
TLSCA-SVM Fault Diagnosis Optimization Method Based on Transfer Learning



Abstract
:1. Introduction
2. SCA-SVM Algorithm
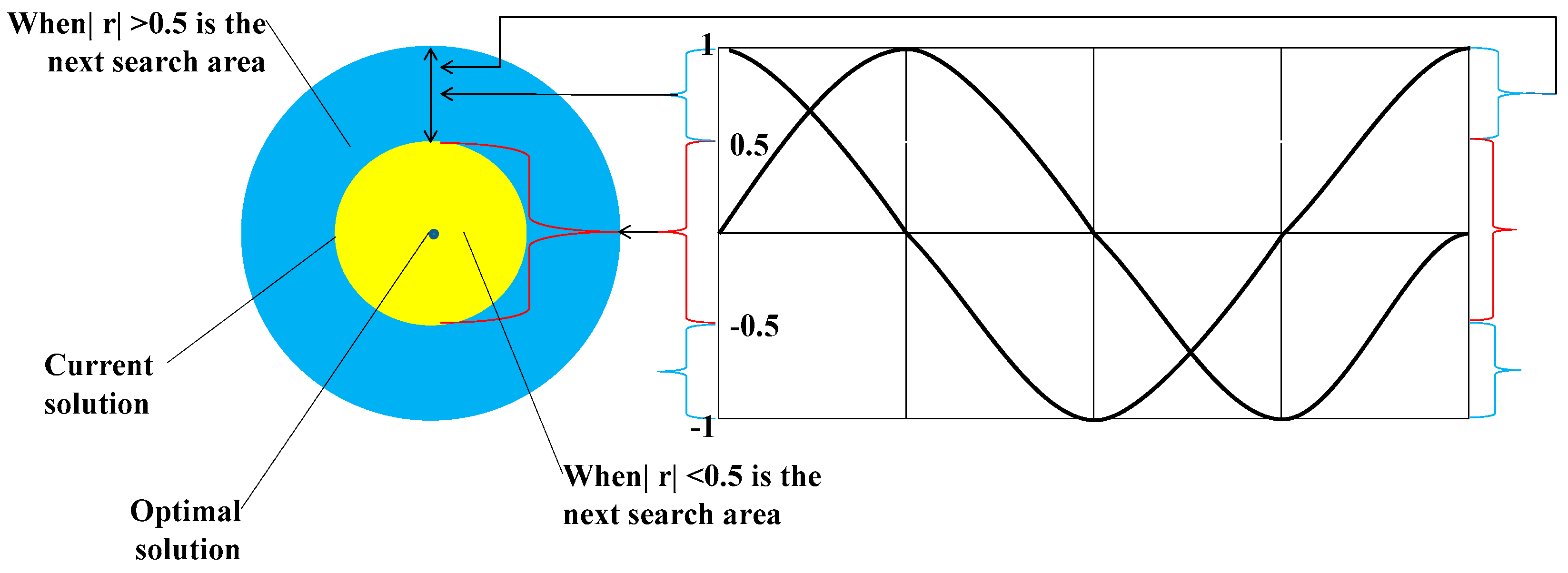
2.1. Principles of SCA Optimization Parameters
2.2. The Classification Principle of SVM
3. Fault Diagnosis Model of TLSCA-SVM Algorithm
3.1. Principles of Transfer Learning
3.2. TLSCA-SVM Algorithm
3.3. Fault Diagnosis Process of TLSCA-SVM Algorithm
4. Acquisition and Process Fault Samples of Analog Circuits
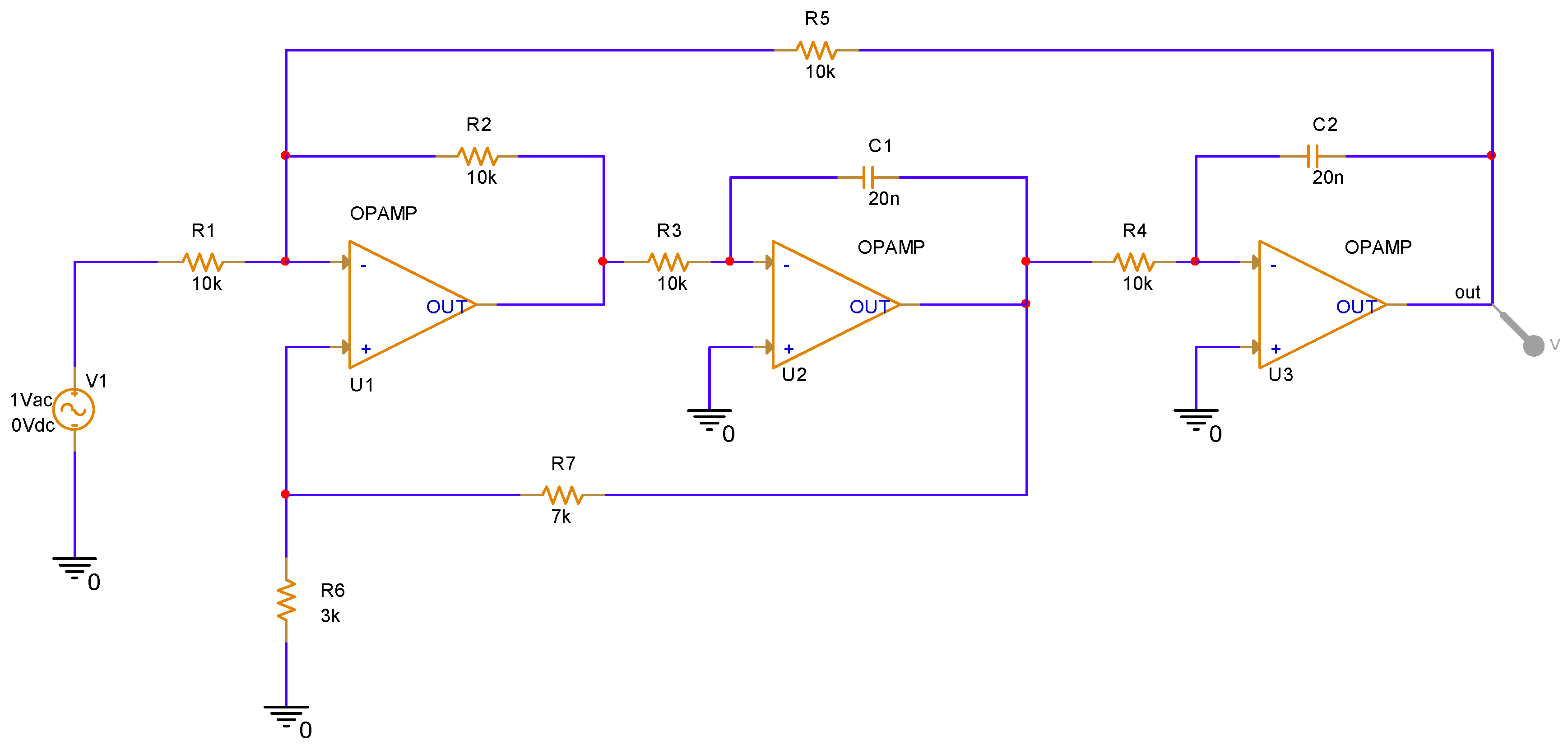
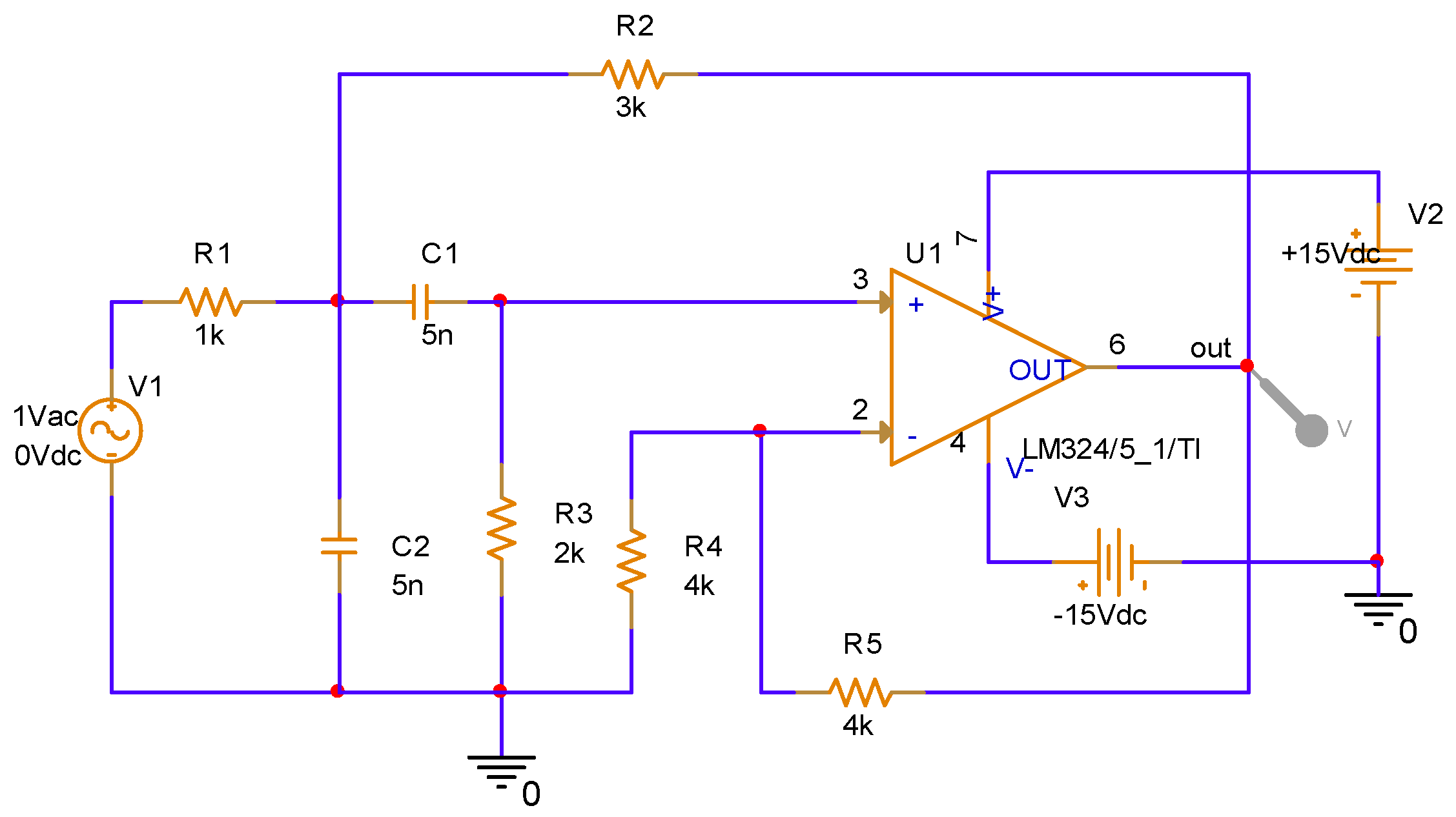
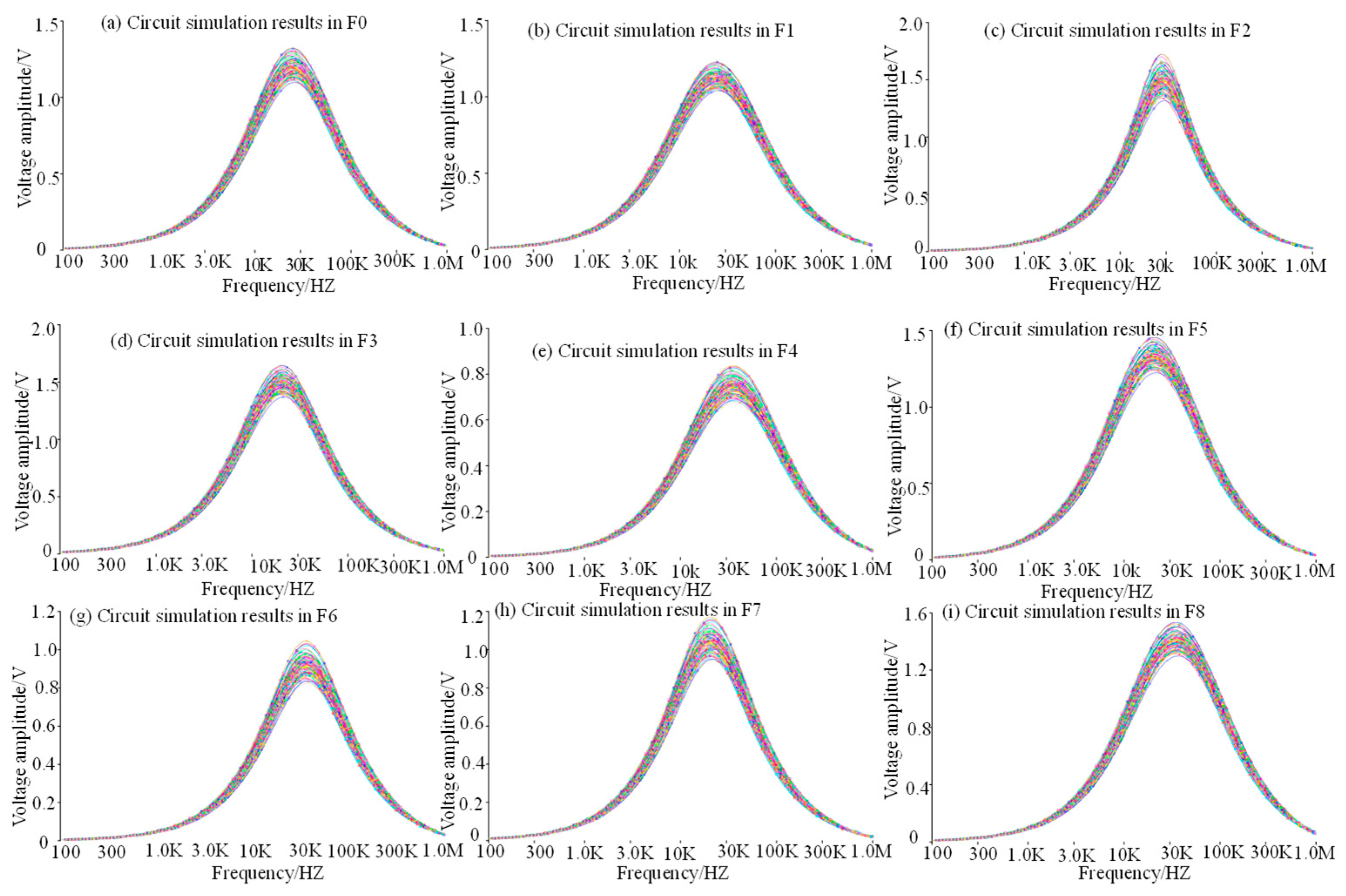
4.1. Data Processing of Sallen-Key Band-Pass Filter Circuit with Injected Fault
4.2. Data Processing of the CSTV Filter Circuit Injected into the Fault
4.3. Feature Processing of Analog Circuit Fault Data
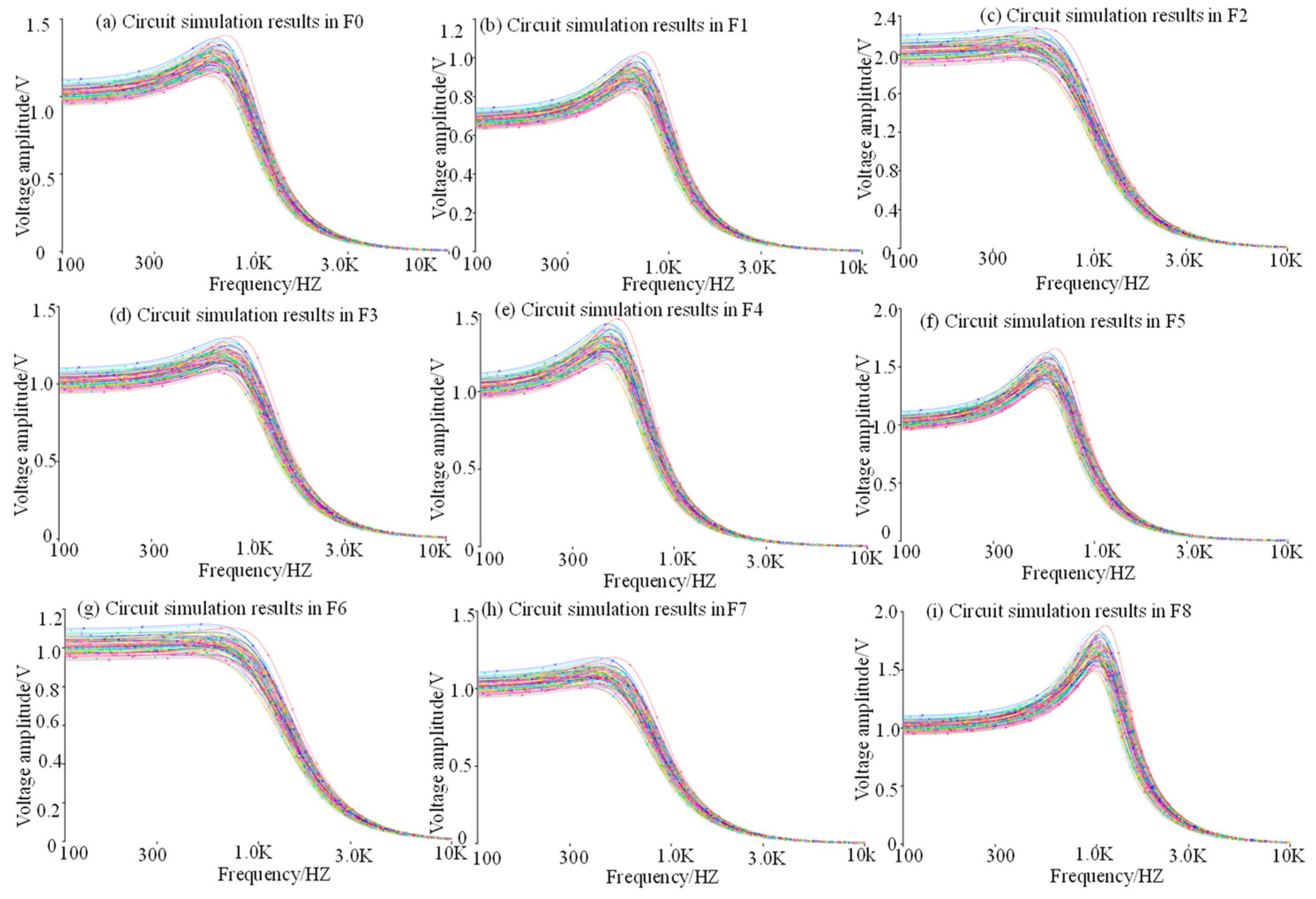
4.3.1. Extract Fault Signal
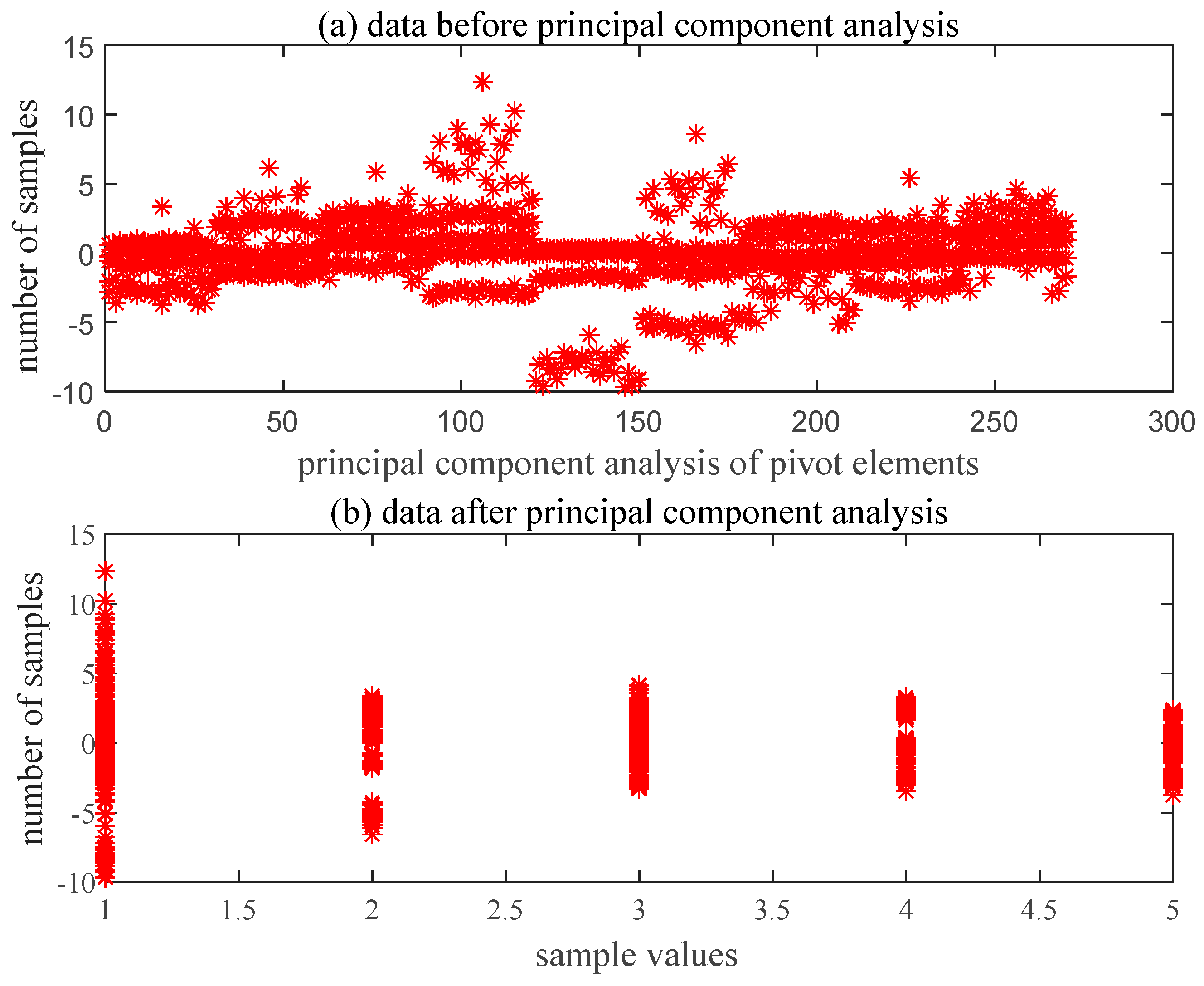
4.3.2. Feature Extraction and Dimensionality Reduction of Fault Signals
5. Algorithm Horizontal and Vertical Comparison Experiment Results
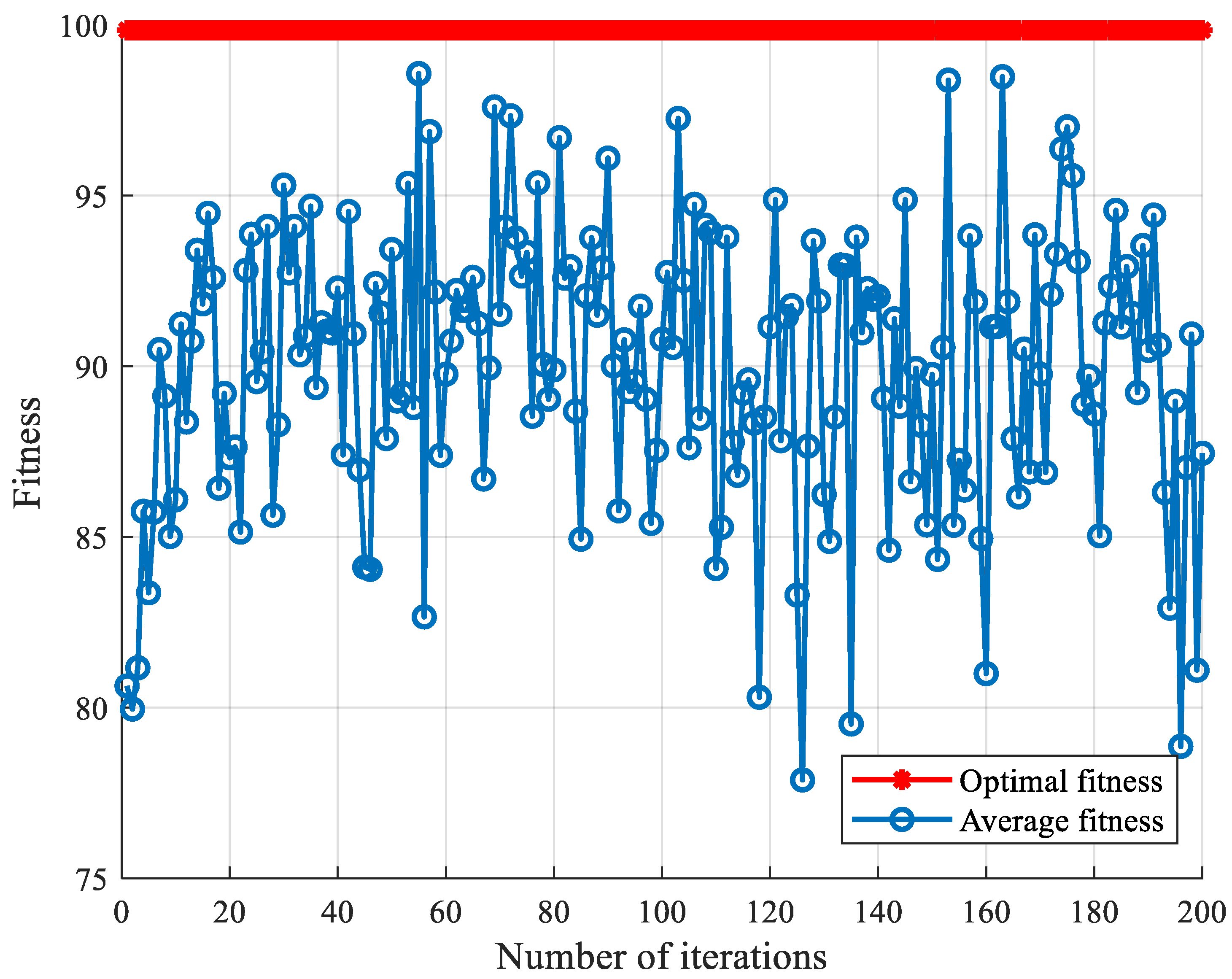
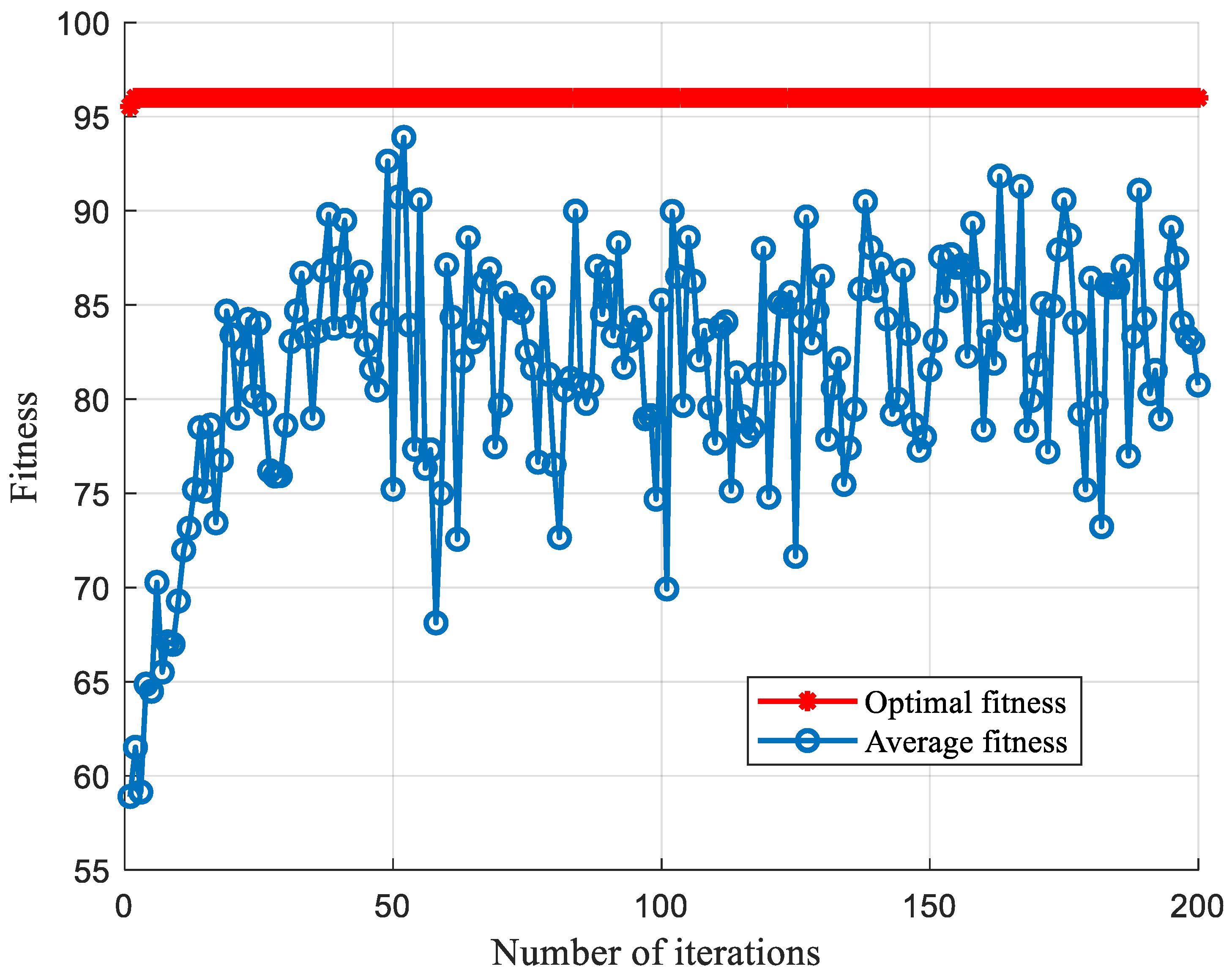
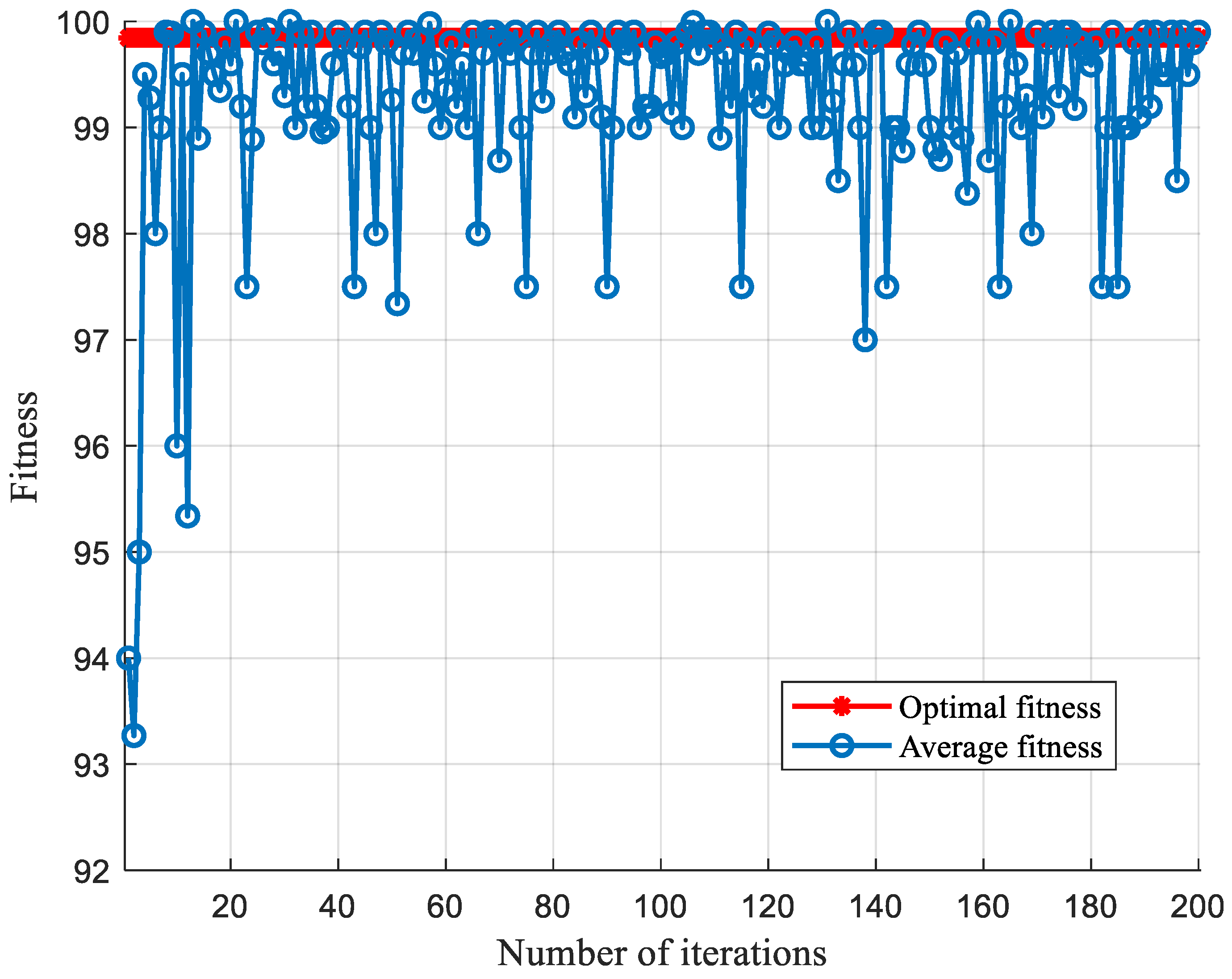
5.1. SCA Optimization Parameter Comparison
5.1.1. Comparison of Optimized Parameters under Sallen-Key Band-Pass Filter Circuit
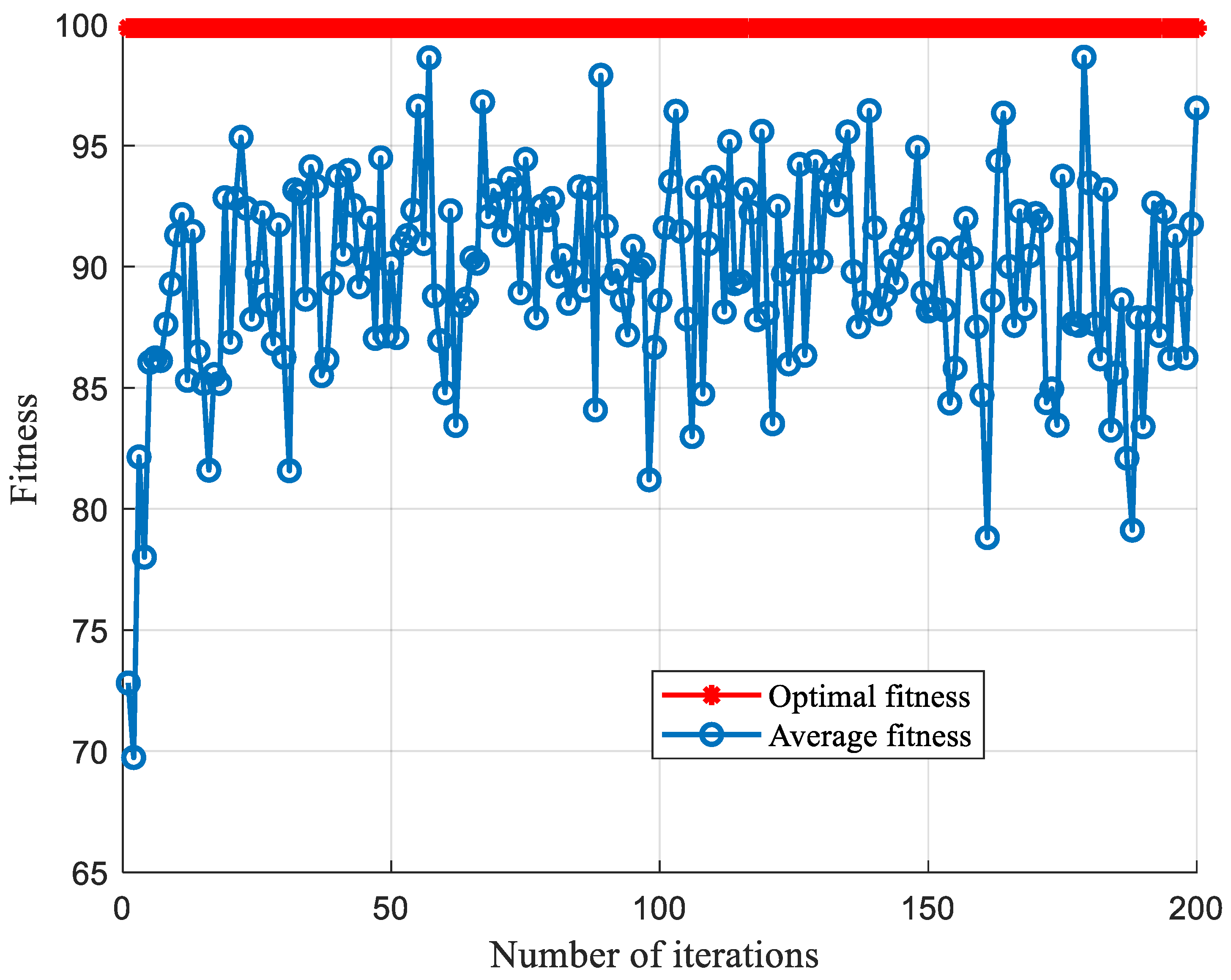
5.1.2. Comparison of Optimized Parameters under CSTV Filter Circuit
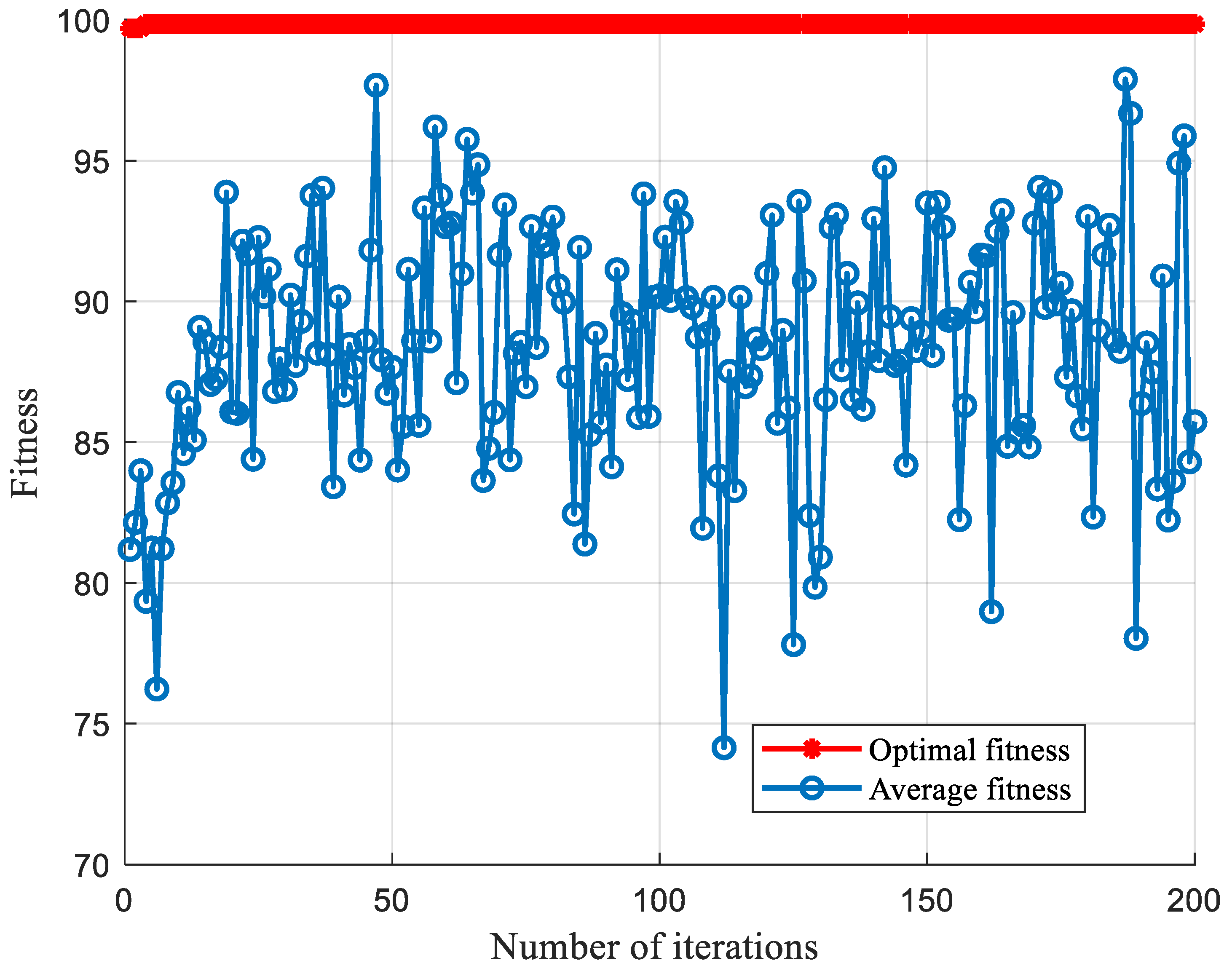
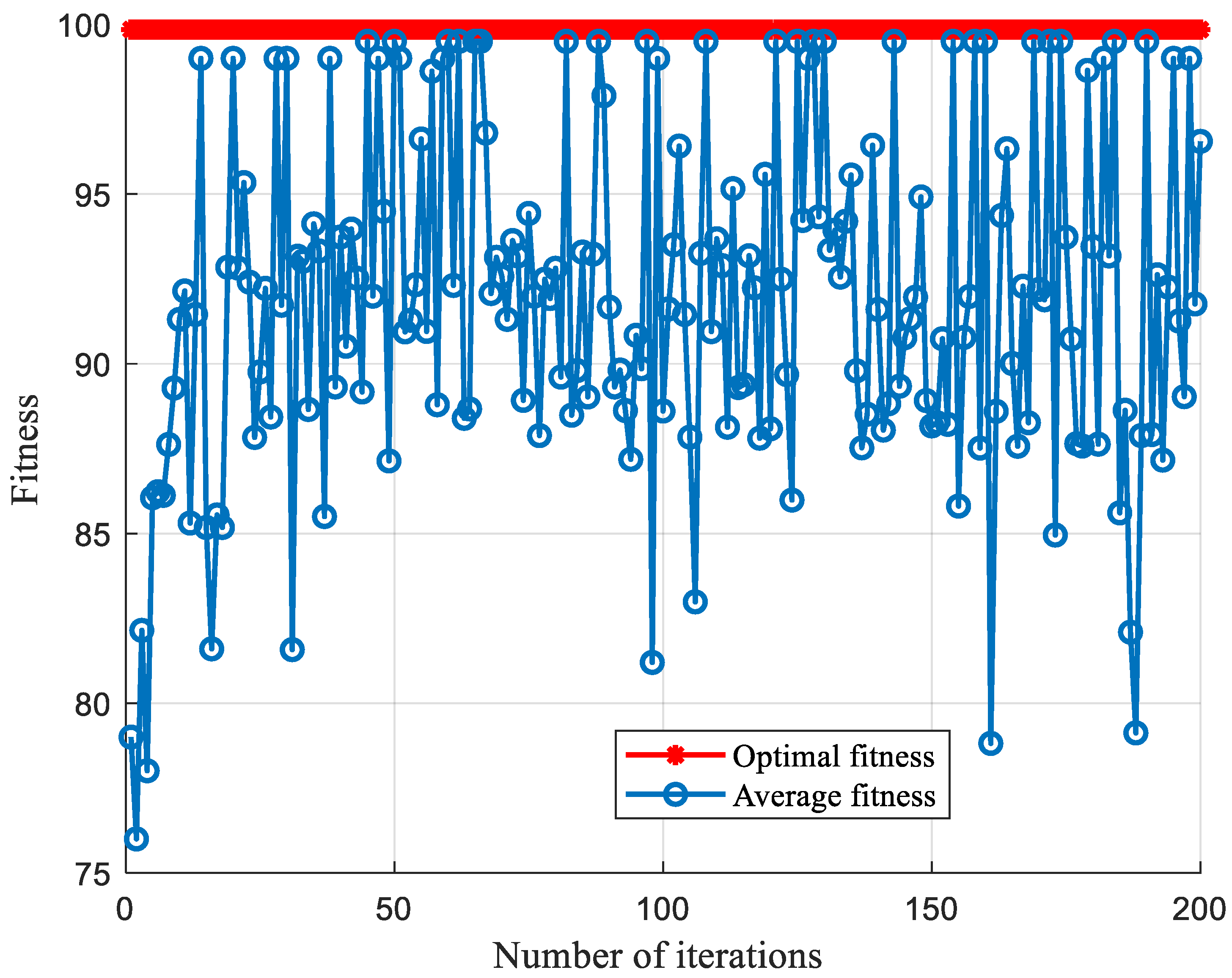
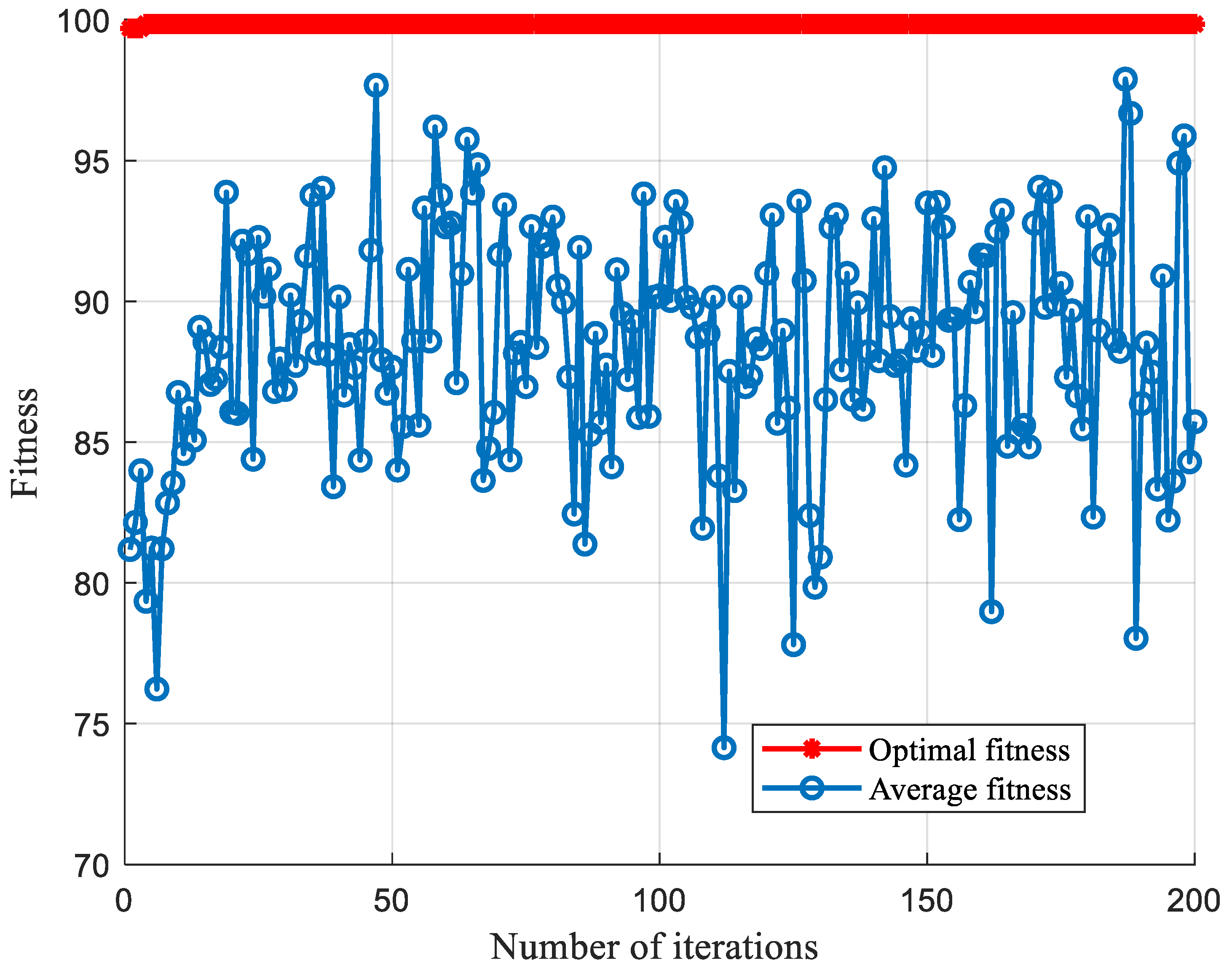
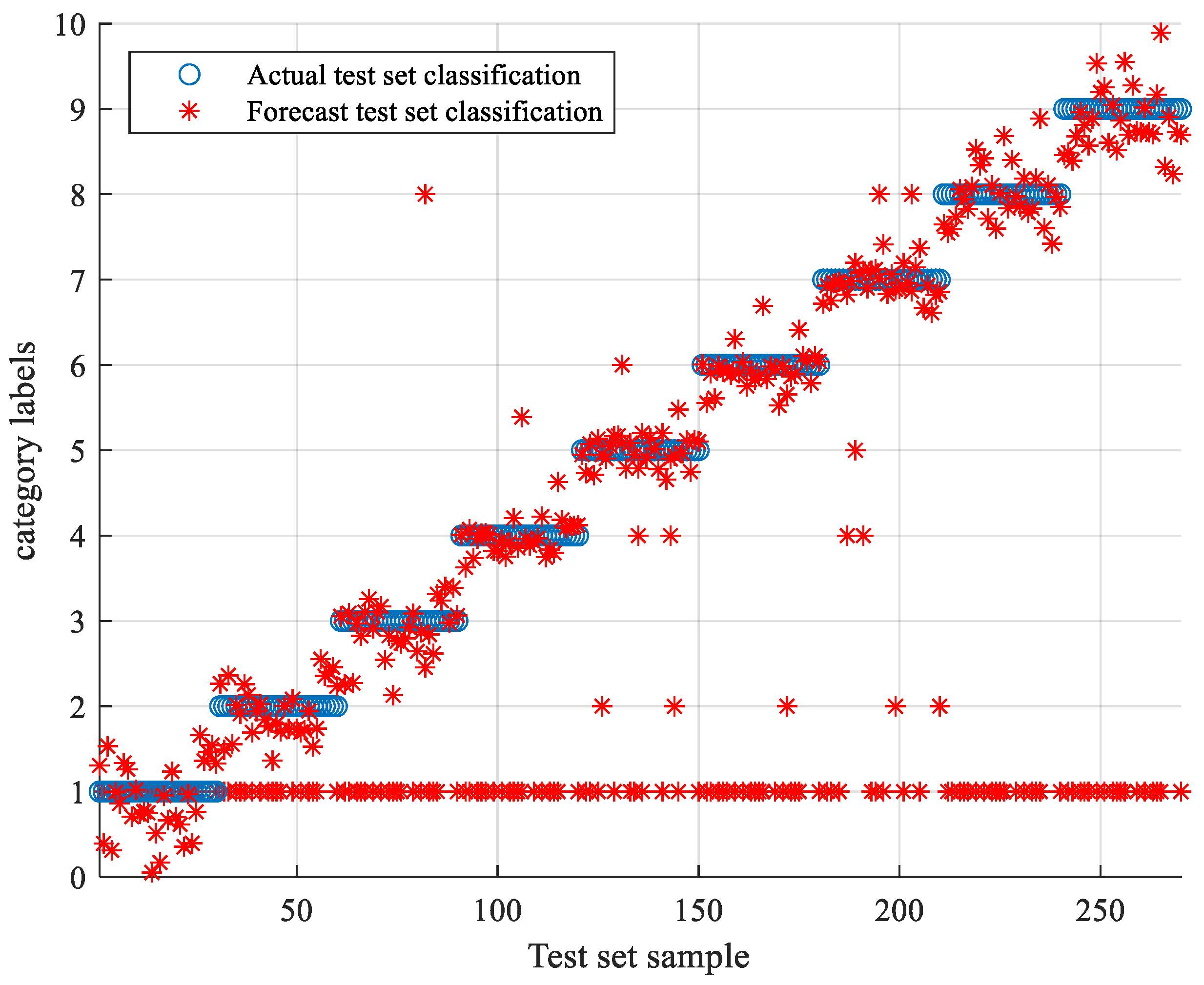
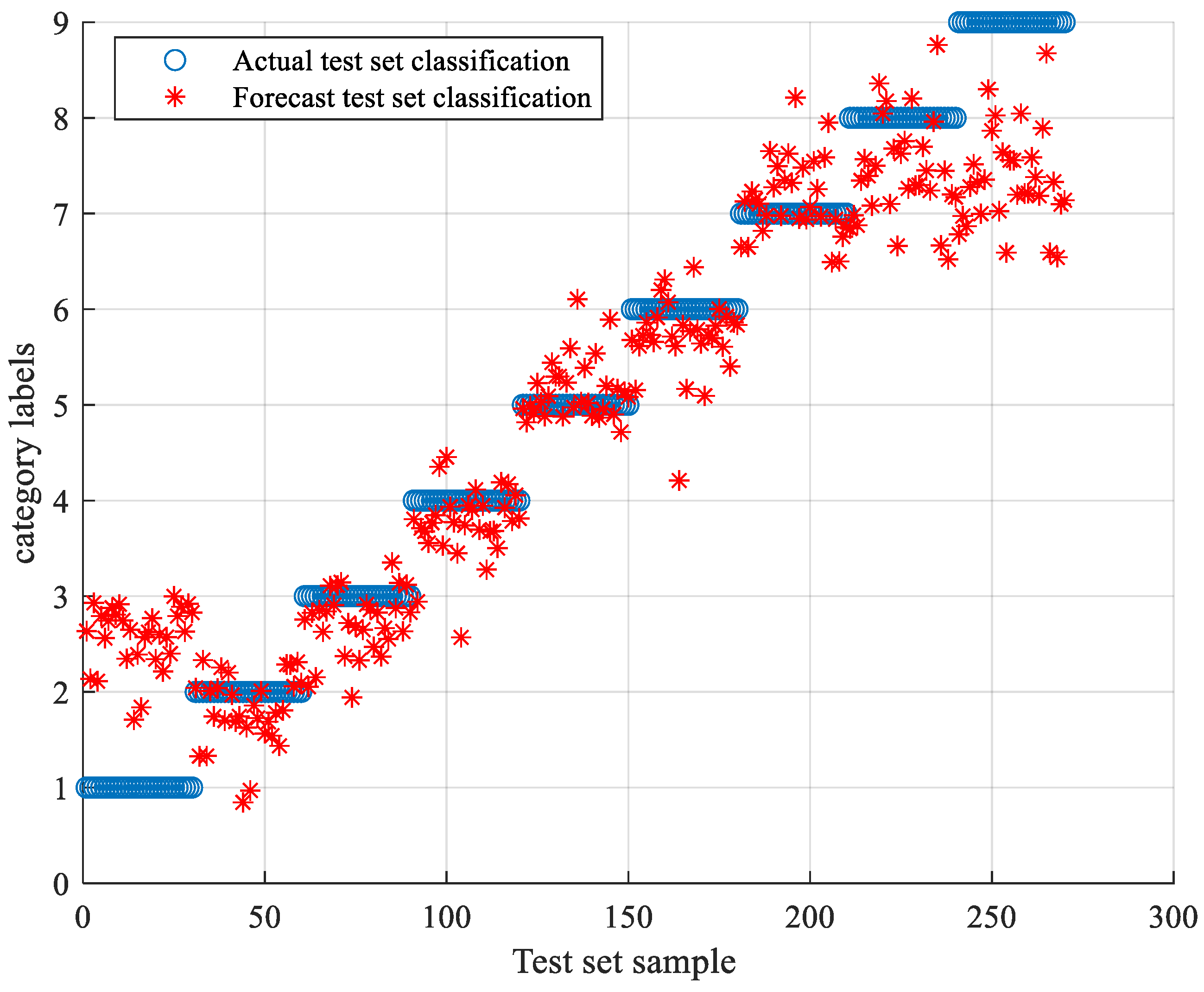
5.2. Comparison of SCA-SVM Classification Algorithms
5.2.1. Comparison of Classification Algorithms under Sallen-Key Bandpass Filter Circuit
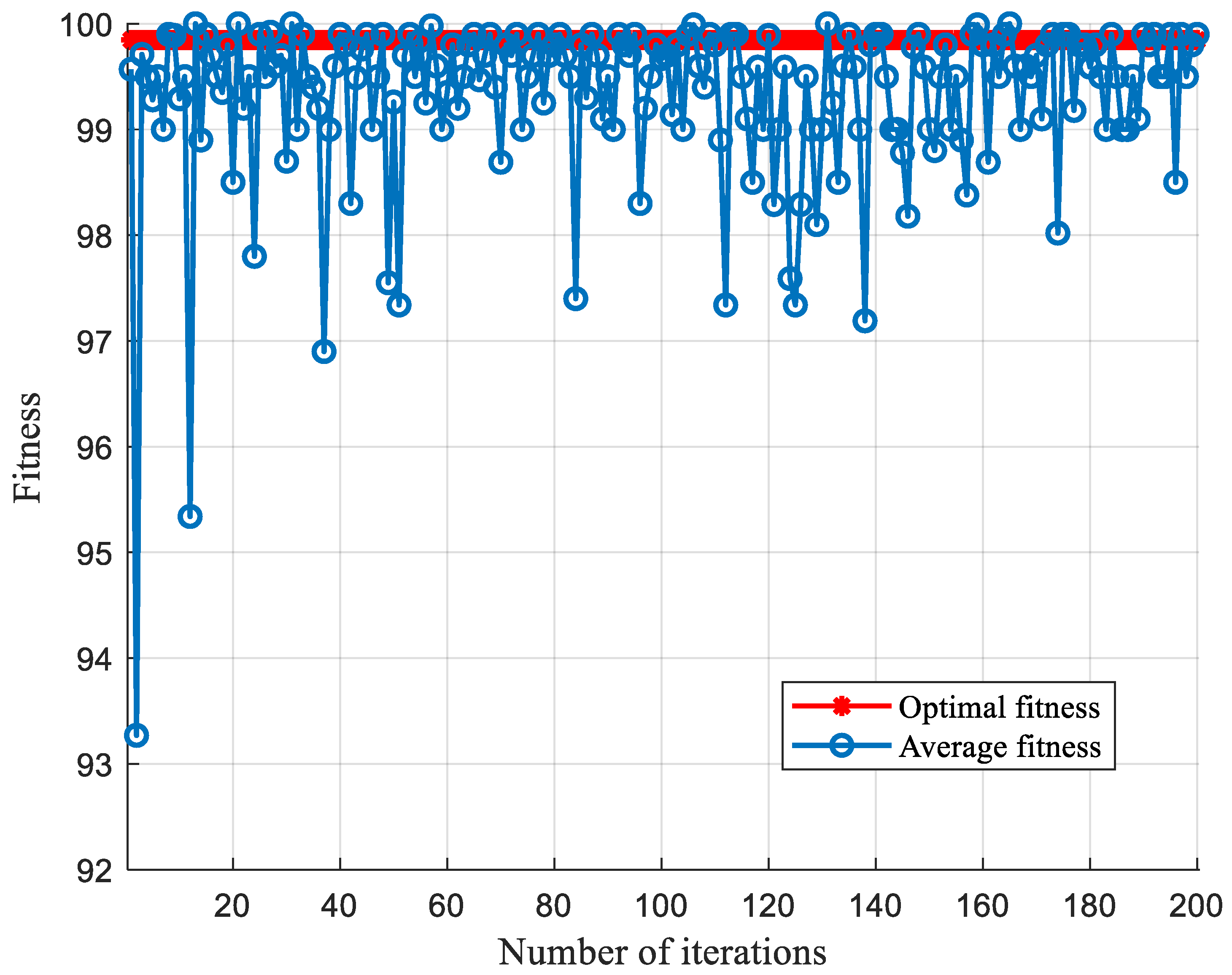
5.2.2. Comparison of Classification Algorithms under CSTV Filter Circuit
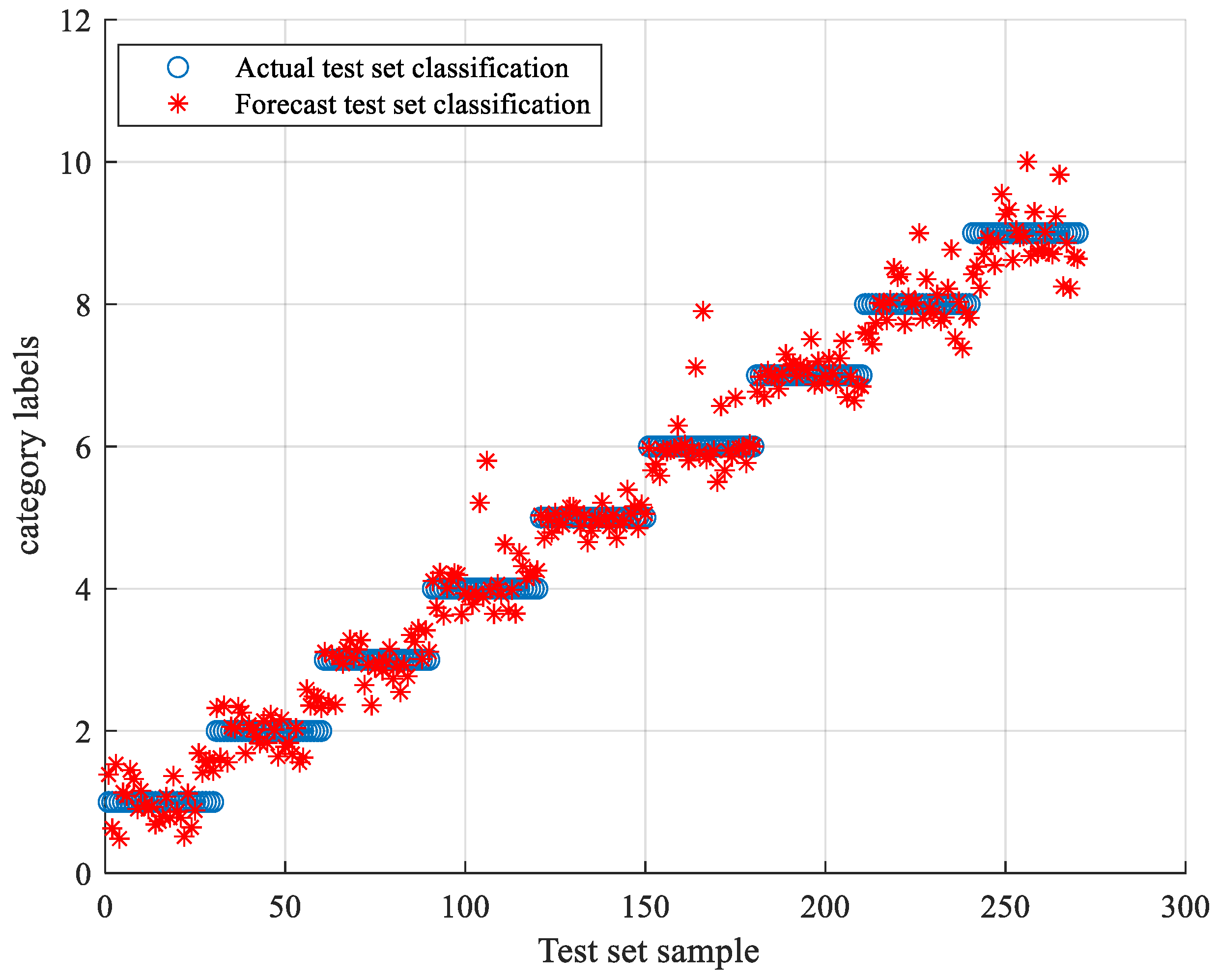
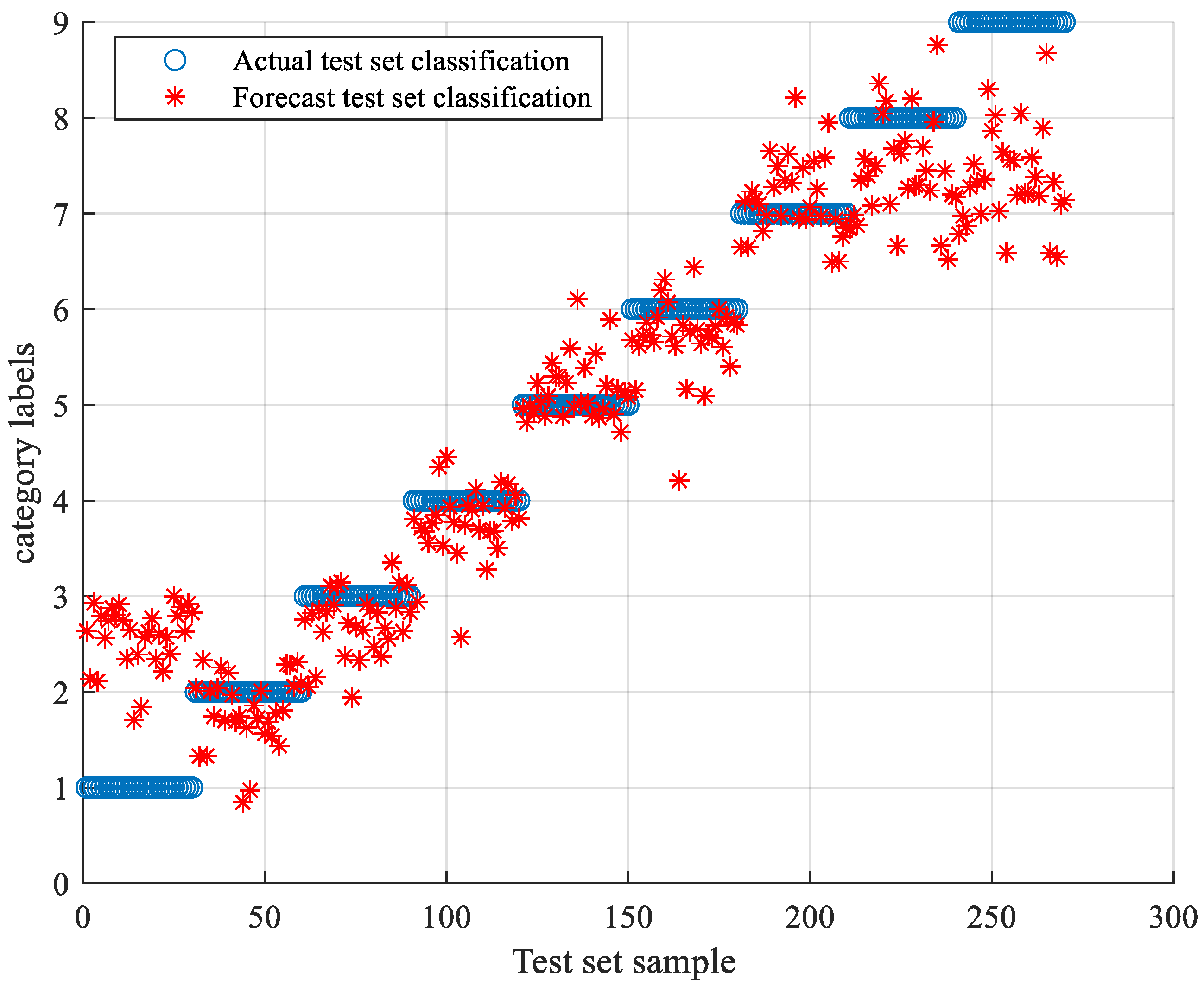
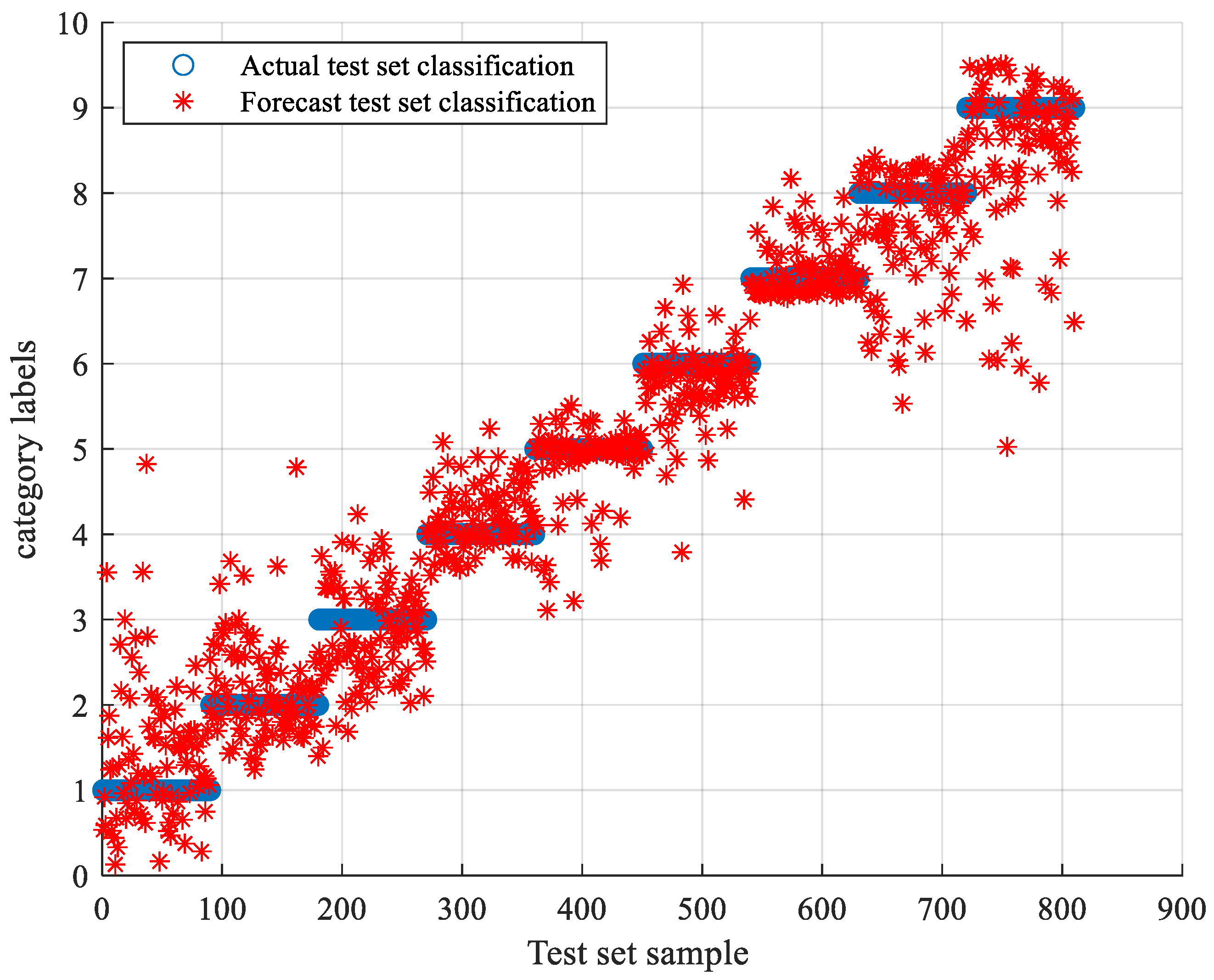
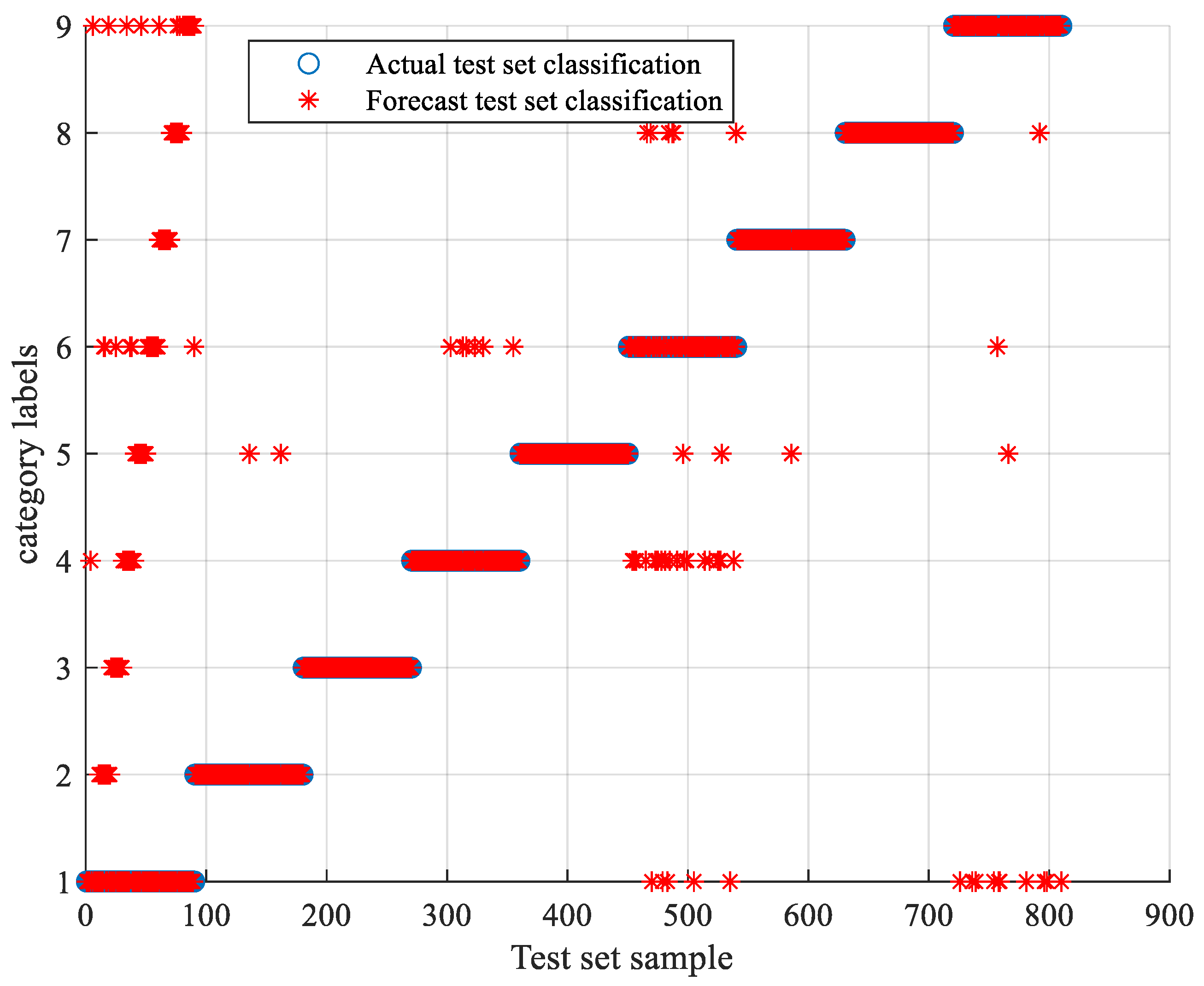
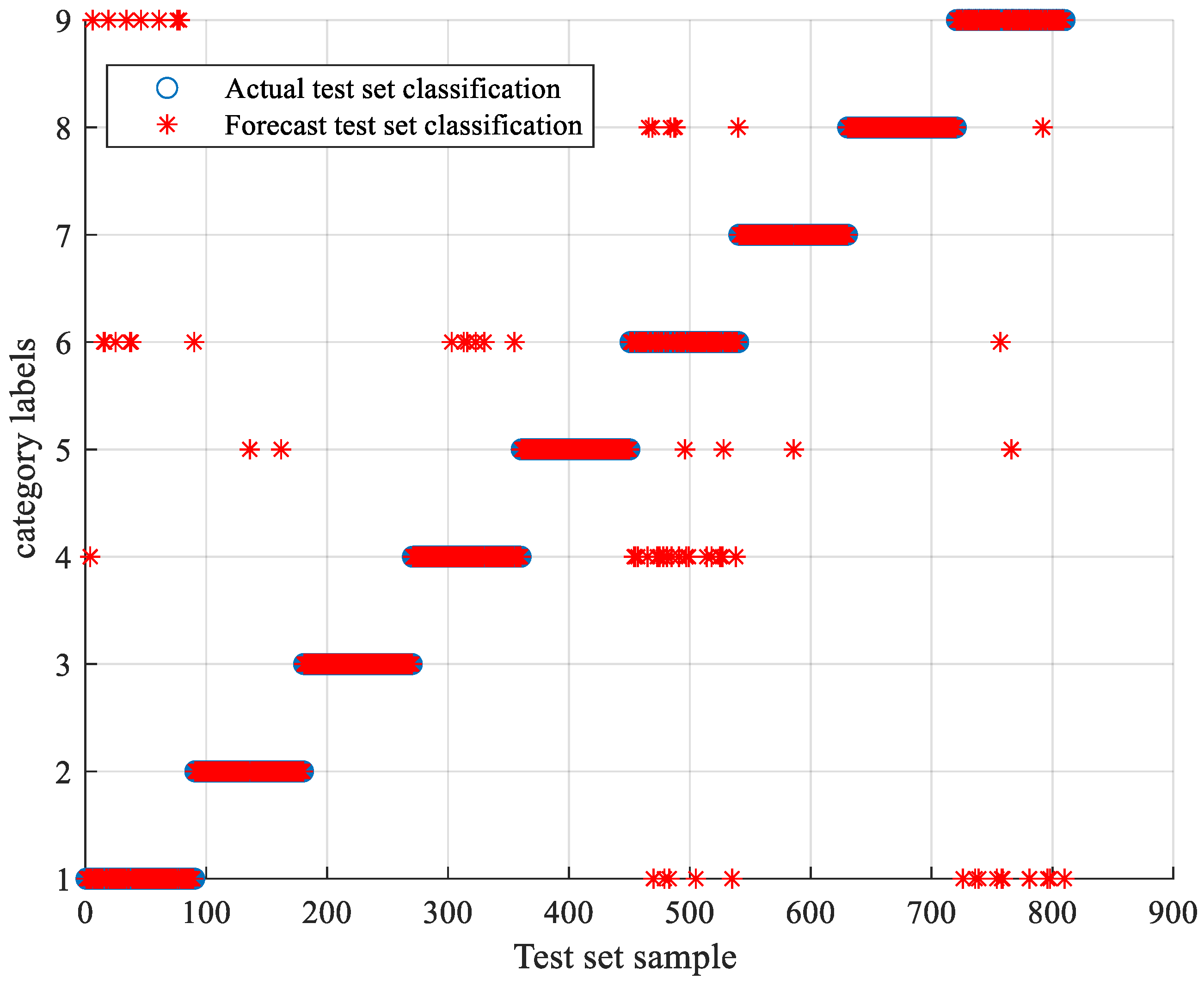
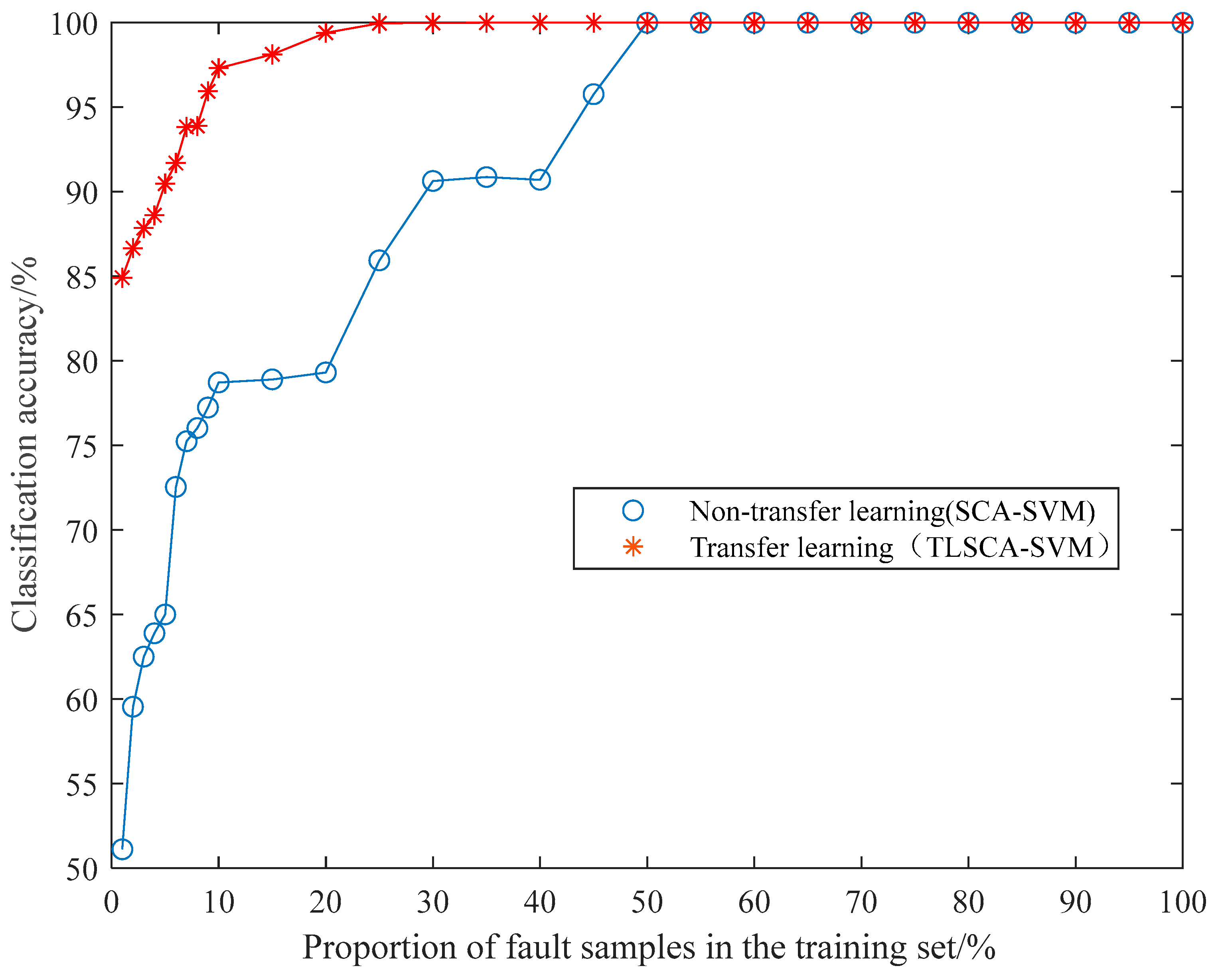
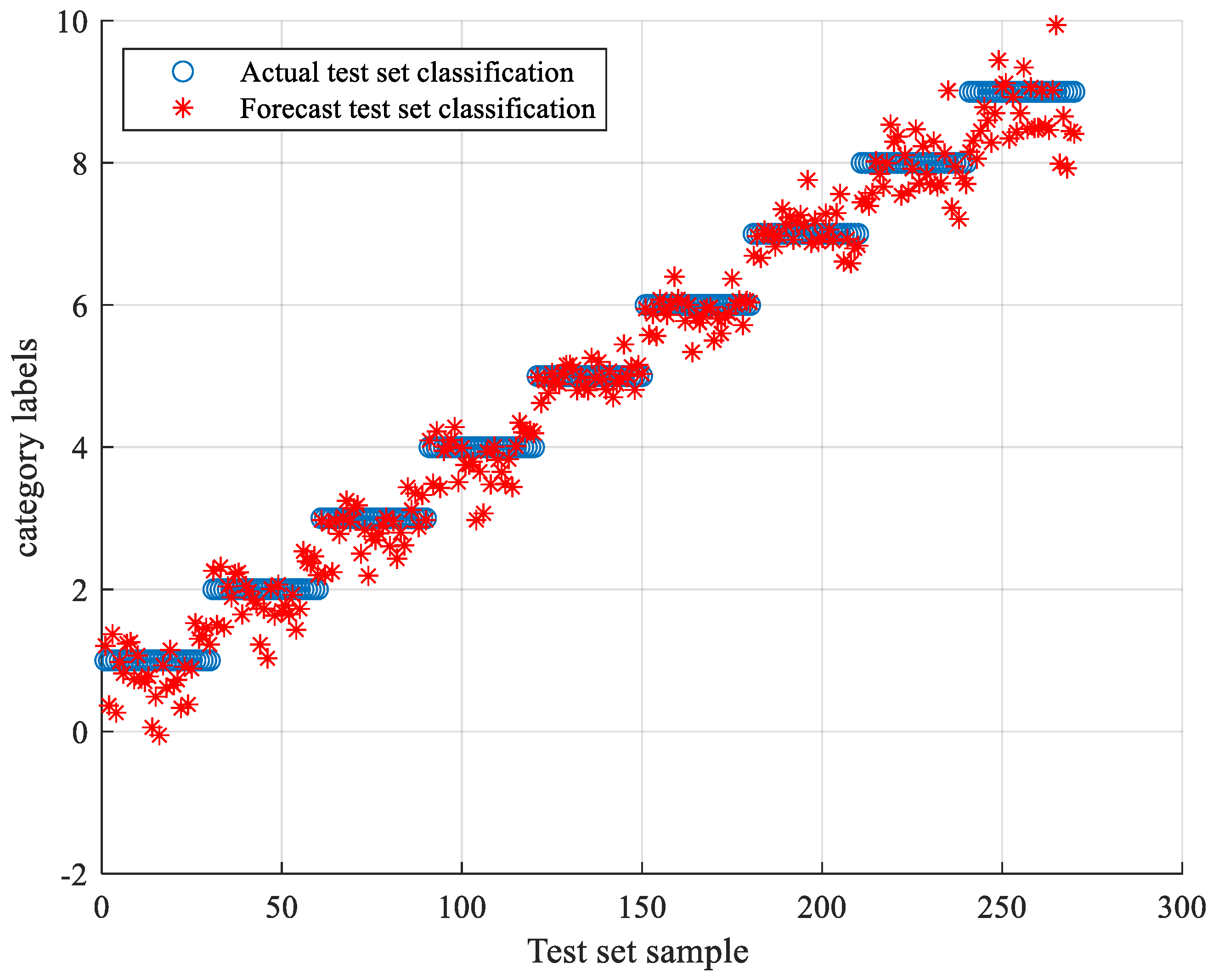
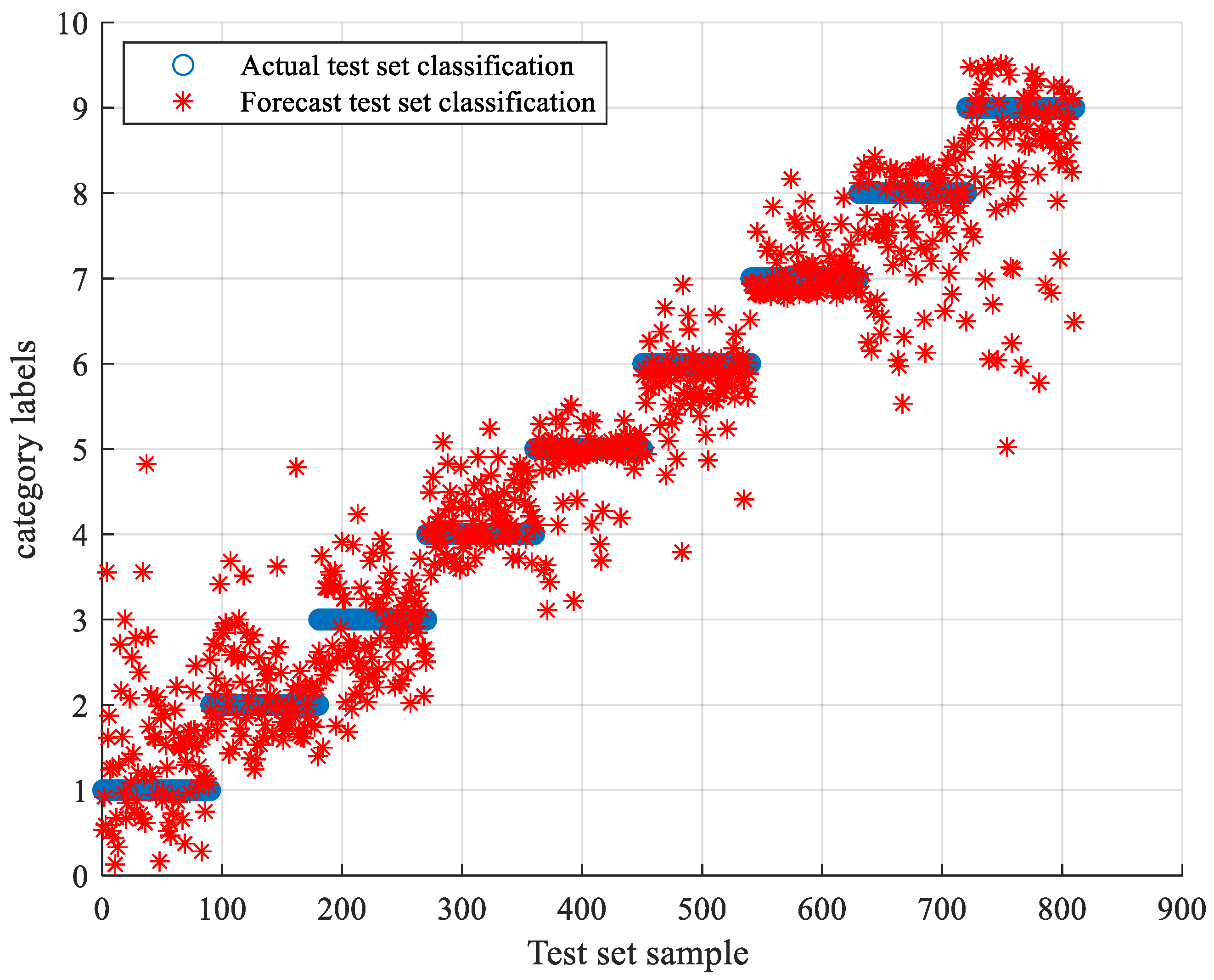
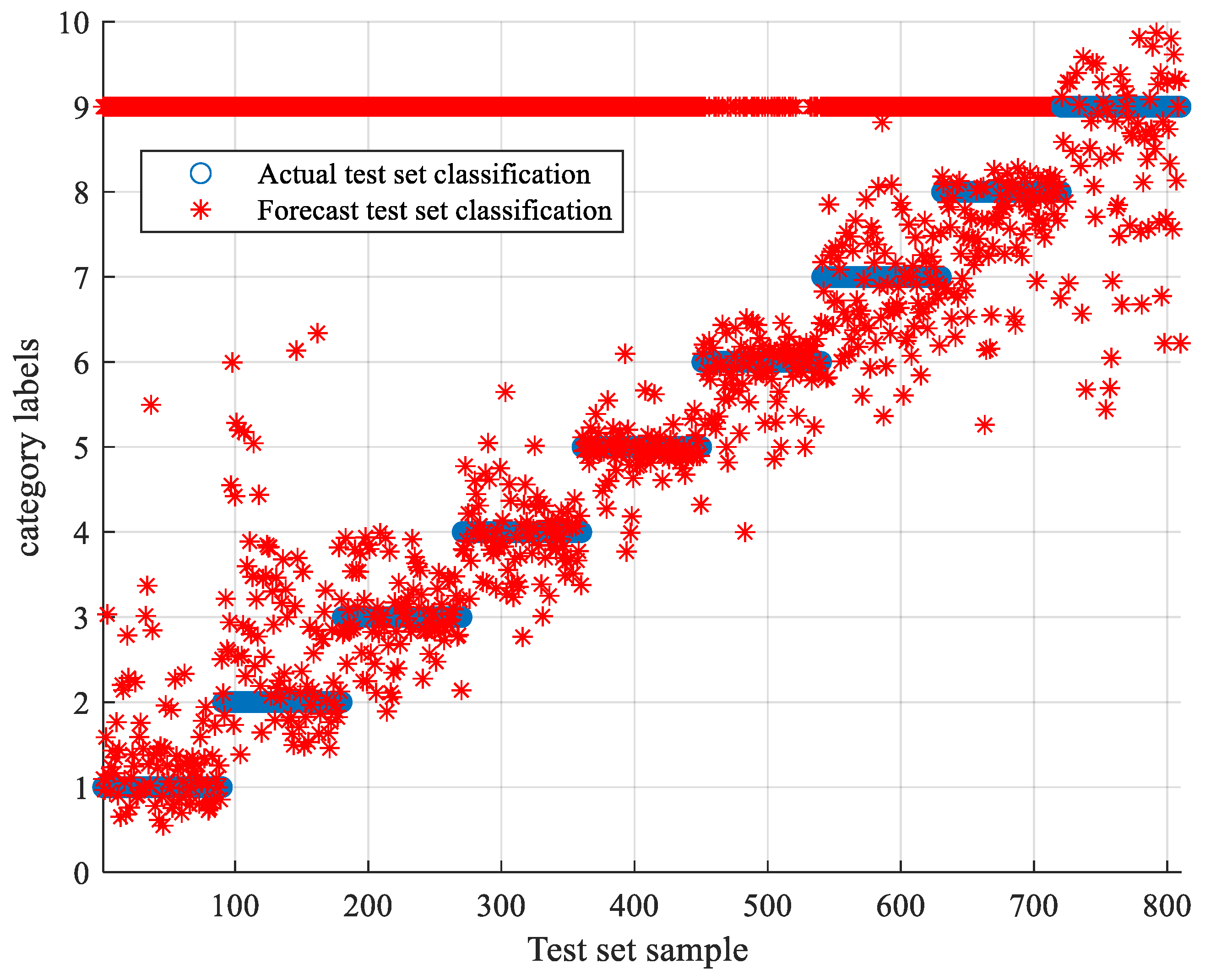
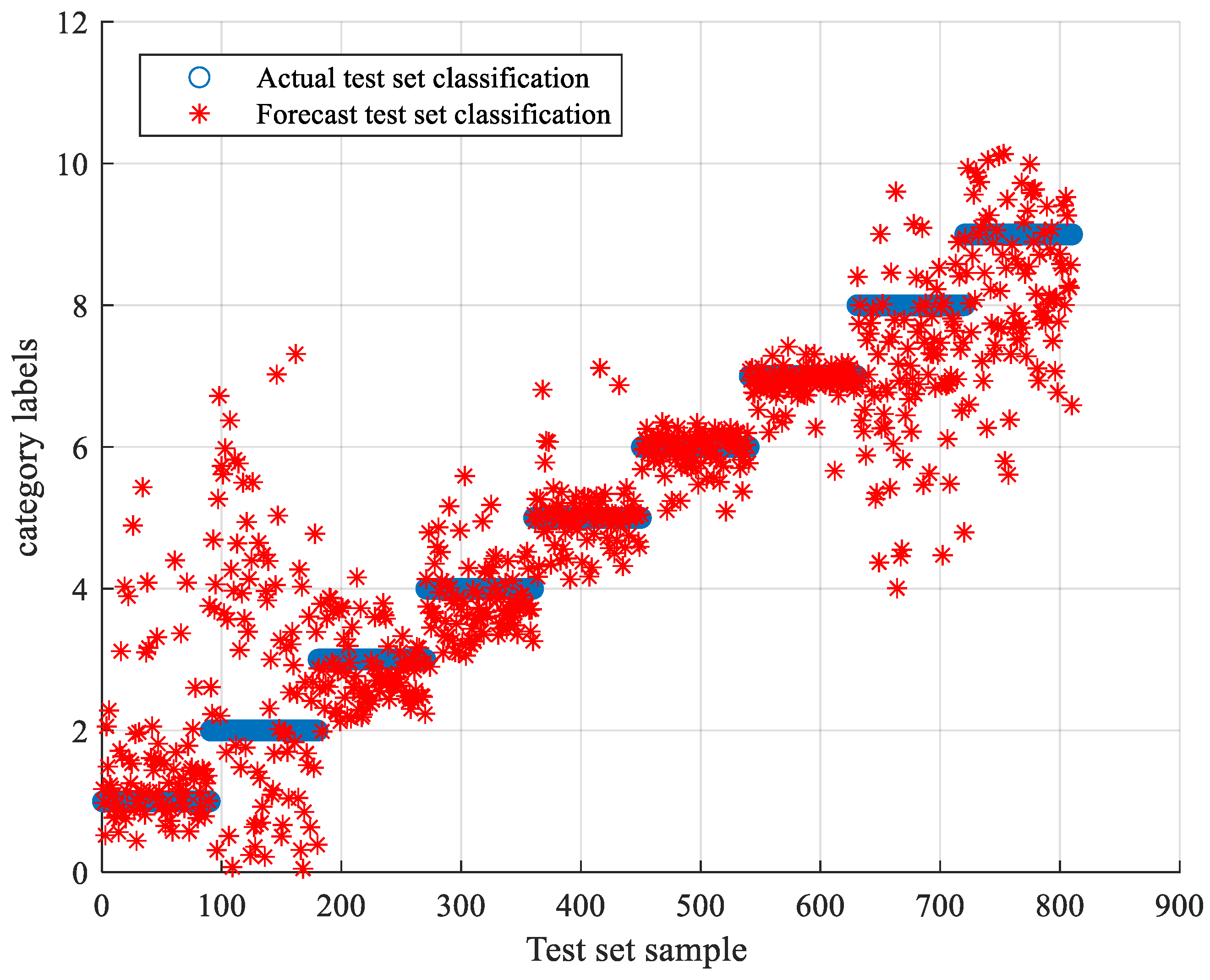
5.3. TLSCA-SVM Comparative Test Results
6. Conclusions
- (a)
- By comparing optimization parameter algorithms such as Grid Search, GA, PSO, ACA, SA, etc., the SCA is proposed. The SCA optimization-parameter algorithm can improve the optimization speed and shorten the optimization time on the premise of meeting the parameter-optimization requirements. The entire algorithm has both high classification accuracy and fast classification performance.
- (b)
- The SCA-SVM fault-classification method has superior performance in the fault diagnosis. A complex CSTV circuit is used to verify the versatility of the method. Several comparison experiments show that the method is not only superior, but also universal in performance to other algorithms. Different classification algorithms are used, such as BP, SOM, ELM, decision tree, random forest and SCA-SVM to compare. It can be concluded that the accuracy of the SCA-SVM classification algorithm is superior to other comparison algorithms in terms of the classification effect.
- (c)
- With regard to the problems of most optimization algorithms, this paper reasonably avoids them. The classification algorithm of this paper is analyzed. This paper uses the SVM classifier as the main body for fault diagnosis. The SVM classifier itself has a good classification effect, and the difference between the important parameter’s penalty factor and kernel parameter will affect the classification effect of the SVM. The objective of the SCA algorithm is to obtain appropriate parameters. The search method is randomly determined each time an optimal solution is found. That is to say, in the next search, both the local search and the global search are random, i.e., the probability is the same. Each time the optimal solution is approximated, the approximation method is randomly determined. Such an optimization method can avoid local optimal solutions and shorten the optimization time. The classifier formed after finding suitable parameters has a good classification effect in fault classification, and the classification efficiency improved.
- (d)
- Various optimization algorithms were compared, such as Gray Wolf Optimization (GWO), Gravitational Search Algorithm (GSA), competitive swarm optimizer (CSO), etc. The advantages and disadvantages of different optimization algorithms were discovered. Most of the shortcomings focus on non-global search. When the optimization algorithm performs a non-global search, local optimal solutions may appear. After continuous exploration, some algorithms were optimized by combining the characteristics of multiple algorithms. For example, the GWO was combined with SCA to optimize parameters. These issues deserve to be studied in future.
- (e)
- When the training data is deficient, the TLSCA-SVM classification algorithm can effectively diagnose the fault. Because the TL-SCASV algorithm adds an auxiliary condition to the objective function of the SCA-SVM classifier, that is, an error penalty term to construct a new fault diagnosis model, the fault diagnosis is satisfactory. When the fault samples are not complete, it can still effectively classify the faults. It combines the advantages of the SCA-SVM classifier with high accuracy, fast diagnosis speed and good stability in fault diagnosis. The algorithm not only achieves high fault-diagnosis accuracy, but can also operate effectively in the case of a lack of fault samples, and can effectively perform fault classification in multiple circuits.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wen, X.; Xu, Z. Wind turbine fault diagnosis based on ReliefF-PCA and DNN. Expert Syst. Appl. 2021, 178, 115016. [Google Scholar] [CrossRef]
- Li, Y.; Miller, M.S. Seismic Evidence for Thermal and Chemical Heterogeneities in Region Beneath Central America From Grid Search Modeling. Geophys. Res. Lett. 2021, 48, e2021GL092493. [Google Scholar] [CrossRef]
- Ebrahim, M.A.; Ayoub, B.A.A.; Nashed, M.N.F.; Osman, F.A.M. A Novel Hybrid-HHOPSO Algorithm Based Optimal Compensators of Four-Layer Cascaded Control for a New Structurally Modified AC Microgrid. IEEE Access 2020, 9, 4008–4037. [Google Scholar] [CrossRef]
- Ding, Y.; Meng, R.; Yin, H.; Hou, Z.; Sun, C.; Liu, W.; Hao, S.; Pan, Y.; Wang, B. Keratin-A6ACA NPs for gastric ulcer diagnosis and repair. J. Mater. Sci. Mater. Med. 2021, 32, 66. [Google Scholar] [CrossRef] [PubMed]
- Han, H.; Xu, L.; Cui, X.; Fan, Y. Novel chiller fault diagnosis using deep neural network (DNN) with simulated annealing (SA). Int. J. Refrig. 2021, 121, 269–278. [Google Scholar] [CrossRef]
- Tobi, M.A.; Bevan, G.; Wallace, P.; Harrison, D.; Okedu, K.E. Using MLP-GABP and SVM with wavelet packet transform-based feature extraction for fault diagnosis of a centrifugal pump. Energy Sci. Eng. 2021, 1–14. [Google Scholar] [CrossRef]
- Fu, J.; Che, G. Fusion Fault Diagnosis Model for Six-Rotor UAVs Based on Conformal Fourier Transform and Improved Self-Organizing Feature Map. IEEE Access 2021, 9, 14422–14436. [Google Scholar] [CrossRef]
- Jain, M.; William, A.; Mark, S. CNN vs ELM for Image-Based Malware Classification. arXiv 2021, preprint. arXiv:2103.13820. [Google Scholar]
- Li, Z.; Wang, L.; Huang, L.; Zhang, M.; Cai, X.; Xu, F.; Wu, F.; Li, H.; Huang, W.; Zhou, Q.; et al. Efficient management strategy of COVID-19 patients based on cluster analysis and clinical decision tree classification. Sci. Rep. 2021, 11, 9626. [Google Scholar] [CrossRef]
- Wab, Y.; Yang, Y.; Xu, M.; Huang, W. Intelligent fault diagnosis of planetary gearbox based on refined composite hierarchical fuzzy entropy and random forest. ISA Trans. 2021, 109, 340–351. [Google Scholar]
- Yu, D.; Zhang, A.; Wei, M. SCA-SVM Fault Diagnosis of Analog Circuits Based on Transfer Learning. In Proceedings of the 2021 IEEE 10th Data Driven Control and Learning Systems Conference (DDCLS), Suzhou, China, 14–16 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 818–823. [Google Scholar]
- Yin, S.; Ding, S.X.; Xie, X.; Luo, H. A review on basic data-driven approaches for industrial process monitoring. IEEE Trans. Ind. Electron. 2014, 61, 6418–6428. [Google Scholar] [CrossRef]
- Zhong, T.; Qu, J.; Fang, X.; Li, H.; Wang, Z. The intermittent fault diagnosis of analog circuits based on EEMD-DBN. Neurocomputing 2021, 436, 74–91. [Google Scholar] [CrossRef]
- Su, X.; Cao, C.; Zeng, X.; Feng, Z.; Shen, J.; Yan, X.; Wu, Z. Application of DBN and GWO-SVM in analog circuit fault diagnosis. Sci. Rep. 2021, 11, 7969. [Google Scholar] [CrossRef] [PubMed]
- Jing, Z.; Liang, Y. Electronic circuit fault diagnosis based on SCA-SVM. In Proceedings of the 2018 10th International Conference on Communications, Circuits and Systems (ICCCAS), Chengdu, China, 22–24 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 44–49. [Google Scholar]
- Gianvito, P.; Mignone, P.; Magazzù, G.; Zampieri, G.; Ceci, M.; Angione, C. Integrating genome-scale metabolic modelling and transfer learning for human gene regulatory network reconstruction. Bioinformatics 2022, 38, 487–493. [Google Scholar]
- Lago, V.; Alegre, A.; Lago, V.; Carot-Sierra, J.M.; Bme, A.T.; Montoliu, G.; Domingo, S.; Alberich-Bayarri, Á.; Martí-Bonmatí, L. Machine Learning ased Integration of Prognostic Magnetic Resonance Imaging Biomarkers for Myometrial Invasion Stratification in Endometrial Cancer. J. Magn. Reson. Imaging 2021, 54, 987–995. [Google Scholar]
- Gao, Z.; Liu, L.X. An overview on fault diagnosis, prognosis and resilient control for wind turbine systems. Processes 2021, 9, 300. [Google Scholar] [CrossRef]
- Li, L.; Ding, S.X.; Luo, H.; Peng, K.; Yang, Y. Performance-Based Fault-Tolerant Control Approaches for Industrial Processes with Multiplicative Faults. IEEE Trans. Ind. Inform. 2020, 16, 4759–4768. [Google Scholar] [CrossRef]
- Niu, P.; Niu, S.; Liu, N.; Chang, L. The defect of the Grey Wolf optimization algorithm and its verification method. Knowl.-Based Syst. 2019, 171, 37–43. [Google Scholar] [CrossRef]
- Singh, N.; Singh, S.B. A novel hybrid GWO-SCA approach for optimization problems. Eng. Sci. Technol. Int. J. 2017, 20, 1586–1601. [Google Scholar] [CrossRef]
- Xie, C.; Xiang, H.; Zeng, T.; Yang, Y.; Yu, B.; Liu, Q. Cross knowledge-based generative zero-shot learning approach with taxonomy regularization. Neural Netw. 2021, 139, 168–178. [Google Scholar] [CrossRef]
- Ntalampiras, S. One-shot learning for acoustic diagnosis of industrial machines. Expert Syst. Appl. 2021, 178, 114984. [Google Scholar] [CrossRef]
- Liu, T.; Yang, Y.; Fan, W.; Wu, C. Few-shot learning for cardiac arrhythmia detection based on electrocardiogram data from wearable devices. Digit. Signal Process. 2021, 116, 103094. [Google Scholar] [CrossRef]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques—Part I: Fault diagnosis with model-based and signal-based approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef] [Green Version]
- Luo, H.; Li, K.; Kaynak, O.; Yin, S.; Huo, M.; Zhao, H. A Robust Data-Driven Fault Detection Approach for Rolling Mills with Unknown Roll Eccentricity. IEEE Trans. Control. Syst. Technol. 2019, 28, 2641–2648. [Google Scholar] [CrossRef]
- Chaehan, S. Exploring Meta Learning: Parameterizing the Learning-to-learn Process for Image Classification. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Korea, 13–16 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 199–202. [Google Scholar]
- Blau, F.; Kahn, L.; Comey, M.; Eng, A.; Meyerhofer, P.; Willén, A. Culture and gender allocation of tasks: Source country characteristics and the division of non-market work among US immigrants. Rev. Econ. Househ. 2020, 18, 907–958. [Google Scholar] [CrossRef]
- Tao, D.; Diao, X.; Wang, T.; Guo, J.; Qu, X. Freehand interaction with large displays: Effects of body posture, interaction distance and target size on task performance, perceived usability and workload. Appl. Ergon. 2021, 93, 103370. [Google Scholar] [CrossRef]
- Du, X. Complex environment image recognition algorithm based on GANs and transfer learning. Neural Comput. Appl. 2020, 32, 16401–16412. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Khawaja, A.W.; Kamari, N.; Zainuri, M. Design of a Damping Controller Using the SCA Optimization Technique for the Improvement of Small Signal Stability of a Single Machine Connected to an Infinite Bus System. Energies 2021, 14, 2996. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, X.; Xing, S.; Sun, C.; Chen, X. Sparse representation theory for support vector machine kernel function selection and its application in high-speed bearing fault diagnosis. ISA Trans. 2021, 118, 207–218. [Google Scholar] [CrossRef]
- Yong, S.B.; Lee, S.; Filatov, M.; Choi, C.H. Optimization of Three State Conical Intersections by Adaptive Penalty Function Algorithm in Connection with the Mixed-Reference Spin-Flip Time-Dependent Density Functional Theory Method (MRSF-TDDFT). J. Phys. Chem. A 2021, 125, 1994–2006. [Google Scholar]
- Zhou, J.; Huang, S.; Wang, M.; Qiu, Y. Performance evaluation of hybrid GA–SVM and GWO–SVM models to predict earthquake-induced liquefaction potential of soil: A multi-dataset investigation. Eng. Comput. 2021, 2, 1–19. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, Y.; Liu, J. Dynamic sine cosine algorithm for large-scale global optimization problems. Expert Syst. Appl. 2021, 177, 114950. [Google Scholar] [CrossRef]
- Huang, J.; Kumar, G.S.; Ren, J.; Zhang, J.; Sun, Y. Accurately predicting dynamic modulus of asphalt mixtures in low-temperature regions using hybrid artificial intelligence model. Constr. Build. Mater. 2021, 297, 123655. [Google Scholar] [CrossRef]
- Zhang, C.; He, Y.; Yuan, L.; He, W.; Xiang, S.; Li, Z. A Novel Approach for Diagnosis of Analog Circuit Fault by Using GMKL-SVM and PSO. J. Electron. Test. 2016, 32, 531–540. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, L.; Zhang, B.; Yang, B.; Zhao, Y. A fault prediction model of adaptive fuzzy neural network for optimal membership function. IEEE Access 2020, 8, 101061–101067. [Google Scholar] [CrossRef]
- Soltan, A.; Ahmed, G.; Soliman, M. Fractional order Sallen-Key and KHN filters: Stability and poles allocation. Circuits Syst. Signal Process. 2015, 34, 1461–1480. [Google Scholar] [CrossRef]
- Bao, H.; Wu, P.; Bao, B.-C.; Chen, M.; Wu, H. Sallen–Key low-pass filter-based inductor-free simplified Chua’s circuit. J. Eng. 2017, 2017, 653–655. [Google Scholar] [CrossRef]
- Song, G.; Li, Q.; Luo, G.; Jiang, S.; Wang, H. Analog circuit fault diagnosis using wavelet feature optimization approach. In Proceedings of the 2015 12th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Qingdao, China, 16–18 July 2015; IEEE: Piscataway, NJ, USA, 2015; Volume 1. [Google Scholar]
- Rahimilarki, R.; Gao, Z.; Jin, N.; Zhang, A. Convolutional neural network fault classification based on time-series analysis for benchmark wind turbine machine. Renew. Energy 2022, 185, 916–931. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Malfunction Coding | Failure Mode | Nominal Value | Fault Value |
|---|---|---|---|
| F0 | NF | - | - |
| F1 | R2+ | 3 KΩ | 4.5 KΩ |
| F2 | R2− | 3 KΩ | 1.5 KΩ |
| F3 | R3+ | 2 KΩ | 3 KΩ |
| F4 | R3− | 2 KΩ | 1 KΩ |
| F5 | C1+ | 5 nF | 7.5 nF |
| F6 | C1− | 5 nF | 2.5 nF |
| F7 | C2+ | 5 nF | 7.5 nF |
| F8 | C2− | 5 nF | 2.5 nF |
| Malfunction Coding | Failure Mode | Nominal Value | Fault Value |
|---|---|---|---|
| F0 | NF | - | - |
| F1 | R1+ | 10 KΩ | 15 KΩ |
| F2 | R1− | 10 KΩ | 5 KΩ |
| F3 | R2+ | 10 KΩ | 15 KΩ |
| F4 | R2− | 10 KΩ | 5 KΩ |
| F5 | C1+ | 20 nF | 30 nF |
| F6 | C1− | 20 nF | 10 nF |
| F7 | C2+ | 20 nF | 30 nF |
| F8 | C2− | 20 nF | 10 nF |
| Optimization Parameter Algorithm | Accuracy Rating/% | Elapsed Time/s |
|---|---|---|
| Grid Search | 100 | 62.37 |
| GA | 87.04 | 31.35 |
| PSO | 99.67 | 19.87 |
| ACA | 98.13 | 30.52 |
| SA | 89.65 | 17.54 |
| SCA | 100 | 10.85 |
| Optimization Parameter Algorithm | Accuracy Rating/% | Elapsed Time/s |
|---|---|---|
| Grid Search | 99.85 | 73.07 |
| GA | 81.54 | 34.08 |
| PSO | 97.08 | 27.15 |
| ACA | 95.38 | 39.87 |
| SA | 83.66 | 26.31 |
| SCA | 99.89 | 18.49 |
| Classification Algorithm | Accuracy Rating/% | Elapsed Time/s |
|---|---|---|
| BP | 99.25 | 31.57 |
| SOM | 82.76 | 7.20 |
| ELM | 94.70 | 1.43 |
| Decision Tree | 93.07 | 4.26 |
| Random Forest | 97.88 | 9.75 |
| SCA-SVM | 100 | 10.85 |
| Classification Algorithm | Accuracy Rating/% | Elapsed Time/s |
|---|---|---|
| BP | 96.89 | 40.69 |
| SOM | 74.15 | 17.49 |
| ELM | 91.85 | 9.12 |
| Decision Tree | 89.45 | 19.99 |
| Random Forest | 95.12 | 10.90 |
| SCA-SVM | 99.89 | 18.49 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, A.; Yu, D.; Zhang, Z. TLSCA-SVM Fault Diagnosis Optimization Method Based on Transfer Learning. Processes 2022, 10, 362. https://doi.org/10.3390/pr10020362
Zhang A, Yu D, Zhang Z. TLSCA-SVM Fault Diagnosis Optimization Method Based on Transfer Learning. Processes. 2022; 10(2):362. https://doi.org/10.3390/pr10020362
Chicago/Turabian StyleZhang, Aihua, Danlu Yu, and Zhiqiang Zhang. 2022. "TLSCA-SVM Fault Diagnosis Optimization Method Based on Transfer Learning" Processes 10, no. 2: 362. https://doi.org/10.3390/pr10020362
APA StyleZhang, A., Yu, D., & Zhang, Z. (2022). TLSCA-SVM Fault Diagnosis Optimization Method Based on Transfer Learning. Processes, 10(2), 362. https://doi.org/10.3390/pr10020362