1. Introduction
Governments are mandated to deliver services to the public through a wide range of responsibilities in diverse sectors, including but not limited to health care [
1], waste management [
2], roadworks [
3], land affairs [
4], emergency services [
5], and energy [
6]. These services are intended to improve welfare and security by targeting various societal levels. Nevertheless, at times, the quality of these services falls short of public expectations, hence generating a series of complaints from members of the public. In traditional governance, it is common for citizens to express their complaints through physical channels, often through visits to relevant government offices or by sending formal letters to the respective government agencies [
7]. Another way is through elected representatives, whom constituents can approach to relay their concerns [
8]. These conventional modes, however, have demonstrated significant inefficiencies, primarily attributed to the extensive administrative processes involved. It often causes a substantial number of complaints to be lost in the long chain of procedures before reaching the decision-making ranks [
9]. Another issue is the inadequate workforce to handle these complaints [
10], making complaints, albeit received, sidelined due to insufficient resources to carry out follow-up actions. These problems inevitably make governments fail to translate citizen feedback into tangible improvements in public service delivery.
In today’s information era, e-government, or digital government services, emerges as a contemporary way to provide more effective provision and management of public services, by bringing in digital transformation. This revolution towards the digitization of government services is, in fact, a necessity to streamline administrative processes [
11], hence reducing the need for paperwork [
12] and, consequently, the associated costs and time [
13]. The public is also provided with access to information about ongoing governmental activities, policymaking, and policy implementation [
14]. These digital services are accessible from any location and at any time of the day, augmenting the overall experience of the public. Consequently, e-government promises an expedited, cost-effective, and efficient means of registering citizen complaints over public services. The better accessibility and efficiency offered by e-government means citizens can express their complaints through a broader array of accessible channels and significantly shortened procedural chains [
15]. Besides this, better transparency provides a more direct look into the management and follow-up actions associated with these complaints. In the end, the enhanced accessibility and efficiency, combined with increased transparency, foster a sense of accountability within governmental institutions [
16], improving the public’s confidence in the ability of their government to address their needs effectively.
Indeed, e-government has allowed a crowdsourced process of citizen complaints facilitated by multiple channels for complaint submission. While crowdsourcing improves public engagement [
17], it, however, makes the government unable to process the much-increased influx of complaints efficiently [
18]. It raises the need for a more capable mechanism to classify these complaints, thereby expediting their routing to appropriate governmental bodies. Recently, Large Language Models (LLM) have triggered the rise of Generative Artificial Intelligence (GenAI) [
19], including GPT-4 (OpenAI), Bard (Google), and Claude 2 (Anthropic). LLM and GenAI promise huge potential for automated classification. However, they are prone to hallucinations [
20], which increases the risk of delivering seemingly plausible but improper solutions to citizen complaints. They also require relatively extensive data and a huge amount of energy to train and run the models [
21], making it impractical to classify crowdsourced citizen complaints at different scales of applications with highly fluctuating amounts of input. Another promising solution is Transfer Learning, which applies pre-trained models on new problems [
22]. However, it remains impractical when no pre-trained models are available locally. Using pre-trained models from other regions is highly risky since the characteristics of citizens and their complaints are tightly related to the socio-cultural and physical features of an area.
In that sense, basic data mining remains more practical to facilitate a low-cost classification of crowdsourced citizen complaints with less energy required at various scales of applications. In the literature [
23], commonly used data mining algorithms for classification purposes include k-Nearest Neighbors (kNN) [
24], Random Forest (RF) [
25], Support Vector Machine (SVM) [
26], and AdaBoost [
27]. Still, each algorithm interacts with large datasets differently, which influences the behavior of the classification process, potentially resulting in less-than-optimal outcomes [
28,
29,
30]. Their application thus demands a cautious understanding of these behaviors, effectively leveraging their capabilities while being aware of their constraints. Therefore, this research aimed to discover the accuracy of these prominent algorithms in classifying crowdsourced citizen complaints. Practically, this study attempted to run the algorithms alternately over the same large dataset of citizen complaints, perform accuracy testing for each algorithm, and conduct comparative testing to discover the best algorithm for the given dataset. Consequently, the dataset should contain raw complaint data gathered through multiple e-government channels, through which this study can observe the behavior of each algorithm over the real-world problem in question: the massive influx of citizen complaints induced by digitized government services. This study went on to answer the following research questions:
RQ1 How accurate are k-Nearest Neighbors, Random Forest, Support Vector Machine, and AdaBoost in classifying crowdsourced citizen complaints?
RQ2 What is the most accurate data mining algorithm for the purpose?
RQ3 How do their accuracies differ for the classification process?
3. Case Study: Crowdsourced Citizen Complaints in Tangerang City, Indonesia
Asia, home to over 60% of the world’s population, has seen tremendous growth in digital transformation [
76]. Its expansion in technological and innovation capabilities, supported by a sizeable market, has given it a crucial role in the global digital revolution. In fact, Asia is one of the world’s largest producers and markets for digital products and services [
77]. Besides countries in Eastern Asia (e.g., China, South Korea, Japan, and Taiwan), which have become major global players, Southeast Asian countries have emerged as a new frontrunner in digital transformation. In terms of innovation, Southeast Asia is home to a growing number of tech startups and unicorns, with the region’s vibrant startup ecosystem contributing to global digital innovation [
78]. In areas such as fintech, e-commerce, and other digital services, Southeast Asia is at the forefront of modernization, offering unique solutions tailored to local needs and contexts.
In Southeast Asia, Indonesia has captured most of the region’s digital transformation. The rapid growth of digitalization in Indonesia has been driven by the growing Internet penetration, not only in terms of user base [
79] but also Internet-based digitalization in numerous sectors [
80], including governmental affairs. In Indonesia, the shifting to e-government is undergoing in various public sectors, with urban areas in Java Island being the leading region of digital innovations in the delivery of public services [
81,
82]. The sheer growth of e-government in Indonesia is, in fact, fostered by its supporting regulations. The Presidential Regulation (
Perpres) of the Republic of Indonesia no. 95 of 2018 [
83] governs all matters related to e-government in the country. It states that, to realize a clean, effective, transparent, and accountable government, an electronic-based government system is a necessity. It has become a regulatory framework for every region in Indonesia to provide quality and reliable public services to all subsets of the population.
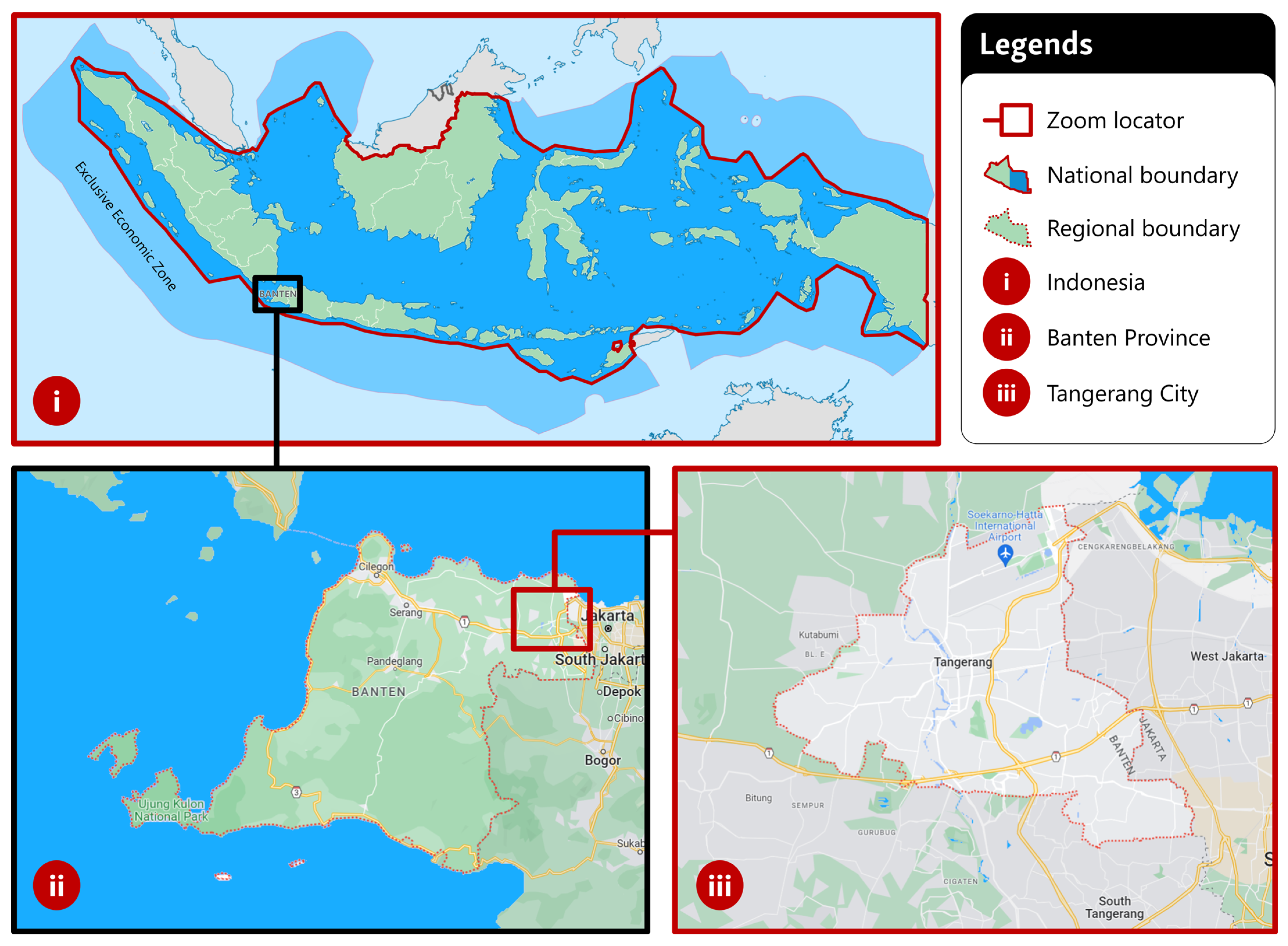
Since Indonesia’s population is concentrated on Java Island, it is typical to see more significant progress in the implementation of e-government in regions within the island [
81]. In the western part of Java, Tangerang City (
Figure 1) has shown a rather notable example of e-government [
84], mainly because it is part of Jabodetabekpunjur [
85], Indonesia’s main urban agglomeration, and home to many commuters working in Jakarta [
86], the epicenter of economic activities in the country. In terms of international significance, Tangerang City hosts the Soekarno–Hatta International Airport, one of Asia’s busiest airports [
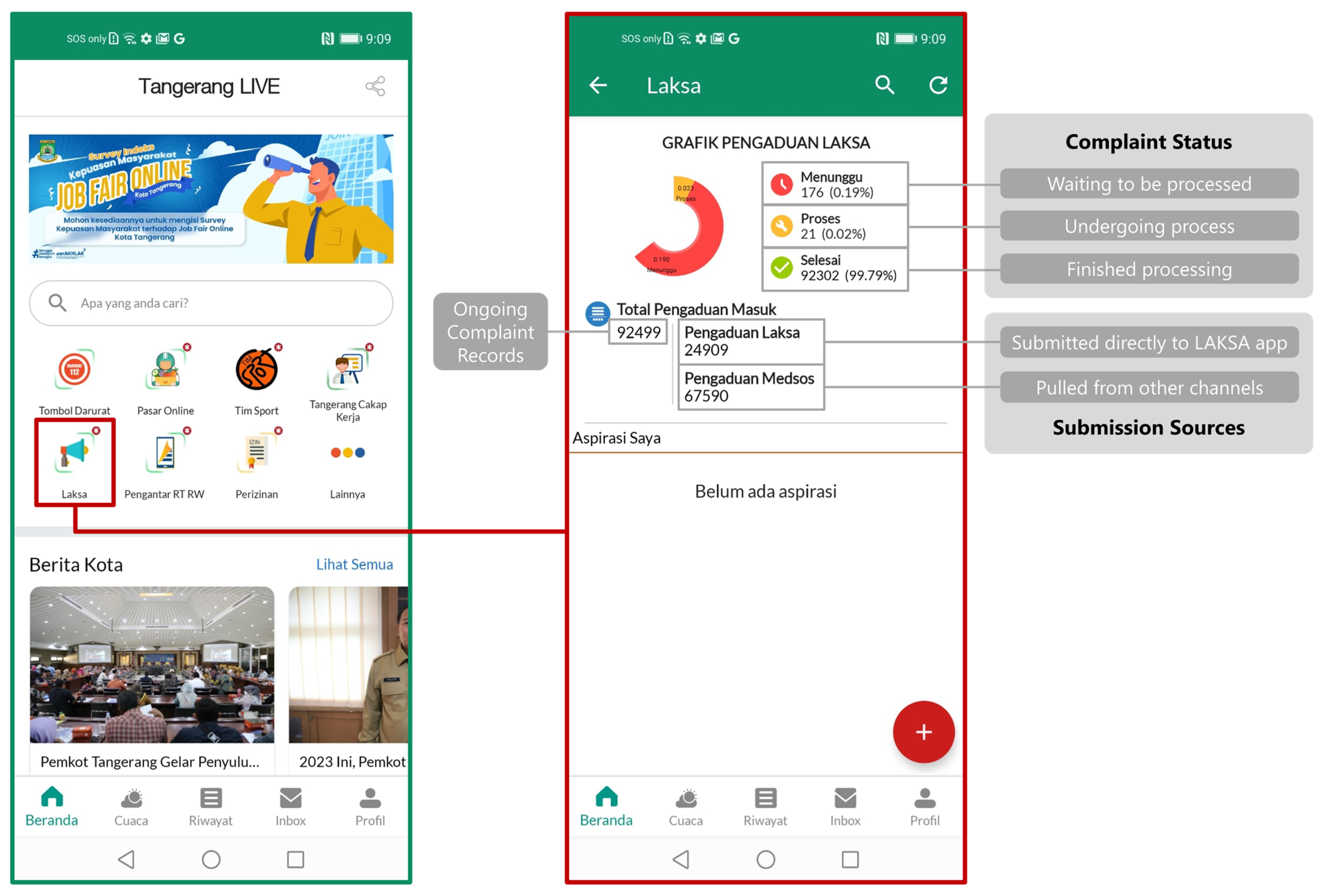
87]. In 2016, the City Government of Tangerang released a super app called Tangerang LIVE [
88] (
Figure 2, left side). The city government developed the super app to provide various services and information to citizens in one platform, integrating issue-specific apps on e-commerce, license and permits, emergency services, sports, and many others [
89]. Citizens can access these services digitally, making it easier and more convenient for them to access information and services from the government.
In the super app, the city government includes LAKSA (
Figure 2, right side). The LAKSA app (
Layanan Aspirasi Kotak Saran Anda) gives the citizens of Tangerang City a direct digital channel to crowdsource suggestions and criticisms over public services to the government [
90]. For security and legal purposes, the LAKSA app is only accessible for the residents of Tangerang City. They are distinguished by detecting residential region-identifying numbers in national identity cards (
Kartu Tanda Penduduk, or KTP) used during user registration. In its back-end operations, LAKSA also aggregates complaints crowdsourced through other digital channels. Currently, the city government pulls complaints submitted initially to its official Facebook and Instagram accounts and complaint-related comments from its online news sites [
91]. However, multi-channel crowdsourcing has made it difficult for the government to manage the massive datasets, thereby requiring an accurate classification algorithm to ensure an agile and correct routing of the complaints to relevant governmental bodies. Thus, this study used the LAKSA app as the case study to find the most accurate algorithms to classify crowdsourced citizen complaints.
6. Discussion
In the observed case of Tangerang City, West Java, Indonesia, the city government, as has also been reported by Nindito et al. [
102] and Madyatmadja et al. [
103], has implemented pioneering crowdsourcing of public complaints in the country through its LAKSA app, official social media accounts, and government-run online news sites. Despite these innovative initiatives, the local government struggles to efficiently redirect public complaints to the relevant government bodies. Confirming similar problems noted by Almira et al. [
104], Nyansiro et al. [
105], and Bakunzibake et al. [
106], manual monitoring, decision-making, and metadata recording processes consume a considerable amount of time and resources. In a more extended period, it has proven, as also stated by Sunindyo et al. [
107] and Goel et al. [
108], to be a significant bottleneck in the management and resolution of citizen complaints. Since the availability of officially annotated datasets was constrained by manual processes, it was consequently challenging for this study to obtain a dataset containing the most recent citizen complaints. This supports the pressing need to develop and implement more sophisticated and automated solutions that can classify public complaints, to make it easier for government officials to redirect the complaints to the appropriate government bodies [
109,
110,
111].
In responses to the first (RQ1) and second research questions (RQ2), separately employing four classification algorithms, i.e., k-Nearest Neighbors, Random Forest, Support Vector Machine, and AdaBoost, produced different levels of accuracy. Looking at
Table 12, the SVM algorithm performed well above the other three in classifying citizen complaints. This is particularly evident since its combination with four separate kernels resulted in slightly varied classification accuracies, with an accuracy range between 88.1% and 89.2%, which still remained higher than the results of other algorithms under different configurations. The results further demonstrated the versatility of SVM for classification purposes, which have been proven in various fields [
112,
113,
114]. Meanwhile, RF and kNN followed in the second and third places, respectively. Still, their small margin to the performance of SVM implied the possibility of utilizing them for different datasets of crowdsourced citizen complaints, as also demonstrated by Sano et al. [
115] for RF and Tjandra et al. [
116] for kNN. In last place, AdaBoost gave more varied results depending on the base learners used. Interestingly, AdaBoost produced lower performances than the independent accuracy of RF and SVM. This confirms Reyzin and Schapire [
117], who found that, in certain conditions, boosting algorithms could deliver a worse performance, despite a higher margin distribution.
Furthermore, as data mining techniques, the four classification algorithms being observed could perform differently under different configurations. For kNN (
Table 8), this study found significant increases in accuracy along with a rise in “k” values under 40. However, after reaching the maximum accuracy at k = 40, its accuracy decreased consistently, albeit with smaller margins for the same incremental increases or decreases. This confirms that the behavior of the kNN algorithm significantly depends on the number of “k” [
58,
118], with larger “k” values increasing the accuracy significantly, until the configuration reaches an optimum value. Meanwhile, the RF algorithm performed variably under different numbers of trees, with the optimum value being 50 trees (
Table 9). Confirming previous studies [
119,
120], it implies the typical behavior of the Random Forest algorithm, which produces a threshold for an optimal number of trees. However, there were no significant differences in accuracy for the same incremental changes in the number of trees below and above the optimum value. In parallel to other studies [
121,
122,
123], the diminishing returns in the classification accuracy of RF, as the number of trees increases beyond an optimal point, may be attributed to overfitting or increased model complexity, which could negatively impact the generalizability of the algorithm.
For the SVM algorithm, the configurations focused on the use of separate kernels. In general, the levels of accuracy, when employing different kernels (
Table 10), did not produce significant results for the given dataset. The best-performing configuration, i.e., SVM with a linear kernel, confirms the findings of Raghavendra and Deka [
124] regarding its predictive ability. Meanwhile, the polynomial and sigmoid kernels performed somewhat equally. The worst performing kernel, i.e., radial basis function, although it insignificantly differed from the other three kernels, implied a dataset-specific capability of the kernel in learning, but not in predicting [
125]. Still, the insignificant differences in performance across the various kernel types highlight the importance of selecting an appropriate kernel to achieve optimal classification results for a given dataset. On the other hand, the accuracy levels of classification using the AdaBoost algorithm with three separate base learners, i.e., RF, Decision Trees, and SVM, show relatively different results (
Table 11), with SVM (with a linear kernel) as the base learner performing the best. This makes sense, since SVM also produced the best accuracy among the four observed algorithms in this study. Despite not being conventionally preferable for AdaBoost [
126,
127], SVM was proven to be a highly performing base learner for AdaBoost, especially for the given dataset of crowdsourced citizen complaints.
Moreover, all the observed algorithms, despite having different levels of accuracy for overall classification (
Table 12), exhibited similar trends when predicting complaint data in individual categories.
Table 13 showed the raw data of predictions correctly classified by each algorithm into the categories, which were compared to the original amount of data for the respective categories in the initial training dataset (
Table 3). Looking at the percentage of correct predictions, all the algorithms performed well in the “infrastructure” and “social” categories with levels of accuracy above 90%. In contrast, the average accuracy of their predictions for “disaster” and “nation-related affairs” did not even reach half of the amount of original data for the categories. This may have occurred because there was a smaller amount of data available for the “disaster” and “nation-related affairs” in the original dataset, making the algorithms unable to grasp adequate knowledge from the pattern training. Considering the amount of training data available for each category and the levels of accuracy that came with it, the results confirm the findings of Kale and Patil [
128] and Bzdok et al. [
129], who stated that the accuracy of text mining increases logarithmically when the amount of training data increases. This implies that further training remains necessary to improve the accuracy of predictive classification in any given dataset.
7. Conclusions
E-government systems aim to streamline and enhance government–citizen interactions. Tangerang is a prime example of a city that has embraced e-government, with its administration developing an electronic system (LAKSA) for receiving public complaints through various channels. However, the actual implementation of this e-government system has encountered challenges, particularly in the management of massive complaint data sourced from less-moderated platforms, such as social media and online news sites. These data often appear unstructured, lacking categories or classes that would facilitate efficient channeling to the appropriate government agencies. This research, to overcome this obstacle, proposed the application of data mining techniques, specifically classification algorithms, as a practical solution for categorizing and organizing vast amounts of unstructured complaint data. For the given dataset from the Government of Tangerang City, this study assessed four algorithms, i.e., kNN, RF, SVM, and AdaBoost, to discover one with the best accuracy for classification. It would allow the government to better manage the challenges posed by unstructured complaint data and ensure the timely and appropriate handling of public complaints. This proactive approach would not only improve the overall efficiency of e-government systems but also strengthen the relationship between governments and their constituents in an increasingly digital world.
This study measured the accuracy of each algorithm in classifying the citizen complaint data of Tangerang City that was aggregated by the LAKSA app. The primary measure involved a confusion matrix over four classification categories, which compared the amount of correct prediction data with the testing data. The results showed that, according to accuracy level, the best classification algorithm to classify the complaint data was the Support Vector Machine algorithm using the linear kernel, with an accuracy rate of 89.2%. SVM, in fact, remained the best-performing algorithm under different configurations with any of the observed kernels. Practically, other classification algorithms with a minimum accuracy threshold of 85%, i.e., k-Nearest Neighbors and Random Forest, could also be used for the dataset. However, AdaBoost, for the given dataset, was prone to low levels of accuracy, except when paired with SVM as its base learner. Besides, this study found that categories with a lower amount of training data (“disaster” and “nation-related affairs”) demonstrated lower accuracy levels. In contrast, those with a higher volume of training data (“infrastructure” and “social”) exhibited considerably higher accuracy levels. This observation underscores the need for continuous supervised training with a larger volume of training data to enhance accuracy across all categories.
In addition, the findings hold significant potential for informing the decision-making process within the Government of Tangerang City. Insights from the accuracy testing of classification algorithms allow authorities to make informed choices on the most effective methods for categorizing and managing the massive amount of unstructured citizen complaint data. Besides, the results offer broader relevance beyond the case study, as they can serve as valuable references for other administrative regions across Indonesia. Particularly, these findings can guide the implementation of data classification strategies, specifically in the context of public complaints, enhancing e-government systems on a national scale. Beyond its practical applications, this study also provides a foundation for further research in the field of data classification. The performance assessment of various algorithms enables researchers to explore alternative word weighting methods, such as Bag-of-Words and Word2Vec, to further optimize the classification process. Moreover, future research needs to develop an Indonesian text mining library. The extremely rare availability of such resources presents a challenge for researchers and practitioners, as it limits the accessibility of localized tools and techniques. Thus, future studies can contribute to the body of knowledge of Indonesian text mining resources, ultimately benefiting the broader scientific community and the country’s e-government efforts.



 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}



