1. Introduction
One of the main factors that amplified the financial crisis of 2007–2008 was the failure to capture major risks associated with over-the-counter (OTC) derivative-related exposures (
Basel Committee on Banking Supervision 2010a). Counterparty exposure, at any future time, is the amount that would be lost in the event that a counterparty to a derivative transaction would default, assuming zero recovery at that time. Banks are required to hold regulatory capital against their current and future exposures to all counterparties in OTC derivative transactions.
A key component of the counterparty exposure framework is modeling the evolution of underlying risk factors, such as interest and exchange rates, equity and commodity prices, and credit spreads. Risk Factor Evolution (RFE) models are, arguably, the most important part of counterparty exposure modeling, since small changes in the underlying risk factors may have a profound impact on the exposure and, as a result, on the regulatory and economic capital buffers. It is, therefore, crucial for financial institutions to put significant effort in the design and calibration of RFE models and, in addition, have a sound framework in place in order to assess the forecasting capability of the model.
Although the Basel Committee on Banking Supervision has stressed the importance of the ongoing validation of internal models method (IMM) for counterparty exposure (
Basel Committee on Banking Supervision 2010b), there are no strict guidelines on the specifics of this validation process. As a result, there is some degree of ambiguity regarding the regulatory requirements that financial institutions are expected to meet. In an attempt to reduce this ambiguity,
Anfuso et al. (
2014) introduced a complete framework for counterparty credit risk (CCR) model backtesting which is compliant with Basel III and the new Capital Requirements Directives (CRD IV). A detailed backtesting framework for CCR models was also introduced by
Ruiz (
2014), who expanded the corresponding framework for Value-at-Risk (VaR) models by the Basel Committee (
Basel Committee on Banking Supervision 1996).
The most ubiquitous model for the evolution of exchange rates is Geometric Brownian Motion (GBM). Under GBM, the exchange rate dynamics are assumed to follow a continuous-time stochastic process, in which the returns are log-normally distributed. Although simplicity and tractability render GBM a particularly popular modeling choice, it is generally accepted that it cannot adequately describe the empirical facts exhibited by real exchange rate returns (
Boothe and Glassman 1987). More specifically, exchange rate returns can be leptokurtic, exhibiting tails that exceed those of the normal distribution. As a result, a scenario-generation framework based on GBM may assign unrealistically low probabilities to extreme scenarios, leading to the under-estimation of counterparty exposure and, consequently, regulatory and economic capital buffers.
The main reason for the inability of GBM to produce return distributions with realistically heavy tails is the assumption of constant drift and volatility parameters. In this paper, we present a way to address this limitation without entirely departing from the convenient GBM framework. We propose a model where the GBM parameters are allowed to switch between different states, governed by an unobservable Markov process. Thus, we model exchange rates with a hidden Markov model (HMM) and generate scenarios for counterparty exposure using this approach.
Our paper expands the counterparty exposure literature by introducing a hidden Markov model for the evolution of exchange rates. We provide a detailed description of HMMs and their estimation process. In our numerical experiments, we use GBM and HMM to generate scenarios for the Euro against two major and two emerging currencies. We perform a thorough backtesting exercise, based on the framework proposed by
Ruiz (
2014), and find similar performances for GBM and a two-state HMM. Finally, we use the generated scenarios to calculate credit exposure for foreign exhange (FX) options, and find significant differences between the two models, which are even more pronounced for deep out-of-the-money instruments.
The remainder of the paper is organized as follows.
Section 2 provides the fundamentals of HMMs, along with the algorithms for determining their parameters from data.
Section 3 gives background information on modeling the evolution of exchange rates.
Section 4 outlines the framework for performance evaluation of RFE models. A numerical study is presented in
Section 5. Finally, in
Section 6, we draw conclusions and discuss future research directions.
2. An Introduction to Hidden Markov Models
The hidden Markov model (HMM) is a statistical model in which a sequence of observations is generated by a sequence of unobserved states. The hidden state transitions are assumed to follow a first-order Markov chain. The theory of hidden Markov models (HMMs) originates from the work of Baum et al. in the late 1960s (
Baum and Petrie (
1966);
Baum and Eagon (
1967)). In the rest of this section, we introduce the theory of hidden Markov models (HMMs), following
Rabiner (
1990).
2.1. Formal Definition of a HMM
In order to formally define a hidden Markov model (HMM), the following elements are required:
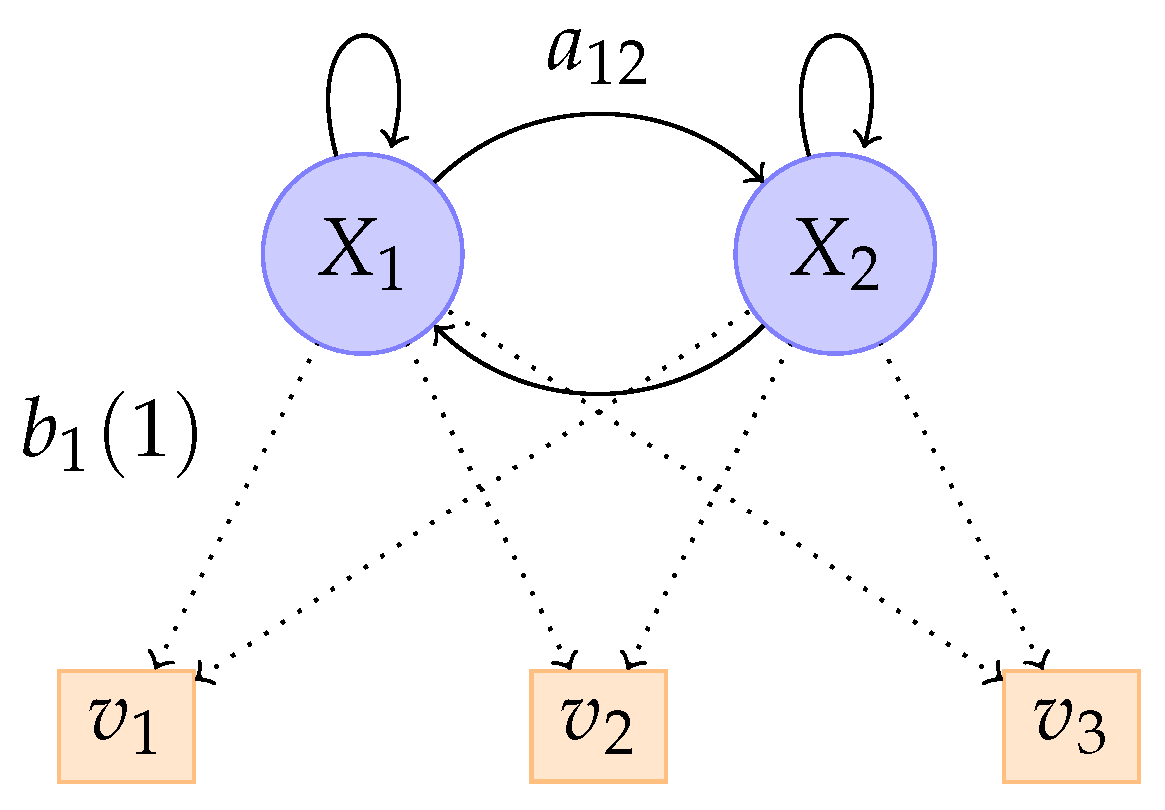
N, the number of hidden states. Even though the states are not directly observed, in many practical applications they have some physical interpretation. For instance, in financial time-series, hidden states may correspond to different phases of the business cycle, such as prosperity and depression. We denote the states by , and the state at time t by .
M, the number of distinct observation symbols per state. These symbols represent the physical output of the system being modeled. The individual symbols are denoted by .
The transition probability distribution between hidden states,
, where
The observation symbol probability distribution in state
j,
, where
The initial distribution of the hidden states,
, where
The parameter set of the model is denoted by
. A graphical representation of a hidden Markov model with two states and three discrete observations is given by
Figure 1.
In the case where there are an infinite amount of symbols for each hidden state,
is omitted and the observation probability
, conditional on the hidden state
, can be replaced by
If the observation symbol probability distributions are Gaussian, then , where is the Gaussian probability density function, and and are the mean and standard deviation of the corresponding state , respectively. In that case, the parameter set of the model is , where u and are vectors of means and standard deviations, respectively.
2.2. The Three Basic Problems for HMMs
The idea that HMMs should be characterized by three fundamental problems originates from the seminal paper of
Rabiner (
1990). These three problems are the following:
Problem 1 (Likelihood). Given the observation sequence and a model , how do we compute the conditional probability in an efficient manner?
Problem 2 (Decoding). Given the observation sequence and a model λ, how do we determine the state sequence which optimally explains the observations?
Problem 3 (Learning). How do we select model parameters that maximize ?
2.3. Solutions to the Three Basic Problems
2.3.1. Likelihood
Our objective is to calculate the likelihood of a particular observation sequence,
, given the model
. The most intuitive way of doing this is by summing the joint probability of
O and
Q for all possible state sequences
Q of length
T:
The probability of a particular observation sequence
O, given a state sequence
, is
as we have assumed that the observations are independent. The probability of a state sequence
Q can be written as
The joint probability of
O and
Q is the product of the above two terms; that is,
Although the calculation of using the above definition is rather straightforward, the associated computational cost is huge.
Thankfully, a dynamic programming approach, called the Forward Algorithm, can be used instead.
Consider the forward variable
, defined as
We can solve for
inductively using Algorithm 1.
| Algorithm 1 The Forward Algorithm. |
|
Correspondingly, we can define a backward variable
as
Again, we can solve for
inductively using Algorithm 2.
| Algorithm 2 The Backward Algorithm. |
|
2.3.2. Decoding
In order to identify the best sequence
for the given observation sequence
, we need to define the quantityx
To actually retrieve the state sequence, it is necessary to keep track of the argument which maximizes Equation (
16), for each
t and
j. We do so via the array
. The complete procedure for finding the best state sequence is presented in Algorithm 3.
| Algorithm 3 Viterbi algorithm. |
|
2.3.3. Learning
The model which maximizes the probability of an observation sequence
O, given a model
, cannot be determined analytically. However, a local maximum can be found using an iterative algorithm, such as the Baum-Welch method or the expectation-maximization (EM) method (
Dempster et al. 1977). In order to describe the iterative procedure of obtaining the HMM parameters, we need to define
, the probability of being at the state
at time
t, and the state
at time
, given the model and observation sequence; that is,
Using the earlier defined forward and backward variables,
can be rewritten as
We define
as the probability of being in state
at time
t. It is clear that
Using these formulas, the parameters of a HMM can be estimated, in an iterative manner, as follows:
If
is the current model and
is the re-estimated one, then it has been shown, by
Baum and Eagon (
1967);
Baum and Petrie (
1966), that
.
In case the observation probabilities are Gaussian, the following formulas are used to update the model parameters
u and
:
3. Modelling the Evolution of Exchange Rates
As discussed in the introduction, the first step in calculating the future distribution of counterparty exposure is the generation of scenarios using the models that represent the evolution of the underlying market factors. These factors typically include interest and exchange rates, equity and commodity prices, and credit spreads. This article is concerned with the modeling of exchange rates.
3.1. Geometric Brownian Motion
In mathematical finance, the Geometric Brownian Motion (GBM) model is the stochastic process which is usually assumed for the evolution of stock prices (
Hull 2009). Due to its simplicity and tractability, GBM is also a widely used model for the evolution of exchange rates.
A stochastic process,
, is said to follow a GBM if it satisfies the following stochastic differential equation:
where
is a Wiener process, and
and
are constants representing the drift and volatility, respectively.
The analytical solution of Equation (
33) is given by:
With this expression in hand, and knowing that , one can generate scenarios simply by generating standard normal random numbers.
3.2. A Hidden Markov Model for Drift and Volatility
One of the main shortcomings ofthe GBM model is that, due to the assumption of constant drift and volatility, some important characteristics of financial time-series, such as volatility clustering and heavy-tailedness in the return distribution, cannot be captured. To address these limitations, we consider a model with an additional stochastic process. The observations of the exchange rates are assumed to be generated by a discretised GBM, in which both the drift and volatility parameters are able to switch, according to the state of an unobservable process which satisfies the Markov property. In other words, the conditional probability distribution of future states depends solely upon the current state, not on the sequence of states that preceded it. The observations also satisfy a Markov property with respect to the states (i.e., given the current state, they are independent of the history).
Thus, we consider a hidden Markov model with Gaussian emissions
, as was presented in
Section 2.1. We denote the hidden states by
, and the state at time
t as
. The unobservable Markov process governs the distribution of the log-return process
, where
. The dynamics of
Y are then as follows:
where
and
are independent standard normal random numbers.
The transition probabilities of the hidden process, as well as the drift and volatility of the GBM, can be estimated from a series of observations, using the algorithms presented in
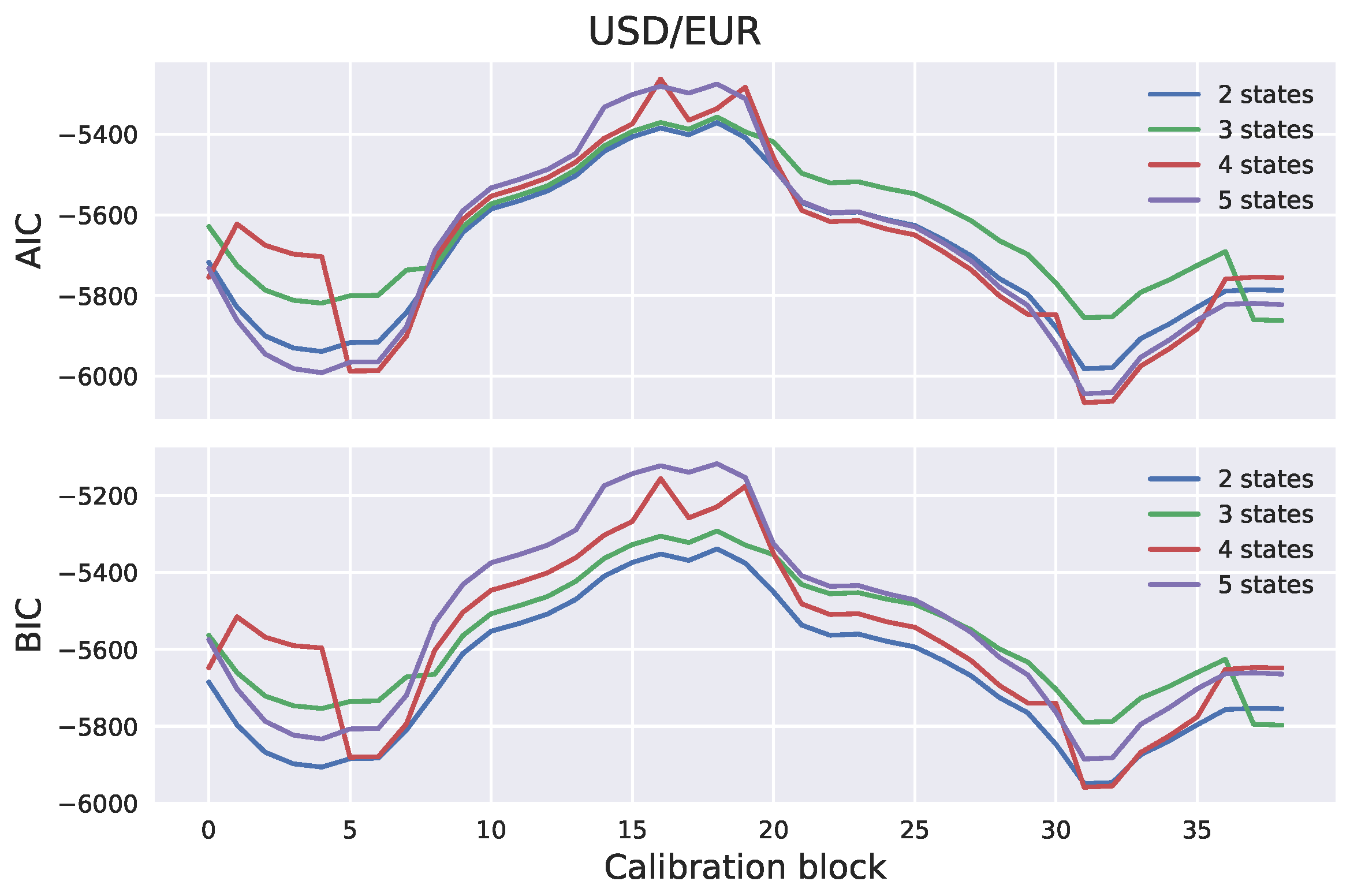
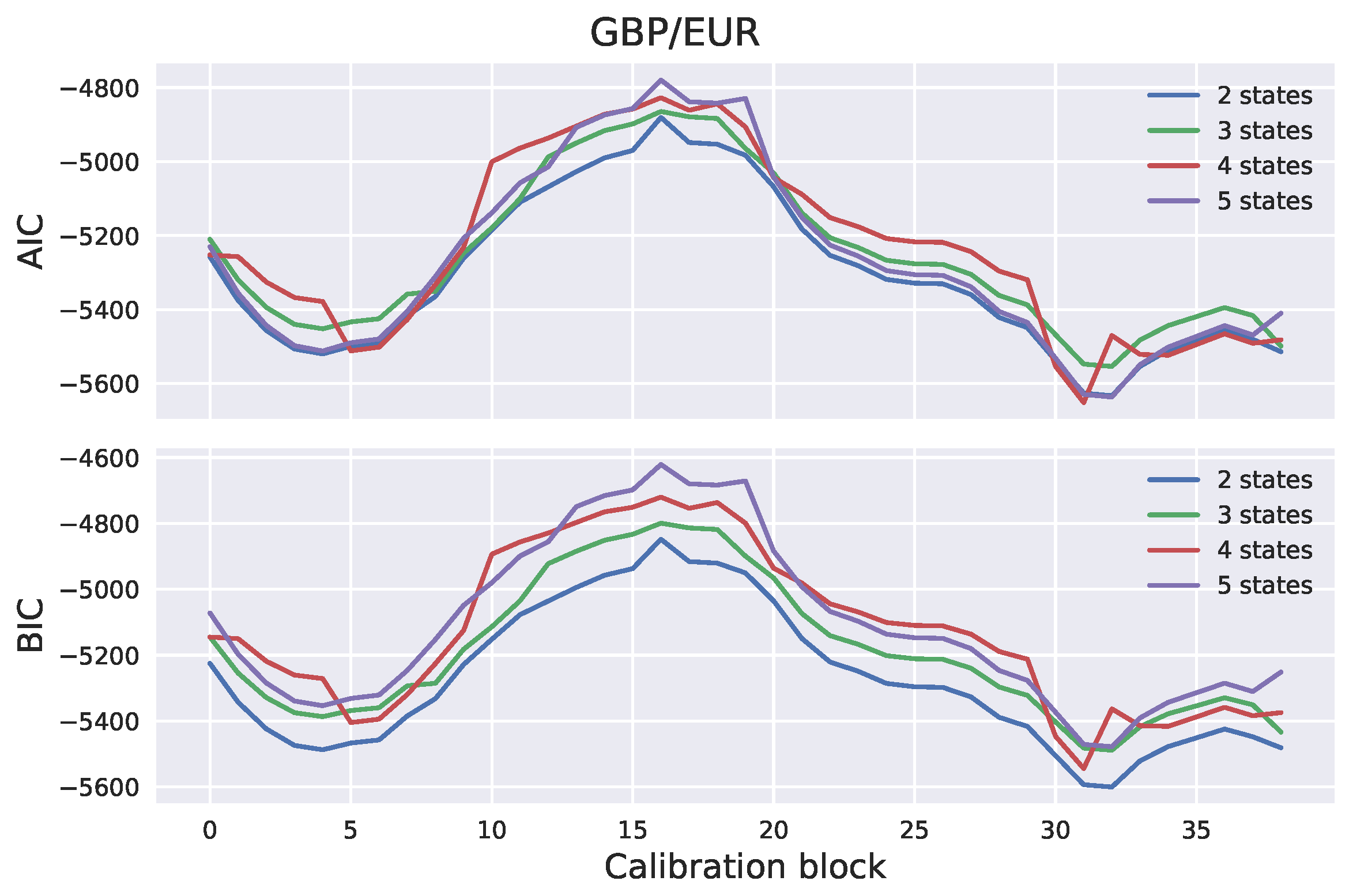
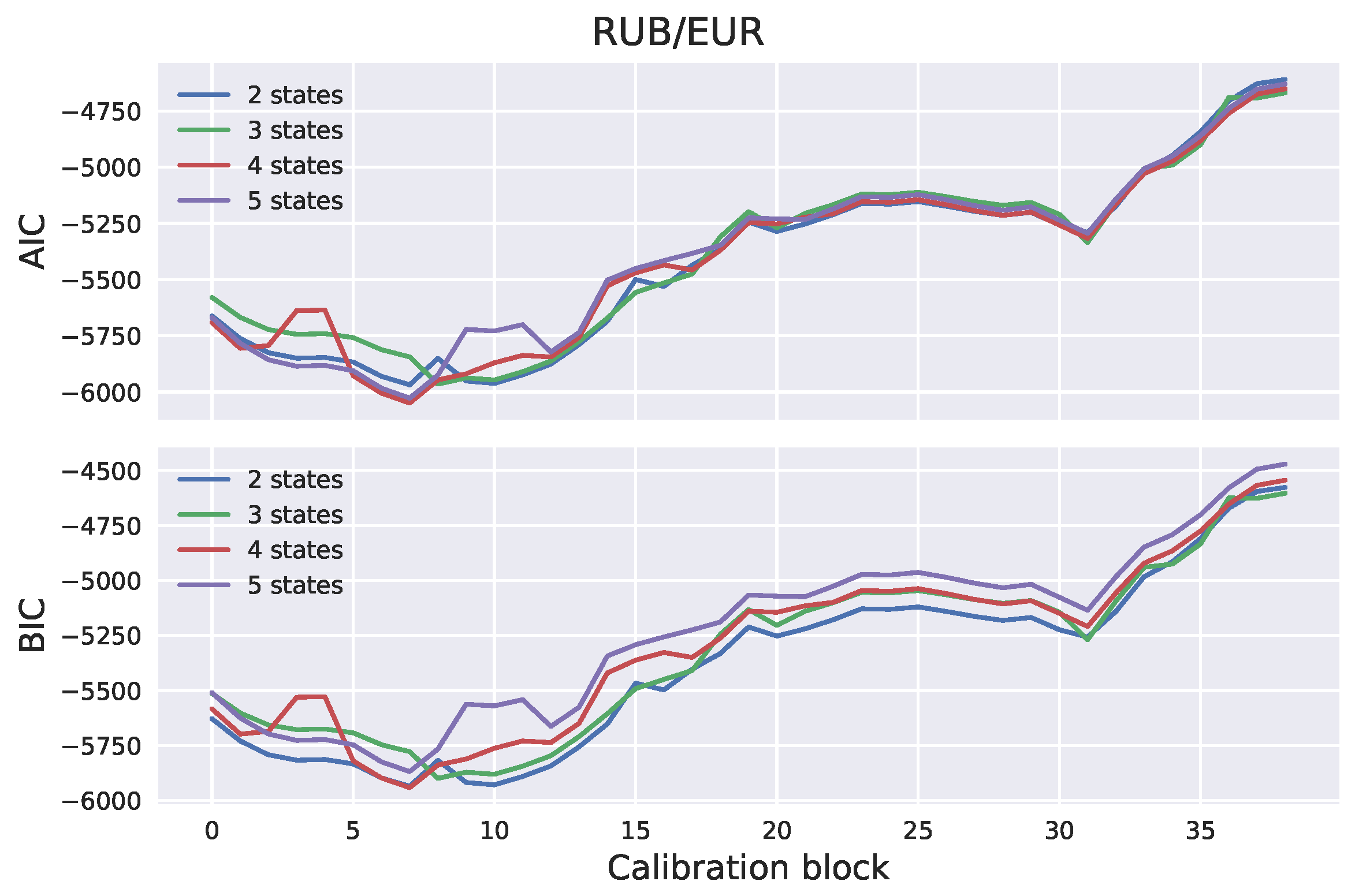
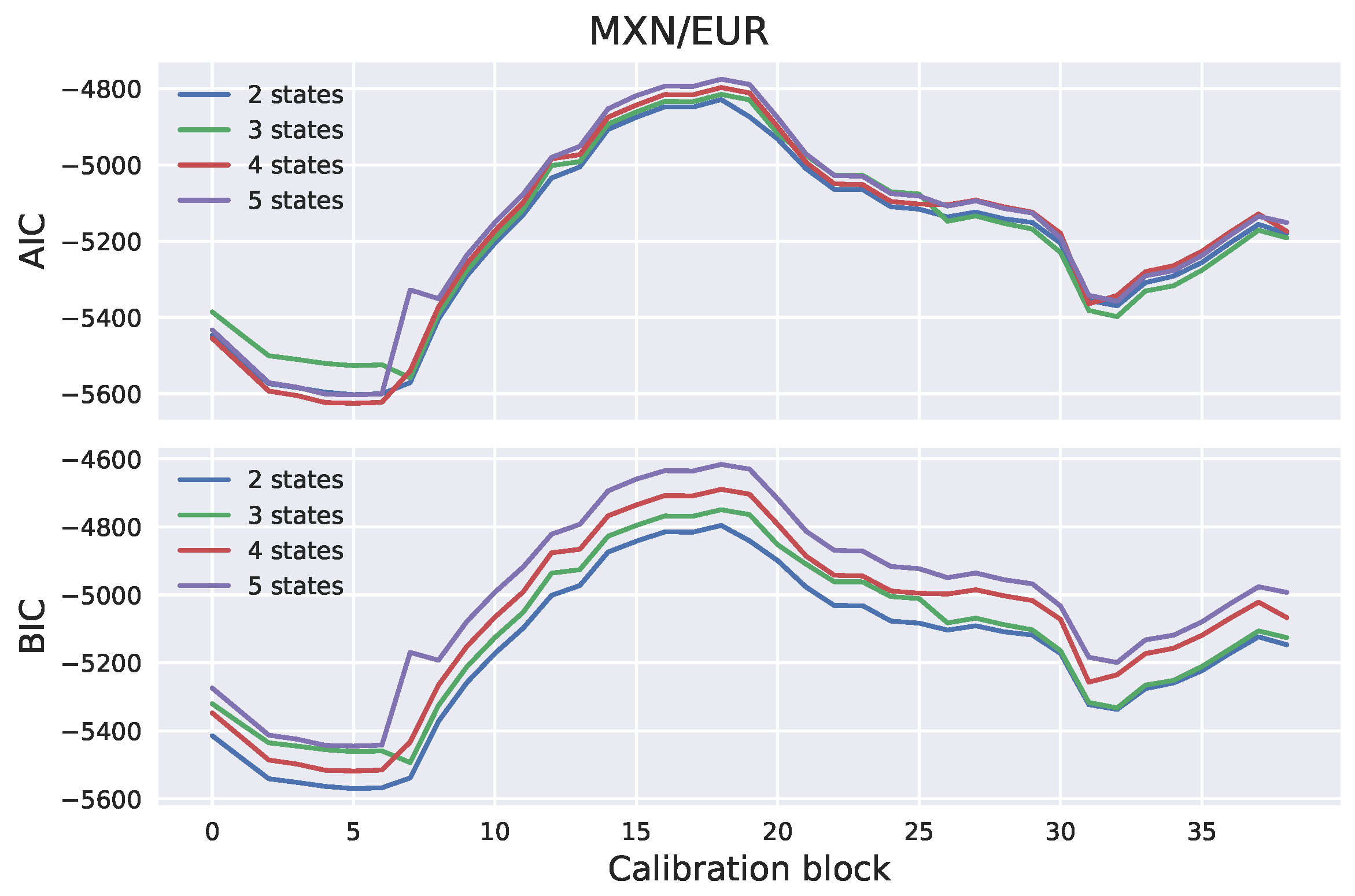
Section 2. The number of hidden states has to be specified in advance. In many practical applications, the number of hidden states can be determined based on intuition. For example, stock markets are often characterized as “bull” or “bear”, based on whether they are appreciating or depreciating in value. A bull market occurs when returns are positive and volatility is low. On the other hand, a bear market occurs when returns are negative and volatility is high. It would, therefore, be in line with intuition to assume that stock market observations are driven by a two-state process. The number of states can also be determined empirically; for example, using the Akaike information criterion (AIC) or the Bayesian information criterion (BIC). Once the model parameters have been estimated, scenarios can be generated by generating the hidden Markov chain and sampling the log-returns from the corresponding distributions.
6. Conclusions
In this paper, we presented a hidden Markov model for the evolution of exchange rates with regards to counterparty exposure. In the proposed model, the observations of the exchange rates were assumed to be generated by a discretized GBM, in which both the drift and volatility parameters are able to switch, according to the state of a hidden Markov process. The main motivation of using such a model is the fact that GBM can assign unrealistically low probabilities to extreme scenarios, leading to the under-estimation of counterparty exposure and the corresponding capital buffers. The proposed model is able to produce distributions with heavier tails and capture extreme movements in exchange rates without entirely departing from the convenient GBM framework.
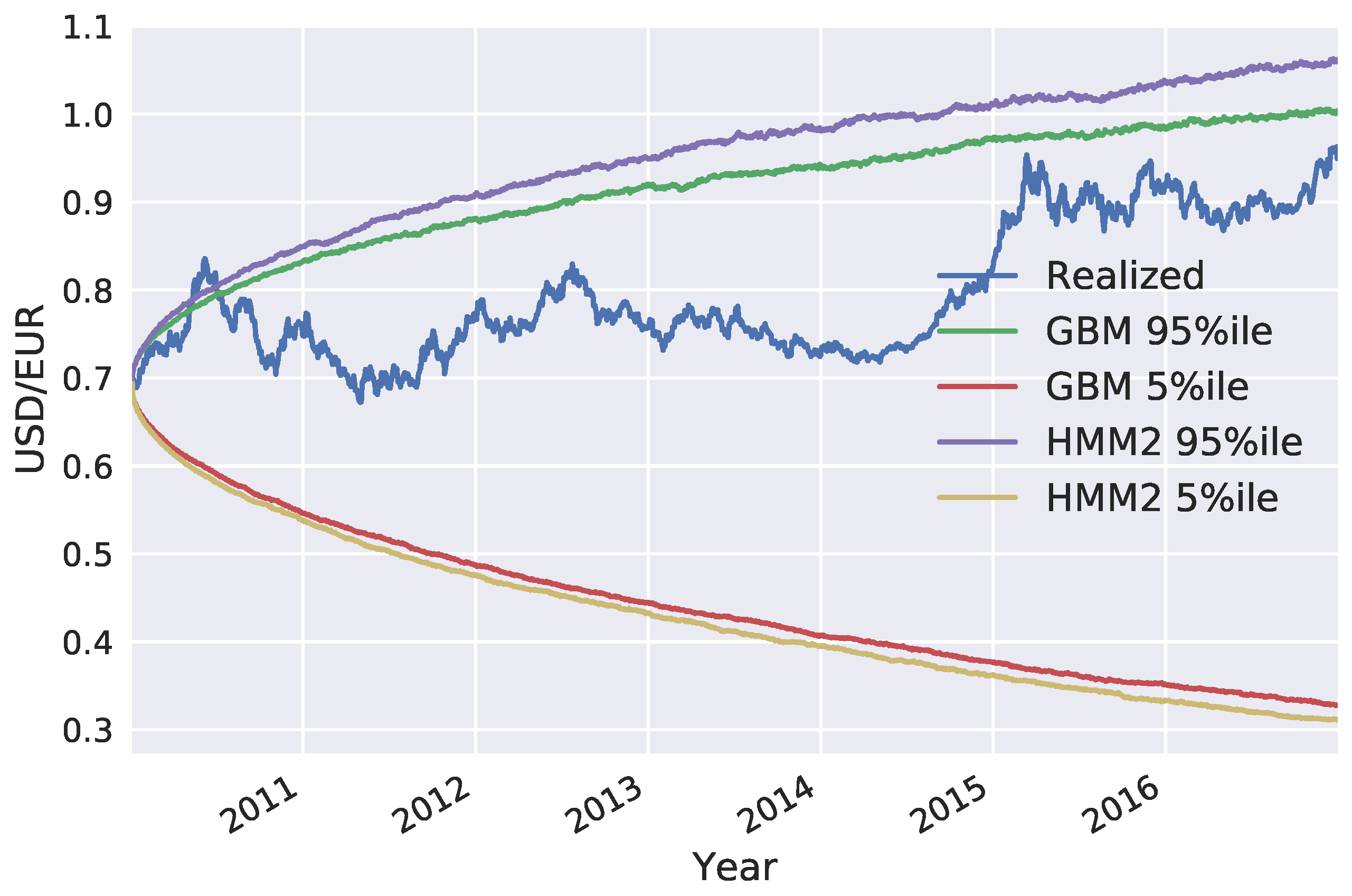
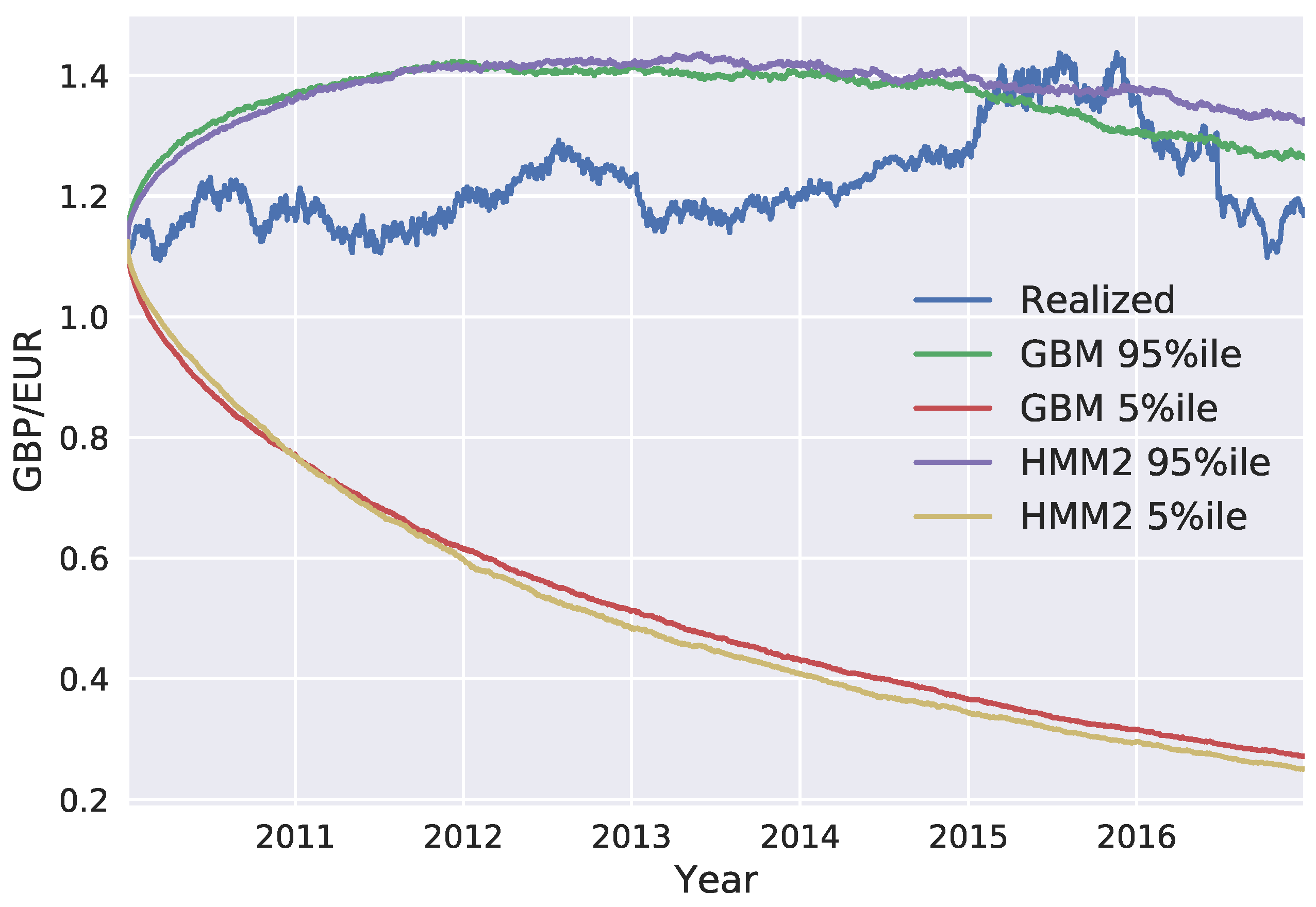
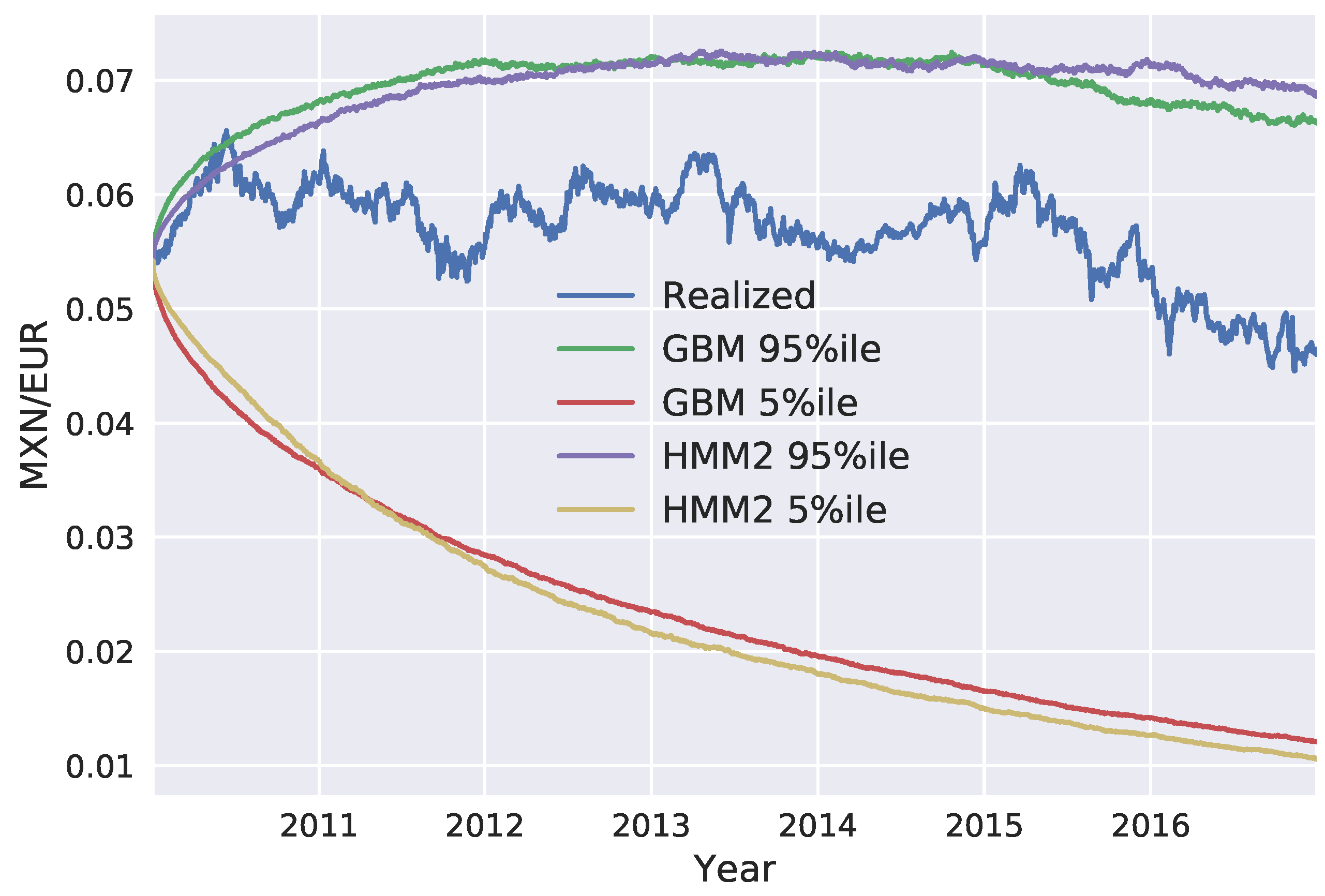
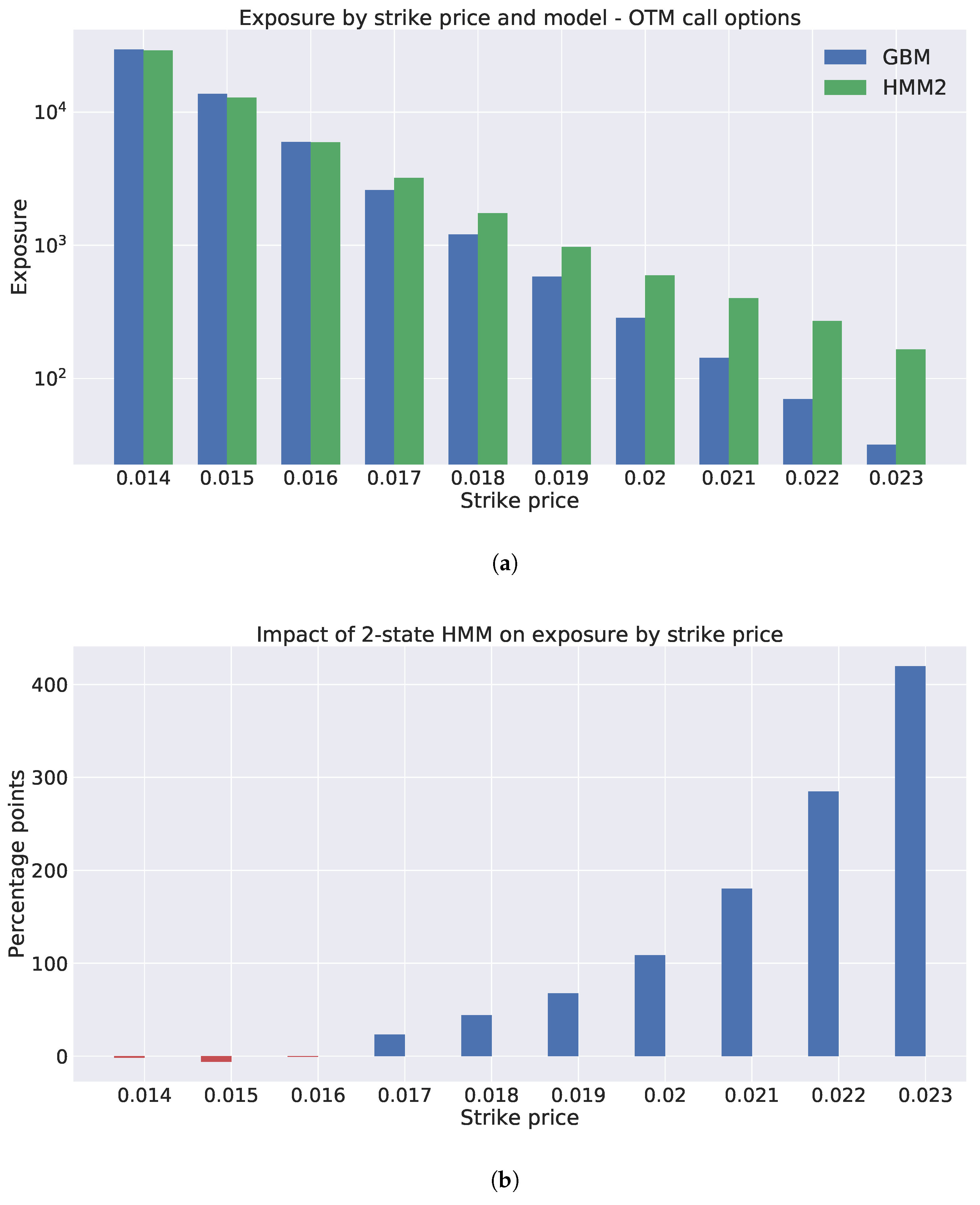
We generated exchange rate scenarios for four currency pairs: USD/EUR, GBP/EUR, RUB/EUR, and MXN/EUR. A risk factor evolution model backtesting exercise was performed, in line with Basel III requirements, and the the percentiles of the long-term distribution cones were obtained. The performances of the one-state and two-state models (GBM and the two-state HMM, respectively) were found to be very similar, with the two-state model HMM being slightly more conservative. However, when the generated scenarios were used to calculate exposure profiles for options on the RUB/EUR exchange rate, we found significant differences between the results of the two models. These differences were even more pronounced for deep out-of-the-money options.
Our study highlights some of the limitations of backtesting as a tool for comparing the performance of RFE models. Backtesting can be a useful way to objectively assess model performance. However, it can only be performed over short time horizons; with our available data, we could perform a statistically sound test of modeling assumptions for a time horizon of maximum length three months. It is, therefore, important to put effort into the interpretation of backtesting results, before they are translated into conclusions about model performance. Our results show how two models with similar performances in a backtesting exercise can result in very different exposure values and, consequently, in very different regulatory and economic capital buffers. This can lead to regulatory arbitrage and potentially weaken financial stability and, further, turn into a systemic risk.
The research presented in this paper can be extended in a number of ways, such as considering the evolution of risk factors other than exchange rates. Another topic worthy of investigation is the enhancement of the backtesting framework presented by
Ruiz (
2014), by considering statistical tests similar to the ones presented by
Berkowitz (
2001) and
Amisano and Giacomini (
2007). Finally, an interesting research direction is the development of an agent-based simulation model with heterogeneous modeling approaches, with regards to the RFE models. This model could potentially give valuable insights into the impact of heterogeneous models in financial stability.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}