1. Introduction
In finance the trade-off between return and risk is a key consideration when choosing the best portfolio. Performance measures are important tools for assessing portfolio risk and return. The Sharpe ratio
Sharpe (
1966) is a popular performance measure for portfolio managers, evaluating the performance of a portfolio by calculating the mean and standard error. The portfolio with the maximum Sharpe ratio represents the highest return-to-risk trade-off. Therefore, the investment goal is to achieve the maximum Sharpe ratio. The portfolio that maximizes the Sharpe ratio lies on the mean-variance-efficient frontier. This portfolio corresponds to the point where the capital market line is tangent to the frontier, and, as such, it is known as the tangency portfolio
Markowitz (
1952). While the Sharpe ratio is commonly used in investment strategies, the squared Sharpe ratio is also used as a performance measure in the literature; see, e.g.,
Treynor and Black (
1973) and
Grinold and Kahn (
1999), among many others. In this paper, we focus on the squared maximum Sharpe ratio (SMSR) widely used in testing arbitrage pricing theory.
Chamberlain and Rothschild (
1982) used SMSR to establish a bound for the sum of squared pricing errors in beta pricing equations.
MacKinlay (
1995) used SMSR to examine the multifactor model’s plausibility in explaining anomalies in the capital asset pricing model.
Zhang (
2009) developed test statistics based on the sample SMSR of factors extracted from individual stocks.
Barillas et al. (
2020) used SMSR in an asymptotic analysis under general distributional assumptions for model comparison. An important aspect of an investment is forming a suitable portfolio by estimating the optimal weights for the desired assets. Before forming a portfolio, selecting an investment opportunity set of assets is crucial. In the absence of a risk-free asset, the investment opportunities can be determined based on the Sharpe ratios of risky assets and their correlation. The maximum squared Sharpe ratio is a suitable index that summarizes the performance of an investment opportunity in a single value, based on the Sharpe ratios of assets and the correlation coefficients between them. The main assumption for the appropriateness of the Sharpe ratio and related measures is the normality of asset returns. When returns are non-normal with a non-linear dependence structure, these measures could be either overestimated or underestimated.
Choy and Yang (
2021) demonstrated that under the assumption of a multivariate normal distribution for excess returns, the sample SMSR has a significant upward bias, and they improved several estimators of SMSR. Dealing with non-normal returns in portfolio selection is an important consideration for investors, as it can significantly impact their portfolio’s performance. Investors can account for non-normal returns by adjusting expected returns, using alternative risk measures such as value at risk and conditional value at risk, and considering alternative asset classes. Another common approach to accounting for non-normal dependence structure is the use of copulas (see,
Cherubini et al. 2004;
Embrechts et al. 2002,
2003;
Fantazzini 2008;
He and Gong 2009), which are a powerful tool for modeling the dependence structure between different assets in a portfolio. By using copulas, investors can gain a more accurate understanding of how different assets move relative to each other, helping them build more efficient and diversified portfolios. Although the squared maximum Sharpe ratio was developed in recent years, little research has been done to address its compatibility as a measure of performance. As argued by
Kourtis (
2016), the expected squared Sharpe ratio rises with the number of assets and the maximum Sharpe ratio, while it falls with the length of the data. In this paper, we focus on the SMSR of a two-asset portfolio. This index summarizes the joint performance of a bivariate random vector of asset returns as a single value, which could help in selecting the components of a two-asset portfolio. A topic in statistical arbitrage technique, pairs trading, explores how to identify a suitable pair for trading
Ramos-Requena et al. (
2020). This paper makes two contributions toward the squared maximum Sharpe ratio. First, we study the effect of dependence on SMSR. Several theoretical properties of the bivariate Sharpe ratio, in terms of copulas, are given in
Section 2. The copula-based bivariate Sharpe ratio is presented in
Section 3. In
Section 4, we provide an estimator for the proposed copula-based bivariate Sharpe ratio. A simulation study is performed in this section. A real-data analysis is provided in
Section 5.
Section 6 concludes the paper.
2. Bivariate Squared Maximum Sharpe Ratio
Consider two assets,
A and
B, with the returns
and
over a time interval
t (e.g.,
and
could be the daily returns, so
one day), respectively, defined on a common probability space
, endowed with a filtration
representing the information available to the investor up to time
T. Let
b be a benchmark investment strategy, and let
denote its return over a time interval
t. The benchmark
b may be riskless, hence
may be a fixed constant. We only present the case that the processes from which the excess returns are sampled are stationary. That is, the means and the variances of returns and the covariance between them are fixed for any time interval
t. The excess returns over the risk-free asset are random variables, which we denote by continuous random variables
and
. Let
, be a two-asset portfolio with dependent components
X and
Y, where
is the weight of
X and
is the weight of
Y. Let
and
be the mean and variance of
X and
,
be the mean and variance of
Y. We assume that variances exist and are non-zero. By definition, the Sharpe ratios (SRs) of
X and
Y are given by
and
, respectively. The Sharpe ratio of the portfolio
P as a function of the weight
w is given by
where
. It is known that the maximum happens at
that is
.
Definition 1. Let be the Pearson’s correlation of the excess returns X and Y with the Sharpe ratios and , respectively. The bivariate squared maximum Sharpe ratio of a two-asset portfolio with the components X and Y (denoted by SMSR) is defined by For the case of uncorrelated assets, i.e., , we have . For the cases or , .
Remark 1. By considering the SMSR(X,Y) as a bivariate Sharpe ratio, which is a function of the marginal Sharpe ratios and the correlation coefficient of the asset’s returns as outlined in this paper, one can effectively choose the components of a portfolio. For instance, when forming a portfolio with two assets, such as between the options and , the more suitable option is the one with a higher SMSR(X,Y) value. This approach can serve as a pre-selection of suitable assets for portfolio formation, followed by determining the optimal weights of these selected assets in the next step.
As noted in
Dowd (
2000), using the traditional Sharpe ratio may result in significant errors when determining whether the true correlation is non-zero. When forming a portfolio with two assets, let us consider two options:
and
. In a given period, suppose that the Sharpe ratio of the returns for both options are equal, i.e.,
and
, but the correlation coefficient of
is equal to 0.4 and the correlation of
is equal to 0.8. Based on
, which option is suitable for forming a portfolio? To provide a proper answer, we need to examine the impact of correlation on the bivariate squared maximum Sharpe ratio.
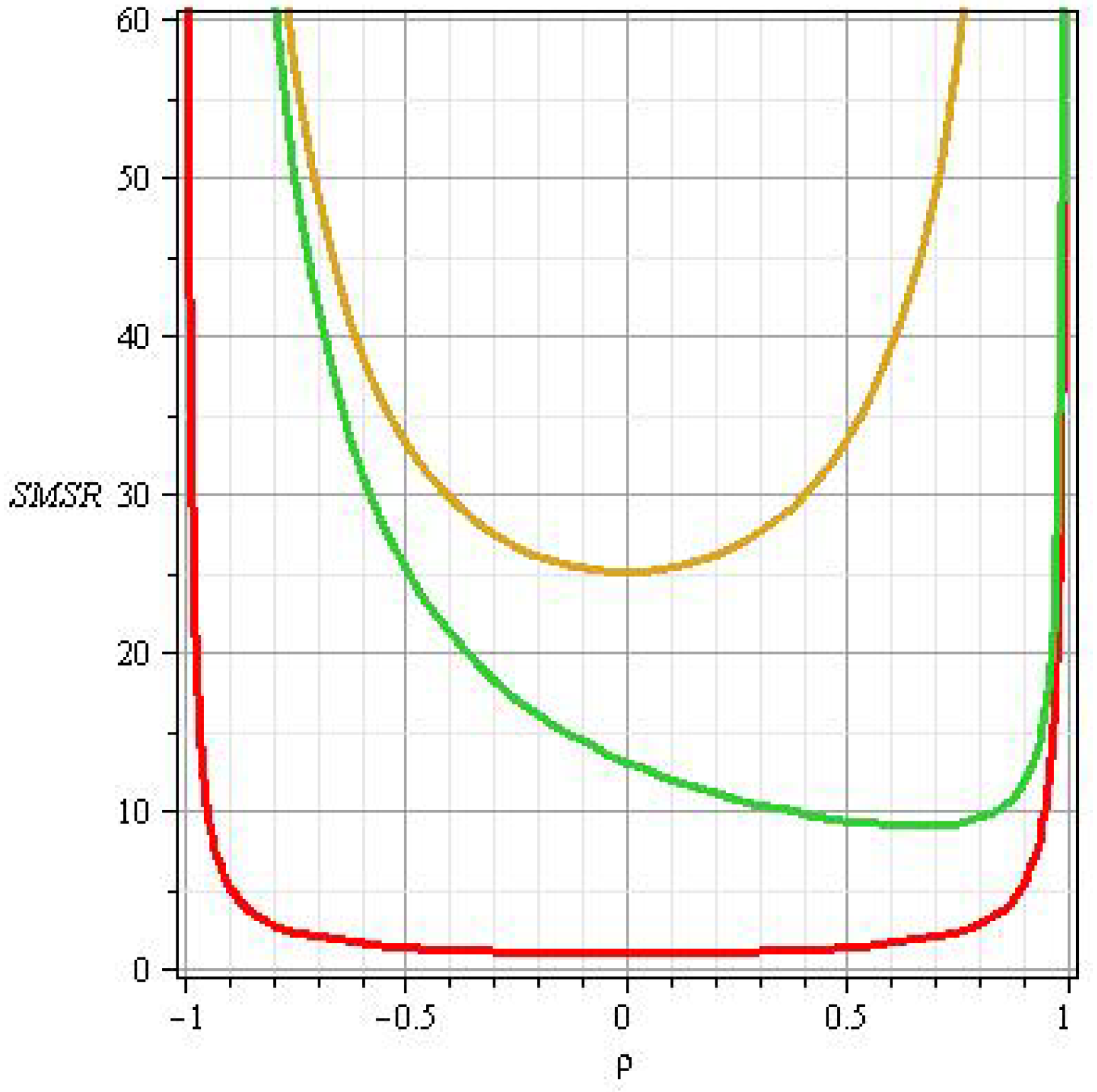
Proposition 1. Let and be the Sharpe ratios of X and Y and let . For SMSR(X,Y) defined by (2), the following hold: - (i)
SMSR(X,Y) is decreasing in ρ, for ;
- (ii)
SMSR(X,Y) is increasing in ρ, for ;
- (iii)
SMSR, for each , and the equality holds if, and only if, .
Proof. The derivative of SMSR(X,Y) with respect to
is given by
where
. Note that
. For
, we have that
. For
, we have that
and
and thus,
. Similarly, for
, we have that
and
or
and
, and thus
, which completes the proof of parts (i) and (ii). For part (iii), let
. From parts (i) and (ii), for
, we have that
, and for
,
. Since
, it follows that SMSR
, for each
. To prove the last part, if
, then
for
, and
, for
, that is
. Conversely, if
, then
for
and
for
, that is
. □
Figure 1 shows the plot of
as a function of
for different values of
and
to illustrate the results of Proposition 1.
Proposition 2. For each , .
Proof. The result from the inequalities and that hold for each and and . □
Figure 2 shows the upper and lower bound for
that is provided in Proposition 2. In the statistical literature, it is common to assume that log-returns are distributed as a normal distribution. The following example illustrates the effect of dependence on
of log-normal returns.
Example 1. Let X and Y be log-normal random variables with the bivariate density function given by Mielke et al. (1977)wherefor , , , , , and ; where α and β are the marginal distribution shape parameters, A and B are the scale parameters, r is the dependence parameter. Clearly, X and Y have the univariate log-normal distribution with the means and the variances given byand Let . Then, it is easy to see that , if, and only if, .
The squared Sharpe ratio for the pair is given by Let . We note that Thus, the function has a minimum at the point and from Proposition 1, the following properties hold:
If , then is decreasing in r;
If , then is increasing in r;
For each , , and the equality holds, if .
3. Copula-Based Squared Maximum Sharpe Ratio
Let
X and
Y be two continuous random variables with the univariate marginal cumulative distribution functions (CDF)
and
for
and the joint CDF
. In Formula (
2),
and
are calculated from the marginal CDFs and
is associated with the joint CDFs of
X and
Y. Following Sklar’s Theorem, see,
Nelsen (
2006), there exists a unique copula
C such that
where
is the joint CDF of the pair
whose margins are uniform on [0, 1]. The copula
C characterizes the dependence in the pair
Nelsen (
2006). Let
denotes the covariance of random variables
X and
Y, whose associated copula is
C. By using Hoeffding’s identity
Hoeffding (
1994) and transformations
and
, from (
3) we have
or equivalently,
When the joint CDF of
is non-normal, we can model it by selecting suitable parametric forms for the marginal CDFs
F,
G, and the copula
C in (
3). For example,
F might be the CDF of normal random variables with the parameters
and
and
G might the CDF of a gamma random variable with the parameters
and
and the copula
C might be taken from a parametric family of copulas. Popular choices of copulas are described in
Joe (
2014) and
Nelsen (
2006). The main advantage of this approach is that the distributions
F,
G, and
C in (
3) can be chosen independently of one another. The means
,
and the variances
and
of
X and
Y are calculated from the marginal CDFs, and their Pearson’s correlation coefficient can be obtained by
In the following, we define the copula-based version of the squared maximum Sharpe ratio of a two-asset portfolio with the components X and Y and the associated copula C, denoted .
Definition 2. Let be a pair of continuous random variables with the marginal CDF F (of X) and G (of Y) and associated copula C. We define the copula-based squared maximum Sharpe ratio of a two-asset portfolio with the excess returns X and Y and the marginal, the Sharpe ratios and , by A copula
C is said to be positive quadrant dependent (PQD) if for all
,
, and negative quadrant dependent (NQD) if
, where
, is the copula of independent random variables
Nelsen (
2006). The following result compares the
of a pair of dependent returns under a copula
C with the
of the independent copula
.
Proposition 3. Let be two excess returns with the Sharpe ratios and and the associated copula C.
- (i)
If C is PQD, then , if and only if, , where ;
- (ii)
If C is NQD then, .
Proof. Note that
. Let
We note that
. If
C is PQD, then
. By using (
5), we have that
. For
, it is easy to see that
, if and only if,
. If
C is NQD, then
, and thus
, which completes the proof. □
Remark 2. The above result shows that, when the returns are positively or negatively dependent, but considered independent, the SMSR(X,Y) is more or less estimated.
Example 2. Let X and Y be two exponential random variables with means and , respectively, and the associated FGM copula Nelsen (2006) given by So, , , and . Therefore, , which is decreasing with respect to the dependency parameter θ and does not depend on the marginal parameters and . The value of the decreases as the dependence between X and Y increases. For the case of independence, i.e., , we have . Note that the copula is PQD (NQD) for .
The following example compares two investment opportunity sets and with the common marginal CDFs and different dependence structures.
Example 3. Let X and Y be two beta random variables having the CDFswith and , and the associated copula be the FGM copula given by (8). The joint CDF of is given bywith . It is easy to see that We note that , if and only if, . The Pearson’s correlation is given by The expression for is given by Let . It follows that if and only if, , where . From Proposition 1,
If , then is decreasing in ;
If , then is increasing in .
Since ρ is an increasing function of θ, then the following hold
If , then is decreasing in θ;
If , then is increasing in θ.
For , let have the FGM copula . Then, from Proposition 1, the following hold
If , then ;
If , then ;
If , then the value of and care not comparable.
Note that , where , if and only if, , where . Since for , the copula is PQD, then from Proposition 3, , if . For , is NQD, and then, .
4. Estimators of Squared Maximum Sharpe Ratio
Let
,
, be a sample of size
n from a pair
. A natural estimator of
defined by (
2) is its sample version given by
where
,
,
and
is the sample Pearson’s correlation coefficient. We note that the expression (
2) for
can be rewritten as
where
with
Under the explicit assumption that the returns are normally distributed, from the standard theory of normal quadratic form, see, e.g.,
Anderson et al. (
1958), we have that
where
is the non-central F-distribution
Anderson et al. (
1958) with 2 and
degree of freedom and non-centrality parameter
. Note that
Thus, is a biased estimator of .
An estimator for the copula-based
defined by (
7) could be found as follows:
- Step 1.
Based on a random sample , find suitable models for the marginal distributions, namely and , using the standard goodness-of-fit tests;
- Step 2.
Compute the marginal Sharpe ratios and from the estimated marginal distributions by and ;
- Step 3.
Choose a suitable copula model, namely
, using the copula goodness-of-fit testing
Genest et al. (
2009) for the dependence structure of data;
- Step 4.
Compute the copula-based estimator of Pearson’s correlation coefficient
, denoted by
using
- Step 5.
Compute the copula-based estimator of
by
When dealing with time-series data for underlying commodities, the initial step involves conducting standard tests, such as those proposed by
Box and Pierce (
1970) and
Ljung and Box (
1978), on the log-returns and their squared values to identify any presence of autocorrelation and heteroscedasticity within the series. If these tests yield insignificant results, the log-returns can be considered as a random sample from a distribution
F, leading us to proceed with Step 1. In cases where strong autocorrelation and heteroscedasticity are observed, it is necessary to apply a time-series model initially to eliminate temporal dependence. Subsequently, the marginal parameters can be derived using the filtered residuals, and a copula can be fitted to these residuals, which are then transformed to uniform marginals. An estimator for the copula-based
as defined by (
7) can be obtained as follows:
- Step 1.
Fit appropriate models to the time-series data and obtain their standardized residuals;
- Step 2.
Transform the marginal standardized residuals into uniformly distributed samples;
- Step 3.
Estimate the dependence structure of two uniformly distributed residuals using copula modeling by maximum likelihood method;
- Step 4.
Generate n random samples , with the estimated copula models. Apply probability integral transform to , and then, calculate the Pearson’s moment correlation and the marginal Sharpe ratios and based on the means and variances of the estimated models;
- Step 5.
Compute the copula-based estimator of
by (
12).
In this section, we compare the values of the copula-based () and empirical () squared maximum Sharpe ratio by simulation. In the simulation, we consider the effect of sample size, marginal distributions, dependence structure, and the level of dependency. The simulation study was carried out according to a factorial design involving four factors that affect the estimation process:
- (1)
Sample size: ;
- (2)
Type of marginal distributions: symmetric (normal distribution) and skewed (gamma distribution);
- (3)
Dependence structure, represented by the copula C:
Clayton (an asymmetric copula with the lower tail dependence)
Frank (a symmetric copula)
Gumbel (an asymmetric copula with the upper tail dependence)
- (4)
Degree of dependence in terms of Kendall’s tau
at
, which corresponds to
for the Clayton copula and
for the Frank copula. For the Gumbel copula we consuder
which corresponds to
.
For each combination of factors, 1000 random samples were generated, and the values of
were computed. The results are shown in
Table 1 and
Table 2. The tables provide the copula structure, dependency level (Kendall’s
), the exact values of
, considered sample sizes (
n), the simulated bias (Bias), and mean square error (MSE) for the empirical estimator
defined by (
2) and the copula-based estimator
defined by (
12), as well as the relative efficiency (RE) and negative bias of two estimators. The results show that the MSE and bias in all cases decrease with the sample size, as expected. As we see, the relative efficiency of the copula-based estimator compared to the empirical method increases significantly when the sample size and level of dependence increase. From
Table 2, it can be seen that when the marginal distributions are skewed, the copula-based estimator will have a much better performance than the empirical method. In summary, when the assets are normally distributed, using the copula-based method or empirical method to estimate the
does not make much difference.
5. Empirical Analysis
In this section, we will compare the estimation of
using real data analysis. We will use the copula-based method under the assumption of normality and also under the independence of returns. The stock market considered is SP 500, and the daily asset returns of five stocks, namely, Amazon, Apple, Google, Tesla, and Microsoft, are used. The period is from the 1 January 2018 to the 31 December 2022. The data sets are selected from “
finance.yahoo.com (accessed on 26 February 2023)”. As an application of
in selecting stocks for investment, we consider each stock pair as an investment opportunity to build a portfolio with two assets. Using these five stocks, we can form 10 two-asset portfolios with the investment opportunity pairs in the set {(Amazon, Microsoft), (Apple, Microsoft), (Google, Microsoft), (Microsoft, Tesla), (Amazon, Apple), (Apple, Tesla), (Apple, Google), (Google, Tesla), (Amazon, Google), and (Amazon, Tesla).} Looking at the summary statistics and histograms (not shown here), it seems that all returns are almost symmetric. The high positive values of kurtosis for all returns indicate that the underlying distributions of all returns are heavy-tailed.
As the stock returns follow a time-series pattern, we seek appropriate models to analyze them. Common approaches for modeling and predicting the volatility of financial time series include the Autoregressive Moving Average (ARMA) model, the Autoregressive Conditional Heteroscedasticity (ARCH) model, the Generalized Autoregressive Conditional Heteroscedasticity (GARCH) model, and hybrid ARMA-GARCH models. The fitted time-series models are detailed in
Table 3. Various models have been employed to model the volatility of Tesla’s returns, and overall, the GARCH(1,1) model outperformed others:
where
represents the conditional variance,
denotes the residual returns defined as
, with
being an i.i.d. process with zero mean and unit variance, and
,
are the estimated parameters detailed in
Table 3. The volatility of the returns from Amazon, Apple, Google, and Microsoft has also been modeled using different approaches, and overall, the ARMA(1,0)-GARCH(1,1) model demonstrated a better fit:
with the estimated parameters provided in
Table 3. We examined four symmetric distributions—Normal, Cauchy, Logistic, and Student-
t Johnson et al. (
1995)—for filtered conditional residuals.
Table 4 displays the estimated parameters, Loglikelihood, Akaike’s Information Criterion (AIC), the Kolmogorov–Smirnov (K-S) statistic, and
p-values of the fitted distributions. It is evident that the distribution of all filtered returns deviates significantly from normal, and the Student-
t distribution emerges as a suitable choice. The density function of Student-
t vs. the degree of freedom is given by:
The marginal squared Sharpe ratios estimated under the fitted models and the normality assumption (empirical) are shown in
Table 5. Next, we estimated the dependence parameters using the maximum likelihood method. Before modeling the dependence structure between margin-filtered returns, we transformed the standardized residuals into uniformly distributed data. To model the dependence of each pair of returns, we utilized the filtered residuals of the fitted time series models and identified a suitable copula for them. We considered some commonly used families of copulas in finance, including elliptical copulas (Gaussian, Student-
t) and Archimedean copulas (Gumbel, Frank, and Clayton). Parameter estimation is based on the so-called inference for margins, which is a two-stage method, see,
Joe (
2014). The fitted copulas are presented in
Table 6. To select the most appropriate copulas, we employed the BiCopSelect function in the R package VineCopula
Nagler et al. (
2023). A review and comparison of copula goodness-of-fit test procedures can be found in
Genest et al. (
2009). The log-likelihood values, the Cramér–von Mises statistic
, the Akaike information criterion (AIC), and the Bayesian Information Criteria (BIC) of the fitted models are detailed in
Table 6. The Gaussian copula and Student-
t copula outperform the other three, based on a larger log-likelihood and smaller AIC and BIC values. The returns of portfolios (1), (2), (3), (5), (7), and (9) fit well with the Student-
t copula, as follows:
where
and
are the CDF of the Student-
t random variable with the degrees of freedom
and its inverse, and
is the bivariate Student-
t distribution with the correlation parameter
and the degrees of freedom
Joe (
2014). The returns of the portfolio (4) fit well with the BB1 copula
Joe (
2014) given by
The returns of the portfolios (6), (8), and (10) fit with the survival of the BB1 copula, i.e.,
. The estimated parameters
and
are given in
Table 6. Finally,
Table 7 shows the value of the copula-based
defined by (
12), the value of the
under the independence assumption, and the empirical value of the
defined by (
9). The value of the Pearson correlation coefficient of the returns for each portfolio is calculated with the copula-based method (
11) and the ordinary empirical value is shown in
Table 7. It can be seen that all five stocks have a high positive correlation with each other, and the correlation between Microsoft and the other four stocks is higher. According to the results of
Table 5 and
Table 7, the copula-based estimator is consistent with Part 3 of Proposition 1. The value of
for each pair of stocks is greater than the squared Sharpe ratio of the marginal stocks. The estimated values of
in
Table 7 are consistent with the result of Proposition 3, that is, in the case that stocks have positive dependence, the value of the copula-based estimator of
is always smaller than the value of
under the assumption of independence. Therefore, if dependence is not considered in the estimation of
, it gives misleading results. As an application of
in selecting stocks for investment, if we consider each stock pair as an investment opportunity set to build a portfolio with two assets, according to
Table 7, the order of selecting options based on the three estimation methods is not the same. Therefore, incorrectly considering the assumption of independence will produce the wrong results. Based on the value of
, the first three options are the (Microsoft, Amazon), (Microsoft, Apple), and (Microsoft, Tesla) pairs.




{kind=link}
{kind=link}