1. Introduction
Currently, the electrical grid is controlled and managed following traditional schemes and techniques that do not consider the dynamics, variability, and stochastic nature of renewable energies, as well as the impact on inertia reduction, which leads to unexpected behaviors.
Currently, the concept of smart grids aiming to connect decentralized renewable power is becoming more popular in the power sector. Additionally, several classic static loads have become controllable, and new active agents have been raised with the aim of participating in grid management, such as electric vehicles or energy storage systems.
The potential contribution of smart grids to reduce the GHG emissions to net zero by 2050 according to EU targets [
1], through the integration of renewable energy sources (RES), is highly significant. To achieve the RES penetration target of close to 100% by 2050 [
2], these alternative resources will have to strongly support all aspects of the power system, from the stability of the network to the security of the electricity supply.
The majority of RES are connected to the grid through some kind of power electronic interface [
3], which allows the regulation of power delivered to the grid to achieve a balance between production and consumption.
However, as the power generated by RES is highly variable, operations aiming to balance generation and consumption may result in inefficient use of RES and oversized electronic interfaces. The use of software interfaces is possible for certain loads, which allows for controlling the power demand, raising new possibilities in the operation of electrical grids [
4].
These new technologies bring new challenges and problems to deal with, such as ensuring proper integration of RES and energy storage into the electrical smart grids; achieving dynamic state estimation and observability of the novel smart power systems; taking advantage of existing and innovative technology and data efficiently and optimally; designing novel tools for stability and analysis development; and ensuring information exchange [
5].
In this context of smart grids, this study aimed to cover a key research challenge in the field, such as the development of a knowledge-based system based on neuro- fuzzy and scheduling technics, in order to ensure the optimal use of energy from RES. Within this hybrid approach, the proposed explainable system considered the complex interrelation between power generated from RES in a smart grid and load prosumers’ (producers and consumers of energy from RES) behaviors. Precisely, the smart grid represented in this research is a household with an installed power system based on photovoltaic panels.
This manuscript is organized as follows.
Section 2 describes the clustering and classification framework, which supposes the identification of the proper machine learning techniques for the classification and clustering of load prosumers’ behaviors.
Section 3 introduces the mathematical formulation of the energy from the RES scheduling approach, correlated with the types of appliances used by prosumers.
Section 4 describes the convergence of the proposed knowledge-based system with the main goal of the research. The efficiency of the proposed scheduling strategy relies on the numerical results computed using a real data benchmark, for two case studies. Finally, this study is concluded with
Section 5.
2. Clustering and Classification Framework
2.1. Clustering Concept
Clustering means grouping data on the basis of information found in the data, in order to describe a process or the relations created inside of them. The idea is that the information within a group should be similar to one another and distinct from, or unrelated to, information from other groups. The more distinct or better the clustering, the more homogeneity or resemblance there is within a group, and the larger the contrast across groups.
There are many types of clustering: hierarchical, partitioned, exclusive, overlapping, or fuzzy. The definition of a partitioned clustering is the division of a data collection into distinct, non-overlapping clusters where each data set is contained inside a single subset. A hierarchical clustering, or collection of hierarchical clusters arranged as a tree, is what we obtain when a cluster includes two sub-clusters. With the exception of the leaf nodes, every node in a tree is the union of its branches. The definition of partitioned clustering is the division of a data collection into distinct, non-overlapping clusters, where each data set is contained inside a single subset. A hierarchical clustering, or collection of hierarchical clusters arranged as a tree, is what we obtain when a cluster includes two sub-clusters. With the exception of the leaf nodes, every node in a tree is the union of its children. The hierarchical approaches can be further divided into agglomerative and divisive algorithms, corresponding to bottom-up and top-down strategies, to build a hierarchical clustering tree. The most frequently used agglomerative algorithms use data points that have been combined to create a clustering tree that ends, comprising just one cluster: the entire data set. The clustering tree can be used to interpret the data structure and estimate the number of clusters [
6,
7].
A data collection is divided into numerous clusters by partitioned clustering algorithms, usually through attempts to minimize some criterion or error function. Usually predetermined, the cluster count can also be included in the error function [
8]. The partitioned algorithm can be repeated for a set of alternative cluster sizes if the number of clusters is unknown where the number of samples in the data set is. The advantage of partitive methods over hierarchical ones is that they are independent of previously identified clusters. Similarly, partitive methods rely on clusters as implicit assumptions. Each object is assigned to a single cluster via exclusive clustering. An overlapping or non-exclusive clustering is used, in the largest context, to reflect the fact that an object may simultaneously belong to multiple groups.
Fuzzy clustering [
9,
10] is a generalization of crisp clustering, where each data sample belongs to exactly one cluster. In this case, each sample is a member of each cluster to a different membership degree. The probabilities must also add up to 1 in probabilistic (crisp) clustering, which calculates the likelihood that each point belongs to each cluster. Moreover, clustering can be based on a variety of models [
11].
2.2. Clustering Based on Self-Organizing Maps Neural Networks
A neural networks’ self-organizing maps (SOM) consist of a standard grid of map units, which are often in two dimensions. A prototype vector with the input vector dimension represents each unit. A neighborhood link connects the units to those that are next to them. The accuracy and generalizability of this form of neural network are mostly dependent on the number of map units, which typically ranges from a few dozen to several thousand (NN) [
12].
This paper focused on a self-organizing neural network, due to its good capabilities in clustering approaches. It is very useful for data visualization, since the representation in space of the grid, facilitated by its low dimensionality, reveals a great amount of information about the data. On the other hand, SOMs have the ability to convert the nonlinear statistical relationships between high-dimensional data into the simple geometric relationship of their image points on a regular two-dimensional grid of nodes; the map generated can be used for the classification and visualization of high-dimensional data [
13]. Unlike many other types of NNs, an SOM does not need a target output to be specified. Instead, where the node weights match the input vector, that area of the lattice is selectively optimized to more closely resemble the data for the class. From an initial distribution of random weights, and over many iterations, the SOM eventually settles into a map of stable zones. Each zone is effectively a feature classifier.
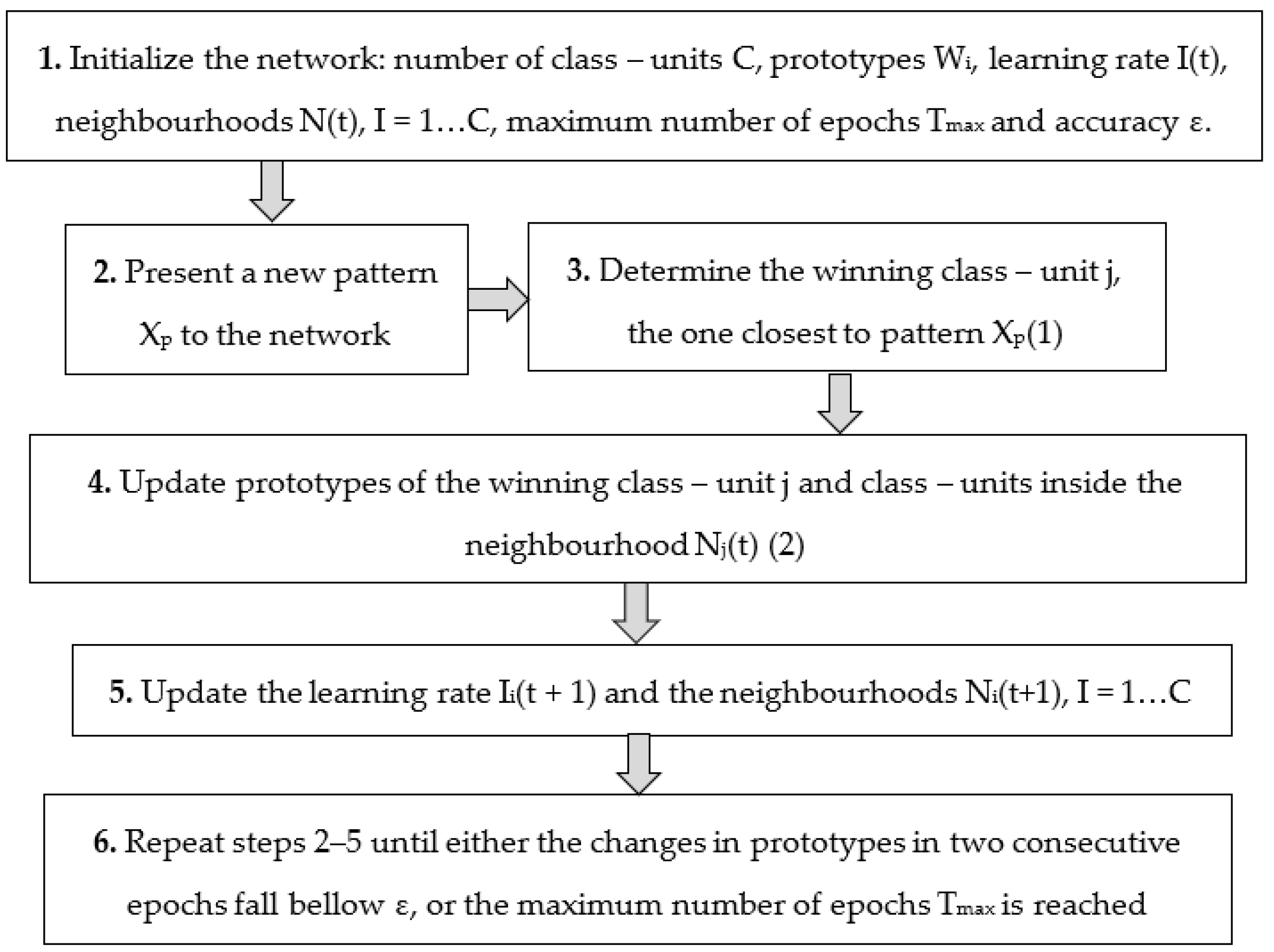
For SOM training, the standard Kohonen learning algorithm is usually used. It is an unsupervised, iterative training process, and produces a vector quantizer by updating the prototypes of the class units. At each training step, a sample vector is randomly chosen from the input data set, and the distances between and among all of the prototype vectors are computed. Then, the best-matching unit (BMU) is computed, and the prototype vectors are updated. Then, the BMU and its topological neighbors are moved closer to the input vector in the input space.
The Kohonen algorithm steps are presented in
Figure 1.
The notations used in the algorithm are computed, as shown in Equations (1) and (2):
The SOM training algorithms apply to large data sets. A flexible net is created by the SOM during training, and is folded onto the input data “cloud.” Onto adjacent map units are mapped data points in the input space that are close to one another. Therefore, the SOM can be thought of as a topology-preserving mapping from the input space onto the 2D grid of map units.
As just the prototype vectors and the current training vector need to be stored in memory, the computational complexity scales linearly with the number of data samples. It can also be implemented in parallel and in a neural, online learning environment. The complexity increases quadratically as the number of map units grows [
14,
15].
The requirement for a priori knowledge of the number of classes to be divided throughout the classification process makes the typical Kohonen algorithm challenging.
2.3. Clustering Based on Fuzzy Inference Systems
Fuzzy inference systems (FISs) are intelligent technics that are able to capture human behavior and consider its adaptive characteristics. FISs consist of the fuzzified, the rule base, the fuzzy inference engine, and the defuzzyfier.
Fuzzyfication consists of decomposing data inputs into one or more fuzzy sets. Each data set is associated with one membership function, which can be triangular-, Gaussian-, or trapezoidal-shaped. This process allows the system inputs to be expressed in linguistic terms, and not as integral–differential equations or models traditionally used in systems theory. Therefore, the universe of discourse of the crisp input variables is converted by these membership functions. The inference engine determines how the fuzzy logic operators (or, and, sum, prod) are performed. To express the linear or nonlinear relationships identified in the analyzed system, the inference uses fuzzy IF–THEN rule types. These can be applied simply, and together build the knowledge base/rule base. There are two important types of inference: Mamdami and Sugeno [
16], which compute the output of each rule. The defuzzification module converts the outputs of inference to crisp values using different methods: center of gravity, weighted average, and so on [
17].
An FIS can start to classify the environment on behalf of the human, according to his desires, once the clustering algorithm integrated has extracted the membership functions and the set of rules from the user input/output data.
The Fuzzy-C-Means (FCM) [
18,
19,
20] is a fuzzy clustering approach that extracts fuzzy membership functions from user data, using fuzzy partitioning prototypes. It uses a set of instances with r attributes that have been arbitrarily grouped into p clusters, reflecting a data set that is partitioned into r parts. Then, the centers for each cluster are determined by the algorithm which uses the instances that were arbitrarily labeled. In order to assign each instance with a degree of membership to each cluster, these centers are used to calculate the distances of each instance from each cluster center. The dataset’s division becomes fuzzified in this way.
In order to reduce the dissimilarity function between data points and cluster centers in the training data set, this approach attempts to repeatedly change the data set’s partitioning. FCM evaluates the separation between the clusters using the r-dimensional Euclidean features.
This fuzzy clustering algorithm was chosen as a result of its ability to operate on fuzzy data, in which a data point may, at any given time, have a degree of fuzzy belonging to more than one cluster. When the goal is to create models at a specific level of information granulation that can be described in terms of fuzzy sets, this is a quick and efficient method for generating fuzzy information functions from user data [
21,
22,
23]. In addition, FCM proved to be effective in dealing with a variety of highly complex problems, such as energy scheduling in smart grids that integrate photovoltaic panels [
24,
25,
26], due to their generalization features and their ability to take into consideration consumers’ energy preferences.
In our approach, we measured, with the help of smart metering instruments, the amount of energy from RES consumed by a series of programmable interruptible consumers in the house, i.e., a washing machine, dishwasher, and air conditioner, to obtain profiles of electric energy consumers, for each day of the week. The result of these computations was a database of daily profiles used for training two SOM architecture types (SOM1 and SOM2) and the FCM algorithm. These structures were then tested to classify new load profiles (see
Figure 2).
3. Energy from Renewable Sources Scheduling Approach
3.1. Classification of Appliances Load Profiles
In this research, the considered smart grid was represented by a household with an installed power system based on photovoltaic panels of 3.3 kW (see
Figure 3), smart loads, and with the possibility of operating, due to the existing connections, on grid or off grid.
Table 1 lists the specifications of the 12 incorporated Luxor ECO LINE P60-275W PV panels (Luxor Solar, Stuttgart, Germany). The system that allowed for energy exchanges with the power national grid contained a Huawei SUN2000-3KTL inverter (Huawei, Shenzhen, China).
The considered solar panel system was installed in March 2021. The first eight years of use were the time frame for which the PV module manufacturers guaranteed at least 85% of their initial performance.
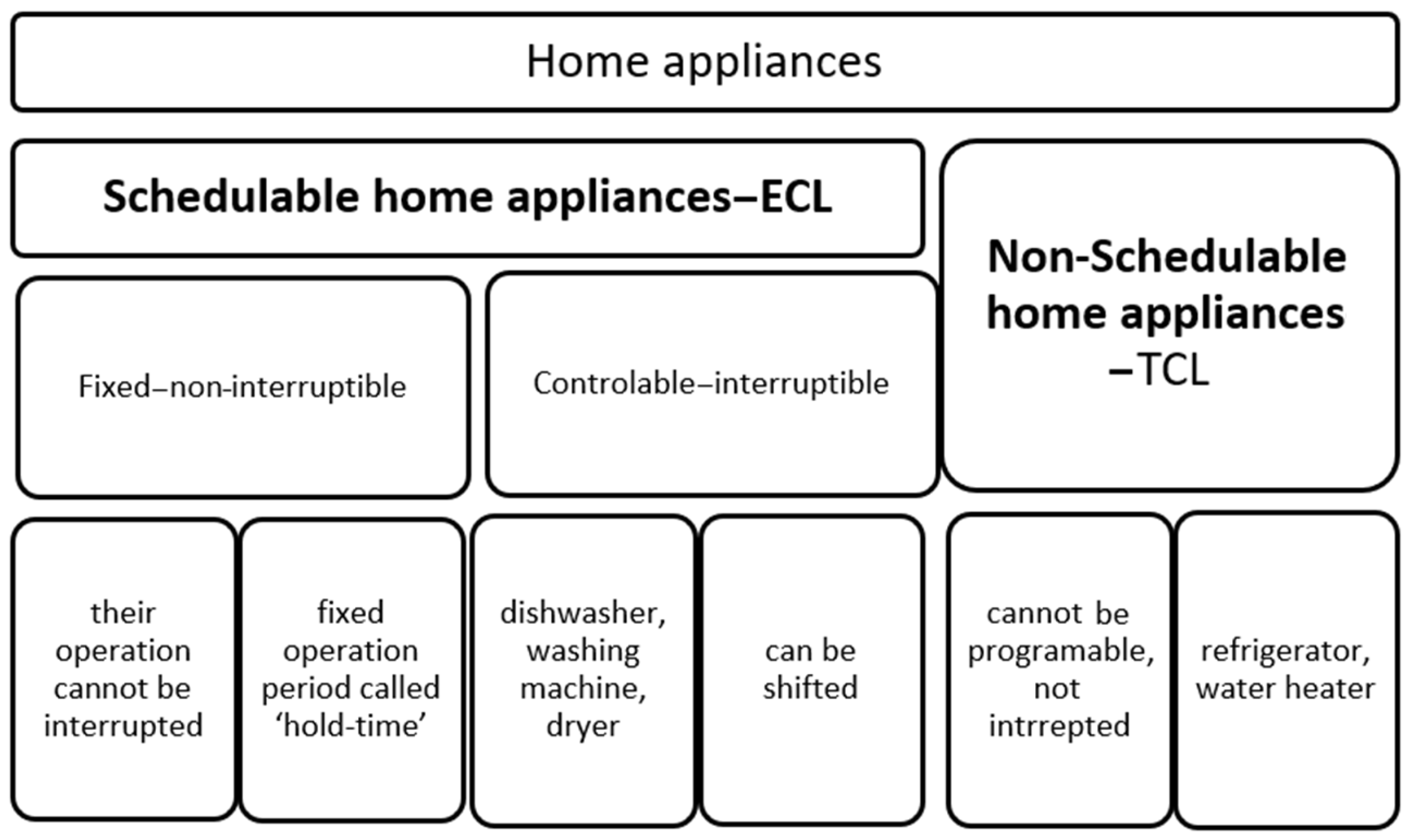
In the scientific literature [
27], the concept of smart loads is associated with appliances in a smart home that can be controlled or not. Based on this clustering criteria, we identified in [
28] a classification of these in non-schedulable (TCL) and schedulable home appliances (ECL) (see
Figure 4).
The non-schedulable loads can be controlled manually by prosumers. This aspect often interferes with the comfort level of their users, who have to move for action; for this reason, sometimes the TCL’s operation can be delayed.
In the other clusters of appliances are the loads which can be scheduled, such as air conditioners and water heaters [
29]. The continuity, in terms of operation time, represents the second criteria based on which ECLs can be classified as being interruptible (controllable) and non-interruptible or hold-time appliances (fixed).
The total energy (
), consumed at each time slot
t by fixed appliances (
, controllable appliances (
), and non-schedulable (
), can be calculated using Equation (3):
Our research study considered the appliances mentioned in
Table 2, the washing machine and the dishwasher, because of their ability to be shifted fully, or to be on certain operation cycles, for a run at later intervals.
Table 2 presents the home appliances that were considered in our approach, whose specific characteristics were proposed in [
28], including the load type, and the power consumed (kW).
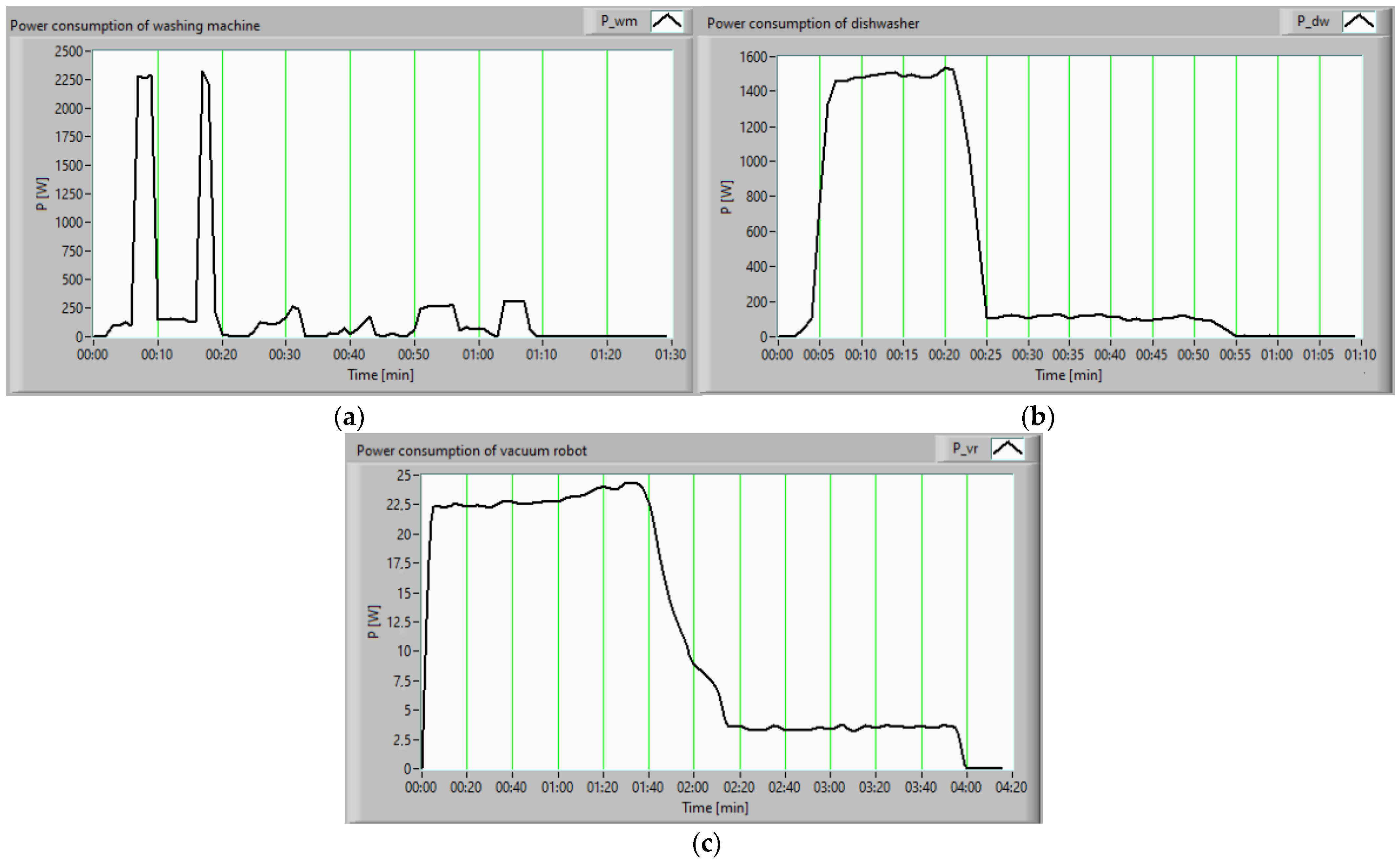
The consumption profiles of the washing machine, dishwasher, and vacuum cleaner, represented in
Figure 5a–c, allowed us to program them with the help of shift algorithms, so that the energy produced from RES at different times of the day could be utilized to the maximum.
3.2. Smart Home Energy Scheduling
Finding the lowest-cost schedule to process a series of orders, indicated with I, using a set of dissimilar parallel controlled or uncontrolled home appliances, denoted with M, was the approach used to solving the scheduling of home appliances problem.
The processing of the order i ∈ I must start just after scheduled release ri, and finish no later than the due date di. Every one of the appliances can process order i.
The order i ∈ I on appliance m ∈ M processing costs and times, in relative terms, are Cim and Pim. As a result, the goals may be formulated as follows: to reduce the processing costs of all of the orders, the important decisions in this scheduling problem are the assignment of orders to appliances, the order in which orders are placed on each appliance, and the start time for all orders.
Given a set of electrical tasks to be distributed throughout N
TIME time samples (e.g., the appliance begins), the energy scheduling problem [
28] can be represented in this approach (see Equation (4)) as the minimization of a cost function:
where
expresses whether or not a task is running at time;
is the energy cost at time
i;
is the power consumed by the task in time interval
i.
With regard to the total power used at each time and the lack of interruptions for each activity, the following restrictions (Equations (5)–(7)) are specifically placed on this minimization problem [
29,
30]:
According to a predetermined policy, the shiftable tasks can set to 1.
We consider Equation (8) one per shiftable load
k:
where
is the PV production at time
i;
is the averaged consumption profile for the considered day of the week;
is the computed averaging of the last 10 days, excluding the power consumed by the shiftable loads.
Then, as Equation (9) indicates, we must determine when to begin the task in order to minimize costs:
where
is the power consumed by the load at relative time
j; is the energy cost;
is the total cycle time of the load.
Our experimental strategy was based on this algorithm, which schedules smart home users to best optimize their usage of energy from renewable sources against that from the national energy grid.
4. Neuro-Fuzzy Knowledge-Based System
4.1. Design of Neuro-Fuzzy Knowledge-Based System
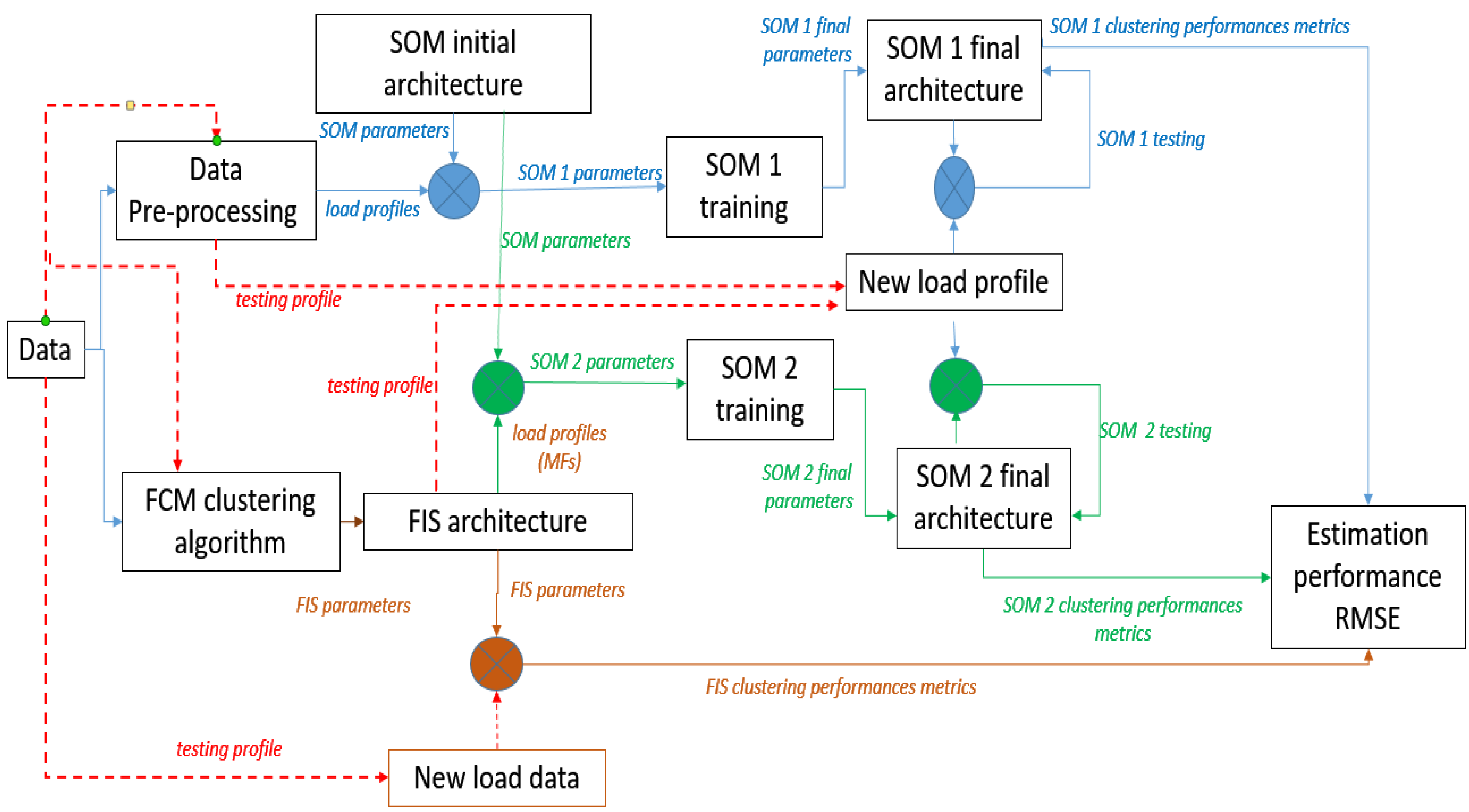
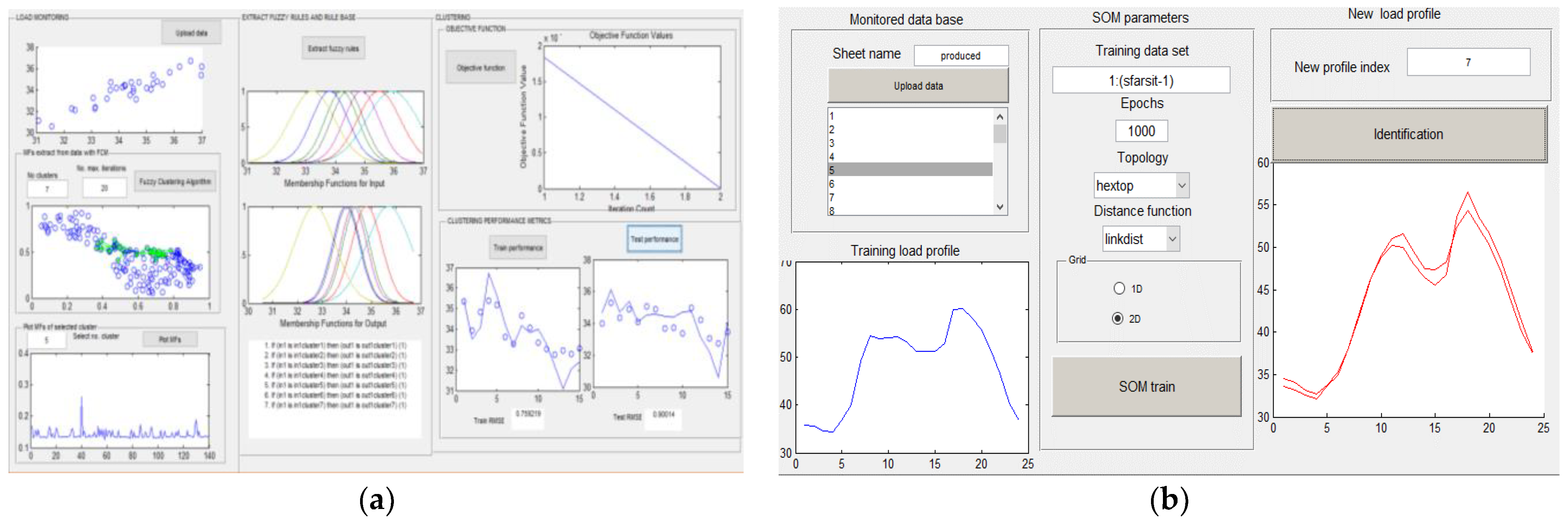
The data monitored related to the load’s values, saved in .dat or .xls format, and correlated with the day of the week, were used by the FCM algorithm to extract the MFs associated with the number of clusters, in a maximum number of iterations. The second step of modeling and simulation was dedicated to the automated extraction of fuzzy rules based on the MFs associated with the clusters, and to the design of a fuzzy rule base. The rules were represented in verbose format, based on the use of linguistic expressions. Then, the root mean square error (RMSE) was computed, and a training and testing phase of the clustering was conducted about the objective function. The FCM was based on an iteration loop built on top of the following routines: initializing the problem, computing Euclidean distance n, and performing one iteration of clustering (see
Figure 6a).
On the other hand, the initial stage in the Kohonen SOM example was architecture parametrization, which included the topology, training epochs, training data set, distance function, and grid representation. The load profiles of the customers were then classified in the testing and evaluation phases. The user had the possibility of selecting actual consumer profiles to upload from the monitored database for the SOM data training set. The user could also set the number of epochs that the training algorithm ran in the neuro-fuzzy system interface. The application provided the ability to assess and visually display the network’s performance progres-sion after training, including topology, neighbor connections, neighbor distances, sample hits, and SOM weight positions (see
Figure 6b). The neuro-fuzzy knowledge-based system is shown in
Figure 6.
4.2. Simulation and Testing of Neuro-Fuzzy Knowledge-Based System
Firstly, we evaluated the clustering performances of the SOMs by changing the data used for their training. An initial architecture was considered (SOM initial architecture). For this architecture, in the training we used the profiles obtained that were presented in
Section 3.2.
The SOM architecture was trained using weight and bias learning rules with batch updates. Weights and biases updates occurred at the end of an entire pass through the input data. Training stopped when the maximum number of epochs (repetitions) was reached. This number was changed to visualize the performances of the SOMs in this stage.
When the training stopped, the SOM with the best parameters (topology and distance function) was selected as SOM1 (see
Figure 2). In our case, the hexagonal topology and the link distance function had the best performances in clustering. On the other hand, for training we used the profiles obtained with the help of FCM clustering, an algorithm presented in
Section 4.1. The SOM architecture, after training, became SOM2 (see
Figure 2).
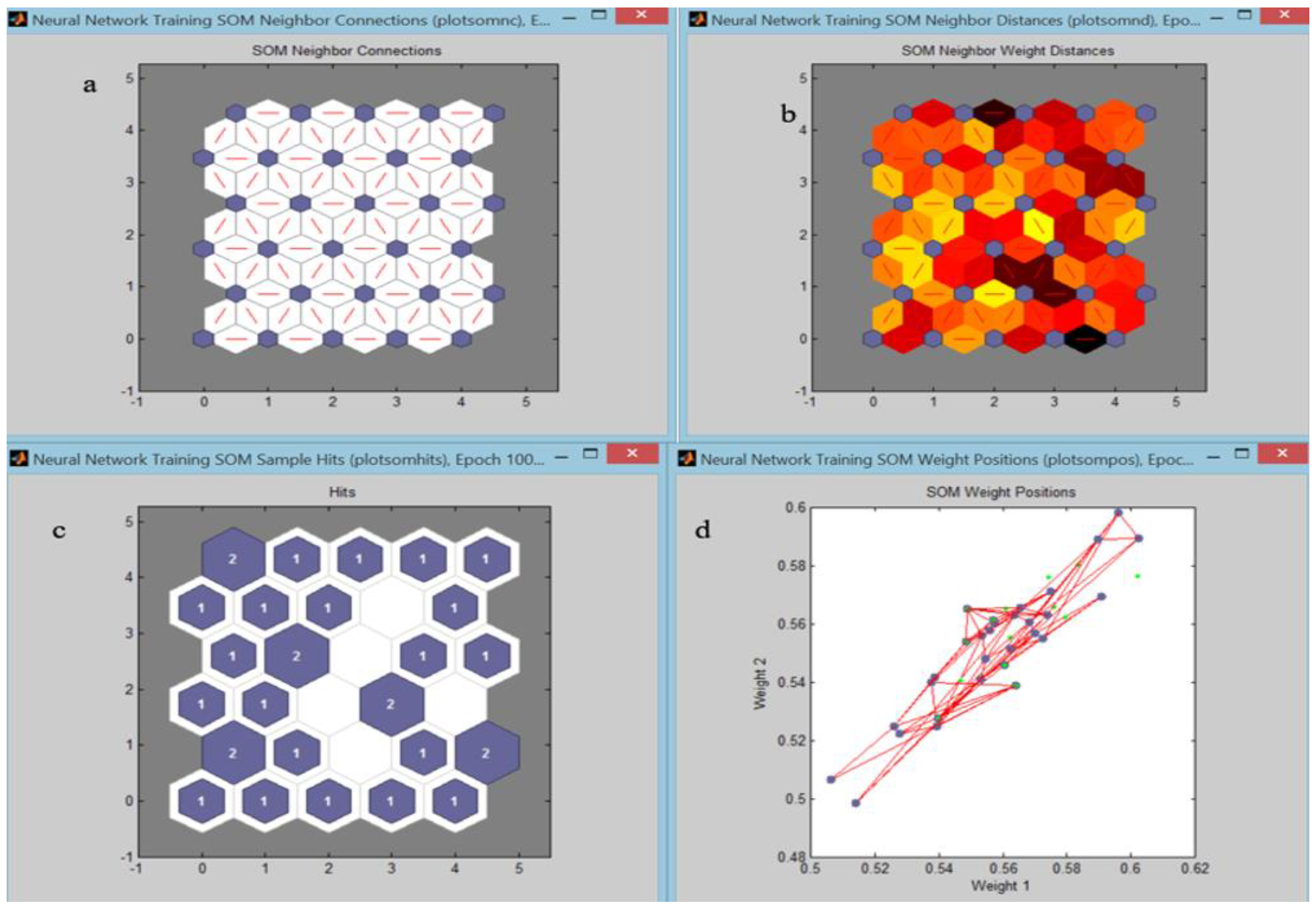
The proposed neuro-fuzzy tool provided the possibility to evaluate and visualize the progress of the SOM network’s performances for neighbor connections, neighbor distances, sample hits, and SOM weight positions. To evaluate these performances, in the testing phase, SOM1 and SOM2 received a new profile that was not considered in the parametrization or learning phases (
Figure 7b).
Figure 7a shows the SOM layer, with neurons as gray-blue patches, and their direct neighbor relations with red lines. The SOM had a two-dimensional topology, and the relationships among the cluster’s centers can be visualized in the weight distance matrix (called U- matrix) (
Figure 7b). The blue hexagons represent the neurons; the red lines connect neighboring neurons.
The colors in the regions containing the red lines indicate the distances between neurons. The darker colors represent larger distances, and the lighter colors represent smaller distances. A band of dark segments crosses from the lower-right region to the upper-center region.
The relative number of vectors for each neuron is shown via the size of a color patch (
Figure 7c). It plots an SOM layer, with each neuron showing the number of input vectors classified.
Figure 7d plots the input data along the weights. The input vectors are represented as green dots, and show how the SOM classified the input space by showing blue-grey dots for each neuron’s weight vector, and connecting neighboring neurons with red lines.
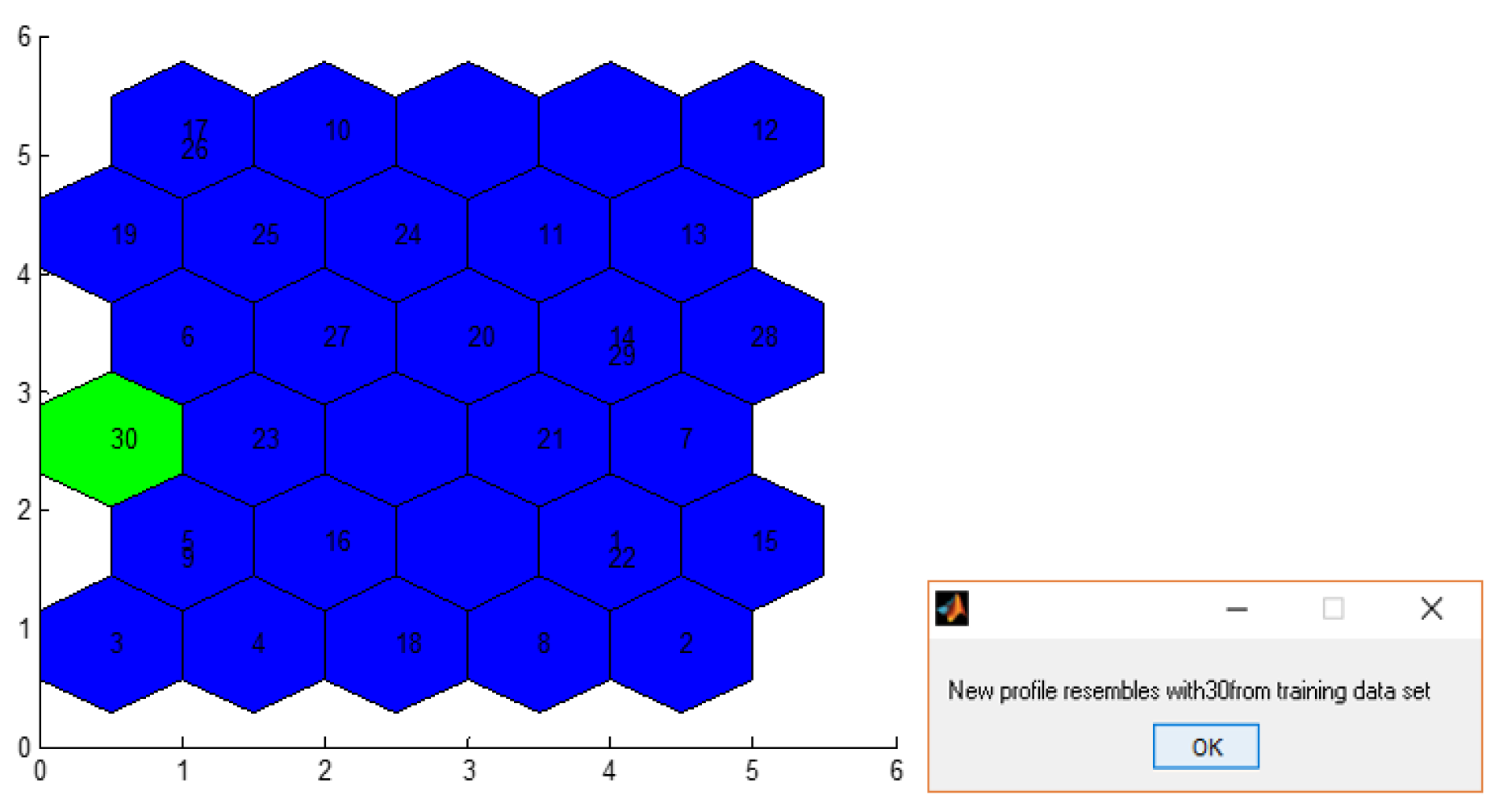
Since SOM training did not need a target output to be specified, unlike many other types of neural networks, as a metric of SOM performances is considered the winning node (best matching unit—BMU), which is calculated and displayed in green color in
Figure 8.
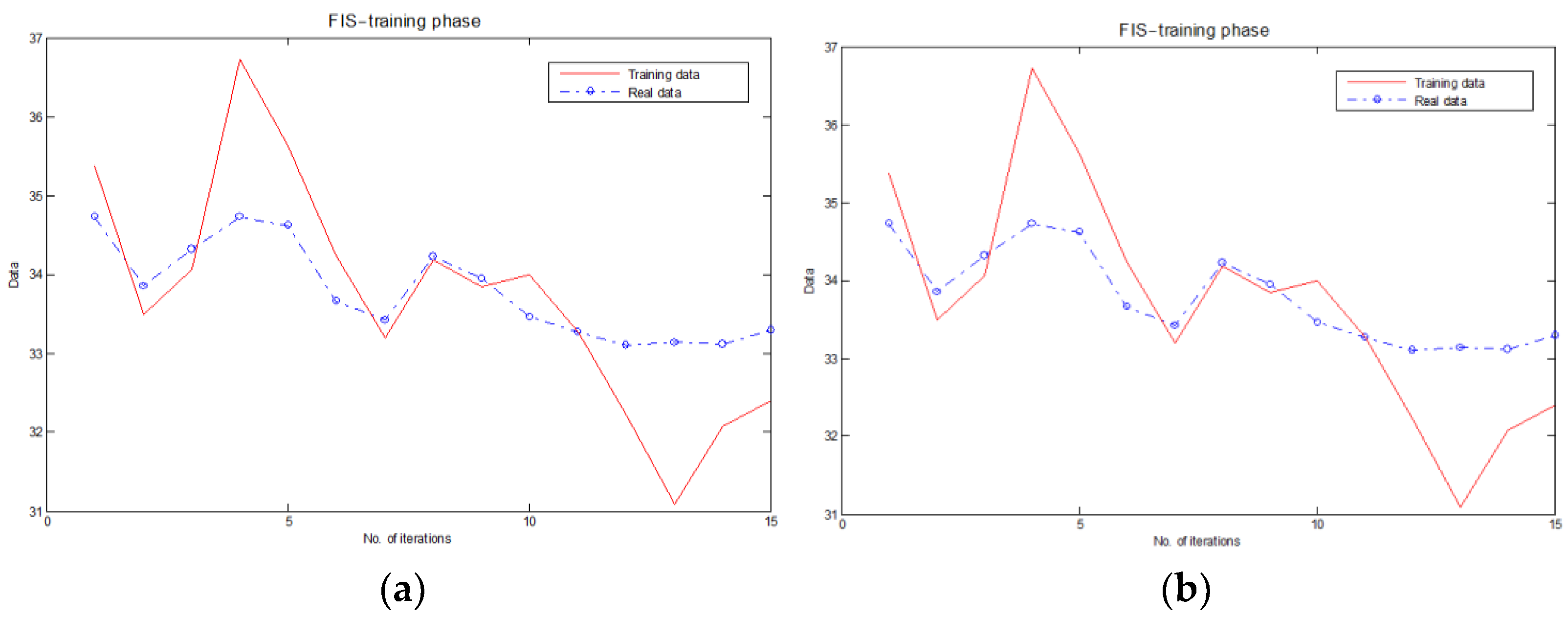
Secondly, we compared the performances in clustering of SOM1, SOM2, and FIS. The data flow, described in the scenario presented above, was the same. In addition, we could visualize the progress of the FIS with the FCM clustering process as an objective function. At each iteration, the FCM algorithm minimized this function to find the best location for the clusters, and its values were returned in graphical format. The progress of FIS errors, in the training and testing phase, are presented in
Figure 9a,b.
The research allowed us to identify the strengths and the weaknesses of each clustering method used. Thus, the FCM and SOM tended to do well only for a small number of clusters and/or a fixed number of samples. Increasing the number of samples from 100 to 300 usually improved the error rate a little. The learning algorithms implemented in the SOMs proved to be poor for improving the error rate, from an RMSE = 0.65 to an RMSE = 0.50 when additional samples were used. The FCM algorithm showed a more significant improvement, from an RMSE = 0.71 to an RMSE = 0.48.
The errors increased in magnitude with the number of clusters, and with dimensions of high classes.
This type of neural network is mainly used in data visualization, since the representation in space of the grid, facilitated by its low dimensionality, reveals a great amount of information on the data.
4.3. Scheduling of Loads for Optimal Use of Energy
This part is dedicated to the implementation and analysis of the proposed approach related to the scheduling algorithm. For this proposition, the reference consisted of available data sets that were relevant to the amounts of energy produced from RES: the 2 February 2023 (scenario 1), and the 5 January 2023 (scenario 2).
In both scenarios, the identified load profile with the neuro-fuzzy knowledge-based system and the energy generated by the RES were considered to be references.
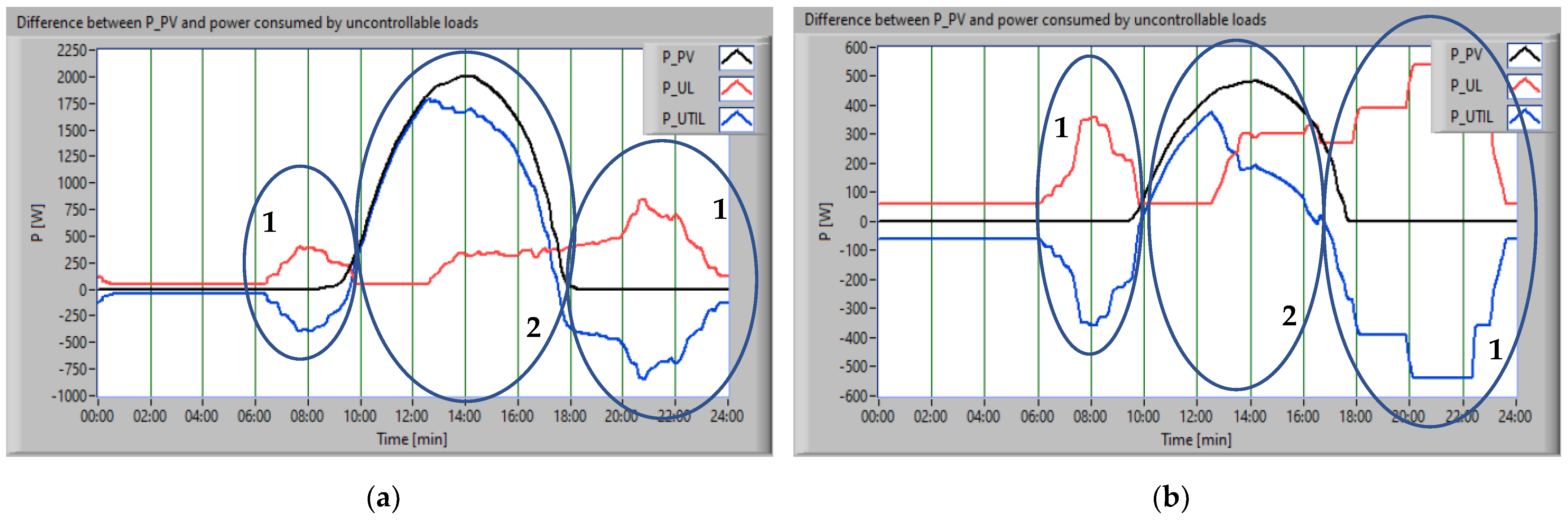
From the analysis of the consumption profiles associated with uncontrollable consumers (P
UL) and that of the energy produced from RES (P
PV), a gap could be observed between the moment when the energy was produced and the real initial behavior of the consumers, in the absence of scheduling. The difference (P
util) was more evident in the case of the second scenario, when the amount of energy produced was smaller (Equation (10)).
The scheduling approach firstly considered the constraint related to uncontrollable loads supply with energy from the RES. Thus,
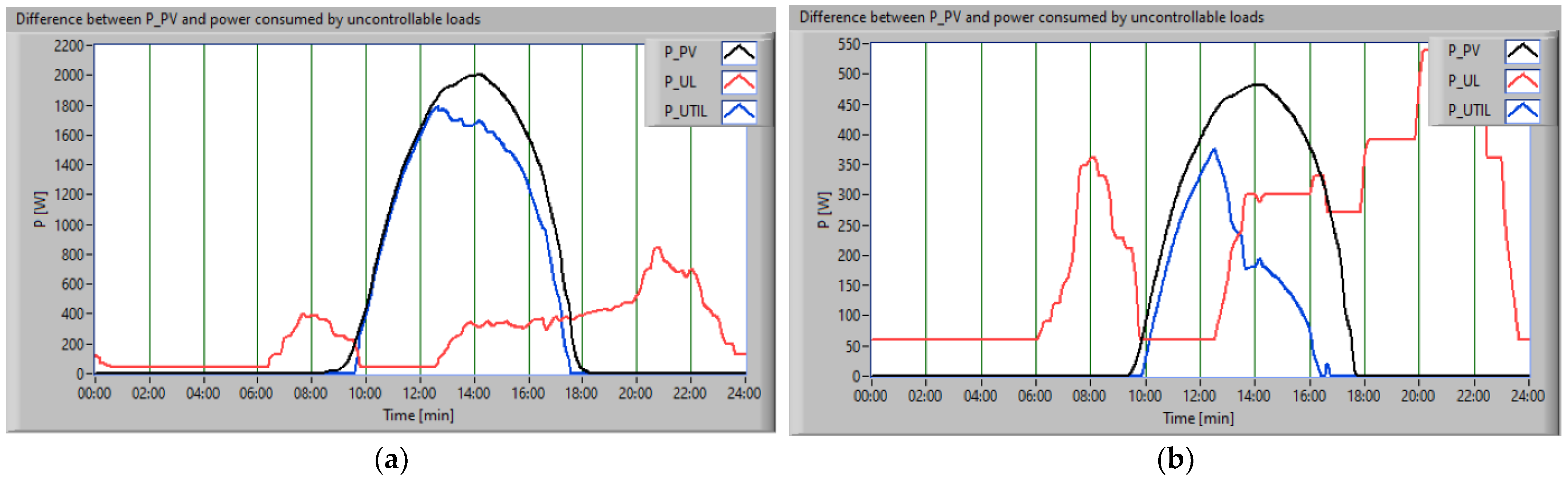
Figure 10 presents the P
PV (black), the consumption of uncontrollable loads (red), and the difference between power and consumption (blue), for both scenarios.
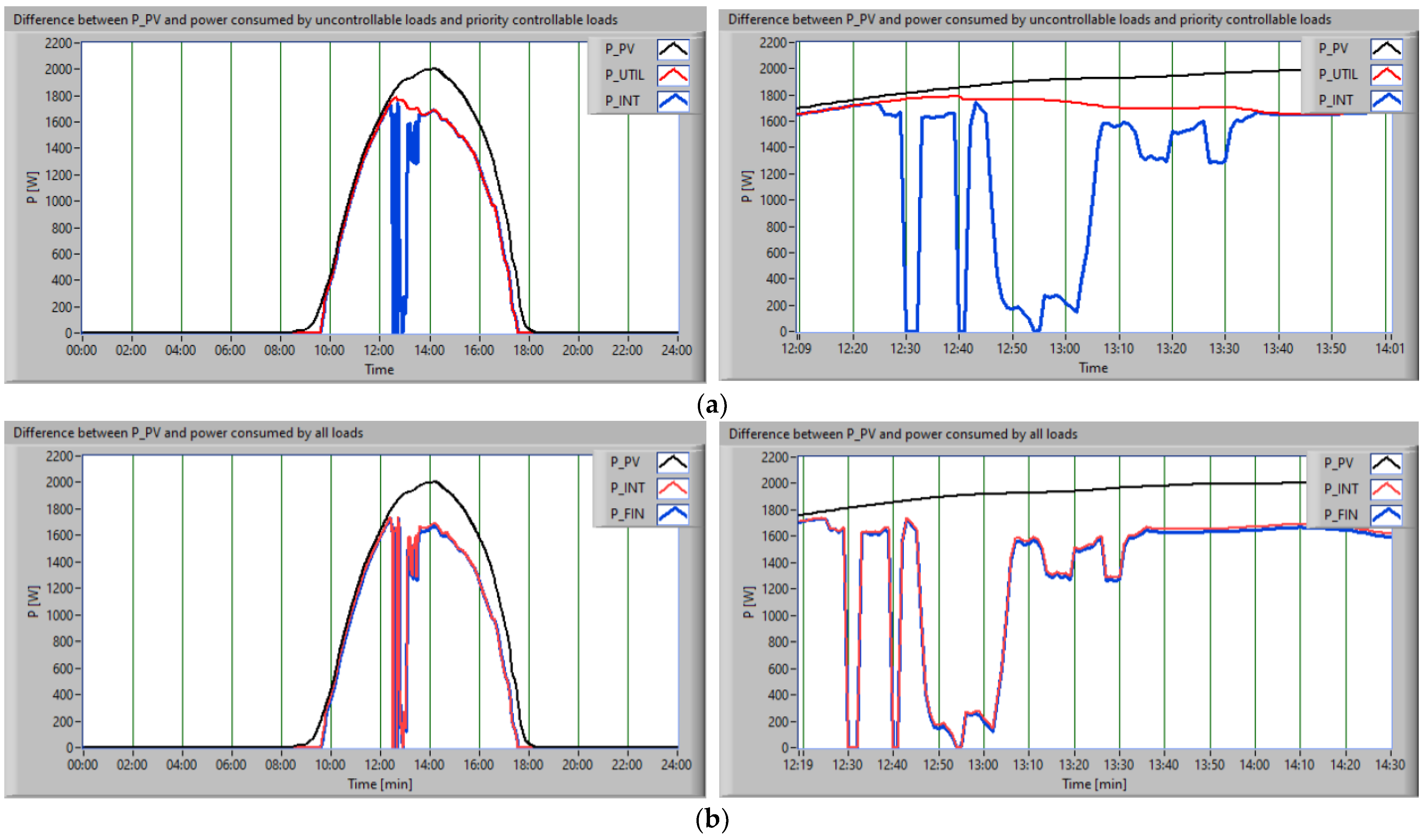
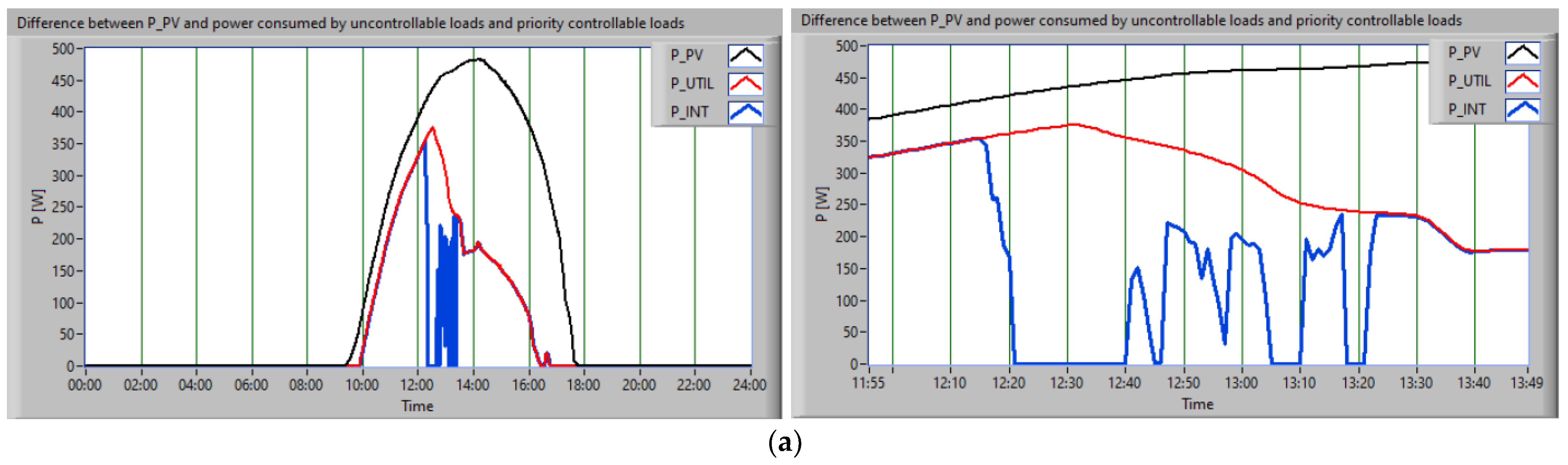
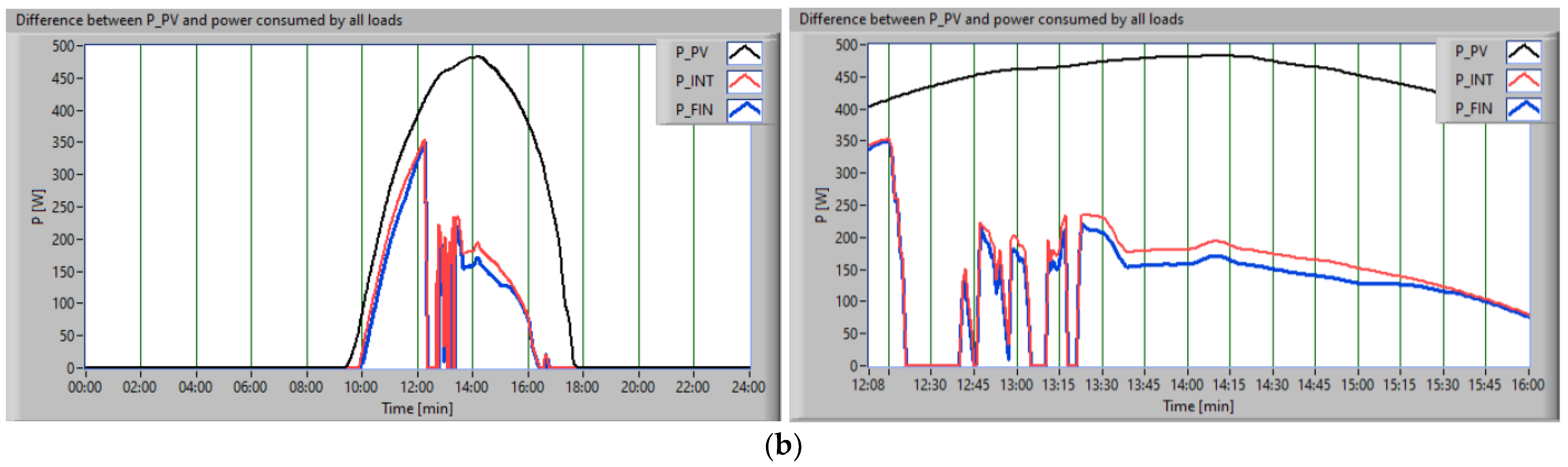
The application of a scheduling approach involved the association of loads with priority levels, as follows: the uncontrollable consumers were satisfied initially, then the consumer with the highest priority was the washing machine, due to its characteristics mentioned in
Section 3.1 (
Figure 11a, the red profile), then the dishwasher (
Figure 11a, the blue profile), and the mobile vacuum cleaner (
Figure 11b, the red profile).
Figure 12 shows, for the second scenario, the scheduling of the amount of energy. In black is represented P
PV; in red is the difference between the P
PV, uncontrollable loads, and the washing machine consumption; and in blue is the amount of energy available after the dishwasher supply (
Figure 12a).
The next stage of implementation of the proposed algorithm consisted of supplying with energy from the RES an interruptible controllable consumer whose operation could be interrupted, that is, the vacuum cleaner (
Figure 12b).
Following the analysis of the results obtained by applying the scheduling algorithm, three distinct cases were identified. The first case was associated with the night–morning time period when, due to the degree of occupancy of the house and due to the routine of its occupants, the amount of energy consumed by uncontrollable consumers exceeded the smaller amount of energy produced from the RES. The second situation concerned the afternoon period when, due to atmospheric conditions, we had a surplus of green energy. The last case was assigned to the evening–night period when we had a reduced amount of green energy produced, and a higher consumption.
Figure 13a. illustrates how the national grid supplies any excess energy when it is utilized beyond that produced by RES (Situation 1). In both cases, it is desirable to turn on the controlled loads when there is an excess of energy produced by the photovoltaic system (Situation 2).
As opposed to the first scenario, the amount of green is considerably less in the second scenario, shown in
Figure 13b; this is because of the characterisics of weather in January: there are significantly fewer sunny days. As a result, the optimization strategy took longer, and there were more periods when loads needed to be sorted via the proposed algorithm.
5. Conclusions and Research in Progress
The objective of this research was to create a knowledge-based system, based on neuro-fuzzy and scheduling techniques, capable of ensuring the best use of en-ergy from RESs. The incorporation of tools based on neuro-fuzzy technology ensured the best possible distribution of green energy generated in a smart grid, which was represented by a household with a photovoltaic power system already installed.
The context of smart grids integrating renewable energy sources, as well as the dif-ficulties and prospects in the area, were described in the article’s introduction.
This article’s second topic dealt with clustering and classification techniques. As a result, the neuro-fuzzy tools were chosen as the strategy suitable for estimating load consumption habits.
In the third portion of the study, an algorithm for energy scheduling in a smart house was integrated into the spe-cific context of a smart home that had an installed power capacity of 3.3 kW.
The hybrid system was introduced and tested in the fourth portion of the research. Its validation was completed, using an actual database. The data were observed between the 2nd of February and the 5 January 2023, for two representative days in terms of the energy from RES produced and consumed. The find-ings acquired and provided in
Section 4.3 served as evidence of the suggested algorithm’s usefulness.
The research reported here lacks a cost-based analysis of the sustainability of the smart grid system. This type of analysis should consider different sizes/technologies of PV panels integrated into smart grids, or different numbers of smart loads to shift. The cash inflow is directly impacted by the annual directly saved energy by self-consumption, the net metering contribution, and government contributions (eventual feed-in tariff tax deductions). Furthermore, the cash outflow depends on the investment costs of the smart grid and the annual maintenance costs. The maintenance costs for a residential plant are very low in comparison with the initial investment afforded, being equal to 0.5% of the initial investment cost.
All of these financial aspects related to the difference between the discounted annual cash inflows and outflows were difficult to quantify for reporting. The limitation is due to a series of factors that we could not quantify: incomplete national legislation regarding prosumers, a dysfunctional liberalized green energy market, and a compensatory green certificate system that has not yet been implemented.
All we can assume is that for the smart home’s operational scheduling, the total daily net cost, i.e., costs for acquiring electricity from the grid minus revenues from selling renewable electricity to the grid, results in some revenues.
However, the case study was conducted on a single-family smart home with an in-stalled renewable energy capacity of 3.3 kW, and this framework placed a cap on the number of controlled loads that could be chosen. The National Energy Strategy, which provides a subsidy for this purpose and supports the installation of photovoltaic systems with an installed capacity of 3.3 kW in single-family homes, also established the framework. Finding energy management solutions for smart houses that guarantee the largest percentage of consumption from the homes’ own production is, therefore, of greatest importance.
The proposed smart grid that integrated PV panels can be upgraded with energy storage capacities so that the approach can involve multi-objective optimization. Furthermore, a future research approach that we want to address is the analysis of scheduling algorithm convergence times, and the carbon footprint that the implementation of the proposed neuro-fuzzy hybrid system generates.




 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}