4.2.1. Variation of Mesh over Development Periods
It will be convenient to commence with a consideration of the case in which an enlargement of mesh size is effected by the coalescence of just two consecutive development periods, say
and
. In the notation of
Section 2.2.2,
is partitioned into the
subsets by cut-points
for
and
for
.
In this case, (13) and (15) yield
and
The variance of loss reserve estimate in (29) and (33) is now replaced by the following.
where
is yet to be determined and is the quantity corresponding to
in (33) when development periods
and
are merged, as above.
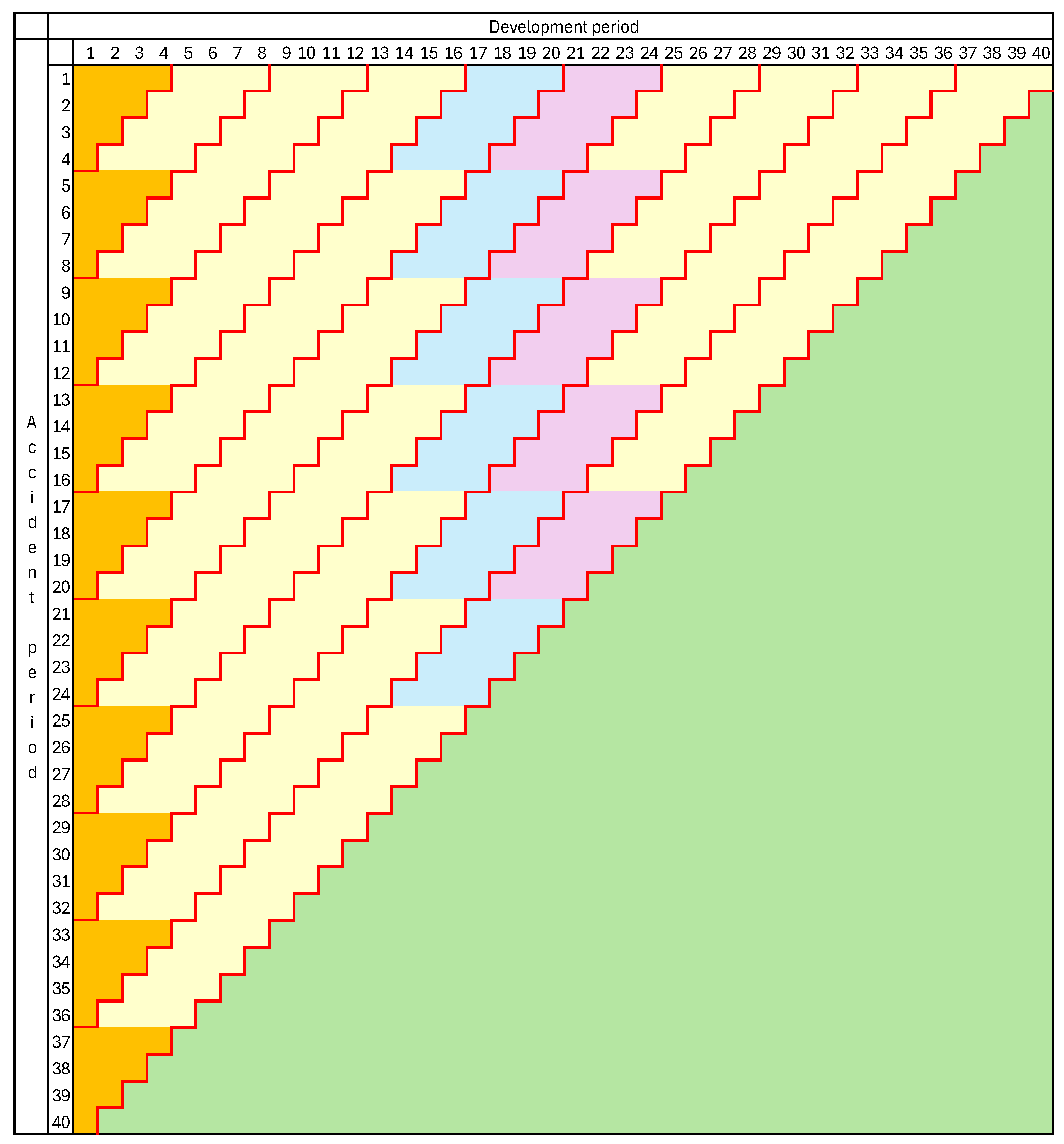
To calculate how differs from , it is necessary to consider three cases as follows.
Case I: . In this case , which means that past development includes the two merged development periods , and so accident period will in the future pass through only development periods with “normal” age-to-age factors. It also follows from (58) that , which corresponds with .
Case II: . In this case , which means that past development has not yet reached development period , the first of the two to be merged, and so the accident period will in the future pass through both development periods . It also follows from (58) that .
Case III: . In this case , which means that past development has passed through the first of the “abnormal” development periods, , but not the second, +1. It may be noted that the merged cell is incomplete, since the unmerged cell lies in the future. It also follows from (58) that , which corresponds with .
It is evident from the description of Case I that, the data point
is available in row
, and the variance of the estimated loss reserve may be calculated in the “normal” way. Specifically, (60) may be applied with
:
with the last two terms on the right obtained from (60) and (61).
Case II may be dealt with similarly, and again (61) arises. The fact that accident period is still to pass through the two merged development periods has no effect on the stochastic behavior of the variance.
Case III is a little different. Here (61) is replaced by
In this case, the data point must be forfeited as it forms part of an incomplete merged cell, and so the valuation standpoint must be taken at the end of the development period instead of the usual .
The following proposition summarizes the situation.
Proposition 7. With defined by (34), the relevant variances of loss reserve estimates are the following:
For
For
For
It is evident from this result and (29) that the variance of estimated loss reserve is unchanged by the merger of the two development periods for all . However, this equality does not hold for , and the question of interest concerns the relative magnitudes of .
To study this question, one can write
And
where (34) has been used to obtain the last three relations.
It is evident from (64) that
The following result, proven in
Appendix A.2, establishes the ordering of
.
Proposition 8. For the case , a necessary and sufficient condition that iswhere and the threshold value is given bywith Corollary 1. It follows from (70) that , and so a sufficient condition that is that , where take the same values as in Proposition 8.
The main conclusion to be drawn from Proposition 8 is that
does not always exceed
. That is to say, the merger of development periods (or decreasing granularity) does not always result in increased predictive variance. This result differs from the corresponding one for the EDF chain ladder in
Taylor (
2025).
The difference arises from the unique feature of the Mack chain ladder according to which the variance of predicted loss reserve is conditioned by, and in fact is proportional to, the squared amount of claims paid to the date of valuation (see (32)). It is seen above that when development periods and are merged, the estimated variance of forecast loss reserve accident for accident period becomes proportional to instead of .
If is small relative to , then it can turn out that . This is precisely what happens when is larger than its expected value by a sufficient margin.
Corollary 1 points out that the threshold value , and, to this extent, will tend to exceed ; i.e., decreasing granularity will tend to lead to increased variance of loss reserve forecast, but not invariably.
A numerical example of these thresholds is now given. It is based on the numerical example from
Mack (
1993), which in turn uses the data set from
Taylor and Ashe (
1983). The data set is reproduced in
Appendix B.
The parameter estimates of
and
given by Mack just after his
Table 1, after mild smoothing, are taken as parameters for the purpose of this example and are displayed in
Table 1 below.
The effect of merging two development years on the variance of predicted loss reserve will be studied. For this purpose, values of
will be calculated from (34) for
, and then
will be calculated from (36). The standard deviation of the estimated loss reserve is then derived from (32). The results of these calculations are reported in
Table 2, which also includes values of
, the estimate ultimate claim cost of accident year
, as estimated at the end of development year
.
The interpretation of this table is as follows. Consider accident year 2. Its forecast ultimate claim cost, on the basis of the full triangle in
Table 1, is 5,445,867 with a standard deviation of 79,922 (which is also the standard deviation of the loss reserve). Now suppose that development years 9 and 10 are merged, i.e.,
.
Then, according to Proposition 7, variances of forecast loss reserves are unchanged except in the case of accident year 2, which must be calculated as at the end of development year 8; i.e., the valuation point is changed from end of calendar year 10 to 9. The table then shows that the ultimate cost of the accident year is estimated as 5,212,813, with a standard deviation of 118,419. The standard deviation has increased by 48%.
A similar situation is found for all other mergers of development years. For example, if development years 4 and 5 are merged, i.e.,
, then the affected row of
Table 2 will be that relating to accident year 7, and here the increase in variance of forecast reserve is 35%. In fact, it is seen from the table that any merger of two consecutive development years leads to an increase in variance.
Proposition 8 shows that this result will occur only if the observed development factors are not too large. This aspect of the data set is now studied.
Table 3 displays the threshold values
of the age-to-age factors in the numerical example under study, calculated from (69). The intermediate quantities
and
are also shown, as well as the observed value of
corresponding to the threshold value
The table is read as follows. For accident year
, for example, corresponding to the merger of development years 4 and 5 (see the commentary on
Table 2), the loss reserve must be evaluated at the end of development year
(instead of 7). According to Proposition 8, this will lead to an increased variance of loss reserve unless
indicates that
0.97 (=1.047/1.08, from
Table A2).
Indeed, the observed values of
well below the threshold value
for all
in the table. This indicates that variance is increased for any merger of a pair of development years, a result that is consistent with
Table 2.
Remark 2. The above analysis has considered only the merger of development periods and . However, the analysis can be repeated for further mergers. Suppose, for example, that the original development periods were months and one wished to form quarterly periods, perhaps involving the merger of and One could commence with the merger of periods and , as just analyzed. This led to the subset cut-points One could then merge period with the first two. This would create new cut-points
The above analysis would then apply equally to this merger of two development periods. Two-period mergers could be continued in this way until the desired final set of merged development periods was attained. The conclusions would be as above, specifically that
The reduction in granularity increases the variance of the estimated loss reserve unless a condition parallel to (68) is breached;
At each merger, the thresholds appearing in (68) can be calculated, and the occurrence or non-occurrence of that breach assessed.
4.2.2. Variation of Mesh over Accident Periods
Section 4.2.1 considered just the merger of development periods into longer periods. It might be desired that accident periods be merged at the same time. As an example, suppose that accident periods
and
are merged. Consistently with the notation adopted in
Section 3, let the new accident periods be denoted by
, where
and the new accident period
comprises the merged
and
.
In parallel with the notation introduced in
Section 2.2.2,
will denote cumulative claim payments to the end of (a possibly merged) development period
with respect to the newly defined accident period
, and so, for
,
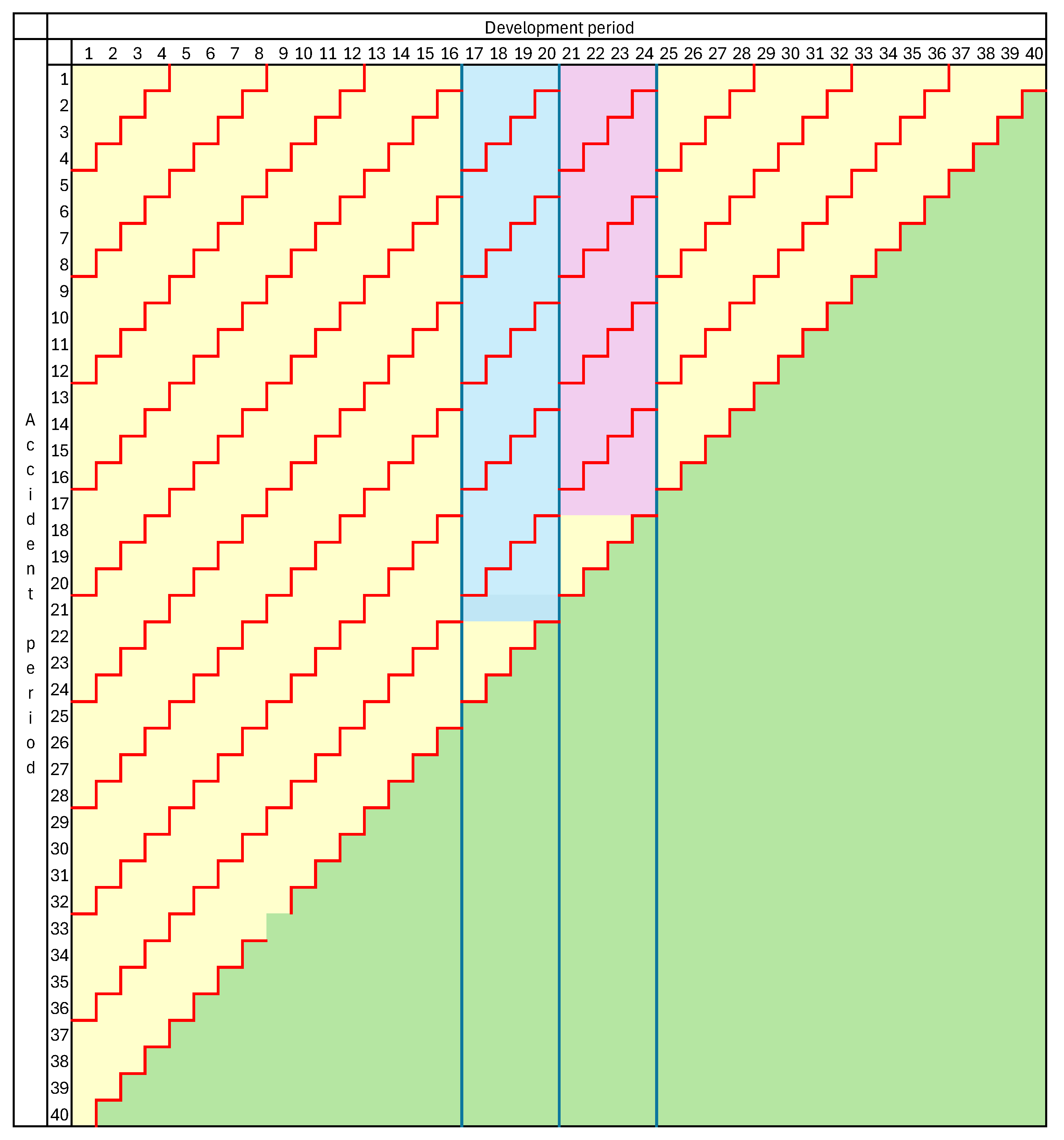
Note that is used to index development periods that may have already been merged. For the purpose of the present sub-section, is taken to denote the claim triangle after any such mergers.
Let the data set consisting of all completed development periods after this merger of accident years be denoted
. Let
denote the corresponding lower triangle, and
. This data set is illustrated in
Figure 4 for the case
with accident periods
merged.
Consider the extent to which Assumptions 1 to 6 of
Section 3.1 continue to hold in these changed circumstances. The briefest reflection reveals that Assumptions 2, 4 and 5 continue to hold, so attention is now turned to the other assumptions.
This assumption evidently holds for all accident periods
other than
, so consider this one. Note that
where the penultimate equality follows from Assumption 1 in
Section 3.1. The only data point on which right side here is
, and so it follows that
This shows that Assumption 1 continues to hold in the present circumstances. Note that the age-to-age factors are unchanged by the merger of accident periods.
In this case,
by Assumption 2. Then, by Assumption 3 and an argument similar to that leading to (75),
This shows that Assumption 3 continues to hold in the present circumstances. Note that the variance factors are unchanged by the merger of accident periods.
In this case, Assumption 6 of
Section 3.1 must be modified to the following.
Assumption 6**. .
Here, and in the following, the ** notation always indicates quantities relating to .
When Assumptions 1 to 5 and 6** hold, the Mack chain ladder model applies to the data set
. It is seen from
Figure 4 that a Mack chain ladder model could be imposed on this data set in the usual way, even for the merged accident period, but with the exception of cell (11, 30), or in general cell
. For completeness, the merged cell containing this one must also include
in order to be usable, but this is as yet unobserved.
Hence, the chain ladder would be imposed on the data set
, and it would be required that the forecast of the merged accident period be based on the last complete observation
. Subject to the exclusion of this single cell, parameter estimation is exactly as for a conventional Mack chain ladder. The same is true for the forecast, except for the merged accident period
. As foreshadowed just above, the forecast of ultimate claim cost in this case is (c.f. (56))
Corresponding to (23) and (57) is
As noted in relation to (57), the value of is known for the purpose of (78) though not usable in the estimation of an age-to-age factor.
Lemma 1 now gives the variance of the estimated loss reserve for the combined accident periods
and
. The proof is given in
Appendix A.3.
Lemma 1. The variance takes the following form:where
is given by and It is now possible to compare
and
The difference between the variance of estimated loss forecast for merged and unmerged accident periods is now given by
It is of interest to find characterizations of the positivity and negativity of this difference. Lemma 2 is useful for this purpose. The strategy here is to re-express (85) in such a way that all
terms appearing are the same, and similarly all
terms. Specifically, the only
terms appearing are
and the only
terms are
. The proof is given in
Appendix A.4.
Lemma 2. For brevity here, and are abbreviated to and
. Then the subject of (85) may be expressed as where Proposition 9. A necessary and sufficient condition that iswhere, for brevity, , and is defined bywhere Note the similarity between (69) and (89). After the conversion of quantities to tilda versions, the two results are almost identical.
A fairly weak condition is required to establish that
, as testified by Corollary 2, which is proved in
Appendix A.6.
Corollary 2. A sufficient condition that is that Note that, as increases, the lower bound on the critical value becomes steadily smaller. For large values of , the bound approaches zero. This means that only very small values of are shown to guarantee that increased granularity reduces the variance of the predicted loss reserve. This result stands in stark relief against that of Corollary 1 in the case of an increased granularity within a single accident period.
The physical meaning of large or small values of
is not clear, but it is a function of
that does have a clear meaning (see (84)). There is therefore value in examining the relation between
and
.
Table 4 does so, examining three key values of
.
For an intuition for these values, recall from (64) that and from (70) and (87) that, in many applications, and will be small relative to unity.
By (84),
measures the volume of claims in the accident period
relative to that in
. Combining Corollary 2 with
Table 4 gives an indication of how variation of
changes the effect of granularity on the variance of forecast loss reserve. For example, if accident period
heavily dominates
(
), then
is large, and Corollary 2 indicates that the separation of the two accident periods is unlikely to be of benefit to the variance. This is consistent with intuition.
As a further example, suppose that
, implying equal claim volumes in accident periods
and
. Suppose also that
and
. Then, by
Table 4,
will be somewhat greater than 0.59. Then, if condition (93) is satisfied, Corollary 2 reveals that
is somewhat less than 1.7.
If the conclusion of Corollary 2 is a relatively tight inequality, then there is considerable benefit in the increased granularity of maintaining the separation of accident periods and .
The reasons why a decrease in granularity does not always lead to an enlargement of the variance of forecast loss reserve are apparent from (79) and (83).
In the former of these relations, it is seen that the merger of the two accident periods causes both to be forecasts as at time
(instead of
in one case), resulting in a loss of information. This is exactly what happened in the merger of development periods in
Section 4.2.1.
On the other hand, however, relation (83) shows that, when the separation of accident periods is maintained, positive covariance arises between their forecasts of loss reserve. This is the term involving , and it increases the variance of loss reserve of the aggregated accident periods.
Whether or not increased granularity is beneficial depends on the net effect of these opposing forces.
Remark 3. The above analysis has considered only the merger of accident periods and . However, the analysis can be repeated for further mergers. Suppose, for example, that the original development periods were months and one wished to form quarterly periods, perhaps involving the merger of and . One could commence with the merger of periods and , as just analyzed.
One could then merge period with the combination of the first two. The above analysis would then apply equally to this merger of two accident periods. Two-period mergers could be continued in this way until the desired final set of merged accident periods was attained. The conclusions would be as above, specifically that
The reduction in granularity increases the variance of estimated loss reserve unless (88) holds with the relation >;
At each merger, the thresholds appearing in (88) can be calculated and the likelihood of that relation assessed.




{kind=link}
{kind=link}
{kind=link}
{kind=link}