Abstract
We consider a two-dimensional ruin problem where the surplus process of business lines is modelled by a two-dimensional correlated Brownian motion with drift. We study the ruin function for the component-wise ruin (that is both business lines are ruined in an infinite-time horizon), where u is the same initial capital for each line. We measure the goodness of the business by analysing the adjustment coefficient, that is the limit of as u tends to infinity, which depends essentially on the correlation of the two surplus processes. In order to work out the adjustment coefficient we solve a two-layer optimization problem.
1. Introduction
In classical risk theory, the surplus process of an insurance company is modelled by the compound Poisson risk model. For both applied and theoretical investigations, calculation of ruin probabilities for such model is of particular interest. In order to avoid technical calculations, diffusion approximation is often considered e.g., (Asmussen and Albrecher 2010; Grandell 1991; Iglehart 1969; Klugman et al. 2012), which results in tractable approximations for the interested finite-time or infinite-time ruin probabilities. The basic premise for the approximation is to let the number of claims grow in a unit time interval and to make the claim sizes smaller in such a way that the risk process converges to a Brownian motion with drift. Precisely, the Brownian motion risk process is defined by
where is the initial capital, is the net profit rate and models the net loss process with the volatility coefficient. Roughly speaking, is an approximation of the total claim amount process by time t minus its expectation, the latter is usually called the pure premium amount and calculated to cover the average payments of claims. The net profit, also called safety loading, is the component which protects the company from large deviations of claims from the average and also allows an accumulation of capital. Ruin related problems for Brownian models have been well studied; see, for example, Asmussen and Albrecher (2010); Gerber and Shiu (2004).
In recent years, multi-dimensional risk models have been introduced to model the surplus of multiple business lines of an insurance company or the suplus of collaborating companies (e.g., insurance and reinsurance). We refer to Asmussen and Albrecher (2010) [Chapter XIII 9] and Avram and Loke (2018); Avram and Minca (2017); Avram et al. (2008a, 2008b); Albrecher et al. (2017); Azcue and Muler (2018); Azcue et al. (2019); Foss et al. (2017); Ji and Robert (2018) for relevant recent discussions. It is concluded in the literature that in comparison with the well-understood 1-dimensional risk models, study of multi-dimensional risk models is much more challenging. It was shown recently in Delsing et al. (2019) that multi-dimensional Brownian model can serve as approximation of a multi-dimensional classical risk model in a Markovian environment. Therefore, obtained results for multi-dimensional Brownian model can serve as approximations of the multi-dimensional classical risk models in a Markovian environment; ruin probability approximation has been used in the aforementioned paper. Actually, multi-dimensional Brownian models have drawn a lot of attention due to its tractability and practical relevancy.
A d-dimensional Brownian model can be defined in a matrix form as
where are, respectively, (column) vectors representing the initial capital and net profit rate, is a non-singular matrix modelling dependence between different business lines and is a standard d-dimensional Brownian motion (BM) with independent coordinates. Here ⊤ is the transpose sign. In what follows, vectors are understood as column vectors written in bold letters.
Different types of ruin can be considered in multi-dimensional models, which are relevant to the probability that the surplus of one or more of the business lines drops below zero in a certain time interval with T either a finite constant or infinity. One of the commonly studied is the so-called simultaneous ruin probability defined as
which is the probability that at a certain time all the surpluses become negative. Here for , is called finite-time simultaneous ruin probability, and is called infinite-time simultaneous ruin probability. Simultaneous ruin probability, which is essentially the hitting probability of to the orthant , has been discussed for multi-dimensional Brownian models in different contexts; see Dȩbicki et al. (2018); Garbit and Raschel (2014). In Garbit and Raschel (2014), for fixed the asymptotic behaviour of as has been discussed. Whereas, in Dȩbicki et al. (2018), the asymptotic behaviour, as , of the infinite-time ruin probability , with has been obtained. Note that it is common in risk theory to derive the later type of asymptotic results for ruin probabilities; see, for example, Avram et al. (2008a); Embrechts et al. (1997); Mikosch (2008).
Another type of ruin probability is the component-wise (or joint) ruin probability defined as
which is the probability that all surpluses get below zero but possibly at different times. It is this possibility that makes the study of more difficult.
The study of joint distribution of the extrema of multi-dimensional BM over finite-time interval has been proved to be important in quantitative finance; see, for example, He et al. (1998); Kou and Zhong (2016). We refer to Delsing et al. (2019) for a comprehensive summary of related results. Due to the complexity of the problem, two-dimensional case has been the focus in the literature and for this case some explicit formulas can be obtained by using a PDE approach. Of particular relevance to the ruin probability is a result derived in He et al. (1998) which shows that
where are known constants and f is a function defined in terms of infinite-series, double-integral and Bessel function. Using the above formula one can derive an expression for in two-dimensional case as follows
where the expression for the distribution of single supremum is also known; see He et al. (1998). Note that even though we have obtained explicit expression of in (2) for the two-dimensional case, it seems difficult to derive the explicit form of the corresponding infinite-time ruin probability by simply putting in (2).
By assuming , we aim to analyse the asymptotic behaviour of the infinite-time ruin probability as . Applying Theorem 1 in Dȩbicki et al. (2010) we arrive at the following logarithmic asymptotics
provided is non-singular, where , inequality of vectors are meant component-wise, and is the inverse matrix of the covariance function of , with and . Let us recall that conventionally for two given positive functions and , we write if .
For more precise analysis on , it seems crucial to first solve the two-layer optimization problem in (3) and find the optimization points . As it can be recognized in the following, when dealing with d-dimensional case with the calculations become highly nontrivial and complicated. Therefore, in this contribution we only discuss a tractable two-dimensional model and aim for an explicit logarithmic asymptotics by solving the minimization problem in (3).
In the classical ruin theory when analysing the compound Poisson model or Sparre Andersen model, the so-called adjustment coefficient is used as a measure of goodness; see, for example, Asmussen and Albrecher (2010) or Rolski et al. (2009). It is of interest to obtain the solution of the minimization problem in (3) from a practical point of view, as it can be seen as an analogue of the adjustment coefficient and thus we could get some insights about the risk that the company is facing. As discussed in Asmussen and Albrecher (2010) and Li et al. (2007) it is also of interest to know how the dependence between different risks influences the joint ruin probability, which can be easily analysed through the obtained logarithmic asymptotics; see Remark 2.
The rest of this paper is organised as follows. In Section 2, we formulate the two-dimensional Brownian model and give the main results of this paper. The main lines of proof with auxiliary lemmas are displayed in Section 3. In Section 4 we conclude the paper. All technical proofs of the lemmas in Section 3 are presented in Appendix A.
2. Model Formulation and Main Results
Due to the fact that component-wise ruin probability does not change under scaling, we can simply assume that the volatility coefficient for all business lines is equal to 1. Furthermore, noting that the timelines for different business lines should be distinguished as shown in (1) and (3), we introduce a two-parameter extension of correlated two-dimensional BM defined as
with and mutually independent Brownian motions . We shall consider the following two dependent insurance risk processes
where are net profit rates, u is the initial capital (which is assumed to be the same for both business lines, as otherwise, the calculations become rather complicated). We shall assume without loss of generality that . Here, is different from (see (1)) in the sense that it corresponds to the (scaled) model with volatility coefficient standardized to be 1.
In this contribution, we shall focus on the logarithmic asymptotics of
Define
and let
The following theorem constitutes the main result of this contribution.
Theorem 1.
For the joint infinite-time ruin probability (4) we have, as ,
Remark 2.
(a) Following the classical one-dimensional risk theory we can call quantities on the right hand side in Theorem 1 as adjustment coefficients. They serve sometimes as a measure of goodness for a risk business.
(b) One can easily check that adjustment coefficient as a function of ρ is continuous, strictly decreasing on and it is constant, equal to on . This means that as the two lines of business becomes more positively correlated the risk of ruin becomes larger, which is consistent with the intuition.
Define
where is the inverse matrix of with and .
The proof of Theorem 1 follows from (3) which implies that the logarithmic asymptotics for is of the form
where
and Proposition 3 below, wherein we list dominating points that optimize the function g over and the corresponding optimal values .
In order to solve the two-layer minimization problem in (9) (see also (7)) we define for the following functions:
Since appears in the above formula, we shall consider a partition of the quadrant , namely
For convenience we denote and . Hereafter, all sets are defined on , so will be omitted.
Note that can be represented in the following form:
Denote further
In the next proposition we identify the so-called dominating points, that is, points for which function defined in (7) achieves its minimum. This identification might also be useful for deriving a more subtle asymptotics for .
Notation:In the following, in order to keep the notation consistent, is understood as if
Proposition 3.
- (i)
- Suppose that .For we havewhere, is the unique minimizer of .For we havewhere are the only two minimizers of .
- (ii)
- Suppose that . We havewhere is the unique minimizer of .
- (iii)
- (iv)
- Suppose that . We havewhere is the unique minimizer of .
- (v)
- Suppose that . We have andwhere the minimum of is attained at , with and is the unique minimizer of .
- (vi)
- Suppose that . We havewhere the minimum of is attained when .
Remark 4.
In case that , we have and thus scenarios (ii) and (vi) do not apply.
3. Proofs of Main Results
As discussed in the previous section, Proposition 3 combined with (8), straightforwardly implies the thesis of Theorem 1. In what follows, we shall focus on the proof of Proposition 3, for which we need to find the dominating points by solving the two-layer minimization problem (9).
The solution of quadratic programming problem of the form (7) (inner minimization problem of (9)) has been well understood; for example, Hashorva (2005); Hashorva and Hüsler (2002) (see also Lemma 2.1 of Dȩbicki et al. (2018)). For completeness and for reference, we present below Lemma 2.1 of Dȩbicki et al. (2018) for the case where .
We introduce some more notation. If , then for a vector we denote by a sub-block vector of . Similarly, if further , for a matrix we denote by the sub-block matrix of M determined by I and J. Further, write for the inverse matrix of whenever it exists.
Lemma 5.
Let be a positive definite matrix. If , then the quadratic programming problem
has a unique solution and there exists a unique non-empty index set such that
Furthermore,
For the solution of the quadratic programming problem (7) a suitable representation for is worked out in the following lemma.
For let and , with boundary functions given by
and the unique intersection point of given by
as depicted in Figure 1.
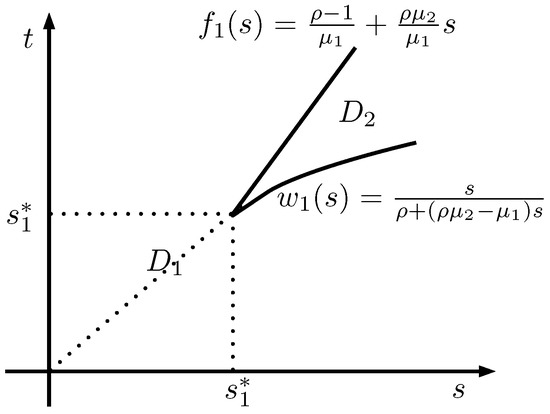
Figure 1.
Partition of into .
3.1. Proof of Proposition 3
We shall discuss in order the case when
and the case when in the following two subsections. In both scenarios we shall first derive the minimizers of the function on regions and (see (10)) separately and then look for a global minimizer by comparing the two minimum values. For clarity some scenarios are analysed in forms of lemmas.
3.1.1. Case
By Lemma 6, we have that
We shall derive the minimizers of on separately.
Minimizers of on . We have, for any fixed s,
where the representation (11) is used. Two roots of the above equation are:
Note that, due to the form of the function given in (11), for any fixed s, there exists a unique minimizer of on which is either an inner point or (the one that is larger than s), or a boundary point s. Next, we check if any of is larger than s. Since , . So we check if . It can be shown that
Two scenarios and will be distinguished.
Next, since
the unique minimizer of on is given by with
Next, for we have that (recall given in (18))
Therefore, by (19) we conclude that the unique minimizer of on is again given by . Consequently, for all , we have that the unique minimizer of on is given by , and
Minimizers of on . Similarly, we have, for any fixed t,
Two roots of the above equation are:
Next, we check if any of is greater than t. Again as . So we check if . It can be shown that
Thus, for Scenario we have that
and in this case
with
Next, note that
Therefore, the unique minimizer of on is given by with
In this case,
Though it is not easy to determine explicitly the optimizer, we can conclude that the minimizer should be taken at , or , where . Further, we have from the discussion in (19) that
and
Combining the above discussions on , we conclude that Proposition 3 holds for .
3.1.2. Case
We shall derive the minimizers of on separately. We start with discussions on , for which we give the following lemma. Recall defined in (20) (see also (6)), defined in (24), defined in (25) and defined in (14) for . Note that where it applies, is understood as and is understood as 0.
Lemma 7.
We have:
- (a)
- The function is a decreasing function on and both and are decreasing functions on .
- (b)
- The function decreases from at to some positive value and then increases to at (defined in (5)) and then increases to at the root of the equation
- (c)
- For , we havewhere both equalities hold only when and
- (d)
- It holds that
Moreover, for we have
- (i)
- (ii)
- (iii)
- (iv)
- (v)
Recall that by definition (cf. (12)). For the minimum of on we have the following lemma.
Lemma 8.
We have
- (i)
- If , thenwhere is the unique minimizer of on .
- (ii)
- If , then andwhere the minimum of on is attained at , with and is the unique minimizer of
- (iii)
Next we consider the minimum of on . Recall defined in (20), defined in (17) and defined in (18). We first give the following lemma.
Lemma 9.
We have
- (a)
- Both and are decreasing functions on .
- (b)
- That is the unique point on such thatand
- (i)
- ,
- (ii)
- (c)
- For all , it holds that .
For the minimum of on we have the following lemma.
Lemma 10.
We have
- (i)
- If , thenwhere is the unique minimizer of on .
- (ii)
- If , thenwhere is the unique minimizer of on .
- (iii)
- If , thenwhere is the unique minimizer of on .
- (iv)
- If , then andwhere the minimum of on is attained at , with .
- (v)
Consequently, combining the results in Lemma 8 and Lemma 10, we conclude that Proposition 3 holds for . Thus, the proof is complete.
4. Conclusions and Discussions
In the multi-dimensional risk theory, the so-called “ruin” can be defined in different manner. Motivated by diffusion approximation approach, in this paper we modelled the risk process via a multi-dimensional BM with drift. We analyzed the component-wise infinite-time ruin probability for dimension by solving a two-layer optimization problem, which by the use of Theorem 1 from Dȩbicki et al. (2010) led to the logarithmic asymptotics for as , given by explicit form of the adjustment coefficient (see (8)). An important tool here is Lemma 5 on the quadratic programming, cited from Hashorva (2005). In this way we were also able to identify the dominating points by careful analysis of different regimes for and specify three regimes with different formulas for (see Theorem 1). An open and difficult problem is the derivation of exact asymptotics for in (4), for which the problem of finding dominating points would be the first step. A refined double-sum method as in Dȩbicki et al. (2018) might be suitable for this purpose. A detailed analysis of the case for dimensions seems to be technically very complicated, even for getting the logarithmic asymptotics. We also note that a more natural problem of considering , with general , leads to much more difficult technicalities with the analysis of .
Define the ruin time of component i, , by and let be the order statistics of ruin times. Then the component-wise infinite-time ruin probability is equivalent to while the ruin time of at least one business line is . Other interesting problems like have not yet been analysed. For instance, it would be interesting for to study the case . The general scheme on how to obtain logarithmic asymptotics for such problems was discussed in Dȩbicki et al. (2010).
Random vector has exponential marginals and if it is not concentrated on a subspace of dimension less than d, it defines a multi-variate exponential distribution. In this paper for dimension , we derived some asymptotic properties of such distribution. Little is known about properties of this multi-variate distriution and more studies on it would be of interest. For example a correlation structure of is unknown. In particular, in the context of findings presented in this contribution, it would be interesting to find the correlation between and .
Author Contributions
Investigation, K.D., L.J., T.R.; writing—original draft preparation, L.J.; writing—review and editing, K.D., T.R.
Funding
T.R. & K.D. acknowledge partial support by NCN grant number 2015/17/B/ST1/01102 (2016-2019).
Acknowledgments
We are thankful to the referees for their carefully reading and constructive suggestions which significantly improved the manuscript.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| BM | Brownian motion |
Appendix A
In this appendix, we present the proofs of the lemmas used in Section 3.
Proof of Lemma 6.
Referring to Lemma 5, we have, for any fixed , there exists a unique index set
such that
and
Since or , we have that
- (S1)
- On the set ,
- (S2)
- On the set ,
- (S3)
- On the set , .
Clearly, if then
In this case,
Next, we focus on the case where . We consider the regions and B separately.
Analysis on . We have
Next we analyse the intersection situation of the functions on region .
Clearly, for any we have . Furthermore, has a unique positive solution given by
Finally, for we have that does not intersect with on but for the unique intersection point is given by (cf. (14)). To conclude, we have, for
and for
Additionally, we have from Lemma 5 for all .
Analysis on B. The two scenarios and will be considered separately. For we have
It is easy to check that
and thus
For we have
Next we analyze the intersection situation of the functions on region B.
Clearly, for any . and do not intersect on . and has a unique intersection point (cf. (14)).
To conclude, we have, for
and for
Additionally, it follows from Lemma 5 that for all .
Consequently, the claim follows by a combination of the above results. This completes the proof. □
Proof of Lemma 7.
- (a)
- The claim for follows by noting its following representation:The claims for and follow directly from their definition.
- (b)
- First note thatNext it is calculated thatThus, the claim of (b) follows by analysing the sign of over .
- (c)
- For any we have and thusFurther, sinceit follows that
- (d)
Analysing the properties of the above two functions, we have is strictly decreasing on with
and thus there is a unique intersection point of the two curves and which is . Therefore, the claim of (i) follows. Similarly, the claim of (ii) follows since
Finally, the claims of (iii), (iv) and (v) follow easily from (a), (b) and (26). This completes the proof. □
Proof of Lemma 8.
Consider first the case where . Recall (22). We check if any of is greater than t. Clearly, . Next, we check whether . It is easy to check that
where (recall (25))
Then
Consequently, it follows from (c) of Lemma 7 the claim of (i) holds for .
Next, we consider . Recall the function defined in (13). Denote the inverse function of by
We have from Lemma 6 that
Further note that is the unique minimizer of . For we have from (d) in Lemma 7 that
and further
where is the unique minimizer of on . Therefore, the claim for is established.
For , because of (26) we have
and the unique minimum of on is attained at . Moreover, for all we have
Thus,
and the unique minimum of on is attained when on . This completes the proof. □
Proof of Lemma 9.
- (a)
- The claim for has been shown in the proof of (a) in Lemma 7. Next, we show the claim for , for which it is sufficient to show that for all . In fact, we have
- (b)
- In order to prove (i), the following two scenarios will be discussed separately:
First consider (S1). If , then
where
Analysing the function f, we conclude that
Further, for we have
Thus, the claim in (i) is established for (S1). Similarly, the claim in (i) is valid for (S2).
Next, note that
with
Analysing the properties of the above two functions, we have is strictly decreasing on with
and thus there is a unique intersection point of and . It seems not clear at the moment whether this unique point is or not, since we have to solve a polynomial equation of order 4. Instead, it is sufficient to show that
In fact, basic calculations show that the above is equivalent to
which is valid due to the fact that . Finally, the claim in (c) follows since
This completes the proof. □
Proof of Lemma 10.
Two cases and should be distinguished. Since the proofs for these two cases are similar, we give below only the proof for the more complicated case .
Note that, for , as in (19),
and thus the claim for follows directly from (i)–(ii) of (b) in Lemma 9.
Next, we consider the case (note here ). We have by (i) of (d) in Lemma 7 and (i)–(ii) of (b) in Lemma 9 that
Thus, it follows from Lemma 6 that
and is the unique minimizer of on . Here we used the fact that
Next, if , then
and thus
Furthermore, the unique minimum of on A is attained at , with .
Finally, for , we have
and thus
where the unique minimum of on is attained when on . This completes the proof. □
References
- Albrecher, Hansjörg, Pablo Azcue, and Nora Muler. 2017. Optimal dividend strategies for two collaborating insurance companies. Advances in Applied Probability 49: 515–48. [Google Scholar] [CrossRef]
- Asmussen, Søren, and Hansjörg Albrecher. 2010. Ruin Probabilities, 2nd ed. Advanced Series on Statistical Science & Applied Probability, 14; Hackensack: World Scientific Publishing Co. Pte. Ltd. [Google Scholar]
- Avram, Florin, and Sooie-Hoe Loke. 2018. On central branch/reinsurance risk networks: Exact results and heuristics. Risks 6: 35. [Google Scholar] [CrossRef]
- Avram, Florin, and Andreea Minca. 2017. On the central management of risk networks. Advances in Applied Probability 49: 221–37. [Google Scholar] [CrossRef]
- Avram, Florin, Zbigniew Palmowski, and Martijn R. Pistorius. 2008a. Exit problem of a two-dimensional risk process from the quadrant: Exact and asymptotic results. Annals of Applied Probability 19: 2421–49. [Google Scholar] [CrossRef]
- Avram, Florin, Zbigniew Palmowski, and Martijn R. Pistorius. 2008b. A two-dimensional ruin problem on the positive quadrant. Insurance: Mathematics and Economics 42: 227–34. [Google Scholar] [CrossRef]
- Azcue, Pablo, and Nora Muler. 2018. A multidimensional problem of optimal dividends with irreversible switching: A convergent numerical scheme. arXiv arXiv:804.02547. [Google Scholar]
- Azcue, Pablo, Nora Muler, and Zbigniew Palmowski. 2019. Optimal dividend payments for a two-dimensional insurance risk process. European Actuarial Journal 9: 241–72. [Google Scholar] [CrossRef]
- Dȩbicki, Krzysztof, Enkelejd Hashorva, Lanpeng Ji, and Tomasz Rolski. 2018. Extremal behavior of hitting a cone by correlated Brownian motion with drift. Stochastic Processes and their Applications 12: 4171–206. [Google Scholar] [CrossRef]
- Dȩbicki, Krzysztof, Kamil MarcinKosiński, Michel Mandjes, and Tomasz Rolski. 2010. Extremes of multidimensional Gaussian processes. Stochastic Processes and their Applications 120: 2289–301. [Google Scholar] [CrossRef][Green Version]
- Delsing, Guusje, Michel Mandjes, Peter Spreij, and Erik Winands. 2018. Asymptotics and approximations of ruin probabilities for multivariate risk processes in a Markovian environment. arXiv arXiv:1812.09069. [Google Scholar]
- Embrechts, Paul, Claudia Klüppelberg, and Thomas Mikosch. 1997. Modelling Extremal Events of Applications of Mathematics (New York). Berlin: Springer, vol. 33. [Google Scholar]
- Foss, Sergey, Dmitry Korshunov, Zbigniew Palmowski, and Tomasz Rolski. 2017. Two-dimensional ruin probability for subexponential claim size. Probability and Mathematical Statistics 2: 319–35. [Google Scholar]
- Garbit, Rodolphe, and Kilian Raschel. 2014. On the exit time from a cone for Brownian motion with drift. Electronic Journal of Probability 19: 1–27. [Google Scholar] [CrossRef]
- Gerber, Hans U., and Elias SW Shiu. 2004. Optimal Dvidends: Analysis with Brownian Motion. North American Actuarial Journal 8: 1–20. [Google Scholar] [CrossRef]
- Grandell, Jan. 1991. Aspects of Risk Theory. New York: Springer. [Google Scholar]
- Hashorva, Enkelejd. 2005. Asymptotics and bounds for multivariate Gaussian tails. Journal of Theoretical Probability 18: 79–97. [Google Scholar] [CrossRef]
- Hashorva, Enkelejd, and Jürg Hüsler. 2002. On asymptotics of multivariate integrals with applications to records. Stochastic Models 18: 41–69. [Google Scholar] [CrossRef]
- He, Hua, William P. Keirstead, and Joachim Rebholz. 1998. Double lookbacks. Mathematical Finance 8: 201–28. [Google Scholar] [CrossRef]
- Iglehart, L. Donald. 1969. Diffusion approximations in collective risk theory. Journal of Applied Probability 6: 285–92. [Google Scholar] [CrossRef]
- Ji, Lanpeng, and Stephan Robert. 2018. Ruin problem of a two-dimensional fractional Brownian motion risk process. Stochastic Models 34: 73–97. [Google Scholar] [CrossRef]
- Klugman, Stuart A., Harry H. Panjer, and Gordon E. Willmot. 2012. Loss Models: From Data to Decisions. Hoboken: John Wiley and Sons. [Google Scholar]
- Kou, Steven, and Haowen Zhong. 2016. First-passage times of two-dimensional Brownian motion. Advances in Applied Probability 48: 1045–60. [Google Scholar] [CrossRef]
- Li, Junhai, Zaiming Liu, and Qihe Tang. 2007. On the ruin probabilities of a bidimensional perturbed risk model. Insurance: Mathematics and Economics 41: 185–95. [Google Scholar] [CrossRef]
- Mikosch, Thomas. 2008. Non-life Insurance Mathematics. An Introduction with Stochastic Processes. Berlin: Springer. [Google Scholar]
- Rolski, Tomasz, Hanspeter Schmidli, Volker Schmidt, and Jozef Teugels. 2009. Stochastic Processes for Insurance and Finance. Hoboken: John Wiley & Sons, vol. 505. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).