Modeling and Application of Customer Lifetime Value in Online Retail


Abstract
1. Introduction
- Better comparable results of the deployment of selected models. Theoretically orientated studies build on secondary sources, most often on the results of the validation of the proposed model in the original article. The problem with studies built on secondary sources rather than comparative empirical research is that the conclusions about the behavior of a model and its comparison with another model are based on the use of entirely different datasets and conditions. This brings up the issue of relevant generalizations based on different results.
- New findings for the empirical process of building an information base on individual models. For example, Gupta et al. [11] consider persistence models, e.g., the Vector Autoregressive model (VAR), as very appropriate for CLV calculation; however, they add that there are very few examples using these models because the demands for data are high. Only the introduction of other applications, for example particular model to new datasets, can enhance the debate about the appropriateness or limits of a particular model in comparison to others, and extend it further by a discussion about the areas of usability.
2. Background
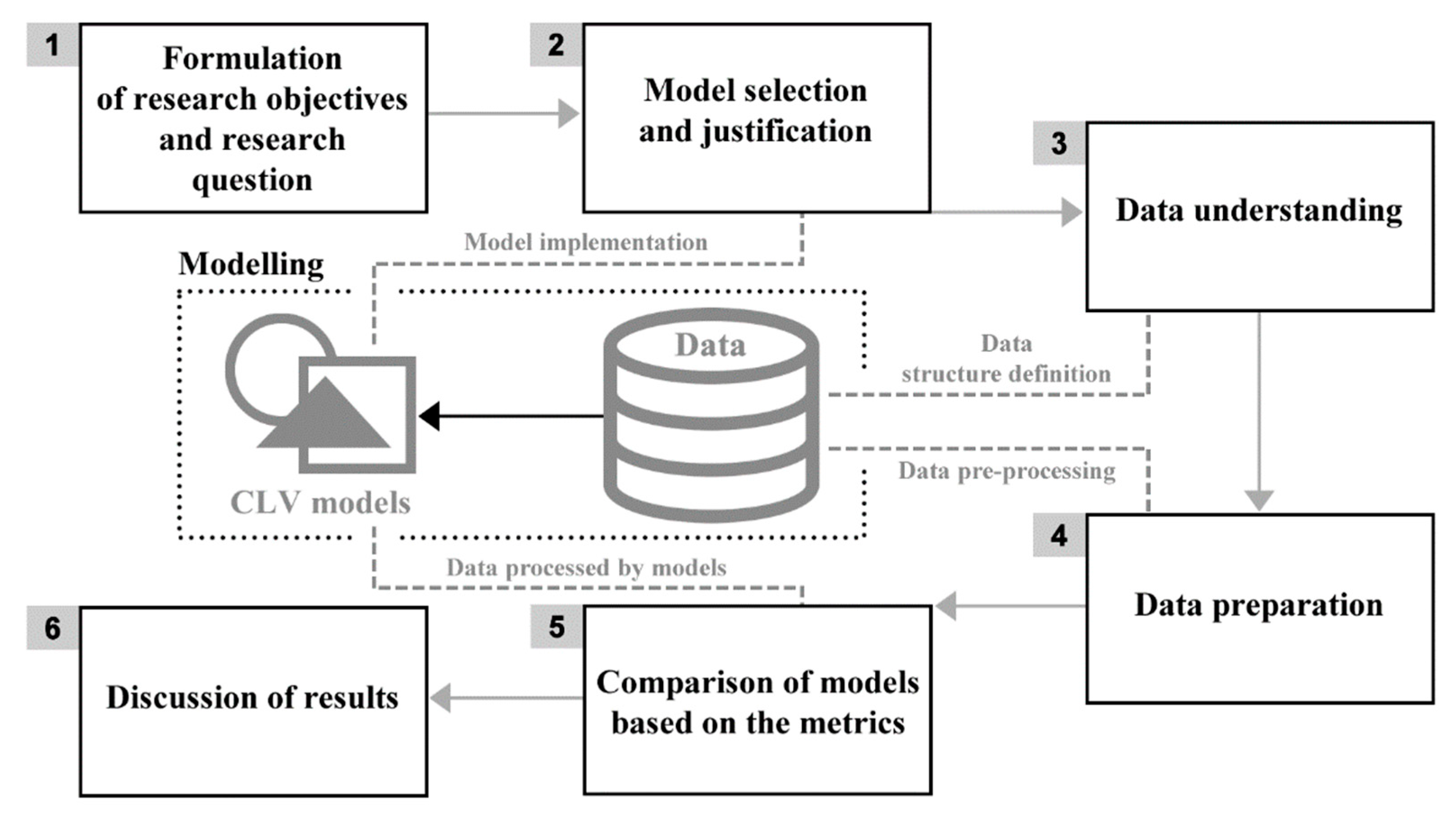
3. Methodology and Data Collection
3.1. Selection of Models for Comparison and Their Description
- Non-contractual relation: Customers are not contractually bound, and it is only up to them whether and when they make a purchase from the given retailer.
- Non-membership: Customers do not have to be members of a club. Many retailers have their loyalty programs, but with regard to selecting a model, there should be a universal approach to customers, lifting this prerequisite.
- Always-a-share: A customer who stopped shopping can return at any time.
- Variable-spending environment: The retailer offers a broad portfolio of products with varying prices (the opposite of a specialized shop focusing on a single core product).
- Continuous: The customer can make a purchase anytime, repeatedly and several times a day.
3.1.1. Extended Pareto/NBD Model
- While alive, the number of transactions made by a customer follows a Poisson process.
- Customer’s unobserved lifetime is exponentially distributed.
- Heterogeneity in transaction rates across all customers follows a gamma distribution.
- Heterogeneity in dropout rates across all customers follows a gamma distribution.
- The transaction rate and dropout rate vary independently across customers.
- The monetary value of a customer’s transaction varies randomly around their average order value.
- Average transaction values vary across customers but do not vary over time for any given individual.
- The distribution of average transaction values across customers is independent of the transaction process.
3.1.2. Markov Chain Model with Decision Tree Learning
3.1.3. Status Quo Model
- A customer who has not made a purchase for more than a year is considered inactive.
- Active customers are assumed to make a purchase every following week that has the same value as their average weekly purchase in the last year of the period (52 weeks).
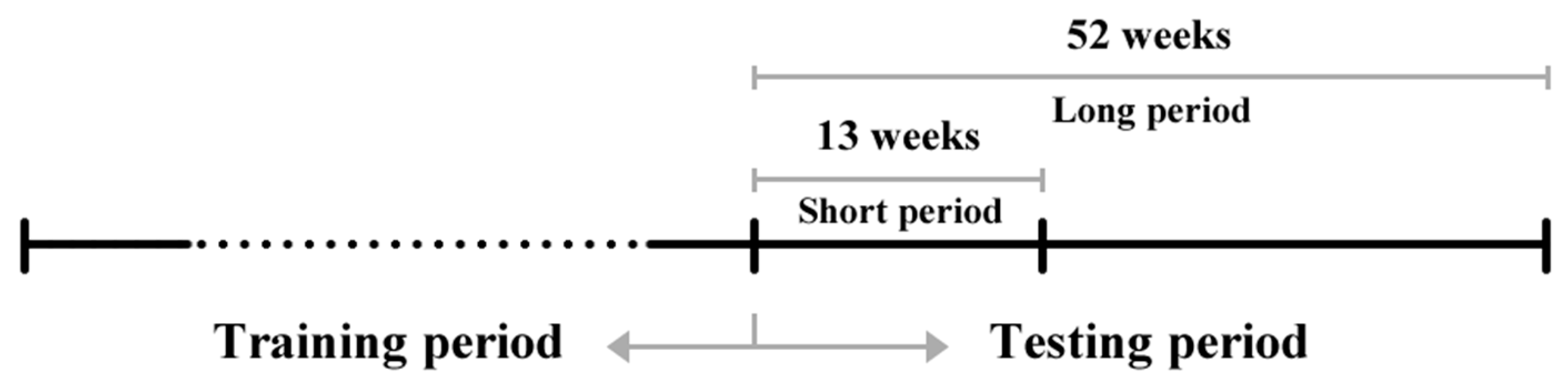
3.2. Data Collection and Pre-Processing
3.3. Description of Datasets
3.4. Evaluation Metrics
4. Results
5. Discussion and Implications
5.1. Managerial Implications
- Individual customer level has a wide range of applications from marketing campaign selection to customer support preferences. Individual customer scoring, as expressed by the selection of the top 10% of the most profitable customers, needs to be addressed with business goals in mind. For practical utilization, this means considering whether to include or exclude such customers from marketing campaigns. Experimentation with a segmented or even personalised campaign in order to leverage and support the expected high value from such customers is advised. For classification into top 10% of the most profitable customers the sensitivity is an important metric in order to assess the model’s ability to execute the correct classification of top customers, which could be useful for the selection of specific marketing campaigns.
- Segmented groups of customers are well suited for aggregated analysis of customer base growth drivers.
- Customer base level of CLV applications is useful in business planning and strategic management.
5.2. Limitations and Further Research Directions
- A thorough analysis of the time constraints in model execution.
- Using optimization method for likelihood minimization of parameter estimation that does not allow box constraints.
- Rewriting model execution to support parallel computing, at least for the parameter estimation.
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A




References
- Haenlein, M.; Kaplan, A.M.; Schoder, D. Valuing the Real Option of Abandoning Unprofitable Customers When Calculating Customer Lifetime Value. J. Mark. 2006, 70, 5–20. [Google Scholar] [CrossRef]
- Online Retailing: Britain, Europe, US and Canada 2015. Centre for Retail Research. Available online: http://www.retailresearch.org/onlineretailing.php (accessed on 27 December 2017).
- Jain, D.C.; Singh, S.S. Customer lifetime value research in marketing: A review and future directions. J. Interact. Mark. 2002, 16, 34–46. [Google Scholar] [CrossRef]
- Fader, P.S.; Hardie, B.G.S. Probability Models for Customer-Base Analysis. J. Interact. Mark. 2009, 23, 61–69. [Google Scholar] [CrossRef]
- Damm, R.; Monroy, C.R. A review of the customer lifetime value as a customer profitability measure in the context of customer relationship management. Intang. Cap. 2011, 7, 261–279. [Google Scholar] [CrossRef]
- Chang, W.; Chang, C.; Li, Q. Customer Lifetime Value: A Review. Soc. Behav. Personal. 2012, 40, 1057–1064. [Google Scholar] [CrossRef]
- Estrella-Ramón, A.M.; Sánchez-Pérez, M.; Swinnen, G.; VanHoof, K. A marketing view of the customer value: Customer lifetime value and customer equity. S. Afr. J. Bus. Manag. 2013, 44, 47–64. [Google Scholar]
- EsmaeiliGookeh, M.; Tarokh, M.J. Customer Lifetime Value Models: A literature Survey. Int. J. Ind. Eng. Prod. Res. 2013, 24, 317–336. [Google Scholar]
- Singh, S.S.; Jain, D.C. Measuring Customer Lifetime Value: Models and Analysis. INSEAD Working Paper No. 2013/27/MKT 2013. [Google Scholar] [CrossRef]
- Rozek, J.; Karlicek, M. Customer Lifetime Value as the 21st Century Marketing Strategy Approach. Cent. Eur. Bus. Rev. 2014, 3, 28–35. [Google Scholar] [CrossRef]
- Gupta, S.; Hanssens, D.; Hardie, B.; Kahn, W.; Kumar, V.; Lin, N.; Ravishanker, N.; Sriram, S. Modeling Customer Lifetime Value. J. Serv. Res. 2006, 9, 139–155. [Google Scholar] [CrossRef]
- Donkers, B.; Verhoef, P.C.; De Jong, M.G. Modeling CLV: A test of competing models in the insurance industry. Quant. Mark. Econ. 2007, 5, 163–190. [Google Scholar] [CrossRef]
- Batislam, E.M.; Denizel, M.; Filiztekin, A. Empirical Validation and Comparison of Models for Customer Base Analysis. Int. J. Res. Mark. 2007, 24, 201–209. [Google Scholar] [CrossRef]
- Dresch, A.; Lacerda, D.P.; Antunes, J.A.V., Jr. Design Science Research: A Method for Science and Technology Advancement; Springer: Berlin, Germany, 2015. [Google Scholar]
- Hubka, V.; Eder, W.E. Design Science: Introduction to the Needs, Scope and Organization of Engineering Design Knowledge; Springer: Berlin, Germany, 1996. [Google Scholar]
- Wieringa, R.J. Design Science Methodology for Information Systems and Software Engineering; Springer: Berlin, Germany, 2014. [Google Scholar]
- Kumar, V.; Pansari, A. National Culture, Economy, and Customer Lifetime Value: Assessing the Relative Impact of the Drivers of Customer Lifetime Value for a Global Retailer. J. Int. Mark. 2016, 24, 1–21. [Google Scholar] [CrossRef]
- Persson, A. Profitable Customer Management: A Study in Retail Banking; Hanken School of Economics: Helsinki, Finland, 2011. [Google Scholar]
- Hevner, A.R.; Chatterjee, S. Design Research in Information Systems: Theory and Practice; Springer: London, UK, 2010. [Google Scholar]
- Kotler, P.; Keller, K.L. Marketing Management, 15th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2015. [Google Scholar]
- Kumar, V.; Pozza, I.D.; Petersen, J.A.; Denish Shah, D. Reversing the Logic: The Path to Profitability through Relationship Marketing. J. Int. Mark. 2009, 23, 147–156. [Google Scholar] [CrossRef]
- Fader, P.S. Customer Centricity: Focus on the Right Customers for Strategic Advantage; Wharton Digital Press: Philadelphia, PA, USA, 2012. [Google Scholar]
- Doyle, P. Value-based marketing. J. Strateg. Mark. 2000, 8, 299–311. [Google Scholar] [CrossRef]
- Srivastava, R.K.; Shervani, T.A.; Fahey, L. Market-Based Assets and Shareholder Value: A Framework for Analysis. J. Mark. 1998, 62, 2–18. [Google Scholar] [CrossRef]
- Gupta, S. Customer-Based Valuation. J. Interact. Mark. 2009, 23, 169–178. [Google Scholar] [CrossRef]
- Persson, A.; Ryals, L. Customer assets and customer equity: Management and measurement issues. Mark. Theory 2010, 10, 417–436. [Google Scholar] [CrossRef]
- Ryals, L.; Knox, S. Measuring and managing customer relationship risk in business markets. Ind. Mark. Manag. 2007, 36, 823–833. [Google Scholar] [CrossRef]
- Kim, S.-Y.; Jung, T.-S.; Suh, E.-H.; Hwang, H.-S. Customer segmentation and strategy development based on customer lifetime value: A case study. Expert Syst. Appl. 2006, 31, 101–107. [Google Scholar] [CrossRef]
- Hwang, H.; Jung, T.; Suh, E. An LTV model and customer segmentation based on customer value: A case study on the wireless telecommunication industry. Expert Syst. Appl. 2004, 26, 181–188. [Google Scholar] [CrossRef]
- Singh, S.S.; Jain, D.C. Measuring Customer Lifetime Value. In Review of Marketing Research; Naresh, K.M., Ed.; Emerald Group Publishing Limited: Bingley, UK, 2010; Volume 6, pp. 37–62. [Google Scholar]
- Pfeifer, P.E.; Haskins, M.E.; Conroy, R.M. Customer Life Time Value, Customer Profitability, and the Treatment of Acquisition Spending. J. Manag. Issues 2005, 17, 11–25. [Google Scholar]
- Boyce, G. Valuing customers and loyalty: The rhetoric of customer focus versus the reality of alienation and exclusion of (de valued) customers. Crit. Perspect. Account. 2000, 11, 649–689. [Google Scholar] [CrossRef]
- Ryals, L. Profitable relationships with key customers: How suppliers manage pricing and customer risk. J. Strateg. Mark. 2006, 14, 101–113. [Google Scholar] [CrossRef]
- Ryals, L. Are your customers worth more than money? J. Retail. Consum. Serv. 2002, 9, 241–251. [Google Scholar] [CrossRef]
- Williams, C.; Williams, R. Optimizing acquisition and retention spending to maximize market share. J. Mark. Anal. 2015, 3, 159–170. [Google Scholar] [CrossRef]
- Abdolvand, N.; Baradaran, V.; Albadvi, A. Activity-level as a link between customer retention and consumer lifetime value. Iran. J. Manag. Stud. 2015, 8, 567–587. [Google Scholar]
- Qi, J.Y.; Qu, Q.X.; Zhou, Y.P.; Li, L. The impact of users’ characteristics on customer lifetime value raising: Evidence from mobile data service in China. Inf. Technol. Manag. 2015, 16, 273–290. [Google Scholar] [CrossRef]
- Nenonen, S. Storbacka, K. Driving shareholder value with customer asset management: Moving beyond customer lifetime value. Ind. Mark. Manag. 2016, 52, 140–150. [Google Scholar] [CrossRef]
- Blattberg, R.C.; Getz, G.; Thomas, J.S. Customer Equity: Building and Managing Relationships as Valuable Assets; Harvard Business Press: Boston, MA, USA, 2001. [Google Scholar]
- Rust, R.T.; Lemon, K.N.; Zeithaml, V.A. Return on Marketing: Using Customer Equity to Focus Marketing Strategy. J. Mark. 2004, 68, 109–127. [Google Scholar] [CrossRef]
- Gupta, S.; Lehmann, D.R.; Stuart, J.A. Valuing Customers. J. Mark. Res. 2004, 41, 7–18. [Google Scholar] [CrossRef]
- Zhang, J.Q.; Dixit, A.; Friedmannc, R. Customer Loyalty and Lifetime Value: An Empirical Investigation of Consumer Packaged Goods. J. Mark. Theory Pract. 2010, 18, 127–140. [Google Scholar] [CrossRef]
- Blattberg, R.C.; Deighton, J. Manage Marketing by the Customer Equity Test. Harv. Bus. Rev. 1996, 74, 136–144. [Google Scholar] [PubMed]
- Berger, P.D.; Nasr, N.I. Customer Lifetime Value: Marketing Models and Applications. J. Interact. Mark. 1998, 12, 17–30. [Google Scholar] [CrossRef]
- European B2C E-commerce Report 2016; Ecommerce Foundation: Brussels, Belgium, 2017.
- E-commerce in Europe 2015. Available online: http://www.postnord.com/globalassets/global/english/document/publications/2015/en_e-commerce_in_europe_20150902.pdf (accessed on 27 December 2017).
- Fader, P.S.; Hardie, B.G.S.; Lee, K.L. Counting your Customers the Easy Way: An Alternative to the Pareto/NBD Model. Mark. Sci. 2005, 24, 275–284. [Google Scholar] [CrossRef]
- Haenlein, M.; Kaplan, A.M.; Beeser, A.J. A Model to Determine Customer Lifetime Value in a Retail Banking Context. Eur. Manag. J. 2007, 25, 221–234. [Google Scholar] [CrossRef]
- Paauwe, P.; Van der Putten, P.; Van Wezel, M. DTMC: An actionable e-customer lifetime value model based on markov chains and decision trees. In Proceedings of the Ninth International Conference on Electronic Commerce (ICEC ‘07), Minneapolis, MN, USA, 19–22 August 2007; pp. 253–262. [Google Scholar]
- Villanueva, J.; Yoo, S.; Hanssens, D.M. The Impact of Marketing-Induced Versus Word-of-Mouth Customer Acquisition on Customer Equity Growth. J. Mark. Res. 2008, 45, 48–59. [Google Scholar] [CrossRef]
- Jerath, K.; Fader, P.S.; Hardie, B.G.S. New Perspectives on Customer “Death” Using a Generalization of the Pareto/NBD Model. Mark. Sci. 2011, 30, 866–880. [Google Scholar] [CrossRef]
- Schmittlein, D.C.; Morrison, D.G. Prediction of Future Random Events with the Condensed Negative Binomial Distribution. J. Am. Stat. Assoc. 1983, 78, 449–456. [Google Scholar] [CrossRef]
- Schmittlein, D.C.; Bemmaor, A.C.; Morrison, D.G. Technical Note—Why Does the NBD Model Work? Robustness in Representing Product Purchases, Brand Purchases and Imperfectly Recorded Purchases. Mark. Sci. 1985, 4, 255–266. [Google Scholar] [CrossRef]
- Schmittlein, D.C.; Morrison, D.G.; Colombo, R. Counting Your Customers—Who Are They and What Will They Do Next. Manag. Sci. 1987, 33, 1–24. [Google Scholar] [CrossRef]
- Colombo, R.; Jiang, W. A Stochastic RFM Model. J. Interac. Mark. 1999, 13, 2–12. [Google Scholar] [CrossRef]
- Fader, P.S.; Hardie, B.G.S. Forecasting Repeat Sales at CDNOW: A Case Study. Interfaces 2001, 31, S94–S107. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Knox, G.; van Oest, R. Customer Complaints and Recovery Effectiveness: A Customer Base Approach. J. Mark. 2014, 78, 42–57. [Google Scholar] [CrossRef]
- Gladya, N.; Baesensa, B.; Crouxa, C. A modified Pareto/NBD approach for predicting customer lifetime value. Expert Syst. Appl. 2009, 36, 2062–2071. [Google Scholar] [CrossRef]
- Schmittlein, D.C.; Peterson, R.A. Customer Base Analysis: An Industrial Purchase Process Application. Mark. Sci. 1994, 13, 41–67. [Google Scholar] [CrossRef]
- Reinartz, W.J.; Kumar, V. On the Profitability of Long-Life Customers in a Noncontractual Setting: An Empirical Investigation and Implications for Marketing. J. Mark. 2000, 64, 17–35. [Google Scholar] [CrossRef]
- Fader, P.S.; Hardie, B.G.S.; Lee, K.L. RFM and CLV: Using Iso-Value Curves for Customer Base Analysis. J. Mark. Res. 2005, 42, 415–430. [Google Scholar] [CrossRef]
- Fader, P.S.; Hardie, B.G.S. The Gamma-Gamma Model of Monetary Value, 2013. Available online: http://www.brucehardie.com/notes/025/gamma_gamma.pdf (accessed on 27 December 2017).
- Pfeifer, P.E.; Carraway, R.L. Modeling customer relationships as Markov chains. J. Interact. Mark. 2000, 14, 43–55. [Google Scholar] [CrossRef]
- Burcher, N. Paid, Owned, Earned: Maximising Marketing Returns in a Socially Connected World; Kogan Page: Philadelphia, PA, USA, 2012. [Google Scholar]
- Platzer, M.; Reutterer, T. Ticking Away the Moments: Timing Regularity Helps to Better Predict Customer Activity. Mark. Sci. 2016, 35, 779–799. [Google Scholar] [CrossRef]
- McCarthy, D.; Fader, P.S.; Hardie, B.G.S. V(CLV): Examining Variance in Models of Customer Lifetime Value. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2739475 (accessed on 27 December 2017).
- Casterán, H.; Meyer-Waarden, L.; Reinartz, W. Modeling Customer Lifetime Value, Retention, and Churn. In Handbook of Market Research; Homburg, C., Klarmann, M., Vomberg, A., Eds.; Springer: Berlin, Germany, 2017; pp. 1–33. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset (Online Store) | Common Data Used by All Four Models (Minimal Dataset) | Specially Added Data for MC Model | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Customer_ID | Week_Number | Monday_Date | Profit_EUR | Channel_POE | Channel_Type | Medium_Source | Avg_Purchase_Day | Item_Quantity | Transaction_Shippin | Transaction_Revenue | Zip_firstchar | |
| B | 282006 | 98 | 2014-11-17 | 7.69 | O | email_newsletter | 3.0 | 1 | 1.19 | 23.90 | 1 | |
| D | 65298 | 302 | 2014-09-15 | 11.84 | E | organic | organic_google | 4.5 | 1 | 0.00 | 42.96 | 8 |
| F | 1182543 | 158 | 2013-01-07 | 7.37 | P | email_newsletter | 4.0 | 4 | 0.00 | 33.52 | 3 | |
| F | 883193 | 103 | 2011-12-19 | 3.48 | P | campaign | cpc_google | 4.0 | 1 | 0.00 | 37.74 | 5 |
| F | 1349757 | 197 | 2013-10-07 | 6.96 | P | feed | feed_heureka | 2.0 | 3 | 0.00 | 62.00 | 6 |
| Dataset (Online Store) | Number of Transactions | Number of Customers | Sum of Profit EUR | Average Transaction Profit EUR | Data Range (In Weeks) |
|---|---|---|---|---|---|
| A | 19,433 | 14,758 | 148,999 | 7.87 | 218 |
| B | 136,611 | 90,896 | 2,573,842 | 19.24 | 151 |
| C | 106,129 | 50,255 | 557,085 | 5.53 | 173 |
| D | 119,439 | 73,472 | 1,625,073 | 14.33 | 364 |
| E | 62,744 | 43,899 | 1,101,526 | 17.73 | 381 |
| F | 2,409,019 | 798,703 | 18,037,523 | 7.88 | 301 |
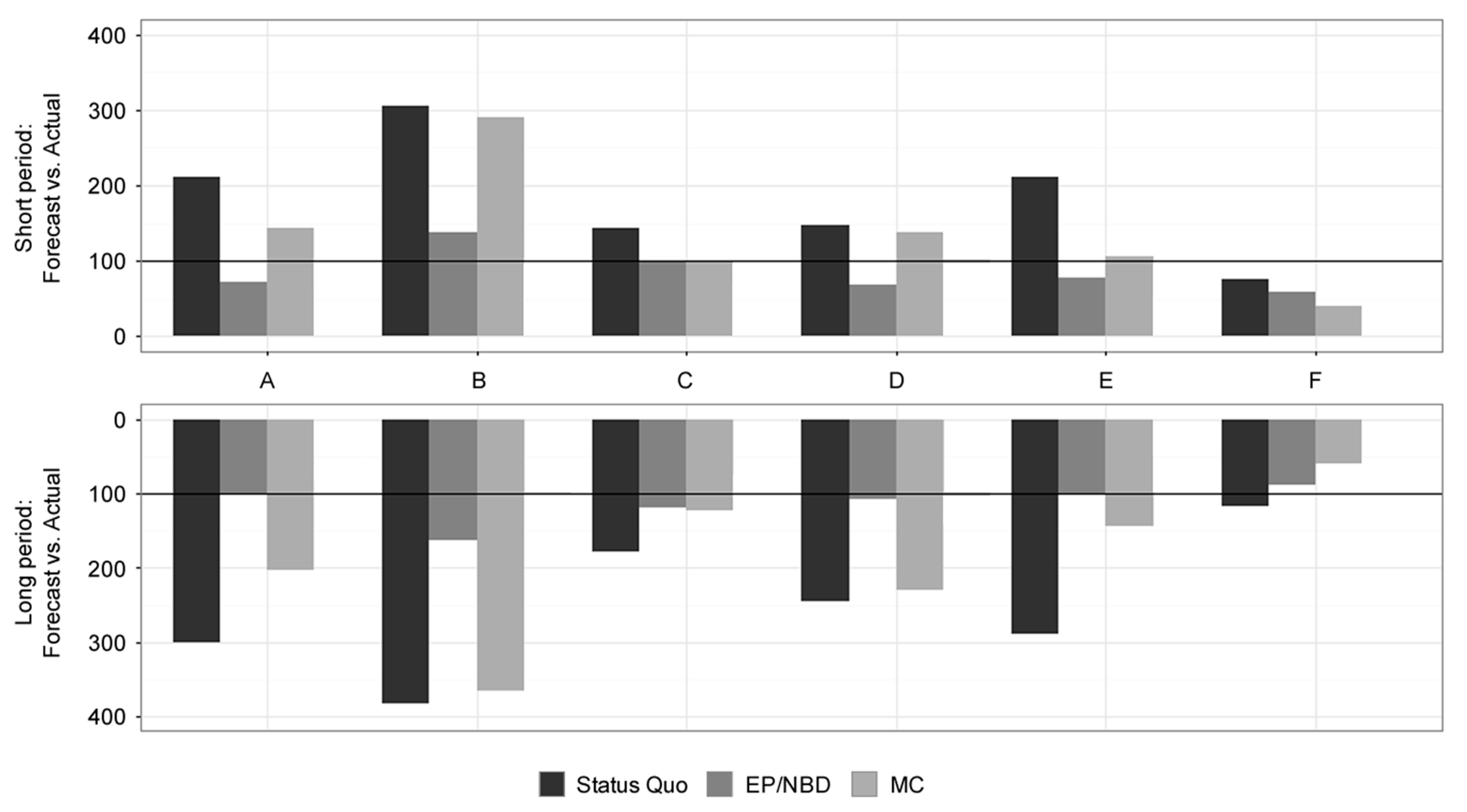
| Forecast vs. Actual (in %) | Short Period (13 Weeks) | Long Period (52 Weeks) | ||||
|---|---|---|---|---|---|---|
| Dataset (Online Store) | Status Quo | EP/NBD | MC | Status Quo | EP/NBD | MC |
| A | 211.61 | 71.68 | 143.47 | 301.58 | 101.50 | 203.57 |
| B | 305.11 | 137.27 | 290.91 | 382.93 | 163.50 | 365.03 |
| C | 143.54 | 100.72 | 99.50 | 177.68 | 118.10 | 122.95 |
| D | 146.55 | 68.91 | 137.17 | 245.18 | 107.85 | 229.85 |
| E | 212.12 | 78.12 | 106.46 | 288.30 | 100.98 | 144.62 |
| F | 76.54 | 58.06 | 39.07 | 116.83 | 87.82 | 59.69 |
| Weighted mean (by profit) | 91.13 | 62.47 | 53.90 | 138.28 | 92.97 | 82.35 |
| Relative standard deviation (%) | 55.66 | 26.56 | 99.89 | 47.69 | 18.50 | 88.66 |
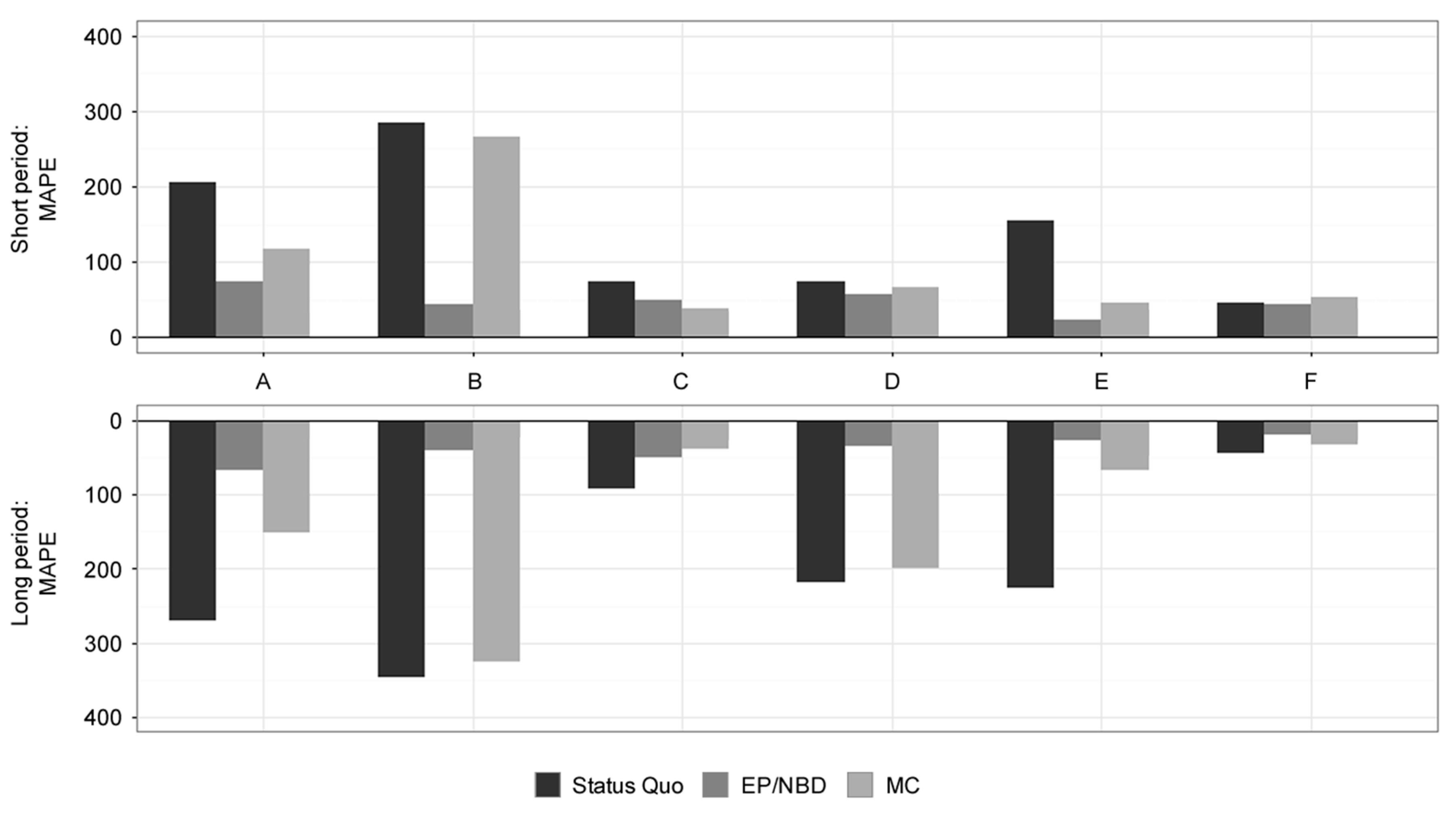
| MAPE (Weekly Level, in %) | Short Period (13 Weeks) | Long Period (52 Weeks) | ||||
|---|---|---|---|---|---|---|
| Dataset (Online Store) | Status Quo | EP/NBD | MC | Status Quo | EP/NBD | MC |
| A | 206.36 | 74.48 | 116.65 | 269.73 | 66.48 | 151.74 |
| B | 284.09 | 43.97 | 266.14 | 346.08 | 40.44 | 325.23 |
| C | 73.17 | 49.22 | 38.01 | 92.94 | 49.14 | 38.04 |
| D | 74.14 | 57.38 | 67.04 | 217.40 | 34.48 | 198.87 |
| E | 155.06 | 23.68 | 44.75 | 226.14 | 26.41 | 67.88 |
| F | 45.09 | 43.32 | 53.19 | 43.78 | 18.88 | 33.36 |
| Weighted mean (by profit) | 58.61 | 43.41 | 62.89 | 64.36 | 20.50 | 50.43 |
| Relative standard deviation (%) | 87.67 | 8.36 | 69.88 | 117.79 | 30.06 | 137.69 |
| MAE (Customer Level, in %) | Short Period (13 Weeks) | Long Period (52 Weeks) | ||||
|---|---|---|---|---|---|---|
| Dataset (Online Store) | Status Quo | EP/NBD | MC | Status Quo | EP/NBD | MC |
| A | 113.15 | 156.17 | 162.47 | 97.20 | 105.24 | 138.29 |
| B | 116.87 | 151.28 | 123.02 | 101.42 | 118.03 | 103.58 |
| C | 113.27 | 132.94 | 174.49 | 90.25 | 102.55 | 138.94 |
| D | 140.84 | 214.65 | 165.58 | 108.72 | 146.70 | 130.54 |
| E | 130.20 | 213.40 | 185.69 | 105.93 | 164.67 | 148.81 |
| F | 148.58 | 191.80 | 308.01 | 91.86 | 111.62 | 197.56 |
| Weighted mean (by profit) | 146.50 | 190.51 | 294.18 | 93.04 | 113.70 | 189.74 |
| Relative standard deviation (%) | 5.05 | 5.35 | 15.52 | 3.72 | 7.32 | 11.74 |
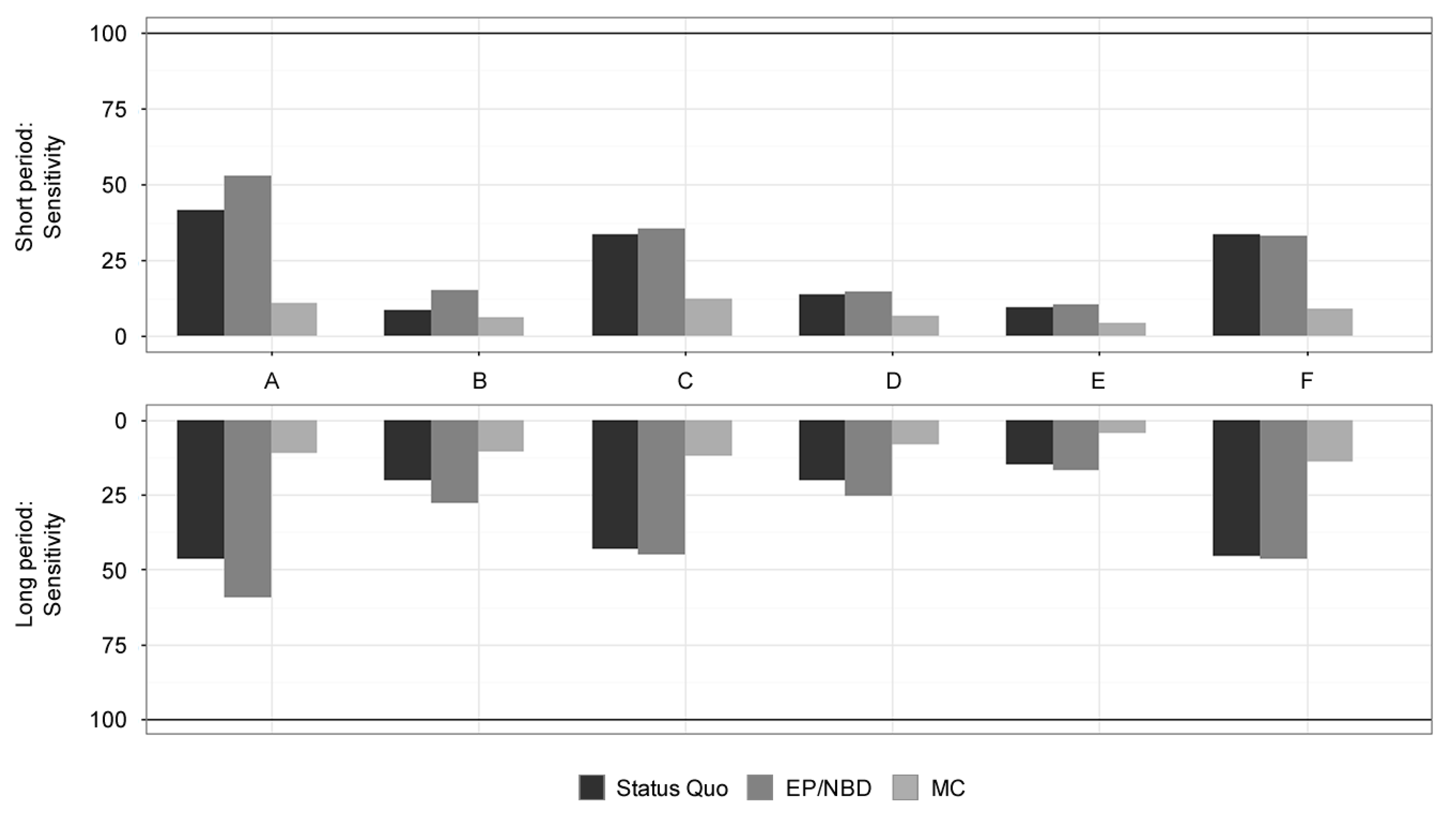
| Sensitivity (Customer Level, in %) | Short Period (13 Weeks) | Long Period (52 Weeks) | ||||
|---|---|---|---|---|---|---|
| Dataset (Online Store) | Status Quo | EP/NBD | MC | Status Quo | EP/NBD | MC |
| A | 41.33 | 52.67 | 10.67 | 46.67 | 59.33 | 11.00 |
| B | 8.75 | 14.95 | 6.15 | 20.20 | 27.78 | 10.54 |
| C | 33.30 | 35.50 | 12.10 | 43.10 | 45.20 | 12.00 |
| D | 13.60 | 14.60 | 6.60 | 20.10 | 25.20 | 8.10 |
| E | 9.60 | 10.20 | 4.20 | 15.10 | 16.60 | 4.10 |
| F | 33.35 | 32.98 | 9.13 | 45.41 | 46.23 | 14.12 |
| Weighted mean (by customer base) | 31.30 | 31.55 | 8.95 | 41.64 | 43.36 | 13.21 |
| Relative standard deviation (%) | 21.85 | 19.26 | 13.32 | 21.88 | 17.88 | 16.21 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jasek, P.; Vrana, L.; Sperkova, L.; Smutny, Z.; Kobulsky, M. Modeling and Application of Customer Lifetime Value in Online Retail. Informatics 2018, 5, 2. https://doi.org/10.3390/informatics5010002
Jasek P, Vrana L, Sperkova L, Smutny Z, Kobulsky M. Modeling and Application of Customer Lifetime Value in Online Retail. Informatics. 2018; 5(1):2. https://doi.org/10.3390/informatics5010002
Chicago/Turabian StyleJasek, Pavel, Lenka Vrana, Lucie Sperkova, Zdenek Smutny, and Marek Kobulsky. 2018. "Modeling and Application of Customer Lifetime Value in Online Retail" Informatics 5, no. 1: 2. https://doi.org/10.3390/informatics5010002
APA StyleJasek, P., Vrana, L., Sperkova, L., Smutny, Z., & Kobulsky, M. (2018). Modeling and Application of Customer Lifetime Value in Online Retail. Informatics, 5(1), 2. https://doi.org/10.3390/informatics5010002