



Improving Accuracy and Interpretability of CNN-Based Fault Diagnosis through an Attention Mechanism


Abstract
:1. Introduction
2. Related Works
2.1. Region Proposals Convolutional Neural Networks
2.2. Mask-Based Convolutional Neural Networks
2.3. Squeeze-and-Excitation Networks
3. Basic Knowledge
3.1. Convolutional Neural Networks
3.2. Sliding Window Processing
4. Attention-Based CNN for Fault Diagnosis
4.1. Prior Knowledge about Category-Attribute Correlation
4.1.1. Pearson Correlation Coefficient
4.1.2. Category-Attribute Correlation Matrix
4.2. Integrating Prior Knowledge into CNNs Based on Attention Mechanism
5. Case Study in Tennessee Eastman Chemical Process Benchmark
5.1. Tennessee EASTMAN Chemical Process Benchmark
5.2. Experiments
5.2.1. SWP for the TE Chemical Process Data Sets
5.2.2. Model Training
5.3. Results Analysis
5.3.1. Evaluation Indicators
5.3.2. Evaluation Result and Performance Comparison
5.3.3. Analysis of Model Interpretability

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | FDR (%) | FPR (%) | |||||
|---|---|---|---|---|---|---|---|
| The Proposal | DL [47] | EDBN-2 [48] | MPLS [23] | PCA [49] | The Proposal | EDBN-2 [48] | |
| Normal | 96.85 | - | 90.80 | - | 86.25 | 1.60 | 3.34 |
| Fault 1 | 99.76 | 100.00 | 100.00 | 100.00 | 96.56 | 0.00 | 0.00 |
| Fault 2 | 99.76 | 99.75 | 100.00 | 98.88 | 96.88 | 0.00 | 0.08 |
| Fault 3 | 93.08 | - | - | 18.75 | - | 4.60 | - |
| Fault 4 | 100.00 | 100.00 | 100.00 | 100.00 | 96.88 | 0.00 | 0.01 |
| Fault 5 | 99.75 | 98.88 | 100.00 | 100.00 | 96.88 | 0.40 | 0.00 |
| Fault 6 | 100.00 | 100.00 | 100.00 | 100.00 | 99.48 | 0.00 | 0.00 |
| Fault 7 | 100.00 | 100.00 | 100.00 | 100.00 | 99.27 | 0.00 | 0.00 |
| Fault 8 | 98.23 | 97.88 | 98.29 | 98.63 | 94.90 | 0.20 | 0.22 |
| Fault 9 | 95.24 | - | - | 12.13 | - | 0.30 | - |
| Fault 10 | 98.79 | 99.25 | 80.81 | 91.13 | 87.81 | 0.14 | 0.67 |
| Fault 11 | 99.77 | 89.25 | 99.74 | 83.25 | 77.81 | 0.00 | 0.00 |
| Fault 12 | 99.78 | 99.75 | 100.00 | 99.88 | 97.81 | 0.30 | 0.00 |
| Fault 13 | 100.00 | 99.75 | 91.98 | 95.50 | 79.17 | 0.00 | 0.00 |
| Fault 14 | 99.09 | 95.13 | 100.00 | 100.00 | 98.23 | 0.20 | 0.00 |
| Fault 15 | 92.33 | - | - | 23.25 | - | 7.20 | - |
| Fault 16 | 97.97 | 99.50 | 75.56 | 94.28 | 79.90 | 0.12 | 0.67 |
| Fault 17 | 100.00 | 99.75 | 100.00 | 97.13 | 86.46 | 0.00 | 0.00 |
| Fault 18 | 100.00 | 99.50 | 93.43 | 91.25 | 72.81 | 0.00 | 0.00 |
| Fault 19 | 98.30 | 96.75 | 95.53 | 94.25 | 91.56 | 0.40 | 0.27 |
| Fault 20 | 98.80 | 99.38 | 93.17 | 91.50 | 88.54 | 0.60 | 0.00 |
| Fault 21 | 98.60 | - | 83.44 | 72.75 | 95.00 | 1.80 | 1.17 |
| Average | 98.46 | - | 94.31 | - | - | 1.54 | 5.69 |
- The raw data of and are indistinguishable, and the model cannot produce distinguishable features on the outputs of M1 after the raw data is processed by a convolutional layer and a pooling layer.
- From M1 to M2, some distinguishable striped features began to appear, as indicated by the red arrow. However, it can be seen that the striped features in the M2 outputs of and show some differences, which implies that the extracted features are biased. Specifically, taking the area framed by dotted rectangle in the outputs of M2 as an example, that of shows light yellow, while that of shows light green. These deviations may affect the performance of classification, so it is necessary to eliminate them in subsequent operations.
- From M2 to A1, one can find that the clearer striped features begin to appear for the areas framed by dotted ellipse that needs attention, which indicates that the prior knowledge has been integrated into the feature maps output from M2. Moreover, the colors of the areas framed by dotted rectangle in the M2 and A1 of and are darker and tend to be the same, which indicates that the deviation in the feature maps began to be ignored owing to the prior knowledge integration.
- From A1 to M3, the stripes of the feature maps become more clearly distinguishable, which indicates that some detailed features are further extracted. However, the deviation features framed by dotted rectangular are also enhanced.
- From M3 to A2, it can be seen that the prior knowledge has been significantly enhanced in the feature maps by comparing the areas framed by dotted ellipse in M3 and A2 and the deviation features in feature maps have been basically eliminated by comparing the areas framed by dotted rectangular in M3 and A2. However, one can also find that, except for the stripes representing the prior knowledge, which are quite clear, the other stripes are quite vague, which indicates that some detailed features in the feature maps are ignored due to excessive attention paid to the prior knowledge.
- From A2 to M4, one can find that the vague stripes become clear, which indicates that the detailed features in the feature maps is enhanced and the prior knowledge is retained.
- Compared to the raw data and the feature maps output from M4, the latter are distinguishable. Moreover, the color of stripes framed by the dotted rounded rectangle in M4 changes in the time dimension, which indicates that the feature maps output from M4 not only clearly contains the prior knowledge, but also that the prior knowledge is further enhanced in the time dimension. Furthermore, some detailed features (those lighter stripes) are also contained in the outputs of M4.
5.3.4. Analysis of Hyperparameter d
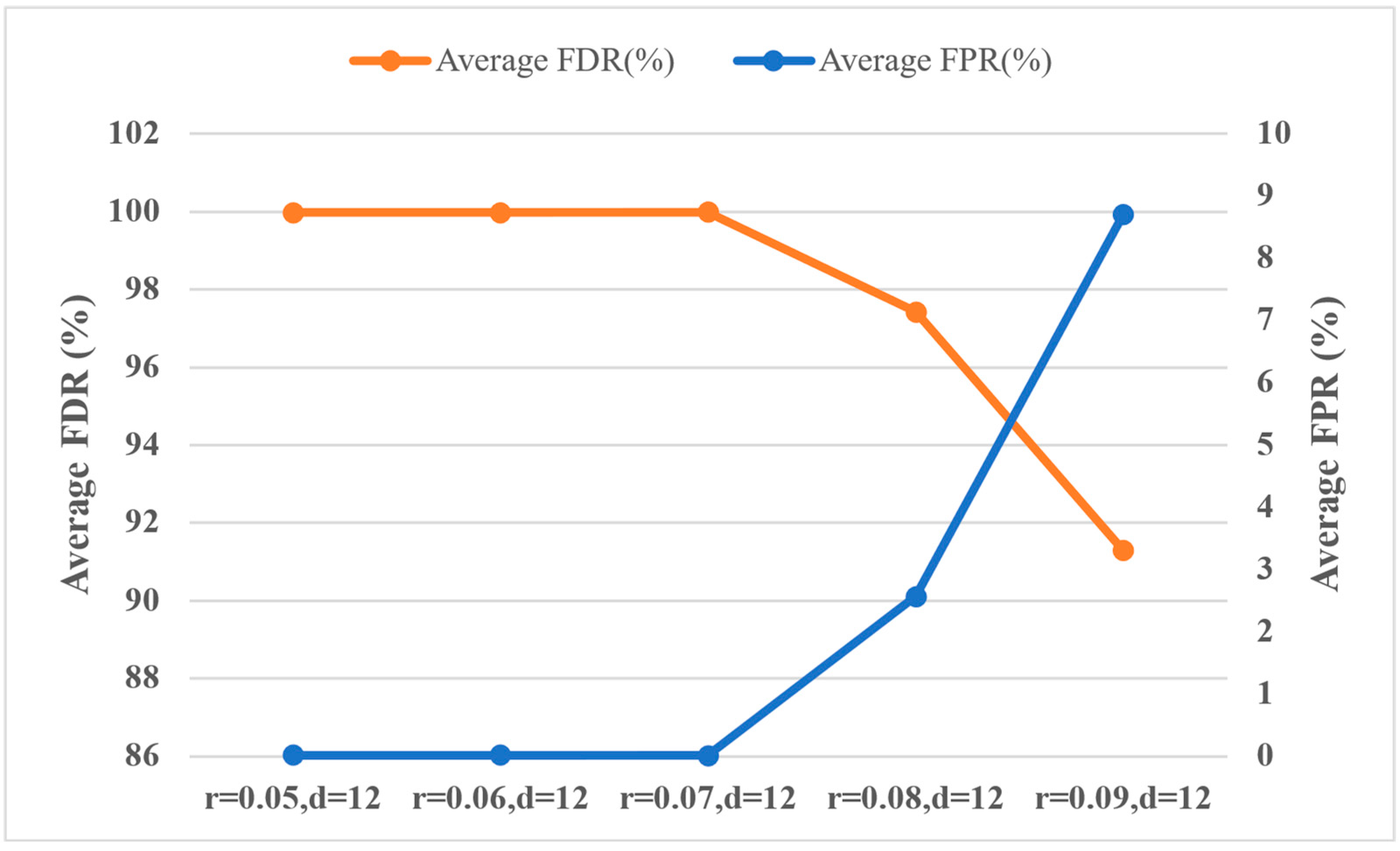
5.3.5. Analysis of Hyperparameter r
5.4. Discussion on the Calculation of Attention Matrix
6. Conclusions and Future Works
- This study only validates the effectiveness of the proposal on the TE chemical process dataset; it is necessary to use the proposal to solve other fault diagnosis problems, such as rolling bearing fault diagnosis [52], ice detection of wind turbine blades [53], and gearbox fault diagnosis [54], to further verify the proposal. This is crucial, as it ensures that the proposed method can be easily applied for fault diagnosis in different scenarios.
- This study improves the accuracy and interpretability of fault diagnosis by integrating prior knowledge, but the definition of prior knowledge uses label information, which leads to some irrationality, and thus alternative prior knowledge definitions that do not use label information need to be further studied. A feasible solution is to define the attention matrix as outliers in the data, and then use unsupervised outlier detection methods, such as those presented in [50,51], to obtain the attention matrix.
- Although visualization techniques are used to analyze model interpretability in this study, developing and using quantitative interpretability metrics, such as those presented in the study [55], are worthy of further study for validating the interpretability of the proposed method more specifically.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cai, B.; Zhao, Y.; Liu, H.; Xie, M. A Data-Driven Fault Diagnosis Methodology in Three-Phase Inverters for PMSM Drive Systems. IEEE Trans. Power Electron. 2017, 32, 5590–5600. [Google Scholar] [CrossRef]
- Feng, J.; Yao, Y.; Lu, S.; Liu, Y. Domain Knowledge-based Deep-Broad Learning Framework for Fault Diagnosis. IEEE Trans. Ind. Electron. 2020, 68, 3454–3464. [Google Scholar] [CrossRef]
- Gao, X.; Hou, J. An improved SVM integrated GS-PCA fault diagnosis approach of Tennessee Eastman process. Neurocomputing 2016, 174, 906–911. [Google Scholar] [CrossRef]
- Jiang, G.; He, H.; Yan, J.; Xie, P. Multiscale Convolutional Neural Networks for Fault Diagnosis of Wind Turbine Gearbox. IEEE Trans. Ind. Electron. 2019, 66, 3196–3207. [Google Scholar] [CrossRef]
- Lei, Y.; Jia, F.; Lin, J.; Xing, S.; Ding, S.X. An Intelligent Fault Diagnosis Method Using Unsupervised Feature Learning Towards Mechanical Big Data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- He, M.; He, D. Deep Learning Based Approach for Bearing Fault Diagnosis. IEEE Trans. Ind. Appl. 2017, 53, 3057–3065. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lin, J.; Zhou, X.; Lu, N. Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data. Mech. Syst. Signal Process. 2016, 72–73, 303–315. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Wang, F.; Wang, Y. Rolling bearing fault diagnosis using adaptive deep belief network with dual-tree complex wavelet packet. ISA Trans. 2017, 69, 187–201. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, J.; Zheng, Y.; Jiang, W.; Zhang, Y. Fault diagnosis of rolling bearings with recurrent neural network-based autoencoders. ISA Trans. 2018, 77, 167–178. [Google Scholar] [CrossRef]
- Wu, H.; Zhao, J. Deep convolutional neural network model based chemical process fault diagnosis. Comput. Chem. Eng. 2018, 115, 185–197. [Google Scholar] [CrossRef]
- Huang, T.; Zhang, Q.; Tang, X.; Zhao, S.; Lu, X. A novel fault diagnosis method based on CNN and LSTM and its application in fault diagnosis for complex systems. Artif. Intell. Rev. 2022, 55, 1289–1315. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Z.; Wang, X.; Li, W. Sarkodie-Gyan and S. Feng. A hybrid deep-learning model for fault diagnosis of rolling bearings. Measurement 2021, 169, 108502. [Google Scholar] [CrossRef]
- Yu, S.; Wang, M.; Pang, S.; Song, L.; Qiao, S. Intelligent fault diagnosis and visual interpretability of rotating machinery based on residual neural network. Measurement 2022, 196, 111228. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q.; Sun, J.Q. Intelligent rotating machinery fault diagnosis based on deep learning using data augmentation. J. Intell. Manuf. 2020, 31, 433–452. [Google Scholar] [CrossRef]
- Li, C.; Li, S.; Wang, H.; Gu, F.; Ball, A.D. Attention-based deep meta-transfer learning for few-shot fine-grained fault diagnosis. Knowl.-Based Syst. 2023, 264, 110345. [Google Scholar] [CrossRef]
- Yang, H.; Li, X.; Zhang, W. Interpretability of deep convolutional neural networks on rolling bearing fault diagnosis. Meas. Sci. Technol. 2022, 33, 055005. [Google Scholar] [CrossRef]
- Yang, D.; Karimi, H.R.; Gelman, L. An explainable intelligence fault diagnosis framework for rotating machinery. Neurocomputing 2023, 541, 126257. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q. Understanding and improving deep learning-based rolling bearing fault diagnosis with attention mechanism. Signal Process. 2019, 161, 136–154. [Google Scholar] [CrossRef]
- Yu, J.; Liu, G. Knowledge extraction and insertion to deep belief network for gearbox fault diagnosis. Knowl.-Based Syst. 2020, 197, 105883. [Google Scholar] [CrossRef]
- Xie, T.; Xu, Q.; Jiang, C.; Lu, S.; Wang, X. The fault frequency priors fusion deep learning framework with application to fault diagnosis of offshore wind turbines. Renew. Energ. 2023, 202, 143–153. [Google Scholar] [CrossRef]
- Liao, J.; Dong, H.; Sun, Z.; Sun, J.; Zhang, S.; Fan, F. Attention-embedded quadratic network (qttention) for effective and interpretable bearing fault diagnosis. IEEE Trans. Instrum. Meas. 2023, 72, 1–13. [Google Scholar] [CrossRef]
- Peng, D.; Wang, H.; Desmet, W.; Gryllias, K. RMA-CNN: A residual mixed-domain attention CNN for bearings fault diagnosis and its time-frequency domain interpretability. J. Dyn. Monit. Diagn. 2023, 2, 115–132. [Google Scholar] [CrossRef]
- Yin, S.; Ding, S.X.; Haghani, A.; Hao, H.; Zhang, P. A comparison study of basic data-driven fault diagnosis and process monitoring methods on the benchmark Tennessee Eastman process. J. Process Control 2012, 22, 1567–1581. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vision 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Qi, L.; Huo, J.; Wang, L.; Shi, Y.; Gao, Y. A mask based deep ranking neural network for person retrieval. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 496–501. [Google Scholar]
- Liu, L.Y.F.; Liu, Y.; Zhu, H. Masked convolutional neural network for supervised learning problems. Stat 2020, 9, e290. [Google Scholar] [CrossRef] [PubMed]
- Cai, L.; Li, H.; Dong, W.; Fang, H. Micro-expression recognition using 3D DenseNet fused Squeeze-and-Excitation Networks. Appl. Soft Comput. 2022, 119, 108594. [Google Scholar] [CrossRef]
- Roy, S.K.; Dubey, S.R.; Chatterjee, S.; Chaudhuri, B.B. FuSENet: Fused squeeze-and-excitation network for spectral-spatial hyperspectral image classification. IET Image Process. 2020, 14, 1653–1661. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Wei, W.W. Multivariate Time Series Analysis and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Yu, Z.; Peng, W.; Li, X.; Hong, X.; Zhao, G. Remote heart rate measurement from highly compressed facial videos: An end-to-end deep learning solution with video enhancement. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 151–160. [Google Scholar]
- Puth, M.T.; Neuhäuser, M.; Ruxton, G.D. Effective use of Pearson’s product–moment correlation coefficient. Anim. Behav. 2014, 93, 183–189. [Google Scholar] [CrossRef]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences; Academic Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Downs, J.J.; Vogel, E.F. A plant-wide industrial process control problem. Comput. Chem. Eng. 1993, 17, 245–255. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Olden, J.D.; Jackson, D.A. Illuminating the “black box”: A randomization approach for understanding variable contributions in artificial neural networks. Ecol. Model. 2002, 154, 135–150. [Google Scholar] [CrossRef]
- Lv, F.; Wen, C. Fault Diagnosis Based on Deep Learning. In Proceedings of the 2016 American Control Conference (ACC), Boston, MA, USA, 6–8 July 2016; pp. 6851–6856. [Google Scholar]
- Wang, Y.; Pan, Z.; Yuan, X.; Yang, C.; Gui, W. A novel deep learning based fault diagnosis approach for chemical process with extended deep belief network. ISA Trans. 2020, 96, 457–467. [Google Scholar] [CrossRef]
- Jing, C.; Hou, J. SVM and PCA based fault classification approaches for complicated industrial process. Neurocomputing 2015, 167, 636–642. [Google Scholar] [CrossRef]
- Samariya, D.; Thakkar, A. A comprehensive survey of anomaly detection algorithms. Ann. Data Sci. 2023, 10, 829–850. [Google Scholar] [CrossRef]
- Smiti, A. A critical overview of outlier detection methods. Comput. Sci. Rev. 2020, 38, 100306. [Google Scholar] [CrossRef]
- Li, B.; Chow, M.-Y.; Tipsuwan, Y.; Hung, J.C. Neural-network-based motor rolling bearing fault diagnosis. IEEE Trans. Ind. Electron. 2000, 47, 1060–1069. [Google Scholar] [CrossRef]
- Du, Y.; Zhou, S.; Jing, X.; Peng, Y.; Wu, H.; Kwok, N. Damage detection techniques for wind turbine blades: A review. Mech. Syst. Signal Process. 2020, 141, 106445. [Google Scholar] [CrossRef]
- Cheng, W.; Wang, S.; Liu, Y.; Chen, X.; Nie, Z.; Xing, J.; Zhang, R.; Huang, Q. A novel planetary gearbox fault diagnosis method for nuclear circulating water pump with class imbalance and data distribution shift. IEEE Trans. Instrum. Meas. 2023, 72, 1–13. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Notions of explainability and evaluation approaches for explainable artificial intelligence. Inform. Fusion 2021, 76, 89–106. [Google Scholar] [CrossRef]







| Study | Accuracy | Interpretability |
|---|---|---|
| Jia et al. [7] | Through a deeper network | / |
| Huang et al. [11], Xu et al. [12] | Through a hybrid network | / |
| Li et al. [18] | / | Through visualization techniques |
| Yu and Liu [19], Xie et al. [20] | / | Through prior knowledge integration |
| Li et al. [18], Liao et al. [21], Peng et al. [22] | / | Through attention mechanisms |
| Categories | Data Set | Length of Time Series | (Normal/Fault Category) |
|---|---|---|---|
| Normal | Training set | 500 | 488 (488/0) |
| Test set | 960 | 948 (948/0) | |
| Faults 1–21 | Training set | 500 | 488 (9/479) |
| Test set | 960 | 948 (49/899) |
| Layer | Input Feature Maps Size | Output Feature Maps Size | Kernel Size/Stride/Padding | |
|---|---|---|---|---|
| Feature extractor | Conv-1 * | |||
| MaxPool-1 | ||||
| Conv-2 * | ||||
| MaxPool-2 | ||||
| Atten-1 | - | |||
| Conv-3 * | ||||
| MaxPool-3 | ||||
| Atten-2 | - | |||
| Conv-4 * | ||||
| MaxPool-4 | ||||
| Classifier | FC-1 # | - | ||
| Softmax | 22 | 22 | - |
| Number of samples with category | ||
| Number of samples without category |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Zhang, J.; Liu, R.; Zhao, S. Improving Accuracy and Interpretability of CNN-Based Fault Diagnosis through an Attention Mechanism. Processes 2023, 11, 3233. https://doi.org/10.3390/pr11113233
Huang Y, Zhang J, Liu R, Zhao S. Improving Accuracy and Interpretability of CNN-Based Fault Diagnosis through an Attention Mechanism. Processes. 2023; 11(11):3233. https://doi.org/10.3390/pr11113233
Chicago/Turabian StyleHuang, Yubiao, Jiaqing Zhang, Rui Liu, and Shuangyao Zhao. 2023. "Improving Accuracy and Interpretability of CNN-Based Fault Diagnosis through an Attention Mechanism" Processes 11, no. 11: 3233. https://doi.org/10.3390/pr11113233
APA StyleHuang, Y., Zhang, J., Liu, R., & Zhao, S. (2023). Improving Accuracy and Interpretability of CNN-Based Fault Diagnosis through an Attention Mechanism. Processes, 11(11), 3233. https://doi.org/10.3390/pr11113233