Abstract
This paper considers a mean-variance portfolio selection problem when the stock price has a 3/2 stochastic volatility in a complete market. Specifically, we assume that the stock price and the volatility are perfectly negative correlated. By applying a backward stochastic differential equation (BSDE) approach, closed-form expressions for the statically optimal (time-inconsistent) strategy and the value function are derived. Due to time-inconsistency of mean variance criterion, a dynamic formulation of the problem is presented. We obtain the dynamically optimal (time-consistent) strategy explicitly, which is shown to keep the wealth process strictly below the target (expected terminal wealth) before the terminal time. Finally, we provide numerical studies to show the impact of main model parameters on the efficient frontier and illustrate the differences between the two optimal wealth processes.
1. Introduction
In the last several decades, various stochastic volatility models have been developed in the literature to explain the volatility smile and heavy tails of return distribution as widely observed in the financial market; see, for example, Heston (1993); Hull and White (1987); Lewis (2000); and Stein and Stein (1991). Among them, a non-affine model with a mean reverting structure called the 3/2 stochastic volatility model Lewis (2000) enjoys empirical support in the bond and stock market by previous works, such as Ahn and Gao (1999); Bakshi et al. (2006); and Jones (2003). Effort has been made under the 3/2 stochastic volatility in derivative pricing problems such as Carr and Sun (2007); Drimus (2012); and Yuen et al. (2015). It seems, however, that little attention has been paid to portfolio selection problems under Markowitz (1952) mean-variance criterion.
The single-period asset allocation theory under the mean-variance criterion is first introduced by the seminal paper Markowitz (1952). Thereafter, there has been increasing attention on extensions and applications of Markowitz’s work. Two milestones are the work of Li and Ng (2000) and Zhou and Li (2000) that generalize Markowitz’s work to a multi-period and continuous-time setting by using embedding techniques. In Zhou and Li (2000), they assume that all the market parameters are deterministic functions or constants. To extend the results to more realistic models with random parameters, on the assumption that the return rate, volatility, and risk premium are all bounded stochastic processes, the backward stochastic differential equation (BSDE) approach is introduced by Lim and Zhou (2002) to solve a mean-variance problem in a complete market. From then on, many papers work on the mean-variance portfolio selection problem under various financial models by using the BSDE approach. Chiu and Wong (2011) consider the problem where asset prices are cointegrated. Shen et al. (2014) investigate the same problem under a constant elasticity of variance model by assuming that the risk premium process satisfies an exponential integrability. Zhang and Chen (2016) extend the results in Shen et al. (2014) by further incorporating a liability process. Shen and Zeng (2015) study the optimal investment-reinsurance problem for a mean-variance insurer in an incomplete market where the risk premium process is proportional to a Markovian, affine-form, and square-root process, and a modified locally square-integrable optimal strategy is derived by imposing an exponential integrability of order 2 on the risk premium process. Under similar conditions considered in Shen and Zeng (2015), a mean-variance problem under the Heston model with a liability process and a financial derivative is considered in Li et al. (2018). Other relevant works on mean-variance portfolio selection problems by applying not only the BSDE approach, but also other approaches (for example, the dynamic programming approach and the martingale approach Pliska (1986)) include Bielecki et al. (2005); Chang (2015); Ferland and Watier (2010); Han and Wong (2020); Lv et al. (2016); Pan and Xiao (2017); Pan et al. (2018); Peng and Chen (2020a, 2020b); Shen (2015, 2020); Shen et al. (2020); Tian et al. (2021); and Yu (2013).
The literature mentioned above under Markowitz’s paradigm, however, shares one characteristic, that is, all deals with pre-committed strategies Strotz (1956). The resulting optimal strategy always depends on the initial wealth level, and thus is called time-inconsistent. Recently, the time-consistent mean-variance portfolio selection problem has received considerable attention. To tackle the time-inconsistency, Basak and Chabakauri (2010) derive a time-consistent strategy which is determined by applying a backward recursion starting from the terminal date. Björk et al. (2017) develop a game theoretical approach under Markovian settings which essentially studies the subgame-perfect Nash equilibrium, and they derive the equilibrium strategy and equilibrium value function by solving an extended Hamilton–Jacobi–Bellman (HJB) equation. Along this approach, previous works include Li et al. (2012, 2015); Lin and Qian (2016); and Zhu and Li (2020), to name but only a few. Alternatively, Pedersen and Peskir (2017) introduce the dynamically optimal approach to investigate the time-inconsistency of mean-variance problems. They overcome the time-inconsistency by recomputing the statically optimal (pre-committed) strategy during the investment period, and they can therefore obtain dynamically optimal (time-consistent) strategies by solving infinitely many optimization problems.
Motivated by these aspects, we consider a dynamic mean-variance portfolio selection problem within the framework developed in Pedersen and Peskir (2017) in a complete market with two primitive assets: a risk-free asset and a stock with 3/2 stochastic volatility. In particular, the market is completed by fixing a perfectly negative correlation between the stock price and the volatility. To make the problem analytically tractable, the return rate of the stock is a constant so that the risk premium process is linear in the reciprocal of volatility process. We adopt the BSDE approach to solve this problem. The Lagrange multiplier is first applied to transform the mean-variance problem into an unconstrained optimization problem. By making an assumption on model parameters, the uniqueness and existence of solution to a special type BSDE Bender and Kohlmann (2000) is established. We then solve the BSDE explicitly and obtain the optimal strategy in a closed-form for the unconstrained optimization problem. Furthermore, we derive the analytic expression of the statically optimal strategy of the mean-variance portfolio selection problem by the Lagrange duality theorem. Finally, by solving the statically optimal strategy at each time, we obtain the dynamically optimal strategy which is shown to keep the corresponding wealth process strictly below the target (expected terminal wealth) before the terminal time. To summarize, this paper has main contributions in three aspects: (1) We make an assumption on the model parameters instead of on the risk premium process. This assumption guarantees the existence and uniqueness of solutions to the BSDEs. (2) We manage to derive the square-integrable optimal strategy instead of the locally square-integrable optimal strategy and verify the admissibility. (3) We provide both the static and dynamic optimality.
The rest of this paper is organized as follows. Section 2 formulates the financial market and the portfolio selection problem. In Section 3, we derive the explicit solutions to the BSDEs as well as the closed-from expression of the optimal investment strategy of the unconstrained problem. Section 4 presents the static and dynamic optimality of the mean-variance portfolio selection problem. In Section 5, we provide numerical examples to present the efficient frontier under the statically optimal strategy and illustrate the differences between the two optimal controlled wealth processes. Section 6 concludes the paper.
2. Formulation of the Problem
Let be a finite horizon and be a complete probability space which carries a one-dimensional standard Brownian motion . The right-continuous, -complete filtration is generated by the Brownian motion W.
We consider a market where two primitive assets—one risk-free asset and one stock—are available to the investor. The price of the risk-free asset B solves
with at time fixed and given, where stands for the interest rate. The price of the stock follows
with at time . The return rate of the stock price is a constant and is the stochastic variance of the stock price described by a 3/2 model (see, for example, Lewis (2000)):
with the initial value of at time , where three parameters, , and , are all assumed to be positive. We hereby put the minus sign in front of in (2) to emphasize the assumption that the dynamics of the stock price and the volatility are perfectly negative correlated.
We shall consider Markov controls denoting the wealth invested in the stock at time , and such a deterministic function is called a feedback control law. We assume that there are no transaction costs in the trading as well as other restrictions. The investor wishes to create a self-financing portfolio of the risk-free asset B and the stock S dynamically. Thus, the controlled wealth process of the investor can be described by the system of SDEs below.
with at time . We let denote the probability measure with initial value at time .
Definition 1.
Given any fixed , if for any , it holds that
- 1.
- ,
- 2.
- ,
then the (Markovian) strategy u is called admissible. We denote by the set of admissible portfolio strategies.
We are first interested in determining an admissible strategy that solves the following portfolio problem:
Definition 2.
The mean-variance portfolio problem is an optimization problem denoted by
where ξ is a fixed and given constant playing the financial role of a target. The corresponding value function is denoted by .
Remark 1.
Here, we impose , in line with previous studies such as Lim and Zhou (2002); Shen and Zeng (2015), and Shen et al. (2014). Otherwise, the investor can simply take the risk-free strategy over which dominates any other admissible strategy.
As a result of the quadratic nonlinearity of the variance operator, problem (4) falls outside of Bellman’s principle. Denote by the optimal strategy in problem (4) which refers to the static optimality (refer to Definition 1 in Pedersen and Peskir (2017)) and is relative to the initial position . The investor might not be committed to the statically optimal strategy chosen at the very initial position during the following investment period . Therefore, we shall also consider a dynamic formulation of problem (4). Here, we opt for the framework developed in Pedersen and Peskir (2017). We now review the definition of dynamic optimality in problem (4) for the readers’ convenience.
Definition 3.
For a triple fixed and given, we call a Makrov strategy dynamically optimal in problem (4), if for every and every strategy with and , there is a Markov strategy w satisfying and such that
The dynamically optimal strategy is essentially derived by solving the statically optimal strategy at each time and implementing it in an infinitesimally small period of time, which in turn implies that we shall first address problem (4) in the sense of static optimality so as to derive the dynamic optimality.
We observe that problem (4) is, in fact, a convex optimization problem with linear constraint . Thus, we can handle the constraint by introducing a Lagrange multiplier , and define the following Lagrangian:
Then, the Lagrangian duality theorem (see, for example, Luenberger (1968)) indicates that we can derive the static optimality in problem (4) by solving the following equivalent min-max stochastic control problem:
This shows that we can solve problem (6) with two steps, of which the first step is to solve the unconstrained stochastic optimization problem with respect to given a fixed and the second step is to solve the static optimization problem with respect to the Lagrange multiplier . Therefore, we can first address the following unconstrained quadratic-loss minimization problem:
with fixed and given.
3. Solution to the Unconstrained Problem
In this section, we opt for the BSDE approach so as to solve problem (7) above. Before formulating the main results in this section, we make the following notations to facilitate the discussions below. For any -valued, -adapted stochastic process , a continuous process associated with is defined by . Let be a generic constant, we denote by
- : the space of -adapted, -valued stochastic processes f satisfying
- : the space of -adapted, -valued stochastic processes f satisfying
- the space of -adapted, -valued stochastic processes f satisfying
Therefore, we have the following Banach space:
with the norm .
In addition, we introduce
It can be easily checked that due to . The following standing assumption is imposed on the model parameters throughout the paper:
Assumption 1.
.
Remark 2.
The following linear BSDE of is considered so as to solve problem (7):
Clearly, due to the randomness and unboundedness of the driver of (9), this linear BSDE is without the uniform Lipschitz continuity with respect to both and . Thus, BSDE (9) is out of scope of EI Karoui et al. (1997). Nevertheless, we observe that BSDE (9) follows a stochastic Lipschitz continuity which is first proposed in Bender and Kohlmann (2000). To proceed, some useful results on the BSDE with the stochastic Lipschitz continuity adapted from Definition 2 and Theorem 3 in Bender and Kohlmann (2000) are presented below.
Definition 4.
We call a pair standard data for the BSDE of :
if the following four conditions hold:
- 1.
- There exist two -valued, -adapted stochastic processes and such thatWe refer to this inequality as the stochastic Lipschitz continuity.
- 2.
- There exists a positive constant satisfying .
- 3.
- The terminal condition ζ satisfies in which β is a positive constant.
- 4.
- .
Lemma 1.
The BSDE of
admits a unique solution if is standard data for a sufficiently large β, in particular, for .
Before adapting the above results to establish the uniqueness and existence of the solution to BSDE (9), we recall the following useful result from Theorem 5.1 in Zeng and Taksar (2013).
Lemma 2.
Suppose the process follows the Cox–Ingersoll–Ross (CIR) model:
where and σ are positive constants. Then, we have
Lemma 3.
Assume Assumption 1 holds, then there is a constant such that the unique solution with to BSDE (9) exists.
Proof.
Let and . Denote in this case the non-negative -adapted process by
and accordingly, define the increasing process by
We then have
where the positive constant is independent of . By Itô’s lemma, we then have the following dynamics of the reciprocal of the variance process (2):
which is a CIR process. It follows from Lemma 2 that if
then we have
In what follows, we shall give the explicit expression of the unique solution of BSDE (9).
Lemma 4.
Assume Assumption 1 holds, then the unique solution of BSDE (9) has the following explicit expression:
for , where , and and are solutions to the following system of ODEs:
Proof.
We first introduce the likelihood process from the dynamics
Similar to the reasoning in Lemma 3, it can be easily verified from Assumption 1 above that
That is, the Novikov’s condition is satisfied for . Thus, is a uniformly integrable martingale under measure and we can define an equivalent probability measure on through the Radon–Nikodym derivative
From the Girsanov’s theorem, Brownian motions under and are related to each other through
and we can rewrite (9) under the -measure as follows:
We see that the driver of BSDE (12) again satisfies the stochastic Lipschitz continuity with, in this case, for any fixed and given and such that using Hölder’s inequality we have for some
where is constant-independent of , the second equality follows from the fact that is a martingale due to Assumption 1, and the last strict inequality is due to Assumption 1. This shows that the terminal condition and the driver of BSDE (12) constitute standard data. Then, by Lemma 1 above, the BSDE (12) admits a unique solution satisfying
with some and . Moreover, we see that under measure
This shows that is a local martingale under measure . By the Burkholder–Davis–Gundy inequality and Hölder’s inequality, we then find that
where the positive constant might vary between lines; the equality follows from the fact that is a martingale due to Assumption 1, and the last strict inequality is due to Assumption 1 and . This shows that is, in fact, a uniformly integrable martingale under measure (refer to Corollary 5.17 in Le Gall (2016)). Upon noticing the boundary condition that , we have the expectational form for below.
Denote by
where is the expectation at time such that under -measure. Due to the Markovian structure of the variance process with respect to , we can obviously rewrite as follows:
Note that the variance process has -dynamics:
Suppose the deterministic function , then applying the Feynman–Kac theorem yields the following PDE governing function g:
We conjecture that g admits the following exponential expression:
with boundary condition . Its derivatives are given by
Lemma 5.
Proof.
By reformulating the Riccati ODE of , we have
where and are given in (8) above. After some tedious calculations upon considering , we obtain (15). Integrating both sides of ODE of from t to T upon considering the boundary condition gives (16). Furthermore, differentiating (15) with respect to t yields
□
Denote by the reciprocal process of . Then, a direct application of Itô’s lemma to yields the backward stochastic Riccati equation (BSRE) of below.
where . As given in (10) is the unique solution of BSDE (9), from the relationship of and , we see that BSRE (17) admits a unique solution as well.
Lemma 6.
Proof.
The Equation (18) can be directly derived from the relationship of and above. □
We now define a Doléans-Dade exponential of by
In the next lemma, we shall study the integrablity of which will be useful when we verify the admissibility of optimal strategy (20) below.
Lemma 7.
Assume Assumption 1 holds, then the Doléans–Dade exponential (19) satisfies
Proof.
We know that the following equation of k
admits two positive solutions
for any given constant , where the first solution satisfies . In particular, when , we have . Using Assumption 1, Lemma 5, and the reasoning given in the proof of Lemma 3 above, we see that
Then, Theorem 15.4.6 in Cohen and Elliott (2015) yields
This completes the proof. □
To end this section, we shall relate the optimal Markovian strategy and the corresponding value function of problem (7) to the solution of BSRE (17).
Proposition 1.
Assume Assumption 1 holds, then for fixed and given, the optimal (Markovian) strategy of problem (7) is
for . The corresponding value function is
The controlled wealth process evolves as
where is given in (19). Moreover, the optimal strategy belongs to .
Proof.
Using Itô’s lemma to , we obtain
Furthermore, applying Itô’s lemma to yields
We observe that the stochastic integral on the right-hand side of (23) is a local martingale, and thus we can define stopping times as follows:
such that , almost surely as . We integrate (23) from to and take expectations on both sides of (23):
where . From the definition of function in Lemma 4 above, we see that for any , -a.s. Moreover, in view of Definition 1, we have for . As a result of the Lebesgue’s dominated convergence theorem and the monotone convergence theorem working on (24), then we have
Upon considering explicit expressions of and (18), we obtain the optimal Markov strategy (20) and the value function (21) for problem (7).
A direction application of Itô’s lemma to then yields the controlled wealth process (22).
In the following, we show that the optimal strategy (20) is admissible. For this, we first show that
Indeed, from Assumption 1 and Lemma 7 above we find that
where is a constant that differs between lines and . This shows that the second condition in Definition 1 that is satisfied by Jensen’s inequality. In view of (26), we further find that the first condition in Definition 1 that holds as well as
where is a constant that differs between lines and last strict inequality comes from (26) and the fact that is a CIR process (see the proof of Lemma 3 above) with finite second moment at time which is continuous in t (see, for example, Cox et al. (1985)). These results show that the optimal strategy (20) is admissible. □
4. Static and Dynamic Optimality of the Problem
In this section, we derive the static and dynamic optimality of problem (4) by exploiting the results above. In regard to the static optimality of problem (4), it now suffices to maximize the following optimization problem with respect to the Lagrange multiplier in view of (5) and (6) above:
Reformulating (27) in terms of a quadratic functional over , we find that the value function of problem (4) can be obtained from
Upon considering the exponential expression of function given in Lemma 4 above, the right-hand side of (28) is then a quadratic function of with strictly negative leading coefficient. Therefore, to the right-hand side of (28) the maximum is uniquely attained at
Theorem 1.
Assume Assumption 1 holds, then for given and fixed such that , the statically optimal (Makrovian) strategy of problem (4) is
for , where functions and are given in (15) and (16). The corresponding value function is
The controlled wealth process is given by
where is given in (19). Moreover, the statically optimal strategy belongs to .
Proof.
Substituting (29) into (28) gives the value function (31). Replacing the constant in (20) and (22) with yields the statically optimal strategy (30) and the wealth process (32), respectively. In view of the proof in Proposition 1 above, it is obvious that the statically optimal strategy (30) is admissible. □
As discussed in Section 2, the statically optimal strategy (30) derived in Theorem 1 relies on the initial value . This implies that once the investor arrives at a new position at later times, the statically optimal strategy determined at the initial position would be sub-optimal. Now, we give the dynamically optimal strategy of problem (4) within the framework developed in Pedersen and Peskir (2017).
Theorem 2.
Assume Assumption 1 holds, then for given and fixed such that , the dynamically optimal (Markovian) strategy of problem (4) for is
The corresponding controlled wealth process is
satisfying for .
Proof.
To derive a candidate for the dynamic optimality over , we identify with t, with x, and with v in the statically optimal strategy given in (30). We then immediately find a candidate of the dynamically optimal strategy
In what follows, we show that this candidate (35) is indeed dynamically optimal in problem (4). To see this, we take any other admissible control such that and , and we set under the measure . We note from (30) with replaced by that , and thus we have for any . Then, by continuity of and w, there exists a ball such that for any when is small enough and satisfies . We observe from (25) that is, in fact, the unique continuous function such that the minimum within the expectation on the right-hand side of (25) (with and in place of and , respectively) is attained up to probability one. Therefore, we can set exiting time , and we see that for
where is a fixed positive constant. Now, from (25) with and in place of and , respectively, we find that
where is a constant at position , and the strict inequality makes use of the fact that as the pair has continuous sample paths with probability one under measure. From (36) we see that
This shows that for any , the candidate (35) is the dynamically optimal (Markovian) strategy for problem (4).
5. Numerical Examples
In this section, numerical examples are provided to analyze the impact of different parameters on the efficient frontier when the wealth process is controlled by the statically optimal strategy as well as to illustrate the differences between the dynamically optimal wealth and the statically optimal wealth derived in Section 4. Unless otherwise stated, we consider the following model parameters adapted from previous empirical studies (see, for example, Drimus (2012)): .
Figure 1 shows us how the interest rate r affects the efficient frontier. We find that higher interest rate r results in larger with the same . One of the possible reasons is that although the investor can get higher return by investing in the risk-free asset, the risk premium decreases as r increases so that the investor indeed derives less expected return from the stock, and thus undertakes more risk. In summary, the impact of r on the stock is more significant than that on the risk-free asset.
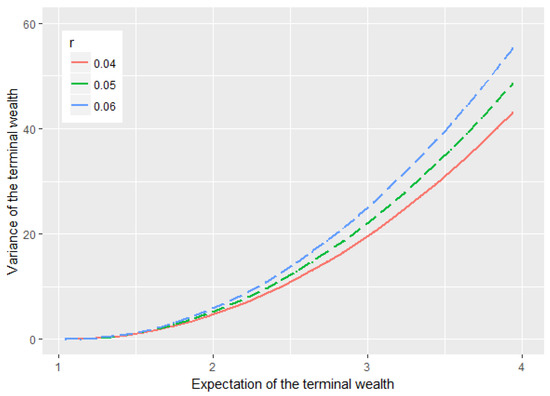
Figure 1.
The impact of r on the efficient frontier.
Figure 2 shows how the return rate of the stock influences the efficient frontier. Higher level of the return rate of the stock price lowers the variance of terminal wealth with the same , which is quite clear due to the fact that the investor receives more risk premium as increases and the investor can therefore undertake less risk by investing less into the stock and more into the risk-free asset so as to have the same expected terminal wealth.
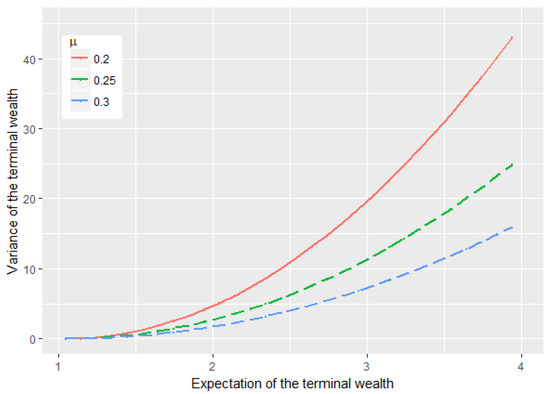
Figure 2.
The impact of on the efficient frontier.
The impact of the parameter on the efficient frontier is presented in Figure 3 below. We see that larger results in larger with the same . One possible reason is that as partly stands for the mean-reversion speed of the reciprocal of the stochastic volatility (recall the proof of Lemma 3 above), a larger results in a faster speed of towards the long-term level . Meanwhile, we see that the long-term level is, in fact, decreasing in . These two aspects in turn make the volatility of the stock stays longer around the relatively higher level . Therefore, the investor has to undertake more risk.
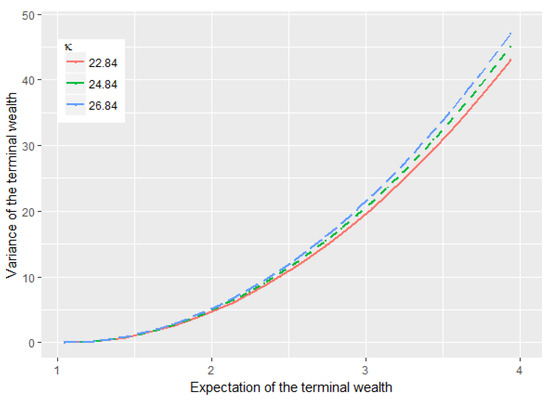
Figure 3.
The impact of on the efficient frontier.
The effect of the parameter on the efficient frontier is given in Figure 4, which shows that decreases with the same as increases. Again, from the proof of Lemma 3 above, we see that plays a role as the volatility of the reciprocal of volatility process , and a larger results in milder movements of the volatility process . In addition, we see that the long-run level of volatility decreases as increases. Therefore, these two factors help the investor bear less risk.
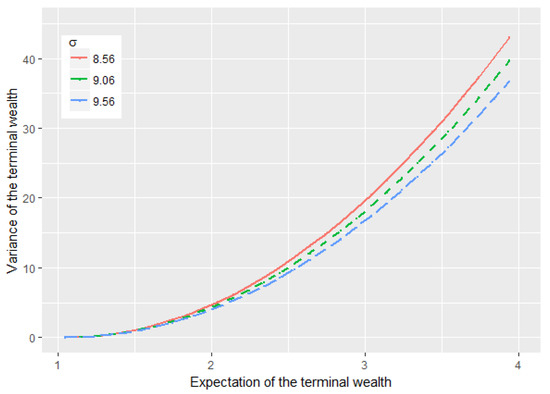
Figure 4.
The impact of on the efficient frontier.
To end this section, we show the dynamics of wealth processes controlled by the statically optimal strategy (30) and the dynamically optimal strategy (33), respectively. By setting 500 equidistant time points over , we simulate two paths of optimal wealth processes and . Figure 5 illustrates the significant difference between the dynamically optimal wealth process and the statically optimal wealth process . In particular, we see that the result supports the conclusion of Theorem 2 above: the dynamically optimal wealth is strictly smaller than the expected terminal wealth when .
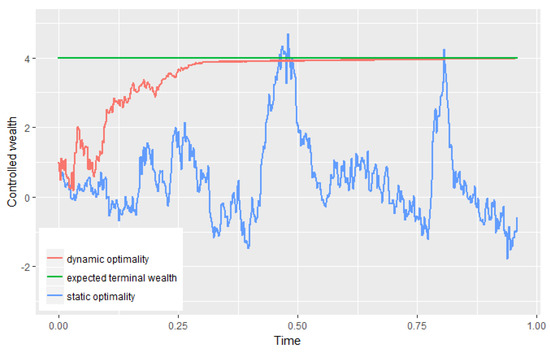
Figure 5.
Statically optimal wealth and dynamically optimal wealth .
6. Conclusions
In this paper, a dynamically optimal mean-variance portfolio selection problem within the framework developed in Pedersen and Peskir (2017) in a stochastic environment has been investigated. A 3/2 stochastic volatility model is used to characterize the stochastic volatility of the stock. Considering the methodology in Pedersen and Peskir (2017) to tackle the time-inconsistency of the optimality under mean-variance criterion, we first address the static optimality and solve it by using a general BSDE approach. Under an assumption on model parameters, we obtain the static optimality and the corresponding value function explicitly. By solving the static optimality in an infinitesimally small period of time, the closed-form expression of the dynamic optimality is derived. Considering some technical difficulties, however, we have only studied the case without any state constraint. One branch of research topics in the future is to impose pathwise constraints on the wealth process; see, for example, Pedersen and Peskir (2018).
Funding
This research received partial financial support from the University of Copenhagen.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing is not applicable to this article.
Acknowledgments
We would like to thank Jesper Lund Pedersen for general comments and discussions during this work.
Conflicts of Interest
The author declares no conflict of interest.
References
- Ahn, Dong-Hyun, and Bin Gao. 1999. A parametric nonlinear model of term structure dynamics. The Review of Financial Studies 12: 721–62. [Google Scholar] [CrossRef]
- Bakshi, Gurdip, Nengjiu Ju, and Hui Ou-Yang. 2006. Estimation of continuous time models with an application to equity volatility dynamics. Journal of Financial Economics 82: 227–49. [Google Scholar] [CrossRef]
- Basak, Suleyman, and Georgy Chabakauri. 2010. Dynamic mean-variance asset allocation. The Review of Financial Studies 23: 2970–3016. [Google Scholar] [CrossRef]
- Bender, Christian, and Michael Kohlmann. 2000. BSDEs with stochastic Lipschitz condition. Working Paper, Universität Konstanz, Fakultät für Mathematik und Informatik. Available online: http://hdl.handle.net/10419/85163 (accessed on 20 December 2020).
- Bielecki, Tomasz R., Hanqing Jin, Stanley R. Pliska, and Xun Yu Zhou. 2005. Continuous-time mean-variance portfolio selection with bankruptcy prohibition. Mathematical Finance 15: 213–44. [Google Scholar] [CrossRef]
- Björk, Tomas, Mariana Khapko, and Agatha Murgoci. 2017. On time-inconsistent stochastic control in continuous time. Finance and Stochastics 21: 331–60. [Google Scholar] [CrossRef]
- Carr, Peter, and Jian Sun. 2007. A new approach for option pricing under stochastic volatility. Review of Derivatives Research 10: 87–150. [Google Scholar] [CrossRef]
- Chang, Hao. 2015. Dynamic mean-variance portfolio selection with liability and stochastic interest rate. Economic Modelling 51: 172–82. [Google Scholar] [CrossRef]
- Chiu, Mei Choi, and Hoi Ying Wong. 2011. Mean-variance portfolio selection of cointegrated assets. Journal of Economic Dynamics and Control 35: 1369–85. [Google Scholar] [CrossRef]
- Cohen, Samuel N., and Robert James Elliott. 2015. Stochastic Calculus and Applications, 2nd ed. New York: Birkhäuser/Springer. [Google Scholar]
- Cox, John C., Jonathan E. Ingersoll, Jr., and Stephen A. Ross. 1985. A theory of the term structure of interest rates. Econometrica 53: 385–407. [Google Scholar] [CrossRef]
- Drimus, Gabriel G. 2012. Options on realized variance by transform methods: A non-affine stochastic volatility model. Quantitative Finance 12: 1679–94. [Google Scholar] [CrossRef]
- EI Karoui, Nicole, Shige Peng, and Marie Claire Quenez. 1997. Backward stochastic differential equations in finance. Mathematical Finance 7: 1–71. [Google Scholar] [CrossRef]
- Ferland, René, and François Watier. 2010. Mean-variance efficiency with extended CIR interest rates. Applied Stochastic Models in Business and Industry 26: 71–84. [Google Scholar] [CrossRef]
- Han, Bingyan, and Hoi Ying Wong. 2020. Mean–variance portfolio selection under Volterra Heston model. Applied Mathematics and Optimization 2020: 1–28. [Google Scholar] [CrossRef]
- Heston, Steven L. 1993. A closed-form solution for options with stochastic volatility with applications to bond and currency options. The Review of Financial Studies 6: 327–43. [Google Scholar] [CrossRef]
- Hull, John, and Alan White. 1987. The pricing of options on assets with stochastic volatilities. The Journal of Finance 42: 281–300. [Google Scholar] [CrossRef]
- Jones, Christopher S. 2003. The dynamics of stochastic volatility: Evidence from underlying and options markets. Journal of Econometrics 116: 181–224. [Google Scholar] [CrossRef]
- Lewis, Alan L. 2000. Option Valuation under Stochastic Volatility. Newport Beach: Finance Press. [Google Scholar]
- Le Gall, Jean-François. 2016. Brownian Motion, Martingales, and Stochastic Calculus. Berlin and Heidelberg: Springer. [Google Scholar]
- Li, Danping, Ximin Rong, and Hui Zhao. 2015. Time-consistent reinsurance–investment strategy for a mean–variance insurer under stochastic interest rate model and inflation risk. Insurance: Mathematics and Economics 64: 28–44. [Google Scholar] [CrossRef]
- Li, Danping, Yang Shen, and Yan Zeng. 2018. Dynamic derivative-based investment strategy for mean-variance asset-liability management with stochastic volatility. Insurance: Mathematics and Economics 78: 72–86. [Google Scholar] [CrossRef]
- Li, Duan, and Wan-Lung Ng. 2000. Optimal dynamic portfolio selection: Multiperiod mean-variance formulation. Mathematical Finance 10: 387–406. [Google Scholar] [CrossRef]
- Li, Zhongfei, Yan Zeng, and Yongzeng Lai. 2012. Optimal time-consistent investment and reinsurance strategies for insurers under Heston’s SV model. Insurance: Mathematics and Economics 51: 191–203. [Google Scholar] [CrossRef]
- Lim, Andrew E.B., and Xun Yu Zhou. 2002. Mean–variance portfolio selection with random parameters in a complete market. Mathematics of Operations Research 27: 101–20. [Google Scholar] [CrossRef]
- Lin, Xiang, and Yiping Qian. 2016. Time-consistent mean-variance reinsurance-investment strategy for insurers under CEV model. Scandinavian Actuarial Journal 7: 646–671. [Google Scholar] [CrossRef]
- Luenberger, David G. 1968. Optimization by Vector Space Methods. New York: Wiley. [Google Scholar]
- Lv, Siyu, Zhen Wu, and Zhiyong Yu. 2016. Continuous-time mean-variance portfolio selection with random horizon in an incomplete market. Automatica 69: 176–80. [Google Scholar] [CrossRef]
- Markowitz, Harry. 1952. Portfolio selection. The Journal of Finance 7: 77–91. [Google Scholar]
- Pan, Jian, and Qingxian Xiao. 2017. Optimal mean–variance asset-liability management with stochastic interest rates and inflation risks. Mathematical Methods of Operations Research 85: 491–519. [Google Scholar] [CrossRef]
- Pan, Jian, Zujin Zhang, and Xiangying Zhou. 2018. Optimal dynamic mean-variance asset-liability management under the Heston model. Advances in Difference Equations 2018: 258. [Google Scholar] [CrossRef]
- Pedersen, Jesper Lund, and Goran Peskir. 2017. Optimal mean-variance portfolio selection. Mathematics and Financial Economics 11: 137–60. [Google Scholar] [CrossRef]
- Pedersen, Jesper Lund, and Goran Peskir. 2018. Constrained dynamic optimality and binomial terminal wealth. SIAM Journal on Control and Optimization 56: 1342–57. [Google Scholar] [CrossRef]
- Peng, Xingchun, and Fenge Chen. 2020a. Mean-variance asset-liability management with inside information. Communications in Statistics-Theory and Methods 2020: 1–22. [Google Scholar] [CrossRef]
- Peng, Xingchun, and Fenge Chen. 2020b. Mean-variance asset–liability management with partial information and uncertain time horizon. Optimization 2020: 1–28. [Google Scholar] [CrossRef]
- Pliska, Stanley R. 1986. A stochastic calculus model of continuous trading: Optimal portfolios. Mathematics of Operations Research 11: 371–82. [Google Scholar] [CrossRef]
- Shen, Yang. 2015. Mean-variance portfolio selection in a complete market with unbounded random coefficients. Automatica 55: 165–75. [Google Scholar] [CrossRef]
- Shen, Yang. 2020. Effect of variance swap in hedging volatility risk. Risks 8: 70. [Google Scholar] [CrossRef]
- Shen, Yang, and Yan Zeng. 2015. Optimal investment–reinsurance strategy for mean–variance insurers with square-root factor process. Insurance: Mathematics and Economics 62: 118–37. [Google Scholar] [CrossRef]
- Shen, Yang, Xin Zhang, and Tak Kuen Siu. 2014. Mean-variance portfolio selection under a constant elasticity of variance model. Operations Research Letters 42: 337–42. [Google Scholar] [CrossRef]
- Shen, Yang, Jiaqin Wei, and Qian Zhao. 2020. Mean-variance asset-liability management problem under non-Markovian regime-switching models. Applied Mathematics and Optimization 81: 859–97. [Google Scholar] [CrossRef]
- Stein, Elias M., and Jeremy C. Stein. 1991. Stock price distributions with stochastic volatility: An analytic approach. The Review of Financial Studies 4: 727–52. [Google Scholar] [CrossRef]
- Strotz, Robert H. 1956. Myopia and inconsistency in dynamic utility maximization. The Review of Economic Studies 23: 165–80. [Google Scholar] [CrossRef]
- Tian, Yingxu, Junyi Guo, and Zhongyang Sun. 2021. Optimal mean-variance reinsurance in a financial market with stochastic rate of return. Journal of Industrial and Management Optimization 17: 1887–912. [Google Scholar] [CrossRef]
- Yu, Zhiyong. 2013. Continuous-time mean-variance portfolio selection with random horizon. Applied Mathematics and Optimization 68: 333–59. [Google Scholar] [CrossRef]
- Yuen, Chi Hung, Wendong Zheng, and Yue Kuen Kwok. 2015. Pricing exotic discrete variance swaps under the 3/2-stochastic volatility models. Applied Mathematical Finance 22: 421–49. [Google Scholar] [CrossRef]
- Zeng, Xudong, and Michael Taksar. 2013. A stochastic volatility model and optimal portfolio selection. Quantitative Finance 13: 1547–58. [Google Scholar] [CrossRef]
- Zhang, Miao, and Ping Chen. 2016. Mean–variance asset–liability management under constant elasticity of variance process. Insurance: Mathematics and Economics 70: 11–18. [Google Scholar] [CrossRef]
- Zhou, Xun Yu, and Duan Li. 2000. Continuous-time mean-variance portfolio selection: A stochastic LQ framework. Applied Mathematics and Optimization 42: 19–33. [Google Scholar] [CrossRef]
- Zhu, Jiaqi, and Shenghong Li. 2020. Time-consistent investment and reinsurance strategies for mean-variance insurers under stochastic interest Rate and stochastic volatility. Mathematics 8: 2183. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).