
An Enhanced Fault Localization Technique for Distribution Networks Utilizing Cost-Sensitive Graph Neural Networks

Abstract
1. Introduction
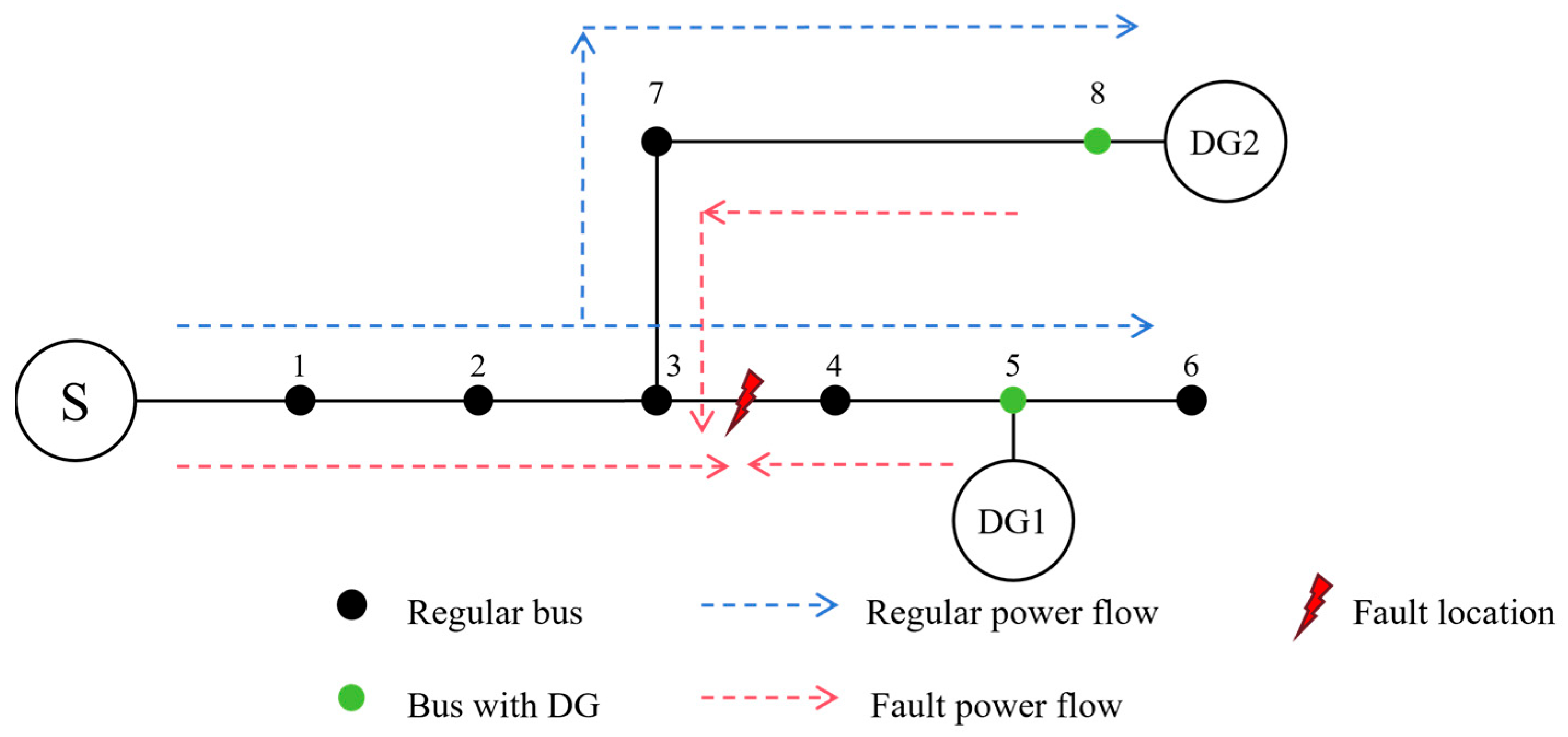
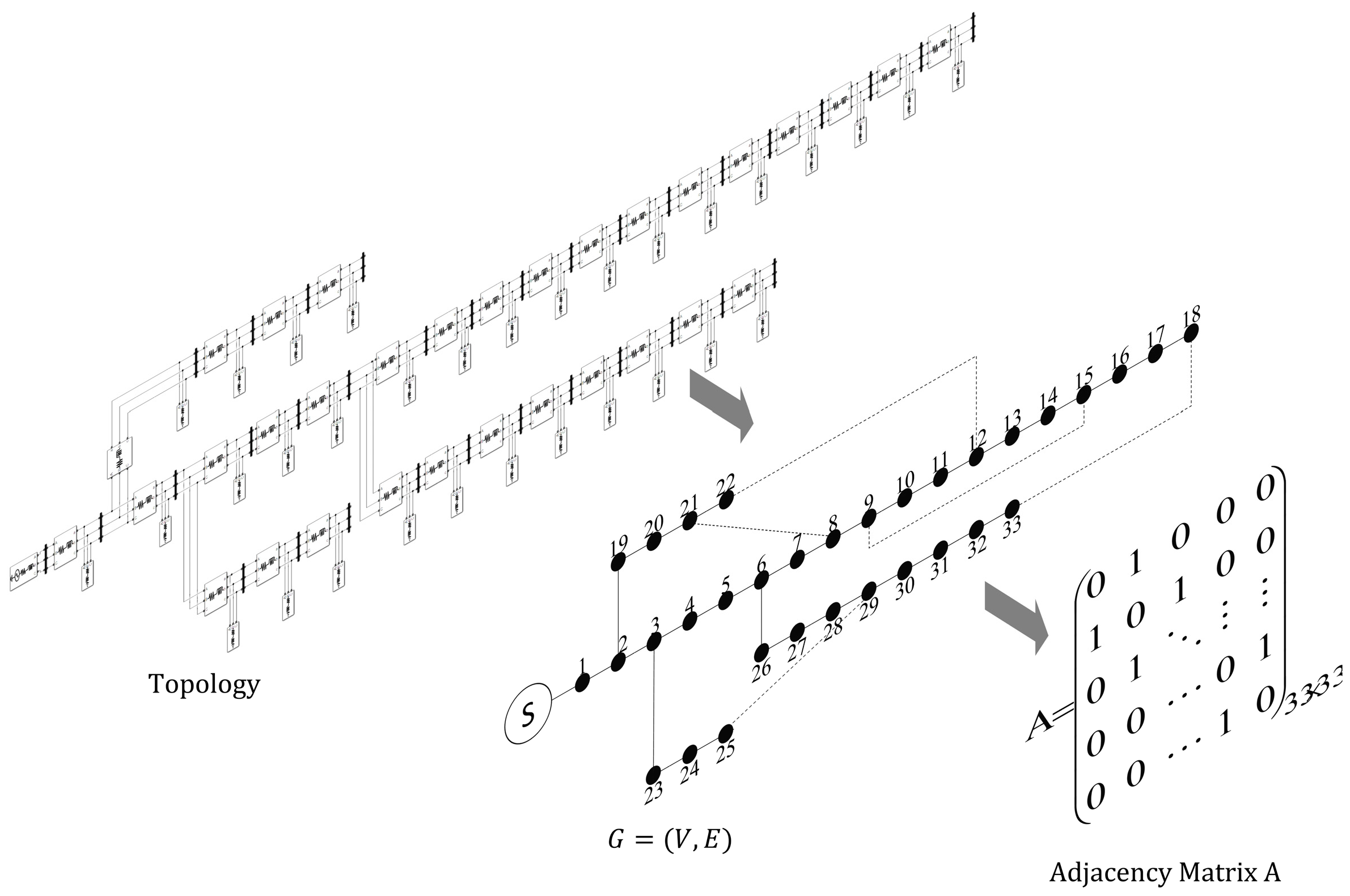
2. Distribution Network System with Distributed Power Sources
2.1. Typical Distribution Network System
2.2. Distribution Network Fault Simulation
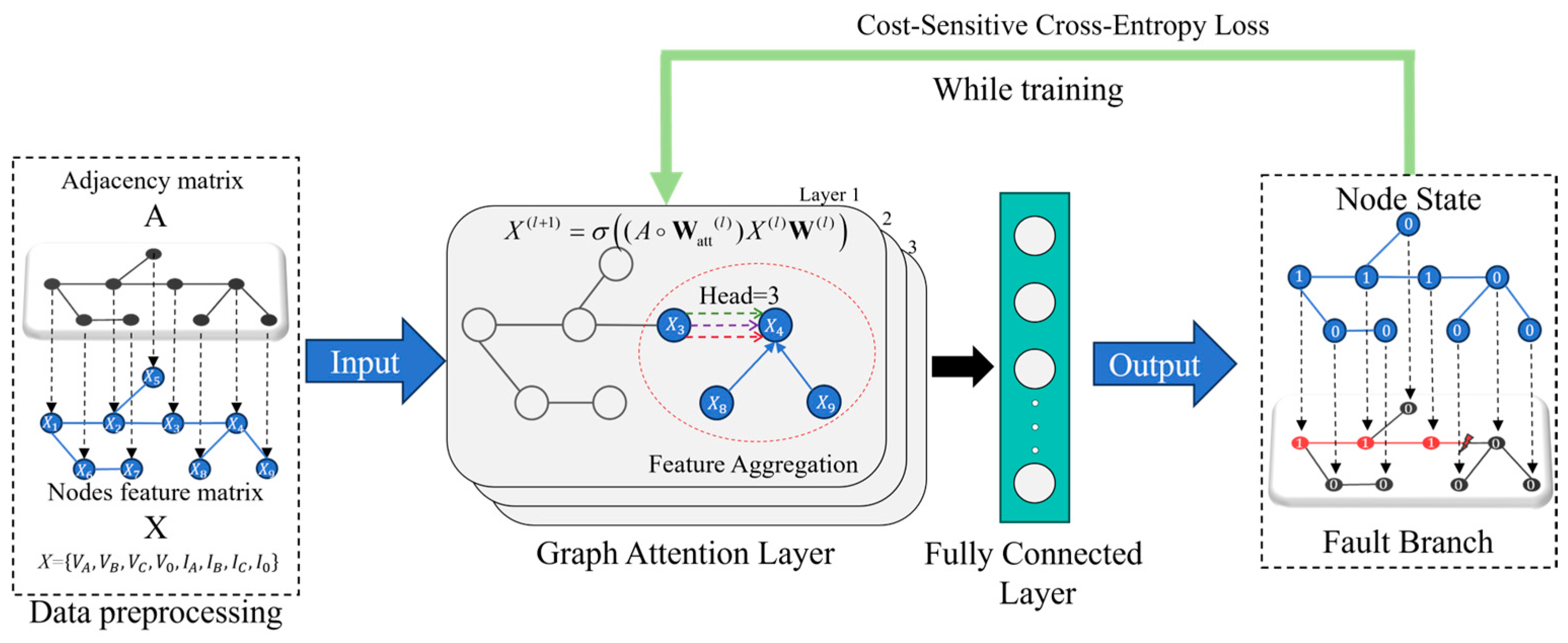
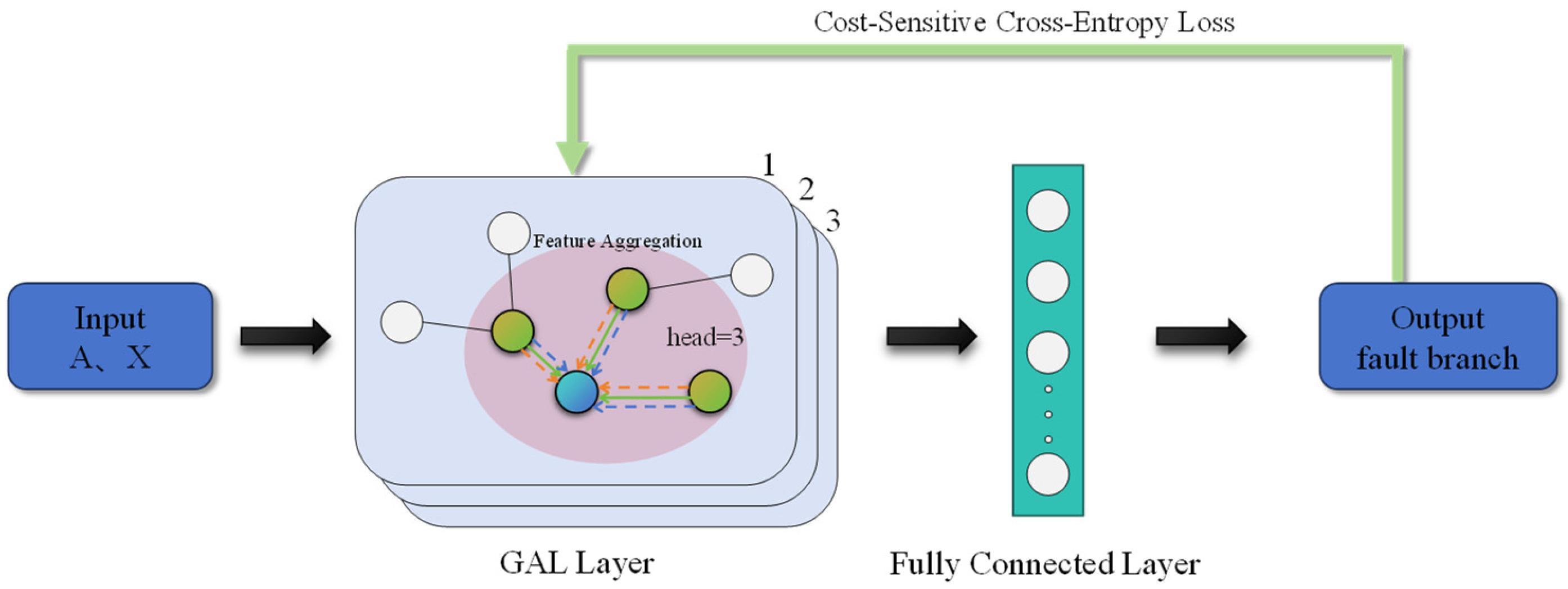
3. Cost-Sensitive Graph Attention Mechanism
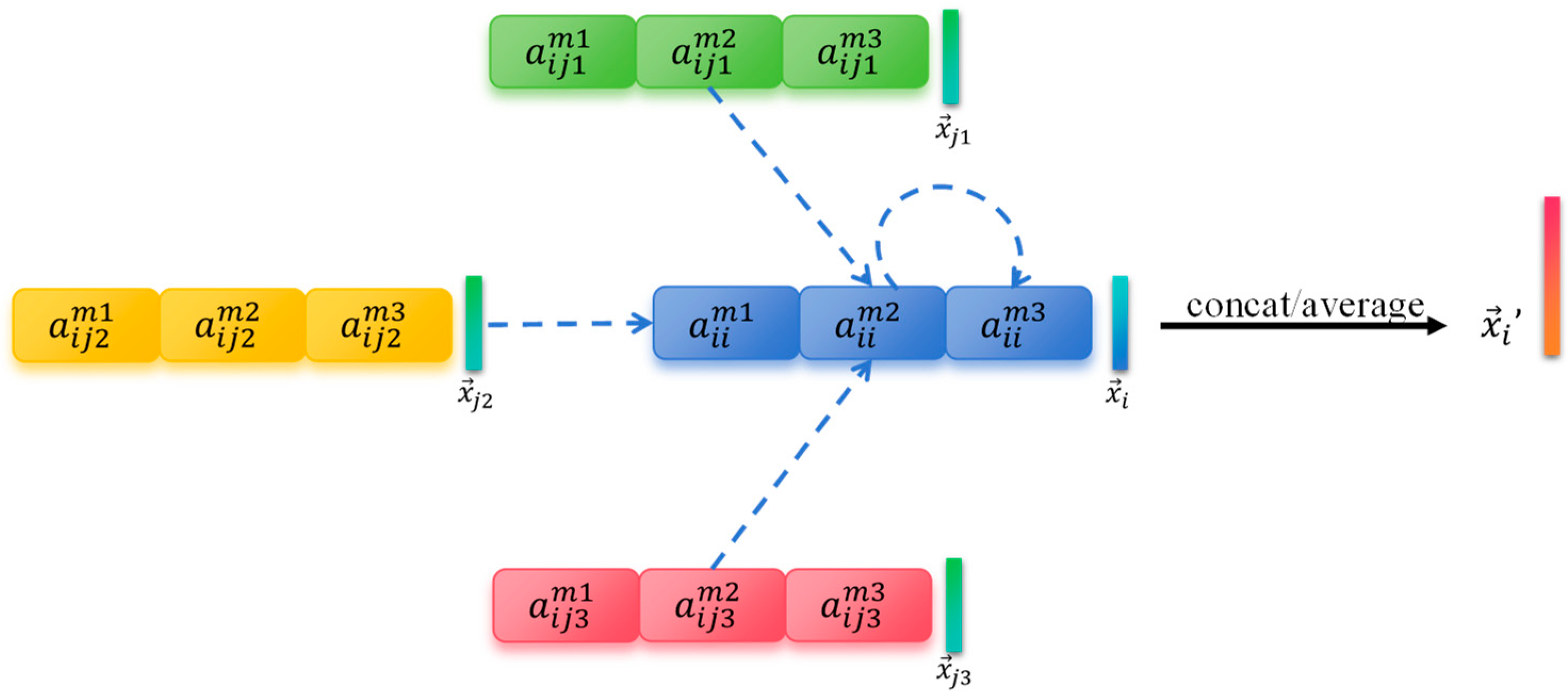
3.1. Graph Attention Network
3.2. Cost-Sensitive Learning
3.2.1. Cost-Sensitive Matrix Based on Misclassification Ratio
3.2.2. Cost-Sensitive Loss Function and Evaluation Indicators
3.3. Model Input Analysis
3.4. Fault Location Model
| Algorithm 1: Pseudo-code for the model. Training process of the CS-GAT |
| Input: , batch-size, epochs, learning-rate
Output: |
| 1. Initialize parameters of each GAL and cost-sensitive matrix |
| 2. Training data normalization and random ordering |
| 3. Splicing of batch training data |
| 4. for epoch to epochs do |
| 5. |
| 6. |
| 7. Calculate the cost-sensitive matrix |
| 8. Calculate the cost-sensitive loss: |
| 9. Backpropagation to update parameters |
| 10. end for |
4. Results and Discussion
4.1. Platform Construction and Data Collection
4.1.1. Construction of Simulation Model
4.1.2. Data Storage and Computation
4.2. Analysis of Model-Related Parameters
4.2.1. Selection of Model Parameters
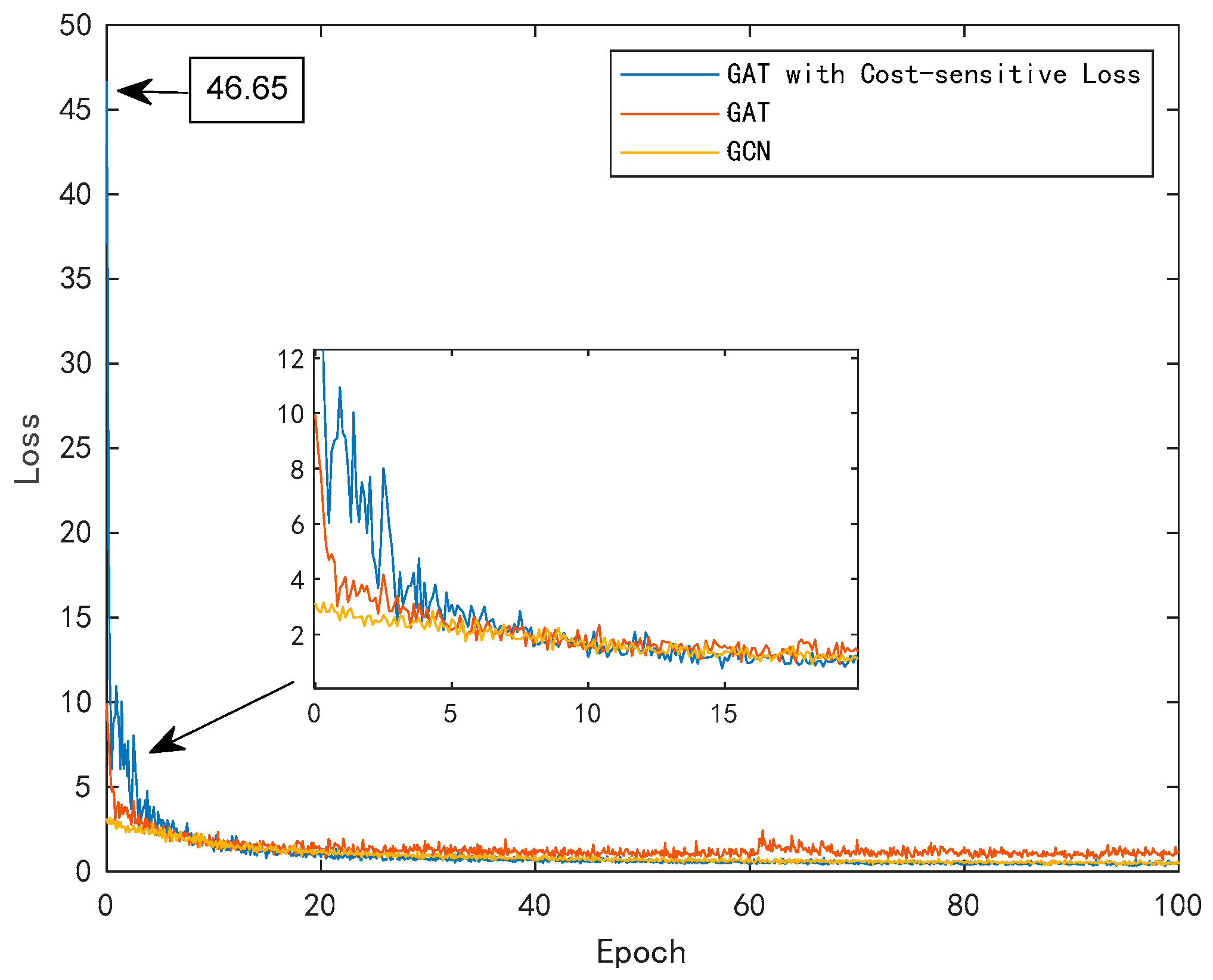
4.2.2. Selection of Training Parameters
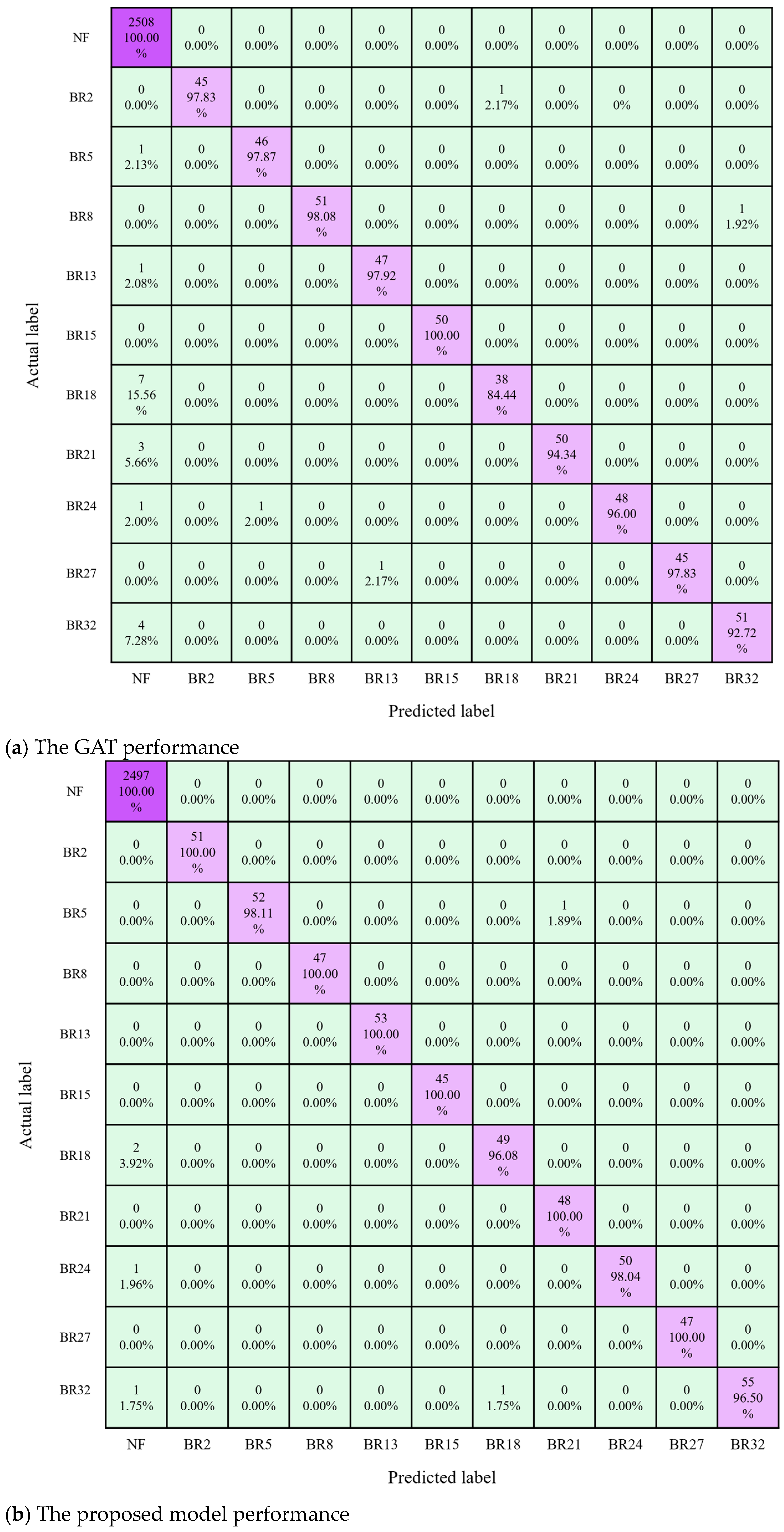
4.3. Fault Location Performance Analysis
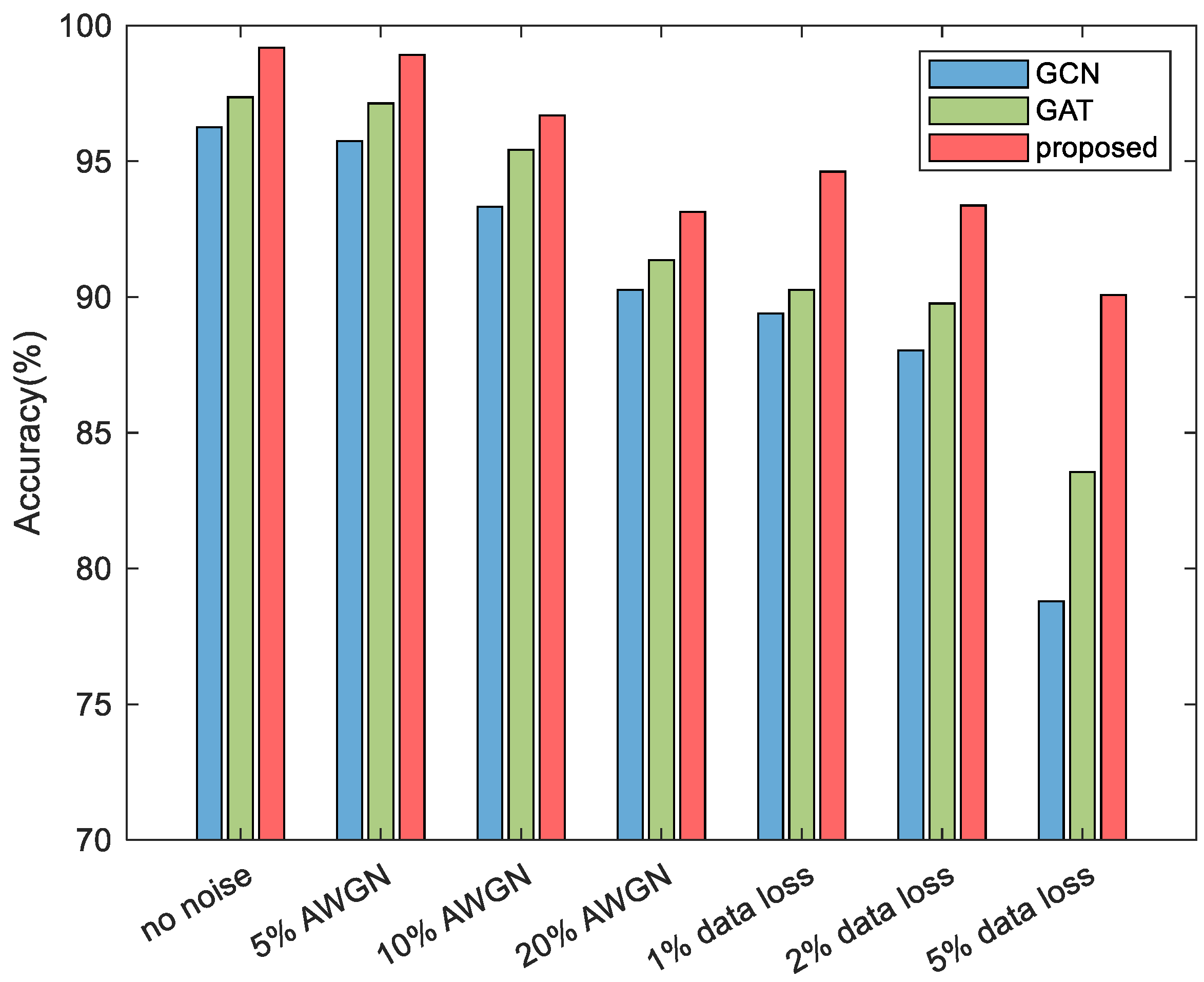
4.4. Impact of Data Disturbance
4.5. Impact of Fault Resistance on Model Performance
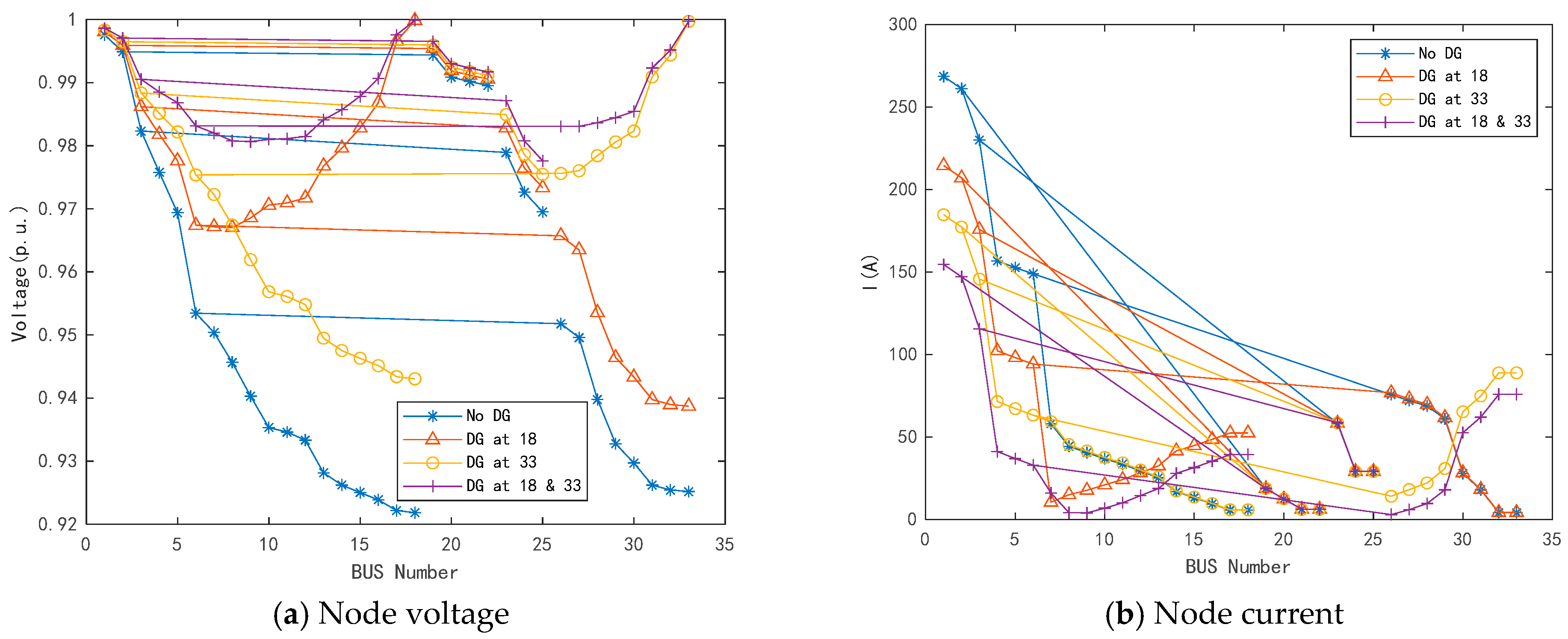
4.6. Impact of DG Access on Model Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gurajapathy, S.S.; Mokhlis, H.; Illias, H.A. Fault location and detection techniques in power distribution systems with distributed generation: A review. Renew. Sustain. Energy Rev. 2017, 74, 949–958. [Google Scholar] [CrossRef]
- Xu, J.; Wu, Z.; Yu, X.; Hu, Q.; Zhu, C.; Dou, X.; Gu, W.; Wu, Z. A new method for optimal FTU placement in distribution network under consideration of power service reliability. Sci. China Technol. Sci. 2017, 60, 1885–1896. [Google Scholar] [CrossRef]
- Dashti, R.; Ghasemi, M.; Daisy, M. Fault location in power distribution network with presence of distributed generation resources using impedance based method and applying π line model. Energy 2018, 159, 344–360. [Google Scholar] [CrossRef]
- Vieira, F.L.; Filho, J.M.C.; Silveira, P.M.; Guerrero, C.A.V.; Leite, M.P. High impedance fault detection and location in distribution networks using smart meters. In Proceedings of the 18th International Conference on Harmonics and Quality of Power (ICHQP), Ljubljana, Slovenia, 13–16 May 2018; pp. 1–6. [Google Scholar]
- Yuan, Y.; Low, S.H.; Ardakanian, O.; Tomlin, C.J. Inverse Power Flow Problem. IEEE Trans. Control Netw. Syst. 2023, 10, 261–273. [Google Scholar] [CrossRef]
- Yue, Y.; Zhao, H.; Zhao, Y.; Wang, H. A study of distribution network fault location including Distributed Generator based on improved genetic algorithm. In Proceedings of the 3rd International Conference on System Science, Engineering Design and Manufacturing Informatization, Chengdu, China, 20–21 October 2012; pp. 103–106. [Google Scholar]
- Jiang, K.; Tong, X. Fault section location method based on fuzzy self-correction bat algorithm in non-solidly earthed distribution network. In Proceedings of the 2017 2nd International Conference on Power and Renewable Energy (ICPRE), Chengdu, China, 20–23 September 2017; pp. 485–489. [Google Scholar]
- Meng, F.; Zhao, S.; Li, Z.; Li, S. Distribution Network Fault Location Based on Improved Binary Particle Swarm Optimization. In Proceedings of the 2018 Chinese Intelligent Systems Conference, Wenzhou, China, 13–14 December 2018; Lecture Notes in Electrical Engineering. Springer: Singapore, 2018; Volume 528, pp. 181–189. [Google Scholar]
- Tao, C.; Wang, J.; Wang, T.; Yang, Y. An improved spiking neural P systems with anti-spikes for fault location of distribution networks with distributed generation. In Proceedings of the Bio-inspired Computing: Theories and Applications (BIC-TA 2017) Communications in Computer and Information Science, Harbin, China, 1–3 December 2017; Springer: Singapore, 2017; Volume 791, pp. 380–395. [Google Scholar]
- Sapountzoglou, N.; Lago, J.; Raison, B. Fault diagnosis in low voltage smart distribution grids using gradient boosting trees. Electr. Power Syst. Res. 2020, 182, 106254. [Google Scholar] [CrossRef]
- Zhao, J.; Ma, N.; Hou, H.; Zhang, J.; Ma, Y.; Shi, W. A fault section location method for small current grounding system based on HHT. In Proceedings of the China International Conference on Electricity Distribution (CICED), Tianjin, China, 17–19 September 2018; pp. 1769–1773. [Google Scholar]
- Liang, R. Fault location method in power network by applying accurate information of arrival time differences of modal traveling waves. IEEE Trans. Ind. Inform. 2020, 16, 3124–3132. [Google Scholar] [CrossRef]
- Naidu, O.D.; Pradhan, A.K. Precise traveling wave-based transmission line fault location method using single-ended data. IEEE Trans. Ind. Inform. 2021, 17, 5197–5207. [Google Scholar] [CrossRef]
- Shafiullah, M.; Abido, M.A.; Abdel-Fattah, T. Distribution grids fault location employing ST based optimized machine learning approach. Energies 2018, 11, 2328. [Google Scholar] [CrossRef]
- Moloi, K.; Yusuff, A.A. A Support Vector Machine Based Fault Diagnostic Technique in Power Distribution Networks. In Proceedings of the 2019 Southern African Universities Power Engineering Conference/Robotics and Mechatronics/Pattern Recognition Association of South Africa (SAUPEC/RobMech/PRASA), Bloemfontein, South Africa, 28–30 January 2019; pp. 229–234. [Google Scholar]
- Swetapadma, A.; Yadav, A. A novel single-ended fault location scheme for parallel transmission lines using k-nearest neighbor algorithm. Comput. Electr. Eng. 2018, 69, 41–53. [Google Scholar] [CrossRef]
- Ru, J.; Luo, G.; Shang, B.; Luo, S.; Liu, W.; Wang, S. Fault Line Selection and Location of Distribution Network Based on Improved Random Forest Method. In Proceedings of the 2022 4th International Conference on Smart Power & Internet Energy Systems (SPIES), Beijing, China, 27–30 October 2022; pp. 1179–1184. [Google Scholar]
- Rafinia, A.; Moshtagh, J. A new approach to fault location in three-phase underground distribution system using combination of wavelet analysis with ANN and FLS. Int. J. Electr. Power Energy Syst. 2014, 55, 261–274. [Google Scholar] [CrossRef]
- Mirshekali, H.; Dashti, R.; Keshavarz, A.; Shaker, H.R. Machine learning-based fault location for smart distribution networks equipped with micro-PMU. Sensors 2022, 22, 945. [Google Scholar] [CrossRef] [PubMed]
- Shadi, M.R.; Ameli, M.T.; Azad, S. A real-time hierarchical framework for fault detection, classification, and location in power systems using PMUs data and deep learning. Int. J. Electr. Power Energy Syst. 2022, 134, 107399. [Google Scholar] [CrossRef]
- Liao, W.; Bak-Jensen, B.; Pillai, J.R.; Wang, Y.; Wang, Y. A review of graph neural networks and their applications in power systems. J. Mod. Power Syst. Clean Energy 2022, 10, 345–360. [Google Scholar] [CrossRef]
- Hu, J.; Hu, W.; Chen, J.; Cao, D.; Zhang, Z.; Liu, Z.; Chen, Z.; Blaabjerg, F. Fault Location and Classification for Distribution Systems Based on Deep Graph Learning Methods. J. Mod. Power Syst. Clean Energy 2023, 11, 35–51. [Google Scholar] [CrossRef]
- Chanda, D.; Soltani, N.Y. Graph-Based Multi-Task Learning for Fault Detection in Smart Grid. In Proceedings of the 2023 IEEE 33rd International Workshop on Machine Learning for Signal Processing (MLSP), Rome, Italy, 17–20 September 2023; pp. 1–6. [Google Scholar]
- Chen, K.; Hu, J.; Zhang, Y.; Yu, Z.; He, J. Fault location in power distribution systems via deep graph convolutional networks. IEEE J. Sel. Areas Commun. 2020, 38, 119–131. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Kashem, M.A.; Ganapathy, V.; Jasmon, G.B.; Buhari, M.I. A novel method for loss minimization in distribution networks. In Proceedings of the DRPT2000. International Conference on Electric Utility Deregulation and Restructuring and Power Technologies. Proceedings (Cat. No. 00EX382), London, UK, 4–7 April 2000; IEEE: Piscataway, NJ, USA, 2000; pp. 251–256. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operation | Stored in Two-Dimensional Array Format | Stored in CSC Format | ||
|---|---|---|---|---|
| Time Complexity | Space Complexity | Time Complexity | Space Complexity | |
| Matrix-vector multiplication | ||||
| Matrix-matrix multiplication | ||||
| Matrix transposition | ||||
| Matrix addition | ||||
| GAL Layers | F1-Score (%) | Time Cost (min) |
|---|---|---|
| 2 | 81.49 | 42 |
| 3 | 98.82 | 93 |
| 4 | 84.27 | 158 |
| Number of Heads | F1-Score (%) | Time Cost (min) |
|---|---|---|
| 2 | 93.42 | 64 |
| 3 | 97.95 | 97 |
| 4 | 98.36 | 131 |
| 5 | 98.62 | 186 |
| 6 | 98.61 | 243 |
| Batch-Size | F1-Score (%) | Time Cost of 100 Epochs (min) |
|---|---|---|
| 32 | 98.76 | 161 |
| 64 | 98.80 | 99 |
| 128 | 97.61 | 57 |
| Model | F1-Score (%) |
|---|---|
| proposed | 98.97% |
| GAT | 96.09% |
| GCN | 95.40% |
| Training Set Size (%) | F1-Score (%) |
|---|---|
| 90% | 98.23 |
| 70% | 96.71 |
| 50% | 91.23 |
| 30% | 72.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Huang, B.; Zhou, B.; Chen, J.; Wang, Y. An Enhanced Fault Localization Technique for Distribution Networks Utilizing Cost-Sensitive Graph Neural Networks. Processes 2024, 12, 2312. https://doi.org/10.3390/pr12112312
Wang Z, Huang B, Zhou B, Chen J, Wang Y. An Enhanced Fault Localization Technique for Distribution Networks Utilizing Cost-Sensitive Graph Neural Networks. Processes. 2024; 12(11):2312. https://doi.org/10.3390/pr12112312
Chicago/Turabian StyleWang, Zilong, Birong Huang, Bingyang Zhou, Jianhua Chen, and Yichen Wang. 2024. "An Enhanced Fault Localization Technique for Distribution Networks Utilizing Cost-Sensitive Graph Neural Networks" Processes 12, no. 11: 2312. https://doi.org/10.3390/pr12112312
APA StyleWang, Z., Huang, B., Zhou, B., Chen, J., & Wang, Y. (2024). An Enhanced Fault Localization Technique for Distribution Networks Utilizing Cost-Sensitive Graph Neural Networks. Processes, 12(11), 2312. https://doi.org/10.3390/pr12112312