
Analysis and Assessment of Controllability of an Expressive Deep Learning-Based TTS System


Abstract
:1. Introduction
- Related work is presented in Section 2;
- Section 3.2 describes the proposed system for controllable expressive speech synthesis; Section 4 presents the methodology that allows for discovering the trends of audio features in the latent space;
- Section 5 presents objective results using this methodology and results regarding the acoustic quality with measures of errors between generated acoustic features and ground truth;
- The procedure and results of the perceptual experiment is described in Section 6;
- Finally, we conclude and detail our plans for future work in Section 7.To obtain the results of the experiments of this paper, the software presented in [3] was used. It is available online (https://github.com/noetits/ICE-Talk, accessed on 29 August 2021) A code capsule (https://doi.org/10.24433/CO.1645822.v1, accessed on 29 August 2021) provides an example of use of the software with LJ-speech dataset [4] which in the public domain.
2. Related Work and Challenges
3. System
3.1. DCTTS
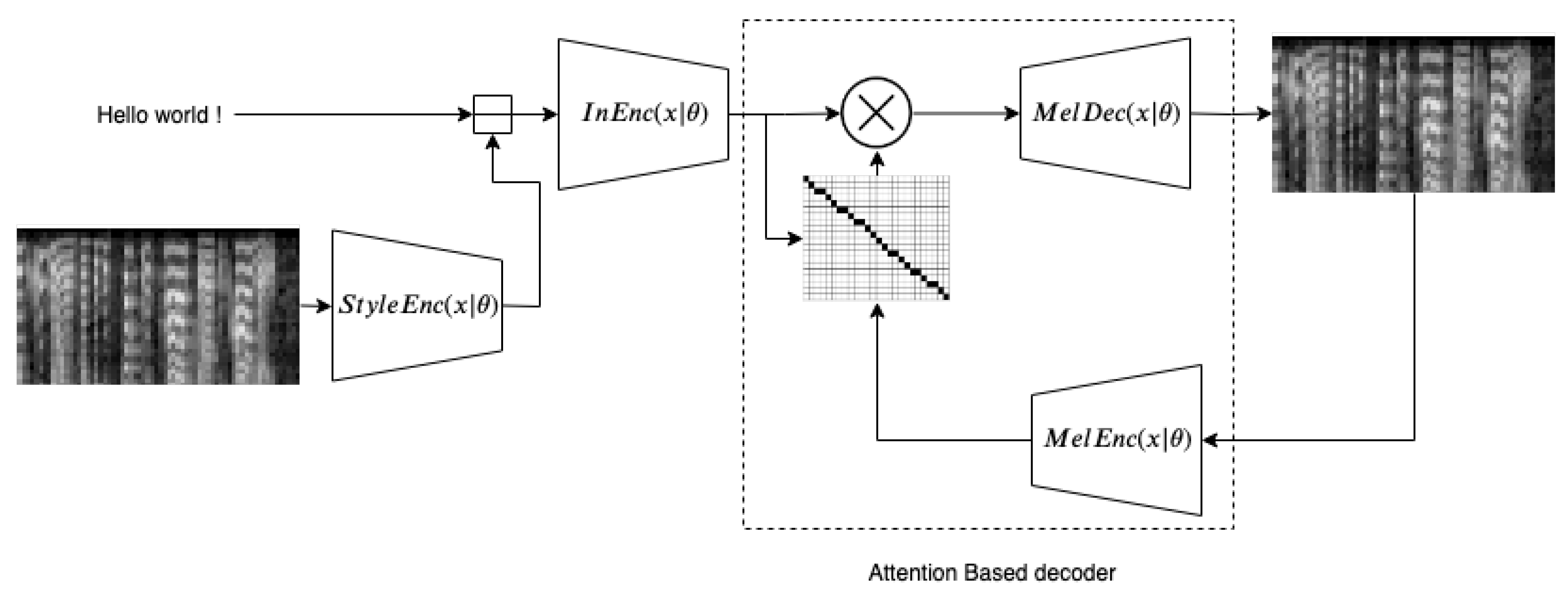
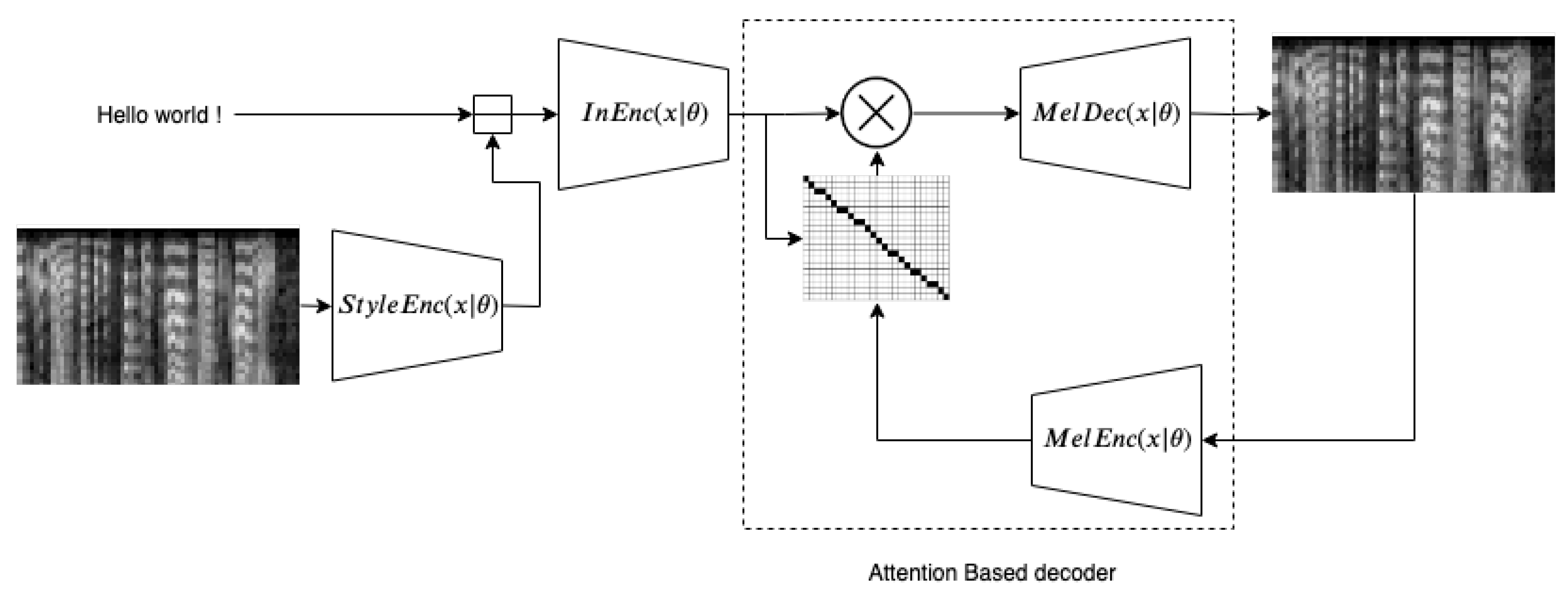
3.2. Controllable Expressive TTS
4. Post-Analysis for Interpretation of Latent Spaces
- The mel-spectrogram is encoded to a vector of length 8 that contains expressiveness information. This vector is computed for each utterance of the dataset.
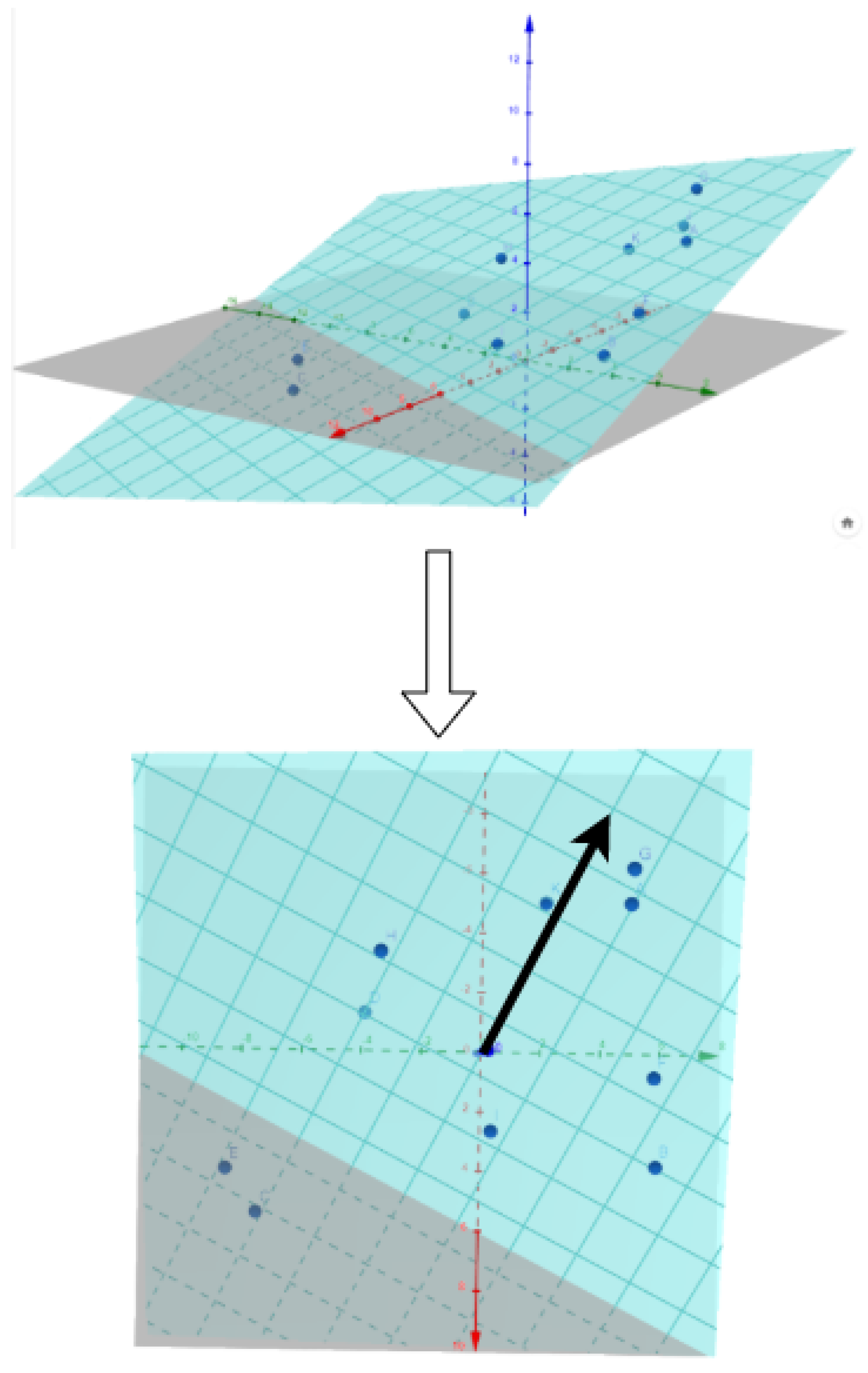
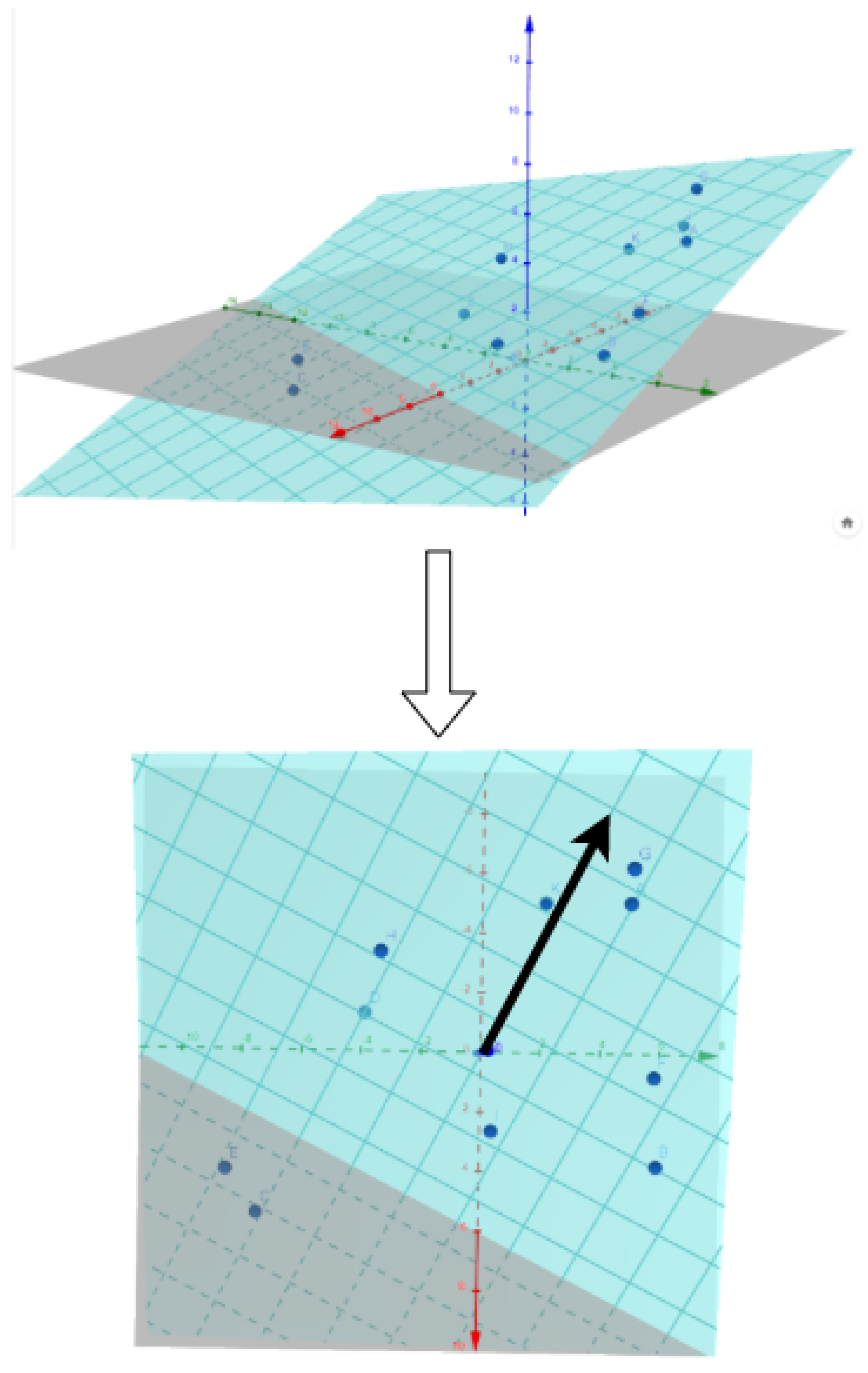
- Dimensonality reduction is used to have an ensemble of 2D vectors instead. Figure 3 shows a scatter plot of these 2D points.
- Then a trend is extracted for each audio feature. For, e.g., , its value is computed for each utterance of the dataset. We therefore obtain an corresponding to each 2D-point of the scatter plot.
- We approximate the plane
- To assess that this plane is a good approximation of , implying a linear relation between a direction of the space and , we compute the correlation between the approximations with the ground truth values of .
- If we compute the gradient of the plane (which is in fact ), we have the direction of the greatest slope, which is plotted in blue.
5. Objective Experiments
- F0: logarithmic F0 on a semitone frequency scale, starting at 27.5 Hz (semitone 0)
- F1–3: Formants one to three center frequencies
- Alpha Ratio: ratio of the summed energy from 50 to 1000 Hz and 1–5 kHz
- Hammarberg Index: ratio of the strongest energy peak in the 0–2 kHz region to the strongest peak in the 2–5 kHz region.
- Spectral Slope 0–500 Hz and 500–1500 Hz: linear regression slope of the logarithmic power spectrum within the two given bands.
- mfcc1–4: Mel-Frequency Cepstral Coefficients 1 to 4
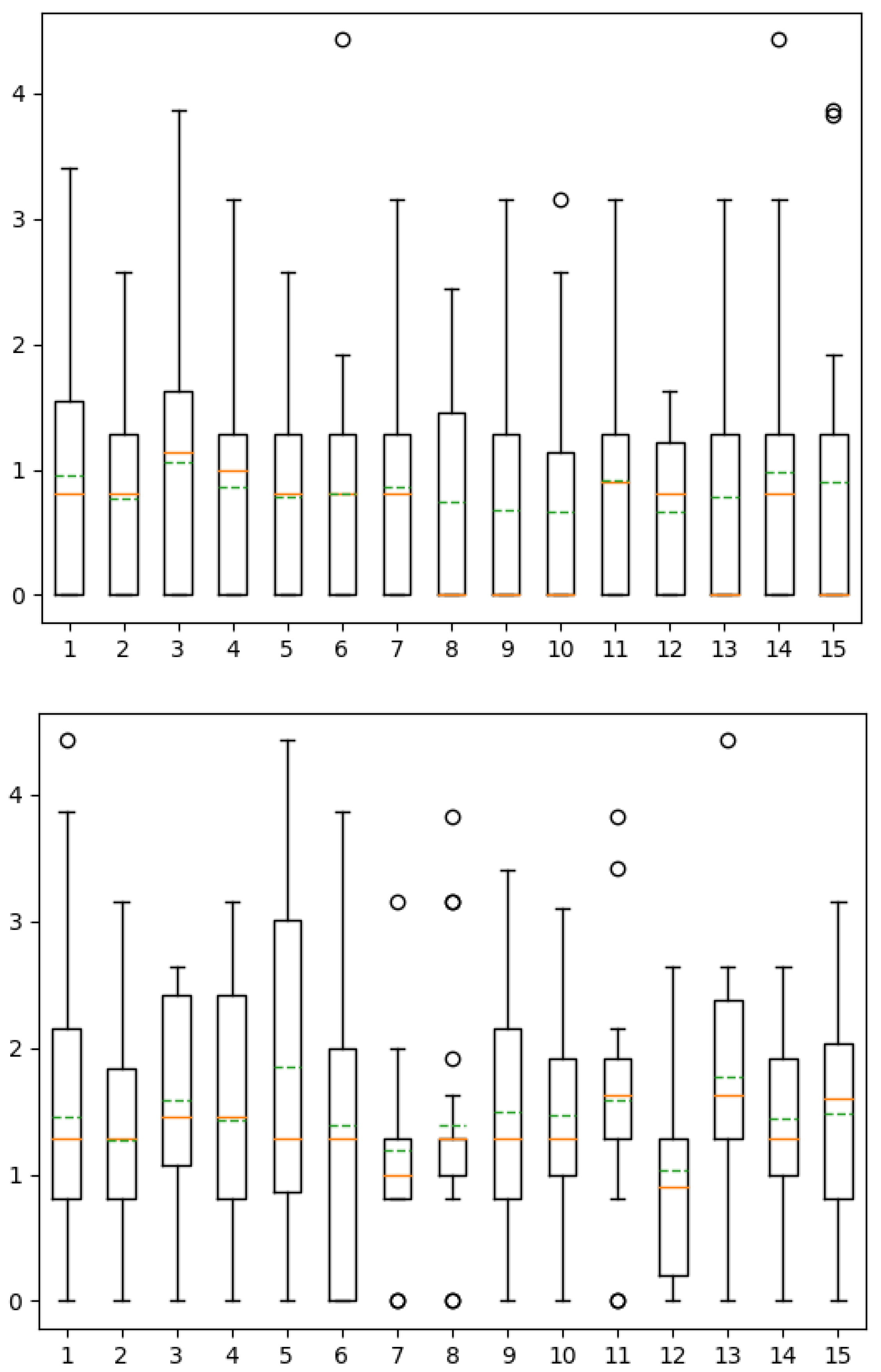
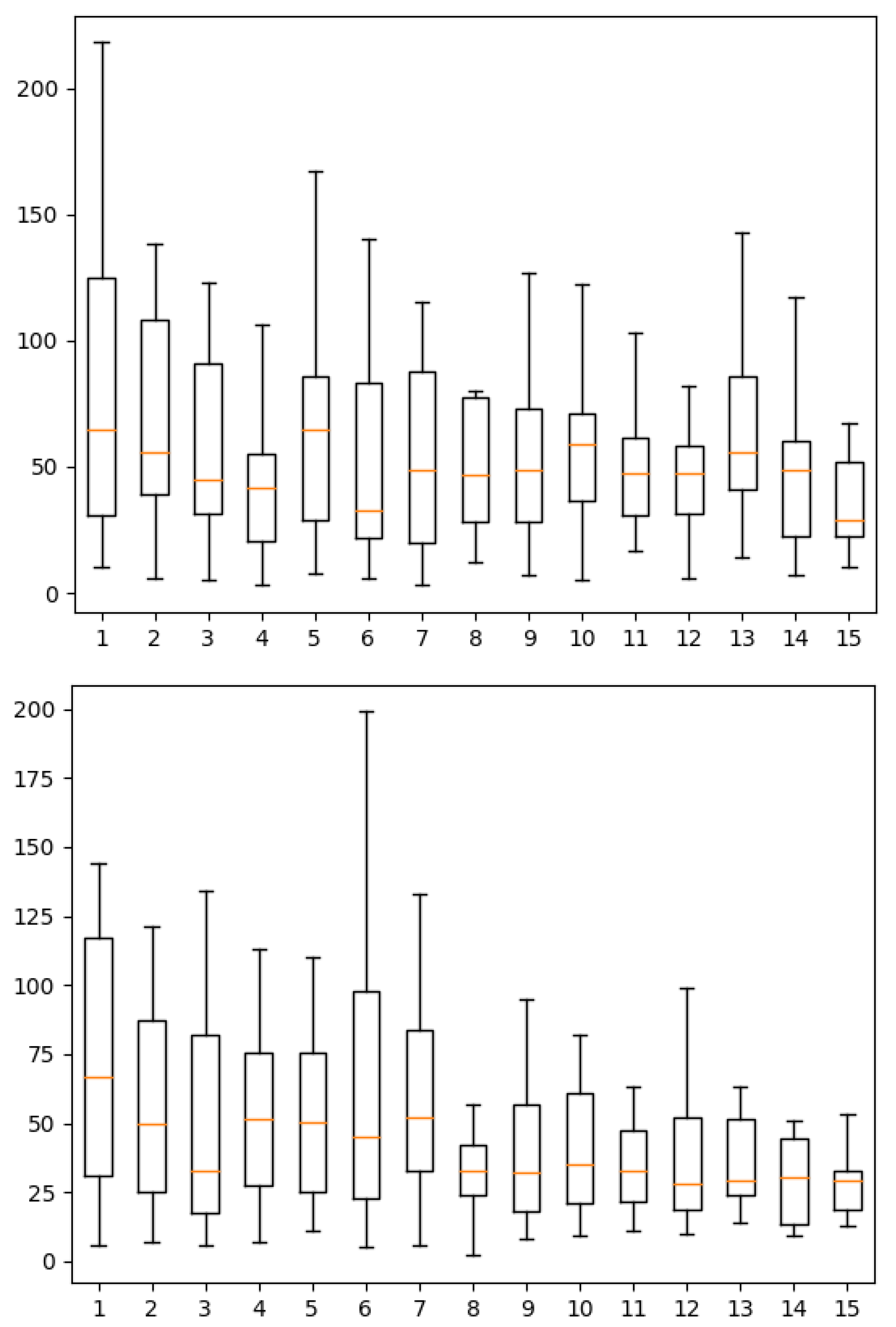
5.1. Quantitative Analysis
5.1.1. Correlation Analysis
- Features are sorted by APCC in decreasing order;
- For each feature, APCC with previous features are computed;
- If the maximum of these , the feature is eliminated;
- Finally, only features that have a are kept.
5.1.2. Distortion Analysis: A Comparison with Typical Seq2seq
- MCD [25] measuring speech quality:
- VDE [26]:
- F0 MSE measuring a distance between F0 contours of prediction and ground truth:
- lF0 MSE, similar to previous one in logarithmic scale:
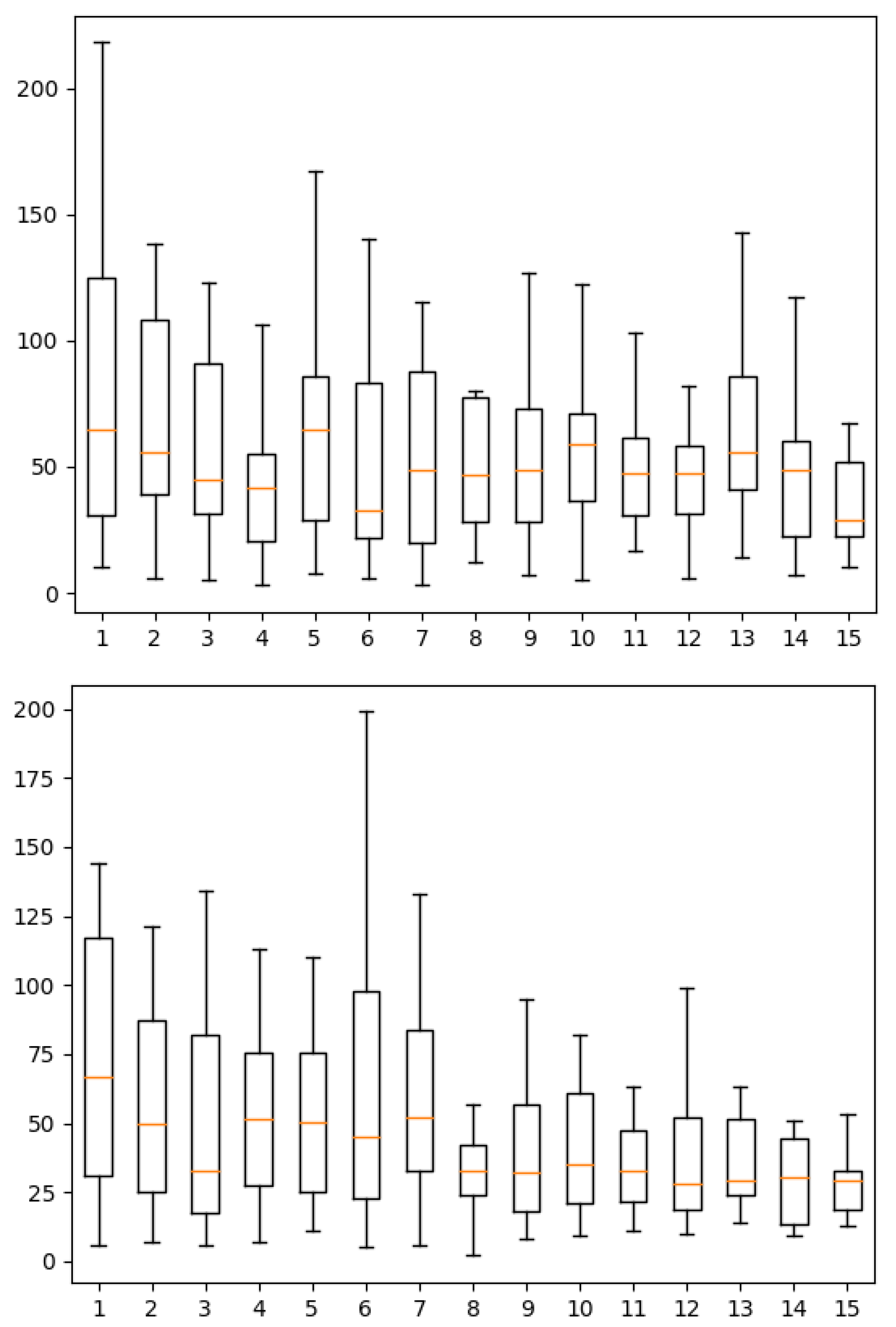
5.2. Qualitative Analysis
6. Subjective Experiment
6.1. Methodology
- The model trained with Blizzard2013 dataset is used to generate a latent space with continuous variations of expressiveness as presented in Section 3.2.
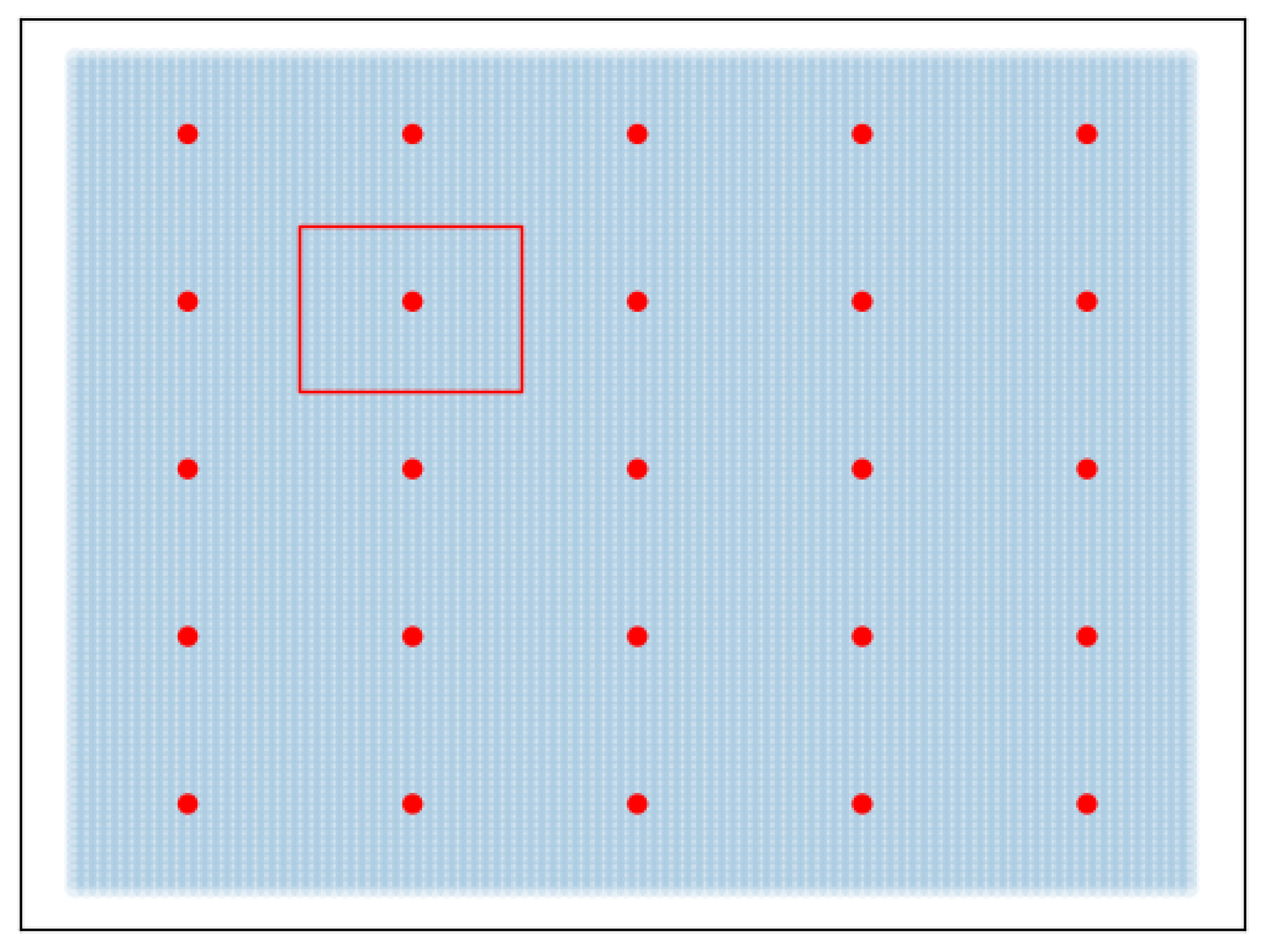
- In the 2D interface, we sample a set of points inside the region of the space in which the dataset points are located. The limits of the rectangle are defined by projecting sentences of the whole dataset in the 2D space with PCA and selecting , , , and of all points. In other words, we use the smallest rectangle containing the dataset points. We use a resolution of 100 for x and y axes, making a total of 10,000 points in the space.
- This set of 2D points is projected to the 8D latent space of the trained unsupervised model with inverse PCA. The 8D vectors are then fed to the model for synthesis.
- Five different texts are used to synthesize the experiment materials. This makes a total of 50,000 expressive sentences synthesized with the model.
- First, before the experiment, to illustrate what kind of task it will contain and familiarize you with it, here is a link to a demonstration interface: https://jsfiddle.net/g9aos1dz/show, accessed on 29 August 2021.
- You can choose the sentence and you have a 2D space on which you can click. It will play the sentence with a specific expressiveness depending on its location.
- Familiarize yourself with it and listen to different sentences with a different expressiveness.
- Then for the experiment, use headphones to hear well, and be in a quiet environment where you will not be bothered.
- You will be asked to listen to a reference audio sample and find the red point in the 2D space that you feel to be the closest in expressiveness.
- Be aware that expressiveness varies continuously in the entire 2D space.
- You can click as much as you like on the 2D space and replay a sample. When you are satisfied with your choice, click on submit.
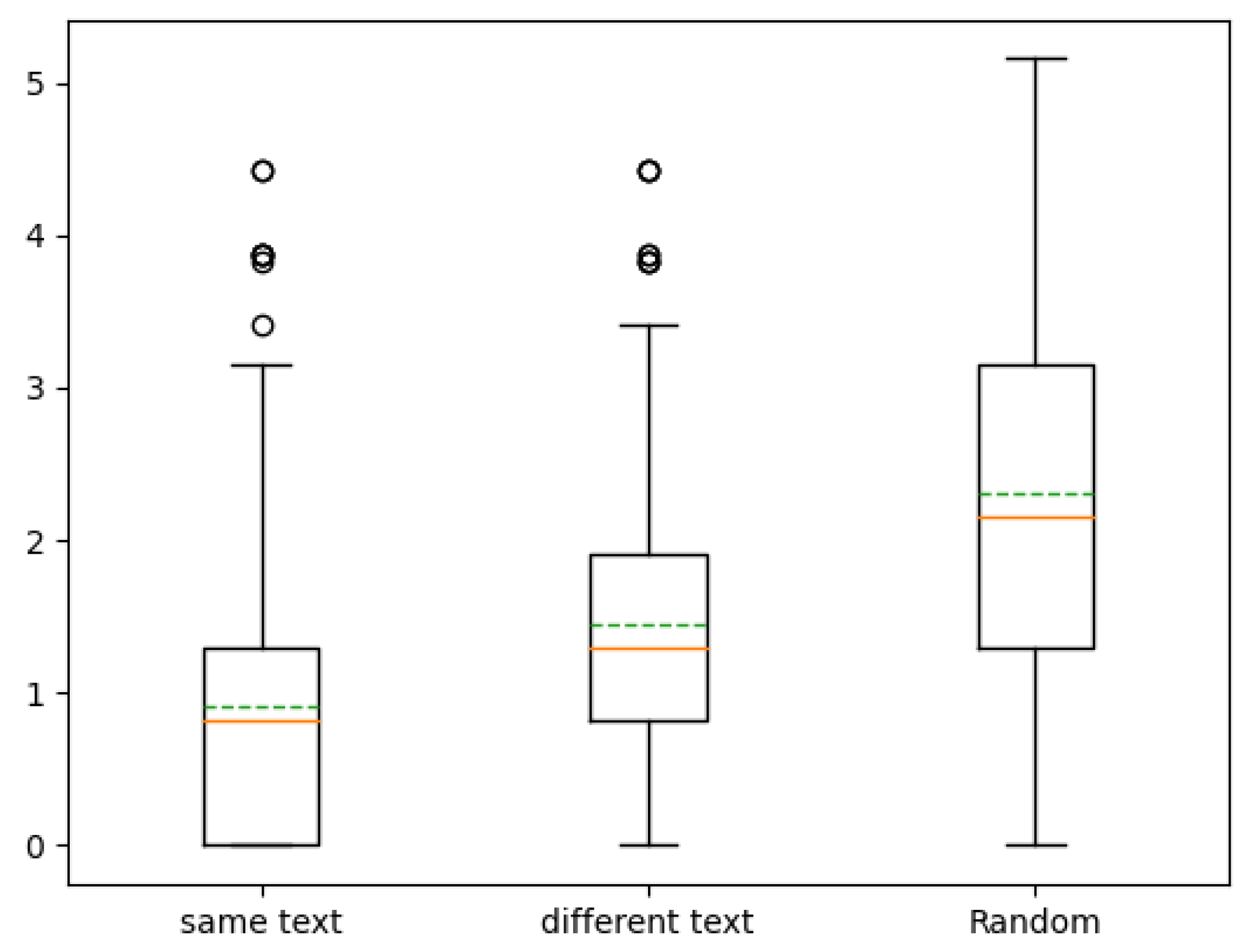
- There are two different versions, in the first one, the sentence is the same in the reference and in the 2D space. In the second, they are not. You just need to select the red point that in your opinion has the closest expressiveness.
- It would be great if you could do this for a set of 15 samples in each level. You can see your evolution on the page.
6.2. Evaluation
6.2.1. Controllability Score
6.2.2. Results and Discussion
7. Summary and Conclusions
8. Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Burkhardt, F.; Campbell, N. Emotional speech synthesis. In The Oxford Handbook of Affective Computing; Oxford University Press: New York, NY, USA, 2014; p. 286. [Google Scholar]
- Tits, N. A Methodology for Controlling the Emotional Expressiveness in Synthetic Speech—A Deep Learning approach. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), Cambridge, UK, 3–6 September 2019; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Tits, N.; Haddad, K.E.; Dutoit, T. ICE-Talk 2: Interface for Controllable Expressive TTS with perceptual assessment tool. Softw. Impacts 2021, 8, 100055. [Google Scholar] [CrossRef]
- Ito, K. The LJ Speech Dataset. 2017. Available online: https://keithito.com/LJ-Speech-Dataset/ (accessed on 29 August 2021).
- Tits, N.; El Haddad, K.; Dutoit, T. The Theory behind Controllable Expressive Speech Synthesis: A Cross-Disciplinary Approach. In Human-Computer Interaction; IntechOpen: London, UK, 2019. [Google Scholar] [CrossRef] [Green Version]
- Watts, O.; Henter, G.E.; Merritt, T.; Wu, Z.; King, S. From HMMs to DNNs: Where do the improvements come from? In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5505–5509. [Google Scholar]
- Zen, H.; Tokuda, K.; Black, A.W. Statistical parametric speech synthesis. Speech Commun. 2009, 51, 1039–1064. [Google Scholar] [CrossRef]
- Zen, H.; Senior, A.; Schuster, M. Statistical parametric speech synthesis using deep neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 7962–7966. [Google Scholar]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.W.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Wang, Y.; Skerry-Ryan, R.J.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards End-to-End Speech Synthesis. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Skerry-Ryan, R.; Battenberg, E.; Xiao, Y.; Wang, Y.; Stanton, D.; Shor, J.; Weiss, R.; Clark, R.; Saurous, R.A. Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron. In Proceedings of the International Conference on Machine Learning 2018, Stockholm, Sweden, 10–15 July 2018; pp. 4693–4702. [Google Scholar]
- Klimkov, V.; Ronanki, S.; Rohnke, J.; Drugman, T. Fine-Grained Robust Prosody Transfer for Single-Speaker Neural Text-To-Speech. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 4440–4444. [Google Scholar] [CrossRef] [Green Version]
- Karlapati, S.; Moinet, A.; Joly, A.; Klimkov, V.; Sáez-Trigueros, D.; Drugman, T. CopyCat: Many-to-Many Fine-Grained Prosody Transfer for Neural Text-to-Speech. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 4387–4391. [Google Scholar] [CrossRef]
- Akuzawa, K.; Iwasawa, Y.; Matsuo, Y. Expressive Speech Synthesis via Modeling Expressions with Variational Autoencoder. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 3067–3071. [Google Scholar] [CrossRef] [Green Version]
- Taigman, Y.; Wolf, L.; Polyak, A.; Nachmani, E. Voiceloop: Voice fitting and synthesis via a phonological loop. arXiv 2017, arXiv:1707.06588. [Google Scholar]
- Hsu, W.N.; Zhang, Y.; Weiss, R.J.; Zen, H.; Wu, Y.; Wang, Y.; Cao, Y.; Jia, Y.; Chen, Z.; Shen, J.; et al. Hierarchical Generative Modeling for Controllable Speech Synthesis. arXiv 2018, arXiv:1810.07217. [Google Scholar]
- Henter, G.E.; Lorenzo-Trueba, J.; Wang, X.; Yamagishi, J. Deep Encoder-Decoder Models for Unsupervised Learning of Controllable Speech Synthesis. arXiv 2018, arXiv:1807.11470. [Google Scholar]
- Wang, Y.; Stanton, D.; Zhang, Y.; Ryan, R.S.; Battenberg, E.; Shor, J.; Xiao, Y.; Jia, Y.; Ren, F.; Saurous, R.A. Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis. In Proceedings of the International Conference on Machine Learning 2018, Stockholm, Sweden, 10–15 July 2018; pp. 5180–5189. [Google Scholar]
- Shechtman, S.; Sorin, A. Sequence to sequence neural speech synthesis with prosody modification capabilities. arXiv 2019, arXiv:1909.10302. [Google Scholar]
- Raitio, T.; Rasipuram, R.; Castellani, D. Controllable neural text-to-speech synthesis using intuitive prosodic features. arXiv 2020, arXiv:2009.06775. [Google Scholar]
- Tits, N.; El Haddad, K.; Dutoit, T. Neural Speech Synthesis with Style Intensity Interpolation: A Perceptual Analysis. In Companion of the 2020 ACM/IEEE International Conference on Human-Robot Interaction; Association for Computing Machinery: New York, NY, USA, 2020; pp. 485–487. [Google Scholar] [CrossRef] [Green Version]
- Tachibana, H.; Uenoyama, K.; Aihara, S. Efficiently trainable text-to-speech system based on deep convolutional networks with guided attention. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4784–4788. [Google Scholar]
- Tits, N.; Wang, F.; Haddad, K.E.; Pagel, V.; Dutoit, T. Visualization and Interpretation of Latent Spaces for Controlling Expressive Speech Synthesis through Audio Analysis. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 4475–4479. [Google Scholar] [CrossRef] [Green Version]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; André, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S.; et al. The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing. IEEE Trans. Affect. Comput. 2016, 7, 190–202. [Google Scholar] [CrossRef] [Green Version]
- Kubichek, R. Mel-cepstral distance measure for objective speech quality assessment. In Proceedings of the IEEE Pacific Rim Conference on Communications Computers and Signal Processing, Victoria, BC, Canada, 19–21 May 1993; Volume 1, pp. 125–128. [Google Scholar]
- Nakatani, T.; Amano, S.; Irino, T.; Ishizuka, K.; Kondo, T. A method for fundamental frequency estimation and voicing decision: Application to infant utterances recorded in real acoustical environments. Speech Commun. 2008, 50, 203–214. [Google Scholar] [CrossRef]






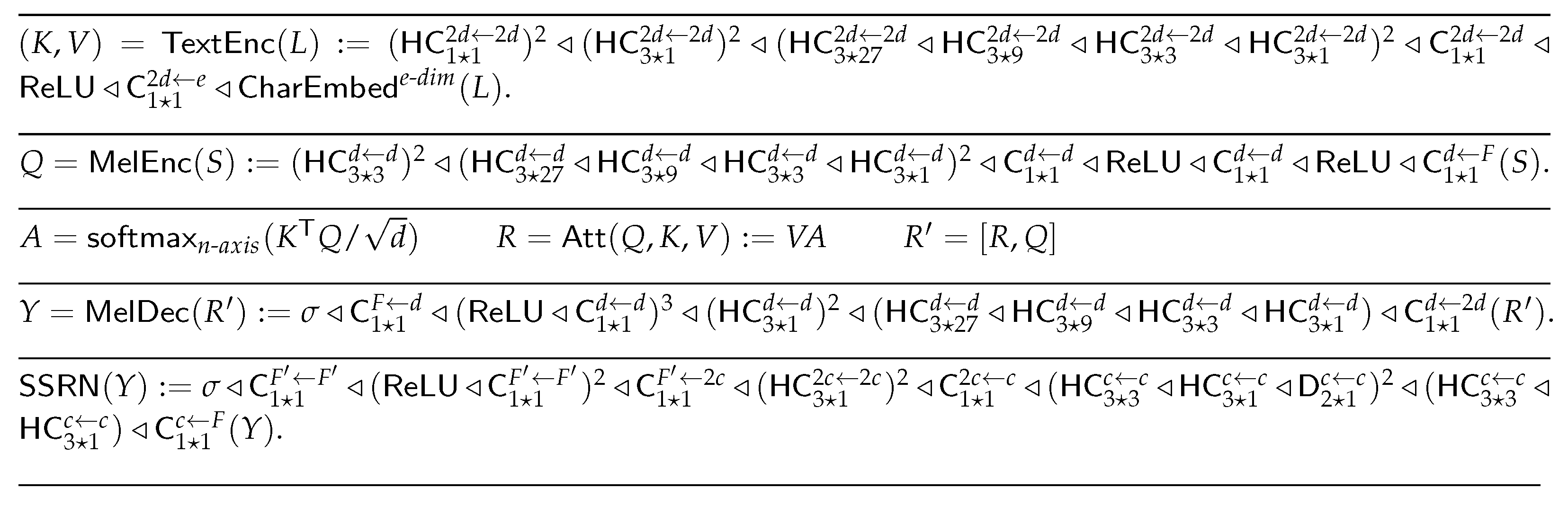{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| APCC | |
|---|---|
| F0 percentile50.0 | 0.723824 |
| mfcc1V mean | 0.619622 |
| mfcc1 mean | 0.554794 |
| logRelF0-H1-A3 mean | 0.493066 |
| mfcc4V mean | 0.492359 |
| HNRdBACF mean | 0.482579 |
| F1amplitudeLogRelF0 mean | 0.473154 |
| slopeV0-500 mean | 0.420381 |
| StddevVoicedSegmentLengthSec | 0.388952 |
| F3amplitudeLogRelF0 stddevNorm | 0.360528 |
| mfcc2V mean | 0.360144 |
| hammarbergIndexV mean | 0.356113 |
| mfcc1V stddevNorm | 0.350918 |
| loudness meanFallingSlope | 0.350369 |
| loudness percentile20.0 | 0.340973 |
| loudness meanRisingSlope | 0.323489 |
| F1frequency mean | 0.318096 |
| MCD | VDE | lF0_MSE | F0_MSE | |
|---|---|---|---|---|
| DTW | 9.973914 | 0.015488 | 0.436348 | 1219.128507 |
| shift | 13.331841 | 0.236024 | 6.283607 | 9481.103150 |
| MCD | VDE | lF0_MSE | F0_MSE | |
|---|---|---|---|---|
| DTW | 9.624296 | 0.009699 | 0.311803 | 957.290498 |
| shift | 12.675999 | 0.218258 | 5.838526 | 8931.599942 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tits, N.; El Haddad, K.; Dutoit, T. Analysis and Assessment of Controllability of an Expressive Deep Learning-Based TTS System. Informatics 2021, 8, 84. https://doi.org/10.3390/informatics8040084
Tits N, El Haddad K, Dutoit T. Analysis and Assessment of Controllability of an Expressive Deep Learning-Based TTS System. Informatics. 2021; 8(4):84. https://doi.org/10.3390/informatics8040084
Chicago/Turabian StyleTits, Noé, Kevin El Haddad, and Thierry Dutoit. 2021. "Analysis and Assessment of Controllability of an Expressive Deep Learning-Based TTS System" Informatics 8, no. 4: 84. https://doi.org/10.3390/informatics8040084
APA StyleTits, N., El Haddad, K., & Dutoit, T. (2021). Analysis and Assessment of Controllability of an Expressive Deep Learning-Based TTS System. Informatics, 8(4), 84. https://doi.org/10.3390/informatics8040084