1. Introduction
Increased exposure to catastrophic losses and the complexity of financial instruments require sophisticated risk assessment tools in areas such as (re) insurance, banking, finance, among others. Extreme value theory plays an important methodological role in risk management by providing appropriate instruments to deal with values as large as or even higher than those ever observed. These techniques include heavy-tailed models and measures to evaluate tail dependence, namely to infer to what extent the occurrence of a risk value in some variable influences an analogous occurrence in another variable.
Linear ARMA (autoregressive moving average) with heavy-tailed noise may be suitable to model time series presenting peaks of observations. However, in place of a summation, a maximum operator is more propitious to derive extremal properties. Max-autoregressive and moving maximum models were developed within this spirit, such as MARMA (max-autoregressive moving average) introduced in
Davis and Resnick (
1989) and M4 (multivariate maxima of moving maxima) processes presented in
Smith and Weissman (
1996). The Pareto model, which is closed under geometric multiplication and minimization, also motivated the first-order Pareto processes presented in
Arnold (
2001). Further analysis may be found in
Ferreira (
2016) and references therein.
A random variable (rv) is modeled by Pareto(
) if it has distribution function (df)
This model is a particular case of Pareto-type tail models, the class of regular varying tail distributions, that is,
where
is a slowly varying function (i.e.,
is a real function of positive real values satisfying
, as
,
). Parameter
is usually denoted as the tail index of the Pareto rv.
Consider
a Gaver–Lewis Pareto (GLP) process, presented in
Arnold (
2001). More precisely, for each positive integer
n, we have
where
is an independent and identically distributed (iid) sequence with common df Pareto(
) given in Equation (
1) and independent of the Bernoulli(
p) iid sequence
with
, and
independent of
. If
Pareto(
), then
is stationary also with marginal df Pareto(
). The GLP process corresponds to the exponentiated version of the Gaver–Lewis process introduced in
Gaver and Lewis (
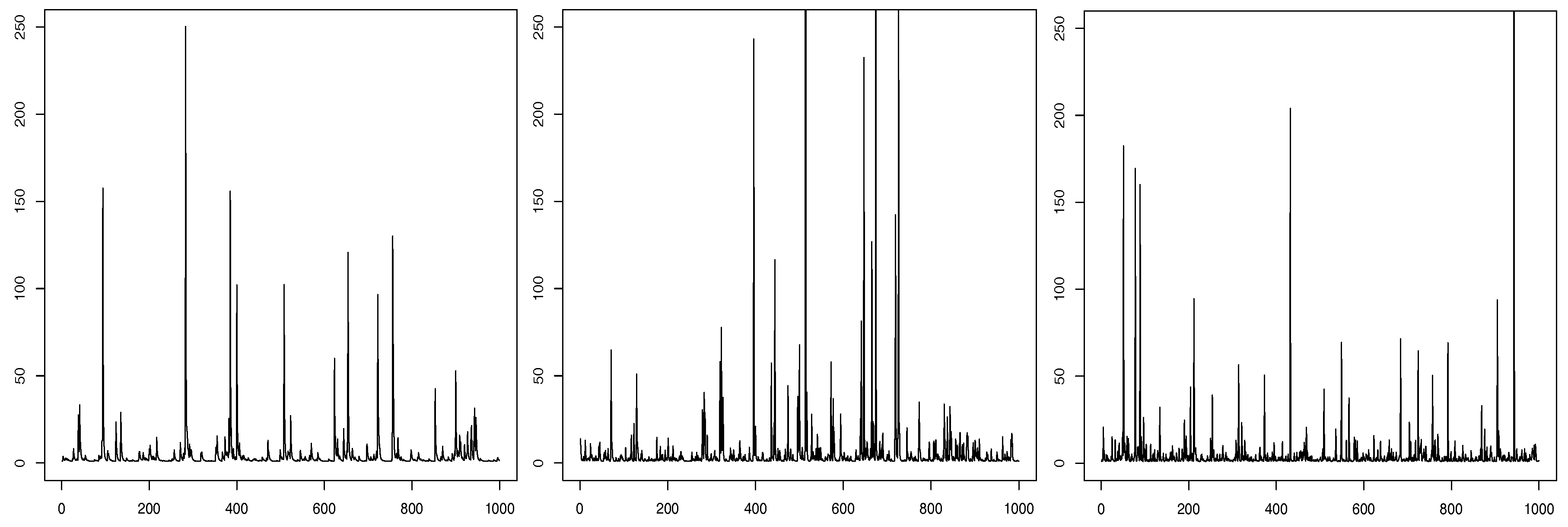
1980), and hence its name. Simulated samples from the GLP process with marginals Pareto(
) and
are plotted in
Figure 1.
This is a model within the heavy-tailed class where mean values (of different orders) may not exist. For instance, in this case, the mean exists only if
and the variance/covariance exists whenever
. In
Arnold (
2001), the autocorrelation was derived as
for
. Moreover, in heavy-tailed models, the extremal observations are important, and a dependence analysis based on central measures like the most common autocorrelation may be misleading if the dependence in the tails presents a different structure from the remaining.
Here, we focus on the extremal behavior of the GLP process, namely the tail dependence structure. Despite being a heavy-tailed model, it is practically unknown in modeling extreme values. We shall see that it has interesting properties, such as asymptotic tail independence, i.e., the probability that one observation exceeds an increasing large value given that the previous one has already exceeded it, approaches zero. The rate of the convergence, usually denoted
coefficient of asymptotic tail independence (
Ledford and Tawn (
1996);
Wadsworth and Tawn (
2012)) captures a residual tail dependence, revealing a kind of “penultimate” clustering, i.e., an aggregation of not so high values. This is a not so fortuitous behavior in real applications and can be observed in the well-known Gaussian processes (see
Bortot and Tawn (
1998),
Ramos and Ledford (
2013), and references therein). In practice, ignoring this phenomena will result in misleading inference (see, e.g.,
Poon et al. (
2003)). However, not all series associated with environmental, social or economic phenomena are susceptible to Gaussian modeling, especially when they have heavy tails. The most common extremal models MARMA and M4, as well as, the Yeh–Arnold–Robertson Pareto (III) and the Lawrence–Lewis Pareto processes (see, respectively,
Ferreira (
2012) and
Ferreira (
2016) and references therein) are not tail independent and new processes have been appearing (
Heffernan et al. (
2007);
Ferreira and Canto e Castro (
2010);
Ferreira and Ferreira (
2014) and
Ferreira and Ferreira (
2015) ). The GLP is an additional contribution within this class. Coefficient
will also be extended to observations that are lag-
m apart, providing an alternative to the autocorrelation function (acf).
This paper is organized as follows. The tail dependence measures and conditions to be analyzed are detailed in
Section 2 and applied to the GLP process in
Section 3. The tail characterization provides us with methods to estimate the autoregressive parameter
p, which will be compared through simulation in
Section 4. An illustration with a real dataset is addressed in
Section 5.
2. Tail Dependence
A stationary sequence
has extremal index
if, for each
, there is a sequence of normalized levels
, i.e.,
as
, such that
(
Leadbetter et al. (
1983)). The extremal index is a measure for the clustering propensity, being interpreted as the arithmetic inverse of the mean number of exceedances of an increasing threshold per independent cluster. The null case is often ignored, corresponding to a degenerate limiting distribution for the maximum. The value
is associated to iid sequences but not only these. Below, we shall see that it is a form of asymptotic independence of extremes.
Some dependence conditions allow us to derive the extremal index through the joint distribution of s consecutive terms of .
The long-range condition D(
) of
Leadbetter (
1974) states that
, as
, for some sequence
, where
with
,
and
for
. Consider
such that,
Observe that D(
) is a milder condition than the usual mixing, such as strong-mixing.
Under condition D(
), we say that the local dependence condition D
(
) of
Chernick et al. (
1991) holds for
, if for some
satisfying Equation (
7), we have
with
(
denoting the integer part of
x). The validation of D
(
) implies that D
(
) holds for
.
If D
(
) holds, the extremal index exists and can be computed through (
Chernick et al. (
1991))
Observe that, under D
(
), we have
. Condition D
(
) is also implied by
This corresponds to condition D
(
) of
Leadbetter et al. (
1983) whenever
, which locally restricts the occurrence of clusters of exceedances and thus leads to
. Condition D
(
) of
Leadbetter and Nandagopalan (
1989) is obtained with
and locally restricts upcrossing clustering.
Observe that, under D
(
), we can write
and thus state
where
means
, as
, for some constant
c. Observe that, if
, then
, meaning that consecutive observations are tail dependent. On the other hand, under a unit extremal index, we have
, as
, and thus consecutive observations are asymptotically tail independent. This feature has been observed in some real data and theoretical examples (
Ledford and Tawn (
1996);
Bortot and Tawn (
1998);
Ramos and Ledford (
2013)).
Ledford and Tawn (
1996) introduced the asymptotic tail independence coefficient,
, in order to measure the rate of convergence of
towards 0, where
is the quantile function, capturing a kind of pre-asymptotic dependence. More precisely, the asymptotic tail independence coefficient,
, exists whenever it holds
Thus, under Equation (
9), we can state,
Observe that, if
and
, we have
and thus an effect of clustering of high values. Under a unit extremal index, the coefficient
measures the rate of convergence of
towards 1, capturing a kind of pre-asymptotic clustering, despite a resembling of the process to an iid sequence at increasingly high thresholds.
Analogous with the acf, we extend the coefficient
and state the tail dependence within random pairs that are lag-
m apart,
,
, through the coefficient
, i.e.,
where
.
The tail dependent class has been greatly enhanced within the methodology of extreme values. However, this approach results in the overestimation of extremal dependence if the series is actually asymptotically independent. An illustration with financial data may be seen in
Poon et al. (
2003). The most recent literature has been addressing this issue, namely, with the introduction of new models comprising asymptotic tail independence (
Heffernan et al. (
2007);
Ferreira and Canto e Castro (
2010); (
Ferreira and Ferreira) (
2014,
2015). In the next section, we will show that the GLP belongs to this latter class of models.
3. The Tail Dependence of the Gaver–Lewis Process
In the following, and without loss of generality, we will take .
“Mixing”conditions roughly state that two rvs become increasingly independent as they get more apart in time. One of its forms is the
-mixing condition, defined by
with
denoting the
field generated by the indicated random variables (
Bradley (
2005)).
Proposition 1. The GLP process is -mixing.
Proof. The
-mixing condition will be proved through the sufficient conditions of regeneration and aperiodicity (see, e.g.,
Bradley (
2005); Corollary 3.6).
In the following, consider notation , with .
First, we show that GLP is regenerative, that is, it has a regeneration set, i.e., a recurrent set
R such that, for some
, a distribution
and
, we have
for all Borel set
B over
. If, for any regeneration set
R and any Borel set
B over
, we have
for some
and
, then the process is said to be aperiodic (
Asmussen (
1987)).
Consider
(and thus recurrent since it is in the state space
of the process) and
B a Borel set over
. Let
,
and
Pareto(
). For all
, we have
and thus regeneration holds by considering
,
and
. Observe that
S is also regenerative since it is recurrent (
) and,
,
, for any
, and thus
, with
and
as above. Now, we have
Therefore, the aperiodicity condition in Equation (
10) is satisfied if we take
and
. ☐
Note that condition
given in Equation (
6) is weaker than
-mixing and thus holds for GLP by the previous result.
Proposition 2. The GLP process satisfies condition D() for sequences satisfying Equation (7) and such that , as . Proof. We have successively, for
,
,
☐
Corollary 1. The GLP process has .
This result reveals that high observations of the GLP process behave similar to an iid scenario. However, there is a weak dependence that may be evaluated through the Ledford and Tawn coefficient
in Equation (
9). Moreover, we will see that it relates with parameter
p of the process.
Proposition 3. The GLP process has .
Proof. Consider
and take
. Observe that
☐
The fluctuation probability in the GLP process, given by
is a simple measure that will be useful in the following.
Corollary 2. The GLP process verifies the following equalities:
This result states a characterizing feature that can be helpful in model specification. Moreover, in order to satisfy , we must have and .
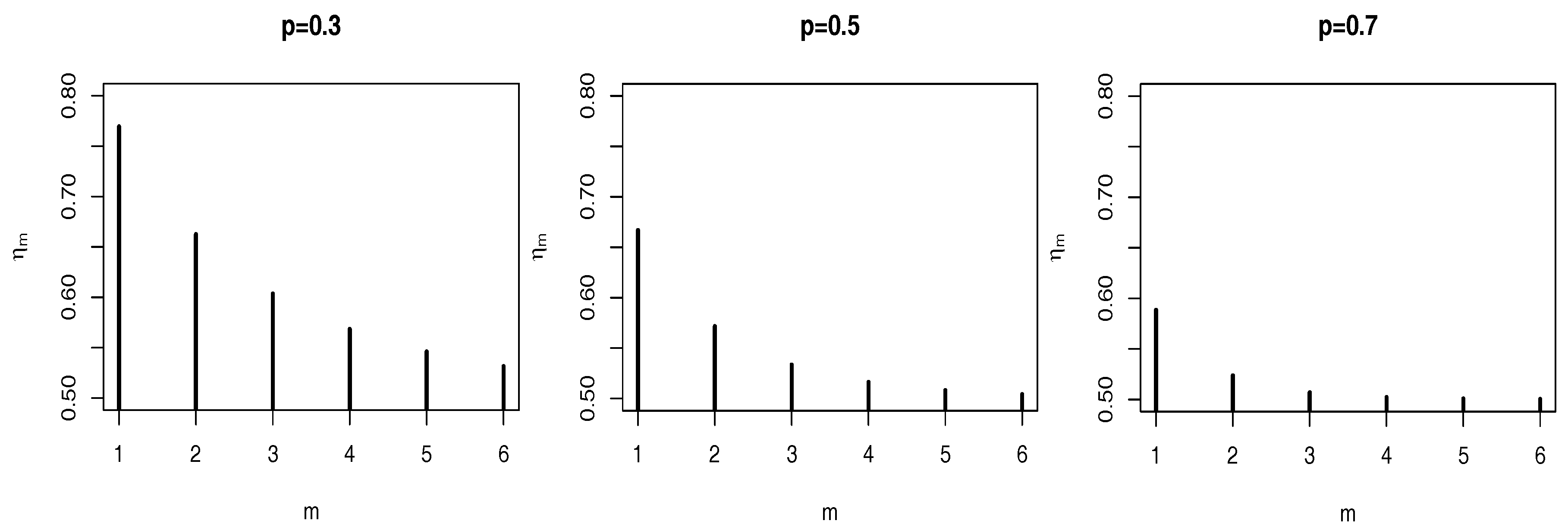
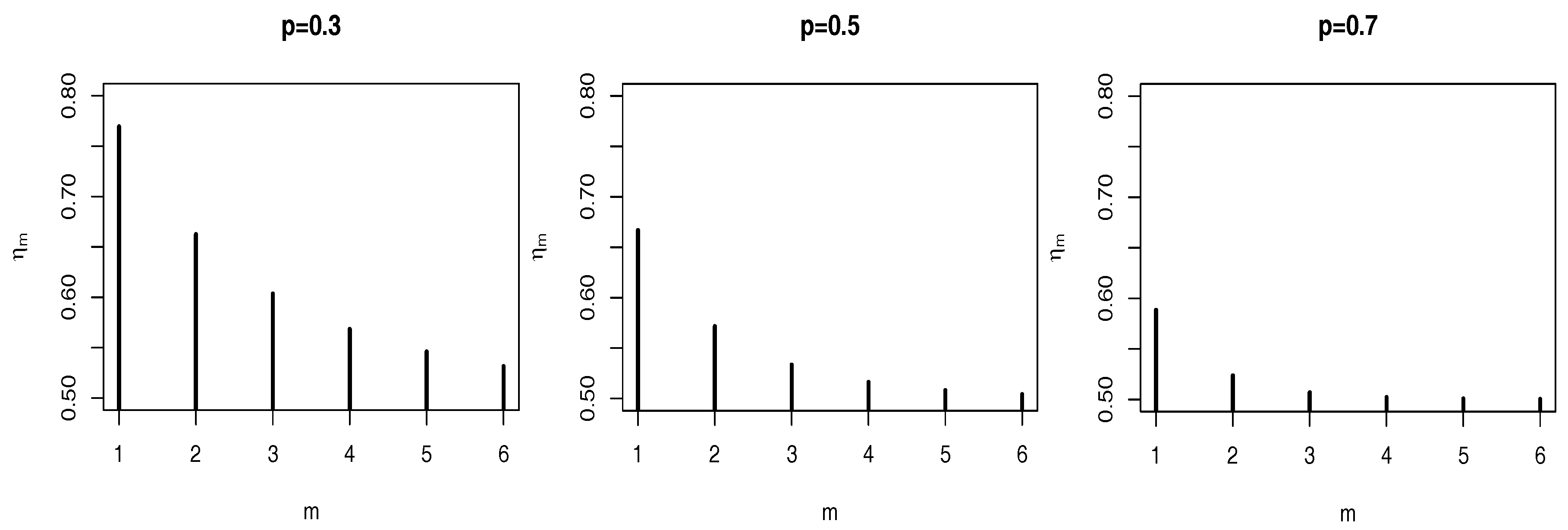
Another interesting property for model identification is based on the lag-
m coefficient
, analogous with the acf for linear models. The plots in
Figure 2 exhibit a power decay as the acf of AR(1) processes. Observe also that the smaller the value of
p, the higher we must choose the lag-
m in order to have "almost" independent observations, i.e.,
.
Proposition 4. The GLP process has lag-m coefficient given by Proof. Consider
. The product of powered Pareto rvs is still Pareto-type tail distributed (see, e.g.,
Arnold (
2001)) and thus, applying Equation (
2) and the theorem of the dominated convergence, we have successively, as
,
where
and
are slowly varying functions. ☐
4. Estimation
Relations (i) and (ii) stated in Corollary 2 will provide us with estimators for the autoregressive parameter
p. More precisely, from (i), we have
with
corresponding to the empirical counterpart of
f,
provided that
(notation
means the indicator function). From the iid property of the generating process
(and with
as specified for stationarity), we have ergodicity and thus consistence of the proposed estimators. In addition,
corresponds to the mean of Bernoulli trials with Markov dependence. From
Klotz (
1973), we have that
converges in distribution to a centered Gaussian model, and thus
by the Delta Method, as
. For more details, see
Ferreira (
2012).
From (ii), the estimation of
p is based on the estimation of
through
as long as
. Observe that
corresponds to the tail index of
. The most common method developed in literature is the Hill estimator (
Hill (
1975))—thus the superscript “H”. More precisely, we have
where
are the
k larger order statistics of
T that exceed
u. It is usual to consider
and plot
as a function of
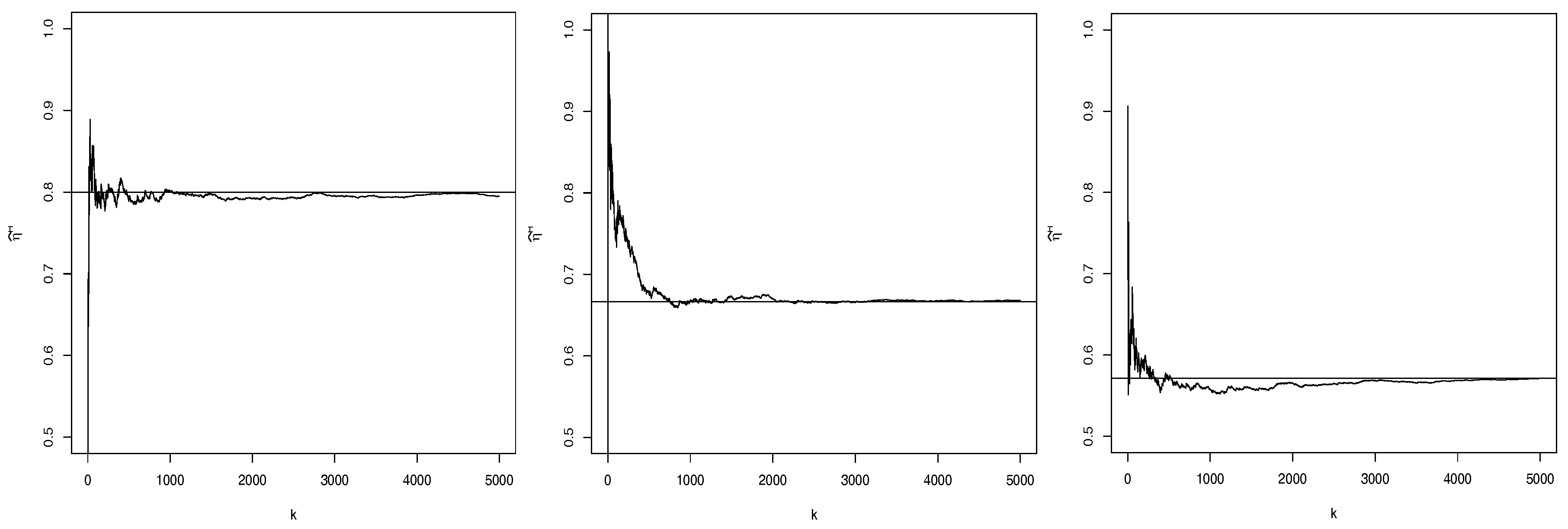
k. In
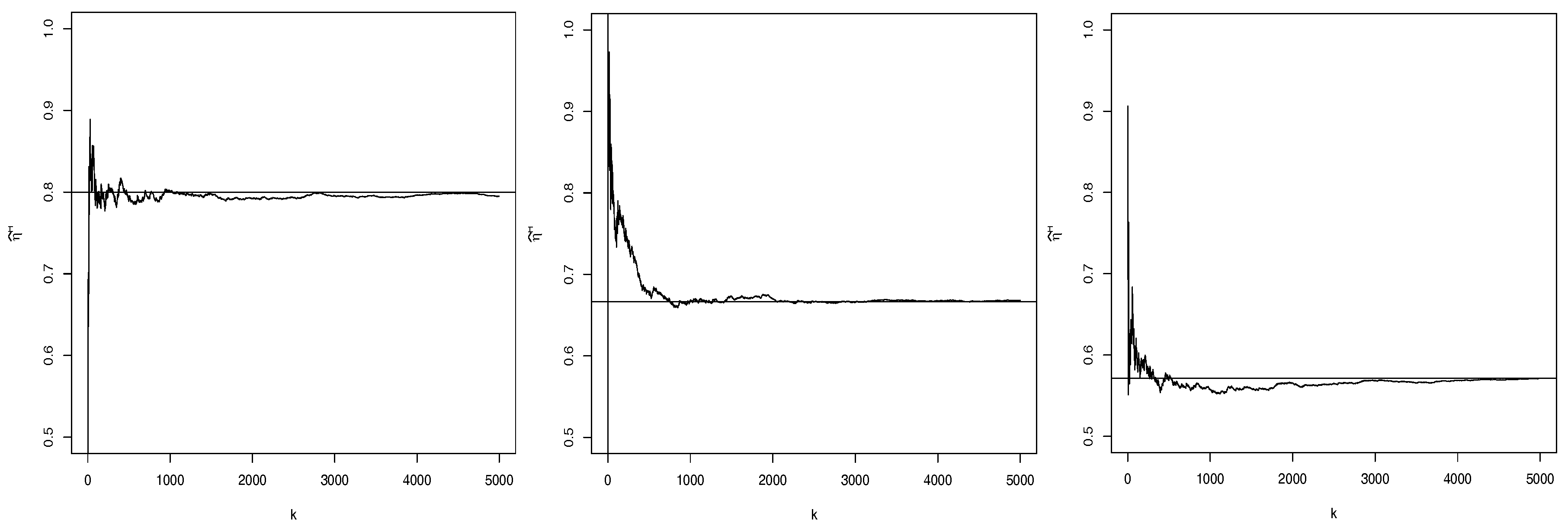
Figure 3, we can see the Hill trajectories of
for the respective GLP models considered in
Figure 1. The paths are quite stable around the true value of
for a large range of values of
k. Indeed, variable
T corresponds to the minimum of unit Pareto rvs, where the Hill estimator behaves particularly well. Consistency and asymptotic normality of the Hill estimator
can be seen in
Draisma et al. (
2004).
Expecting to observe time series data behaving exactly as the GLP functional Equation (
3) is not realistic. At best, we might observe perturbed versions of the GLP process, for instance “noisy” processes of the form
,
, where
is an iid sequence of standard Gaussian rvs and
. Thus, the simulations cover the GLP and “noisy” GLP sample paths for
. We consider 1000 replicas of sizes
for
, and marginals Pareto(
). The computed estimates of the root mean squared error (rmse) and absolute bias (abias) are reported in
Table 1, where the estimator
is based on thresholds
u corresponding to the sample minimum (
), the median (
) and the percentile 80 (
). We also register the number of fails resulting, respectively, from
and
. Not surprisingly, they are more associated to small sample sizes, where the case
seems particularly sensitive. Indeed, the results tend to be slightly worse under large
, where the process approximates to independence. In practice, the difficulty in deciding between tail dependence (
) and asymptotic independence (
) is well known. For a survey on this topic, see, e.g.,
Poon et al. (
2003) and
Beirlant et al. (
2004). The results get better as the sample sizes increase. We observe that estimator
is the best for the GLP process but not so robust for “noisy” GLP. In what concerns estimator
, it seems to present an overall better performance under
.
The estimation of the tail index parameter
may be conducted through the Hill estimator
(
Hill (
1975)), which is consistent and asymptotically normal under strong mixing conditions (see
Rootzn et al. (
1990)).
5. Application
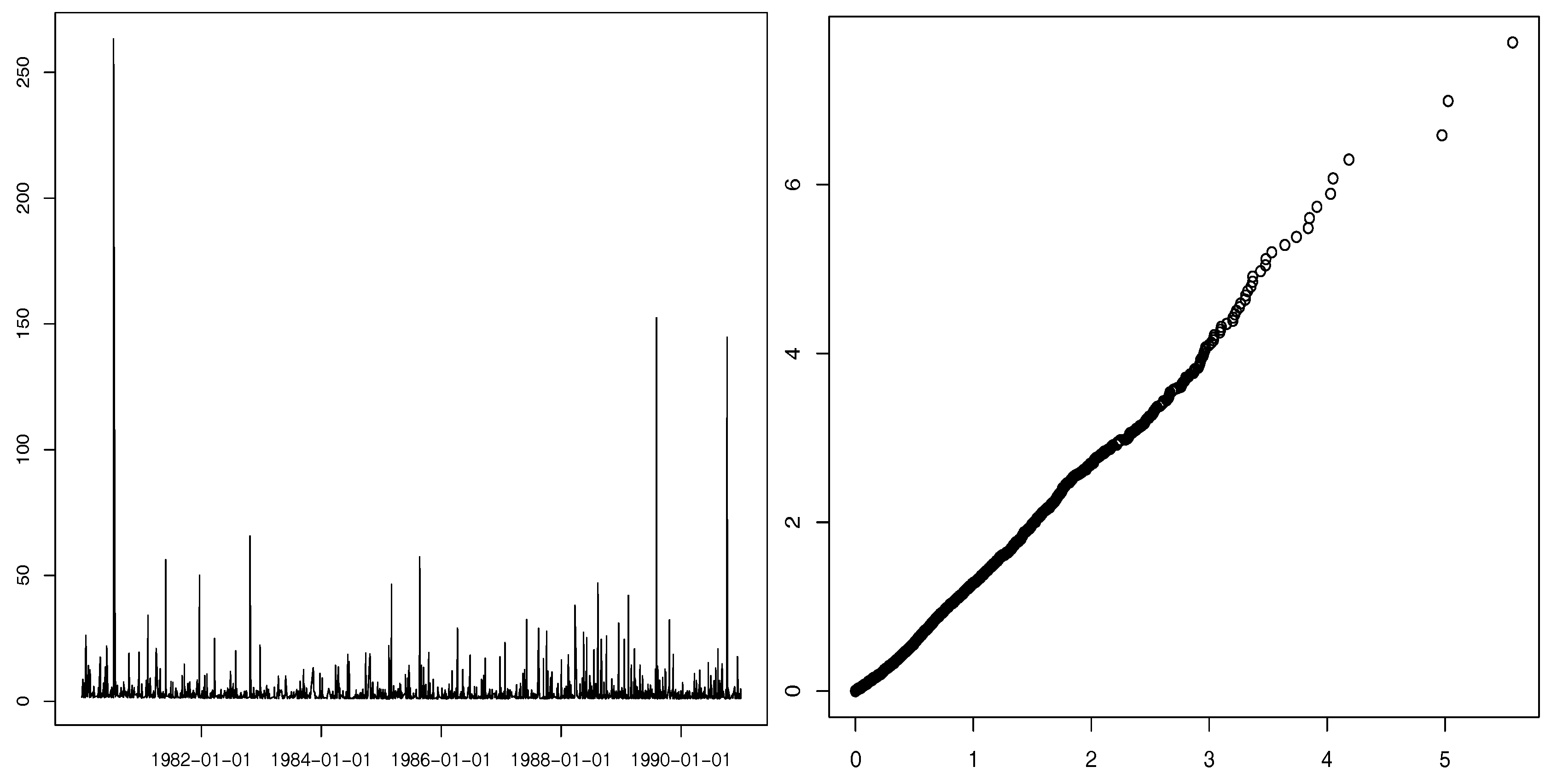
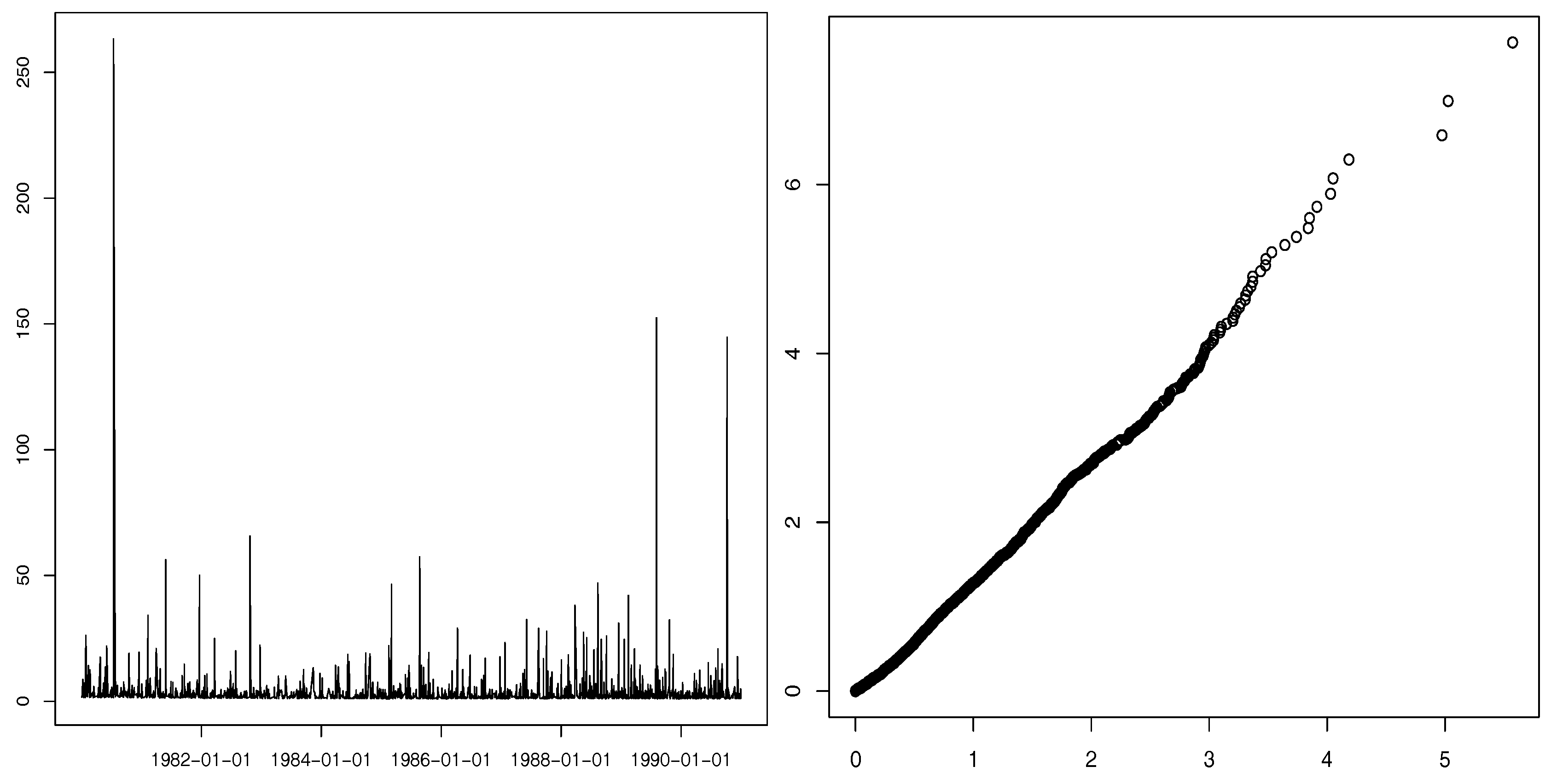
Insurance loss data is typically well modeled by heavy-tailed processes. We consider the daily closing values for the Danish fire losses registered from January 1980 to December 1990, plotted in
Figure 4 (left). Observe the high values that appear suddenly, similar to the GLP simulated sample paths (see
Figure 1), as well as the close linearity of the Pareto quantile-quantile plot (right panel of
Figure 4). In
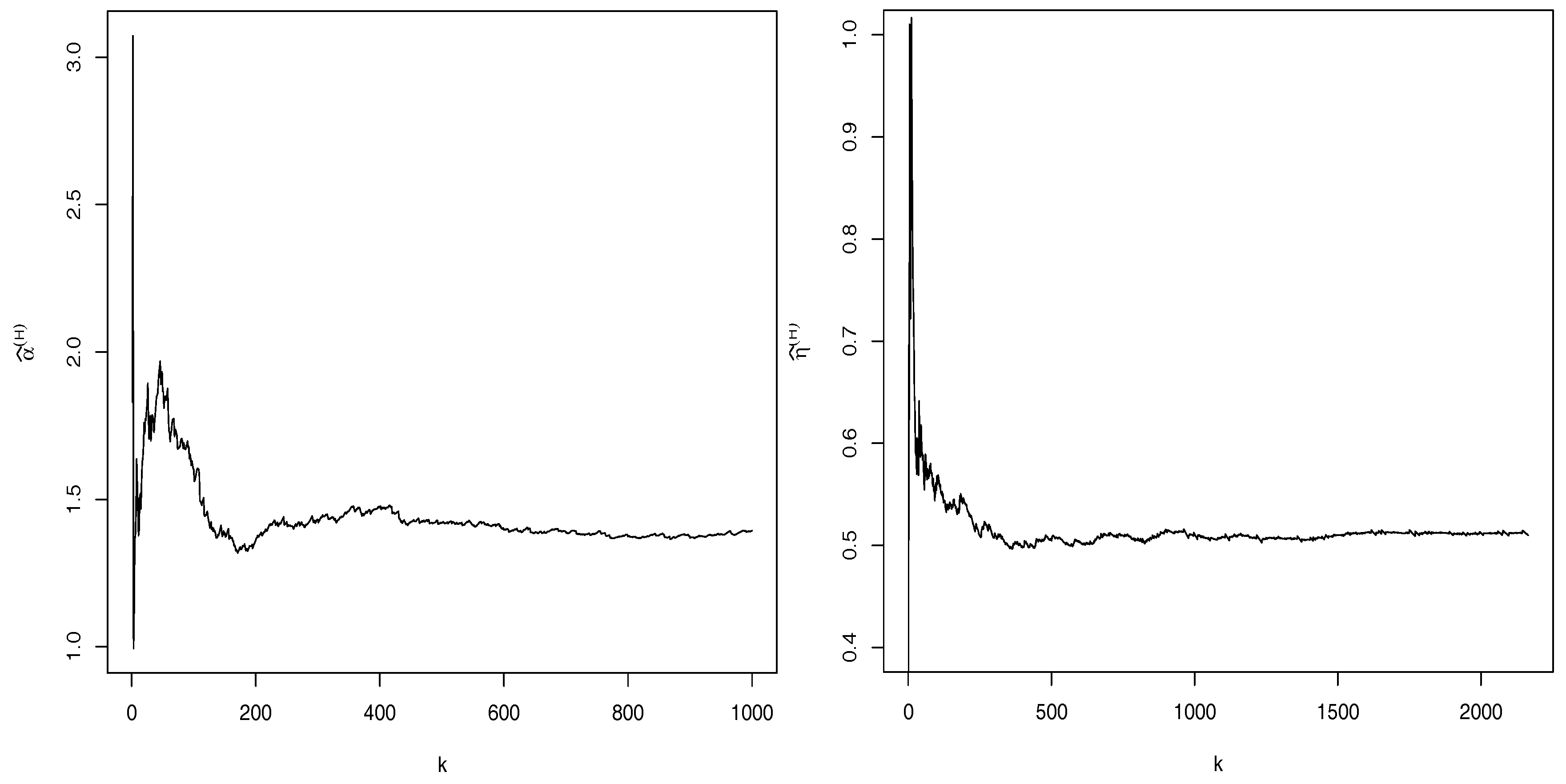
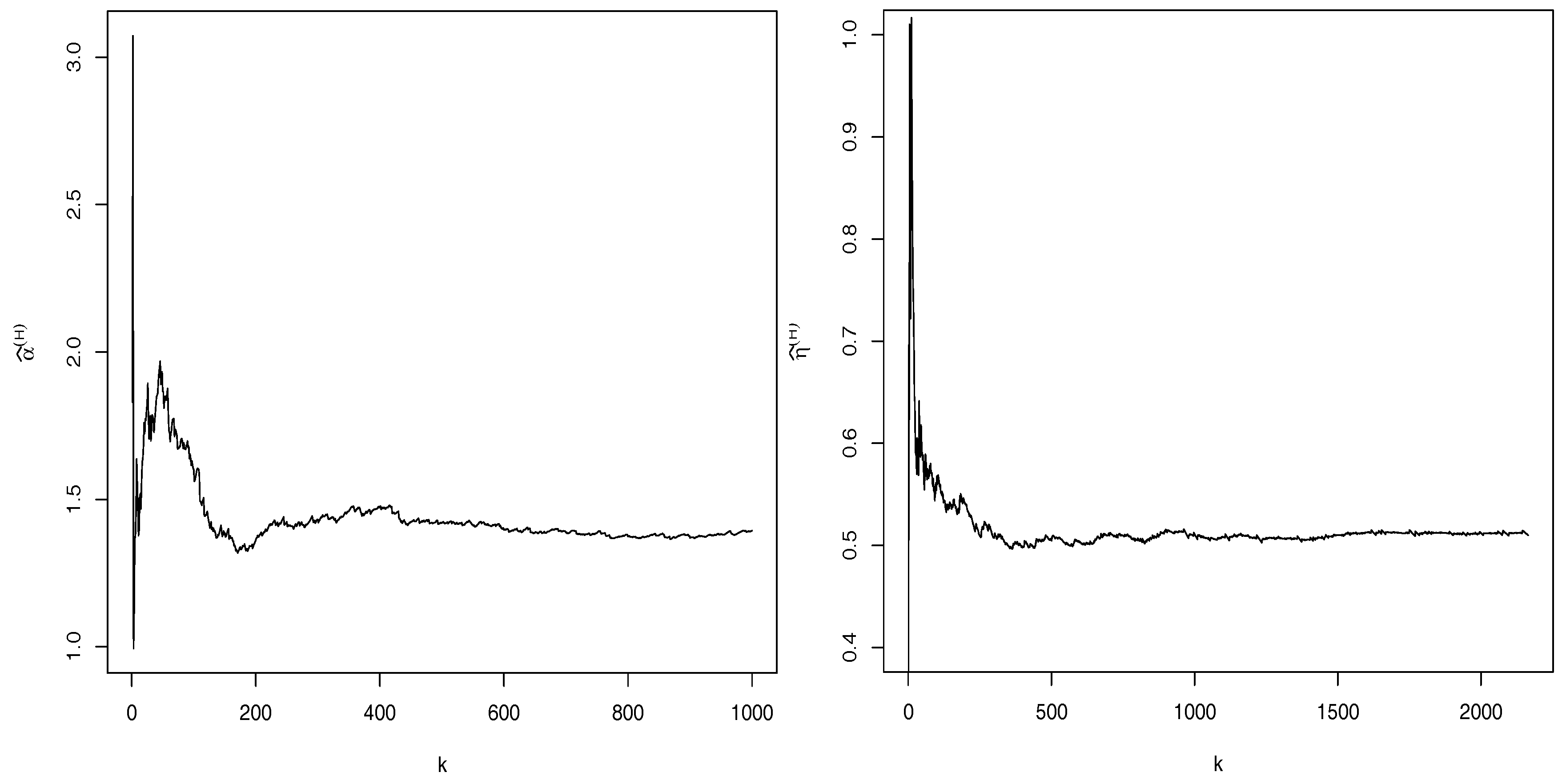
Figure 5 (left), the almost plane region of Hill’s sample path led us to the estimate
. Thus, we cannot assume the existence of the acf and should avoid an analysis based on this tool. We conduct the estimate of the GLP parameter
p through
and
. More precisely, based on Equation (
14), we obtain
and, using Equation (
15), we derive
,
and
, where the quantiles
,
and
were considered according to the simulation study (see also the sample path estimates of Hill in the right panel of
Figure 5). Formula (
12) of the lag-
m coefficient
of Proposition 4 is a similar tool to the role of the acf in identifying linear models.
Table 2 presents the estimates of
, for
, obtained from estimator
, which consists of the Hill estimator, respectively applied to lag-
m apart random pairs
, as well as, estimates of
and
derived from Equation (
12) by replacing
p, respectively, by
and
. The closeness between the two type of estimates,
and
, shows a further contribution in favor of the model.
The GLP process thus seems to have potential in the modeling of this type of data. More tools regarding goodness-of-fit analysis will be addressed in a future work.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}