
Credit Risk Assessment and Financial Decision Support Using Explainable Artificial Intelligence

 , , , , and
, , , , and 
Abstract
1. Introduction
1.1. Various Aspects of XAI
- Human agency and oversight: Judgments must be informed, and human monitoring is required.
- Transparency: AI system decisions should be conveyed in a form that is suitable for the relevant stakeholder. People need to be aware that they are engaging with artificial intelligence systems.
- Accountability: Mechanisms for accountability, auditability, and assessment of algorithms, data, and design processes must be implemented in AI systems. To improve decision making and risk assessment, it is important to comprehend the elements and characteristics that influence credit risk projections.
1.2. Major Contributions of the Proposed Work
- Analysis of the feature importance and significance in determining model output.
- Presentation of a model in both local and global surrogates.
- Presentation of both a classification analysis and a regression analysis.
- XAI scenarios for both acceptance and rejection, along with a description of the features.
- A description of the preprocessing and feature selection techniques used to ensure accurate classification without any class imbalances.
1.3. Structure of the Work
- Data gathering and preparation: We assemble pertinent credit information, such as client details, credit history, bank documents, and transactional records. The data are preprocessed by cleaning, normalized, and formatting to allow their use in analysis.
- Feature engineering: We extrapolate useful characteristics from the data that can be used to forecast credit risk. The characteristics of the consumer, their income and job history, the quantity of the loan, their credit utilization ratio, their payment history, and other factors could be among these. We ensure that the features are relevant, informative, and nonredundant.
- Model selection: It is important to choose a machine learning algorithm or model that can provide explainable results. Popular algorithms for credit risk analysis include logistic regression, decision tree, random forest, and gradient boosting models. These algorithms often provide feature importance measures that can be used to interpret the model’s predictions.
- Training the model: After splitting the data into training and testing sets, we use the training set to train the chosen model on historical credit data. During this phase, the model learns patterns and relationships between features and credit risk outcomes.
- Model interpretation: After training, the model’s feature importance scores or coefficients are analyzed. These values indicate the relative importance of each feature in predicting credit risk. Higher values suggest stronger influences, while lower values suggest weaker influences.
- Model evaluation: We assess the performance of the model on the testing set by using appropriate evaluation metrics such as accuracy, precision, recall, and F1-score to evaluate the model’s predictive power, generalization ability, and reliability.
- Model deployment and monitoring: After evaluating the model, we deploy it for credit risk analysis. We continuously monitor the model’s performance and periodically retrain it with new data to maintain accuracy and adapt to changing credit risk patterns.
- Explanations and insights: We provide explanations for the model’s predictions. This could involve explaining why a particular applicant is classified with a high or low credit risk by highlighting the significant factors influencing the decision. For this, we utilize techniques such as feature importance plots, partial dependence plots, and individual instance explanations to enhance transparency. The explainability of an AI model is crucial in credit risk analysis, as it is important to gain the trust of stakeholders and ensure compliance with regulations. XAI enables lenders, regulators, and customers to understand the reasoning behind credit decisions and identify any potential biases or unfair practices.
2. Literature Review
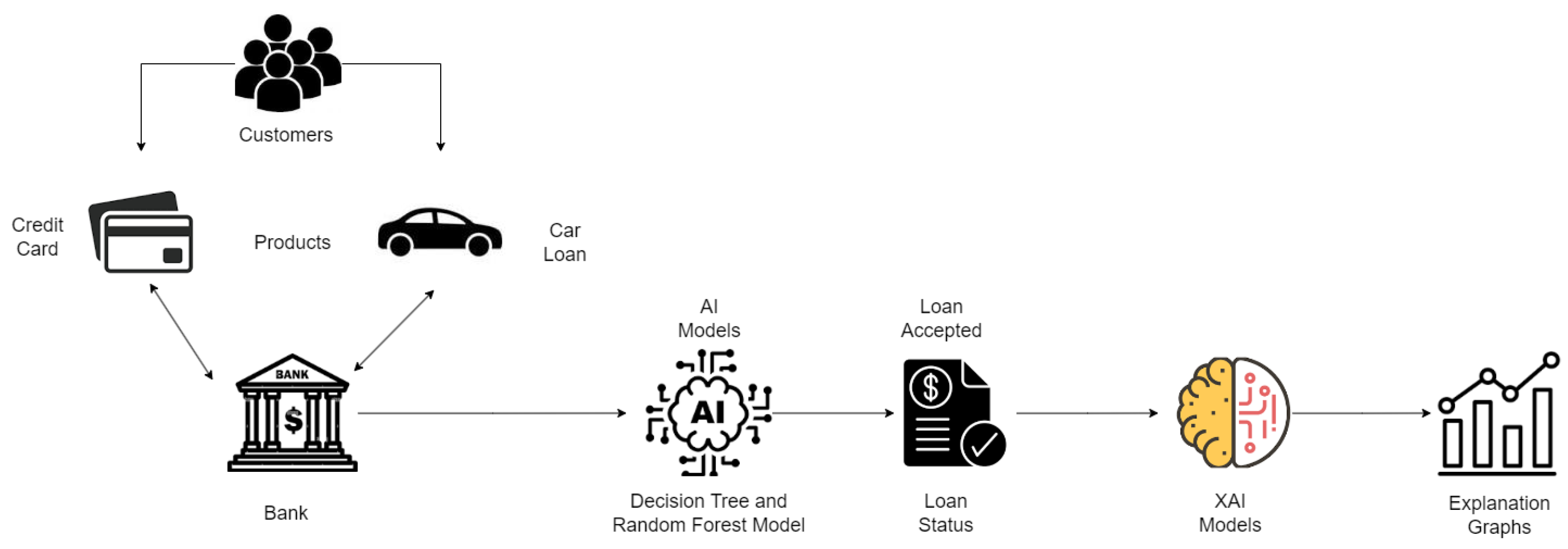
3. System Model and Architecture
3.1. System Model
3.1.1. Decision Tree
- Splitting: When a dataset is supplied to the tree, it divides by splitting the dataset into various categories.
- Pruning: It works for the shredding of the trees. Furthermore, it works for classification by subsiding the data in a better way. The pruning ends when the leaf node is reached.
- Selection: The best tree model is selected from the available trees that works smoothly for the data. This selection is based on the below factors.
- Entropy: This is the measure of the homogeneity of the trees. If the trees are homogeneous, then it would be zero.
- Information gain: When the entropy decreases, the information gain increases; this allows a further split of the trees into branches for further classification.
3.1.2. Random Forest
3.1.3. LIME
3.1.4. SHAP
| Algorithm 1: Algorithm for credit explanation. |
 |
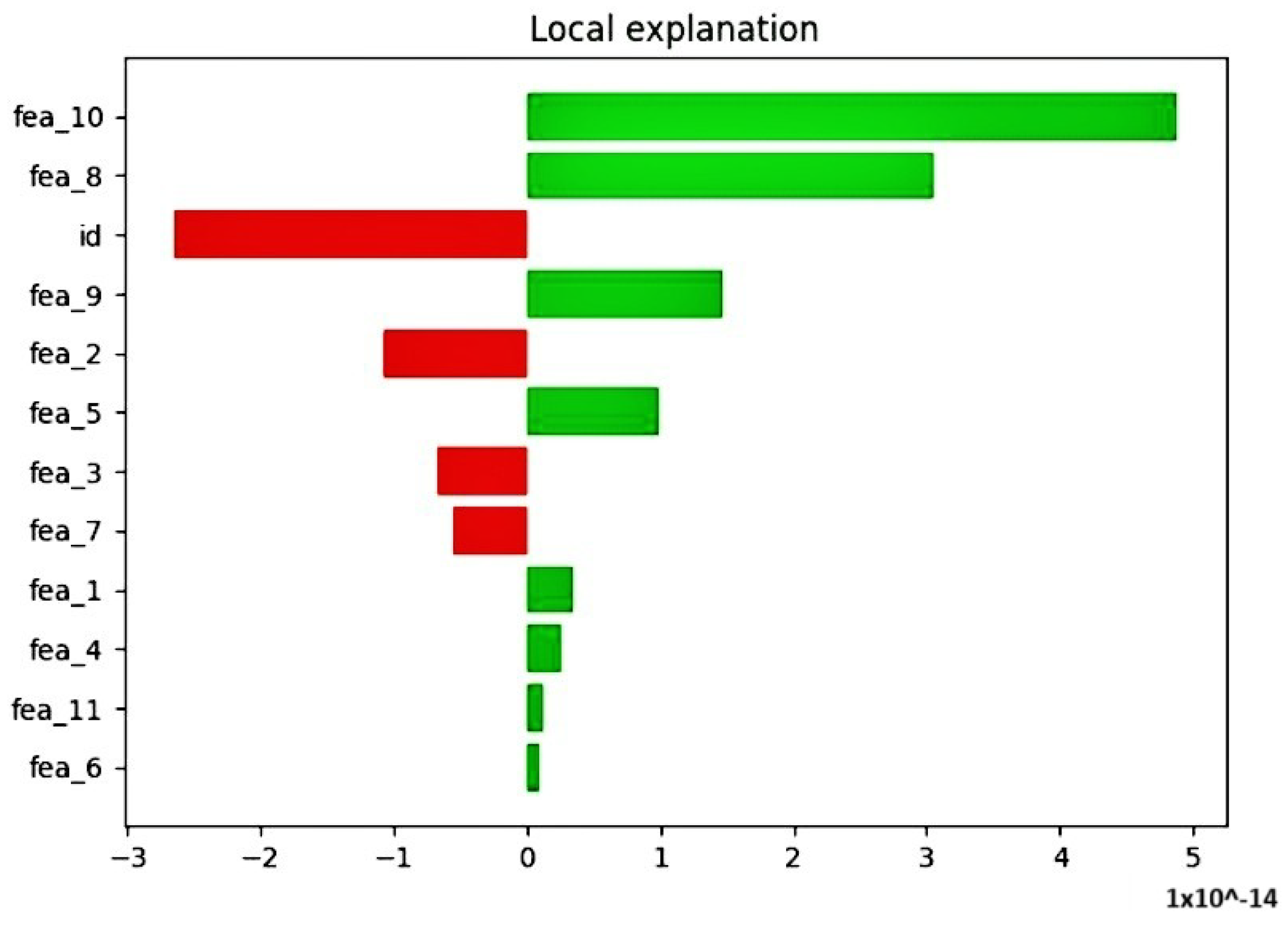
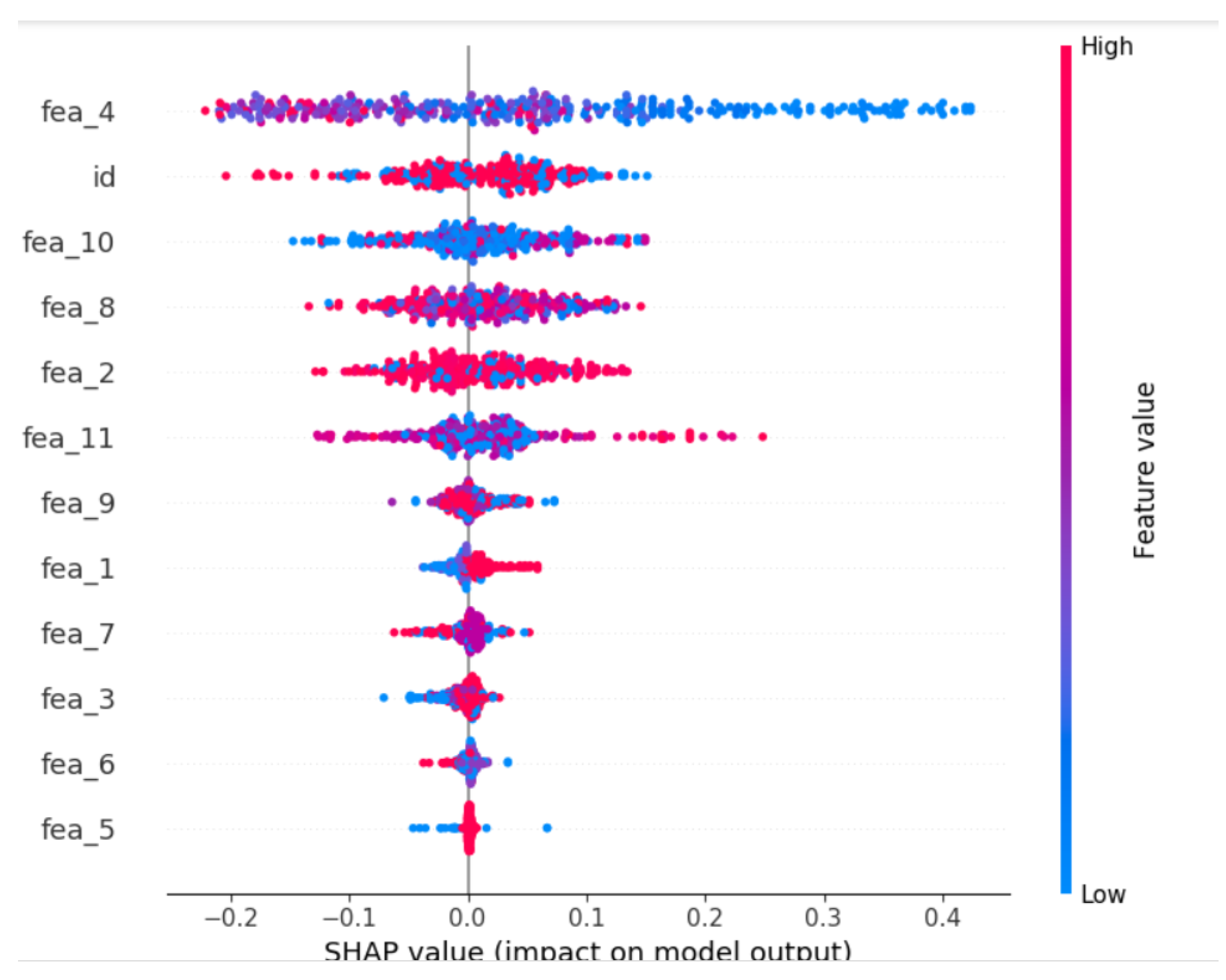
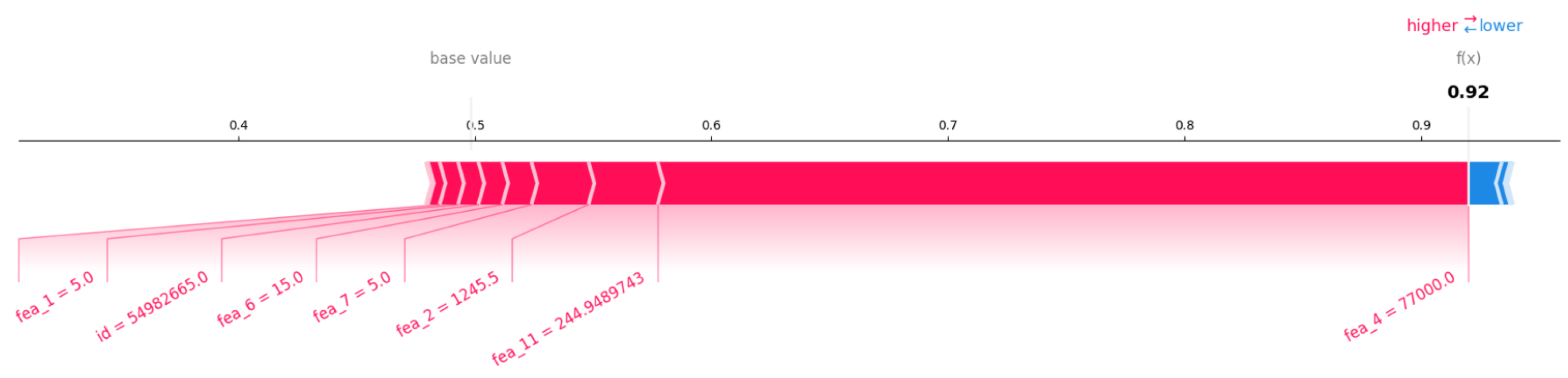
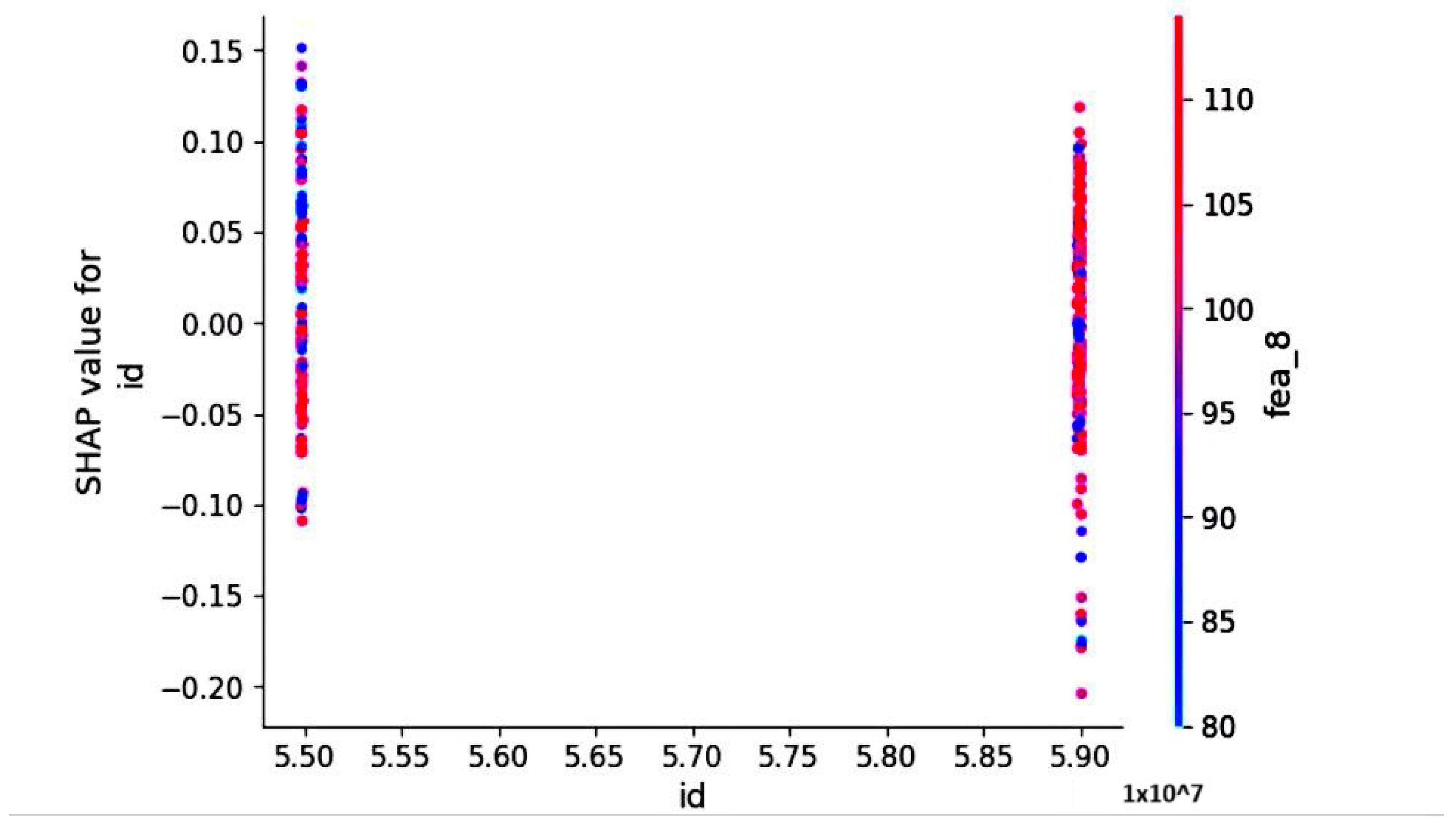
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bastos, João A., and Sara M. Matos. 2022. Explainable models of credit losses. European Journal of Operational Research 301: 386–94. [Google Scholar] [CrossRef]
- Biecek, Przemysław, Marcin Chlebus, Janusz Gajda, Alicja Gosiewska, Anna Kozak, Dominik Ogonowski, Jakub Sztachelski, and Piotr Wojewnik. 2021. Enabling machine learning algorithms for credit scoring–explainable artificial intelligence (xai) methods for clear understanding complex predictive models. arXiv arXiv:2104.06735. [Google Scholar]
- Bussmann, Niklas, Paolo Giudici, Dimitri Marinelli, and Jochen Papenbrock. 2020. Explainable ai in fintech risk management. Frontiers in Artificial Intelligence 3: 26. [Google Scholar] [CrossRef] [PubMed]
- Choi, Edward, Mohammad Taha Bahadori, Joshua A. Kulas, Andy Schuetz, Walter F. Stewart, and Jimeng Sun. 2017. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. Paper presented at NIPS’16: Proceedings of the 30th International Conference on Neural Information Processing Systems, Long Beach, CA, USA, December 4–9. [Google Scholar]
- Cohen, Joseph, Xun Huan, and Jun Ni. 2023. Shapley-based explainable ai for clustering applications in fault diagnosis and prognosis. arXiv arXiv:2303.14581. [Google Scholar] [CrossRef]
- de Lange, Petter Eilif, Borger Melsom, Christian Bakke Vennerød, and Sjur Westgaard. 2022. Explainable ai for credit assessment in banks. Journal of Risk and Financial Management 15: 556. [Google Scholar] [CrossRef]
- Demajo, Lara Marie, Vince Vella, and Alexiei Dingli. 2020. Explainable AI for interpretable credit scoring. In Computer Science and Information Technology. Chennai: AIRCC Publishing Corporation. [Google Scholar] [CrossRef]
- Doersch, Carl. 2021. Tutorial on variational autoencoders. arXiv arXiv:1606.05908v3. [Google Scholar]
- European Union. 2016. Regulation (EU) 2016/867 of the European Central Bank of 18 May 2016 on the collection of granular credit and credit risk data (ECB/2016/13). Official Journal of the European Union CELEX:32016R0867. [Google Scholar]
- Fahner, Gerald. 2018. Developing transparent credit risk scorecards more effectively: An explainable artificial intelligence approach. Paper presented at Data Analytics 2018, Athens, Greece, November 18–22. [Google Scholar]
- Galindo, Jorge, and Pablo Tamayo. 2000. Credit risk assessment using statistical and machine learning: Basic methodology and risk modeling applications. Computational Economics 15: 107–143. [Google Scholar] [CrossRef]
- Giudici, Paolo, and Emanuela Raffinetti. 2020. Shapley-lorenz decompositions in explainable artificial intelligence. SSRN Electronic Journal 1: 1–15. [Google Scholar] [CrossRef]
- Gramegna, Alex, and Paolo Giudici. 2021. Shap and lime: An evaluation of discriminative power in credit risk. Frontiers in Artificial Intelligence 4: 752558. [Google Scholar] [CrossRef]
- Guan, Charles, Hendra Suryanto, Ashesh Mahidadia, Michael Bain, and Paul Compton. 2023. Responsible credit risk assessment with machine learning and knowledge acquisition. Human-Centric Intelligent Systems 3: 232–43. [Google Scholar] [CrossRef]
- Hand, David J. 2009. Measuring classifier performance: A coherent alternative to the area under the roc curve. Machine Learning 77: 103–23. [Google Scholar] [CrossRef]
- Heng, Yi, and Preethi Subramanian. 2022. A Systematic Review of Machine Learning and Explainable Artificial Intelligence (XAI) in Credit Risk Modelling. Berlin: Springer, pp. 596–614. [Google Scholar] [CrossRef]
- Hu, Yong, and Jie Su. 2022. Research on credit risk evaluation of commercial banks based on artificial neural network model. Procedia Computer Science 199: 1168–76. [Google Scholar] [CrossRef]
- Joseph, Andreas. 2020. Parametric Inference with Universal Function Approximators. arXiv arXiv:1903.04209. [Google Scholar]
- Liao, Q. Vera, Moninder Singh, Yunfeng Zhang, and Rachel K. E. Bellamy. 2020. Introduction to explainable ai. Paper presented at the Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, CHI EA ’20, New York, NY, USA, April 25–30; pp. 1–4. [Google Scholar] [CrossRef]
- Lundberg, Scott, and Su-In Lee. 2017a. A Unified Approach to Interpreting Model Predictions. Paper presented at the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, December 4–9. [Google Scholar]
- Lundberg, Scott M, and Su-In Lee. 2017b. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems. Edited by I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan and R. Garnett. Red Hook: Curran Associates, Inc., vol. 30. [Google Scholar]
- Mestikou, Mohamed, Katre Smeti, and Yassine Hachaïchi. 2023. Artificial intelligence and machine learning in financial services market developments and financial stability implications. Financial Stability Board 1: 1–6. [Google Scholar] [CrossRef]
- Misheva, Branka, Joerg Osterrieder, Ali Hirsa, Onkar Kulkarni, and Stephen Lin. 2021. Explainable ai in credit risk management. Social Science Research Network 1: 1–16. [Google Scholar]
- Molnar, Christoph. 2022. Interpretable Machine Learning, 2nd ed. Morrisville: Lulu Press. Available online: http://christophm.github.io/interpretable-ml-book/ (accessed on 31 July 2024).
- Nag, Anindya, Md Mehedi Hassan, Dishari Mandal, Nisarga Chand, Md Babul Islam, VP Meena, and Francesco Benedetto. 2024. A review of machine learning methods for iot network-centric anomaly detection. Paper presented at the 2024 47th International Conference on Telecommunications and Signal Processing (TSP), Virtually, July 10–12; pp. 26–31. [Google Scholar]
- Pedregosa, Fabian, Gael Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, and et al. 2012. Scikit-learn: Machine learning in python. Journal of Machine Learning Research 12: 2825–30. [Google Scholar]
- Qadi, Ayoub El, Natalia Diaz-Rodriguez, Maria Trocan, and Thomas Frossard. 2021. Explaining credit risk scoring through feature contribution alignment with expert risk analysts. arXiv arXiv:2103.08359. [Google Scholar]
- Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. 2016. “Why should i trust you?”: Explaining the predictions of any classifier. arXiv arXiv:1602.04938. [Google Scholar]
- Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. 2018. Anchors: High-precision model-agnostic explanations. Paper presented at the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, February 2–7. [Google Scholar]
- Sadok, Hicham, Fadi Sakka, and Mohammed El Hadi El Maknouzi. 2022. Artificial intelligence and bank credit analysis: A review. Cogent Economics & Finance 10: 2023262. [Google Scholar] [CrossRef]
- Salih, Ahmed, Zahra Raisi, Ilaria Boscolo Galazzo, Petia Radeva, Steffen Petersen, Gloria Menegaz, and Karim Lekadir. 2023. Commentary on explainable artificial intelligence methods: Shap and lime. arXiv arXiv:2305.02012v3. [Google Scholar]
- Srivastava, Gautam, Rutvij H Jhaveri, Sweta Bhattacharya, Sharnil Pandya, Rajeswari, Praveen Kumar Reddy Maddikunta, Gokul Yenduri, Jon G. Hall, Mamoun Alazab, and Thippa Reddy Gadekallu. 2022. Xai for cybersecurity: State of the art, challenges, open issues and future directions. arXiv arXiv:2206.03585. [Google Scholar]
- Torrent, Neus Llop, Giorgio Visani, and Enrico Bagli. 2021. Psd2 explainable ai model for credit scoring. arXiv arXiv:2011.10367. [Google Scholar]
- Tyagi, Swati. 2022. Analyzing machine learning models for credit scoring with explainable ai and optimizing investment decisions. arXiv arXiv:2209.09362. [Google Scholar]
- Ul Islam Khan, Mahbub, Md Ilius Hasan Pathan, Mohammad Mominur Rahman, Md Maidul Islam, Mohammed Arfat Raihan Chowdhury, Md Shamim Anower, Md Masud Rana, Md Shafiul Alam, Mahmudul Hasan, Md Shohanur Islam Sobuj, and et al. 2024. Securing electric vehicle performance: Machine learning-driven fault detection and classification. IEEE Access 12: 71566–84. [Google Scholar] [CrossRef]
- Vincenzo Moscato, Antonio Picariello, and Giancarlo Sperlí. 2021. A benchmark of machine learning approaches for credit score prediction. Expert Systems with Applications 165: 113986. [Google Scholar] [CrossRef]
- Walambe, Rahee, Ashwin Kolhatkar, Manas Ojha, Akash Kademani, Mihir Pandya, Sakshi Kathote, and Ketan Kotecha. 2020. Integration of explainable ai and blockchain for secure storage of human readable justifications for credit risk assessment. Paper presented at the International Advanced Computing Conference, Panaji, India, December 5–6; pp. 55–72. [Google Scholar]
- Wattenberg, Martin, Fernanda Viégas, and Ian Johnson. 2016. How to Use t-Sne Effectively. Distill 1: 1–6. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
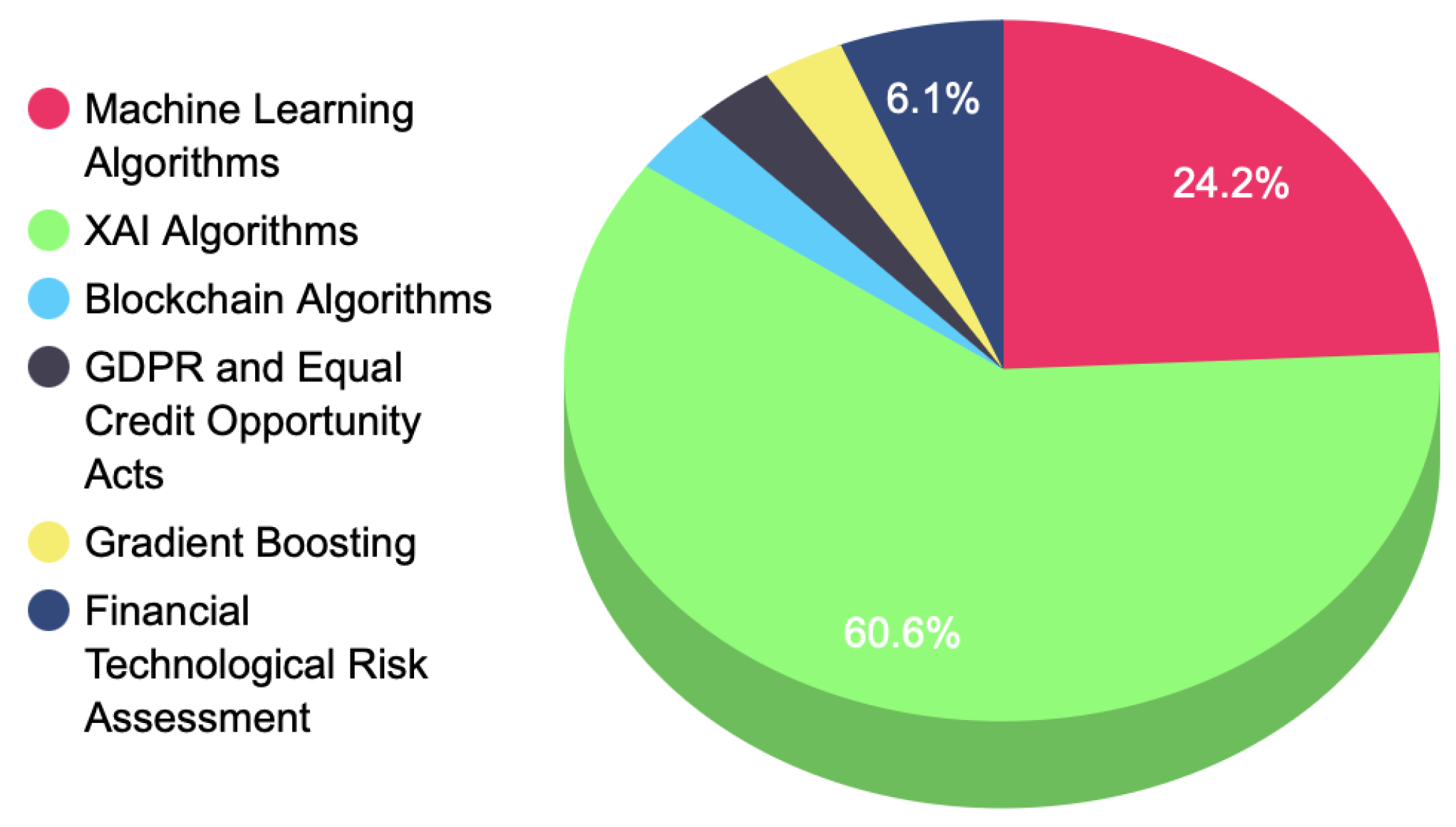
| Ref. No | Methods | Advantages | Research Challenges |
|---|---|---|---|
| Vincenzo Moscato (2021) | Benchmarking for machine learning approaches | Comprehensive ML analysis | Simple implementation with limited to LIME |
| Bussmann et al. (2020) | Financial technological risk assessment | 15,000 sample companies are evaluated | Limited to only Shapley values, no LIME |
| Bastos and Matos (2022) | Financial regression analysis | Mathematical approach and sound regression analysis | Lack of XAI modeling |
| Demajo et al. (2020) | The General Data Protection Regulation (GDPR) and the Equal Credit Opportunity Act (ECOA) | In-depth study and analysis | Lack of modeling and graphs. |
| Gramegna and Giudici (2021) | Gradient-boosting-based XAI modeling | Modeling of LIME and Shapley cluster analysis | Lack of feature importance analysis |
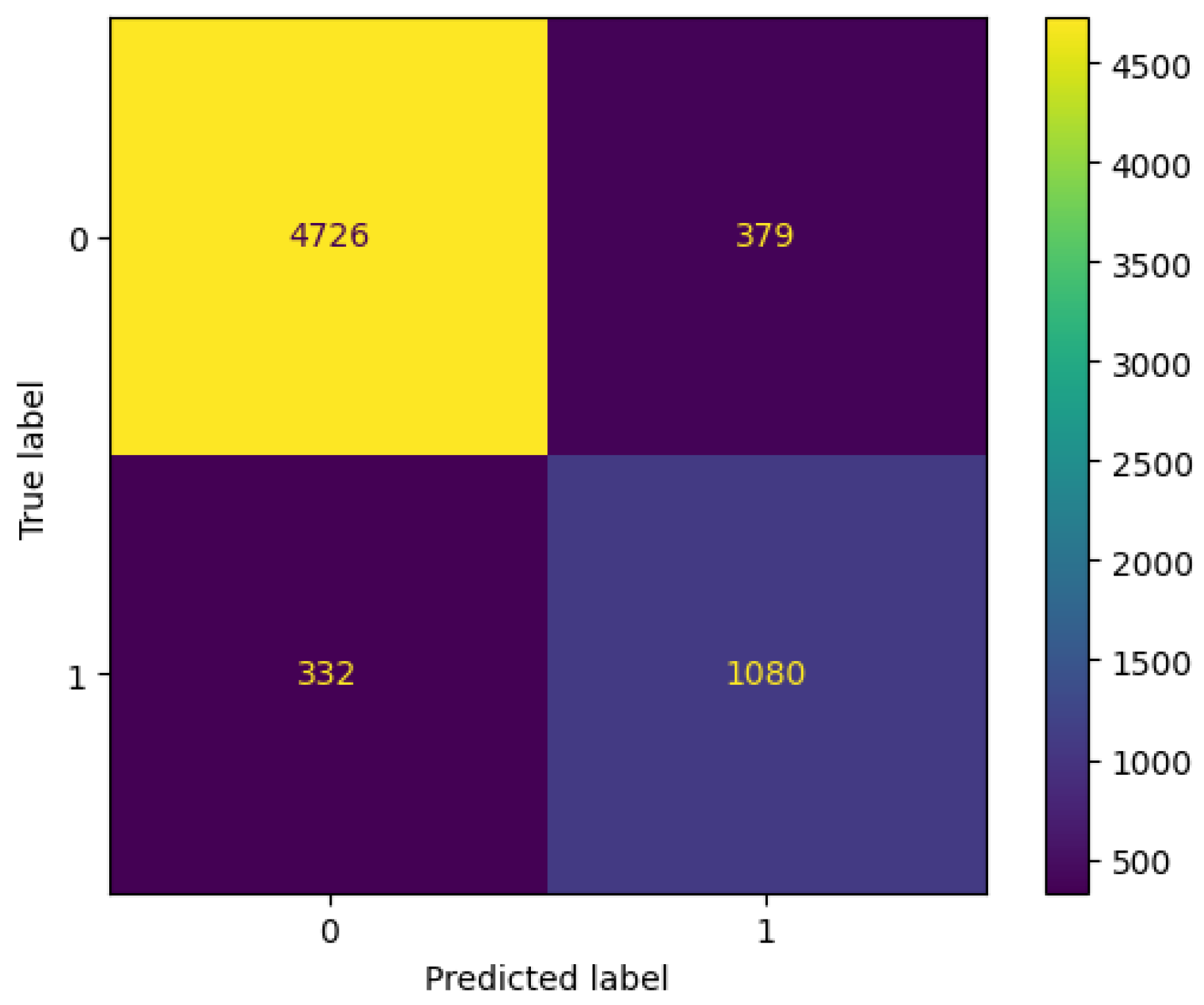
| Model | Accuracy | Precision | Re-Call | F1-Score |
|---|---|---|---|---|
| Decision Tree | 0.898 | 0.897 | 0.9 | 0.898 |
| Random Forest | 0.93 | 0.93 | 0.93 | 0.93 |
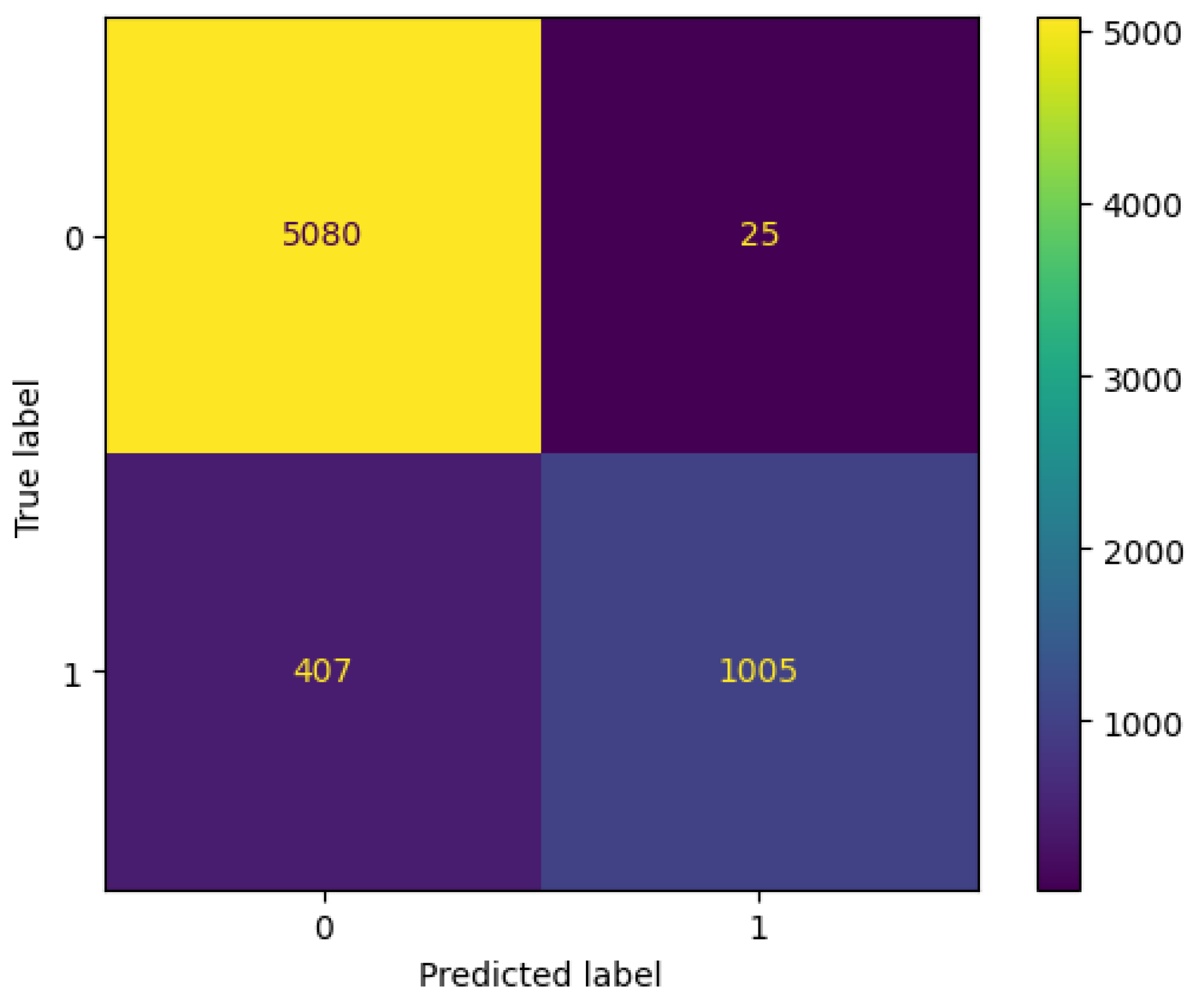
| Model | Accuracy | Precision | Re-Call | F1-Score |
|---|---|---|---|---|
| Decision Tree | 0.90 | 0.89 | 0.896 | 0.90 |
| Random Forest | 0.93 | 0.94 | 0.93 | 0.93 |
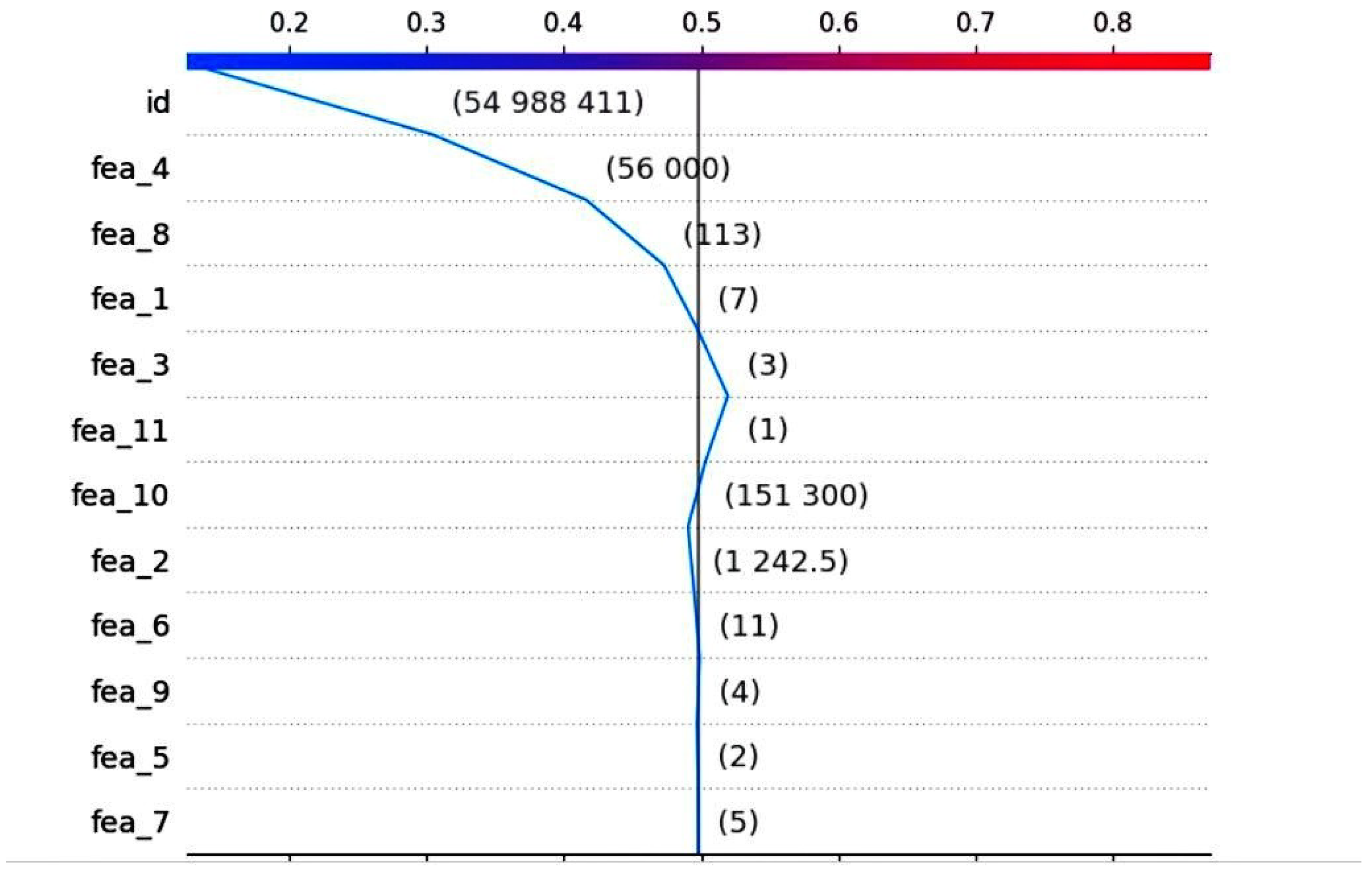
| Rank | Column_Value | SHAP_Value |
|---|---|---|
| 11 | fea_11 | 0.012727 |
| 9 | fea_9 | 0.001865 |
| 7 | fea_7 | −0.000221 |
| 5 | fea_5 | −0.000859 |
| 6 | fea_6 | −0.004011 |
| 2 | fea_2 | −0.004452 |
| 3 | fea_3 | −0.021649 |
| 1 | fea_1 | −0.024858 |
| 8 | fea_8 | −0.056779 |
| 4 | fea_4 | −0.112070 |
| 0 | id | −0.164115 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nallakaruppan, M.K.; Chaturvedi, H.; Grover, V.; Balusamy, B.; Jaraut, P.; Bahadur, J.; Meena, V.P.; Hameed, I.A. Credit Risk Assessment and Financial Decision Support Using Explainable Artificial Intelligence. Risks 2024, 12, 164. https://doi.org/10.3390/risks12100164
Nallakaruppan MK, Chaturvedi H, Grover V, Balusamy B, Jaraut P, Bahadur J, Meena VP, Hameed IA. Credit Risk Assessment and Financial Decision Support Using Explainable Artificial Intelligence. Risks. 2024; 12(10):164. https://doi.org/10.3390/risks12100164
Chicago/Turabian StyleNallakaruppan, M. K., Himakshi Chaturvedi, Veena Grover, Balamurugan Balusamy, Praveen Jaraut, Jitendra Bahadur, V. P. Meena, and Ibrahim A. Hameed. 2024. "Credit Risk Assessment and Financial Decision Support Using Explainable Artificial Intelligence" Risks 12, no. 10: 164. https://doi.org/10.3390/risks12100164
APA StyleNallakaruppan, M. K., Chaturvedi, H., Grover, V., Balusamy, B., Jaraut, P., Bahadur, J., Meena, V. P., & Hameed, I. A. (2024). Credit Risk Assessment and Financial Decision Support Using Explainable Artificial Intelligence. Risks, 12(10), 164. https://doi.org/10.3390/risks12100164