Abstract
Feature selection is an effective method to reduce the number of data features, which boosts classification performance in machine learning. This paper uses the Tsallis-entropy-based feature selection to detect the significant feature. Support Vector Machine (SVM) is adopted as the classifier for classification purposes in this paper. We proposed an enhanced Teaching-Learning-Based Optimization (ETLBO) to optimize the SVM and Tsallis entropy parameters to improve classification accuracy. The adaptive weight strategy and Kent chaotic map are used to enhance the optimal ability of the traditional TLBO. The proposed method aims to avoid the main weaknesses of the original TLBO, which is trapped in local optimal and unbalance between the search mechanisms. Experiments based on 16 classical datasets are selected to test the performance of the ETLBO, and the results are compared with other well-established optimization algorithms. The obtained results illustrate that the proposed method has better performance in classification accuracy.
1. Introduction
Machine learning has been widely used in many practical applications such as data mining, text processing, pattern recognition, and medical image analysis, which often rely on large data sets [1,2]. From utilizing label information, feature selection algorithms are mainly categorized as filters or wrapper approaches [3,4]. The wrapper-based methods are commonly used to finish the classification task [5]. The main step includes classifiers, evaluation criteria of features, and finding the optimal features [6].
The SVM algorithm is one of the most popular supervised models and is regarded as one of the most robust methods in the machine learning field [7,8]. SVM has some robust characteristics compared to other methods, such as excellent generalization performance, which is able to generate high-quality decision boundaries based on a small subset of training data points [9]. The largest problems encountered in setting up the SVM model are how to select the kernel function and its parameter values. Inappropriate parameter settings will lead to poor classification results [10].
Swarm intelligence algorithms can solve complex engineering problems, but different optimization algorithms solve different engineering problems with different effects [11,12]. The optimization algorithms can reduce the time and improve the segmentation accuracy. There many optimization algorithms are proposed, such as Genetic Algorithm (GA) [13], Particle Swarm Optimization (PSO) [14], Differential Evolution (DE) [15], Ant Colony Optimization (ACO) [16], Artificial Bee Colony (ABC) algorithm [17], Grey Wolf Optimizer (GWO) [18], Ant Lion Optimizer (ALO) [19], Moth-flame Optimization (MFO) [20], Whale Optimization Algorithm (WOA) [21], Invasive weed optimization algorithm [22], Flower Pollination Algorithm [23]. Although all algorithms have advantages, no-free lunch (NFL) [24] has proved that no algorithm can solve all optimization problems.
There is no perfect optimization algorithm, and the optimization algorithm should be improved to solve engineering problems better. Many scholars study the strategies for improving optimization algorithm. The strategies commonly used by scholars are as follows adaptive weight strategy and chaotic map. Zhang Y. proposed an improved particle swarm optimization algorithm with an adaptive learning strategy [25]. The adaptive learning strategy increased the population diversity of PSO. Dong Z. proposed a self-adaptive weight vector adjustment strategy based on a chain segmentation strategy [26]. The self-adaptive solved the shape of the true Pareto front (PF) of the multi-objective problem. Li E. proposed a multi-objective decomposition algorithm based on adaptive weight vector and matching strategy [27]. The adaptive weight vector solved the degradation of the performance of the solution set. The chaotic map is also a general nonlinear phenomenon, and its behavior is complex and semi-random. It is mathematically defined as the randomness generated by a simple deterministic system [28]. Xu C. proposed an improved boundary bird swarm algorithm [29]. The algorithm combined the good global convergence and robustness of the birds’ swarm algorithm. Tran, N. T. presented a method for fatigue life prediction of 2-DOF compliant mechanism which combined the differential evolution algorithm and the adaptive neuro-fuzzy inference system [30]. The experiment result shows that the accuracy of the proposed method is high.
Teaching-Learning-Based Optimization (TLBO) is proposed by R. V. Rao, which solves the global problem of continuous nonlinear functions [31]. The TLBO approach works on the philosophy of teaching and learning. Many scholars study the strategies to improve the optimization ability for a different problem. Gunji A. B. proposed improved TLBO for solving assembly sequence problems [32]. Zhang H. proposed a hybridizing TLBO [33]. The approach can enable better tracking accuracy and efficiency. Ho, N.L. presented a hybrid Taguchi-teaching learning-based optimization algorithm (HTLBO) [34]. The proposed method had good agreement with the predicted results. The strategies can improve the optimal ability of TLBO. In this paper, for solving the problem of learning efficiency and initial parameter setting, we use several strategies to enhance the optimal ability of the TLBO.
The main contribution of our work includes:
- (1)
- The enhanced Teaching-Learning-Based Optimization (ETLBO) is proposed to improve optimal ability. The adaptive weight and Kent chaotic map are used to enhance the TLBO. These two strategies can improve the searching ability of the students and teachers in TLBO.
- (2)
- We adopt the Tsaliis entropy-based feature selection method for finding the crucial feature. The selected feature x and the parameter of Tsallis entropy are optimized by ETLBO.
- (3)
- The parameter c of the SVM classifier is optimized by ETLBO for obtaining high classification accuracy. The core idea of this method is to automatically determine the parameter of Tsallis entropy and parameter c of the SVM under different data.
The proposed method is tested on several feature selection and classification problems in terms of several comment evaluation measures. The results are compared with other well-established optimization methods. The obtained results showed that the proposed ETLBO got better and promising results in almost all the tested problems compared to other methods.
The rest of the paper is described as follows: Section 2 introduces Tsallis’s entropy-based feature selection formula. Section 3, Enhance Teaching-learning-based optimization, and the ETLBO optimizes the feature selection design is introduced. In Section 4 and Section 5, the feature selection results and the algorithm analysis are given. Finally, the conclusions are summarized in Section 6.
2. Related work
2.1. Tsallis Entropy-Based Feature Selection (TEFS)
TEFS estimates the importance of a feature by calculating its information gain (IG) with respect to the target feature. The IG is calculated by subtracting the Tsallis entropy of features concerning target from the total entropy of the target feature. The Tsallis entropy and IG are defined as follow:
where, represents the Tsallis entropy of a feature m, represents the Tsallis entropy of a target in terms of a feature n, m is the number of target feature, n is the total number of the feature.
IG measures the significance of a feature by calculating how much information a feature obtains us about the target.
2.2. SVM Classifier
SVM finds the optimal separation of hyperplanes between classes by focusing on the training cases of the edges of effectively discarded classes. For training samples in different dimensional spaces, a classifier can be accurately summarized. The main core of SVM is finding a suitable kernel function , where is a nonlinear function, and the function is used to transfer the nonlinear space of the sample input to two hyperplanes. The formula can be written as:
where, is the weight vector, is the threshold value, and represents the inner product operation. The objective of SVM is to determine the , and when minimizing the , it can be seen below:
where, is the slack variable, C is the penalty parameter.
The most commonly used kernel is the Gaussian kernel, used for data conversion in SVM. The Gaussian kernel is defined as:
where, denotes the width parameter, and δ controls the mapping results.
The strategy of reducing multi-class problems to a set of dichotomies enables support vector machines to be used more appropriately with fewer computational requirements, that is, to consider all classes at once and thus to obtain a multi-class support vector machine. One way to do this is by solving a single optimization problem, similar to the “one for all” approach on a fundamental basis. There are n decision functions or hyperplanes, and the problems can convert to one problem as:
where, . The resulting decision function can be represented as:
2.3. Fitness Function Design
The main indexes influencing FS are the classification error accuracy and the number of features. So, how to balance the number of features and the classification is the essential key for the FS problem. Whereas, is the Normalized Mutual Information (NMI) [13]. The formula can be seen as follow:
where, X is the set of clusters and S is the set of classes. The MI is the mutual information between X and S [35]. It can be defined as follow:
where, , , is the probability of the , , and . The comes from the maximum likelihood estimation of probability.
3. Enhance Teaching-Learning-Based Optimization (ETLBO)
In this section, we introduce the proposed method in detail. Firstly, we introduce the TLBO and the strategies used in the proposed method. And then, the ETLBO is introduced. Finally, the flowchart of the proposed method is described.
3.1. Teacher Phase
It is the first part of the algorithm where the learner with the highest marks acts as a teacher, and the teacher’s task is to increase the mean marks of the class. The update process of i-th learner in teacher phase is formulated as:
where, is the solution of the i-th learner, represents the teacher’s solution, means the average of all learners, rand is a random number in (0,1), and is the teaching factor that decides the value of mean to be changed. The value can be either 1 or 2, which is again a heuristic step and decided randomly with equal probability .
In addition, the new solution is accepted only if it is better than the previous solution, it can be formulated as:
where, f means the fitness function.
3.2. Learner Phase
The second part of the algorithm is where the learner updates its knowledge through interaction with other learners. In each iteration, two learners interact with and , in which the more innovative learner improves the marks of other learners. In the learner phase, one learner learns new things if the other learner has more knowledge than himself. The phenomenon is described as follows:
The temporary solution is accepted only if it is better than the previous solution; it can be formulated as:
3.3. Adaptive Weight Strategy
The adaptive weight strategy is easier to jump out of local minima, facilitating global optimization. While the TLBO solves the problem of the complex optimized function, the algorithm will easily fall into the local optimum. And a smaller inertia factor is beneficial for precise local search for the current search domain. We design a new weight strategy t which can be written as follows:
where, iter is the current number of the iteration; Max_iter is the max number of the iteration.
3.4. Kent Chaotic Map (KCM)
Chaotic mapping is one kind of nonlinear mapping that can generate a random number sequence. It is sensitive to initial values, which ensures that the encoder can generate an unrelated encoding sequence. There are many kinds of chaotic maps, such as Logistic map, Kent map, etc. In this paper, we use the Kent map as the improved strategy. The formula of the Kent map can be seen as follow:
where, a is a variable value, x is the initial value of the . In this paper, .
3.5. Proposed Method
There are two phases in the basic TLBO search process to update the individual’s position. In the teacher phase, we use the Kent chaotic map to improve the original state of the teacher. The teacher can be endowed with different abilities to teach the different students. This strategy allows the abilities of different teachers to be demonstrated. In the learner phase, we design a learning efficiency to improve the students’ learning state. The adaptive weight strategy can improve itself with the iteration increases. The students will learn more knowledge at the beginning phase of the iteration. The students can obtain enough knowledge at the end of the iteration, and the adaptive weight gets small. The students can learn the different knowledge at the different phases. The formula can be represented as follow:
where, t is the adaptive weight.
The proposed classification method can be divided into two parts: feature selection and the parameter selection of the SVM. At first, the Tsallis entropy of the target is calculated using Equation (1). Then the entropy of each feature concerning the target is calculated and subtracted from the target’s entropy using Equation (2). In this process, the selected feature x and the parameter of Tsallis entropy are optimized by the ETLBO. The parameter can decide the ability of the Tsallis entropy.
In the second part, we use the ETLBO to optimize parameter c of SVM. The penalty coefficient c is the compromise between the smoothness of the fitting function and the classification accuracy. When c is too large, the training accuracy is high, and the generalization ability is poor; while c is too small, errors will be increased. Therefore, a reasonable selection of parameter c can obviously improve the model’s classification accuracy and generalization ability.
Finally, the selected feature x, the parameter of Tsallis entropy, and the parameter c of SVM are optimized by ETLBO. We use the parameter optimized by the ETLBO and the SVM to classify the test dataset. The SVM classifier output the classification result. The flowchart of the proposed method is shown in Figure 1.
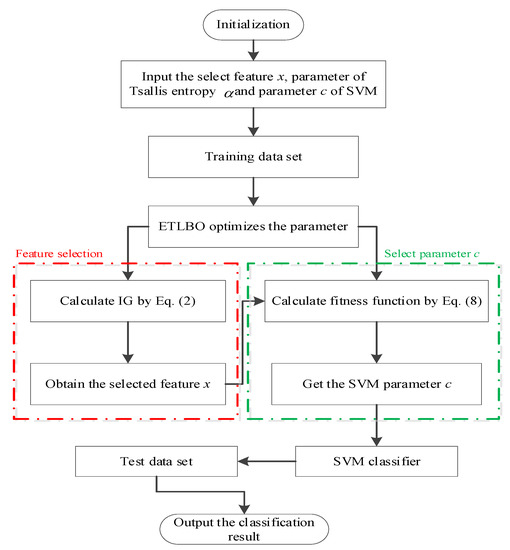
Figure 1.
The flowchart of the proposed method.
4. Experiment and Result
To analysis the effectiveness of the proposed method, five optimization algorithms are used for comparison, such as PSO [13], WOA [20], HHO [36], TLBO [29], HSOA [37], and HTLBO [34]. The PSO, WOA, HHO, and TLBO are the original optimization algorithms. These optimization algorithms have the strong ability to find the optimal value of the mathematical function. While these algorithms optimize the engineering problems, the optimization performance is not well. Many schoolers study the strategies to improve the optimization algorithms. The HSOA and HTLBO are improved methods. These two algorithms use the hybrid way to enhance the optimization ability of the SOA and TLBO. The improved methods have the excellent performance to solve the problems which mentioned in the reference [34,37]. However, these algorithms may not solve all problems. Therefore, we select these algorithms as compared algorithms to test the performance of the proposed method.
The set of parameters is the same as the reference. All the methods are coded and implemented in MATLAB 2018B. To keep the fairness of the compared algorithms, each algorithm runs 30 times independently. To test the performance of the comparison algorithm, we set the number of populations to 30 and the maximum iteration to 500. The proposed ETLBO is training in MATLAB2018B. Experiments are managed on a computer with an i7-11800H central processing unit.
The results of the proposed method are described in this section. First, the fitness values obtained by the different optimization algorithms are compared to show the performances of these approaches. Then, we analyze the classification result of the compared algorithms. Finally, the discussion of the proposed method is described.
4.1. Datasets and Evaluation Index
The benchmark datasets used in the evaluations are introduced. The dataset selects 16 standard datasets from the University of California (UCI) data repository [38]. Table 1 records the primary information of these selected datasets.

Table 1.
The datasets used in the experiments.
To evaluate the result of the health index diagnosis, we use the F-score, the accuracy of the classification and the CPU time as the metric index.
The function of F-score can be defined as follow:
where, is the number of negative classes, is the number of negative classes, is the number of positive classes, and is the number of positive classes.
4.2. Experiment 1: Feature Selection
Table 2 shows the fitness value of the compared algorithms. The table shows that when the number of features is small, the compared algorithms can reduce the number of features. When the number of features increases, it takes a huge challenge for the optimization algorithms. The ETLBO obtains better performance than compared algorithms. Table 3 shows the std of the fitness values. It can be known from the given table that the ETLBO has strong robustness.
Table 2.
The fitness values of compared algorithms.
Table 3.
The std of fitness values.
Table 4 shows the number of the selected attributes. The compared algorithms can reduce the number of features. The attributes are little, and the compared algorithms obtain the same result. The ETLBO gets the least attributes among the compared algorithms when the attributes are large. The total attributes of the dataset, the ETLBO also obtain the least attributes than other algorithms. It means that the ETLBO can reduce the number of features. However, reducing the number of features does not mean the classification accuracy is high.
Table 4.
The average number of selected attributes.
Table 5 shows the parameter obtained by ETLBO. It can be seen from the table that the ETBLO obtains the different values under the diverse dataset. The ETBLO not only reduce the number of features but also acquires the parameter α of Tsallis entropy and the parameter c of SVM. We will test the performance of the compared algorithms in the next section.
Table 5.
The parameter obtained by ETLBO.
4.3. Experiment 2: Classification
Table 6 shows the classification results of compared algorithms. Table 7 shows the f-score of the compared methods. The table result shows that the ETLBO is better than the original TLBO. The strategies improve the optimal ability of the TLBO. At the same time, the HSOA and ETLBO are better than the other algorithms. It means that the strategies significantly boost the original optimization algorithms. It can be known that the methods can be ordered as follows in terms of them F-score result: ETLBO > HTLBO > HSOA > HHO > PSO > WOA > TLBO. To sum up, the ETLBO obtains the high f-score values.
Table 6.
The classification accuracy of compared algorithms.
Table 7.
The f-score of compared algorithms.
To sum up, the ETLBO obtained the best result in compared algorithms. The ETLBO not only reduces the number of features but also obtains high classification accuracy. Table 8 shows that the std of classification accuracy. The ETLBO has a better stable ability than other algorithms. The proposed method has strong robustness to finish the classification task.
Table 8.
The std of classification accuracy.
A statistical test is an essential and vital measure to evaluate and prove the performance of the tested methods. Parameter statistical test is based on various assumptions. This section uses well-known non-parametric statistical test types, Wilcoxon’s rank-sum test [39]. Table 9 shows the results of the Wilcoxon rank-sum test. It can be found that the ETLBO is significantly different from other methods.
Table 9.
Wilcoxon’s rank-sum test of classification accuracy.
The CPU time is also an important index for the practical engineering testing problem. The CPU time results of the compared algorithms can be seen in Table 10. The CPU time ordering of each algorithm is: TLBO < PSO < WOA < HHO < ETLBO < HTLBO < HSOA. Although the ETLBO costs considerable CPU time, the classification accuracy has good performance. At the same time, the ETLBO uses less CPU time than HSOA. It means that the strategies have good adaptive effectiveness for the TLBO. The strategies enhance the TLBO under less CPU time than the improved method.
Table 10.
The CPU time of the compared algorithms.
4.4. Experiment 3: Compared with Different Classifiers
In this section, we compare with the different classifiers. The compared classifiers contain K-NearestNeighbor (KNN), original SVM, and random forest (RF) [40]. Table 11 shows the configuration parameters and characteristics of the classifier models.
Table 11.
Configuration parameters and characteristics of the classifier models.
Table 12 demonstrates the evaluation index of the compare algorithsm. The BTLBO obtains the best result than other compared classifiers in all index. The BTLBO outperforms KNN, SVM, and RF by yielding an improvement of 3.45%, 2.94%, and 1.62% in F-score index. To sum up, the optimization algorithms obtain the optimal parameter of the SVM. The classification accuracy is higher than other compared classifiers.
Table 12.
The evaluation index of compared algorithms.
5. Discussion
The proposed method has an optimal ability to solve the Tsallis-entropy-based feature selection problem in the feature selection domain. The ETLBO selects the suitable parameter of the Tsallis-entropy. At the same time, the proposed method reduces the number of features successfully. The optimization algorithms have a robust optimal ability; however, they do not adapt to solve the different optimized problems. So some adaptive strategies are very effective for improving themselves.
The proposed method obtains better classification accuracy than the compared algorithms in the classification field. The proposed method finds the proper parameter of the SVM classifier. The proposed method has a higher classification accuracy and strong robustness than the compared algorithms. At the same time, the proposed method is better than orther compared classifiers. So, the ETLBO algorithms can be used in the classification task field.
The proposed method’s limitation is that the optimization algorithm needs iteration to find the optimal solution, which is time-consuming. Improving the optimization capability and reducing the number of iterations can solve this problem. Therefore, it is necessary to search for powerful optimization algorithms and new strategies in future work.
6. Conclusions
In this paper, an enhanced teaching-learning-based optimization is proposed. The adaptive weight strategy and Kent chaotic map are used to enhance the TLBO. The ETLBO optimizes the selected feature x, the parameter of Tsallis entropy, and the parameter c of SVM. The proposed method reduces the number of features through the UCI data experiment and finds the critical features for classification. Finally, the classification accuracy of the proposed method is better than compared algorithms.
We will design an effective and useful function to reduce the number of features in future work. We will focus on solving the randomness of the TLBO and obtaining more stability parameters of the fitness function. At the same time, we will also test the novel strategies to boost the TLBO.
Author Contributions
Conceptualization, D.W. and H.J.; methodology, D.W. and H.J.; software, D.W. and Z.X.; validation, H.J. and Z.X.; formal analysis, D.W., R.Z. and H.W.; investigation, D.W. and H.J.; writing—original draft preparation, D.W. and M.A.; writing—review and editing, D.W., L.A., M.A. and H.J.; visualization, D.W., H.W., M.A. and H.J.; funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by National fund cultivation project of Sanming University (PYS2107), the Sanming University Introduces High-level Talents to Start Scientific Research Funding Support Project (21YG01S), The 14th five year plan of Educational Science in Fujian Province (FJJKBK21-149), Bidding project for higher education research of Sanming University (SHE2101), Research project on education and teaching reform of undergraduate colleges and universities in Fujian Province (FBJG20210338), Fujian innovation strategy research joint project (2020R0135). This study was financially supported via a funding grant by Deanship of Scientific Research, Taif University Researchers Supporting Project number (TURSP-2020/300), Taif University, Taif, Saudi Arabia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ji, B.; Lu, X.; Sun, G.; Zhang, W.; Li, J.; Xiao, Y. Bio-inspired feature selection: An improved binary particle swarm optimization approach. IEEE Access 2020, 8, 85989–86002. [Google Scholar] [CrossRef]
- Kumar, S.; Tejani, G.G.; Pholdee, N.; Bureerat, S. Multiobjecitve structural optimization using improved heat transfer search. Knowl.-Based Syst. 2021, 219, 106811. [Google Scholar] [CrossRef]
- Sun, L.; Wang, L.; Ding, W.; Qian, Y.; Xu, J. Feature selection using fuzzy neighborhood entropy-based uncertainty measures for fuzzy neighborhood multigranulation rough sets. IEEE Trans. Fuzzy Syst. 2020, 99, 1–14. [Google Scholar] [CrossRef]
- Zhao, J.; Liang, J.; Dong, Z.; Tang, D.; Liu, Z. NEC: A nested equivalence class-based dependency calculation approach for fast feature selection using rough set theory. Inform. Sci. 2020, 536, 431–453. [Google Scholar] [CrossRef]
- Liu, H.; Zhao, Z. Manipulating data and dimension reduction methods: Feature selection. In Encyclopedia Complexity Systems Science; Springer: New York, NY, USA, 2009; pp. 5348–5359. [Google Scholar]
- Al-Tashi, Q.; Said, J.A.; Helmi, M.R.; Seyedali, M.; Hitham, A. Binary optimization using hybrid grey wolf optimization for feature selection. IEEE Access 2019, 7, 39496–39508. [Google Scholar] [CrossRef]
- Homayoun, H.; Mahdi, J.; Xinghuo, Y. An opinion formation based binary optimization approach for feature selection. Phys. A Stat. Mech. Its Appl. 2018, 491, 142–152. [Google Scholar]
- Mafarja, M.M.; Mirjalili, S. Hybrid whale optimization algorithm with simulated annealing for feature selection. Neurocomputing 2017, 260, 302–312. [Google Scholar] [CrossRef]
- Aljarah, L.; Ai-zoubl, A.M.; Faris, H.; Hassonah, M.A.; Mirjalili, S.; Saadeh, H. Simultaneous feature selection and support vector machine optimization using the grasshopper optimization algorithm. Cogn. Comput. 2018, 2, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Lin, S.; Ying, K.; Chen, S.; Lee, Z. Particle swarm optimization for parameter determination and feature selection of support vector machines. Expert Syst. Appl. 2008, 35, 1817–1824. [Google Scholar] [CrossRef]
- Sherpa, S.R.; Wolfe, D.W.; Van Es, H.M. Sampling and data analysis optimization for estimating soil organic carbon stocks in agroecosystems. Soil Sci. Soc. Am. J. 2016, 80, 1377. [Google Scholar] [CrossRef]
- Lee, H.M.; Yoo, D.G.; Sadollah, A.; Kim, J.H. Optimal cost design of water distribution networks using a decomposition approach. Eng. Optim. 2016, 48, 16. [Google Scholar] [CrossRef]
- Roberge, V.; Tarbouchi, M.; Okou, F. Strategies to accelerate harmonic minimization in multilevel inverters using a parallel genetic algorithm on graphical processing unit. IEEE Trans. Power Electron. 2014, 29, 5087–5090. [Google Scholar] [CrossRef]
- Russell, E.; James, K. A new optimizer using particle swarm theory. In Proceedings of the 6th International Symposium on Micro Machine and Human Science, MHS’95, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Rahnamayan, S.; Tizhoosh, H.; Salama, M. Opposition-based differential evolution. IEEE Trans. Evolut. Comput. 2008, 12, 64–79. [Google Scholar] [CrossRef] [Green Version]
- Liao, T.; Socha, K.; Marco, A.; Stutzle, T.; Dorigo, M. Ant colony optimization for mixed-variable optimization problems. IEEE Trans. Evolut. Comput. 2013, 18, 53–518. [Google Scholar] [CrossRef]
- Taran, S.; Bajaj, V. Sleep apnea detection using artificial bee colony optimize hermite basis functions for eeg signals. IEEE Trans. Instrum. Meas. 2019, 69, 608–616. [Google Scholar] [CrossRef]
- Precup, R.; David, R.; Petriu, E.M. Grey wolf optimizer algorithm-based tuning of fuzzy control systems with reduced parametric sensitivity. IEEE Trans. Ind. Electron. 2017, 64, 527–534. [Google Scholar] [CrossRef]
- Hatata, A.Y.; Lafi, A. Ant lion optimizer for optimal coordination of doc relays in distribution systems containing dgs. IEEE Access 2018, 6, 72241–72252. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-flame optimization algorithm: A novel natureinspired heuristic paradigm. Knowl.-Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Mohamed, A.; Ahmed, A.; Aboul, E. Whale optimization algorithm and moth-flame optimization for multilevel thresholding image segmentation. Expert Syst. Appl. 2017, 83, 51–67. [Google Scholar]
- Sang, H.; Pan, Q.; Li, J.; Wang, P.; Han, Y.; Gao, K.; Duan, P. Effective invasive weed optimization algorithms for distributed assembly permutation flowshop problem with total flowtime criterion. Swarm Evolut. Comput. 2019, 444, 64–73. [Google Scholar] [CrossRef]
- Zhou, Y.; Luo, Q.; Chen, H.; He, A.; Wu, J. A discrete invasive weed optimization algorithm for solving traveling salesman problem. Neurocomputing 2015, 151, 1227–1236. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evolut. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Liu, X.; Bao, F.; Chi, J.; Zhang, C.; Liu, P. Particle swarm optimization with adaptive learning strategy. Knowl.-Based Syst. 2020, 196, 105789. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, X.; Tang, L. Moea/d with a self-adaptive weight vector adjustment strategy based on chain segmentation. Inform. Sci. 2020, 521, 209–230. [Google Scholar] [CrossRef]
- Li, E.; Chen, R. Multi-objective decomposition optimization algorithm based on adaptive weight vector and matching strategy. Appl. Intell. 2020, 6, 1–17. [Google Scholar] [CrossRef]
- Feng, J.; Zhang, J.; Zhu, X.; Lian, W. A novel chaos optimization algorithm. Multimedia Tools Appl. 2016, 76, 1–32. [Google Scholar] [CrossRef]
- Xu, C.B.; Yang, R. Parameter estimation for chaotic systems using improved bird swarm algorithm. Mod. Phys. Lett. B 2017, 1, 1750346. [Google Scholar] [CrossRef]
- Tran, N.T.; Dao, T.-P.; Nguyen-Trang, T.; Ha, C.-N. Prediction of Fatigue Life for a New 2-DOF Compliant Mechanism by Clustering-Based ANFIS Approach. Math. Probl. Eng. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Rao, R.V.; Savsani, V.J.; Vakharia, D.P. Teaching learning based optimization: A novel method for constrained mechanical design optimization problems. Comput. Aided Des. 2011, 43, 303–315. [Google Scholar] [CrossRef]
- Gunji, A.B.; Deepak, B.; Bahubalendruni, C.; Biswal, D. An optimal robotic assembly sequence planning by assembly subsets detection method using teaching learning-based optimization algorithm. IEEE Trans. Autom. Sci. Eng. 2018, 1, 1–17. [Google Scholar] [CrossRef]
- Zhang, H.; Gao, Z.; Ma, X.; Jie, Z.; Zhang, J. Hybridizing teaching-learning-based optimization with adaptive grasshopper optimization algorithm for abrupt motion tracking. IEEE Access 2019, 7, 168575–168592. [Google Scholar] [CrossRef]
- Ho, N.L.; Dao, T.-P.; Le Chau, N.; Huang, S.-C. Multi-objective optimization design of a compliant microgripper based on hybrid teaching learning-based optimization algorithm. Microsyst. Technol. 2018, 25, 2067–2083. [Google Scholar] [CrossRef]
- Estevez, P.A.; Tesmer, M.; Perez, C.; Zurada, J. Normalized mutual information feature selection. IEEE Trans. Neural Netw. 2009, 20, 189–201. [Google Scholar] [CrossRef] [Green Version]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Jia, H.; Xing, Z.; Song, W. A new hybrid seagull optimization algorithm for feature selection. IEEE Access 2019, 12, 49614–49631. [Google Scholar] [CrossRef]
- Newman, D.J.; Hettich, S.; Blake, C.L.; Merz, C.J. UCI Repository of Machine Learning Databases. Available online: http://www.ics.uci.edu/~mlearn/MLRepository.html (accessed on 1 June 2016).
- Derrac, J.S.; Garcia, D.; Molina, F.; Herrera, A. Practical tutorial on the use of non-parametric statistical test as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evolut. Comput. 2011, 1, 13–18. [Google Scholar] [CrossRef]
- Machaka, R. Machine learning-based prediction of phases in high-entropy alloys. Comput. Mater. Sci. 2020, 188, 110244. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).