1. Introduction
With the rapid development of the manufacturing industry and the increasingly fierce global market competition, enterprises have continuously raised their demands for production efficiency and flexibility. To quickly adapt to market demands and shorten production lead times, components for large-scale equipment are often allocated to multiple factories for simultaneous manufacturing, a process known as distributed manufacturing [
1]. Distributed manufacturing enables the production of high-quality products at lower costs and reduced risks [
2], which has led to its growing adoption in practice [
3].
The distributed flexible job shop scheduling problem (DFJSP) is an extension of HFSP in the distributed manufacturing environment [
4]. As a pivotal issue in the realm of distributed manufacturing, DFJSP has garnered significant attention from both academia and industry. Distributed flexible job shop scheduling has been widely applied in industries such as automotive manufacturing, food processing, precision manufacturing and processing, and pharmaceutical production. DFJSP can be elaborated as follows: Multiple jobs need to be processed within factories that are geographically dispersed. Each factory boasts a certain number of interchangeable machines capable of handling the tasks. Each job comprises multiple operations, and each operation can potentially be performed on multiple machines [
5]. The scheduling objective, subject to various constraints such as operation sequence, machine capacity, and processing time constraints, is to optimize one or more performance metrics. These metrics typically include makespan, total energy consumption, and overall cost. Due to its complexity and wide range of practical applications, DFJSP is classified as an NP-hard problem, making it difficult to solve using simple analytical methods. As a result, researchers have proposed a variety of approaches to solve the DFJSP, including heuristic algorithms, meta-heuristic algorithms, and intelligent optimization algorithms. Notable methods include tabu search algorithm [
6], genetic algorithms [
7,
8], chemical reaction algorithm [
9], differential evolution algorithms [
10], and estimation of distribution algorithm [
11], among others. Many previous studies have assumed a homogeneous factory environment, where each factory is equipped with identical machines, and each job can be processed on the same set of machines. However, in reality, factories often differ in terms of machine availability, machine processing times, and types of machines used, which leads to a heterogeneous factory environment [
12].
Knowledge-driven domain structures have been demonstrated to enhance the convergence of populations [
13]. The memetic framework is widely used for its efficiency [
14]. However, various studies have demonstrated that the memetic framework struggles with efficiency in solving the DFJSP, especially when multiple objectives are involved. To overcome this limitation, a co-evolutionary framework has been proposed, inspired by the interdependent relationships observed in nature. This approach, much like cooperative evolutionary [
15,
16], competitive evolutionary [
17,
18], and memetic evolutionary [
19,
20] algorithms, is based on parasitic behavior and aims to model the interactions between different components of the system.
Reinforcement learning (RL) is an effective method for learning and controlling complex and uncertain environments. In RL, an agent interacts with its environment to learn a strategy that maximizes cumulative rewards [
21,
22]. RL comprises five principles: (1) input and output systems; (2) rewards; (3) artificial intelligence environment; (4) Markov Decision Process (MDP); and (5) training and inference [
23]. As a widely recognized and foundational RL algorithm, the AAC algorithm combines an Actor network and a Critic network. In policy-based RL, the goal is to directly optimize the policy to maximize rewards. In contrast, value-based reinforcement learning focuses on estimating the value of each state or state–action pair, indirectly determining the optimal policy by selecting the action that yields the highest reward in each state. The AAC algorithm merges these two approaches, enabling the policy (Actor) to be optimized based on feedback from the value function (Critic) [
24]. The Actor network generates actions, while the Critic network estimates the state value function or the state–action value function. Ultimately, both networks are trained through a policy gradient algorithm. For the Critic, deep Q-networks (DQNs) can be used to estimate the temporal difference of the action–state value function. Owing to its benefits, the Actor-Critic framework has found widespread application across a range of problems.
In this study, a deep reinforcement advantage Actor-Critic-based co-evolution algorithm (DRAACCE) is proposed to solve the energy-aware DHFJSP. The contributions of this work are summarized as follows.
(1) The study utilizes the DHFJSP in real-world production scheduling contexts, specifically addressing the heterogeneity of factories. It recognizes that each factory may have varying processing times for the same operation, thereby capturing the practical constraints typically encountered in production environments.
(2) A co-evolutionary framework is introduced. In this framework, two populations are used to handle global and local searches. Knowledge acquired from the global search is passed on to the elite population for co-evolution, helping to explore the solution space more efficiently. Furthermore, a linear ranking-based factory selection operator is introduced to address the constraints of heterogeneous factories, ensuring the selection of factories with lower average processing times while also preserving diversity by allowing other factories a chance to be selected.
(3) The study uses dueling DQN to learn the relationship between the solution space and the actions of the operators. Unlike a traditional DQN, which calculates the Q-value for each action separately, a dueling DQN splits the Q-value into two parts: the state-value function , representing the overall value of a state; and the advantage function , which quantifies the advantage of each action relative to the state. This decomposition reduces the variance in value estimation, allowing the network to focus on more efficient learning by concentrating on the state’s overall value rather than individual actions. Additionally, by sharing the state-value function, the dueling DQN avoids redundant computations, improving computational efficiency.
(4) The core of the proposed method is the DRAACCE algorithm, which combines the Actor-Critic framework with the co-evolutionary approach. The Actor is responsible for selecting actions and gathering experience data from the environment. The Critic evaluates the value of these actions, offering feedback signals based on the dueling DQN approach. This ensures that the Actor receives more accurate feedback, improving the learning process.
The structure of this paper is as follows:
Section 2 introduces related work in recent years.
Section 3 introduces the DHFJSP and the MILP model.
Section 4 details the proposed method. Experimental results are provided in
Section 5.
Section 6 concludes the paper and outlines directions for future work.
2. Related Work
To the best of our knowledge, previous studies mainly focused on the distributed job shop scheduling problems in homogeneous factories. De Giovanni and Pezzella [
8] were the first to define the DFJSP and introduce an enhanced genetic algorithm to solve it. Ying and Lin [
25] proposed the distributed hybrid flow shop scheduling problem with multiprocessor tasks and introduced a self-tuning iterated greedy algorithm to minimize makespan. Shao et al. [
26] proposed a multi-neighbor search-based iterated greedy algorithm to address the distributed hybrid flow shop scheduling problem with the objective of minimizing makespan. Chang and Liu [
7] presented a hybrid genetic algorithm within a novel encoding mechanism to tackle the DFJSP. Du et al. [
11] and Zhang et al. [
27] addressed crane transportation constraints in the DFJS. Du employed an optimization algorithm that combines estimation of distribution algorithm and variable neighborhood search, while Zhang applied a Q-learning-based hyper-heuristic evolutionary algorithm.
However, the studies mentioned above assume that all factories are identical, overlooking the differences in factory characteristics. In reality, factories often vary in terms of their manufacturing resources and equipment setups, which results in different processing times for the same job when handled by different factories. Shao et al. [
28] studied the distributed heterogeneous hybrid flow shop problem and proposed MOEA based on multi-neighborhood local search. Li et al. [
29] proposed an enhanced artificial bee colony (IABC) algorithm that combines simulated annealing with a solution preservation mechanism to improve the solution update process. Wang and Wang [
30] introduced a bi-population cooperative memetic algorithm (BCMA), which features a cooperation model based on key factories and localized integration, utilizing several problem-specific neighborhoods to improve the local search. Meng et al. [
31] developed three new MILP models, alongside a constraint programming model, to address the problem. However, due to the complexity and challenges of distributed heterogeneous manufacturing systems, research in this area remains limited. Additionally, the growing environmental concerns have led to widespread interest in significantly reducing energy consumption. As a result, researching the energy-aware DHFJSP is of considerable importance.
Table 1 presents a comparison of the related work.
4. Proposed Algorithm: DRAACCE
This section provides a detailed description of DRAACCE. First, in
Section 4.1, the framework of DRAACCE is presented, and the entire process is explained in detail. Next, in
Section 4.2, the reasons behind the formation of the DRAACCE framework are discussed, due to the use of the parasitic behavior-based co-evolutionary framework (PCE), and PCE itself is explained in detail. Following that,
Section 4.3 provides a detailed introduction to and illustration of the composition of the individuals. The remaining sections describe the various important components of DRAACCE.
4.1. Framework of DRAACCE
The framework of DRAACCE is illustrated in
Figure 2. The algorithm begins with a random initialization method. Then, the individuals are sorted in descending order based on their fitness. The co-evolution algorithm is employed to evolve the population, thereby identifying the elite individuals. These elite individuals play a crucial role in guiding the evolution toward promising solution regions by updating the population. To accelerate the convergence speed while maintaining population diversity, DRAACCE uses distinct search strategies for elite and non-elite individuals. Elite individuals undergo further refinement through a combination of neighborhood search, the advantage Actor-Critic network, and an energy-saving strategy to enhance their quality.
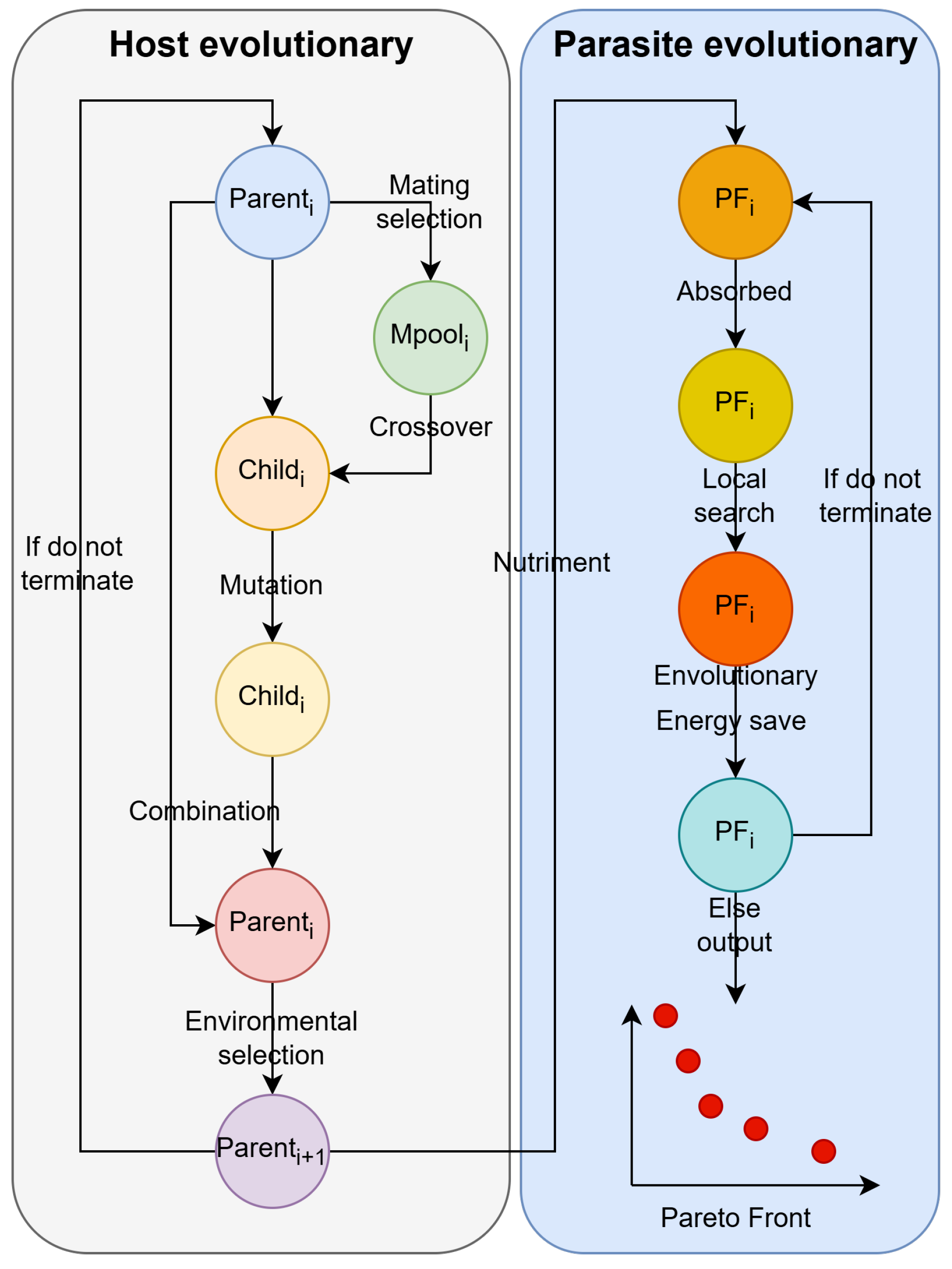
4.2. Parasitic Behavior-Based Co-Evolutionary Framework
The PCE is illustrated in
Figure 3. PCE not only determines the framework of DRAACCE but also provides a detailed description of the co-evolution process. To enable the host to thoroughly explore the non-dominated solutions, the framework divides the evolutionary process into two main components: the host H and the parasite P. This division allows for a more dynamic and efficient search for optimal solutions in the scheduling problem. The evolutionary process unfolds in several key stages: Firstly, the host H undergoes one generation using NSGA-II [
32]. Secondly, the parasites P absorb Pareto solutions from H. Then, the parasites conduct a local search and AAC network to find more potential non-dominated solutions. Afterwards, the parasites adopt an energy-saving strategy to reduce TEC. Finally, the parasites P produce the ultimate set of non-dominated solutions.
As far as we know, Qin [
33] introduced the concept of parasitic cooperative evolution, and Li [
34] has already proposed a PCE algorithm for solving multiple optimization benchmarks. However, the algorithm proposed is notably distinct from the PCE presented by Li.
(1) Li’s method employs a tournament selection algorithm for mating selection, where each individual has the same probability to be selected. In contrast, this paper uses linear ranking selection, which ranks individuals based on their fitness from highest to lowest, and the probability of the
i-th individual being selected is denoted as
, which is calculated using the following equation.
where
represents the total number of individuals, both
a and
b are constants, and 0
1.
(2) During the crossover process, this paper determines the probability of replacing parental genes based on the fitness of the parents, whereas Li’s approach involves random replacement.
(3) Li’s approach uses a precedence operation cross (POX) operation only once on the parent generation to produce two offspring, often resulting in only one valid offspring. In contrast, the approach presented in this paper applies fitness-based POX separately to both parents to generate two offspring. This not only enhances the validity of the generated offspring but also avoids unnecessary offspring from negatively impacting the population.
4.3. Encoding Scheme
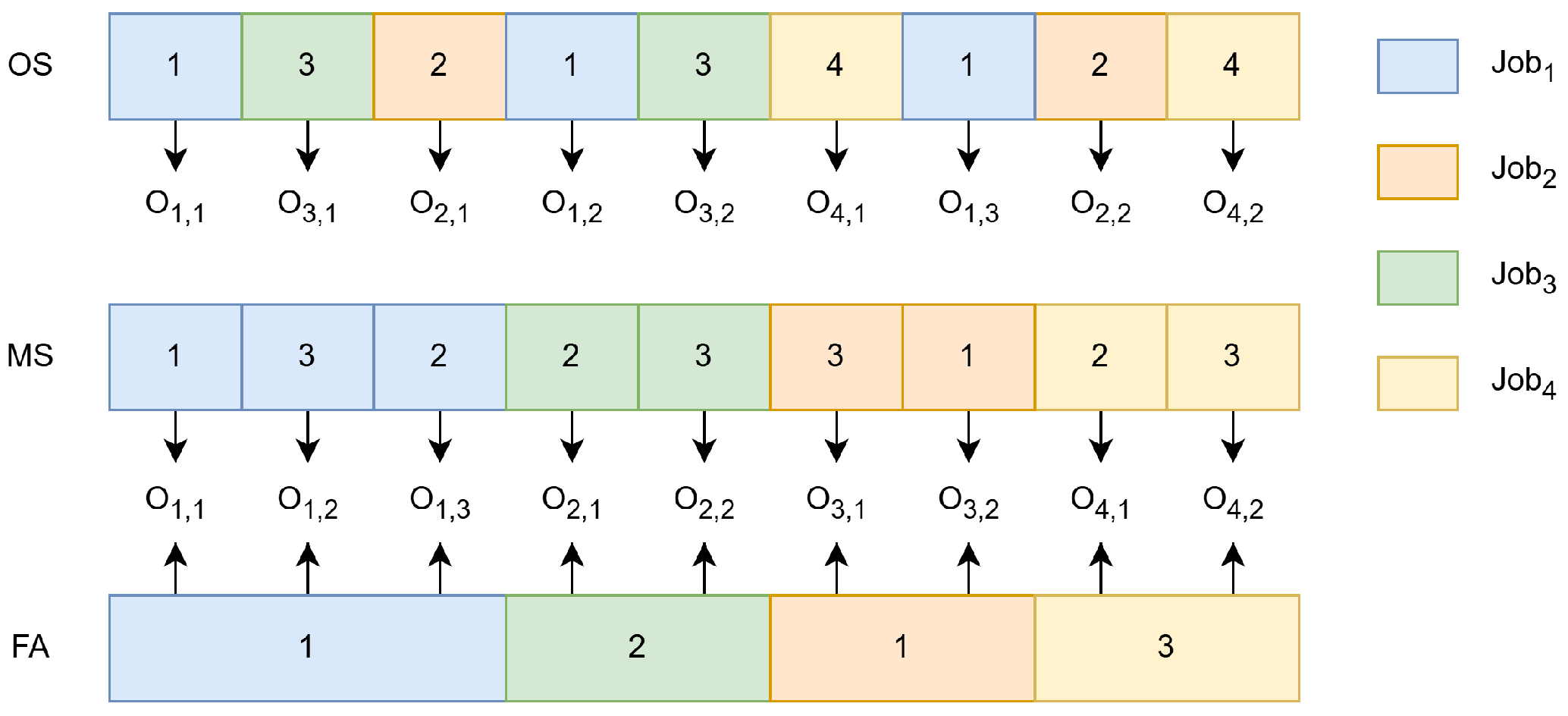
In the DRAACCE, there are three sub-problems that need to be solved concurrently: determining the processing order for each operation, selecting a factory for each job, and assigning a processing machine to each operation. Therefore, the solution to the problem represented in this work adopts a three-level coding model.
Figure 4 illustrates the representation of the solution. The first level is the operation sequence (OS) vector, the second level is the machine selection (MS) vector, and the third level is the factory assignment (FA) vector. The individuals in the DERAACCE algorithm are composed of OS, MS, and FA.
During the decoding process, jobs are allocated to the appropriate heterogeneous factories according to the FA vector. Then, the OS for each factory is retrieved from the OS vector. Subsequently, an optional machine is chosen for each operation based on the MS vector, and the processing time for that operation can be obtained. Finally, once the machine assignments are made, the starting and finishing times for each operation are computed. From these times, the MCT and TEC for the entire workshop are determined.
4.4. Initialization Population
To achieve significant diversity in the training of the DQN, the algorithm adopts a method of random initialization. Firstly, it randomly generates a sequence of operations. It then randomly chooses a machine from a pool of candidate machines for each operation. Lastly, it randomly assigns each job to a factory.
4.5. Evolution and Environmental Selection
The algorithm employs the POX operator for the OS and adopts the Uniform Crossover (UX) operator for both FA and MS. The evolutionary process of this algorithm is described as follows: (1) Two parent individuals are selected based on linear ranking selection. (2) The two parents undergo the POX and UX operation with a probability of
, resulting in two offspring. (3) Each offspring undergoes two mutation strategies with a rate of
: either randomly changing the MS of two operations or randomly selecting two operations and swapping their positions. Then, environmental selection is used to select individuals for the next generation. The environmental selection process is based on the method described in [
32].
4.6. Local Search
Local search is a powerful technique for improving the efficiency of evolutionary algorithms by refining existing solutions and accelerating convergence toward optimal or near-optimal solutions. For the DRAACCE algorithm, the local search focuses on identifying more non-dominated solutions in the distributed job shop scheduling problem. The effectiveness of the local search is highly dependent on the selection of key production factors, such as OS, MS, and FA, which play a significant role in determining the solution quality. Therefore, this paper proposes nine local search strategies tailored to the problem characteristics, specifically as follows:
(1) N7: In N7, a block is defined as a sequence of consecutive critical operations that are performed on the same machine along the entire processing path [
35]. These operations are considered “critical” because any delay or disruption in their execution can significantly impact the overall schedule. N7 focuses on optimizing the job shop scheduling problem by modifying the operation sequence (OS) within these critical blocks.
(2) Operation Swap: To increase diversity, two operations in the OS from the factory with the highest makespan are randomly swapped.
(3) Critical Operation Swap: Select two critical operations and swap their positions in order to decrease the makespan.
(4) Insert Operation: Randomly select two operations from all the operations from the factory with maximum makespan and insert the latter before the former.
(5) Insert Critical Operation: Randomly select two operations in the critical factory. Then, insert the second operation before the first operation.
(6) Randomly Select Factory Assignment: Randomly pick a job from the critical factory and reassign it to a different factory.
(7) Linear Ranking Factory Assignment: Prior studies have randomly inserted a job into another factory in an attempt to achieve load balancing and reduce completion times [
36]. However, the success rate of this random approach was very low. To increase the success rate of reducing makespan, a job is randomly selected from the factory with the maximum makespan and reassigned to a factory that has a shorter average processing time. The probability of each factory being selected is
, which is calculated using the following equation:
(8) Random Machine Selection: Randomly select a critical operation and assign it to a different available machine within the same factory.
(9) Ranking Machine Selection: Randomly select a critical operation from the machine with the longest processing time and assign it to a machine with a shorter processing time. The probability of each machine being selected is
, which is calculated using the following equation:
4.7. Advantage Actor-Critic-Based Strategy Selection Model
In this paper, we use AAC to choose the most suitable operator. AAC is a powerful deep reinforcement learning algorithm capable of learning data distributions and making correct choices through the analysis of historical experiences. As key components of reinforcement learning, well-designed actions and states can effectively represent the scheduling environment, thereby enhancing the efficiency of the learning process. In this study, a transaction is represented as (
,
,
,
), where
is the state,
is the chosen action,
is the reward, and
is the subsequent state.
is a vector formed by combining the OS, MS, and FA. The length of OS and MS corresponds to the total number of operations, while the length of FA corresponds to the number of jobs.
in AAC consists of the local search actions described in
Section 4. The value of
s given by the following definition: if the old solution is replaced by the new one,
is 5; if the new solution and the old solution are incomparable,
is 10; otherwise,
is 0 [
37]. This model inputs state
into the AAC network and determines the selected action
based on the
-greedy strategy. By applying action
to state
, the next state
is generated.
To tackle the challenge of a large and exhaustive state space, AAC utilizes neural networks to learn the distribution of all states within the environment. The AAC algorithm is mainly composed of two key components: the Actor and the Critic. The Actor is a policy network responsible for selecting appropriate actions based on the current state. The Critic, on the other hand, is a valuation network used to evaluate the quality of the policies generated by the Actor. In the Actor-Critic algorithm, there are two update targets: the policy gradient update for the Actor network and the value function update for the Critic network. In AAC algorithm, the Actor network employs the REINFORCE algorithm for gradient updates, while the Critic network adopts the loss function used in DQNs to estimate the temporal difference of the action–state value function for its updates.
In this paper, we will draw inspiration from dueling DQNs for updating the Critic, and divide the Critic into two networks, namely
and
, where
serves as the valuation network and
as the target network. A dueling DQN uses a dual network and introduces the advantage function
. The action-value function is calculated using the following formula:
where
=
. The REINFORCE algorithm is described as follows: At the beginning of training,
and
share the same parameters. Next, randomly select a batch of transactions from the experience pool
S. Then, feed the transaction at time
t, denoted as
, into
, and output the q-values for all actions in the current state as
. Similarly, input the next state into
and obtain the q-values for the next state
. In this paper, the REINFORCE algorithm is used to update the policy gradient, and the formula for this algorithm is as follows:
where
represents the policy gradient and
represents the probability of choosing action
in state
. The parameter
is updated using the following loss function:
where
represents the performance of the target policy.
Algorithm 1 illustrates the training part of AAC. By continuously updating
and
, we can obtain a better evaluation of the Actor network and improve the selection probability of actions.
| Algorithm 1 Training part of advantage Actor-Critic |
- 1:
Input: Experience pool S, policy network , valuation network , target network , epochs, counter, maxcount. - 2:
Output: Policy network , valuation network . - 3:
- 4:
for
do - 5:
if % then - 6:
- 7:
end if - 8:
- 9:
Random transition from S - 10:
- 11:
- 12:
- 13:
- 14:
- 15:
Update - 16:
Update - 17:
end for
|
4.8. Energy-Saving Strategy
This paper adopts energy-saving strategies based on fully active scheduling [
38]. The detailed description of this strategy is as follows: Firstly, scan the operation sequence forward to identify potential idle slots and insert the current operation
into one of them to reduce idle time. Then, traverse the improved schedule backward to look for positions where the current operation can be inserted to further minimize idle time. This strategy not only reduces TEC but also shortens MCT. The produce of DRAACCE is shown in Algorithm 2.
| Algorithm 2 Produce of DRAACCE |
- 1:
Input: Crossover rate , mutation probability , learning rate , discount factory , greedy factor , batch size , experience pool size S, epochs, population size , update threshold and MAXNFE. - 2:
Output: The Pareto solutions - 3:
Initial host population H, size equals - 4:
Initial parasite population P size equals zero - 5:
Initial AAC network: - 6:
- 7:
while
do - 8:
Generate by linear ranking selection - 9:
Generate by crossover and mutation - 10:
NFE = NFE + - 11:
- 12:
- 13:
- 14:
- 15:
- 16:
AAC-based strategies selection: - 17:
- 18:
- 19:
- 20:
end while - 21:
|
6. Conclusions
This paper presents a deep reinforcement advantage Actor-Critic-based co-evolutionary algorithm for the energy-efficient DHFJSP. First, a PCE using linear ranking selection was proposed to solve the problem. Then, a new evolution strategy was adopted to enhance convergence and diversity. Furthermore, a deep reinforcement learning algorithm AAC with a dueling DQN was used to model the solution distribution and choose the most suitable local search strategy. Finally, the performance of the DRAACCE algorithm in DHFJSP was verified through numerical experiments conducted on 20 instances and a real-world case.
For future work, the following aspects can be considered. First, incorporating an end-to-end network for the DHFJS, which could enhance its generalization ability. Second, extending the model to address the differential DHFJSP, which includes variations in the number of machines, machine failures, or maintenance scenarios, could further improve its robustness and applicability. Finally, researching on dynamic DHFJSP, which includes factors commonly encountered in real-world environments, such as machine failures, emergency order insertion, and maintenance scheduling.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}