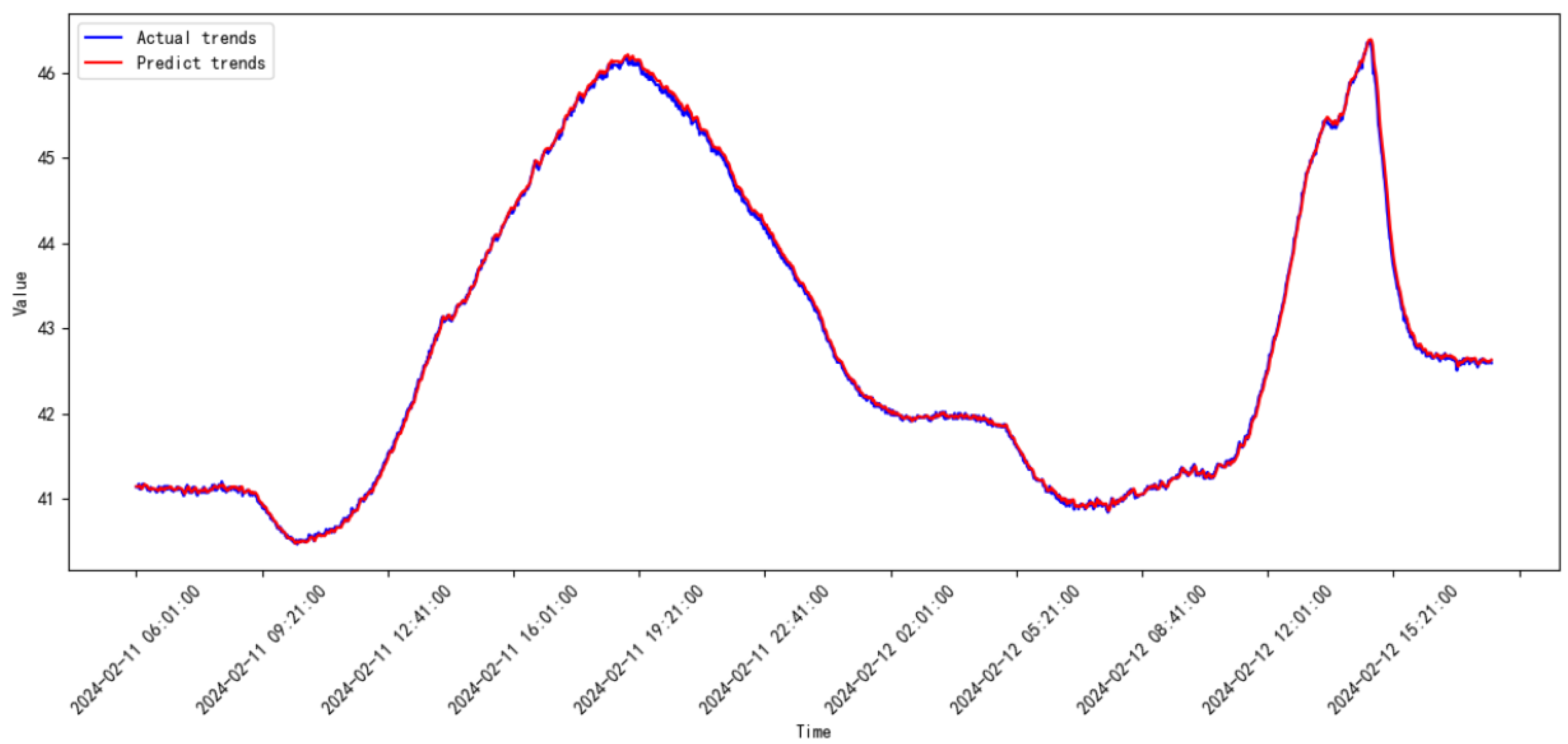
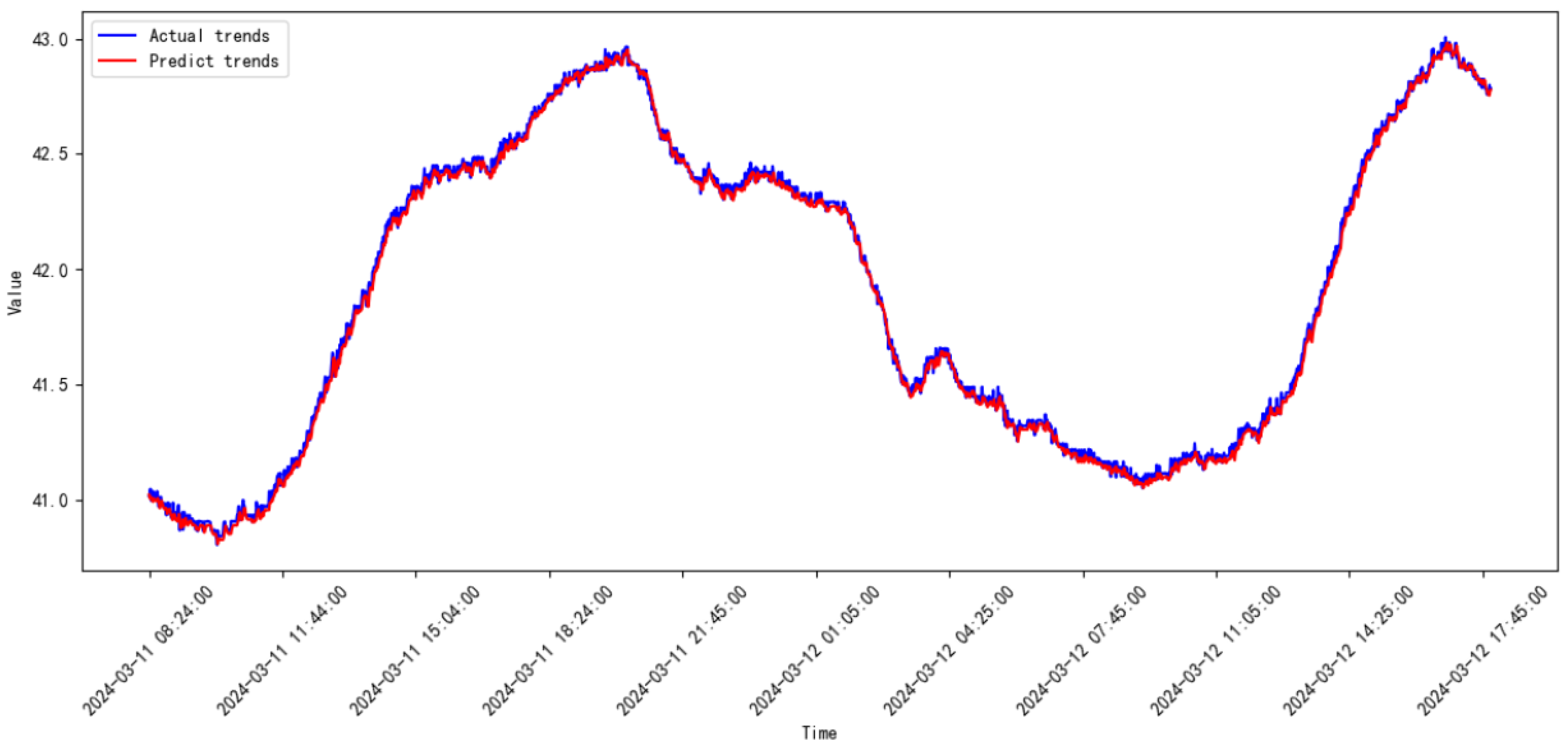
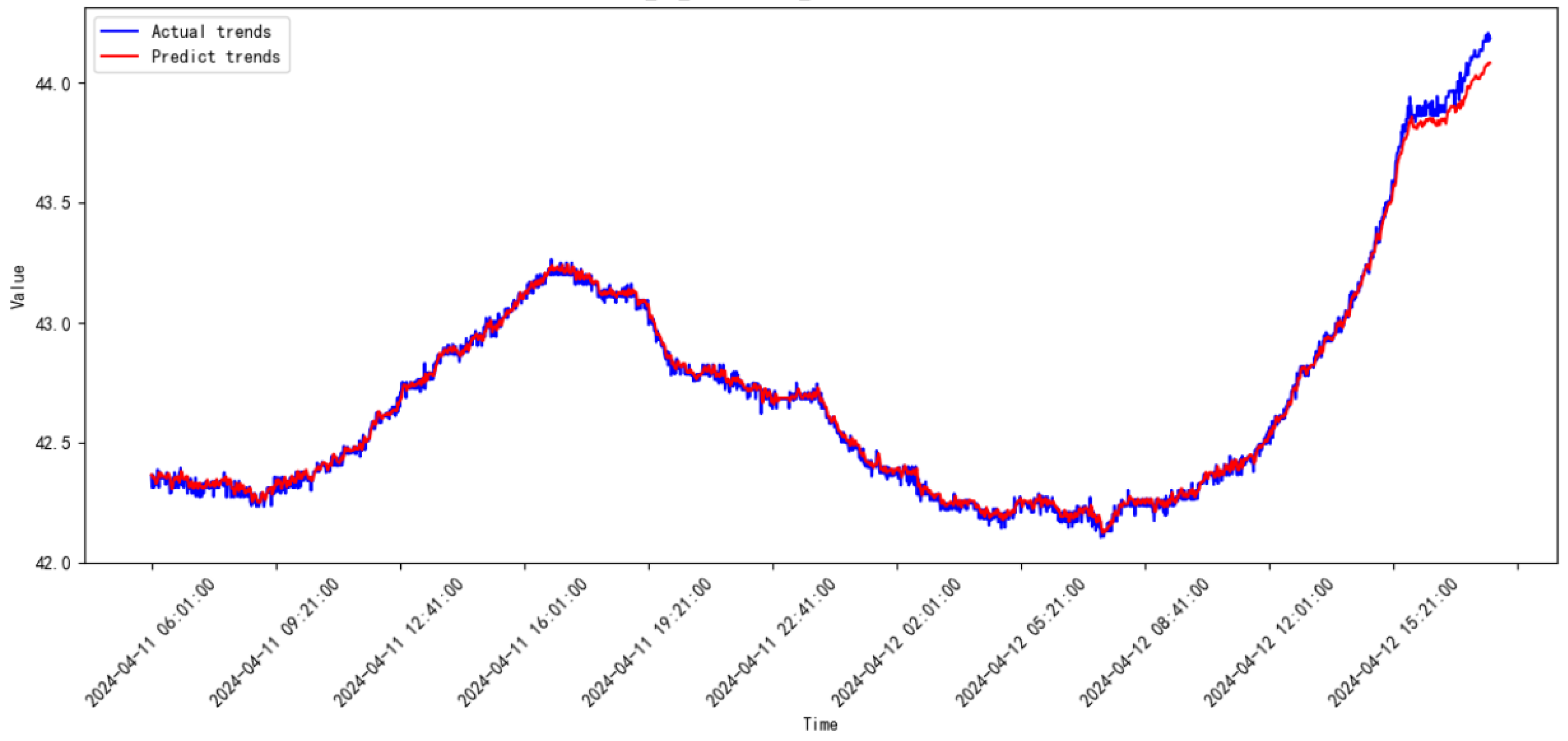
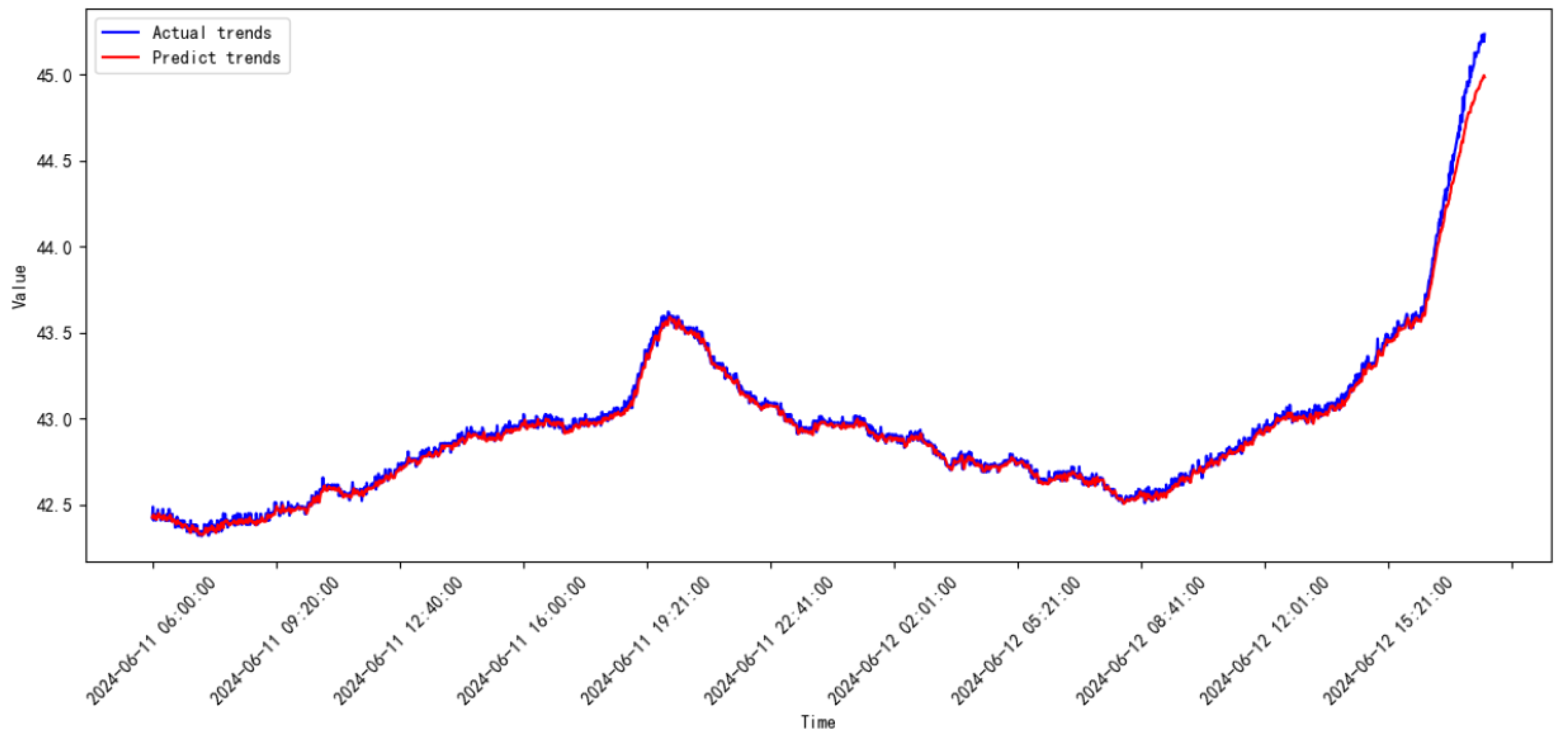
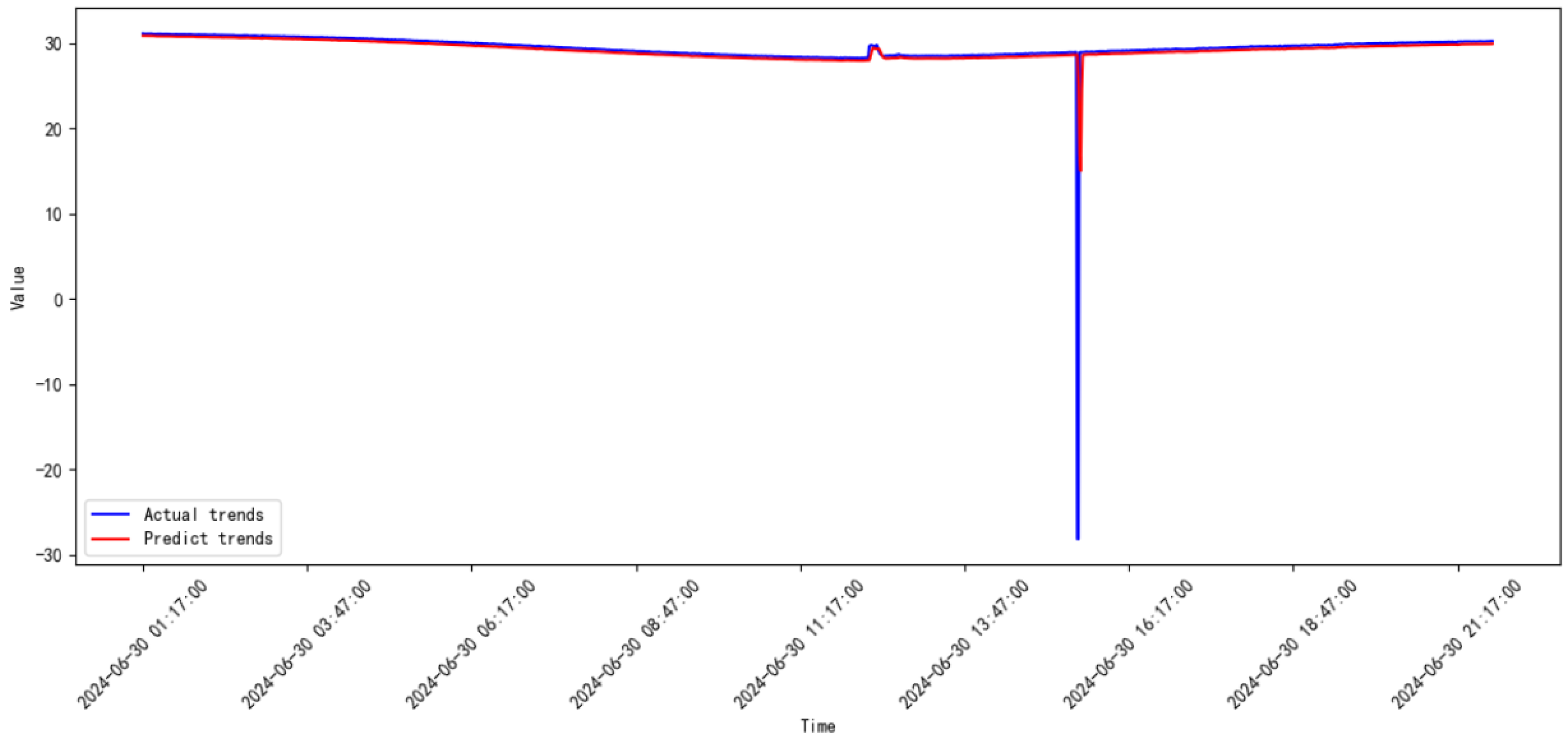
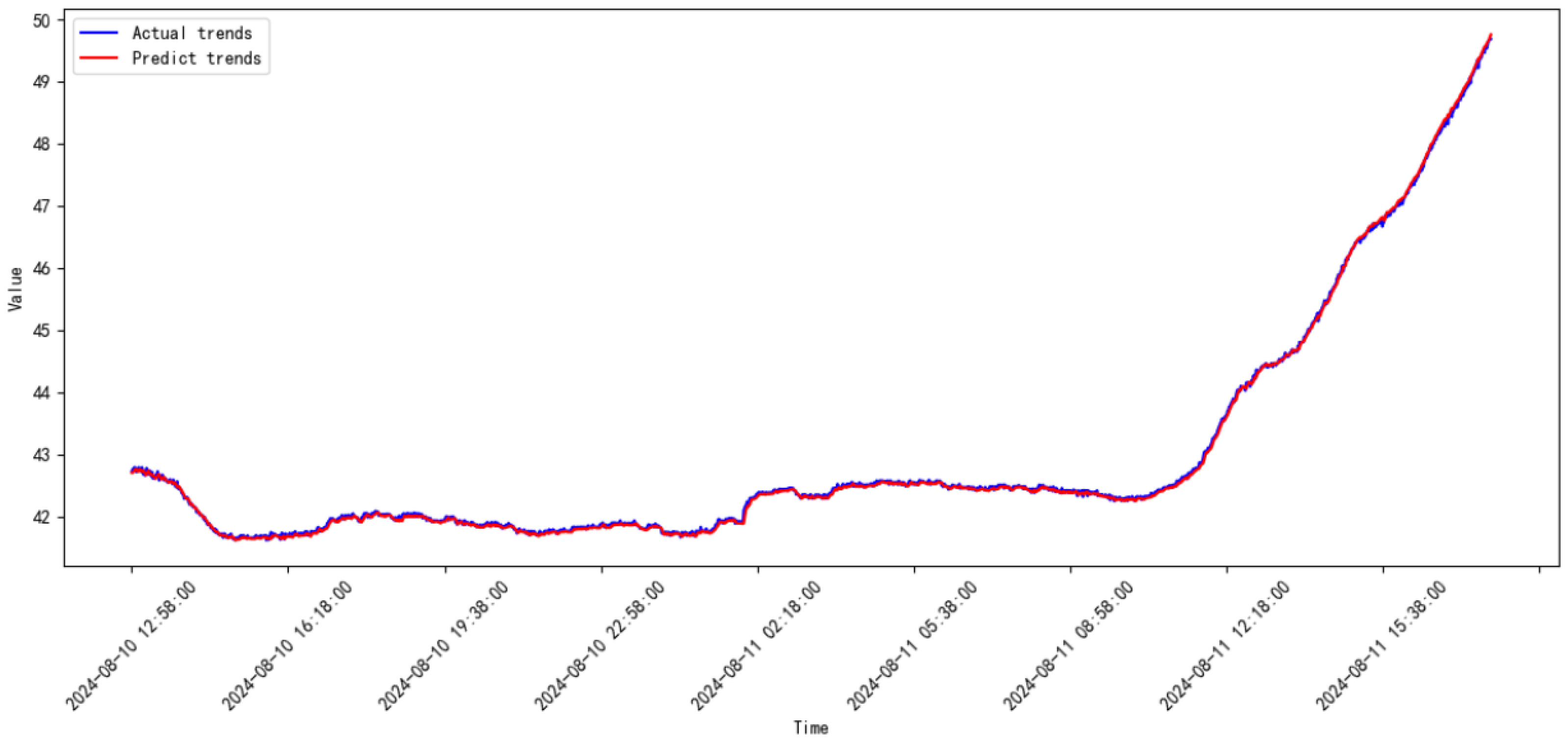
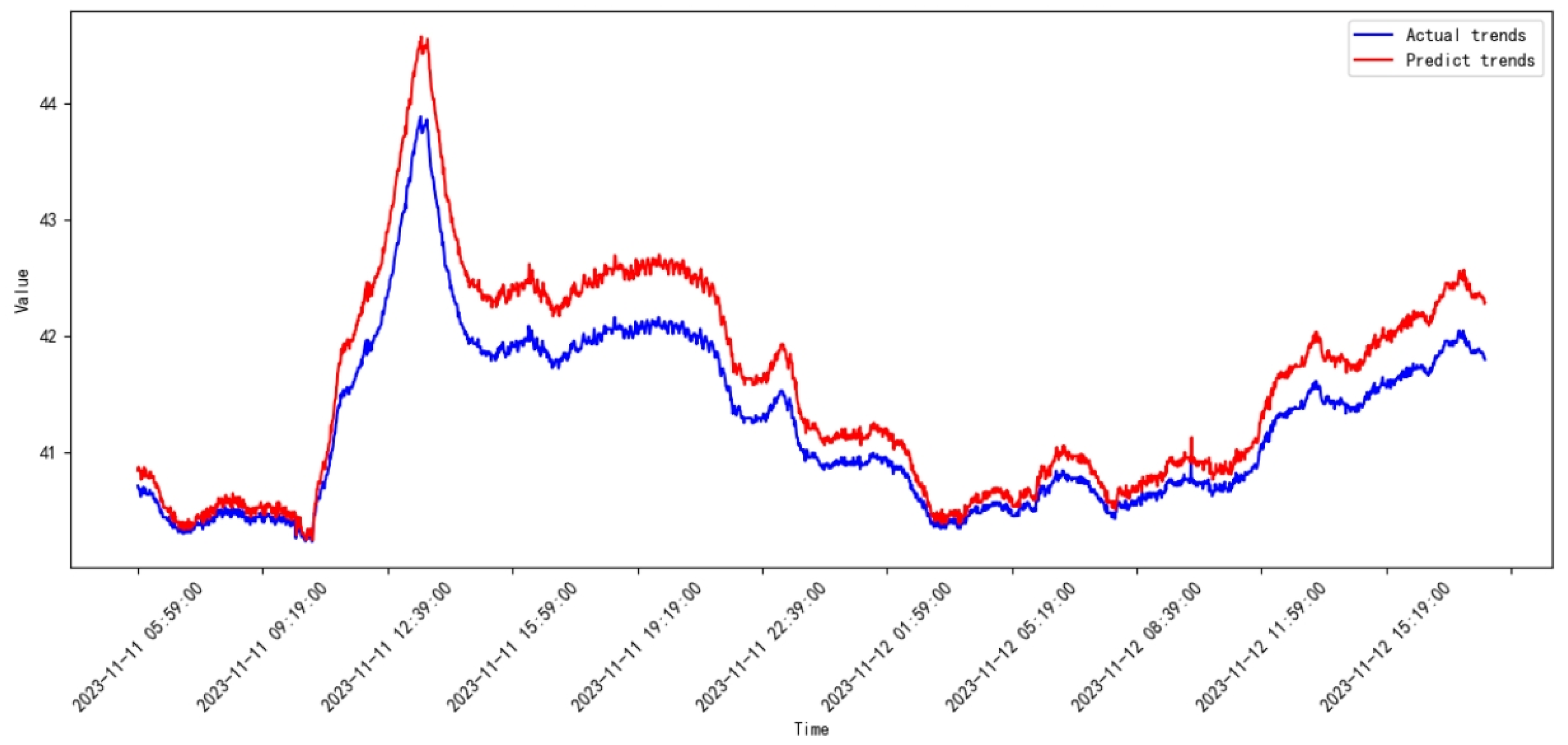
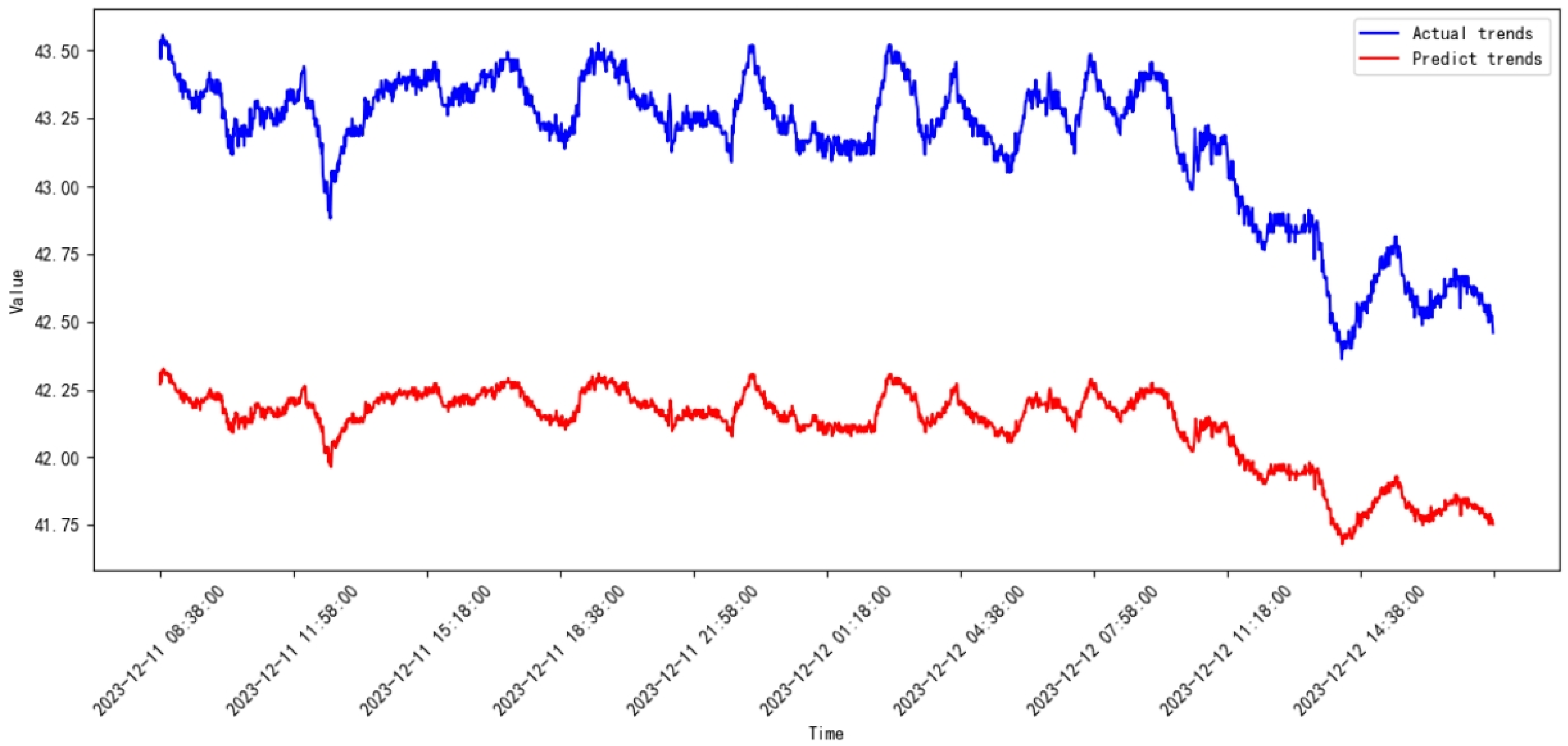
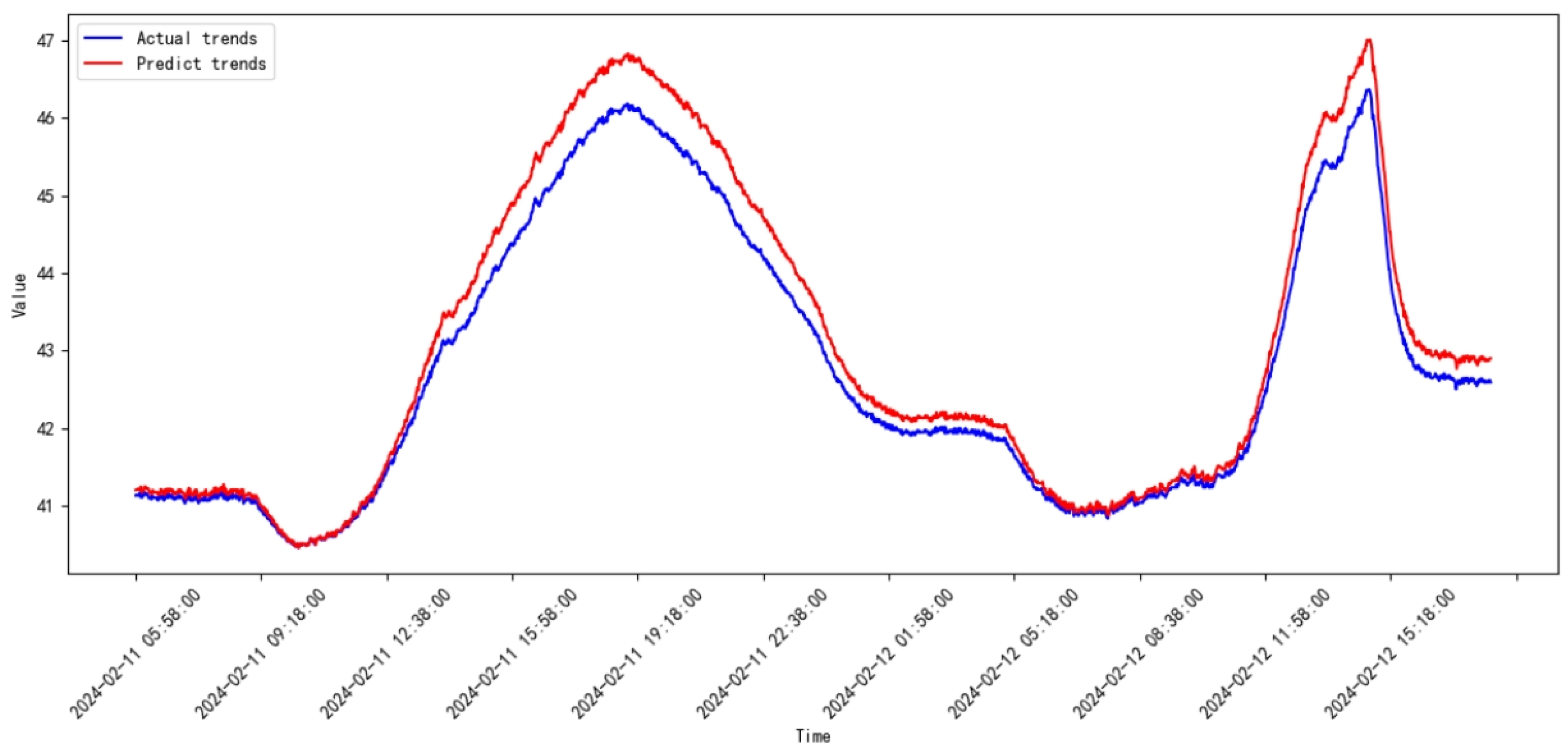
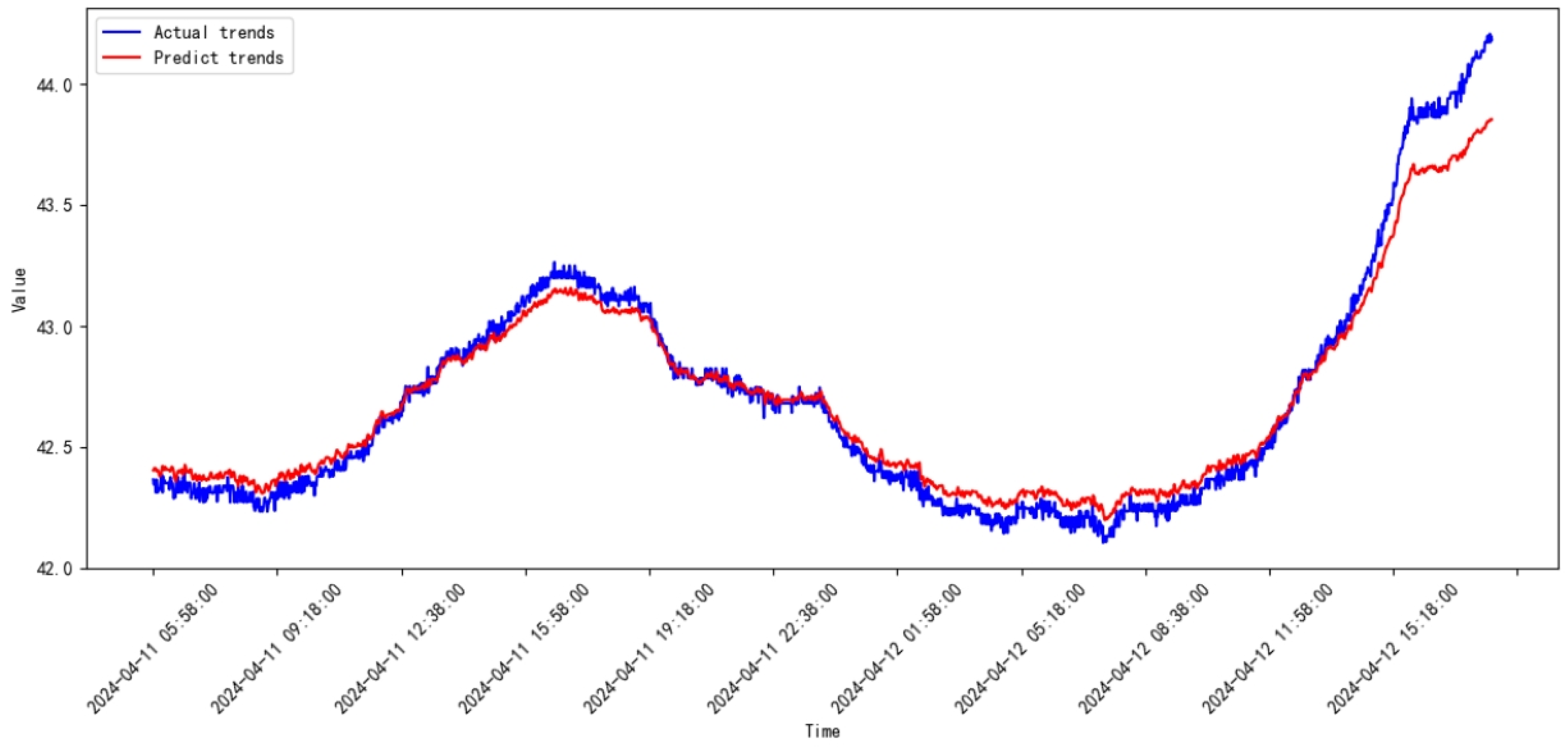
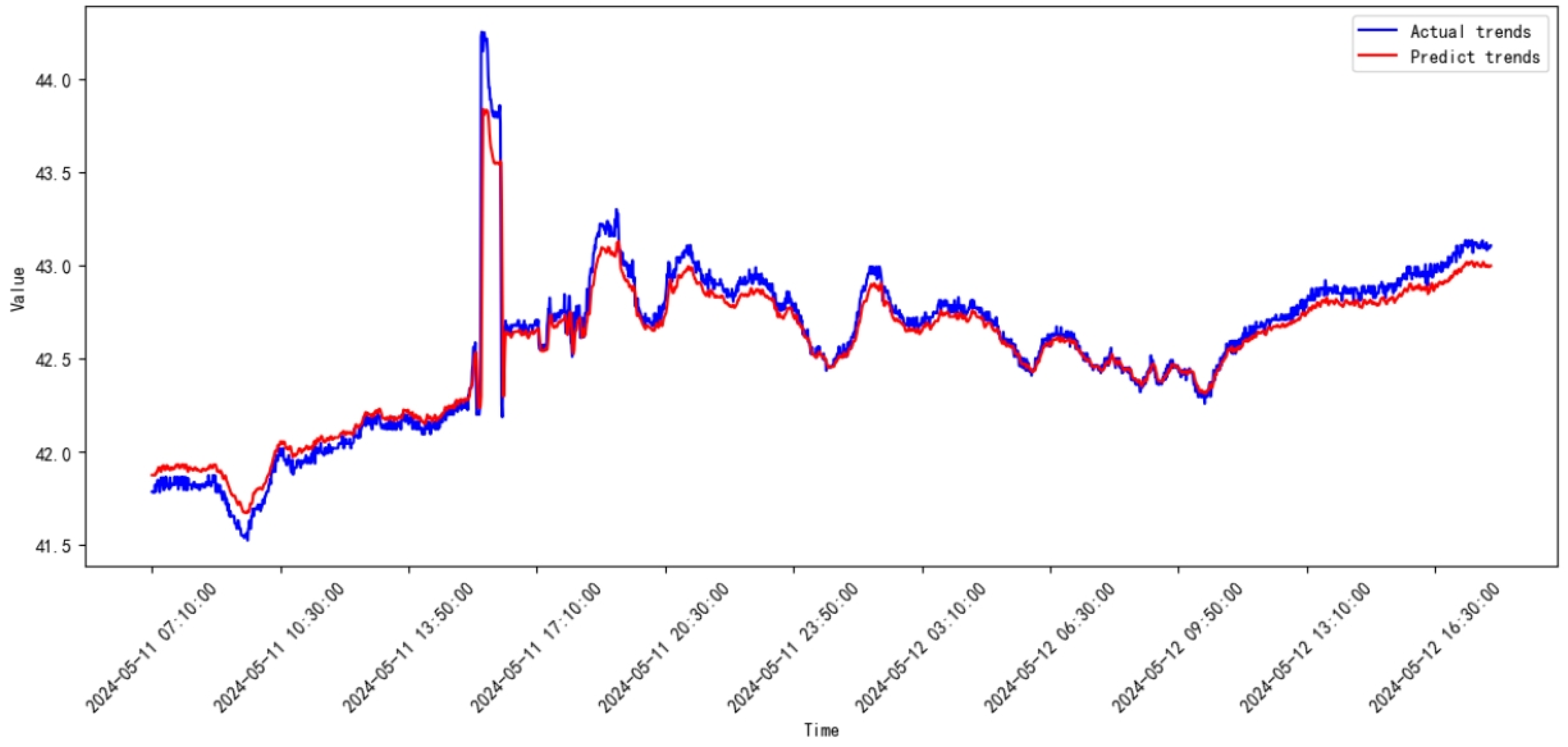
3.3. Comparative Study
3.4. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LSTM | Long short-term memory; |
| SVR | Support vector regression; |
| RNN | Recurrent neural network; |
| DL | Deep learning. |
References
- Romanssini, M.; de Aguirre, P.C.C.; Compassi-Severo, L.; Girardi, A.G. A Review on Vibration Monitoring Techniques for Predictive Maintenance of Rotating Machinery. Eng 2023, 4, 1797–1817. [Google Scholar] [CrossRef]
- Achouch, M.; Dimitrova, M.; Ziane, K.; Sattarpanah Karganroudi, S.; Dhouib, R.; Ibrahim, H.; Adda, M. On Predictive Maintenance in Industry 4.0: Overview, Models, and Challenges. Appl. Sci. 2022, 12, 8081. [Google Scholar] [CrossRef]
- Zhang, L.; An, G.; Lang, J.; Yang, F.; Yuan, W.; Zhang, Q. Investigation of the unsteady flow mechanism in a centrifugal compressor adopted in the compressed carbon dioxide energy storage system. J. Energy Storage 2024, 104, 114488. [Google Scholar] [CrossRef]
- Moravič, M.; Marasová, D.; Kaššay, P.; Ozdoba, M.; Lopot, F.; Bortnowski, P. Experimental Verification of a Compressor Drive Simulation Model to Minimize Dangerous Vibrations. Appl. Sci. 2024, 14, 10164. [Google Scholar] [CrossRef]
- Zeng, X.; Xu, J.; Han, B.; Zhu, Z.; Wang, S.; Wang, J.; Yang, X.; Cai, R.; Du, C.; Zeng, J. A Review of Linear Compressor Vibration Isolation Methods. Processes 2024, 12, 2210. [Google Scholar] [CrossRef]
- Li, Z.; Kong, W.; Shao, G.; Zhu, F.; Zhang, C.; Kong, F.; Zhang, Y. Investigation on Aerodynamic Performance of a Centrifugal Compressor with Leaned and Bowed 3D Blades. Processes 2024, 12, 875. [Google Scholar] [CrossRef]
- Li, D.; Zhang, M.; Chen, J.; Wang, G.; Xiang, H.; Wang, K. A novel modulation-sourced model and a modulation-carrier spectrum-based demodulation method for rotating machinery signal analysis. Mech. Syst. Signal Process. 2023, 200, 110522. [Google Scholar] [CrossRef]
- Karpenko, M.; Ževžikov, P.; Stosiak, M.; Skačkauskas, P.; Borucka, A.; Delembovskyi, M. Vibration Research on Centrifugal Loop Dryer Machines Used in Plastic Recycling. Machines 2024, 12, 12–29. [Google Scholar] [CrossRef]
- Li, D.; Zhang, M.; Kang, T.; Ma, Y.; Xiang, H.; Yu, S.; Wang, K. Frequency Energy Ratio Cell Based Operational Security Domain Analysis of Planetary Gearbox. IEEE Trans. Reliab. 2023, 72, 49–60. [Google Scholar] [CrossRef]
- Zhang, M.; Li, D.; Wang, K.; Li, Q.; Ma, Y.; Liu, Z.; Kang, T. An adaptive order-band energy ratio method for the fault diagnosis of planetary gearboxes. Mech. Syst. Signal Process. 2022, 165, 108336. [Google Scholar] [CrossRef]
- Ghorbanian, K.; Gholamrezaei, M. An artificial neural network approach to compressor performance prediction. Appl. Energy 2015, 86, 1210–1221. [Google Scholar] [CrossRef]
- Wang, Z.; Li, J.; Fan, K.; Ma, W.; Lei, H. Prediction Method for Low Speed Characteristics of Compressor Based on Modified Similarity Theory With Genetic Algorithm. IEEE Access 2018, 6, 36834–36839. [Google Scholar] [CrossRef]
- Zhang, C.; Dong, X.; Liu, X.; Sun, Z.; Wu, S.; Gao, Q.; Tan, C. A method to select loss correlations for centrifugal compressor performance prediction. Aerosp. Sci. Technol. 2019, 93, 105335. [Google Scholar] [CrossRef]
- Samuel, M.H.; Harry, B.; Paolo, P.; Lawrence, S.; Kenneth, M.B. Using Machine Learning Tools to Predict Compressor Stall. J. Energy Resour. Technol. 2020, 142, 070915. [Google Scholar]
- Wu, X.; Liu, B.; Ricks, N.; Ghorbaniasl, G. Surrogate Models for Performance Prediction of Axial Compressors Using through-Flow Approach. Energies 2020, 13, 169. [Google Scholar] [CrossRef]
- Liu, Y.; Duan, L.; Yuan, Z.; Wang, N.; Zhao, J. An Intelligent Fault Diagnosis Method for Reciprocating Compressors Based on LMD and SDAE. Sensors 2019, 19, 1041. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Asl, B.; Razban, A.; Chen, J. Air compressor load forecasting using artificial neural network. Expert Syst. Appl. 2021, 168, 114209. [Google Scholar] [CrossRef]
- Tian, H.; Ju, B.; Feng, S. Reciprocating compressor health monitoring based on BSInformer with deep convolutional AutoEncoder. Measurement 2023, 222, 113575. [Google Scholar] [CrossRef]
- Zhong, L.; Liu, R.; Miao, X.; Chen, Y.; Li, S.; Ji, H. Compressor Performance Prediction Based on the Interpolation Method and Support Vector Machine. Aerospace 2023, 10, 558. [Google Scholar] [CrossRef]
- Jeong, H.; Ko, K.; Kim, J.; Kim, J.; Eom, S.; Na, S.; Choi, G. Evaluation of Prediction Model for Compressor Performance Using Artificial Neural Network Models and Reduced-Order Models. Energies 2024, 17, 3686. [Google Scholar] [CrossRef]
- Peng, Z.; Wang, Q.; Liu, Z.; He, R. Remaining Useful Life Prediction for Aircraft Engines Under High-Pressure Compressor Degradation Faults Based on FC-AMSLSTM. Aerospace 2024, 11, 293. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Layers/Component | Parameters |
|---|---|---|
| Proposed model | Input layer | Input shape (time steps, data) |
| LSTM layer | Units = 50, Dropout = 0.2 | |
| Self-attention | , , | |
| Dense | Units = 1, Activation = tanh | |
| Dense | Neurons = 64, Activation = ReLu | |
| Dense | Units = 1, Activation = Linear | |
| SVR | Kernel function | RBF |
| Regularization | 1.0 | |
| Penalty | 0.1 |
| Model | Date | MSE | RMSE |
|---|---|---|---|
| Proposed model | 2023.08–2023.09 | 0.00664 | 0.81521 |
| 2023.09–2023.10 | 0.00663 | 0.08145 | |
| 2023.10–2023.11 | 0.00315 | 0.05613 | |
| 2023.11–2023.12 | 0.00145 | 0.03811 | |
| 2023.12–2024.01 | 0.01698 | 0.13031 | |
| 2024.01–2024.02 | 0.00211 | 0.04604 | |
| 2024.02–2024.03 | 0.00085 | 0.02919 | |
| 2024.03–2024.04 | 0.00098 | 0.03132 | |
| 2024.04–2024.05 | 0.00511 | 0.07149 | |
| 2024.05–2024.06 | 0.00184 | 0.04293 | |
| 2024.06–2024.07 | 5.28854 | 2.29968 | |
| 2024.07–2024.08 | 0.00149 | 0.03863 | |
| SVR | 2023.08–2023.09 | 0.27853 | 0.52776 |
| 2023.09–2023.10 | 0.06902 | 0.26272 | |
| 2023.10–2023.11 | 0.12634 | 0.35544 | |
| 2023.11–2023.12 | 1.11663 | 1.05671 | |
| 2023.12–2024.01 | 2.33272 | 1.52732 | |
| 2024.01–2024.02 | 0.13196 | 0.36327 | |
| 2024.02–2024.03 | 0.00194 | 0.04406 | |
| 2024.03–2024.04 | 0.00825 | 0.09083 | |
| 2024.04–2024.05 | 0.00943 | 0.09714 | |
| 2024.05–2024.06 | 0.01621 | 0.12731 | |
| 2024.06–2024.07 | 5.51947 | 2.34935 | |
| 2024.07–2024.08 | 0.34647 | 0.58862 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, L.; Zhang, L.; Liu, J.; Qiu, L. Industrial Compressor-Monitoring Data Prediction Based on LSTM and Self-Attention Model. Processes 2025, 13, 474. https://doi.org/10.3390/pr13020474
Pu L, Zhang L, Liu J, Qiu L. Industrial Compressor-Monitoring Data Prediction Based on LSTM and Self-Attention Model. Processes. 2025; 13(2):474. https://doi.org/10.3390/pr13020474
Chicago/Turabian StylePu, Liming, Lin Zhang, Jie Liu, and Limin Qiu. 2025. "Industrial Compressor-Monitoring Data Prediction Based on LSTM and Self-Attention Model" Processes 13, no. 2: 474. https://doi.org/10.3390/pr13020474
APA StylePu, L., Zhang, L., Liu, J., & Qiu, L. (2025). Industrial Compressor-Monitoring Data Prediction Based on LSTM and Self-Attention Model. Processes, 13(2), 474. https://doi.org/10.3390/pr13020474