1. Introduction
We introduce a methodology by using risk measures that can detect more general risk-return tradeoff opportunities than classical arbitrage ones. An arbitrage portfolio provides a cash flow that can never be negative at zero cost. We define the weaker concept that describes a portfolio delivering cash flows with negative risk at zero cost, which we call a desirable portfolio or opportunity.
We use optimization techniques to quantitatively measure and detect the existence of desirable opportunities (or optimal portfolios from a financial point of view) which we define through convex risk measures. Then, we apply the theory to analyze market integration and to study the credit quality of bonds issued in defaultable markets. In the following, we give a short review of risk measures, as they are essential tools in our analysis.
Risk measures are popular tools in gauging and mitigating the risk of financial positions. In particular, they are helpful in determining capital requirements which are necessary to maintain the solvency of a company. For a thorough review of risk measures and the many useful references within, we refer to
Föllmer and Weber (
2015). Most of the popular risk measures are either coherent or convex
1. The former was introduced in
Artzner et al. (
1999), while, for the latter, we refer to
Föllmer and Schied (
2011).
Coherent risk measures are convex but not the other way around. Convex risk measures are more convenient when dealing with optimization. In particular, this is the case when the constraints of admissible assets of an optimization problem form a convex set rather than a cone. This is argued in
Weber et al. (
2013) and
Föllmer and Weber (
2015). Hence, the main results here are presented according to a class of convex risk measures covering a wide range of practical risk measures such as CVaR.
We use convex risk measures and ignore transaction costs, which implies a linear pricing functional to formulate and detect the desirable opportunities in markets by forming a static optimal portfolio in a sense to be precisely defined.
We study two optimization problems. In the first one, the optimal value is subject to some constraints determined through a convex risk measure where we simply maximize profit for a given negative risk. In the second problem, we maximize the profit and minimize risk simultaneously, subject to some sequential arbitrage constraints introduced in
Balbás and López (
2008). These optimization problems are applied to quantify and detect the desirable portfolios in markets.
We present two applications of this portfolio optimization theory. In the first one, we use the theory to build an indicator to measure market integration and identify inefficiencies in the market. However, the second, and main, application of this work is to introduce a numerically implementable procedure to gauge the credit quality of bonds in a defaultable market assumed not to provide any desirable opportunities. For the numerical implementation, as an example, we use the CVaR risk measure.
Normally, a bond price is driven by two main factors. The first is the real bond price calculation based on an interest rate model assuming that there are no premiums to compensate embedded options or other contingencies such as default risk. The other part is a premium for the embedded options, the risk of default, or other contingencies. To reflect this risk of default, most bonds in the market are rated by rating agencies. Normally, the most credible bonds are the ones issued by governments. Our goal is to measure this credit premium and basically study the credit quality of defaultable bonds. Although there might be other types of risks affecting the price of a bond, here we assume that the risk of default is the dominating one.
The outline of the paper is as follows. In
Section 2, we discuss some basic facts and preliminaries. In
Section 3, the concept of desirable portfolios, based on optimization theory and risk measures, is defined. A dual problem plays a critical role in providing Karush-Kuhn-Tucker-like conditions. The model calibration and numerical implementations are explained in
Section 4. In
Section 5, we apply the model to market integration, and see how the dual solution allows us to measure “potential pricing errors” and market inefficiencies. Finally, in
Section 6, we show the application of the theory to measure the credit quality of defaultable bonds.
2. Preliminaries
Assume that uncertainty in a market is modeled by the probability space
, and that
is an
matrix representing a portfolio of
n bonds with possible future cash flows at times
. The column
j of matrix
A, denoted by
, represents the future cash flows of bond
j in the portfolio, i.e.,
at the future dates
, while row
i represents the total cash flows of these
n bonds at time
. Here,
represents the maturity date of the cash flows, the last time when a payment is made in the portfolio.
2 In addition, suppose that
, with
, is the current price of the j-th bond.
Assume that any future cash flow
of a bond, or in general of a portfolio, is reinvested and the accumulated wealth generated by this cash flow is denoted by
. Here, we assume that this reinvestment is in fixed income markets. Although the cash flows are predetermined, because of the fluctuations in interest rates, the accumulated wealth is a random variable at the maturity time
T. For now, we assume that this is the only source of randomness that makes
uncertain. This provides the motivation to define the accumulated wealth function
, where
and
is a vector in
.
Suppose that , where Y is a Banach space of random variables equipped with a norm , and with the dual space Z. By ignoring transaction costs, we can assume that is a linear function.
To control the risk over the space Y, we use risk measures. In our work, this space is interpreted as the space of all future gains. In general, a risk measure can be defined over the space , the set of all real valued random variables. For any random variable X belonging to , the quantity can be interpreted as the risk associated with the future wealth or gain X in a period of time. First, we review some axioms of risk measures.
Suppose that X and Y represent gains of two investments and consider the following properties:
Subadditivity: For all , .
Positive homogeneity: For all and , .
Translation invariance: For all and all , .
Monotonicity: For all , if then .
Convexity: For all ,
A risk measure is called coherent if it satisfies the subadditivity, positive homogeneity, translation invariance, and monotonicity. A risk measure that satisfies monotonicity, translation invariance, and convexity is called a convex risk measure. Thus, coherent risk measures are convex, but not the other way around.
Artzner et al. (
1999) define coherent risk measures; however, in their paper, the random variable
X represents a loss. They also find a representation theorem on a finite probability space.
Since the work of
Artzner et al. (
1999), their results have been extended in a variety of ways to define different types of risk measures. For instance, deviations and expectation bounded risk measures were introduced by
Rockafellar et al. (
2006). Their paper provides some insights on the structure of the sub-gradient sets associated with risk measures. Distortion risk measures were introduced by
Wang (
2000). The properties of distortion risk measures are analyzed in
Balbás et al. (
2009). All these risk measures are defined on a probability space. There are also empirical risk measures that are defined on data sets. These are discussed in
Section 4. We mention and review two important and well-known risk measures: The value-at-risk of
X for
is given by
where
is the distribution function of
X. The conditional value-at-risk (CVaR) is given by
when
is continuous at
Note that VaR is not a subadditive risk measure, and hence it can penalize diversification in a portfolio. However, in practice, when the probability level is high enough, VaR is typically subadditive, see
Daníelsson et al. (
2013), and that practical advantages may outweigh its theoretical deficiencies. Moreover,
Dhaene et al. (
2008) warn against blind adherence to coherent risk measures and point out that the desired property of subadditivity also depends on the precise business context at hand.
It is shown in
Artzner et al. (
1999) that VaR is not a convex risk measure. In addition, since VaR is smaller than CVaR, VaR might ignore the risk of large losses. In addition, it is harder to use VaR in optimization problems as it is not convex or subadditive. Our theory is not applicable to non-convex risk measures such as VaR.
While the definition of VaR is consistent through the literature, there are different terminologies and definitions for CVaR. Other terminologies such as Average Value at Risk (AVaR), Tail Value at Risk, and Expected Shortfall are used.
The representation in Equation (
1) is introduced in
Rockafellar and Uryasev (
2000). CVaR expressed in the form of Equation (
1) requires a continuous distribution. In
Acerbi and Tasche (
2002), another form of CVaR, called AVaR, is defined according to VaR where there is no requirement for the continuity of the distribution. In
Rockafellar and Uryasev (
2002), CVaR is defined for general distributions even discrete ones. To see different definitions of CVaR and how they are related with each other, we refer to
Föllmer and Schied (
2011).
The composition of
and
, denoted by
, defines a risk measure on
into
that satisfies subadditivity, positive homogeneity, and convexity if the risk measure
does so. If
is a convex risk measure, then the additivity of
leads to the convexity of
, i.e., for all cash flows
,
and for all
, we have:
The domain of
can be considered as a set of cash flows. For this reason, it would be more appropriate to call
a risk statistic, defined in more detail in
Section 4. In addition, due to the effect of interest rates,
in our model is not necessarily translation invariant, even if
is; we defer the discussion about this to
Section 4.
Throughout this paper, without any loss in generality, we assume that the risk measure is normalized, i.e., , and so we conclude that . Using a suitable representation of or plays an important role in the next few sections. In the following, we specify the type of representation that we are going to use.
Recall that Y (which includes ) is a Banach space equipped with the norm , and with the dual space Z.
Assumption 1. Suppose that is any risk measure on Banach space Y that admits the following representation. There exists such that for every :whereis compact with respect to the product topology of and the usual topology on . It is easy to see that satisfies convexity, and it is also continuous with respect to the norm topology defined by .
The properties of a risk measure under Assumption 1 are discussed in
Balbás et al. (2010a) for
. This assumption is met by many convex and coherent risk measures such as down side semi-deviations, CVaR, Wang’s distortion measure, the absolute deviation, and the standard deviation.
Therefore, we can take representation in Equation (
3) of Assumption 1 as our primal hypothesis on
, in the sense that any convex continuous risk measure can either satisfy it or it can be approximated by such risk measures with a compact sub-gradient set
3. In particular, the above approximation can be applied to
where the dual space of
Y is
and
. Throughout
Section 3, we suppose that
and Assumption 1 is in force.
If
satisfies convexity in Equation (
2), then, for every
, we have:
where
and
is the Euclidean inner product on
.
Using the previous representation or directly applying Fenchel’s duality theorem, see Theorem A.62 of
Föllmer and Schied (2011), we can further show the following.
Corollary 1. Assume that satisfies subadditivity and positive homogeneity, thenwhereand is the Euclidean inner product on . Remark 1. By max in the above corollary or in the rest of the section, we implicitly mean that the maximum is attained. For example, in Corollary 1, it turns out that there exists such that
4. Model Calibration
The numerical implementation of optimization problem in Equation (
8) and hence the primal problem in Equation (
5) relies on the closed form of the sub-gradient set
. The sub-gradient set of some risk measures has already been derived. For example, the sub-gradient of
is given in closed form by
Rockafellar et al. (2006). Thus, one can propose two approaches for the numerical implementations. One approach is to identify
and then solve the optimization problems accordingly, but the structure of a sub-gradient set is not known in general. Alternatively, one can concentrate on
and its sub-gradient set instead, which we discuss in the following. However, we must first make sure that risk measures
are consistent with the theory developed in
Section 3.
Remark 2. In Equation (4), instead of the representation of Assumption 1, one could use a representation of such as that of Corollary 1. The arguments of Section 3 are still valid for the risk measure ; however, the results and the optimization problems depend on the representation of and its sub-gradient set. The structure of the sub-gradient set of risk measure , that is built on , can be totally different than that of . For instance, this can be observed in the following simple model.
Assume that the probability space includes only two scenarios, i.e.,
with
,
. Take the risk measure to be
, for some
To model the evolution of the interest rate, we use the following one period simple tree model
Since
is
, from
Rockafellar et al. (2006), it can be proven that the sub-gradient set of
is the following,
Using this sub-gradient, and the representation provided by Corollary 1, after some manipulations, one can show that the sub-gradient set of
is given by
While the sub-gradient of
is given by Equation (
18), the sub-gradient set in Equation (
19) is different. Even in this simple example, finding the sub-gradient set requires some manipulations, not necessarily applicable to real portfolio examples. Therefore, we need a tractable and practical approach to identify the sub-gradient set in a numerical implementation. In the following, we try to solve this problem by using statistical risk measures, see
Kou et al. (2013) for more details.
A special feature of the risk measure
is that its domain is not a random space. One can think that
is defined on a data set. In other words, each vector in
can be interpreted as a set of data. This is the idea behind risk statistics, as defined in
Kou et al. (2013), that they use to define some risk measures and prove their representation theorems. We first review their definitions of risk statistics.
Definition 3. The function is a natural risk statistic if it satisfies the following conditions:
- C(1)
For all and , where 1 is the m-dimensional vector , (translation invariance).
- C(2)
For all and , , (positive homogeneity).
- C(3)
For all vectors and in , if then , (monotonicity).
- C(4)
For all vectors and in , if for then , (comonotonic subadditivity).
- C(5)
For any permutation of , we have , (permutation invariance).
Definition 4. The function is a coherent risk statistic if it satisfies conditions C(1), C(2), C(3), and subadditivity.
Definition 5. The function is a law-invariant coherent risk statistic if it satisfies conditions C(1), C(2), C(3), C(5), and subadditivity.
In
Kou et al. (2013), the representation theorem of these risk measures is obtained. In numerical implementation using risk statistics, we first need to specify a sub-gradient set. For simplicity, we take the maximal sub-gradient set, for instance
, of a natural risk statistic. However, numerical implementations of natural, coherent, and law-invariant coherent risk statistics in our model lead to both conceptual and practical problems. We already mentioned that risk statistics are compatible with our framework, but, in numerical implementations, we must also check the consistency of their axioms with the set of the available data.
Here, the data used are a set of cash flows of a bonds portfolio. In
Kou et al. (2013), static data at a fixed time are used, while here the data are time dependent, and therefore, certain axioms of the above risk measures are not consistent with our setup. For example, the translation invariance property is not valid in our framework due to the effect of the interest rate over the cash flow at different times.
The same problem occurs for axiom C(5). For instance, consider a one-period maturity,
then by C(5),
. However, by definition,
is equal to
, that represents the risk associated to the future wealth of a portfolio that pays one unit of currency at time
and nothing at time
. Of course, due to the uncertainty of factors such as random interest rates, this risk is different from
. In the following, we provide a representation theorem based on subadditivity, positive homogeneity, and monotonicity. All of these axioms are consistent with the portfolio data and with the framework in
Section 2.
Theorem 3. If is a risk statistic that satisfies subadditivity and positive homogeneity, then where is the subset of If, in addition, the risk measure satisfies monotonicity, then
This theorem is a result of Fenchel’s duality theorem and it can be proved following
Ahmed et al. (2008). Regarding the above theorem, it is also important to recall what
,
, and
mean. For instance, recall that
; in simple words, this is the current risk of future income at time
T, obtained by investing one dollar at time
, one dollar at time
,…, and one dollar at time
. There are similar interpretations for
and
. In our numerical example, we use the following special version of the above risk statistic.
Definition 6. The function is the risk statistic DF (default free) if it satisfies the properties of subadditivity, positive homogeneity, monotonicity, and admits the following representation: Remark 3. Despite our simple data set and representation theorem in Definition 6, the numerical implementations lead to meaningful results, in particular reasonable credit premiums, explained in Section 6. However, a more sophisticated implementation would require using an empirical distribution or a set of simulated data for . As it turns out, this is in fact possible. The risk statistic in Theorem 3 admits a general structure. As in Definition 6, a more specific choice of leads to new risk measures. In Assa and Morales (2010), under some circumstances, it is shown that a specific with a single member is an estimator for . This estimator is built using an empirical distribution, and the main criteria is that the original risk measure ρ should be a distribution-based one. On the other hand, in Krätschmer et al. (2014), it is shown that this estimator is a plug-in estimator, and it is strongly consistent which means that the estimator converges to almost surely. From this perspective, the risk statistics DF with specified weights , can be considered as an estimator of . We determine the weights through the dual optimization problem. To apply the risk measure DF, we need to specify the original risk measure and then estimate , , , and for all .
Suppose that , (here is the confidence level), and let the instantaneous short rate be modeled by the stochastic process on the space satisfying the usual conditions. Then, we obtain , and similar expressions for and . Therefore, after choosing an interest rate model, we need to calibrate the model and estimate the previous expression. We do this in two steps.
Step 1. Calibrating an interest rate model: for the simplicity of computation, we use the Vasicek model for the interest rate:
, where
,
b,
are constants and
is a standard Brownian motion
4. Here, we use the generalized method of moments (GMM) to estimate the parameters, see
Hansen (1982).
It is worth mentioning that there are alternative interest rate models. For a discussion and comparison of interest rate models, we refer to
Boero and Torricelli (1996). In addition, the inversion of the yield curve is another popular approach to estimate the parameters, see Chapter 24 of
Björk (2009).
The calibration results, based on the one-month US daily treasury yield rates from 2 January 2013 to 30 September 2014
5 and the GMM method, are:
,
,
, and
.
Step 2. Estimating , , and for all : using Itô’s formula and Fubini’s theorem for stochastic processes, see Theorem 64 of Chapter 4 of
Protter (2004), one can show that:
where
and
. Therefore, using Itô’s isometry, we can see that
has a normal distribution with mean of
and variance
. Hence, the random variable
has a lognormal distribution. In general, the sum of these lognormal random variables has a complicated distribution, especially when there is dependence between these random variables and this is the case for
. The distribution of this random variable has no closed form. In the following, we overcome this challenge through simulations to estimate
,
, and
for all
.
We only explain how to estimate
, as a similar procedure can be carried out for
and
. First, by using Fubini’s theorem for stochastic processes, we can deduce that
Equation (
21) has an advantage over Equation (
20) because, on the right hand side of Equation (
21), there is no integral term and hence the simulation is simpler. Now, using Euler’s discretization procedure, one can simulate the processes
and
, and so for a fixed
T simulate
,
. Hence, we can generate simulated values for the random variable
using Equation (
21). By generating a large number of random values, we can then estimate the cumulative distribution function of
Z and hence approximate
, for
.
Next, we consider data from a real portfolio, composed of six bonds taken from FINRA.
6 The profiles of these bonds are given in
Table 1. Based on these bonds, we have
and the cash flow times can be determined accordingly. The estimation results at 99% confidence level, i.e.,
are as follow:
,
, and part of the result for
is shown in
Table 2, with four decimal accuracy, where each entry
represents the value
for
. Note that, for example,
corresponds to the first coupon payment time which is
, and
corresponds to the last payment time which is
; therefore, we have 15 payment times in total. At payment times such as
, we have two coupons from Bond 1 and Bond 2, but, for
, we only have one coupon from Bond 3. In the next example, we provide the solution of the dual and primal problems.
In the following, we take the first approach discussed in
Section 3.1. However, the numerical examples and discussions could be easily modified for the second approach explained in
Section 3.2.
Example 1. For the portfolio that consists of Bonds 1 to 4 in Table 1, the optimal value of problem in Equation (6) using risk statistics DF and the above parameter estimations is zero. Next, we add Bond 5 to this portfolio, and in this case the optimal value is approximately equal to . The solution of the primal problem is equal to , , , , .
The solution of the dual problem is equal to , , , , , , , , , …
This example shows that Bonds 1 and 3 have no effect in maximizing the income within this set of bonds, as the primal solution yields . In addition, it shows that by selling one unit of Bond 2 and buying units of Bond 4, the estimated income is 7.8, as in the primal solution , and .
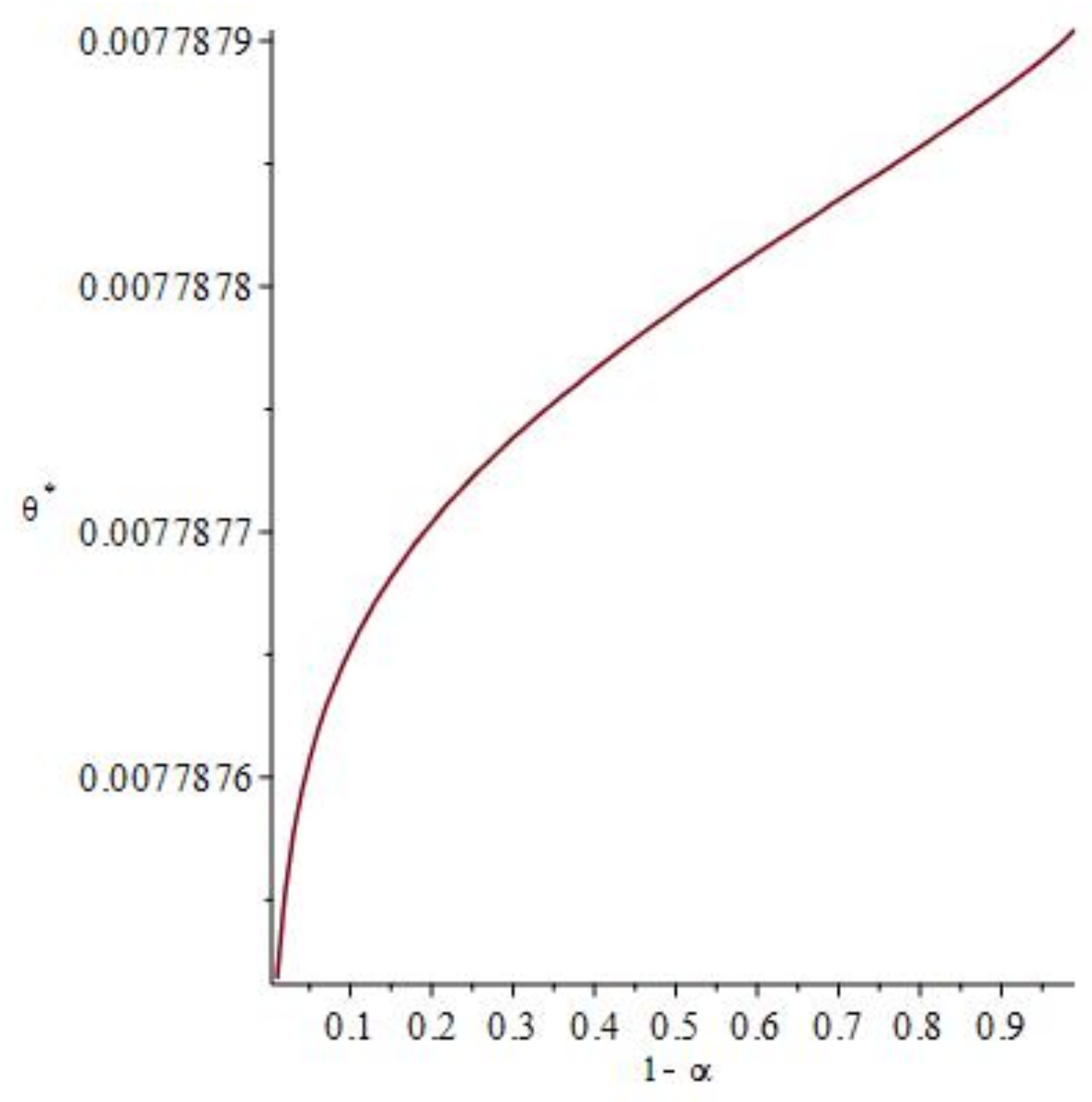
Remark 4. At this point, it is worth investigating the sensitivity of the solution with respect to changes in the confidence level α. This is illustrated in Figure 1 about which we have two observations: First, as the confidence level decreases (i.e. the tolerance level increases), the degree of risk-aversion also decreases and the investor will be willing to take more risk. In this case, the optimal value or income increases to reward the extra risk taken. Second, despite the increase in tolerance level , the model is actually robust, this means that, although the values of α vary between 0
and 1,
the values of only change marginally. In other words, the variation in the optimal desirable portfolio value is robust with respect to changes in α. 6. Application to Credit Premium Measurement
In this section, we discuss the second application of the theory by measuring the credit risk premium of corporate bonds. As there is an extensive credit risk literature, we only mention the following popular books with many useful references within for interested reader:
Bluhm et al. (2010) and
Duffie and Singleton (2012). Nevertheless, to the best of our knowledge, the following methodology in measuring credit risk premium, using risk measures, is new.
Suppose that
are the current prices of
default free bonds (with no embedded option or risk premium) for which we want to use as a base to calculate the credit premium of the defaultable bond
(with no embedded options) with the current price
. Since
is defaultable, we have
, where
is the price of the bond in the absence of the risk of default, and
is the credit premium of the bond that we are interested in estimating. Suppose that our subjective measure of risk is fixed and according to
, then the following proposition can provide an approximation (a lower bound) to the credit premium. Recall that we have taken the first approach of
Section 3.1.
Proposition 1. If the set of the prices does not provide any desirable portfolio, then , where is the optimal value of the dual problem in Equation (6) for this set of bonds.
The proof of this proposition is omitted as it follows from the same methodology as in
Balbás and López (2008), in particular Propositions 3.1 and 4.1 of their paper. However, their work is not based on a probability model, but the proofs can be adapted to the set up of this proposition.
As it was mentioned earlier, any non-zero optimal value could be due to the existence of a desirable portfolio or other embedded risk premiums such as default risk. However, if we assume that the market is free from any desirable opportunity, then the above proposition can provide an estimation for the credit premiums. Note that the procedure is based on Corollary 2 to estimate these credit premiums. The same procedure can be carried out by Corollary 3. Indeed, applying the latter should provide more accurate credit premiums than with Corollary 2, because it also counts the inconsistencies arising from the existence of strong sequential arbitrage opportunities in the market.
To implement the numerical procedure, we use the risk measure
with a confidence level of
, the estimated parameters of
Section 4, and the risk statistic DF explained in the last section. We choose a small portfolio as our market.
Remark 5. The above methodology can be also used to analyze the price of bonds with embedded options. Suppose that is the price of a default-free bond with an embedded option that has a price of . Hence, , where is the price of an equivalent bond without any embedded option. Then, similar to Proposition 1, one can obtain lower bounds for .
Example 3. Suppose that we want to estimate the credit worthiness of Bond 6 in Table 1 with the available data. We already observed in Examples 1 and 2 that Bonds 1 to 4 do not create a desirable portfolio. Therefore, this shows that these bonds are consistently priced with respect to the interest rate model and based on the assumption that there is no desirable opportunity in market; hence they can be used as a benchmark according to Proposition 1 to measure the credit quality of Bond 6 within the available data. For Bonds 1, 2, 3, 4, and 6, the optimization problem in Equation (8) in this case produces an optimal solution of . Therefore, by Proposition 1, a lower bound for the credit premium of Bond 6 is approximately equal to 0.44. 




{kind=link}