This subsection describes the principles of the Lightweight OpenPose, YOLOv5, SKPT-LSTM, and improved DeepSORT algorithms utilized in this study.
2.2.1. Lightweight OpenPose Algorithm
The behavioral postures of the human body are primarily determined by the relative positions of the human skeletal joints. Human posture estimation algorithms accurately locate skeletal keypoints in complex scenarios. The Lightweight OpenPose [
32] algorithm is one of the most widely adopted skeletal keypoint extraction methods. Developed by Intel in response to the computationally intensive nature of the OpenPose [
33] algorithm, it has gained widespread application in various fields [
34,
35,
36]. Utilizing a “bottom-up” approach, this algorithm achieves the real-time detection of skeletal information for multiple individuals and exhibits excellent robustness.
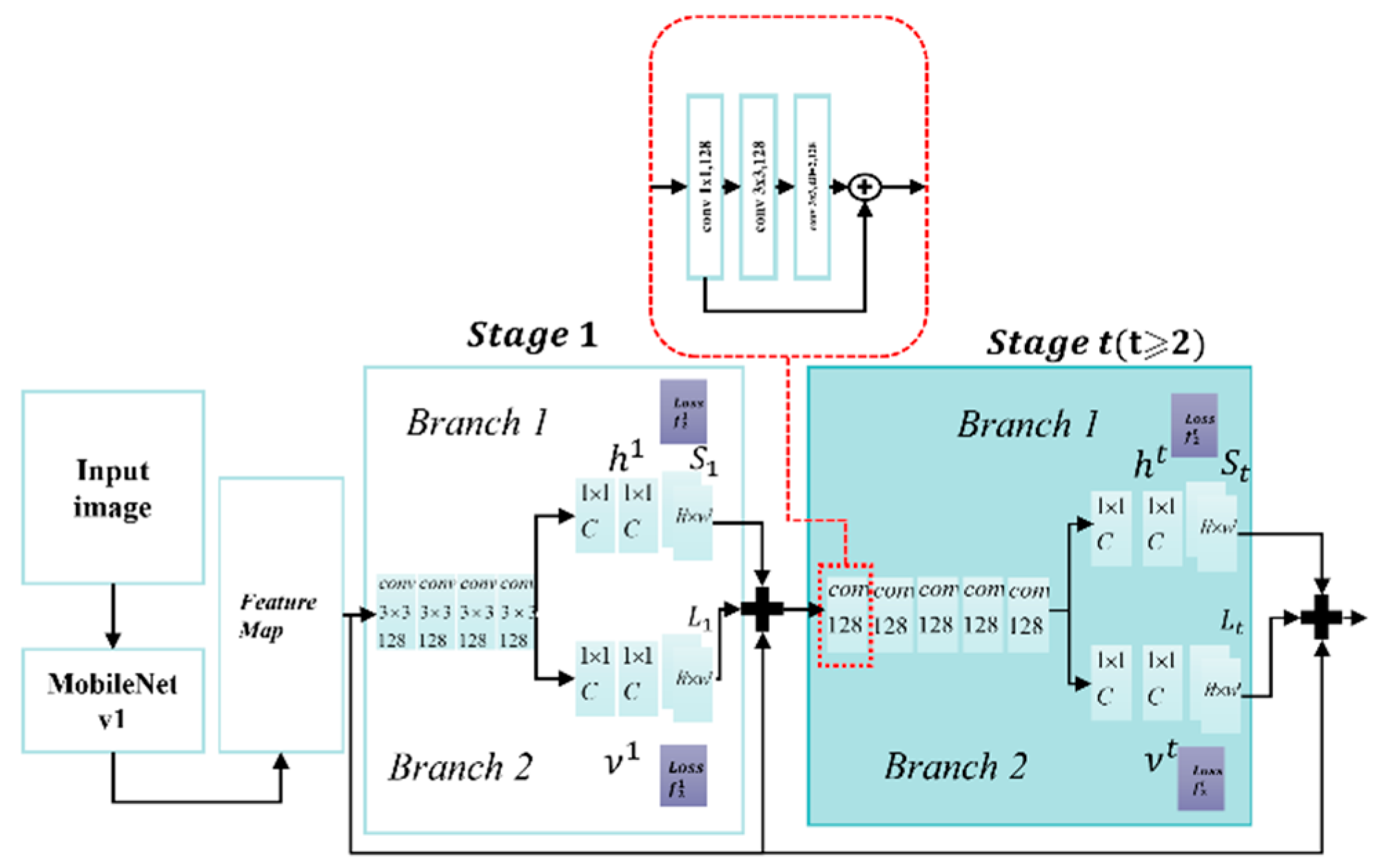
The network architecture of the Lightweight OpenPose algorithm is illustrated in
Figure 4. It employs MobileNet v1 [
37] as the backbone for the feature extraction. Following the feature extraction, the network underwent several refinement modules that were divided into two branches. One branch predicts the confidence map of keypoints and generates a heat map (point confidence map (PCM)) whereas the other predicts the part affinity fields between each keypoint to produce a vector map (part affinity fields (PAF)). Loss calculations and optimization were conducted for both PCM and PAF at each stage, as shown in Equations (1) and (2). Post-processing of the PCM and PAF outputs results in a skeletal keypoint group
for all human bodies in the input image, as outlined in Equation (3).
The symbols
and
represent the confidence maps of the keypoints for the first and t stages, respectively. Similarly,
and
denote the vector fields for the first and
tth stages, respectively.
represents the prediction network for point confidence maps (PCM) and
represents the prediction network for part affinity fields (PAF).
In Equation (3), represents the skeletal keypoint group of the ith individual in the current image. In Equation (4), represents the minimum outer bounding rectangle of all keypoints, that is, the target box, and is the confidence level of the current keypoint group. In Equation (5), represents the coordinates of the upper-left corner of the human target box, and represent the width and height of the target box, respectively. In Equation (6), and represent the horizontal and vertical coordinates of the skeletal keypoints, respectively, and j represents the ID pair of skeletal keypoints.
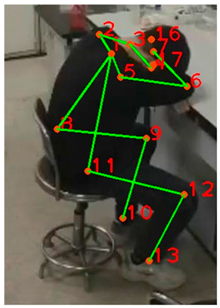
The information of 18 skeletal keypoints extracted by the Lightweight OpenPose algorithm is depicted in
Figure 5.
2.2.2. YOLOv5 Object Detection Algorithm
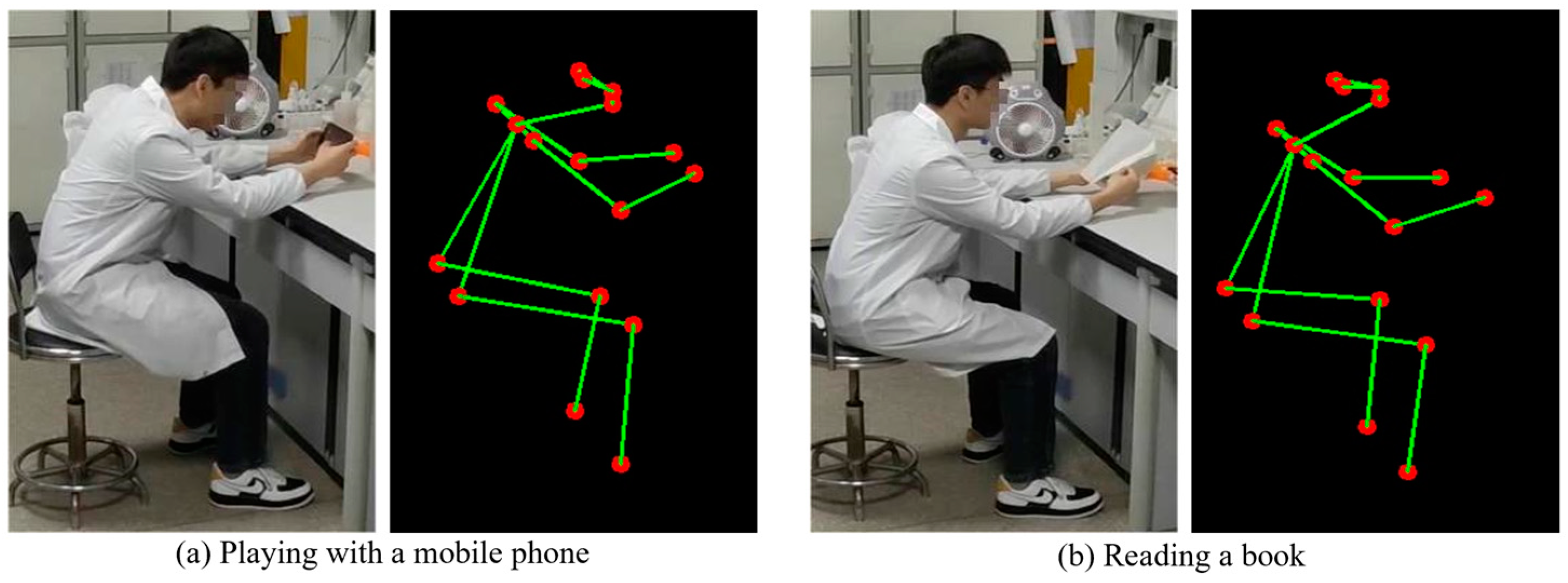
For behaviors with high similarity, relying solely on the position features of skeletal keypoints can make it difficult to distinguish between them, as shown in
Figure 6, where the left side depicts the “Reading a book” behavior and the right side depicts the “Playing with a mobile phone” behavior. Therefore, this study adopted the YOLOv5 algorithm as an item detector to detect the positions of relevant items, thereby improving the recognition accuracy for highly similar behaviors.
The YOLOv5 algorithm is a one-stage object detection algorithm [
38] which treats the object detection task as a regression problem. It can accurately and rapidly locate objects in images for classification and return their positions to the images. YOLOv5 is suitable for a wide range of scenarios [
39,
40,
41].
The network architecture of YOLOv5, as depicted in
Figure 7, accepts images with a resolution of 640 × 640 pixels as the input. After feature extraction using the backbone, the features were passed through the neck layer. In the neck layer, features of different scales were fused, resulting in the generation of three feature maps of sizes 20 × 20, 40 × 40, and 80 × 80. Subsequently, after Non-Maximum Suppression (NMS) processing, the algorithm outputs the category
and confidence
of the target objects, as well as the bounding box positions
where
and
represent the horizontal and vertical coordinates of the upper-left corner of the bounding box, respectively, and
and
represent the horizontal and vertical coordinates of the lower-right corner of the bounding box, respectively.
2.2.3. SKPT-LSTM Behavior Recognizer
Human behavior can be regarded as a time-series classification problem determined by changes in a series of human poses over a certain period of time. Recurrent neural networks (RNNs) [
42] are designed to handle data with temporal properties. They possess a “memory” characteristic, allowing them to utilize previous input information to influence the current output. However, traditional RNNs suffer from vanishing or exploding gradient problems, which lead to training failure.
Long Short-Term Memory (LSTM) networks [
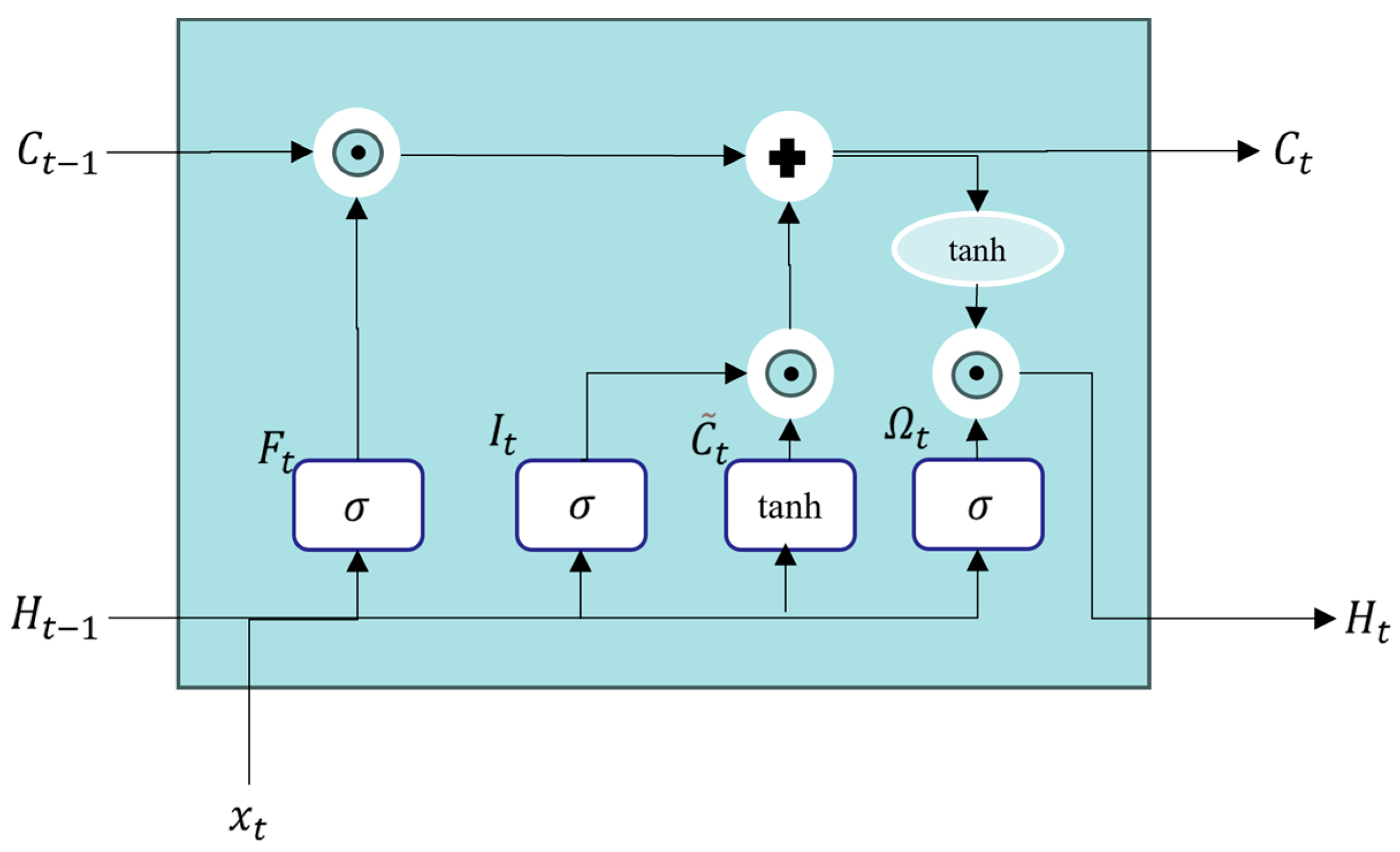
43] are a variant of RNNs that address this issue by introducing gate units to control the importance of sequence information, enabling the network to effectively learn long-term dependencies and successfully accomplish tasks. The structure of the LSTM unit is shown in
Figure 8.
In
Figure 8,
represents the forget gate,
represents the input gate,
represents the candidate memory, and
represents the output gate.
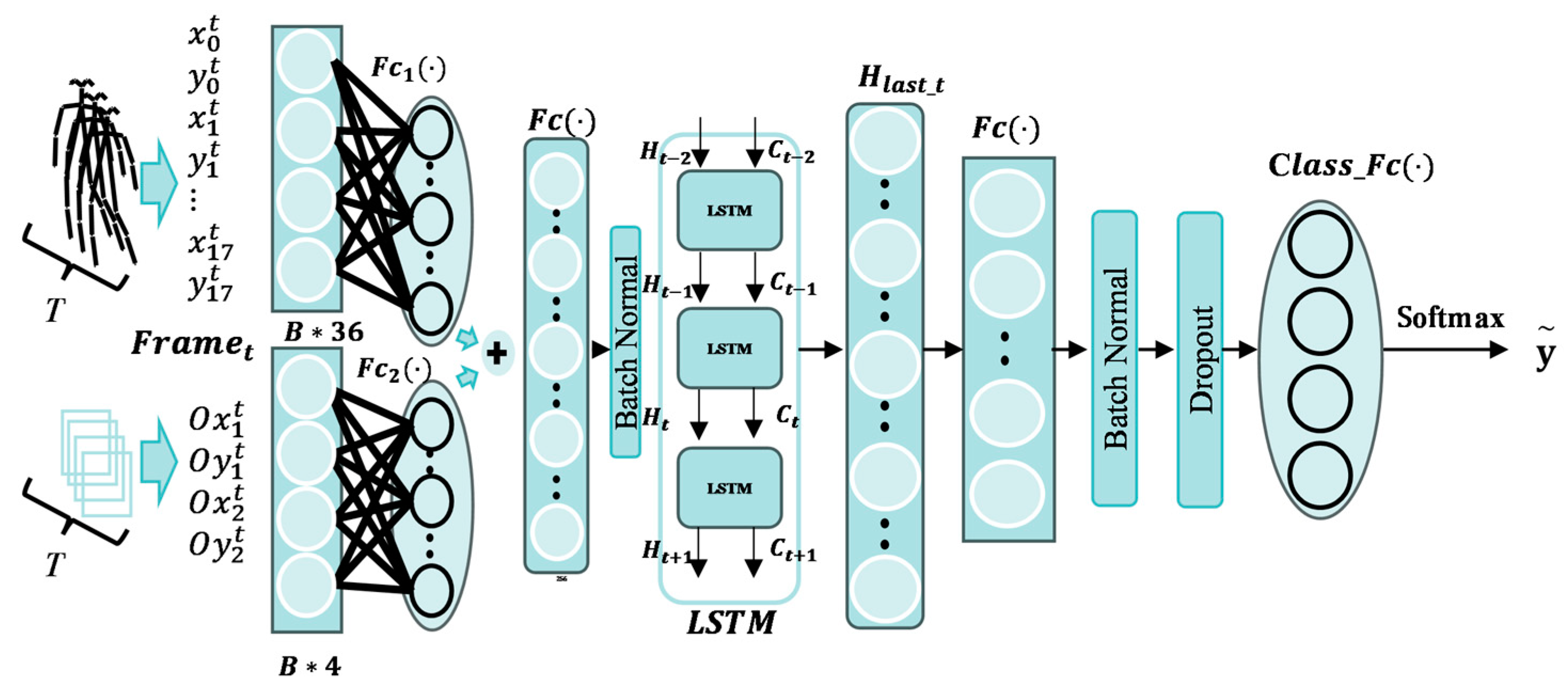
To accomplish the behavior recognition task in this study, we improved the LSTM network by integrating the sequences of skeletal keypoint coordinates and object position coordinates of the target over a certain time range to identify its behavior. This improved network is referred to as the Sequence Key Point Tracking LSTM (SKPT-LSTM) network. The structure of this network is illustrated in
Figure 9.
In
Figure 9, the SKPT-LSTM network structure diagram,
represents the total number of time steps in a sample,
represents the input data from the
tth time step;
represent the horizontal and vertical coordinates of the skeletal keypoints representing “nose” at time step t;
represent the positions of the object detected by the object detector at time step t;
is a fully connected layer capable of extracting features from skeletal keypoint coordinates;
is a fully connected layer capable of extracting features from object position coordinates;
is the feature fusion layer. As shown in Equations (7)–(10).
The SKPT-LSTM network divides the data into two streams before inputting them into the LSTM network: a stream of human-body keypoint coordinates and a stream of item location coordinates. After extracting the features through two fully connected layers (512 neurons per layer), the features of the two streams were summed, fused, and batch-normalized before being inputted into the LSTM network (containing two LSTM units, each with a hidden layer containing 512 neurons). In the last time step of the SKPT-LSTM network, the final hidden layer states of the LSTM network were passed through two fully connected layers containing 256 neurons to extract the features. Finally, a Class_FC layer was processed using a softmax activation function to output the class probabilities of the behaviors. The ReLU activation function was used for all the fully connected layers, except for the last Class_FC layer. The output of the SKPT-LSTM network is the probability that a series of poses from the current input belong to a certain behavior.
The input of the SKPT-LSTM network is represented by (11):
In Equation (11),
represent the normalized and standardized coordinates of the skeletal keypoints
at time step
and the detected bounding box positions of the relevant objects, including the upper-left and lower-right corners, respectively.
represents the total number of time steps in a sample. The normalization and standardization equations are represented by Equations (12)–(14), respectively.
In the above equation,
represent the original unprocessed initial horizontal and vertical coordinate points, respectively, and
denote the width and height of the current video frame, respectively.
In Equation (14), the represents the normalized coordinate value, where denote the mean and standard deviation of the normalized samples, respectively.
The loss function chosen for training the SKPT-LSTM network was the multiclass cross-entropy loss function, as represented by Equation (15).
In the above equation, represents the probability of each behavior category output by the SKPT-LSTM network, represents the true category to which the training sample belongs; is the number of categories for the sample, and represents the current sample.
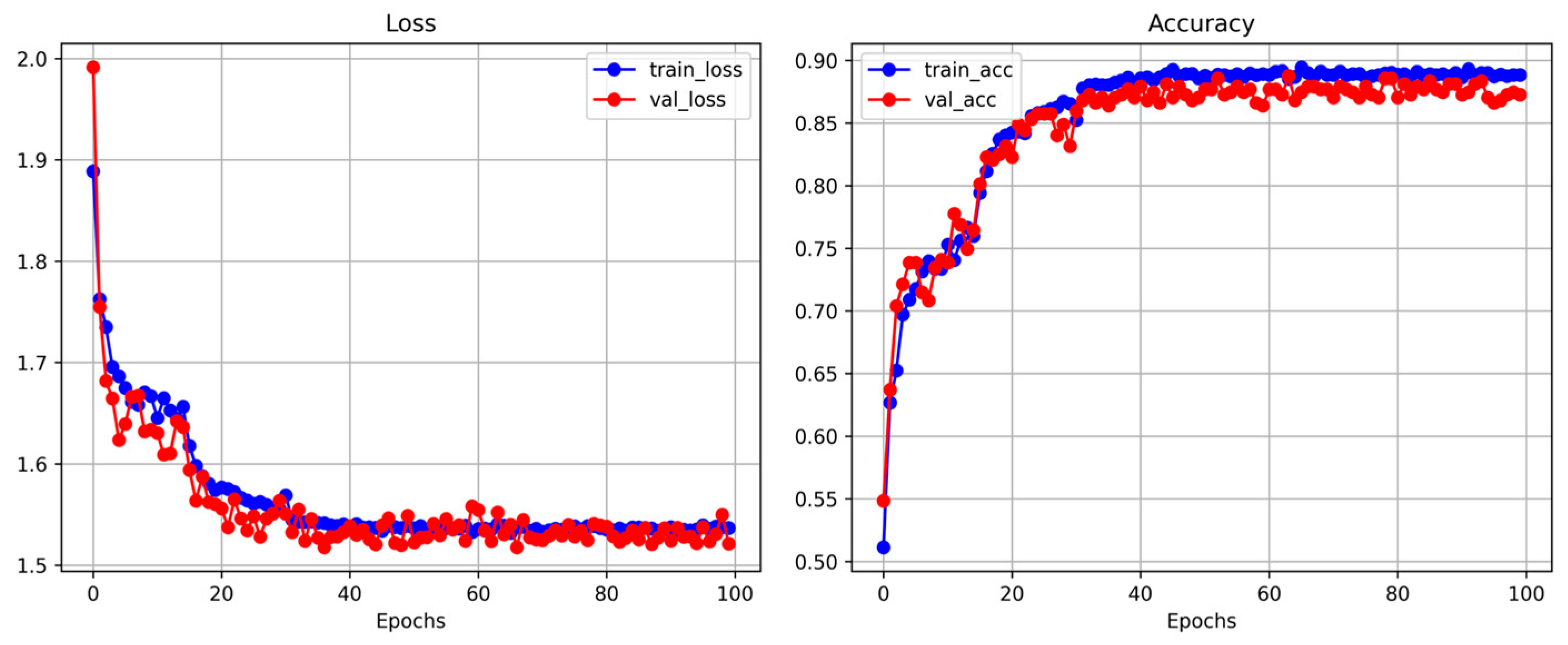
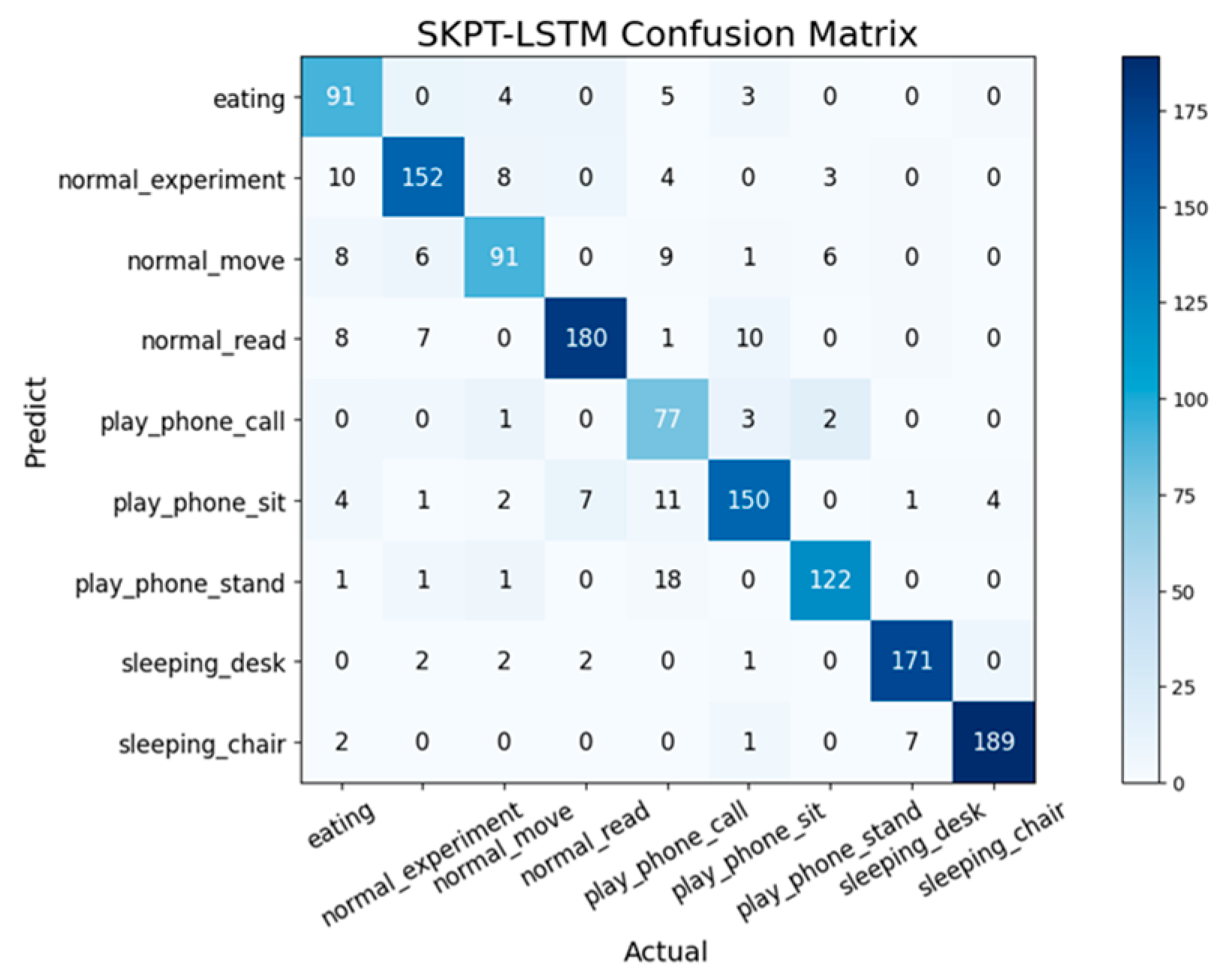
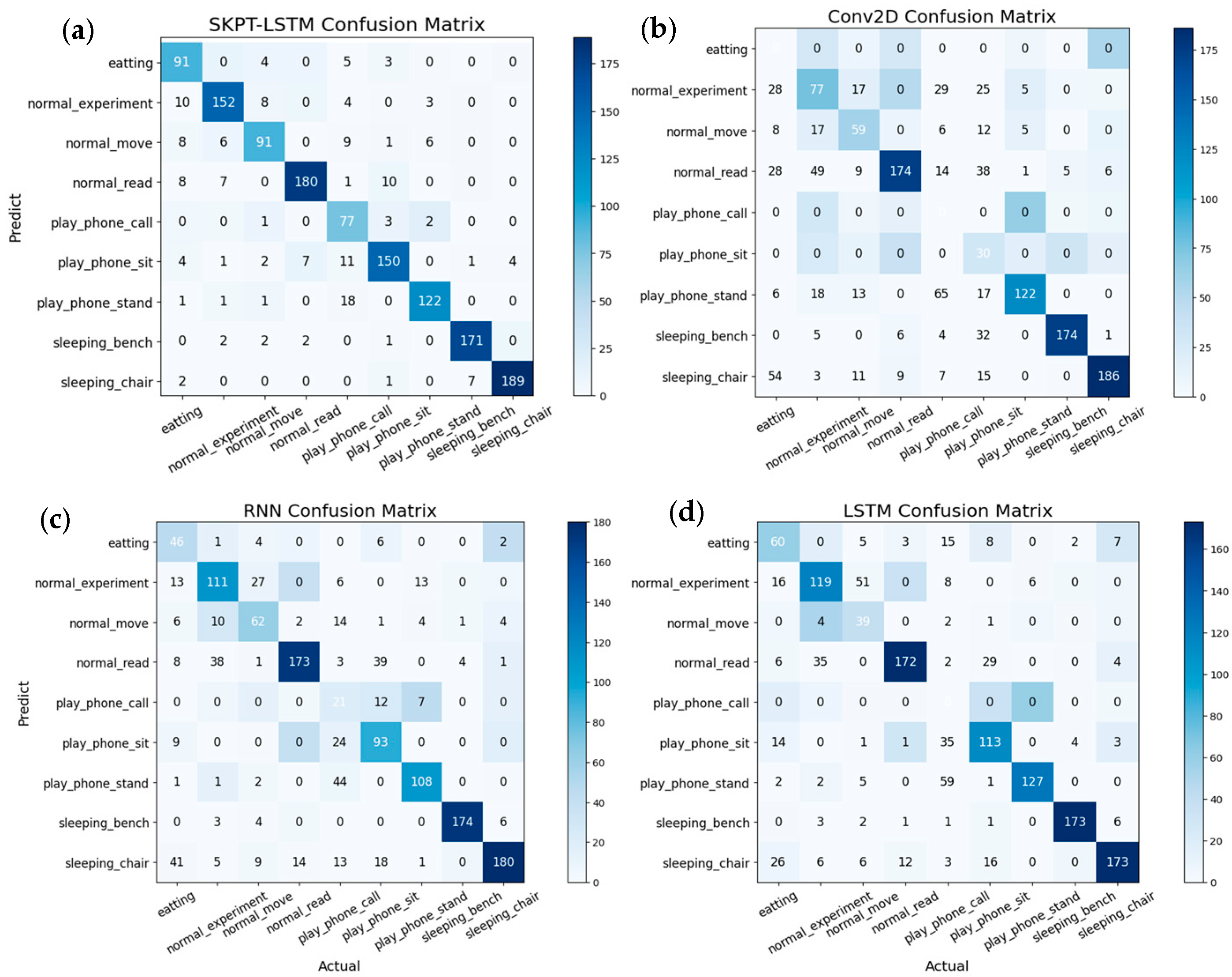
The performance of the SKPT-LSTM network was evaluated using the accuracy, precision, recall, and F1 score metrics. Accuracy was calculated as the ratio of the number of correctly detected samples to the total number of samples detected by the model. Precision represents the ratio of correctly predicted positive samples to all samples predicted as positive by the model. Recall, also known as sensitivity, is the ratio of the correctly predicted positive samples to the total number of positive samples. The F1 score, which balances precision and recall, was computed as the harmonic mean of the precision and recall. The formulas for these evaluation metrics are derived from
Table 3 and are shown in Equations (16)–(19).
In
Table 3, TP represents the number of positive samples correctly classified by the model, FP represents the number of positive samples incorrectly classified by the model, FN represents the number of negative samples incorrectly classified by the model, and TN represents the number of negative samples correctly classified.
2.2.4. Improved DeepSORT Algorithm
The DeepSORT algorithm [
44] is a simple, high-precision, and fast multi-target tracking algorithm. It first utilizes a detector to obtain the detection information of targets in the previous moment and then uses Kalman filtering to predict the position information of the targets in the next moment. Next, by combining the appearance features, motion information, and target information detected by the detector at the next moment, the similarity between the targets at the two moments was calculated, and the Hungarian algorithm was used for matching. Finally, it completes the trajectory update, thereby achieving the target-tracking task. Owing to its excellent performance, the DeepSORT algorithm is widely used for various tracking tasks [
45,
46,
47,
48].
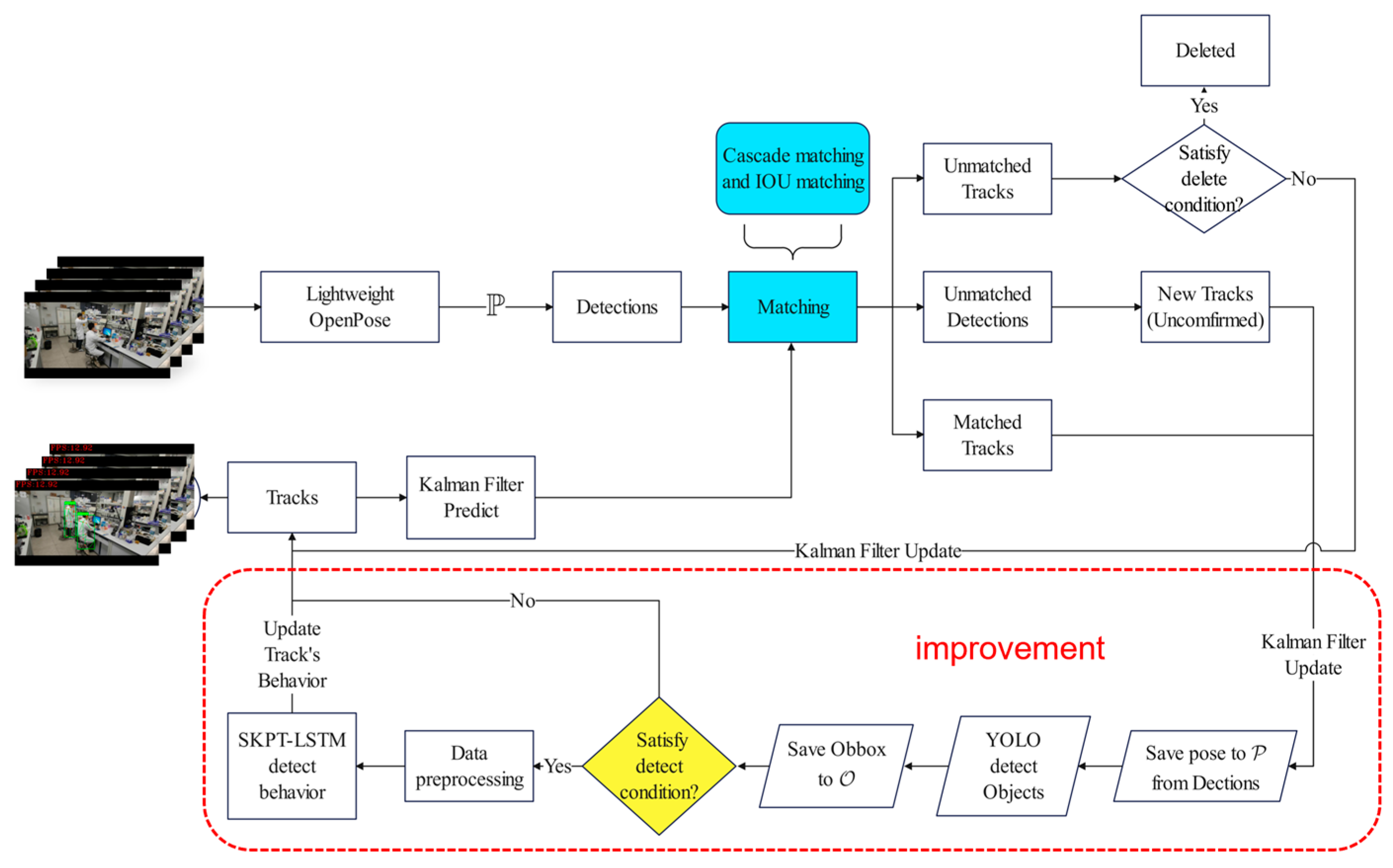
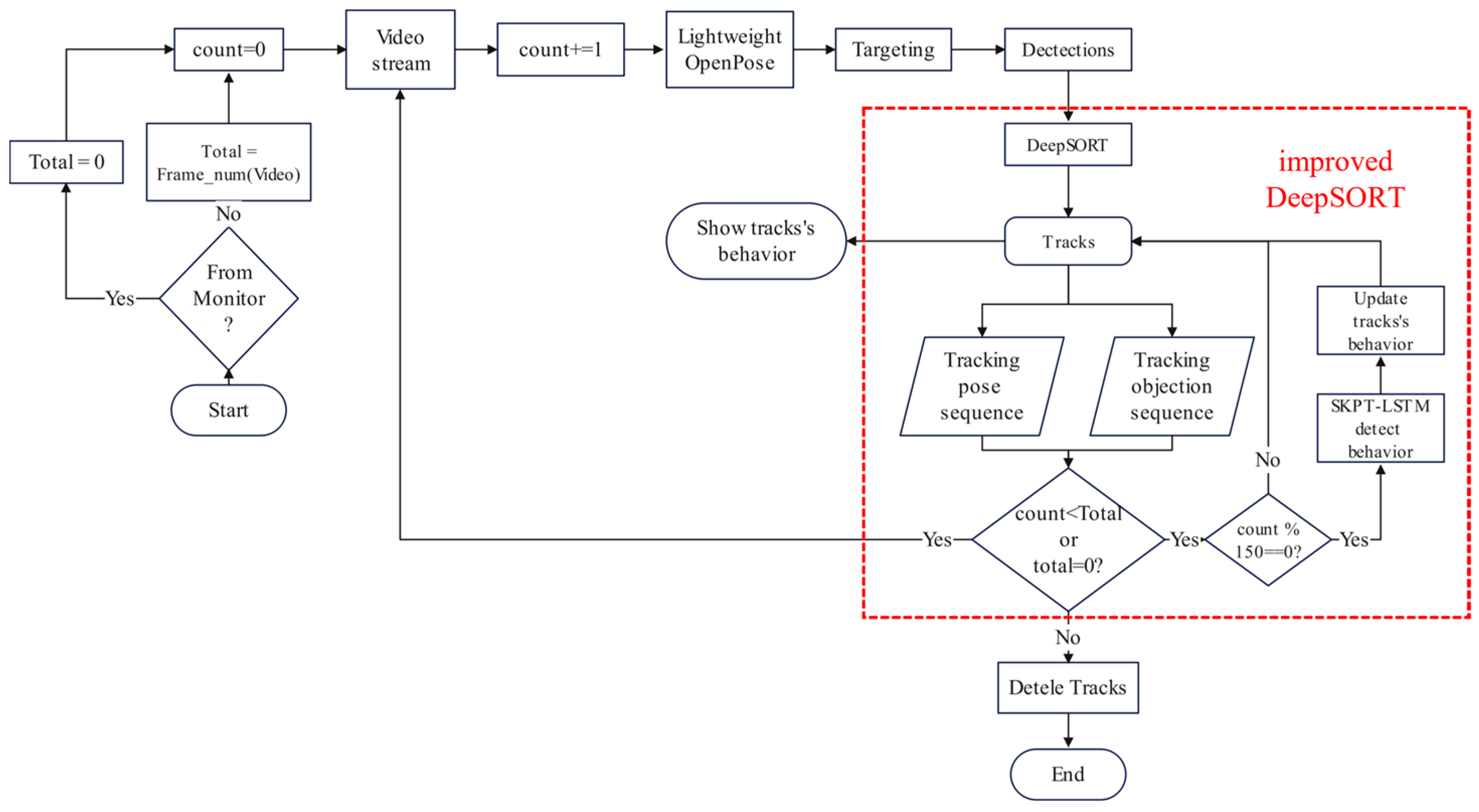
In the task of human behavior recognition, the DeepSORT algorithm can track the position of each human target in consecutive video streams frame-by-frame, forming trajectories and assigning each target a unique “ID” to distinguish different targets. However, it cannot recognize the behavior of targets at the current moment. In this study, we improved the DeepSORT algorithm for laboratory personnel behavior recognition. The improved DeepSORT algorithm is shown in
Figure 10.
Step 1: Input the video stream frame by frame into the Lightweight OpenPose human posture estimator to obtain all the human skeletal keypoints group in the current video frame as in Equation (3) and generate an external rectangular box (Equation (5)) with all the skeletal keypoints to select the human body. The body frame position information and human skeletal keypoint information are input into the DeepSORT algorithm as detection information (Equation (20)) to generate a new Track (Equation (21)).
Step 2: Kalman filtering predicts the position of the target trajectory at the next moment after transforming the target frame information obtained from the detector (Equation (5)) into the target frame center coordinates, aspect ratio, height, and motion information. This matches the detector’s detection information at the next moment. For a target that fails to match, the decision is made according to the corresponding rules, that is, whether to delete it or match it again in the next frame.
Step 3: For successfully matched target trajectories, the position is updated, and the information of human skeleton points from the matched detection data are stored sequentially in P (Equation (22)). The area where the target was located was then extended outwards by a certain number of pixels (ensuring that all parts of the target were included), cropped, and detected using the YOLO object detector (Equation (24)). The detected relevant object position information is synchronized and stored in (Equation (23)), and the process then moves to the next frame of target tracking.
Step 4: When a target is successfully tracked for a certain period (i.e., when the information saved in the target trajectory reaches a certain quantity), the tracked sequential skeleton keypoint and object position information are processed. They were fed into the SKPT-LSTM network to recognize the target behavior and simultaneously update the behavioral state
of the target (Equation (25)).
In Equation (20), represents the ith detected target, and denotes the appearance feature vector used during cascade matching.
In Equation (21), and represent the mean and variance of the trajectory used by the Kalman Filter (KF) for prediction and update, respectively. denote the target’s identifier (used to distinguish it from other targets), state of the trajectory, and appearance feature vector of the currently tracked target, respectively.
In Equation (22), stores the poses from time 0 to t, and is updated using the pose from the latest detection at time t.
Equation (23), represents the collection of the positions of relevant items detected by the YOLO object detector within the range of human targets from time 0 to t. The calculation formula is shown in (23).
In Equation (24), the function converts the mean and variance of the target trajectory at time t into a bounding box. The function crops the area near the target with a margin specifying the extent to which the cropping area extends outwards. The function was used to detect the positions of the relevant items using the YOLO algorithm. If no detection was detected, . If multiple identical relevant items were found within the range, .
The track successfully matched the detection information and underwent simultaneous updates of P and during the Kalman filter-update process.
In Equation (25), represents the behavior of the human target. When the target was successfully tracked for a certain period, its behavior was identified using the SKPT-LSTM behavior recognizer.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}