
Governors in the Digital Era: Analyzing and Predicting Social Media Engagement Using Machine Learning during the COVID-19 Pandemic in Japan


Abstract
1. Introduction
- RQ1: How do the profile characteristics of Japanese prefectural governors correlate with their level of activity on social media during the COVID-19 pandemic?
- RQ2: Is there a relationship between the social media activity level of Japanese prefectural governors and citizen engagement, and which governors demonstrate the highest influence?
- RQ3: What is the impact of profile- and tweet-related features, such as hashtags, mentions, timing, number of friends or followers, language used, and posting timing, on citizen engagement, and which features hold the greatest significance?
- RQ4: Can machine learning models accurately predict citizen engagement using various sets of profile and tweet features, as well as embeddings, and which models demonstrate the highest prediction accuracy?
- Conducting an analysis of the profile- and tweet-related factors that influence citizen engagement with government tweets related to COVID-19.
- Estimating the correlation between the activity level of governors and public engagement and ranking them based on their social media impact.
- Identifying the most significant features that impact citizen engagement with specific tweets.
- Evaluating the accuracy of machine learning (ML) models in predicting tweet engagement using various sets of profile and tweet features, as well as embeddings. Additionally, developing an assisting tool for decision makers to predict the citizen engagement rate of a given tweet.
2. Related Work
- The majority of the studies focus primarily on the analysis of English tweets, overlooking potential insights provided by other languages.
- Profiles of governors are not analyzed to explore the correlation between their characteristics and social media activity levels.
- A limited utilization of word embedding techniques to identify important features exists.
- The performance of different classification algorithms in predicting tweet engagement has not been sufficiently explored.
- The potential of using ML models as assisting tools for decision makers to predict tweet engagement and enhance the influence of their messages to the public has not been explored.
3. Methods
3.1. Research Framework
- Data Collection:
- Identify the Twitter accounts of the prefecture governors.
- Collect profile-related information such as age, number of terms in power, verification status, etc.
- Gather COVID-19-related tweets and their metadata from the identified Twitter accounts.
- Data Pre-processing:
- Translate the Japanese text into English.
- Clean and pre-process the collected information.
- Activity Level Analysis:
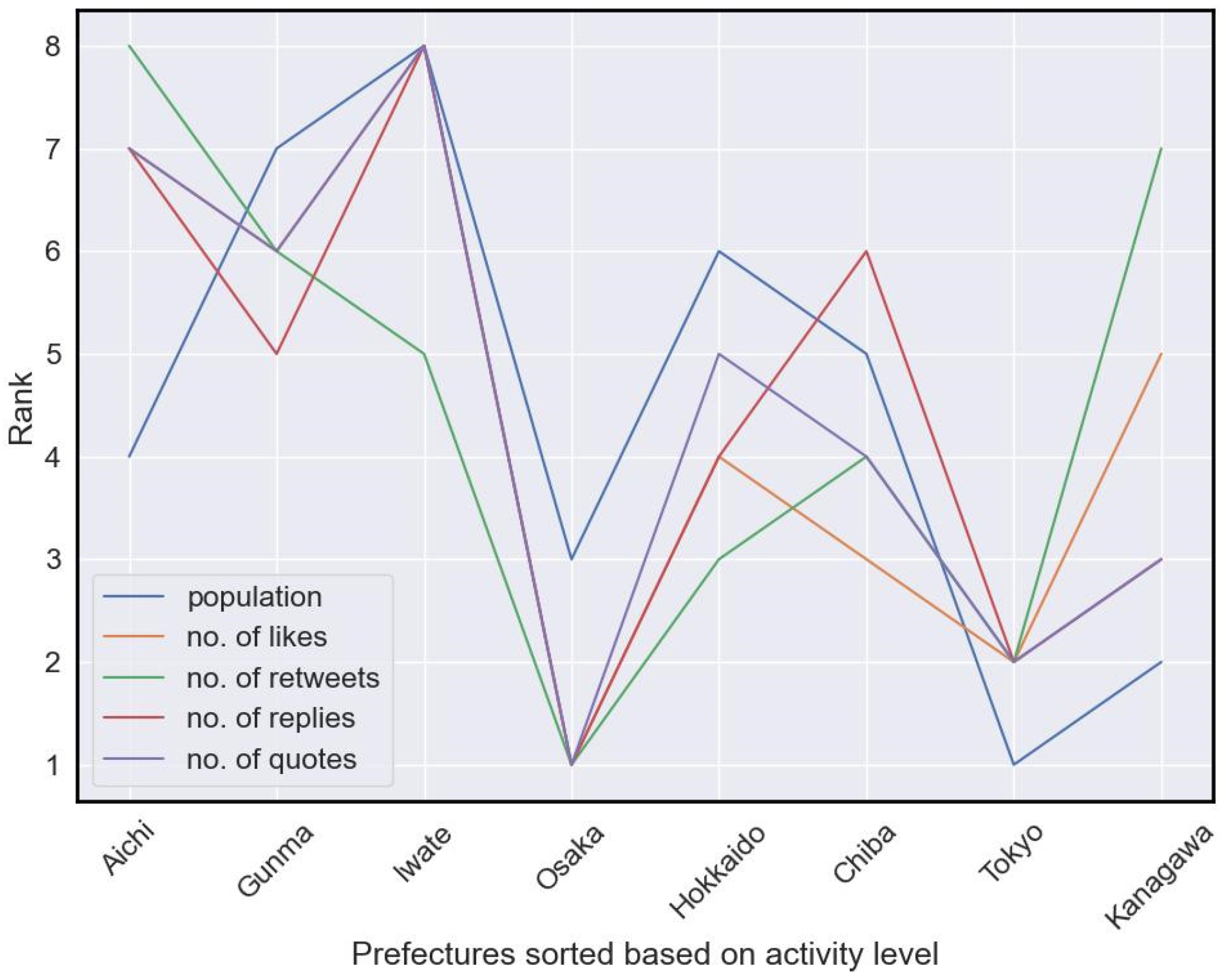
- Rank the accounts based on their activity level during the pandemic, considering factors such as frequency of tweeting and overall engagement.
- Correlation Analysis:
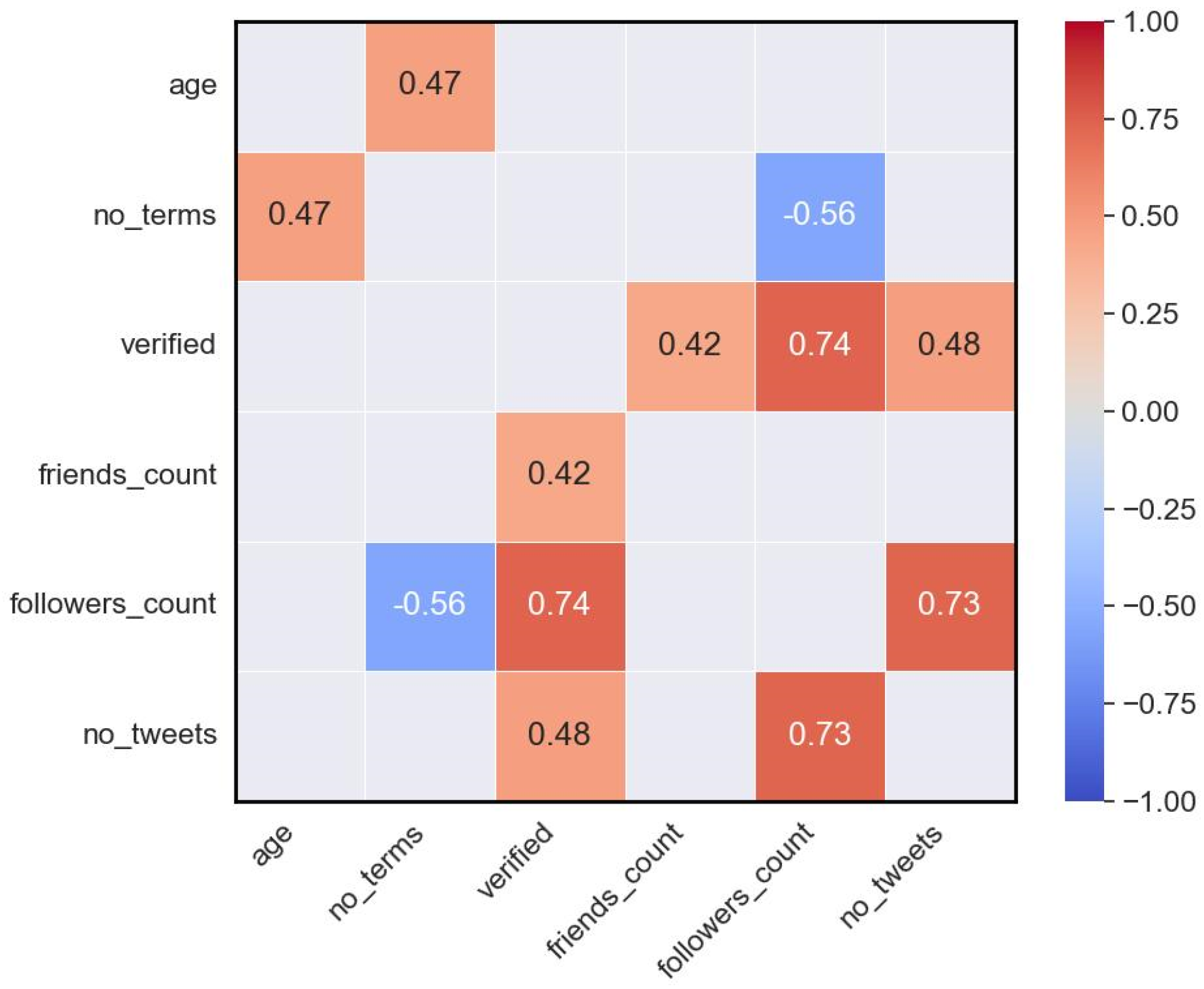
- Estimate the correlation between the activity level of governors and their profile characteristics.
- Measure the correlation between the four engagement metrics.
- Investigate the correlation between the activity level and citizen engagement.
- Feature Analysis:
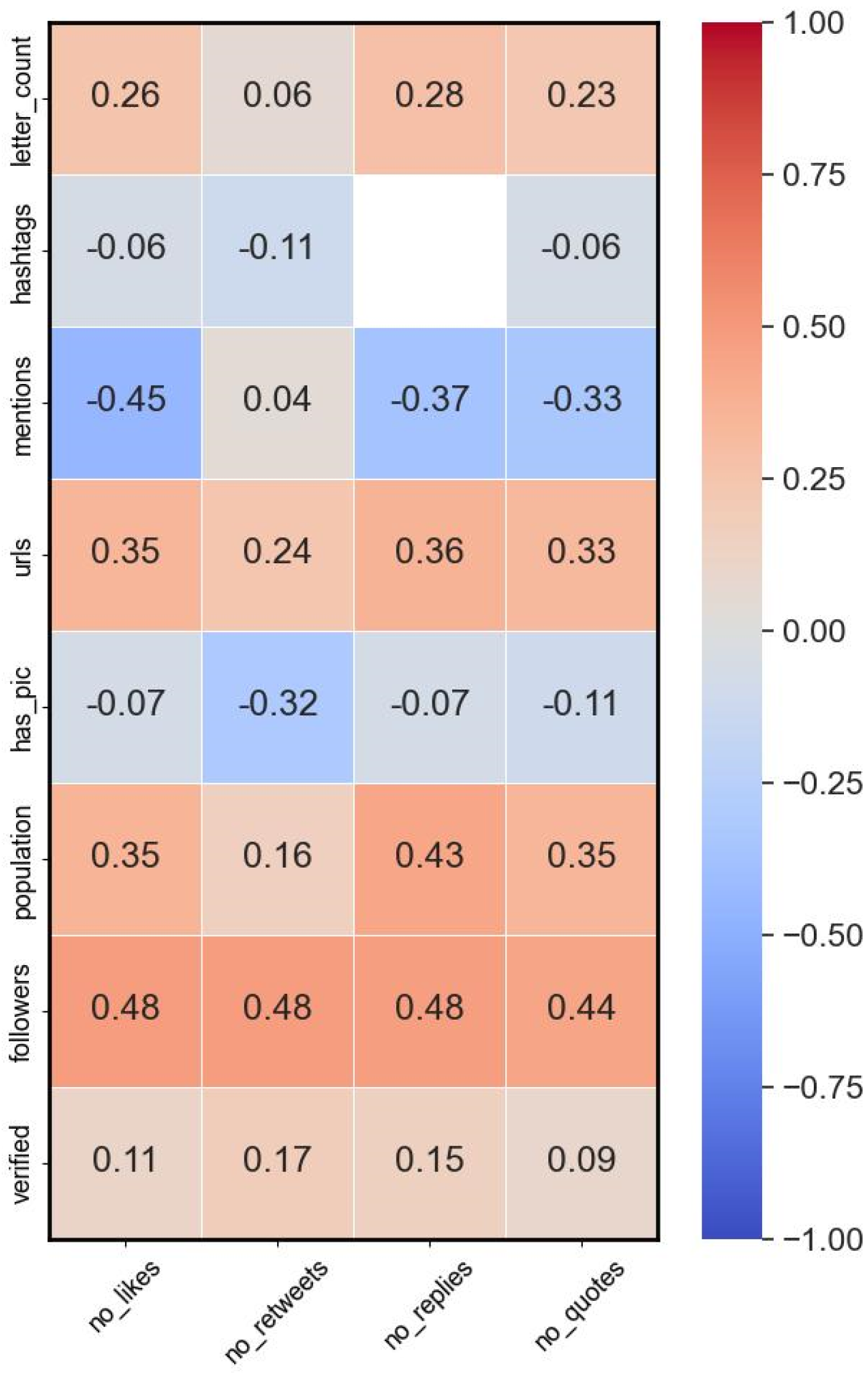
- Estimate the effect of profile- and tweet-related features on public engagement.
- Identify the most significant features that influence public engagement.
- Identify the optimal times for high engagement.
- Machine Learning Model Development:
- Train 63 ML models using various feature sets (with/without word embeddings) to predict the expected engagement a tweet might receive.
- Model Evaluation and Selection:
- Assess the performance of the trained models, considering metrics such as the accuracy, weighted average precision, recall, and F1-score.
- Identify the top three models based on their predictive accuracy.
3.2. Data Collection and Pre-Processing
3.3. Data Analysis Methods
3.4. Machine Learning Modeling
4. Results and Discussion
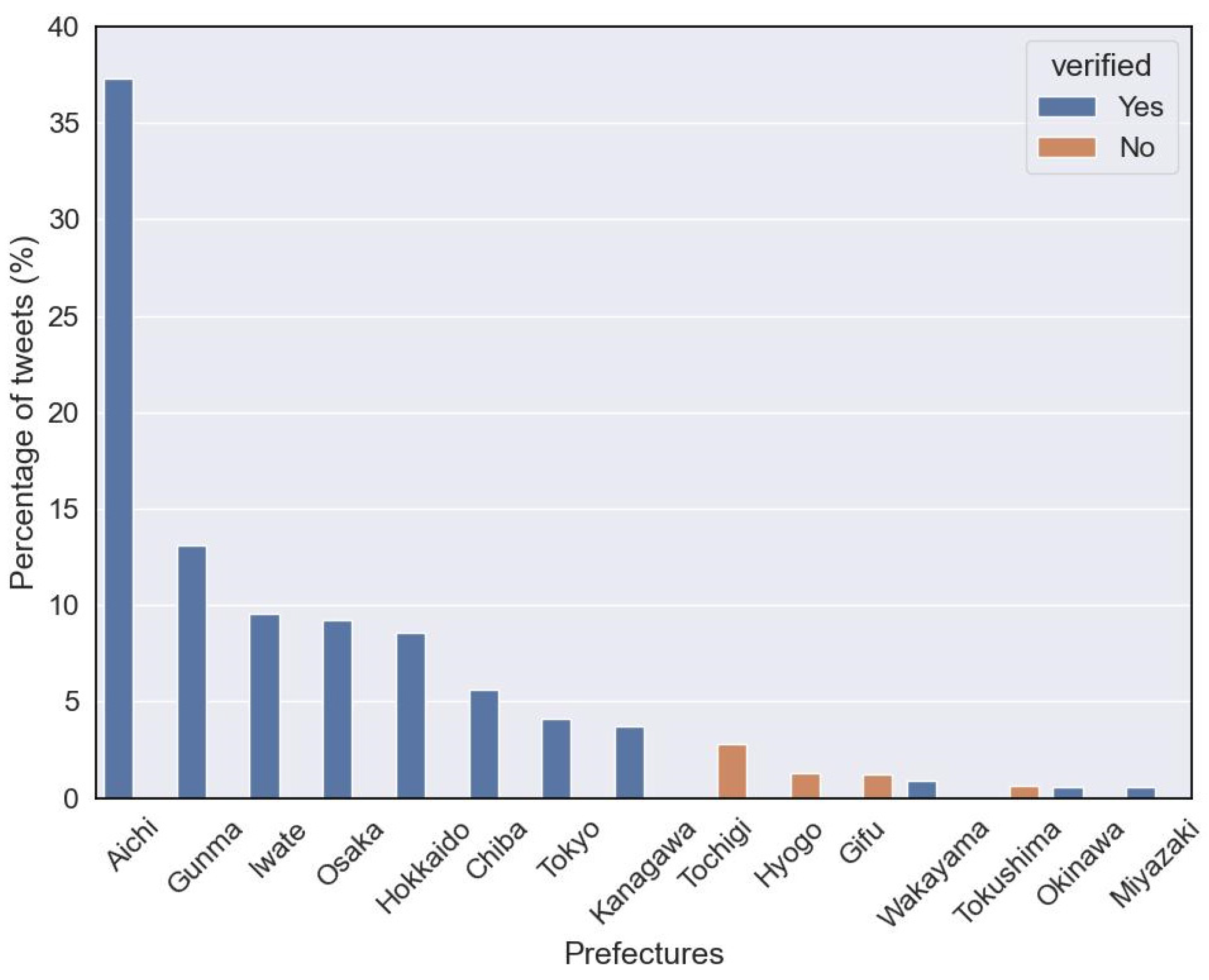
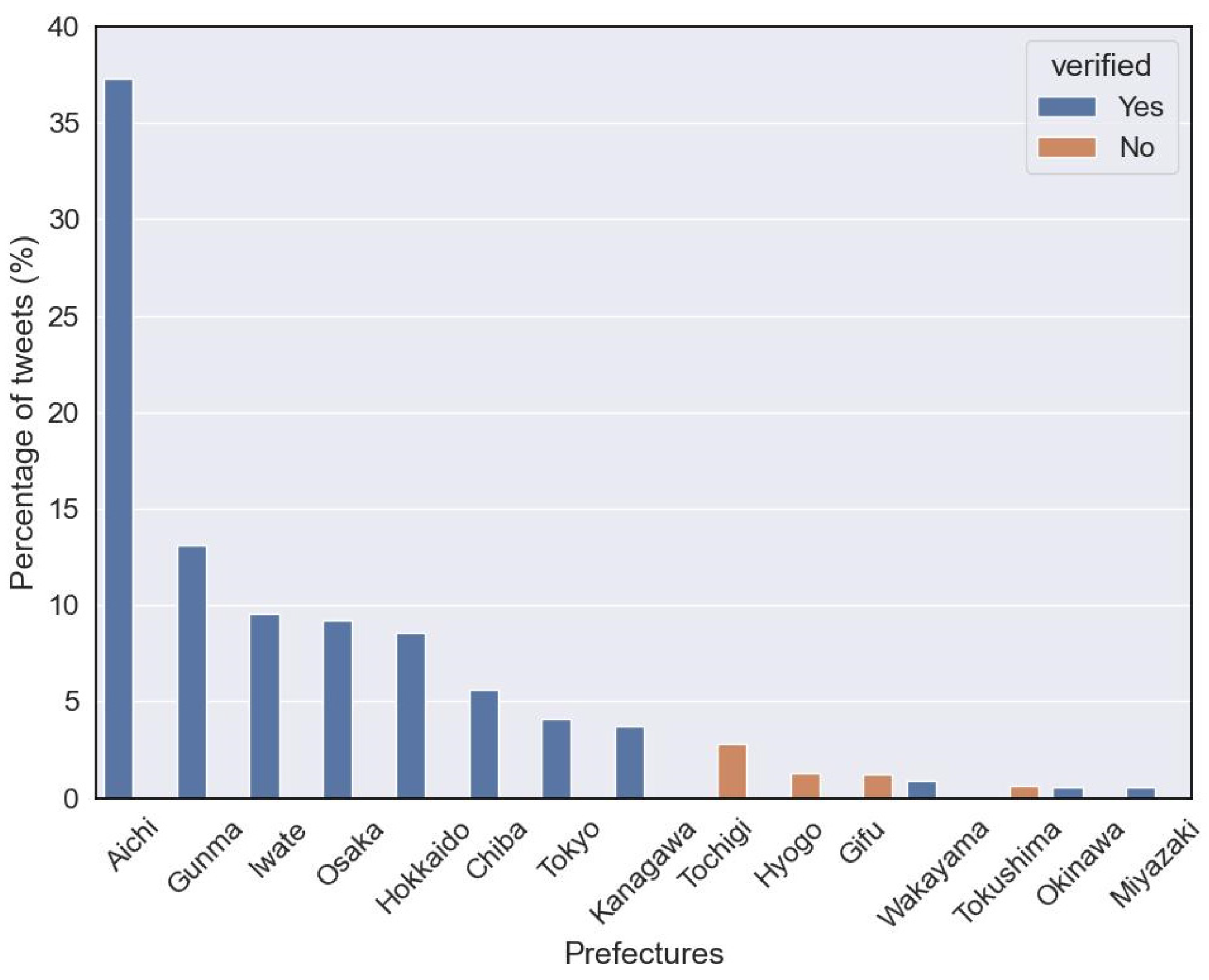
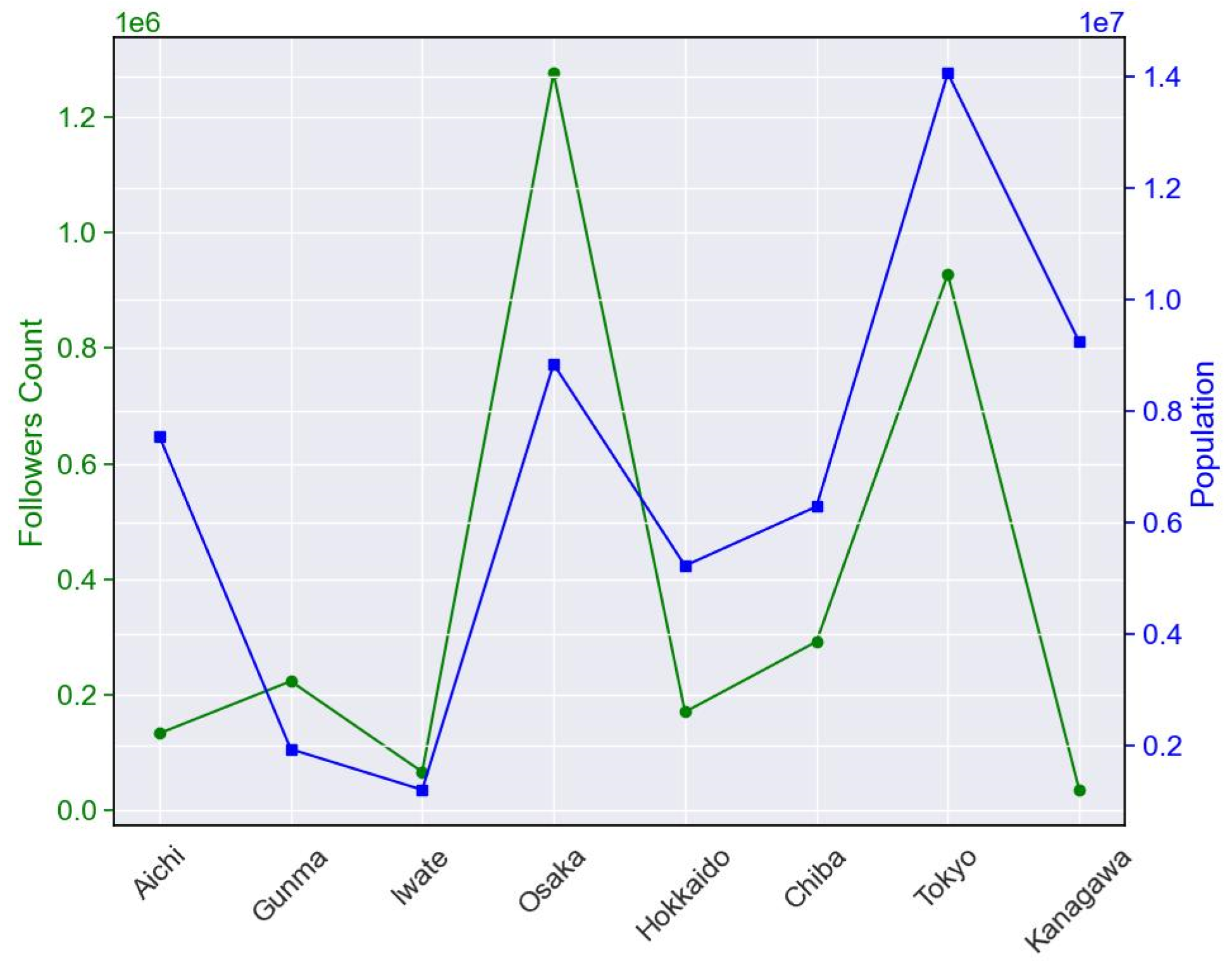
4.1. Governors’ Social Media Influence: Unraveling the Relationship between Activity Level, Verification Status, and Follower Counts during COVID-19
4.2. Governors’ Twitter Adoption Temporal Patterns and COVID-19 Responsiveness, and the Correlation between Their Profile Factors and Activity Levels
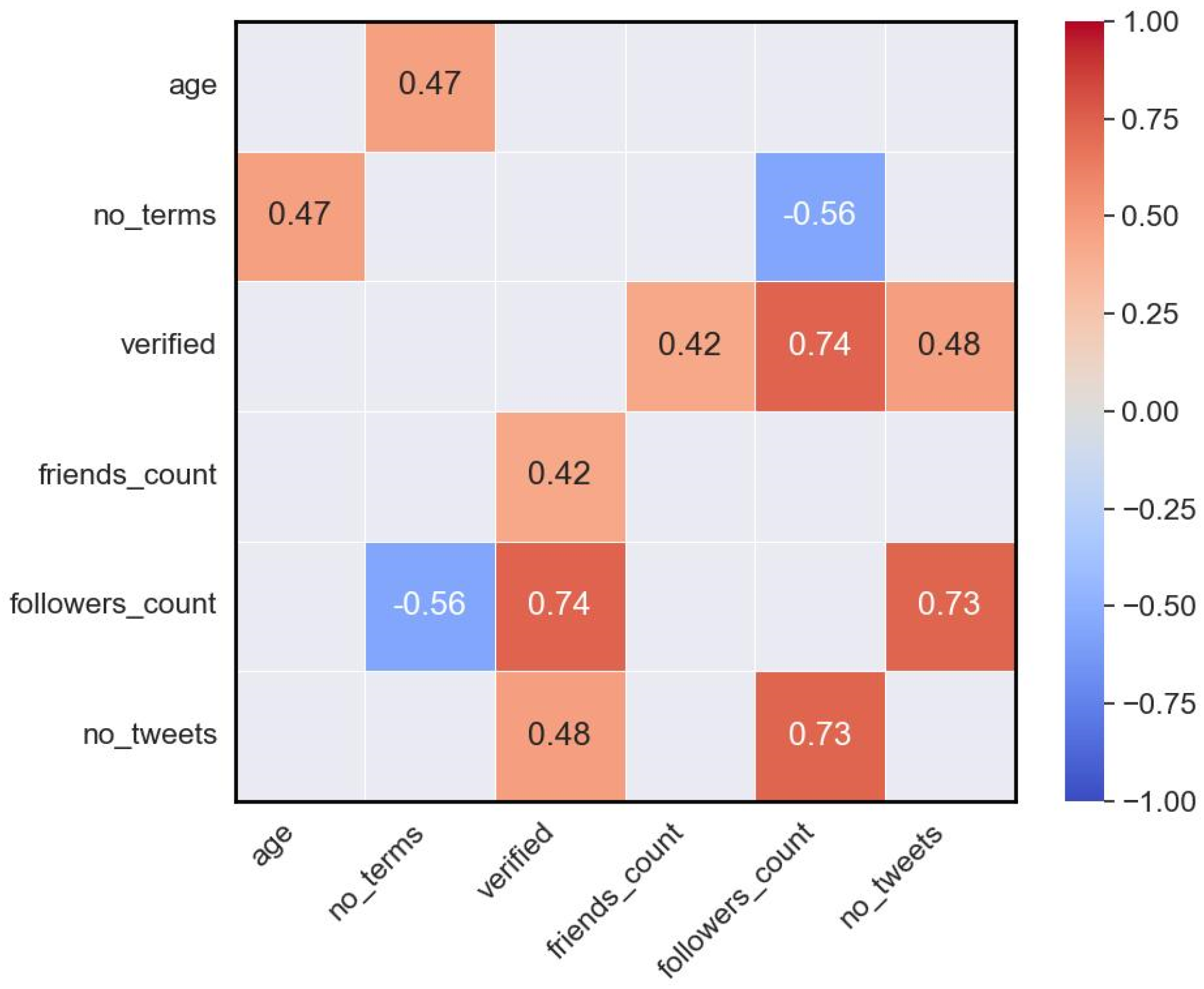
4.3. Citizen Engagement with Governors’ COVID-19 Tweets: Correlation Analysis of Engagement Metrics, and Optimal Tweet Scheduling
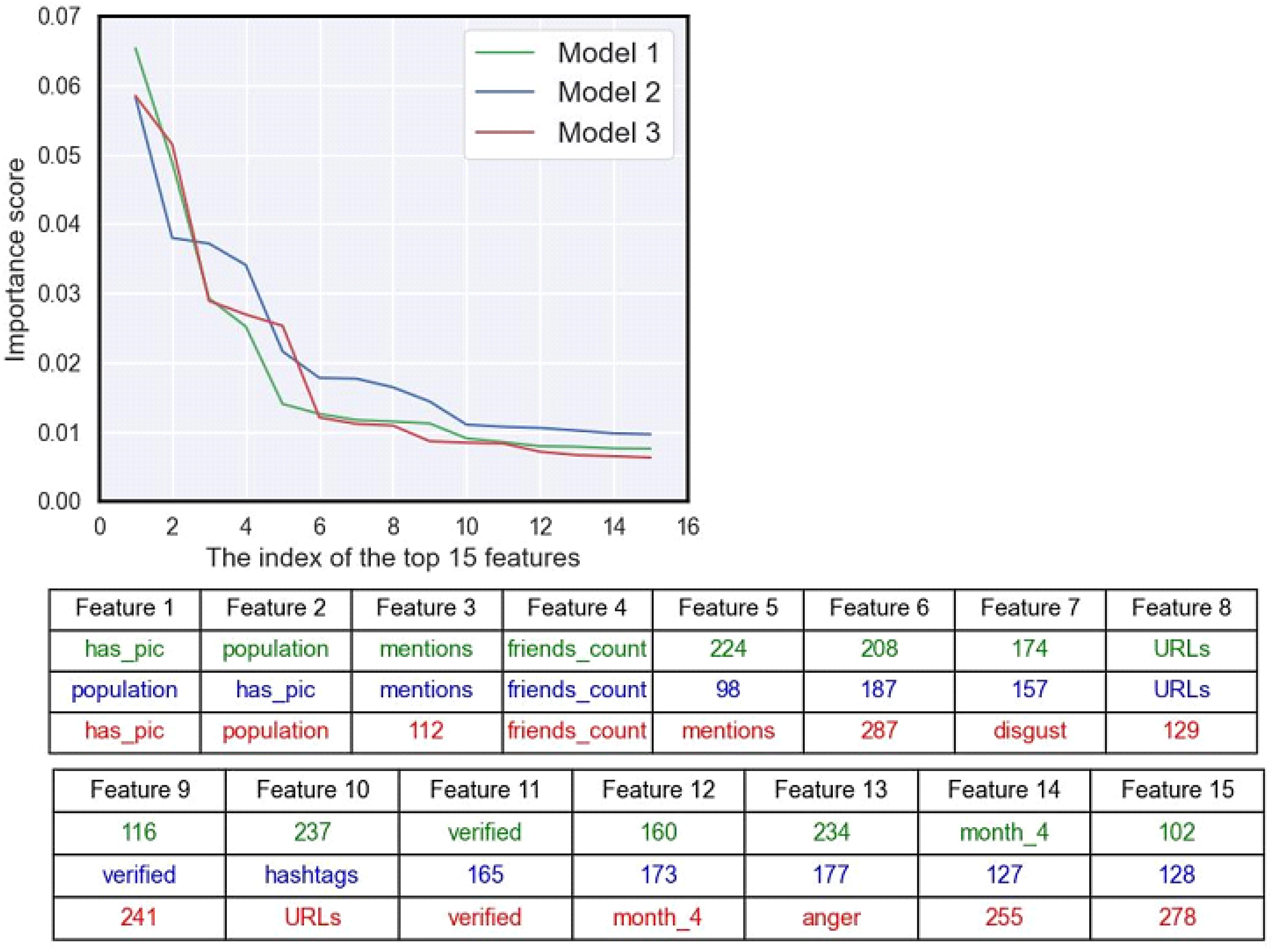
4.4. Predicting Citizen Engagement of COVID-19 Tweets: ML Models and Feature Analysis
- Profile- and tweet-related features (feature set 1).
- A combination of the first set with one of the embeddings.
- Model 1: This model utilized feature set 1 with FastText embeddings and an XGBoost classifier. It achieved a training accuracy of 0.98, testing accuracy of 0.8, and validation accuracy of 0.8.
- Model 2: This model utilized feature set 1 with Glove embeddings and an XGBoost classifier. It achieved a training accuracy of 0.98, testing accuracy of 0.79, and validation accuracy of 0.81.
- Model 3: This model utilized feature set 1 with Word2Vec embeddings and an XGBoost classifier. It achieved a training accuracy of 0.98, testing accuracy of 0.79, and validation accuracy of 0.79.
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Situation Report. Available online: https://www.mhlw.go.jp/stf/covid-19/kokunainohasseijoukyou_00006.html (accessed on 3 June 2023).
- Lee, H.; Noh, E.B.; Choi, S.H.; Zhao, B.; Nam, E.W. Determining Public Opinion of the COVID-19 Pandemic in South Korea and Japan: Social Network Mining on Twitter. Healthc. Inform. Res. 2020, 26, 335–343. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Wang, S.; Zhang, M.; Hu, T.; Hohl, A.; She, B.; Gong, X.; Li, J.; Liu, X.; Gruebner, O.; et al. Social Media Mining under the COVID-19 Context: Progress, Challenges, and Opportunities. Int. J. Appl. Earth Obs. Geoinf. 2022, 113, 102967. [Google Scholar] [CrossRef] [PubMed]
- Tsao, S.-F.; Chen, H.; Tisseverasinghe, T.; Yang, Y.; Li, L.; Butt, Z.A. What Social Media Told Us in the Time of COVID-19: A Scoping Review. Lancet Digit. Health 2021, 3, e175–e194. [Google Scholar] [CrossRef] [PubMed]
- Lin, X.; Spence, P.R.; Sellnow, T.L.; Lachlan, K.A. Crisis Communication, Learning and Responding: Best Practices in Social Media. Comput. Hum. Behav. 2016, 65, 601–605. [Google Scholar] [CrossRef]
- Qorib, M.; Oladunni, T.; Denis, M.; Ososanya, E.; Cotae, P. COVID-19 Vaccine Hesitancy: Text Mining, Sentiment Analysis and Machine Learning on COVID-19 Vaccination Twitter Dataset. Expert Syst. Appl. 2023, 212, 118715. [Google Scholar] [CrossRef] [PubMed]
- Chon, M.-G.; Kim, S. Dealing with the COVID-19 Crisis: Theoretical Application of Social Media Analytics in Government Crisis Management. Public Relat. Rev. 2022, 48, 102201. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.L.; Lo, K. Text Mining Approaches for Dealing with the Rapidly Expanding Literature on COVID-19. Brief. Bioinform. 2021, 22, 781–799. [Google Scholar] [CrossRef] [PubMed]
- Moffitt, J.D.; King, C.; Carley, K.M. Hunting Conspiracy Theories during the COVID-19 Pandemic. Soc. Media + Soc. 2021, 7, 20563051211043212. [Google Scholar] [CrossRef]
- Duan, H.K.; Vasarhelyi, M.A.; Codesso, M.; Alzamil, Z. Enhancing the Government Accounting Information Systems Using Social Media Information: An Application of Text Mining and Machine Learning. Int. J. Account. Inf. Syst. 2023, 48, 100600. [Google Scholar] [CrossRef]
- Lyu, H.; Wang, J.; Wu, W.; Duong, V.; Zhang, X.; Dye, T.D.; Luo, J. Social Media Study of Public Opinions on Potential COVID-19 Vaccines: Informing Dissent, Disparities, and Dissemination. Intell. Med. 2022, 2, 1–12. [Google Scholar] [CrossRef]
- Biradar, S.; Saumya, S.; Chauhan, A. Combating the Infodemic: COVID-19 Induced Fake News Recognition in Social Media Networks. Complex Intell. Syst. 2023, 9, 2879–2891. [Google Scholar] [CrossRef]
- John, S.A.; Keikhosrokiani, P. Chapter 17—COVID-19 Fake News Analytics from Social Media Using Topic Modeling and Clustering. In Big Data Analytics for Healthcare; Keikhosrokiani, P., Ed.; Academic Press: Cambridge, MA, USA, 2022; pp. 221–232. ISBN 978-0-323-91907-4. [Google Scholar]
- Boghiu, Ș.; Gîfu, D. A Spatial-Temporal Model for Event Detection in Social Media. Procedia Comput. Sci. 2020, 176, 541–550. [Google Scholar] [CrossRef] [PubMed]
- Rufai, S.R.; Bunce, C. World Leaders’ Usage of Twitter in Response to the COVID-19 Pandemic: A Content Analysis. J. Public Health 2020, 42, 510–516. [Google Scholar] [CrossRef] [PubMed]
- Slavik, C.E.; Buttle, C.; Sturrock, S.L.; Darlington, J.C.; Yiannakoulias, N. Examining Tweet Content and Engagement of Canadian Public Health Agencies and Decision Makers During COVID-19: Mixed Methods Analysis. J. Med. Internet Res. 2021, 23, e24883. [Google Scholar] [CrossRef] [PubMed]
- Tang, L.; Liu, W.; Thomas, B.; Tran, H.T.N.; Zou, W.; Zhang, X.; Zhi, D. Texas Public Agencies’ Tweets and Public Engagement During the COVID-19 Pandemic: Natural Language Processing Approach. JMIR Public Health Surveill. 2021, 7, e26720. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Min, C.; Zhang, W.; Ma, X.; Evans, R. Factors Driving Citizen Engagement with Government TikTok Accounts During the COVID-19 Pandemic: Model Development and Analysis. J. Med. Internet Res. 2021, 23, e21463. [Google Scholar] [CrossRef] [PubMed]
- Gong, X.; Ye, X. Governors Fighting Crisis: Responses to the COVID-19 Pandemic across U.S. States on Twitter. Prof. Geogr. 2021, 73, 683–701. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Classifier | Training Accuracy | Testing Accuracy | Validation Accuracy | Weig. Avg. Precision | Weig. Avg. Recall | Weig. Avg. F1-Score |
|---|---|---|---|---|---|---|---|
| Feature Set 1 | Log. reg. | 0.475 | 0.472 | 0.485 | 0.31 | 0.472 | 0.374 |
| Dec. tree | 1 | 0.75 | 0.748 | 0.751 | 0.75 | 0.75 | |
| Rand. forest | 1 | 0.775 | 0.777 | 0.777 | 0.775 | 0.774 | |
| SVM | 0.598 | 0.58 | 0.596 | 0.596 | 0.58 | 0.557 | |
| KNN | 0.818 | 0.722 | 0.731 | 0.727 | 0.722 | 0.723 | |
| Naive bayes | 0.569 | 0.56 | 0.58 | 0.578 | 0.56 | 0.564 | |
| XGBoost | 0.946 | 0.792 | 0.788 | 0.794 | 0.792 | 0.792 | |
| Word2Vec | Log. reg. | 0.681 | 0.657 | 0.662 | 0.657 | 0.657 | 0.656 |
| Dec. tree | 0.96 | 0.598 | 0.613 | 0.598 | 0.598 | 0.597 | |
| Rand. forest | 0.96 | 0.684 | 0.707 | 0.683 | 0.684 | 0.683 | |
| SVM | 0.765 | 0.713 | 0.721 | 0.713 | 0.713 | 0.712 | |
| KNN | 0.789 | 0.693 | 0.707 | 0.694 | 0.693 | 0.692 | |
| Naive bayes | 0.556 | 0.521 | 0.534 | 0.53 | 0.521 | 0.52 | |
| XGBoost | 0.959 | 0.707 | 0.722 | 0.706 | 0.707 | 0.705 | |
| Glove | Log. reg. | 0.667 | 0.663 | 0.653 | 0.662 | 0.663 | 0.662 |
| Dec. tree | 0.96 | 0.627 | 0.617 | 0.626 | 0.627 | 0.626 | |
| Rand. forest | 0.96 | 0.678 | 0.696 | 0.677 | 0.678 | 0.677 | |
| SVM | 0.705 | 0.679 | 0.691 | 0.677 | 0.679 | 0.676 | |
| KNN | 0.779 | 0.675 | 0.689 | 0.676 | 0.675 | 0.674 | |
| Naive bayes | 0.562 | 0.534 | 0.55 | 0.544 | 0.534 | 0.534 | |
| XGBoost | 0.96 | 0.702 | 0.71 | 0.701 | 0.702 | 0.701 | |
| FastText | Log. reg. | 0.674 | 0.652 | 0.663 | 0.651 | 0.652 | 0.649 |
| Dec. tree | 0.96 | 0.618 | 0.616 | 0.618 | 0.618 | 0.618 | |
| Rand. forest | 0.96 | 0.68 | 0.697 | 0.679 | 0.68 | 0.679 | |
| SVM | 0.716 | 0.682 | 0.701 | 0.683 | 0.682 | 0.681 | |
| KNN | 0.787 | 0.695 | 0.704 | 0.695 | 0.695 | 0.695 | |
| Naive bayes | 0.565 | 0.523 | 0.558 | 0.534 | 0.523 | 0.522 | |
| XGBoost | 0.96 | 0.69 | 0.725 | 0.69 | 0.69 | 0.69 | |
| BERT | Log. reg. | 0.67 | 0.641 | 0.656 | 0.641 | 0.641 | 0.639 |
| Dec. tree | 0.962 | 0.602 | 0.607 | 0.602 | 0.602 | 0.602 | |
| Rand. forest | 0.962 | 0.68 | 0.682 | 0.68 | 0.68 | 0.678 | |
| SVM | 0.636 | 0.606 | 0.629 | 0.617 | 0.606 | 0.603 | |
| KNN | 0.765 | 0.657 | 0.679 | 0.658 | 0.657 | 0.656 | |
| Naive bayes | 0.474 | 0.468 | 0.483 | 0.485 | 0.468 | 0.412 | |
| XGBoost | 0.961 | 0.705 | 0.698 | 0.704 | 0.705 | 0.704 | |
| Feature Set 1 + Word2Vec | Log. reg. | 0.475 | 0.472 | 0.485 | 0.31 | 0.472 | 0.374 |
| Dec. tree | 1 | 0.733 | 0.738 | 0.735 | 0.733 | 0.734 | |
| Rand. forest | 1 | 0.757 | 0.766 | 0.757 | 0.757 | 0.755 | |
| SVM | 0.598 | 0.58 | 0.596 | 0.596 | 0.58 | 0.557 | |
| KNN | 0.824 | 0.727 | 0.742 | 0.732 | 0.727 | 0.727 | |
| Naive bayes | 0.569 | 0.56 | 0.58 | 0.578 | 0.56 | 0.564 | |
| XGBoost | 0.982 | 0.79 | 0.792 | 0.792 | 0.79 | 0.79 | |
| Feature Set 1 + Glove | Log. reg. | 0.475 | 0.472 | 0.485 | 0.31 | 0.472 | 0.374 |
| Dec. tree | 1 | 0.708 | 0.725 | 0.707 | 0.708 | 0.707 | |
| Rand. forest | 1 | 0.757 | 0.775 | 0.757 | 0.757 | 0.754 | |
| SVM | 0.598 | 0.58 | 0.596 | 0.596 | 0.58 | 0.557 | |
| KNN | 0.832 | 0.744 | 0.758 | 0.748 | 0.744 | 0.745 | |
| Naive bayes | 0.569 | 0.56 | 0.58 | 0.578 | 0.56 | 0.564 | |
| XGBoost | 0.984 | 0.794 | 0.809 | 0.795 | 0.794 | 0.793 | |
| Feature Set 1+ FastText | Log. reg. | 0.475 | 0.472 | 0.485 | 0.31 | 0.472 | 0.374 |
| Dec. tree | 1 | 0.708 | 0.725 | 0.707 | 0.708 | 0.707 | |
| Rand. forest | 1 | 0.757 | 0.775 | 0.757 | 0.757 | 0.754 | |
| SVM | 0.598 | 0.58 | 0.596 | 0.596 | 0.58 | 0.557 | |
| KNN | 0.832 | 0.744 | 0.758 | 0.748 | 0.744 | 0.745 | |
| Naive bayes | 0.569 | 0.56 | 0.58 | 0.578 | 0.56 | 0.564 | |
| XGBoost | 0.984 | 0.795 | 0.8 | 0.795 | 0.795 | 0.794 | |
| Feature Set 1 + BERT | Log. reg. | 0.475 | 0.472 | 0.485 | 0.31 | 0.472 | 0.374 |
| Dec. tree | 1 | 0.693 | 0.714 | 0.704 | 0.704 | 0.704 | |
| Rand. forest | 1 | 0.731 | 0.729 | 0.719 | 0.718 | 0.715 | |
| SVM | 0.598 | 0.58 | 0.596 | 0.596 | 0.58 | 0.557 | |
| KNN | 0.828 | 0.743 | 0.749 | 0.747 | 0.743 | 0.743 | |
| Naive bayes | 0.569 | 0.56 | 0.58 | 0.578 | 0.56 | 0.564 | |
| XGBoost | 0.983 | 0.783 | 0.782 | 0.784 | 0.783 | 0.783 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shady, S.; Shoda, V.P.; Kamihigashi, T. Governors in the Digital Era: Analyzing and Predicting Social Media Engagement Using Machine Learning during the COVID-19 Pandemic in Japan. Informatics 2024, 11, 17. https://doi.org/10.3390/informatics11020017
Shady S, Shoda VP, Kamihigashi T. Governors in the Digital Era: Analyzing and Predicting Social Media Engagement Using Machine Learning during the COVID-19 Pandemic in Japan. Informatics. 2024; 11(2):17. https://doi.org/10.3390/informatics11020017
Chicago/Turabian StyleShady, Salama, Vera Paola Shoda, and Takashi Kamihigashi. 2024. "Governors in the Digital Era: Analyzing and Predicting Social Media Engagement Using Machine Learning during the COVID-19 Pandemic in Japan" Informatics 11, no. 2: 17. https://doi.org/10.3390/informatics11020017
APA StyleShady, S., Shoda, V. P., & Kamihigashi, T. (2024). Governors in the Digital Era: Analyzing and Predicting Social Media Engagement Using Machine Learning during the COVID-19 Pandemic in Japan. Informatics, 11(2), 17. https://doi.org/10.3390/informatics11020017