Abstract
We introduce a neural network approach for assessing the risk of a portfolio of assets and liabilities over a given time period. This requires a conditional valuation of the portfolio given the state of the world at a later time, a problem that is particularly challenging if the portfolio contains structured products or complex insurance contracts which do not admit closed form valuation formulas. We illustrate the method on different examples from banking and insurance. We focus on value-at-risk and expected shortfall, but the approach also works for other risk measures.
1. Introduction
Different financial risk management problems require an assessment of the risk of a portfolio of assets and liabilities over a given time period. Banks, mutual funds and hedge funds usually calculate value-at-risk numbers for different risks over a day, a week or longer time periods. Under Solvency II, insurance companies have to calculate one-year value-at-risk, whereas the Swiss Solvency Test demands a computation of one-year expected shortfall. A determination of these risk figures requires a conditional valuation of the portfolio given the state of the world at a later time, called risk horizon. This is particularly challenging if the portfolio contains structured products or complicated insurance policies which do not admit closed form valuation formulas. In theory, the problem can be approached with nested simulation, which is a two-stage procedure. In the outer stage, different scenarios are generated to model how the world could evolve until the risk horizon, whereas in the inner stage, cash flows occurring after the risk horizon are simulated to estimate the value of the portfolio conditionally on each scenario; see, e.g., Lee (1998), Glynn and Lee (2003), Gordy and Juneja (2008), Broadie et al. (2011) or Bauer et al. (2012). While nested simulation can be shown to converge for increasing sample sizes, it is often too time-consuming to be useful in practical applications. A more pragmatic alternative, usually used for short risk horizons, is the delta-gamma method, which approximates the portfolio loss with a second order Taylor polynomial; see, e.g., Rouvinez (1997), Britten-Jones and Schaefer (1999) or Duffie and Pan (2001). If first and second derivatives of the portfolio with respect to the underlying risk factors are accessible, the method is computationally efficient, but its accuracy depends on how well the second order Taylor polynomial approximates the true portfolio loss. Similarly, the replicating portfolio approach approximates future cashflows with a portfolio of liquid instruments that can be priced efficiently; see e.g., Wüthrich (2016), Pelsser and Schweizer (2016), Natolski and Werner (2017) or Cambou and Filipović (2018). Building on work on American option valuation (see e.g., Carriere 1996; Longstaff and Schwartz 2001; Tsitsiklis and Van Roy 2001), Broadie et al. (2015) as well as Ha and Bauer (2019) have proposed to regress future cash flows on finitely many basis functions depending on state variables known at the risk horizon. This gives good results in a number of applications. However, typically, for it to work well, the basis functions have to be chosen well-adapted to the problem.
In this paper we use a neural network approach to approximate the value of the portfolio at the risk horizon. Since our goal is to estimate tail risk measures such as value-at-risk and expected shortfall, we employ importance sampling when training the networks and estimating the risk figures. In addition, we try different regularization techniques and test the adequacy of the neural network approximations using the defining property of the conditional expectation. Neural networks have also been used for the calculation of solvency capital requirements by Hejazi and Jackson (2017), Fiore et al. (2018) and Castellani et al. (2019). But they all exclusively focus on value-at-risk, do not make use of importance sampling and apply neural networks in a slightly different way. Hejazi and Jackson (2017) develop a neural network interpolation scheme within a nested simulation framework. Fiore et al. (2018) and Castellani et al. (2019) both use reduced-size nested Monte Carlo to generate training samples for the calibration of the neural network. Here, we directly regress future cash-flows on a neural network without producing training samples.
The remainder of the paper is organized as follows. In Section 2, we set up the underlying risk model, introduce the importance sampling distributions we use in the implementation of our method and recall how value-at-risk and expected shortfall can be estimated from a finite sample of simulated losses. Section 3 discusses the training, validation and testing of our network approximation of the conditional valuation functional. In Section 4 we illustrate our approach on three typical risk calculation problems: the calculation of risk capital for a single put option, a portfolio of different call and put options and a variable annuity contract with guaranteed minimum income benefit. Section 5 concludes the paper.
2. Asset-Liability Risk
We denote the current time by 0 and are interested in the value of a portfolio of assets and liabilities at a given risk horizon . Suppose all relevant events taking place until time are described by a d-dimensional random vector defined on a measurable space that is equipped with two equivalent probability measures, and . We think of as the real-world probability measure and use it for risk measurement. is a risk-neutral probability measure specifying the time- value of the portfolio through
where v is a measurable function from to describing the part of the portfolio whose value is directly given by the underlying risk factors ; are random cash flows occurring at times ; and model the evolution of a numeraire process used for discounting.
Our goal is to compute for a risk measure and the time net liability , which can be written as
for
Our approach works for a wide class of risk measures . But for the sake of concreteness, we concentrate on value-at-risk and expected shortfall. We follow the convention of McNeil et al. (2015) and define value-at-risk at a level , such as , or , as the left -quantile
and expected shortfall as
There exist different definitions of VaR and ES in the literature. But if the distribution function of L is continuous and strictly increasing, they are all equivalent1.
2.1. Conditional Expectations as Minimizing Functions
Let be the probability measure on given by
where is the distribution of X under and is a regular conditional version of given X. We assume that Y belongs to . Then L is of the form for a measurable function minimizing the mean squared distance
see, e.g., Bru and Heinich (1985). Note that l minimizes (3) if and only if
where is a regular conditional -distribution of Y given X. This shows that l is unique up to -almost sure equality and can alternatively be characterized by
for any probability measure on that is equivalent to . In particular, if is the probability measure on under which X has distribution , and Y is in , then l can be determined by minimizing
instead of (3). Since we are going to approximate the expectation (4) with averages of Monte Carlo samples, this will give us some flexibility in simulating .
2.2. Monte Carlo Estimation of Value-at-Risk and Expected Shortfall
Let be independent -simulations of X. By we denote the same sample reordered so that
To obtain -simulation estimates of and , we apply the VaR and ES definitions (1)–(2) to the empirical measure . This yields
where
see also McNeil et al. (2015). It is well known that if is differentiable at with , then is an asymptotically normal consistent estimator of order ; see, e.g., David and Nagaraja (2003). If in addition, L is square-integrable, the same is true for ; see Zwingmann and Holzmann (2016).
2.3. Importance Sampling
Assume now that X is of the form for a transformation and a k-dimensional random vector Z with density . To give more weight to important outcomes, we introduce a second density g on satisfying for all , where . Let be a k-dimensional random vector with density g and independent simulations of . We reorder the simulations such that
and consider the random weights
Since is integrable, one obtains from the law of large numbers that for every threshold ,
is an unbiased consistent estimator of the exceedance probability
If in addition, g can be chosen so that is square-integrable, it follows from the central limit theorem that (6) is asymptotically normal with a standard deviation of order . In any case, converges to 1 and the random measure approximates the distribution of L. Accordingly, we adapt the -simulation estimators (5) by replacing with . This yields the g-simulation estimates
where
If the -quantile of were known, the exceedance probability could be estimated by means of (6) with . To make the procedure efficient, one would try to find a density g on from which it is easy to sample and such that the variance
becomes as small as possible. Since
does not depend on g, it can be seen that g is a good importance sampling (IS) density if
is small. We use the same criterion as a basis to find a good IS density for estimating and ; see, e.g., Glasserman (2003) for more background on importance sampling.
2.4. The Case of an Underlying Multivariate Normal Distribution
In many applications X can be modelled as a deterministic transformation of a random vector with a multivariate normal distribution. Examples are included in Section 4 below. In this case, it can be written as
for a function , a -matrix A and a k-dimensional random vector Z with a standard normal density f. To keep the problem tractable, we look for a suitable IS density g in the class of -densities with different mean vectors and covariance matrix equal to the k-dimensional identity matrix . To determine a good choice of m, let be the vector with components
If , we choose . Otherwise, is standard normal. Denote its -quantile by . Then Z falls into the region
with probability , and tends to be large for . We choose m as the maximizer of subject to , which leads to
It is easy to see that this yields
So, if D is sufficiently similar to the region , it can be seen from (7) that this choice of IS density will yield a reduction in variance.
3. Neural Network Approximation
Usually, the distribution of the risk factor vector X is assumed to be known. For instance, in all our examples in Section 4, they are of the form (8). On the other hand, in many real-world applications, there is no closed form expression for the loss function mapping X to L. Therefore, we approximate with for a neural network ; see e.g., Goodfellow et al. (2016). We concentrate on feedforward neural networks of the form
where
- , , and are the numbers of nodes in the hidden layers
- are affine functions of the form for matrices and vectors for
- is a non-linear activation function used in the hidden layers and applied component-wise. In the examples in Section 4 we choose
- is the final activation function. For a portfolio of assets and liabilities a natural choice is . To keep the presentation simple, we will consider pure liability portfolios with loss in all our examples below. Accordingly, we choose .
The parameter vector consists of the components of the matrices and vectors , . So it lives in for . It remains to determine the architecture of the network (that is, J and ) and to calibrate . Then VaR and ES figures can be estimated as described in Section 2 by simulating .
3.1. Training and Validation
In a first step we take the network architecture (J and as given and try to find a minimizer of , where the expectation is either with respect to or for an IS distribution on . To do that we simulate realizations , , of under the corresponding distribution. The first simulations are used for training and the other for validation. More precisely, we employ a stochastic gradient descent method to minimize the Monte Carlo approximation based on the training samples
of . At the same time we use the validation samples to check whether
is decreasing as we are updating .
3.1.1. Regularization through Tree Structures
If the number q of parameters is large, one needs to be careful not to overfit the neural network. For instance, in the extreme case, the network could be so flexible that it can bring (9) down to zero even in cases where the true conditional expectation is not equal to Y. To prevent this, one can generate the training samples by first simulating realizations of X and then for every , drawing simulations from the conditional distribution of Y given . In the simple example of Section 4.1, we chose . In Section 4.2 and Section 4.3 we used .
3.1.2. Stochastic Gradient Descent
In principle, one can use any numerical method to minimize (9). But stochastic gradient descent methods have proven to work well for neural networks. We refer to Ruder (2016) for an overview of different (stochastic) gradient descent algorithms. Here, we randomly2 split the training samples into b mini-batches of size B. Then we update based on the -gradients of
We use batch normalization and Adam updating with the default values from TensorFlow.
After b gradient steps, all of the training data have been used once and the first epoch is complete. For further epochs, we reshuffle the training data, form new mini-batches and perform b more gradient steps. The procedure is repeated until the training error (9) stops to decrease or the validation error (10) starts to increase.
3.1.3. Initialization
We follow standard practice and initialize the parameters of the network randomly. The final operation of the network is
Since the network tries to approximate Y, and in all our examples below we use , we initialize the last bias as
For the other parameters we use Xavier initialization; see Glorot and Bengio (2010).
3.2. Backtesting the Network Approximation
After having determined an approximate minimizer for a given network architecture, one can test the adequacy of the approximation of the true conditional expectation . The quality of the approximation depends on different aspects:
- (i)
- Generalization error:The true conditional expectation is of the form for the unique3 measurable function minimizing the mean squared distance . To approximate l we choose a network architecture and try to find a that minimizes the empirical squared distanceBut if the samples , do not represent the distribution of well, (11) might not be a good approximation of the true expectation .
- (ii)
- Numerical minimization method:The minimization of (11) usually is a complex problem, and one has to employ a numerical method to find an approximate solution . The quality of will depend on the performance of the numerical method being used.
- (iii)
- Network architecture:It is well known that feedforward neural networks with one hidden layer have the universal approximation property; see, e.g., Cybenko (1989); Hornik et al. (1989) or Leshno et al. (1993). That is, they can approximate any continuous function uniformly on compacts to any degree of accuracy if the activation function is of a suitable form and the hidden layers contain sufficiently many nodes. As a consequence, can be made arbitrarily small if the hidden layer is large enough and is chosen appropriately. However, we do not know in advance how many nodes we need. And moreover, feedforward neural networks with two or more hidden layers have shown to yield better results in different applications.
Since we simulate from an underlying model, we are able to choose the size of the training sample large and train extensively. In addition, for any given network architecture, we also evaluate the empirical squared distance (11) on the validation set , . So we suppose the generalization error is small and our numerical method finds a good approximate minimizer of (11). However, since we do not know whether a given network architecture is flexible enough to provide a good approximation to the true loss function l, we test for each trained network whether it satisfies the defining properties of a conditional expectation.
The loss function is characterized by
for all measurable functions such that is integrable. Ideally, we would like to satisfy the same condition. But there will be an approximation error, and (12) cannot be checked for all measurable functions satisfying the integrability condition. Therefore, we select finitely many measurable subsets , . Then we generate more samples of and test whether the differences
- (a)
- (b)
- (c)
are sufficiently close to zero. If this is not the case, we change the network architecture and train again.
4. Examples
As examples, we study three different risk assessment problems from banking and insurance. For comparison we generated realizations of under as well as , where is the IS distribution on obtained by changing the distribution of X. In all our examples, X has a transformed normal distribution as in Section 2.4. In each case we used 1.5 million simulations with mini-batches of size 10,000 for training, 500,000 simulations for validation and 500,000 for backtesting. After training and testing the network, we simulated another 500,000 realizations of X, once under and then under , to estimate and .
We implemented the algorithms in Python. To train the networks we used the TensorFlow package.
4.1. Single Put Option
As a first example, we consider a liability consisting of a single put option with strike price and maturity on an underlying asset starting from and evolving according to
for an interest rate , a drift , a volatility , a -Brownian motion and a -Brownian motion . As risk horizon we choose . The time -value of this liability is
Using Itô’s formula, one can write
where Z and V are two independent standard normal random variables under . It is well-known that L is of the form , where P is the Black–Scholes formula for a put option. This allows us to calculate reference values for and .
To train the neural network approximation of L, we simulated realizations of the pair for and . For comparison, we first simulated according to and then according to for an IS distribution . Clearly, L is decreasing in Z. Therefore, we chose so as to make Z normally distributed with mean equal to the -quantile of a standard normal and variance 1. Since is a simple one-dimensional function, we selected a network with a single hidden layer containing 5 nodes. This is sufficient to approximate P and faster to train than a network with more hidden layers. We did not use the tree structure of Section 3.1.1 for training (that is, ) and trained the network over 40 epochs.
It can be seen in Figure 1 that the empirical squared distance on both, the training and validation data, decreases with a very similar decaying pattern. This provides a first validation of our approximation procedure.
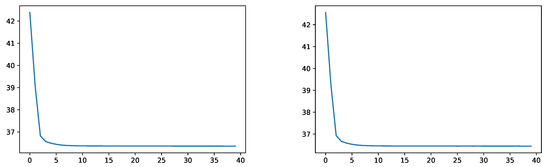
Figure 1.
Empirical squared distance without IS during training (left) and on the validation data (right).
Figure 2 shows the empirical evaluation of (a) and (b) of Section 3.2 on the test data after each training epoch.
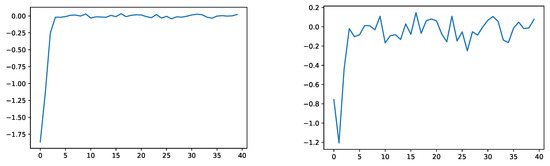
Figure 2.
Empirical evaluation of (a) (left) and (b) (right) of Section 3.2.
Similarly, Figure 3 illustrates the empirical evaluation of (c) of Section 3.2 on the test data after each training epoch for the sets
where denotes the -quantile of .
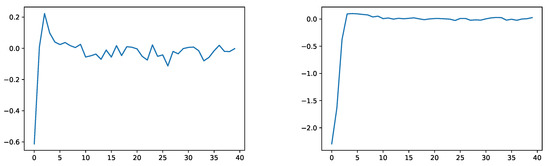
Figure 3.
Empirical evaluation of (c) of Section 3.2 for the sets (left) and (right).
Training, validation and testing with IS worked similarly.
Once the network has been trained and tested, one can estimate VaR and ES numbers. Figure 4 shows our results for increasing sample sizes. The left panel shows our estimate of without and with IS. Plugging the 0.5%-quantile of into the Black–Scholes formula gives a reference value of 8.3356. Our method yielded 8.3358 without and 8.3424 with importance sampling. The right panel shows our results for . Transforming simulations of with the Black–Scholes formula and using the empirical ES estimate (5) resulted in a reference value of 8.509. Without importance sampling, the neural network learned a value of 8.456 versus 8.478 with importance sampling. It can be seen that in both cases, IS made the method more efficient. It has to be noted that for increasing sample sizes, the VaR and ES estimates converge to the corresponding risk figures in the neural network model, which are not exactly equal to their analogs in the correct model. But it can be seen that the blue lines are close to their final values after very few simulations.
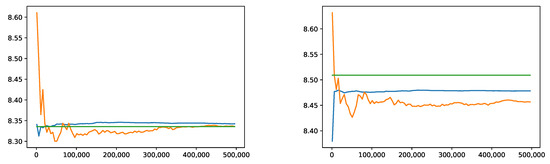
Figure 4.
Convergence of the empirical 99.5%-VaR (left) and 99%-ES (right) without IS (orange) and with IS (blue) compared to the reference values obtained from the Black–Scholes formula (green).
4.2. Portfolio of Call and Put Options
In our second example we introduce a larger set of risk factors. We consider a portfolio of 20 short call and put options on different underlying assets with initial prices and dynamics
for -Brownian motions and -Brownian motions , such that is a multivariate Gaussian process under with an instantaneous correlation of 30% between different components and is a multivariate Gaussian process under , also with instantaneous correlation of 30% between different components. We set for all and . The drift and volatility parameters are assumed to be and , . As in the first example, we choose a maturity of and a risk horizon of . We assume all options have the same strike price . Then the time- value of the liability is
where X is the vector .
In this example we trained a neural network with two hidden layers containing 15 nodes each. We first simulated according to and trained for 100 epochs. Figure 5 shows the decay of the empirical squared distance on the training and validation data set.
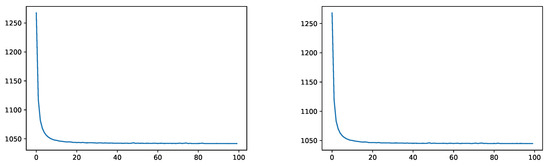
Figure 5.
Empirical squared distance without IS during training (left) and on the validation data (right).
After training and testing the network under , we did the same under for the IS distributions resulting from the procedure of Section 2.4 for (for VaR) and (for ES). The two plots in Figure 6 show the empirical evaluations of (a) and (b) on the test data under the IS measure corresponding to .
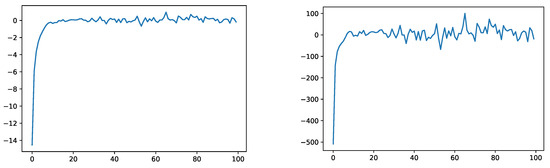
Figure 6.
Empirical evaluation of (a) (left) and (b) (right) of Section 3.2 under corresponding to .
As an additional test, we consider the two sets
and
where is the -quantile of under , and evaluate (c) on the test data generated under the IS distribution corresponding to . The results are depicted in Figure 7.
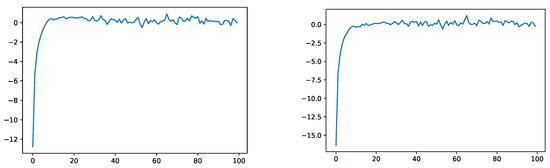
Figure 7.
Empirical evaluation of (c) of Section 3.2 for the sets (left) and (right) under corresponding to .
After training and testing, we generated simulations of X to estimate and . The convergence for increasing sample sizes is shown in Figure 8. The reference values, 104.92 for -VaR and 105.59 for -ES, were obtained from the empirical estimates (5) by simulating and using the Black–Scholes formula for each of the 20 options. The neural network estimates of -VaR were 104.56 without and 104.48 with IS. Those of -ES were 105.03 without and 104.65 with IS. In both cases, IS made the procedure more efficient.
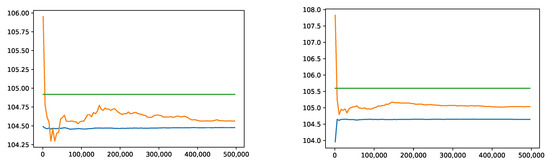
Figure 8.
Convergence of the empirical 99.5%-VaR (left) and 99%-ES (right) without IS (orange) and with IS (blue) compared to the reference values obtained from the Black–Scholes formula (green).
4.3. Variable Annuity with GMIB
As a third example we study a variable annuity (VA) with guaranteed minimum income benefit (GMIB). We consider the contract analyzed by Ha and Bauer (2019) using polynomial regression. At time 0 the contract is sold to an x-year old policyholder. If she is still alive at maturity T, she can choose between the balance of an underlying investment account and a lifetime annuity. Therefore, in case of survival, the time-T value of the contract is
where is the account value, b a guaranteed rate and the time-T value of an annuity paying one unit of currency to a -year old policyholder at times for as long as the person lives.
The contract is exposed to three types of risk: investment risk, interest rate risk and mortality risk. We suppose the log-account value , the interest rate and the mortality rate of our policyholder start from known constants and for , have -dynamics
for given parameters and -Brownian motions and forming a three-dimensional Gaussian process with instantaneous correlations , and . We assume that our policyholder does not live longer than 120 years. Therefore, we set for . The dynamics for under the risk-neutral probability are assumed to be
where are -Brownian motions constituting a three-dimensional Gaussian process with the same instantaneous correlations as the corresponding -Brownian motions. As Ha and Bauer (2019), we assume there is no risk premium for mortality and a constant risk premium for interest rate risk, such that Provided that the policyholder is still alive at the risk horizon , the value of the contract at that time is
where we denote . Discounting with takes into account that the policyholder might die between and T. On the other hand, a possible death time between 0 and is not considered. This results in a conservative estimate of the capital requirement for the issuer of the contract. Alternatively, one could model the loss as , where is the event that the policyholder survives until time .
We follow Ha and Bauer (2019) and set , , , , , , , , , , , , , , , , , . Then
where
is the time-t value of a pure endowment contract with maturity . Since r and are affine, one has
for the function , with and as given in the Appendix of Ha and Bauer (2019). Moreover, one can write
for the probability measure given by
Under , is a three-dimensional normal vector, and the conditional -distribution of given X is normal too (the precise form of these distributions is given in the Appendix of Ha and Bauer (2019)). This makes it possible to efficiently simulate under , where
To approximate L we chose a network with two hidden layers containing 4 nodes each and trained it for 40 epochs. Figure 9 shows the empirical squared distance without IS on the training and validation data set.
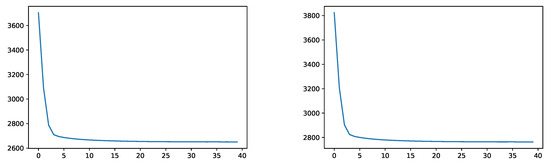
Figure 9.
Empirical squared distance without IS during training (left) and on the validation data (right).
The panels in Figure 10 illustrate the empirical evaluations of the test criteria (a) and (b) from Section 3.2.
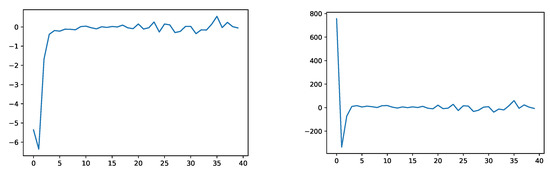
Figure 10.
Empirical evaluation of (a) (left) and (b) (right) of Section 3.2 under .
To test (c) from Section 3.2 we considered the sets
where and denote the -quantiles of and under ; see Figure 11.
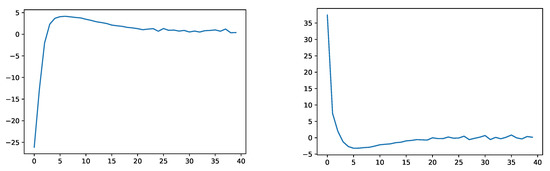
Figure 11.
Empirical evaluation of (c) of Section 3.2 for the sets (left) and (right) under .
We also trained and tested under for an IS distribution on . Our results are reported in Figure 12. Our estimate of was 138.64 without and 138.52 with IS. In comparison, the VaR estimate obtained by Ha and Bauer (2019) using 37 monomials and 40 million simulations is 139.74. Our estimates of came out as 141.12 without and 142.12 with IS. There exist no reference values for this case.
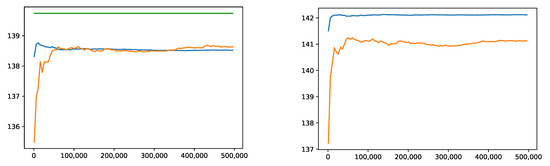
Figure 12.
Convergence of the empirical 99.5%-VaR (left) and 99%-ES (right) without IS (orange) and with IS (blue) compared to the reference value from Ha and Bauer (2019) (green).
5. Conclusions
In this paper we have developed a deep learning method for assessing the risk of an asset-liability portfolio over a given time horizon. It first computes a neural network approximation of the portfolio value at the risk horizon. Then the approximation is used to estimate a risk measure, such as value-at-risk or expected shortfall, from Monte Carlo simulations. We have investigated how to choose the architecture of the network, how to learn the network parameters under a suitable importance sampling distribution and how to test the adequacy of the network approximation. We have illustrated the approach by computing value-at-risk and expected shortfall in three typical risk assessment problems from banking and insurance. In all cases the approach has worked efficiently and produced accurate results.
Author Contributions
P.C., J.E., and M.V.W. have contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
As SCOR Fellow, John Ery thanks SCOR for financial support.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bauer, Daniel, Andreas Reuss, and Daniela Singer. 2012. On the calculation of the solvency capital requirement based on nested simulations. ASTIN Bulletin 42: 453–99. [Google Scholar]
- Britten-Jones, Mark, and Stephen Schaefer. 1999. Non-linear Value-at-Risk. Review of Finance, European Finance Association 5: 155–80. [Google Scholar]
- Broadie, Mark, Yiping Du, and Ciamac Moallemi. 2011. Efficient risk estimation via nested sequential estimation. Management Science 57: 1171–94. [Google Scholar] [CrossRef]
- Broadie, Mark, Yiping Du, and Ciamac Moallemi. 2015. Risk estimation via regression. Operations Research 63: 1077–97. [Google Scholar] [CrossRef]
- Bru, Bernard, and Henri Heinich. 1985. Meilleures approximations et médianes conditionnelles. Annales de l’I.H.P. Probabilités et Statistiques 21: 197–224. [Google Scholar]
- Cambou, Mathieu, and Damir Filipović. 2018. Replicating portfolio approach to capital calculation. Finance and Stochastics 22: 181–203. [Google Scholar] [CrossRef]
- Carriere, Jacques F. 1996. Valuation of the early-exercise price for options using simulations and nonparametric regression. Insurance: Mathematics and Economics 19: 19–30. [Google Scholar] [CrossRef]
- Castellani, Gilberto, Ugo Fiore, Zelda Marino, Luca Passalacqua, Francesca Perla, Salvatore Scognamiglio, and Paolo Zanetti. 2019. An Investigation of Machine Learning Approaches in the Solvency II Valuation Framework. SSRN Preprint. [Google Scholar]
- Cybenko, G. 1989. Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems 2: 303–14. [Google Scholar] [CrossRef]
- David, Herbert A., and Haikady N. Nagaraja. 2003. Order Statistics, 3rd ed. Wiley Series in Probability and Statistics; Hoboken: Wiley. [Google Scholar]
- Duffie, Darrell, and Jun Pan. 2001. Analytical Value-at-Risk with jumps and credit risk. Finance and Stochastics 5: 155–80. [Google Scholar] [CrossRef]
- Fiore, Ugo, Zelda Marino, Luca Passalacqua, Francesca Perla, Salvatore Scognamiglio, and Paolo Zanetti. 2018. Tuning a deep learning network for Solvency II: Preliminary results. In Mathematical and Statistical Methods for Actuarial Sciences and Finance: MAF 2018. Berlin: Springer. [Google Scholar]
- Glasserman, Paul. 2003. Monte Carlo Methods in Financial Engineering. Stochastic Modelling and Applied Probability. Berlin: Springer. [Google Scholar]
- Glorot, Xavier, and Yoshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics 9: 249–56. [Google Scholar]
- Glynn, Peter, and Shing-Hoi Lee. 2003. Computing the distribution function of a conditional expectation via Monte Carlo: Discrete conditioning spaces. ACM Transactions on Modeling and Computer Simulation 13: 238–58. [Google Scholar]
- Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep Learning. Cambridge: MIT Press. [Google Scholar]
- Gordy, Michael B., and Sandeep Juneja. 2008. Nested simulation in portfolio risk measurement. Management Science 56: 1833–48. [Google Scholar] [CrossRef]
- Ha, Hongjun, and Daniel Bauer. 2019. A least-squares Monte Carlo approach to the estimation of enterprise risk. Working Paper. Forthcoming. [Google Scholar]
- Hejazi, Seyed Amir, and Kenneth R. Jackson. 2017. Efficient valuation of SCR via a neural network approach. Journal of Computational and Applied Mathematics 313: 427–39. [Google Scholar] [CrossRef]
- Hornik, Kurt, Maxwell Stinchcombe, and Halbert White. 1989. Multilayer feedforward networks are universal approximators. Neural Networks 2: 359–66. [Google Scholar] [CrossRef]
- Lee, Shing-Hoi. 1998. Monte Carlo Computation of Conditional Expectation Quantiles. Ph.D. thesis, Stanford University, Stanford, CA, USA. [Google Scholar]
- Leshno, Moshe, Vladimir Lin, Allan Pinkus, and Shimon Schocken. 1993. Multilayer feedforward networks with a non-polynomial activation function can approximate any function. Neural Networks 6: 861–67. [Google Scholar] [CrossRef]
- Longstaff, Francis, and Eduardo Schwartz. 2001. Valuing American options by simulation: A simple least-squares approach. The Review of Financial Studies 14: 113–47. [Google Scholar] [CrossRef]
- McNeil, Alexander J., Rüdiger Frey, and Paul Embrechts. 2015. Quantitative Risk Management: Concepts, Techniques and Tools, rev. ed. Princeton: Princeton University Press. [Google Scholar]
- Natolski, Jan, and Ralf Werner. 2017. Mathematical analysis of replication by cashflow matching. Risks 5: 13. [Google Scholar] [CrossRef]
- Pelsser, Antoon, and Janina Schweizer. 2016. The difference between LSMC and replicating portfolio in insurance liability modeling. European Actuarial Journal 6: 441–94. [Google Scholar] [CrossRef] [PubMed]
- Rouvinez, Christophe. 1997. Going Greek with VaR. Risk Magazine 10: 57–65. [Google Scholar]
- Ruder, Sebastian. 2016. An overview of gradient descent optimization algorithms. arXiv arXiv:1609.04747. [Google Scholar]
- Tsitsiklis, John, and Benjamin Van Roy. 2001. Regression methods for pricing complex American-style options. IEEE Transactions on Neural Networks 12: 694–703. [Google Scholar] [CrossRef] [PubMed]
- Wüthrich, Mario V. 2016. Market-Consistent Actuarial Valuation. EAA Series; Berlin: Springer. [Google Scholar]
- Zwingmann, Tobias, and Hajo Holzmann. 2016. Asymptotics for the expected shortfall. arXiv arXiv:1611.07222. [Google Scholar]
| 1. | More precisely, is usually defined as an - or (1-quantile depending on whether it is applied to L or . So up to the sign convention, all VaR definitions coincide if is strictly increasing. Similarly, different definitions of ES are equivalent if is continuous. |
| 2. | If the training data is generated according to a tree structure as in Section 3.1.1, one can either group the simulations , , , so that pairs with the same -component stay together or not. In our implementations, both methods gave similar results. |
| 3. | More precisely, uniqueness holds if functions are identified that agree -almost surely. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).