1. Introduction
The aim of this article was to investigate the interconnectedness between sampling and asset returns’ distributions. To this end, we empirically perform a number of analyses across asset classes, markets and for several sampling frequencies. The topic is quite relevant as both vendors and financial institutions may rely on scenarios generated under the assumption that financial series returns are normally distributed. There are some works which claim that standardized daily returns “are approximately unconditionally normally distributed”
Andersen et al. (
2001) or that “are IID Gaussian, with variance equal to 1”
Rogers (
2018).
A more realistic work hypothesis is that time series follow a t-skew distribution. The t-skew distribution can be seen as a mixture of skew-normal distributions
Kim (
2001) which generalize the normal distribution thanks to an extra parameter regulating the skewness. By construction, then, they can model heavy tails and skews that are common in financial markets. Thus, their adoption in finance is gaining momentum for modeling distributions
Harvey (
2013) and risk
Gao and Zhou (
2016). Further, t-skew has the power to link-up with observation-driven models such as the dynamic conditional score (DCS)
Creal et al. (
2013) or based on data partitioning
Orlando et al. (
2019,
2020). This paper tries to help in gaining insights on returns’ distributions and on the most suitable way of fitting them.
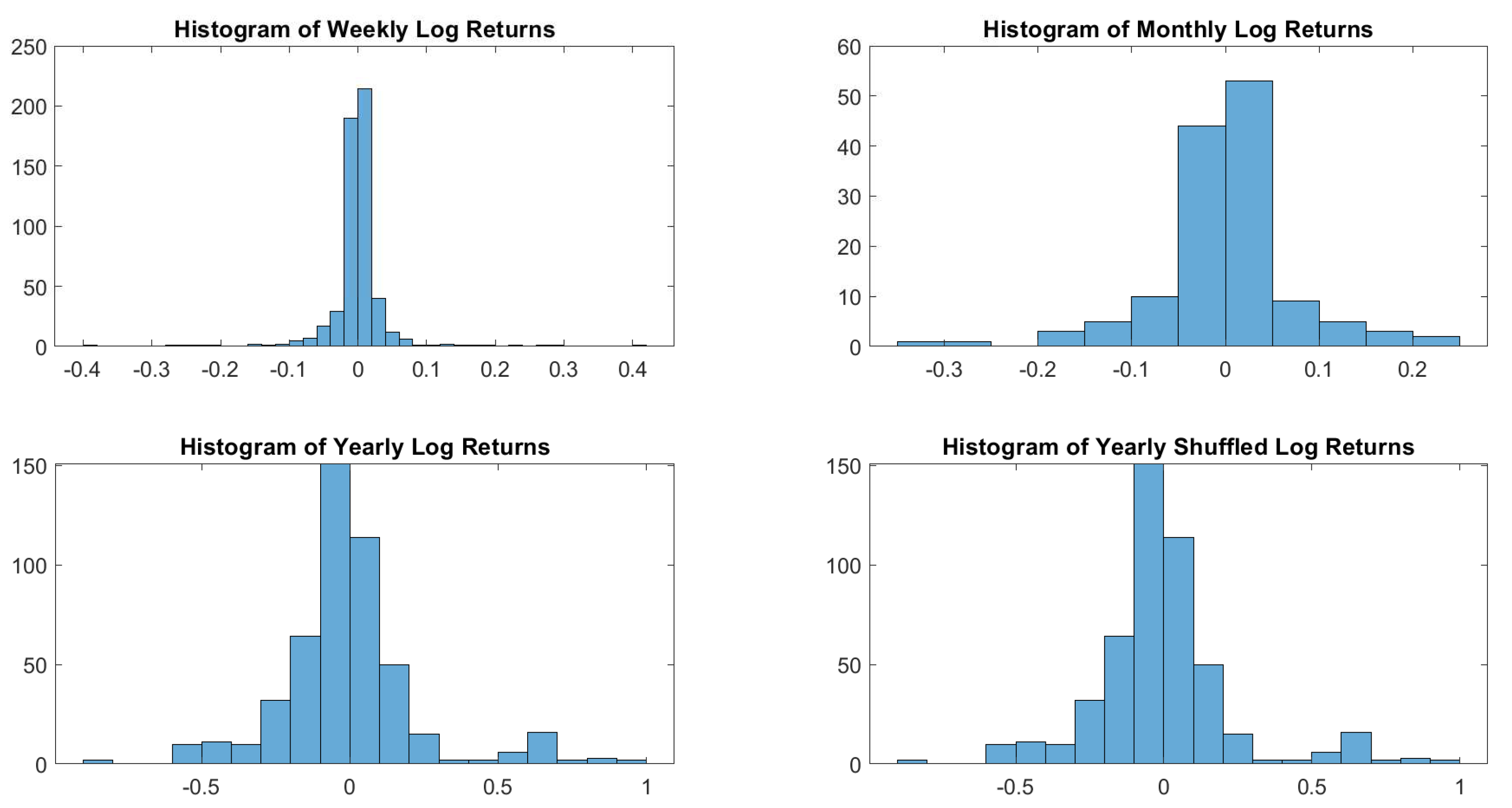
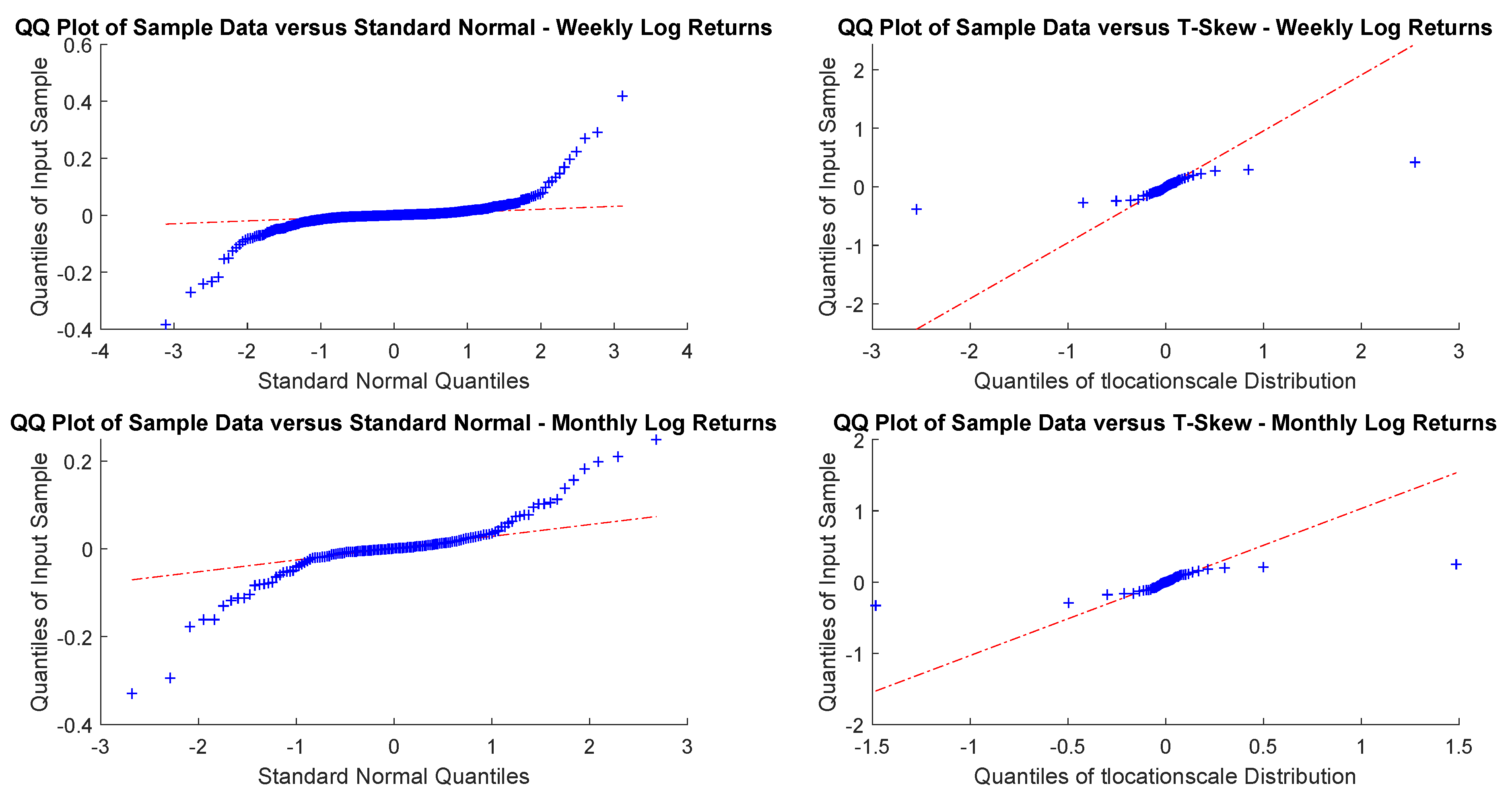
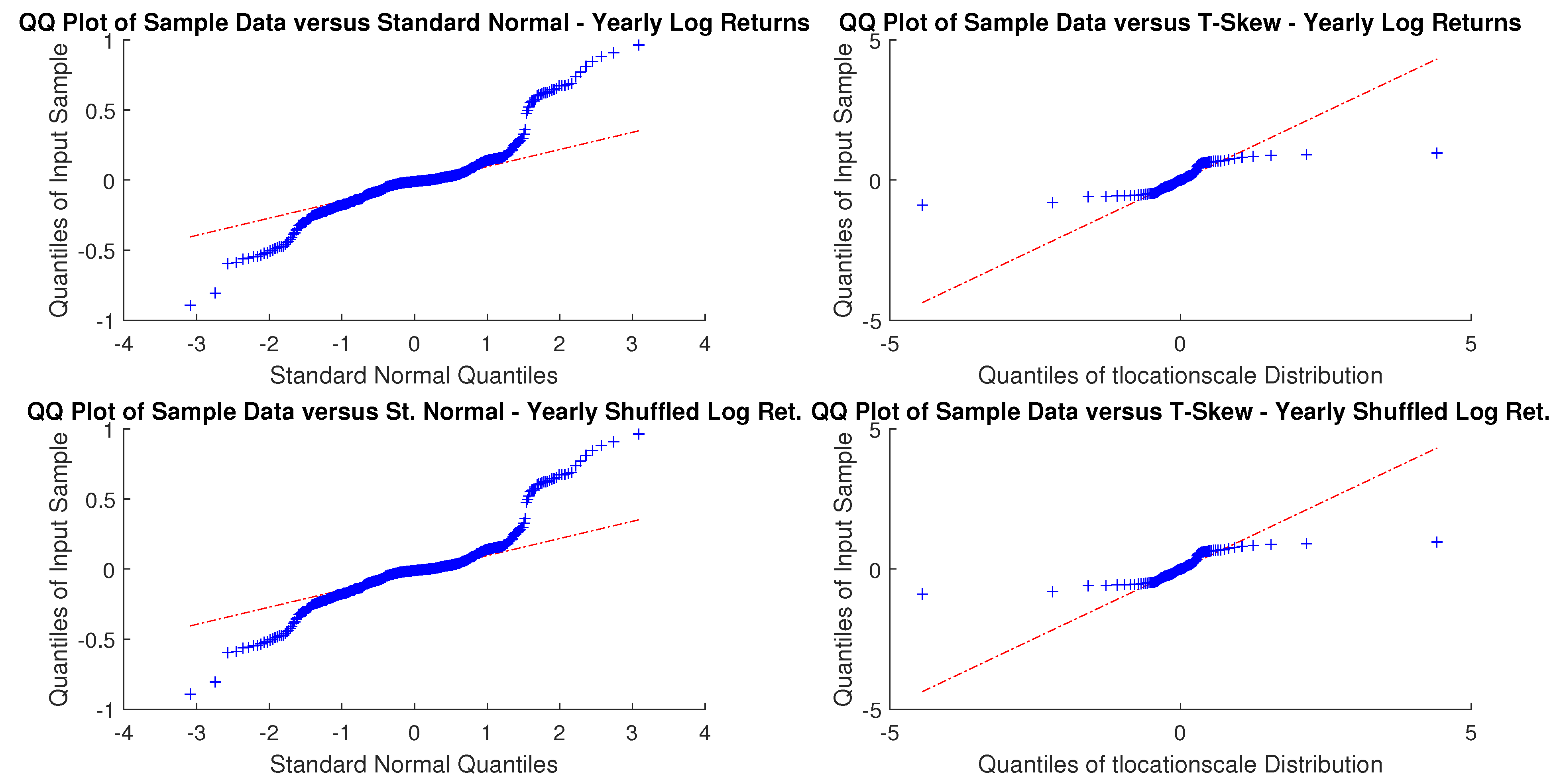
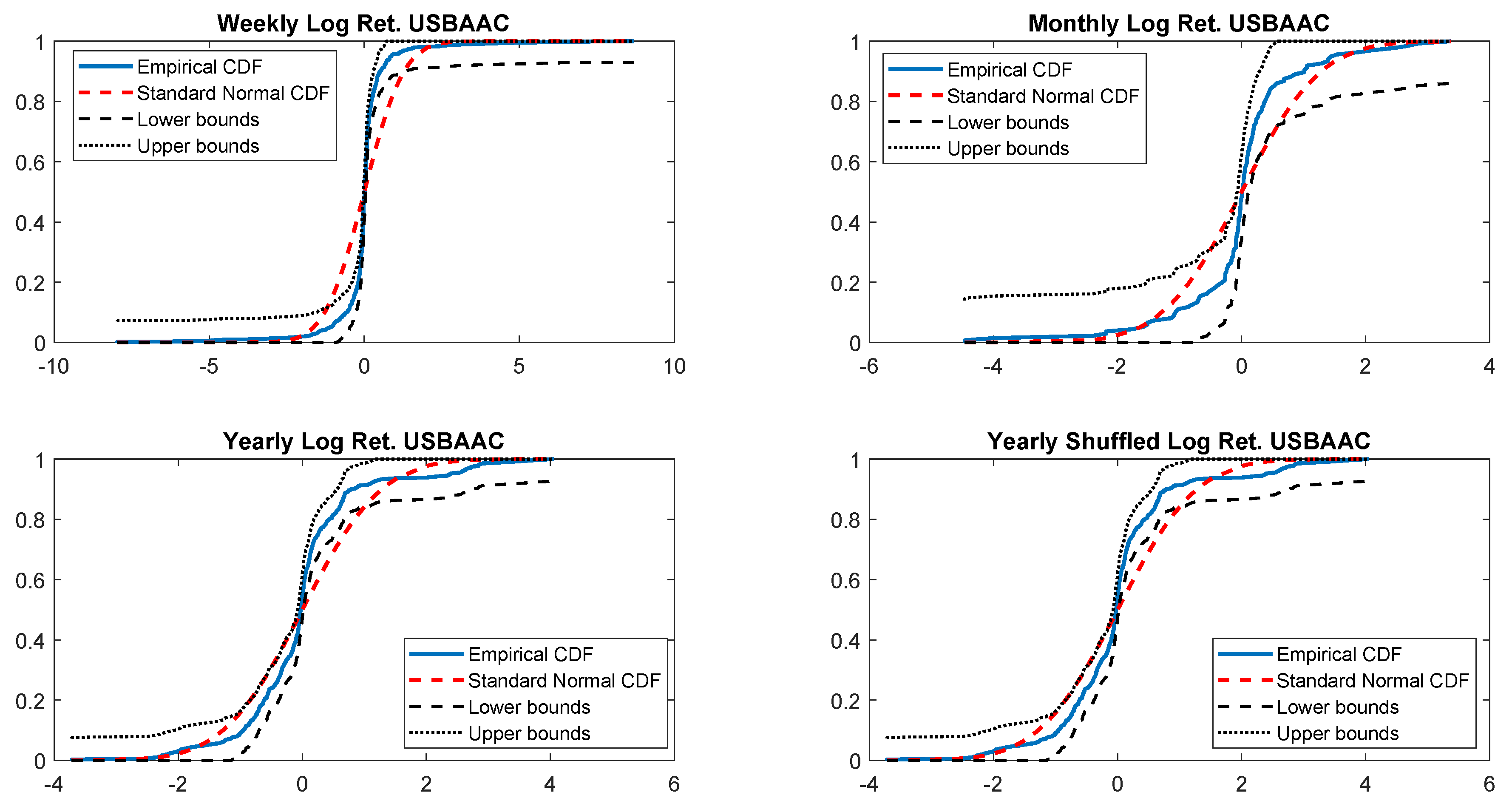
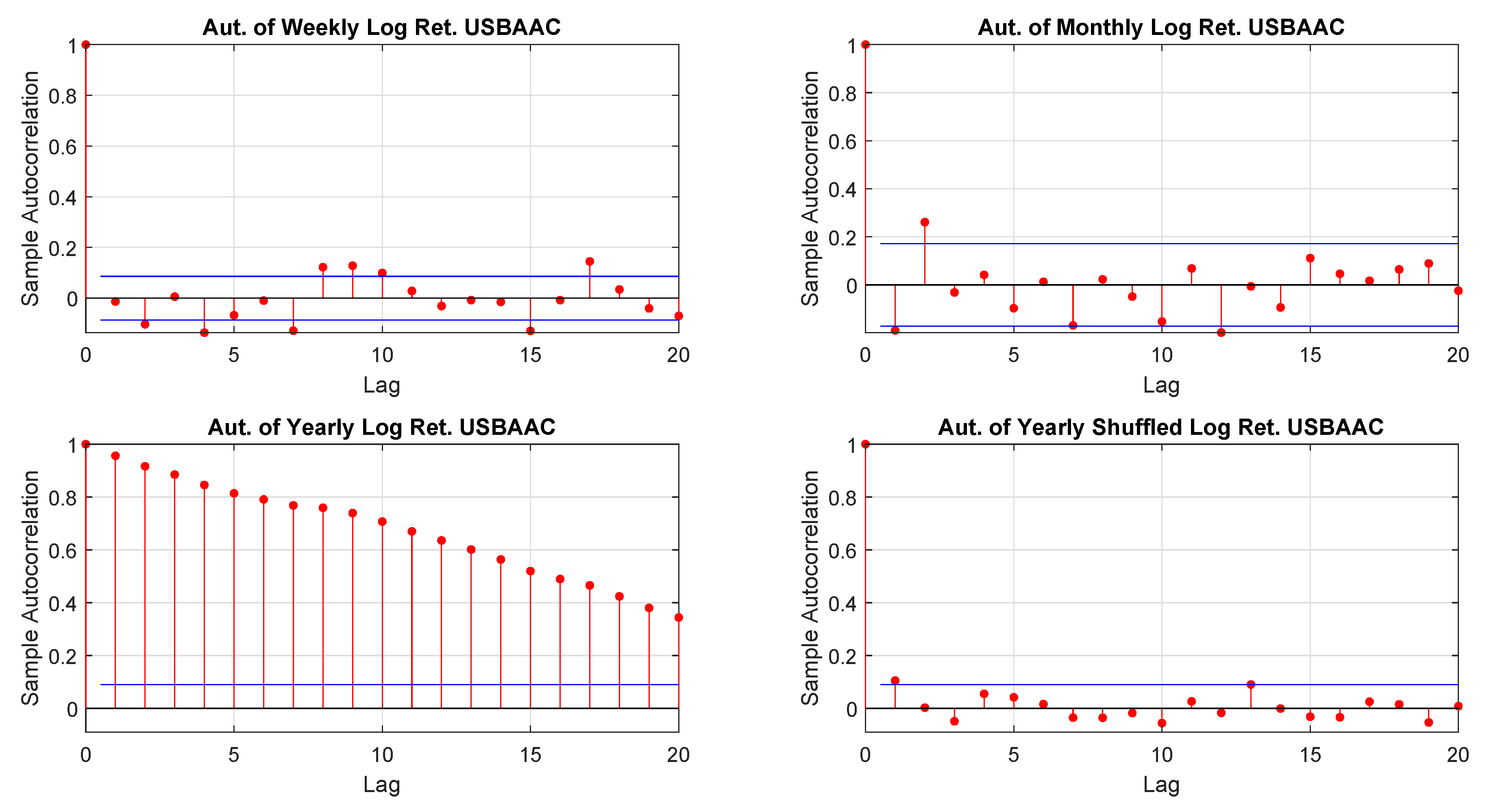
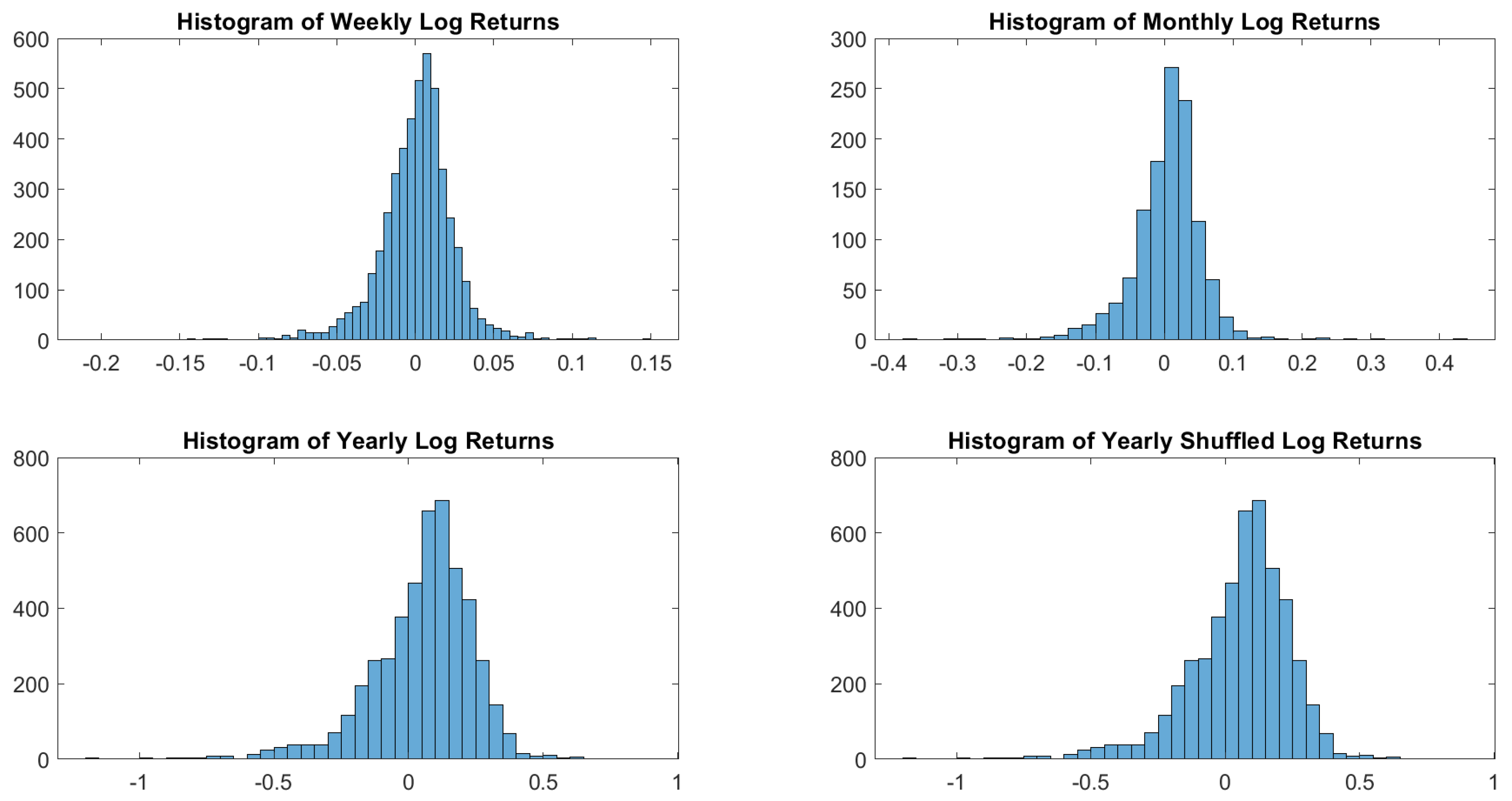
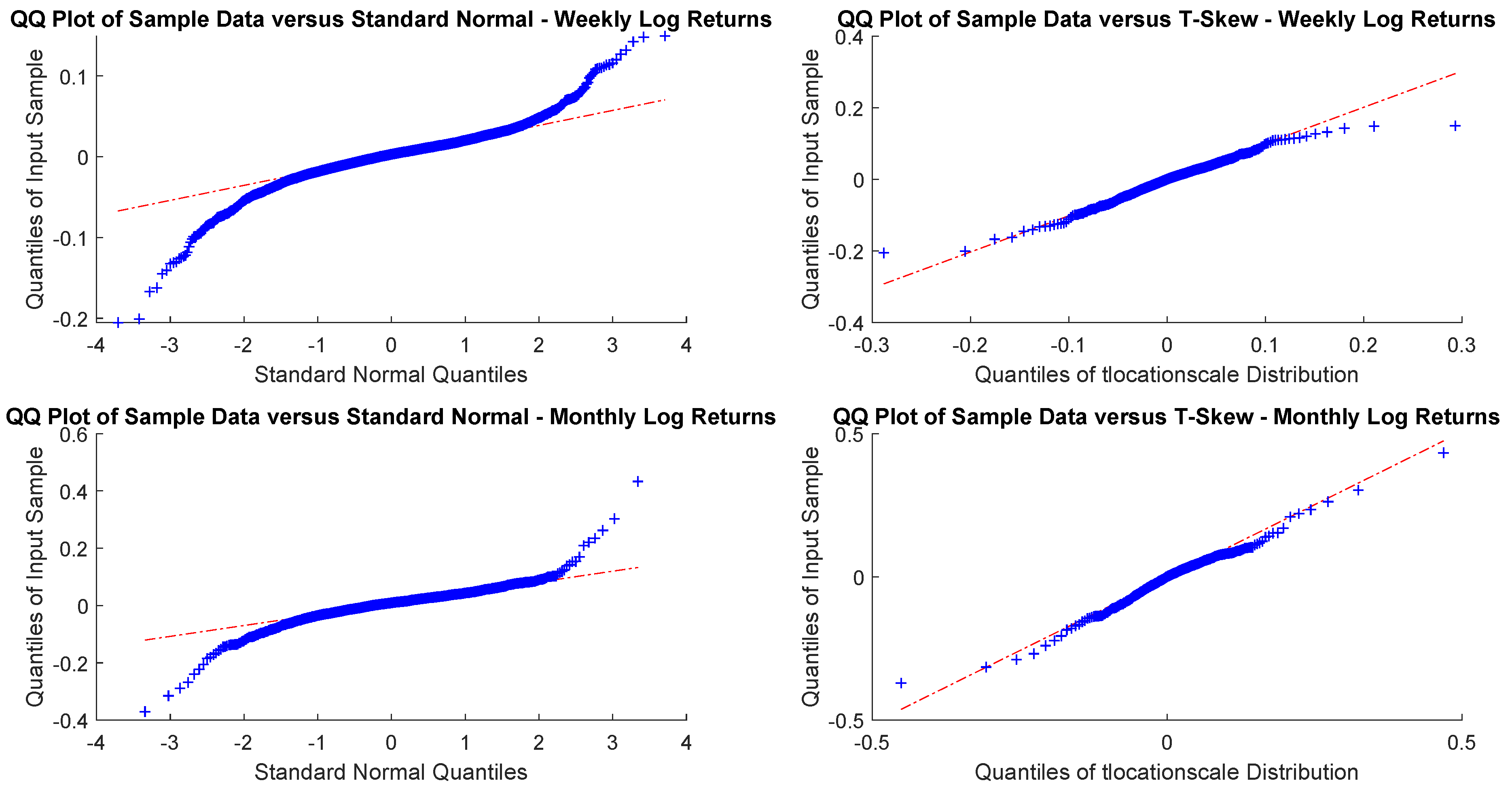
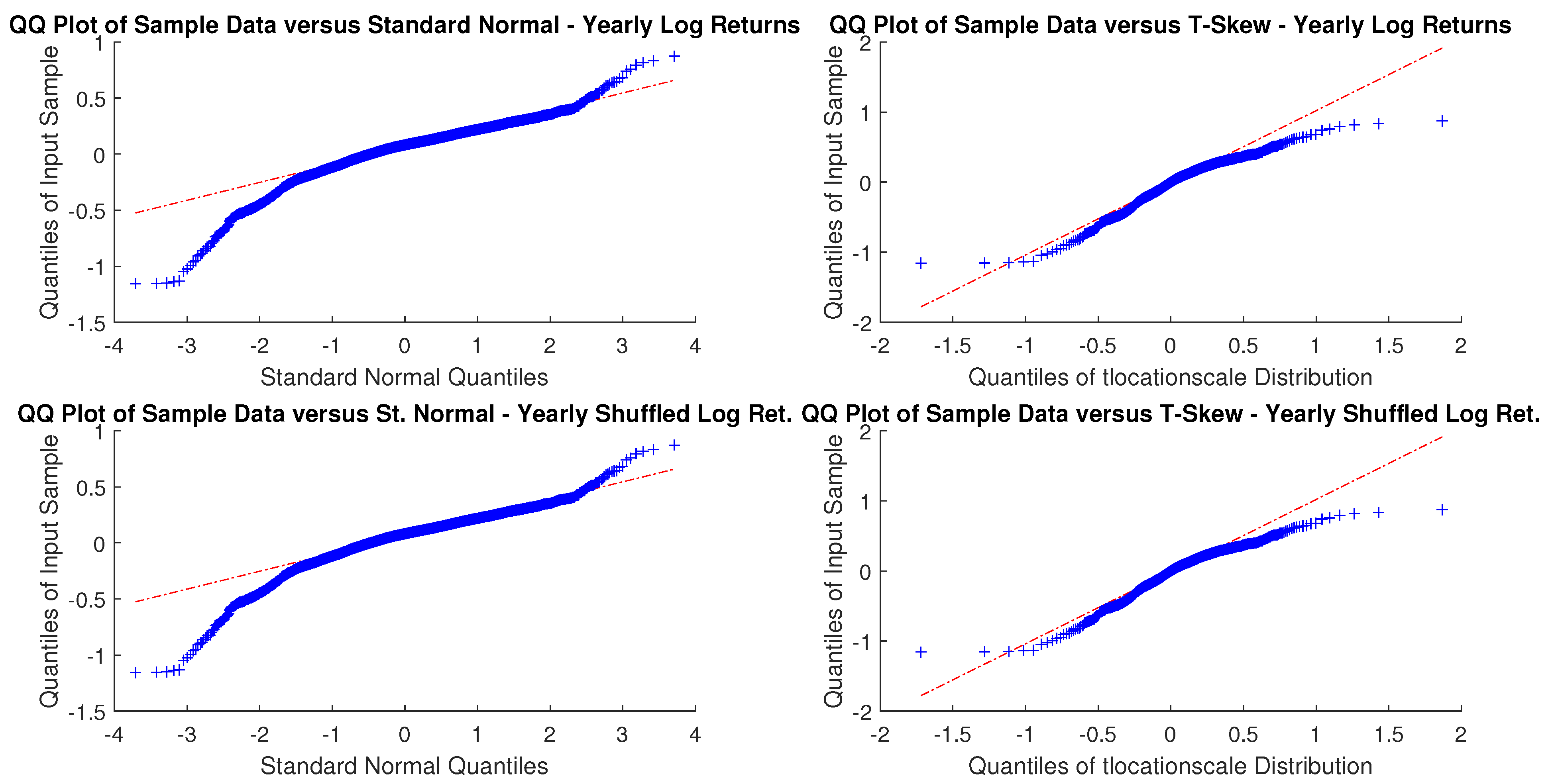
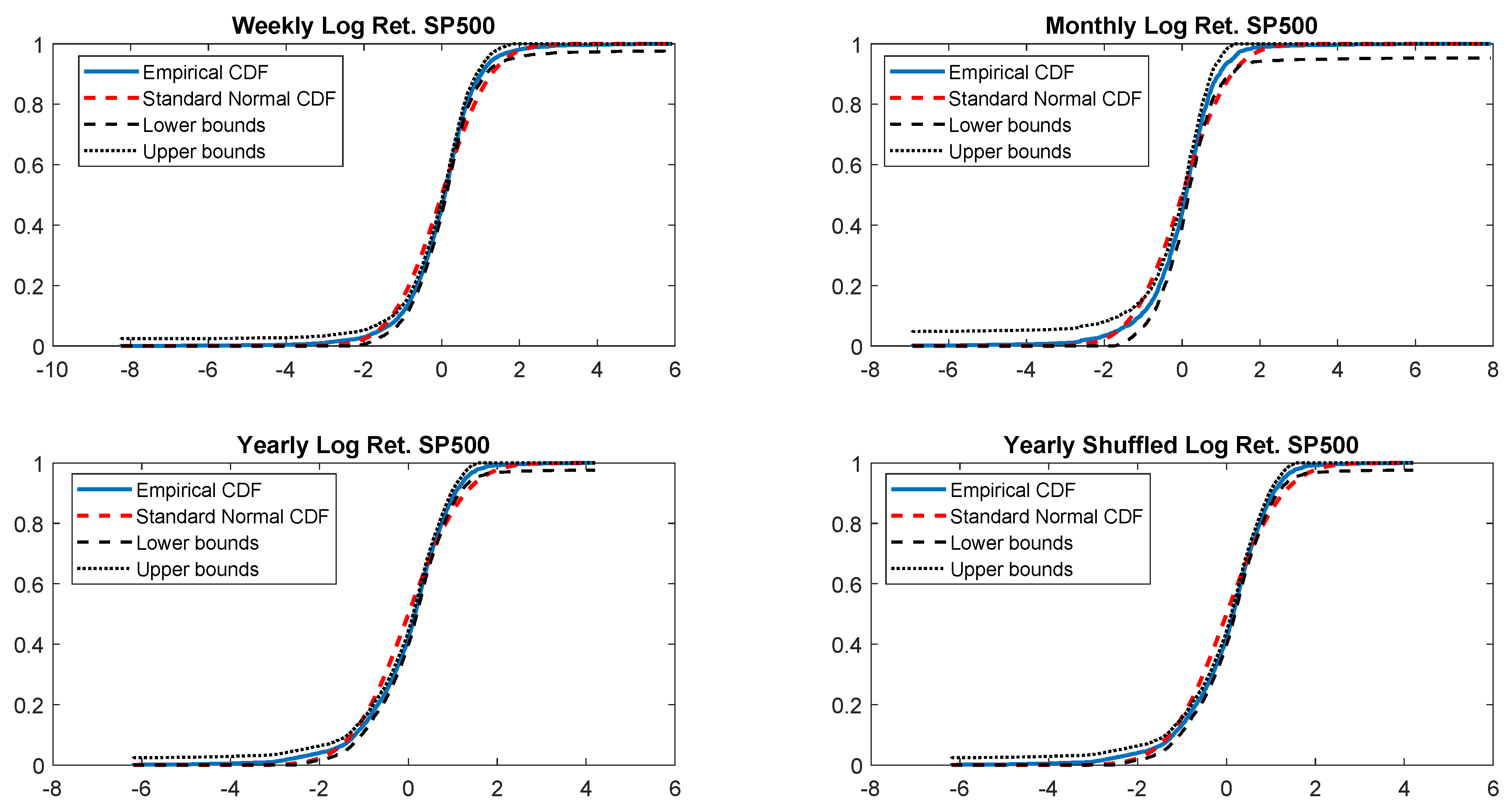
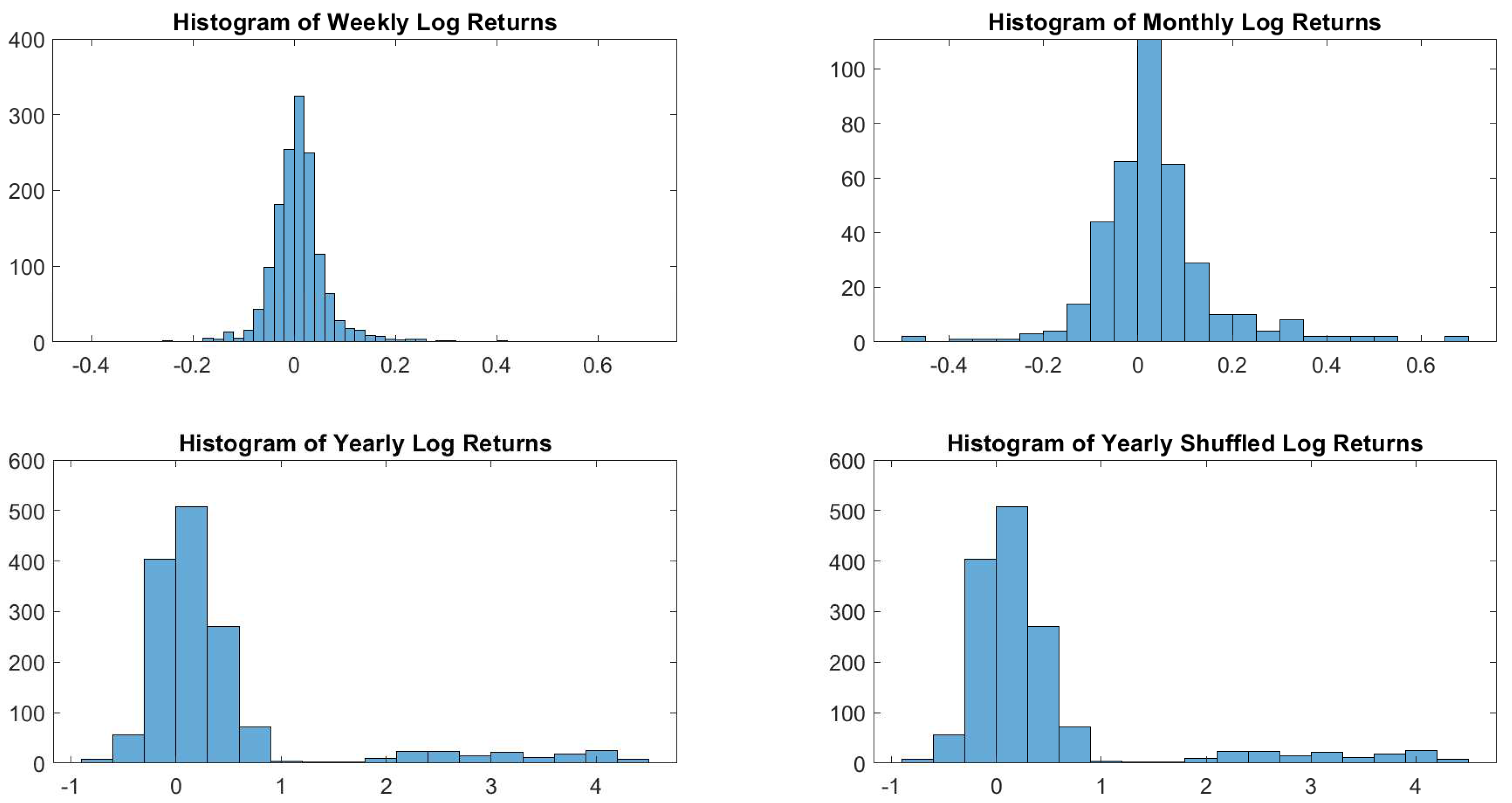
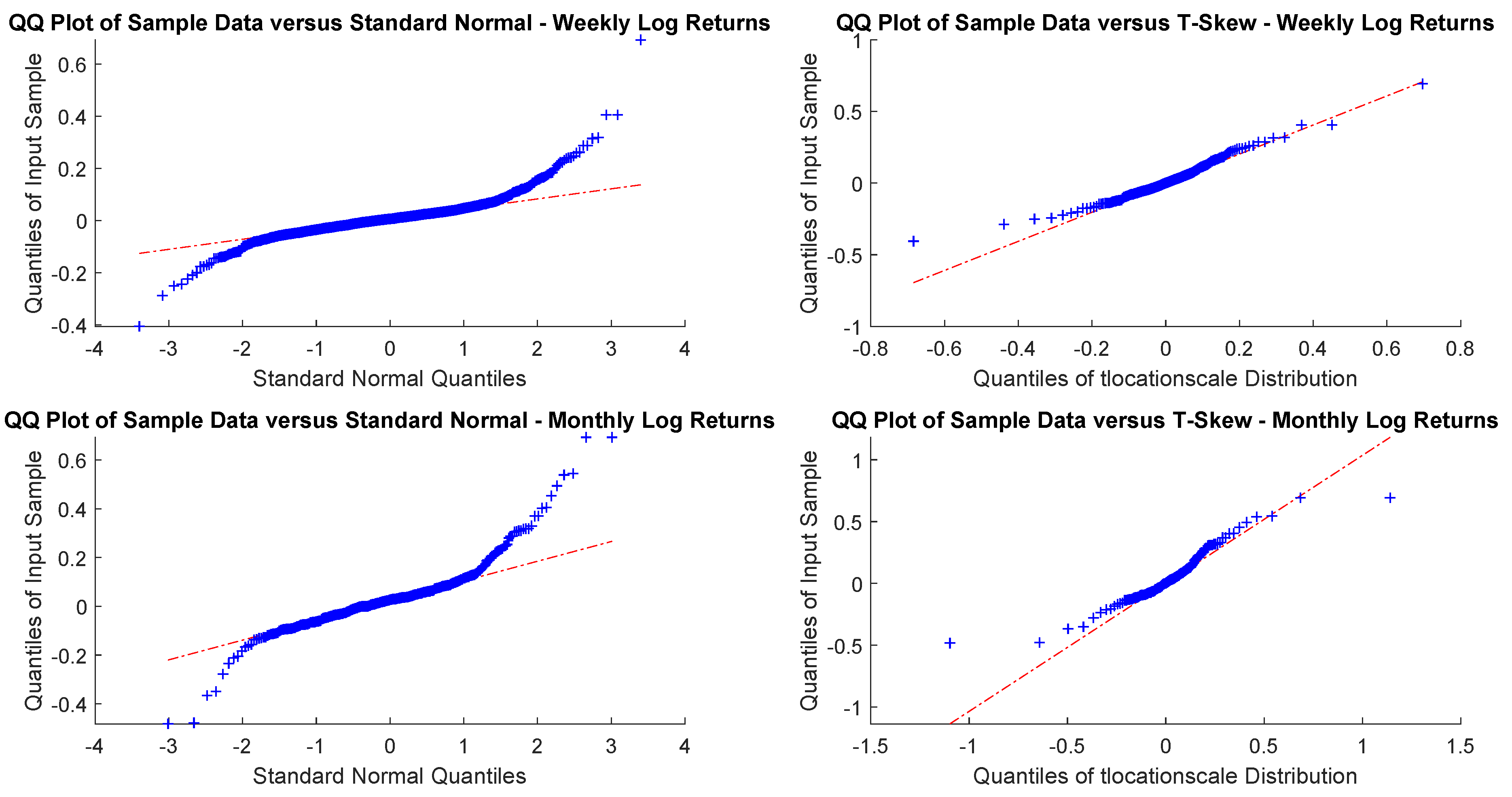
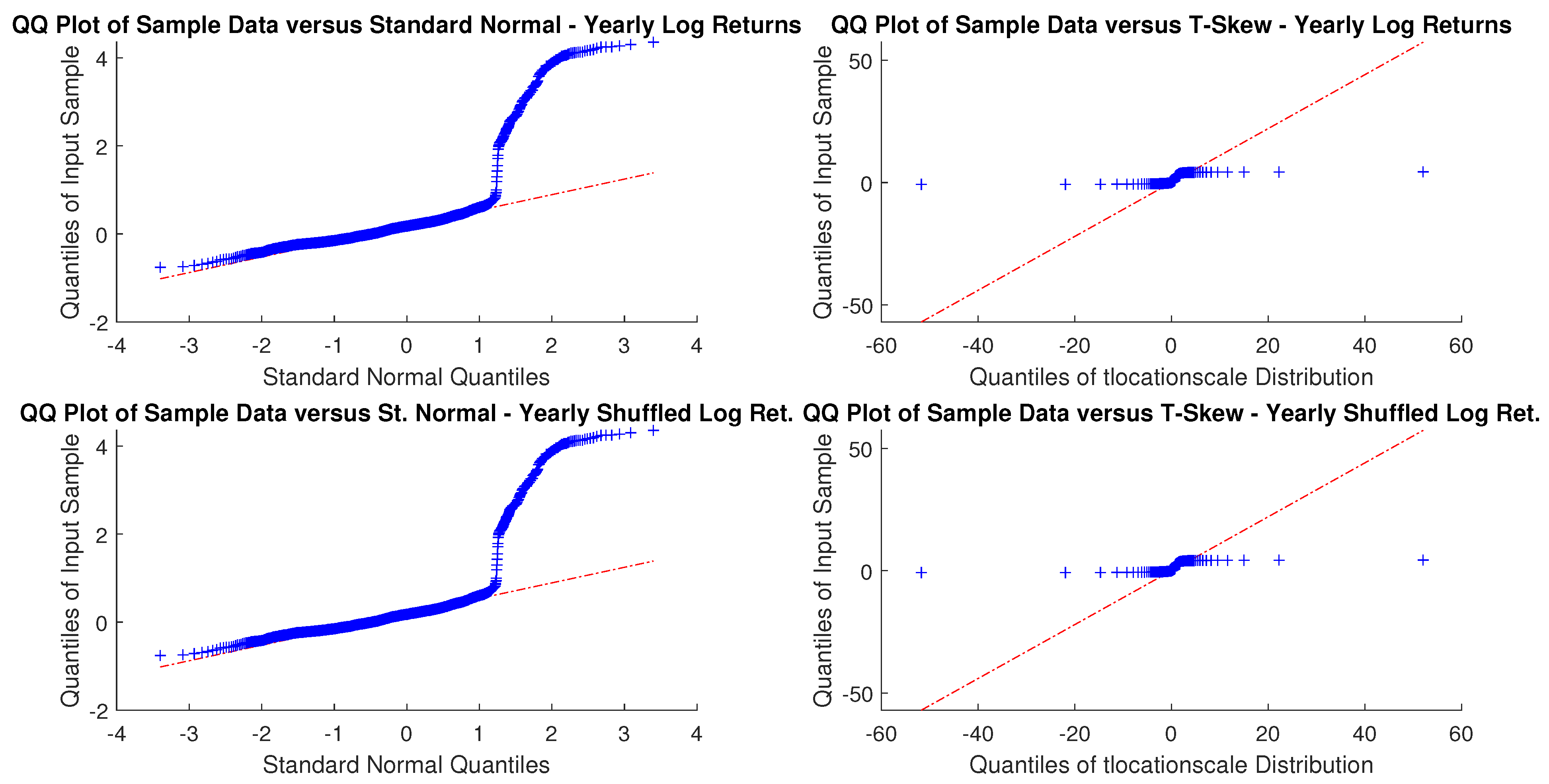
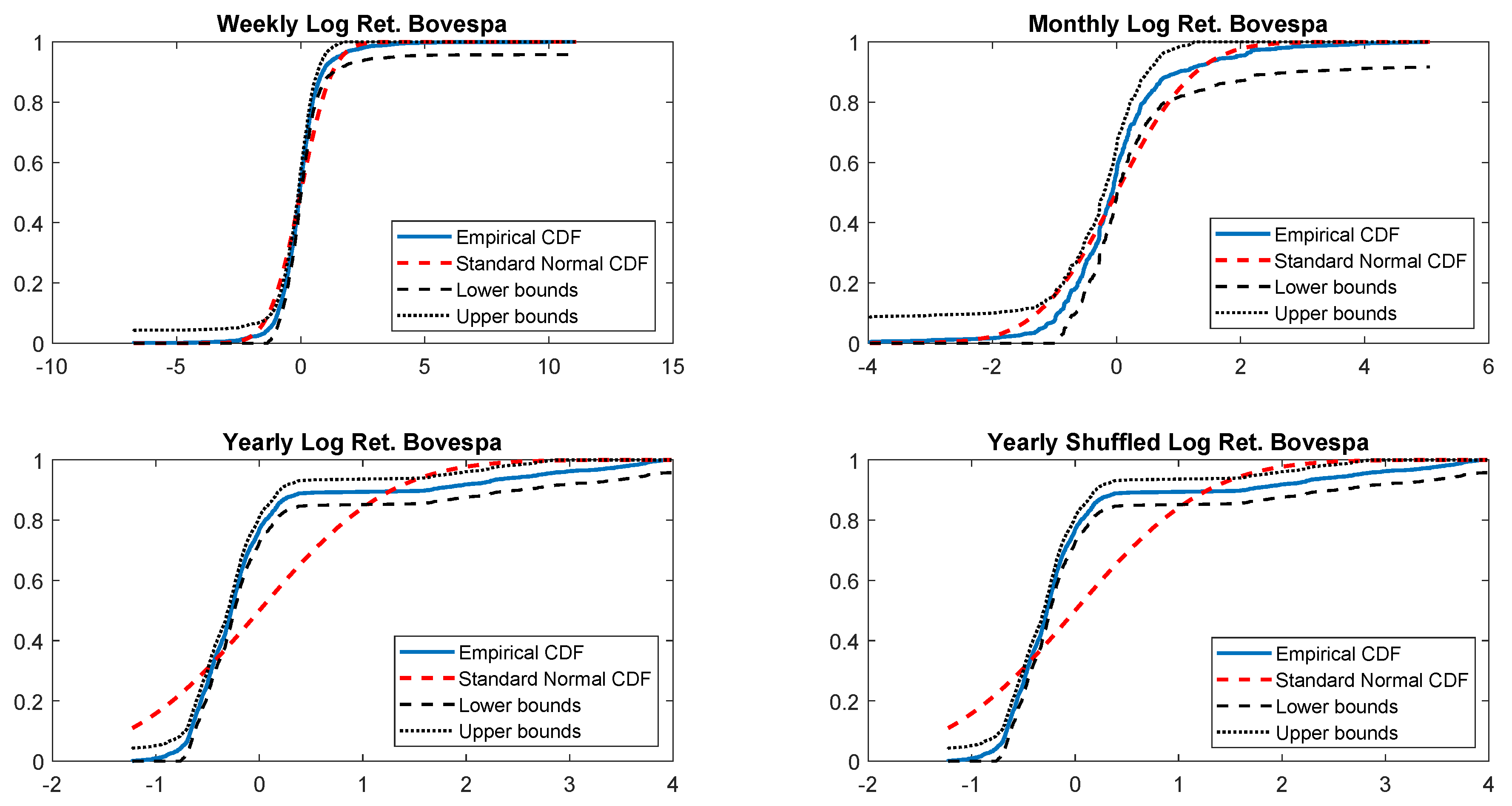
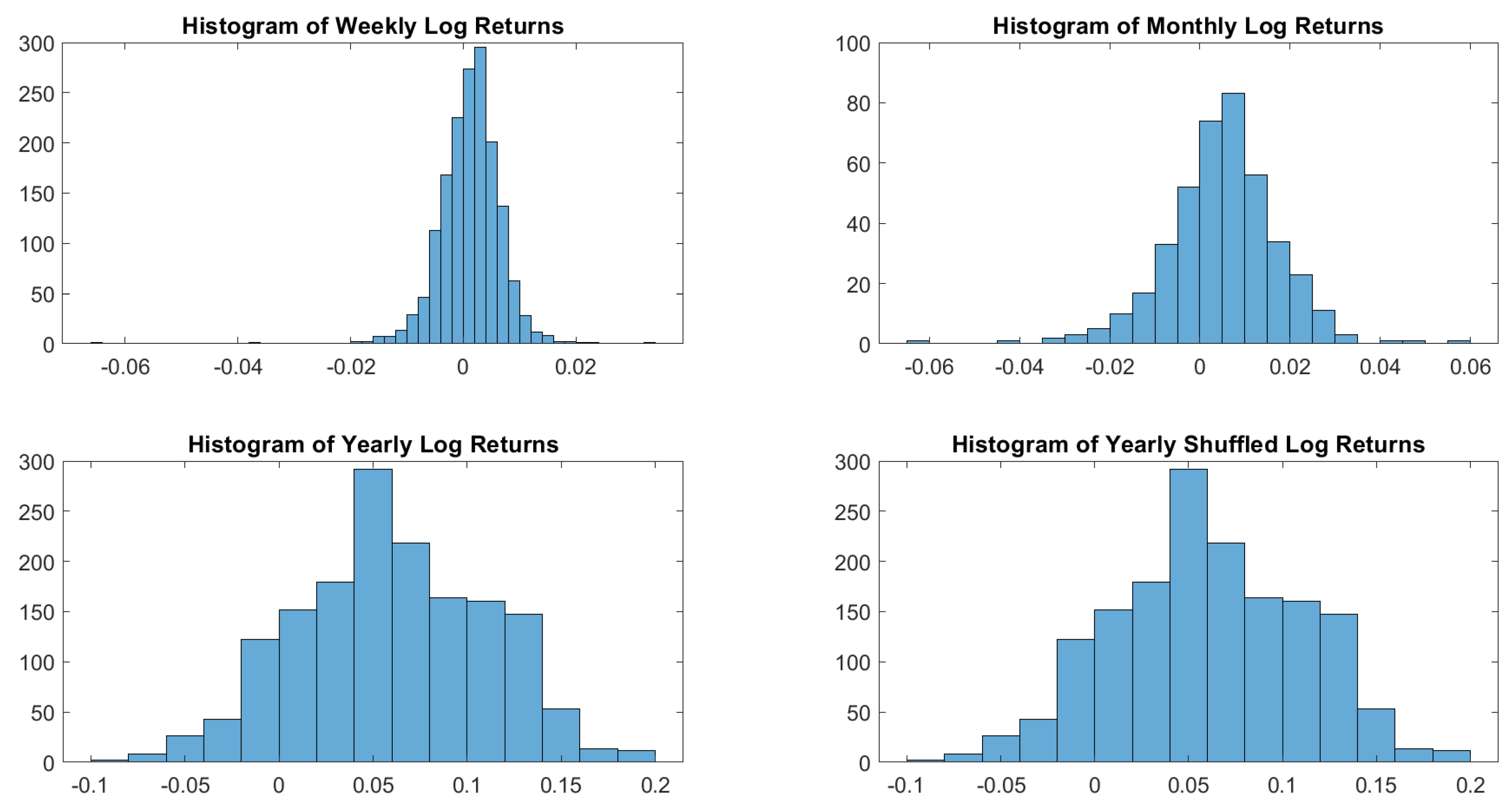
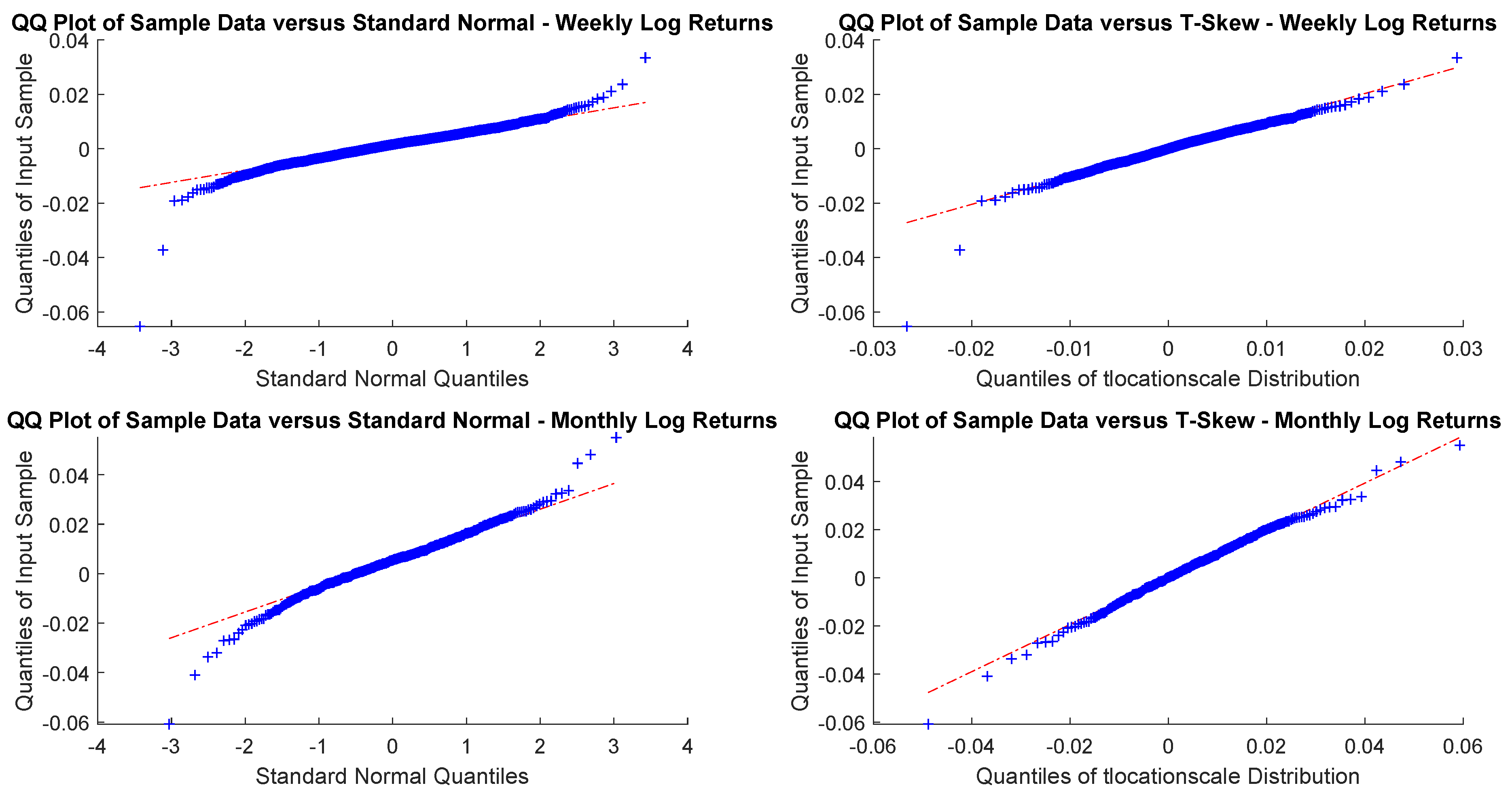
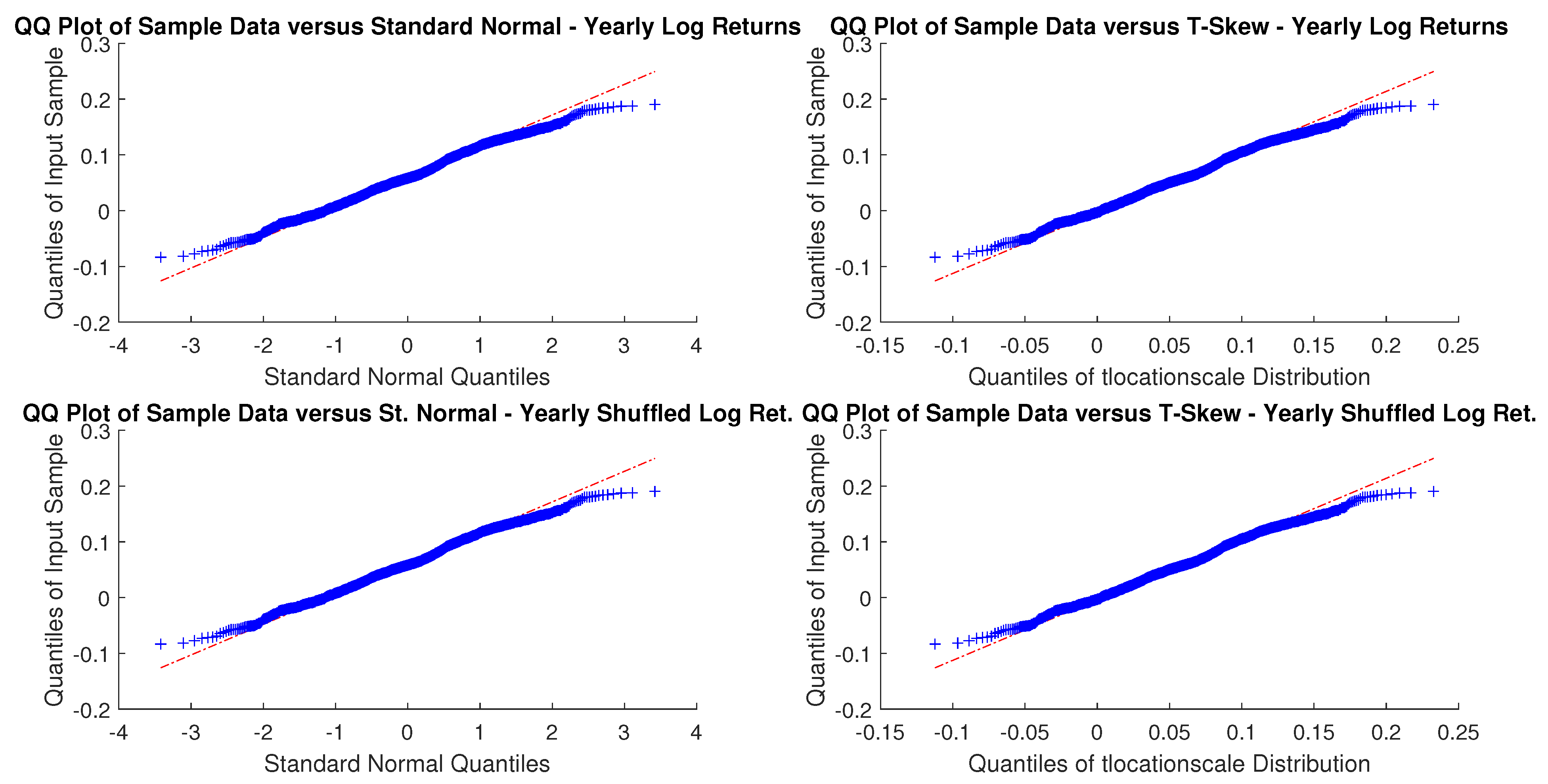
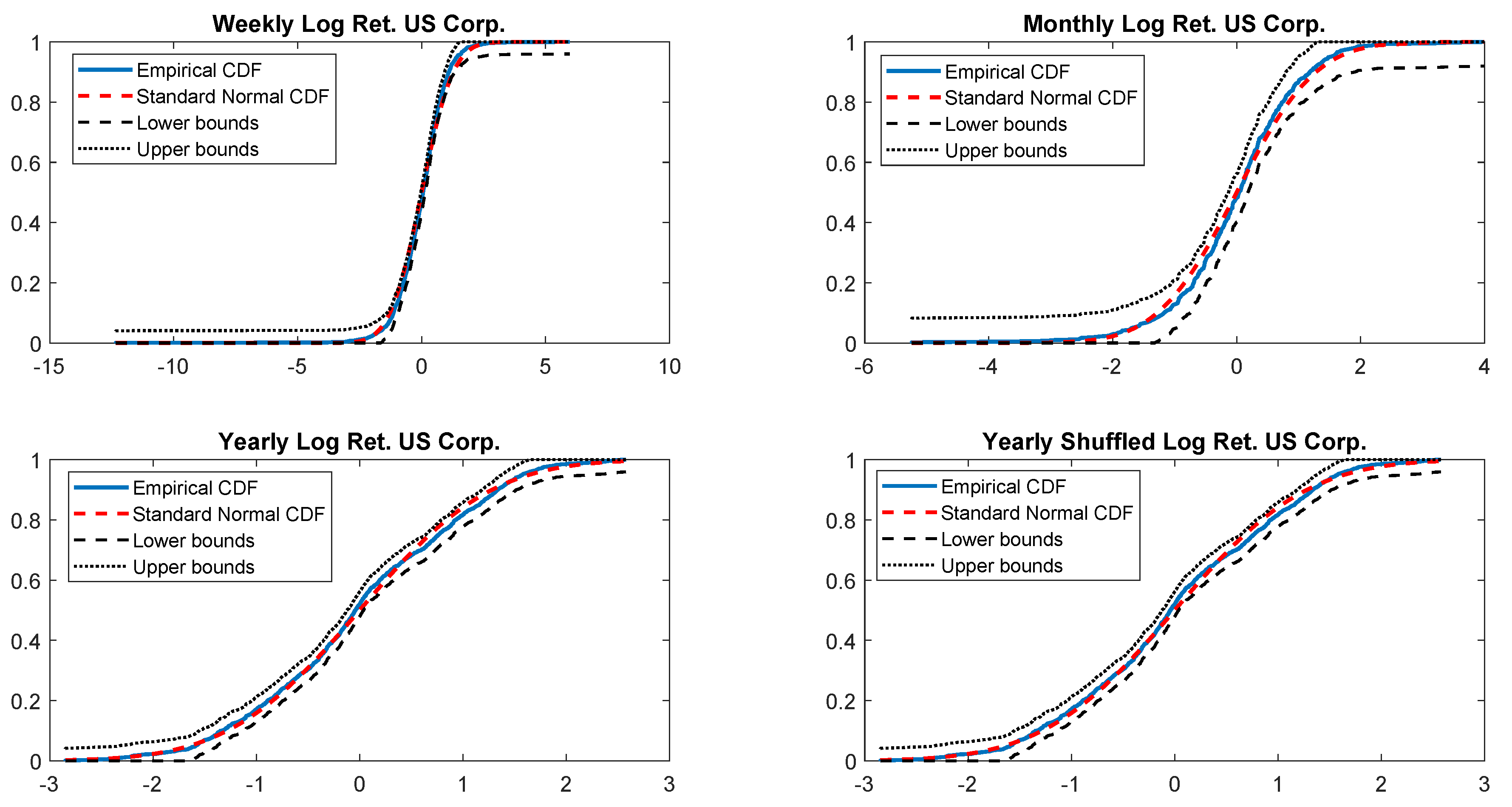
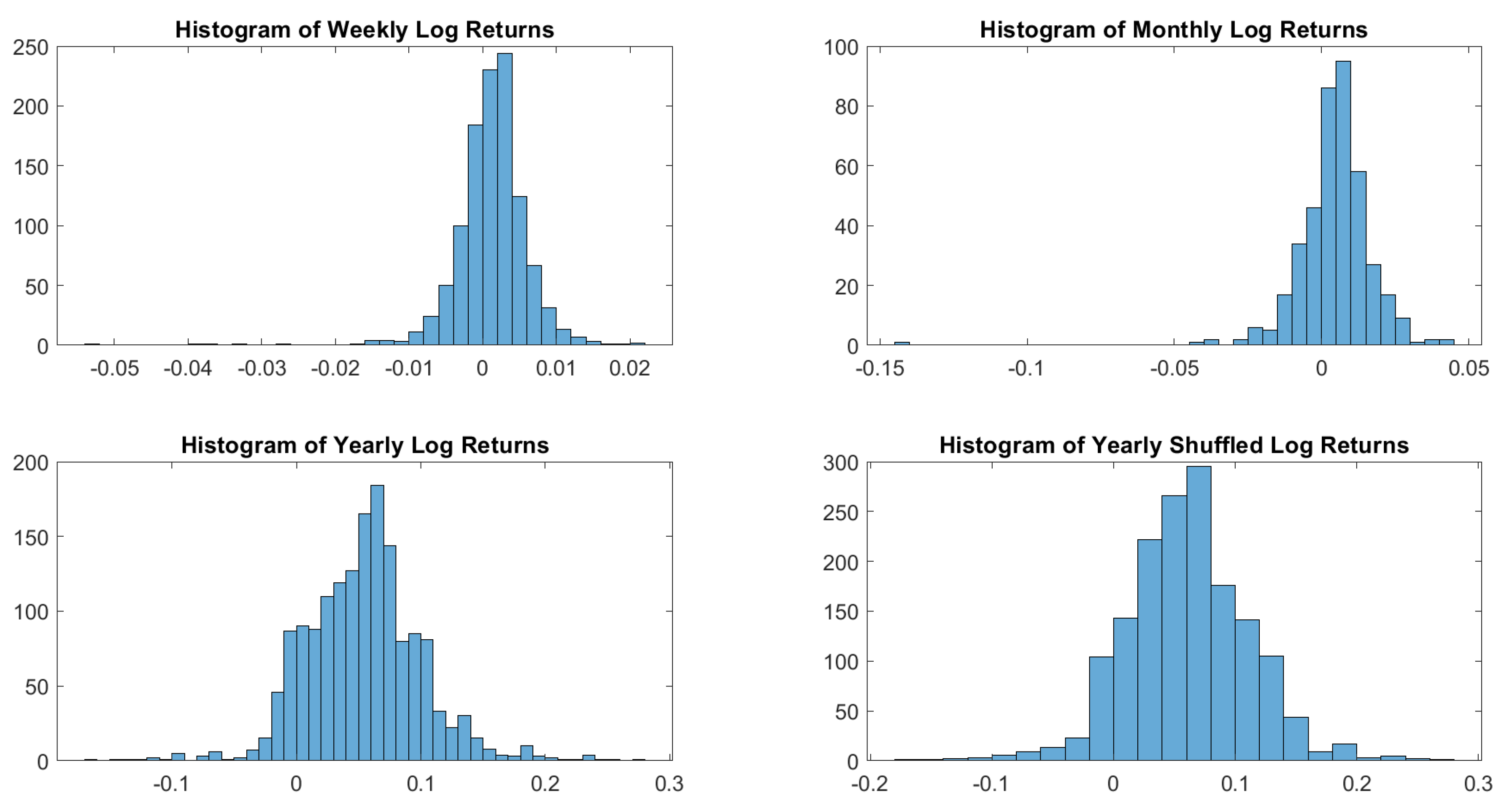
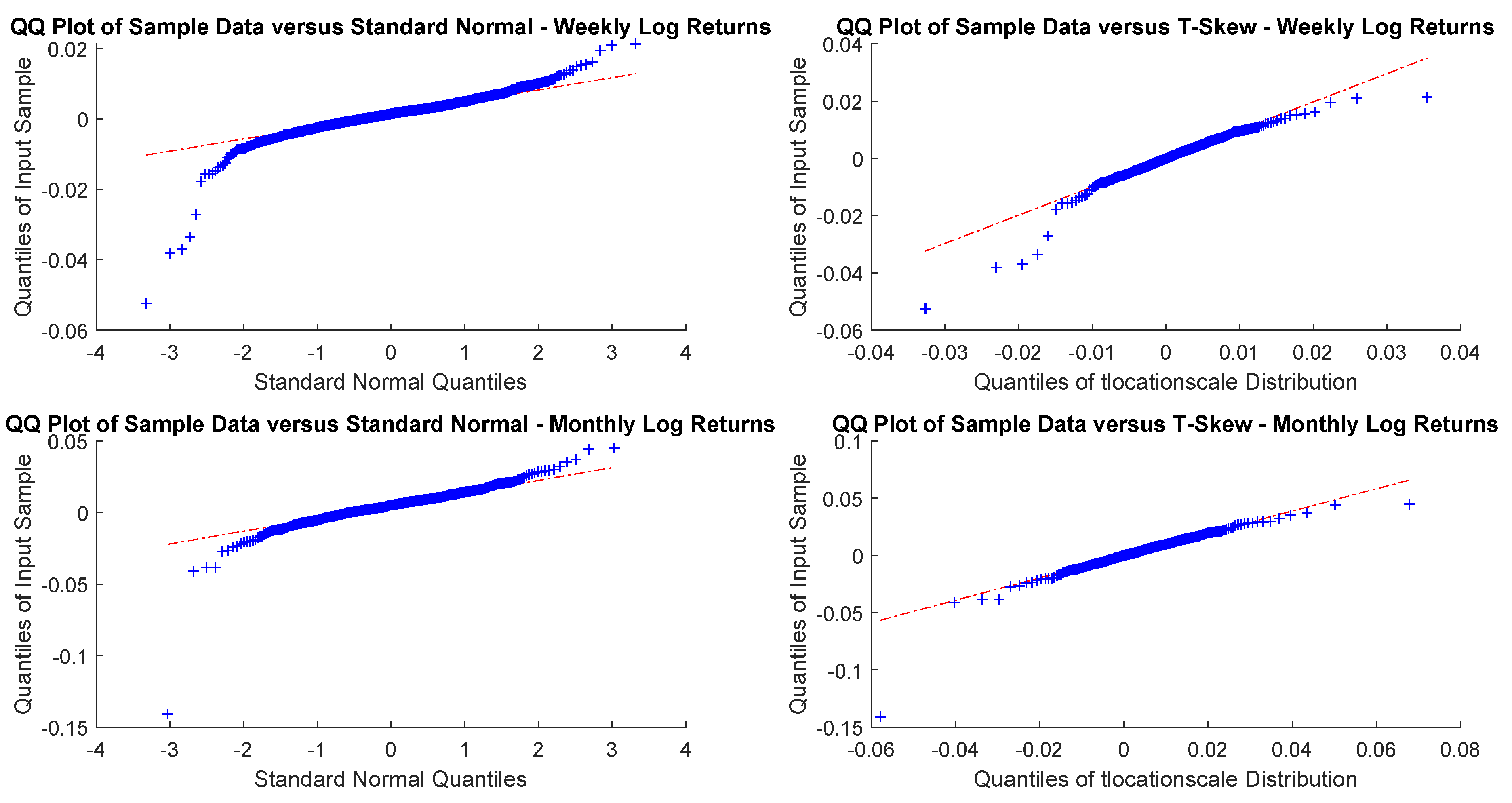
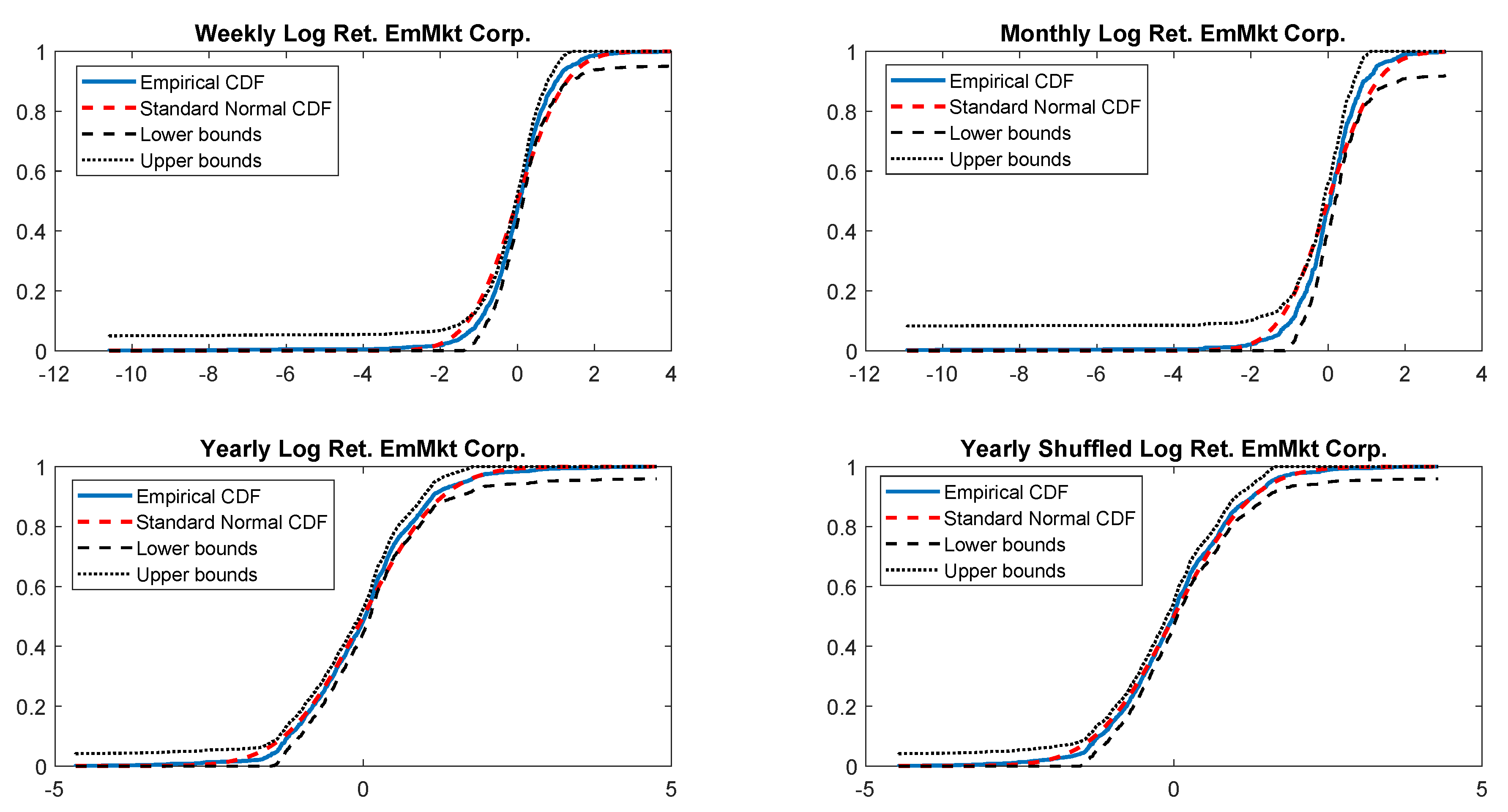
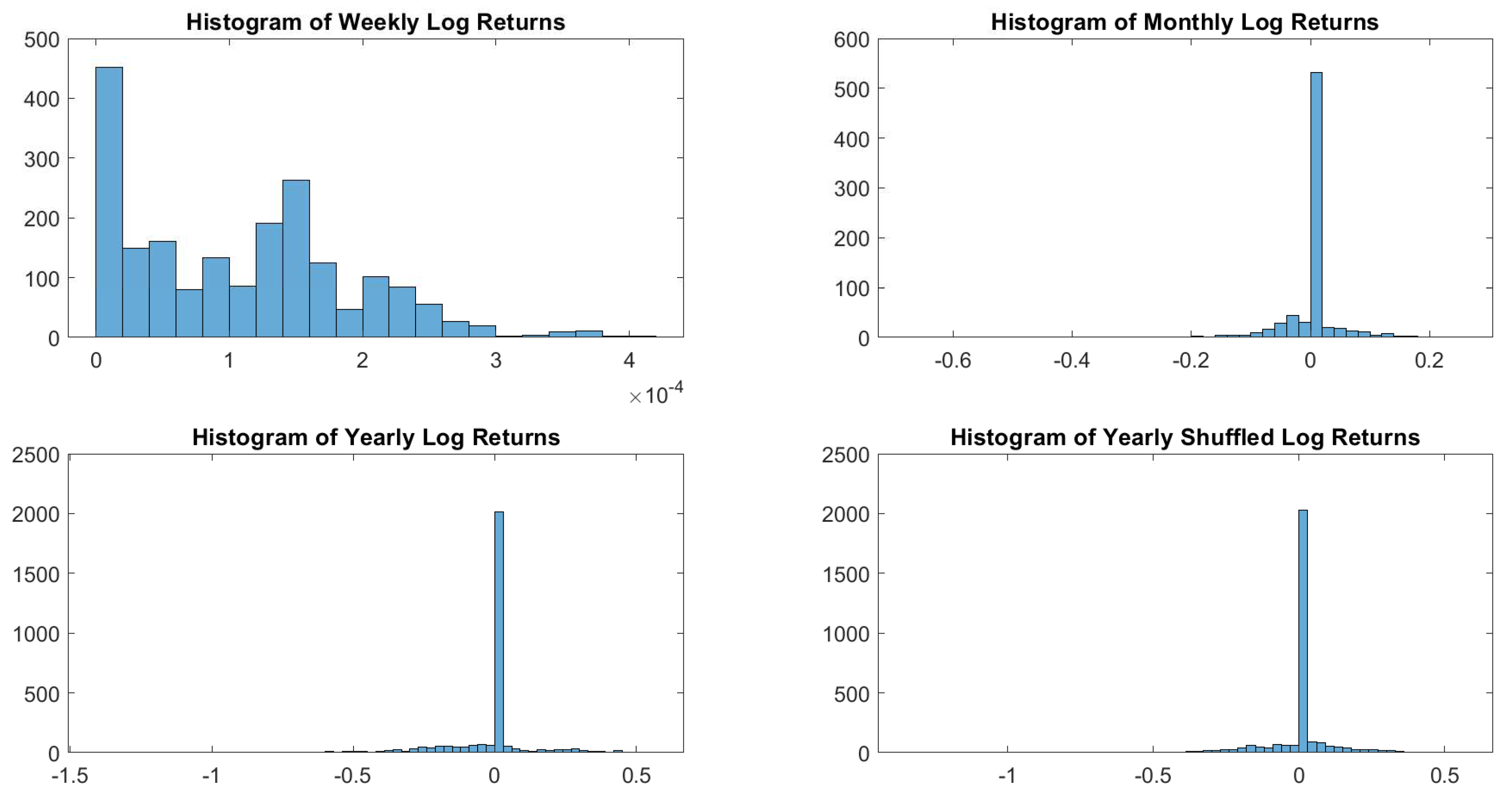
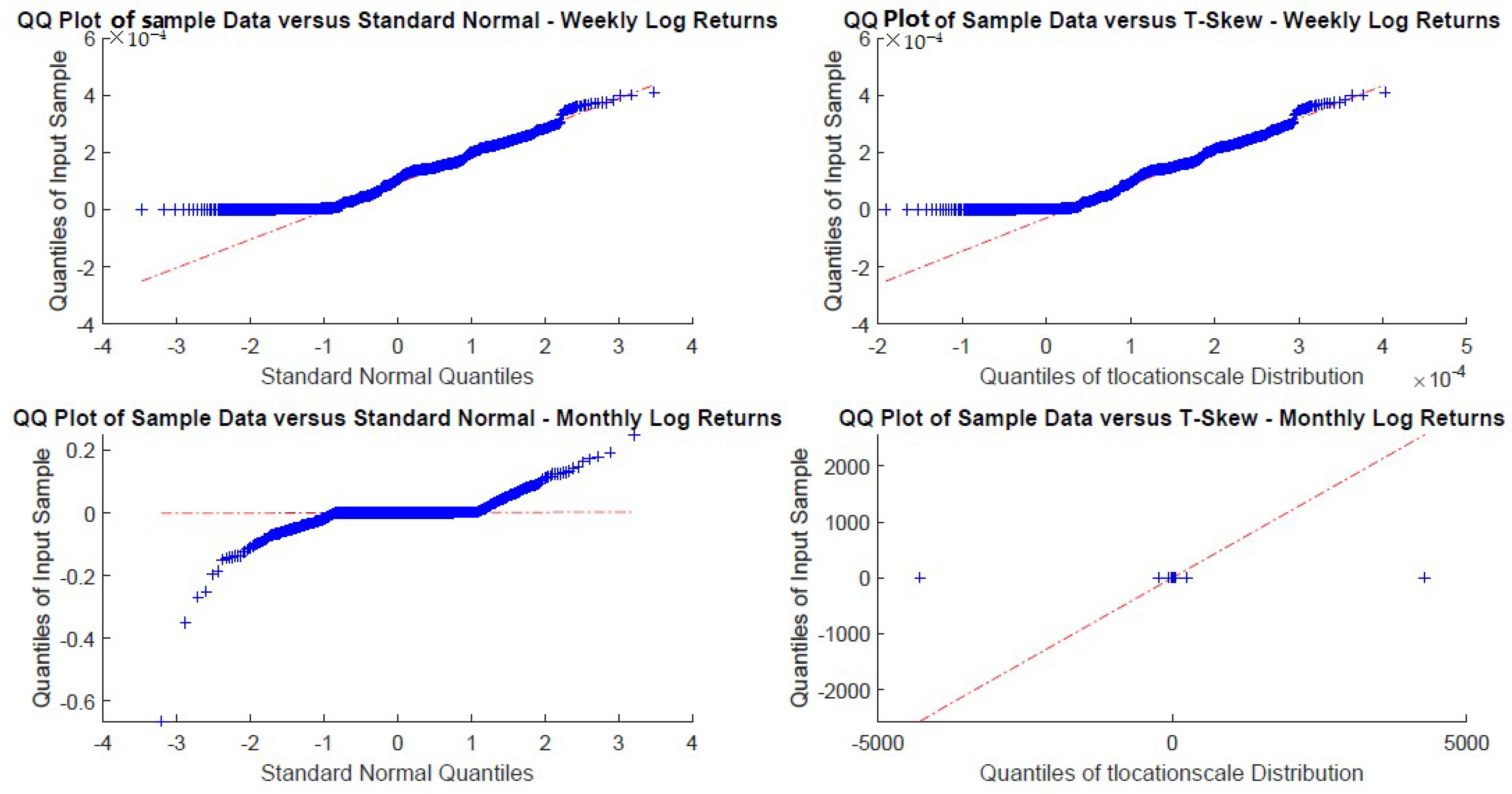
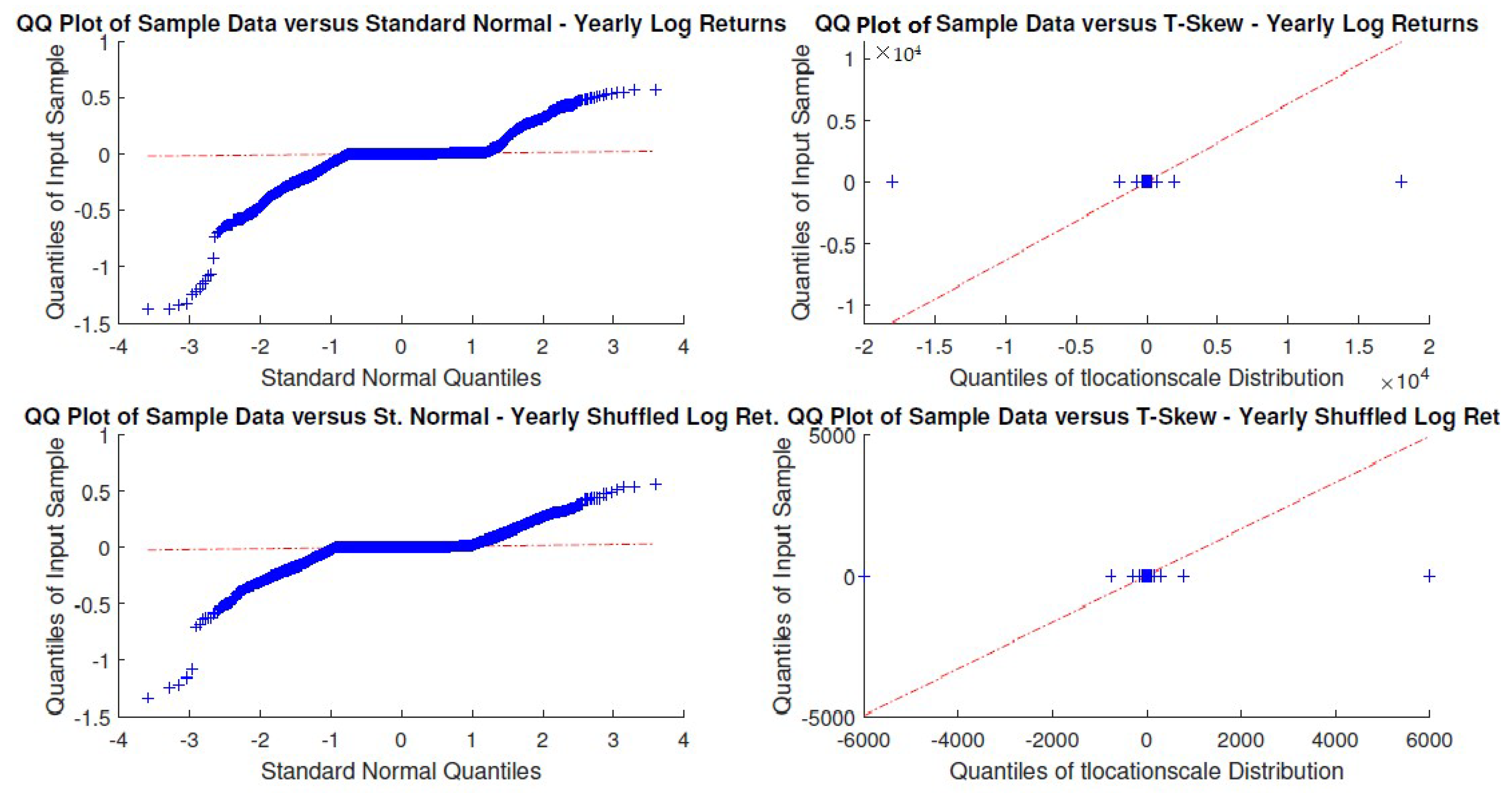
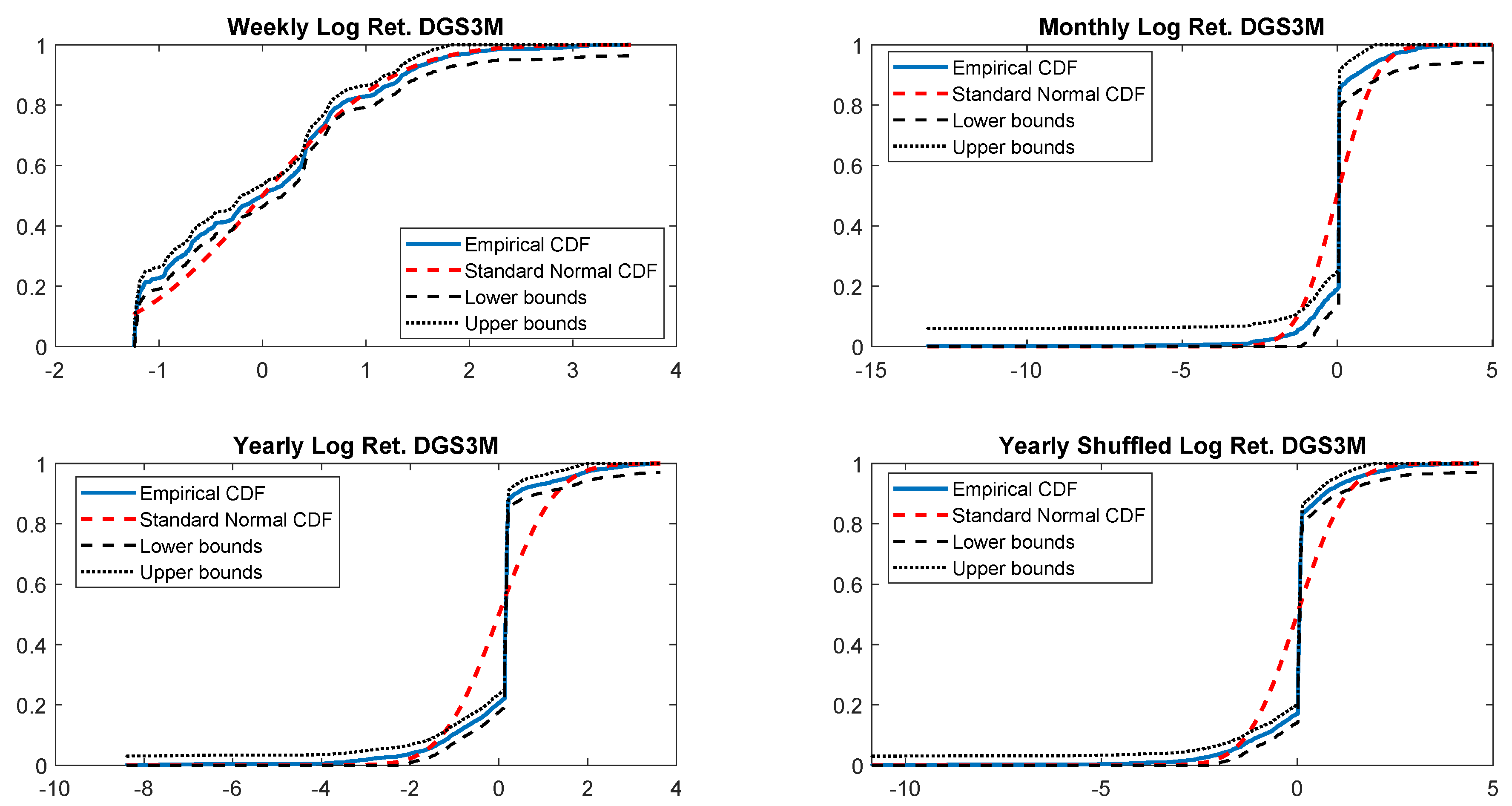
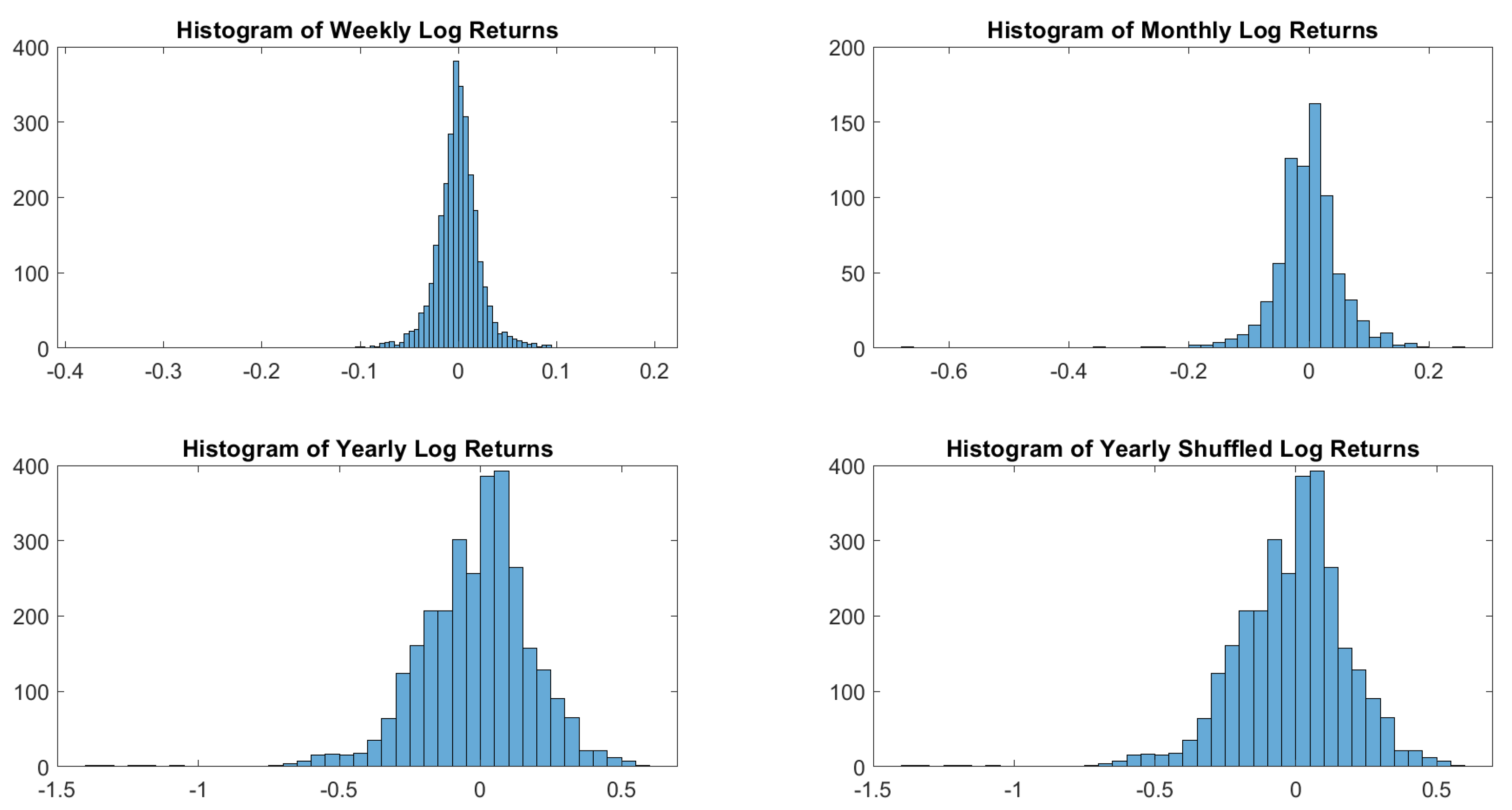
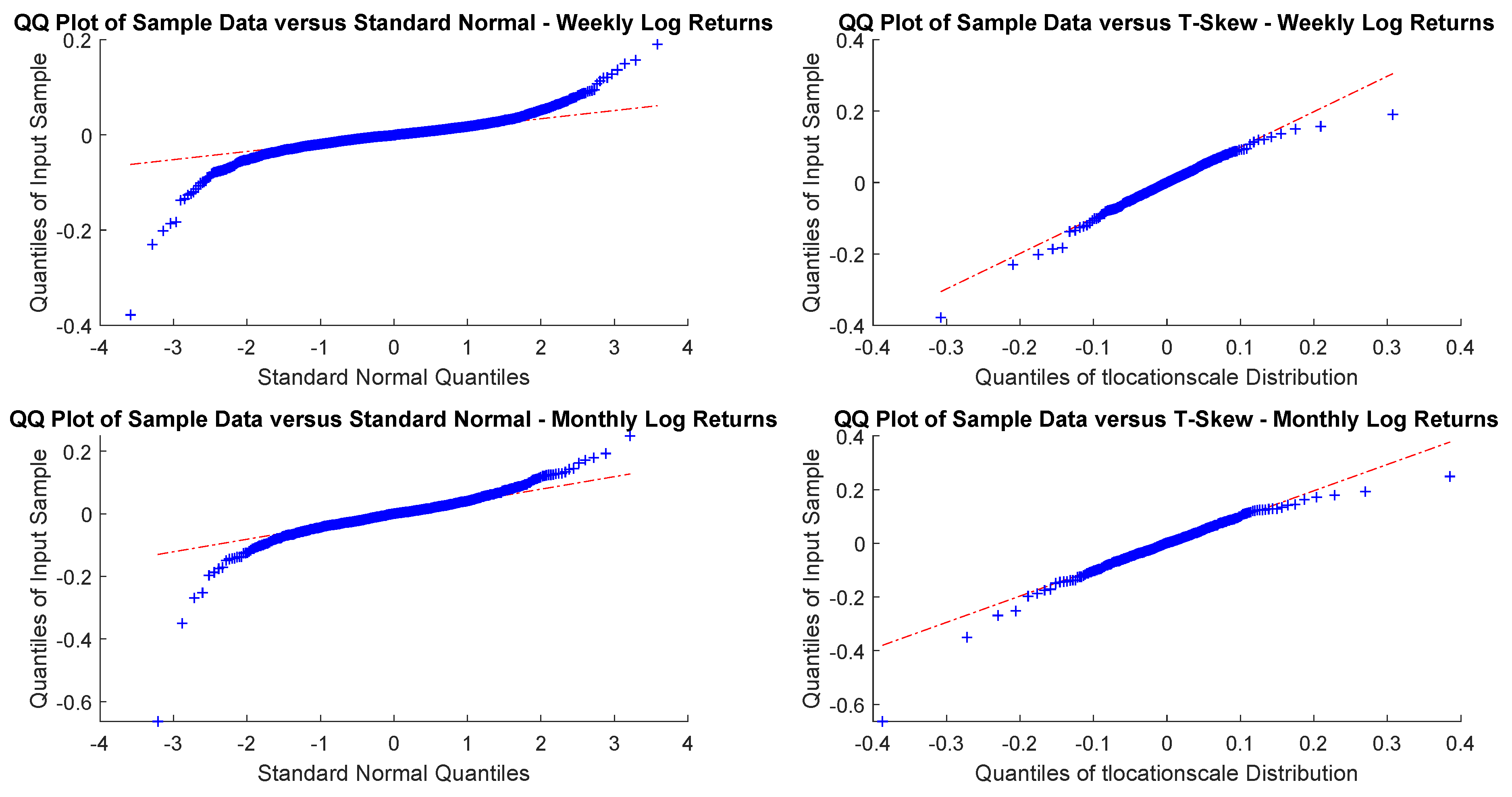
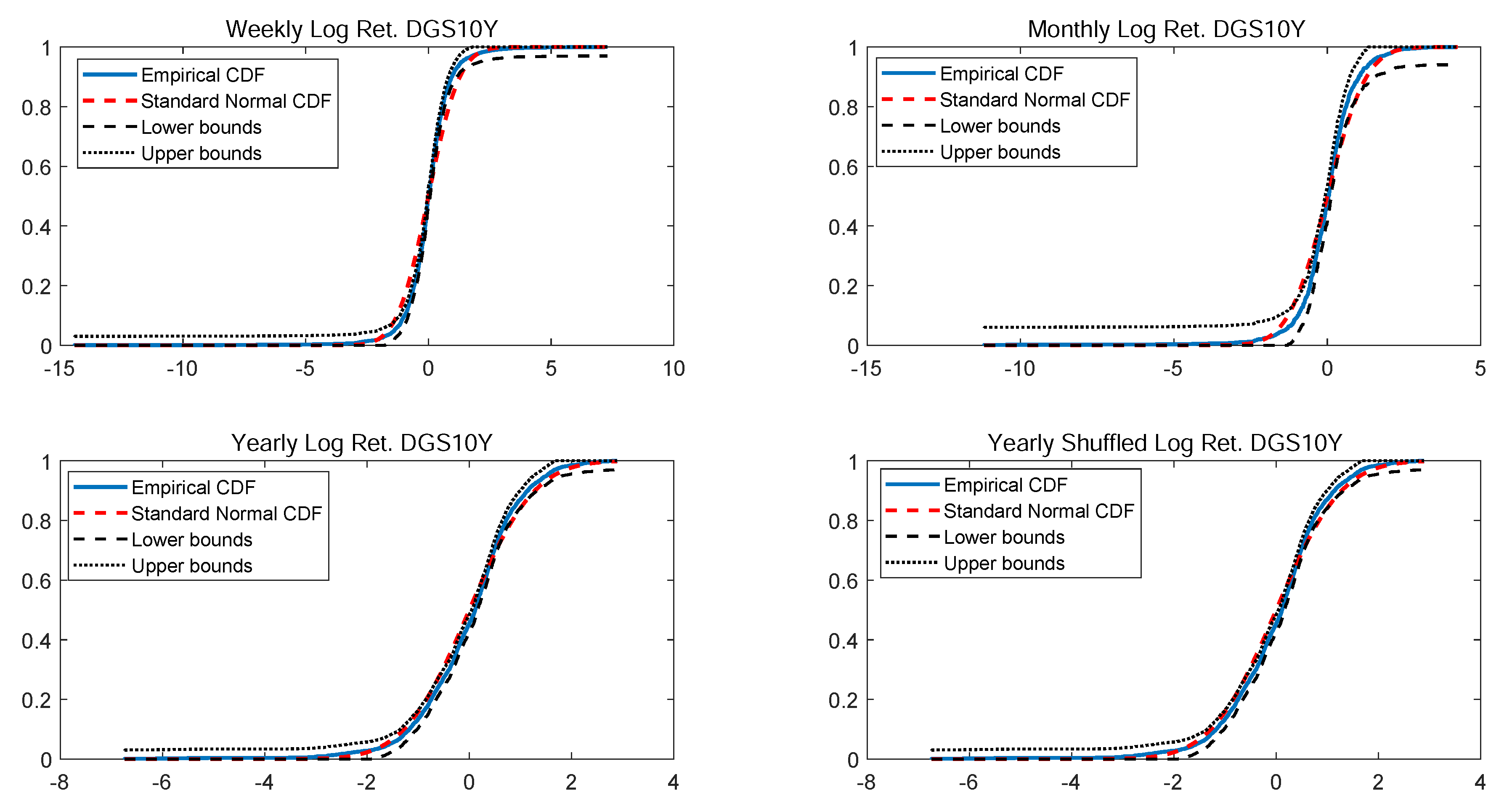
In particular, according to the tests carried out on our dataset, the distributions of log-returns do not seem to be normally distributed. The same applies on the returns standardized by the standard deviation. In a different context,
Tiwari and Gupta (
2019) found that the Jarque–Bera test strongly rejects the hypothesis of Gaussian distribution for all considered time series concerning G7 stock markets. Therefore, through the paper, we report a number of tests to decide the better distribution between Gaussian, t-skew, generalized hyperbolic, generalized Pareto and exponential Pareto. In terms of applications, being able to correctly identify the distribution is important for risk management as the tail conditional expectation provides information about the mean of the tail of the loss distribution, “while the tail variance (TV) measures the deviation of the loss from this mean along the tail of the distribution”
Eini and Khaloozadeh (
2020). Another application is in option pricing. For instance,
Yeap et al. (
2018) propose a t-skew model with “a fat-tailed, skewed distribution and infinite-activity (pure jump) stock dynamics, which is achieved through modeling the length of time intervals as stochastic”.
Having described the framework of our investigation, now we are in position to perform some tests on swaps, equities (for both developed and emerging markets) and corporate bonds (for both developed and emerging markets) sampled on weekly, monthly and yearly basis.
Section 2 contains a literature review,
Section 3 describes the dataset and the methods we intend to adopt for our analysis,
Section 4 reports the results we obtained on the original data as well as on the time series of the rescaled returns, the last
Section 5 draws the conclusions.
2. Literature Review
Distribution of returns is important because econometric models depend upon specific distributional assumptions, and in the case of implied volatilities, on further assumptions concerning the distributional and dynamic properties of stock market volatility. Wrong assumptions call into question the robustness of findings based on those models. One may always opt for an alternative approaches such as those based on squared returns over a given horizon, that provides model-free unbiased estimates of the ex-post realized volatility. Unfortunately, however, “squared returns are also a very noisy volatility indicator and hence do not allow for reliable inference regarding the true underlying latent volatility”
Andersen et al. (
2001). To overcome such limitations,
Andersen et al. (
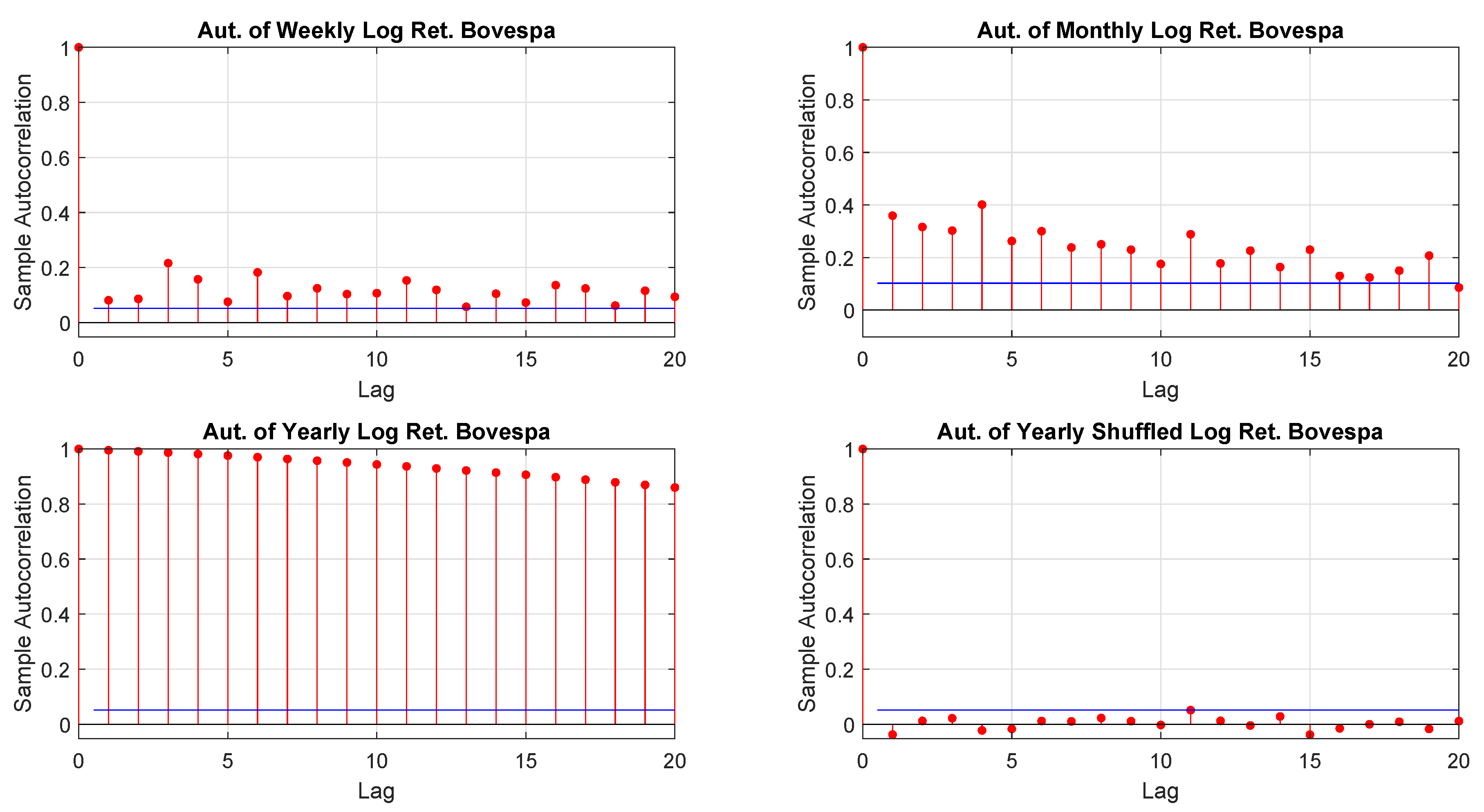
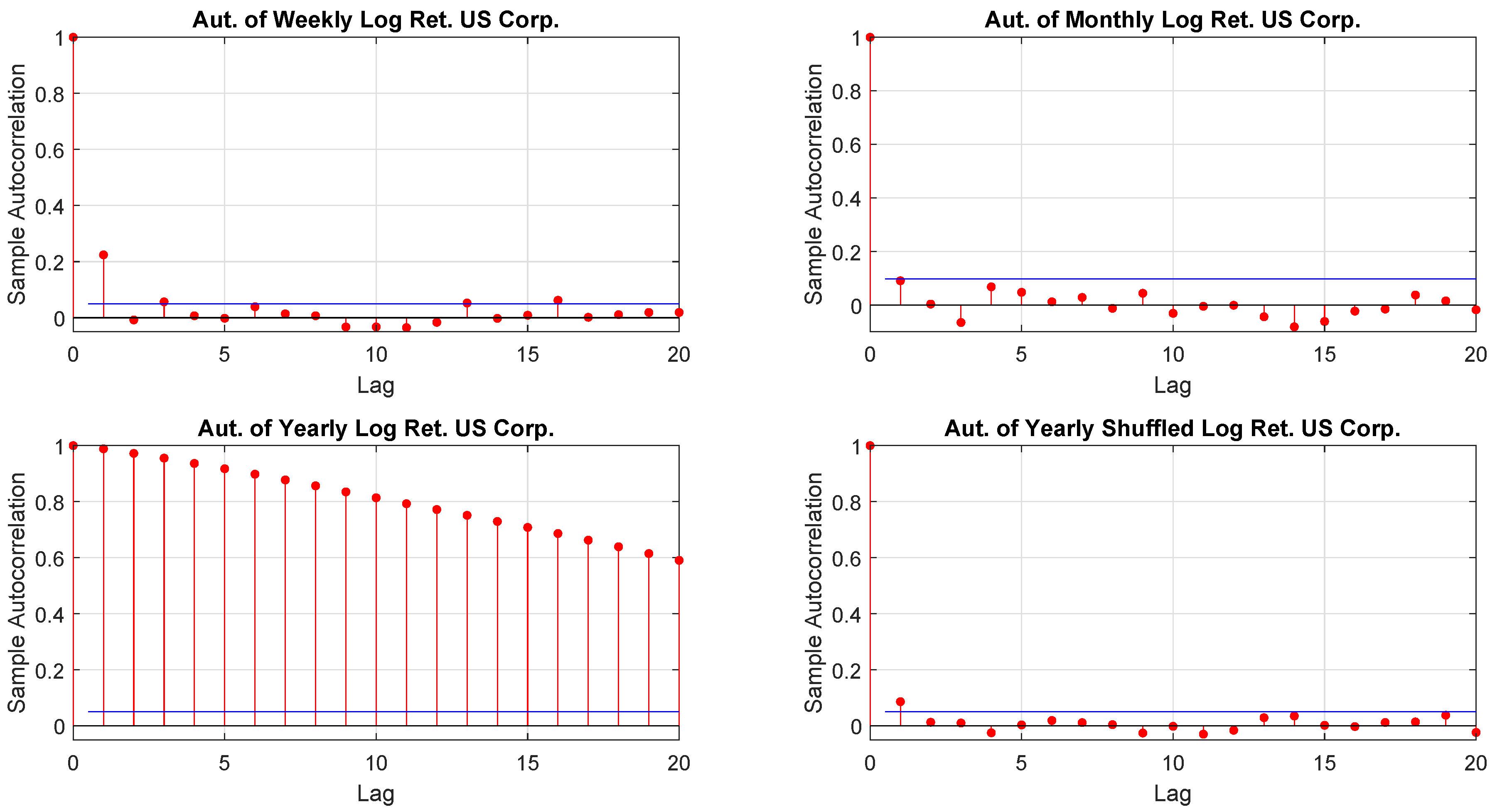
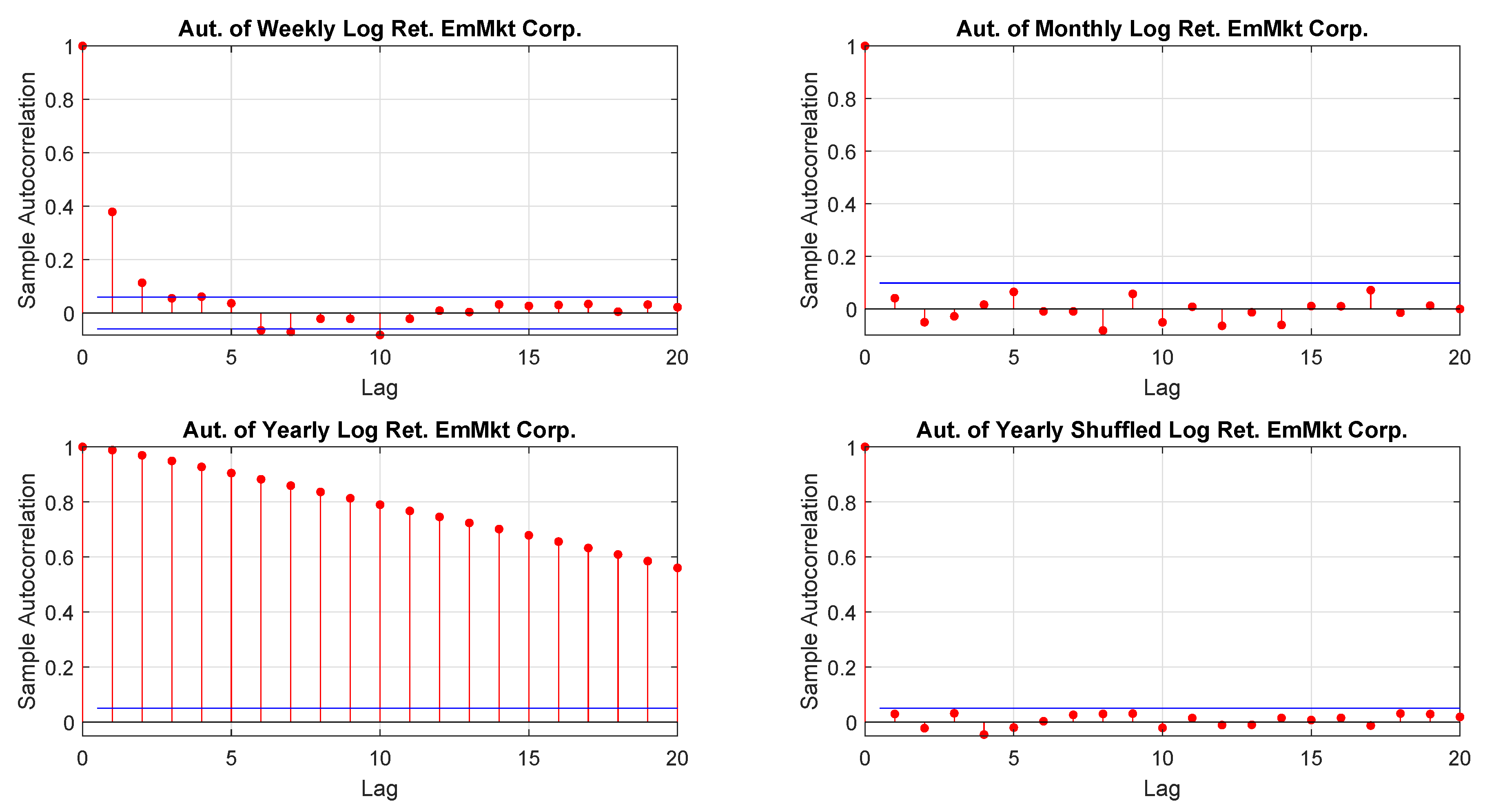
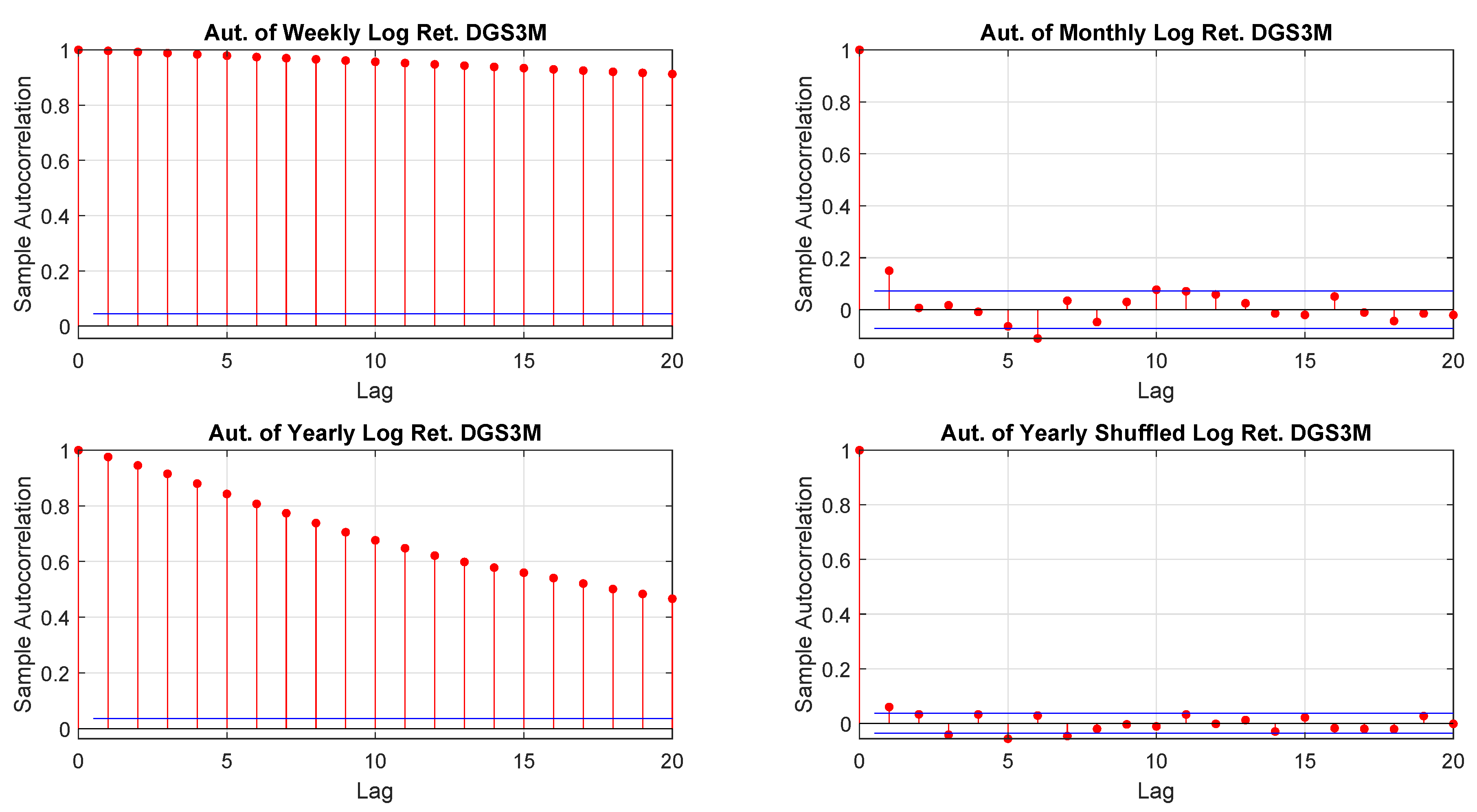
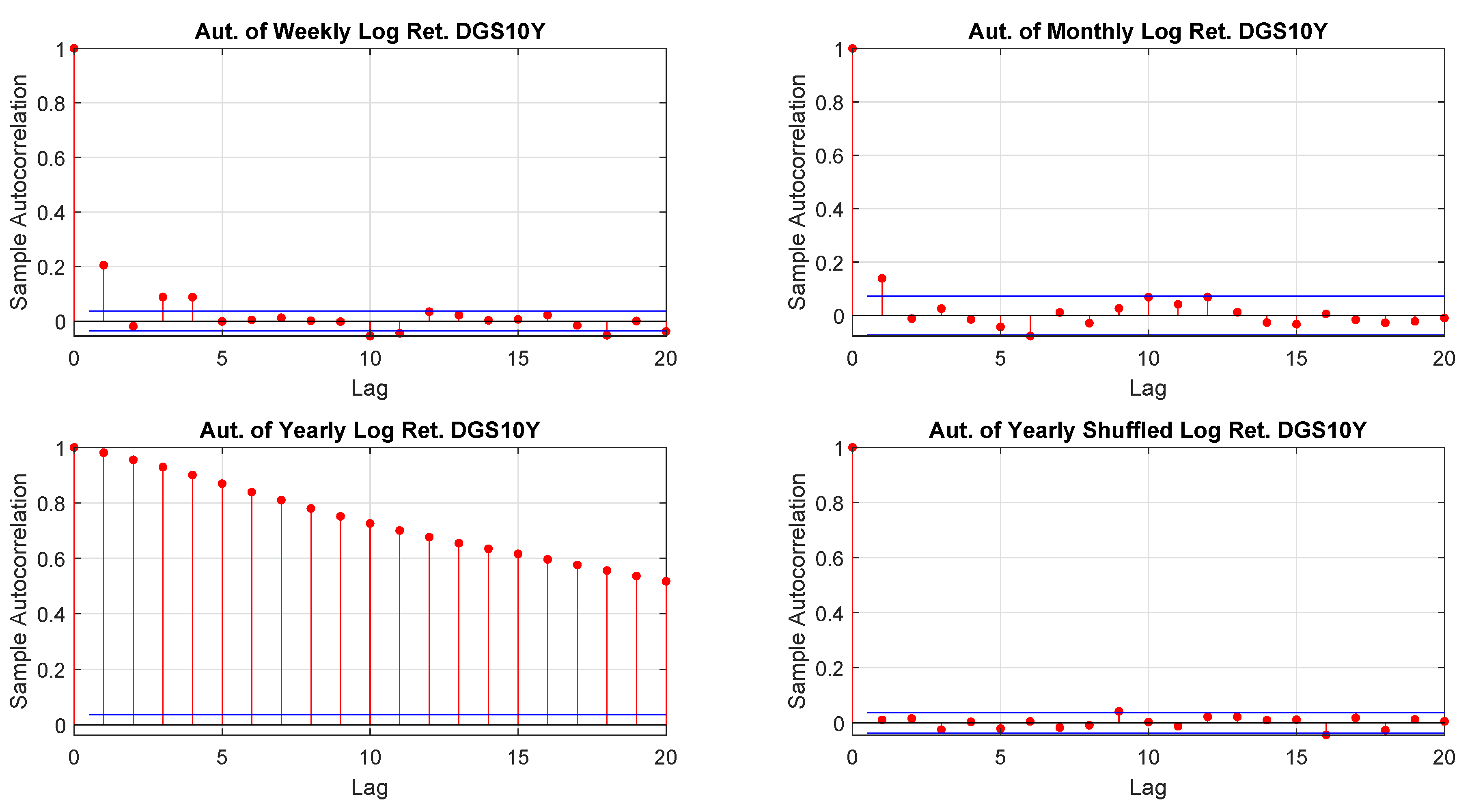
2001) suggested a model free volatility estimate by summing squares and cross-products of intraday high-frequency returns. That approach, however, relies on a reliable high-frequency return observation which, often is not guaranteed. Moreover, it is not necessarily true that the characteristics of a time series are independent on the time horizon and the sampling frequency so that, for example, one may extrapolate seeminglessly from daily data monthly or yearly distributions. Furthermore, time horizon and sampling frequency not only may influence the moments of a given distribution of returns but, also, the way in which data are hierarchically and spatially organized
Tumminello et al. (
2007).
Among alternatives, parametric approaches skew normal distributions, as introduced by
Azzalini (
1985) and
Henze (
1986), have became quite popular because they suit well in modeling skewed data defined as follows
where
is the parameter controlling the skewness and
and
denote the
are the standard normal density and the normal cumulative distribution, respectively.
By further enhancing those distributions,
Kim (
2001) proposes a family of t-skew distributions in terms of a scale mixture of skew-normal distributions.
The random variable
X is said to be t-skew distributed with parameter
and
if its probability density function is
where
,
and
are the standard normal density and the normal cumulative distribution, respectively.
The salient features of the family of t-skew distributions are their mathematical tractability, the inclusion of the normal law and the shape parameter regulating the skewness, apart from the ability of fitting heavy-tailed and skewed data, scale mixtures of skew-normal densities come from a family of t-skew distributions.
Such an extension allows for a continuous variation from normality to non-normality and it has found a number of applications on fitting heavy-tailed and skewed data. Other applications of such distributions are related to copula modeling.
Yoshiba (
2018) found that the AC t-skew copula describes well the dependence structures of both “unfiltered daily returns and GARCH or EGARCH filtered daily returns of the three stock indices: the Nikkei225, S&P500 and DAX”. This is because financial time series are characterized by asymmetry. For instance,
Patton (
2006) reported evidence that “the mark–dollar and yen–dollar exchange rates are more correlated when they are depreciating against the dollar than when they are appreciating”. A drawback of t-skew models is that it is more difficult to handle compared to Gaussian distributions and that there is no closed form analytic formula for computing the elements of the expected information matrix. However, numerical methods are available, e.g.,
Martin et al. (
2020).
Moreover, the multiple questions related to parametric models and model-free have led to further development of observation-driven models such as the so-called dynamic conditional score (DCS)
Creal et al. (
2013) where the updating of the score function is a mechanism that acts as a kind of partitioning of the dataset
Lavielle and Teyssiere (
2006);
Orlando et al. (
2020). DCS models, often based on t-skew distributions, have been conceived for describing the distribution of returns
Harvey (
2013) and they find a number applications in finance from forecasting Value at Risk (VaR) and expected shortfall (ES)
Gao and Zhou (
2016) to FX
Ayala and Blazsek (
2019), from commercial and residential mortgage defaults
Babii et al. (
2019) to hedging for crude oil future
Gong et al. (
2019). For a review, see
Blazsek and Licht (
2020).
5. Conclusions
According to the tests carried out on our dataset, the distributions of log-returns do not seem to be normally distributed. The same applies on the returns standardized by the standard deviation. In a different context,
Tiwari and Gupta (
2019) found that the Jarque–Bera test strongly rejects the hypothesis of Gaussian distribution for all considered time series concerning G7 stock markets.
A more realistic work hypothesis is that time series follow a t-skew distribution. The t-skew distribution can be seen as a mixture of skew-normal distributions
Kim (
2001) which generalize the normal distribution thanks to an extra parameter regulating the skewness. By construction, then, they can model heavy tails and skews that are common in financial markets. Thus, their adoption in finance is gaining momentum for modeling distributions
Harvey (
2013) and risk
Gao and Zhou (
2016). Further, t-skew has the power to link-up with observation-driven models such as the dynamic conditional score (DCS)
Creal et al. (
2013) or based on data partitioning
Orlando et al. (
2019);
Orlandoet al. (
2020). This paper tries to help in gaining insights on returns’ distributions and on the most suitable way of fitting them. According to the empirical results we reported, the distributions that fit better the data are the t-skew and the hyperbolic Pareto. As the latter is more difficult to handle, this research suggests that the t-skew represents a suitable alternative. That is relevant in terms of policy implications because risk management or option pricing
Mininni et al. (
2020) should rely on models able to describe fat tails, skewed distributions and jumps in assets’ dynamics
Orlando et al. (
2018) rather than on Gaussian distributions that may underestimate the extremes (and leave the investors exposed to unexpected losses). For those reasons, regulators and financial institutions should pay particular attention to model risk (i.e., risk resulting from using insufficiently accurate models) when they choose a particular distribution.
Last but not least, t-skew models could be used as linkages between financial markets. To this end,
Yoshiba (
2018) provides a solution for computing the MLE and keeping the correlation matrix positive semi-definite during the optimization process.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





























