
Machine Learning Approaches for Auto Insurance Big Data


Abstract
1. Introduction
2. Related Work
3. Background
3.1. Machine Learning
3.2. Machine Learning Approach to Predict a Driver’s Risk
3.3. Classifiers
3.3.1. Regression Analysis
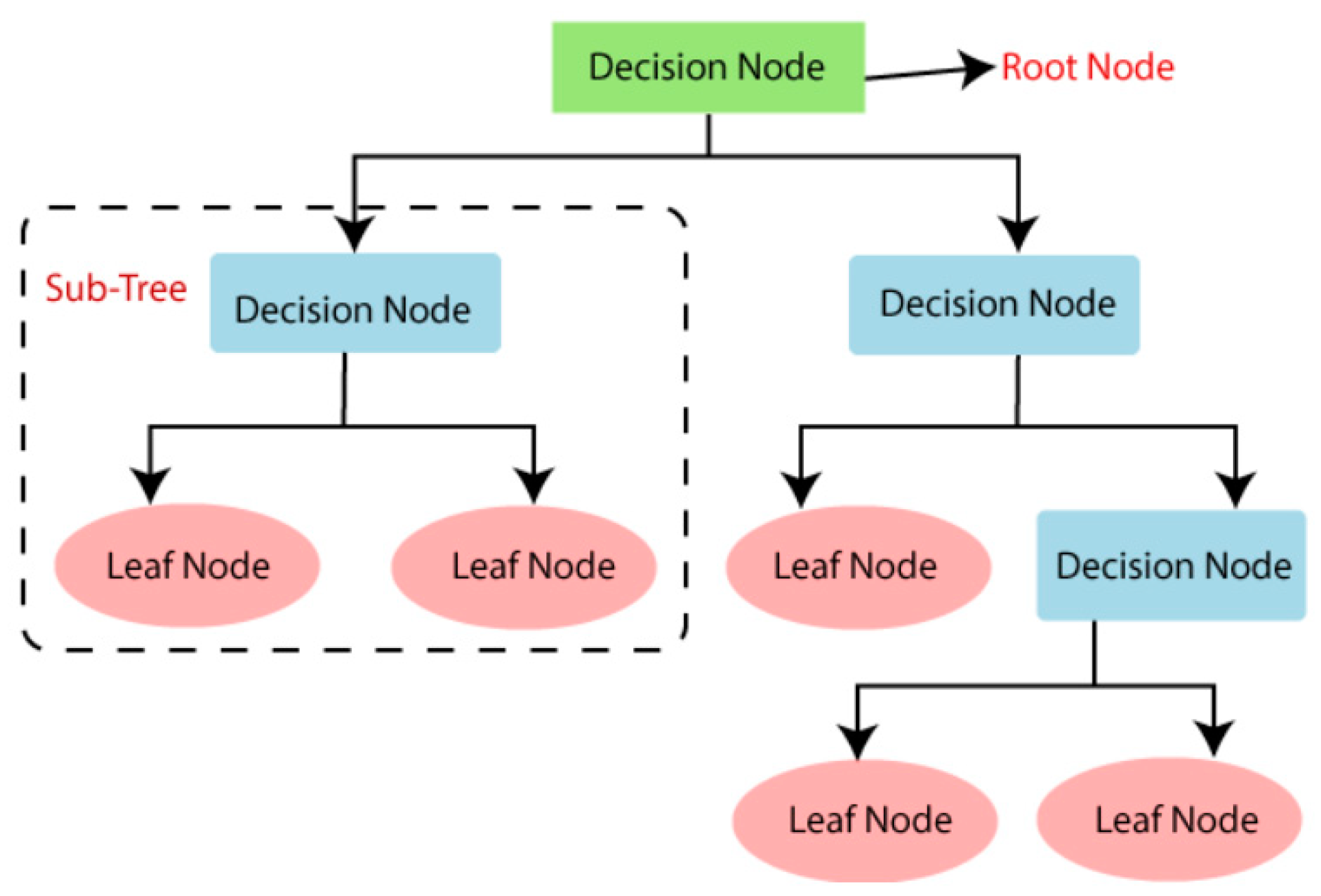
3.3.2. Decision Tree
3.3.3. XGBoost
3.3.4. Random Forest
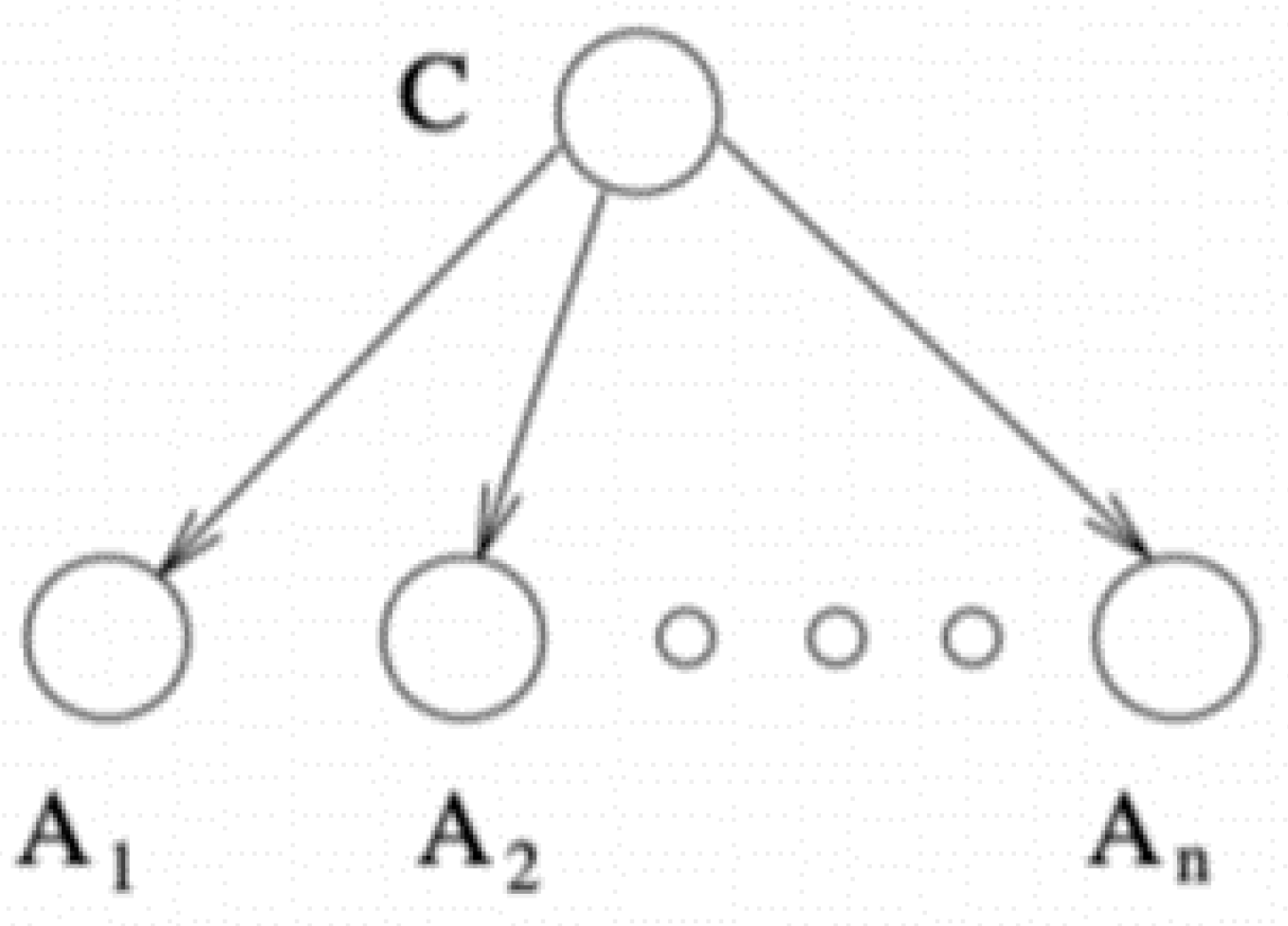
3.3.5. K-Nearest Neighbor
3.3.6. Naïve Bayes
4. Evaluation Models (Prediction Performance)
4.1. Confusion Matrix
4.2. Kappa Statistics
4.3. Sensitivity and Specificity
4.4. Precision and Recall
4.5. The F-Measure
5. Dataset
- Values of −1 indicate that the feature was missing from the observation.
- Feature names include the bin for binary features and cat for categorical features.
- ○
- Binary data has two possible values, 0 or 1.
- ○
- Categorical data (one of many possible values) have been processed into a value range for its lowest and highest value, respectively.
- Features are either continuous or ordinal.
- ○
- The value range appears as a range that has used feature scaling; therefore, feature scaling is not required.
- Features belonging to similar groupings are tagged as ind, reg, car, and calc.
- ○
- ind refers to a customer’s personal information, such as their name.
- ○
- reg refers to a customer’s region or location information.
- ○
- calc is Porto Seguro’s calculated features.
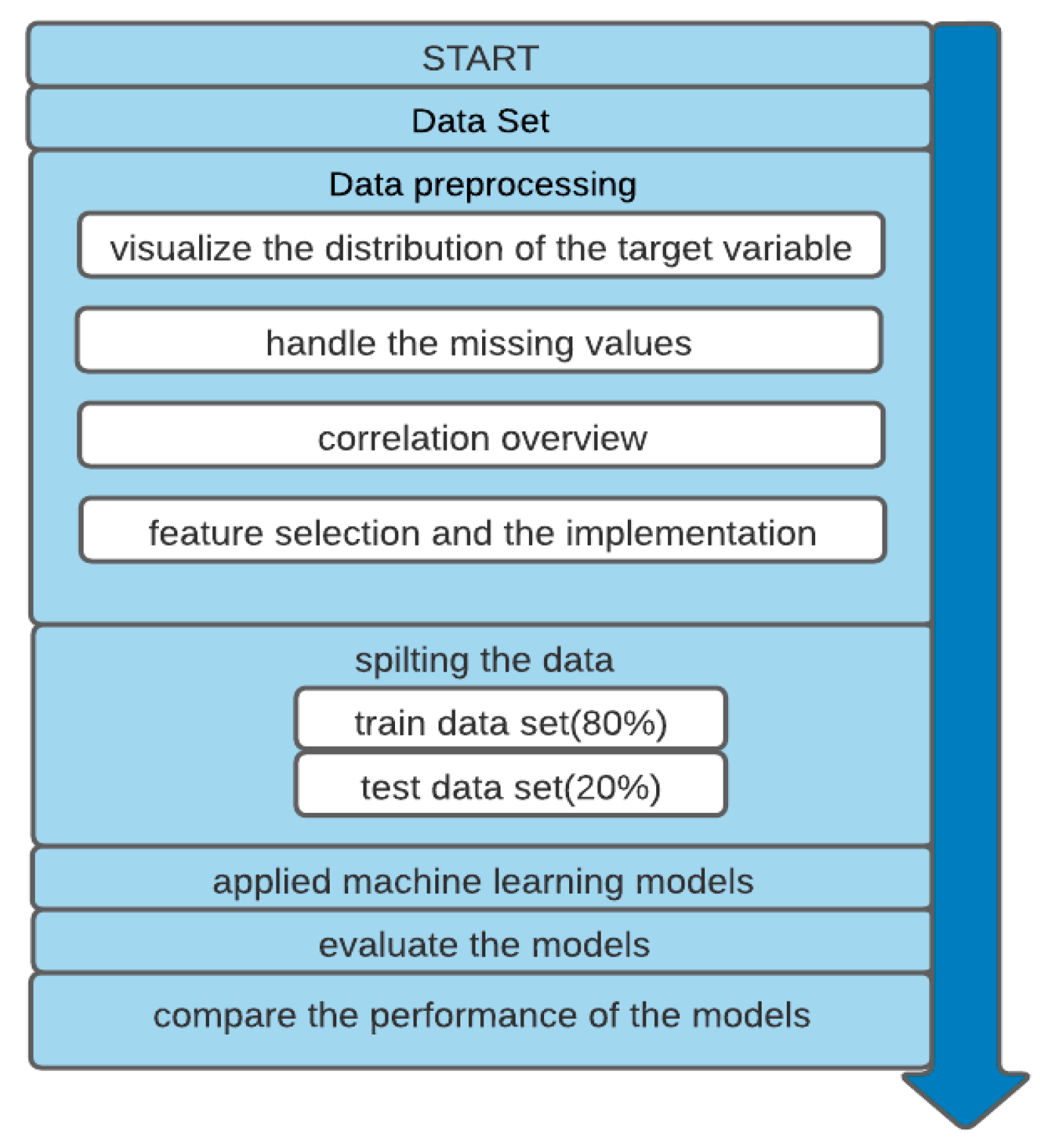
6. Proposed Model
6.1. Data Preprocessing
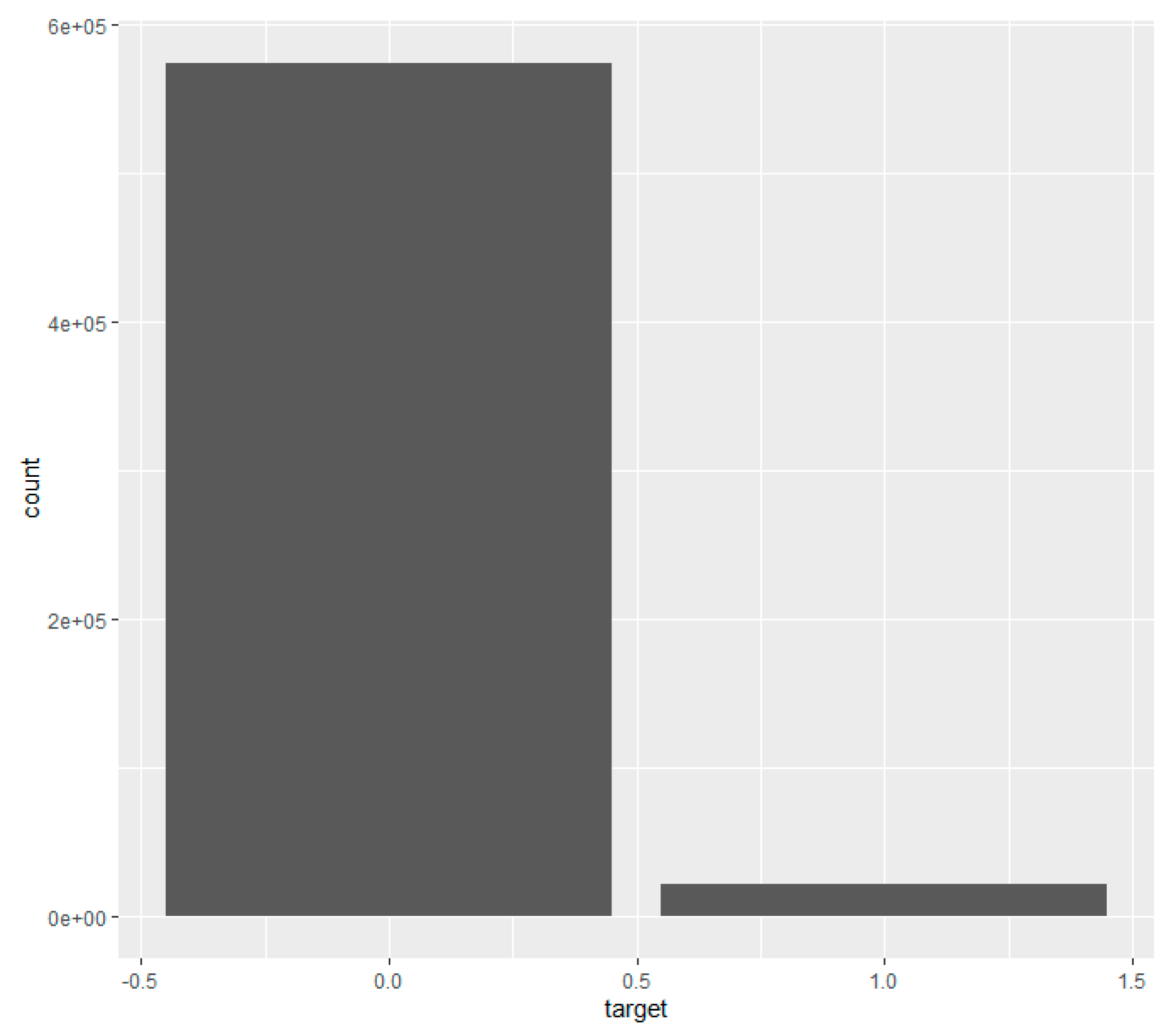
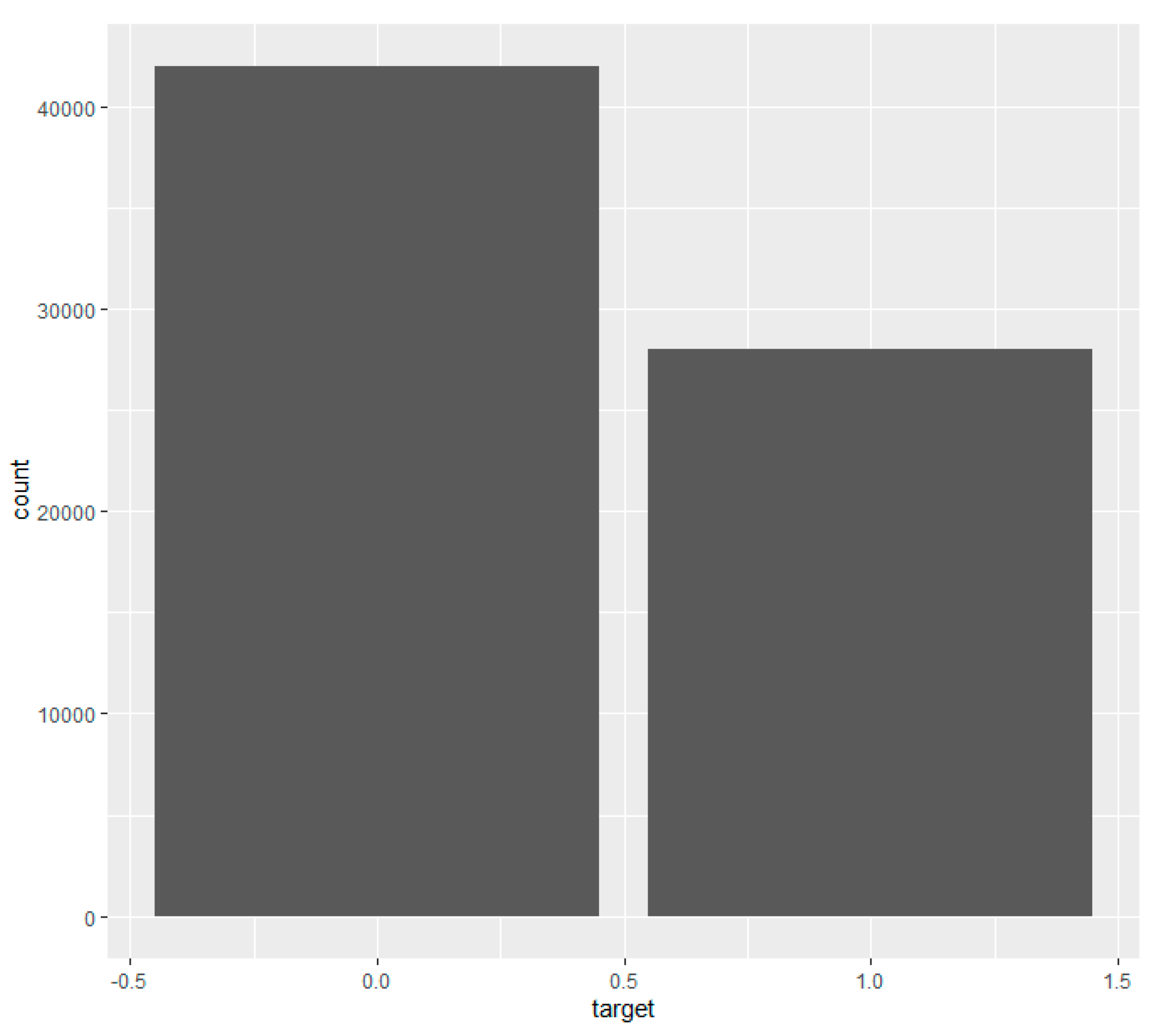
6.1.1. Claims Occurrence Variable
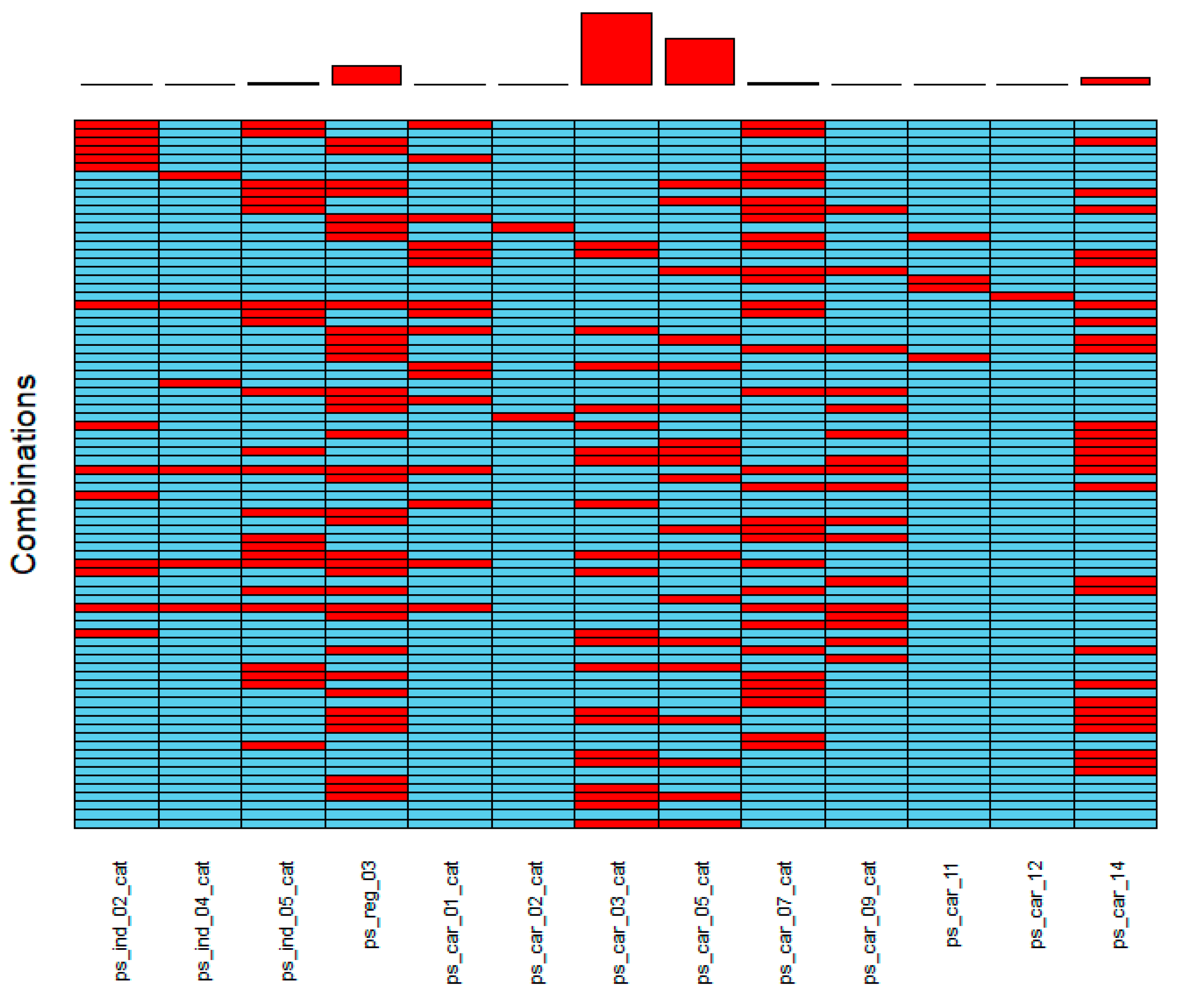
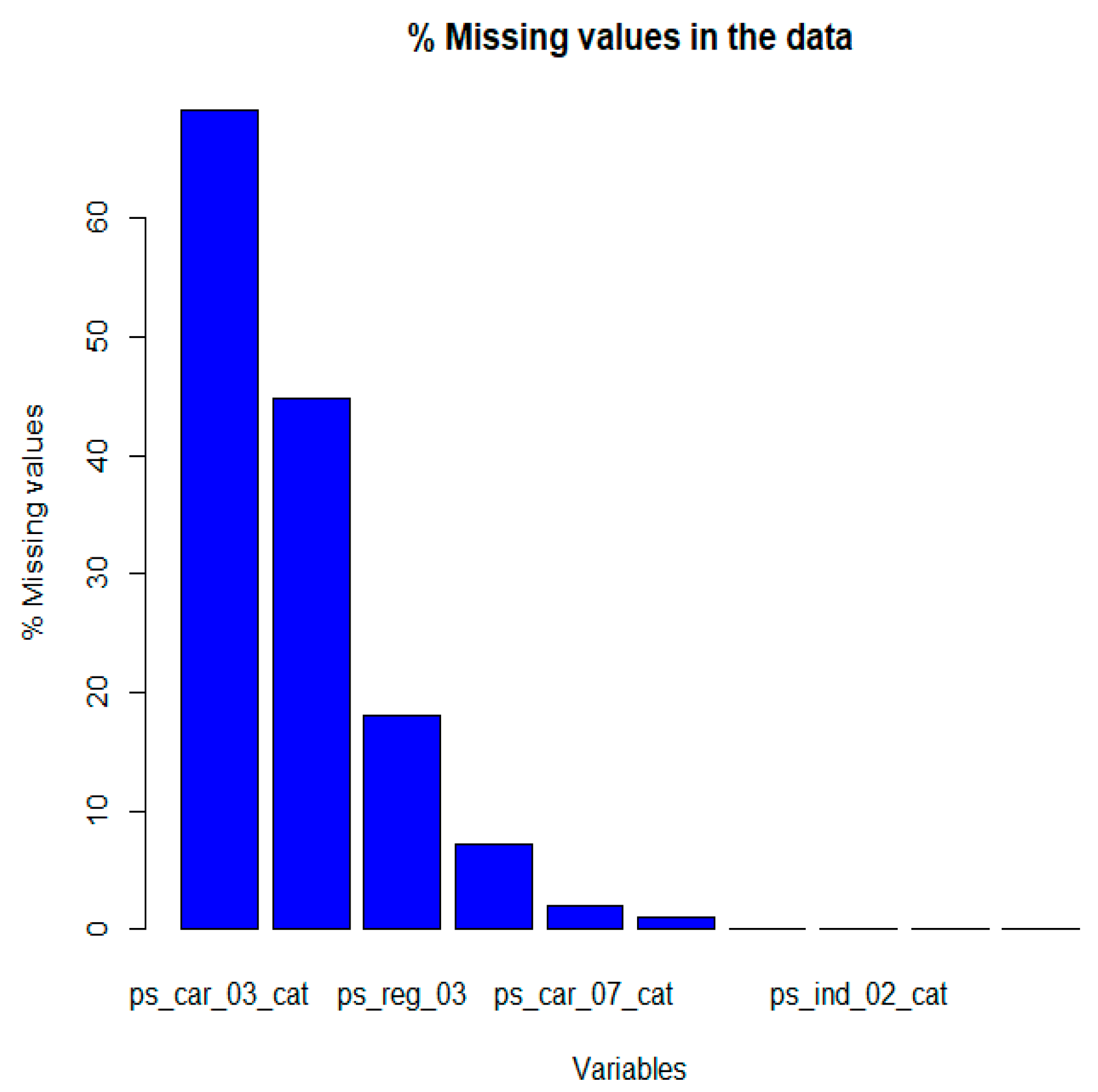
6.1.2. Details on Missing Values
- The features of ps_car_03_cat and ps_car_05_cat have the largest number of missing values. They also share numerous instances where missing values occur in both for the same row.
- Some features share many missing value rows with other features, for instance, ps_reg_03. Other features have few missing values, like ps_car_12, ps_car_11, and ps_car_02.cat.
- We find that about 2.4% of the values are missing in total in each of the train and test datasets.
- From this figure, the features have a large proportion of missing values, being roughly 70% for ps_car_03_cat and 45% for ps_car_05_cat; therefore, these features are not that reliable, as there are too few values to represent the feature’s true meaning. Assigning new values that are missing to each customer record for these features may also not convey the feature’s purpose and negatively impact the learning algorithm’s performance. Due to these reasons, the features have been dropped and removed from the datasets.
- After we drop ps_car_03_cat and ps_car_05_cat, the features missing values in datasets become 0.18 instead of 2.4. The missing values for the rest of the variables are replaced such that missing values in every categorical and binary variable are replaced by the mode of the column values. In contrast, missing values in every continuous variable are replaced by the mean of the column values. This is because categorical data works well using the mode, and continuous data works well using the mean. Both methods are also quick and straightforward for inputting values (Badr 2019).
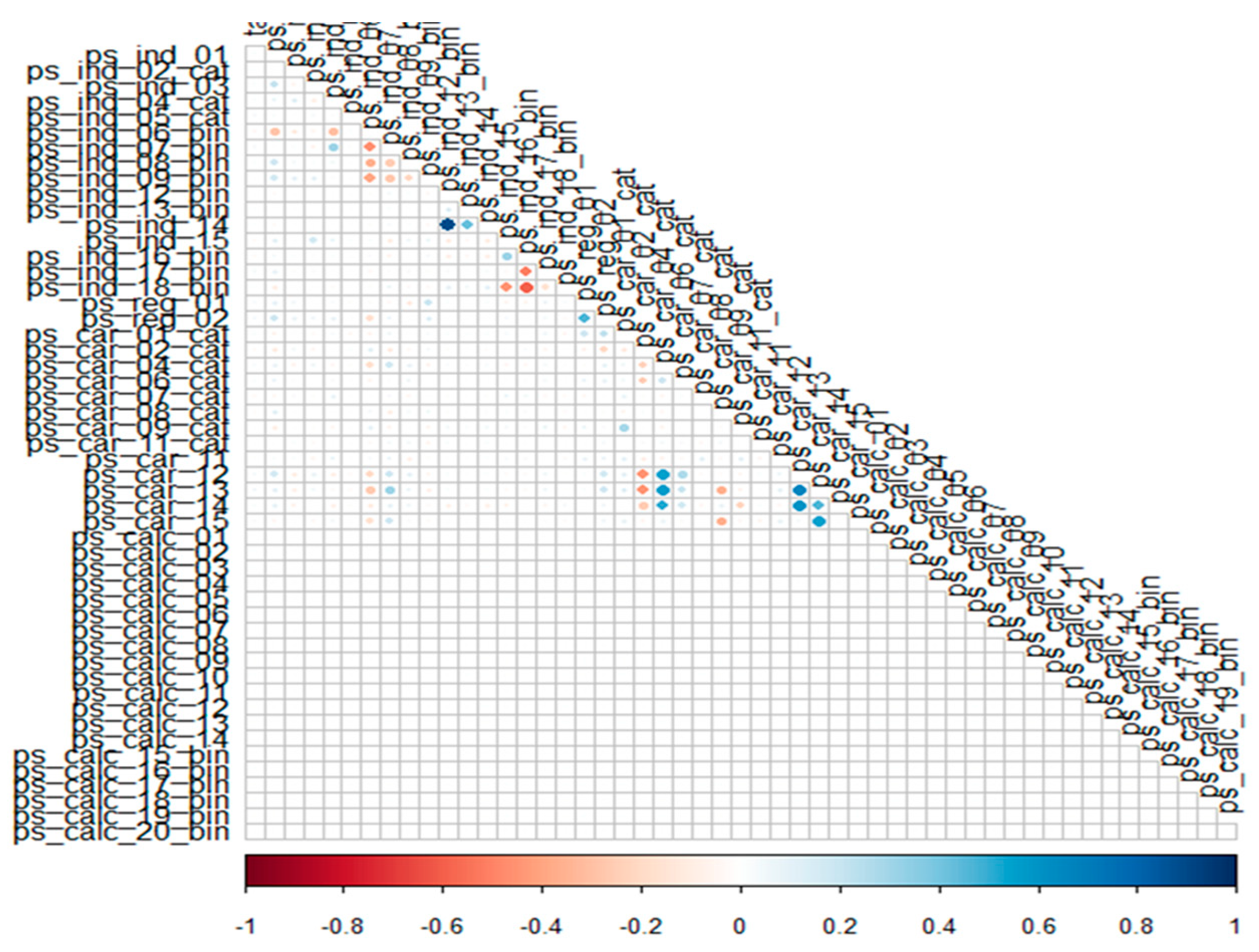
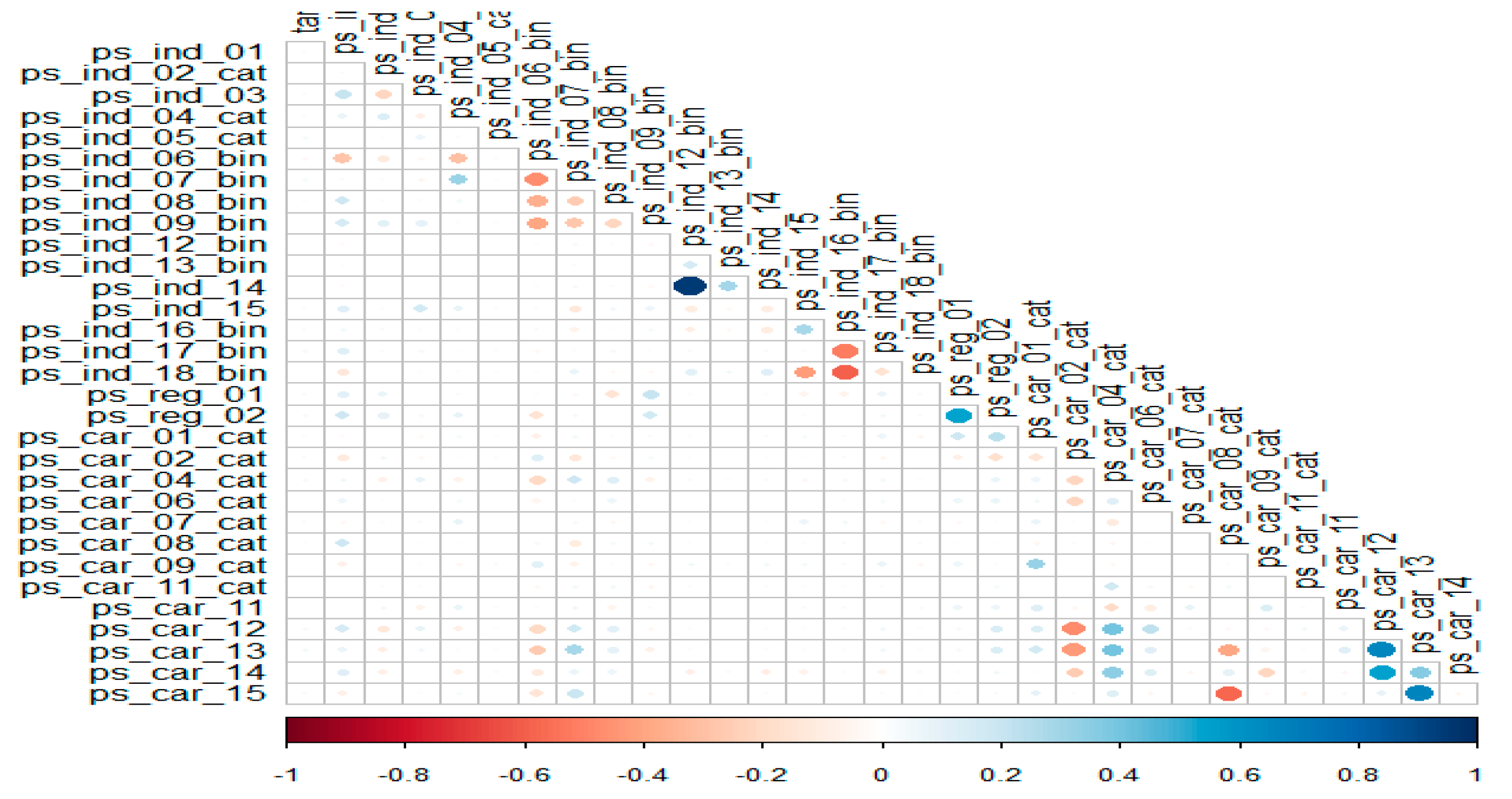
6.1.3. Correlation Overview
6.1.4. Hyper-Parameter Optimization
6.1.5. Features Selection and Implementation
7. Results
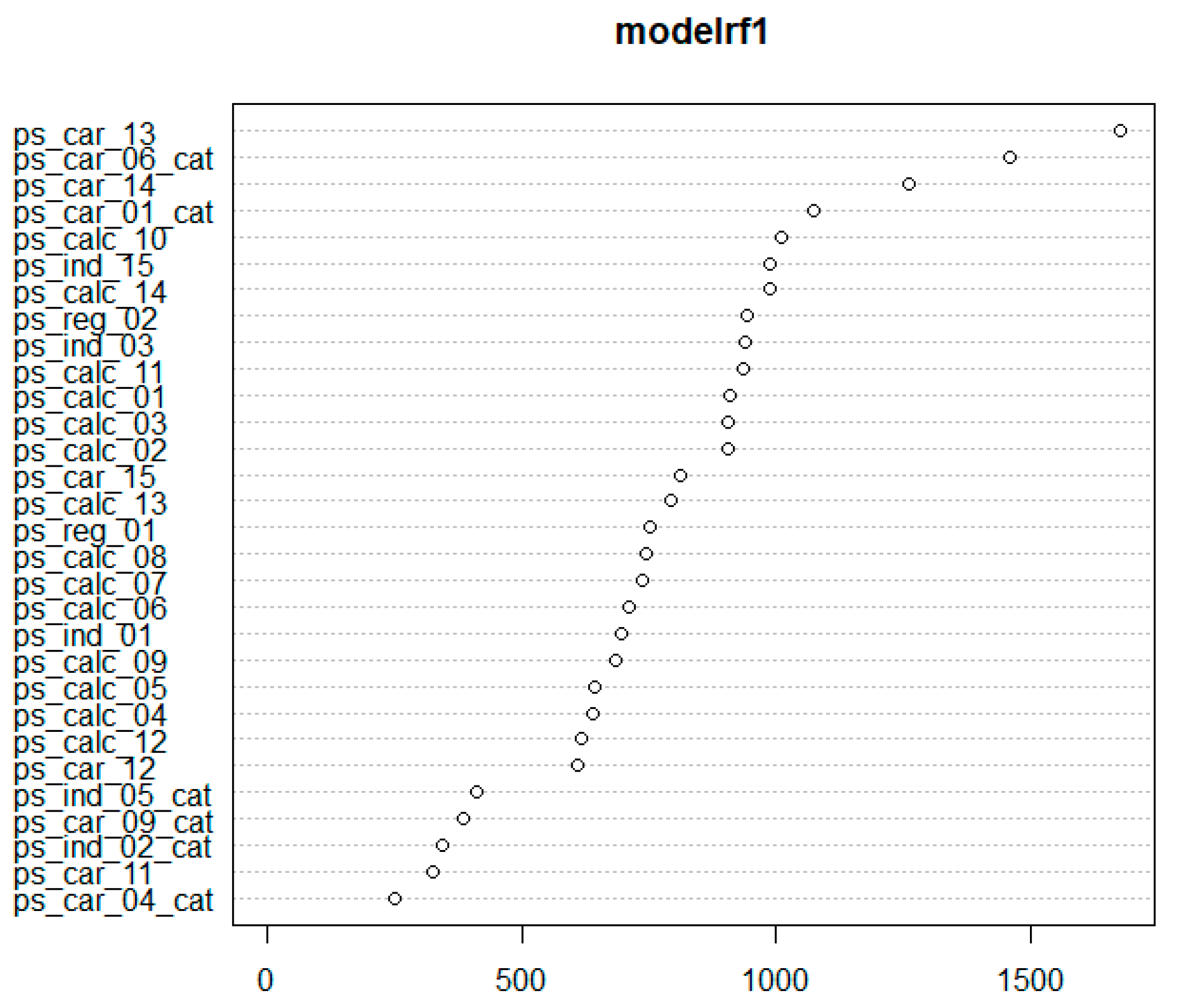
Variable Importance
8. Conclusions
Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abdelhadi, Shady, Khaled Elbahnasy, and Mohamed Abdelsalam. 2020. A proposed model to predict auto insurance claims using machine learning techniques. Journal of Theoretical and Applied Information Technology 98: 3428–3437. [Google Scholar]
- Ariana, Diwan, Daniel E. Guyer, and Bim Shrestha. 2006. Integrating multispectral reflectance and fluorescence imaging for defect detection on apples. Computers and Electronics in Agriculture 50: 148–61. [Google Scholar] [CrossRef]
- Badr, W. 2019. Different Ways to Compensate for Missing Values in a Dataset (Data Imputation with Examples). Available online: https://towardsdatascience.com/6-different-ways-to-compensate-formissing-values-data-imputation-with-examples-6022d9ca0779 (accessed on 17 October 2019).
- Bradley, Andrew P. 1997. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognition 30: 1145–59. [Google Scholar] [CrossRef]
- Breiman, Leo. 2001. Random forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef]
- Chen, Tianqi, and Carlos Guestrin. 2016. XGBoost: A scalable tree boosting system. Paper presented at the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13–17. [Google Scholar]
- Columbus, Louis. 2017. McKinsey’s State of Machine Learning and AI, 2017. Forbes. Available online: https://www.forbes.com/sites/louiscolumbus/2017/07/09/mckinseys-state-of-machine-learning-and-ai-2017 (accessed on 17 December 2020).
- Columbus, Louis. 2018. Roundup of Machine Learning Forecasts and Market Estimates, 2018. Forbes Contrib. Available online: https://www.forbes.com/sites/louiscolumbus/2018/02/18/roundup-of-machine-learning-forecasts-and-marketestimates-2018 (accessed on 17 December 2020).
- Cunningham, Padraig, and Sarah Jane Delany. 2020. k-Nearest Neighbour Classifiers–. arXiv arXiv:2004.04523. [Google Scholar]
- D’Angelo, Gianni, Massimo Tipaldi, Luigi Glielmo, and Salvatore Rampone. 2017. Spacecraft Autonomy Modeled via Markov Decision Process and Associative Rule-Based Machine Learning. Paper presented at 2017 IEEE International Workshop on Metrology for Aerospace (MetroAeroSpace), Padua, Italy, June 21–23; pp. 324–29. [Google Scholar]
- D’Angelo, Gianni, Massimo Ficco, and Francesco Palmieri. 2020. Malware detection in mobile environments based on Autoencoders and API-images. Journal of Parallel and Distributed Computing 137: 26–33. [Google Scholar] [CrossRef]
- Dewi, Kartika Chandra, Hendri Murfi, and Sarini Abdullah. 2019. Analysis Accuracy of Random forest Model for Big Data—A Case Study of Claim Severity Prediction in Car Insurance. Paper presented at 2019 5th International Conference on Science in Information Technology (ICSITech), Yogyakarta, Indonesia, October 23–24; pp. 60–65. [Google Scholar]
- Fang, Kuangnan, Yefei Jiang, and Malin Song. 2016. Customer profitability forecasting using Big Data analytics: A case study of the insurance industry. Computers & Industrial Engineering 101: 554–64. [Google Scholar]
- Friedman, Nir, Dan Geiger, and Moises Goldszmidt. 1997. Bayesian network classifiers. Machine Learning 29: 131–63. [Google Scholar] [CrossRef]
- Ganganwar, Vaishali. 2012. An overview of classification algorithms for imbalanced datasets. International Journal of Emerging Technology and Advanced Engineering 2: 42–47. [Google Scholar]
- Gao, Guangyuan, and Mario V. Wüthrich. 2018. Feature extraction from telematics car driving heatmaps. European Actuarial Journal 8: 383–406. [Google Scholar] [CrossRef]
- Gao, Guangyuan, Shengwang Meng, and Mario V. Wüthrich. 2019. Claims frequency modeling using telematics car driving data. Scandinavian Actuarial Journal 2019: 143–62. [Google Scholar] [CrossRef]
- Géron, Aurélien. 2019. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. Newton: O’Reilly Media. [Google Scholar]
- Gonçalves, Ivo, Sara Silva, Joana B. Melo, and João MB Carreiras. 2012. Random sampling technique for overfitting control in genetic programming. In European Conference on Genetic Programming. Berlin and Heidelberg: Springer, pp. 218–29. [Google Scholar]
- Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Machine learning basics. Deep Learning 1: 98–164. [Google Scholar]
- Grosan, C., and A. Abraham. 2011. Intelligent Systems. Berlin: Springer. [Google Scholar]
- Guillen, Montserrat, Jens Perch Nielsen, Mercedes Ayuso, and Ana M. Pérez-Marín. 2019. The use of telematics devices to improve automobile insurance rates. Risk Analysis 39: 662–72. [Google Scholar] [CrossRef]
- Günther, Clara-Cecilie, Ingunn Fride Tvete, Kjersti Aas, Geir Inge Sandnes, and Ørnulf Borgan. 2014. Modelling and predicting customer churn from an insurance company. Scandinavian Actuarial Journal 2014: 58–71. [Google Scholar] [CrossRef]
- Hossin, Mohammad, and M. N. Sulaiman. 2015. A review on evaluation metrics for data classification evaluations. International Journal of Data Mining & Knowledge Management Process 5: 1. [Google Scholar]
- Hultkrantz, Lars, Jan-Eric Nilsson, and Sara Arvidsson. 2012. Voluntary internalization of speeding externalities with vehicle insurance. Transportation Research Part A: Policy and Practice 46: 926–37. [Google Scholar] [CrossRef]
- Jiang, Shengyi, Guansong Pang, Meiling Wu, and Limin Kuang. 2012. An improved K-nearest-neighbor algorithm for text categorization. Expert Systems with Applications 39: 1503–9. [Google Scholar] [CrossRef]
- Jing, Longhao, Wenjing Zhao, Karthik Sharma, and Runhua Feng. 2018. Research on Probability-based Learning Application on Car Insurance Data. In 2017 4th International Conference on Machinery, Materials and Computer (MACMC 2017). Amsterdam: Atlantis Press. [Google Scholar]
- Kansara, Dhvani, Rashika Singh, Deep Sanghvi, and Pratik Kanani. 2018. Improving Accuracy of Real Estate Valuation Using Stacked Regression. Int. J. Eng. Dev. Res. (IJEDR) 6: 571–77. [Google Scholar]
- Kayri, Murat, Ismail Kayri, and Muhsin Tunay Gencoglu. 2017. The performance comparison of multiple linear regression, random forest and artificial neural network by using photovoltaic and atmospheric data. Paper presented at 2017 14th International Conference on Engineering of Modern Electric Systems (EMES), Oradea, Romania, June 1–2; pp. 1–4. [Google Scholar]
- Kenett, Ron S., and Silvia Salini. 2011. Modern analysis of customer satisfaction surveys: Comparison of models and integrated analysis. Applied Stochastic Models in Business and Industry 27: 465–75. [Google Scholar] [CrossRef]
- Kotsiantis, Sotiris B., Ioannis D. Zaharakis, and Panayiotis E. Pintelas. 2006. Machine learning: A review of classification and combining techniques. Artificial Intelligence Review 26: 159–90. [Google Scholar] [CrossRef]
- Kotsiantis, Sotiris B., I. Zaharakis, and P. Pintelas. 2007. Supervised machine learning: A review of classification techniques. Emerging Artificial Intelligence Applications in Computer Engineering 160: 3–24. [Google Scholar]
- Kowshalya, G., and M. Nandhini. 2018. Predicting fraudulent claims in automobile insurance. Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, April 20–21; pp. 1338–43. [Google Scholar]
- Kuhn, Max, and Kjell Johnson. 2013. Applied Predictive Modeling. New York: Springer, vol. 26. [Google Scholar]
- Lunardon, Nicola, Giovanna Menardi, and Nicola Torelli. 2014. ROSE: A Package for Binary Imbalanced Learning. R Journal 6: 79–89. [Google Scholar] [CrossRef]
- Mau, Stefan, Irena Pletikosa, and Joël Wagner. 2018. Forecasting the next likely purchase events of insurance customers: A case study on the value of data-rich multichannel environments. International Journal of Bank Marketing 36: 6. [Google Scholar] [CrossRef]
- Mccord, Michael, and M. Chuah. 2011. Spam detection on twitter using traditional classifiers. In International Conference on Autonomic and Trusted Computing. Berlin and Heidelberg: Springer, pp. 175–86. [Google Scholar]
- Musa, Abdallah Bashir. 2013. Comparative study on classification performance between support vector machine and logistic regression. International Journal of Machine Learning and Cybernetics 4: 13–24. [Google Scholar] [CrossRef]
- Pesantez-Narvaez, Jessica, Montserrat Guillen, and Manuela Alcañiz. 2019. Predicting motor insurance claims using telematics data—XGBoost versus logistic regression. Risks 7: 70. [Google Scholar] [CrossRef]
- Roel, Verbelen, Katrien Antonio, and Gerda Claeskens. 2017. Unraveling the predictive power of telematics data in car insurance pricing. Journal of the Royal Statistical Society SSRN. , 2872112. [Google Scholar] [CrossRef]
- Sabbeh, Sahar F. 2018. Machine-learning techniques for customer retention: A comparative study. International Journal of Advanced Computer Science and Applications 9: 273–81. [Google Scholar]
- Schmidt, Jonathan, Mário R. G. Marques, Silvana Botti, and Miguel A. L. Marques. 2019. Recent advances and applications of machine learning in solid-state materials science. npj Computational Materials 5: 1–36. [Google Scholar] [CrossRef]
- Singh, Ranjodh, Meghna P. Ayyar, Tata Venkata Sri Pavan, Sandeep Gosain, and Rajiv Ratn Shah. 2019. Automating Car Insurance Claims Using Deep Learning Techniques. Paper presented at 2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM), Singapore, September 11–13; pp. 199–207. [Google Scholar]
- Smith, Kate A., Robert J. Willis, and Malcolm Brooks. 2000. An analysis of customer retention and insurance claim patterns using data mining: A case study. Journal of the Operational Research Society 51: 532–41. [Google Scholar] [CrossRef]
- Song, Yan Yan, and L. U. Ying. 2015. Decision tree methods: Applications for classification and prediction. Shanghai Archives of Psychiatry 27: 130. [Google Scholar] [PubMed]
- Stucki, Oskar. 2019. Predicting the Customer Churn with Machine Learning Methods: Case: Private Insurance Customer Data. Master’s dissertation, LUT University, Lappeenranta, Finland. [Google Scholar]
- Subudhi, Sharmila, and Suvasini Panigrahi. 2017. Use of optimized Fuzzy C-Means clustering and supervised classifiers for automobile insurance fraud detection. Journal of King Saud University-Computer and Information Sciences 32: 568–75. [Google Scholar] [CrossRef]
- Weerasinghe, K. P. M. L. P., and M. C. Wijegunasekara. 2016. A comparative study of data mining algorithms in the prediction of auto insurance claims. European International Journal of Science and Technology 5: 47–54. [Google Scholar]
- Wu, Shaomin, and Peter Flach. 2005. A scored AUC metric for classifier evaluation and selection. Paper presented at Second Workshop on ROC Analysis in ML, Bonn, Germany, August 11. [Google Scholar]
- Wüthrich, Mario V. 2017. Covariate selection from telematics car driving data. European Actuarial Journal 7: 89–108. [Google Scholar] [CrossRef]
- Yerpude, Prajakta. 2020. Predictive Modelling of Crime Dataset Using Data Mining. International Journal of Data Mining & Knowledge Management Process (IJDKP) 7: 4. [Google Scholar]
- Zhou, Zhi Hua. 2012. Ensemble Methods: Foundations and Algorithms. Boca Raton: CRC Press. [Google Scholar]
| 1 | https://www.insure.com/car-insurance/ (accessed on 21 December 2020). |
| 2 | https://www.iii.org/fact-statistic/facts-statistics-auto-insurance (accessed on 19 December 2020). |
| 3 | https://www.kaggle.com/alinecristini/atividade2portoseguro (accessed on 15 December 2020). |
| 4 | https://www.kaggle.com/c/porto-seguro-safe-driverprediction/overview (accessed on 15 December 2020). |
| 5 | https://www.kaggle.com/c/porto-seguro-safe-driver-prediction/data (accessed on 15 December 2020). |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ARTICLE & YEAR | PURPOSE | Algorithms | Performance Metrics | The Best Model |
|---|---|---|---|---|
| (Smith et al. 2000) | Classification to predict customer retention patterns | DT, NN | Accuracy ROC | NN |
| (Günther et al. 2014) | Classification to predict the risk of leaving | LR and GAMS | ROC | LR |
| (Weerasinghe and Wijegunasekara 2016) | Classification to predict the number of claims (low, fair, or high) | LR, DT, NN | Precision Recall Specificity | NN |
| (Fang et al. 2016) | Regression to forecast insurance customer profitability | RF, LR, DT, SVM, GBM | R-squares RMSE | RF |
| (Subudhi and Panigrahi 2017) | Classification to predict insurance fraud | DT, SVM, MLP | Sensitivity Specificity Accuracy | SVM |
| (Mau et al. 2018) | Classification to predict churn, retention, and cross-selling | RF | Accuracy AUC ROC F-score | RF |
| (Jing et al. 2018) | Classification to predict claims occurrence | Naïve Bayes, Bayesian, Network model | Accuracy | Both have the same accuracy. |
| (Kowshalya and Nandhini 2018) | Classification to predict insurance fraud and percentage of premium amount | J48, RF, Naïve Bayes | Accuracy Precision Recall | RF |
| (Sabbeh 2018) | Classification to predict churn problem | RF, AB, MLP, SGB, SVM, KNN, CART, Naïve Bayes, LR, LDA. | Accuracy | AB |
| (Stucki 2019) | Classification to predict churn and retention | LR, RF, KNN, AB, and NN | Accuracy F-Score AUC | RF |
| (Dewi et al. 2019) | Regression to predict claims severity | Random forest | MSE | RF |
| (Pesantez-Narvaez et al. 2019) | Classification to predict claims occurrence | XGBoost, LR | Sensitivity Specificity Accuracy RMSE ROC | XGBoost |
| (Abdelhadi et al. 2020) | Classification to predict claims occurrence | J48, NN, XGBoost, naïve base | Accuracy ROC | XGBoost |
| Actual Positive | Actual Negative | |
|---|---|---|
| Predicted positive | True positive (TP) | False negative(FN) |
| Predicted negative | False positive (FP) | True negative (TN) |
| Model | Parameters | Range | Optimal Value |
|---|---|---|---|
| RF | 1. mtry | [2,28,54] | 28 |
| C50 | 1. Model 2. Winnow 3. Trials | [rules, tree] [FALSE, TRUE] [1,10,20] | Tree FALSE 20 |
| XGBoost | 1. Eta 2. max_depth 3. colsample_bytree 4. Subsample 5. nrounds 6. Gamma | [3,4] [1,2,3] [0.6,0.8] [0.50,0.75,1] [50,100,150] [0 to 1] | 0.4 3 0.6 1 150 0 |
| J48 | 1. C 2. M | [0.010, 0.255,0.500] [1,2,3] | 0.5 1 |
| knn | 1. K | [1 to 10] | 3 |
| cart | 1. cp | 0 to 0.1 | 0.00274052 |
| Naïve Bayes | 1. Laplace 2. Adjust 3. Usekernel | [0 to 1] [0 to 1] [FALSE, TRUE] | 0 1 FALSE |
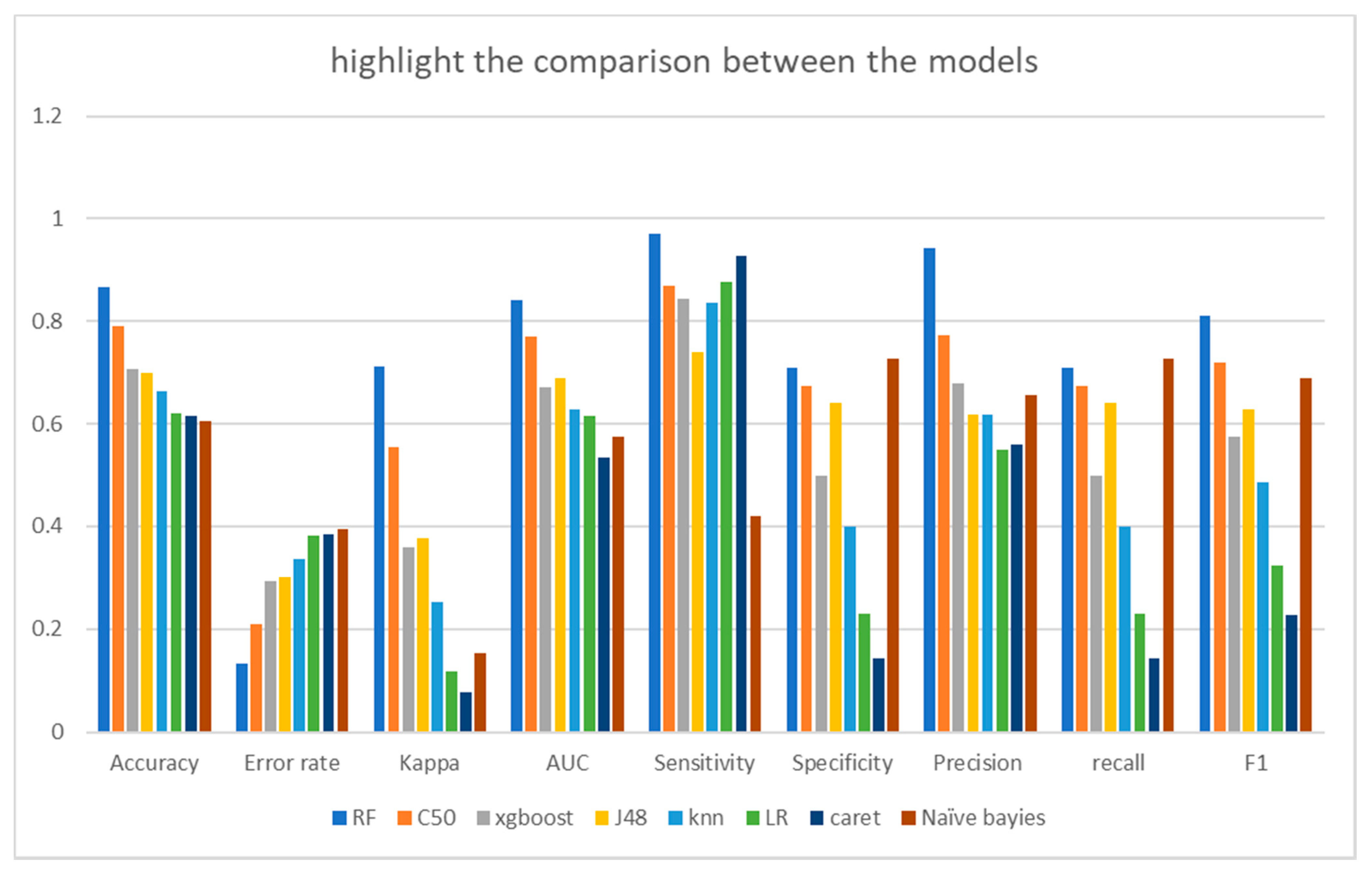
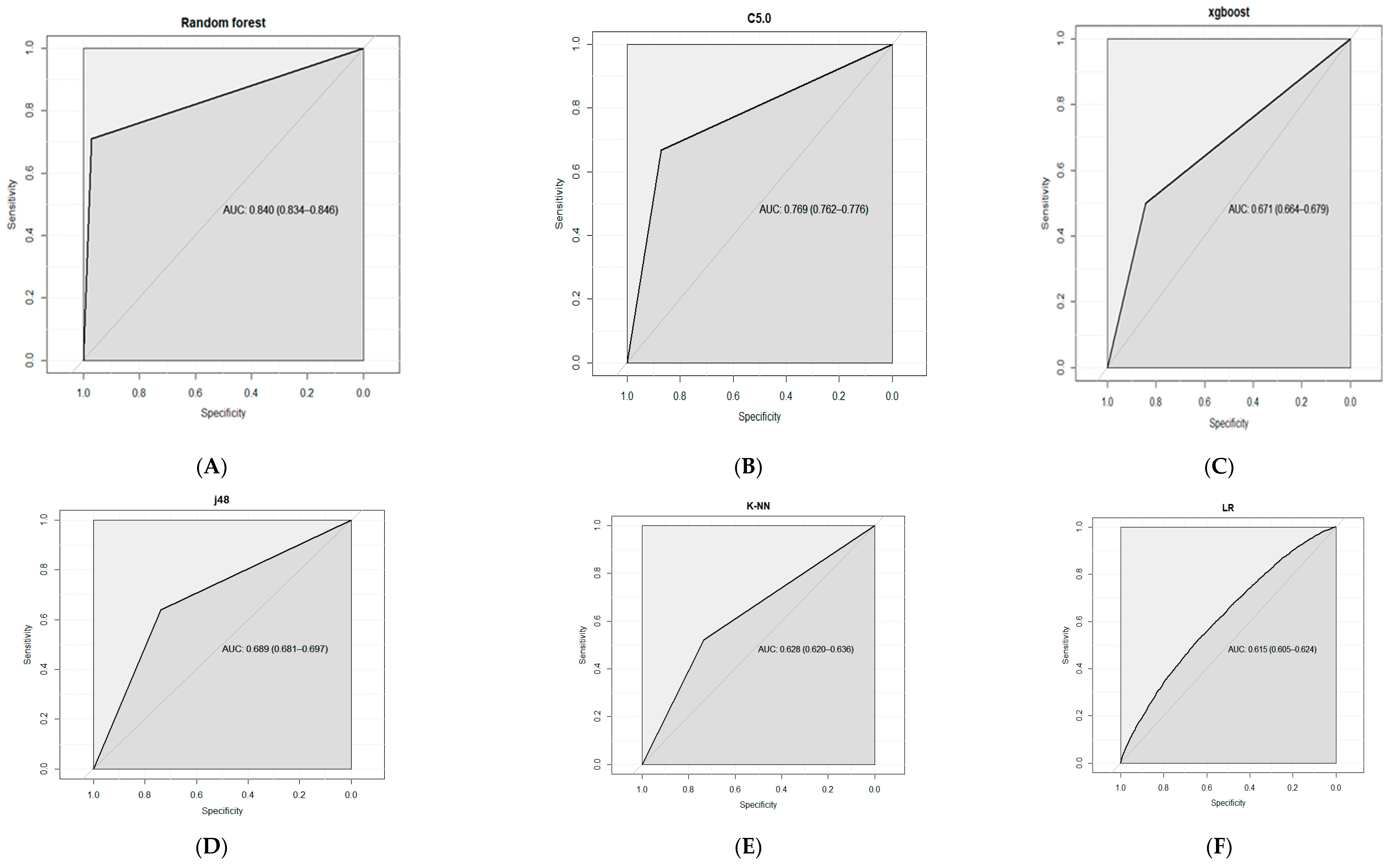
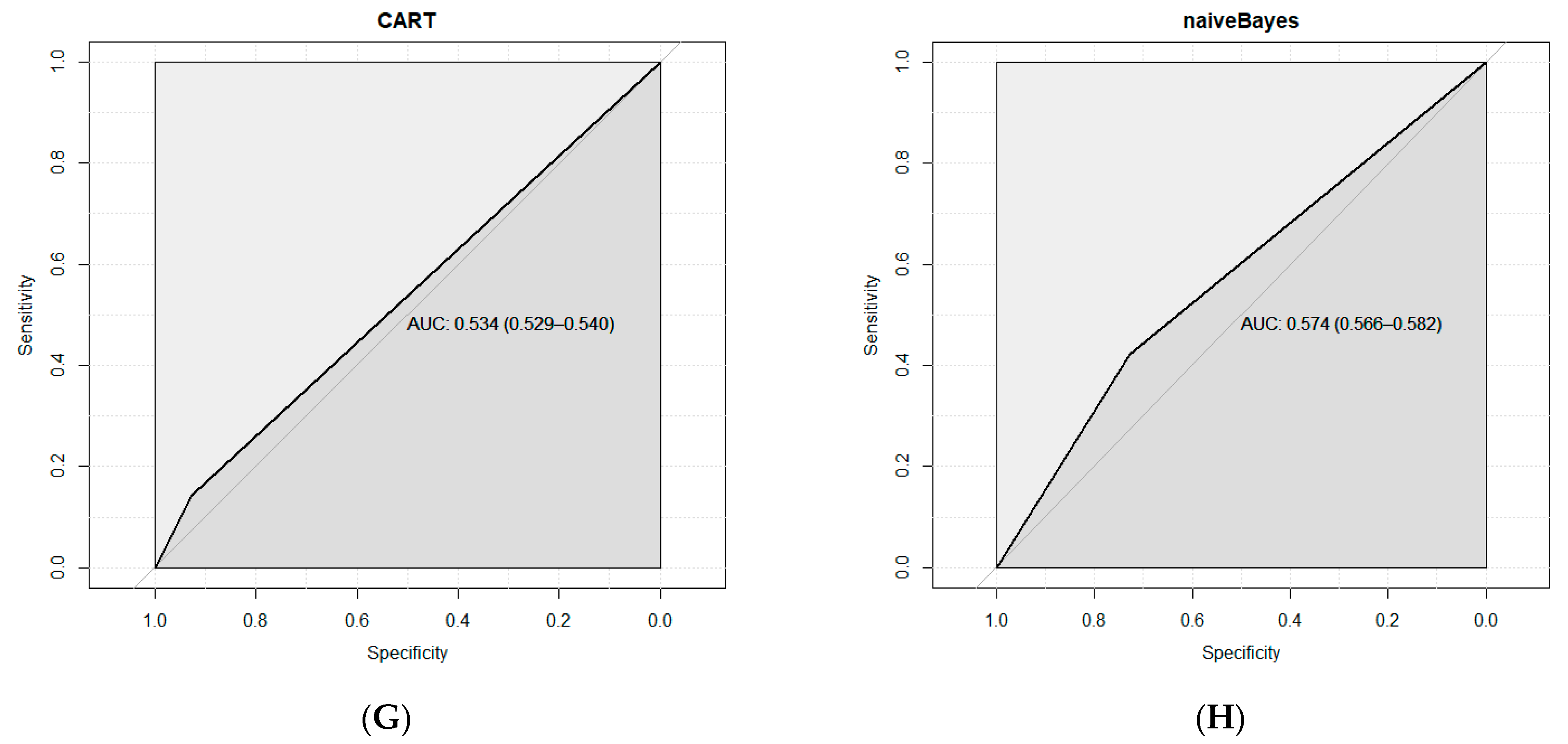
| Model | Accuracy | Error Rate | Kappa | AUC | Sensitivity | Specificity | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|---|---|
| RF | 0.8677 | 0.1323 | 0.7117 | 0.84 | 0.9717 | 0.71 | 0.9429 | 0.71 | 0.8101 |
| C50 | 0.7913 | 0.2087 | 0.5546 | 0.769 | 0.8684 | 0.6743 | 0.7717 | 0.6743 | 0.7197 |
| XGBoost | 0.7067 | 0.2933 | 0.3589 | 0.671 | 0.8434 | 0.4994 | 0.6777 | 0.4994 | 0.575 |
| J48 | 0.6994 | 0.3006 | 0.3761 | 0.689 | 0.7385 | 0.6399 | 0.6174 | 0.6399 | 0.6284 |
| knn | 0.6629 | 0.3371 | 0.2513 | 0.628 | 0.836 | 0.4003 | 0.6167 | 0.4003 | 0.4855 |
| LR | 0.6192 | 0.3808 | 0.1173 | 0.615 | 0.8761 | 0.2296 | 0.55 | 0.2296 | 0.3239 |
| caret | 0.6148 | 0.3852 | 0.0786 | 0.534 | 0.9264 | 0.1422 | 0.5601 | 0.1422 | 0.2268 |
| Naïve Bayes | 0.6056 | 0.3944 | 0.1526 | 0.574 | 0.421 | 0.7273 | 0.6558 | 0.7273 | 0.6897 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hanafy, M.; Ming, R. Machine Learning Approaches for Auto Insurance Big Data. Risks 2021, 9, 42. https://doi.org/10.3390/risks9020042
Hanafy M, Ming R. Machine Learning Approaches for Auto Insurance Big Data. Risks. 2021; 9(2):42. https://doi.org/10.3390/risks9020042
Chicago/Turabian StyleHanafy, Mohamed, and Ruixing Ming. 2021. "Machine Learning Approaches for Auto Insurance Big Data" Risks 9, no. 2: 42. https://doi.org/10.3390/risks9020042
APA StyleHanafy, M., & Ming, R. (2021). Machine Learning Approaches for Auto Insurance Big Data. Risks, 9(2), 42. https://doi.org/10.3390/risks9020042