Existing study reveals that RL and DRL offer significant benefits in addressing dynamic decision optimization problems and also provide novel ideas and approaches for addressing ISPEA problems in flexible job shops. Compared with common single-agent RL, MARL can achieve better solutions for complex decision-making and optimization problems by leveraging the different relationships between agents. For instance, multiple cooperative agents can collaborate to complete more complex tasks, while multiple competitive agents can learn each other’s strategies through gaming. Hence, the QMIX, a MARL algorithm that is suitable for handling cooperative relationships, is adopted in this study to address the dynamic ISPEA problem. Specifically, according to the aforementioned ISPEA problem description, four types of agents, namely workpiece selection, machine selection, AGV selection, and target selection agents,, are set up in the QMIX architecture, and the state space, action space, and rewards of each supporting agent, which transform the dynamic ISPEA problem into a Markov game, are illustrated in this section. Moreover, a dynamic event handling strategy is formulated, and the QMIX algorithm is also improved to enhance the performance of the collaborative optimization between agents.
4.1. Dynamic Event Handling Strategy
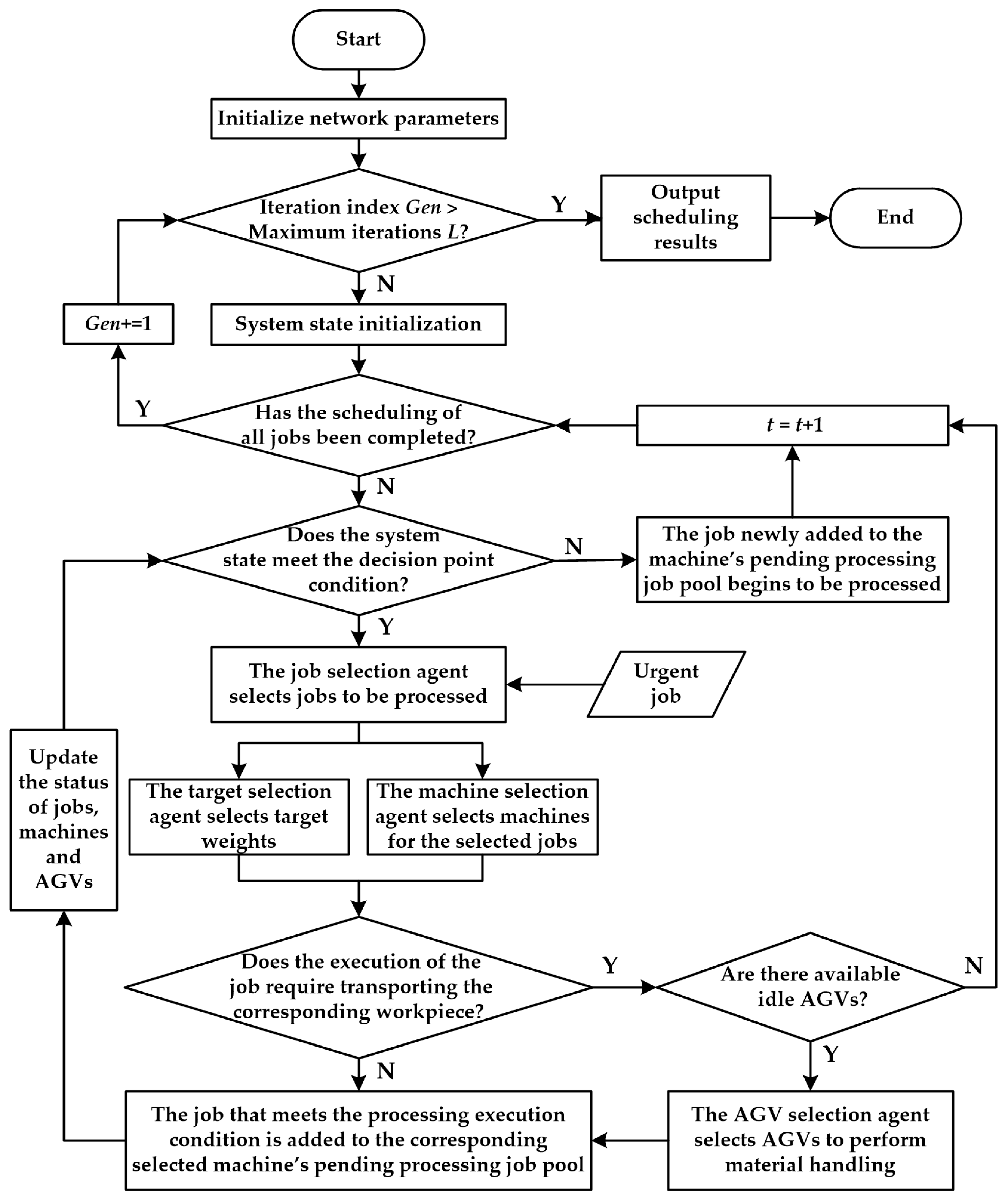
Urgent jobs usually require a manufacturing system to be able to respond quickly, so the event-driven strategy was adopted in this study to handle urgent job insertion events. The essence of scheduling problems is allocating limited resources to meet the job requirements within a reasonable time to achieve one or more objectives. Accordingly, emergency order insertions will bring about changes in the production status of the workshop, and these changes can be captured through the changes in the values of some of the feature variables utilized to monitor the operational status of manufacturing systems. Therefore, the strategy for handling urgent job insertions involves the following two parts:
When an urgent job is inserted at a random time, its process information will be recorded and the job will be added to the existing job pool following its insertion to wait for the assignment of scheduling objectives and machines.
- (2)
State Feature Evaluation
To monitor the workshop production status, some feature variables, e.g., average job completion rate and the average expected processing time of the remaining operations, are designed, which also serve as a foundation for designing the state space and action space for various types of agents. After an urgent job is inserted, it will be merged into the initial job set to form a new job set. Correspondingly, the values of state feature variables will be updated based on the updated job information. By monitoring the state feature variables, the agent can perceive the occurrence of dynamic events to some extent and can be trained to handle them effectively.
4.2. Transformation of the ISPEA Problem
To solve the ISPEA problem using a MADL approach, no matter whether it is static or dynamic, it needs to be defined as a Markov game in the form of (
N,
S,
A,
T,
γ,
R), where
N is the number of agents,
S represents the state space,
A represents the action space,
T is the state transfer function,
γ represents the discount factor for cumulative rewards, and
R denotes the reward received by various agents after executing actions in state
s and transitioning to state
s’. Moreover, the concept of a decision point is proposed in this study. A decision point can be interpreted as the opportunity presented when idle jobs and idle machines that are capable of executing idle jobs coexist. To illustrate the key components of the Markov game, some parameter and variable symbols are also defined, as shown in
Table 2.
- (1)
State space definition
The state space defines the set of all possible states that the agent can encounter in the environment and determines the information that is available to the agent for decision-making. In this study, the state representation designed to capture the information of the manufacturing system is mainly related to the current operational status of the manufacturing system, job conditions, and resource availability, as illustrated in
Table 3.
- (2)
Action space definition
The action space comprises the possible actions that the agent can take in a given state, which determine the agent’s ability to optimize the system performance and user experience. The action spaces of the four types of agents are different from each other, as displayed in
Table 4,
Table 5,
Table 6 and
Table 7, and the scheduling process is achieved through collaborative efforts among these agents. Note that the composite action rules in
Table 4 comprise simple action rules represented by abbreviations: EDD—earliest due date; FIFO—first in first out; LIFO—last in first out; LOR—least operation remaining; LSO—longest subsequent operation; LWKR—least work remaining; MOR—most operation remaining; MWKR—most work remaining; SSO—shortest subsequent operation.
In
Table 5, some machine selection rules are not simply based on the known parameter information but require relatively complex processing to obtain the decision-making support information. For example, for Mrule5 and Mrule6, it is necessary to traverse all available idle machines for the upcoming operation of the selected job and extract all idle intervals for the available idle machines from time zero based on the information from the already executed operations. Then, a suitable machine can be selected after obtaining the total idle time of each available idle machine. Additionally, for Mrule7 and Mrule8, it is necessary to first obtain the idle time increment of each available idle machine
k, which is the difference between the decision point time and the completion time of the last operation closest to the decision point time on machine
k (
). Then, the EC increment (
) is the sum of the processing EC for the upcoming operation and the idle EC increment, i.e.,
, and the suitable machine will be selected by
. Moreover, for Mrule13 and Mrule14, the total idle time of each available idle machine
k will be updated to the sum of the known total idle intervals (
) and the newly generated idle interval, and the total processing time of each available idle machine
k will be updated to the sum of the processing time of the already processed operations (
) and the processing time of the upcoming operation. Then, the total production EC of machine
k (
) will be updated, i.e.,
, and the available idle machine with the lowest/highest total production EC will be selected. In general, once a specific machine is chosen to execute the selected job, the values of decision variables
Xijk and
can be directly determined.
Similarly, for Arule3 and Arule4 in
Table 7, it is necessary to acquire all available idle AGVs at the decision point and obtain the corresponding location
of each available idle AGV
h. Then, the distances between each available idle AGV’s location and the transport job’s target machine can be compared, which are defined as the known parameter
in
Table 1, and the AGV with the minimum/maximum transport distance will be selected to execute the assigned transport job. Overall, the transport jobs needed in production are determined by the machine selected to execute each job. Once an AGV is assigned to execute a transport task at the decision point, the values of decision variables
Zijh and
can be directly acquired; then, the value of the decision variable
can be indirectly obtained.
- (3)
Reward function
The reward function plays a crucial role in guiding the agent’s learning process by providing feedback on the desirability of its actions, so its design should be closely related to the scheduling objectives. In this study, the reward function is defined as follows:
where
and
are the total standby EC of machines and AGVs, respectively, before the action selection is executed.
4.4. QMIX Architecture
QMIX is a value-based MARL algorithm integrating the ideas of Actor–Critic and DQN algorithms, which adopts centralized learning and distributed execution strategies to train multiple agents. The centralized critic network receives the global state to guide the update of the actor network. Meanwhile, the DQN idea is employed to establish estimation and target networks for the critic network, and the time difference error TDerror is calculated to update the critic network.
QMIX utilizes a network to decompose the joint Q-value into a sophisticated nonlinear combination of the Q-values obtained by each agent according to its local observations, and the global and individual strategies are consistent. The standard QMIX architecture, as shown in
Figure 2, consists of a mixing network, an agent network structure, and a set of hypernetworks. Each agent has its own network, which takes the current observation and the previous action
as inputs and outputs an individual value function
at each time step. The weights and biases of the mixing network are produced by the hypernetworks. The hypernetworks take the current system state
st as input and output a vector that is reshaped into an appropriately sized matrix to form the weights and biases of the mixing network. To guarantee the non-negativity of the mixing network weights, the hypernetwork is designed with a linear layer followed by an absolute value activation function. The intermediate layer biases are obtained through a linear layer, and the final biases are generated by a nonlinear two-layer hypernetwork using an ReLU activation function.
Note that the continuous empirical data generated by the agent–environment interaction in the RL process often show strong correlations, which can easily result in overfitting during training and affect the algorithm’s generalization ability. Additionally, the reward function incrementally shapes the agent’s strategy throughout the long-term learning process, affecting the balance between the agent’s interests and the group’s interests. To better achieve the collaborative optimization of various scheduling objectives and improve the algorithm optimization performance, the following three aspects of the classic QMIX are improved in this study:
- (1)
Multi-Objective Solving Strategy
The current research on applying RL to address workshop scheduling problems seldom touches on the EC objective, and the related work usually transforms the scheduling problem into an SOP by assigning a specific weight to the EC objective. However, this approach restricts the range of searching for optimal solutions in the solution space. Considering that the Pareto solutions of an MOP are usually not unique, the designed target selection agent is integrated into the QMIX architecture, which can adjust the weights of the two optimization objectives of the ISPEA problem within a round according to the different decision environments, thereby expanding the search scope and effectively achieving multi-objective optimization solutions.
- (2)
Reward Correction Strategy
RL relies on step-by-step immediate rewards that accumulate to generate the overall reward for a round. In unsupervised situations, if RL relies solely on reward signals, these signals are delayed, and it may take a long time to determine whether the current action is effective. Therefore, only relying on immediate rewards may result in a discrepancy between the actual scheduling results and the cumulative overall reward. Correspondingly, a reward correction strategy is formulated, which adds delayed rewards based on the objectives to correct the overall results at the end of a round.
The reward correction strategy integrates immediate rewards and delayed rewards to form a comprehensive reward function, ensuring the timely and correct utilization of reward signals. When designing the reward function, it is essential to strike a balance between immediate and delayed rewards to avoid overly pursuing short-term rewards while neglecting long-term benefits. Therefore, experiments are needed to adjust the weights of these rewards to find the most effective learning strategy.
Combining this with the dynamic event handling strategy, when an urgent job is inserted, a delayed reward needs to be offered based on the difference between the completion time and delivery time of the inserted job, and the reward function represented by Formula (20) will be updated as follows:
where
and
represent the theoretical minimum completion time and minimum total processing EC, respectively, and
TD is expressed as
- (3)
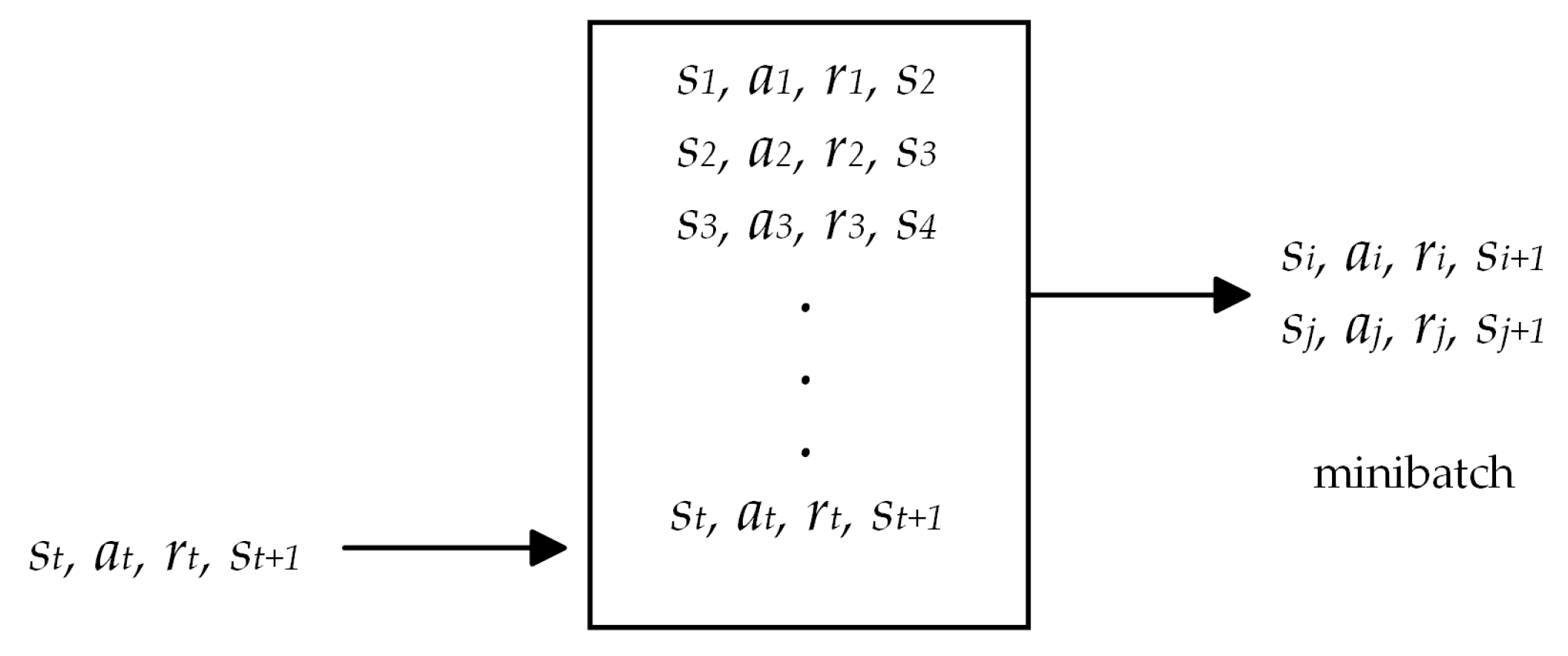
Prioritized Experience Replay Mechanism
Prioritized experience replay (PER) is a technique to enhance the DQN learning process. Classical experience replay stores interactions between the agent and the environment in a replay buffer. During the training process, a batch of transitions is randomly sampled from this buffer to update the network weights, as shown in
Figure 3. This method treats all experiences equally, but their contribution to learning may not be the same in reality. Some experiences might be more valuable due to their rarity or the abundance of information they provide. Accordingly, PER tackles this issue by assigning a priority to each experience, enabling the more informative or crucial experiences to be sampled more frequently during training and improving the efficiency of the learning process.
The typical workflow of PER is as follows:
- (1)
Priority assignment: Instead of randomly sampling experiences, priorities are determined based on the TDerror corresponding to each experience. The TDerror reflects the surprise of an experience, and a larger TDerror means the agent has more to learn from this experience.
- (2)
Sampling: During network updates, experiences are sampled from the replay buffer according to their priority probabilities, and experiences with a higher TDerror are more likely to be selected.
- (3)
Weight update: To guarantee the learning process remains unbiased, updates from the sampled experiences are weighted according to the reciprocal of their sampling probabilities, preventing some experiences from being oversampled and exerting too much influence on learning.
- (4)
Stochastic sampling: To reduce the computational cost of calculating the precise TDerror for all experiences in the replay buffer, PER uses an approximate priority method.
To sum up, PER allows the agent to focus on the most beneficial experiences to improve training efficiency. Although PER introduces additional computational overhead due to the need to maintain priority and adjust updates, it can significantly enhance the performance of QMIX.
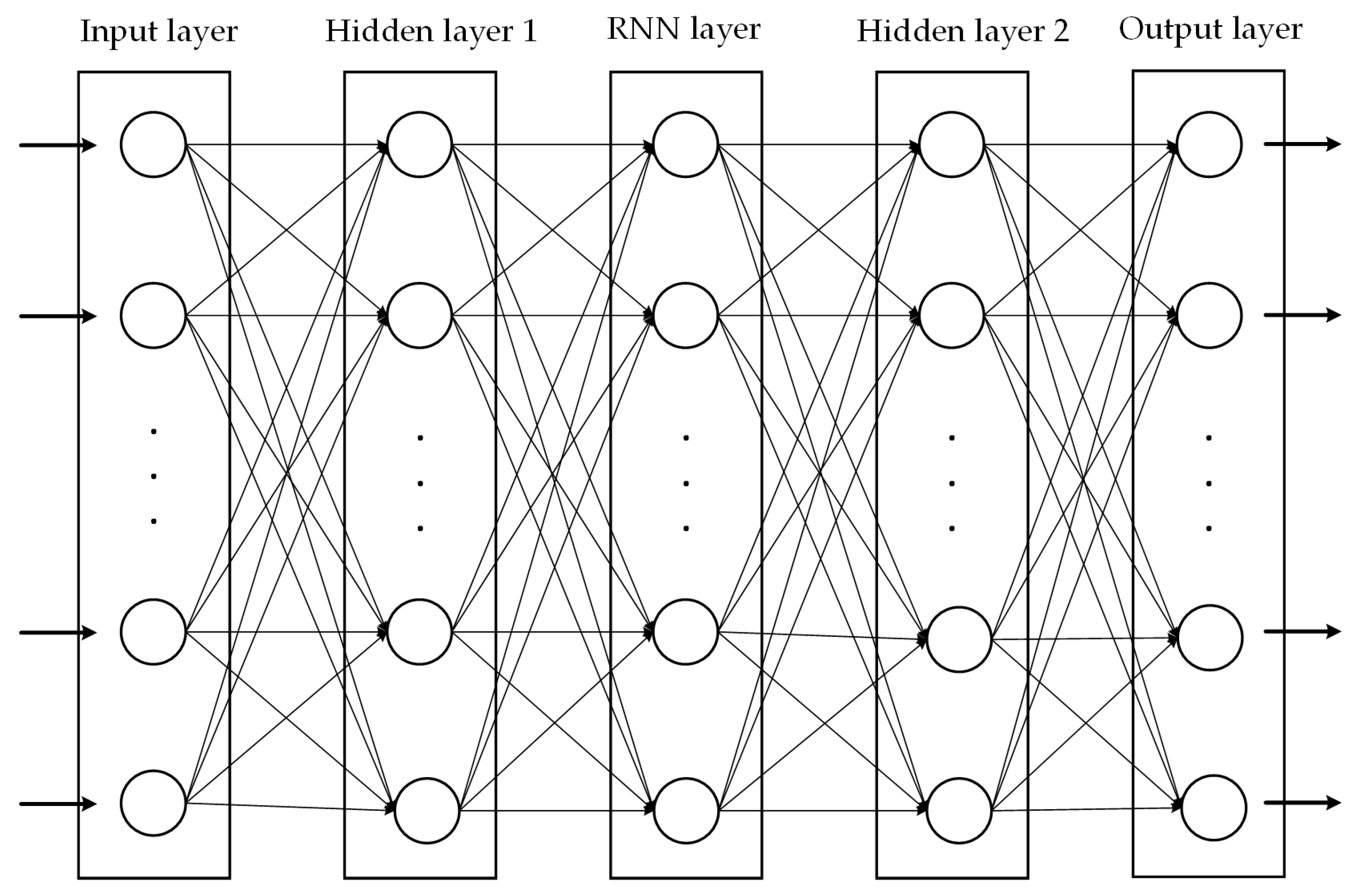
Within the improved QMIX algorithm framework, each agent is equipped with two sets of neural network models: an estimation network and a target network. These two types of networks have identical architectures but differ in their parameter update mechanisms. Specifically, the parameters of the estimation network are continuously updated with each training iteration. In contrast, the parameters of the target network are relatively static and only updated by copying the current parameters of the estimation network after a certain number of iterations. This design aims to reduce the correlation between Q-value estimates and Q-value targets, thereby enhancing the overall stability of the algorithm. The neural network architecture consists of an input layer, two hidden layers, a recurrent neural network (RNN) layer, and an output layer. The detailed network structure is illustrated in
Figure 4. The specific configuration of the relevant parameters is provided in
Table 8. Note that the number of nodes in the input layer varies according to the agent, and is equal to the sum of the elements of the current agent observation and the action taken in the previous time step. Each node in the output layer corresponds to the Q-value of each action in the current state.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}