Unstructured Text in EMR Improves Prediction of Death after Surgery in Children

 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
2.1. NSQIP Cohort
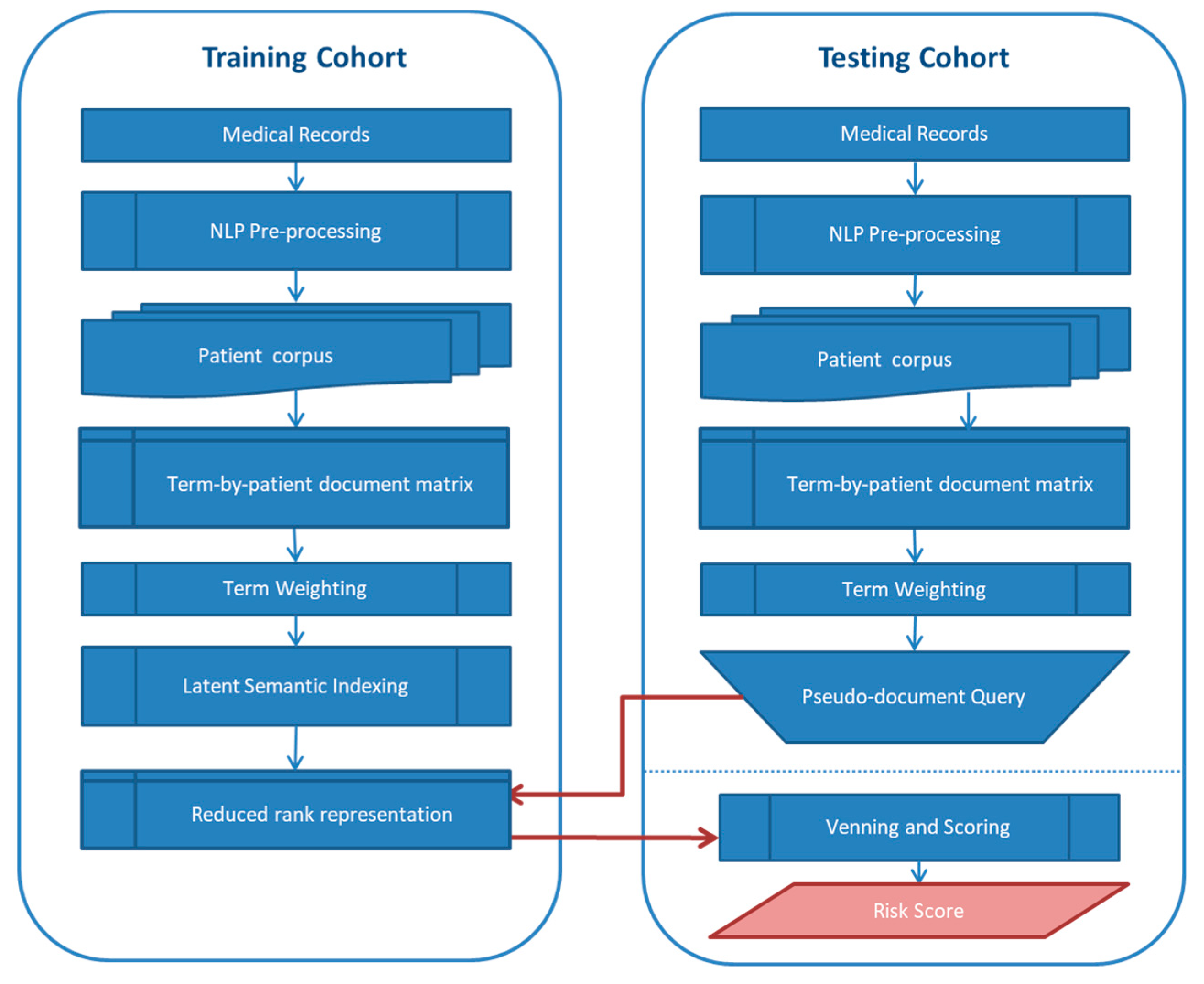
2.2. Text Mining and Development of Text-Based Risk Score
2.3. Hypothesis Testing and Prediction
3. Results
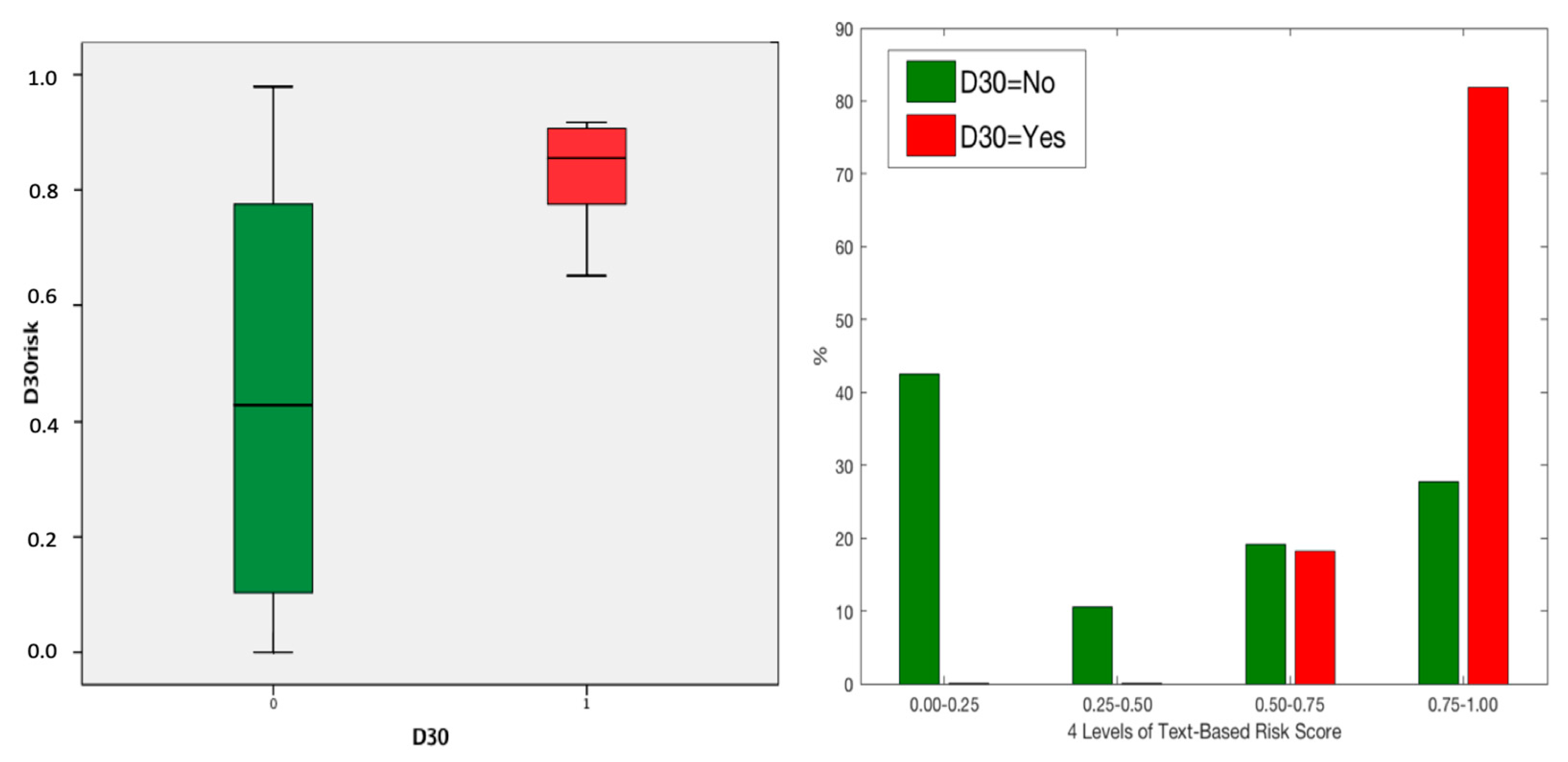
3.1. Association between Free Text-Based Risk Score and Death after Surgery
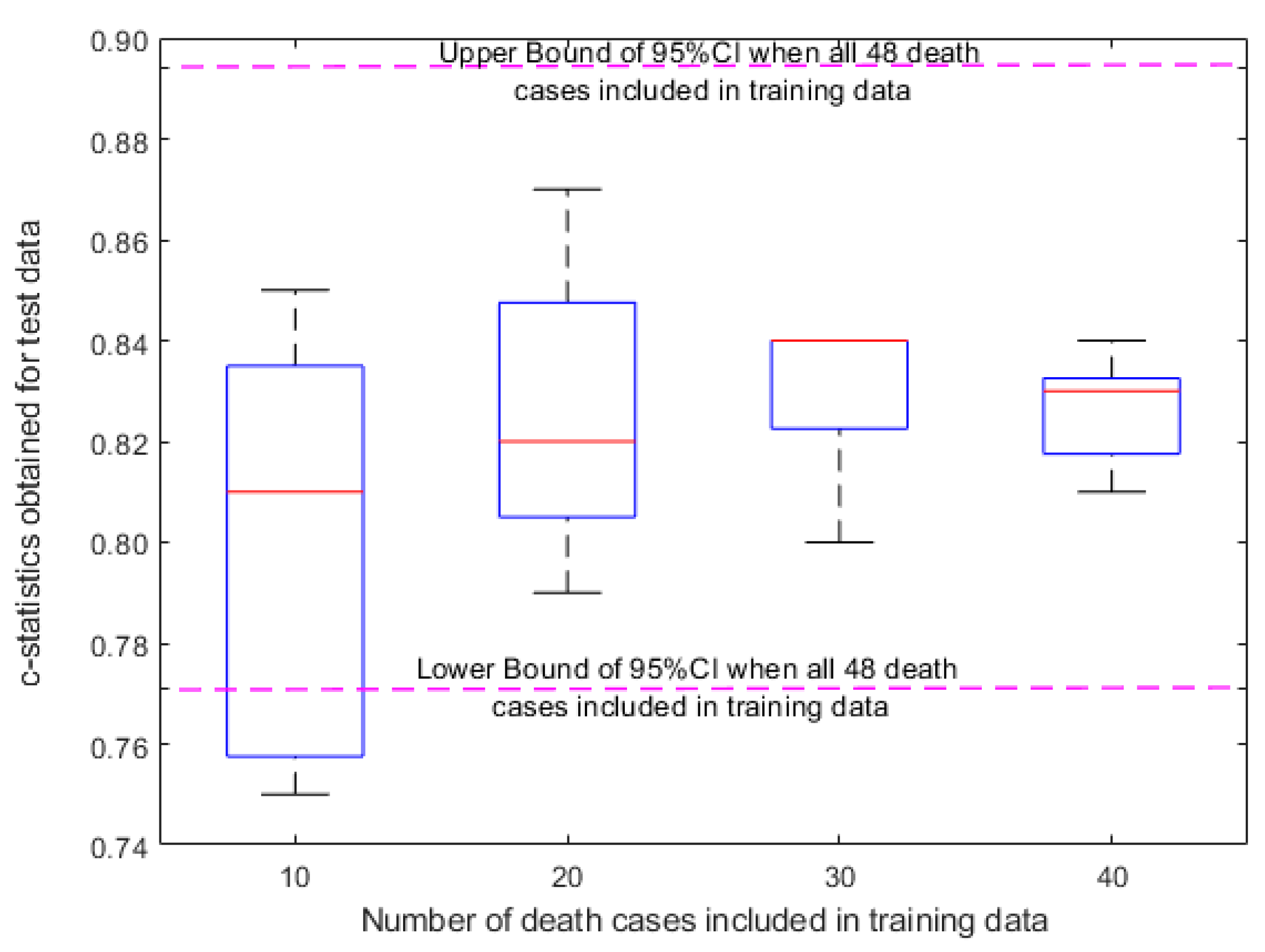
3.2. Sensitivity Analysis for Text-Based Risk Scores
3.3. Prediction of Postsurgical Mortality in the NSQIP Cohort
3.4. Association between Free Text-Based Risk Score and Other Adverse Surgery Outcomes
3.5. The Role of Free Text-Based Risk Score in Predicting Other Adverse Surgery Outcomes
4. Discussion
Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- BS Systems. Health IT and Patient Safety: Building Safer Systems for Better Care; BS Systems: Zusmarshausen, Germany, 2011. [Google Scholar]
- Van der Griend, B.F.; Lister, N.A.; McKenzie, I.M.; Martin, N.; Ragg, P.G.; Sheppard, S.J.; Davidson, A.J. Postoperative mortality in children after 101,885 anesthetics at a tertiary pediatric hospital. Anesth. Analg. 2011, 112, 1440–1447. [Google Scholar] [CrossRef] [PubMed]
- Akbilgic, O.; Langham, M.R.; Walter, A.I.; Jones, T.L.; Huang, E.Y.; Davis, R.L. A novel risk classification system for 30-day mortality in children undergoing surgery. PLoS ONE 2018, 13, e0191176. [Google Scholar] [CrossRef] [PubMed]
- Cheon, E.C.; Palac, H.L.; Paik, K.H.; Hajduk, J.; De Oliveira, G.S.; Jagannathan, N.; Suresh, S. Unplanned, Postoperative Intubation in Pediatric Surgical Patients: Development and Validation of a Multivariable Prediction Model. Anesthesiology 2016, 125, 914–928. [Google Scholar] [CrossRef] [PubMed]
- Stey, A.M.; Vinocur, C.D.; Moss, R.L.; Hall, B.L.; Cohen, M.E.; Kraemer, K.; Ko, C.Y.; Kenney, B.D. Variation in intraoperative and postoperative red blood cell transfusion in pediatric surgery. Transfusion 2016, 56, 666–672. [Google Scholar] [CrossRef] [PubMed]
- Brown, E.G.; Anderson, J.E.; Burgess, D.; Bold, R.J.; Farmer, D.L. Pediatric surgical readmissions: Are they truly preventable? J. Pediatr. Surg. 2017, 52, 161–165. [Google Scholar] [CrossRef] [PubMed]
- Oldham, K.T. Optimal Resources for Children’s Surgical Care. J. Pediatric Surg. 2015, 49, 667–677. [Google Scholar] [CrossRef] [PubMed]
- Langham, M.R.; Walter, A.; Boswell, T.C.; Beck, R.; Jones, T.L. Identifying children at risk of death within 30 days of surgery at an NSQIP pediatric hospital. Surgery 2015, 158, 1481–1491. [Google Scholar] [CrossRef]
- Akbilgic, O.; Langham, M.R.; Davis, R.L. Race, Preoperative Risk Factors, and Death after Surgery. Pediatrics 2018, 141, e20172221. [Google Scholar] [CrossRef]
- Harris, A.H.S. Path from predictive analytics to improved patient outcomes. Ann. Surg. 2017, 265, 461–463. [Google Scholar] [CrossRef]
- Bilimoria, K.Y.; Liu, Y.; Paruch, J.L.; Zhou, L.; Kmiecik, T.E.; Ko, C.Y.; Cohen, M.E. Development and evaluation of the universal ACS NSQIP surgical risk calculator: A decision aid and informed consent tool for patients and surgeons. J. Am. Coll. Surg. 2013, 217, 833–842. [Google Scholar] [CrossRef]
- Parikh, R.B.; Kakad, M.; Bates, D.W. Integrating Predictive Analytics into High-Value Care. JAMA 2016, 315, 651–652. [Google Scholar] [CrossRef] [PubMed]
- Amarasingham, R.; Audet, A.M.; Bates, D.W.; Cohen, I.G.; Entwistle, M.; Escobar, G.J.; Liu, V.; Etheredge, L.; Lo, B.; Ohno-Machado, L.; et al. Consensus Statement on Electronic Health Predictive Analytics: A Guiding Framework to Address Challenges. eGEMs 2016, 4, 1163. [Google Scholar] [CrossRef] [PubMed]
- Jensen, K.; Soguero-Ruiz, C.; Mikalsen, K.O.; Lindsetmo, R.O.; Kouskoumvekaki, I.; Girolami, M.; Skrovseth, S.O.; Augestad, K.M. Analysis of free text in electronic health records for identification of cancer patient trajectories. Sci. Rep. 2017, 7, 46226. [Google Scholar] [CrossRef]
- Lin, J.; Jiao, T.; Biskupiak, J.E.; McAdam-Marx, C. Application of electronic medical record data for health outcomes research: A review of recent literature. Expert Rev. Pharmacoecon. Outcomes Res. 2013, 13, 191–200. [Google Scholar] [CrossRef] [PubMed]
- Friedman, C.; Shagina, L.; Lussier, Y.; Hripcsak, G. Automated encoding of clinical documents based on natural language processing. J. Am. Med. Inform. Assoc. 2004, 11, 392–402. [Google Scholar] [CrossRef]
- Zeng, Q.T.; Goryachev, S.; Weiss, S.; Sordo, M.; Murphy, S.N.; Lazarus, R. Extracting principal diagnosis, co-morbidity and smoking status for asthma research: Evaluation of a natural language processing system. BMC Med. Inform. Decis. Mak. 2006, 6, 30. [Google Scholar] [CrossRef] [PubMed]
- Savova, G.K.; Masanz, J.J.; Ogren, P.V.; Zheng, J.; Sohn, S.; Kipper-Schuler, K.C.; Chute, C.G. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): Architecture, component evaluation and applications. J. Am. Med. Inform. Assoc. 2010, 17, 507–513. [Google Scholar] [CrossRef]
- Lin, F.P.Y.; Pokorny, A.; Teng, C.; Epstein, R.J. TEPAPA: A novel in silico feature learning pipeline for mining prognostic and associative factors from text-based electronic medical records. Sci. Rep. 2017, 7, 6918. [Google Scholar] [CrossRef]
- Ford, E.; Carroll, J.A.; Smith, H.E.; Scott, D.; Cassell, J.A. Extracting information from the text of electronic medical records to improve case detection: A systematic review. J. Am. Med. Inform. Assoc. 2016, 23, 1007–1015. [Google Scholar] [CrossRef]
- Kim, Y.S.; Yoon, D.; Byun, J.; Park, H.; Lee, A.; Kim, I.H.; Lee, S.; Lim, H.S.; Park, R.W. Extracting information from free-text electronic patient records to identify practice-based evidence of the performance of coronary stents. PLoS ONE 2017, 12, e0182889. [Google Scholar] [CrossRef]
- Thomas, A.A.; Zheng, C.; Jung, H.; Chang, A.; Kim, B.; Gelfond, J.; Slezak, J.; Porter, K.; Jacobsen, S.J.; Chien, G.W. Extracting data from electronic medical records: Validation of a natural language processing program to assess prostate biopsy results. World J. Urol. 2014, 32, 99–103. [Google Scholar] [CrossRef] [PubMed]
- Frost, D.W.; Vembu, S.; Wang, J.; Tu, K.; Morris, Q.; Abrams, H.B. Using the Electronic Medical Record to Identify Patients at High Risk for Frequent Emergency Department Visits and High System Costs. Am. J. Med. 2017, 130, 601.e17–601.e22. [Google Scholar] [CrossRef] [PubMed]
- Weissman, G.E.; Hubbard, R.A.; Ungar, L.H.; Harhay, M.O.; Greene, C.S.; Himes, B.E.; Halpern, S.D. Inclusion of Unstructured Clinical Text Improves Early Prediction of Death or Prolonged ICU Stay. Crit. Care Med. 2018, 46, 1125–1132. [Google Scholar] [CrossRef] [PubMed]
- Murff, H.J.; FitzHenry, F.; Matheny, M.E.; Gentry, N.; Kotter, K.L.; Crimin, K.; Dittus, R.S.; Rosen, A.K.; Elkin, P.L.; Brown, S.H.; et al. Automated identification of postoperative complications within an electronic medical record using natural language processing. JAMA 2011, 306, 848–855. [Google Scholar] [CrossRef] [PubMed]
- American College of Surgeons National Surgical Quality Improvement Program-Pediatrics User Guide for the ACS NSQIP Pediatric Participant Use File; American College of Surgeons: Chicago, IL, USA, 2013.
- Berry, M.; Browne, M. Understanding Search Engines: Mathematical Modeling and Text Retrieval, 1st ed.; SIAM: Philadelphia, PA, USA, 1999. [Google Scholar]
- DeLong, E.R.; DeLong, D.M.; Clarke-Pearson, D.L. Comparing the Areas under Two or More Correlated Receiver Operating Characteristic Curves: A Nonparametric Approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef] [PubMed]
- Merrick, S.; Shaker, M. ASA Relative Value Guide (RVG): A Defining Moment in Fair Pricing of Medical Services. ASA Monit. 2014, 78, 26–27. [Google Scholar]
- Kraemer, K.; Cohen, M.E.; Liu, Y.; Barnhart, D.C.; Rangel, S.J.; Saito, J.M.; Bilimoria, K.Y.; Ko, C.Y.; Hall, B.L. Development and Evaluation of the American College of Surgeons NSQIP Pediatric Surgical Risk Calculator. J. Am. Coll. Surg. 2016, 223, 685–693. [Google Scholar] [CrossRef]
- Moses, H.; Matheson, D.H.M.; Dorsey, E.R.; George, B.P.; Sadoff, D.; Yoshimura, S. The anatomy of health care in the United States. JAMA 2013, 310, 1947–1963. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Sets | Categories | Count | Mean Text-Based Risk; 95% CI | Mann-Whitney U Test p Value |
|---|---|---|---|---|
| Non-NSQIP (Training) | D30 = No | 4690 | 0.35; 0.34–0.36 | <0.001 |
| D30 = Yes | 48 | 0.64; 0.59–0.72 | ||
| NSQIP (Testing) | D30 = No | 1748 | 0.44; 0.42–0.46 | <0.001 |
| D30 = Yes | 11 | 0.84; 0.78–0.90 |
| Outcome | Count | Mean Text-Based Risk Value with 95%CI | p Value | |
|---|---|---|---|---|
| Death within 30 days of surgery | No | 1748 | 0.44; 0.42–0.45 | <0.001 |
| Yes | 11 | 0.84; 0.78–0.90 | ||
| Death within 90 days of surgery | No | 1738 | 0.44; 0.42–0.45 | <0.001 |
| Yes | 21 | 0.82; 0.77–0.87 | ||
| Postoperative superficial (incisional) surgical site infection | No | 1736 | 0.44; 0.42–0.45 | 0.015 |
| Yes | 23 | 0.62; 0.52–0.74 | ||
| Intra- or post-operative blood transfusion within 72 h of surgery start time | No | 1625 | 0.45; 0.43–0.47 | <0.001 |
| Yes | 134 | 0.31; 0.25–0.37 | ||
| Unplanned readmission within 30 days of surgery | No | 1621 | 0.43; 0.41–0.45 | <0.001 |
| Yes | 138 | 0.57; 0.51–0.62 | ||
| Postoperative Unplanned Intubation | No | 1735 | 0.43; 0.42–0.45 | 0.001 |
| Yes | 24 | 0.71; 0.61–0.81 | ||
| First Unplanned Return to Operating Room | No | 1690 | 0.44; 0.42–0.45 | 0.039 |
| Yes | 69 | 0.52; 0.43–0.60 | ||
| Outcome | c-Statistics with 95%CI | Selected Preoperative Risk Factors | |
|---|---|---|---|
| Death within 30 days of surgery | No CV | 0.96; 0.92–1.00 | Text-based risk score, ventilator dependency, bleeding disorder, inotropic support, Emergent Case |
| Five-fold CV | 0.92; 0.84–0.99 | ||
| Death within 90 days of surgery | No CV | 0.95; 0.92–0.99 | Text-based risk score, ventilator dependency, neonate, bleeding disorder, Emergent case |
| Five-fold CV | 0.94; 0.89–0.99 | ||
| Postoperative superficial incisional surgical site infection | No CV | 0.72; 0.61–0.83 | Text-based risk score, neonate |
| Five-fold CV | 0.67; 0.55–0.79 | ||
| Intra- or post-operative blood transfusion within 72 h of surgery start time | No CV | 0.76; 0.71–0.80 | Text-based risk score, oxygen support, neuromuscular disorder, hematologic disorder, inotropic support, malignancy, urgent case |
| Five-fold CV | 0.73; 0.69–0.78 | ||
| Unplanned readmission within 30 days of surgery | No CV | 0.67; 0.62–0.72 | Text-based risk score, neonate, SIRS, Sepsis |
| Five-fold CV | 0.66; 0.61–0.70 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akbilgic, O.; Homayouni, R.; Heinrich, K.; Langham, M.R.; Davis, R.L. Unstructured Text in EMR Improves Prediction of Death after Surgery in Children. Informatics 2019, 6, 4. https://doi.org/10.3390/informatics6010004
Akbilgic O, Homayouni R, Heinrich K, Langham MR, Davis RL. Unstructured Text in EMR Improves Prediction of Death after Surgery in Children. Informatics. 2019; 6(1):4. https://doi.org/10.3390/informatics6010004
Chicago/Turabian StyleAkbilgic, Oguz, Ramin Homayouni, Kevin Heinrich, Max Raymond Langham, and Robert Lowell Davis. 2019. "Unstructured Text in EMR Improves Prediction of Death after Surgery in Children" Informatics 6, no. 1: 4. https://doi.org/10.3390/informatics6010004
APA StyleAkbilgic, O., Homayouni, R., Heinrich, K., Langham, M. R., & Davis, R. L. (2019). Unstructured Text in EMR Improves Prediction of Death after Surgery in Children. Informatics, 6(1), 4. https://doi.org/10.3390/informatics6010004