1. Introduction
With the gradual depletion of fossil fuels and the continuous increase in energy demand arising from human societal development, wind power has been extensively developed and utilized as a renewable energy source in recent years [
1]. According to the “Global Wind Report 2023” released by the Global Wind Energy Council (GWEC), global wind power added 78 GW of installed capacity in 2022, reaching a total installed capacity of 906 GW [
2]. Wind speed is the primary factor affecting the operational characteristics of wind turbines, and its randomness, intermittency, and volatility pose a significant challenge for the optimal operation of wind turbines [
3,
4]. Accurate forecasting of the distribution characteristics of short-term wind speeds is an effective means of improving the safety and economic efficiency of wind turbine operations.
Based on the different timescales of wind speed forecasting, time series wind speed forecasting can be divided into three categories: ultra-short-term forecasting, short-term forecasting, and medium-to-long-term forecasting [
5]. Time series wind speed forecasting methods can be classified into statistical forecasting methods, artificial intelligence forecasting methods, and hybrid forecasting methods based on the forecasting mechanism employed [
6,
7]. Statistical forecasting methods use statistical models to extract the historical features of time series wind speeds and forecast future wind speeds based on these features. Commonly used statistical forecasting models include the AR model [
8,
9], ARMA model [
10,
11,
12], and ARIMA [
13,
14,
15]. Statistical forecasting models exhibit good forecasting performance when the historical data are sufficient and relatively stable. However, their forecasting capability tends to degrade when dealing with incomplete historical data or non-stationary data. Especially with time series data with random distribution characteristics, the predictive performance of statistical prediction models is difficult to meet the prediction needs.
With the rapid development of artificial intelligence technology, its application to time series wind speed forecasting has received considerable attention in terms of research and applications [
16,
17]. Machine learning, with its strong capability for nonlinear mapping, has demonstrated excellent performance in wind speed forecasting [
18,
19,
20]. In a previous study [
21], a novel hybrid model was developed for short-term wind speed forecasting, and the calculation results illustrated that the proposed hybrid model outperformed single and recently developed forecasting models. A complete ensemble empirical mode decomposition with adaptive noise-least absolute shrinkage and selection operator-quantile regression neural network (CEEMDAN-LASSO-QRNN) model was developed for multistep wind speed probabilistic forecasting [
22], and the experimental results indicated a higher accuracy and robustness of the proposed model in multistep wind speed probabilistic forecasting. Yang et al. [
23] developed an innovative ensemble system based on mixed-frequency modeling to perform wind speed point and interval forecasting, and a multi-objective optimizer-based ensemble forecaster was proposed to provide deterministic and uncertain information regarding future wind speeds. The calculation results demonstrated that the system outperformed the benchmark techniques and could be employed for data monitoring and analysis on wind farms. Dong et al. [
24] proposed an ensemble system of decomposition, adaptive selection, and forecasting to simulate the actual wind speed data of a wind farm. The calculation results indicated that the proposed forecasting model had outstanding forecasting accuracy for time series wind speeds. Machine learning methods can explore the nonlinear relationships of data, but they cannot explore the spatiotemporal distribution characteristics between data, resulting in low accuracy of machine learning methods in predicting time series data.
Deep learning exhibits exceptional capabilities in nonlinear mapping and time series data analysis, leading to superior performance in time series wind speed forecasting [
25,
26]. For instance, Lv et al. [
27] applied a deep learning model to forecast time series wind speeds after removing data noise. The computational results demonstrated that the proposed method could accurately forecast time series wind speed sequences. A dynamic adaptive spatiotemporal graph neural network (DASTGN) was proposed for forecasting wind speed, and extensive experiments on real wind speed datasets in the Chinese seas showed that DASTGN improved the performance of the optimal baseline model by 3.05% and 3.69% in terms of MAE and RMSE, respectively [
28]. A wind speed forecasting model based on hybrid variational mode decomposition (VMD), improved complete ensemble empirical mode decomposition with additive noise (ICEEMDAN), and a long short-term memory (LSTM) neural network has also been proposed [
29]. By comparing and analyzing seven other forecasting models, the proposed model was found to have the best forecasting accuracy. Other studies [
26,
30,
31,
32,
33] have presented a novel transformer-based deep neural network architecture integrated with a wavelet transform for forecasting wind speed and wind energy (power) generation for 6 h in the future, and the calculation results demonstrated that the integration of the transformer model with wavelet decomposition improved the forecasting accuracy. A single deep learning model can only explore the distribution characteristics (spatial or temporal distribution characteristics) of a certain aspect of data, and cannot simultaneously explore the spatiotemporal distribution and coupling characteristics of data. Therefore, a hybrid forecasting model with spatial and temporal feature mining capabilities is an effective method to improve the accuracy of ultra-short-term wind speed forecasting.
Integrating the advantages of different deep learning models to construct hybrid forecasting models can effectively overcome the limitations of individual deep learning forecasting models and further improve wind speed forecasting accuracy [
34,
35]. A hybrid forecasting model was developed by combining the strengths of a convolutional neural network (CNN) model and a bidirectional long short-term memory (BiLSTM) model, and was then applied to short-term wind speed forecasting [
36,
37]. The computational results demonstrated that the hybrid CNN-BiLSTM forecasting model could accurately capture the spatiotemporal distribution characteristics of wind speed information, leading to a higher forecasting accuracy than that of individual deep learning models. Assigning different weights to multiple deep learning models for ensemble construction in short-term wind speed forecasting allows each model’s strengths to be fully utilized, thereby enhancing the overall forecasting accuracy of the ensemble model and expanding its practical applicability [
38].
Based on an existing study on wind speed forecasting, this study presents a forecasting model based on VMD-AOA-GRU for ultra-short-term time series wind speed (UTSWS). In the proposed model, historical wind speed data from wind turbines were first decomposed into different frequency sub-sequences using variational mode decomposition (VMD). Then, the arithmetic optimization algorithm (AOA) was utilized to optimize the temporal length of the training data for each sub-sequence and the hyperparameters of the forecasting model of the gated recurrent unit (GRU), such as the number of hidden neurons, training epochs, learning rate, and learning rate decay period, to improve the convergence speed and forecasting accuracy of the GRU model. Finally, the forecasting accuracies of various hybrid forecasting models were compared to demonstrate the superiority of the proposed algorithm.
Compared with existing wind speed forecasting models, our proposed model has the following advantages:
- (1)
A UTSWS forecasting model based on VMD-AOA-GRU is proposed.
- (2)
VMD is employed to extract high-frequency wind speed features from time series wind speeds.
- (3)
The hyperparameters of the GRU model are optimized using the AOA to construct a hybrid AOA-GRU model.
- (4)
The proposed model outperforms other models for the four wind speed datasets.
The remainder of this paper is organized as follows: In
Section 2, the principles of time series wind speed forecasting are introduced. The computational principles and decomposition process of VMD are presented in
Section 3. The computational principles and process of the AOA are described in
Section 4, including the calculation process for the accelerated function of the math optimizer, the global exploration phase, and the local exploitation phase.
Section 5 describes the construction process for the AOA-GRU hybrid model, including the principles of GRU and the construction of the AOA-GRU model. The construction and validation processes for the VMD-AOA-GRU model are outlined in
Section 6. In
Section 7, the multi-step forecasting results of various models are compared, including GRU, VMD-GRU, VMD-AOA-GRU, LSTM, VMD-LSTM, PSO-ELM, VMD-PSO-ELM, PSO-BP, VMD-PSO-BP, PSO-LSSVM, VMD-PSO-LSSVM, ARIMA, and VMD-ARIMA. The results of this study are summarized in
Section 8.
2. Principles of Time Series Wind Speed Forecasting
Wind speed sequences are essentially time series data, and for a specific wind farm, the wind speed time series can vary significantly under different climatic conditions. We assume that a set of real wind speed time series is denoted as
Ak = {
a1,
a2,
a3, …,
ak}, where
ak represents the wind speed at the
kth time step. Then, the wind speed,
ak+1, at the (
k + 1)
th time step can be calculated using Equation (1).
where
f(·) represents the forecasting model, and
k represents the length of the sliding time window.
Equation (1) expresses single-step wind speed forecasting. The principle of multi-step forecasting of time series wind speeds is similar to that of single-step forecasting. Taking two-step forecasting as an example, the wind speed,
ak+2, at time
k + 2 can be calculated using Equation (2).
In Equation (2), the wind speed sequence {
a1,
a2,
a3, …,
ak} is shifted one step to the left, and the forecasting value
ak+1 at time
k + 1 is then added to the wind speed sequence as an input to the forecasting model. Similarly, the predicted value
ak+n at time
k +
n can be calculated using Equation (3).
As indicated by the above equations, in time series wind speed forecasting, as the forecasting step increases, the forecasting error will accumulate with each step in the forecasting model, f(·), leading to a decrease in forecasting accuracy.
The principle of time series wind speed forecasting is illustrated in
Figure 1.
3. Variational Mode Decomposition
VMD is a non-stationary signal decomposition method introduced by Dragomiretskiy et al. in 2014 [
39]. VMD achieves signal decomposition by introducing variational constraints, thus effectively overcoming the mode mixing and endpoint effects issues present in traditional empirical mode decomposition (EMD) methods.
VMD assumes that any signal
f(
t) can be represented by a series of sub-signals
uk with specific center frequencies and finite bandwidths, and the sum of the bandwidths of all of the sub-signals is equal to the original signal. Then, the variational constraint equation shown in Equation (4) can be obtained.
In Equation (4), K represents the number of variational modes, {uk, ωk} represents the kth decomposed mode component with its corresponding center frequency, ∂t is the partial derivative with respect to time t, δ(t) represents the Dirac function, and ⊗ represents the convolution operator.
To transform a constrained variational problem into a non-constrained variational problem, VMD introduces quadratic penalty factors,
α, and Lagrange multipliers,
λ(
t), to construct the augmented Lagrangian function
L({
uk}, {
ωk},
λ), thereby converting the constrained problem into an unconstrained one. The constructed Lagrangian function is expressed in Equation (5).
The augmented Lagrangian function L({uk}, {ωk}, λ) is solved using the alternative direction method of multipliers (ADMM); the specific steps are as follows:
Step 1: Initialize {}, {}, λ1 and the iteration number n = 0.
Step 2: Execute the iteration n = n + 1.
Step 3: Update {
}, {
}, and
λn based on Equations (6)–(8), respectively.
In the above equations, f(ω) represents the Fourier transform of signal f(t), and τ is the noise tolerance parameter.
Step 4: If the convergence condition is satisfied, the iteration stops; otherwise, return to Step 2 for further refinement.
In Equation (9), e is the convergence condition for stopping the iteration.
The above calculation process demonstrates that VMD transforms the signal from the time domain to the frequency domain for decomposition. For non-stationary time series signals, this approach effectively preserves the non-stationary information while ensuring the robustness of the decomposition process.
4. Arithmetic Optimization Algorithm (AOA)
The arithmetic optimization algorithm (AOA) is a metaheuristic optimization algorithm based on the concept of mixed arithmetic operations; it was proposed by Abualigah et al. in 2021 [
40]. The AOA is characterized by its fast convergence speed and high precision. The AOA consists of three parts: the mathematical optimizer acceleration function, global exploration stage, and local exploitation stage. A mathematical optimizer acceleration function is employed to select the optimization strategy. In the global exploration stage, multiplication and division strategies are utilized for global search, enhancing the dispersion of solutions and improving the global optimization ability of the AOA. In the local exploitation stage, addition and subtraction strategies are used to reduce the dispersion and strengthen the local optimization ability of the AOA.
- (1)
Mathematical Optimizer Acceleration Function
At the beginning of each iteration loop, the global exploration and local exploitation stages are selected using a mathematical optimizer acceleration function. Suppose that there are
N candidate solutions for the problem to be solved in the solution space,
Z, and the position of the
ith candidate solution in the
Z-dimensional solution space is
Xi(
xi1,
xi2, …,
xiZ), where
i = 1, 2, …,
N. The solution set can then be represented by Equation (10).
The AOA selects the search stage using the mathematical optimizer acceleration function. When
r1 ≥ MOA, the AOA performs the global exploration stage, and when
r1 < MOA, the AOA performs the local exploitation stage. Here,
r1 is a random number in the range [0, 1]. The MOA is calculated using Equation (11).
Min and Max represent the minimum and maximum values of the mathematical optimizer acceleration function, which are typically set to 0.2 and 1, respectively; t is the current number of iterations, and T is the overall number of iterations.
- (2)
Global Exploration Stage
In the global exploration stage, the AOA employs two search strategies: multiplication and division. When
r2 ≥ 0.5, the multiplication search strategy is executed, and when
r2 < 0.5, the division search strategy is executed. The formulas for the multiplication and division search strategies are given in Equation (12).
In Equation (12), UB and LB represent the upper and lower bounds of the solution space, respectively,
r2 is a random number between [0, 1], and
μ is the control parameter for adjusting the search process, with a typical value of 0.499. MOP is the mathematical optimizer probability, which is calculated as shown in Equation (13).
where
α represents the sensitive parameter, which defines the local exploitation accuracy during the iteration process; it typically has a value of 5.
- (3)
Local Exploitation Stage
In the local exploitation stage, addition and subtraction operations are employed by the AOA to fine-tune the solutions obtained during the global exploration stage. The formulae for the addition and subtraction operations are expressed in Equation (14).
In Equation (14), r3 is a random variable with a value in the range of [0, 1]. When r3 < 0.5, the subtraction operation is performed; when r3 ≥ 0.5, the addition operation is executed.
5. AOA-GRU Hybrid Model
5.1. GRU Algorithm Principles
The gated recurrent unit (GRU) is a variant of the long short-term memory (LSTM) neural network proposed by Cho et al. in 2014 [
41,
42]. The GRU not only effectively solves the problems of gradient vanishing and gradient explosion in recurrent neural networks (RNNs), but also avoids the problems of a large number of parameters, low training efficiency, and slow convergence speed in LSTM models. Since its inception, the GRU model has been widely used in the study of time series problems.
The internal structure of the GRU model is illustrated in
Figure 2.
Figure 2 shows that the GRU model has two gate control units, namely, the update and reset gates. The update gate determines how much information from the previous and current time steps is continuously transmitted to the future, whereas the reset gate determines how much information from the past should be forgotten.
- (1)
Reset Gate
The calculation formula for the reset gate is given by Equation (15).
In Equation (15), xt represents the input vector at time step t, St−1 represents the hidden state at time step t−1, Wt and Ut are the weight matrices of the reset gate, Br is the bias matrix of the reset gate, and rt is the output of the reset gate at time step t.
The output range of the sigmoid activation function is [0, 1], and its mathematical expression is as follows:
- (2)
Update Gate
The calculation formula for the update gate is given by Equation (17).
In Equation (17), Wz and Uz are the weight matrices of the update gate, Bz is the bias matrix of the update gate, and zt is the output of the update gate at time step t.
- (3)
Candidate Hidden State of the GRU Model
The candidate hidden state of the GRU model is calculated using Equation (18).
where
and
are the weight matrices of the candidate hidden state in the GRU model,
is the bias matrix of the candidate hidden state,
represents the candidate hidden state of the GRU model, and the tanh function is the hyperbolic tangent activation function, which has an output range of [−1, 1].
- (4)
Hidden State of the GRU Model
The hidden state of the GRU model is calculated using Equation (19).
where
St represents the hidden state of the GRU model.
- (5)
GRU Model Output
The output of the GRU model can be calculated using Equation (20).
where
yt represents the output vector of the GRU model,
is the weight matrix, and
By is the bias matrix.
5.2. Hyperparameters Affecting the Forecasting Performance of GRU Models
When the hyperparameters of the GRU model are reasonably set, the model exhibits good forecasting accuracy. The hyperparameters affecting the forecasting performance of the GRU model include the number of hidden layers, number of hidden layer neurons, training epochs, initial learning rate, and learning rate decay period. To elucidate the relationship between model hyperparameters and forecasting accuracy, the hyperparameters of the GRU model are adjusted using the grid search method, and the impact of changes in model hyperparameters on the forecasting accuracy of the wind speed series Dataset1 are observed (relevant information on the wind speed series Dataset1 can be found in
Section 6.1). The variation ranges of each parameter adjusted using the grid search method are listed in
Table 1.
- (1)
Impact of the number of hidden layers on the model forecasting performance
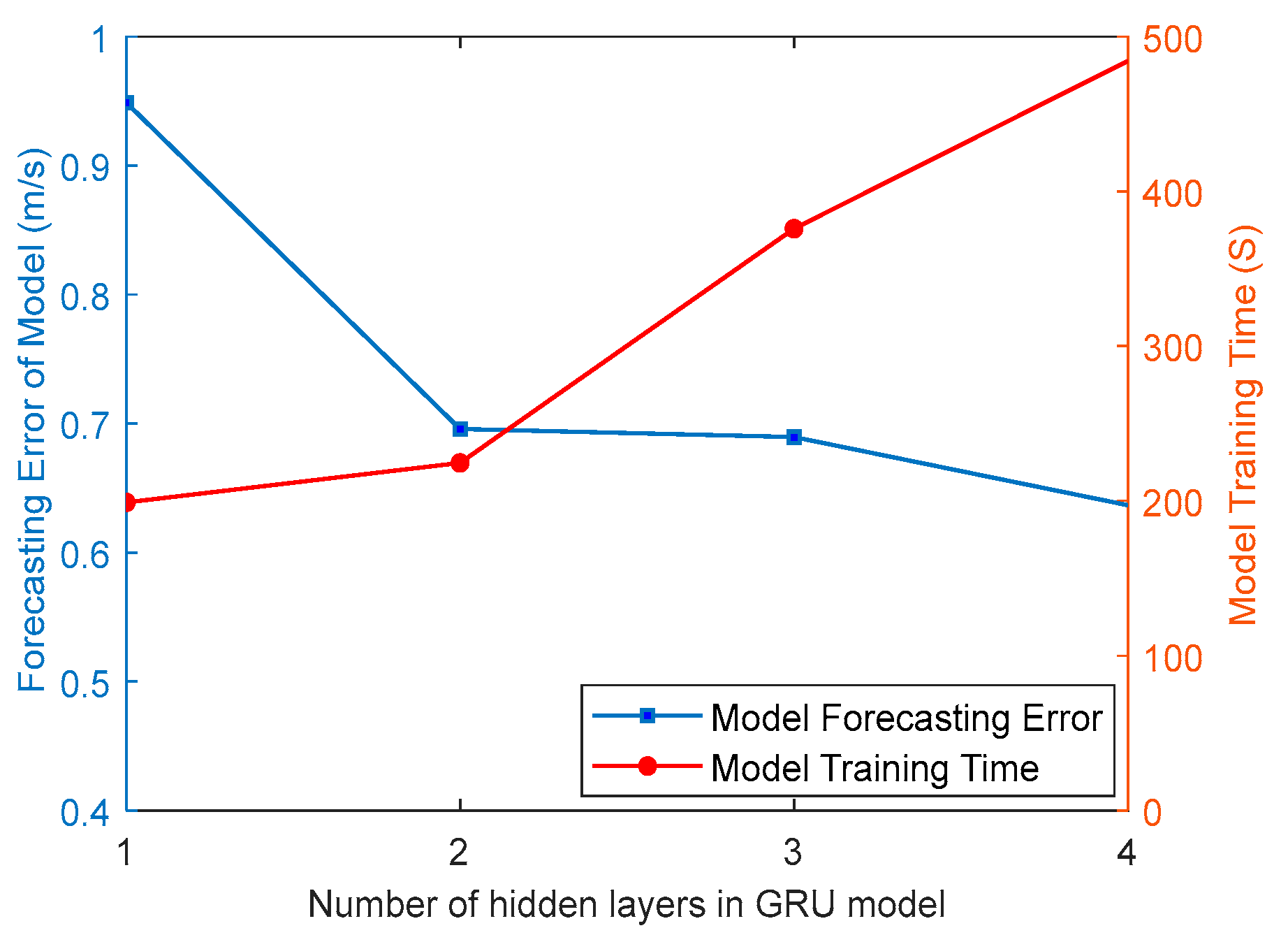
In theory, the greater the number of hidden layers the GRU model has, the higher the GRU model forecasting accuracy will be. However, the training time and computational memory requirements of the GRU model increase rapidly with the number of hidden layers. Additionally, a higher number of hidden layers may lead to issues such as overfitting and gradient vanishing. Therefore, selecting the appropriate number of hidden layers is critical for setting the hyperparameters of the GRU model.
Figure 3 shows the relationship between the model forecasting error (RMSE), model training time, and number of hidden layers (1, 2, 3, or 4) for the time series wind speed sequence in Dataset1. The solid blue line with squares represents the model forecasting error for different numbers of hidden layers, and the solid red line with dots represents the model training time. It can be observed that when the number of hidden layers is set to one, the GRU model has a relatively large forecasting error but requires less training time. As the number of hidden layers increases, the model forecasting accuracy improves; however, the training time also increases. When the number of hidden layers is two, the GRU model achieves the best balance between forecasting accuracy and training time.
- (2)
Influence of the number of hidden layer neurons on the model forecasting performance
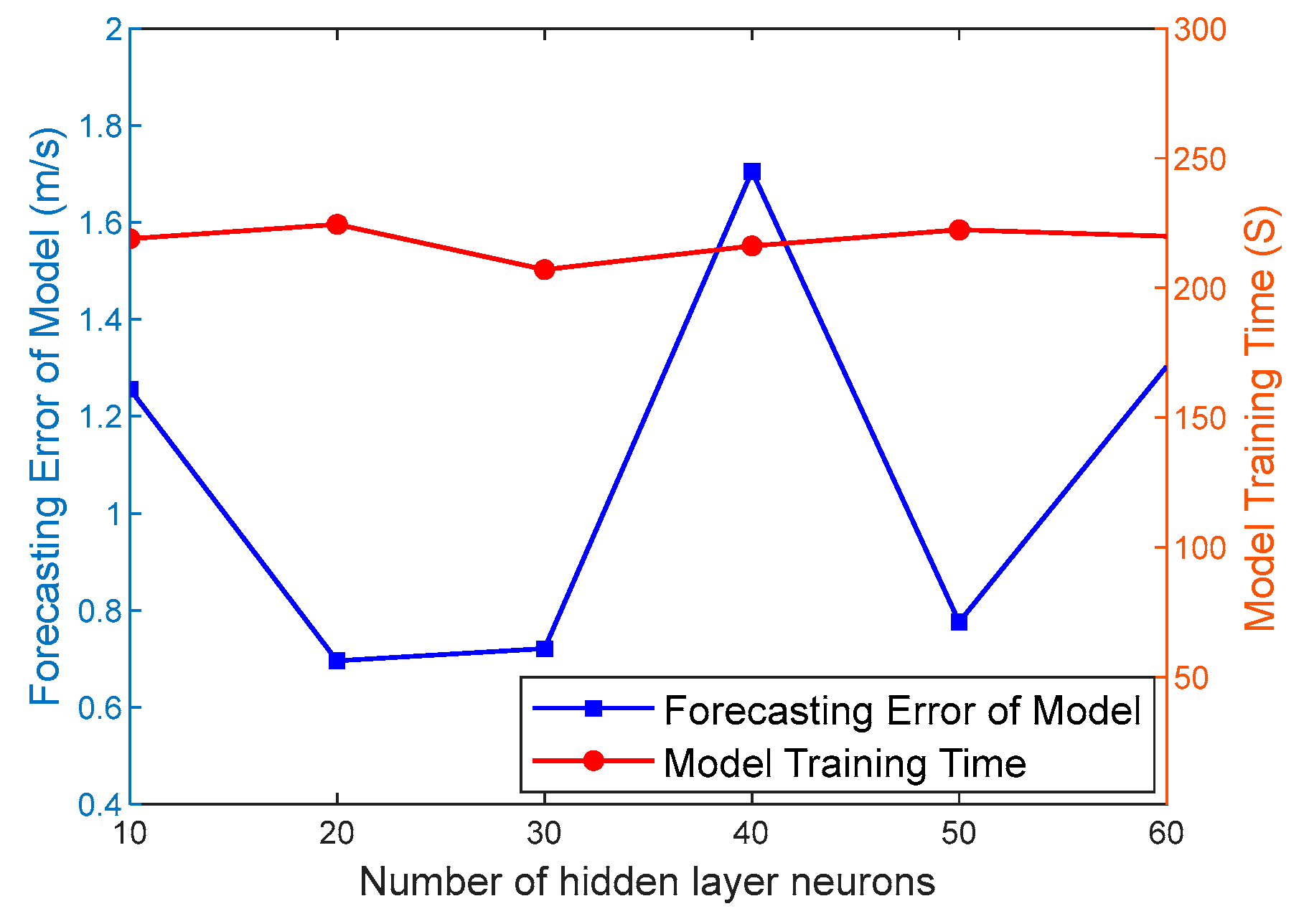
The number of hidden layer neurons also has a significant impact on the forecasting performance of the GRU model. When the number of hidden layer neurons is small, the GRU model is prone to underfitting; when there are too many neurons, the GRU model is prone to overfitting. Therefore, selecting a reasonable number of hidden layer neurons is also an important aspect of the hyperparameter settings in the GRU model.
Figure 4 shows the correlations between the number of hidden layer neurons, model forecasting error, and training time. As shown in
Figure 4, when the number of hidden layer neurons is 20, the forecasting accuracy and training time of the GRU model reach an optimal balance.
- (3)
Impact of training epochs on the model forecasting performance
One training epoch represents a complete operation on the data in a neural network. The weight matrix in the GRU network must be updated every time the data are fully trained. Too few training epochs cannot accurately extract temporal features from the training data, resulting in underfitting of the GRU model. Excessive training epochs increase the training time of the GRU model. Therefore, determining a reasonable number of training epochs and accurately extracting temporal features from the data are important aspects to be considered in the hyperparameter setting of the GRU model.
As shown in
Figure 5, when the number of training epochs for the GRU model is set to 70, the model achieves the lowest forecasting error, and the increase in training time is relatively minimal.
- (4)
Impact of the learning rate and learning rate decay period on the model forecasting performance
The learning rate is a crucial hyperparameter that controls the learning progress of the GRU model. Setting a learning rate that is too high or too low can affect both the model training time and forecasting accuracy. Typically, a higher learning rate is used in the initial stages of model training to enhance the initial learning speed. After a certain number of training iterations, it is necessary to decrease the learning rate to improve the model forecasting accuracy.
Figure 6a illustrates the impact of the learning rate on the model forecasting accuracy and training time. As shown in
Figure 6a, the GRU model achieves the best forecasting performance when the initial learning rate is set to 0.06.
Figure 6b shows the influence of the learning rate decay period on the model forecasting accuracy and training time. As shown in
Figure 6b, the GRU model performs optimally when the learning rate decay period is set to 30.
Based on the information in
Figure 3,
Figure 4,
Figure 5 and
Figure 6, it is evident that setting the number of hidden layers, number of neurons in the hidden layer, number of training epochs, learning rate, and learning rate decay period appropriately can effectively improve the forecasting accuracy of the GRU model.
5.3. AOA Optimized Hyperparameters of the GRU Model
Based on the discussion in
Section 5.2, it is clear that setting appropriate hyperparameters for the GRU model can improve the forecasting accuracy while reducing the model training time. However, in practical engineering applications, the training dataset is continually changing, and the GRU model hyperparameters must be adjusted accordingly. When the grid search method is used to adjust the GRU model, the hyperparameters are inefficient and may not meet the demands of real-world applications. Therefore, in this study, the AOA is utilized to optimize the GRU model hyperparameters, including the training data sequence length, number of hidden layer neurons, training epochs, initial learning rate, and learning rate decay period. The number of hidden layers in the GRU model is determined using a grid search method and remains constant throughout the optimization process. The construction process for the AOA-GRU model is illustrated in
Figure 7.
The specific AOA optimization process for the hyperparameters of the GRU model is as follows.
Step 1: Construct an AOA candidate solution structure, Xi(xi1, xi2, xi3, xi4, xi5), including the training data time series length, xi1, number of hidden layer neurons, xi2, training iterations, xi3, initial learning rate, xi4, and learning rate decay period, xi5. Determine the range and number of candidate solutions.
Step 2: Based on the position coordinates Xi(xi1, xi2, xi3, xi4, xi5) of each candidate solution, construct their respective GRU forecasting models and forecast the wind speed sequence.
Step 3: Calculate the forecasting error of each GRU model based on its forecasting results and use the forecasting error as the fitness value for each candidate solution of the AOA.
Step 4: Save the coordinates of the candidate solution with the best fitness value as X*(x1, x2, x3, x4, x5), representing the optimal model hyperparameters.
Step 5: Utilize the AOA to update the coordinates of each candidate solution Xi(xi1, xi2, xi3, xi4, xi5) and rebuild each GRU model based on the updated coordinates to forecast the wind speed.
Step 6: Based on the forecasting results of the GRU model, recalculate the forecasting errors of each GRU model and determine the position coordinates X*(x1, x2, x3, x4, x5) of the candidate solution with the best fitness value, i.e., the optimal training data length and model hyperparameters.
Step 7: Check whether the termination condition is satisfied. If not, return to Step 5 and continue the process. If the termination condition is satisfied, proceed to Step 8.
Step 8: Build the final GRU forecasting model based on the coordinates of the global optimal candidate solution, X*(x1, x2, x3, x4, x5), to forecast the wind speed.
7. Comparison of Different Forecasting Models
To further demonstrate the superiority of the proposed VMD-AOA-GRU forecasting model, a comparative analysis was conducted for the multiple-step forecasting of various models. The compared models included the LSTM, GRU, PSO-BP, PSO-ELM, PSO-LSSVM, VMD-GRU, VMD-LSTM, VMD-PSO-BP, VMD-PSO-ELM, VMD-PSO-LSSVM, and VMD-AOA-GRU models. In order to ensure that these models were under fair comparison conditions during the comparison process, except for the VMD-AOA-GRU model, the hyperparameters of all other models were optimized using the grid search method. The forecasting results for these models are shown in
Figure 11. The training and testing datasets used for the comparative analysis were consistent with those presented in
Section 6.1.
In
Figure 11, the black solid line represents the observed wind speed, the blue dashed line represents the forecasting of the LSTM model, the purple dashed line represents the forecasting of the GRU model, the orange dashed line represents the forecasting of the PSO-BP model, the green dashed line represents the forecasting of the PSO-ELM model, the cyan dashed line represents the forecasting of the PSO-LSSVM model, and the red solid line represents the forecasting of the VMD-AOA-GRU model. Based on the observations and analysis shown in
Figure 11, the following conclusions can be drawn.
- (1)
All of the machine learning models accurately capture the trends of the actual wind speed, demonstrating that the use of machine learning models for ultra-short-term wind speed forecasting is feasible.
- (2)
At the wind speed inflection points, the VMD-AOA-GRU, VMD-LSTM, VMD-GRU, VMD-PSO-BP, VMD-PSO-ELM, and VMD-PSO-LSSVM models accurately forecast the positions of the inflection points (the highest accuracy in single-step forecasting). In contrast, the other models exhibit a lag in forecasting the positions of the inflection points compared with the actual wind speed. This further validates that the VMD algorithm can accurately extract the high-frequency components of the time series wind speed, thereby enhancing the accuracy of wind-speed forecasting.
- (3)
Among the forecasting models, the VMD-AOA-GRU model shows the closest similarity to the distribution characteristics of the actual time series wind speed. This demonstrates that the forecasting performance of the VMD-AOA-GRU model is superior to that of the other models.
Table 6 lists the forecasting errors of each forecasting model under the four testing wind speed sequences at one, two, and three steps. The following conclusions are drawn based on the results in
Table 6:
- (1)
The forecasting accuracy of the hybrid VMD models is higher than that of the non-hybrid VMD models, indicating that deep mining of high-frequency features in the time series wind speed through VMD can effectively improve the forecasting accuracy of the forecasting model.
- (2)
The forecasting accuracy of the LSTM and GRU models is lower than that of some machine learning models, indicating that although the LSTM and GRU models have the theoretical potential to achieve high forecasting accuracy by mining temporal correlations in the data, their forecasting accuracy is affected by improper hyperparameter settings.
- (3)
The forecasting accuracy of the VMD-AOA-GRU model is higher than that of all other models, demonstrating that optimizing the hyperparameters of the GRU model through AOA effectively enhances the forecasting accuracy of the GRU model.
- (4)
As the forecasting time step increases, the forecasting accuracy of all models gradually decreases, which aligns with the inherent characteristics of forecasting models.
8. Conclusions
This study proposes an ultrashort-term forecasting model for time series wind speeds based on VMD-AOA-GRU. The model first uses VMD to decompose the time series wind speed data into different frequency modal components, effectively extracting high-frequency wind speed features. Then, the AOA is employed to optimize the hyperparameters of the GRU model to construct a high-accuracy AOA-GRU forecasting model. The time series modal components decomposed by VMD are then employed to train and test the AOA-GRU model, achieving multi-step forecasting of ultra-short-term time series wind speeds. The forecasting results for the GRU, VMD-GRU, VMD-AOA-GRU, LSTM, PSO-BP, PSO-ELM, PSO-LSSVM, VMD-LSTM, VMD-PSO-BP, VMD-PSO-ELM, and VMD-PSO-LSSVM models were compared, and the results are as follows:
- (1)
The forecasting accuracies of the hybrid VMD models (VMD-AOA-GRU, VMD-LSTM, VMD-PSO-BP, VMD-PSO-ELM, and VMD-PSO-LSSVM) are higher than those of the non-hybrid VMD models (GRU, LSTM, PSO-BP, PSO-ELM, and PSO-LSSVM), indicating that the VMD can deeply explore high-frequency components in time series wind speed, particularly the high-frequency features at inflection points, effectively improving the accuracy of the forecasted time series wind speed.
- (2)
Although the LSTM and GRU deep learning models can capture the temporal correlations in time series wind speeds, their forecasting accuracy may be lower than that of some commonly used machine learning models (PSO-BP, PSO-ELM, and PSO-LSSVM) when their hyperparameter settings are improper. This indicates that a reasonable setting of hyperparameters for deep learning models significantly affects the forecasting accuracy.
- (3)
The forecasting accuracy of the GRU model can be effectively improved by using the AOA to optimize the hyperparameters of the GRU model. The calculation results show that the forecasting accuracy of the VMD-AOA-GRU model constructed in this study is higher than that of the other models.
- (4)
As the forecasting time step increases, the forecasting accuracy of the model gradually decreases.
The study results in this paper can be widely used for the optimization control of wind turbines, thereby improving the operational efficiency of wind turbines and reducing their fatigue losses. However, during the research process, this paper did not consider the accuracy of wind direction forecasting, a topic that will need to be a focus of subsequent research.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}