
How to Gain Confidence in the Results of Internal Risk Models? Approaches and Techniques for Validation


Abstract
1. Introduction
“… a triple (), where is a set of mathematical functions, is a set of both implicit and explicit assumptions, and is a set of predefined uses of a model. Mathematical functions are mappings between a pre-defined set of terms and real numbers with a predefined set of parameters calibrated using the pre-defined criteria.”
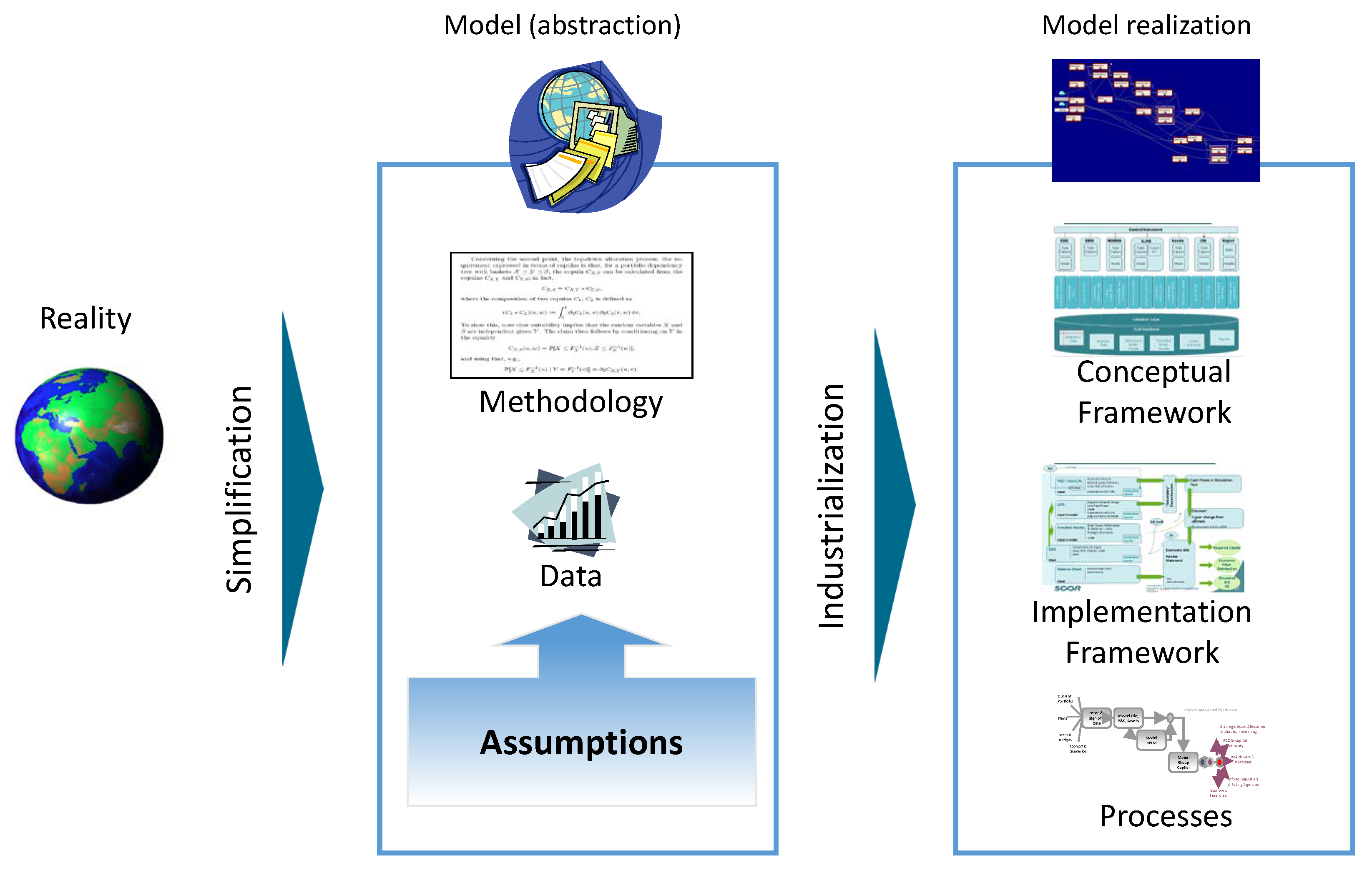
2. Structure of an Internal Model and Validation Procedure
“… it does not seem helpful just to say that all models are wrong. The very word model implies simplification and idealization. The idea that complex physical, biological or sociological systems can be exactly described by a few formulae is patently absurd. The construction of idealized representations that capture important stable aspects of such systems is, however, a vital part of general scientific analysis and statistical models, especially substantive ones, do not seem essentially different from other kinds of model.”
- Determining the relevant assumptions on which the model should be based. For instance, deciding if the stochastic variable representing a particular risk presents fat tails (higher probability of large claims than in the normal distribution) or can be modeled with light tail (i.e., Gaussian) distributions, or if the dependencies between various risks are linear or non-linear. Should all the dependencies between risks be taken into account, or can we neglect some?, and so on.
- Choosing the data that best describe a particular risk and controlling the frequency of data updates. It is essential to ensure that the input data correspond to the current risk exposure. An example of the dilemma, when modeling pandemic: Are the data from the Great Plague of the 14th century still relevant in today’s health environment? Can we use claims data dating back 50 years if available? It is very clear that the model results will depend crucially on the various choices of data that were made but also on the quality of the data. This is true, for instance, with COVID-19 data that are currently not reliable enough, as the pandemic is not over. Some care in including these data is required Miller et al. (2022).
- Selecting the appropriate methodology to develop the model. Actuaries will usually decide if they want to use a frequency/severity model, a loss-ratio model for attritional losses, or a natural catastrophe model, depending on the risk they want to model. Similarly, selecting the right methodology to generate consistent economic indicators to value assets and liabilities is crucial to obtain reliable results on the diversification between assets and liabilities.
- First, the company must choose a conceptual framework to develop the software. The basic architecture of the applications should be reduced to a few powerful components: the user interface, the object model including the communication layer, the mathematical kernel, and the information backbone. This is quite a standard architecture in financial institutions and is called the three-tier architecture (databases, services, and user interfaces), where the user interfaces can access any service of the object model and of the mathematical kernel, that can in turn access any data within the information backbone. Such a simple architecture ensures interoperability of the various IT systems and thus also their robustness (Dorofeev and Shestakov 2018).
- The next step is the implementation framework: how this architecture is translated into an operative design. The software must follow four overarching design principles:
- (i)
- Extensibility: Allowing for an adaptation to new methods as they gradually progress with time, easily adapting to changes in the data model when new or higher quality data become available. The data model, the modules, and the user interfaces evolve with time.
- (ii)
- Maintainability: Low maintenance and the ability to keep up with the changes, for example, in data formats. Flexibility in terms of a swift implementation with respect to a varying combination of data and methods.
- (iii)
- Testability: The ability to test the IT components for errors and malfunctions at various hierarchy levels using an exhaustive set of predefined test cases.
- (iv)
- Re-usability: The ability to recombine programming code and system parts. Each code part should be implemented only once if possible. In this way, the consistency of code segments is increased significantly.
Very often, companies will use commercial software for their internal models. Nevertheless, their choice of software should be guided by these principles. Sometimes, it would be easier to use open-source software like Python or R, which are supported by a large community of users and contain many very useful libraries. - The last step is to design processes around the model. Several processes must be put in place to ensure the production of reliable results, but also to develop a specific governance framework for the model changes due to either progress in the methodology or discoveries from the validation process (see, for instance, point 3 in Article 242 of Appendix B). The number of processes will depend on the implementation structure of the model, but they always include, at least, input data verification and results verification. Process owners must be designated for each process, and accountability must be clearly defined.

3. Model Implementation and Testing
3.1. Calibration
- If a causal dependence is known, it should be modeled explicitly.
- Otherwise, if there is no specific knowledge, non-symmetric copulas (e.g., Clayton copula) should be systematically used in the presence of a tail dependence for large claims.
- If there are enough data, we calibrate the parameters statistically.
- In absence of data, we use stress scenarios and expert opinion to estimate conditional probabilities.
- Prior information (i.e., indications from regulators or previous studies);
- Observations (i.e., the available data);
- Experts’ opinions (i.e., the knowledge of the experts).
3.2. Component Testing
- An economic scenario generator, to explore the various states of the world economy;
- A stochastic model to compute the uncertainty of P&C reserving triangles;
- A stochastic model for natural catastrophes;
- A stochastic model for pandemics (if there is a significant life book);
- A model for credit risk;
- A model for operational risk; and
- A model for risk aggregation.
3.2.1. Testing Economic Scenario Generators with Probability Integral Transform
- We define an in-sample period to build the economic scenario generator with its innovation vectors and parameter calibrations (e.g., for the GARCH model). The out-of-sample period starts at the end of the in-sample period. Starting at each regular out-of-sample time point, we run a large number of simulation scenarios and observe the scenario forecasts for each of the many variables of the model (see Blum (2005)).
- The scenario forecasts of a variable x at time , sorted in ascending order, constitute an empirical cumulative distribution forecast. Considering many scenarios, this distribution converges asymptotically (with respect to the number of scenarios) to the marginal cumulative probability distribution , where is the information available up to the time of the simulation start. In the case of a one-step-ahead forecast, . The empirical distribution slightly deviates from . The discrepancy can be quantified (Blum 2005). For instance, its absolute value is less than 0.019 with a confidence of 95% when choosing 5000 scenarios for any value of x and any tested variable. This is accurate enough, given the limitations due to the rather low number of historical observations.
- For a set of out-of-sample time points , we now have a distribution forecast as well as a historically observed value . The cumulative distribution is used for the following probability integral transform (PIT): ). The probabilities , which are confined between 0 and 1 by definition, are used in the further course of the test. A proposition proved by Diebold et al. (1998) states that the are i.i.d. (independent and identically distributed) with a uniform distribution if the conditional distribution forecast coincides with the true process by which the historical data have been generated. The proof is extended to the multivariate case in Diebold et al. (1999). If the series of significantly deviates from either the distribution or the i.i.d. property, the model does not pass the out-of-sample test.
3.2.2. Testing the One-Year Change of P&C Reserves
- The approach proposed by Wüthrich and Merz (2008) as an extension of the chain-ladder following Mack’s assumptions (Mack 1993). They obtain an estimation of the mean square error of the one-year change based on the development of the reserve triangles using the chain-ladder method.
- An alternative way to model the one-year risk, developed by Ferriero, is the capital over time (COT) method (Ferriero 2016). The latter assumes a modified jump-diffusion Lévy process to the ultimate risk and provides a formula, based on this process, to determine the one-year risk as a portion of the ultimate risk.
- a model where the stochastic errors propagate linearly (linear model);
- a model where the stochastic errors propagate multiplicatively (multiplicative model).
3.2.3. Testing the Convergence of Monte Carlo Simulations
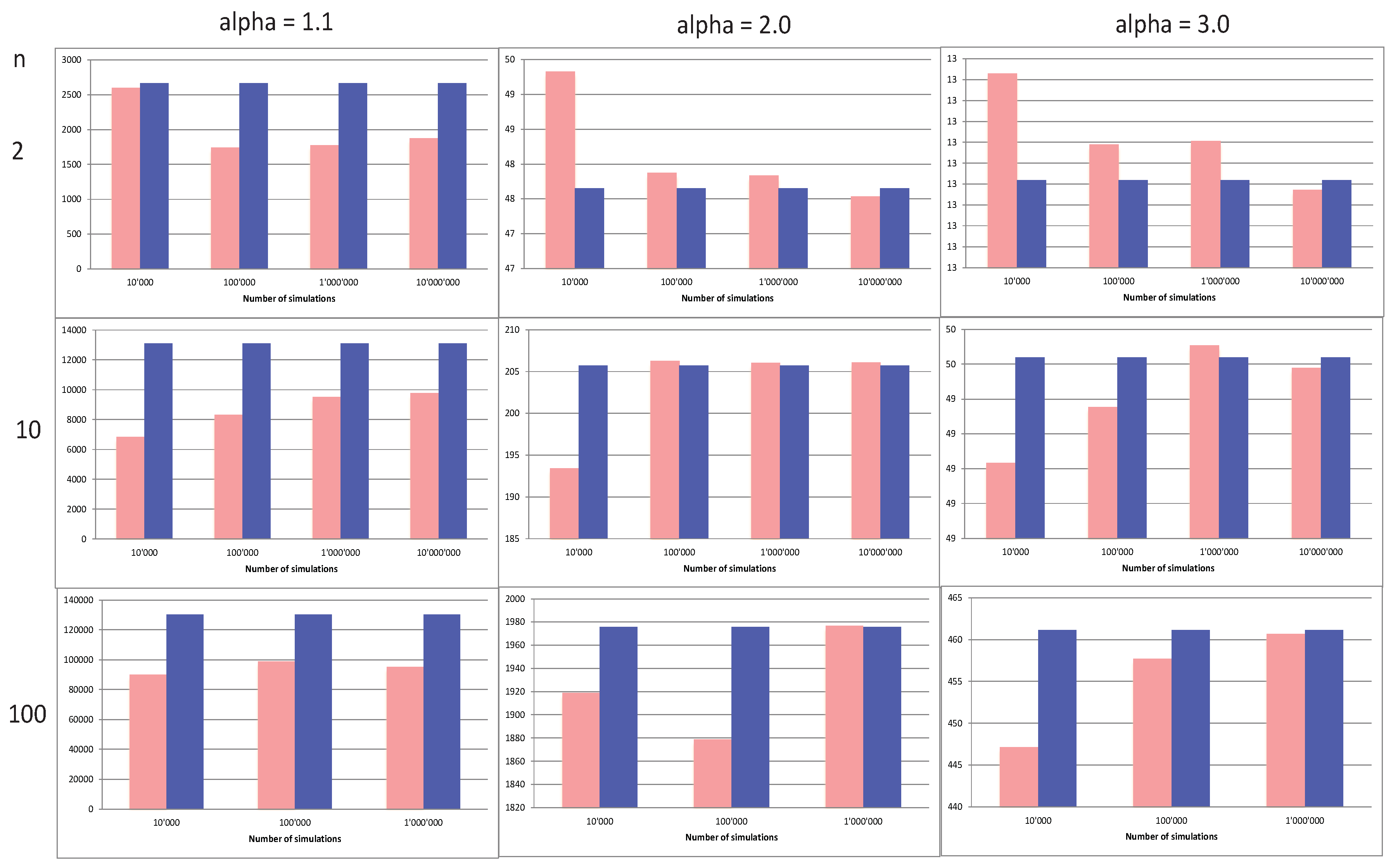
- The normalized TVAR of , , decreases as n increases;
- The TVaR decreases as increases;
- The rate of convergence of increases with n;
- The heavier the tail (i.e., the lower the ), the slower the convergence;
- In the case of a very heavy tail and a strong dependence ( and ), we do not see any satisfactory convergence, even with 10 million simulations and for any n;
- When , the convergence is good from 1 million, 100,000 simulations onwards, respectively.
3.3. Stress Test to Validate the Distribution
- Testing the sensitivity of the results to certain parameters (sensitivity analysis);
- Testing the predictions against real outcomes (historical test, via P&L attribution for lines of business (LoB) and assets);
- Testing the model outcomes against predefined scenarios.
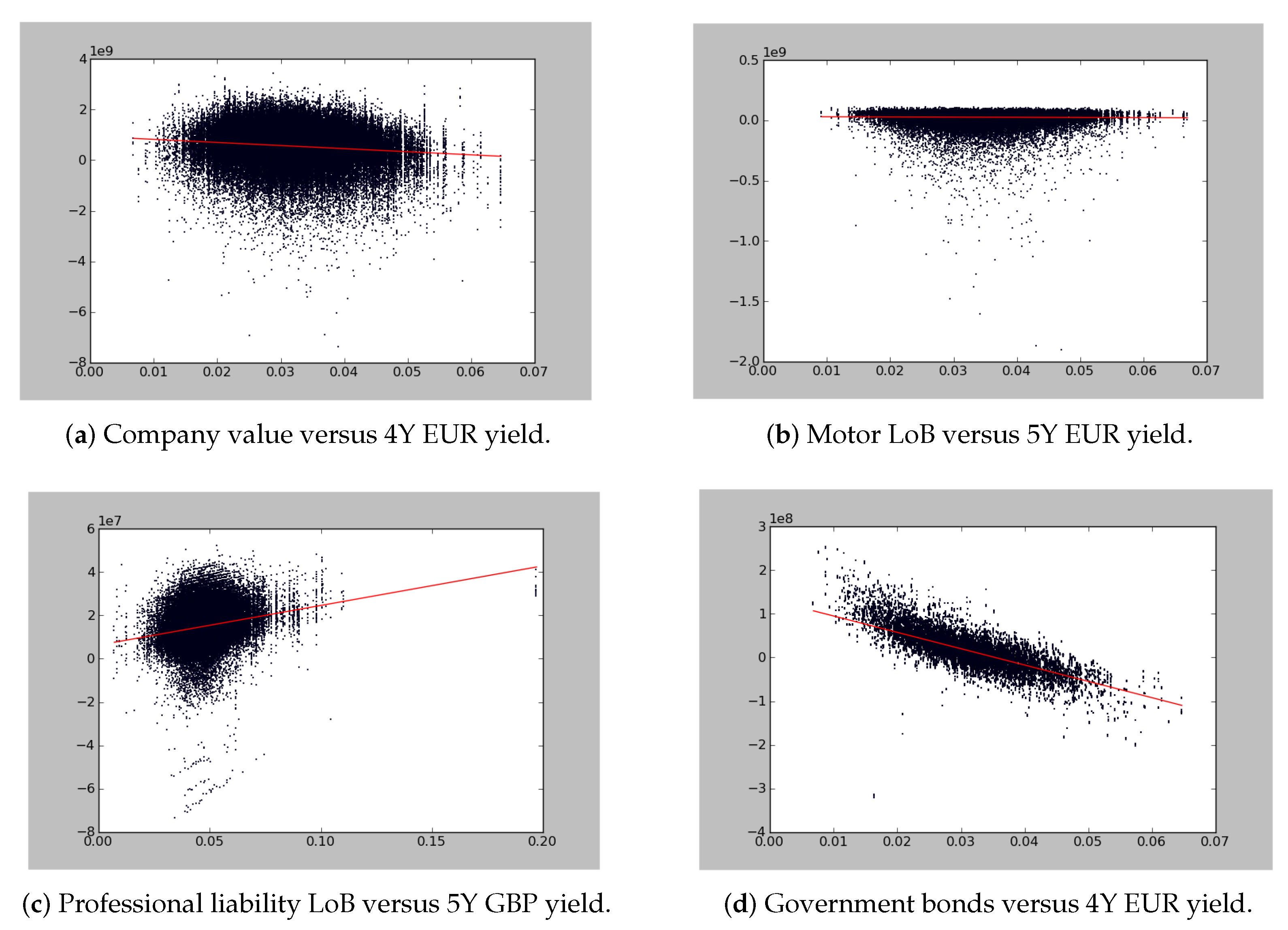
3.4. Using Monte Carlo Simulations to Validate Dependence Assumptions
- Are these scenarios credible, given the company portfolio? Would such scenarios really affect the company?
- Are there other possible scenarios that we know of and that do not appear in the worst Monte Carlo simulations?
4. Conclusions
- Ensure a good calibration of the model through various statistical techniques;
- Use data to statistically test certain parts of the model (like the computation of the risk measure, or some particular model like economic scenario generator or reserving risk);
- Test the P&L attribution to LoBs against real outcomes;
- Test the sensitivity of the model to crucial parameters;
- Compare the model output to stress scenarios;
- Compare the real outcome to the probability predicted by the model;
- Examine the simulation output to check the quality of the bankruptcy scenarios.
Funding
Conflicts of Interest
Appendix A. Article 124 on “Validation Standards” of the European Directive
Insurance and reinsurance undertakings shall have a regular cycle of model validation which includes monitoring the performance of the internal model, reviewing the ongoing appropriateness of its specification, and testing its results against experience.
The model validation process shall include an effective statistical process for validating the internal model which enables the insurance and reinsurance undertakings to demonstrate to their supervisory authorities that the resulting capital requirements are appropriate.
The statistical methods applied shall test the appropriateness of the probability distribution forecast compared not only to loss experience but also to all material new data and information relating thereto.
The model validation process shall include an analysis of the stability of the internal model and in particular the testing of the sensitivity of the results of the internal model to changes in key underlying assumptions. It shall also include an assessment of the accuracy, completeness and appropriateness of the data used by the internal model.
Appendix B. Article 241 on “Model Validation Process” of the Delegated Regulation of the 17th of January 2015
- The model validation process shall apply to all parts of the internal model and shall cover all requirements set out in Articles 101, Article 112(5), Articles 120 to 123 and Article 125 of Directive 2009/138/EC. In the case of a partial internal model the validation process shall in addition cover the requirements set out in Article 113 of that Directive.
- In order to ensure independence of the model validation process from the development and operation of the internal model, the persons or organisational unit shall, when carrying out the model validation process, be free from influence from those responsible for the development and operation of the internal model. This assessment shall be in accordance with paragraph 4.
- For the purpose of the model validation process insurance and reinsurance undertakings shall specify all of the following:
- (a)
- the processes and methods used to validate the internal model and their purposes;
- (b)
- for each part of the internal model, the frequency of regular validations and the circumstances which trigger additional validation;
- (c)
- the persons who are responsible for each validation task;
- (d)
- the procedure to be followed in the event that the model validation process identifies problems with the reliability of the internal model and the decision-making process to address those problems.
Appendix C. Article 242 on “Validation Tools” of the Delegated Regulation of the 17th of January 2015
- Insurance and reinsurance undertakings shall test the results and the key assumptions of the internal model at least annually against experience and other appropriate data to the extent that data are reasonably available. These tests shall be applied at the level of single outputs as well as at the level of aggregated results. Insurance and reinsurance undertakings shall identify the reason for any significant divergence between assumptions and data and between results and data.
- As part of the testing of the internal model results against experience insurance and reinsurance undertakings shall compare the results of the profit and loss attribution referred to in Article 123 of Directive 2009/138/EC with the risks modeled in the internal model.
- The statistical process for validating the internal model, referred to in the second paragraph of Article 124 of Directive 2009/138/EC, shall be based on all of the following: (a) current information, taking into account, where it is relevant and appropriate, developments in actuarial techniques and the generally accepted market practice; (b) a detailed understanding of the economic and actuarial theory and the assumptions underlying the methods to calculate the probability distribution forecast of the internal model. 4. Where insurance or reinsurance undertakings observe in accordance with the fourth paragraph of Article 124 of Directive 2009/138/EC that changes in a key underlying assumption have a significant impact on the Solvency Capital Requirement, they shall be able to explain the reasons for this sensitivity and how the sensitivity is taken into account in their decision-making process. For the purposes of the fourth subparagraph of Article 124 of Directive 2009/138/EC the key assumptions shall include assumptions on future management actions.
- The model validation process shall include an analysis of the stability of the outputs of the internal model for different calculations of the internal model using the same input data.
- As part of the demonstration that the capital requirements resulting from the internal model are appropriate, insurance and reinsurance undertakings shall compare the coverage and the scope of the internal model. For this purpose, the statistical process for validating the internal model shall include a reverse stress test, identifying the most probable stresses that would threaten the viability of the insurance or reinsurance undertaking.
| 1 | SCOR is the fifth-largest reinsurance company with gross written premium of more than 19.7 billion EUR (10 billion for P&C and 9.7 billion for life and health in 2022). |
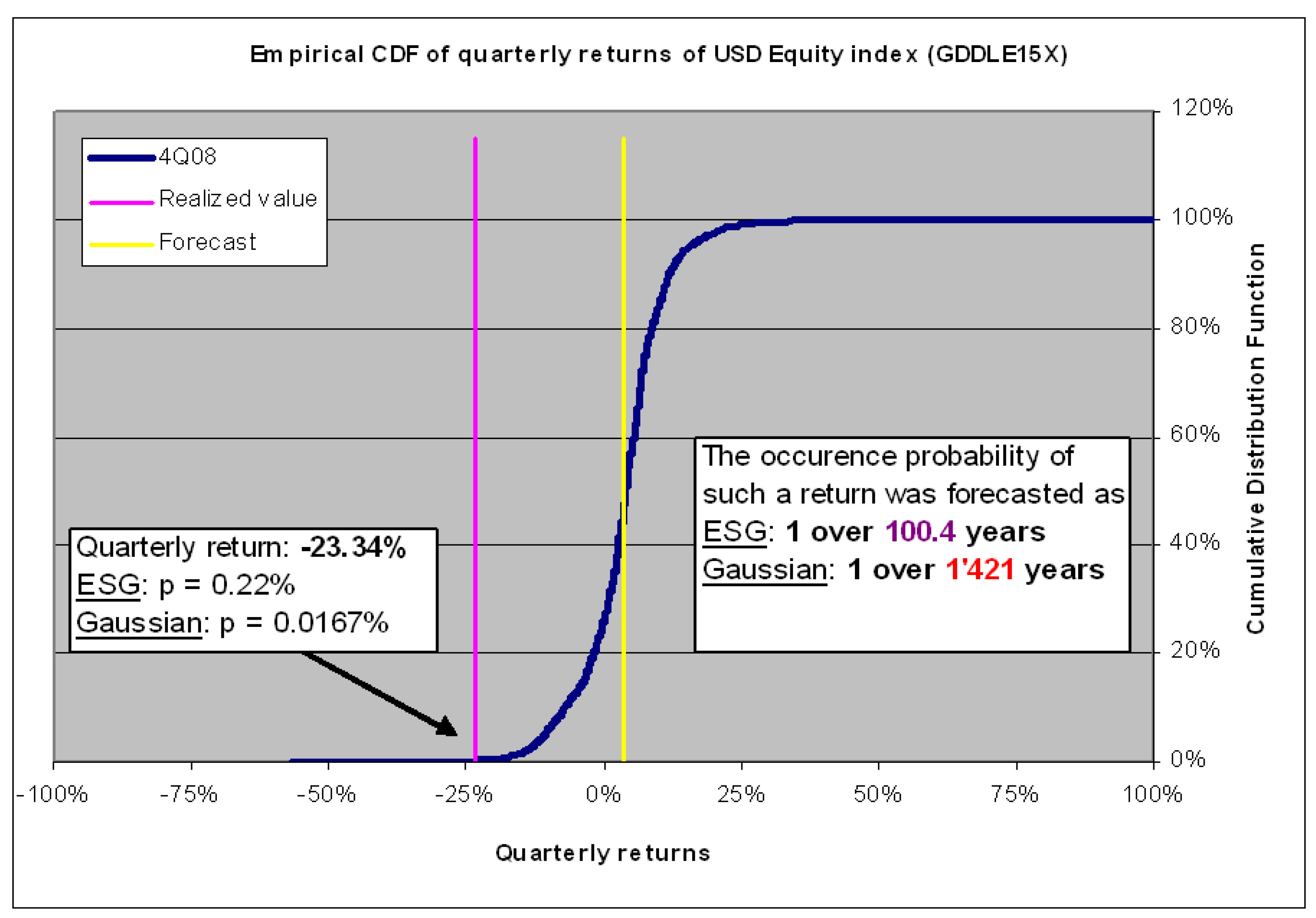
| 2 | The yearly return of 2008 was the second-worst performance of the S&P 500 measured over 200 years. Only the year 1933 presented a worse performance! |
| 3 | |
| 4 |
References
- Abramov, Vilen, and M. Kazim Khan. 2017. A Practical Guide to Market Risk Model Validations (Part II—VaR Estimation). SSRN 3080557. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2916853 (accessed on 4 May 2023).
- Abramov, Vilen, Matt Lowdermilk, and Xianwen Zhou. 2017. A Practical Guide to Market Risk Model Validations (Part I—Introduction). SSRN 2916853. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3080557 (accessed on 4 May 2023).
- Acerbi, Carlo, and Balazs Szekely. 2014. Back-testing expected shortfall. Risk 27: 76–81. [Google Scholar]
- Arbenz, Philipp, and Davide Canestraro. 2012. Estimating copulas for insurance from scarce observations, expert opinion and prior information: A bayesian approach. ASTIN Bulletin: The Journal of the IAA 42: 271–90. [Google Scholar]
- Bignozzi, Valeria, and Andreas Tsanakas. 2016. Parameter uncertainty and residual estimation risk. Journal of Risk and Insurance 83: 949–78. [Google Scholar] [CrossRef]
- Blum, Peter. 2005. On Some Mathematical Aspects of Dynamic Financial Analysis. Ph.D. thesis, ETH Zurich, Zürich, Switzerland. [Google Scholar]
- Bruneton, Jean-Philippe. 2011. Copula-based hierarchical aggregation of correlated risks. the behaviour of the diversification benefit in gaussian and lognormal trees. arXiv arXiv:1111.1113. [Google Scholar]
- Bürgi, Roland, Michel M. Dacorogna, and Roger Iles. 2008. Risk aggregation, dependence structure and diversification benefit. In Stress Testing for Financial Institutions. Edited by Daniel Rösch and Harald Scheule. London: Riskbooks, Incisive Media. [Google Scholar]
- Busse, Marc, Ulrich Müller, and Michel Dacorogna. 2010. Robust estimation of reserve risk. ASTIN Bulletin: The Journal of the IAA 40: 453–89. [Google Scholar]
- Campbell, Sean D. 2005. A Review of Backtesting and Backtesting Procedures. Finance and Economics Discussion Series (FEDS). Available online: https://www.federalreserve.gov/econres/feds/a-review-of-backtesting-and-backtesting-procedures.htm (accessed on 4 May 2023).
- Christoffersen, Peter. 1998. Evaluating interval forecasts. International Economic Review 39: 841–62. [Google Scholar] [CrossRef]
- Christoffersen, Peter, and Denis Pelletier. 2004. Backtesting value-at-risk: A duration-based approach. Journal of Financial Econometrics 2: 84–108. [Google Scholar] [CrossRef]
- Clemente, Gian Paolo, and Nino Savelli. 2013. Internal model techniques of premium and reserve risk for non-life insurers. Mathematical Methods in Economics and Finance 8: 21–34. [Google Scholar]
- Cox, David. 1995. Comment on “model uncertainty, data mining and statistical inference”. Journal of the Royal Statistical Society: Series A (Statistics in Society) 158: 455–56. [Google Scholar]
- Dacorogna, Michel, Alessandro Ferriero, and David Krief. 2018a. One-year change methodologies for fixed-sum insurance contracts. Risks 6: 75. [Google Scholar] [CrossRef]
- Dacorogna, Michel, Laila Elbahtouri, and Marie Kratz. 2018b. Validation of aggregated risks models. Annals of Actuarial Science 12: 433–54. [Google Scholar] [CrossRef]
- Dacorogna, Michel M., Ulrich A. Müller, Olivier V Pictet, and Casper G. De Vries. 2001. Extremal forex returns in extremely large data sets. Extremes 4: 105–27. [Google Scholar] [CrossRef]
- Diebold, Francis X., Todd A. Gunther, and Anthony S. Tay. 1998. Evaluating density forecasts with applications to financial risk management. International Economic Review 39: 863–83. [Google Scholar] [CrossRef]
- Diebold, Francis X., Jinyong Hahn, and Anthony S. Tay. 1999. Multivariate density forecast evaluation and calibration in financial risk management: High-frequency returns on foreign exchange. Review of Economics and Statistics 81: 661–73. [Google Scholar] [CrossRef]
- Dorofeev, Dmitriy, and Sergey Shestakov. 2018. 2-tier vs. 3-tier architectures for data processing software. Paper presented at the 3rd International Conference on Applications in Information Technology, Aizu-Wakamatsu, Japan, November 1–3; pp. 63–68. [Google Scholar]
- Embrechts, Paul. 2017. A darwinian view on internal models. Journal of Risk 20: 1–21. [Google Scholar] [CrossRef]
- Ferriero, Alessandro. 2016. Solvency capital estimation, reserving cycle and ultimate risk. Insurance: Mathematics and Economics 68: 162–68. [Google Scholar] [CrossRef]
- Fröhlich, Andreas, and Annegret Weng. 2015. Modelling parameter uncertainty for risk capital calculation. European Actuarial Journal 5: 79–112. [Google Scholar] [CrossRef]
- Fröhlich, Andreas, and Annegret Weng. 2018. Parameter uncertainty and reserve risk under Solvency II. Insurance: Mathematics and Economics 81: 130–41. [Google Scholar] [CrossRef]
- Grant, Stuart W., Gary S. Collins, and Samer A. M. Nashef. 2018. Statistical primer: Developing and validating a risk prediction model. European Journal of Cardio-Thoracic Surgery 54: 203–8. [Google Scholar] [CrossRef] [PubMed]
- Kratz, Marie, Yen H. Lok, and Alexander J. McNeil. 2018. Multinomial VaR backtests: A simple implicit approach to backtesting expected shortfall. Journal of Banking and Finance 88: 393–407. [Google Scholar] [CrossRef]
- Landry, Maurice, Jean-Louis Malouin, and Muhittin Oral. 1983. Model validation in operations research. European Journal of Operational Research 14: 207–20. [Google Scholar] [CrossRef]
- Lloyd’s. 2023. Internal Model Validation Guidance. Available online: https://www.lloyds.com/resources-and-services/capital-and-reserving/capital-guidance/model-validation/ (accessed on 1 April 2023).
- Mack, Thomas. 1993. Distribution-free calculation of the standard error of chain ladder reserve estimates. ASTIN Bulletin: The Journal of the IAA 23: 213–25. [Google Scholar] [CrossRef]
- Mc Neil, Alexander J., Rüdiger Frey, and Paul Embrechts. 2016. Quantitative Risk Management, 2nd ed. Princeton: Princeton Series in Finance. [Google Scholar]
- Meese, Richard A., and Kenneth Rogoff. 1983. Empirical exchange rate models of the seventies: Do they fit out of sample? Journal of International Economics 14: 3–24. [Google Scholar] [CrossRef]
- Miller, April R., Samin Charepoo, Erik Yan, Ryan W. Frost, Zachary J. Sturgeon, Grace Gibbon, Patrick N. Balius, Cedonia S. Thomas, Melanie A. Schmitt, Daniel A. Sass, and et al. 2022. Reliability of COVID-19 data: An evaluation and reflection. PLoS ONE 17: e0251470. [Google Scholar] [CrossRef]
- Morini, Massimo. 2011. Understanding and Managing Model Risk: A Practical Guide for Quants, Traders and Validators. New York: John Wiley & Sons. [Google Scholar]
- Müller, Ulrich A., Roland Bürgi, and Michel M. Dacorogna. 2004. Bootstrapping the Economy—A Non-Parametric Method of Generating Consistent Future Scenarios. Available online: https://ideas.repec.org/p/pra/mprapa/17755.html (accessed on 1 April 2023).
- Seitshiro, Modisane B., and Hopolang P. Mashele. 2020. Assessment of model risk due to the use of an inappropriate parameter estimator. Cogent Economics & Finance 8: 1710970. [Google Scholar] [CrossRef]
- Sornette, Didier, A. B. Davis, K. Ide, K. R. Vixie, V. Pisarenko, and J. R. Kamm. 2007. Algorithm for model validation: Theory and applications. Proceedings of the National Academy of Sciences of the United States of America 104: 6562–67. [Google Scholar] [CrossRef]
- Stricker, Markus, David Ingram, and Dave Simmons. 2013. Economic capital model validation. In White Paper, Willis Economic Capital Forum. London: Willis Limited. [Google Scholar]
- Wüthrich, Mario V., and Michael Merz. 2008. Stochastic Claims Reserving Methods in Insurance. New York: John Wiley & Sons. [Google Scholar]
- Zariņa, Ilze, Irina Voronova, and Gaida Pettere. 2019. Internal model for insurers: Possibilities and issues. Paper presented at the International Scientific Conference “Contemporary Issues in Business, Management and Economics Engineering”, Vilnius, Lithuania, May 9–10. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
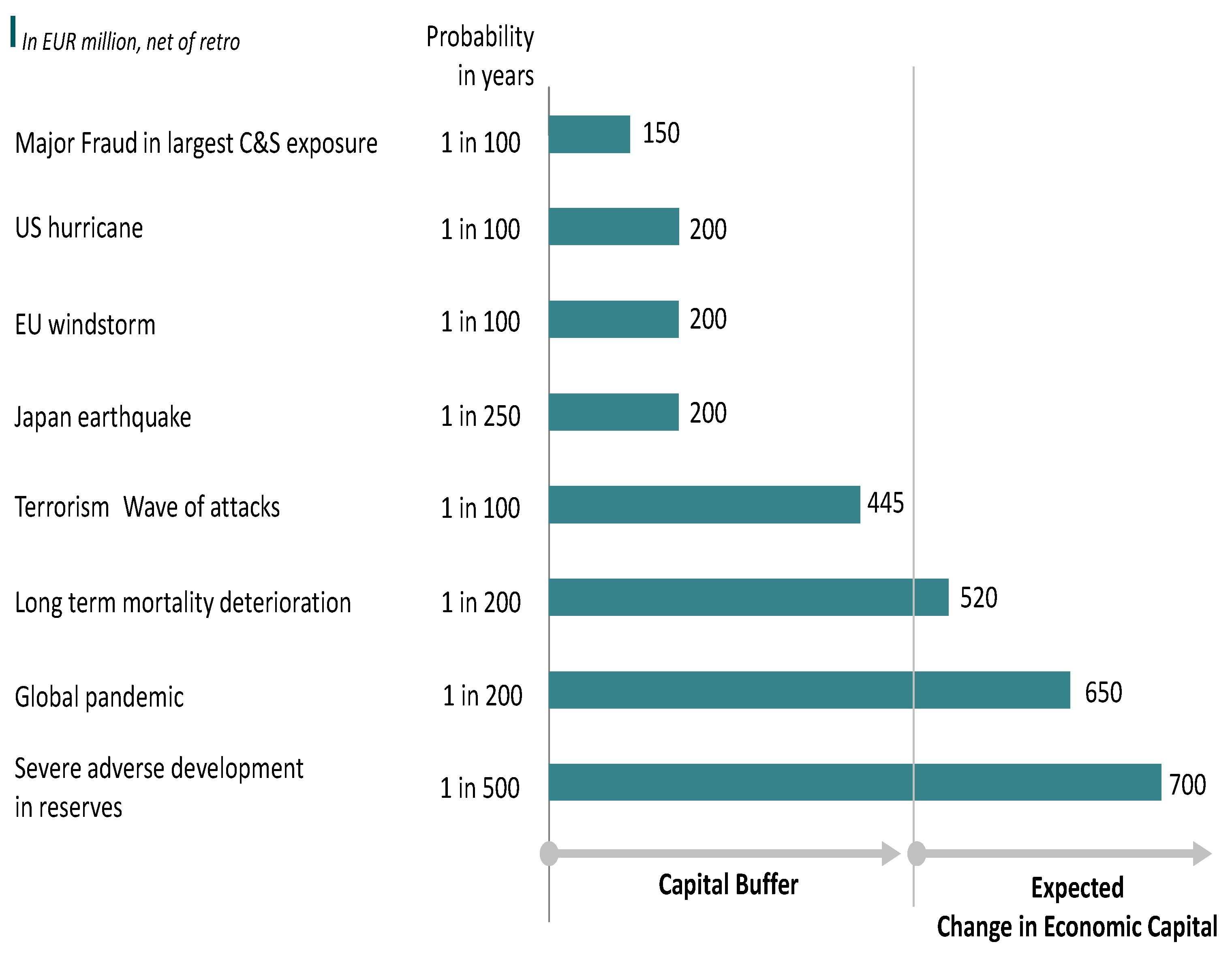{kind=link}
{kind=link}
| Method | Mean | Std. Dev. | MAD | MRAD |
|---|---|---|---|---|
| Linear Model: | ||||
| Theoretical value | 18.37 | 3.92 | – | – |
| COT, without jumps | 19.08 | 3.93 | 0.71 | 4.14% |
| COT, with jumps | 18.81 | 3.86 | 0.43 | 2.47% |
| Merz–Wüthrich | 252.89 | 149.6 | 234.5 | 1365.6% |
| Multiplicative Model: | ||||
| Theoretical value | 29.36 | 21.97 | – | – |
| COT, without jumps | 26.75 | 19.84 | 2.54 | 8.19% |
| COT, with jumps | 28.30 | 20.98 | 1.07 | 3.48% |
| Merz–Wüthrich | 22.82 | 15.77 | 12.7 | 43.2% |
| n = 2 | n = 10 | n = 100 | |
|---|---|---|---|
| α = 3 | |||
| 0.30% | 0.14% | −0.10% | |
| −1.30% | −0.25% | 0.15% | |
| α = 2 | |||
| 0.38% | 0.14% | 0.05% | |
| −2.61% | −0.44% | −0.14% | |
| α = 1.1 | |||
| −33.3% | −27.3% | −26.9% | |
| 1786% | 742% | 653% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dacorogna, M. How to Gain Confidence in the Results of Internal Risk Models? Approaches and Techniques for Validation. Risks 2023, 11, 98. https://doi.org/10.3390/risks11050098
Dacorogna M. How to Gain Confidence in the Results of Internal Risk Models? Approaches and Techniques for Validation. Risks. 2023; 11(5):98. https://doi.org/10.3390/risks11050098
Chicago/Turabian StyleDacorogna, Michel. 2023. "How to Gain Confidence in the Results of Internal Risk Models? Approaches and Techniques for Validation" Risks 11, no. 5: 98. https://doi.org/10.3390/risks11050098
APA StyleDacorogna, M. (2023). How to Gain Confidence in the Results of Internal Risk Models? Approaches and Techniques for Validation. Risks, 11(5), 98. https://doi.org/10.3390/risks11050098