
Bayesian Inference for the Loss Models via Mixture Priors


Abstract
:1. Introduction
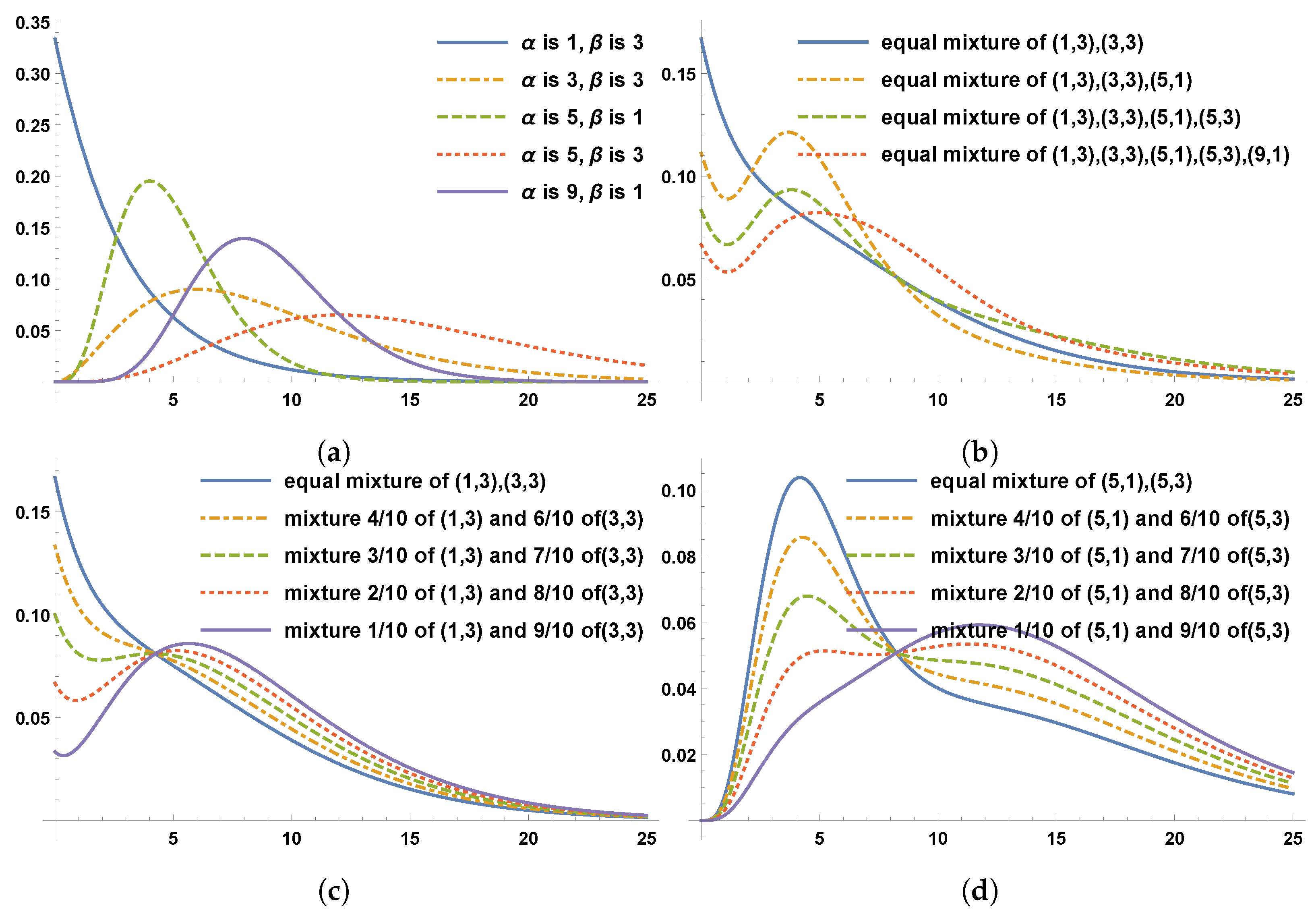
2. Mixture Distribution
2.1. Example: Exponential with a Mixture of Gamma Distributions
3. Bayesian Approach to Composite Models based on the Mixture Prior Distribution
3.1. Bayesian Inference for Composite Exponential–Pareto Based on the Mixture Prior Distribution
- Get sorted sample observations
- Start with , compute , if , then , otherwise go to step 3.
- Let , compute , if , then , otherwise go to next step.
3.2. Bayesian Inference for the Composite IG–Pareto Based on the Mixture Prior Distribution
4. Simulation
4.1. Simulation for Composite Exponential–Pareto
- Start with , check to see if , if yes, then . Otherwise, go to step 2.
- For , if , then , otherwise we consider and continue until we find the correct value for m. The idea is to find the value for m so that . The Mathematica code uses the algorithm to find m and compute .
4.2. Simulation for Composite Inverse-Gamma–Pareto
5. Numerical Example
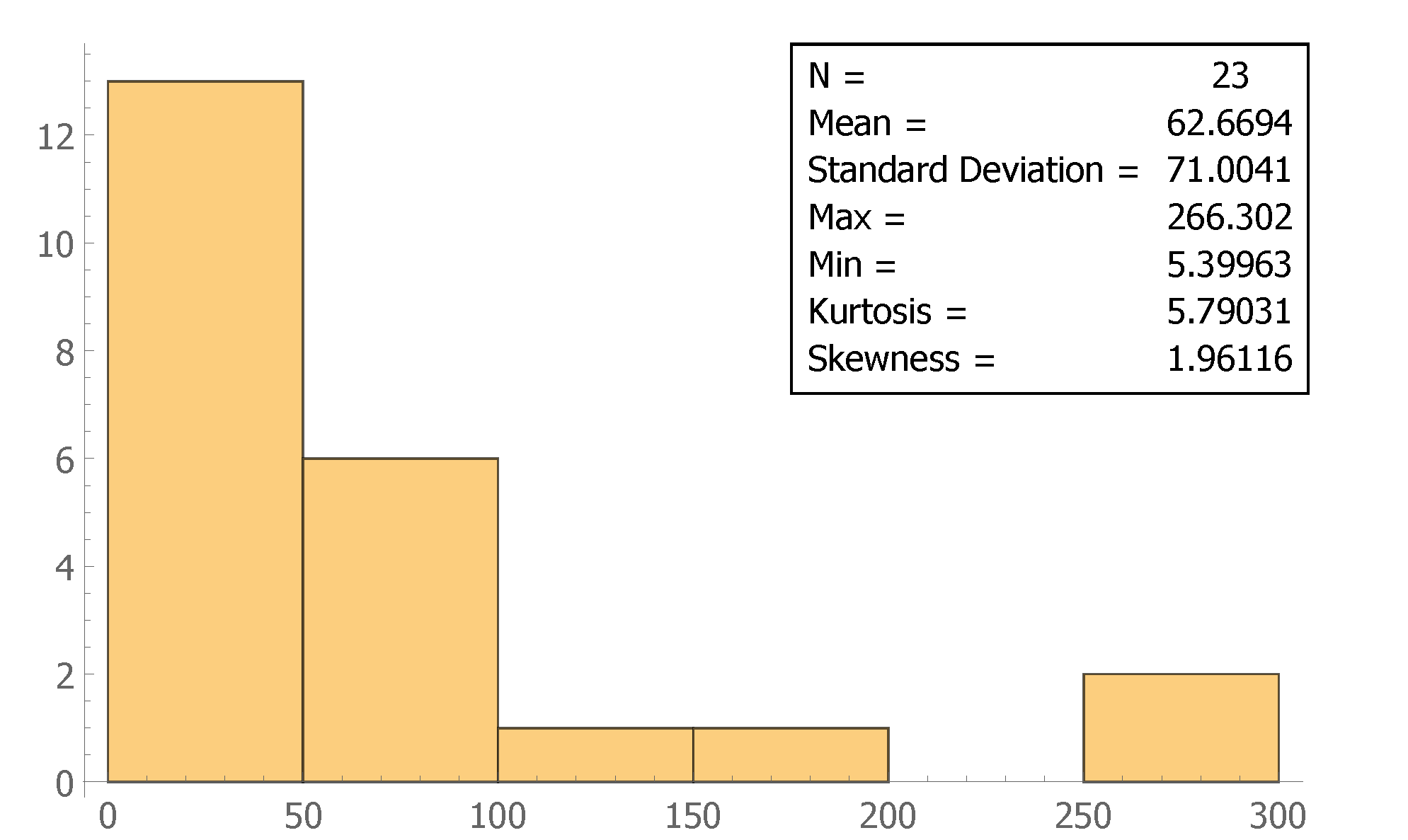
5.1. Data and Basic Descriptive Statistics
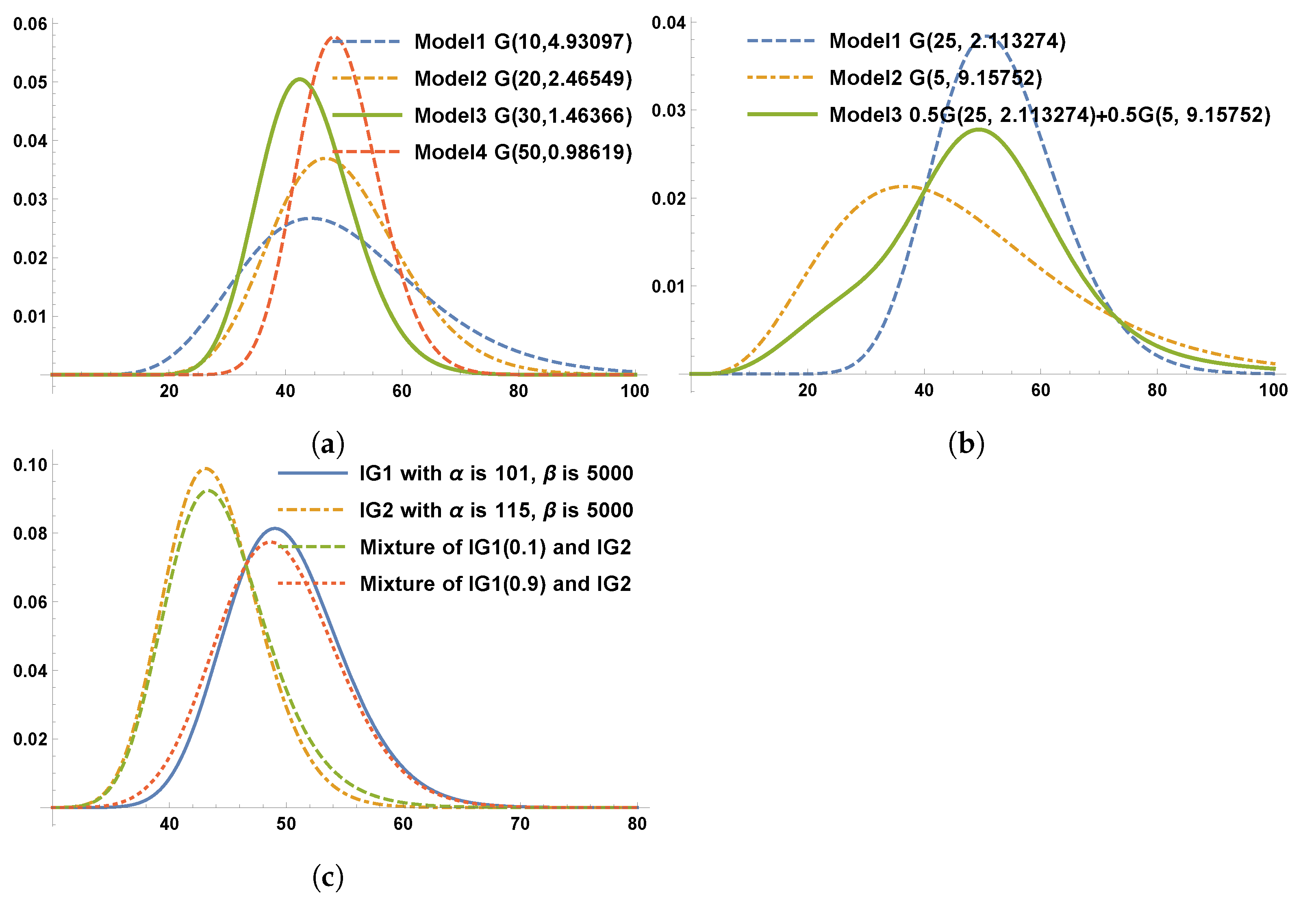
5.2. Model Selection
5.2.1. Goodness-of-Fit Measures for Maximum Likelihood Method
5.2.2. Bayesian Inference of IG–Pareto
- If , negative support for
- If , barely worth mentioning
- If , substantial evidence for
- If , strong evidence for
- If , very strong evidence for
- If , decisive evidence for
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abdul Majid, Muhammad Hilmi, and Kamarulzaman Ibrahim. 2021a. Composite Pareto Distributions for Modeling Household Income Distribution in Malaysia. Sains Malaysiana 50: 2047–58. [Google Scholar] [CrossRef]
- Abdul Majid, Muhammad Hilmi, and Kamarulzaman Ibrahim. 2021b. On Bayesian approach to composite Pareto models. PLoS ONE 16: e0257762. [Google Scholar] [CrossRef] [PubMed]
- Aminzadeh, Mostafa S., and Min Deng. 2017. Bayesian Predictive Modeling for Exponential-Pareto Composite Distribution. Variance 12: 59–68. [Google Scholar]
- Aminzadeh, Mostafa S., and Min Deng. 2019. Bayesian Predictive Modeling for Inverse Gamma-Pareto Composite Distribution. Communications In Statistics, Theory, and Methods 48: 1938–54. [Google Scholar] [CrossRef]
- Ando, Tomohiro. 2010. Bayesian Model Selection and Statistical Modeling. Orange: Chapman & Hall/CRC. [Google Scholar]
- Bakar, S. A. Abu, Nor A. Hamzah, Mastoureh Maghsoudi, and Saralees Nadarajah. 2015. Modeling loss data using composite models. Insurance: Mathematics and Economics 61: 146–54. [Google Scholar]
- Bhati, Deepesh, Enrique Calderín-Ojeda, and Mareeswaran Meenakshi. 2019. A new heavy-tailed class of distributions which includes the Pareto. Risks 7: 99. [Google Scholar] [CrossRef]
- Cooray, Kahadawala, and Chin-I. Cheng. 2013. Bayesian Estimators of the Lognormal-Pareto Composite Distribution. Scandinavian Actuarial Journal 2015: 500–15. [Google Scholar] [CrossRef]
- Deng, Min, and Mostafa S. Aminzadeh. 2019. Bayesian predictive analysis for Weibull-Pareto composite model with an application to insurance data. Communications in Statistics-Simulation and Computation 51: 2683–709. [Google Scholar] [CrossRef]
- Deng, Min, Mostafa S. Aminzadeh, and Min Ji. 2021. Bayesian Predictive Analysis of Natural Disaster Losses. Risks 9: 12. [Google Scholar] [CrossRef]
- Dominicy, Yves, and Corinne Sinner. 2017. Distributions and composite models for size-type data. Advances in Statistical Methodologies and Their Application to Real Problems 159. [Google Scholar] [CrossRef]
- Kass, Robert E., and Adrian E. Raftery. 1995. Bayes factors. Journal of the American Statistical Association 90: 773–95. [Google Scholar] [CrossRef]
- Klugman, Stuart A., Harry H. Panjer, and Gordon E. Willmot. 2012. Loss Models from Data to Decisions, 3rd ed. New York: John Wiley. [Google Scholar]
- Miljkovic, Tatjana, and Bettina Grün. 2016. Modeling loss data using mixtures of distributions. Insurance Mathematics, and Economics 70: 387–96. [Google Scholar] [CrossRef]
- Preda, Vasile, and Roxana Ciumara. 2006. On Composite Models: Weibull-Pareto and Lognormal-Pareto—A comparative Study. Romanian Journal of Economic Forecasting 8: 32–46. [Google Scholar]
- Rufo, María Jesús, Carlos. J. Pérez, and Jacinto Martín. 2010. Merging experts’ opinions: A Bayesian hierarchical model with a mixture of prior distributions. European Journal of Operational Research 207: 284–89. [Google Scholar] [CrossRef]
- Saleem, Muhammad. 2010. Bayesian Analysis of Mixture Distributions. Ph.D. thesis, Quaid-i-Azam University Islamabad, Islamabad, Pakistan. Available online: http://prr.hec.gov.pk/jspui/bitstream/123456789/1430/1/824S.pdf (accessed on 1 August 2023).
- Scollnik, David P. M., and Chenchen Sun. 2012. Modeling with Weibull-Pareto Models. North American Actuarial Journal 16: 260–72. [Google Scholar] [CrossRef]
- Teodorescu, Sandra, and Raluca Vernic. 2006. A composite Exponential-Pareto distribution. The Annals of the “Ovidius” University of Constanta, Mathematics Series 14: 99–108. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| (a): Comparison of the Bayes estimator without the mixture prior (K = 1) and with the mixture prior (K = 2) when are given | |||||||
| = 5 | |||||||
| K | n | ||||||
| 1 | 30 | 245 | NA | 5.11732 | 0.42551 | ||
| 2 | 30 | 260 | 235 | 52.921 | 48.027 | 5.11662 | 0.42337 |
| 2 | 30 | 260 | 235 | 55 | 46.32143 | 5.12472 | 0.45379 |
| 1 | 100 | 245 | NA | 5.06908 | 0.41555 | ||
| 2 | 100 | 260 | 235 | 52.921 | 48.027 | 5.06875 | 0.41351 |
| 2 | 100 | 260 | 235 | 55 | 46.32143 | 5.09362 | 0.54073 |
| (b): Mean and of MLE of | |||||||
| = 5 | |||||||
| n | |||||||
| 30 | 7.39707 | 4.88656 | |||||
| 100 | 6.09238 | 1.74385 | |||||
| (a): Comparison of the Bayes estimator without the mixture prior (K = 1) and with the mixture prior (K = 2) for given | |||||||
| = 5 | |||||||
| K | n | ||||||
| 1 | 30 | 100 | NA | 5.07243 | 0.27438 | ||
| 2 | 30 | 110 | 98 | 545.312 | 484.727 | 5.07036 | 0.26801 |
| 2 | 30 | 110 | 98 | 560 | 471.651 | 5.07327 | 0.27393 |
| 1 | 100 | 100 | NA | 5.03404 | 0.24642 | ||
| 2 | 100 | 110 | 98 | 545.312 | 484.727 | 5.03312 | 0.23956 |
| 2 | 100 | 110 | 98 | 560 | 471.651 | 5.03479 | 0.25197 |
| (b): Mean and of MLE of | |||||||
| = 5 | |||||||
| n | |||||||
| 30 | 7.44702 | 5.34616 | |||||
| 100 | 6.05374 | 1.70871 | |||||
| (a): Comparison of the Bayes estimator without the mixture prior (K = 1) and with the mixture prior (K = 2) when are given | |||||||
| = 5 | |||||||
| K | n | ||||||
| 1 | 30 | 2 | NA | 5.44943 | 1.70629 | ||
| 2 | 30 | 2 | 2.5 | 2.41379 | 2.06897 | 5.42456 | 1.63481 |
| 2 | 30 | 2 | 2.5 | 3 | 1.6 | 5.39921 | 1.70996 |
| 1 | 30 | 5 | NA | 5.30638 | 1.19520 | ||
| 2 | 30 | 5 | 5.5 | 0.99237 | 0.91603 | 5.2944 | 1.16326 |
| 2 | 30 | 5 | 5.5 | 1.1 | 0.81818 | 5.30043 | 1.21116 |
| 1 | 100 | 2 | NA | 5.16417 | 1.08021 | ||
| 2 | 100 | 2 | 2.5 | 2.41379 | 2.06897 | 5.16189 | 1.06654 |
| 2 | 100 | 2 | 2.5 | 3 | 1.6 | 5.13296 | 1.06718 |
| 1 | 100 | 5 | NA | 5.15904 | 0.92941 | ||
| 2 | 100 | 5 | 5.5 | 0.99237 | 0.91603 | 5.15621 | 0.91892 |
| 2 | 100 | 5 | 5.5 | 1.1 | 0.81818 | 5.14846 | 0.92938 |
| (b): Mean and of MLE of | |||||||
| = 5 | |||||||
| n | |||||||
| 30 | 5.90731 | 2.8898 | |||||
| 100 | 5.16417 | 1.08021 | |||||
| (a): Comparison of the Bayes estimator without the mixture prior (K = 1) and with the mixture prior (K = 2) when are given | |||||||
| = 5 | |||||||
| K | n | ||||||
| 1 | 30 | 2.5 | NA | 5.58552 | 1.85126 | ||
| 2 | 30 | 2.4 | 2.6 | 2.10417 | 1.90384 | 5.58569 | 1.85072 |
| 2 | 30 | 2.4 | 2.6 | 3 | 1.07692 | 5.79744 | 2.10257 |
| 1 | 30 | 1 | NA | 5.75102 | 2.27942 | ||
| 2 | 30 | 1 | 1.1 | 5.025 | 4.52273 | 5.30832 | 1.20807 |
| 2 | 30 | 1 | 1.1 | 5.5 | 4.09091 | 5.32796 | 1.23492 |
| 1 | 100 | 2.5 | NA | 5.21317 | 1.08963 | ||
| 2 | 100 | 2.4 | 2.6 | 2.10417 | 1.90384 | 5.21335 | 1.08946 |
| 2 | 100 | 2.4 | 2.6 | 3 | 1.07692 | 5.28317 | 1.14863 |
| 1 | 100 | 1 | NA | 5.22784 | 1.18276 | ||
| 2 | 100 | 1 | 1.1 | 5.025 | 4.52273 | 5.16032 | 0.96434 |
| 2 | 100 | 1 | 1.1 | 5.5 | 4.09091 | 5.17063 | 0.97477 |
| (b): Mean and of MLE of | |||||||
| = 5 | |||||||
| n | |||||||
| 30 | 6.183 | 3.69041 | |||||
| 100 | 5.21317 | 1.08963 | |||||
| Model | MLE and SE(MLE) | |||
|---|---|---|---|---|
| Exponential Exp() | ||||
| Exp–Pareto | 126.291 | 254.582 | 255.717 | |
| Inverse-gamma | 117.129 | 238.258 | 248.529 | |
| IG( ) | ||||
| IG–Pareto | 105.701 | 213.402 | 214.538 | |
| K | Model | Prior Distributions | Bayesian Estimates | ||
|---|---|---|---|---|---|
| 1 | gamma(10, 4.93097) | ||||
| 1 | gamma(20, 2.46549) | ||||
| 1 | gamma(30, 1.64366) | ||||
| 1 | gamma(50, 0.98619) | ||||
| 2 | gamma(25, 2.11327) gamma(5, 9.15752) | ||||
| 2 | gamma(27.5299, 2) gamma(1.74239, 25) |
| Paired Models | Paired Models | Paired Models | |||
|---|---|---|---|---|---|
| 1.1069 | 1.0393 | 4.3506 | |||
| 1.1505 | 1.0742 | 19.0717 | |||
| 1.1891 | 4.5218 | 4.2094 | |||
| 5.0054 | 19.8221 | 18.4525 | |||
| 21.9418 | 1.0336 | 4.3837 |
| Model | Prior Distributions | Bayesian Estimates | ||
|---|---|---|---|---|
| gamma(25, 2) gamma(5, 9.27388) | 5.0458 | |||
| gamma(26, 2) gamma(1.86478, 25) | 4.9772 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, M.; Aminzadeh, M.S. Bayesian Inference for the Loss Models via Mixture Priors. Risks 2023, 11, 156. https://doi.org/10.3390/risks11090156
Deng M, Aminzadeh MS. Bayesian Inference for the Loss Models via Mixture Priors. Risks. 2023; 11(9):156. https://doi.org/10.3390/risks11090156
Chicago/Turabian StyleDeng, Min, and Mostafa S. Aminzadeh. 2023. "Bayesian Inference for the Loss Models via Mixture Priors" Risks 11, no. 9: 156. https://doi.org/10.3390/risks11090156
APA StyleDeng, M., & Aminzadeh, M. S. (2023). Bayesian Inference for the Loss Models via Mixture Priors. Risks, 11(9), 156. https://doi.org/10.3390/risks11090156