
SMPT: A Semi-Supervised Multi-Model Prediction Technique for Food Ingredient Named Entity Recognition (FINER) Dataset Construction

 , , , ,
, , , ,
Abstract
:1. Introduction
- 1.
- Train a base classifier on annotated data.
- 2.
- Use this classifier to predict labels for unlabeled data and move some of the confident samples into the labeled set.
- 1.
- The SMPT method. It is a deep ensemble learning model that adopts the self-training concept that builds on pre-trained language model (LM) in the iterative data labeling process. Then, the voting scheme is used as the final decision to determine the entity’s label. Furthermore, this approach can be applied to other domains besides food and nutrients.
- 2.
- The FINER dataset. It is an annotated dataset for food ingredient entities. The dataset is made public and accessible on Figshare [20].
2. Related Works
3. Dataset Construction
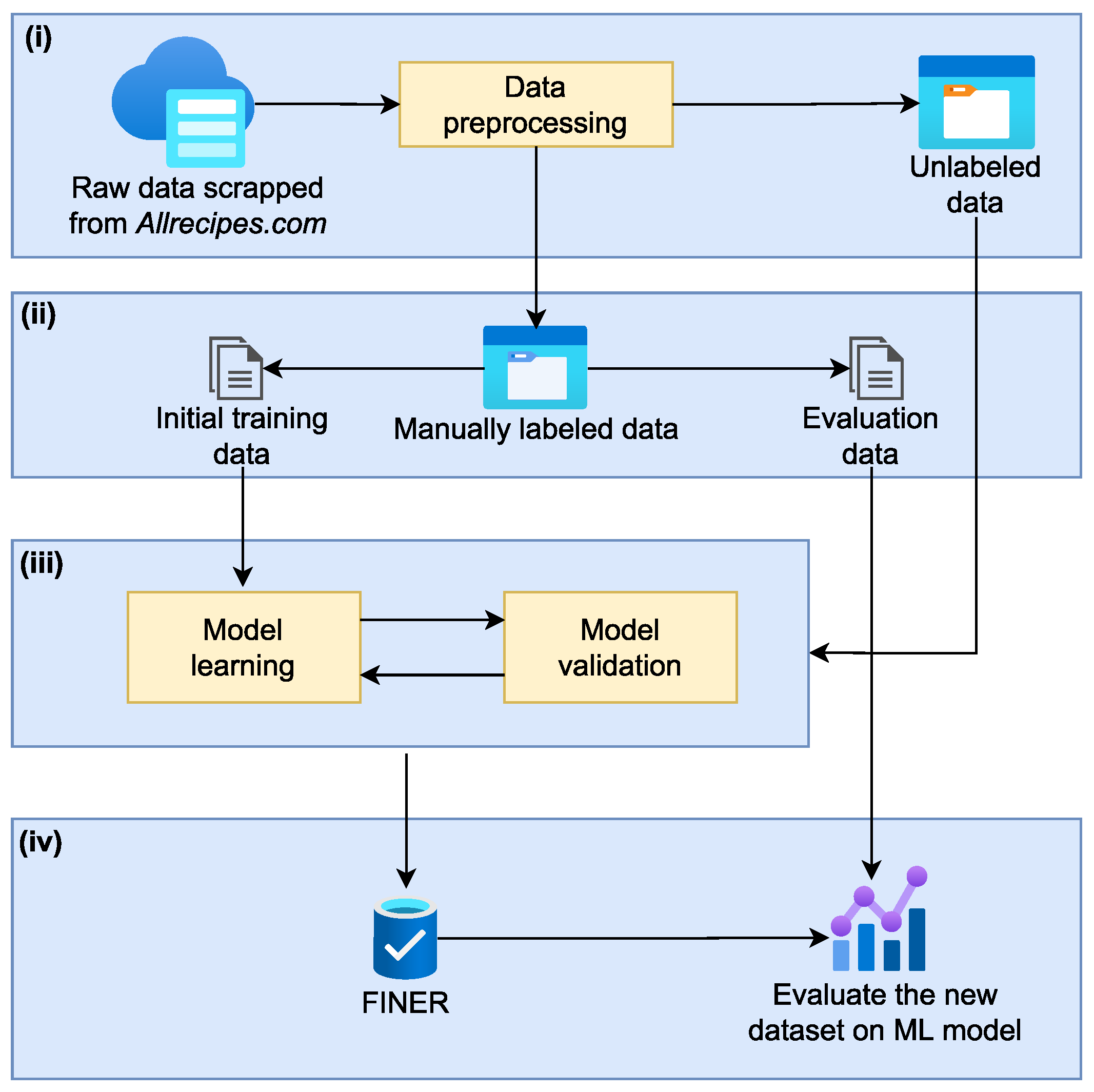
3.1. Dataset Construction Workflow
- (i)
- Data preparation. We begin by cleaning the text data collected from the Allrecipes website, followed by a number of pre-processing steps. The explanation is provided in detail in Section 3.2.
- (ii)
- Manual data labeling. We manually label 2000 instances and split them in half for the initial training and evaluation sets. Using the initial training set, a baseline NER annotator is developed. The evaluation set is preserved for the final evaluation stage of the complete dataset.
- (iii)
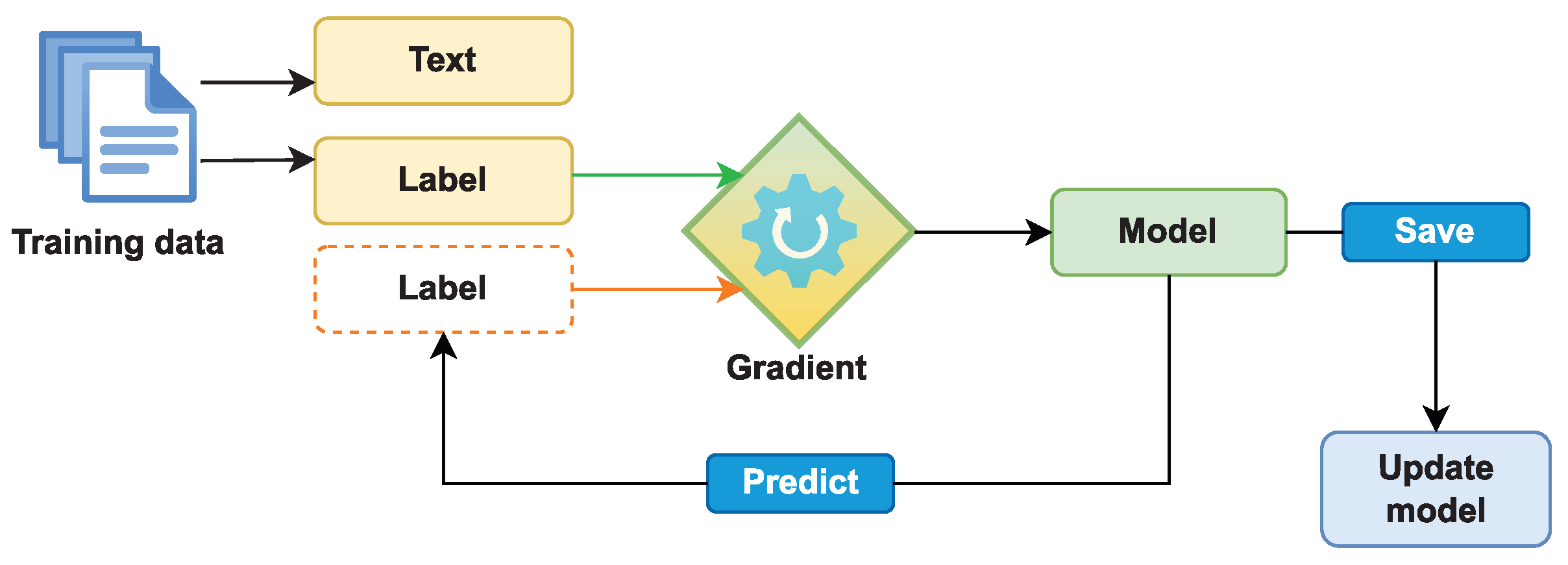
- Training and automatic data labeling. In this stage, a baseline model is developed utilizing the initial training set from the previous stage. This model is then applied to a set of unlabeled data to predict its labels. Then, we have a newly created set of labeled data, some of which have been incorporated into the previous set. This procedure is repeated until no more unlabeled data are available.
- (iv)
- Final data evaluation. After a number of repetitions, we reside at the dataset named Food Ingredient NER or FINER. Using several classifiers, including CRF, Bi-LSTM, and BERT, we indirectly evaluate the quality of the dataset. Their performance is evaluated using the reserved evaluation set.
3.2. Data Preparation
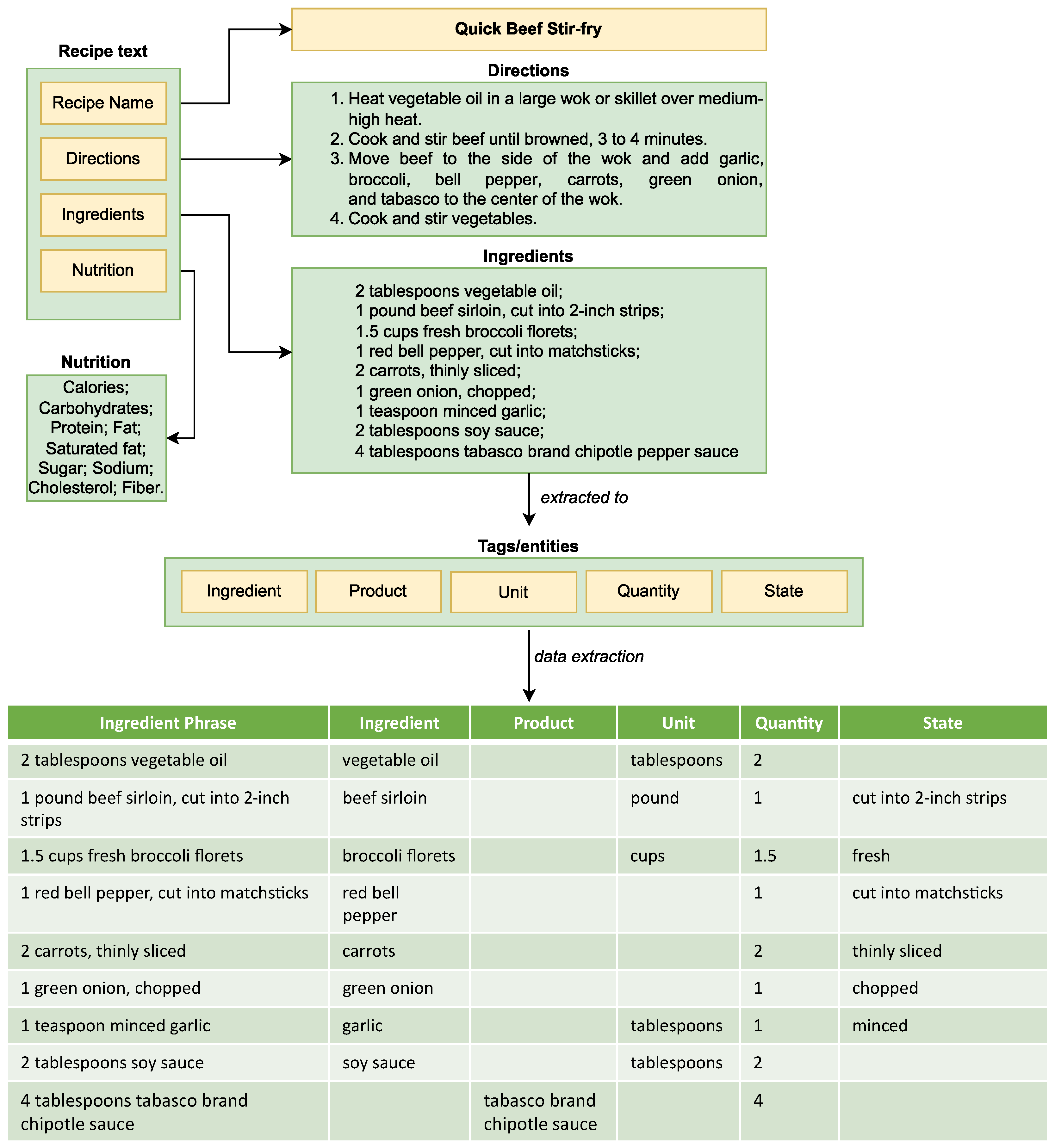
- 1.
- Each phrase in the ingredients section is split into individual phrases to simplify the extraction procedure. Then after preprocessing, the resulting dataset consists of 181,970 phrases.
- 2.
- Standardize the unit and quantity measurements. For example, in the units, all abbreviations are converted to their true form; thus, “tbsp” becomes “tablespoon”. In quantity, we convert all fractional numbers to decimal form so that “½” becomes “0.5”.
- 3.
- Since our dataset comprises a list of ingredients, stop words and punctuation may not always be meaningless to the text’s intent, but they could help interpret entities. Therefore, we have created custom lists of stop words and punctuation. For example, “1 (2 ounces) package butter” indicates that one package of butter equals 2 ounces. Although “2 ounces” is enclosed in parentheses, we keep the parentheses since they provide information for translating the number of ingredients to standard units.
3.3. Named Entity Labeling
- 1.
- INGREDIENT: the name of the food or ingredient. For example, garlic, apple, carrots, vegetable oil, etc.
- 2.
- PRODUCT: the food or ingredient from a specific brand mentioned. Examples include Archer farms dark chocolate hot cocoa mix, Tabasco brand chipotle pepper sauce, etc.
- 3.
- QUANTITY: The amount of the food or ingredient associated with the unit. Examples: 1½, 25, 0.5, etc.
- 4.
- STATE: The processing state of the food or ingredient. For example, chopped, grilled, minced, cut into 2-inch strips, etc.
- 5.
- UNIT: a measurement unit, such as pound, gram, fluid ounce, tablespoon, cup, etc.
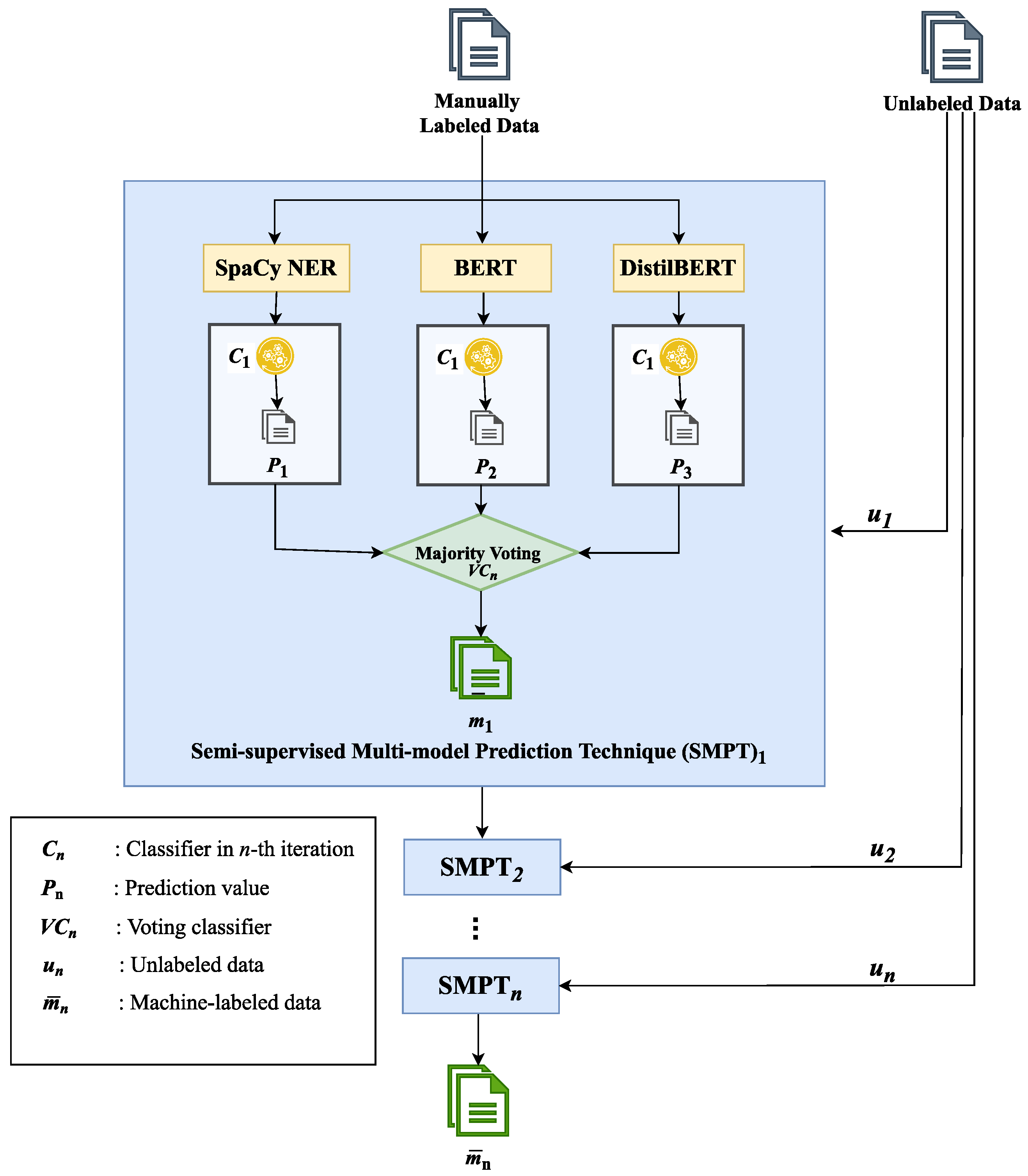
3.4. Semi-Supervised Multi-Model Prediction Technique (SMPT)
3.4.1. Models
- spaCy NER [17]: spaCy is a Python and Cython-based open-source library for natural language processing that provides various NLP tools for tokenization, POS-tagging, and named entity recognition text.
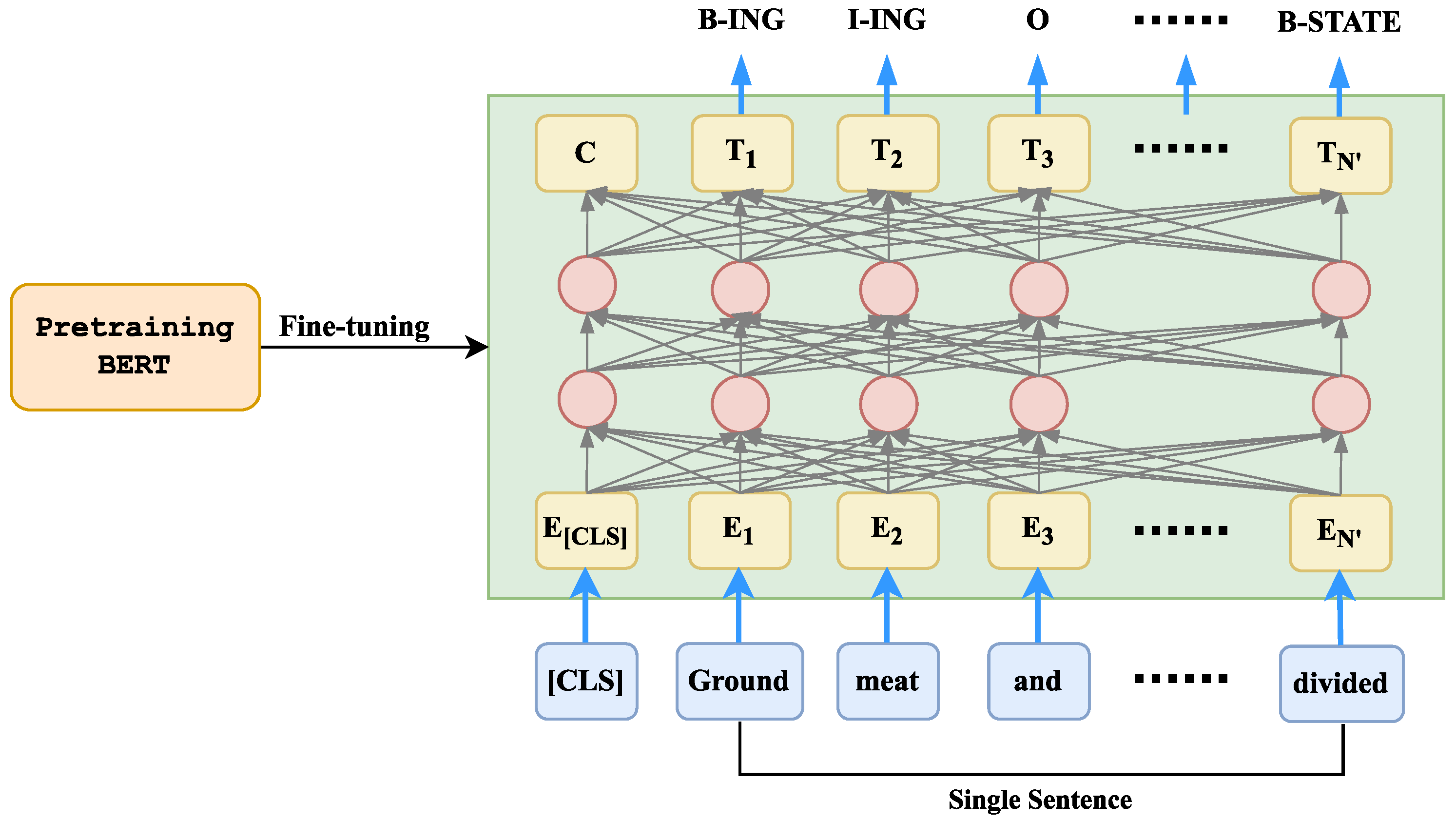
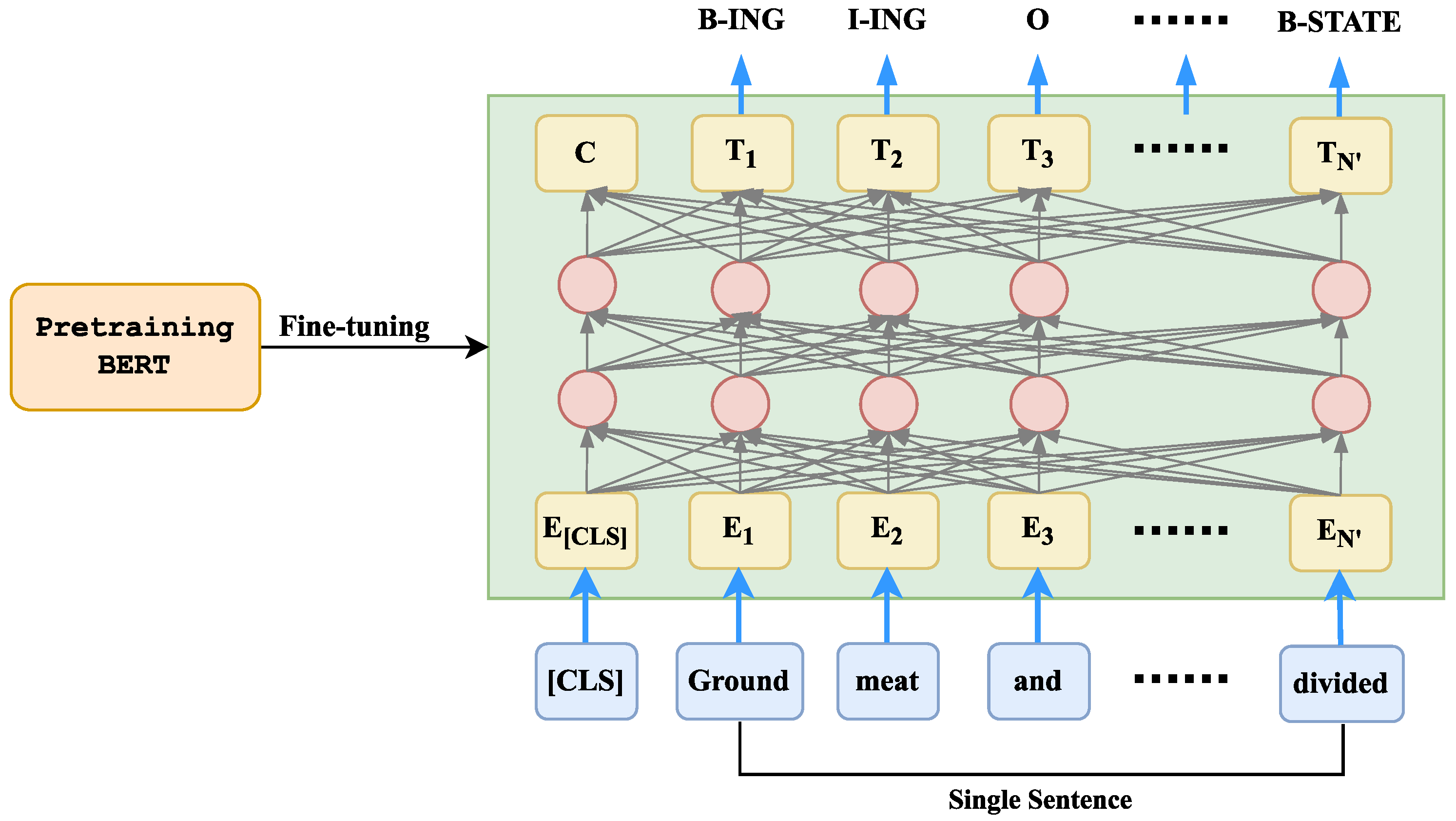
- BERT: BERT [18] is a language representation model that uses stacked transformer encoders that learn deep bidirectional representation from a large unlabeled corpus. An additional output layer is added to fine-tune the representation in downstream NLP tasks. Fine-tuning slightly modifies the neural network architecture for improved predictions in target tasks while training the whole network. Pre-trained BERT inherits the model weights learned during the pre-training, allowing downstream tasks to benefit from these powerful representations rather than learning from scratch.
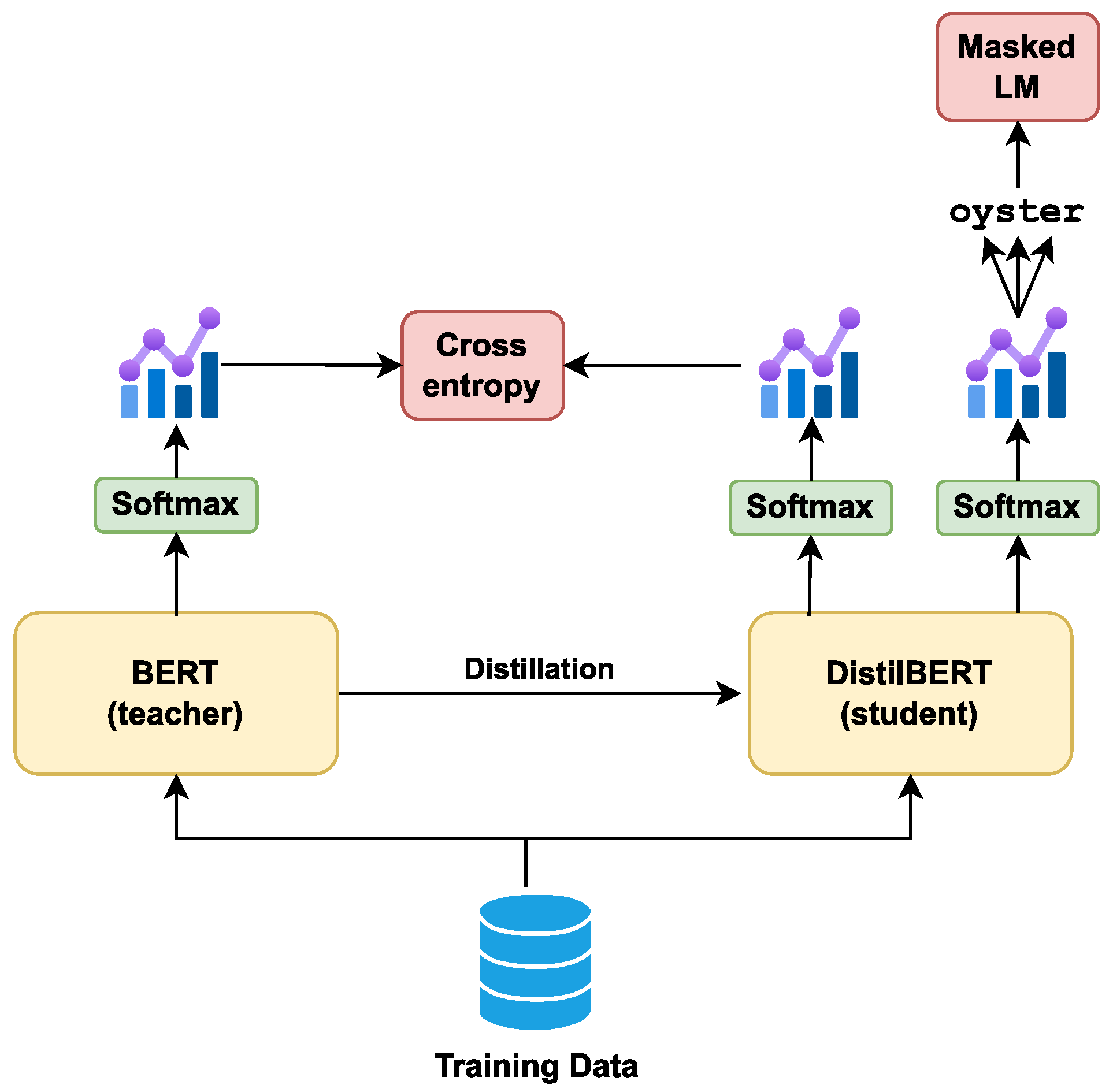
- DistilBERT: DistilBERT [19] is a compact version of BERT and is claimed to be lighter and faster than BERT with roughly comparable performance. It has 40% lesser parameters compared to bert-base-uncased and performs 60% faster with over 95% of the performance of BERT, as evaluated on the GLUE language understanding benchmark in this study [19]. To reduce the computational requirements of modern large neural networks, DistilBERT uses a knowledge distillation technique known as teacher-student learning. Knowledge distillation is a compression technique that entails training a small model to replicate the behavior of a larger model. As shown in Figure 6, the masked language model (MLM) loss is used to train the student model and the cross-entropy loss between the teacher and the student. This mechanism encourages the student model to generate a probability distribution over the predicted tokens as close to that of the teachers as possible.
3.4.2. Training and Labeling Methods
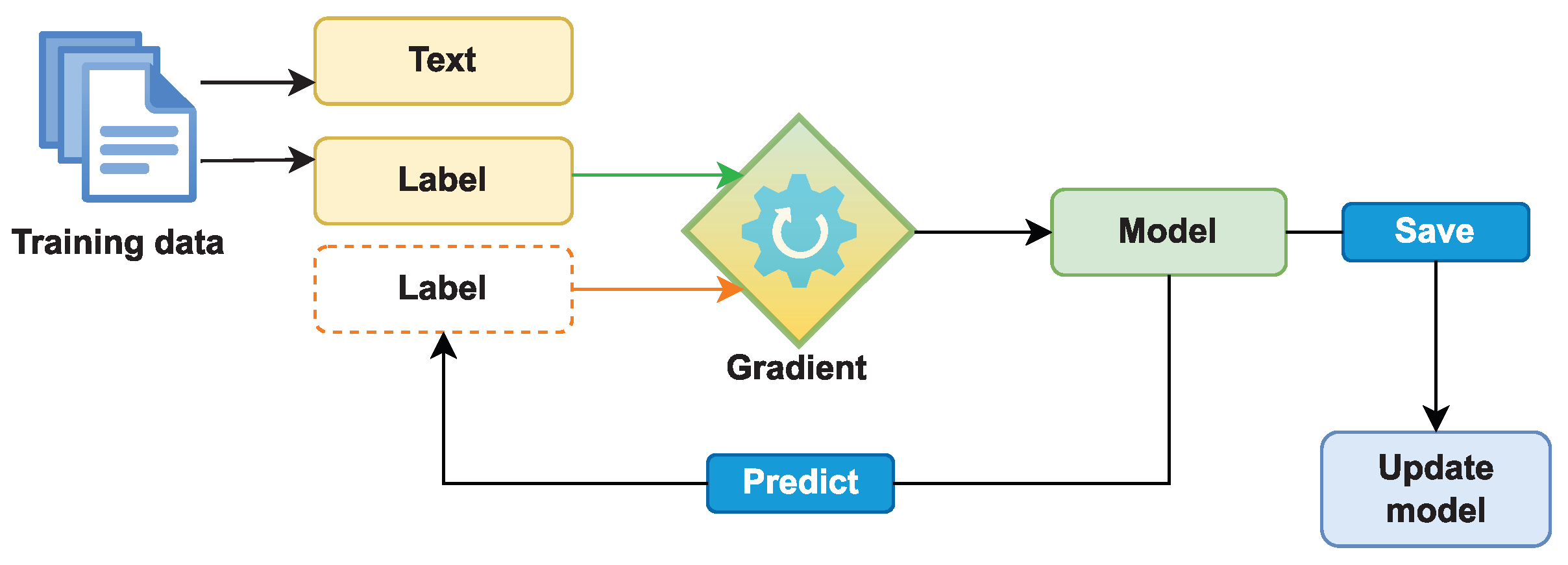
- A.
- Training
- 1.
- In the first step, we develop a set of C baseline classifiers using our initial training set (1000 manually annotated instances). In our experiment, the classifiers include spaCy NER, BERT, and DistilBERT.
- 2.
- In the second step, each classifier C makes its own predictions for the test set. However, the final decisions on the unlabeled tokens are made by the majority voting scheme:where is the final prediction label (class), M is number of classes, the number of classifiers, and denotes the vote given to class m by classifier c. If the max vote is not unique, the token will be given “O” label representing that the token is not a chunk.
- 3.
- Finally, the above machine-labeled tokens with unanimous votes are considered reliable and promoted into the training set of labeled instances for the next generation of classifiers. These procedures were repeated until all tokens were labeled.
- B.
- Dataset Building Scheme
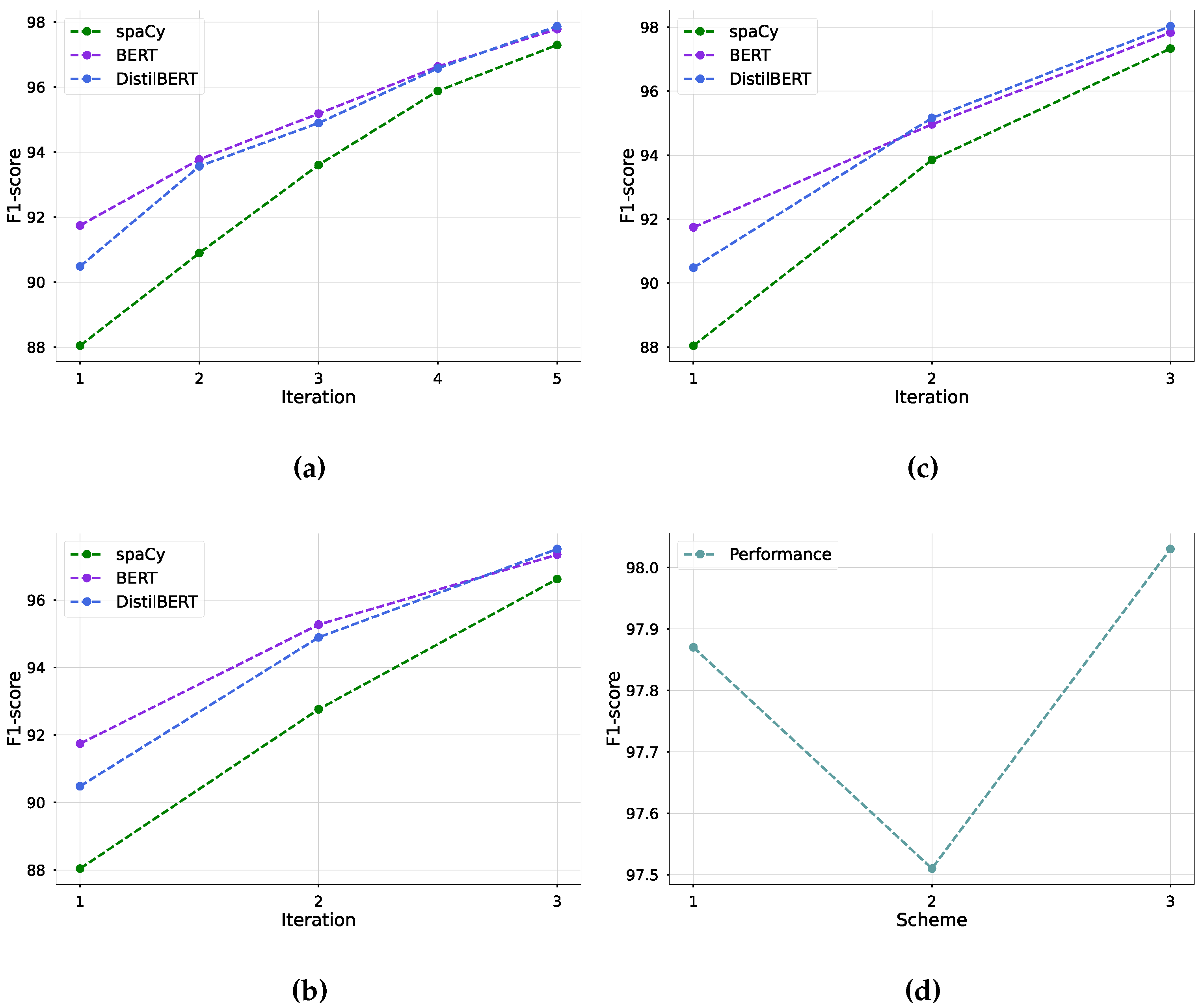
- Scheme 1:
- Scheme 2:
- Scheme 3:
3.5. Evaluation
- 1.
- Recall is the fraction of correctly predicted positive samples (TP) in their classes:
- 2.
- Precision is the proportion of correctly predicted positive samples among the total positive predictions:
- 3.
- F1-score is a metric that measures the model’s accuracy on a dataset, defined as the harmonic mean of precision and recall:
- TP (True Positive), occurs when the outputs of the NER for input tokens exactly match the same ingredient entity in the ground truth dataset.
- FP (False Positive), falsely predicted positive occurs when something that is not an ingredient entity is classified as being one.
- TN (True Negative), the correct negative prediction occurs when the NER method correctly predicts that the token is not an ingredient entity in the ground truth dataset.
- FN (False Negative), occurs when a specific annotation is omitted when the entity should be classified as an ingredient entity. It happens when the ingredient entity is not properly extracted using the NER method.
4. Experimental Results and Data Analysis
4.1. Test Results with Training Scheme
4.2. Evaluation on Machine Learning Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| BiLSTM | Bidirectional Long Short-Term Memory |
| CNN | Convolutional Neural Network |
| CRF | Conditional Random Fields |
| FINER | Food Ingredient Named Entity Recognition |
| LM | Language Model |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| MLM | Masked Language Model |
| NER | Named Entity Recognition |
| NLP | Natural Language Processing |
| SMPT | Semi-Supervised Multi-Model Prediction Technique |
References
- Saunders, J.; Smith, T. Malnutrition: Causes and consequences. Clin. Med. 2010, 10, 624–627. [Google Scholar] [CrossRef]
- Kalra, J.; Batra, D.; Diwan, N.; Bagler, G. Nutritional profile estimation in cooking recipes. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering Workshops (ICDEW), Dallas, TX, USA, 20–24 April 2020; pp. 82–87. [Google Scholar]
- Syed, M.H.; Chung, S.T. MenuNER: Domain-adapted BERT based NER approach for a domain with limited dataset and its application to food menu domain. Appl. Sci. 2021, 11, 6007. [Google Scholar] [CrossRef]
- Pellegrini, C.; Ozsoy, E.; Wintergerst, M.; Groh, G. Exploiting Food Embeddings for Ingredient Substitution. In Proceedings of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies—HEALTHINF, Vienna, Austria, 11–13 February 2021; SciTePress: Setúbal, Portugal, 2021; pp. 67–77. [Google Scholar]
- Min, W.; Jiang, S.; Liu, L.; Rui, Y.; Jain, R. A survey on food computing. ACM Comput. Surv. (CSUR) 2019, 52, 92. [Google Scholar] [CrossRef] [Green Version]
- Popovski, G.; Seljak, B.K.; Eftimov, T. FoodBase corpus: A new resource of annotated food entities. Database 2019, 2019, baz121. [Google Scholar] [CrossRef] [PubMed]
- Krishnan, V.; Ganapathy, V.; Named Entity Recognition. Stanford Lecture CS229. 2005. Available online: http://cs229.stanford.edu/2005/KrishnanGanapathy-NamedEntityRecognition.pdf (accessed on 4 February 2021).
- Komariah, K.S.; Shin, B.K. Nutrition-Based Food Recommendation System for Prediabetic Person. In Proceedings of the Korea Software Congress 2020 (KSC 2020), Seoul, Republic of Korea, 21–23 December 2020; pp. 660–662. [Google Scholar]
- Marin, J.; Biswas, A.; Ofli, F.; Hynes, N.; Salvador, A.; Aytar, Y.; Weber, I.; Torralba, A. Recipe1m+: A dataset for learning cross-modal embeddings for cooking recipes and food images. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 187–203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bień, M.; Gilski, M.; Maciejewska, M.; Taisner, W.; Wisniewski, D.; Lawrynowicz, A. RecipeNLG: A cooking recipes dataset for semi-structured text generation. In Proceedings of the 13th International Conference on Natural Language Generation, Dublin, Ireland, 15–18 December 2020; pp. 22–28. [Google Scholar]
- Batra, D.; Diwan, N.; Upadhyay, U.; Kalra, J.S.; Sharma, T.; Sharma, A.K.; Khanna, D.; Marwah, J.S.; Kalathil, S.; Singh, N.; et al. Recipedb: A resource for exploring recipes. Database 2020, 2020, baaa077. [Google Scholar] [CrossRef]
- Wróblewska, A.; Kaliska, A.; Pawłowski, M.; Wiśniewski, D.; Sosnowski, W.; Ławrynowicz, A. TASTEset–Recipe Dataset and Food Entities Recognition Benchmark. arXiv 2022, arXiv:2204.07775. [Google Scholar]
- Popovski, G.; Seljak, B.K.; Eftimov, T. A survey of named-entity recognition methods for food information extraction. IEEE Access 2020, 8, 31586–31594. [Google Scholar] [CrossRef]
- Boushehri, S.S.; Qasim, A.B.; Waibel, D.; Schmich, F.; Marr, C. Systematic comparison of incomplete-supervision approaches for biomedical imaging classification. bioRxiv 2021. [Google Scholar] [CrossRef]
- Zoph, B.; Ghiasi, G.; Lin, T.Y.; Cui, Y.; Liu, H.; Cubuk, E.D.; Le, Q. Rethinking pre-training and self-training. Adv. Neural Inf. Process. Syst. 2020, 33, 3833–3845. [Google Scholar]
- Lee, H.W.; Kim, N.R.; Lee, J.H. Deep neural network self-training based on unsupervised learning and dropout. Int. J. Fuzzy Log. Intell. Syst. 2017, 17, 1–9. [Google Scholar] [CrossRef] [Green Version]
- spaCy. Available online: https://spacy.io/ (accessed on 5 March 2022).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Komariah, K.S.; Purnomo, A.T.; Sin, B.K. FINER: Food Ingredient NER Dataset. Available online: https://doi.org/10.6084/m9.figshare.20222361.v3 (accessed on 7 April 2022).
- Yadav, V.; Bethard, S. A survey on recent advances in named entity recognition from deep learning models. arXiv 2019, arXiv:1910.11470. [Google Scholar]
- Li, J.; Sun, A.; Han, J.; Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef]
- Goyal, A.; Gupta, V.; Kumar, M. Recent named entity recognition and classification techniques: A systematic review. Comput. Sci. Rev. 2018, 29, 21–43. [Google Scholar] [CrossRef]
- Cenikj, G.; Popovski, G.; Stojanov, R.; Seljak, B.K.; Eftimov, T. BuTTER: BidirecTional LSTM for Food Named-Entity Recognition. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 3550–3556. [Google Scholar]
- Allrecipes. Available online: https://www.allrecipes.com/ (accessed on 14 December 2022).
- Food. Available online: https://www.food.com/ (accessed on 14 December 2022).
- Tarla Dalal Indian Recipes. Available online: https://www.tarladalal.com/ (accessed on 14 December 2022).
- The Spruce Eats. Available online: https://www.thespruceeats.com/ (accessed on 14 December 2022).
- Epicuriuous. Available online: https://www.epicurious.com/ (accessed on 14 December 2022).
- Food Network. Available online: https://www.foodnetwork.com/ (accessed on 14 December 2022).
- Taste. Available online: https://www.taste.com.au/ (accessed on 14 December 2022).
- Diwan, N.; Batra, D.; Bagler, G. A named entity based approach to model recipes. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering Workshops (ICDEW), Dallas, TX, USA, 20–24 April 2020; pp. 88–93. [Google Scholar]
- Kim, J.; Ko, Y.; Seo, J. Construction of machine-labeled data for improving named entity recognition by transfer learning. IEEE Access 2020, 8, 59684–59693. [Google Scholar] [CrossRef]
- Du, J.; Grave, E.; Gunel, B.; Chaudhary, V.; Celebi, O.; Auli, M.; Stoyanov, V.; Conneau, A. Self-training improves pre-training for natural language understanding. arXiv 2020, arXiv:2010.02194. [Google Scholar]
- Komariah, K.S.; Sin, B.K. BERT Pre-trained Models for Data Augmentation in Twitter Medical Named-Entity Recognition. In Proceedings of the Korea Computer Congress 2021 (KCC 2021), Jeju, Republic of Korea, 23–25 June 2021; pp. 870–872. [Google Scholar]
- Arslan, Y.; Allix, K.; Veiber, L.; Lothritz, C.; Bissyandé, T.F.; Klein, J.; Goujon, A.; Arslan, Y.; Allix, K.; Veiber, L.; et al. A comparison of pre-trained language models for multi-class text classification in the financial domain. In Companion Proceedings of the Web Conference 2021 (WWW ’21); Association for Computing Machinery: New York, NY, USA, 2021; pp. 260–268. [Google Scholar] [CrossRef]
- Stojanov, R.; Popovski, G.; Cenikj, G.; Seljak, B.K.; Eftimov, T. A fine-tuned bidirectional encoder representations from transformers model for food named-entity recognition: Algorithm development and validation. J. Med. Internet Res. 2021, 23, e28229. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Nakayama, H.; Kubo, T.; Kamura, J.; Taniguchi, Y.; Liang, X. doccano: Text Annotation Tool for Human. 2018. Available online: https://github.com/doccano/doccano (accessed on 11 February 2022).
- Partalidou, E.; Spyromitros-Xioufis, E.; Doropoulos, S.; Vologiannidis, S.; Diamantaras, K. Design and implementation of an open source Greek POS Tagger and Entity Recognizer using spaCy. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, Thessaloniki, Greece, 14–17 October 2019; pp. 337–341. [Google Scholar]
- Thickstun, J. The Transformer Model in Equations; University of Washington: Seattle, WA, USA, 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.025312. [Google Scholar]
- Zheng, A. Evaluating Machine Learning Models: A Beginner’s Guide to Key Concepts and Pitfalls; O’Reilly Media: Sebastopol, CA, USA, 2015. [Google Scholar]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for multi-class classification: An overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Sutton, C.; McCallum, A. An introduction to conditional random fields. Found. Trends Mach. Learn. 2012, 4, 267–373. [Google Scholar] [CrossRef]
- Patil, N.; Patil, A.; Pawar, B. Named entity recognition using conditional random fields. Procedia Comput. Sci. 2020, 167, 1181–1188. [Google Scholar] [CrossRef]
- Komariah, K.S.; Shin, B.K. Medical Entity Recognition in Twitter using Conditional Random Fields. In Proceedings of the 2021 International Conference on Electronics, Information, and Communication (ICEIC), Jeju, Republic of Korea, 31 January–3 February 2021; pp. 1–4. [Google Scholar]
- Lee, C. LSTM-CRF models for named entity recognition. IEICE Trans. Inf. Syst. 2017, 100, 882–887. [Google Scholar] [CrossRef] [Green Version]
- Chiu, J.P.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Panchendrarajan, R.; Amaresan, A. Bidirectional LSTM-CRF for named entity recognition. In Proceedings of the 32nd Pacific Asia Conference on Language, Information and Computation, Hong Kong, China, 1–3 December 2018. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv 2016, arXiv:1603.01354. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | Source | Dataset Size (Recipes) | Entities |
|---|---|---|---|---|
| FoodBase [6] | Ruled-based approach | AllRecipes | 1000 curated; 21,790 uncurated version | Based on Hansard corpus semantic tags: AG (food and drink) AE (animal) AF (plant) |
| Recipe1M+ [9] | Deep learning approach | Various cooking sites and image search engines for image data extension | 1 million recipes and 13 million food images | - |
| RecipeDB [11] | Ruled-based approach | Food.com AllRecipes Tarladalal The Spruce Eats Epicurious Food Network Taste | 118,171 | Name State Unit Quantity Size Temp Dry/Fresh |
| RecipeNLG [10] | Deep learning approach | Recipe1M+ and auhtors private data gathered from various cooking sites | Over 1 million new data | - |
| TASTEset [12] | Deep learning approach | AllRecipes Food.com Tasty Yummly | 700 | Food Quantity Unit Process Physical Quality Color Taste Purpose Part |
| FINER (Ours) | Deep learning approach | AllRecipes | 64,782 | Ingredient Product Quantity Unit State |
| Dataset | Total (# of Sentences) |
|---|---|
| Initial Training Data | 1000 |
| Evaluation Data | 1000 |
| Unlabeled Data | 179,970 |
| Total | 181,970 |
| Tag | Description |
|---|---|
| B (Begin) | Denotes that the tag is the start of a chunk. |
| I (Inside) | denotes that the tag is located inside a chunk. |
| O (Outside) | Identifies a token as non-chunk (outside). |
| Iteration | The Set | Scheme 1 (s = 2) |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| . | . | . |
| n |
| Total number of words | 1,397,960 |
| Total number of sentences | 181,970 |
| Total number of entities (without O tags) | 1,177,660 |
| Total number of tags tags (without O tag) | 10 |
| Entity Type | Count | Ratio (%) |
|---|---|---|
| B-INGREDIENT | 210,082 | 15.03 |
| B-PRODUCT | 17,325 | 1.24 |
| B-QUANTITY | 209,867 | 15.01 |
| B-STATE | 135,315 | 9.68 |
| B-UNIT | 174,993 | 12.52 |
| I-INGREDIENT | 240,436 | 17.20 |
| I-PRODUCT | 55,212 | 3.95 |
| I-QUANTITY | 1919 | 0.14 |
| I-STATE | 130,158 | 9.31 |
| I-UNIT | 2.353 | 0.17 |
| O | 220,300 | 15.76 |
| Total | 1,397,960 | 100 |
| Iteration | Scheme 1 () | Scheme 2 () | Scheme 3 () | |||
|---|---|---|---|---|---|---|
| Data | Time (second) | Data | Time (second) | Data | Time (second) | |
| 1 | 2000 | 146 | 5000 | 268 | 10,000 | 914 |
| 2 | 6000 | 392 | 30,000 | 1.757 | 110,000 | 10.134 |
| 3 | 18,000 | 1.365 | 144,970 | 12.099 | 59,970 | 5.018 |
| 4 | 54,000 | 4.916 | - | - | - | - |
| 5 | 99,970 | 9.436 | - | - | - | - |
| Total | 179,970 | 16.255 | 179,970 | 14.124 | 179,970 | 16.066 |
| CRF | BiLSTM-CRF | BERT | ||||
|---|---|---|---|---|---|---|
| micro-avg | macro-avg | micro-avg | macro-avg | micro-avg | macro-avg | |
| Precision | 0.953 | 0.950 | 0.973 | 0.956 | 0.978 | 0.961 |
| Recall | 0.964 | 0.957 | 0.974 | 0.962 | 0.980 | 0.971 |
| F1-score | 0.958 | 0.953 | 0.973 | 0.959 | 0.979 | 0.966 |
| Class | CRF | BiLSTM-CRF | BERT | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| B-INGREDIENT | 0.948 | 0.951 | 0.949 | 0.969 | 0.974 | 0.972 | 0.979 | 0.981 | 0.980 |
| B-PRODUCT | 0.909 | 0.896 | 0.902 | 0.932 | 0.959 | 0.946 | 0.963 | 0.972 | 0.967 |
| B-QUANTITY | 0.998 | 0.998 | 0.998 | 0.999 | 0.999 | 0.999 | 1.000 | 0.999 | 0.999 |
| B-STATE | 0.955 | 0.947 | 0.951 | 0.969 | 0.971 | 0.970 | 0.981 | 0.979 | 0.980 |
| B-UNIT | 0.994 | 0.994 | 0.994 | 0.996 | 0.997 | 0.997 | 0.999 | 0.998 | 0.998 |
| I-INGREDIENT | 0.929 | 0.956 | 0.942 | 0.958 | 0.975 | 0.967 | 0.979 | 0.976 | 0.977 |
| I-PRODUCT | 0.846 | 0.923 | 0.883 | 0.918 | 0.973 | 0.945 | 0.927 | 0.986 | 0.956 |
| I-QUANTITY | 0.992 | 0.958 | 0.975 | 0.982 | 0.985 | 0.989 | 0.992 | 0.994 | 0.993 |
| I-STATE | 0.929 | 0.951 | 0.940 | 0.952 | 0.978 | 0.965 | 0.964 | 0.983 | 0.974 |
| I-UNIT | 1.000 | 1.000 | 1.000 | 0.999 | 0.998 | 0.999 | 1.000 | 1.000 | 1.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Komariah, K.S.; Purnomo, A.T.; Satriawan, A.; Hasanuddin, M.O.; Setianingsih, C.; Sin, B.-K. SMPT: A Semi-Supervised Multi-Model Prediction Technique for Food Ingredient Named Entity Recognition (FINER) Dataset Construction. Informatics 2023, 10, 10. https://doi.org/10.3390/informatics10010010
Komariah KS, Purnomo AT, Satriawan A, Hasanuddin MO, Setianingsih C, Sin B-K. SMPT: A Semi-Supervised Multi-Model Prediction Technique for Food Ingredient Named Entity Recognition (FINER) Dataset Construction. Informatics. 2023; 10(1):10. https://doi.org/10.3390/informatics10010010
Chicago/Turabian StyleKomariah, Kokoy Siti, Ariana Tulus Purnomo, Ardianto Satriawan, Muhammad Ogin Hasanuddin, Casi Setianingsih, and Bong-Kee Sin. 2023. "SMPT: A Semi-Supervised Multi-Model Prediction Technique for Food Ingredient Named Entity Recognition (FINER) Dataset Construction" Informatics 10, no. 1: 10. https://doi.org/10.3390/informatics10010010
APA StyleKomariah, K. S., Purnomo, A. T., Satriawan, A., Hasanuddin, M. O., Setianingsih, C., & Sin, B.-K. (2023). SMPT: A Semi-Supervised Multi-Model Prediction Technique for Food Ingredient Named Entity Recognition (FINER) Dataset Construction. Informatics, 10(1), 10. https://doi.org/10.3390/informatics10010010