Persistence of Bank Credit Default Swap Spreads


Federal Reserve Board, 20th & C St., NW, Washington, DC 20551, USA
†
I thank the anonymous referees for valuable comments. I also thank Jeff Gould for research assistance and David Jenkins for editing assistance The analysis and conclusions set forth are those of the author and do not necessarily represent those of the Board of Governors or its staff.
Risks 2019, 7(3), 90; https://doi.org/10.3390/risks7030090
Submission received: 27 June 2019
/
Revised: 19 July 2019
/
Accepted: 29 July 2019
/
Published: 26 August 2019
Abstract
:Credit default swap (CDS) spreads measure the default risk of the reference entity and have been frequently used in recent empirical papers. To provide a rigorous econometrics foundation for empirical CDS analysis, this paper applies the augmented Dickey–Fuller, Phillips–Perron, Kwiatkowski–Phillips–Schmidt–Shin, and Ng–Perron tests to study the unit root property of CDS spreads, and it uses the Phillips–Ouliaris–Hansen tests to determine whether they are cointegrated. The empirical sample consists of daily CDS spreads of the six large U.S. banks from 2001 to 2018. The main findings are that it is log, not raw, CDS spreads that are unit root processes, and that log CDS spreads are cointegrated. These findings imply that, even though the risks of individual banks may deviate from each other in the short run, there is a long-run relation that ties them together. As these CDS spreads are an important input for financial systemic risk, there are at least two policy implications. First, in monitoring systemic risk, policymakers should focus on long-run trends rather than short-run fluctuations of CDS spreads. Second, in controlling systemic risk, policy measures that reduce the long-run risks of individual banks, such as stress testing and capital buffers, are helpful in mitigating overall systemic risk.
1. Introduction
Since their launch, credit default swaps (CDS) have been a frequent research topic. Researchers apply methods similar to those for other types of securities—such as stocks—to the empirical analysis of CDS spreads. Their purposes vary, including detecting the information content of these securities (Blanco et al. 2005), assessing the risks of individual firms or sovereign countries (Acharya et al. 2014), and finding the determinants of CDS spreads (Galil et al. 2014).
However, unlike stock prices, whose values come from the values of the underlying entities, CDS spread values are derived from the risks of the reference entities and are typically between 0 and 1. As stocks and CDS are intrinsically different concepts, we cannot assume they have the same dynamic properties.
In addition, CDS spreads for large banks are an important input for calculating financial systemic risk, as shown by Huang et al. (2009, 2012a, 2012b). Thus, the dynamics of CDS spreads can provide some insight into the dynamics of overall financial systemic risk.
Given the intrinsically different natures of stocks and CDS, as well as the importance of CDS in both empirical research and systemic risk analysis, a rigorous time-series analysis of CDS spreads is needed. Different time-series tests have been developed in the literature, and many papers have applied them to studying the time-series properties of various macroeconomic or financial data. For example, Kwiatkowski et al. (1992) studied the unit root property of 14 annual time series of U.S. macroeconomics and stock price data. Ng and Perron (2001) tested the unit root hypothesis for inflation data from the G-7 countries. Engle and Granger (1987) used cointegration tests to show that consumption and income as well as long- and short-term interest rates are cointegrated, while wages and prices as well as nominal GNP and the nominal money measures of M1 and M3 are not. However, up to now, no study has been devoted to analyzing the time-series properties of CDS spreads.
The goal of this paper is to fill such a gap in the literature by providing a rigorous time-series analysis of CDS spreads. Specifically, we apply the augmented Dickey–Fuller, Phillips–Perron, Kwiatkowski–Phillips–Schmidt–Shin, and Ng–Perron tests to study the unit root property of CDS spreads, and we use the Phillips–Ouliaris–Hansen tests to determine whether they are cointegrated. The empirical sample consists of daily CDS spreads of six large U.S. banks that have been designated as global systemically important financial institutions (G-SIFIs). The sample period is from 2001 to 2018. The main findings of this paper are that it is log, not raw, CDS spreads that are unit root processes, and that the log CDS spreads of large U.S. banks are cointegrated. These findings imply that, even though the risks of individual banks may deviate from each other in the short run, there is a long-run relation that ties them together.
2. Data
For any given firm, there are multiple CDS contracts being traded at the same time. The sample CDS data in this paper are from the most actively traded U.S. CDS contracts—five-year maturity, senior unsecured (SNRFOR) tier, ex-restructuring (XR) document clause, and U.S. dollar denomination. As the transaction prices for CDS contracts are proprietary information, we use the publicly available daily CDS quote data provided by Markit.
The sample reference entities consist of six large U.S. banks: Bank of America (BAC), Citigroup (C), Goldman Sachs (GS), J.P. Morgan Chase (JPM), Morgan Stanley (MS), and Wells Fargo (WFC). These banks are chosen for three reasons. First, they are the reference entities of the first traded corporate CDS contracts since the launch of CDS trading in the early 2000s. Thus, their CDS spread time series are among the longest available, which facilitates the unit root study. Second, since the beginning of CDS trading, the CDS contracts of these banks are almost always among the top 10 most-traded CDS contracts, which ensures that their spreads capture risk accurately. Third, these six banks are also among the earliest U.S. financial institutions that were designated as G-SIFIs by the Financial Stability Board. Thus, the joint study of these reference entities can provide useful insight into overall U.S. financial systemic risk.
Figure 1, which plots the daily log CDS spreads of these sample banks from 2001 or 2002 (depending on the bank) to 29 June 2018, suggests that the CDS spread time series may not be covariance stationary.
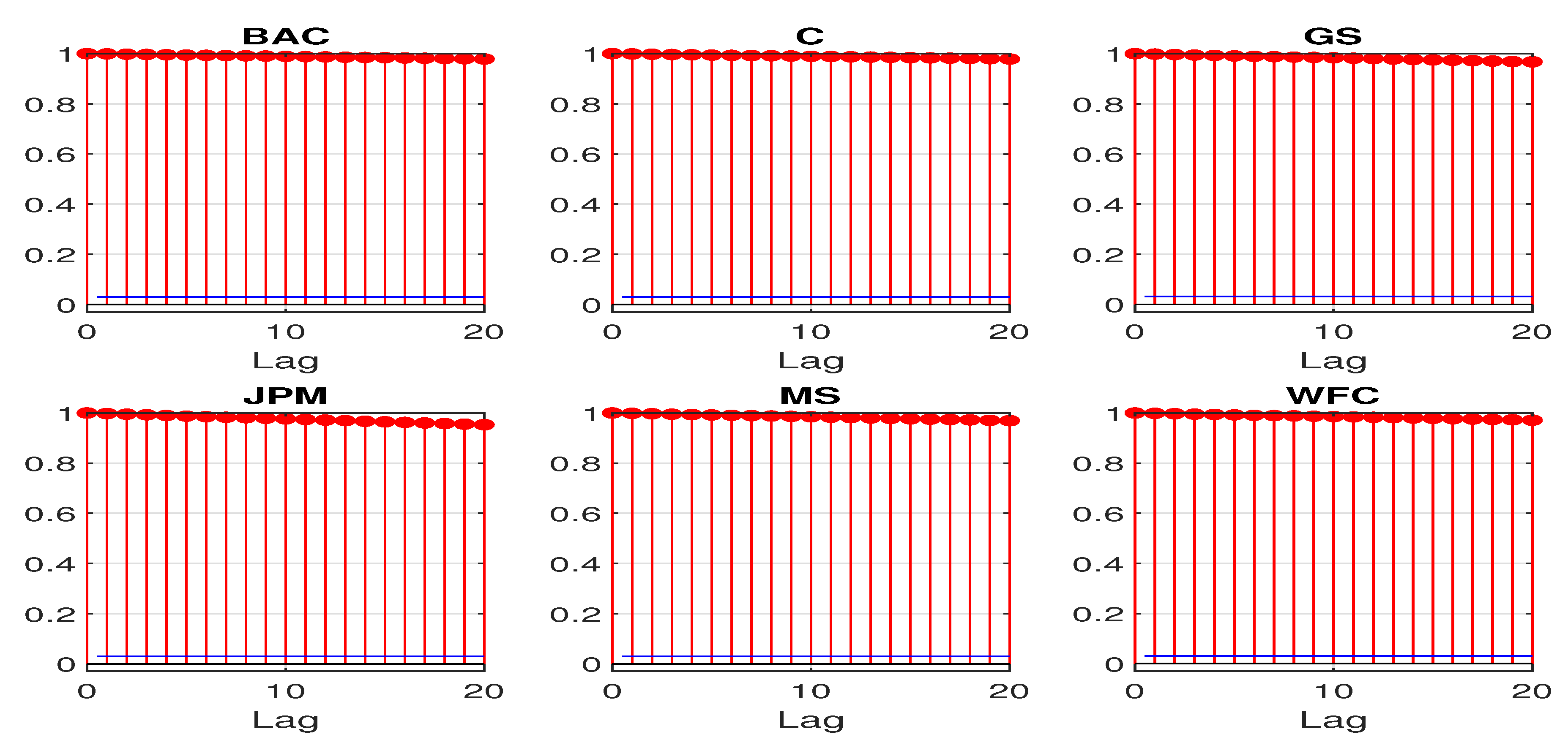
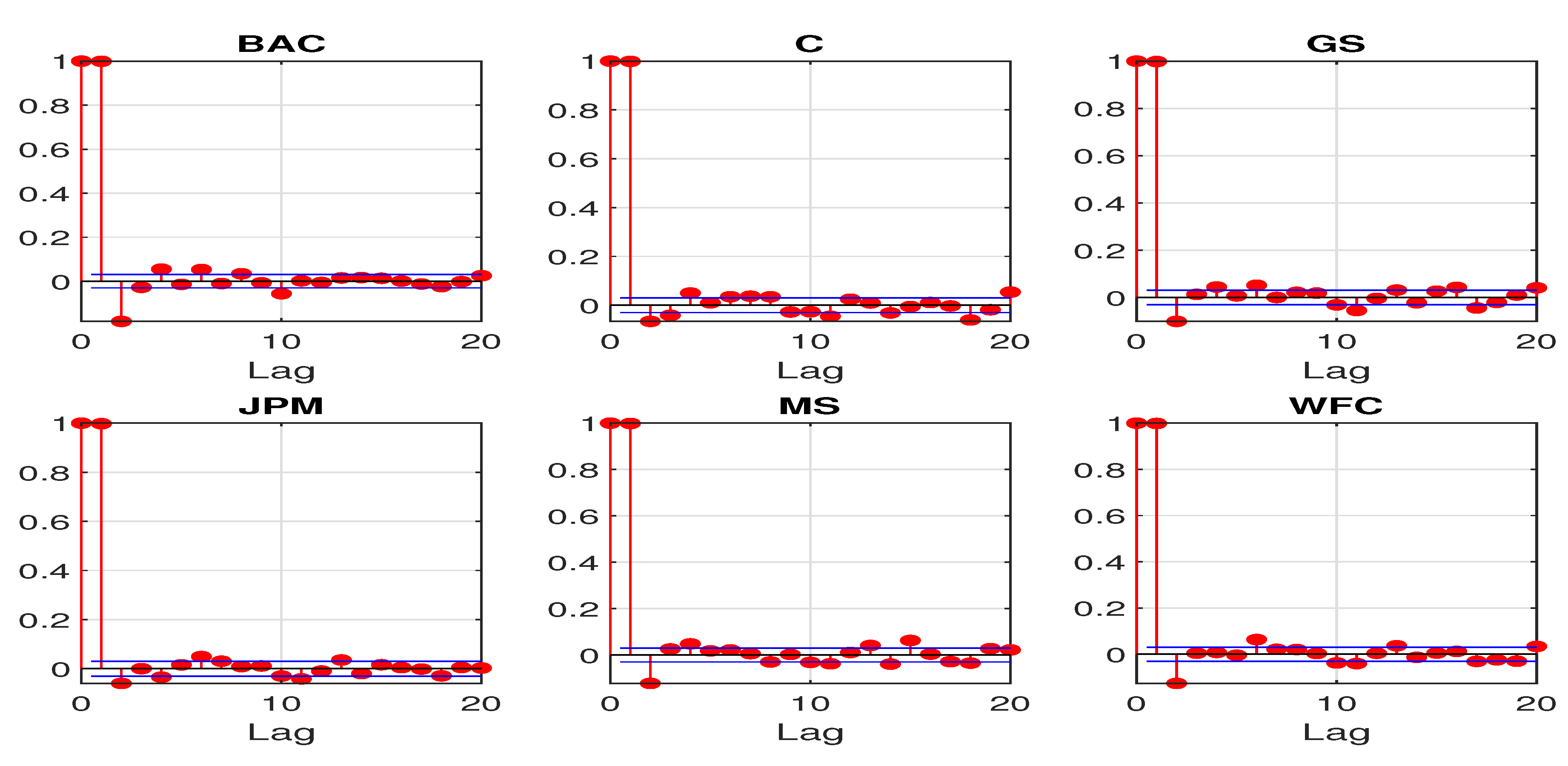
The nonstationary feature can be revealed by some basic sample statistics. Figure 2 and Figure 3 plot the first 20 sample autocorrelations and partial autocorrelations of the log CDS spreads. The sample autocorrelations for all the sample banks remain close to 1 even at lag 20. The sample partial autocorrelations at lag 1 are also almost 1 for all the sample banks. The above statistics all suggest a potential unit root for the daily log CDS spreads.
3. Covariance Stationary versus Unit Root
This section formally investigates whether the CDS spread time series have a unit root via four tests: the parametric Dickey–Fuller tests (Dickey and Fuller 1979), the nonparametric Phillips–Perron (PP) tests (Phillips 1987; Phillips and Perron 1988), the Kwiatkowski–Phillips–Schmidt–Shin (KPSS) test (Kwiatkowski et al. 1992), and the Ng–Perron tests (Ng and Perron 2001).
All of these tests depend on whether there is a time trend in the tested time series , where can be either raw or log CDS spreads. Figure 1 shows a small positive upward trend in our CDS data, likely due to the market’s underestimation of the credit risk before the financial crisis and the subsequent correction. Thus, a time trend is included in the regression
The null hypothesis of a unit root is , and the alternative hypothesis is .
To allow for potential serial correlations in of Equation (1), we first implement the augmented Dickey–Fuller (ADF) tests based on the following autoregressive (AR) regression:
where . The number of AR lags p is determined by starting with a large lag (for example, 30), performing a t test that , and, if it is not rejected, then successively performing an F test that until is rejected for some l. Then, the recommended number of AR lags is .
The ADF test statistics are computed as follows:
where , , and are the ordinary least squares (OLS) estimates of the corresponding population parameters. The simulated critical values of these tests for the sample sizes of 4000 and 5000 (as our empirical sample sizes are in this range) and 100,000 Monte Carlo repetitions are reported in the top of Table 1 in the “” and “t” rows.
The computed ADF and t values in the bottom of Table 1 for the log CDS spreads show that the null hypothesis of a unit root () cannot be rejected even at the 15% significance level for the six sample banks, while it is marginally rejected for Morgan Stanley at the 10% level by the ADF test.
The complete null hypothesis can be tested by a standard F test formula, but its asymptotic distribution is nonstandard. We report the simulated critical values in the “F” rows and the computed test statistics in the “F” columns in Table 1. The “F” test results show that the null hypothesis of a unit root for the log or raw CDS spreads cannot be rejected at the 10% significance level.
The PP tests are the nonparametric counterpart to the parametric ADF tests. Moreover, the PP tests directly account for the potential serial correlations in the residual , thus the AR regression takes the simple form of Equation (1). A summary of the PP test formulae is available in the work of Hamilton (1994) and reproduced in Appendix A.1. The truncation parameter is set at for the sample size T between 4000 and 5000.
The PP test results in Table 1 are very similar to, but sharper than, the ADF test results. The null hypothesis of a unit root for the log CDS spreads cannot be rejected even at the 15% significance level for the six sample banks. In contrast, for the raw CDS spreads, the null hypothesis is rejected at the 5% significance level for Goldman Sachs, J.P. Morgan Chase, and Wells Fargo, and at the 1% level for Morgan Stanley.
Kwiatkowski et al. (1992) noted that the above ADF and PP tests for the null hypothesis of a unit root may have low powers when is less than, but very close to, 1; thus, they suggested flipping the null and alternative hypotheses. As our ADF and PP tests do not reject the null of a unit root for log CDS spreads, we implement the KPSS test to confirm their unit root property. The KPSS test is essentially an upper-tail Lagrange Multiplier (LM) test. We follow the setup in (Kwiatkowski et al. 1992) that has a time trend and summarize the related formulae in Appendix A.2. The lag truncation parameter is set at .
As the asymptotic distribution for the KPSS test is nonstandard, we simulate LM critical values from its asymptotic distribution , where is the second-level Brownian bridge given by
where is a standard Brownian motion. In the numerical simulations, we approximate by partial sums of random variables with 4000 and 5000 steps for the corresponding sample sizes. The number of Monte Carlo repetitions is 100,000. Comparing the computed LM test values with the simulated critical values in Table 1, the null hypothesis of covariance stationarity is rejected for both the log and raw CDS spreads at the 1% significance level. This unit root finding for CDS spreads is very similar to the unit root finding for U.S. stock prices in (Kwiatkowski et al. 1992), even though the CDS data frequency in this paper is daily while their stock data frequency is annual, and even though the CDS data in this paper cover the most recent period (2001–2018) while their stock data end in 1970. Moreover, we study both the raw and log CDS spreads, while Kwiatkowski et al. (1992) used the raw stock prices.
The above results of the ADF, PP, and KPSS tests show clear evidence of unit root for the log CDS spreads, but the evidence is mixed for the raw CDS spreads. Schwert (2002) found that if the data generation process has an moving average (MA) component—for example, —and the MA parameter is close to negative 1, then the ADF and PP tests tend to over-reject the null hypothesis of a unit root. Perron and Ng (1996) (PN) proposed modified PP tests to mitigate this size distortion problem. In addition, as an alternative to the above KPSS test to solve the low-power problem, Elliott et al. (1996) (ERS) proposed an efficient version of the ADF t-statistic and called it the DF-GLS (generalized least squares) test. Combining ERS’s GLS detrending procedure and PN’s modified PP tests, Ng and Perron (2001) (NP) created the efficient modified PP tests, called , for both good size and good power properties.1 They also proposed modified information criteria to select the optimal truncation lag parameter. Appendix A.3 summarizes the technical details of NP’s test procedure.
To confirm the above findings of the ADF, PP, and KPSS tests, we run NP’s tests on the same log and raw CDS spread data. The top of Table 2 reports the critical values simulated from the asymptotic distributions of the tests, as summarized in Appendix A.3, for the setup of a unit root process with a drift. The Brownian motion in the asymptotic distributions is approximated by partial sums of random variables with 4000 and 5000 steps for the corresponding sample sizes. The number of Monte Carlo repetitions is 100,000. The bottom of Table 2 reports the computed test statistics and the associated optimal truncation lag parameter k set to minimize the modified Akaike information criterion (MAIC) developed in (Ng and Perron 2001).
The test values in the bottom of Table 2 for the log CDS spreads show that the null hypothesis of a unit root cannot be rejected at the 10% significance level for the six sample banks. In comparison, the evidence for the raw CDS spreads is relatively mixed. The unit root null hypothesis cannot be rejected at the 10% level for Bank of America, Citigroup, and Goldman Sachs; it can be marginally rejected at the 10% level for J.P. Morgan Chase and for Wells Fargo by and ; and it can be rejected at the 5% level for Morgan Stanley. Indeed, the mixed evidence for the raw CDS spreads is very similar to the mixed findings in (Ng and Perron 2001) for the inflation rate data from the G-7 countries between 1960:Q2 and 1997:Q2. Thus, the clear unit root evidence for the log CDS spreads and the mixed evidence for the raw CDS spreads revealed by the tests confirm the above findings by the ADF, PP, and KPSS tests.
In summary, whether the tests are parametric or nonparametric, whether the null hypothesis is unit root or covariance stationary, and whether the original or modified tests are used, the empirical evidence shows that it is log, not raw, CDS spreads that are unit root processes. The unit root property of log CDS spreads implies that the efficient market hypothesis holds for the CDS market: it is hard for investors to beat the CDS market. The best predictor for the log CDS spread tomorrow is the log CDS spread today. Meanwhile, the first difference of log CDS spreads, not raw CDS spreads, is just the return of holding a CDS contract, if we treat CDS spreads as the prices for the CDS contract. The unit root property of log CDS spreads thus implies that CDS returns are covariance stationary.
4. Cointegration
As all of the sample entities are U.S. G-SIFI banks2, whether their CDS spreads are cointegrated has implications for overall financial systemic risk. Thus, we conduct the Phillips–Ouliaris–Hansen cointegration tests on the six sample banks. Given the log CDS spreads of each pair of banks, and , we run the following OLS regression:
Then, we calculate the ADF and PP tests on the time series of residuals , with the setup of no constant term in the OLS regression:
If the null hypothesis that is a unit root process is rejected, then and are cointegrated.
As the ADF and PP tests are based on the estimated residuals , instead of the original data, Phillips and Ouliaris (1990) show that their asymptotic distributions are different from those in the univariate unit root tests. Moreover, according to the results of Section 3, the true process for individual log CDS spreads is a random walk with a drift:
Hansen (1992) noted that the asymptotic results change when a drift is included in the true process. Thus, we simulate the new critical values for the setup of a constant term and one explanatory variable in the estimated cointegrating regression (Equation (6)), the true process of a random walk with a drift for individual time series (Equation (7)), and the sample sizes of 4000 and 5000, respectively. The top of Table 3 reports the simulated critical values based on 100,000 Monte Carlo repetitions, and the bottom of Table 3 reports the computed (lower triangles) and t (upper triangles) values.
The ADF tests in Table 3 reject the null hypothesis that has a unit root at the 5% significance level for most pairs of sample banks, except for the BAC-C and BAC-WFC pairs. However, the PP and t tests for all pairs of sample banks are significant at the 5% or even 1% level. Phillips and Ouliaris (1990) noticed that the ADF t and PP tests have slower rates of divergence under the alternative hypothesis of cointegration, thus, in large samples such as those in this study, the PP t test has better power properties. Thus, the significant results in the upper triangle of the PP tests panel are relatively more reliable, and we conclude that the daily log CDS spreads of large U.S. banks are generally cointegrated. This cointegration relation among log CDS spreads is very similar to the cointegration finding in (Engle and Granger 1987) for another pair of financial time series: long- and short-term interest rates.
The cointegration among the log CDS spreads of large U.S. banks means that, even though the risks of individual banks may deviate from each other in the short run, there is a long-run relation that ties their risks together. Thus, for portfolio diversification, investors should hold more securities than simply a basket of CDS contracts referring to large U.S. banks to reduce the effect of their common long-run risks. Moreover, foreign investors may face additional layers of risks when trading CDS contracts. As the most actively traded U.S. CDS contracts are denominated in U.S. dollars, foreign investors, unless they have cash flows in U.S. dollars, have to face either the exchange rate risk when converting their local currencies to U.S. dollars in order to trade these liquid CDS contracts, or the liquidity risk when trading the CDS contracts denominated in their local currencies as these CDS contracts are much less actively traded.
5. Conclusions
This paper conducts a rigorous time-series analysis of single-name CDS spreads. To study the univariate unit root property, we apply the ADF, PP, KPSS, and NP tests. To study the multivariate cointegration relationship, we apply the Phillips–Ouliaris–Hansen cointegration tests. The empirical sample consists of six U.S. G-SIFI banks for the period from 2001 to 2018. The main empirical findings are that it is log, not raw, CDS spreads that are clearly unit root processes. Moreover, the log CDS spreads of the U.S. G-SIFI banks are cointegrated, pointing to a long-run relation that ties together the risks of these banks.
The above empirical findings provide some practical guidance for both empirical CDS analysis and financial systemic risk analysis. First, in terms of empirical analysis, as raw CDS spreads do not clearly exhibit either covariance stationarity or a unit root pattern, we should take the logarithm of raw CDS spreads before putting them in regressions. Moreover, as log CDS spreads have a unit root, we may need to take the first difference if we run regressions on a bank’s CDS and other variables of interest to avoid the potential spurious regression problem. However, as the log CDS spreads of large U.S. banks are cointegrated, if we analyze these banks jointly, then error correction representation (Engle and Granger 1987) is the right way to go, because, if we take the first difference in the joint analysis, we are going to lose the long-run trend that ties together these banks. Second, in terms of financial system risk, as the CDS spreads of these G-SIFI banks are an important driving force for U.S. financial systemic risk, the persistence of their CDS spreads implies that financial systemic risk is also persistent, even if it is not a unit root process. This is similar to other risk measures, such as conditional volatility or correlations. The long-run trend that ties together these banks implies that, in the long run, the risks of these banks will move together with overall financial systemic risk.
Consequently, there are at least two policy implications. First, in monitoring systemic risk, policymakers should focus on long-run trends rather than short-run fluctuations of individual CDS spreads. Second, in controlling systemic risk, policy measures that reduce the long-run risks of individual banks, such as stress testing and capital buffers, are helpful in mitigating overall systemic risk.
Funding
This research received no external funding.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ADF | Augmented Dickey–Fuller |
| AR | Autoregressive |
| BAC | Bank of America |
| C | Citigroup |
| CDS | Credit default swaps |
| GLS | Generalized least squares |
| G-SIFI | Global systemically important financial institution |
| GS | Goldman Sachs |
| JPM | J.P. Morgan Chase |
| KPSS | Kwiatkowski–Phillips–Schmidt–Shin |
| LM | Lagrange multiplier |
| MA | Moving average |
| MS | Morgan Stanley |
| NP | Ng and Perron |
| OLS | Ordinary least squares |
| PN | Perron and Ng |
| PP | Phillips–Perron |
| SNRFOR | Senior foreign (unsecured) |
| WFC | Wells Fargo |
| XR | Ex-restructuring |
Appendix A
Appendix A.1.
A summary of the PP and t test statistics is as follows:
where is the OLS sample residual from the estimated regression, q is the lag truncation parameter, and k is the number of parameters in the estimated regression.
Appendix A.2.
A summary of the KPSS LM test is as follows:
where is the same as in the above PP test, and l is the lag truncation parameter.
Appendix A.3.
Ng and Perron (2001) developed the efficient modified PP and Sargan–Bhargava (SB) test (Sargan and Bhargava 1983), and called them tests. They are computed as follows. Given the time series , we first GLS detrend it as proposed in Elliott et al. (1996)
where if there is no time trend in the data and if there is. , and
for some chosen . Ng and Perron (2001) recommended for the case of no time trend and for the case of a time trend. Then, using the GLS detrended data , the three tests are computed as
where
with and obtained from estimating the following ADF regression by OLS
To choose the optimal truncation lag parameter k in the above ADF regression, Ng and Perron (2001) recommended using the modified Akaike information criterion (MAIC).
where and . Then, the optimal k is found by grid searching to minimize . The upper bound satisfies as . Following Ng and Perron (2001), we set .
The asymptotic distributions of the three tests depend on the true process under the null hypothesis of a unit root. If there is no drift in the true process, then
If there is a drift in the true process, then
In both cases, is an Ornstein–Uhlenbeck process defined by with , and , . Under the null hypothesis, . Following Ng and Perron (2001), we set if there is no drift in the true process and −13.5 if there is.
References
- Acharya, Viral, Itamar Drechsler, and Philipp Schnabl. 2014. A Pyrrhic Victory? Bank Bailouts and Sovereign Credit Risk. Journal of Finance 69: 2689–739. [Google Scholar] [CrossRef]
- Blanco, Roberto, Simon Brennan, and Ian W. Marsh. 2005. An Empirical Analysis of the Dynamic Relation between Investment-Grade Bonds and Credit Default Swaps. Journal of Finance 60: 2255–81. [Google Scholar] [CrossRef]
- Dickey, David A., and Wayne A. Fuller. 1979. Distribution of the Estimators for Autoregressive Time Series with a Unit Root. Journal of the American Statistical Association 74: 427–31. [Google Scholar]
- Elliott, Graham, Thomas J. Rothenberg, and James H. Stock. 1996. Efficient Tests for an Autoregressive Unit Root. Econometrica 64: 813–36. [Google Scholar] [CrossRef]
- Engle, Robert F., and Clive W. J. Granger. 1987. Co-Integration and Error Correction: Representation, Estimation, and Testing. Econometrica 55: 251–76. [Google Scholar] [CrossRef]
- Galil, Koresh, Offer Moshe Shapir, Dan Amiram, and Uri Ben-Zion. 2014. The Determinants of CDS Spreads. Journal of Banking and Finance 41: 271–82. [Google Scholar] [CrossRef]
- Hamilton, J. D. 1994. Time Series Analysis. Princeton: Princeton University Press. [Google Scholar]
- Hansen, Bruce E. 1992. Efficient Estimation and Testing of Cointegrating Vectors in the Presence of Deterministic Trends. Journal of Econometrics 53: 87–121. [Google Scholar] [CrossRef]
- Huang, Xin, Hao Zhou, and Haibin Zhu. 2009. A Framework for Assessing the Systemic Risk of Major Financial Institutions. Journal of Banking and Finance 33: 2036–49. [Google Scholar] [CrossRef]
- Huang, Xin, Hao Zhou, and Haibin Zhu. 2012a. Assessing the Systemic Risk of a Heterogeneous Portfolio of Banks during the Recent Financial Crisis. Journal of Financial Stability 8: 193–205. [Google Scholar] [CrossRef]
- Huang, Xin, Hao Zhou, and Haibin Zhu. 2012b. Systemic Risk Contributions. Journal of Financial Services Research 42: 55–83. [Google Scholar] [CrossRef]
- Kwiatkowski, Denis, Peter C. B. Phillips, Peter Schmidt, and Yongcheol Shin. 1992. Testing the Null Hypothesis of Stationarity against the Alternative of a Unit Root: How Sure are we that Economic Time Series Have a Unit Root? Journal of Econometrics 54: 159–78. [Google Scholar] [CrossRef]
- Ng, Serena, and Pierre Perron. 2001. Lag Length Selection and the Construction of Unit Root Tests with Good Size and Power. Econometrica 69: 1519–54. [Google Scholar] [CrossRef]
- Perron, Pierre, and Serena Ng. 1996. Useful Modifications to some Unit Root Tests with Dependent Errors and their Local Asymptotic Properties. The Review of Economic Studies 63: 435–63. [Google Scholar] [CrossRef]
- Phillips, Peter C. B. 1987. Time Series Regression with a Unit Root. Econometrica 55: 277–301. [Google Scholar] [CrossRef]
- Phillips, Peter C. B., and Pierre Perron. 1988. Testing for a Unit Root in Time Series Regression. Biometrika 75: 335–46. [Google Scholar] [CrossRef]
- Phillips, Peter C. B., and Sam Ouliaris. 1990. Asymptotic Properties of Residual Based Tests for Cointegration. Econometrica 58: 165–93. [Google Scholar] [CrossRef]
- Sargan, J. D., and Alok Bhargava. 1983. Testing Residuals from Least Squares Regression for Being Generated by the Gaussian Random Walk. Econometrica 51: 153–74. [Google Scholar] [CrossRef]
- Schwert, G. William. 2002. Tests for Unit Roots: A Monte Carlo Investigation. Journal of Business and Economic Statistics 20: 5–17. [Google Scholar] [CrossRef]
| 1 | We thank an anonymous referee for this suggestion. |
| 2 | The other two U.S. G-SIFI banks are the Bank of New York Mellon Corporation and State Street. However, their CDS contracts are sparsely traded. Fortunately, they are not as large as the six sample banks. To strike a balance between accurate time-series analysis and reasonable systemic risk analysis outcomes, we chose the six sample banks from the eight U.S. G-SIFI banks. |
Figure 1.
Daily log CDS spreads.
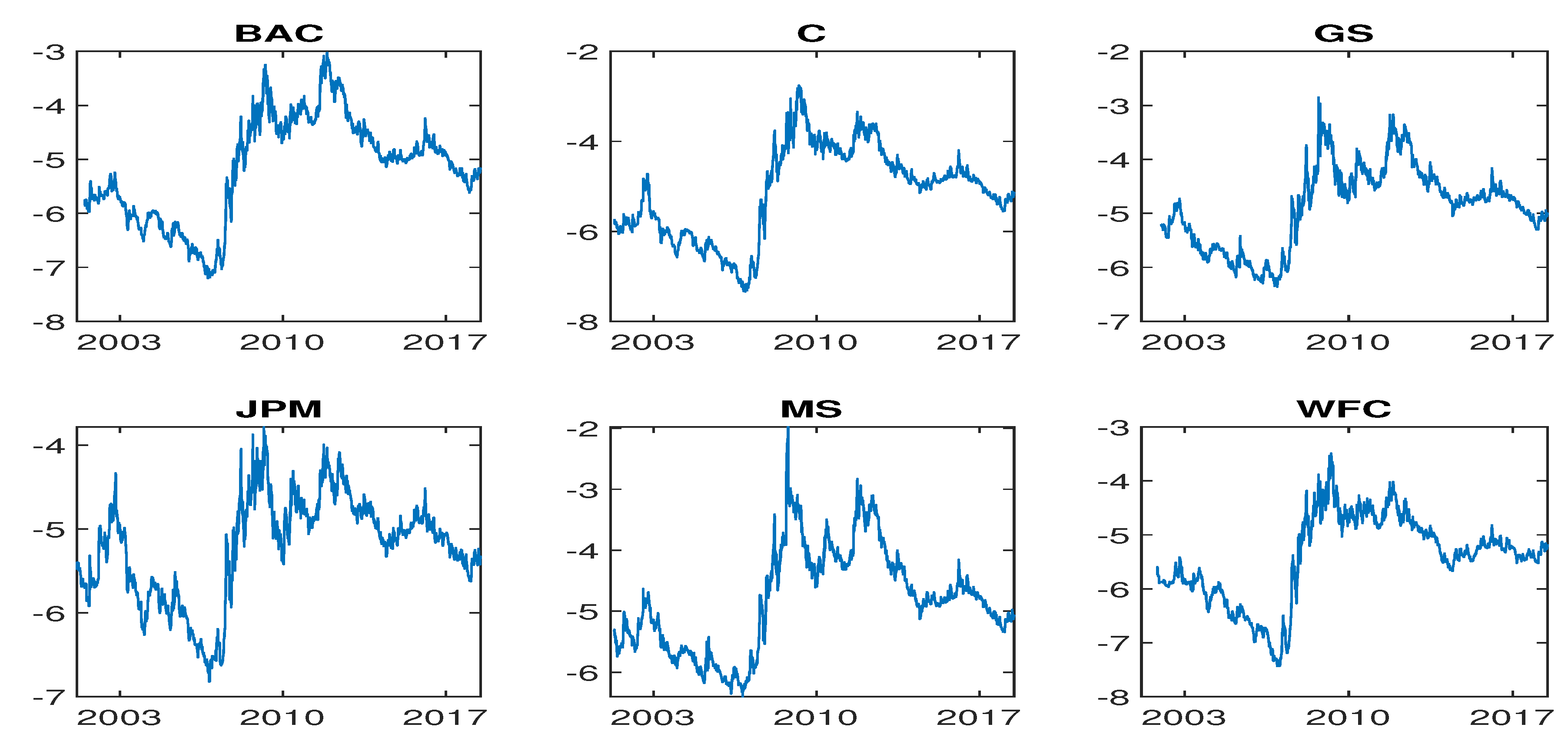
Figure 2.
First 20 sample autocorrelations for daily log CDS spreads.
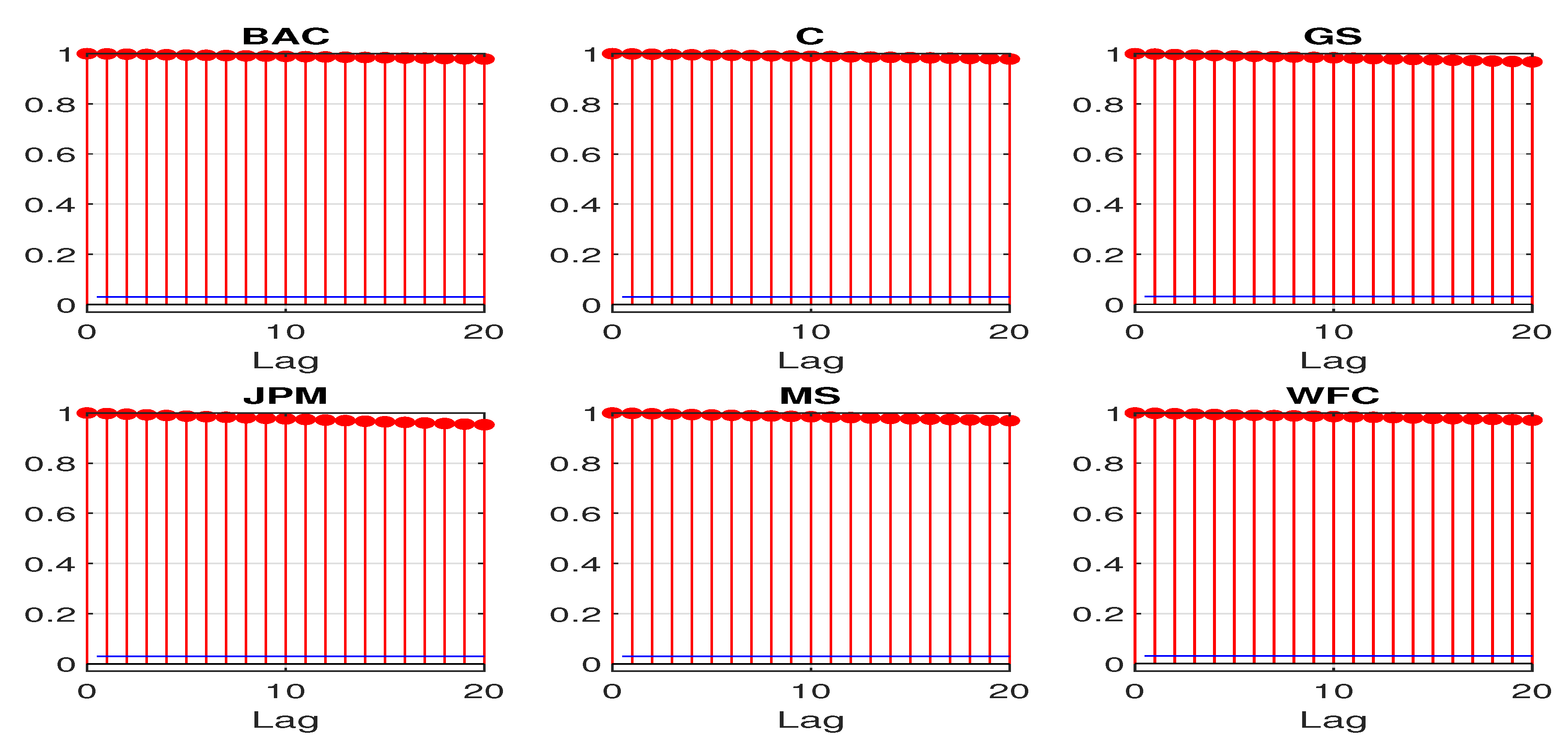
Figure 3.
First 20 sample partial autocorrelations for daily log CDS spreads.
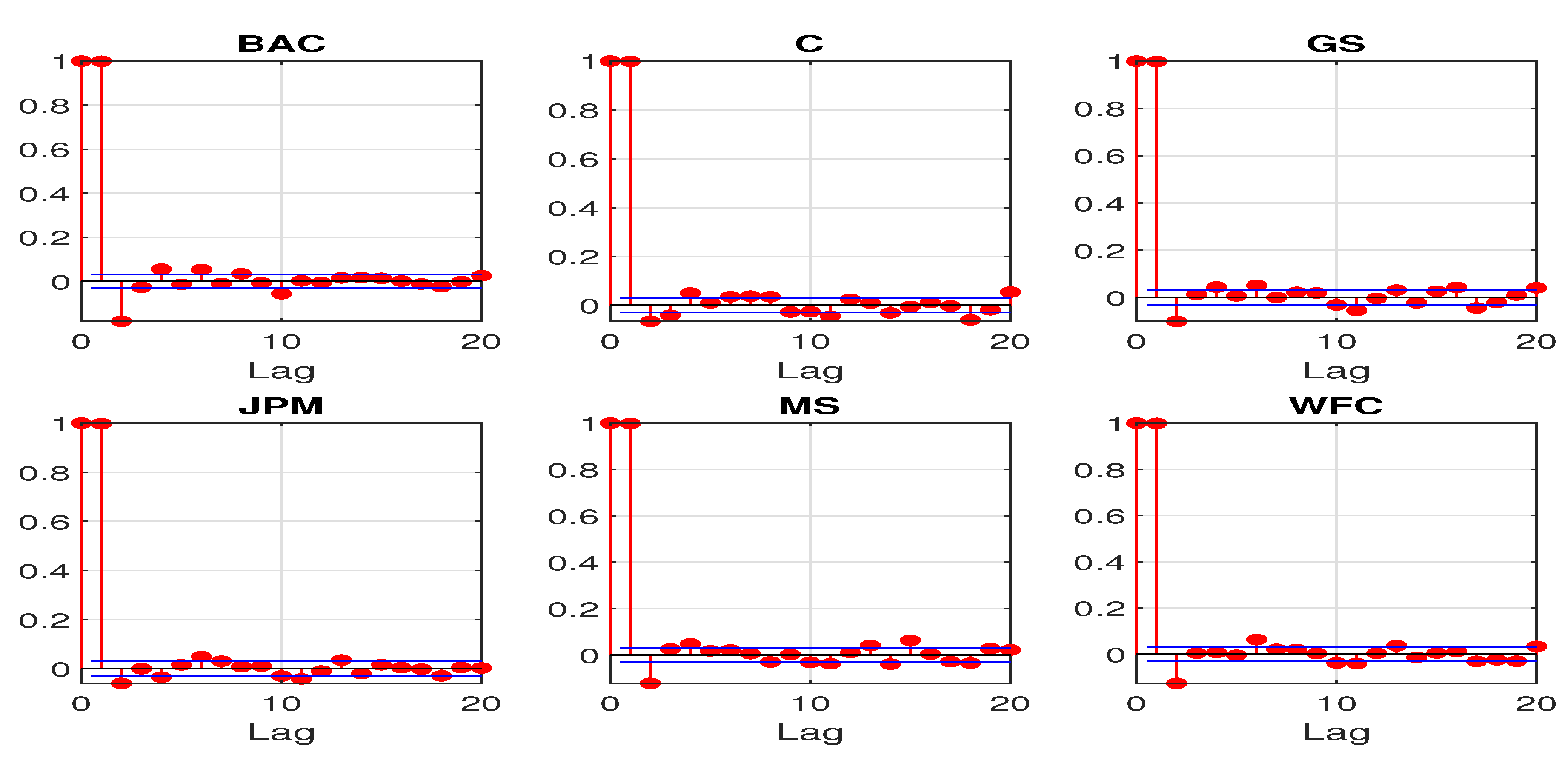
Table 1.
Unit root and covariance stationary tests.

{kind=link}
{kind=link}
{kind=link}
| Simulated Critical Values | |||||||
|---|---|---|---|---|---|---|---|
| Sample size T = 4000 | |||||||
| Sig. level | 0.010 | 0.025 | 0.050 | 0.075 | 0.100 | 0.125 | 0.150 |
| −29.4 | −25.1 | −21.8 | −19.8 | −18.3 | −17.2 | −16.2 | |
| t | −3.97 | −3.66 | −3.42 | −3.26 | −3.13 | −3.03 | −2.95 |
| F | 8.26 | 7.11 | 6.26 | 5.73 | 5.34 | 5.03 | 4.78 |
| 0.22 | 0.18 | 0.15 | 0.13 | 0.12 | 0.11 | 0.10 | |
| Sample size T = 5000 | |||||||
| Sig. level | 0.010 | 0.025 | 0.050 | 0.075 | 0.100 | 0.125 | 0.150 |
| −29.5 | −25.1 | −21.7 | −19.8 | −18.3 | −17.1 | −16.2 | |
| t | −3.97 | −3.66 | −3.41 | −3.25 | −3.13 | −3.03 | −2.94 |
| F | 8.32 | 7.14 | 6.24 | 5.71 | 5.33 | 5.03 | 4.76 |
| 0.22 | 0.18 | 0.15 | 0.13 | 0.12 | 0.11 | 0.10 | |
| Computed Test Statistics | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Log CDS Spreads | Raw CDS Spreads | |||||||||||
| ADF Tests | PP Tests | KPSS Test | ADF Tests | PP Tests | KPSS Test | |||||||
| BAC | −4.36 | −1.38 | 1.05 | −5.77 | −1.63 | 7.75 *** | −10.47 | −2.19 | 2.50 | −15.64 | −2.75 | 7.69 *** |
| C | −4.85 | −1.46 | 1.20 | −5.57 | −1.60 | 7.33 *** | −12.98 | −2.45 | 3.09 | −19.24 * | −3.08 | 7.35 *** |
| GS | −6.69 | −1.73 | 1.55 | −8.81 | −2.04 | 7.54 *** | −12.21 | −2.36 | 2.87 | −25.37 ** | −3.54 ** | 6.80 *** |
| JPM | −12.93 | −2.48 | 3.10 | −12.74 | −2.48 | 5.18 *** | −14.21 | −2.54 | 3.30 | −28.02 ** | −3.71 ** | 5.77 *** |
| MS | −5.63 | −1.57 | 1.42 | −7.33 | −1.84 | 7.97 *** | −18.46 * | −2.91 | 4.30 | −48.79 *** | −4.94 *** | 6.33 *** |
| WFC | −7.97 | −1.97 | 1.94 | −8.03 | −2.00 | 6.55 *** | −13.33 | −2.50 | 3.17 | −26.55 ** | −3.63 ** | 7.72 *** |
Note: (1) *, **, and *** refer to statistical significance at the 10%, 5%, and 1% levels, respectively. (2) The simulated critical values of the , t, and F tests come from the simulated PP and t tests and the ADF F test applied to simulated time series of a random walk with a drift. The critical values are simulated from its asymptotic distribution, where the Brownian motion is approximated by partial sums of random variables with 4000 and 5000 steps for the corresponding sample sizes. The number of Monte Carlo repetitions is 100,000.
Table 2.
Ng and Perron’s tests.
| Simulated Critical Values | |||||||
|---|---|---|---|---|---|---|---|
| Sample size T = 4000 | |||||||
| Sig. level | 0.010 | 0.025 | 0.050 | 0.075 | 0.100 | 0.125 | 0.150 |
| −23.0 | −19.1 | −16.1 | −14.4 | −13.1 | −12.1 | −11.3 | |
| 0.147 | 0.161 | 0.175 | 0.185 | 0.193 | 0.200 | 0.207 | |
| −3.37 | −3.07 | −2.82 | −2.66 | −2.54 | −2.44 | −2.35 | |
| Sample size T = 5000 | |||||||
| Sig. level | 0.010 | 0.025 | 0.050 | 0.075 | 0.100 | 0.125 | 0.150 |
| −23.6 | −19.6 | −16.5 | −14.7 | −13.4 | −12.5 | −11.6 | |
| 0.144 | 0.158 | 0.171 | 0.181 | 0.189 | 0.196 | 0.203 | |
| −3.41 | −3.10 | −2.84 | −2.68 | −2.56 | −2.45 | −2.37 | |
| Computed Test Statistics | ||||||||
|---|---|---|---|---|---|---|---|---|
| Log CDS Spreads | Raw CDS Spreads | |||||||
| k | k | |||||||
| BAC | −6.03 | 0.28 | −1.70 | 9 | −10.46 | 0.22 | −2.25 | 25 |
| C | −5.04 | 0.31 | −1.55 | 29 | −11.85 | 0.20 | −2.40 | 30 |
| GS | −6.64 | 0.27 | −1.79 | 29 | −12.07 | 0.20 | −2.42 | 29 |
| JPM | −12.02 | 0.20 | −2.43 | 12 | −14.84 * | 0.18 * | −2.69 * | 29 |
| MS | −5.36 | 0.30 | −1.59 | 27 | −20.63 ** | 0.15 ** | −3.19 ** | 31 |
| WFC | −7.93 | 0.25 | −1.99 | 19 | −13.16 * | 0.19 | −2.55 * | 30 |
Note: (1) *, **, and *** refer to statistical significance at the 10%, 5%, and 1% levels, respectively. (2) The critical values in the top of the table are simulated from the asymptotic distributions of the tests for the setup of a unit root process with a drift. The Brownian motion in the asymptotic distributions is approximated by partial sums of random variables with 4000 and 5000 steps for the corresponding sample sizes. The number of Monte Carlo repetitions is 100,000.
Table 3.
Cointegration test.
| Simulated Critical Values | |||||||
|---|---|---|---|---|---|---|---|
| Sample size T = 4000 | |||||||
| Sig. level | 0.010 | 0.025 | 0.050 | 0.075 | 0.100 | 0.125 | 0.150 |
| −28.3 | −24.0 | −20.6 | −18.6 | −17.2 | −16.0 | −15.1 | |
| t | −3.91 | −3.60 | −3.35 | −3.18 | −3.05 | −2.95 | −2.85 |
| Sample size T = 5000 | |||||||
| Sig. level | 0.010 | 0.025 | 0.050 | 0.075 | 0.100 | 0.125 | 0.150 |
| −28.4 | −24.1 | −20.7 | −18.7 | −17.2 | −16.1 | −15.1 | |
| t | −3.91 | −3.62 | −3.35 | −3.18 | −3.06 | −2.95 | −2.86 |
| Computed Test Statistics | ||||||
|---|---|---|---|---|---|---|
| Augmented Dickey–Fuller Tests | ||||||
| BAC | C | GS | JPM | MS | WFC | |
| BAC | - | −2.91 | −4.32 *** | −3.48 ** | −3.68 ** | −3.11 |
| C | −17.90 | - | −3.65 ** | −3.43 ** | −3.45 ** | −4.02 *** |
| GS | −43.28 *** | −26.98 ** | - | −3.76 ** | −4.31 *** | −3.63 ** |
| JPM | −25.01 ** | −25.57 ** | −30.43 *** | - | −4.15 *** | −3.52 ** |
| MS | −30.44 *** | −26.32 ** | −38.78 *** | −37.08 *** | - | −3.77 ** |
| WFC | −20.34 * | −35.83 *** | −30.32 *** | −25.58 ** | −31.42 *** | - |
| Phillips–Perron Tests | ||||||
| BAC | C | GS | JPM | MS | WFC | |
| BAC | - | −4.27 *** | −4.97 *** | −3.80 ** | −4.21 *** | −3.56 ** |
| C | −35.69 *** | - | −4.35 *** | −4.09 *** | −4.05 *** | −5.16 *** |
| GS | −48.93 *** | −36.77 *** | - | −4.38 *** | −5.77 *** | −3.75 ** |
| JPM | −28.88 ** | −33.28 *** | −37.60 *** | - | −4.36 *** | −3.78 ** |
| MS | −35.16 *** | −33.09 *** | −64.74 *** | −37.75 *** | - | −3.68 ** |
| WFC | −25.50 ** | −52.48 *** | −28.87 ** | −28.91 ** | −28.23 ** | - |
Notes: (1) In the bottom of the table, the lower triangles of the Augmented Dickey–Fuller and Phillips–Perron test panels report the test statistics, and the upper triangles report the t test statistics. *, **, and *** refer to statistical significance at the 10%, 5%, and 1% levels, respectively. (2) The simulated critical values come from the simulated PP and t tests applied to residuals from the estimated cointegrating regression with a constant term and one explanatory variable, and the true process for individual time series is a random walk with a drift. The number of Monte Carlo repetitions is 100,000.
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Huang, X. Persistence of Bank Credit Default Swap Spreads. Risks 2019, 7, 90. https://doi.org/10.3390/risks7030090
AMA Style
Huang X. Persistence of Bank Credit Default Swap Spreads. Risks. 2019; 7(3):90. https://doi.org/10.3390/risks7030090
Chicago/Turabian StyleHuang, Xin. 2019. "Persistence of Bank Credit Default Swap Spreads" Risks 7, no. 3: 90. https://doi.org/10.3390/risks7030090
APA StyleHuang, X. (2019). Persistence of Bank Credit Default Swap Spreads. Risks, 7(3), 90. https://doi.org/10.3390/risks7030090
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.