
Robustness Prediction in Dynamic Production Processes—A New Surrogate Measure Based on Regression Machine Learning


Abstract
1. Introduction
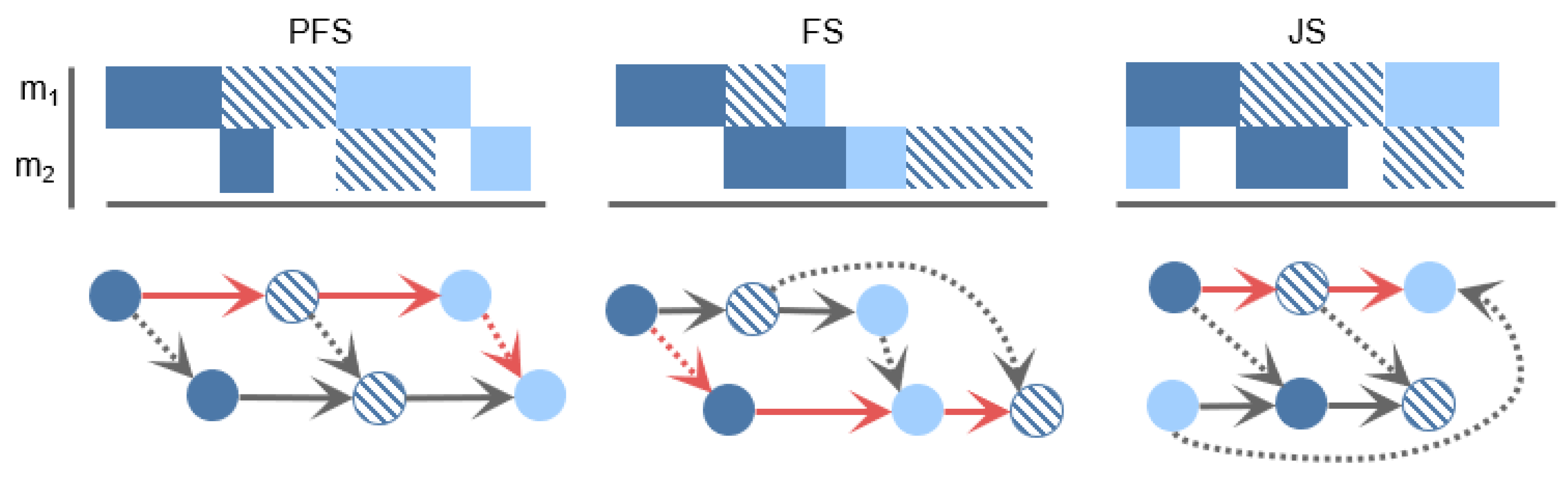
1.1. Production Environments and Schedule Representations
- Every production job has m operations (activities), each to be processed on a different machine (resource);
- Within each job, the machines must be visited in a sequential order ;
- Operations of a job can only start when any previous operations of the job have been completed;
- Each machine can only process one operation at a time;
- The job order is equal for all machines (jobs cannot overtake each other in the line);
- All operations must be processed exactly once and non-preemptively.
1.2. Robustness Measures
1.3. Robust Scheduling Techniques
- Scheduling stage: (A) RS generation in a second stage based on a given DASG. (B) Aggregated with baseline objective optimization.
- Optimization technique: (A) Adding buffer times to critical operations. (B) Creating neighbor solutions, e.g., by swapping operations.
- Evaluation technique: (A) Obtaining robustness by MCE. (B) Estimating robustness by SMs.
- Robustness objective: (A) Standalone robustness [R]. (B) Robustness and stability []. (C) Robustness, stability and baseline objective [].
1.4. Motivation and Contribution of This Work
2. Method
2.1. Scope and Utility
| Algorithm 1 Exemplary local search robust scheduling heuristic (simplified pseudocode) | |
| 1: | ▹ Create initial schedule based for a set of operations O (output: DASG) |
| 2: | ▹ Evaluate the initial schedule considering uncertainties |
| 3: for do | ▹ Conduct a local search for iterations |
| 4: | ▹ Create neighbor solution, e.g., by changing the operation order |
| 5: | ▹ Evaluate the neighbor |
| 6: if then | |
| 7: | ▹ Replace the current schedule if the neighbor has a better fitness |
| 8: end if | |
| 9: end for | |
| 10: return | |
2.2. Hypotheses and Statistical Measures
2.3. Uncertainty Modeling and Operation Parameters
2.4. Prediction Features
2.5. Test Data Generation
| Algorithm 2 Generate one sample (pseudo code) | |
| 1: | ▹ Choose a random number of jobs |
| 2: | ▹ Choose a random number of machines |
| 3: | ▹ Choose non-unique random UPTs from |
| 4: | ▹ Generate RS with EPTs |
| 5: | ▹ Evaluate RS* via MCE |
| 6: return | ▹ Collect features (see Section 2.4) |
2.6. Regression Model Implementation
3. Results
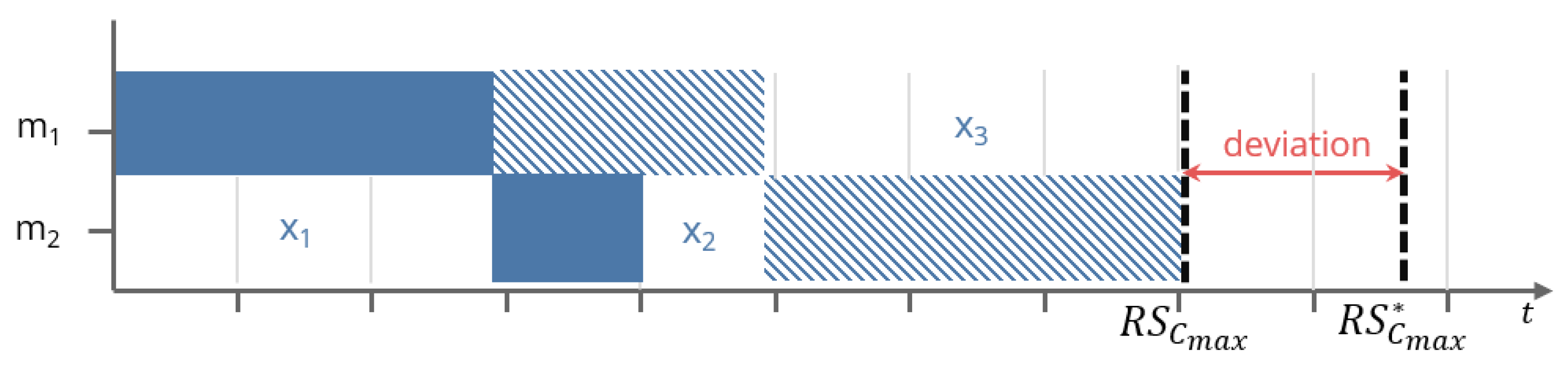
3.1. Idle Time Deviation
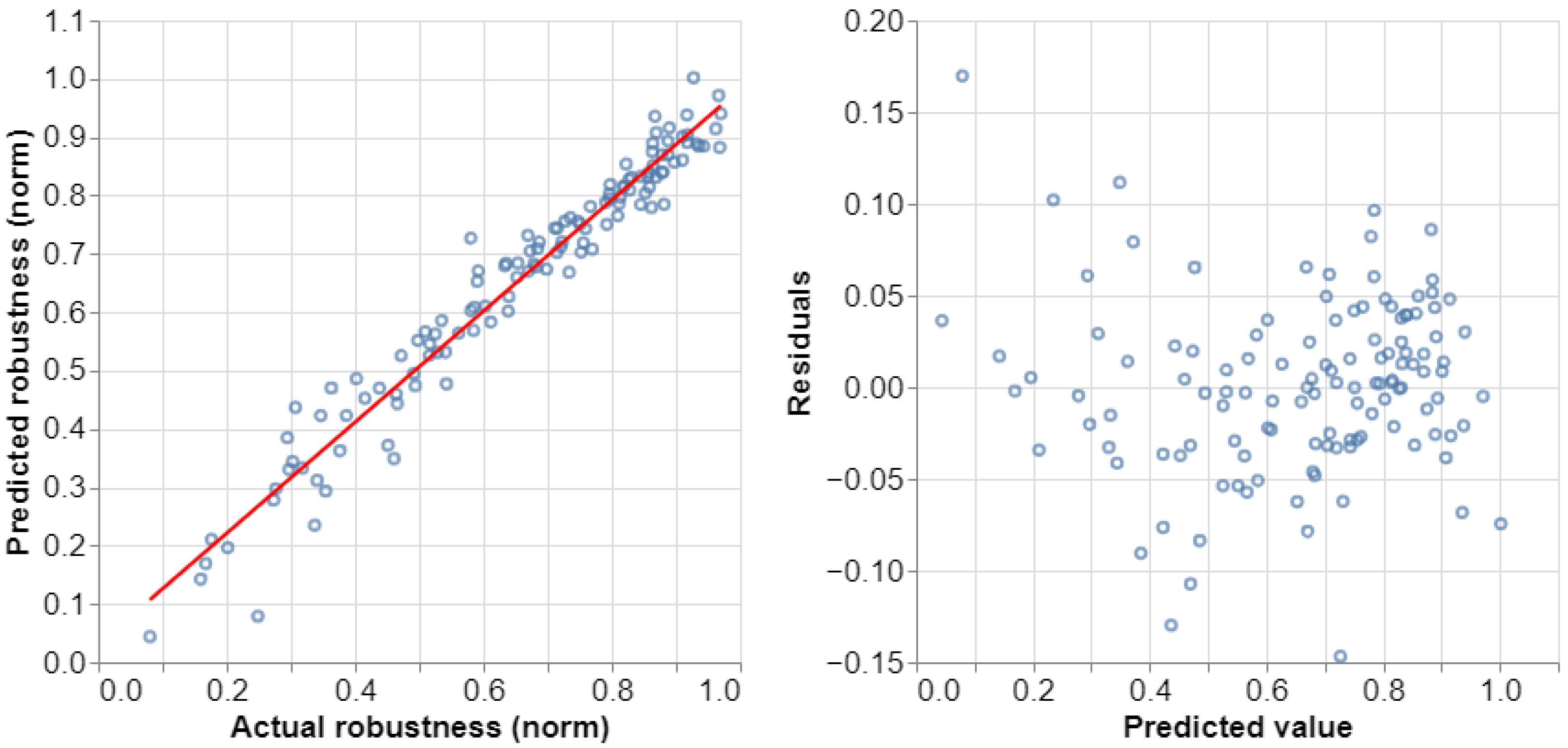
3.2. Regression Model Validation
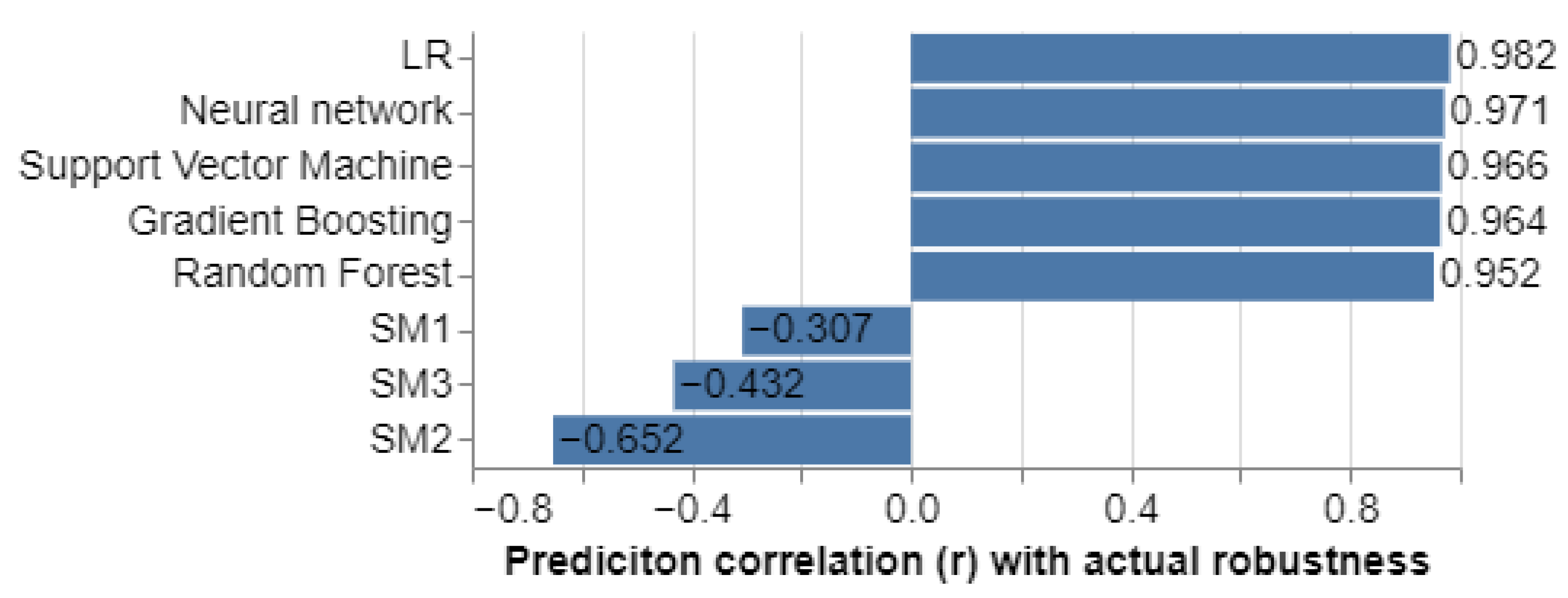
3.3. Surrogate Measure Benchmark
3.4. Application Study
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DASG | Directed acyclic solution graph |
| EPT | Expected processing time |
| FS | Flow shop |
| JS | Job shop |
| LR | Linear regression |
| MCE | Monte Carlo experiment |
| ML | Machine learning |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
| MSE | Mean square error |
| PFS | Permutation flow shop |
| RM | Regression model |
| RMSE | Root mean square error |
| RS | Robust schedule |
| RS* | Robust schedule after (MCE) realization |
| SM | Surrogate measure |
| UPT | Uncertain processing time |
References
- Pinedo, M.L. Scheduling, 4th ed.; Springer US: New York, NY, USA, 2012; p. 1. [Google Scholar] [CrossRef]
- Rossi, F.L.; Nagano, M.S.; Sagawa, J.K. An effective constructive heuristic for permutation flow shop scheduling problem with total flow time criterion. Int. J. Adv. Manuf. Technol. 2016, 90, 93–107. [Google Scholar] [CrossRef]
- Vela, C.R.; Afsar, S.; Palacios, J.J.; Gonzalez-Rodriguez, I.; Puente, J. Evolutionary tabu search for flexible due-date satisfaction in fuzzy job shop scheduling. Comput. Oper. Res. 2020, 119, 104931. [Google Scholar] [CrossRef]
- Leon, J.V.; Wu, D.S.; Storer, R.H. Robustness measures and robust scheduling for job shops. IIE Trans. 1994, 26, 32–43. [Google Scholar] [CrossRef]
- Davenport, A.J.; Gefflot, C.; Beck, J.C. Slack-based Techniques for Robust Schedules. In Proceedings of the Sixth European Conference on Planning (ECP-2001), Toledo, Spain, 12–14 September 2001. [Google Scholar]
- Ouelhadj, D.; Petrovic, S. A survey of dynamic scheduling in manufacturing systems. J. Sched. 2008, 12, 417–431. [Google Scholar] [CrossRef]
- Iglesias-Escudero, M.; Villanueva-Balsera, J.; Ortega-Fernandez, F.; Rodriguez-Montequín, V. Planning and Scheduling with Uncertainty in the Steel Sector: A Review. Appl. Sci. 2019, 9, 2692. [Google Scholar] [CrossRef]
- Xiao, S.; Sun, S.; Jin, J.J. Surrogate measures for the robust scheduling of stochastic job shop scheduling problems. Energies 2017, 10, 543. [Google Scholar] [CrossRef]
- Goren, S.; Sabuncuoglu, I. Robustness and stability measures for scheduling: Single-machine environment. IIE Trans. 2008, 40, 66–83. [Google Scholar] [CrossRef]
- Shen, X.N.; Han, Y.; Fu, J.Z. Robustness measures and robust scheduling for multi-objective stochastic flexible job shop scheduling problems. Soft Comput. 2016, 21, 6531–6554. [Google Scholar] [CrossRef]
- Liu, F.; Wang, S.; Hong, Y.; Yue, X. On the Robust and Stable Flowshop Scheduling Under Stochastic and Dynamic Disruptions. IEEE Trans. Eng. Manag. 2017, 64, 539–553. [Google Scholar] [CrossRef]
- Sundstrom, N.; Wigstrom, O.; Lennartson, B. Conflict Between Energy, Stability, and Robustness in Production Schedules. IEEE Trans. Autom. Sci. Eng. 2017, 14, 658–668. [Google Scholar] [CrossRef]
- Behnamian, J. Survey on fuzzy shop scheduling. Fuzzy Optim. Decis. Mak. 2015, 15, 331–366. [Google Scholar] [CrossRef]
- Delgoshaei, A.; Ariffin, M.K.A.B.M.; Leman, Z.B. An Effective 4–Phased Framework for Scheduling Job-Shop Manufacturing Systems Using Weighted NSGA-II. Mathematics 2022, 10, 4607. [Google Scholar] [CrossRef]
- Goyal, B.; Kaur, S. Flow shop scheduling-especially structured models under fuzzy environment with optimal waiting time of jobs. Int. J. Des. Eng. 2022, 11, 47. [Google Scholar] [CrossRef]
- Xiao, S.; Wu, Z.; Dui, H. Resilience-Based Surrogate Robustness Measure and Optimization Method for Robust Job-Shop Scheduling. Mathematics 2022, 10, 4048. [Google Scholar] [CrossRef]
- Grumbach, F.; Müller, A.; Reusch, P.; Trojahn, S. Robust-stable scheduling in dynamic flow shops based on deep reinforcement learning. J. Intell. Manuf. 2022. [Google Scholar] [CrossRef]
- Soofi, P.; Yazdani, M.; Amiri, M.; Adibi, M.A. Robust Fuzzy-Stochastic Programming Model and Meta-Heuristic Algorithms for Dual-Resource Constrained Flexible Job-Shop Scheduling Problem Under Machine Breakdown. IEEE Access 2021, 9, 155740–155762. [Google Scholar] [CrossRef]
- Minguillon, F.E.; Stricker, N. Robust predictive–reactive scheduling and its effect on machine disturbance mitigation. CIRP Ann. 2020, 69, 401–404. [Google Scholar] [CrossRef]
- Zahid, T.; Agha, M.H.; Schmidt, T. Investigation of surrogate measures of robustness for project scheduling problems. Comput. Ind. Eng. 2019, 129, 220–227. [Google Scholar] [CrossRef]
- Yang, Y.; Huang, M.; Wang, Z.Y.; Zhu, Q.B. Robust scheduling based on extreme learning machine for bi-objective flexible job-shop problems with machine breakdowns. Expert Syst. Appl. 2020, 158, 113545. [Google Scholar] [CrossRef]
- Goren, S.; Sabuncuoglu, I.; Koc, U. Optimization of schedule stability and efficiency under processing time variability and random machine breakdowns in a job shop environment. Nav. Res. Logist. 2011, 59, 26–38. [Google Scholar] [CrossRef]
- Himmiche, S.; Marangé, P.; Aubry, A.; Pétin, J.F. Robustness Evaluation Process for Scheduling under Uncertainties. Processes 2023, 11, 371. [Google Scholar] [CrossRef]
- Jierula, A.; Wang, S.; OH, T.M.; Wang, P. Study on Accuracy Metrics for Evaluating the Predictions of Damage Locations in Deep Piles Using Artificial Neural Networks with Acoustic Emission Data. Appl. Sci. 2021, 11, 2314. [Google Scholar] [CrossRef]
- Singh, U.; Rizwan, M.; Alaraj, M.; Alsaidan, I. A Machine Learning-Based Gradient Boosting Regression Approach for Wind Power Production Forecasting: A Step towards Smart Grid Environments. Energies 2021, 14, 5196. [Google Scholar] [CrossRef]
- Chen, C.; Twycross, J.; Garibaldi, J.M. A new accuracy measure based on bounded relative error for time series forecasting. PLoS ONE 2017, 12, e0174202. [Google Scholar] [CrossRef] [PubMed]
- Ratner, B. The correlation coefficient: Its values range between +1/−1, or do they? J. Target. Meas. Anal. Mark. 2009, 17, 139–142. [Google Scholar] [CrossRef]
- Montaño, J.J.; Palmer, A.; Sesé, A.; Cajal, B. Using the R-MAPE index as a resistant measure of forecast accuracy. Psicothema 2013, 500–506. [Google Scholar] [CrossRef]
- Yamashiro, H.; Nonaka, H. Estimation of processing time using machine learning and real factory data for optimization of parallel machine scheduling problem. Oper. Res. Perspect. 2021, 8, 100196. [Google Scholar] [CrossRef]
- Taillard, E. Benchmarks for basic scheduling problems. Eur. J. Oper. Res. 1993, 64, 278–285. [Google Scholar] [CrossRef]
- Jacoboni, C.; Lugli, P. The Monte Carlo Method for Semiconductor Device Simulation; Springer: Vienna, Austria, 1989. [Google Scholar] [CrossRef]
- Kuroda, M.; Wang, Z. Fuzzy job shop scheduling. Int. J. Prod. Econ. 1996, 44, 45–51. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; pp. 164–199. Available online: http://www.deeplearningbook.org (accessed on 15 March 2023).
- Xiong, J.; Xing, L.N.; Chen, Y.W. Robust scheduling for multi-objective flexible job-shop problems with random machine breakdowns. Int. J. Prod. Econ. 2013, 141, 112–126. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sum of idle times | |
| Number of machines m | |
| Number of operations | |
| Number of overlapping integrals (see Figure 3) | |
| Standard deviation of all | |
| Mean | |
| Mean operation duration | |
| Standard deviation of operation durations | |
| Mean free slack relative to | |
| Mean total slack relative to | |
| Total slack standard deviation |
| Method | MSE | RMSE | MAE | MAPE |
|---|---|---|---|---|
| Equation (1) () | 0.00004 | 0.0065 | 0.0050 | 0.0095 |
| LR | 0.00202 | 0.0450 | 0.0363 | 0.0683 |
| Neural network | 0.00283 | 0.0525 | 0.0408 | 0.0877 |
| Gradient boosting | 0.00292 | 0.0539 | 0.0404 | 0.0903 |
| Random forest | 0.00410 | 0.0639 | 0.0481 | 0.1099 |
| Support vector machine | 0.00428 | 0.0654 | 0.0536 | 0.1017 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grumbach, F.; Müller, A.; Reusch, P.; Trojahn, S. Robustness Prediction in Dynamic Production Processes—A New Surrogate Measure Based on Regression Machine Learning. Processes 2023, 11, 1267. https://doi.org/10.3390/pr11041267
Grumbach F, Müller A, Reusch P, Trojahn S. Robustness Prediction in Dynamic Production Processes—A New Surrogate Measure Based on Regression Machine Learning. Processes. 2023; 11(4):1267. https://doi.org/10.3390/pr11041267
Chicago/Turabian StyleGrumbach, Felix, Anna Müller, Pascal Reusch, and Sebastian Trojahn. 2023. "Robustness Prediction in Dynamic Production Processes—A New Surrogate Measure Based on Regression Machine Learning" Processes 11, no. 4: 1267. https://doi.org/10.3390/pr11041267
APA StyleGrumbach, F., Müller, A., Reusch, P., & Trojahn, S. (2023). Robustness Prediction in Dynamic Production Processes—A New Surrogate Measure Based on Regression Machine Learning. Processes, 11(4), 1267. https://doi.org/10.3390/pr11041267