2.1. Spark Streaming
Spark Streaming is a distributed stream computing data processing framework based on the D Stream model, which allows batch processing of data in a short period of time, with the advantages of fast processing speed and fault tolerance [
22,
23,
24]. D streams are part of the SSF and are composed of sequences of successive resilient distributed datasets (RDDs). The SSF essentially divides the collected data into individual D Streams and converts each D Stream into an RDD to be stored in memory and, eventually, to an external device.
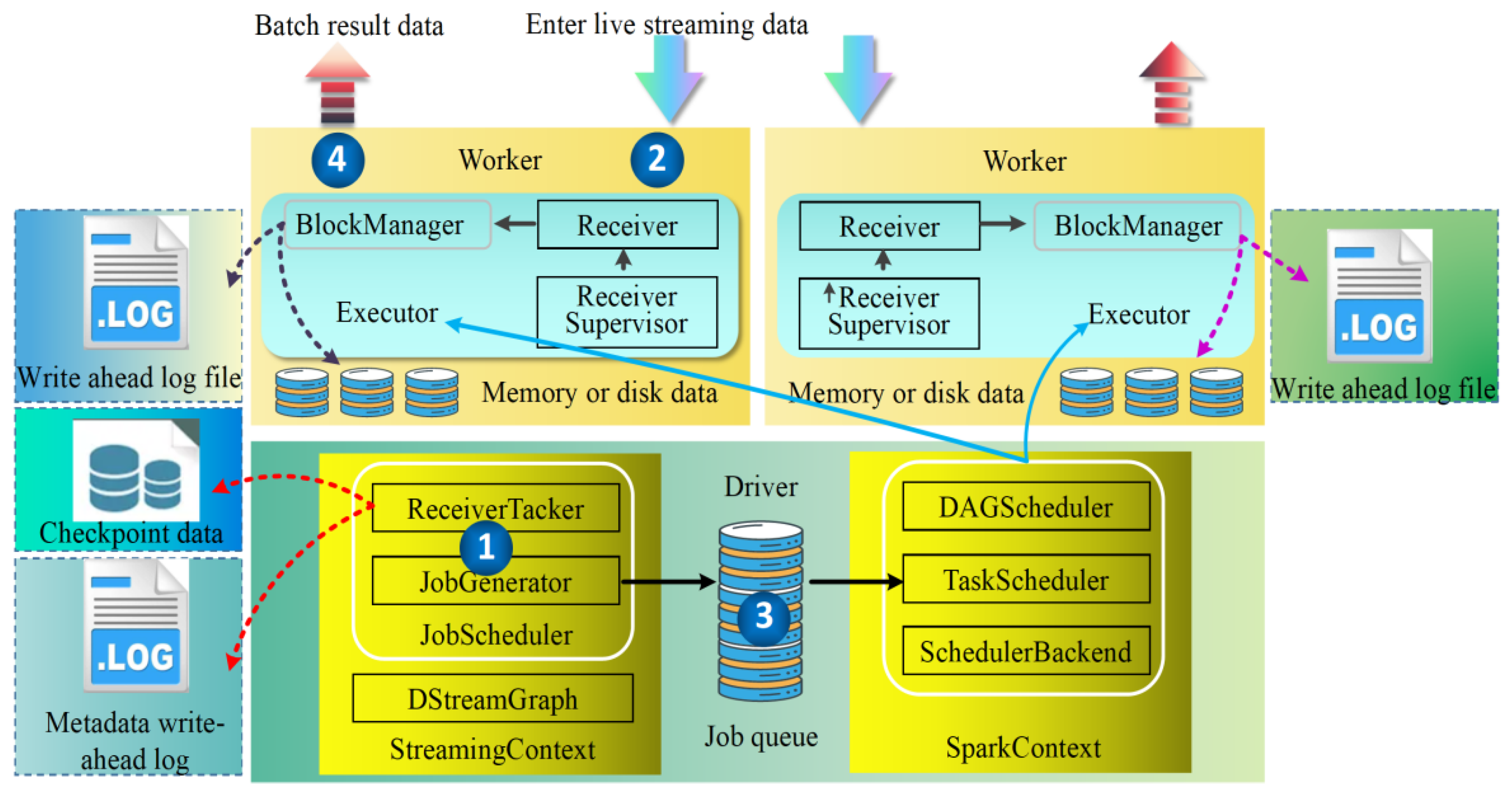
Spark Streaming for stream data processing can be roughly divided into four steps: starting the stream processing engine, receiving and storing stream data, processing stream data and outputting processing results. Its operation architecture is shown in
Figure 1, initializing the streaming context object, instantiating the D Stream graph and job scheduler during the start-up of this object. The D Stream graph is used to store information such as D Streams and the dependencies between D Streams. Job scheduler includes receiver tracker and job generator. The receiver tracker is the manager of the driver-side stream data receiver, and the job generator is the batch job generator. During the start of the receiver tracker, the receiver supervisor in the corresponding executor is notified of the start of the stream data receiver according to the stream data receiver distribution policy, and then, the receiver supervisor starts the stream data receiver. The receiver is started, and it continuously receives real-time streaming data and makes a judgement based on the size of the data coming through. If the amount of data is small, multiple pieces of data are saved into one and then stored in blocks; if the amount of data is large, it is directly stored in blocks. Block storage is divided into two types depending on whether prewritten logging is set up: one type is to use the non-prewritten logging block manager-based block handler method to write directly to the worker’s memory or disk, and the other type is the write ahead log-based block handler method, which writes data to the worker’s memory or disk at the same time as prewriting the log. After the data are stored, the receiver supervisor reports the meta-information about the data storage to the receiver tracker, which then forwards this information to the receiver block tracker. The receiver block tracker is responsible for managing the meta-information about the received data blocks. A timer is maintained in streaming context’s job generator, which performs the job generation operation when the batch time arrives. As the data from the live stream continue to flow in, the Spark framework keeps processing the data and outputting the results accordingly.
2.2. Real-Time Predictive Early Warning SSPG Model Construction
The SSPG model is a PSO-GRU model combined with the SSF for the real-time prediction of gas concentrations. The PSO model is an evolutionary computational technique derived from the study of the predatory behaviour of bird populations, which has a faster convergence rate and better meets the requirements of the algorithm for real-time prediction. The mathematical idea is that, in an n-dimensional space
S ∈
Rn, each population consists of
m particles, where the position of each particle
i is
xi = (
xi1,
xi2,
L,
xin), the velocity is
vi = (
vi1,
vi2,
L,
vin) and the optimal position of each particle is
pi = (
pi1,
pi2,
L,
pin). The optimal position of the whole particle population is
p = (
pg1,
pg2,
L,
pgn). Each particle velocity and position update equation are shown in Equations (1) and (2) [
25,
26,
27].
where
I = 1, 2,
L,
m,
c1 and
c2 are learning factors,
r1 and
r2 are random numbers within [0–1],
t is the time and
ω is the inertia weight; the larger
ω is, the stronger the global search performance.
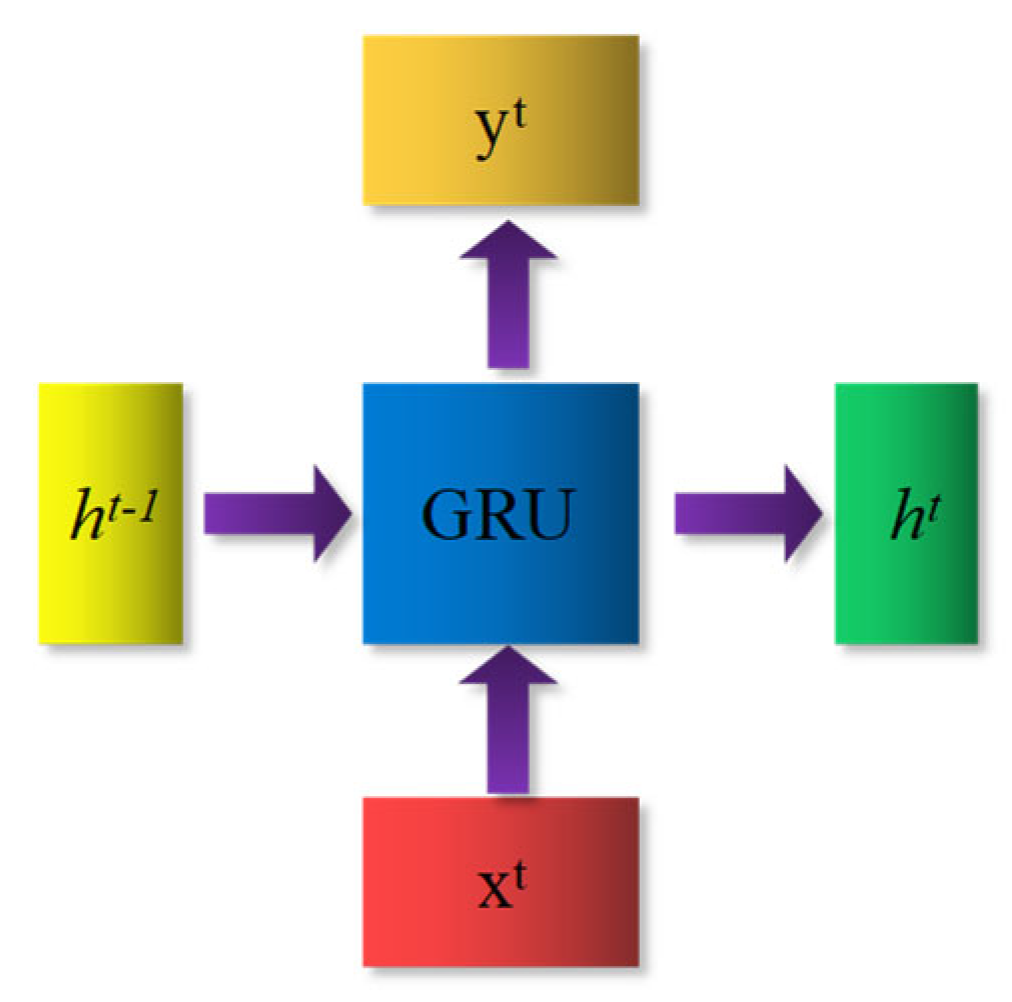
The GRU model is a commonly used gated recurrent neural network [
28]. The GUR has two gates, a reset gate and an update gate. The reset gate determines how to combine the new input with the previous memory, and the update gate determines how much of the previous memory comes into play. There is a current input
xt and a hidden state
ht−1 passed down from the previous node. When combining
xt and
ht−1, the GRU obtains the output
yt of the current hidden point and the hidden state
ht passed down to the next node (
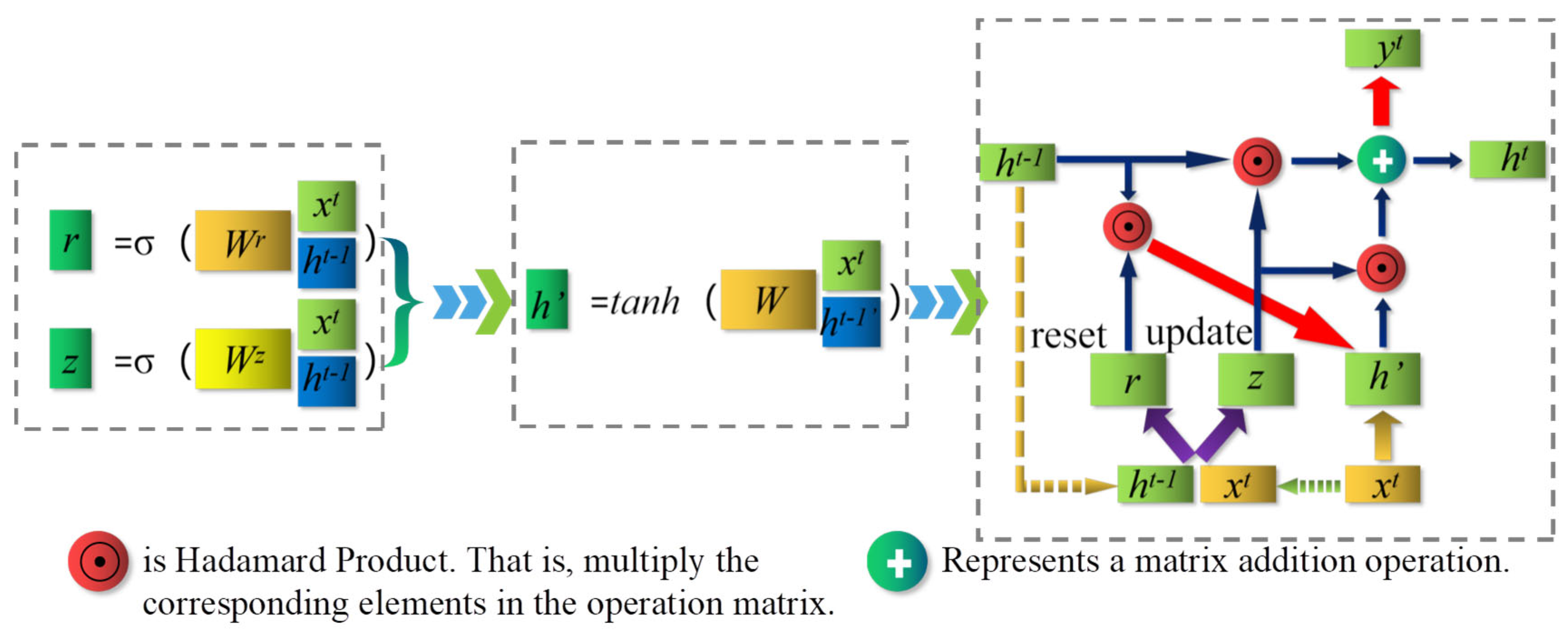
Figure 2). The internal structure of the GRU is shown in
Figure 3.
r is the reset gate (see Equation (3)),
z is the update gate (See Equation (4)),
ht is the hidden layer (see Equation (5)) and
σ is the sigmoid function through which the data can be transformed to a value in the range of [0~1] to act as a gate signal. After obtaining the gating signal, we use reset gating to obtain the data
ht−1’ =
ht−1⊙
r, then splice
ht−1’ with the input
xt and, in pass, as a tanh activation function to deflate the data to a range of [−1~1] to obtain
h’ in
Figure 3.
h’ contains mainly the currently entered
xt data. The GRU has certain advantages in dealing with long time series data, such as the gas concentration [
29]. The model can be divided into three parts: the input layer, hidden layer and output layer. The input layer is mainly used for pre-processing the original data and dividing the dataset, the hidden layer is used for optimising the parameters of the model with the minimum loss value as the evaluation index and the output layer is used for predicting the gas concentration according to the specific optimisation of the hidden layer [
30].
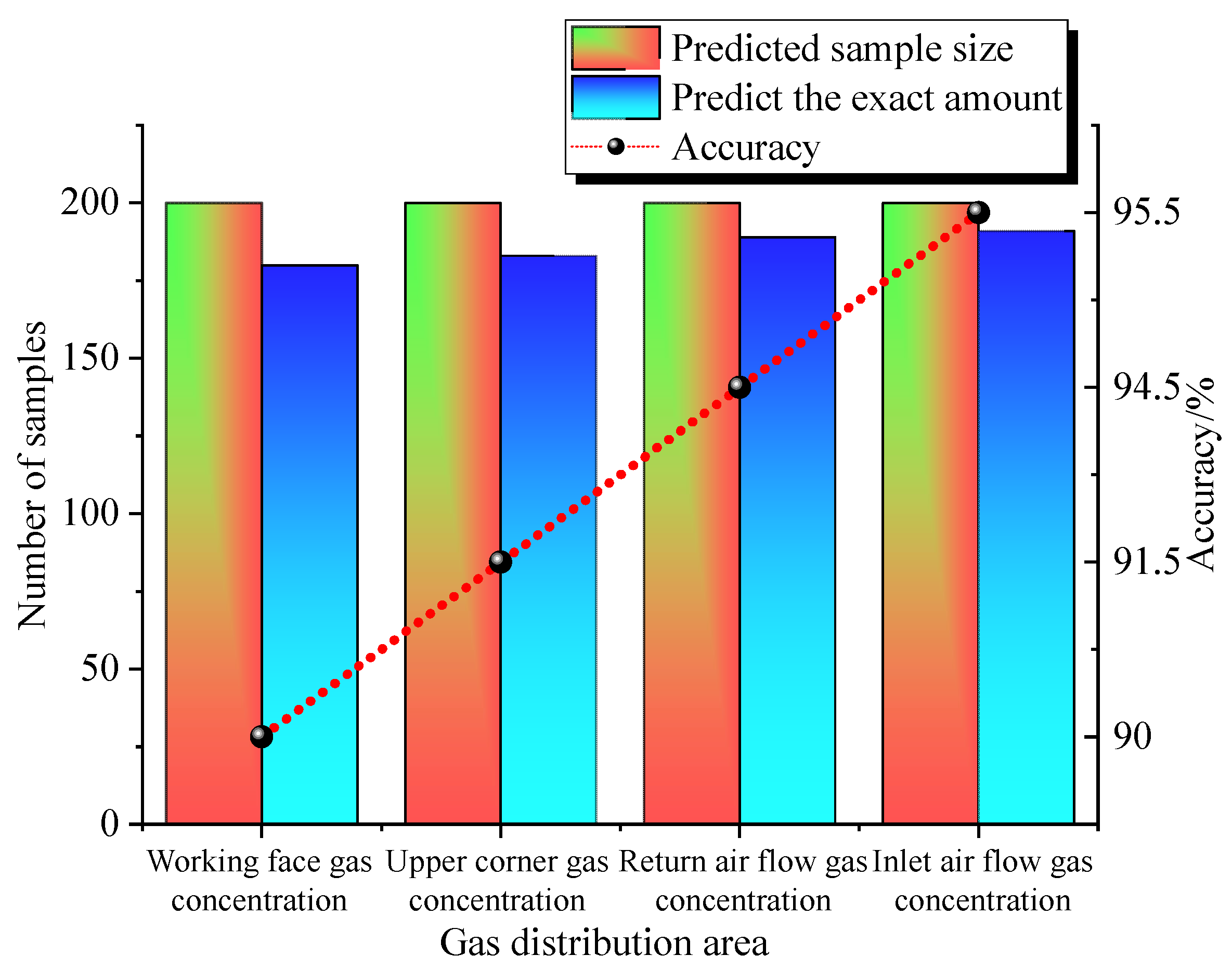
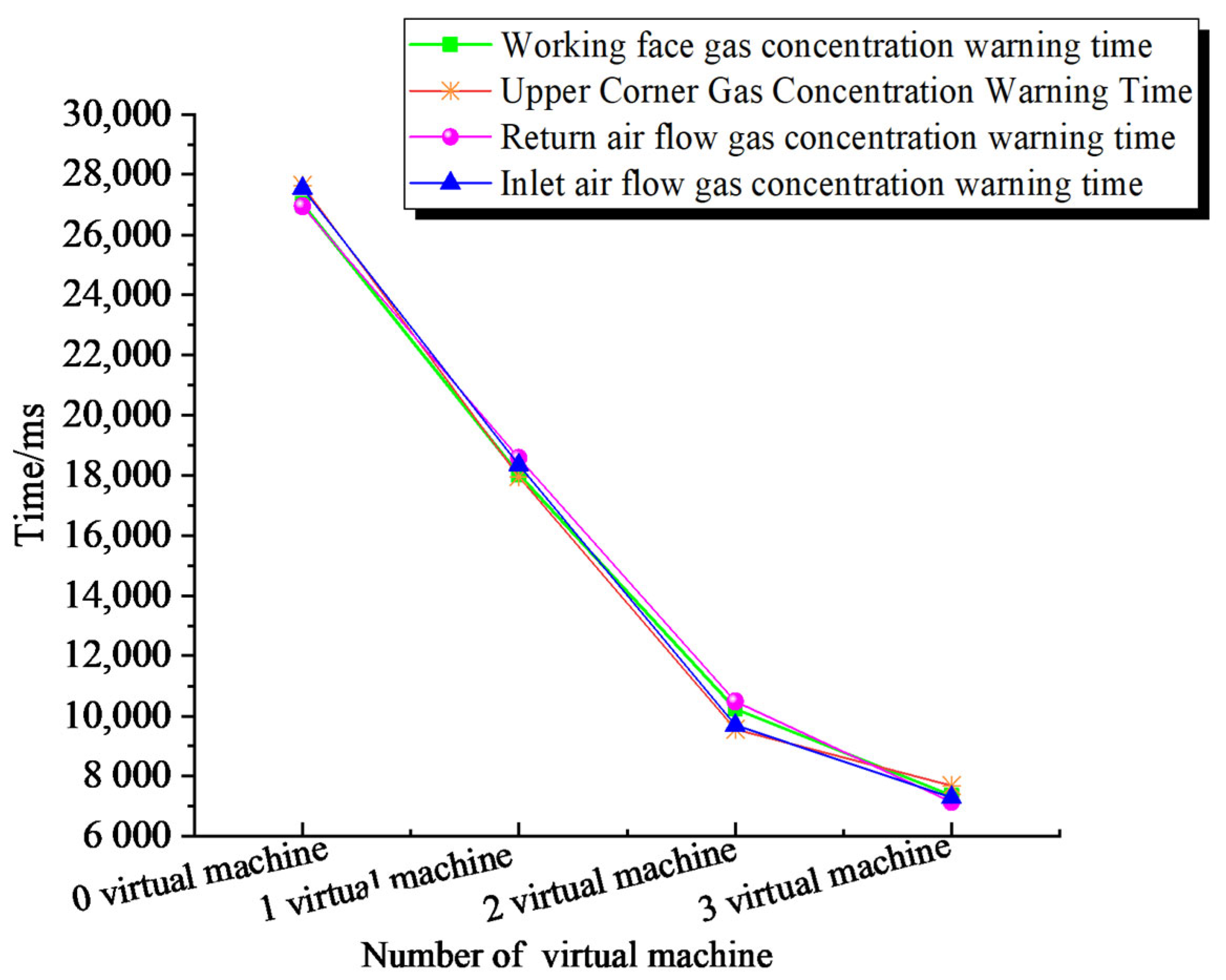
Analytical processing of the data and parameter optimisation of predictive models on the SSF. The GRU neural network requires many parameters to be set when training the data. When predicting gas concentration, the number of neurons, hidden layers, batch sizes and time steps have a large impact on the model and have an influence on the fit and prediction accuracy of the neural network. In this study, these hyperparameters are optimised using the PSO algorithm to optimise the structure of the neural network based on the input data and reduce the training time of the neural network. The features of the number of neurons, hidden layers, batch sizes and time steps are used as features of the particle search for optimisation and are iterated in the PSO algorithm until the optimal solution is output. The steps to achieve the optimisation parameters are as follows:
Step 1: Given some hyperparameters of the GRU neural network, such as network nodes, the number of neurons, hidden layers, batch size and time step of the GRU neural network are initialised and input into the PSO model.
Step 2: Initialise the population size of the particle population, the maximum and minimum values of the particle velocity, the learning rate, the maximum number of iterations and the initial position of the particles.
Step 3: Optimisation training by the PSO model is used to find the best position; obtain and record the optimal solution and update the best position of the particle.
Step 4: After the PSO algorithm training, stop iteration and output the best parameter value when the parameter meets the set condition; otherwise, return to step 3 and continue training.
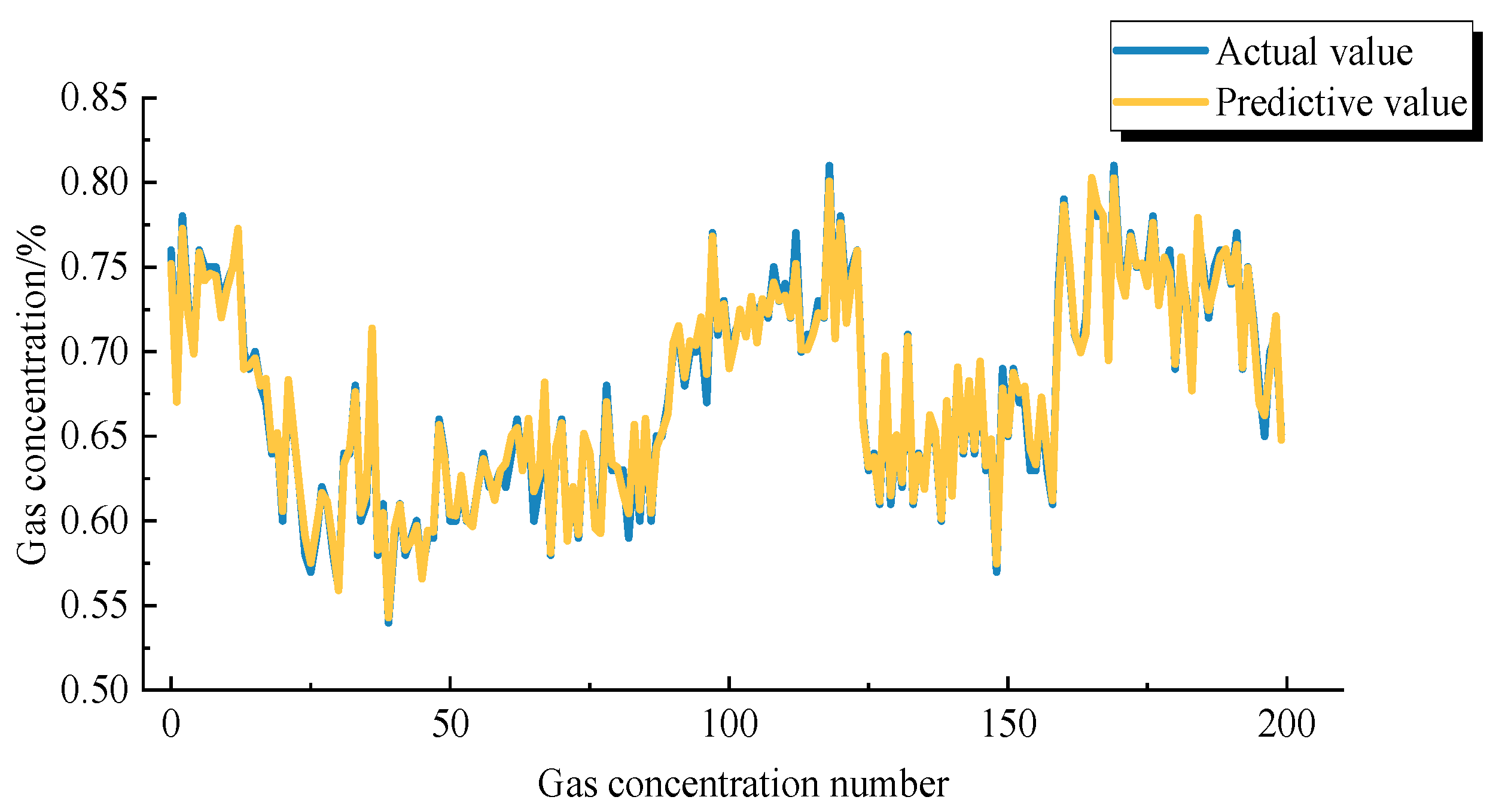
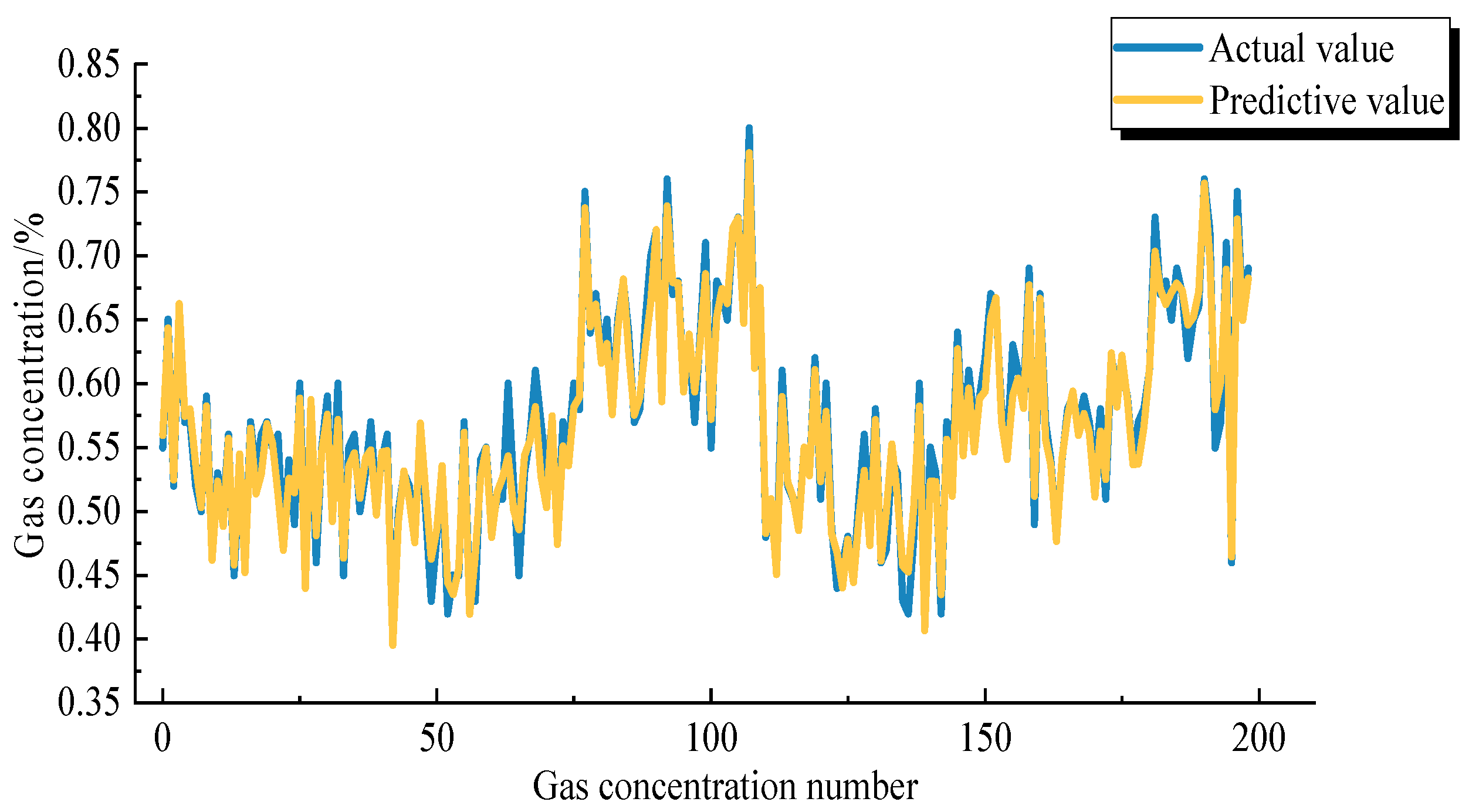
Step 5: The hyperparameters optimised by the PSO algorithm are fed into the GRU network model as the initial hyperparameters of the GRU neural network to be trained, and then, the predicted values are output. Finally, the fitted curve of the predicted and test data can be derived.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}