A Note on Parameter Estimation in the Composite Weibull–Pareto Distribution


Abstract
:1. Introduction
2. Parameter Estimation and Model Selection
3. A Simulation Analysis
- If , then
- If , then
- Average bias of the simulated estimates:
- Average root-mean-square errors:
- Coverage probability: percentage of confidence intervals containing the true value of at the 95% confidence level.
4. Conclusions
Acknowledgments
Conflicts of Interest
References
- Abu Bakar, Shaiful Anuar, Nor Aishah Hamzah, Mastoureh Maghsoudi, and Saralees Nadarajah. 2015. Modeling loss data using composite models. Insurance: Mathematics and Economics 61: 146–54. [Google Scholar]
- Calderín-Ojeda, Enrique. 2016. The distribution of all French communes: A composite parametric approach. Physica A: Statistical Mechanics and its Applications 450: 385–94. [Google Scholar]
- Cooray, Kahadawala. 2009. The Weibull-Pareto composite family with applications to the analysis of unimodal failure rate data. Communications in Statistics—Theory and Methods 38: 1901–15. [Google Scholar]
- Cooray, Kahadawala, and Malwane M. A. Ananda. 2005. Modeling actuarial data with a composite Lognormal-Pareto model. Scandinavian Actuarial Journal 5: 321–34. [Google Scholar]
- Giles, David E., Hui Feng, and Ryan T. Godwin. 2013. On the bias of the maximum likelihood estimator for the two-parameter Lomax distribution. Communications in Statistics—Theory and Methods 42: 1934–50. [Google Scholar]
- Klugman, Stuart A., Harry H. Panjer, and Gordon E. Willmot. 2008. Loss Models: From Data to Decisions, 3rd ed. Hoboken: John Wiley. [Google Scholar]
- Levy, Moshe. 2009. Gibrat’s Law for (all) cities: Comment. American Economic Review 99: 1672–75. [Google Scholar]
- Scollnik, David P. M. 2007. On composite Lognormal-Pareto models. Scandinavian Actuarial Journal 1: 20–33. [Google Scholar]
- Scollnik, David P. M., and Chenchen Sun. 2012. Modeling with Weibull-Pareto models. North American Actuarial Journal 16: 260–72. [Google Scholar]
- Wang, Min, and Wentao Wang. 2017. Bias-corrected maximum likelihood estimation of the parameters of the weighted Lindley distribution. Communications in Statistics—Theory and Methods 46: 530–45. [Google Scholar]
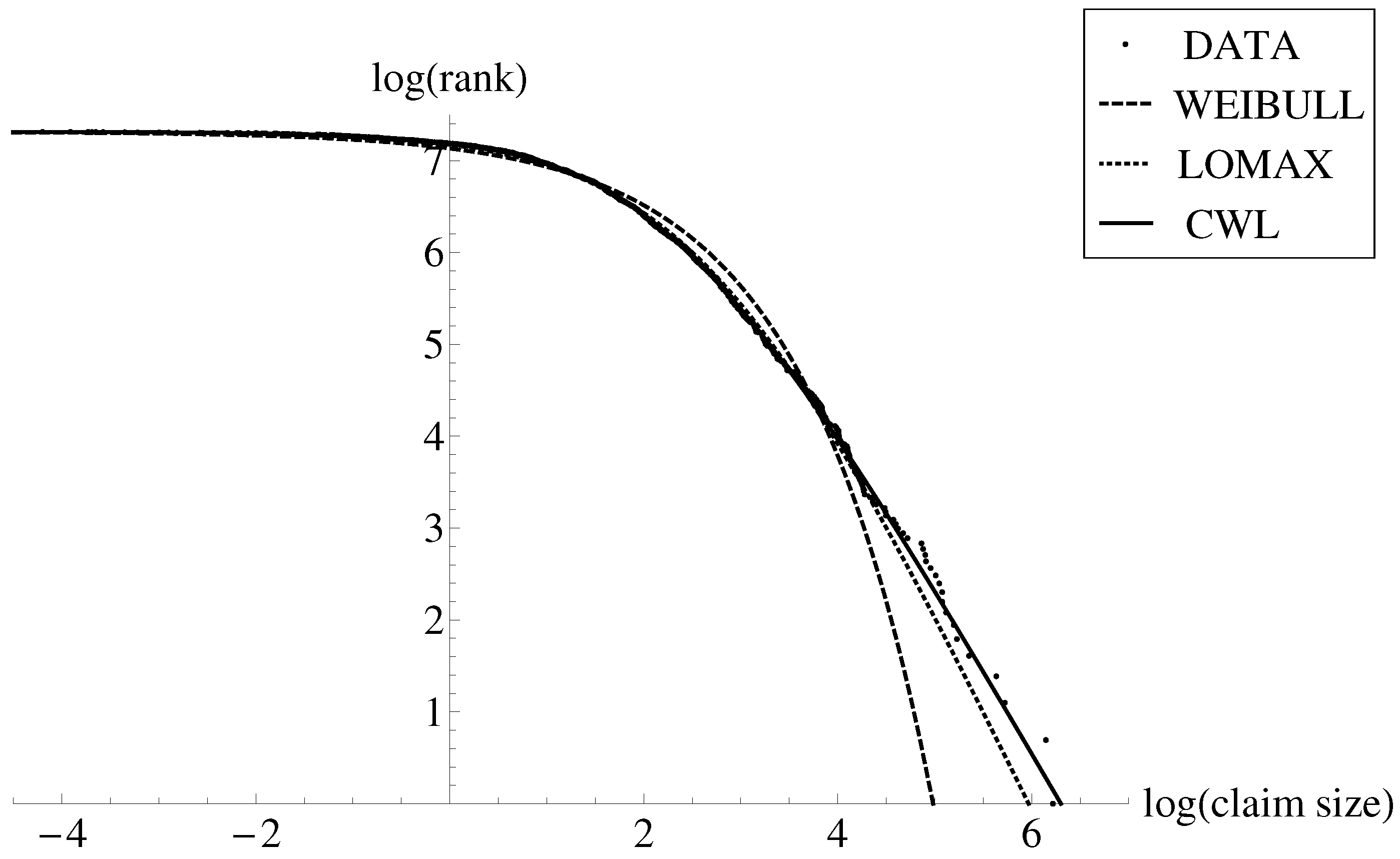

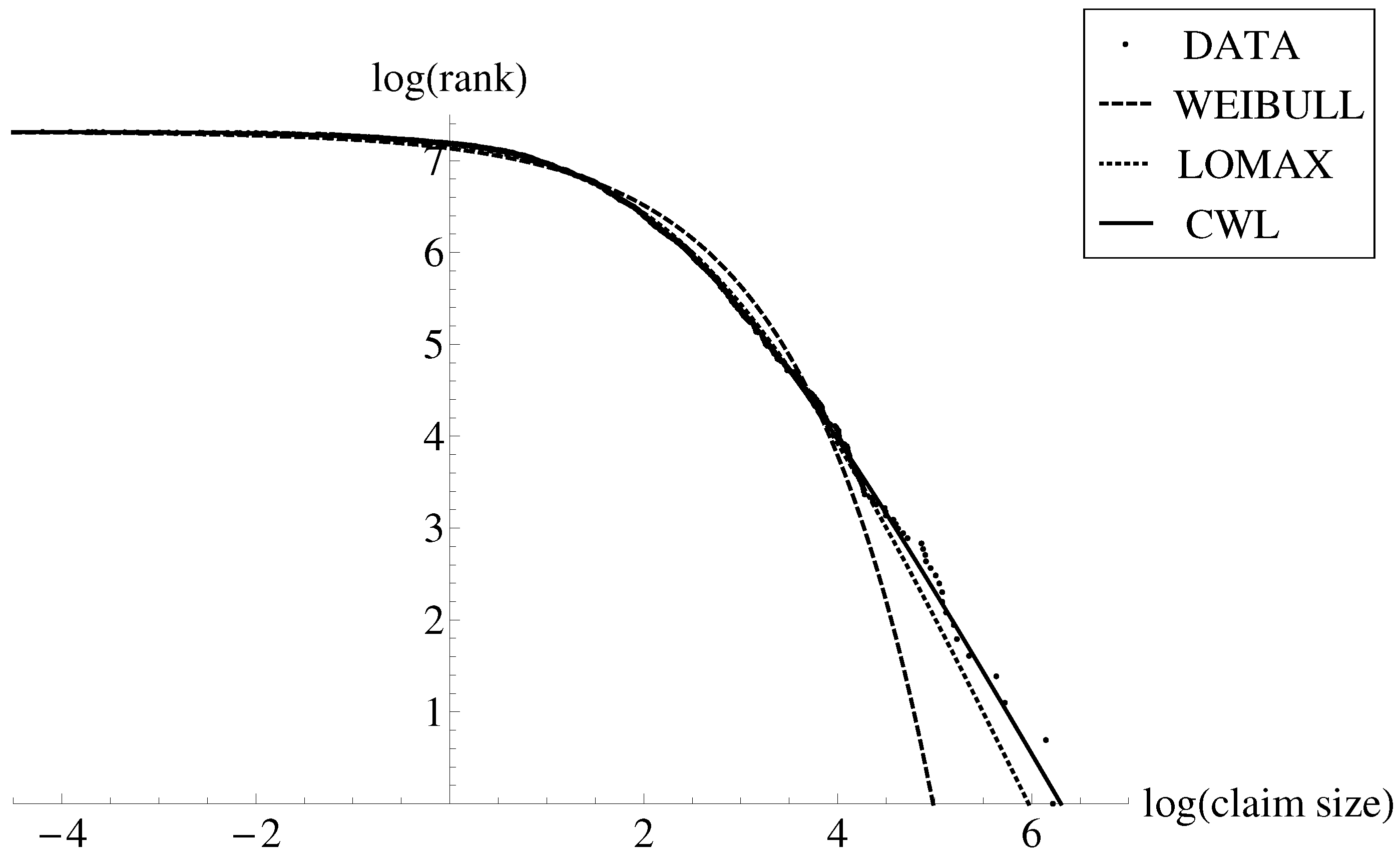{kind=link}
{kind=link}
| Model | R Function | Estimate (S.E.) | NLL | AIC | SBC |
|---|---|---|---|---|---|
| Weibull Lomax | mle | 5047.110 | 10,102.220 | 10,123.473 | |
| Weibull Lomax | mle2 | 5047.110 | 10,102.220 | 10,123.473 | |
| R Function | ||
|---|---|---|
| Sample Size | mle | mle2 |
| R Function | ||
|---|---|---|
| Sample Size | mle | mle2 |
| R Function | ||
|---|---|---|
| Sample Size | mle | mle2 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calderín-Ojeda, E. A Note on Parameter Estimation in the Composite Weibull–Pareto Distribution. Risks 2018, 6, 11. https://doi.org/10.3390/risks6010011
Calderín-Ojeda E. A Note on Parameter Estimation in the Composite Weibull–Pareto Distribution. Risks. 2018; 6(1):11. https://doi.org/10.3390/risks6010011
Chicago/Turabian StyleCalderín-Ojeda, Enrique. 2018. "A Note on Parameter Estimation in the Composite Weibull–Pareto Distribution" Risks 6, no. 1: 11. https://doi.org/10.3390/risks6010011
APA StyleCalderín-Ojeda, E. (2018). A Note on Parameter Estimation in the Composite Weibull–Pareto Distribution. Risks, 6(1), 11. https://doi.org/10.3390/risks6010011