1. Introduction
In the settlement process of a general insurance claims portfolio we denote as claim watching the insurer’s activityconsisting of monitoring and controlling the cost development at single-claim level. Claim watching encompasses prediction of specific events regarding individual claims that can be relevant for cost development and could be influenced by possible appropriate management actions. Obviously, the estimation of the ultimate cost, hence the individual claims reserving, is also a typical claim watching activity. Early-warning systems at single-claim or group-of-claims level can be also included.
In this paper, we propose a machine-learning approach to claim watching, and individual claims reserving, using a prediction model based on the classification and regression trees (CART). The paper is largely based on a path-breaking article produced in 2016 by Mario Wüthrich (
Wüthrich 2016) where individual claims reserving is addressed by CART techniques. The method proposed by Wüthrich was restricted “
for pedagogical reasons” to the prediction of events and the estimation of the number of payments related to individual claims. We extend Wüthrich’s paper providing a so-called
frequency-severity model where claim amounts paid are also considered. Moreover, we enlarge the set of the response and explanatory variables of the model to allow prediction under a double-claim regime, i.e., when two different types of compensation can be required by the same claim. This multi-regime extension enables us to provide meaningful applications to Italian motor insurance claims data. We also propose a further enhancement of the CART approach allowing the joint dynamic modeling of the case reserves, which usually yield useful predictive information.
The claim watching idea and a related frequency-severity model based on CARTs were introduced and developed in
D’Agostino et al. (
2018) and large part of the material presented here was already contained in that paper.
According to a point of view proposed in
Hiabu et al. (
2015), a possible inclusion of a granular data approach in claims reserving could be provided by extending classical aggregate methods, adding more model structure to include underlying effects which are supposed to emerge at an individual claim level. In
Hiabu et al. (
2015) this approach is illustrated by referring to a series of extensions of the Double Chain-Ladder (DCL) model, originated in
Verral et al. (
2010) and developed in successive papers, (see e.g.,
Martínez-Miranda et al. 2011,
2012,
2013). Approaches to claims reserving recently proposed based on embedding a classical actuarial model in a neural net (see e.g.,
Gabrielli et al. 2018;
Wüthrich and Merz 2019) could also be interpreted as going in a similar “top-down” direction. A different path is followed in this paper. We use the large model flexibility provided by machine-learning methods for directly modeling individual claim histories. In this approach model assumptions are specified at granular level and are, in some sense, the minimal required to guarantee a sound statistical meaning to results provided by the powerful algorithms currently available. This allows implantation of claim watching activities which can be considered even more general than traditional claims reserving.
This paper, however, has several limitations. In particular, only point estimates of the ultimate claim cost are considered and the important problem of prediction uncertainty is not addressed, yet. Moreover, these cost estimates do not fully include underwriting year inflation, then an appropriate model should be added to this aim. Therefore, the present paper should be considered to be only a starting point in applying CARTs to claims reserving and claims handling. By analogy, one could say that in introducing machine learning to individual reserving data this paper is playing the same role as
Verral et al. (
2010) was playing in DCL: many improvements and developments should follow.
The present paper is composed of two parts. In the first part one-period prediction problems are considered. Prediction problems typical in claim watching and individual claims reserving are presented in
Section 2 and notation and a basic assumption (i.e., the dependence of the prediction functions on the observation time-lag) are introduced in
Section 3. In
Section 4 we describe the general structure of the frequency-severity approach, providing details on the model assumptions for both the model components. The structure of the feature space, both for static and dynamic variables, is described in
Section 5 and the organization of data required for the CART calibrations is illustrated in
Section 6. In
Section 7 the use of classification trees for the frequency prediction, and regression trees for (conditional) severity predictions is illustrated. In
Section 8 a first extensive example of one-year predictions for a claims portfolio in Italian motor insurance is presented using the
rpart routine implemented in
R. The results of the CART calibration are discussed in detail and a possible use of event predictions for early warning is illustrated.
The second part of the paper considers multiperiod predictions and includes numerical examples and backtesting exercises. In
Section 9 we consider multiperiod predictions and describe the properties required for deriving multiyear forecasts by compounding one-year forecasts. In
Section 10 a simulation approach to multiperiod forecasts is also presented and additional assumptions allowing the joint dynamic modeling of the case reserves are discussed. A first numerical example of multiperiod prediction of a single-claim cost is also provided.
Section 11 is devoted to numerical examples of applications to a large claims portfolio in motor insurance and to some backtesting exercises providing insights into the predictive performance of our CART approach. We first illustrate backtesting results for predictions of one-year event occurrences useful for claim watching. Finally, a typical claim reserving exercise is provided, composed of two steps. In a first step the individual reserve estimate is derived by simulation for all the claims in the portfolio and the resulting total reserve, after the addition of an IBNYR (
incurred but not yet reported) reserve estimate, is compared with the classical chain-ladder reserve, estimated on aggregate payments at portfolio level (an ancillary model for IBNYR reserves is outlined in
Appendix A). Since we perform these estimates on data deprived of the last calendar year observations, we analyze the predictive accuracy of the CART approach with respect to the chain-ladder approach by comparing the realized aggregate payments in the “first next diagonal” with those predicted by the two methods. Some conclusions are presented in
Section 12.
Part I. One-period Predictions
2. A First Look at the Problem and the Model
Let us consider the claim portfolio of a given line of business of a non-life insurer. We are interested in the individual claim settlement processes of this portfolio. For example, for a given claim in the portfolio, we would like to answer questions like these:
- (a)
What is the probability that is closed in the next year?
- (b)
What is the probability that a lawyer will be involved in the settlement of in two years?
- (c)
What is the expectation of a payment in respect of in the next year?
- (d)
What is the expectation of the total claim payments in respect of until finalization?
In general, we will refer to the activity of dealing with this kind of questions as claim watching. In particular, question (b) could be relevant in a possible early-warning system, while questions as (c) and (d) are more concerned with individual claims reserving. The classical claims reserving, i.e., the estimation of the outstanding loss liabilities aggregate over the entire portfolio, could be obtained by summing all the individual claim reserves with some corrections due to non-modeled effects (typically, reserve for IBNYR claims).
For a specified claim
in the portfolio, a typical claim watching question at time
t can be formulated as a prediction problem with the form:
where:
- ·
denotes the information available at time t,
- ·
the vector is the claim feature (also covariates, explanatory variables, independent variables, …), which is observed up to time t, i.e., is -measurable,
- ·
is the prediction function,
- ·
is the response variable (or dependent variable).
Referring to the previous examples, the response in (
1) can be specified as follows:
- (a)
is the indicator function of the event { is closed at time } (with ),
- (b)
is the indicator function of { will involve a lawyer by the time } (with ),
- (c)
is the random variable denoting the amount paid in respect of at time (with ),
- (d)
is the random variable denoting the cumulated paid amount in respect of at time (with ).
The response and the feature can be both quantitative or qualitative variables and we do not assume for the moment a particular structure for the prediction function
, which must be estimated from the data. Usually, the prediction model (
1) is referred to as
regression model if the response is a quantitative variable and
classification model if the response is qualitative (categorical). The prediction function is named, accordingly, as
regression or
classifier function
1.
Questions such as (a) and (b) involve prediction of events while questions such as (c) and (d) concern prediction of paid amounts. With some abuse of actuarial jargon, we will refer to a prediction model for event occurrences as a frequency model. Similarly, we will refer to a prediction model for paid amounts as a severity model. Then, altogether, we need a frequency-severity model. We will develop a frequency-severity model for claim watching with a conditional severity component that is the paid amounts are predicted conditionally on the payment is made. This is because the probability distribution of a paid amount, with a discrete mass in 0, is better modeled by separate recognition of the mass and the remainder of the distribution (assumed continuous).
Remark 1. A model with such a structure can be also referred to as a cascaded model
, see Taylor (2019) for a discussion of this kind of models. This model structure also bears some resemblance to Double Chain-Ladder (DCL), see Martínez-Miranda et al. (2012). In DCL a micro-model of the claims generating process is first introduced to predict the reported number of claims. Future payments are then predicted through a delay function and a severity model. In DCL, however, individual information is assumed to be “(in practice often) unobservable” and the micro-model is only aimed to derive a suitable reserving model for aggregate data. In this paper, instead, extensive individual information is assumed to be always available and each individual claim is identifiable. Moreover, we are interested in both claim watching and individual claims reserving, aggregate reserving being a possible byproduct of the approach. To deal with the prediction problems both in the frequency and the severity component we shall use the classification and regression trees (CART) techniques, namely classification trees for the frequency section and regression trees for the severity section. One of the main advantages of CART methods is the large modeling flexibility (for aggregate claims reserving methods with a good degree of model flexibility though not using machine learning, see e.g.,
Pešta and Okhrin 2014). Carts can deal with any sort of structured and unstructured information, an underlying structural form of the prediction function
can be learned from the data, many explanatory variables can be used, both quantitative and qualitative and observed at different dates. Moreover, the interpretability of results is generally allowed. As methods for providing expectations, CARTs can also be referred to as
prediction trees.
3. Notation and Basic Assumptions
The notation used in this paper is essentially the same as in
Wüthrich (
2016). For simplicity sake we model the claim settlement process using an annual time grid. If allowed by the available data, a discrete time grid with a shorter time step (semester, quarter, month, …) could be used.
Accident year. For a given line of business in non-life insurance, let us consider a claims portfolio containing observations at the current date on the claims occurred during the last I accident years (ay). The accident years are indexed as . Then we are at time (calendar year) .
Reporting delay. For each accident year i, claims may have been observed with a reporting delay (rd) . A claim with accident year i and reporting delay j will have reporting date . As usual, we assume that there exists a maximum possible delay .
Claims identification. Each claim is identified by a claim code cc. For each block there are claims and we denote by the index numbering the claims in block ; the -th claim in is denoted by .
IBNYR claims. Because of the possible reporting delay, at a given date t we can have incurred but not yet reported (IBNYR) claims. Since there is a maximal delay J, at the current date the IBNYR claims are those with delay . The maximum observed reporting delay is .
Remark 2. At time I, claims with can be closed
or reported but not settled
(RBNS). We can estimate a reserve required for these claims. For the IBNYR reserve estimate a specific reserving model is needed (see Appendix A). Predictions in the claim settlement process. For given , the claim settlement process of is defined on the calendar dates . Let us denote by:
- ·
a generic random variable, possibly multidimensional, involved in the claim settlement process of and observed at time , for ,
- ·
the time-lag of .
Using this notation, the prediction problem (
1) for
is reformulated as follows:
where the claim feature
is
-measurable,
, and the response is possibly multidimensional. In the rest of the paper the prediction function
will refer solely to one-year forecast problems. Multiyear prediction problems will be treated compounding one-year predictions.
To give some statistical structure to the prediction model, we make the following basic assumption on the prediction function:
- (H0)
At any date t the one-year prediction function depends only on the time-lag . i.e.,:
Then the function is independent of and is applied to all the features with the same time-lag , providing the expectation of (which has time-lag ).
Under assumption (H0) we can build statistical samples of observed pairs feature-response which can be used to derive an estimate of unobserved responses based on observed features.
In what follows it will be often convenient to rewrite the prediction problem using the
k index. Since
expression (
2), taking account of assumption (H0), takes the form:
4. The General Structure of the Frequency-Severity Model
To give a formal characterization of the entire claim settlement process we have to recall that
denotes the number of claims occurred in accident year
i reported in calendar year
. Then in a general setting we let the relevant indexes vary as follows:
and we consider also
as a stochastic process.
4.1. Frequency and Severity Response Variables
The peculiarity of the frequency model is that the response variables
are defined as a multi-event, which is a vector of 0–1 random variables. Precisely, for all values of
and
k we assume that a frequency-type response at time
for the claim
takes the form:
As concerning severity, we shall assume that in the claim settlement process two different kinds of claim payments are possible, say type-1 and type-2 payments. Then we shall indicate with
and
the random variable denoting a claim payment of type 1 and type 2, respectively, made at time
. For all values of
and
k, a severity-type response for
will be denoted in general as
, which will be specified as
or
according to a type-1 or type-2 cash flow is to be predicted. We shall also denote by
and
) the binary variables:
i.e., the indicator of the event {
A claim payment of type 1 for is made at time } and {
A claim payment of type 2 for is made at time }, respectively.
Remark 3. The assumption of multiple payment types will be necessary in our applications to Italian Motor Third Party Liability (MTPL) data. Essentially, in Italian MTPL incurred claims can be handled, according to their characteristics, under (at least) two different regimes: direct compensation ("CARD" regime) and indirect compensation ("NoCARD" regime). Case reserves in the two regimes are different and a claim can activate one or both, as well as can change regime. In our numerical examples we shall denote NoCARD and CARD payments/reserves as type-1 and type-2 payments/reserves, respectively.
The following model assumptions extend the set of assumptions used in
Wüthrich (
2016).
4.2. Model Assumptions
Let
be a filtered probability space with filtration
such that for
, the process
is
-adapted for
and all the processes:
are
-adapted for
. We make the following assumptions:
- (H1)
The processes, , andare independent.
- (H2)
The random variables in, , andfor different accident years are independent.
- (H3)
The processes, andfor different reporting delays j and different claims ν are independent.
- (H4)
The conditional distribution of is the d-dimensional Bernoulli:
with
and
where is the -measurable frequency feature of and is a probability function, i.e.: - (H5)
For the conditional distribution ofandone has:where is the -measurable severity feature of .
Assumption (H4) implies that for every claims
reported at time
:
and:
Therefore, there exists an
-measurable frequency feature
which determines the conditional probability of each (binary) component of the response variable. Expression (
5) provides the specification of the prediction problem (
3) for the frequency model.
Similarly, assumption (
4) implies that for every claims
reported at time
:
Then there exists an
-measurable severity feature
which determines the conditional expectation of the cash flows
and
. The previous assumptions specify a compound frequency-severity model. From (
6):
If the indicators
and
have been included in the response vector for the frequency model, the corresponding probabilities are provided by (
5) and the severity expectations are then obtained by this compound model. Expression (
7) provides the specification of the prediction problem (
3) for the (two types of) severity model in the framework of this compound model.
Remark 4. As regards model assumptions:
The independence assumptions (H1), (H2) and (H3) were taken to receive a not too much complex model. In particular, assumptions in (H1) are necessary to obtain compound distributions, assumptions in (H3) allow the modeling of variables of individual claims independently for different ν.
However, the specified model is rather general as regarding the prediction functions p and in (5) and (6). These functions at the moment are fully non-parametric and can have any form. In the following sections we will show how these functions can be calibrated with machine-learning methods provided by CARTs. The value of the variance parameters in (4) is irrelevant since the normality assumption is used in this paper only to support the sum of squared errors (SSE) minimization for the calibration of the regression trees. The value of the variance is irrelevant in this minimization. Our model assumptions concern only one-year forecasting (from time t to ). Under proper conditions multiyear predictions can be obtained by compounding one-period predictions. This will be illustrated in Section 9.
4.3. Equivalent One-Dimensional Formulation of Frequency Responses
The frequency prediction problem can be reformulated equivalently by replacing the
d-dimensional binary random variables
by the one-dimensional random variable:
In this case, assumption (H4) is replaced by:
- (H4’)
For the conditional distribution of one has:whereis a probability function, i.e.:
Expression (
5) is then rewritten accordingly:
In the numerical examples presented in this paper we shall use formulation (
8) for the frequency response since the
R package
rpart we use in these examples, multidimensional responses are not supported.
5. Characterizing the Feature Space
Given the high modeling flexibility of CARTs, the feature space
in our applications can be very large and with rather general characteristics. In the following discussion we refer to the frequency features
; the same properties hold for the severity features
. Typically, for all
the feature
is a vector with a large number of components. The feature components can be categorical, ordered or numerical. As pointed out by
Taylor et al. (
2008) the concept of static and dynamic variable is also important when considering the feature components.
Static variables. These are components of which remain unchanged during the life of the claim . Typical static variables are the claim code cc (categorical), the accident year i and the reporting delay j (ordered).
Dynamic variables. These feature components may randomly change over time. This implies that in general we have to understand as containing information on up to time . For example, the entire payment history of the claim up to time may be included in . Therefore, when time passes more and more information is collected and the dimension of increases.
Typical examples of dynamic feature components are the categorical variable
which can take different 0-1 values for
, or the numerical variable
which can take different values in
for
. The categorical variable:
is better modeled as a dynamic variable, since we observe that a closed claim can be reopened.
At time
the structure of feature
of
can be expressed as:
where:
- ·
is a column vector of static variables,
- ·
, is a column vector of dynamic variables observed in year .
Following
Wüthrich (
2016), if
for each variable in
the observed value is preceded by a sequence of
j zeros. An alternative choice could be to insert “NA” instead of zeros, provided that we are able to control how the CART routine used for calibration handles missing values in predictors.
From (
10) one can say that
provides the feature history of
up to time
, while the vector
provides its development in the next year
.
For example, for claim
the feature at time
could be specified as:
where:
- ·
,
- ·
,
- ·
.
In this example the covariates are observed only on the current date and the covariates are observed on dates and . Then it is implicitly assumed a Markov property of order 1 for the processes and and of order 2 for the processes and . In this respect it is useful to introduce the following definition. Let be a dynamic variable included in the feature . We denote by historical depth of the maximum for which is included in . Generalizing the previous example, we can say that if has historical depth , then a Markov property of order is implicitly assumed for the process .
As previously mentioned, in
Section 9 we shall consider multiyear predictions. It is important to observe that in this case a dynamic variable can play the role of both an explanatory and a response variable. This is typical in dynamic modeling. For example, in a prediction from
t to
, the variable
could be chosen as a component of the frequency response variable
in the prediction from
t to
and as a component of the feature
in the next prediction from
to
.
As is also clearly recognized in
Taylor et al. (
2008), an important issue in multiperiod prediction concerns the use of the case reserves. The amount of the type-1 and type-2 case reserve
and
should provide useful information for the claim settlement process. A correct use of this information will typically require a joint dynamic modeling of the claim payment and the case reserve processes. A set of additional model assumptions useful to this aim is provided in
Section 10.3.
6. Organization of Data for the Estimation
Since the considerations we present in this section apply to both the frequency and the severity model, we use here the more general notation of problem (
2), where
is used to denote the feature-response pairs. The exposition can be specified for the frequency or the severity model by skipping to the
or
notation, respectively.
Since the regression functions in (
2) depend on the lag
ℓ, in order to make predictions at time
I we need the
estimates:
Each of these estimates is based on historical observations, which are given by the relevant pairs feature-response of claims reported at time
. Precisely, the estimate
at time
, for
, is based on the set of
lag observations:
where:
with
the minimum reporting delay observed for accident year
i2. Given the model assumptions the pairs
in the calibration set can be considered independent observations of the random variables feature-response for lag
ℓ and can be used for the estimation of the corresponding prediction function in the prediction set. Therefore, we calibrate using CARTs the prediction function
on
, where the pairs feature-response are observed, and apply the resulting calibrated function
to the features in
in order to forecast the corresponding, not yet observed, response variables
. These are predicted as:
In
Table 1 the data structure is illustrated for a very simplified portfolio with
accident years,
and only one claim for each block
, i.e.,
. Columns refer to calendar years
. Cells with “·” refer to dates where the claims are not yet occurred. Cells with “no” (
not observed) refer to dates where the claims are occurred, but their feature is not yet observed because of reporting delay (these features would have
). Observations in the last column cannot be used because at date
I the responses with
are not yet observed. Cells with observations useful for the calibration are highlighted in pink color.
A more convenient presentation of data is provided in
Table 2 where the observations are organized by lag, i.e., with columns corresponding to lags
. Intuitively, the feature
can be thought of as being allocated on the row
of the table from column
back to the first column. Data on the last column
can be dropped, since responses have never been observed at time
I for this lag. Similarly, row 4, corresponding to claims
, can also be dropped.
We are then led to the representation in
Table 3, which shows a “triangular” structure resembling the data structure typically used in classical claims reserving. In this table observations highlighted in pink color in column
ℓ (where the response is observed) provide the dataset
used for the calibration of
. For example, for
data refers to claims with identification number
cc. The feature of claims 1 and 2, belonging to accident year 1, is observed up to time
, but only features observed up to time
can be used for the estimation. For claims 2, 3, which are reported with a one-year delay, historical data is missing for calendar year 1, 2, respectively. Cells highlighted in green color correspond to the data sets
, used for the estimates
of the responses, which replace the missing values in
Table 2.
7. Using CARTs for Calibration
7.1. Basic Concepts of CART Techniques
As we have seen, the general form of our one-year prediction problems at time
I can be given by:
which will be specified as a frequency or a severity model according to the specific application. For each lag we calibrate the prediction function
in (
11) with CART techniques. Classical references for CART methods are the work
Breiman et al. (
1998) and
Section 9.2 in
Hastie et al. (
2008). In a CART approach to the prediction problem (
11) the
function is
piece-wise constant on a specified partition:
of the feature space
, where the elements (regions)
of
are (hyper)rectangles, i.e., for given
ℓ there exist
constants
such that:
The peculiarity of CART techniques consists of the method of choice of partition
. This is determined on the calibration set
by assigning to the same rectangle observations
which are in some sense more similar. The region
is the
r-th
leaf of a binary tree which is grown by successively partitioning
through the solution of standardized binary split questions (see Section 5.1.2 in
Wüthrich and Buser (
2019) for definition). According to the method chosen for the recursive splitting, a
loss function, or
impurity measure,
is specified, and at each step, the split which reduces
most is the one chosen for the next binary split. The rule by which
is computed depends on the method chosen. For example,
can be the empirical mean of the response variables if these are quantitative or it can be the category with maximal empirical frequency (maximal class) if the responses are categorical.
In a first stage a binary tree is grown with a large size, i.e., many leaves. In a second stage the initial tree is
pruned using
K-fold cross-validation techniques. Using the cross-validation error a
cost-complexity parameter is computed as a function of the tree size and the optimal size is that corresponding to a cost-complexity value sufficiently low, according to a given criterion (usually we use the one-standard-error rule). The leaves of this optimally pruned tree are the elements
of the partition
in (
12). The expectations in (
11) are then estimated by applying the optimal partition
to the prediction set
, i.e.,:
where
is given by (
13). In
D’Agostino et al. (
2018) regions
and partition
are also referred to, respectively, as explanatory classes and explanatory structure (for lag
ℓ).
In our applications of CARTs, we shall use the
rpart routine implemented in
R, see e.g.,
Therneau et al. (
2015).
7.2. Applying CARTs in the Frequency Model
In the frequency section of our frequency-severity model the responses are categorical, then we use classification trees for calibration. In
rpart this is obtained with the option
method=‘class’, which also implies that the Gini index is used as impurity measure. As previously pointed out, since the
rpart routine supports only one-dimensional response variables, instead of using the
d-dimensional variables
F we formulate the classification problem using the one-dimensional variables defined in (
8). From (
9) we have:
Therefore, the calibration of the prediction function for lag
ℓ is performed by determining the optimal partition
of the calibration set:
where the calibration of the prediction function reduces to the estimation of the probability distribution
on each leaf
of the optimal partition
. Formally, for each
, the
rpart routine provides the probabilities:
which are estimated as the empirical frequencies on each leaf of the partition
of
. The estimates
required in (
14) are finally obtained by applying
to the prediction set
.
7.3. Applying CARTs in the Severity Model
In the severity section the prediction problem takes the form, from (
6):
where we use the generic notations
S for
, and
for
. Since the severity is a quantitative variable we use regression trees, which are obtained in
rpart with the option
method=‘anova’. In this case, the loss function used is the sum of squared errors (SSE). Given the normality assumption (H5) the SSE minimization performed by the binary splitting algorithm provides a log-likelihood minimization in this non-parametric setting.
The important point here is that since (
16) is a conditional model, the set of observed feature-response pairs where the prediction function is calibrated must include only claims for which a payment was made at the response date. Therefore, the calibration set is formally specified as:
Similarly, the prediction set is given by:
This corresponds to the fact that the severity calibration, as being a conditional calibration, must be run after the corresponding frequency calibration has been made, and must be performed on the leaves of the frequency model where a claim payment was made at time
. From the function
calibrated in this way one obtains:
As in (
7) the estimate of the payment-unconditional expectations is then given by:
The final probability estimate in this expression is given by the frequency model, provided that the binary variable has been included in the response .
8. Examples of One-Year Predictions in Motor Insurance
In these first examples we consider one-year predictions based on data from the Italian MTPL line at the observation date 2015. As previously mentioned, we denote by
NoCARD payments and by
CARD payments (for details on CARD and NoCARD regime see
D’Agostino et al. 2018). We have:
- ·
Observed accident years: from 2010 to 2015. Then with .
- ·
Only claims reported from 2013 onwards are observed, hence for accident year i, one has , with .
- ·
The pairs feature-response are observed for lags (5 estimation steps).
The total number of reported claims in this portfolio is
. The “triangular” structure of the data is illustrated in
Table 4, where the number
of claims in each block
is also reported. In each column, i.e., for each lag, the cells in the calibration set
are highlighted in pink and those in the prediction set
in green color. A rather short claim history (“last 3 diagonals”) is observed in this portfolio. This data however is interesting because the information on lawyer involved is available, which can be useful to illustrate early-warning applications of claim watching.
8.1. Prediction of Events Using the Frequency Model
In this section, we consider the prediction problem of event occurrences in the next year
and, for illustration, we present a frequency model for the lag
, thus considering for prediction only the claims of accident year
, i.e., the claims
. In our data
and
, therefore
. The observations in the calibration set are
. Let us suppose we want to make prediction of the following indicators at time
,
:
This choice produces the 4-dimensional response:
We work however with the variable:
which is a scalar with the 16 possible values
. These values correspond to 16 “states” of the response, as illustrated in
Table 5.
For the feature components of
, we choose the following variables:
All these variables are of 0-1 type; however, frequency features need not be of this kind. For example also the case reserve amounts and could be considered.
With this choice for the response variable and the feature components the prediction problem (
14) takes the form:
where the probability function
is estimated on
.
As already mentioned, we estimate the probability function under side constraint using the routine rpart implemented in R. The input data in is organized as a table (a data frame) where each row corresponds to a claim and in each column the value of the response and of all the feature components observed at different historical dates is reported.
The following
R command is used for the calibration, see
Therneau et al. (
2015) for details
3:
where
dt_freq1 is the calibration set
, and the variables are relabeled as follows:
and:
The rationale of this labelling is that variables with subscript _h, , are observed at time i.e., have historical depth . Therefore for variables with _1 have and variables with _0 have .
With the previous command a large binary tree,
freqtree1, was grown by
rpart. In a second step
freqtree1 has been pruned using 10-fold cross-validation and applying the one-standard-error rule. The resulting pruned tree is reported in
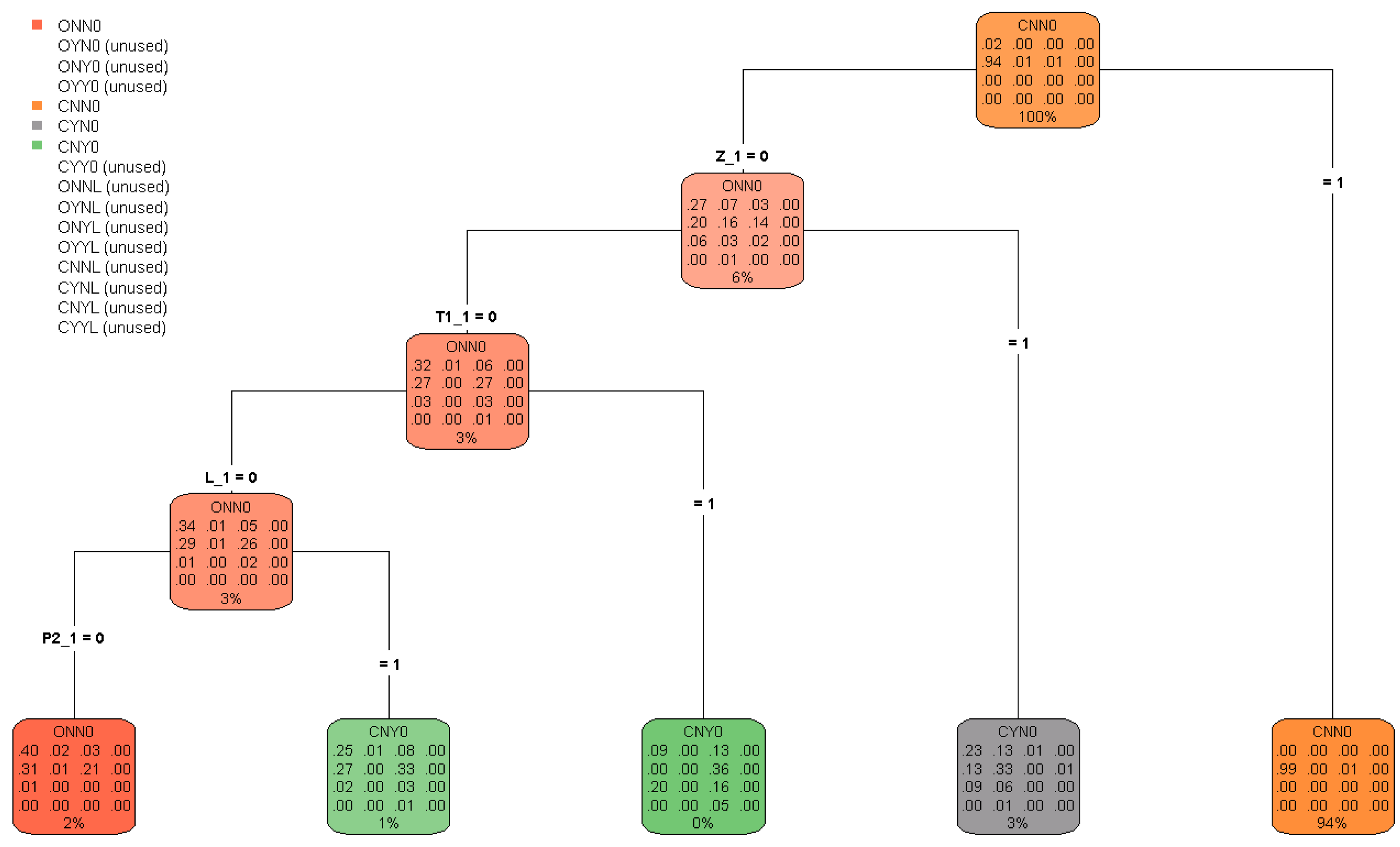
Figure 1, which is obtained by the package
rpart.plot.
The tree has
leaves. In the “palette” associated with each node of the tree the corresponding frequency distribution of the response variable
W observed in the calibration set
is reported. Therefore the palettes associated with the leaves provide the probability estimates
associated with the regions
, of the optimal partition
, as shown by expression (
15). Frequencies in the palettes are expressed in percent and are rounded to the nearest whole number. The
rpart numerical output provides more precise figures.
To illustrate
Figure 1 we order the leaves in sequence from left to right, so that the
r-th leaf from the left corresponds to the region
of
. Let us consider, for example, the claims in the fifth leaf
, which have
. These are the claims in the calibration set that were closed at time 4 and 5 (then with
); these claims are the
of all claims in the calibration set. Since, under model assumptions, the observed frequencies provide the estimate of the corresponding probabilities at the current time
I for event occurrences at time
, one can observe that for claims closed at time
I there is (about) a
probability that they will be closed without payments at time
, while there is (about) a
probability that they will reopened with a payment. Leaf 4 in the tree contains the claims with
and
. These are the claims in the calibration set (
of the total) which were open with a type-1 reserve placed on at time 4 and 5, i.e.,
. From the frequency table reported in the palette, we conclude that for the claims open with type-1 reserve at time
I the most probable state at time
(
probability) is
CYN0, i.e., the state with a type-1 payment and claim closing (
). In leaf 3 we find the claims in the calibration set which at time 4 and 5 were open without type-1 reserve and with a lawyer involved, i.e.,
. These claims are
of the total. From the frequency table we conclude that for claims that at time
I have the same feature the most probable state at time
(
probability) is
CNY0, i.e., the state with a type-2 payment and claim closing (
). In the fourth binary split, which produces the first two leaves in the tree, the splitting criterion is the existence of a type-2 payment (indicator
P2_1) for claims which at time 4 and 5 were open without type-1 reserve and without a lawyer. From the frequency tables in the second and the first leaf (referring to about
and
of the claims of the calibration set, respectively), one finds that if at time
I the claim has a type-2 payment, the most probable state at time
(
) is
CNY0; otherwise the most probable state (
) is
ONN0, i.e., it remains open without payments and without involving a lawyer.
It is interesting to note that although we included in the model also explanatory variables observed with historical depth (i.e., feature variables with subscript _0), none of these variables has been considered useful for prediction by the algorithm (after pruning). Only explanatory variables with (subscript _1) has been used for the splits in the pruned tree.
8.2. Possible Use for Early Warnings
For a given claim with
let us consider questions as those of type (b) presented in
Section 2 (with
). Formally, for a given claim
in
let us consider the event
, with indicator
. This corresponds to the events
hence:
This probability is different in different leaves of the classification tree, then we write:
If denotes the number of claims belonging to leaf r, the expected number of claims with lag 1 that will involve a lawyer in the next year is given by .
The values of
and
are reported in
Table 6, where the leaves are ordered by decreasing value of the probability
. It results that the expected number is
. Since
, only
of the claims in
is expected to involve a lawyer in one year. This data could also be useful for providing information to an early-warning system. For example, a list could be provided of the first 323 claims in the table, i.e., the claims in
for which
.
In
Section 11.2 we will present a backtesting exercise for this kind of predictions.
8.3. Prediction of Claim Payments Using the Conditional Severity Model
Once the optimal classification tree in
Figure 1 has been obtained for the frequency, for each leaf in this tree two regression functions must be calibrated for the severity, one for type-1 and one for type-2 payments. For the sake of brevity, we illustrate two cases:
The estimate of a type-1 (i.e., NoCARD) payment for open claims with type-1 reserve placed on, for which we consider the claims in leaf 4 in the frequency tree in
Figure 1.
The estimate of a type-2 (i.e., CARD) payment for open claims without type-1 reserve placed on and with lawyer involved, for which we consider the claims in leaf 3 in
Figure 1.
Case 1. As pointed out in
Section 7.3, since the severity model is a conditional model, for the calibration of the regression function
only the claims for which a type-1 payment is made at the response date are considered. Hence the calibration set for this regression estimate is the subset of claims in leaf 4 of the frequency tree for which a type-1 payment was observed in the response. It results in this calibration set consisting of 2564 claims. For the calibration of this regression tree the following
R command is used:
where
dt_sev4 is the calibration set and the relabeling is used:
As for the frequency case, after the large binary tree
sevtree4 was grown by
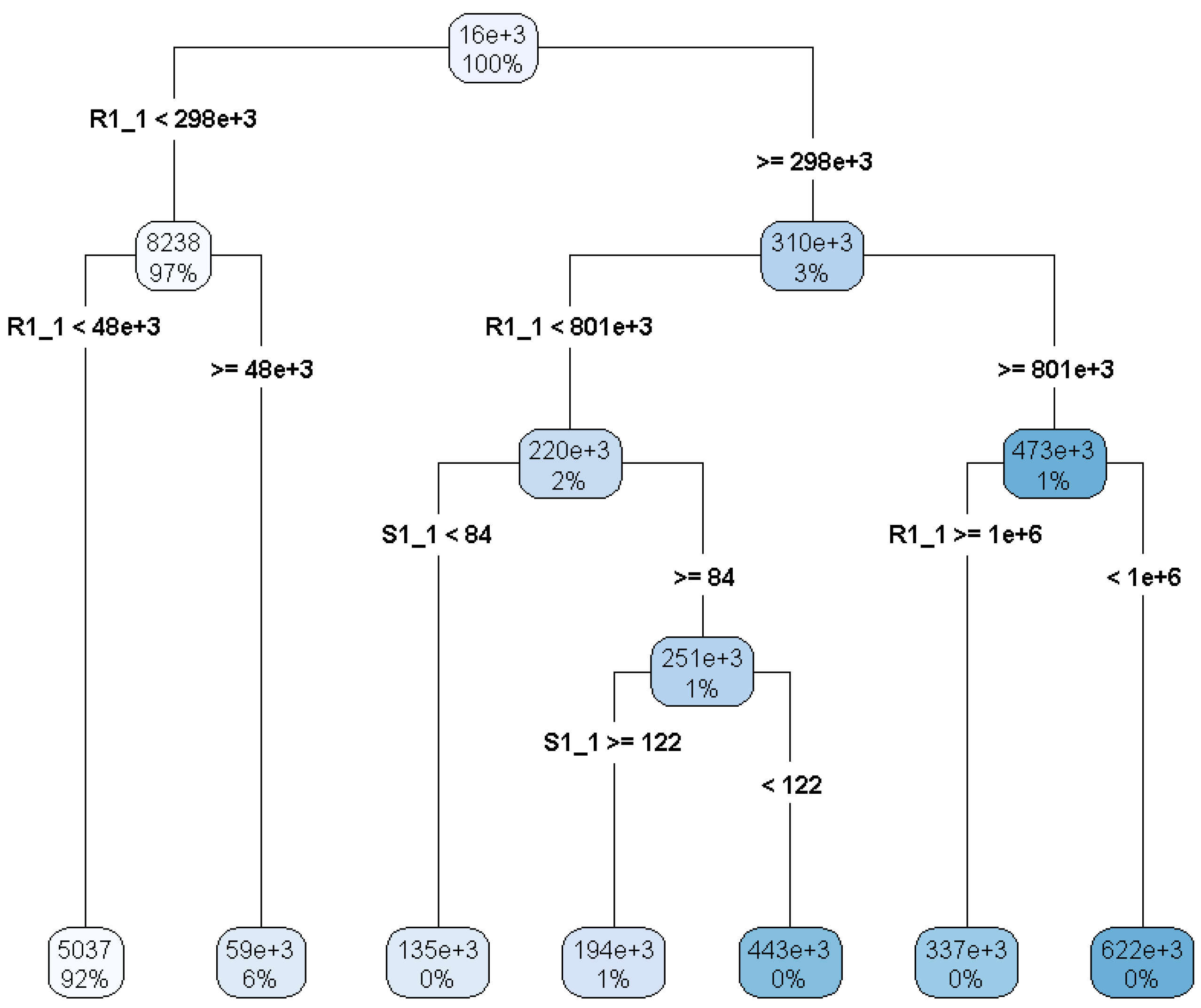
rpart, this was pruned using 10-fold cross-validation and applying the one-standard-error rule. The pruned tree thus obtained is illustrated in
Figure 2, provided by
rpart.plot.
The feature variable and its critical value used for the binary split are indicated on each node. On the palette attached to the node the empirical mean of payments and the percentage number of observations is reported. The partition provided by the pruned tree consists of 7 leaves. Under model assumptions, the average payment reported in the palette provides the expected value at time of the type-1 payment at time .
Case 2. In this case, the calibration set for the severity tree is the subset of claims in leaf 3 of the frequency tree for which a type-2 payment was observed in the response. This calibration set consists of 281 claims. The
R command used for this regression tree is similar to that for Case 1. The tree pruned with the usual method is reported in
Figure 3.
The partition provided by this tree consists now of 3 leaves. The average payment reported in the palette of each leaf provides the expected value at time 6 of the type-2 payment at time 7 for these claims.
Part II. Multiperiod Predictions and Backtesting
9. Multiperiod Predictions
9.1. The Shift-Forward Procedure and the Self-Sustaining Property
The basic idea underlying the extension of a one-period prediction to a multiperiod prediction in the frequency model can be illustrated as follows. At time
, let us consider the claims referring to two contiguous prediction sets
with
, that is the claims classes:
For these two classes the corresponding one-year prediction problem in the frequency model is given by:
Assume that the prediction functions of the two problems have been calibrated on the sets
and
, respectively, with the resulting estimates for time
:
Our aim is to derive an estimate of the two-year response for the claims in class , i.e., with accident year .
Assume that the feature and the response for claims in class
are specified so that:
i.e., the estimated response variable for claims in class
contains an estimate of the next year dynamic component of the feature
of these claims, see expression (
10). Following
D’Agostino et al. (
2018) a property such as (
17) is referred to as
self-sustaining property. Then we can estimate the response at time
as:
where
is the one-year updated feature of
. In this procedure the two-year response estimate for claims in class
(whose one-year response has been estimated using the
prediction function) is obtained by the
prediction function, which has been estimated for claims in class
but is now applied to the claim feature updated using
.
The previous shift-forward procedure applied for all lags
provides all the two-year predictions, i.e., the entire “second new diagonal” of estimates in the “data triangle”, provided that property (
17) holds for each lag.
As an example, let us consider in
Table 7 the time
I estimates for claims of accident year
(class
) and of accident year
(class
), with corresponding lags
and
. We have the problems:
which, after calibration at time 6 on
and
, respectively, provide the estimates for time 7:
We want to derive an estimate of the two-year response for the claims with accident year 6.
If
, i.e., if the one-year response variable for claims of accident year 6 includes an estimate of the next-year updating component of the features
, then we can estimate the response at time 8 as:
where
. This shift-forward procedure allowed by the self-sustaining property is represented in
Table 7 by the first red arrow on the bottom. The same procedure applied for all lags
provides the entire “second new diagonal” of estimates i.e., the cells in light blue color in
Table 7.
To derive the third new diagonal of estimates, i.e., the three-year predictions for lags
, we can repeat the previous procedure, provided that the self-sustaining properties hold:
In the example of
Table 7 the second shift-forward procedure providing the lowest element of the second new diagonal (darker blue cells) is represented by a blue arrow.
In general, for the
h-th new diagonal, the required properties are:
It should be noted that in all these multiyear prediction procedures only the calibrations for lags made at time I are used.
9.2. Illustration in Terms of Partitions
The multiperiod prediction can be also illustrated in terms of partitions of
. We refer here to the one-dimensional formulation of the frequency response. Following
D’Agostino et al. (
2018), in terms of the partition elements provided by the classification trees, the self-sustaining property requires that:
For , the response and the features , are such that for and it is always possible to calculate the function defined as: That is for all the features and the response are specified so that any element of the partition is mapped by into a unique element of the partition . In principle, this could lead to formulate the multiyear prediction in terms of transition probabilities , i.e., the probability of transitioning from one state u of the response to one state w of the response .
9.3. Illustration in Terms of Conditional Expectations
As in
Wüthrich (
2016) the multiperiod prediction can also be expressed in terms of conditional expectations. For the two-year prediction we have:
where in the last equality we replaced the probabilities
with their
-measurable expectations provided by the CART calibration.
10. The Simulation Approach
The analytical calculations involved in both the transition matrix approach and the conditional expectation approach can be very burdensome from a computational point of view. The computational cost depends on the number of dynamic variables to be modeled. For example, with 4 dynamic variables and the number of possible states of the response W for a claim of accident year I is given by is . To avoid these difficulties, we take a simulation approach for multiperiod forecasting.
10.1. A Typical Multiperiod Prediction Problem
To illustrate this approach, we consider one of the most important multiperiod prediction problems, which is the basis for individual claims reserving. In the outstanding portfolio, let us consider a specified claim
occurred in accident year
i and reported with delay
j. The claims portfolio has been observed up to the current date
I and we want to predict on this date the total cost (of type 1 and type 2) in the next
years. Let us define the cumulated costs:
where, obviously,
. We can say that
and
provide the cumulated cost development path, of type 1 and type 2 respectively, of the claim in the future, i.e., on the dates
. We want to predict these paths, i.e., we want to derive, using prediction trees, the estimates:
In our data we have not observations to make predictions beyond the date
, i.e., for
. If one assumes that the claims are finalized at this date, then we can take the expected cumulated cost at time
as an estimate of the individual reserve estimate, i.e.:
where
and
denote the type-1 and type-2, respectively, reserve estimate at time
I of the claim
. The total reserve is obviously obtained as
.
It is worth noting that if the case reserves are dynamically modeled, one could also obtain the estimates:
If these estimates are different from zero the assumption of claims finalization at time
can be relaxed and the final case reserve estimates
and
can be used as type-1 and type-2, respectively,
tail reserve estimates. In this case, one obtains comprehensive reserve estimates by adding the tail reserves in (
19) to the estimates in (
18).
10.2. Simulation of Sample Paths and Reserve Estimates
In the simulation approach the expected cumulated costs of the claim , and as a byproduct the reserve estimates, are obtained by simulating a number N of possible paths of the cost development and then computing the average path, which is obtained as the sample mean of the costs on each date of the paths. We give some details of this procedure. It is convenient to skip again to the “by lag” language in this exposition.
Let us suppose, as usual, that at time I the historical observations on the claims portfolio are sufficient for calibrating the classification tree for the frequency and the regression trees for the conditional severity (of type 1 and 2) for all lags . Therefore, at time I all the optimal frequency partitions of the feature space and the optimal severity partitions corresponding to each leaf of have been derived for .
Let be a given claim in the portfolio, with at time I frequency feature and severity feature , with . The simulation procedure for the development cost of this claim is based on the following steps.
- 0.
- 1.
Find the index r of the leaf of to which the feature belongs.
- 2.
Simulate the state w of the frequency response at time using the probability distribution corresponding to the r-th leaf of .
- 3.
If w implies:
- a.
a type-1 payment (i.e., a NoCARD payment) at time , then assume as the expected paid amount at time the estimate corresponding to the leaf of to which the feature belongs.
- b.
a type-2 payment (i.e., a CARD payment) at time , then assume as the expected paid amount at time the estimate corresponding to the leaf of to which the feature belongs.
- c.
no payments at time , then all payments at time are set to 0.
- 4.
- 5.
If then:
- 5.1.
The features and are updated with the new information provided by the responses , and , and the new features and are then obtained (this requires that the self-sustaining property holds).
- 5.2.
Set and return to step 1.
With this procedure the two sample paths:
of the type-1 and type-2 cumulated cost are simulated for the chosen claim
with lag
. A simulation set of appropriate size is obtained with
N independent iterations
of this procedure. The cost estimates are then obtained as the costs on the average path, i.e.,:
On the terminal date, i.e., for
, these sample averages provide the reserve estimates
and
in (
18).
Once the CART approach has been extended to multiperiod predictions via simulation, it is convenient to make a further extension of the model to allow a joint dynamic modeling of the case reserves. Indeed, as anticipated in
Section 5, to make the best use of the case reserve information in multiperiod predictions also the changes in the case reserve itself must be predicted by a specific model.
10.3. Including Dynamic Modeling of the Case Reserve
To dynamically model the case reserves, we extend the model assumptions in
Section 4.2. Also, for the case reserve the conditional model is preferred, for the usual reason of a discrete probability mass typically present in 0 in the reserve distributions. Our additional assumptions are described as follows.
Assumption (HR4’) is not required if there is only one type of payment, since if we have, say, only type-1 payments, then .
We can consider additional conditioning in expression (
20) and/or (
21) in order to better modeling particular effects. For example, one could condition on the state of the indicator
at the previous date in order to distinguish predictions concerning open claims and reopened claims. All these enhancements of the model have been applied in the following examples.
10.4. Example of Simulated Cost Development Paths
Using the simulation procedure illustrated in
Section 10.2 and the additional assumptions presented in the previous section we can provide examples of multiperiod predictions including the joint dynamic modeling of case reserves. We provide here an example of cost development path simulation for an individual claim, using the data on the same claims portfolio of examples in
Section 8. Before considering a specific claim, we derived all the frequency and the severity partitions for all lags
by calibrating prediction trees on the entire claims portfolio. The run time of all these calibrations is roughly 3 min on a workstation with one 8-core Intel processor@3.60 GHz (4.30 GHz max turbo) and 32 GB RAM. We then considered an individual claim with the following characteristics:
- ·
accident year: ;
- ·
reporting delay: , hence we denote the claim as ;
- ·
the claim is open at time I: ;
- ·
the claim does not involve a lawyer at time I: ;
- ·
no type-1 (NoCARD) payment made at time I: ;
- ·
no type-2 (CARD) payment made at time I: ;
- ·
type-1 reserve at time I: euros;
- ·
type-2 reserve at time I: euros.
Since
we start with
in the simulation procedure, which provides the maximum length sample paths
and
. In each simulation an execution of the
predict.rpart function was invoked for each lag. The computation time required for simulating all sample paths (for the type-1 and type-2 cost) is roughly 4 min. In
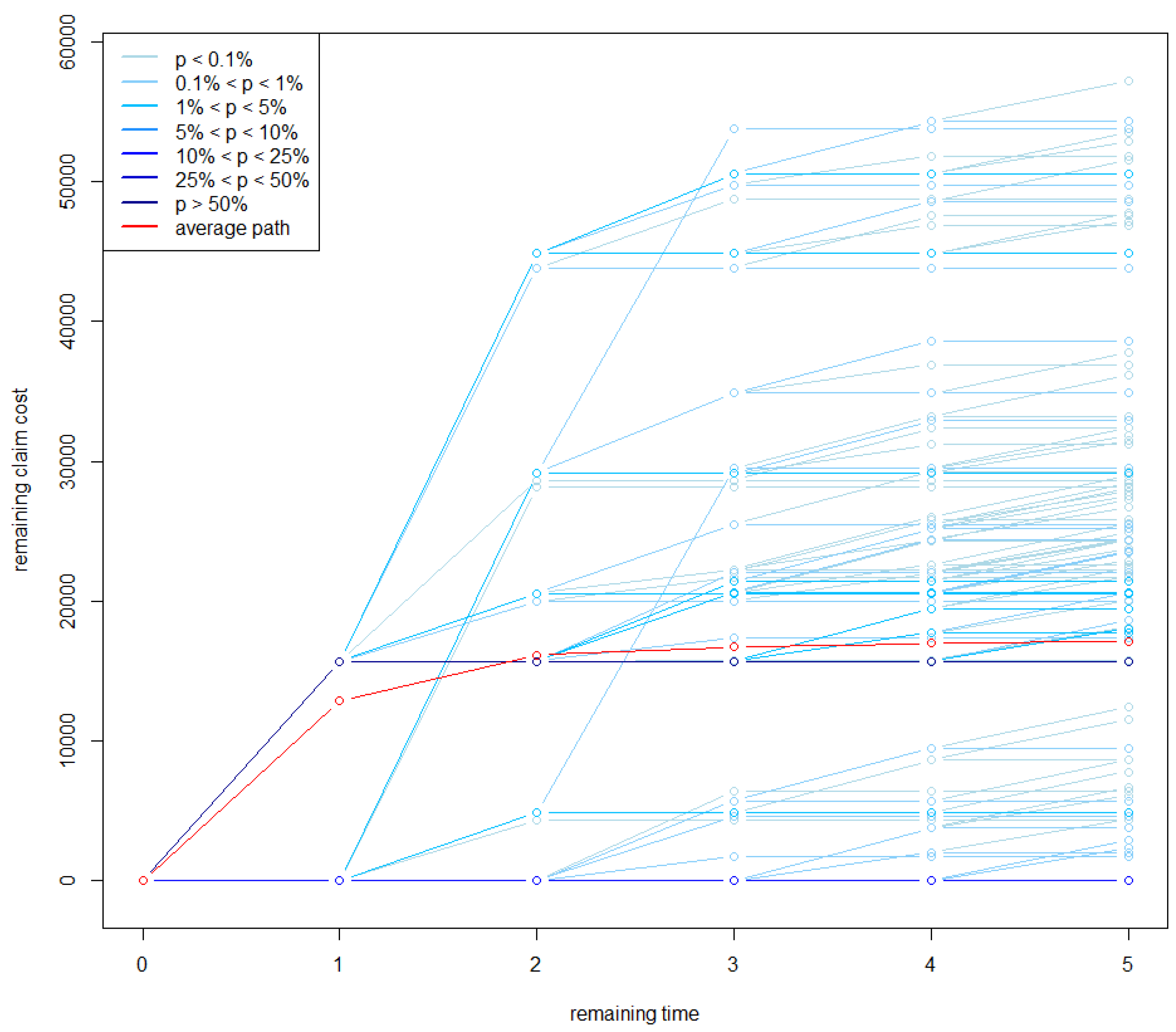
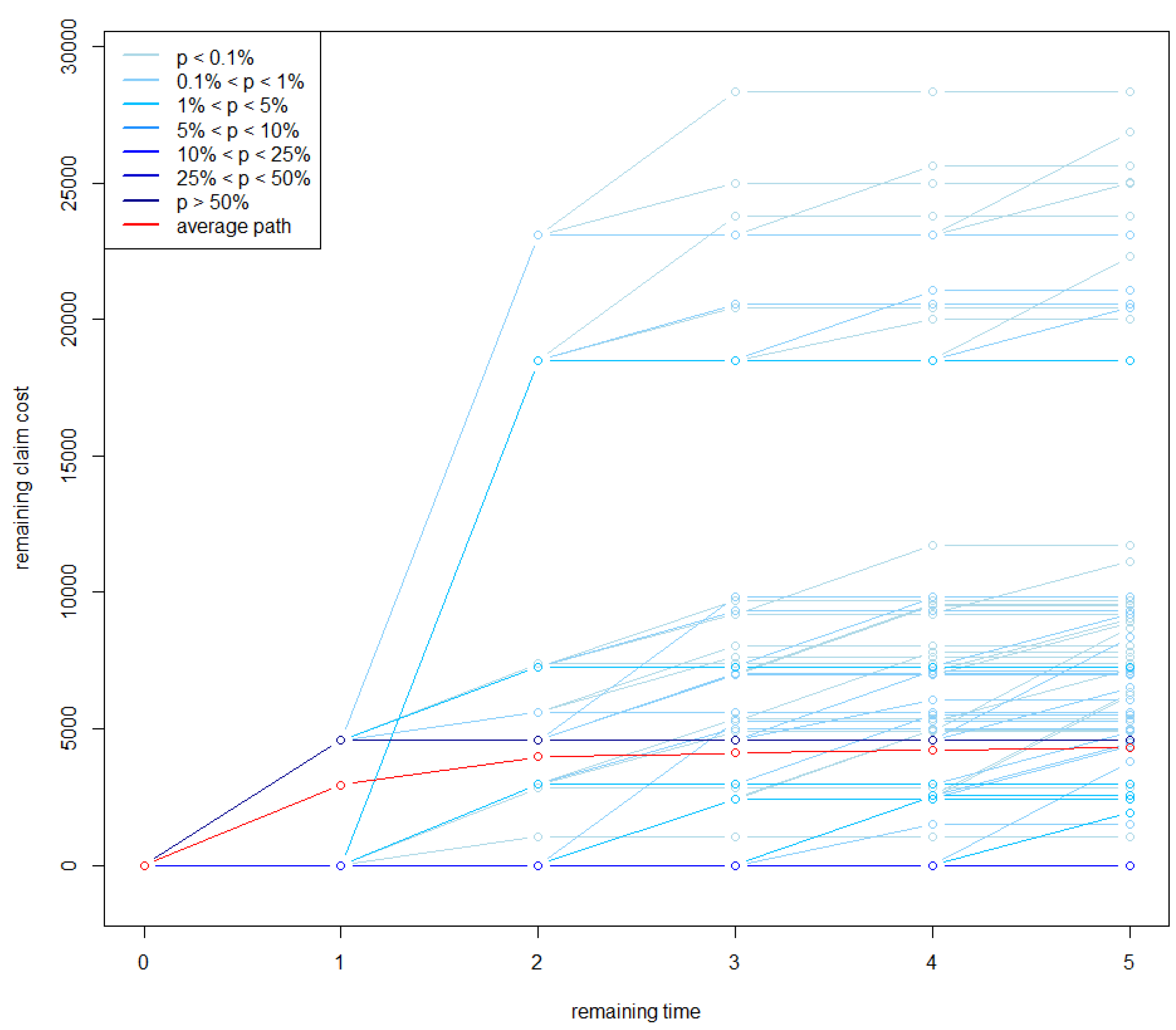
Figure 4 and
Figure 5 simulated sample paths for the type-1 and type-2 cumulated cost, respectively, of
are reported. Since many paths overlap, the simulated paths are shown in blue with the color depth being proportional to the number of overlaps. The average paths in the two figures are shown in red: their final point corresponds to
euros and
euros. If we assume that the claims are finalized at time 11, i.e., after
years for this claim, then these amounts can be taken as an estimate of the individual claim reserves
and
to be placed at the current date on
. This suggests significant decreases in both the outstanding case reserves, namely a decrease of
euros for
and a decrease of 7406 euros for
.
It is interesting to note that with this dynamic approach we also have an estimate of the tail reserves and which are obtained as the average of the 5000 simulated values of and . These estimates result in being euros and euros, which should be added to the corresponding expected cumulated costs, thus giving euros and euros.
The variation coefficient in the simulated sample is for type-1 reserve and for type-2 reserve. The relative standard error of the mean is and , respectively.
Whether the reserve adjustments indicated by the model are actually done could depend on a specific decision. However, these findings should suggest putting the claim under scrutiny.
11. Testing Predictive Performance of CART Approach
In this section, we propose some backtesting exercises in order to get some insight into the predictive performance of our CART approach. We first illustrate backtesting results for predictions of one-year event occurrences useful for claim watching. Multiperiod occurrence predictions could be similarly tested. Finally, we perform a typical claim reserving exercise, which is composed of two steps. In a first step the individual reserve estimate is derived by simulation for all the claims in the portfolio and the resulting total reserve (after the addition of an IBNYR reserve estimate) is compared with the classical chain-ladder reserve, which is estimated on aggregate payments at portfolio level. We perform these estimates on data deprived of the last calendar year observations. Then in a second step we can assess the predictive performance of the CART approach with respect to the chain-ladder approach by comparing the realized aggregate payments in the “first next diagonal” with those predicted by the two methods.
11.1. The Data
In these predictive efficiency tests, we need to calibrate the CART models assuming time as the current date, since observations at time I are used to measure the forecast error. For this reason, data on claims portfolio used in the previous section has not sufficient historical depth. We then use in this section a different dataset containing a smaller variety of claim features (in particular, the variables are not present) but a longer observed claims history. We have:
- ·
Observed accident years: from 2007 to 2016. Then .
- ·
All claims reported are observed, hence for accident year i one has (i.e., ).
Then there are 55 blocks
in the original dataset. The total number of reported claims is 1,337,329. However, since we use claims observed in year 2016 (i.e., responses with
) for testing predictions, we assume
as the current date and we drop from the original dataset all claims with
and all observations with
. This reduces the data for the calibration to 9 observed accident years (45
blocks). In this data the pairs feature-response are observed for lags
. The total number of reported claims in this portfolio observed at time
is
. The number of observations in the calibration set and the prediction set of each lag is reported in
Table 8.
11.2. Prediction of One-Year Event Occurrences
We test the predictive efficiency of some one-year event predictions considering the indicators of type-1 payment, type-2 payment and closure for lag , i.e., we consider the predicted responses for , i.e., for all the claims in block . These response estimates were provided by the classification tree for the frequency calibrated on ( observations). Since these responses are actually observed at time 10, we can assess the predictive performance of the model by comparing predicted and realized values. To this aim, we refer to a specific forecasting exercise.
For a given indicator, let us denote as
positive, or
negative, a claim in the sample
for which the indicator will be 1, or 0, respectively. Our forecasting exercise consists of predicting not only how many claims in the sample will be positive, but also which of them will be positive. i.e., we want to provide the claim code
cc of the
claims in the sample we predict as positive, where
is the number of claims we expect to be positive. Our prediction strategy is very intuitive. Let
, the
r-th leaf of the partition
provided by the calibrated frequency tree. Using notations introduced in
Section 8.2, we denote by
the number of claims belonging to
and by
the probability to be positive for each of these claims. We assume that the leaves are ordered by decreasing value of
and define
, where
. Our forecasting strategy consists then in predicting as positive all the
claims in the first
leaves and, in addition,
claims which are randomly chosen among those in leaf
.
The accuracy of our prediction could be measured by introducing an appropriate gain/loss function giving a specified (positive) score to claims correctly classified and a specified (negative) score to claims incorrectly classified. The choice of such a function, however, depends on the specific use one makes of the prediction, then in order to illustrate the results we prefer to resort here to the so-called
confusion matrices, which we present in
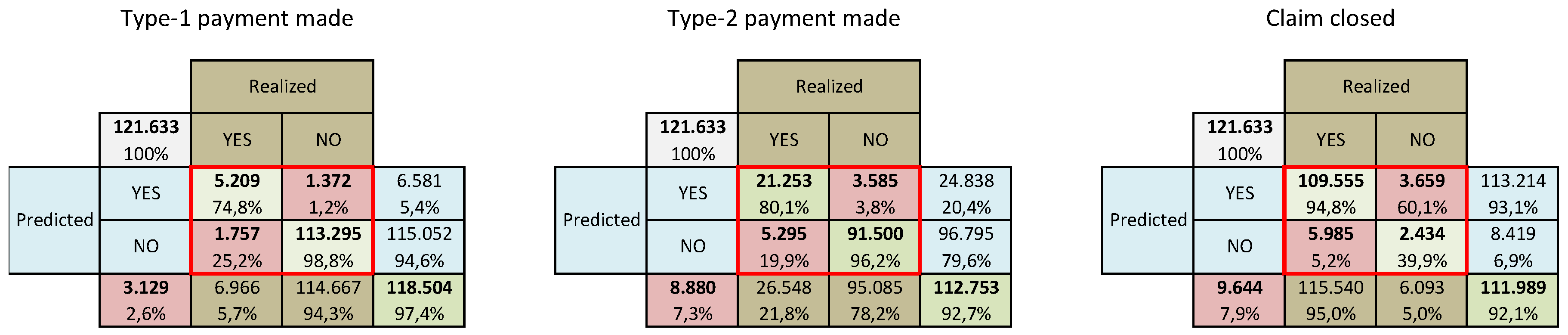
Figure 6. In these matrices blue (brown) cells refer to predicted (realized) values, green (red) cells refer to claims correctly (incorrectly) classified.
Let us consider, for example, the first matrix, concerning the indicator , i.e., {A type-1 payment is made in the next year}. We observe that 6581 claims of the in the prediction set, i.e., the , were predicted by the model to have a type-1 payment, while type-1 payments actually realized were 6966 (). Of the 6581 claims predicted as positive, 5209 resulted in being true positive (TP, green cell) and the remaining 1372 were false positive (FP, red cell). Considering the claims predicted to have not a type-1 payment, i.e., to be negative, 1757 resulted in being false negative (FN, red cell) and the remaining were true negative (TN, green cell). Then, globally, claims were correctly predicted ( of all the predicted claims) and the remaining 6966 were incorrectly predicted. Ratios typically used are also reported, as:
- ·
True positive ratio, also known as sensitivity: TPR = TP/(TP+FN);
- ·
True negative ratio, or specificity: TNR = TN/(TN+FP);
- ·
False negative ratio: FNR TPR;
- ·
False positive ratio: FPR TNR.
The other two matrices have the same structure.
11.3. Prediction of Aggregate Claims Costs
11.3.1. Aggregate RBNS Reserve as Sum of Individual Reserves
We performed the CART calibration for the frequency-severity model extended with the dynamic case reserve model for all the 8 lags in the time-9 dataset. Given the large number of claims in this portfolio these calibrations required 73 min for computations. After the model calibration, for each of the 1,211,392 claims reported at time 9 we simulated
cost development paths for the type-1 and type-2 payments using the procedure illustrated in
Section 10 and we computed the corresponding average paths. In each simulation and for each lag the
predict.rpart function can be invoked only one time for all claims with the same lag. With respect to the simulation of a single claim, this provides, proportionally, a substantial reduction of computation time. The run time for all the simulations was roughly 120 min.
By computing the incremental payments of each average path and summing over the entire portfolio we obtained a CART reserve estimate for the reported but not settled (RBNS) claims. If these total payments are organized by accident year (on the rows) and payment date (on the column) we obtain a “lower triangle” of estimated future payments with the same structure of the usual lower triangles in classical claims reserving.
By the simulation procedure the individual reserve estimates are provided:
Assuming claims finalization at time
, one obtains from these cost estimates the corresponding RBNS reserves, at different levels of aggregation:
The simulation procedure also provides the individual tail reserve estimates:
which can be aggregated as:
These estimates can be added to the corresponding estimates in (
22) in order to provide an adjustment of the reserves computed under the assumption of finalization at time
.
As usual, the aggregate claim cost estimates can be organized by accident year and by
development year (
dy), indexed as
, where in the CART model “development year” is a new wording for the “lag”
. With this representation we obtain the “lower triangle” for the total costs (type 1 + type 2) reported in
Table 9 in green color.
Figures in the aggregate “upper triangle” (pink color) are not reported in order to point out that this kind of data were not used for the prediction. Total estimated costs summed by diagonal (highlighted by different green intensity) as well as summed by accident year (second last column) are also reported. For confidentiality reasons all paid amounts in this numerical example were rescaled so as to obtain a total reserve euros. For each accident year reserve estimate and for the total estimate the coefficient of variation on the simulated sample was computed. These figures, reported in the last column of the table, are rather low. This should be explained by the fact that each aggregate reserve simulation is the sum of a very large number of individual claim costs and the correlation among these individual costs is very low. Obviously, this weak correlation is also a consequence of the independence assumptions in the model.
11.3.2. Inclusion of the IBNYR Reserve Estimate
We are interested in comparing the CART reserve estimates with the classical chain-ladder reserve estimates. To allow this comparison a cost estimate for IBNYR claims must be added to the aggregate RBNS reserve derived in the previous section. Therefore, we complemented the RBNS reserve model with an ancillary model for the IBNYR reserve, which is outlined in
Appendix A. This model is a “severity extension” of the “frequency approach” proposed in
Wüthrich (
2016) for estimating the expected number of IBNYR claims. The results of the ancillary model estimates are summarized (after rescaling) in the second last row of
Table 9, where the IBNYR reserves, by diagonal and overall, are reported. Figures in the last row provide the corresponding RBNS claim reserves adjusted for IBNYR claims.
Remark 5. This separation between RBNS and IBNYR claims is in some respect similar to that obtained in Verral et al. (2010). 11.3.3. Comparison with Chain-Ladder Estimates
In the chain-ladder approach to classical claims reserving the sums of all the individual claim payments in the portfolio observed up to time
I are organized by accident year and development year and an upper triangle of observed paid losses, cumulated along development in each accident year, is obtained. The reserve estimates are then derived by the cumulated paid losses in the lower triangle, which is obtained by applying to the upper triangle the well-known chain-ladder algorithm. This is shown in
Table 10 where, to allow comparison with
Table 9, incremental payments are reported.
As in
Table 9 the upper triangle is highlighted in pink and the lower triangle in green, and the chain-ladder reserves at different aggregation levels—by diagonal, by accident year, overall—are computed. In the last two rows of the table the differences with the CART estimates in the last row of
Table 9 are shown. In some diagonals, i.e., in some future calendar years, there are substantial differences between the chain-ladder and the CART claims cost predictions. However, the overall chain-ladder reserve estimate is
higher than the corresponding CART estimate. When the results provided by the two methods are compared, one should take into account that the chain-ladder estimates do include an underwriting year inflation forecast, since an estimate of historical underwriting year inflation is implicitly projected on future dates by the algorithm. In the CART approach, instead, some degree of expected inflation might be implicitly included in the predicted costs only through the case reserves. An additional component of expected inflation must however be added to the reserve estimates. A similar problem is found in DCL model, see
Martínez-Miranda et al. (
2013) for an estimation method of the underwriting year inflation based on incurred data.
11.3.4. Backtesting the Two Methods on the Next Diagonal
Since we deliberately made the reserve estimates for a claims portfolio observed at time 10 (i.e., 2016) using only data observed up to time 9 (2015), we are now able to perform a backtest on the “first next diagonal” since next-year realized payments (of both type 1 and type 2) are actually known. In
Table 11 the realized payments and the prediction errors (i.e.,
realized − predicted) of the two methods are reported for accident years
.
The backtest exercise shows important errors in some accident years for both the methods. The overall predictions, however, are rather good for the two methods, showing an under-estimate of by chain-ladder and by CARTs. Considering possible adjustments for the expected inflation of CART prediction, we can say that in this case the predictive accuracy of the two methods is roughly similar.
Remark 6. In this backtesting exercise the chain-ladder method has good predictive performance on the total reserve and is not easy to improve. A better assessment of the predictive efficiency of the CART approach in providing estimates of the aggregate reserve as sum of individual reserves could be obtained in cases where the chain-ladder approach poorly performs. For example, repeating the same exercise on different claims data (which for the moment are not authorized for disclosure), we observed on the total reserve estimate a forecast error of with the chain-ladder and with the CART approach.
12. Conclusions
The CART approach illustrated in this paper seems promising for claims reserving and, more generally, for the claim watching activity. The large model flexibility of CARTs allows inclusion in the model of effects in the claims development process, which are difficult to study with classical methods. CARTs are rather efficient also in variable selection. However, the role of expert opinions in the choice of the explanatory variables to be included in the model is still important. Also, in this respect the interpretability of the results provided by CARTs can be very helpful.
Prediction and claims handling methods provided by the CART approach can also have an impact on business organization, in so far as they suggest and promote a closer connection into the insurance firm between the actuarial and the claims settlement activity.
As usual, the reliability of the results depends crucially on the quality of data available. In the proposed CART applications, it is also true, however, that enlarging the richness of data can also extend the scope and the significance of the results. For example, if information at individual policy level is included in the dataset, our CART approach could also provide indications useful for non-life-insurance pricing.
As is well known, a main disadvantage of CARTs is that they are not very robust towards changes in the data, since a small change in the observations may lead to a largely different optimal tree. Also, the sensitivity of the optimal tree to changes of the calibration parameters should be carefully analyzed. Random forests are proposed as the natural answer to the instability problem; however, the interpretability of the results is an important property which should not be lost. Backtesting exercises as those presented in this paper could help to get the instability effects under control.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
