
Machine Learning Applied to Banking Supervision a Literature Review



Abstract
:1. Introduction
- Institutions can have a comprehensive perspective on which risk assessment approaches are available and how they can evaluate their own exposures.
- Central banks can acquire an integrated view of several validated methodologies for risk assessment. These can be the pillars of their next decision support systems by laying down the technologies supporting risk assessment processes. Furthermore, this work can also incite surveys and case studies on the use and adoption of ML at central banks.
- Consultancy companies will benefit from a compendium of ML techniques and risk measures, to better support their clients.
- Academia receives an important contribution that gathers an extensive number of papers on risk assessment and collates the identified methodologies from a supervisory perspective. This will hopefully serve as a stepping stone for future developments in this area, and provide a baseline for testing new methodologies.
2. Methodology
2.1. Engines
2.2. Query
2.3. Steps
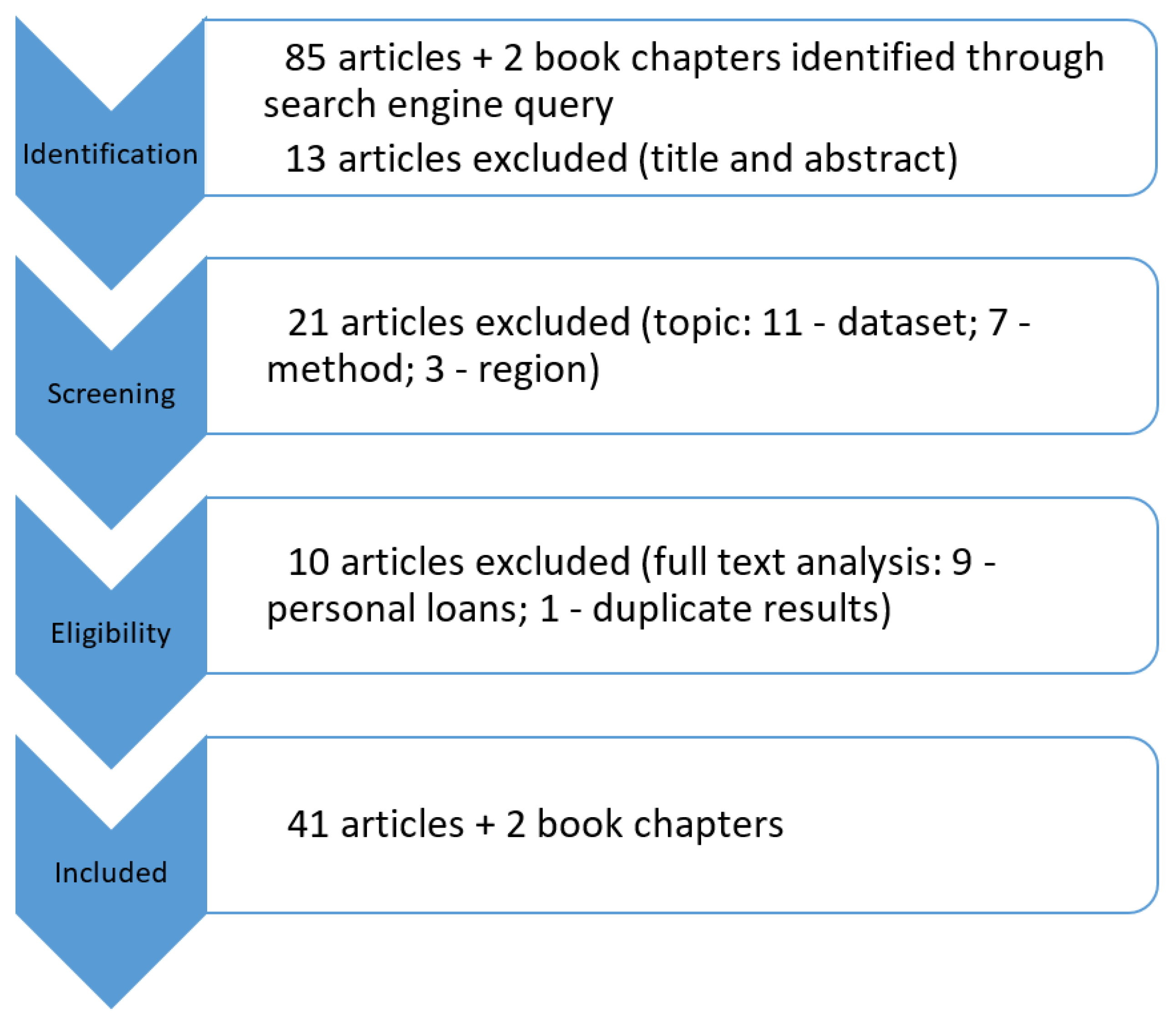
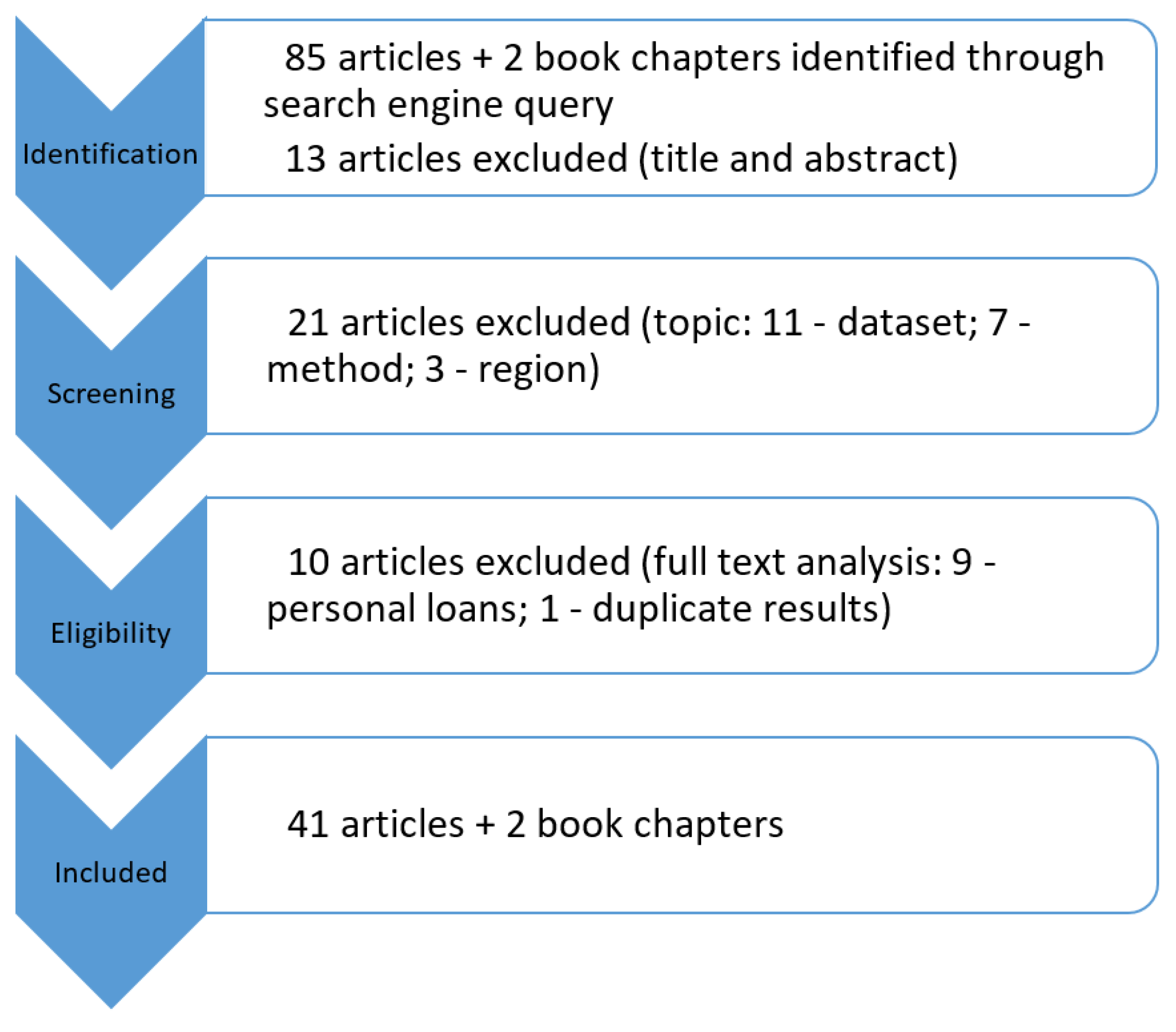
2.3.1. Identification
2.3.2. Screening
- Dataset: when the analysed paper used data other than the banking sector, it was discarded. We are aware that applications of ML to the stock market are a trendy topic in the literature, and that the insurance and pension funds sector is of great importance in the Eurozone. Nevertheless, the regulation is substantially different, and they would merit from a different study and approach;
- Methodology: risk assessment exercises are historically based on quantitative data, combined with expert judgment. Furthermore, it is the quantitative data that holds the largest amount of information regarding risk exposure practices. Therefore, we focus our analysis on quantitative methods, for which a risk assessment classification has already been assigned (leveraging on previous knowledge through supervised learning). We thus excluded works concerning unsupervised learning methods, or sentiment analysis (qualitative);
- Region: this criterion is closely related to the first, since regulation changes according to geography. We chose to focus mainly on works based upon institutions operating in the Eurozone. Nonetheless, relevant works by other central banks were considered eligible.
2.3.3. Eligibility
2.3.4. Considered Papers
3. Results
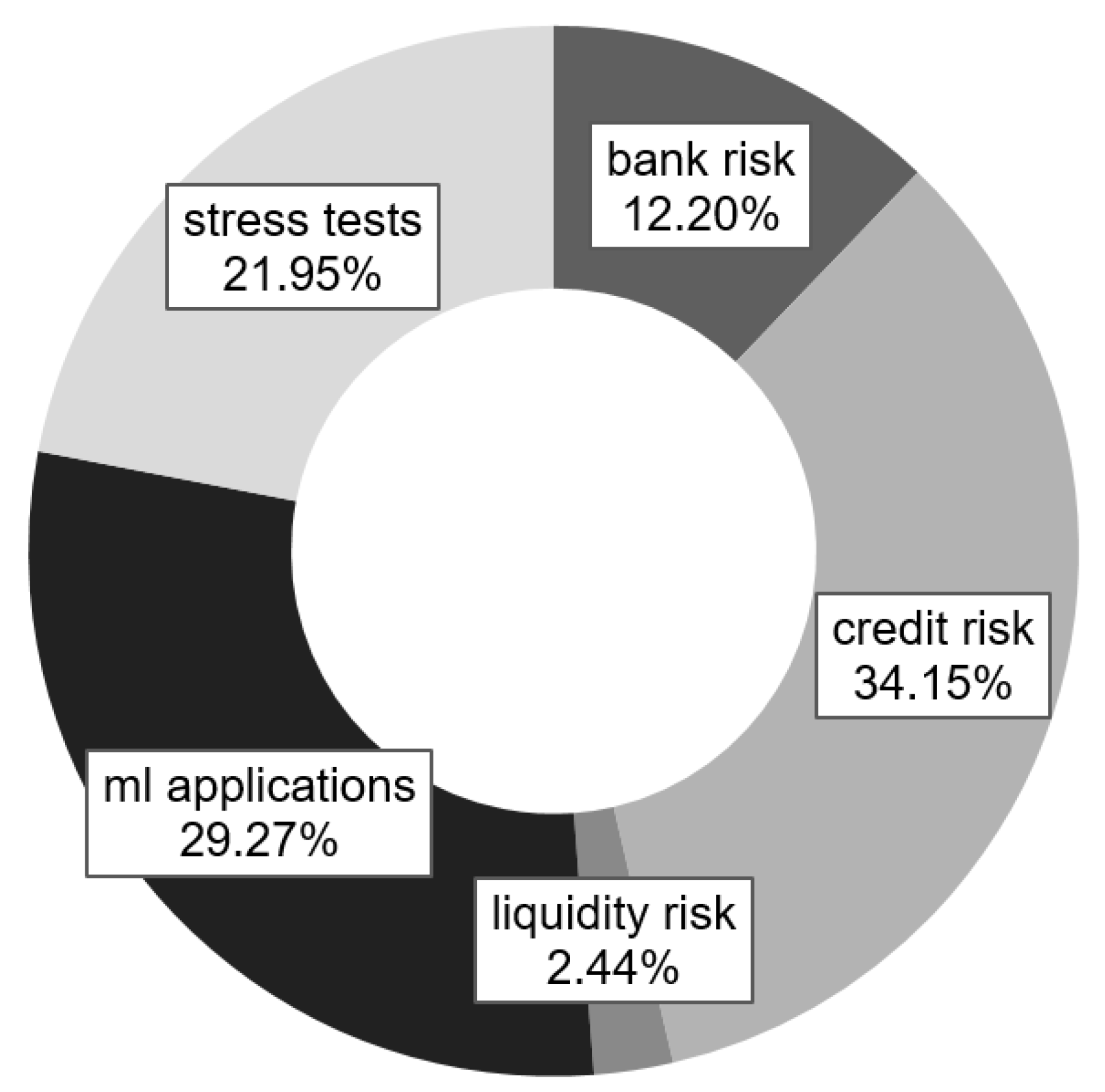
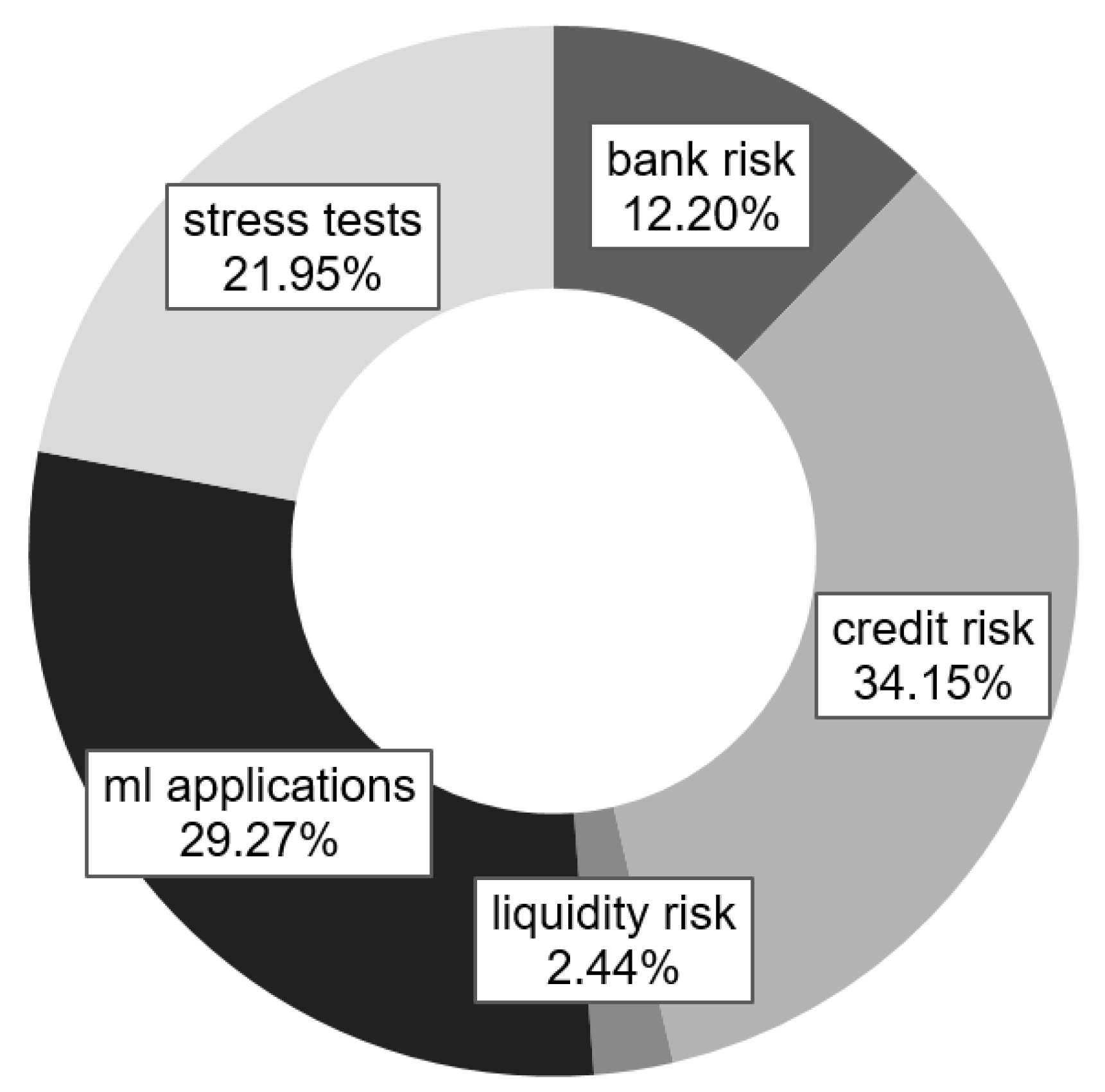
3.1. Distribution
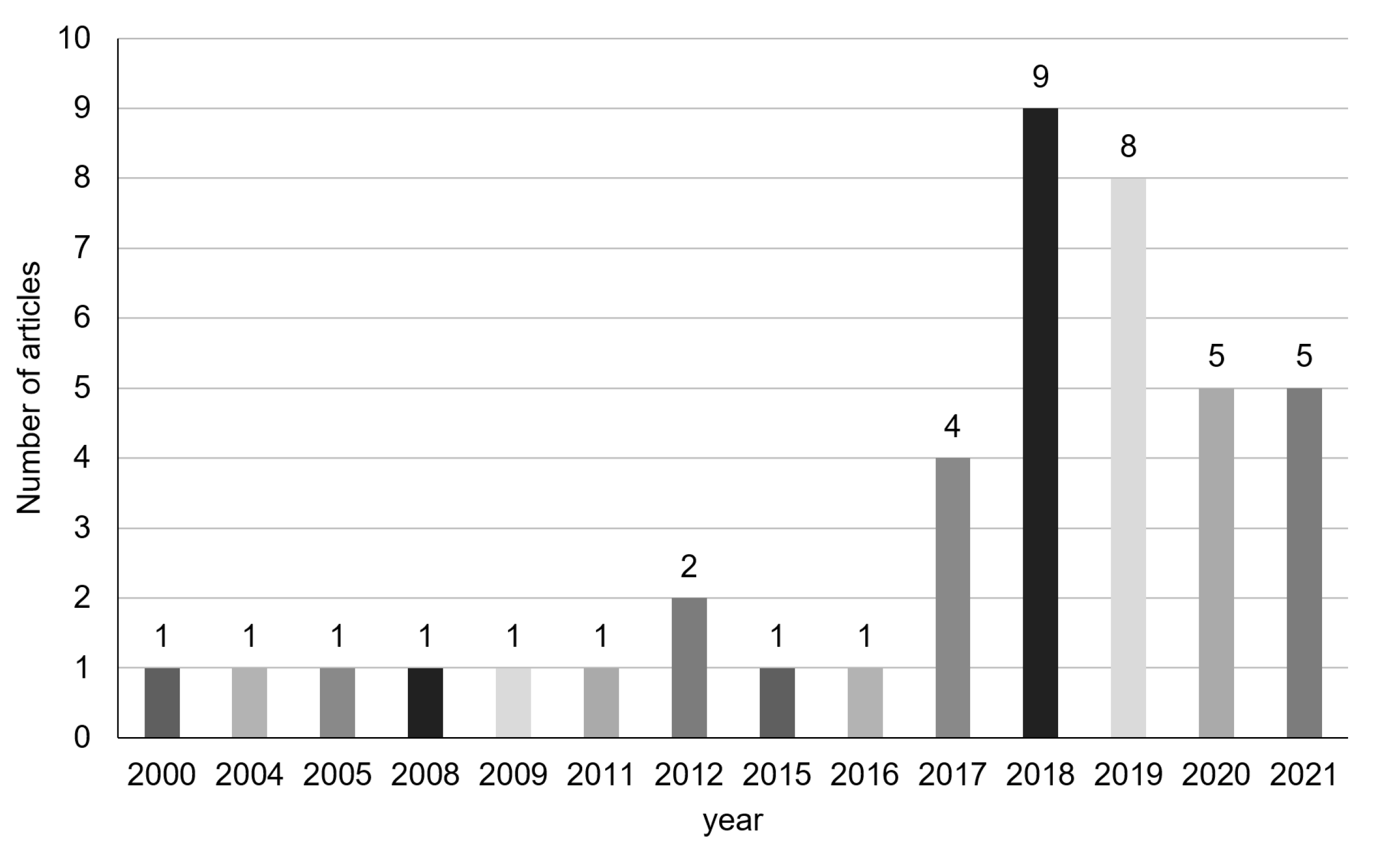
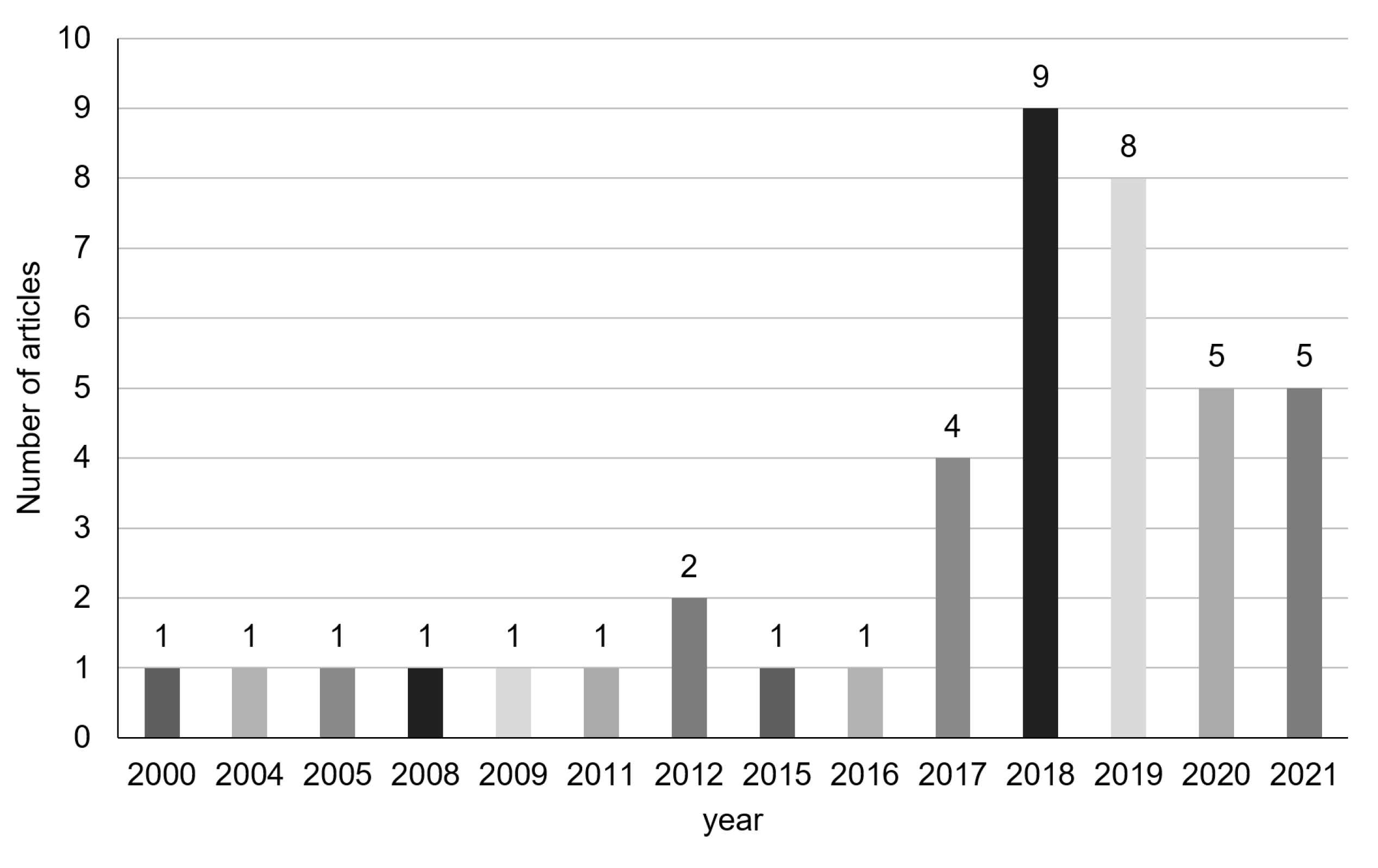
3.2. Evolution
3.2.1. 2000–2011
3.2.2. 2012–2016
3.2.3. 2017–2018
3.2.4. 2019–2021
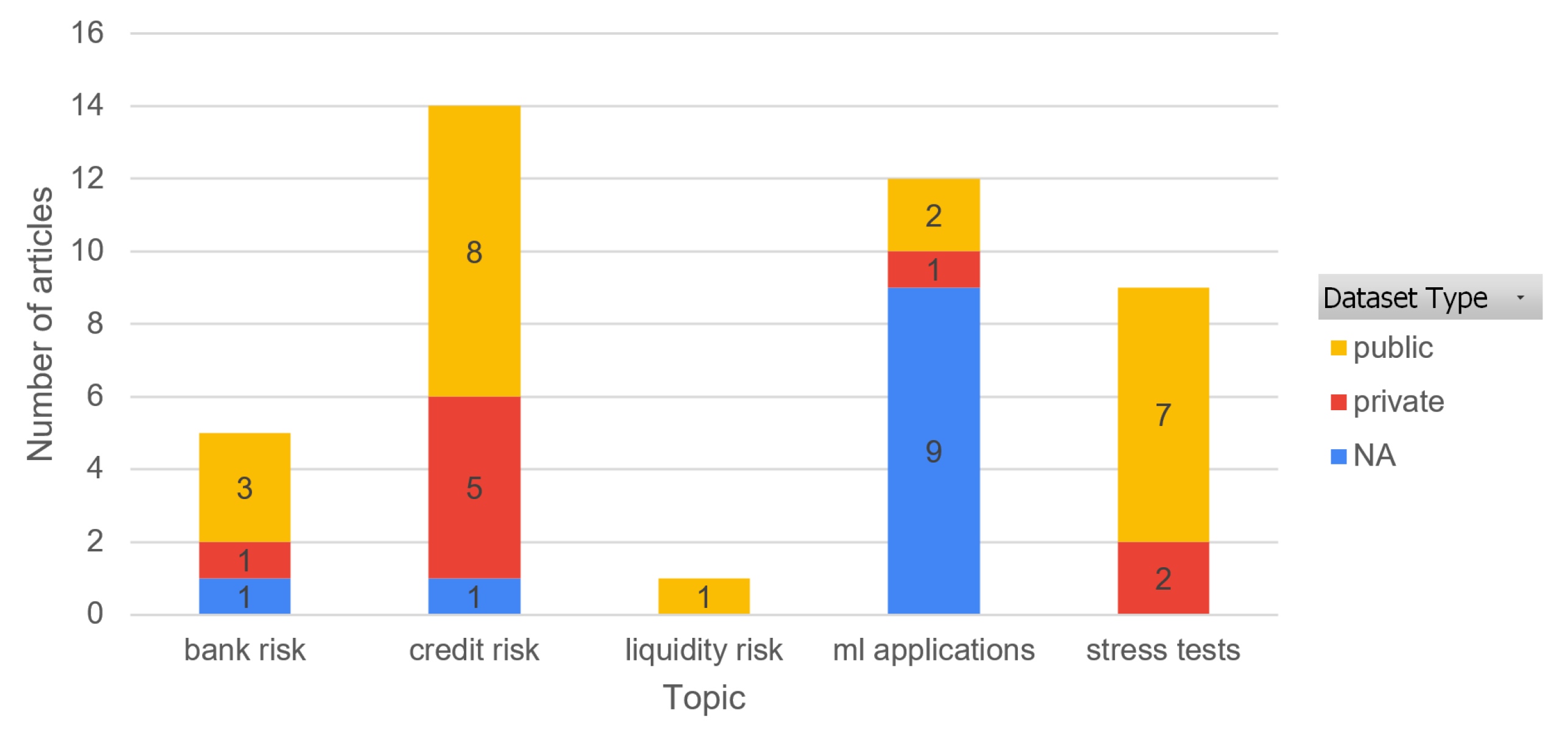
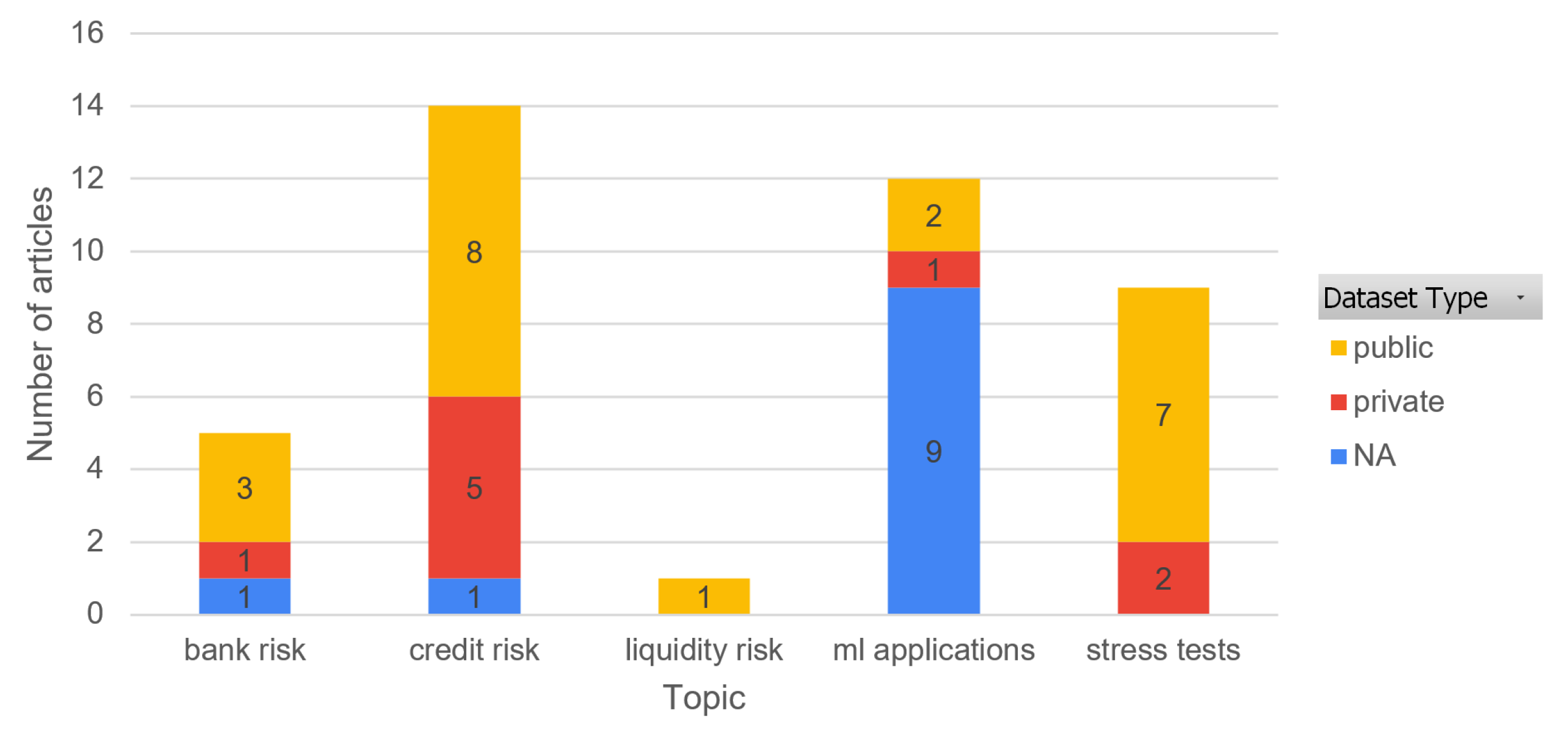
3.3. Datasets
3.4. Related Work
3.5. Global Analysis
4. Conclusions
Limitations and Future Work
- Assessment of credit defaults (the topic most explored in the reviewed literature);
- New stress test methodologies;
- Systemic risk detection;
- Other surveys regarding fin-tech and sup-tech.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Abellán, Joaquín, and Javier G. Castellano. 2017. A comparative study on base classifiers in ensemble methods for credit scoring. Expert Systems with Applications 73: 1–10. [Google Scholar] [CrossRef]
- Ala’raj, Maher, and Maysam F. Abbod. 2016. A new hybrid ensemble credit scoring model based on classifiers consensus system approach. Expert Systems with Applications 64: 36–55. [Google Scholar] [CrossRef]
- Alessi, Lucia, and Carsten Detken. 2018. Identifying excessive credit growth and leverage. Journal of Financial Stability 35: 215–25. [Google Scholar] [CrossRef]
- Alonso, Andrés, and Jose Manuel Carbo. 2020. Machine Learning in Credit Risk: Measuring the Dilemma Between Prediction and Supervisory Cost. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Alonso, Andrés, and Jose Manuel Carbo. 2021. Understanding the Performance of Machine Learning Models to Predict Credit Default: A Novel Approach for Supervisory Evaluation. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Altman, Edward. 1968. Financial Ratios, Discriminant Analysis and The Prediction of Corpporate Bankruptcy. The Journal of Finance XXIII: 589–609. [Google Scholar]
- Angelini, Eliana, Giacomo di Tollo, and Andrea Roli. 2008. A neural network approach for credit risk evaluation. Quarterly Review of Economics and Finance 48: 733–55. [Google Scholar] [CrossRef]
- Antunes, José Américo Pereira. 2021. To supervise or to self-supervise: A machine learning based comparison on credit supervision. Financial Innovation 7. [Google Scholar] [CrossRef]
- Boyacioglu, Melek Acar, Yakup Kara, and Ömer Kaan Baykan. 2009. Predicting bank financial failures using neural networks, support vector machines and multivariate statistical methods: A comparative analysis in the sample of savings deposit insurance fund (SDIF) transferred banks in Turkey. Expert Systems with Applications 36, Pt 2: 3355–66. [Google Scholar] [CrossRef]
- Broeders, Dirk, and Jeremy Prenio. 2018. FSI Insights Innovative technology in financial supervision. FSI Insights on Policy Implementation 2018: 29. [Google Scholar]
- Burstein, Frada, Clyde W. Holsapple, and Daniel J. Power. 2008. Decision Support Systems: A Historical Overview. Berlin/Heidelberg: Springer. [Google Scholar] [CrossRef]
- Chakraborty, Chiranjit, and Andreas Joseph. 2017. Machine Learning at Central Banks. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Chang, Yung Chia, Kuei Hu Chang, and Guan Jhih Wu. 2018. Application of eXtreme gradient boosting trees in the construction of credit risk assessment models for financial institutions. Applied Soft Computing Journal 73: 914–20. [Google Scholar] [CrossRef]
- Chaudhuri, Arindam, and Kajal De. 2011. Fuzzy Support Vector Machine for bankruptcy prediction. Applied Soft Computing Journal 11: 2472–86. [Google Scholar] [CrossRef]
- Chen, Tianqi, and Carlos Guestrin. 2016. XGBoost: A scalable tree boosting system. Paper presented at ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13–17; pp. 785–94. [Google Scholar] [CrossRef] [Green Version]
- Climent, Francisco, Alexandre Momparler, and Pedro Carmona. 2019. Anticipating bank distress in the Eurozone: An Extreme Gradient Boosting approach. Journal of Business Research 101: 885–96. [Google Scholar] [CrossRef]
- Dastile, Xolani, Turgay Celik, and Moshe Potsane. 2020. Statistical and machine learning models in credit scoring: A systematic literature survey. Applied Soft Computing Journal 91: 106263. [Google Scholar] [CrossRef]
- de Portugal, Banco. 2021. Banco de Portugal Microdata Research Laboratory. Available online: https://bplim.bportugal.pt (accessed on 4 May 2021).
- di Castri, Simone, Stefan Hohl, and Arend Kulenkampff. 2019. FSI Insights on policy implementation No. 19: The suptech generations. Financial Stability Institute 19: 19. [Google Scholar]
- Doerr, By Sebastian, Leonardo Gambacorta, and Jose Maria Serena. 2021. How do central banks use big data and machine learning? The European Money and Finance Forum 67: 1–6. Available online: https://www.bis.org/publ/work930.pdf (accessed on 20 May 2021).
- Dwivedi, Yogesh K., Laurie Hughes, Elvira Ismagilova, Gert Aarts, Crispin Coombs, Tom Crick, Yanqing Duan, Rohita Dwivedi, John Edwards, Aled Eirug, and et al. 2021. Artificial Intelligence (AI): Multidisciplinary perspectives on emerging challenges, opportunities, and agenda for research, practice and policy. International Journal of Information Management 57. [Google Scholar] [CrossRef]
- European Banking Authority. 2013. EBA Implementing Technical Standards (ITS). Available online: http://www.eba.europa.eu/documents/10180/532570/EBA-ITS-2013-12+(Final+draft+ITS+on+Hypothetical+Capital+of+a+CCP).pdf (accessed on 20 May 2021).
- European Commission. 2015. Single Supervisory Mechanism. Brussels: European Commission. [Google Scholar]
- Filippopoulou, Chryssanthi, Emilios Galariotis, and Spyros Spyrou. 2020. An early warning system for predicting systemic banking crises in the Eurozone: A logit regression approach. Journal of Economic Behavior and Organization 172: 344–63. [Google Scholar] [CrossRef]
- Galindo, Juan, and Pablo Tamayo. 2000. Credit risk assessment using statistical and machine learning: Basic methodology and risk modeling applications. Computational Economics 15: 107–43. [Google Scholar] [CrossRef]
- Gogas, Periklis, Theophilos Papadimitriou, and Anna Agrapetidou. 2018. Forecasting bank failures and stress testing: A machine learning approach. International Journal of Forecasting 34: 440–55. [Google Scholar] [CrossRef]
- Gusenbauer, Michael. 2019. Google Scholar to overshadow them all? Comparing the sizes of 12 academic search engines and bibliographic databases. Scientometrics 118: 177–214. [Google Scholar] [CrossRef] [Green Version]
- Hammer, Peter L., Alexander Kogan, and Miguel A. Lejeune. 2012. A logical analysis of banks’ financial strength ratings. Expert Systems with Applications 39: 7808–21. [Google Scholar] [CrossRef]
- Hillegeist, Stephen A., Elizabeth K. Keating, Donald P. Cram, and Kyle G. Lundstedt. 2004. Assessing the probability of bankruptcy. Review of Accounting Studies 9: 5–34. [Google Scholar] [CrossRef]
- Huang, Shian Chang, Cheng Feng Wu, Chei Chang Chiou, and Meng Chen Lin. 2021. Intelligent FinTech Data Mining by Advanced Deep Learning Approaches. Computational Economics. [Google Scholar] [CrossRef]
- Jagtiani, Julapa, Larry Wall, and Todd Vermilyea. 2018. The Roles of Big Data and Machine Learning in Bank Supervision. Banking Perspectives, Forthcoming, 1–11. [Google Scholar]
- Kolari, James W., Félix J. López-Iturriaga, and Ivan Pastor Sanz. 2019. Predicting European bank stress tests: Survival of the fittest. Global Finance Journal 39: 44–57. [Google Scholar] [CrossRef]
- Kou, Gang, Xiangrui Chao, Yi Peng, Fawaz E. Alsaadi, and Enrique Herrera-Viedma. 2019. Machine learning methods for systemic risk analysis in financial sectors. Technological and Economic Development of Economy 25: 716–42. [Google Scholar] [CrossRef]
- Kupiec, Paul H. 2018. On the accuracy of alternative approaches for calibrating bank stress test models. Journal of Financial Stability 38: 132–46. [Google Scholar] [CrossRef]
- Le, Hong Hanh, and Jean Laurent Viviani. 2018. Predicting bank failure: An improvement by implementing a machine-learning approach to classical financial ratios. Research in International Business and Finance 44: 16–25. [Google Scholar] [CrossRef]
- Lee, In, and Yong Jae Shin. 2020. Machine learning for enterprises: Applications, algorithm selection, and challenges. Business Horizons 63: 157–70. [Google Scholar] [CrossRef]
- Leo, Martin, Suneel Sharma, and Koilakuntla Maddulety. 2019. Machine learning in banking risk management: A literature review. Risks 7. [Google Scholar] [CrossRef] [Green Version]
- López Iturriaga, Félix J., and Iván Pastor Sanz. 2015. Bankruptcy visualization and prediction using neural networks: A study of U.S. commercial banks. Expert Systems with Applications 42: 2857–69. [Google Scholar] [CrossRef]
- Massaro, Paolo, Ilaria Vannini, and Oliver Giudice. 2020. Institutional Sector Cassifier, a Machine Learning Approach. SSRN Electronic Journal 548. [Google Scholar] [CrossRef]
- Milian, Eduardo Z., Mauro de M. Spinola, and Marly M. de Carvalho. 2019. Fintechs: A literature review and research agenda. Electronic Commerce Research and Applications 34. [Google Scholar] [CrossRef]
- Min, Jae H., and Young Chan Lee. 2005. Bankruptcy prediction using support vector machine with optimal choice of kernel function parameters. Expert Systems with Applications 28: 603–14. [Google Scholar] [CrossRef]
- Moody’s. 2021. Moody’s DataHub. Available online: https://datahub.moodys.io/ (accessed on 21 June 2021).
- Ohlson, James A. 1980. Financial Ratios and the Probabilistic Prediction of Bankruptcy. Journal of Accounting Research 18: 109. [Google Scholar] [CrossRef] [Green Version]
- Petropoulos, Anastasios, Vasilis Siakoulis, Evaggelos Stavroulakis, and Aristotelis Klamargias. 2018. A robust machine learning approach for credit risk analysis of large loan level datasets using deep learning and extreme gradient boosting. The Use of Big Data Analytics and Artificial Intelligence in Central Banking 50: 30–31. [Google Scholar]
- Pompella, Maurizio, and Antonio Dicanio. 2017. Ratings based Inference and Credit Risk: Detecting likely-to-fail Banks with the PC-Mahalanobis Method. Economic Modelling 67: 34–44. [Google Scholar] [CrossRef]
- Ribeiro, Bernardete, Catarina Silva, Ning Chen, Armando Vieira, and João Carvalho Das Neves. 2012. Enhanced default risk models with SVM+. Expert Systems with Applications 39: 10140–52. [Google Scholar] [CrossRef]
- Soui, Makram, Ines Gasmi, Salima Smiti, and Khaled Ghédira. 2019. Rule-based credit risk assessment model using multi-objective evolutionary algorithms. Expert Systems with Applications 126: 144–57. [Google Scholar] [CrossRef]
- Strydom, Moses, and Sheryl Buckley. 2019. Hershey: IGI Global. In AI and Big Data’s Potential for Disruptive Innovation, 1st ed. Engineering Science Reference. Hershey: IGI Global. [Google Scholar] [CrossRef]
- Tavana, Madjid, Amir Reza Abtahi, Debora Di Caprio, and Maryam Poortarigh. 2018. An Artificial Neural Network and Bayesian Network model for liquidity risk assessment in banking. Neurocomputing 275: 2525–54. [Google Scholar] [CrossRef]
- Wang, Tongyu, Shangmei Zhao, Guangxiang Zhu, and Haitao Zheng. 2021. A machine learning-based early warning system for systemic banking crises. Applied Economics 53: 1–19. [Google Scholar] [CrossRef]
- Xia, Yufei, Chuanzhe Liu, Yu Ying Li, and Nana Liu. 2017. A boosted decision tree approach using Bayesian hyper-parameter optimization for credit scoring. Expert Systems with Applications 78: 225–41. [Google Scholar] [CrossRef]
- Zhang, Yicheng, Jipeng Gao, and Haolin Zhou. 2020. ImageNet Classification with Deep Convolutional Neural Networks. In ACM International Conference Proceeding Series. New York: Association for Computing Machinery, vol. 2, pp. 145–151. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Year | Summary Sentence |
|---|---|---|
| Galindo et al. | 2000 | CART decision-trees out-perform statistics for credit risk assessment, using a commercial bank loans dataset |
| Hillegeist et al. | 2004 | Black–Scholes–Merton option-pricing model is a better indicator of bankruptcy probability than Z-Score and O-Score. |
| Min et al. | 2005 | Motivated by the increasing use of machine learning techniques, this paper aims to outperform classical statistics in bankruptcy prediction. An optimised SVM model performs better than MDA, logit and BPN for bankruptcy prediction. |
| Angelini et al. | 2008 | Regulation-imposed capital requirements increase the need for precise credit risk assessment systems. This paper shows ANNs’ very good results predicting the default tendency of a borrower. |
| Boyacioglu et al. | 2009 | Multi-layer perceptrons and learning vector quantization are the most successful models predicting bank failure as a classification problem, in a Turkish case. |
| Chaudhuri et al. | 2011 | Fuzzy-SVM satisfies Basel II demands for detecting bankruptcy probability, outperforming other approaches. This algorithm also proved to have more clustering capabilities than PNN. |
| Hammer et al. | 2012 | The logical analysis of data (LAD) is able to reverse-engineer Fitch risk ratings of bank, showing better results than support-vector machines and logistic regression when evaluating the creditworthiness of banks. |
| Ribeiro et al. | 2012 | This study establishes the limitations of using exclusively quantitative financial data when developing default risk models. The authors propose a new approach that includes contextual knowledge in an SVM model, showing better predictability performance t |
| Lopez Iturriaga et al. | 2015 | Profiling distressed banks using self-organising maps and modelling failure detection with multi-layer perceptron outperforms traditional models of bankruptcy prediction. The resulting model detects 96% of failures, up to 3 years before the bankruptcy ev |
| Ala’raj et al. | 2016 | The proposed hybrid ensemble model improves predicting capability compared to base classifiers, using 7 real-world datasets. It uses a classifier consensus system to compare this new approach with the traditional combination methods. |
| Abellan et al. | 2017 | Selection of the best base classifier in ensemble methods for credit scoring problems. The individual performance of classifiers is not the only criteria for ensemble schemes. |
| Chakraborty et al. | 2017 | An overview of the applications of machine learning to financial problems, the most popular modelling approaches, and three case studies of relevant works for central banks. This study also establishes that machine learning models usually outperform tradi |
| Pompella et al. | 2017 | An EWS is proposed to detect likely-to-fail banks. This method is compared with risk agencies’ rating and detects possibly wrongly rated banks. The authors suggest the adoption of this EWS by regulators. |
| Xia et al. | 2017 | The credit scoring problem is addressed using a XGBoost model with Bayesian hyper-parameter optimisation, not only obtaining better accuracy than baseline models, but also providing feature importance and a decision chart for interpretability. |
| Alessi et al. | 2018 | The use of random forest to predict banking crises secondary to excessive credit growth, using credit and real estate predictors. |
| Broeders et al. | 2018 | A survey on the use of innovative technologies in financial supervision, the challenges faced by supervisory agencies and the need for a clear suptech strategy. Additionally, the experience of early adopters is described. |
| Chang et al. | 2018 | The development of a credit risk model using XGBoost classifier to address the heterogeneous nature of financial data. An under-sampling method is applied to deal with the imbalanced data. |
| Gogas et al. | 2018 | Outperforming the Ohlson’s score with stress-testing tool based on a support-vector machine model to forecast bank failures. The adopted methodology defines a clear boundary between solvent and insolvent banks. |
| Jagtiani et al. | 2018 | The impact of machine learning in banking supervision in terms of new possible analytical solutions and risks involved in those new approaches. |
| Kupiec et al. | 2018 | Addressing the need for validation of bank stress test models, by emphasising model forecast accuracy. A Lasso model shows the best forecasting capabilities for determining capital requirements in stressful conditions. |
| Le et al. | 2018 | Artificial neural networks and k-nearest neighbour methods are more accurate for predicting bank failure than traditional statistics. |
| Petropoulos et al. | 2018 | Predicting the probability of default of Greek banks using data mining techniques to reduce dimensionality, with XGBoost emerging as the best model. The authors aim to fully capture the information within these large datasets to better support the overall |
| Tavana et al. | 2018 | Addressing liquidity risk assessment through a model that uses neural networks and Bayesian networks. The models were capable of distinguishing the most critical factors in liquidity risk measurement. |
| Climent et al. | 2019 | Using XGBoost to identify the best predictors of bank failure and develop a classification model to label failed and non-failed banks in the Eurozone. The data used in this study is composed of 25 annual financial ratios for commercial banks in the Eurozo |
| Dwivedi et al. | 2019 | Expert contributors identify and compile a series of opportunities, impacts and research topics raised by the rapid adoption of AI. The financial sector shows enormous potential in robot advisory and automation, and bankruptcy prediction. |
| Hohl et al. | 2019 | A survey of activities within the scope of suptech, classifying the degree of technological development, and the strategies in place to implement them, highlighting the experimental nature of these initiatives and the need for international coordination. |
| Kolari et al. | 2019 | Successfully undergoing European bank stress-tests depends largely on the risks a bank is exposed to, as opposed to being prepared for specific adverse scenarios. Using Bankscope data, the developed model accurately predicts 90% of the failing banks. |
| Kou et al. | 2019 | A survey depicting the most common methodologies to assess systemic risk in the financial system, using machine learning, big data analysis, network analysis and sentiment analysis. The paper showcases current researches on the use of machine learning in |
| Leo et al. | 2019 | A literature review evidencing machine learning use for risk management purposes in the banking industry, while also noting the experimental nature of most approaches. |
| Milian et al. | 2019 | A literature review aiming to find consensus on a fintech definition, showing how banks and supervisory agencies are using these innovative technologies and dealing with the risks involved. |
| Soui et al. | 2019 | Using evolutionary algorithms to address credit risk assessment by considering it as an optimisation (rule-based) search problem: minimise complexity, maximise accuracy and weight (rules importance). |
| Alonso et al. | 2020 | Comparing machine learning models from credit default prediction. Necessity for a structured strategy for assessing ML models to increase transparency in the use of these technologies, and promote innovation in the financial industry. |
| Dastile et al. | 2020 | A systematic literature review on how statistic and machine learning techniques have been used to address the credit scoring problem. Although machine learning is often incapable of explaining predictions, these models consistently outperform the classic |
| Filippopoulou et al. | 2020 | Developing an EWS to detect systemic banking crisis based on the ECB Macroprudential database. Most of the risk indicators used in the dataset are key to forecast a systemic risk crisis 1 to 4 years before the event. |
| Giudice et al. | 2020 | Developing an automatic classification system for the sector of economic activity for Italian companies, using a multi-step classifier with gradient boosting and support-vector machine models. The developed model is already being used in a production envi |
| Lee et al. | 2020 | A study on types of machine learning applications, exploring the accuracy-interpretability trade-off, and three use cases in financial industry. |
| Alonso et al. | 2021 | Predicting credit default probability with machine learning surpasses traditional statistic methods, potentially leading to savings of up to 17% in regulatory capital requirements. |
| Antunes | 2021 | Establishing the need for supervisory on-site inspection by comparing the results of two machine learning models, one based on the banks’ own risk assessment and the other based on the findings from previous on-site inspections. |
| Doerr et al. | 2021 | Policy brief showing central banks are relying on big data for daily tasks, and identifying a clear need for specialised knowledge on how to adequately use machine learning, and extract greater value from that data. |
| Huang et al. | 2021 | This study is developed under the assumption that the intricate nature of financial data cannot be properly explored through traditional methods. An advanced deep learning model to address the complex and hierarchical features of financial data, that outperforms traditional methods and other advanced approaches. |
| Wang et al. | 2021 | Random forest based EWS outperforms the classic logit approach as the predictive tool to prevent systemic banking crises. This paper shows an expert voting approach to model the multivariate nature of systemic risk assessment data. |
| Authors | Year | Affiliation | Title | Citations |
|---|---|---|---|---|
| Abellan et al. | 2017 | academia | A comparative study on base classifiers in ensemble methods for credit scoring | 88 |
| Ala’raj et al. | 2016 | academia | A new hybrid ensemble credit scoring model based on classifiers consensus system approach | 66 |
| Alessi et al. | 2018 | central bank | Identifying excessive credit growth and leverage | 135 |
| Alonso et al. | 2020 | central bank | Machine Learning in Credit Risk: Measuring the Dilemma Between Prediction and Supervisory Cost | 1 |
| 2021 | central bank | Understanding the Performance of Machine Learning Models to Predict Credit Default: A Novel Approach for Supervisory Evaluation | 0 | |
| Angelini et al. | 2008 | academia | A neural network approach for credit risk evaluation | 305 |
| Antunes | 2021 | central bank | To supervise or to self-supervise: A machine learning based comparison on credit supervision | 0 |
| Boyacioglu et al. | 2009 | academia | Predicting bank financial failures using neural networks, support vector machines and multivariate statistical methods: A comparative analysis in the sample of savings deposit insurance fund (SDIF) transferred banks in Turkey | 272 |
| Broeders et al. | 2018 | industry | FSI Insights Innovative technology in financial supervision | 23 |
| Chakraborty et al. | 2017 | central bank | Machine Learning at Central Banks | 62 |
| Chang et al. | 2018 | academia | Application of eXtreme gradient boosting trees in the construction of credit risk assessment models for financial institutions | 17 |
| Chaudhuri et al. | 2011 | academia | Fuzzy Support Vector Machine for bankruptcy prediction | 155 |
| Climent et al. | 2019 | academia | Anticipating bank distress in the Eurozone: An Extreme Gradient Boosting approach | 10 |
| Dastile et al. | 2020 | academia | Statistical and machine learning models in credit scoring: A systematic literature survey | 0 |
| Doerr et al. | 2021 | industry | How do central banks use big data and machine learning? | 0 |
| Dwivedi et al. | 2019 | academia | Artificial Intelligence (AI): Multidisciplinary perspectives on emerging challenges, opportunities, and agenda for research, practice and policy | 39 |
| Filippopoulou et al. | 2020 | academia | An early warning system for predicting systemic banking crises in the Eurozone: A logit regression approach | 1 |
| Galindo et al. | 2000 | academia | Credit risk assessment using statistical and machine learning: Basic methodology and risk modeling applications | 213 |
| Giudice et al. | 2020 | central bank | Institutional Sector Classifier, a Machine Learning Approach | 0 |
| Gogas et al. | 2018 | academia | Forecasting bank failures and stress testing: A machine learning approach | 20 |
| Hammer et al. | 2012 | academia | A logical analysis of banks’ financial strength ratings | 49 |
| Hillegeist et al. | 2004 | academia | Assessing the probability of bankruptcy | 1393 |
| Hohl et al. | 2019 | industry | FSI Insights on policy implementation The suptech generations | 3 |
| Huang et al. | 2021 | academia | Intelligent FinTech Data Mining by Advanced Deep Learning Approaches | 0 |
| Jagtiani et al. | 2018 | central bank | The Roles of Big Data and Machine Learning in Bank Supervision | 4 |
| Kolari et al. | 2019 | academia | Predicting European bank stress tests: Survival of the fittest | 4 |
| Kou et al. | 2019 | academia | Machine learning methods for systemic risk analysis in financial sectors | 47 |
| Kupiec et al. | 2018 | industry | On the accuracy of alternative approaches for calibrating bank stress test models | 5 |
| Le et al. | 2018 | academia | Predicting bank failure: An improvement by implementing a machine-learning approach to classical financial ratios | 24 |
| Lee et al. | 2020 | academia | Machine learning for enterprises: Applications, algorithm selection, and challenges | 7 |
| Leo et al. | 2019 | (blank) | Machine learning in banking risk management: A literature review | 11 |
| Lopez Iturriaga et al. | 2015 | academia | Bankruptcy visualization and prediction using neural networks: A study of U.S. commercial banks | 129 |
| Milian et al. | 2019 | academia | Fintechs: A literature review and research agenda | 31 |
| Min et al. | 2005 | academia | Bankruptcy prediction using support vector machine with optimal choice of kernel function parameters | 866 |
| Petropoulos et al. | 2018 | central bank | A robust machine learning approach for credit risk analysis of large loan level datasets using deep learning and extreme gradient boosting | 6 |
| Pompella et al. | 2017 | academia | Ratings based Inference and Credit Risk: Detecting likely-to-fail Banks with the PC-Mahalanobis Method | 5 |
| Ribeiro et al. | 2012 | academia | Enhanced default risk models with SVM+ | 57 |
| Soui et al. | 2019 | academia | Rule-based credit risk assessment model using multi-objective evolutionary algorithms | 3 |
| Tavana et al. | 2018 | academia | An Artificial Neural Network and Bayesian Network model for liquidity risk assessment in banking | 30 |
| Wang et al. | 2021 | academia | A machine learning-based early warning system for systemic banking crises | 2 |
| Xia et al. | 2017 | academia | A boosted decision tree approach using Bayesian hyper-parameter optimization for credit scoring | 158 |
| Quartile/Origin | Journal | Number of Papers |
|---|---|---|
| A (ERA) | Advances in Neural Information Processing Systems | 1 |
| Banca d’Italia | Questioni di Economia e Finanza | 1 |
| Banco de España | SSRN Electronic Journal | 2 |
| Bank for International Settlements | FSI Insights on policy implementation | 2 |
| Bank of England | Bank of England | 1 |
| Bank of Greece | Ninth IFC Conference on “Are post-crisis statistical initiatives completed?” | 1 |
| Federal Reserve | Banking Perspectives, Forthcoming | 1 |
| Q1 | Applied Soft Computing Journal | 3 |
| Business Horizons | 1 | |
| Electronic Commerce Research and Applications | 1 | |
| Expert Systems with Applications | 9 | |
| International Journal of Forecasting | 1 | |
| International Journal of Information Management | 1 | |
| Journal of Business Research | 1 | |
| Journal of Economic Behavior and Organization | 1 | |
| Journal of Financial Stability | 2 | |
| Neurocomputing | 1 | |
| Research in International Business and Finance | 1 | |
| Review of Accounting Studies | 1 | |
| Technological and Economic Development of Economy | 1 | |
| Q2 | Applied Economics | 1 |
| Computational Economics | 2 | |
| Economic Modelling | 1 | |
| Financial Innovation | 1 | |
| Global Finance Journal | 1 | |
| Quarterly Review of Economics and Finance | 1 | |
| Risks | 1 | |
| SUERF | SUERF—The European Money and Finance Forum | 1 |
| Authors | ML Methods | Dataset |
|---|---|---|
| Abellan et al. | ada-boosting, bagging, random subspace, DECORATE, rotation forest | public: Australian, German, and Japanese datasets obtained from UCI repository of machine learning; Iranian dataset from “A comparison between statistical and data mining methods for credit scoring in case of limited available data. (2007)”; Polish datase |
| Ala’raj et al. | neural networks, support vector machines, random forests, decision trees, Naive Bayes | public: Australian, German, and Japanese datasets obtained from UCI repository of machine learning; Iranian dataset from “A comparison between statistical and data mining methods for credit scoring in case of limited available data. (2007)”; Polish datase |
| Alessi et al. | logit, decision trees, random forest | public: crisis dataset by Detken et al. 2014, capturing systemic banking crises related to domestic credit cycle |
| Alonso et al. | logit, lasso, CART, random forest, xgboost, deep learning | private: anonymized dataset from Banco Santander, containing more than 75,000 credit operations |
| Alonso et al. | logit, lasso, CART, random forest, xgboost, deep learning, RL & ensemble methods | public: kaggle.com “Give me some credit” dataset |
| Angelini et al. | ann | private: SME loans from na Italian bank |
| Antunes | random forest | public: Central Bank of Brazil financial series repository |
| Boyacioglu et al. | Multi-layer perceptron, Competitive learning, Self-organizing map, Learning vector quantization, Support vector machines, Multivariate discriminant analysis, K-means cluster analysis, Logistic regression analysis | public: financial ratios using CAMELS system; annual publication “Banks Association of Turkey” |
| Broeders et al. | NA | NA |
| Chakraborty et al. | ann, dt, svm, clustering | NA |
| Chang et al. | logit, gmdh, svm, xgboost | private: credit data from a financial institution in Taiwan (2009–2016) |
| Chaudhuri et al. | logit, ann, svm, ga-svm, fuzzy-svm | private: dataset comprising American organizations with capitalization greater than $1 billion that filed for protection (2001–2002). |
| Climent et al. | xgboost | public: Orbis database (2006–2016) |
| Dastile et al. | LR (Logistic Regression), NB (Naïve Bayes), LDA (Linear Discriminant Analysis), XGB (XGBoost), EML (Extreme Learning Machines), k-NN (k-Nearest Neighbor), SVM (Support Vector Machine), ANN (Artificial Neural Network), BA (Bagging), BO (Boosting), RF (Rand) | NA |
| Doerr et al. | NA | NA |
| Dwivedi et al. | evolution | NA |
| Filippopoulou et al. | logit, ewm | public: Macroprudential Database by the ECB |
| Galindo et al. | probit, knn, dt, CART | private: loans from a commercial bank provided by Comision Nacional Bancaria y de Valores (Mexico’s security exchange and banking commission) |
| Giudice et al. | svm, xgboost | private: Bank of Italy Entities Register |
| Gogas et al. | O-score, svm | public: US banks (2007–2013); 481 failed and 962 solvent banks (1443 in total). |
| Hammer et al. | logit, svm, lad | public: 800 banks rated by Fitch along with 24 explanatory variables (2001). |
| Hillegeist et al. | logit, classic statistics | public: Moody’s Default Risk Services’ Corporate Default database and SDC Platinum Corporate Restructurings database (1980–2000) |
| Hohl et al. | evolution | NA |
| Huang et al. | deep CCAE, fuzzy rules, fuzzy rough nn, fuzzy nn, random tree, random forest | public: enterprise financial statement information from Taiwan securities market—Taiwan Economic Journal (2008–2013) |
| Jagtiani et al. | evolution, big data, ml | NA |
| Kolari et al. | AdaBoost, logit, ann, random forest, svm radial, svm linear | public: Bankscope database (2010, 2011 and 2014); 273 banks where 29 failed at least one stress test |
| Kou et al. | comparison | NA |
| Kupiec et al. | comparison; classic methods severely underestimate stress tests | public: quarterly financial data (balance sheet, income statements, etc.) from Federal Reserve Bank of St. Louis FRED economic database (1993–2011) |
| Le et al. | svm, ann, k-NN, linear discriminant analysis, logit | public: Bankscope database (2010–2016); 3000 US banks, 1438 failed, 1562 active. 31 ratios based on financial statements |
| Lee et al. | evolution | NA |
| Leo et al. | evolution | NA |
| Lopez Iturriaga et al. | mlp, som | public: 32 indicators extracted from financial statements—Federal Deposit Insurance Corporation between 2002 and 2012 |
| Milian et al. | evolution | NA |
| Min et al. | mda, logit, svm, ann backpropagation | private: a Korean credit guarantee organization (2000–2002); 1888 institutions, 944 failed and 944 non-failed. |
| Petropoulos et al. | logit, LDA, XGBoost MXNET | private: Bank of Greece corporate loans database (2005–2015). |
| Pompella et al. | ewm | public: Bloomberg indicators extracted from balance sheet, income statement and others (solvency, performance, etc.) (2005 to 2014); 482 banks |
| Ribeiro et al. | svm, svm+, svm+mtl | public: Diane database by COFACE; financial statements of French companies from 2002 to 2006. |
| Soui et al. | “Non-dominated” Sorting Genetic Algorithm (NSGAII), multi-objective evolutionary algorithm based on decomposition (MOEA/D), multi-objective particle swarm optimisation (SMOPSO), Strength Pareto Evolutionary Algorithm (SPEA2) | public: German (1000 observations, 70% good applicants, 30% bad applicants, 20 features) and Australian (690 observations, 383 good applicants, 307 bad applicants, 14 features) datasets from University of California, Irvine; |
| Tavana et al. | ANN, bayes | public: monthly reports on loan data provided by a large US bank (2005–2011); 353 observations, 10 features; balance sheet ratios |
| Wang et al. | logit, svm, adaboost, ann, random forest | public: yearly data for 95 economies with crisis data (1981–2017); 1690 observation of which 210 are crises; 11 features; dataset from Laeven and Valencia 2018, Global Financial Database and IMF International Financial Statistics |
| Xia et al. | AdaBoost, AdaBoost-NN, Bagging-DT, Bagging-NN, DT, LR, NN, RF, SVM, GBDT, XGBoost-MS, XGBoost-GS, XGBoost-RS, XGBoost-TPE | public: three datasets from UCI machine learning repository (German, Australian and Taiwan); two datasets from P2P lending platforms (Lending Club from the US and We.com from China) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guerra, P.; Castelli, M. Machine Learning Applied to Banking Supervision a Literature Review. Risks 2021, 9, 136. https://doi.org/10.3390/risks9070136
Guerra P, Castelli M. Machine Learning Applied to Banking Supervision a Literature Review. Risks. 2021; 9(7):136. https://doi.org/10.3390/risks9070136
Chicago/Turabian StyleGuerra, Pedro, and Mauro Castelli. 2021. "Machine Learning Applied to Banking Supervision a Literature Review" Risks 9, no. 7: 136. https://doi.org/10.3390/risks9070136
APA StyleGuerra, P., & Castelli, M. (2021). Machine Learning Applied to Banking Supervision a Literature Review. Risks, 9(7), 136. https://doi.org/10.3390/risks9070136