1. Introduction
With the rapid development of electric vehicles and renewable energy storage systems, lithium-ion batteries, as key energy storage devices, have garnered significant attention for their performance and safety [
1]. State of Health (SOH) and Remaining Useful Life (RUL) are two crucial parameters for evaluating battery performance [
2,
3]. Accurately estimating these parameters is essential for ensuring the safe and efficient operation of battery systems, as well as for reducing operational costs and preventing unexpected failures [
4].
SOH is defined as the ratio of the current maximum available capacity of the battery to its rated capacity [
5], expressed by the following equation:
where
represents the current maximum available capacity of the battery and
represents the rated capacity of the battery.
When the current maximum available capacity of the battery drops to 80% of its rated capacity, i.e., a SOH of ≤ 80%, the battery reaches its End of Life (EOL), at which point it needs to be replaced. RUL is defined as the expected number of cycles remaining before the battery reaches its EOL, starting from its current state [
6], expressed as follows:
where
represents the number of cycles at which the battery reaches its EOL;
represents the current cycle count of the battery.
Currently, SOH estimation methods can be categorized into two types: model-based methods and data-driven methods. Model-based methods estimate the SOH by constructing equivalent circuit models for the battery. For example, Schwunk et al. [
7] proposed an SOH estimation method based on the PF; Bustos et al. [
8] developed an approach using the DF; Ranga et al. [
9] introduced a method based on the UKF; Rahimifard et al. [
10] proposed an ASVSF-VBL; Fahmy et al. [
11] presented a DAUKF-CCA; and Yang et al. [
12] also implemented an SOH estimation approach using the UKF. However, due to the complexity of the internal battery environment and the uncertainty of external operating conditions, developing an accurate model remains a significant challenge [
13].
In contrast, data-driven methods avoid the complexity of the modeling process by analyzing the historical operating data of batteries and utilizing deep learning or machine learning techniques to estimate the SOH. As a result, these methods have gained significant attention and recognition in recent years [
14]. For example, Alberto et al. [
15] proposed an SOH estimation method based on an FC-FNN; Rahimian et al. [
16] introduced a method using an NN; Safavi et al. [
17] developed an approach combining a CNN-LSTM; Lee et al. [
18] presented a method utilizing an MNN-LSTM; and Teixeira et al. [
19] proposed a GRU-based SOH estimation method.
In data-driven SOH estimation, the selection of health features (HFs) plays a critical role. Jia et al. [
20] extracted HFs from the discharge process and used GPR for SOH estimation. However, in practical applications, the discharge conditions of batteries are often difficult to measure accurately, making data collection challenging. In comparison, data collection during the charging process is more convenient. Feng et al. [
21] used features such as constant-current and constant-voltage charging times as HFs and employed IGPR for SOH estimation. Similarly, Dai et al. [
22] extracted HFs such as constant-current and constant-voltage charging times from the complete charging process and utilized DA-BiLSTM networks for SOH estimation. Liu [
23] further considered that batteries are not always charged from zero during the charging process and extracted the constant-current charging time from a state of charge (SOC) of 20% to the end of charging as an HF, using GPR for SOH estimation. However, this method overlooks scenarios where the battery might not be fully charged.
RUL prediction is primarily based on data-driven methods. For instance, Chang et al. [
24] used the first 50% or 70% of a battery’s data to train an LSTM model and tested it with the remaining data to predict the RUL. Liu et al. [
25] employed the first 50% or 60% of a battery’s data to train a CEEMDAN-PSO-BiGRU model and tested it with the remaining data for RUL prediction. Similarly, Zou et al. [
26] utilized the first 40% or 50% of a battery’s data to train a CEEMDAN-PSO-BiGRU model, testing it with the remaining data for RUL prediction. Tang et al. [
27] adopted the first 50% of a battery’s data to train a CEEMDAN-IGWO-BiGRU model and tested it with the remaining data for RUL prediction. These RUL prediction methods typically focus on a single battery, using its early-stage data for model training and later-stage data for testing. Since only a portion of the historical data is used, the model is unable to fully learn the complete degradation cycle of the battery, resulting in certain limitations [
28]. Furthermore, such methods cannot provide RUL predictions during the early stages of battery usage, which poses constraints in practical applications.
SOH and RUL are both parameters that reflect battery aging, with the SOH representing the current aging state and the RUL indicating future aging trends. To comprehensively estimate the battery’s aging status, it is essential to jointly predict both the SOH and RUL. For example, Li et al. [
29] proposed a joint SOH and RUL prediction method based on GPR-LSSVM; Dong et al. [
30] developed a method using HKFRVM; and Wang et al. [
31] proposed another approach based on GPR-LSSVM for joint SOH and RUL prediction. In these methods, researchers typically extract multiple health features from battery data for SOH estimation and then use dimensionality reduction techniques to fuse these features into a single indirect health feature (IHF), which is used as the input for the SOH estimation model. During the RUL prediction process, these methods rely on predicting IHF values based on cycle numbers and subsequently inferring the SOH and RUL from the predicted IHF. This approach requires minimizing the number of health features, often using only a single composite feature, to simplify the relationship between cycle numbers and features.
Based on this, this paper proposes a joint SOH and RUL prediction method utilizing partial charging data. First, Gaussian Process Regression (GPR) is employed for SOH estimation, followed by Long Short-Term Memory (LSTM) networks for RUL prediction. The proposed method offers the following advantages:
It leverages partial charging data, reducing dependence on complete charging data and making the model more suitable for real-world scenarios with incomplete data.
The method imposes no restriction on the number of input features, allowing for the flexible selection of health features.
It enables RUL prediction during the early stages of battery usage, providing earlier warning capabilities to help extend battery lifespan and prevent unexpected failures.
The remainder of this paper is organized as follows:
Section 2 introduces the theoretical foundations, dataset, correlation analysis, model architecture, and evaluation metrics.
Section 3 presents the model validation, result analysis, and a discussion.
Section 4 summarizes the work of this study.
2. Theoretical Foundation
2.1. GPR
GPR [
32] is a non-parametric Bayesian regression method that models data by assuming a certain relationship between data points. GPR excels in handling small sample datasets and providing uncertainty estimates for predictions, making it highly adaptable. The mathematical foundations of GPR are detailed below.
A Gaussian process is a stochastic process defined over a function space. Its core idea is to assume that the function values follow a Gaussian distribution. For any set of inputs their corresponding function values follow a multivariate Gaussian distribution.
A Gaussian process can be denoted as follows:
where
is the mean function, representing the expected value of the function at input point x;
is the covariance function (or kernel function), which describes the correlation between two input points. The covariance function is typically chosen to be a symmetric positive definite kernel.
In practical applications, the mean function is often assumed to be , leaving only the definition of the covariance function to be specified.
- 2.
Covariance Function and Expectation
The mean function
and the covariance function
are defined as follows:
where
represents the expected value of
, while
represents the covariance between
and
, reflecting the correlation between these two input points.
- 3.
Observation Data Model
Consider a set of observation data
, where
represents the input and
represents the observed value. It is assumed that the observed value is composed of the true function value
and independent and identically distributed Gaussian noise
, as follows:
These observations can be expressed as follows:
where
, and the noise term
follows a Gaussian distribution with a mean of zero and variance
, denoted as
.
- 4.
Joint Gaussian Distribution
Since
follows a Gaussian process
, the observed values
follow a joint Gaussian distribution:
- 5.
Prediction for a New Input Point
For a new input
, the distribution of its corresponding output
can be predicted. According to the properties of Gaussian processes, the joint distribution can be expressed as follows:
where
is the covariance vector between the training points and the test point
, and
is the covariance of the test point with itself.
Using the properties of conditional Gaussian distributions, the predictive distribution of
given
,
, and
follows a Gaussian distribution:
where the mean and variance are given by the following equations:
- 6.
Hyperparameter Optimization and Kernel Function Selection
In practical applications, the kernel function
and its hyperparameters are critical to the performance of GPR. Commonly used kernel functions include the Radial Basis Function (RBF) kernel, the Matern kernel, and the linear kernel, among others. The selection of hyperparameters is typically achieved by maximizing the marginal likelihood, which is expressed as follows:
By optimizing this marginal likelihood function, the optimal hyperparameter settings can be obtained, thereby improving the regression performance of GPR.
2.2. LSTM
LSTM [
33] is a specialized type of Recurrent Neural Network (RNN) that excels at capturing long-term dependencies in sequential data. Traditional RNNs often face challenges such as gradient vanishing or exploding when processing long time series. LSTM effectively mitigates these issues through its unique gating mechanisms.
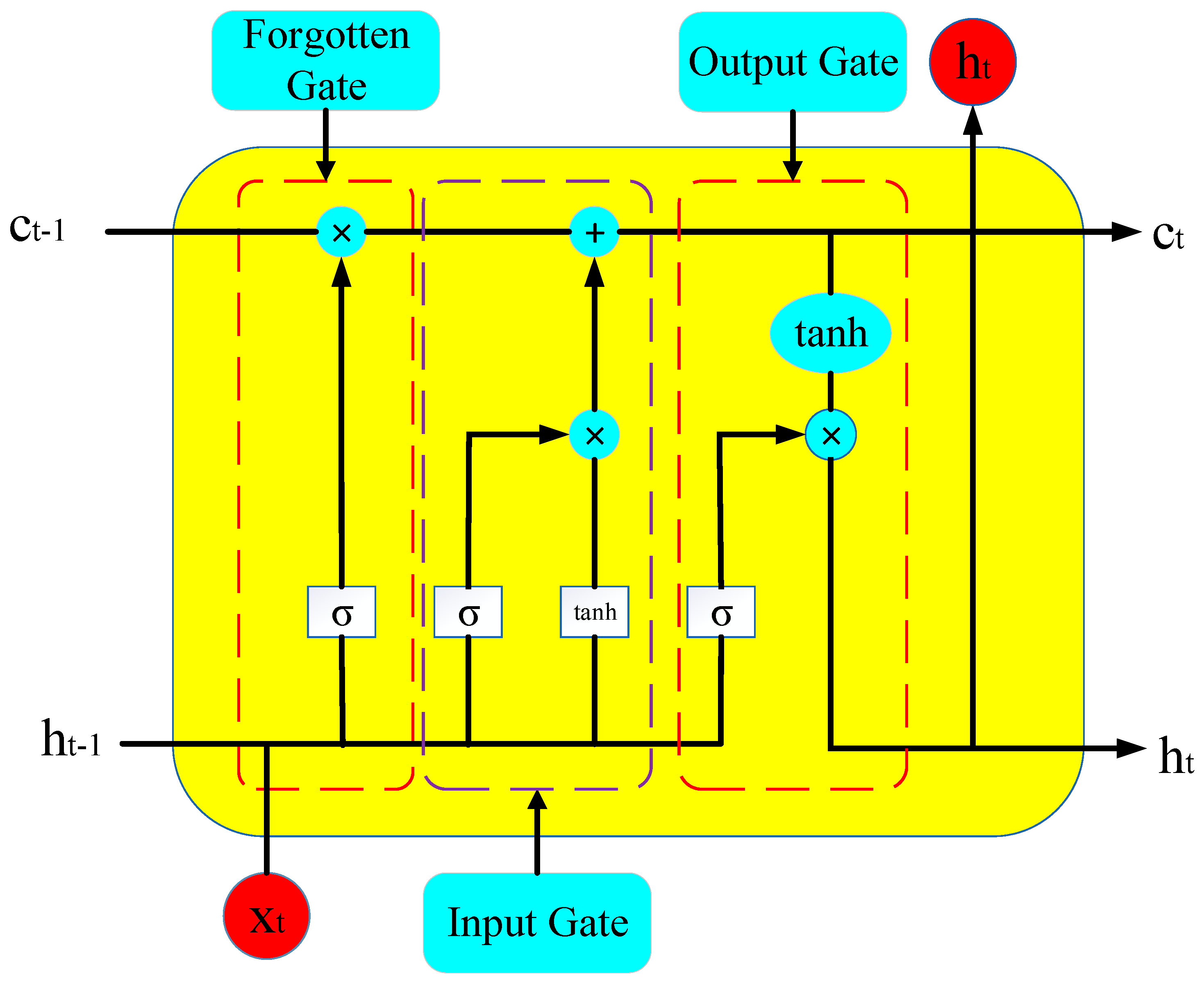
The core of LSTM consists of three gates: the forget gate, the input gate, and the output gate, as shown in
Figure 1. These gating mechanisms are responsible for selectively forgetting, updating, and outputting state information, enabling precise control over sequence information. Through these gates, LSTM can selectively retain or discard past information, making it highly effective for modeling time series data.
The forget gate controls whether information from the previous time step is passed to the next time step. Its calculation formula is as follows:
where
is the output of the forget gate, representing the proportion of information to be forgotten at the current time step.
is the weight matrix of the forget gate, which determines the influence of the previous hidden state and the current input on the forget gate.
is the hidden state from the previous time step, which contains all information from the sequence up to the current time step.
is the input data at the current time step.
is the bias term of the forget gate.
is the sigmoid activation function, with an output range between 0 and 1, determining the degree of forgetting.
- 2.
Input Gate
The input gate controls the updating of new information at the current time step. It consists of two parts:
Input Gate Activation:
where
is the output of the input gate, indicating whether new information is accepted.
is the weight matrix of the input gate.
is the bias term of the input gate.
Candidate values:
where
is the candidate value at the current time step, representing new information that can be added to the cell state.
is the weight matrix for the candidate values.
is the bias term for the candidate values. tanh is the hyperbolic tangent activation function, ensuring the candidate values range between −1 and 1.
- 3.
Cell State
The core of LSTM is the cell state
, which is responsible for carrying long-term dependency information. The update formula for the cell state is as follows:
where
is the cell state at the current time step, containing information for long-term memory.
is the cell state from the previous time step.
represents the update to the cell state by the input gate, determining the new information to be added to the state at the current time step.
- 4.
Output Gate
The output gate controls the final hidden state output. Its calculation formula is as follows:
where
is the output of the output gate, determining the hidden state at the current time step.
is the weight matrix of the output gate.
is the bias term of the output gate.
- 5.
Hidden State
The final hidden state
of the LSTM is calculated through the combination of the output gate and the cell state:
where
is the hidden state at the current time step, containing key information from the current and previous time steps.
is the activation of the current cell state, with an output range between −1 and 1.
2.3. Dataset Description and Health Feature Extraction
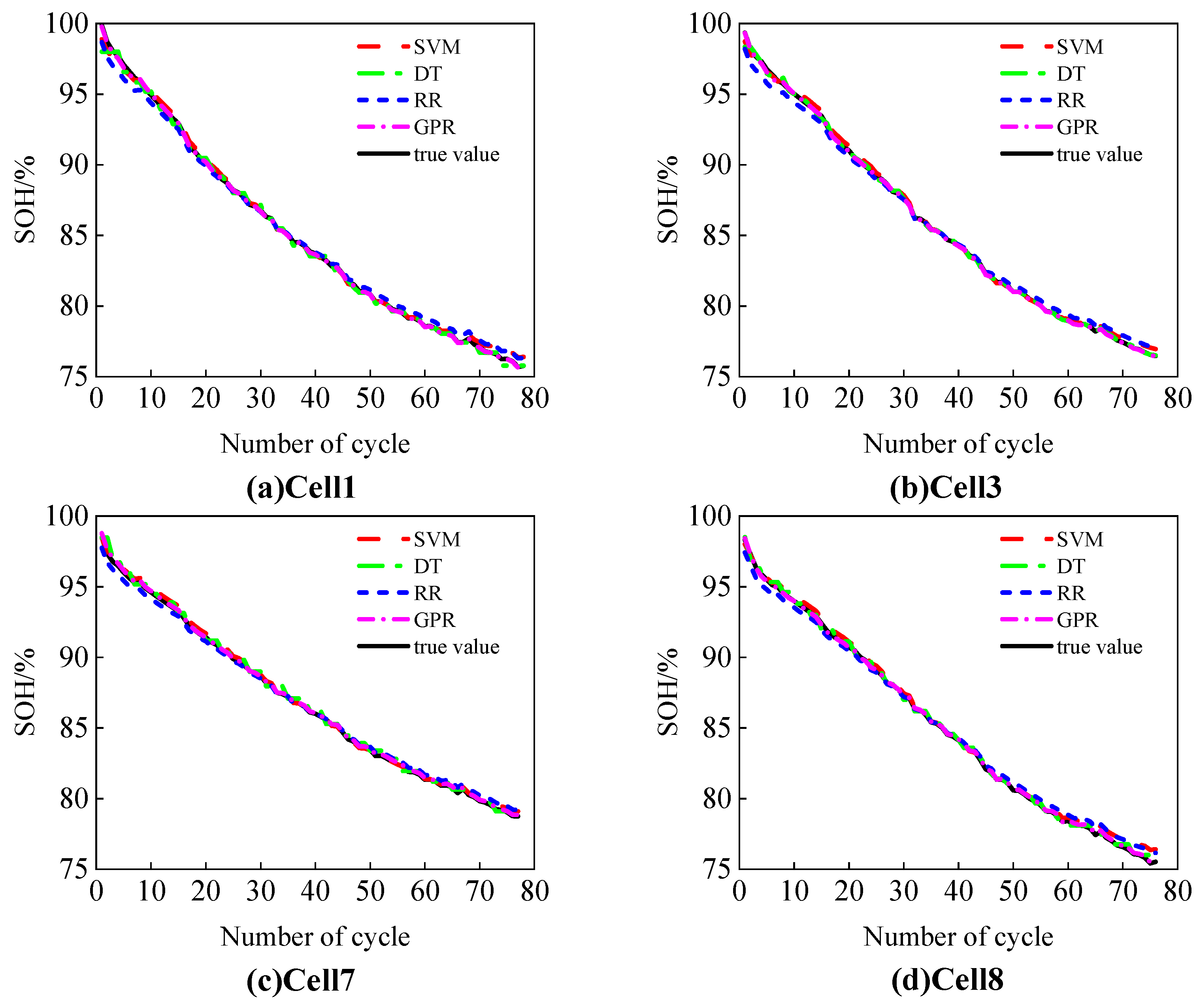
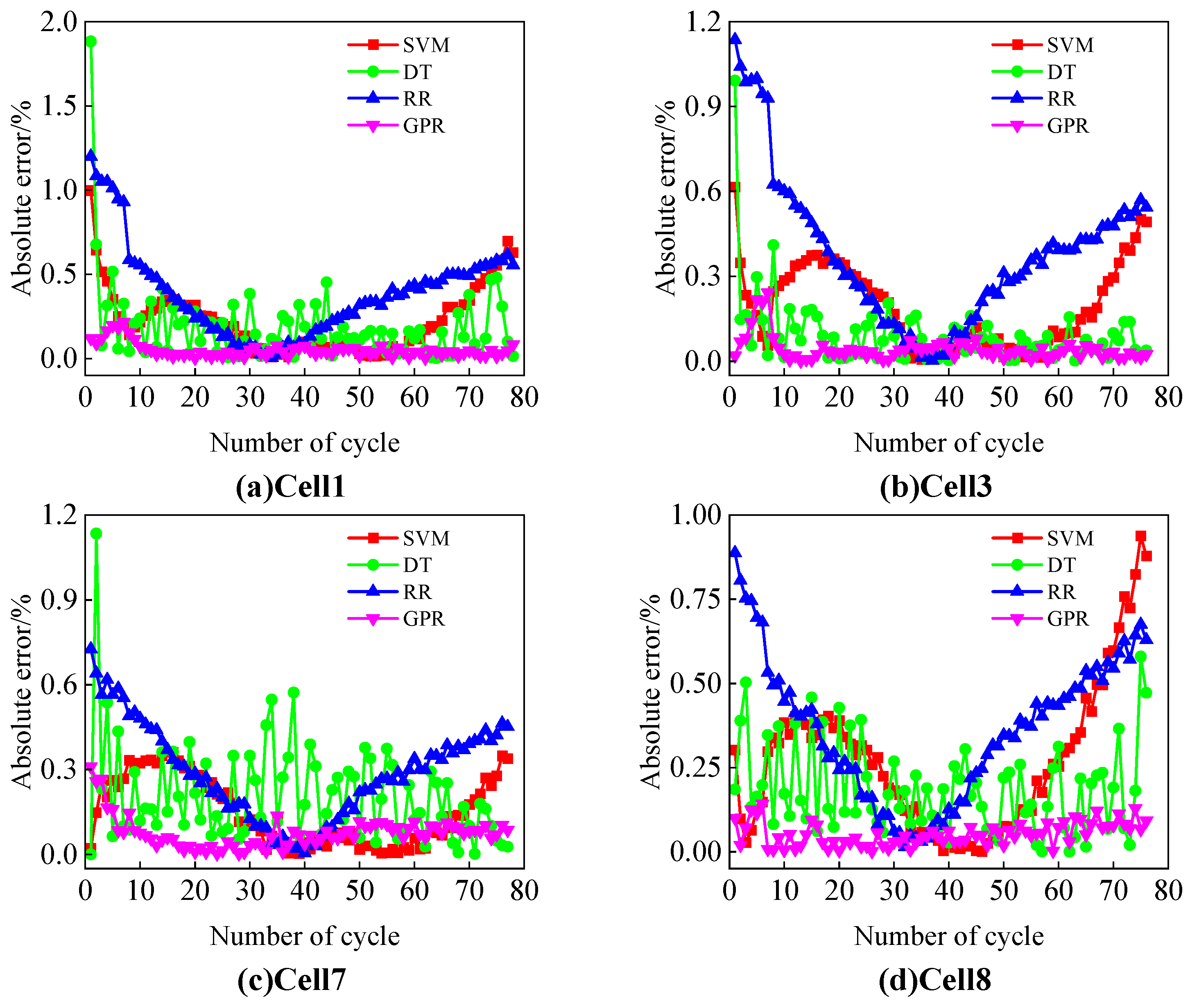
This study uses the Oxford Battery Degradation Dataset as the source of experimental data, selecting four battery cells (Cell1, Cell3, Cell7, and Cell8) for testing. These batteries have a rated capacity of 0.74 Ah and were subjected to aging tests at a constant temperature of 40 °C. After every 100 cycles, a 1C constant current charge–discharge calibration was performed to simulate the aging behavior of the batteries during actual use.
Figure 2 illustrates the voltage curves of the battery at different cycles, using Cell1 as an example. As shown in the figure, as the number of battery cycles increases, both the charging and discharging times gradually shorten, which is visually represented by the voltage curves shifting to the left. This phenomenon indicates that the battery’s SOH degradation trend is consistent with the reduction in charging and discharging times.
In practice, it is challenging to measure battery discharge information. In contrast, collecting information during the charging process is more convenient. Therefore, this study extracts health features (HFs) from the charging process. However, the charging process may not always start from a state of charge (SOC) of 0%, nor necessarily end at full charge. Ultimately, this study uses partial charging data to extract the following HFs:
- (1)
HF1: The constant current charging time in a SOC range of 20% to 80%.
- (2)
HF2: The integral of the voltage curve with respect to time within a SOC range of 20% to 80%.
By extracting HFs from partial charging data, the dependence on data completeness is reduced, thereby enhancing the applicability of the proposed method.
Figure 3 illustrates the normalized degradation trends of the SOH, HF1, and HF2 with the number of cycles, using Cell1 as an example. The results show that both HF1 and HF2 exhibit clear degradation trends as the cycle count increases. These trends are highly consistent with the degradation of the SOH, indicating that the extracted HFs effectively reflect the battery’s aging state.
2.4. Correlation Analysis
To evaluate the correlation between HF1, HF2, and the SOH, this paper employs the Pearson correlation coefficient and the Spearman correlation coefficient for correlation analysis.
The
Pearson correlation coefficient is defined as follows:
where
X denotes the HF and
Y denotes the SOH.
The Spearman correlation coefficient is defined as follows:
where
represents the average value of the HF;
indicates the average SOH value; and
n refers to the total number of samples.
Table 1 summarizes the Pearson and Spearman correlation coefficients between HF1 and HF2 with the SOH for the four batteries (Cell1, Cell3, Cell7, and Cell8). The results show that all correlation coefficients exceed 99.99%, indicating an extremely high correlation between the extracted health features and the SOH. This further validates that HF1 and HF2 effectively represent the battery’s health status.
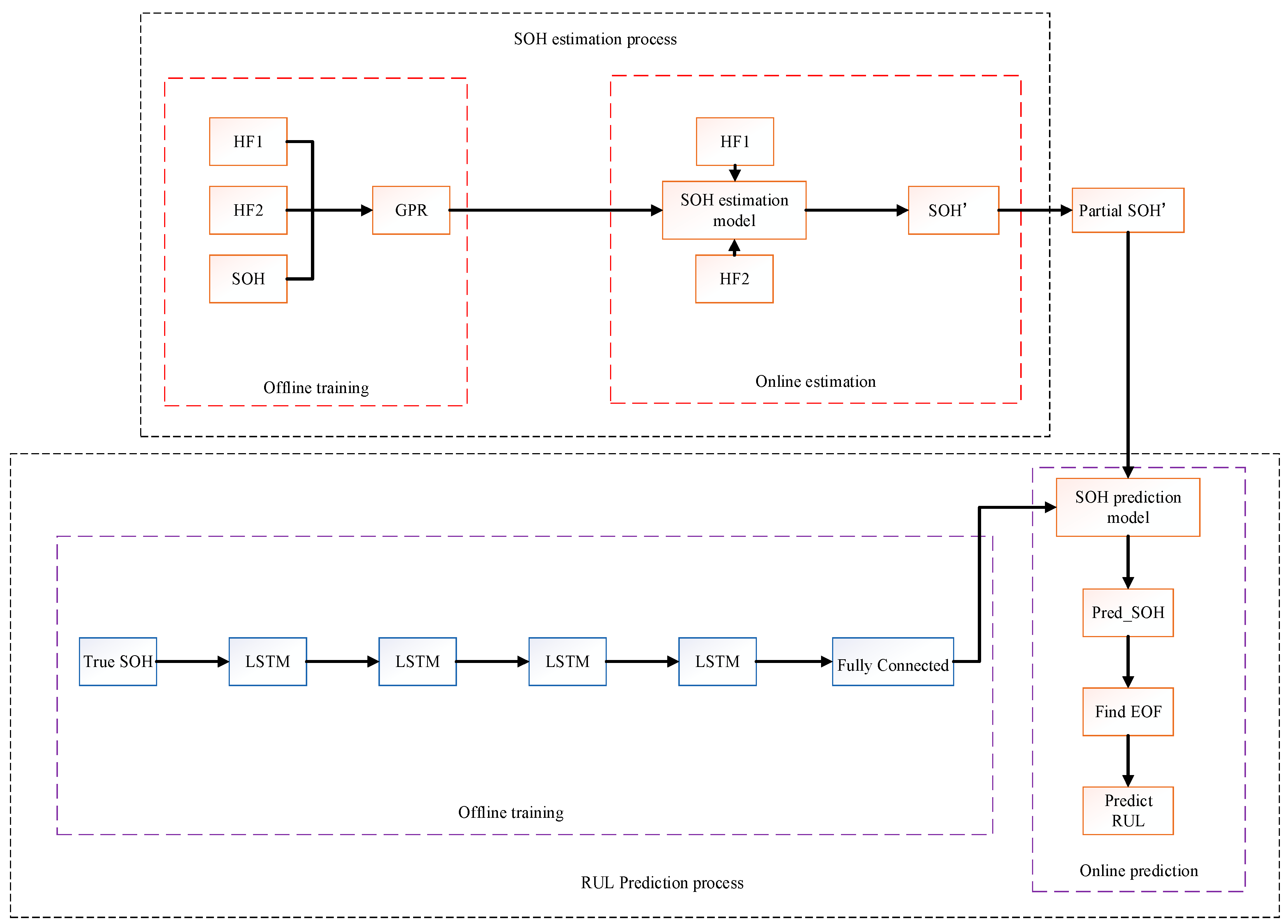
2.5. Model Structure and Parameter Settings
The structure of the proposed model is shown in
Figure 4. As illustrated, the model consists of two parts: SOH estimation and RUL prediction. This structure not only enables the accurate estimation of the battery’s SOH but also facilitates the prediction of its RUL, thereby providing comprehensive state monitoring and decision support for Battery Management Systems (BMSs). All training and testing in this study were conducted in the MATLAB 2023a environment.
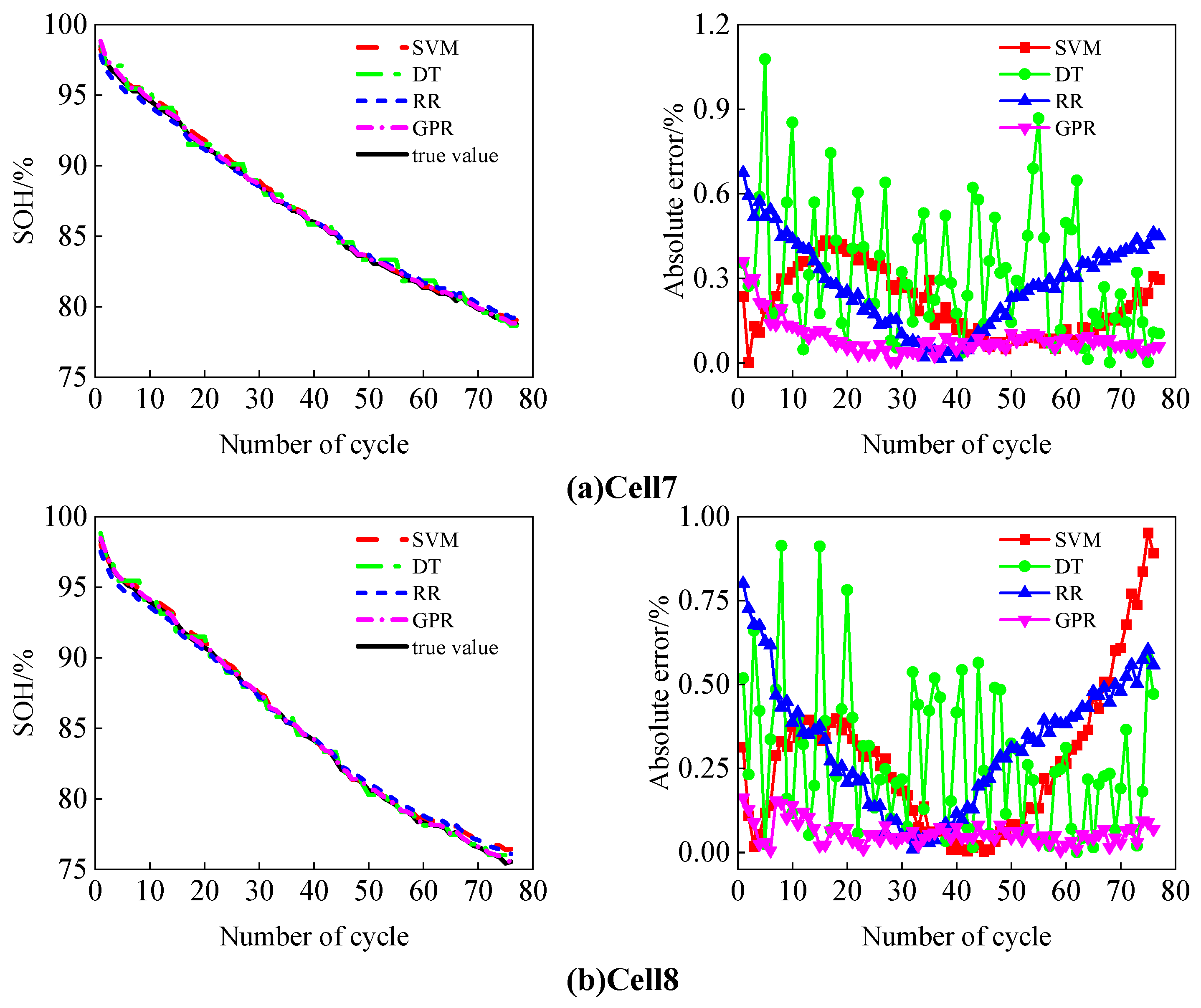
2.5.1. SOH Estimation
The SOH estimation part is divided into two phases: offline training and online testing.
In this phase, HF1 and HF2 were used as input variables, and the SOH was set as the target variable to construct and train the GPR model. The constructed GPR model adopted a squared exponential kernel function, which is mathematically expressed as follows:
where
and
represent the input health features,
is the signal amplitude, and
is the length-scale hyperparameter.
To minimize the impact of differences in feature scales on model training, the input variables HF1 and HF2, and the output variable SOH were normalized to the range [0,1], using the following formula:
where
is the original feature value,
is the normalized feature value, and
and
represent the minimum and maximum values of the feature, respectively.
- 2.
Online Testing Phase:
In this phase, HF1 and HF2 were input into the trained GPR model to obtain the estimated values of the SOH.
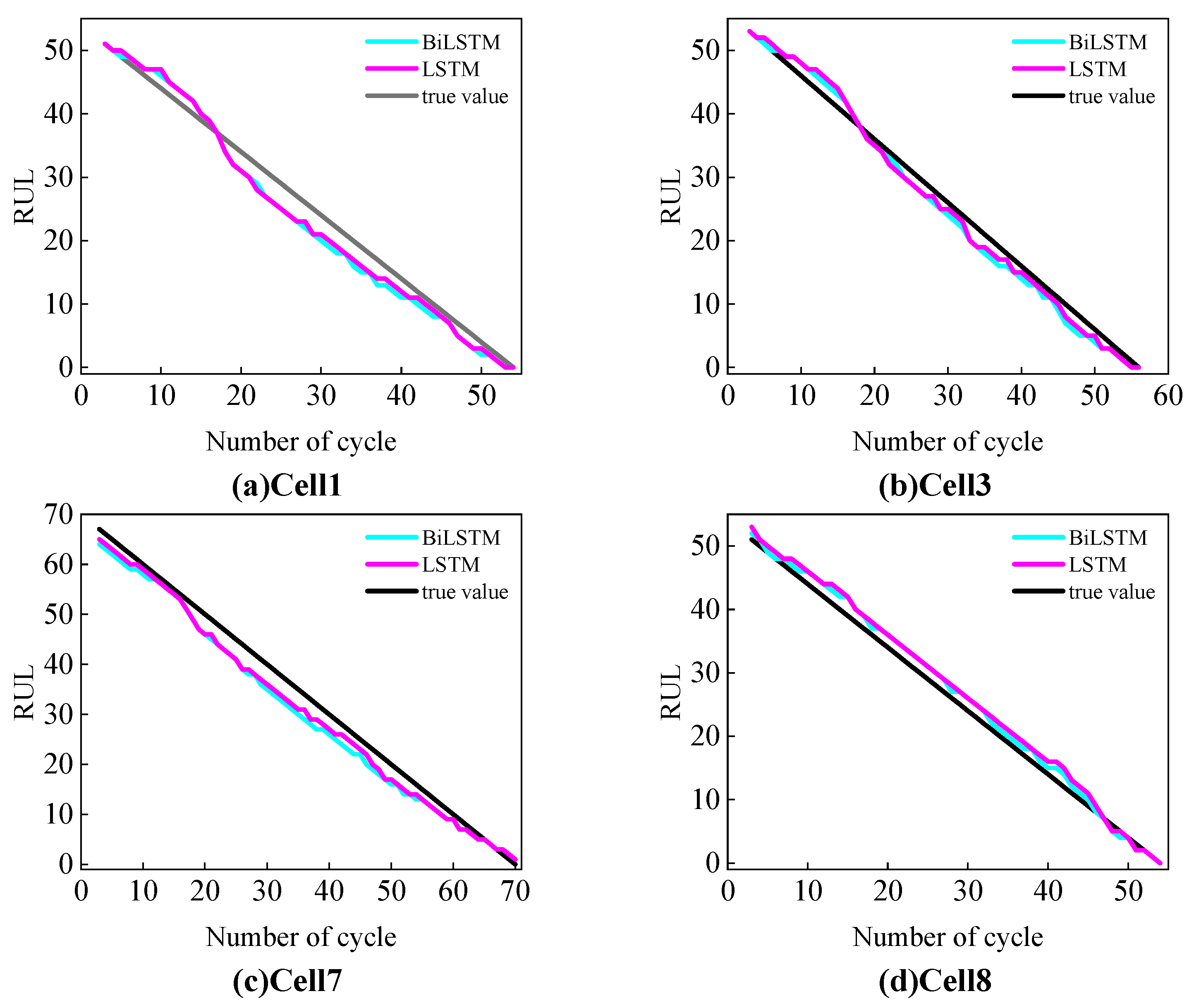
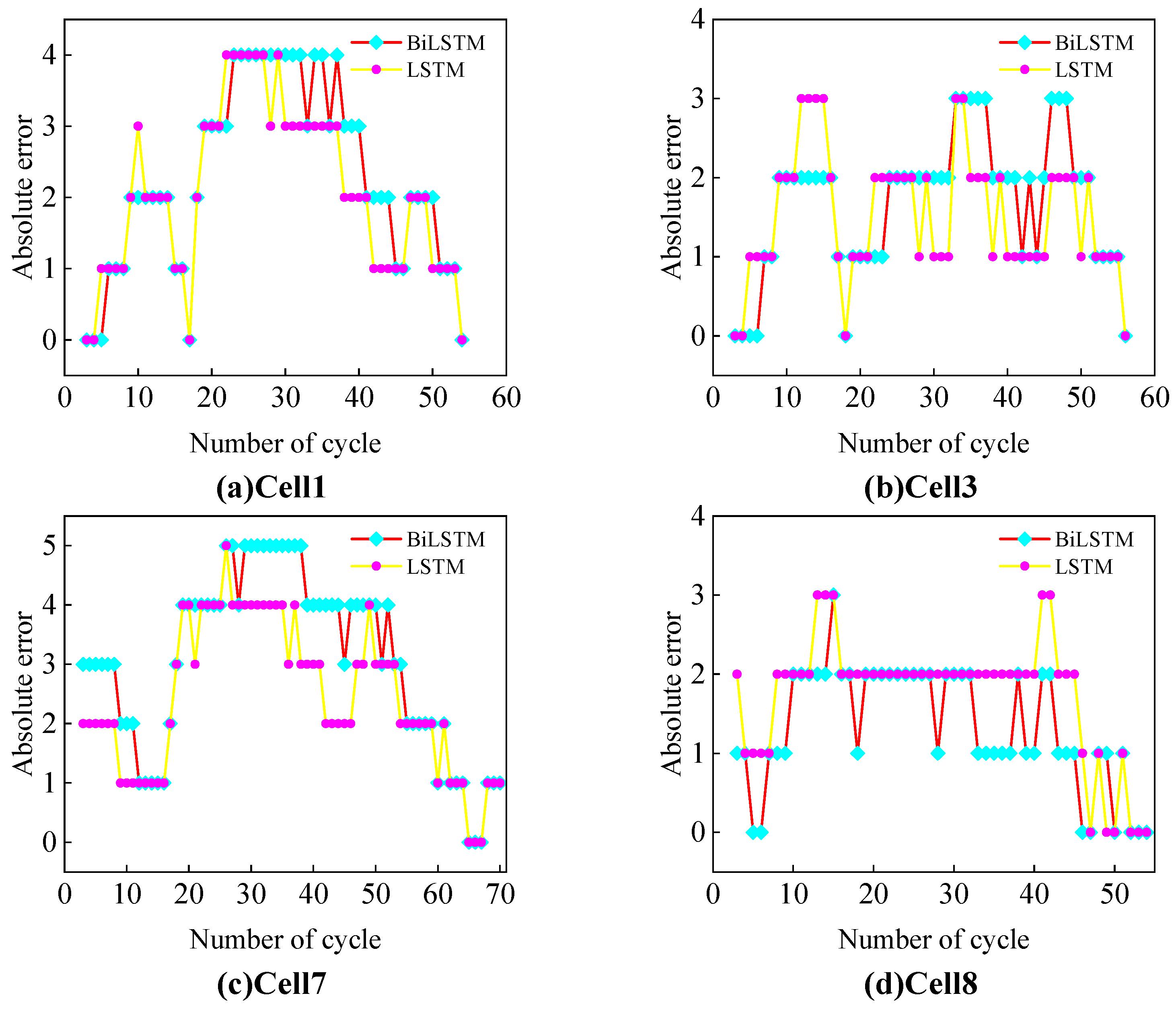
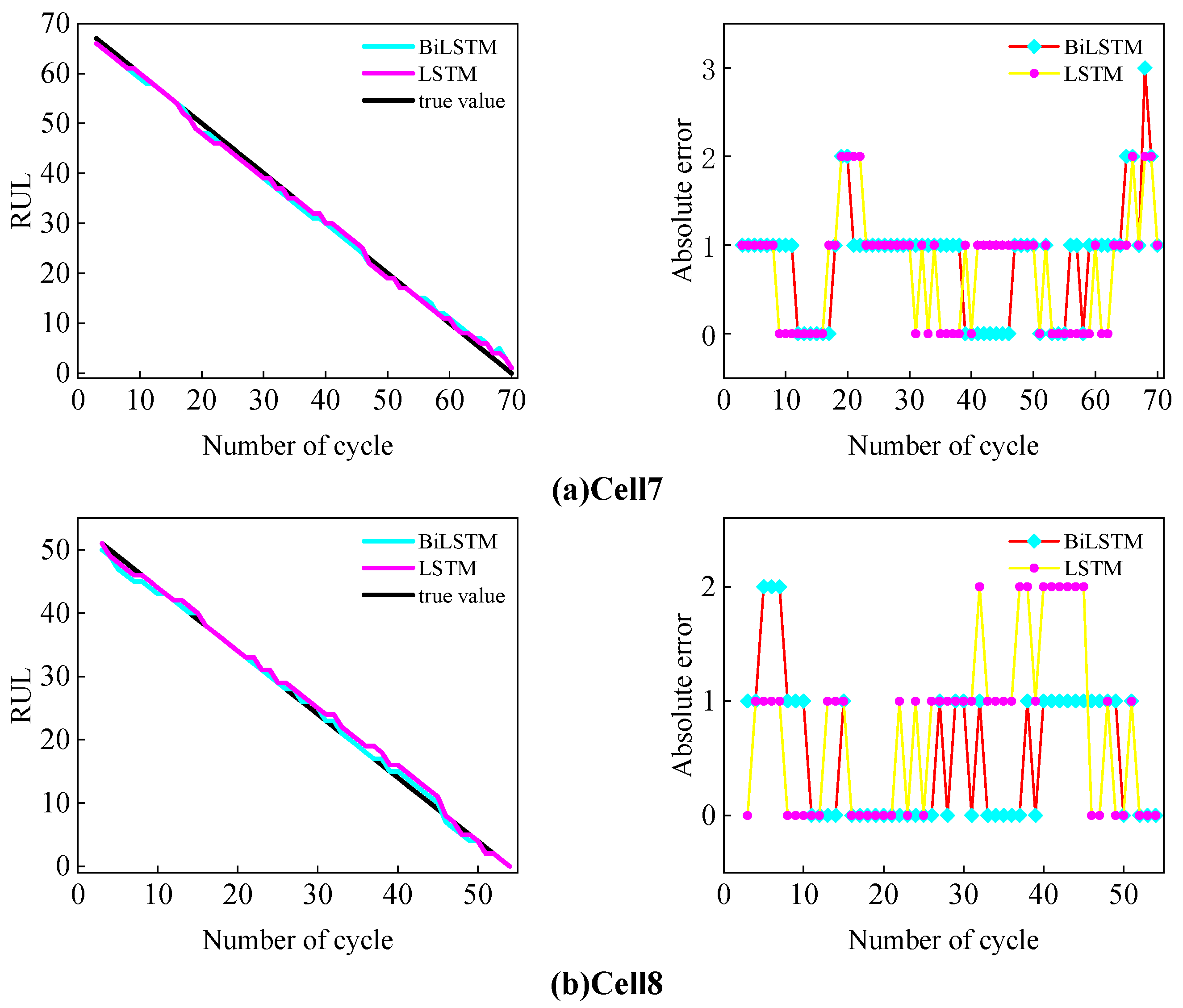
2.5.2. RUL Prediction
In the RUL prediction part, the actual SOH data were first used to train the LSTM model. The model consists of four LSTM layers and one fully connected (FC) layer. Each LSTM layer contains 20 hidden nodes, and the FC layer has one node. The initial learning rate was set to 0.001, and the Adam optimizer was used for training, the maximum number of iterations was 3000, and the sequence length was set to 2.
To enhance the training performance of the model, the SOH data were standardized. The standardized SOH data were used to generate the input and output sequences for the model. Specifically, for each input, two consecutive standardized SOH values were used as the input sequence, and the SOH value at the next time step, , was used as the output sequence.
After obtaining the SOH estimates from the GPR model, the estimates were divided into a sequence of SOH values from cycle 1 to the current SP: . The LSTM model was then used to predict the future SOH values. Within the predicted values, the cycle count at which SOH ≤ 80% was identified. Based on this, the RUL at the current time was calculated as follows: .
Once the model training was completed, the SOH estimates obtained from the GPR model were divided into a sequence fragment ranging from the first cycle to just before the SP. This fragment was used as the input to the LSTM model to predict future SOH values. The cycle corresponding to the EOL was then identified from the predicted values, and the RUL at the current time was calculated accordingly.
2.6. Evaluation Metrics
To evaluate the accuracy of the model’s predictions, the root mean square error (RMSE) and mean absolute error (MAE) were selected as evaluation metrics. The specific calculation methods are as follows:
where
represents the predicted value for the
i-th sample;
represents the actual observed value for the
i-th sample; and
n denotes the number of samples.







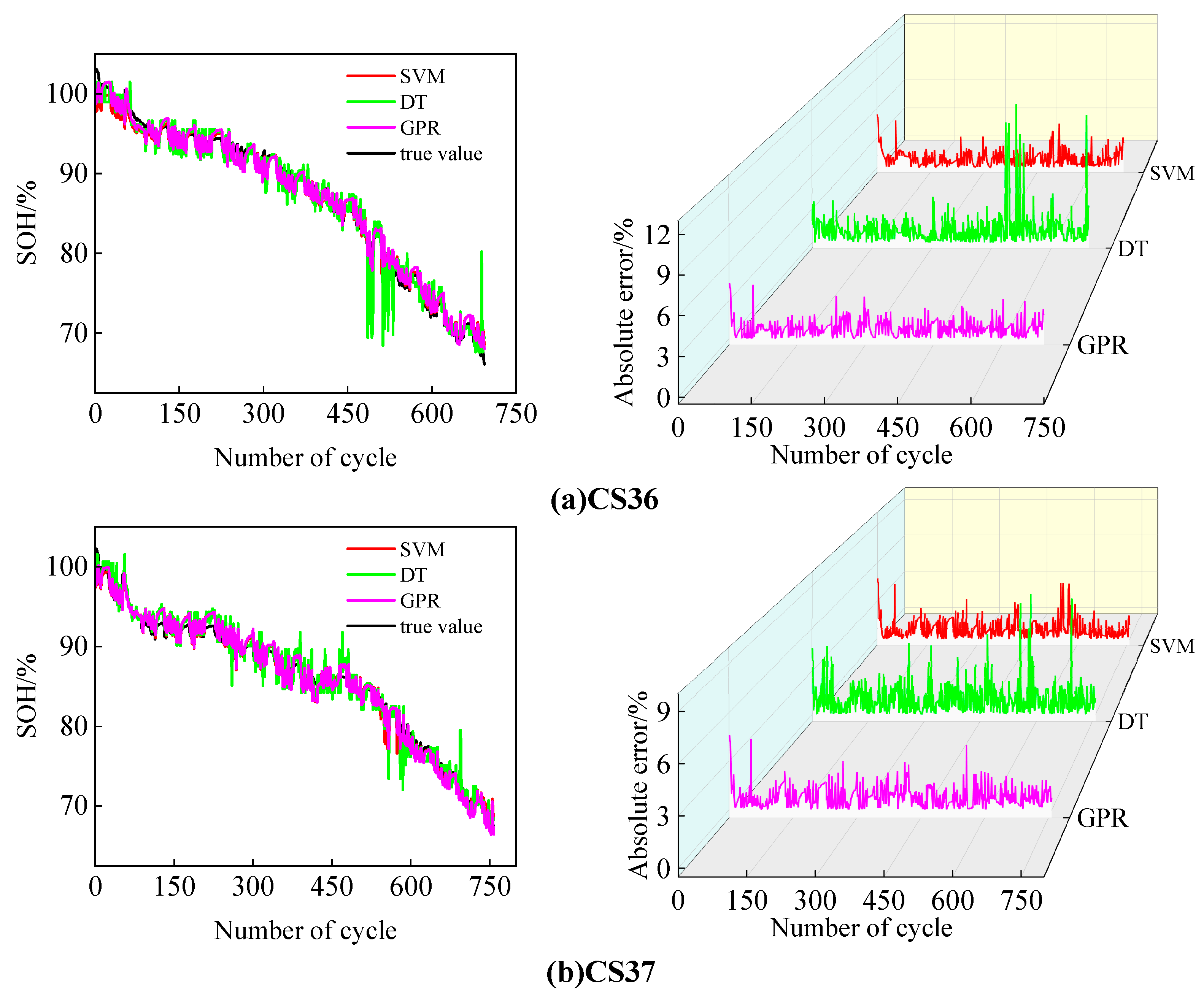


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}