2.2. Waste Characterization and Image Processing
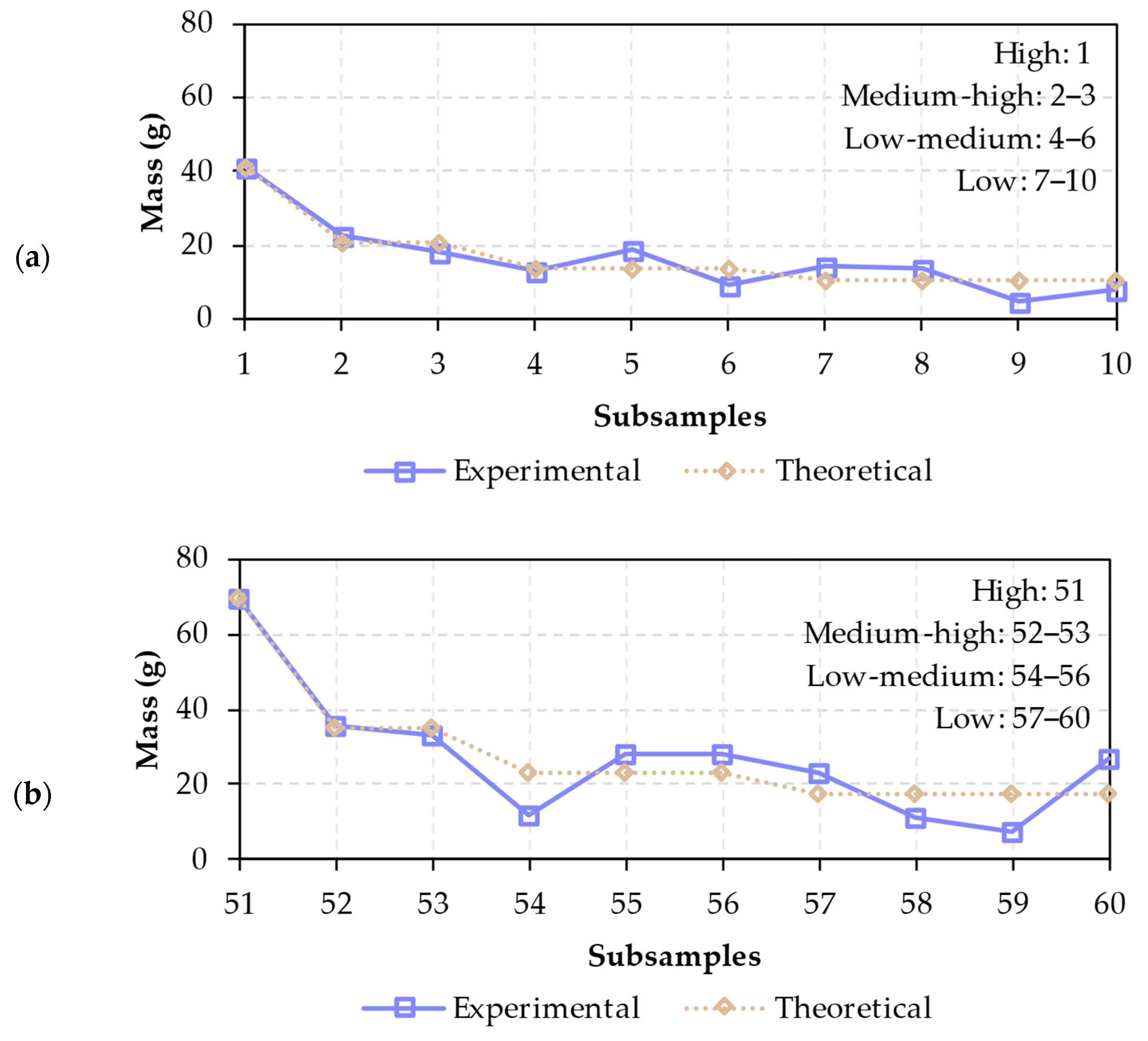
The waste sample was divided into 21 groups of different particles. Each group was defined to cover most of the inspected area, representing a high cover level. Waste fragments were presented as a single monolayer, without overlapping each other, reproducing the conditions of material flows during sorting operations [
14]. On average, eight particles were used to reproduce the high load class.
To study medium-high, low-medium, and low cover levels, each group of particles was divided into two, three, and four monolayer subgroups, respectively. As an example,
Table 2 considers a group of twelve fragments with equal mass, characterizing different properties for each cover level.
The subgroups for the same load class were manually defined, aiming to reduce mass differences between them. Each particle group provided ten subgroups with different waste particles and cover levels, resulting in a total of 210 subsamples. Similar volumes of data points were used in other studies [
15,
25].
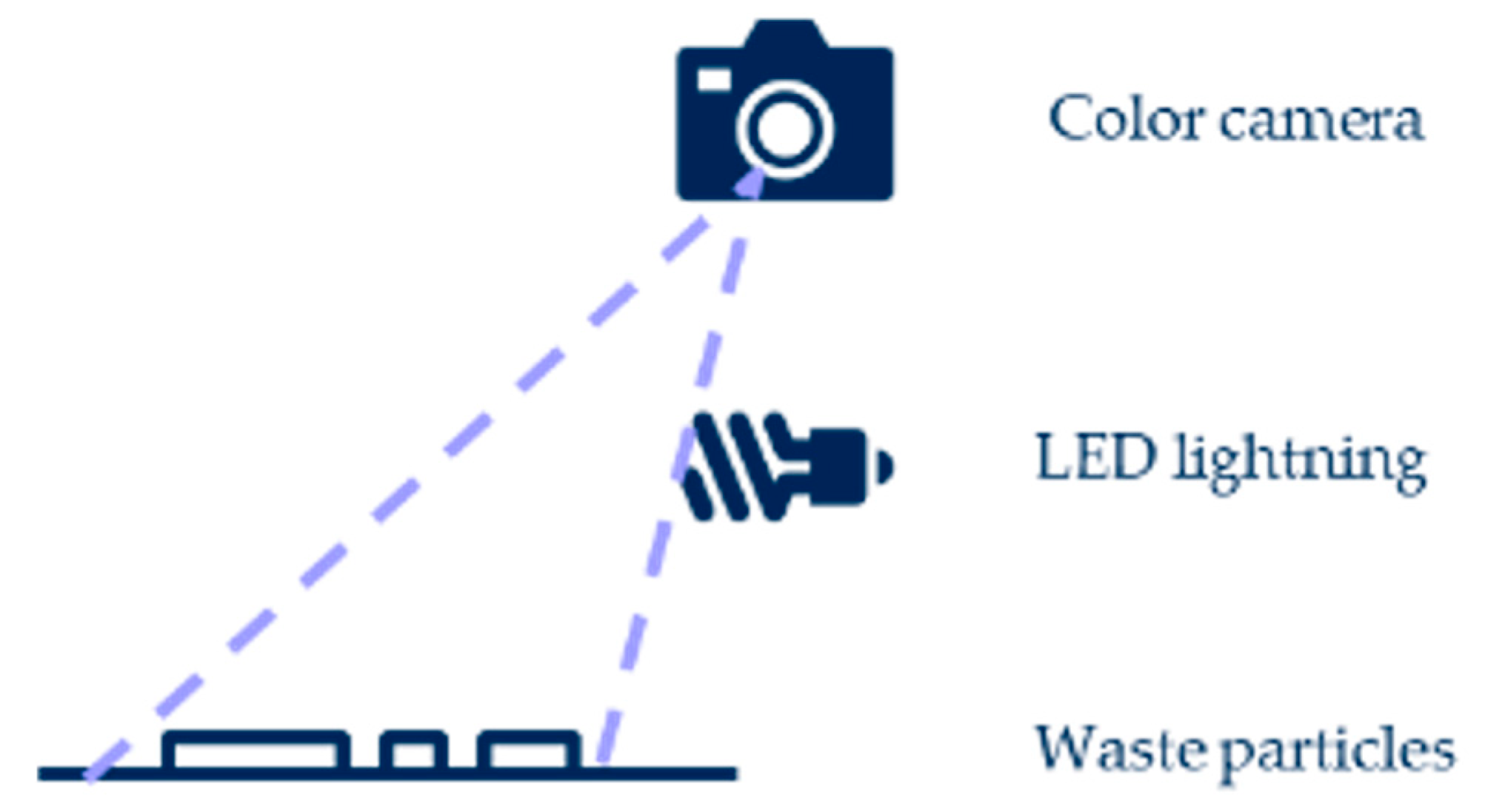
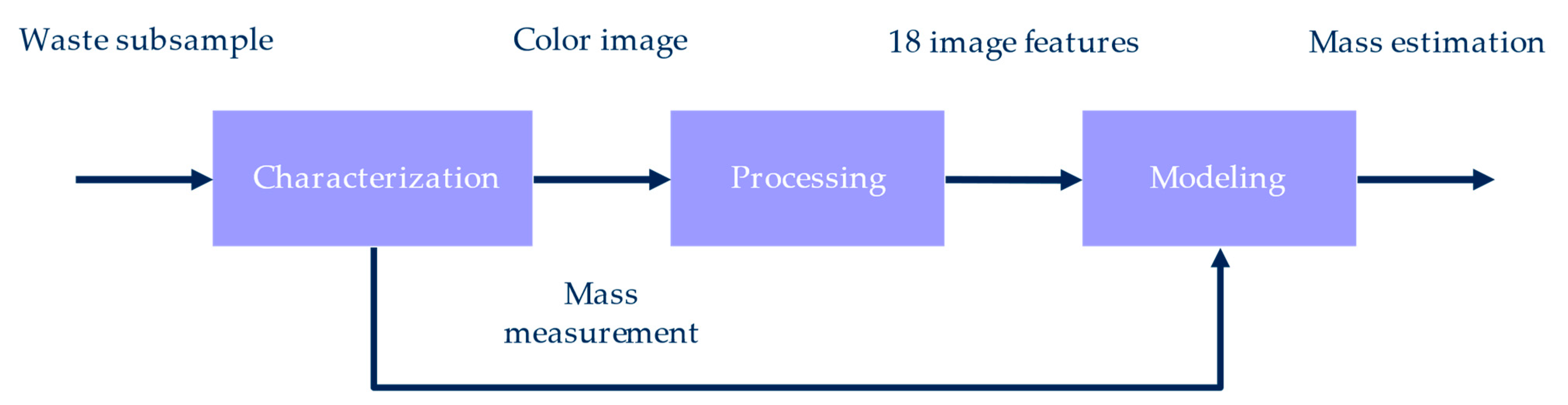
The method to estimate waste mass based on images is shown in
Figure 3. Each subsample was characterized by measuring the mass of all the waste particles and acquiring a color image of them. Next, the picture was processed to compute eighteen quantitative features. Mass measurements were used to adjust the visual models.
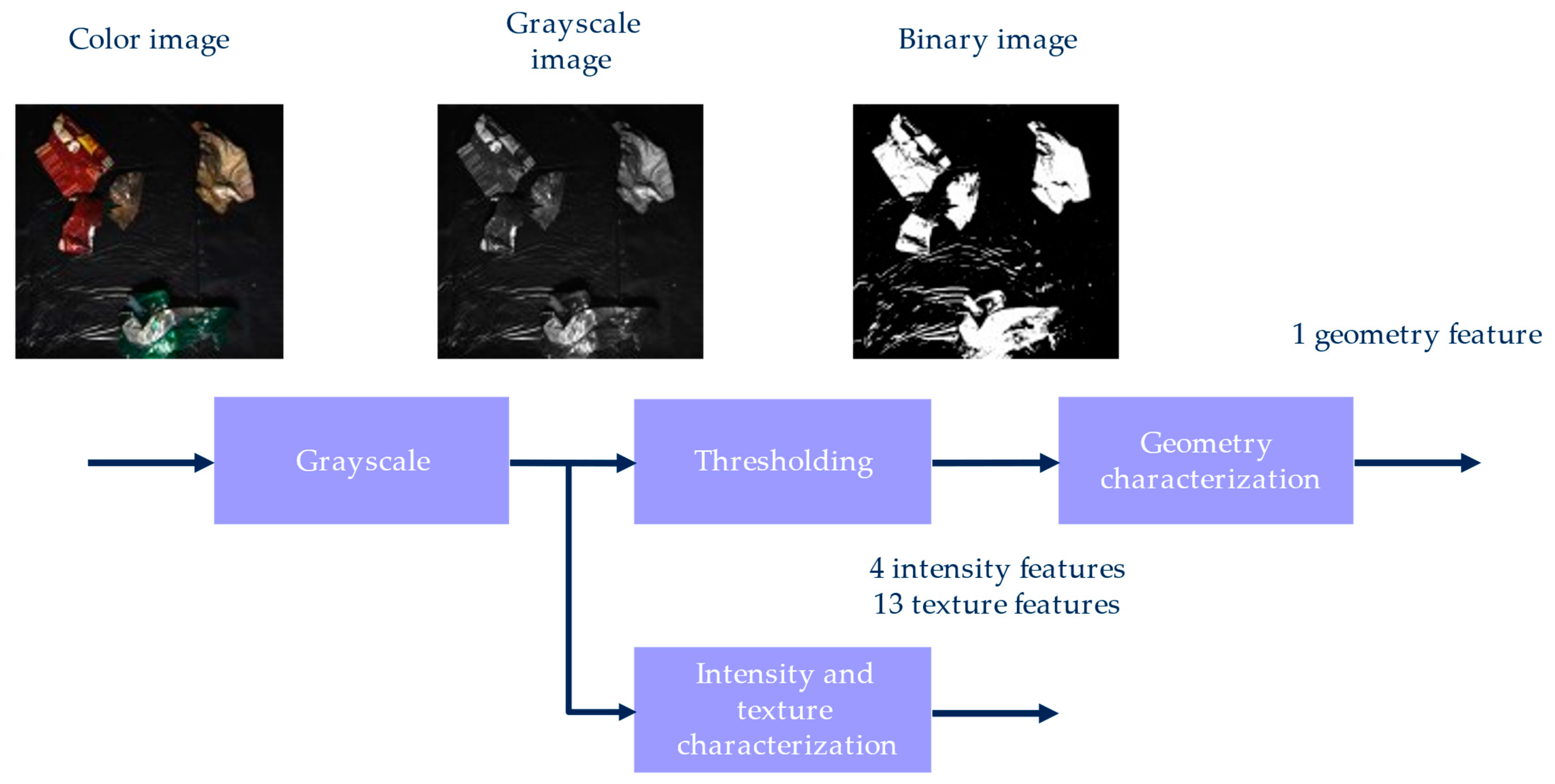
The method for the processing of waste images is summarized in
Figure 4. Color images were converted to grayscale, and the image area covered by waste was quantified by counting waste pixels, segmented via thresholding. Furthermore, four intensity and thirteen texture features were computed from the grayscale images.
As previously commented, color and near-infrared cameras are relevant alternatives for material classification. While color cameras capture three monochrome images that form a color image, near-infrared cameras acquire only one. To reduce the dependence of the method on the use of color images, pictures were converted to grayscale. This way, a single monochrome image was obtained per trigger, as for near-infrared cameras. Color images were converted to grayscale by applying the method defined by OpenCV [
26]. Grayscale pictures were defined as the linear combination of the red, green, and blue color channels, multiplied by 0.299, 0.587, and 0.114, respectively.
In the collected images, waste particles were generally brighter than the black surface where they were distributed, suggesting the alternative of mass estimation based on images. Waste pixels were segmented via thresholding, a common technique applied to different sectors [
1,
27,
28]. In this study, pixels with a value equal to or higher than a predefined value were classified as waste, and the rest were considered background. Different thresholds were tested to reduce the error of waste segmentation. As result, an intensity level of 40 was chosen (16% of the maximum pixel value). Thresholding provided binary images whose pixel values were 0 (background) or 1 (waste). Next, the number of waste pixels was computed to characterize the image area covered by waste. This geometrical feature has been previously used for material characterization [
1,
3,
4,
5] and other applications [
28,
29].
Intensity and texture features were extracted from the whole image (waste and non-waste pixels). Based on the different intensity between the waste fragments and background, variations in the cover ratio could affect the intensity properties of the whole image, such as its mean value. A higher number of waste particles in the image may also raise the number of adjacent pixels with a significant difference in intensity, corresponding to the edges of waste fragments. Moreover, waste particles could have a different texture than the background, modifying the image texture according to the load proportion. These effects were studied by computing intensity and texture features from all the image pixels.
As for the image feature of the number (area) of segmented pixels, intensity and texture properties have been used to characterize materials [
30]. In this work, the set of intensity features included the mean, standard deviation, skewness, and kurtosis [
31]. These properties are listed in
Table 3, considering a monochrome image of
P pixels, where
x(
p) was the value of pixel
p.
Texture characteristics (
Table 4) comprised the thirteen variables defined by Haralick et al. from the gray-level co-occurrence matrix (GLCM) [
32,
33]. The GLCM has as many rows and columns as quantized gray values in the image (
N). The element in row
i and column
j,
p(
i,j), counts the number of times that a pixel of value
i is next to a pixel of value
j, divided by the total number of instances. GLCMs are computed for a distance
d and angle
a, which can be 0, 45, 90, and 135° in the case of 2D images. This work used a distance of one pixel and averaged the values for the four pixel angles.
The texture features included three correlation properties to quantify the linear dependence between gray levels of local pixels and their neighbors [
32]. The third texture variable (correlation) was complemented with the information measures of correlation I and II for general cases without normal distribution [
32,
34].
After the steps of characterization and processing, a dataset of 210 subsamples was obtained. Each subsample included a mass measurement and eighteen image features. A previous analysis of the weight values detected asymmetry in the data distribution, with 70% of subsamples weighing less than 22 g (25% of the mass range). This behavior increased the uncertainty about the performance of a general model for all the subsamples. Therefore, three different mass intervals were modeled: general, light, and heavy. Each one of these ranges was split into training and test sets, with 70% and 30% of the subsamples, respectively.
Table 5 lists the characteristics of the datasets.
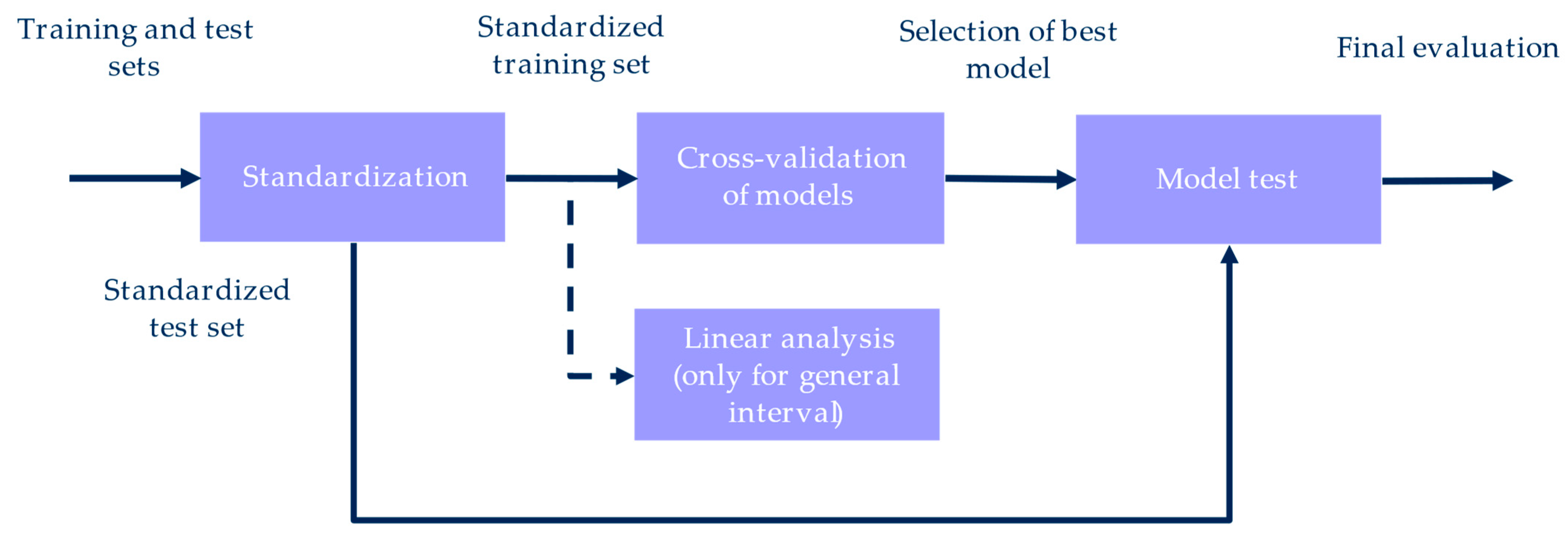
The datasets provided three pairs of training and test sets to model each mass interval. A similar method of machine learning was followed for the three ranges of mass, summarized in
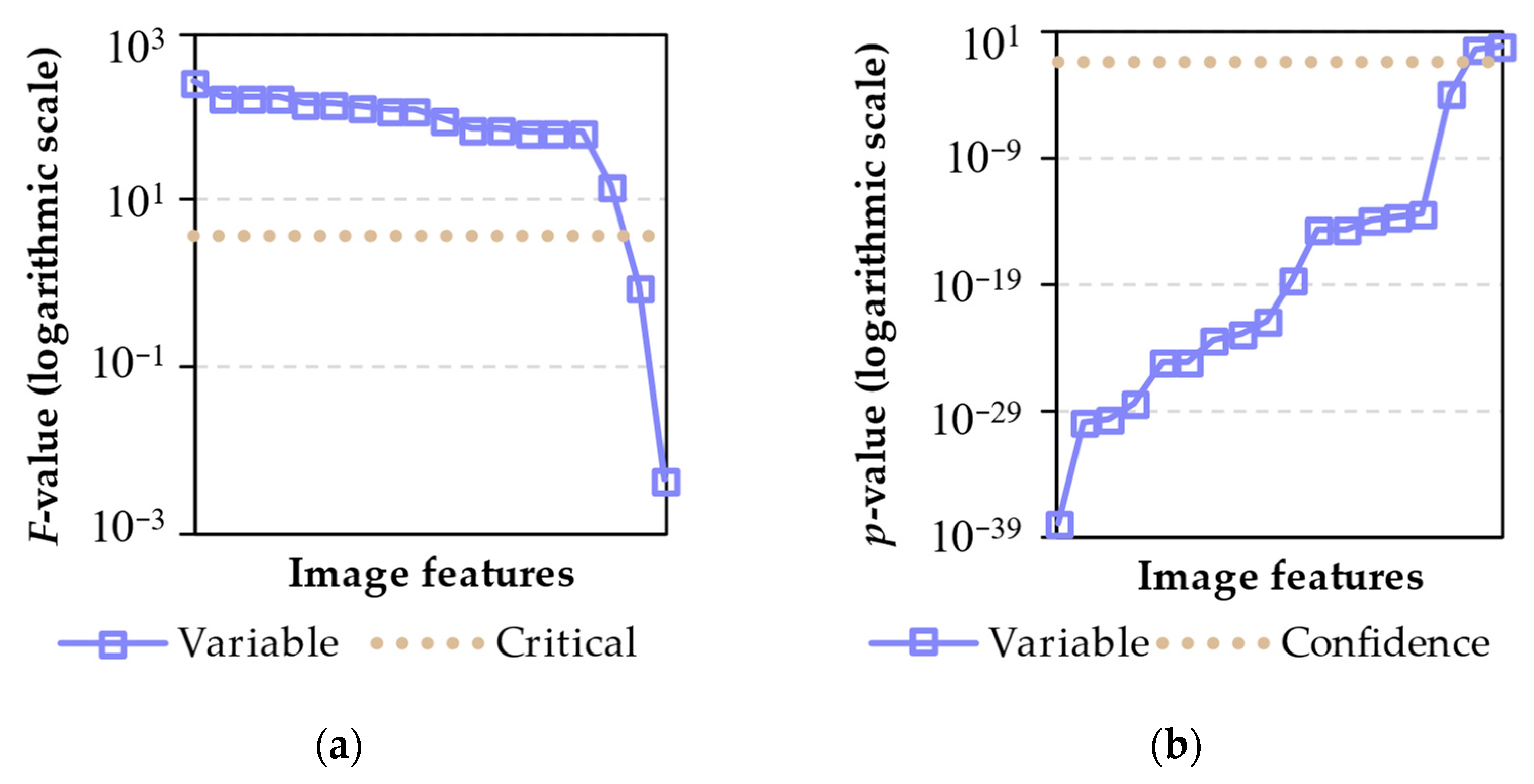
Figure 5. The training and test sets were standardized according to the means and standard deviations of the training set. The linear relationship between mass measurements and image features was analyzed with
F-tests for the general interval of mass. A cross-validation was applied to the training set to select the best model between different alternatives. Then, the test set was employed as unseen data to perform the final evaluation of the best models.
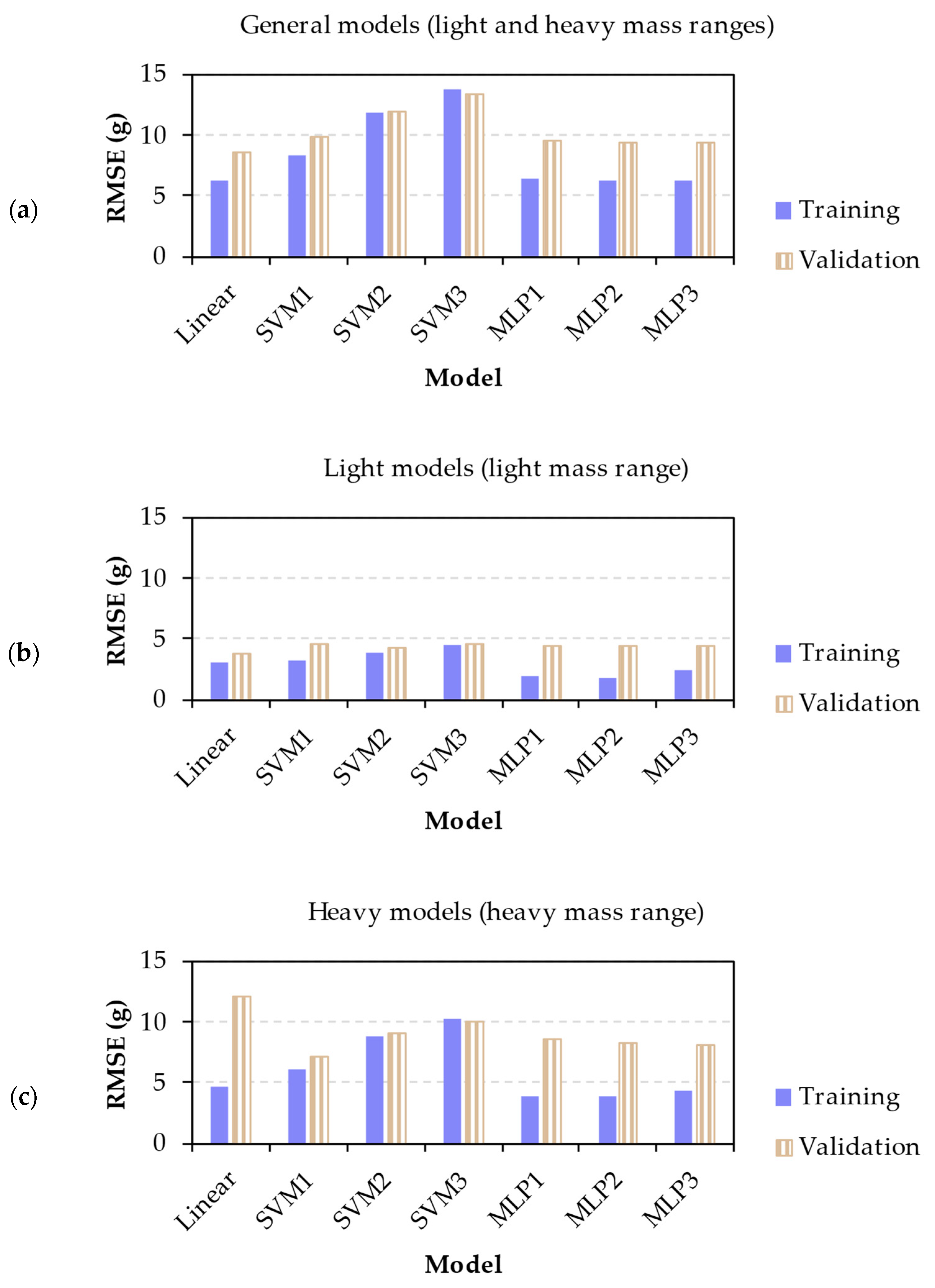
For the three datasets, different options of algorithms and regularization terms were evaluated in the step of cross-validation (
Table 6). Three algorithms were studied from artificial neural networks: linear, support vector machine (SVM), and multilayer perceptron (MLP). The linear algorithm employed the method of ordinary least squares, SVM used a radial basis function as the kernel, and the MLP was defined with a single hidden layer of one hundred neurons. Three values of the regularization term were studied for SVM and MLP: 0.1, 1, and 10.
A five-fold cross-validation was employed to evaluate the seven models. The training set was divided into five groups, combined to provide five pairs of training and validation subsets. Each training subset was formed by four folds, while its corresponding validation subset included the remaining fold. Models were trained with the training subsets, and the root mean square error (RMSE) of their predictions was computed for the training and validation subsets. The results were averaged for the five different groups and for each algorithm.
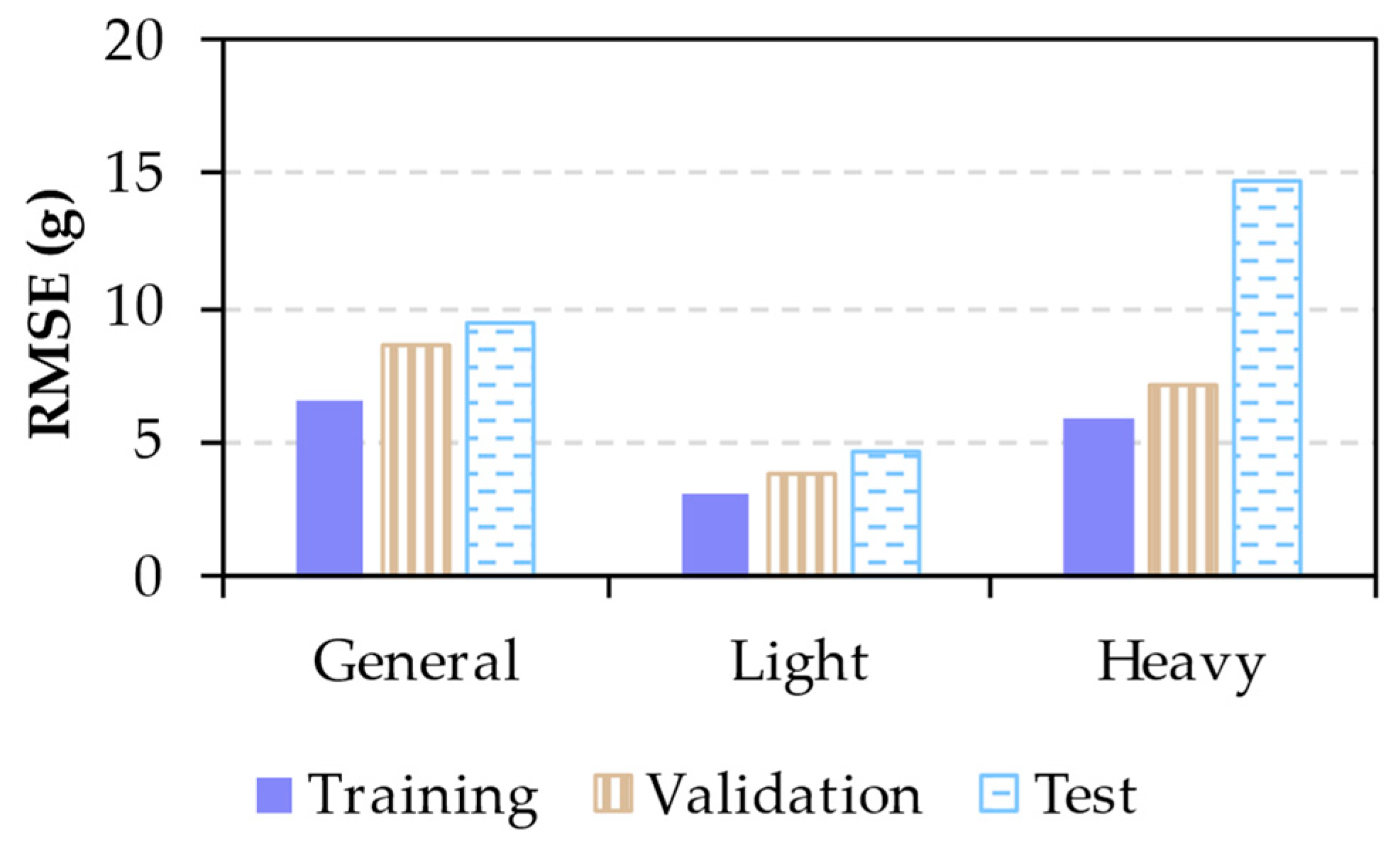
As a final evaluation for each mass interval, the model with the lowest RMSE was trained with the whole training set. Next, the RMSE was computed for the training and test sets, and the predicted and actual values were plotted. The performance of the general model was analyzed in more detail, computing its RMSE for the light and heavy subsamples. Apart from the RMSE, the normalized mean absolute error (nMAE) was obtained to compare the results with a previous study [
5]. This work was selected due to its study of a similar waste sample, formed by lightweight packaging particles of up to 70 g. The nMAE was computed by dividing the mean absolute error by the average mass of the considered range (
Table 5). Finally, the predicted and actual masses of the three models were plotted for their corresponding training and test sets.
The Python programming language (version 3.9) to develop the code for image processing and modeling. With that purpose, the following libraries were employed: OpenCV v4.9.0.80, Scikit-learn v1.4.2, NumPy v1.26.4, SciPy v1.13.0, Mahotas v1.4.13, and Pandas v2.2.2. The computer used was equipped with an Intel Core i7-1165G7 processor (Santa Clara, CA, USA) and a RAM of 16 GB. This processor is a member of the eleventh generation, and it has four cores and frequency of 2.80 GHz.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}