1. Introduction
Safety monitoring in transmission line channels is a key link in power system inspections, which plays an important role in maintaining the continuity and stability of transmission [
1,
2]. Since most transmission lines are distributed in deep mountains and jungles and often pass through flammable areas with lush vegetation such as forests, fires are extremely likely to occur. Not only do wildfires cause damage to power facilities such as transmission towers and transmission lines, causing power supply interruptions, but if they are not handled in time, the fire will spread and cause large-scale forest fires [
3]. Given the rapid spread of wildfires, there is an urgent need for early detection and timely response. However, due to the wide distribution of transmission lines, traditional manual inspection methods have limited coverage and low operational effectiveness, making it difficult to effectively meet the challenge of wildfire detection in transmission line channels [
4]. With the advancement of automated detection technology, its wide detection range and continuous monitoring capabilities are providing new solutions for the timely detection and early warning of forest fires and are expected to significantly improve the efficiency and effectiveness of the safety monitoring of transmission line channels.
Limited by the unique shapes of objects such as wildfires and smoke, detecting wildfire smoke is a challenging computer vision task [
5,
6]. First of all, wildfires often occur against complex backgrounds such as forests and mountains. There is a large amount of useless background interference during detection, which brings challenges to wildfire detection [
7]. Secondly, flames and smoke are shapeless objects with fuzzy sizes and shapes. This characteristic makes them significantly different from conventional object detection tasks [
8]. Whether the object is a minor flame at the initial stage of a fire or a large-scale flame, higher requirements are placed on the generalization ability of the detection model. Although existing wildfire smoke detection technology has achieved some advancements, the above challenges still need to be resolved to improve the accuracy and reliability of detection.
This study was designed to address the challenges in detecting wildfires and smoke in transmission line channels. Although traditional feature-based detection methods have attempted to identify wildfires and smoke using features such as color, shape, and texture, such algorithms based on prior knowledge struggle to eliminate interference from objects such as red objects and clouds that resemble flames and smoke, resulting in low detection accuracy. Although current depth learning detection technology can obtain complex image information by virtue of the automatic feature extraction ability, most algorithms do not fully consider the needs of edge computing in their design, lack lightweight design for resource-constrained edge equipment, and ignore the dynamic characteristics of wildfire smoke that lead the appearance of small targets and changeable shapes at a distance, and the detection performance is also poor in complex terrain conditions.
Specifically, the goal is to develop a detection algorithm that can accurately identify wildfire smoke even though the shape of the target is not fixed. Our goal is to improve detection accuracy while ensuring lightweight algorithms, which is crucial in their deployment using edge devices in the field. By doing so, we hope to improve the efficiency and effectiveness of safety monitoring in transmission line channels and minimize the potential damage caused by wildfires to power facilities and power outages.
Therefore, this article proposes a lightweight dynamic smoke and fire detection algorithm for transmission line channels without fixed shapes such as flames and smoke, which improves detection accuracy while meeting lightweight requirements and facilitates the deployment of edge devices. This paper conducts a lightweight and dynamic design based on YOLOv8 [
9]. On the one hand, a dynamic module is incorporated into the network structure, and on the other hand, lightweight model parameters are maintained to ensure real-time detection. The principal achievements of this paper are as follows:
1. A dynamic lightweight convolution module is put forward, which combines dynamic convolution with a lightweight model to enhance the backbone network’s ability to perceive flames and smoke.
2. In the upsampling section, a dynamic upsampling technique is employed to enhance the model’s detection capacity with the addition of only a small number of parameters.
3. The loss was improved to increase the attention to objects such as flames, and shape optimization was added when performing bounding box regression.
4. We designed a lightweight dynamically enhanced network (LDENet) to detect smoke from wildfires in transmission line corridors. We performed experiments on the dataset and obtained an mAP50 value of 86.6%, with the number of parameters being reduced by 29.6%.
This paper is organized as follows: The first chapter comprehensively introduces the background and significance of detecting wildfire smoke in transmission line channels, emphasizing the potential threat of wildfires to transmission infrastructure and their related impact on electricity supply.
Section 2 provides a detailed overview of the most advanced methods for detecting wildfire smoke, carefully studying various existing technologies, and, through comprehensive analysis, clearly demonstrating the advantages and disadvantages of these methods. In
Section 3, LDENet and its innovative aspects are described in detail. The focus is on DLCM, DySample, and loss function.
Section 4 focuses on a series of different experiments. These experiments were carefully designed and rigorously validated the effectiveness of the proposed model. Finally, this article summarizes the main findings and contributions, pointing out the shortcomings of the research and clarifying future research directions.
2. Related Works
At present, the detection of wildfire smoke in images can be categorized into traditional feature-based detection approaches [
10] and deep learning-based wildfire smoke detection techniques [
11]. Traditional feature-based detection approaches primarily utilize color [
12], shape [
13], and texture [
14] for the identification of wildfires and smoke.
Since forest fires have obvious color features, the color information in the image can be classified using color spaces such as RGB and HSV to detect whether a forest fire has occurred. Yuan et al. [
15] used the image difference in the RGB model to detect smoke and introduced the extended Kalman filter online reshaping detection method to enhance the generalization ability of the model. Sudhakar et al. [
16] converted the RGB image to the Lab color model and then set the color threshold based on the unique color characteristics of the flame to identify forest fires. In addition to using color information to detect forest fire smoke, artificially designed feature descriptors can likewise be employed to extract image features, and classification techniques can be utilized for the detection of forest fire smoke. Dala et al. [
17] utilized local binary patterns (LBPs) [
18] to obtain image texture features and then integrated them into a hybrid model. LBPs brought additional texture information, which effectively improved the detection accuracy in complex environments. Nyma et al. [
19] put forward a local binary co-occurrence model (RGB_LBCoP), which combined local binary patterns with texture co-occurrence features in the RGB color space to depict smoke features and finally used a support vector machine (SVM) [
20] for smoke classification and recognition. Traditional feature-based wildfire smoke detection methods can detect forest fires and smoke by combining features such as color and texture. However, this type of detection algorithm based on prior knowledge cannot exclude objects similar to flames and smoke, such as red objects and clouds, and the detection accuracy for wildfires is not high.
The image features extracted by traditional feature detection methods are relatively simple, while deep learning-based detection methods can acquire more complex image information by using their automatic feature extraction capabilities. In accordance with the distinct detection methods, they can be divided into wildfire smoke detection methods founded on image classification, target detection, and semantic segmentation. Classification-based wildfire smoke detection performs detection by training a classifier. Gong et al. [
21] proposed a dark channel-assisted hybrid attention method to integrate dark channel information into the neural network to improve the ability to distinguish smoke. Khan et al. [
22] designed a stacked encoding efficient network, SE-EFFNet, which used EfficientNet [
23] as the network backbone and added residual connections to ensure the accuracy of fire identification. Recently, some researchers have also used semantic segmentation methods to detect wildfire smoke. Hu et al. [
24] proposed a segmentation algorithm GFUNet based on the U-Net [
25] architecture. The algorithm integrated deep separable pyramid pooling, spatial channel attention algorithm, etc. It was verified on the grassland fire smoke dataset and could effectively segment the smoke area. Yuan et al. [
26] proposed a Newton interpolation network to extract image information by analyzing the feature values in the encoded feature maps at the same position but on different scales.
At present, most researchers use target detection algorithms to detect wildfires and smoke. Object detection algorithms can be divided into two-stage object detection and single-stage object detection. Representative two-stage object detection algorithms include R-CNN [
27], Fast R-CNN [
28], etc. Maroua et al. [
29] proposed a new two-stage target detection algorithm based on Faster R-CNN [
30] for detecting forest fires and smoke. It added a hybrid feature extractor to the backbone network to provide a larger number of feature maps. Zhang et al. [
31] proposed a multi-scale feature extraction model for small-target wildfire detection and introduced an attention module to the region candidate network, so that the model paid more attention to the semantics and location information of small targets. The design of the two-stage detection algorithm is fairly complicated; the model has more parameters, and the detection speed is slow. Therefore, the single-stage target detection algorithm has become the mainstream. The single-stage target detection algorithm directly generates the prediction box and category information, and the representative one is YOLO (You Only Look Once) [
32]. Typical algorithms in the YOLO series include YOLOv3 [
33], v5, v8, and the latest v11. Yang et al. [
34] proposed a network for detecting wildfire smoke. They added the Swin transformer [
35] detection head to the neck of YOLOv5 to improve the detection accuracy of small-target smoke. Yuan et al. [
36] designed FS-YOLO, which more accurately captured flame features by integrating cross-stage hybrid attention, a pyramid network, and pooling methods. Huang et al. [
37] proposed a wildfire detection model. They used GhostNet as the backbone network and added RepViTBlock to the neck to enhance the ability to extract image features. They conducted experiments on a wildfire dataset around power lines and achieved good detection results. Alkhammash et al. [
38] conducted a comparative analysis of the application of YOLOv9, v10, and v11 in smoke and fire detection. The experiment showed that YOLOv11n performed well in accuracy, recall, and other indicators on specific datasets. Mamadaliev et al. [
39] proposed the ESFD-YOLOv8n model for early smoke and fire detection, which improved the effectiveness of flame detection by replacing the C2f module and adopting WIoUv3 loss function. But its effectiveness in detecting long-distance fires is poor, and there may be missed or false detections. Muksimova et al. [
40] proposed an improved Miti DETR model based on drones for wildfire detection, which redesigned the AlexNet backbone network and added new mechanisms but still needs to be strengthened in terms of adaptability to complex environments. Sun et al. [
41] proposed the Smoke DETR model, which improves the network’s ability to extract smoke features by introducing ECPConv and EMA modules based on RT-DETR. Wang et al. [
42] introduced MS Transformer into the YOLOv7 architecture to enhance the flow of feature information in the model. However, the addition of transformer architecture greatly increases the parameter and computational complexity of the model, and the weak computing power of edge devices cannot manage the inference cost of these models.
There are multiple key issues in the fire detection algorithm mentioned above. On the one hand, most algorithms do not fully consider the needs of edge computing in their design and lack lightweight design for resource-constrained edge devices, resulting in a massive demand for computing resources, an obstacle that complicates their deployment using edge devices. On the other hand, in the task of monitoring wildfires and smoke in transmission line channels, wildfires and smoke are mostly small targets at long distances with significant morphological changes. However, existing algorithms have not taken into account the dynamic morphological changes in wildfire smoke. In addition, these algorithms show poor detection performance under complex terrain conditions. Therefore, we propose a dynamic and lightweight YOLO detection algorithm for detecting long-distance small targets such as wildfires and smoke against complex backgrounds within transmission line channels. The dynamic features of wildfires and smoke are extracted using dynamic lightweight convolution modules and dynamic upsampling modules. The optimized loss function can improve the detection accuracy with small targets. Multiple complex datasets are used for training during the model training process to enhance the detection ability of the model in the face of complex backgrounds, ultimately reducing the number of model parameters while improving the detection accuracy.
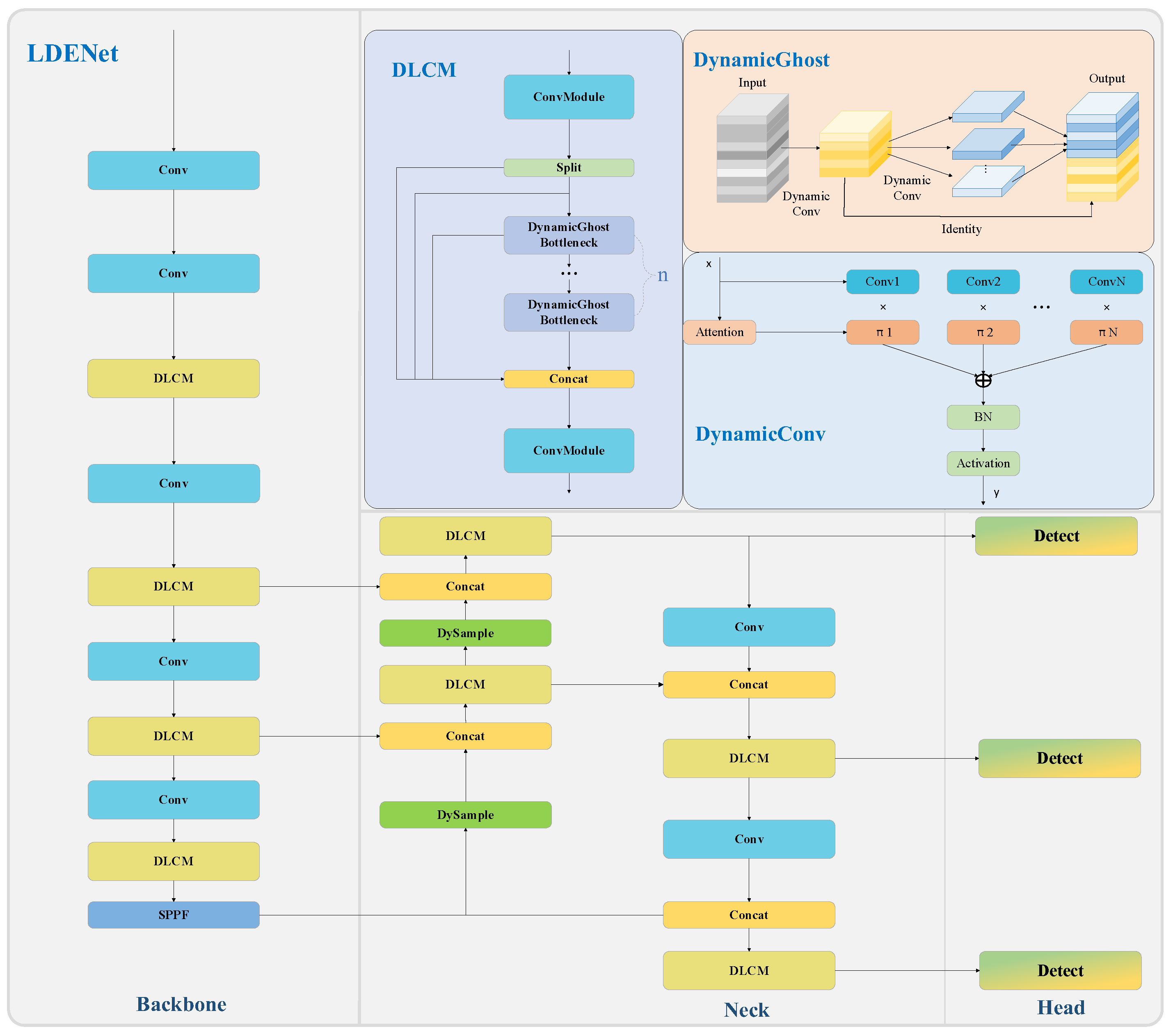
3. Materials and Methods
3.1. YOLOv8
YOLOv8 is a version of YOLO launched by Ultralytics in early 2023. YOLOv8 continues the design ideas of previous generations of YOLO algorithms. Compared with YOLOv5, YOLOv8 has made significant architectural optimizations: the C2f was introduced to replace the C3 module, while the CSP (Cross Stage Partial) module was retained, and a lightweight design was carried out on this basis. In addition, YOLOv8 removes some convolution modules in the design of the neck network, further reducing the number of parameters and improving the calculation efficiency. In addition to architectural improvements, YOLOv8 has also made a series of optimizations to the detection head and loss function to improve detection performance and accuracy.
The network framework of YOLOv8 is made up of three parts, namely, Backbone, Neck, and Head. Backbone uses C2f as the basic module and combines the residual structure to form a feature extraction network. Neck continues the previous PAN-FPN feature pyramid idea and deeply integrates the features extracted by Backbone. Head uses a decoupled head design to decouple the original detection head into two detection heads, which calculate the prediction box and category information, respectively. In view of the uncertainty of the flame and smoke shape in the wildfire smoke detection task, we improved YOLOv8 and proposed a DLCM in Backbone to increase the feature extraction capability of the backbone network. At the same time, the DySample module [
43] was introduced in the Neck part to effectively improve the dynamic perception ability of the model during the upsampling process. Finally, during the entire training process, Shape-IoU [
44] and EMASlideLoss [
45] were utilized to make the whole network pay greater attention to the morphological characteristics of wildfires and smoke.
3.2. DLCM
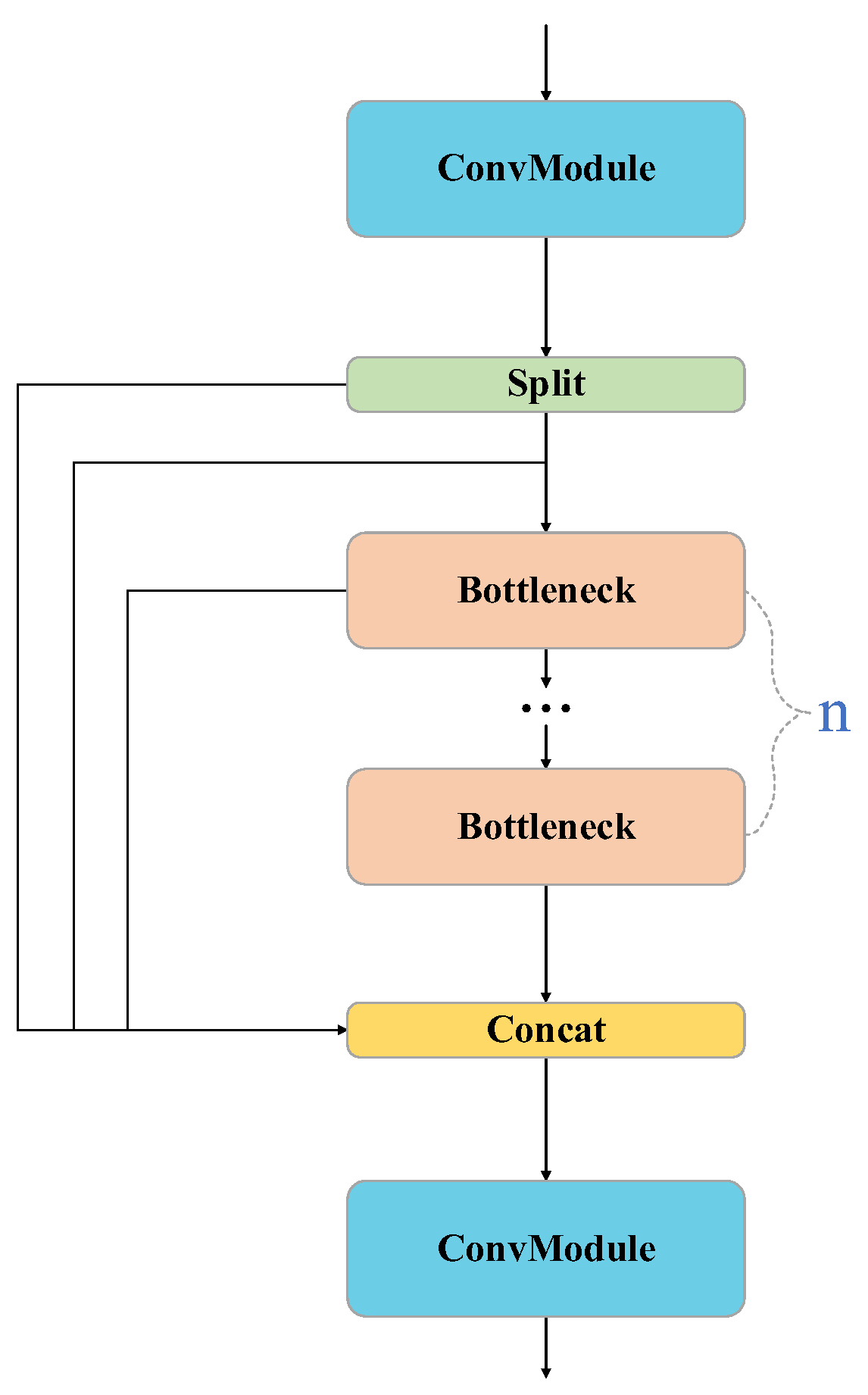
The core module in YOLOv8 is the C2f module, which improves the C3 module of YOLOv5 to obtain a module with better feature extraction capabilities.
Figure 1 shows the C2f module.
In the C2f module, the features are initially processed by a standard convolutional layer to reduce the number of channels by half. The features are then divided by the Split operation, and several Bottleneck modules are adopted to extract features. The different divided blocks are then concatenated, and finally the number of channels is restored by a convolutional layer. In order to further optimize the module structure and improve the feature extraction capability of the module, we proposed the DLCM, which reduces the number of model parameters by combining Dynamic Convolution [
46] and the Ghost Module [
47] and boosts the dynamic feature extraction capability of the C2f module.
3.2.1. DynamicConv
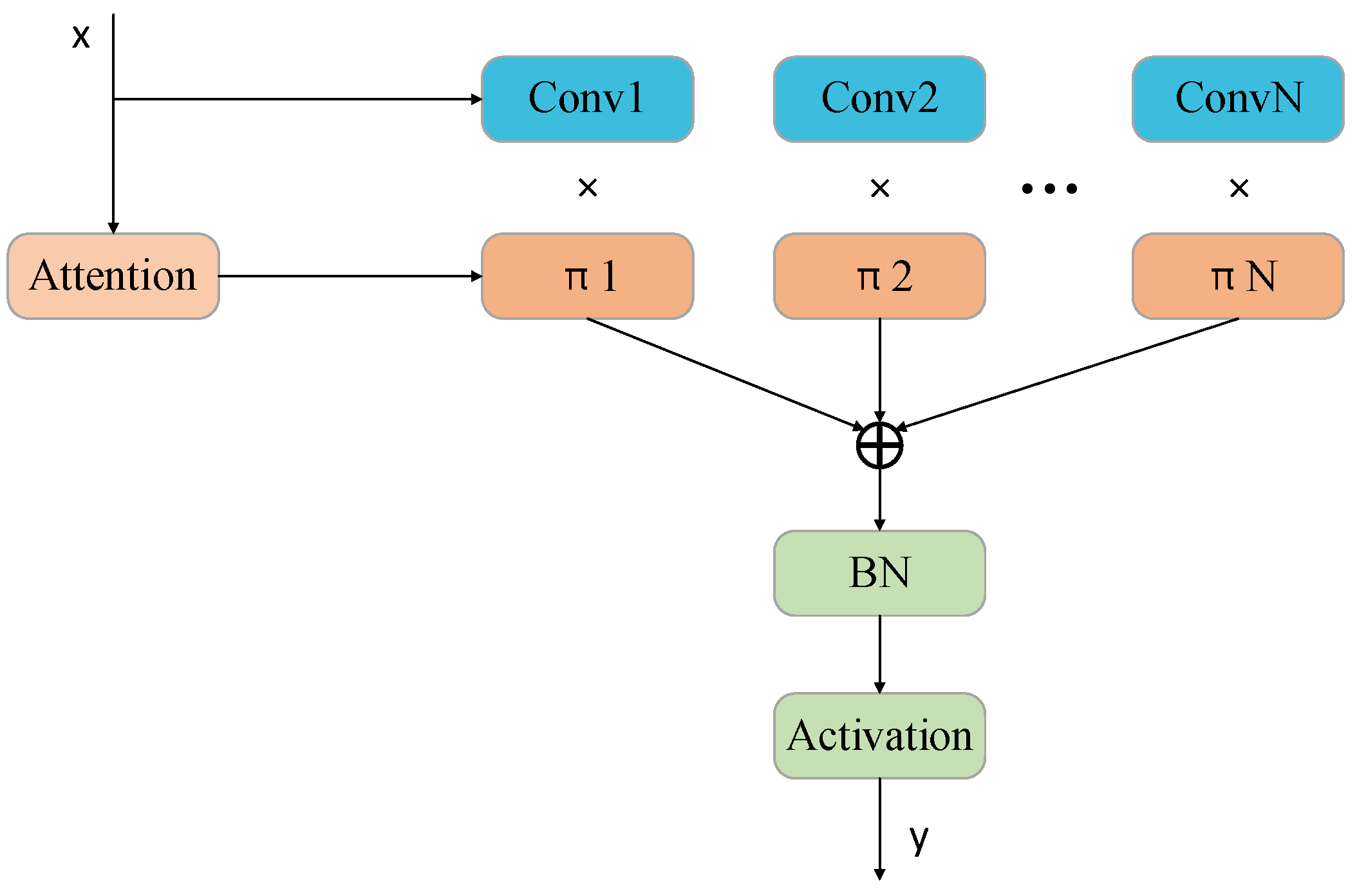
Due to the constant changes in the shape of fire and smoke detection, the feature extraction ability of static convolution is weakened in this context. Therefore, we used dynamic convolution to extract features of the backbone network. Dynamic convolution has N convolution kernels, and each convolution kernel is given its own unique attention weight. Therefore, compared with static convolution, dynamic convolution has a stronger feature extraction ability.
Figure 2 is a schematic diagram of dynamic convolution.
When processing the input features, we first divide them into N blocks of the same size and number of channels. Subsequently, each block is assigned a unique attention weight by introducing an attention weighting mechanism. Finally, these weighted feature blocks are fused through linear summation to form the output of the network. This design enables the weight information in DynamicConv to be adaptively adjusted according to the input features, thus considerably enhancing the flexibility of the model. Since the multiple convolution kernels used by DynamicConv are small in size, the number of parameters of the model will not be significantly increased. Based on this advantage, we chose to replace the conventional convolutional layers in the Bottleneck structure with DynamicConv to achieve the dynamic perception and aggregation of wildfire and smoke image features.
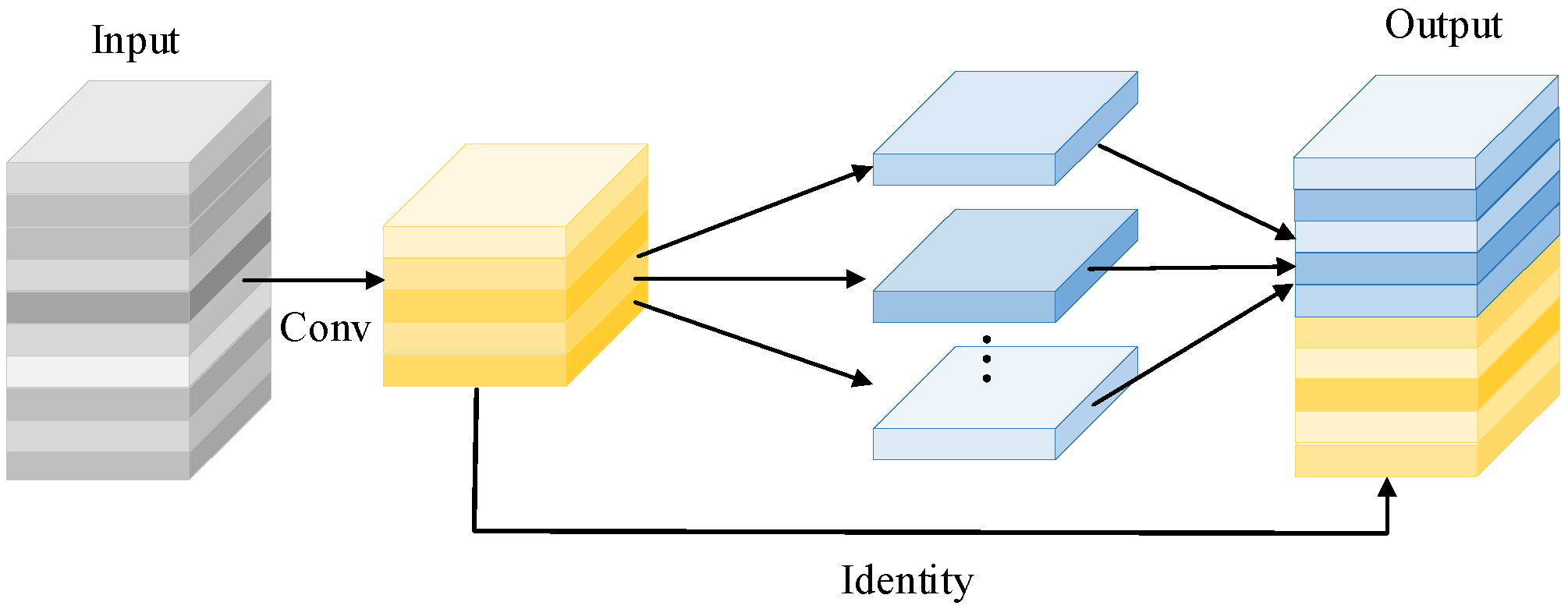
3.2.2. Ghost Module
The feature maps generated by ordinary convolution possess abundant redundant information, which can provide the network model with a comprehensive understanding of the image. However, the cost of generating these redundant feature maps is expensive, so determining how to generate these feature maps through cheaper operations is crucial in the lightweight model. The Ghost Module is capable of generating a large number of feature maps with only a small amount of computation. The structure of the Ghost Module is shown in
Figure 3.
The Ghost Module comprises two key steps. The module decreases the number of channels of the input features by half through a small number of convolution operations, a step that significantly reduces the computational complexity. Secondly, the linear transformation of features is achieved through cheap linear operations, especially group convolution, to obtain new feature representations. Compared to standard convolution, the Ghost Module significantly reduces the required computing resources while maintaining performance. In the C2f module, we replaced the traditional Bottleneck structure with the Ghost Module and combined it with DynamicConv. This improvement not only achieved a lightweight model structure but also enhanced the feature extraction capability of the DLCM. With this design, our model was more efficient in capturing and processing image features of wildfires and smoke while remaining computationally efficient.
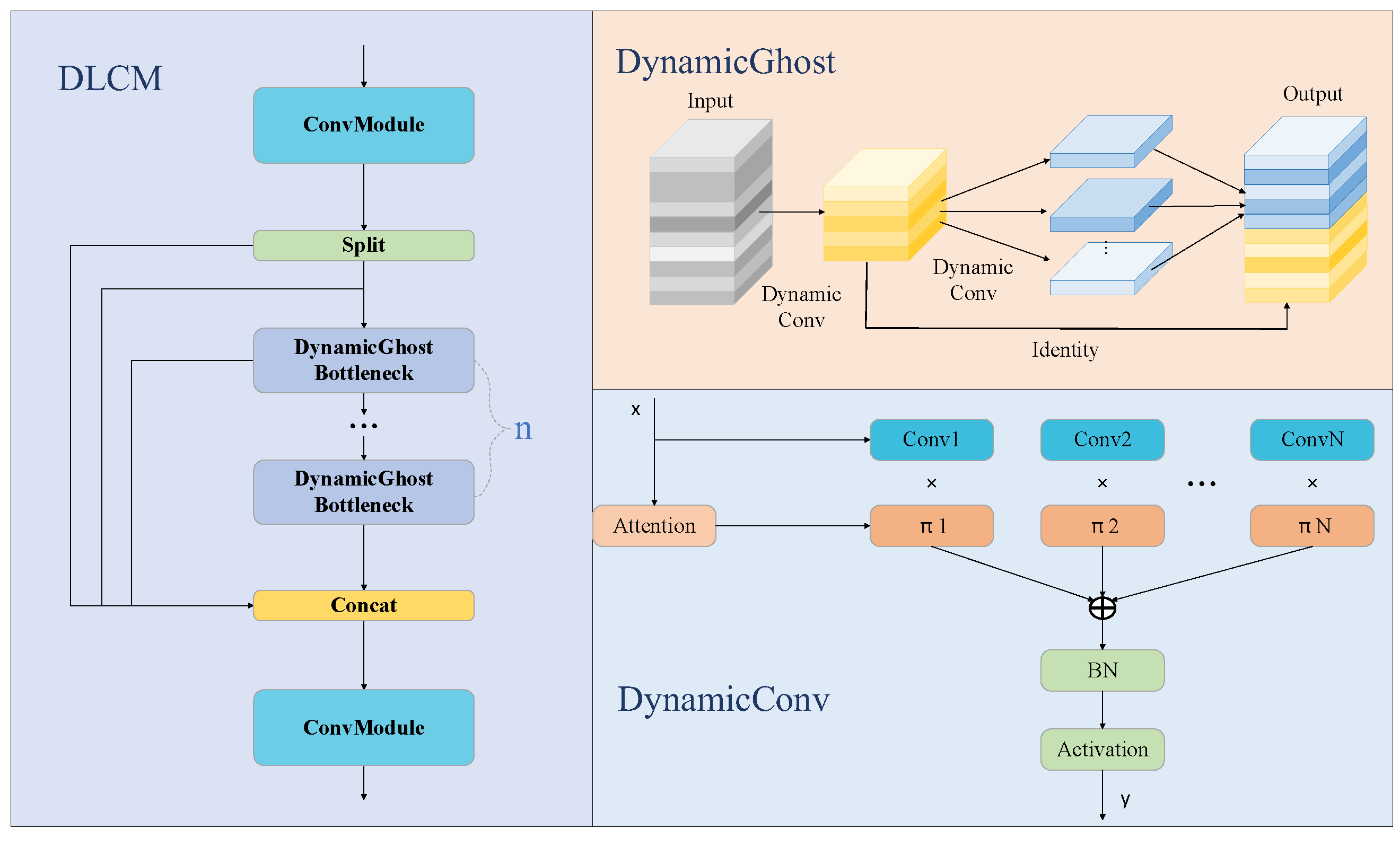
3.2.3. Dynamic Lightweight Conv Module
The DLCM first replaces the two convolutions in the Ghost Module with dynamic convolutions, which enhances the module’s dynamic feature extraction capability. Secondly, the Bottleneck in C2f is substituted with the Ghost Module, which further decreases the quantity of parameters and computations in the entire module.
Figure 4 presents a schematic diagram of the DLCM.
The following (Algorithm 1) is the pseudocode implementation of DLCM:
| Algorithm 1: DLCM |
| 1: Feature = Conv(Input) |
| 2: Feature1, Feature2 = Split(Feature) |
| 3: Feature1 = DynamicGhost(Feature1) |
| 4: Feature_fuse = Concat(Feature1, Feature2) |
| 5: Output = Conv(Feature_fuse) |
First, the input features undergo ordinary convolution to halve the number of channels to reduce the level of calculation. Then, the input is divided into multiple convolution blocks, one part of which extracts feature information through multiple Ghost Modules and the other part of which performs residual operations on the features after passing through Ghost Modules. Finally, the number of channels is restored through ordinary convolution. DLCM significantly reduces the calculation level and parameter number of the model, and it enhances the accuracy of detecting wildfires and smoke through dynamic convolution.
3.3. DySample
In the Neck part, the features of different scales generated by Backbone are fused and extracted. The core component of Neck is the PAN-FPN feature pyramid, which contains an upsampling operation, which is crucial to the final detection accuracy. In YOLOv8, the UpSample upsampling method requires a very high number of calculation parameters, and the upsampling method uses the nearest neighbor algorithm, which only considers the surrounding pixels to generate feature maps. It is not effective for objects with irregular shapes such as wildfire smoke, so we used DySample to perform upsampling operations. DySample is a dynamic and lightweight upsampling method. Its core idea is to use point sampling to restore image sampling. Firstly, it reduces the level of calculation, and secondly, dynamic sampling enables the model to fully capture the characteristics of flames and smoke and generate more accurate feature maps.
First, grid sampling is performed. Given an input feature map with a size of C × H × W, the input feature map is sampled to C × sH × sW using the bilinear interpolation method. Equation (1) is the grid sampling calculation formula:
represents the input feature,
is the linear interpolation method, and
is the interpolated feature map. Then, a linear layer is used to generate the offset
. The calculation formula for the offset is as follows:
The size of the generated offset
is 2 s
2 × H × W. The offset needs to be reshaped to a size of 2 × sH × sW. Then, an original sampling network
is generated, and the reshaped offset is incorporated into the original sampling network to acquire the sampling set
. The calculation formula for the sampling set is as follows:
where
stands for the sampling set,
stands for the sampling network, and
stands for the offset. Finally, the bilinear interpolated feature map
and the sampling set
are resampled to obtain the final upsampled feature map
. The calculation formula is as follows:
3.4. Loss
In YOLOv8, the loss function is structured in two components: classification loss and boundary loss. The classification loss applies the cross-entropy loss function, while the boundary loss function takes the form of the CIOU loss. Although the cross-entropy loss function performs well in many scenarios, it cannot effectively optimize the model due to the dynamic changes in the detection object in wildfire smoke detection. Additionally, the CIOU boundary regression loss solely considers the geometric divergence between the predicted box and the actual box and does not consider the shape information. Therefore, we improved the loss function, using EMASlideLoss for classification loss and Shape-IoU for regression loss.
3.4.1. EMASlideLoss
EMASlideLoss combines the exponential moving average (EMA) and the sliding window mechanism and is a variant of SlideLoss. The design idea of SlideLoss is to use a sliding window to calculate the loss function. By calculating the loss function in each window, the prediction information of different scales and positions is obtained, which improves the detection ability for small objects. Equation (5) shows the calculation method for EMASlideLoss.
represents the average IoU of all bounding boxes. Samples smaller than are negative samples, and samples larger than are positive samples. When , it means that more severe punishment has been given to difficult-to-distinguish negative samples, allowing the model to learn to distinguish difficult samples. When , the loss function acts as a smoothing function. When , the model is encouraged to increase its predictions for correct samples.
EMA smooths the loss by performing the exponential moving average on the window loss of SlideLoss, optimizes the noise, and improves the generalization of the model. Compared with traditional loss functions, EMASlideLoss’s unique smoothing mechanism can adapt to the dynamic changes in smoke and improve detection ability for small-target areas through sliding windows. In wildfire smoke detection, EMASlideLoss can effectively optimize dynamically changing objects such as smoke.
3.4.2. Shape–IoU
In LDENet, we employed the Shape-IoU loss function as a substitute for the CIOU loss function. The Shape-IoU loss function takes into account not just the location of the bounding box but also the shape information of the detected target, making the positioning more accurate. The following is the calculation formula for Shape-IoU:
is used to measure the overlap between the predicted box and the real box.
represents the distance shape, which calculates the horizontal and vertical distances between the predicted bounding box and the centroid of the ground truth bounding box.
focuses on the difference in width and height between the predicted box and the real box. The calculation formula for IoU is as follows:
where
stands for the predicted box and
represents the ground truth bounding box. The calculation formula for
is as follows:
serves as the weight coefficient along the horizontal axis, while
functions as the weight coefficient along the vertical axis,
and
represent the coordinates of the center point of the predicted box,
and
are the center points of the real box, and
is the diagonal distance of the minimum bounding box. The calculation formula for
is as follows:
represents the difference in width and height between the real box and the predicted box. Wildfire smoke typically has irregular and diverse shapes, and traditional loss functions overlook the complexity of smoke shapes. The Shape-IoU loss function can better guide the model to learn the true shape features of smoke by introducing shape information, making the model more accurate in predicting bounding boxes. In addition, the DS term considers the distance of the center point, which enables the model to better adapt to changes in the position of smoke areas with irregular shapes and varying sizes and improve the accuracy of localization.
We combined the EMASlideLoss and Shape-IoU loss functions to replace the loss function in YOLOv8, enhancing the model’s ability to detect small dynamic targets such as wildfire smoke.
3.5. LDENet
We designed a lightweight dynamic enhancement for YOLOv8 and proposed LDENet, which can be used to detect wildfire smoke in transmission line channels. First, DLCM was designed in the Backbone part. Through dynamic convolution and the lightweight Ghost Module, richer feature information was obtained with a lower number of parameters. Then, DySample was introduced into the Neck part to achieve dynamic upsampling with a very small number of parameters and generate more accurate upsampling feature maps. Finally, by improving the loss function, the model’s detection performance for wildfire smoke targets during training was effectively improved. The final network structure of LDENet is shown in
Figure 5.
The following (Algorithm 2) is the pseudocode implementation of LDENet:
| Algorithm 2: LDENet |
| 1: Feature = Conv(Input) |
2: for i = 1 to 4
3: Feature = Conv(Feature)
4: Feature = DLCM(Feature) |
| 5: Feature = SPPF(Feature) |
| 6: Feature = FPN(Feature) |
| 7: Output = Detect_Head(Feature) |
The Backbone part consists of multiple convolutions and DLCMs, and there is an SPPF module at the bottom to enhance the final feature information. The Neck part fuses the different levels of features of Backbone and fuses the bottom features with the high-level features through the feature pyramid network. The fused features contain detailed information and semantic information, which can more comprehensively represent the image features. The DySample module is used in the upsampling operation. Finally, the Head part outputs the classification information and boundary information through the decoupling head. The classification loss is implemented by EMASlideLoss, and the boundary regression loss is implemented by the Shape-IoU loss function.
5. Conclusions
We proposed a dynamic and lightweight enhanced target detection network for detecting wildfires and smoke in transmission line channels. To address the issue of dynamic alterations in wildfire and smoke morphology, we designed the DLCM, which used dynamic convolution to enhance the model’s ability to extract features of wildfire smoke morphology while ensuring a light weight. In addition, the upsampling operator of the neck network was replaced, and DySample was used to further enhance the dynamic perception ability of the model. Finally, the loss function was improved based on the morphological characteristics of wildfire smoke, using the EMASlideLoss classification loss, which is better at small-target detection, and the ShapeIoU boundary regression loss, which considers the target morphological characteristics. Compared with YOLOv8, the final detection accuracy of LDENet is 86.6%, and the model parameters are reduced by 29.7% compared with the basic network.
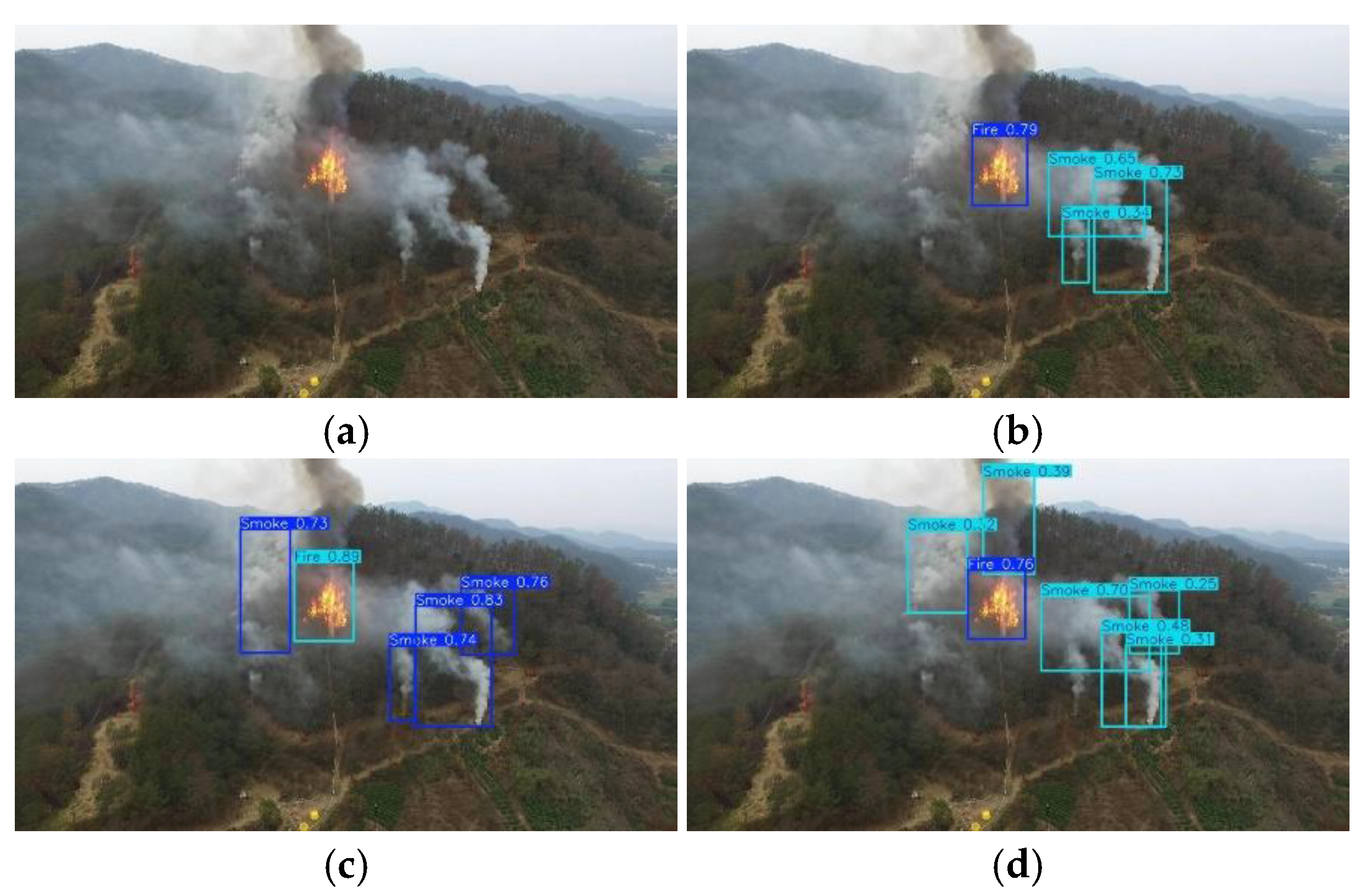
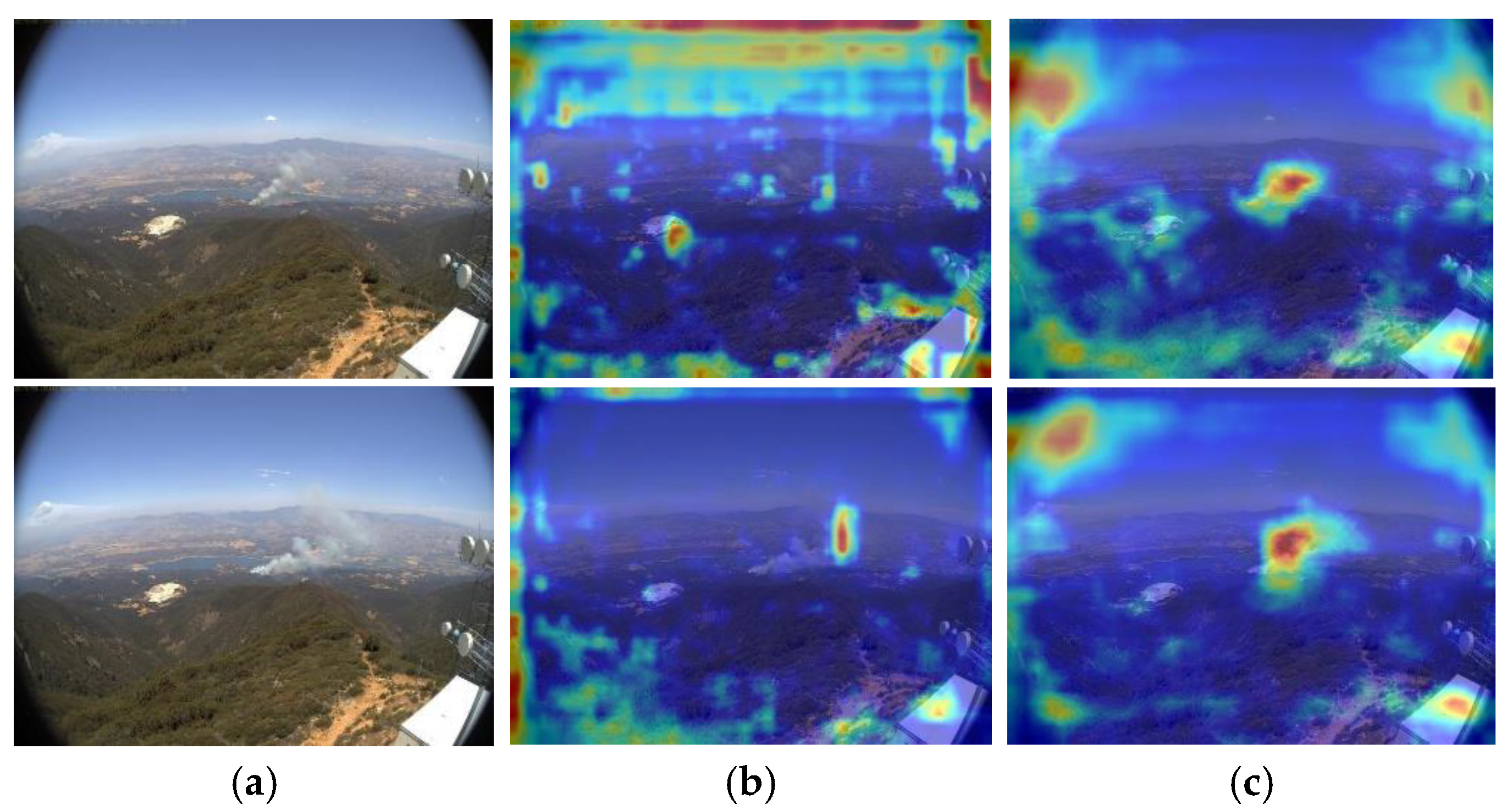
When flames and smoke obstruct each other, LDENet cannot comprehensively detect smoke, so the next key research direction is to address this type of obstruction problem. Since the environment in which power transmission lines are located varies greatly, there is a lack of real datasets in different environments. The next step is to collect more wildfire smoke images in different backgrounds to expand our dataset. In addition, we will continue to explore new lightweight detection methods to optimize performance and efficiency in wildfire and smoke detection.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}