1. Introduction
Currently, oil and gas exploration and development are increasingly expanding into complex areas such as deep, ultra-deep, unconventional, low-permeability, mature fields, and deepwater offshore environments. In particular, ultra-deep drilling poses significant challenges due to numerous unknown factors, high-temperature and high-pressure formations, hard and abrasive rock, among other difficulties [
1]. These factors increase the risks and complexities associated with well construction, leading to a higher likelihood of incidents such as kick or blowouts. Improper handling of kick incidents may escalate to complex situations like blowouts, resulting in well abandonment, threats to the safety of personnel, and substantial economic losses. At present, kick diagnosis methods can be broadly categorized into conventional and intelligent diagnostic methods. Traditional kick diagnostic approaches face challenges in terms of timeliness and accuracy, while intelligent diagnostic methods, despite their promising prospects, still face limitations in generalization capability and have limited practical applications in the field. This situation highlights the urgent need for in-depth research on intelligent diagnostic methods for kick detection in drilling operations.
Orban et al. [
2] proposed a small error flowmeter, which not only offers high measurement accuracy but is also applicable for measuring the flow rate of both water-based and oil-based muds. Schafer et al. [
3] introduced a development-type rolling float flowmeter designed to accurately measure the outflow of pipeline fluids, demonstrating excellent measurement performance. Peter Ablard et al. [
4] utilized a Coriolis flowmeter capable of operating at low to medium pressure, eliminating the impact of temperature and accurately measuring the mass flow rate, temperature changes, and density of oil, gas, and water in the pipeline. Helio Mauricio Santos et al. [
5] developed a microflow kick monitoring technology that employs sonar detectors, achieving significant results in kick monitoring. Deng Yong et al. [
6] employed sonar detectors to monitor liquid level changes in the wellhead conductor and separator, achieving flow monitoring during both well-opening and well-shutdown periods for early warning of kicks.
Hargreaves et al. [
7] monitored deepwater drilling kicks using a Bayesian probability method. By analyzing acoustic data, they employed a Bayesian model to calculate the probability of a kick occurring, thereby determining the likelihood of a kick event. Additionally, Yue et al. [
8] developed a novel early warning system for kicks by combining hierarchical Bayesian methods with expert systems. Gurina et al. [
9] constructed a classification model based on gradient-boosted decision trees, using Measurement While Drilling (MWD) data to predict drilling kick risks. However, although this algorithm can identify about half of the anomalies, it generates approximately 53% false alarms on average each day. Lian [
10] proposed a fusion algorithm using rough set support vector machines to monitor drilling incidents. Nhat et al. [
11] proposed a data-driven Bayesian network model for early kick detection using data obtained from laboratory experiments, leveraging downhole parameters. Kamyab et al. [
12] employed a focused time-delay dynamic neural network for real-time monitoring of early kicks, calculating dynamic drilling parameters in real time through a neural network to monitor kick conditions. Lind et al. [
13] utilized k-means clustering and radial basis function neural network models to predict drilling risks for oil and gas wells. Zhang et al. [
14] summarized the characterization parameters and patterns of kicks, establishing an intelligent early warning model based on BP neural networks, which demonstrated high accuracy and timeliness in its warning results. Duan et al. [
15] proposed the identification of kick risk based on the identification of drilling conditions. Zhu et al. [
16] conducted kick risk monitoring using an unsupervised time-series intelligent model, achieving an accuracy of 95%. Single time-series intelligent models, such as LSTM and GRU, are capable of capturing nonlinear features and long-term dependencies in time-series data, but they also have significant drawbacks. Firstly, they are prone to overfitting, especially when the data are limited or noisy, which results in poor generalization ability. Secondly, these models are susceptible to local minima, leading to unstable training and difficulty in capturing complex patterns in the data. Additionally, single models have limited robustness, with poor adaptability to outliers and data fluctuations, and their prediction results can be significantly affected by the quality of the data. While single time-series intelligent models can capture nonlinear features and long-term dependencies, they also have clear limitations. Ensemble time-series models, by combining multiple different models, can address these shortcomings of single time-series models.
In the early stages of kick events, the comprehensive logging data often exhibit complex inter-related changes and nonlinear fluctuations in time series. These features not only reflect the interactions of multiple factors but also demonstrate the intricate relationships between time and space. However, current intelligent diagnostic methods generally utilize non-temporal single-point data as training sets for modeling, which fail to adequately capture the dynamic temporal attributes of kick events. The lack of effective utilization of time-series information results in difficulties in deeply analyzing the intrinsic connections of multidimensional data across spatial and temporal dimensions. Consequently, the models become overly sensitive to the original structure of the data and fail to effectively leverage spatiotemporal information, thereby limiting improvements in the accuracy of kick risk diagnosis. To address this issue, time-series models based on ensemble learning can significantly enhance model accuracy by integrating multiple algorithms and models to comprehensively consider the trends and dynamic features of time-series data. This approach enables the extraction of latent information from time-series data, identifying key features at different time points and spatial locations, which aids in a more comprehensive understanding of the mechanisms behind kick events. Furthermore, the introduction of the Synthetic Minority Over-sampling Technique and Tomek Links (SMOTE-Tomek) data balancing technique can effectively address the imbalance problem within the dataset, enhancing the model’s ability to identify minority class samples (kick events). SMOTE-Tomek improves the model’s generalization capability by increasing the number of minority class samples and reducing noise samples, making it more reliable in practical applications. Therefore, employing a time-series model based on ensemble learning, combined with the SMOTE-Tomek technique, will help improve the accuracy and reliability of kick risk diagnosis.
2. Methodology
2.1. SMOTE-Tomek Algorithm
SMOTE-Tomek is a data balancing method that combines SMOTE and Tomek Links, specifically designed to address the issue of imbalanced classification. First, SMOTE increases the number of minority class samples by generating new synthetic samples between existing minority class instances, thus enhancing the proportion of the minority class in the dataset and preventing the model from being biased towards the majority class during training [
17]. Next, Tomek Links identifies and removes pairs of samples that are close to the boundary between different classes, particularly those that can lead to classification confusion [
18]. By deleting the majority class samples in these pairs, Tomek Links reduces the presence of hard-to-distinguish samples in the dataset, thereby optimizing the classification boundaries.
For the kick sample data, which presents a highly imbalanced classification problem, the application of SMOTE-Tomek can effectively increase the number of kick class (minority class) samples while cleaning up noise and boundary samples in the data.
2.2. The Long Short-Term Memory (LSTM)
The Long Short-Term Memory (LSTM) network is a specialized branch of recurrent neural networks (RNNs) designed to overcome the vanishing gradient problem encountered by traditional RNNs when handling long-distance sequence dependencies [
19]. By incorporating a gating mechanism, LSTM effectively retains and transmits critical information, demonstrating exceptional ability in learning long-term temporal dependencies. The structure of an LSTM unit consists of three main gates: the forget gate, which decides what information should be discarded from the cell state; the input gate, which determines what new information should be added to the cell state; and the output gate, which decides what information should be output from the current cell state. This gating mechanism allows LSTM to selectively retain or ignore information, ensuring that relevant data are kept while irrelevant information is discarded, thereby supporting precise learning and prediction in scenarios with long-term dependencies. Due to this unique advantage, LSTM is widely applied in various contexts requiring an in-depth analysis of temporal relationships in input data, such as time-series anomaly detection. The LSTM network structure is shown in
Figure 1.
2.3. The Gated Recurrent Unit (GRU)
The Gated Recurrent Unit (GRU) is another variant of the recurrent neural network (RNN), designed to address the issues of long-term dependencies and vanishing gradients in traditional RNNs [
20]. Compared to the RNN, GRU introduces the concepts of an update gate and a reset gate to control the flow and retention of information. The reset gate determines whether to ignore the information from the previous hidden state at the current time step, while the update gate decides how to combine the input at the current time step with the previous hidden state to generate a new hidden state. This gating mechanism allows GRU to more effectively remember and update information when processing long sequences, making it well-suited for various sequence modeling tasks. The GRU network structure is shown in
Figure 2.
In comparison, GRU simplifies the design of LSTM by merging the forget gate and input gate into a single update gate and removing the cell state, retaining only the hidden state. This simplification not only reduces the number of parameters in the model, improving computational efficiency, but also maintains performance levels comparable to LSTM in many cases. Particularly in tasks with relatively small datasets or those requiring fast model training, GRU’s simplified architecture is easier to optimize. Given the challenges of collecting kick data and the limited availability of effective samples, GRU’s simpler structure is more suited to the needs of kick detection. Additionally, real-time kick diagnosis requires the model to operate quickly to meet real-time standards, making GRU’s advantages in speed especially significant.
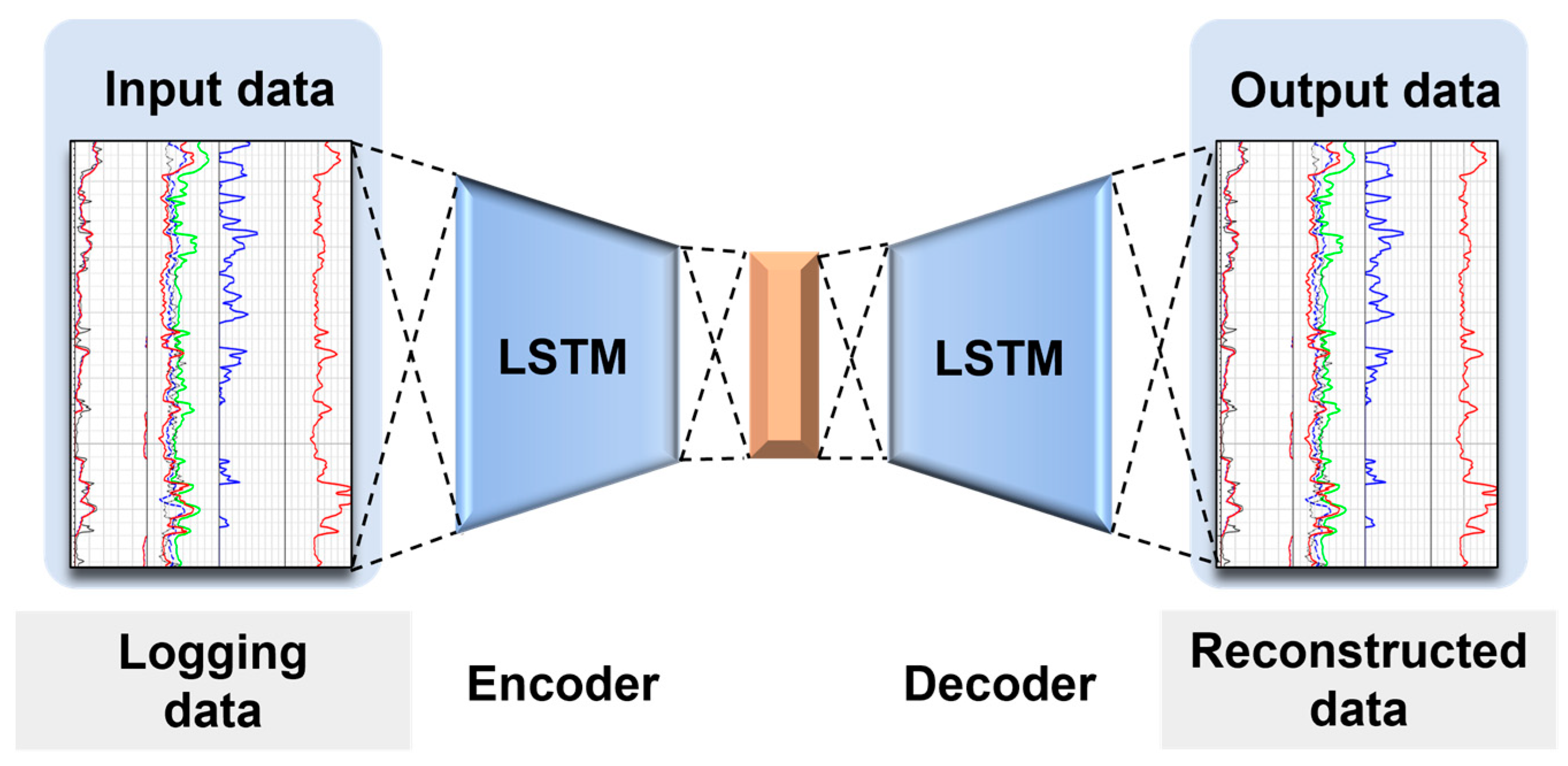
2.4. Temporal Autoencoder
The temporal autoencoder is a neural network model designed to handle data with temporal structures. Similarly to traditional autoencoders, a temporal autoencoder consists of two parts—an encoder and a decoder—with the main objective of learning a compact representation of the data and being able to reconstruct the input. However, unlike ordinary autoencoders, temporal autoencoders take time dimension information into account when processing temporal data. Specifically, the encoder and decoder not only learn the spatial features of the data but also capture the temporal evolution patterns [
21].
In a temporal autoencoder, the encoder first maps the input sequence to a lower-dimensional representation, commonly referred to as the encoding or hidden state. This hidden state contains the key information of the input sequence, including its temporal evolution. The decoder then decodes this hidden state into an output sequence of the same dimensionality as the original input sequence to reconstruct the original data. During training, the temporal autoencoder learns to minimize the reconstruction error, enabling the encoder to capture important features in the data while preserving the structure of the time series. The temporal autoencoder structure is shown in
Figure 3.
Temporal autoencoders have been widely applied in the modeling and analysis of time-series data, especially showing significant advantages in handling anomaly detection tasks. Given the scarcity of kick data samples and the abundance of normal, non-kick data, temporal autoencoders can effectively identify anomalous behaviors by learning the intrinsic representation of normal data and detecting patterns that deviate from the normal mode, thereby facilitating kick detection. This mechanism is particularly useful in imbalanced data scenarios, where it can still accurately identify abnormal patterns, providing a reliable technical means for the timely detection and prevention of kicks.
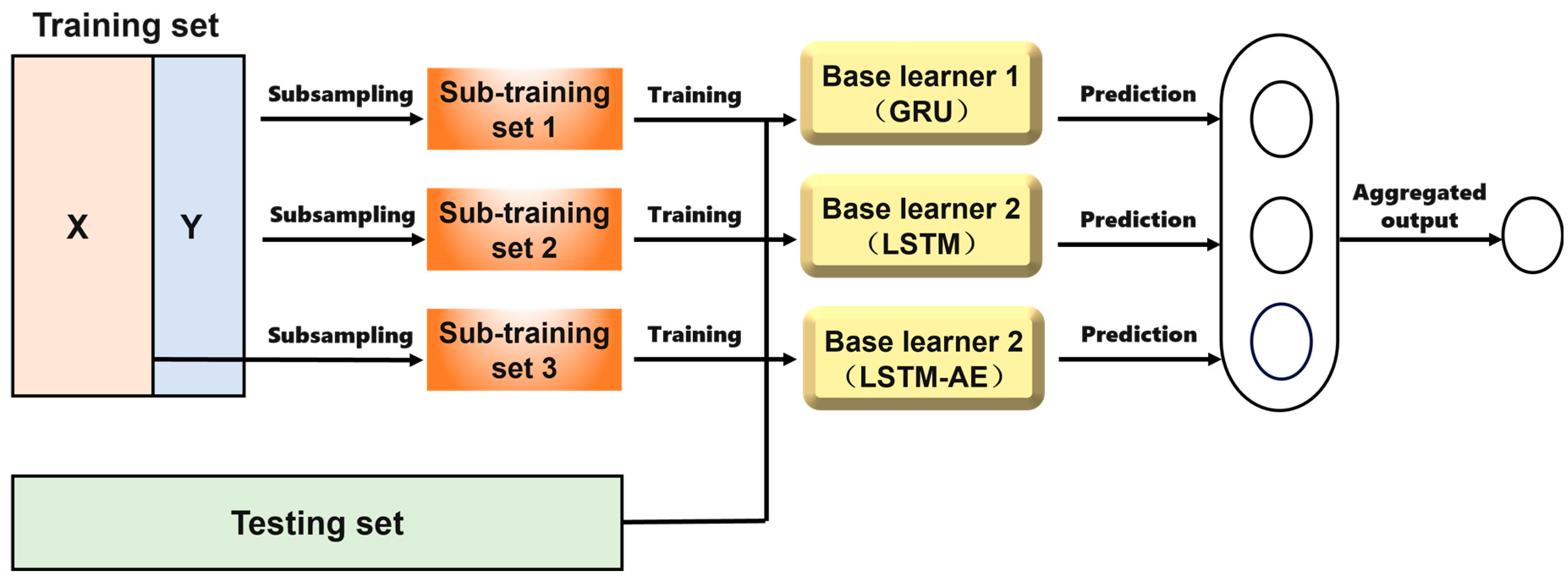
2.5. Ensemble Learning
Ensemble learning improves classification performance by building and combining multiple models. The core idea of this approach is to combine several weak learners to form a strong learner, thereby enhancing the model’s generalization ability. Ensemble learning primarily reduces variance by training multiple models in parallel and averaging their classification results or using majority voting, or it reduces bias by sequentially training multiple models, with each model attempting to correct the errors of the previous one. Ensemble learning has demonstrated superior performance in many practical applications. Bagging, Random Forest, Stacking, and Boosting are common types of ensemble learning methods. The ensemble learning structure is shown in
Figure 4.
Bagging (Bootstrap Aggregating) involves repeatedly sampling the original dataset with replacements to create multiple training sets, which are then used to train several models [
22]. The classification results of these models are aggregated through voting or averaging to form a final decision. This method helps reduce the variance of the model, improving its stability and accuracy, and is particularly suitable for addressing overfitting issues. Random Forest, an extension of Bagging, constructs a strong classifier by training multiple decision trees using random samples and random feature subsets. By introducing randomness in both data sampling and feature selection, Random Forest effectively reduces the variance seen in a single decision tree, resulting in a more stable model. This approach ensures that the combined model performs well across different datasets by mitigating overfitting.
Stacking is a method that integrates the classification abilities of various base models [
23]. Its core strategy involves using a new model, called a meta-learner, to optimally combine the classification results of these base models. In this approach, each base model is first trained on the original dataset to produce classification results, which are then treated as a new dataset for training the meta-learner. By doing so, the Stacking method aims to capture complementary information among different models, significantly enhancing classification accuracy.
Boosting is a technique designed to reduce bias by sequentially training models, where each model aims to correct the errors of its predecessor. This iterative approach ensures that each subsequent model becomes progressively better at classifying hard-to-predict samples, effectively minimizing bias over time. Popular Boosting algorithms, such as AdaBoost and Gradient Boosting, increase the weights of misclassified samples in each iteration, making the final ensemble highly accurate. This step-by-step correction enhances the model’s overall performance, especially for complex datasets.
Ensemble learning significantly enhances model accuracy by merging the classification results of multiple models, allowing it to identify patterns that a single model may overlook when dealing with complex problems. Compared to the overfitting issues common in single models, ensemble methods reduce the risk of overfitting and improve generalization ability by introducing randomness and regularization. Additionally, combining multiple models effectively lowers prediction variance and increases the stability of classification results. Therefore, to improve the accuracy and reliability of kick diagnosis models, adopting an ensemble learning strategy is an effective approach.
5. Results and Discussion
5.1. Meta-Learner Selection Analysis Based on the Stacking Strategy
Considering the central role of the meta-learner in ensemble learning, this paper selected several different meta-learners for comparative testing, including Random Forest, support vector machine (SVM), logistic regression, K-Nearest Neighbors (KNNs), decision tree, and Gradient Boosting Algorithm. Hyperparameter optimization was performed for each meta-learner, and the final experimental results are shown in
Figure 9. Among all the candidate models, KNN demonstrated the best performance, and thus, it was selected as the meta-learner for the Stacking-based ensemble model.
The results indicate that KNN performs the best, with an accuracy of 0.90, an F1 score of 0.89, a precision of 0.91, and a recall of 0.90. Its low missing alarm rate (0.09) and false alarm rate (0.10), along with an AUC of 0.92, demonstrate its excellent performance and strong ability to distinguish between positive and negative cases in kick monitoring tasks. In comparison, logistic regression shows balanced performance, with an accuracy of 0.85, an F1 score of 0.85, missing alarm and false alarm rates of 0.16 and 0.14, and an AUC of 0.87, indicating good discrimination capabilities, though not as high as KNN’s. Other models, such as Random Forest (AUC 0.84), SVM (AUC 0.79), Decision Tree (AUC 0.74), and Gradient Boosting (AUC 0.78), perform relatively worse, especially in terms of missing alarm and false alarm rates, making them less suitable for kick monitoring. These lower AUC values highlight their weaker overall discrimination abilities compared to KNN, confirming KNN as the most reliable model for this application.
5.2. Comparison Between Ensemble Learning Models and Single Models
The results of different intelligent models are shown in
Figure 10. Ensemble models demonstrate a clear advantage in performance. The Stacking model outperforms all other models, with an accuracy of 0.90, an F1 score of 0.89, precision of 0.91, and recall of 0.90. Stacking enhances predictive accuracy and stability by combining multiple base models (LSTM, GRU, LSTM-AE) and leveraging their strengths. Its AUC of 0.92 further highlights its superior ability to discriminate between positive and negative cases, reinforcing its effectiveness for reliable kick monitoring. The Bagging model, with an accuracy of 0.86 and an F1 score of 0.86, while slightly less effective than Stacking, still offers significant benefits in reducing model variance, mitigating overfitting, and improving robustness. Its AUC of 0.84, although lower than Stacking, indicates strong classification capability and solid overall performance. The inclusion of AUC in the analysis confirms that while Bagging is robust, Stacking ensures more comprehensive model performance across varying thresholds.
Time-series models have a unique advantage in capturing the temporal dependencies in time-series data. LSTM and GRU perform similarly in processing time-series data for kick monitoring, with LSTM achieving an accuracy of 0.72 and GRU achieving 0.73. However, single time-series models have limited generalization ability when dealing with complex data, resulting in overall performance that is slightly inferior to ensemble models. Therefore, although they are advantageous for time-series analysis, they are less effective than ensemble models in more comprehensive application scenarios.
As an autoencoder model, LSTM-AE extracts features and reconstructs data by learning a latent representation of the input, making it well suited for handling unlabeled data. LSTM-AE outperforms LSTM and GRU slightly, with an accuracy of 0.75 and an F1 score of 0.71, indicating its strength in capturing inherent patterns and detecting anomalies in the data. Compared to supervised models, LSTM-AE is more practical when labeled data are scarce, serving as a feature extraction tool that can provide richer input information for supervised models. Overall, ensemble models (especially Stacking) perform the best in kick monitoring tasks, making them well suited for handling complex and dynamic real-world applications.
5.3. Dataset Balance Effectiveness Analysis
We compared the performance changes before and after applying the SMOTE-Tomek data balancing technique based on the Stacking model. The results are shown in
Figure 11.
Based on the results, after applying SMOTE-Tomek, the model’s accuracy increased from 0.90 to 0.93, indicating a significant improvement. This suggests that by introducing SMOTE-Tomek, the model can more effectively capture the true patterns and features in imbalanced data. In terms of precision, the precision rate of SMOTE-Tomek reached 0.92, slightly higher than the 0.91 observed without this technique, indicating an enhanced ability of the model to correctly identify positive samples. The recall rate improved from 0.90 to 0.91, demonstrating a further enhancement in the model’s ability to recognize minority class samples, which highlights the effectiveness of SMOTE-Tomek in reducing missed detections. Additionally, the missing alarm rate decreased from 0.09 to 0.07, while the false alarm rate also dropped from 0.10 to 0.08. This change indicates that SMOTE-Tomek not only improves the model’s ability to identify minority class samples but also effectively reduces the rates of false positives and missed alarms, enhancing the model’s practicality and reliability. Finally, the F1 score increased from 0.89 to 0.91, further demonstrating the effectiveness of SMOTE-Tomek in improving model performance by taking into account changes in both precision and recall. In summary, after applying the SMOTE-Tomek technique, the overall performance of the model showed significant improvement, particularly in terms of accuracy, precision, and F1 score, highlighting the effectiveness of this technique in kick monitoring tasks and its potential for practical application.
5.4. Case Study
Analysis using a kick case is shown in
Figure 12. During a kick event, the outlet flow rate and the total pit volume both show an increasing trend. The Bagging method had a diagnosis delay of 3 min and 6 s. Although Bagging reduces model variance and improves stability by combining multiple weak learners, it performs poorly in terms of timeliness when responding to kick risks. This may be due to Bagging’s inability to effectively capture early signals of kick events, resulting in a failure to issue timely alerts in practical applications. In contrast, the model using the Stacking method was able to diagnose kicks 1 min and 36 s in advance. This result demonstrates the efficiency and accuracy of the Stacking method in handling complex data. By leveraging the advantages of multiple base learners, the Stacking model comprehensively analyzes various logging parameters, providing timely warnings before kick risks arise and effectively enhancing diagnostic sensitivity.
After introducing the SMOTE-Tomek data balancing technique, the model’s diagnosis time was further advanced to 2 min and 30 s. This significant improvement indicates the effectiveness of SMOTE-Tomek in handling imbalanced data, allowing the model to better identify minority class samples (i.e., kick events), thereby enhancing overall predictive performance. By increasing the number of minority class samples and reducing noise samples, SMOTE-Tomek improves the model’s generalization ability, making it more reliable in practical applications.
6. Conclusions
This study comprehensively applied various time-series analysis algorithms to construct and optimize multiple kick diagnosis models, accurately fitting the relationship between integrated logging parameters and kick events. To enhance the predictive accuracy and stability of the models, a selection of high-performance models was chosen to construct an ensemble learning kick diagnosis model. The results indicate that single models have certain advantages in processing time-series data and can effectively capture the temporal dependencies of the input data, but their overall performance is relatively weak, with accuracy and recall not reaching ideal levels. By introducing ensemble models such as Stacking and Bagging, the accuracy and F1 score of the models were significantly improved, with the Stacking model achieving an accuracy of 0.90 and an F1 score of 0.89, demonstrating the effectiveness of ensemble methods in enhancing model robustness and generalization ability.
In further experiments, we applied the SMOTE-Tomek data balancing technique to address the issue of data imbalance. The results showed that after applying SMOTE-Tomek, the model’s accuracy increased to 0.93, with precision reaching 0.92 and recall improving from 0.90 to 0.91. These improvements indicate a significant enhancement in the model’s ability to correctly identify kick (minority class) samples. Additionally, the reduction in the missing alarm rate and false alarm rate (from 0.09 to 0.07 and from 0.10 to 0.08, respectively) further validates the effectiveness of this method in reducing false positives and missed detections.
Overall, this study significantly improved the predictive performance and stability of the kick monitoring model by combining time-series analysis with ensemble learning methods and utilizing the SMOTE-Tomek technique. This provides more reliable support for tackling complex kick monitoring tasks in practical applications and offers valuable insights for future research. Future studies could further explore combinations of different ensemble strategies and data processing techniques to optimize model performance in ever-changing environments.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}