
A Bivariate Model for Correlated and Mixed Outcomes: A Case Study on the Simultaneous Prediction of Credit Risk and Profitability of Peer-to-Peer (P2P) Loans

Abstract
1. Introduction
1.1. Background
1.2. Motivation
- For a given loan, its final status and the total profit earned come out simultaneously, with no sequential order of occurrence. Therefore, it is reasonable to model these two outcomes jointly. This approach is analogous to numerous studies in biomedical and health sciences, where researchers often need to model multiple outcomes of various diseases simultaneously (De Leon and Carriere 2000).
- As discussed in (Serrano-Cinca and Gutiérrez-Nieto 2016), the features influencing a loan’s risk and those affecting its profit are different but may have some overlap. Joint modeling provides a robust framework to simultaneously evaluate the effects of predictors on both risk and profit (Fitzmaurice and Laird 1995).
- The simultaneous modeling approach can incorporate the inter-relation of the two outcomes, enabling a balanced evaluation of risk and profit when assessing loans.
1.3. Contribution
- Innovative problem formulation: We formulate loan evaluation as a multi-target problem, making the first attempt in the P2P domain. This allows for the simultaneous evaluation of a loan’s risk and profit using a single unified model.
- Novel loss function: The designed loss function is unique, as it incorporates the intrinsic correlation between multiple outcomes, enhancing the model’s predictive power and coherence.
- Broader applicability: The concept of bivariate learning for correlated outcomes extends beyond the P2P market. It can be easily generalized to other areas where simultaneous prediction of multiple correlated outcomes is required.
2. Related Work
3. Empirical Study
3.1. Data
- (1)
- Loan information: this includes the interest rate, principal amount, application type, credit grade (A–G), loan term, purpose of the loan, installment amount, and verification status.
- (2)
- Credit information of the borrower: this encompasses data such as the number of accounts that have been delinquent in the last two years, the debt-to-income (DTI) ratio, FICO score, number of inquiries in the last six months, number of derogatory public records, revolving line utilization rate, and the total number of open credit accounts.
- (3)
- Other information from the borrower: this covers the borrower’s annual income, length of employment, and home-ownership status (whether they rent, own, or have a mortgage).
3.2. Problem Formulation
3.3. Implementation of the Proposed Model
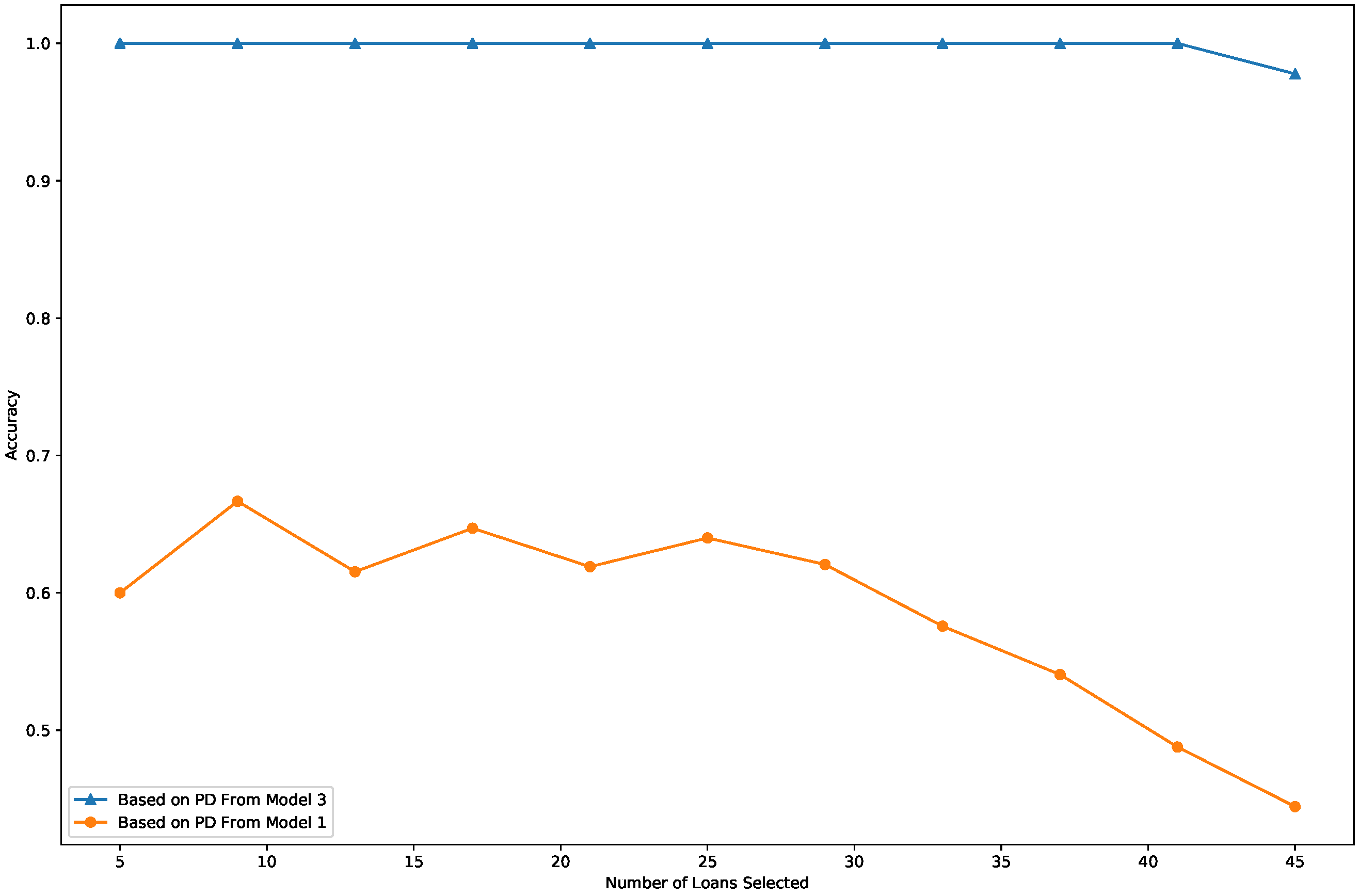
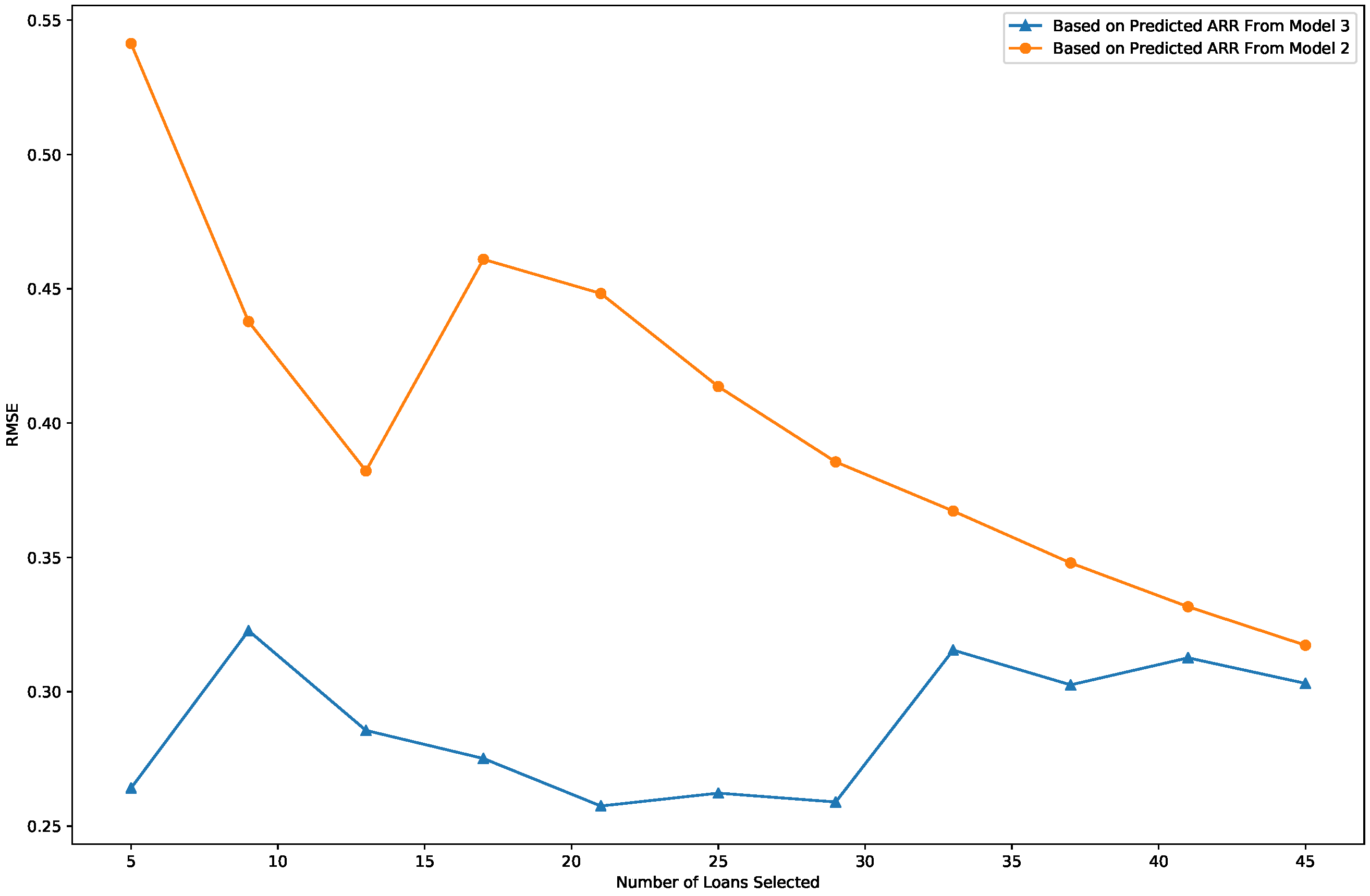
3.4. Performance Evaluation and Comparison
- Model 3: The proposed bivariate model introduced in this article.
3.5. Results
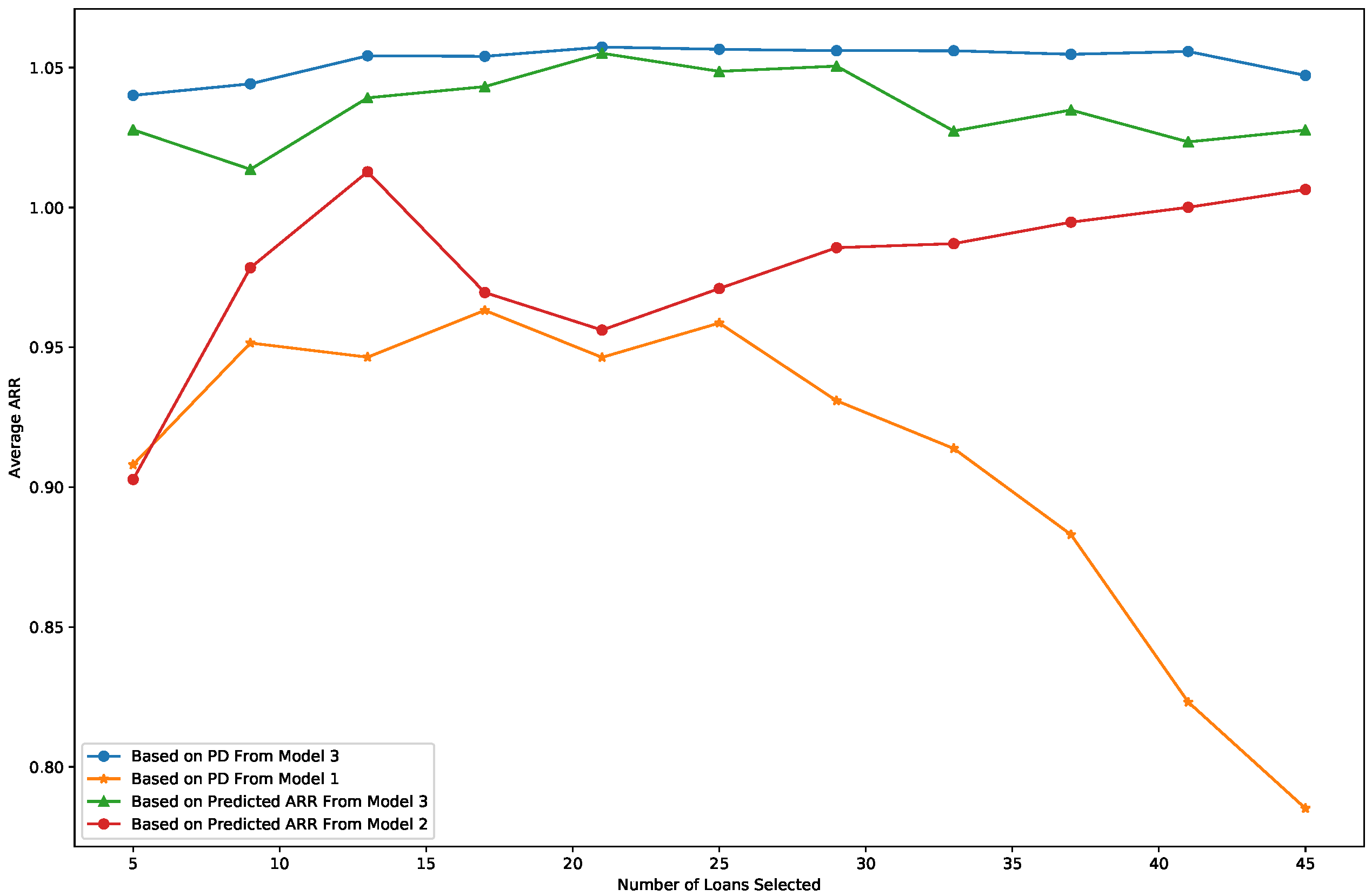
- The average profitability is calculated in terms of the average ARR among the recommended loans. Figure 4 displays the comparison of loan profitability among 4 recommendations. Similar to the logic used in the comparisons of accuracy and RMSE, high-quality loans are those with a low PD in Model 1 or a high predicted ARR in Model 2. For Model 3, two types of recommendations are made based on its two outputs: high-quality loans can be associated with either a low PD or a high predicted ARR. For instance, when the x-axis value in Figure 4 is 45, 45 loans are recommended to investors using different evaluation criteria. Among these 45 loans, the average ARR is approximately 0.78 when selected by Model 1 (orange line) and about 1.01 when selected by Model 2 (red line). For Model 3, the average ARR is 1.05 when selecting loans based on the predicted PD (blue line) and 1.03 when selecting loans based on the predicted ARR (green line). Overall, the average ARR is consistently the highest when loans are selected by Model 3 using the PD output, and it is the second-highest when selected using the predicted ARR output from Model 3.
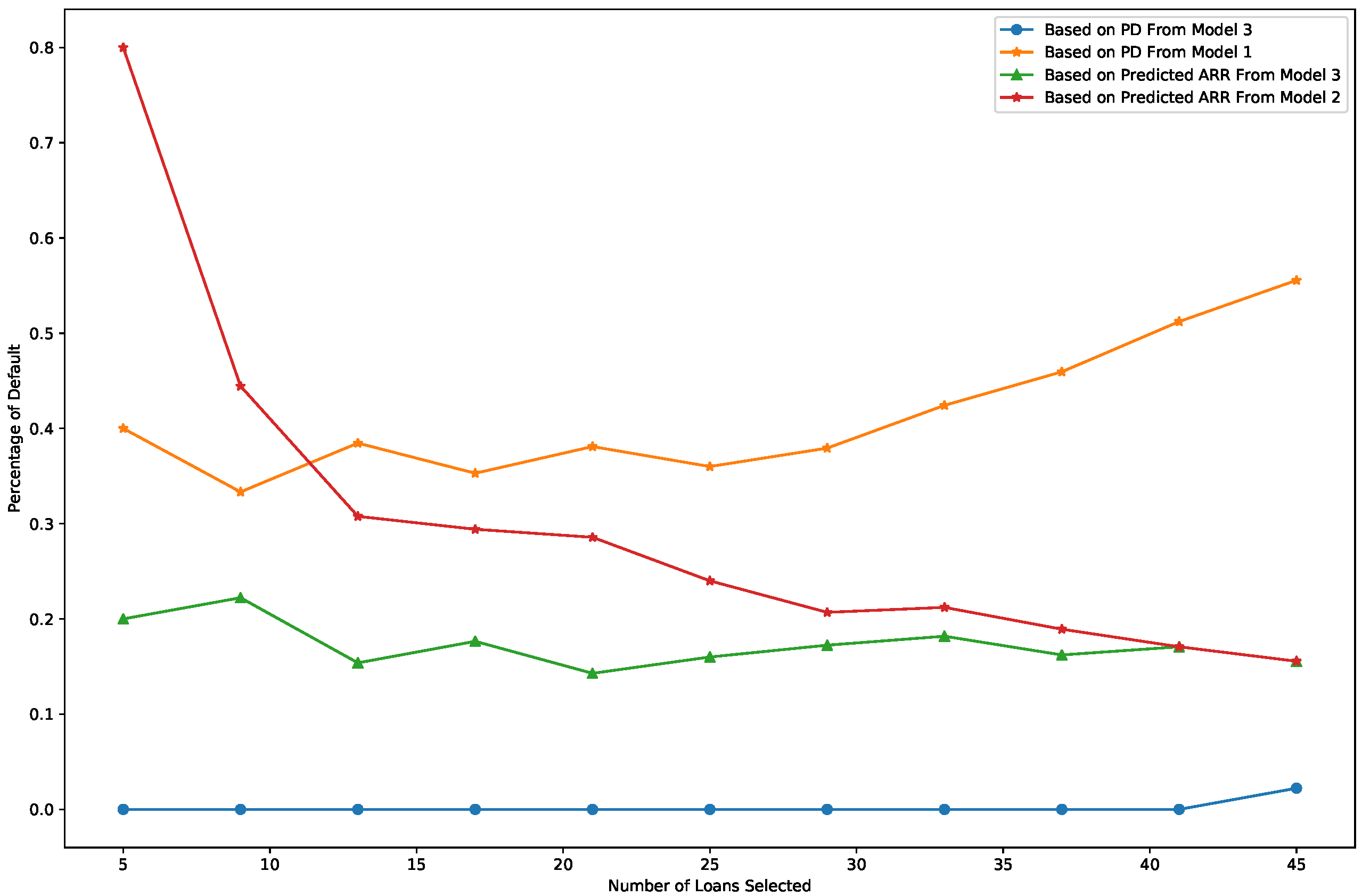
- The default risk is measured as the percentage of defaulted loans among the recommended loans. Figure 5 presents a comparison of risk across the four recommendation methods. The loan selection criteria are the same as those used in the profitability comparison. As shown in Figure 5, the percentage of defaulted loans is very low when loans are selected based on the PD output from Model 3 (blue line), ensuring minimal investment risk. When loans are selected using the predicted ARR from Model 3 (green line), the default rate is the second-lowest among the methods, further demonstrating the model’s ability to balance profitability and risk.
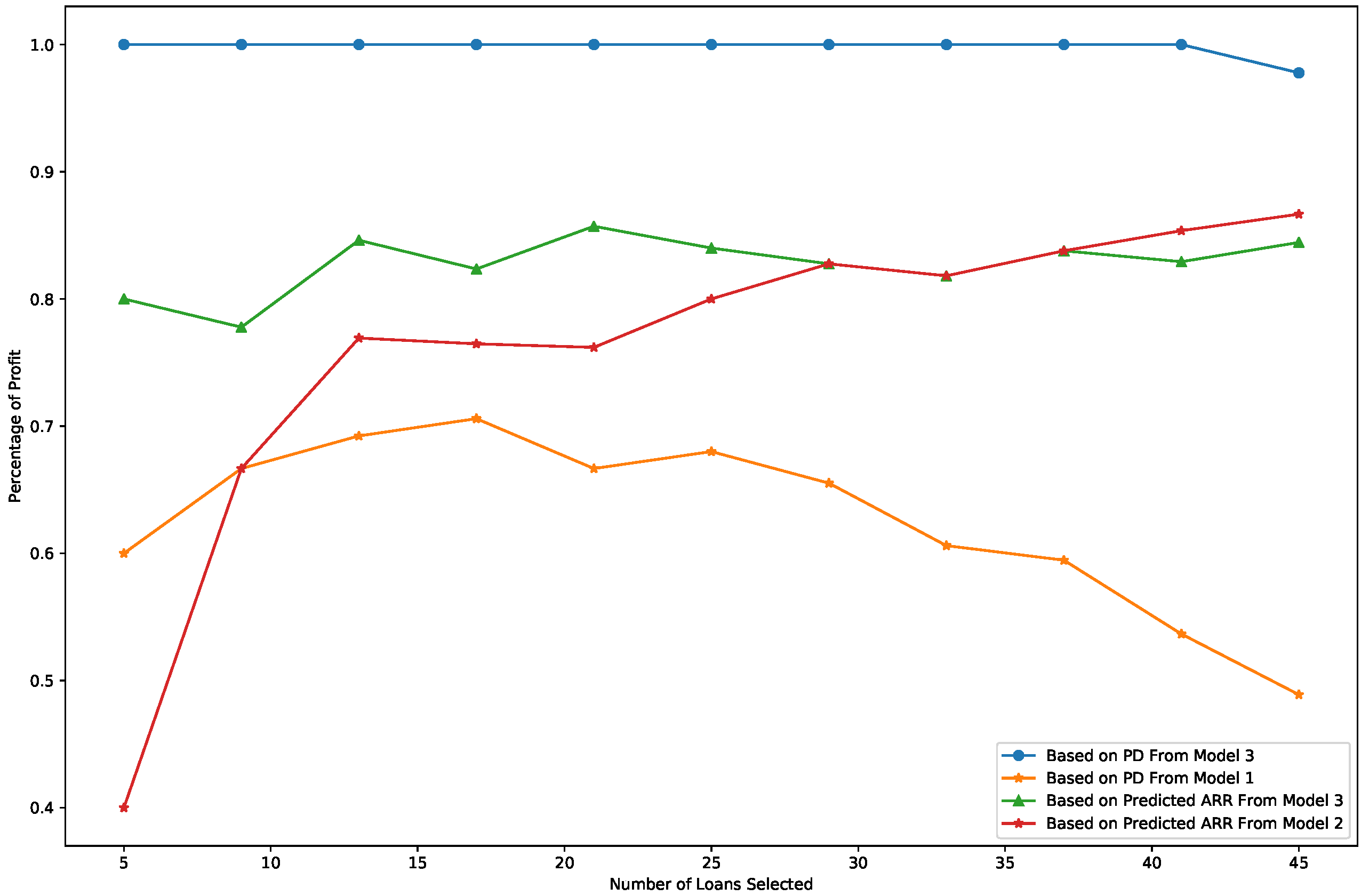
- Portfolio reliability is measured as the percentage of profitable loans among the recommended loans, where profitable loans are defined as those with an ARR greater than 1. Figure 6 illustrates the comparison of portfolio reliability across the models. As shown in Figure 6, the percentage of profitable loans is consistently the highest when loans are selected based on the PD output from Model 3 (blue line), highlighting its superior ability to ensure a reliable portfolio.
4. The Proposed Bivariate Method for Correlated and Mixed Outcomes
- : a data set with N observations, p features, and mixed outcomes;
- i: the observation index, where i = 1, 2, …, N;
- j: the feature index, or the index of independent variables or explanatory variables, where j = 1, 2, …, p;
- : the data vector for the i-th observation. can also be expressed as , where denotes its feature vector with the first element 1 for the interception, is the value of its binary outcome, and is the continuous outcome;
- : the probability that the ith observation belongs to the kth category, where k is either 1 or 0 for the binary classification problem;
- : the coefficient vector estimated by the model, where ;
- : the loss function;
- : the log-likelihood function.
4.1. Define the Loss Function
4.2. Convexity of the Loss Function
4.3. Learning Algorithm of the Bivariate Model
5. Conclusions and Discussion
| Algorithm 1 Learning the bivariate model for the correlated mixed outcomes |
|
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Atchison, Jhon, and Sheng M. Shen. 1980. Logistic-normal distributions: Some properties and uses. Biometrika 67: 261–72. [Google Scholar] [CrossRef]
- Baesens, Bart, Tony Van Gestel, Stijn Viaene, Maria Stepanova, Johan Suykens, and Jan Vanthienen. 1995. Benchmarking state-of-the-art classification algorithms for credit scoring. Journal of the Operational Research Society 54: 627–35. [Google Scholar] [CrossRef]
- Bastani, Kaveh, Elham Asgari, and Hamed Namavari. 2019. Wide and deep learning for peer-to-peer lending. Expert Systems with Applications 134: 209–24. [Google Scholar] [CrossRef]
- Boyd, Stephen, and Lieven Vandenberghe. 2004. Convex Optimization. Cambridge: Cambridge University Press. [Google Scholar]
- Byanjankar, Ajay, and Markus Viljanen. 2019. Predicting expected profit in ongoing peer-to-peer loans with survival analysis-based profit scoring. Paper presented at 11th KES International Conference on Intelligent Decision Technologies (KES-IDT 2019), St. Julians, Malta, June 17–19. [Google Scholar]
- Byanjankar, Ajay, Markku Heikkilä, and Jozsef Mezei. 2015. Predicting credit risk in peer-to-peer lending: A neural network approach. Paper presented at 2015 IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, December 7–10. [Google Scholar]
- Cox, David R., and Nanny Wermuth. 1992. Response models for mixed binary and quantitative variables. Biometrika 79: 441–61. [Google Scholar] [CrossRef]
- De Leon, Alexander R., and Keumhee Chough Carriere. 2000. On the one-sample location hypothesis for mixed bivariate data. Communications in Statistics-Theory and Methods 29: 2573–81. [Google Scholar] [CrossRef]
- Emekter, Riza, Yanbin Tu, Benjamas Jirasakuldech, and Min Lu. 2015. Evaluating credit risk and loan performance in online Peer-to-Peer (P2P) lending. Applied Economics 47: 54–70. [Google Scholar] [CrossRef]
- Everett, Craig R. 2019. Origins and development of credit-based crowdfunding. Banking and Finance Review 11: 1–32. [Google Scholar] [CrossRef]
- Fitzmaurice, Garrett M., and Nan M. Laird. 1995. Regression models for a bivariate discrete and continuous outcome with clustering. Journal of the American statistical Association 90: 845–52. [Google Scholar] [CrossRef]
- Forbes, Catherine, Merran Evans, Nicholas Hastings, and Brian Peacock. 2011. Statistical Distributions. Hoboken: John Wiley & Sons. [Google Scholar]
- Gueorguieva, Ralitza V., and Gerard Sanacora. 2006. Joint analysis of repeatedly observed continuous and ordinal measures of disease severity. Statistics in Medicine 25: 1307–22. [Google Scholar] [CrossRef]
- Gumbel, Emil J. 1961. Bivariate logistic distributions. Journal of the American Statistical Association 56: 335–49. [Google Scholar] [CrossRef]
- Guo, Yanhong, Wenjun Zhou, Chunyu Luo, Chuanren Liu, and Hui Xiong. 2016. Instance-based credit risk assessment for investment decisions in P2P lending. European Journal of Operational Research 249: 417–26. [Google Scholar] [CrossRef]
- Hand, David J. 2009. Measuring classifier performance: A coherent alternative to the area under the ROC curve. Machine Learning 77: 103–23. [Google Scholar] [CrossRef]
- Kim, Ji-Yoon, and Sung-Bae Cho. 2019. Predicting repayment of borrows in peer-to-peer social lending with deep dense convolutional network. Expert Systems 54: e12403. [Google Scholar] [CrossRef]
- Lamb, John, and Kaihong Tee. 2012. Data Envelopment Analysis Models of Investment Funds. European Journal of Operational Research 216: 687–96. [Google Scholar] [CrossRef]
- le Cessie, Saskia, and Johannes C. Van Houwelingen. 1994. Logistic regression for correlated binary data. Journal of the Royal Statistical Society: Series C Applied Statistics 43: 95–108. [Google Scholar] [CrossRef]
- Ma, Xiaojun, Jinglan Sha, Dehua Wang, Yuanbo Yu, Qian Yang, and Xueqi Niu. 2018. Study on a prediction of P2P network loan default based on the machine learning LightGBM and XGboost algorithms according to different high dimensional data cleaning. Electronic Commerce Research and Applications 31: 24–39. [Google Scholar] [CrossRef]
- Malekipirbazari, Milad, and Vural Aksakalli. 2015. Risk assessment in social lending via random forests. Expert Systems with Applications 42: 4621–31. [Google Scholar] [CrossRef]
- Pierrakis, Yannis. 2018. Banking on Each Other: Peer-to-peer lending to business: Evidence from funding circle. In Electronic Commerce Research and Applications. London: Nesta. [Google Scholar]
- Roberts, Arthur Wayne. 1993. Convex functions. In Handbook of Convex Geometry. Amsterdam: Elsevier, vol. 10, pp. 1081–104. [Google Scholar]
- Serrano-Cinca, Carlos, and Begoña Gutiérrez-Nieto. 2016. The use of profit scoring as an alternative to credit scoring systems in peer-to-peer (P2P) lending. Decision Support Systems 89: 113–22. [Google Scholar] [CrossRef]
- Tang, Huan. 2019. Peer-to-peer lenders versus banks: Substitutes or complements? The Review of Financial Studies 32: 1900–38. [Google Scholar] [CrossRef]
- Thmasebinejad, Z., and E. Tabrizi. 2015. Sensitivity analysis in correlated bivariate continuous and binary responses. Applications and Applied Mathematics: An International Journal (AAM) 10: 37. [Google Scholar]
- Tsoumakas, Grigorios, Eleftherios Spyromitros-Xioufis, Aikaterini Vrekou, and Ioannis Vlahavas. 2014. Multi-target regression via random linear target combinations. Paper presented at Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Nancy, France, September 14–18; pp. 225–40. [Google Scholar]
- Wang, Yan, and Xuelei Sherry Ni. 2020a. Improving Investment Suggestions for Peer-to-Peer Lending via Integrating Credit Scoring into Profit Scoring. Paper presented at 2020 ACM Southeast Conference (ACMSE 2020), Tampa, FL, USA, April 2–4. [Google Scholar]
- Wang, Yan, and Xuelei Sherry Ni. 2020b. Risk Prediction of Peer-to-Peer Lending Market by a LSTM Model with Macroeconomic Factor. Paper presented at 2020 ACM Southeast Conference (ACMSE 2020), Tampa, FL, USA, April 2–4. [Google Scholar]
- Wang, Yan, Xuelei Sherry Ni, and Xiao Huang. 2023. Towards Profitability: A Profit-Sensitive Multinomial Logistic Regression for Credit Scoring in Peer-to-Peer Lending. Paper presented at Future Technologies Conference (FTC) 2022, Vancouver, BC, Canada, October 19–20; Cham: Springer International Publishing, vol. 1, pp. 696–718. [Google Scholar]
- Wassell, James T., and Melvin L. Moeschberger. 1993. A bivariate survival model with modified gamma frailty for assessing the impact of interventions. Statistics in Medicine 12: 241–48. [Google Scholar] [CrossRef] [PubMed]
- Xia, Yufei, Chuanzhe Liu, and Nana Liu. 2017a. Cost-sensitive boosted tree for loan evaluation in peer-to-peer lending. Electronic Commerce Research and Applications 24: 30–49. [Google Scholar] [CrossRef]
- Xia, Yufei, Chuanzhe Liu, YuYing Li, and Nana Liu. 2017b. A boosted decision tree approach using Bayesian hyper-parameter optimization for credit scoring. Expert Systems with Applications 78: 225–41. [Google Scholar] [CrossRef]
- Ye, Xin, Lu-an Dong, and Da Ma. 2018. Loan evaluation in P2P lending based on random forest optimized by genetic algorithm with profit score. Electronic Commerce Research and Applications 32: 23–36. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Loan Status | ARR | Profitable | Frequency | Proportion |
|---|---|---|---|---|
| 0 | > 1 | Yes | 904,086 | 80.44% |
| 1 | 1 | No | 200,859 | 17.87% |
| 1 | > 1 | Yes | 18,950 | 1.69% |
| Hyper-Parameter | Search Domain | Value Setting |
|---|---|---|
| Number of epochs S | (100, 5000) | 2000 |
| Number of mini-batches m | (1000, 50,000) | 3000 |
| Learning rate | (0.00001, 0.1) | 0.01 |
| Model 1 | Model 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Grade | Loans | Def | Prof | Loans | Def | Prof | ||
| A | 1 | 0.00 | 1.00 | 1.04 | 23 | 0.04 | 0.96 | 1.05 |
| B | 4 | 0.00 | 1.00 | 1.10 | 10 | 0.20 | 0.80 | 0.91 |
| C | 4 | 0.50 | 0.50 | 0.90 | 9 | 0.11 | 1.00 | 1.10 |
| D | 4 | 0.25 | 1.00 | 1.11 | 2 | 1.00 | 0.00 | 0.60 |
| E | 3 | 0.33 | 0.67 | 0.84 | 1 | 0.00 | 1.00 | 1.15 |
| F | 5 | 0.80 | 0.20 | 0.57 | NA | NA | NA | NA |
| G | 24 | 0.75 | 0.29 | 0.68 | NA | NA | NA | NA |
| Overall | 45 | 0.58 | 0.47 | 0.78 | 45 | 0.13 | 0.89 | 1.01 |
| Model 3 (Based on PD) | Model 3 (Based on Predicted ARR) | |||||||
|---|---|---|---|---|---|---|---|---|
| Grade | Loans | Def | Prof | Loans | Def | Prof | ||
| A | 30 | 0.00 | 1.00 | 1.04 | 17 | 0.12 | 0.88 | 1.03 |
| B | 10 | 0.00 | 1.00 | 1.08 | 8 | 0.13 | 0.88 | 1.01 |
| C | 5 | 0.20 | 0.80 | 1.00 | 11 | 0.18 | 0.82 | 1.07 |
| D | NA | NA | NA | NA | 2 | 0.00 | 1.00 | 1.17 |
| E | NA | NA | NA | NA | 3 | 0.33 | 0.67 | 0.83 |
| F | NA | NA | NA | NA | 4 | 0.25 | 0.75 | 1.02 |
| Overall | 45 | 0.02 | 0.98 | 1.05 | 45 | 0.16 | 0.84 | 1.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Ni, X.S.; Ni, H.; Biswas, S. A Bivariate Model for Correlated and Mixed Outcomes: A Case Study on the Simultaneous Prediction of Credit Risk and Profitability of Peer-to-Peer (P2P) Loans. Risks 2025, 13, 33. https://doi.org/10.3390/risks13020033
Wang Y, Ni XS, Ni H, Biswas S. A Bivariate Model for Correlated and Mixed Outcomes: A Case Study on the Simultaneous Prediction of Credit Risk and Profitability of Peer-to-Peer (P2P) Loans. Risks. 2025; 13(2):33. https://doi.org/10.3390/risks13020033
Chicago/Turabian StyleWang, Yan, Xuelei Sherry Ni, Huan Ni, and Sanad Biswas. 2025. "A Bivariate Model for Correlated and Mixed Outcomes: A Case Study on the Simultaneous Prediction of Credit Risk and Profitability of Peer-to-Peer (P2P) Loans" Risks 13, no. 2: 33. https://doi.org/10.3390/risks13020033
APA StyleWang, Y., Ni, X. S., Ni, H., & Biswas, S. (2025). A Bivariate Model for Correlated and Mixed Outcomes: A Case Study on the Simultaneous Prediction of Credit Risk and Profitability of Peer-to-Peer (P2P) Loans. Risks, 13(2), 33. https://doi.org/10.3390/risks13020033