1. Introduction
Technological advancements are currently extending our reality into a new digital world called the metaverse (or extended reality). The terminology was first introduced in a science fiction novel describing a three-dimensional virtual environment (
Stephenson 1992). Nowadays, the metaverse enhances how we do things in our society, how we entertain others, and is the path to having a plethora of cultural experiences (
Xi et al. 2022). It also enables many creators (individuals, groups, or companies) to open their business outlets digitally. Furthermore, it is accessible anytime, anywhere in the world, mixing our physical world with the digital world. Many metaverses have built their own financial instruments, i.e., metaverse cryptocurrencies, and have adopted them as objects inside their platforms. The goods in the metaverse can be commercialized or transferred through the corresponding metaverse cryptocurrency (
Ordano et al. 2022).
An example of metaverses is Decentraland, one of the game platforms built on a blockchain. This metaverse enables players to buy a private virtual LAND, digital parcels of the metaverse, in which they publish their content (
Ante 2022b;
Ordano et al. 2022). The LAND can be customized by the owner for public or private use. It can also be traded, where each transaction process and each change in ownership is permanently recorded in a smart contract (
Dowling 2022a). Decentraland allows application developers to fully capitalize on the economic interactivity between their applications and users (
Ordano et al. 2022). All the transactions and interactions are performed using MANA, the name of its cryptocurrency. When launched in 2017, MANA was sold for about
$0.02. Its price has, since then, increased to the highest level of around
$5.20 on 26 November 2021, with a market capitalization of around
$9.49 billion; see CoinMarketCap.com (
https://coinmarketcap.com, access on 17 January 2023). Another metaverse comes from a blockchain company, namely, Theta Network. Theta Network is an early pioneer in new blockchain innovations that support many creators in building and customizing their blockchains, specifically video, media, and entertainment blockchains, for online security advancement. It allows them to bring their content to its decentralized data and peer-to-peer delivery network safely (
Theta Labs 2022). THETA, one of its two native cryptocurrency tokens, handles various governance tasks within the network. THETA was launched in 2018 with a value of
$0.18. As of 26 March 2021, it reached its highest value of
$13.27 and highest market capitalization of
$13.27 billion; see CoinMarketCap.com (
https://coinmarketcap.com, 17 January 2023).
Metaverses are examples of the development of non-fungible tokens (NFTs). NFTs are basically blockchain-traded rights to any digital instrument. In addition to an object inside a metaverse, an NFT can be anything digital, such as an image, a video, a song, a virtual character from a game, or a virtual tunic for this virtual character to wear (
Dowling 2022a). While traded through cryptocurrencies, NFTs behave quite differently from cryptocurrencies. More specifically, while cryptocurrencies are regarded as currencies with speculative but fungible behaviors, NFTs are viewed as pure assets with non-fungible characteristics, as their name suggests (
Dowling 2022b). As a new class of emerging digital assets, NFTs are still illiquid, speculative (
Urom et al. 2022), antipersistent (
Pereira et al. 2022), and even immature and inefficient (
Ante 2022b;
Dowling 2022a), as in the early stage of cryptocurrencies (
Cheah and Fry 2015;
Urquhart 2016). Consequently, they may have created a fluctuating price in the cryptocurrencies used as a means of payment.
The unique characteristics of NFTs and their exploding popularity in early 2021 led academia to investigate the NFT market more deeply, resulting in growing, but limited, empirical studies since last year. For instance,
Dowling (
2022a) explored the pricing of parcels of virtual real estate in Decentraland and found that their price series were characterized by market inefficiency and an increase in value. However, the market for NFTs was more efficient than the markets for cryptocurrencies and decentralized finance (DeFi) assets, suggesting more significant portfolio diversification avenues when investing in NFTs (
Karim et al. 2022;
Yousaf and Yarovaya 2022c). When studying the relationship between volumes and returns for the NFT market and three submarkets, namely, CryptoKitties, CryptoPunks, and Decentraland,
Urom et al. (
2022) provided significant evidence of dependence between NFT returns and volumes. Similarly,
Yousaf and Yarovaya (
2022b) pointed out that the trading volumes of three NFTs (i.e., THETA, Tezos [XTZ], Enjin Coin [ENJ]) possessed a stronger connection with their returns and volatilities in extremely bullish market circumstances than other quantile levels, indicating asymmetric return–volume and volatility–volume relationships. There also existed co-integrations and causal short-run connections among various NFT submarkets, including Decentraland (
Ante 2022b). See also
Umar et al. (
2022b). In addition, some studies investigated the relationship between NFTs and other financial assets, including cryptocurrencies. Using a volatility spillover index,
Dowling (
2022b) demonstrated limited volatility spillover effects between three NFTs (i.e., Decentraland LAND tokens, CryptoPunk images, Axie Infinity game characters) and the two largest cryptocurrencies (i.e., Bitcoin [BTC] and Ethereum [ETH]). NFTs also showed weak volatility spillovers with equities, gold, oil, bonds, fiat currencies, and DeFi assets (
Aharon and Demir 2022;
Yousaf and Yarovaya 2022a). This means that these new digital assets were still distinct and decoupled from traditional asset classes. Nevertheless, their relationship might intensify in the face of the COVID-19 pandemic (
Umar et al. 2022a,
2022c).
Despite providing diversification, hedging, and safe-haven opportunities for other assets (
Karim et al. 2022;
Ko et al. 2022;
Yousaf and Yarovaya 2022a,
2022c;
Zhang et al. 2022), NFTs exhibit bubble behaviors (
Maouchi et al. 2022;
Vidal-Thomás 2022a;
Wang et al. 2022a), which are typical features of conventional cryptocurrencies (
Agosto and Cafferata 2020;
Cheah and Fry 2015). NFT bubbles have even higher explosive magnitudes than crypto bubbles (
Maouchi et al. 2022), suggesting that NFTs might be prone to higher risk and uncertainty than cryptocurrencies. Accordingly, it is necessary to manage NFT risks quantitatively with the purpose of helping investors, portfolio risk managers, and policy-makers design appropriate investment strategies, portfolio allocation, and decision-making. Concerning conventional cryptocurrencies, quantitative risk management has been intensively performed for single cryptocurrencies (
Almeida et al. 2022;
Jiménez et al. 2020b,
2022;
Troster et al. 2019) and their aggregates or portfolios (
Boako et al. 2019;
Cheng 2023;
Jiménez et al. 2020a;
Syuhada and Hakim 2020;
Syuhada et al. 2022;
Trucíos et al. 2020;
Wang et al. 2020). While NFTs have been researched from some perspectives, as described above, quantitative risk management for the market for these new digital assets remains unexplored. To the best of our knowledge,
Ko et al. (
2022) and
Yousaf and Yarovaya (
2022a) are the only two studies to have analyzed a portfolio composed of NFTs and conventional assets, including cryptocurrencies. Nevertheless, they focused only on the portfolio weight, based on Markowitz’s mean–variance framework. Furthermore, they did not evaluate the risk forecast accuracy.
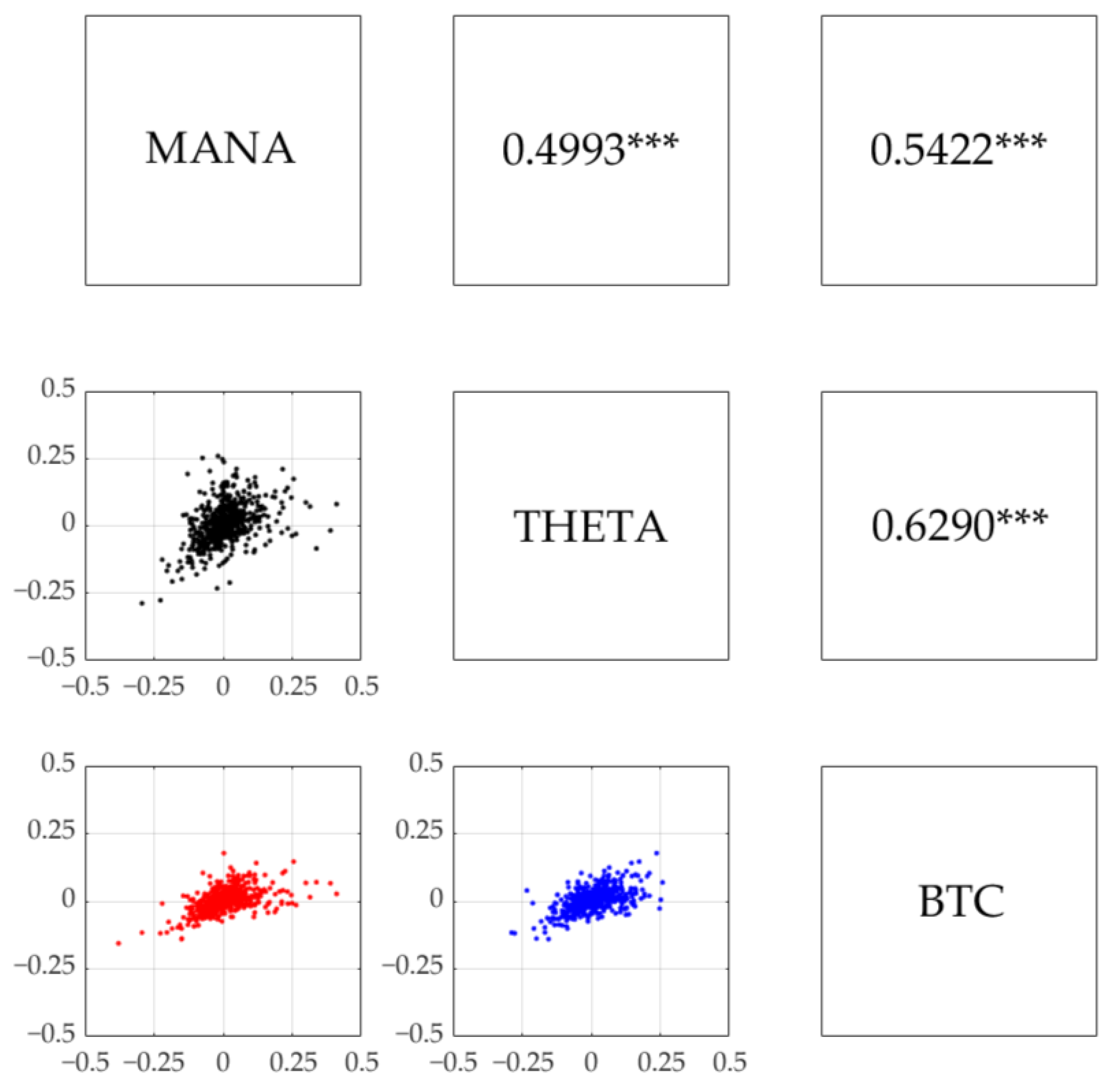
Our study aimed to fill the gap in the above literature by providing an in-depth analysis of quantitative risk management for NFTs, particularly metaverses. We selected the native cryptocurrency of two metaverses, i.e., Decentraland’s MANA and Theta Network’s THETA. The reason for taking these into consideration was that Decentraland is the largest metaverse, ever since the invention of NFTs. It is also supported by the Theta Network, specifically, to secure online transactions, deliver fast and complete information, and track assets in a business network. This suggests that they evidently exhibit a direct relationship. In addition, we included Bitcoin and constructed the following to compare the MANA–THETA aggregate: (1) an aggregate of MANA and Bitcoin and (2) an aggregate of THETA and Bitcoin. Bitcoin was the choice because it is the most prominent cryptocurrency with the largest market capitalization. As argued by
Dowling (
2022a), Bitcoin traders may be the leading traders of MANA and THETA, because of their familiarity with buying and using Bitcoin. Although Bitcoin investor attention was unable to significantly predict NFT market returns (
Borri et al. 2022), the (larger) Bitcoin market was found by
Ante (
2022a) to affect the growth of the (smaller) NFT market. In this paper, we attempted to address the following question: Does an aggregate of MANA and THETA have a higher risk than an aggregate of each metaverse cryptocurrency and Bitcoin? Due to evidence that NFTs, including MANA and THETA, are risky assets offering higher returns than other assets, including Bitcoin (
Yousaf and Yarovaya 2022a), we hypothesized that aggregating MANA and THETA would result in a higher risk than aggregating MANA and Bitcoin and combining THETA and Bitcoin (
H1).
To quantify possible future losses resulting from aggregating the aforementioned cryptocurrencies, one needs to construct aggregate risk measures. These measures may include aggregate value-at-risk (AggVaR) and aggregate expected shortfall (AggES), which are basically the VaR and ES for an aggregate of returns at a given significance level over a specified time horizon. The former is determined based on the probability of the occurrence of the losses. The latter overcomes the former by accounting for the magnitude of all the losses exceeding the former. However, ES is sensitive to extreme losses, resulting in a risk forecast that may be too excessive, inaccurate, and not robust. This motivated
Jadhav et al. (
2009),
Cont et al. (
2010), and
Josaphat and Syuhada (
2021) to modify ES by truncating the losses beyond the VaR. This also led
Zhang et al. (
2014),
Emmer et al. (
2015), and
Kratz et al. (
2018) to approximate it using an average of VaRs at some significance levels based on the Riemann sum concept. Notwithstanding, these approaches removed information about extreme losses that may have important effects. Therefore, we proposed a convex combination of VaR and ES. In the context of aggregates or portfolios, we formulated a modified aggregate risk measure (AggM) by incorporating AggVaR and AggES with optimal weight. The idea behind employing AggM was to adjust the aggregate risk forecast by increasing the risk magnitude measured by AggVaR, while decreasing the risk magnitude measured by AggES such that the potential aggregate risk forecast was ideal. Using
Syuhada’s (
2020) coverage probability approach and
Christoffersen’s (
1998) backtesting technique, we needed to address the following question: Is AggM more accurate and more valid than AggVaR and AggES when quantifying the risk of the MANA–THETA, MANA–BTC, and THETA–BTC aggregates? Since AggM is a combination of AggVaR and AggES, it might have the advantages of both AggVaR and AggES. Accordingly, we hypothesized that the AggM for aggregates of the MANA–THETA, MANA–BTC, and THETA–BTC pairs would have higher forecast accuracy and validity than the respective AggVaR and AggES (
H2).
When computing the above aggregate risk measures, we had to account for the dependence between the returns of the above-mentioned cryptocurrencies. This study aimed to construct a dependent risk model for these cryptocurrencies through copulas. Copulas provide a way to model the dependence between two or more random variables (
McNeil et al. 2015). Thus, we thought copulas might be useful to accommodate the dependence structure in each pair of these cryptocurrencies. Previous studies on cryptocurrencies have employed copulas to examine the best optimal portfolio (
Boako et al. 2019), to determine a cryptocurrency able to maximize returns on investment (
Tiwari et al. 2019), and to monitor the risk of various portfolios (
Syuhada et al. 2022). In this paper, we employed copulas belonging to the Archimedean copula family: Clayton, Gumbel, and Frank. The Clayton (Gumbel) copula enabled us to handle lower (upper) tail dependence. Meanwhile, the Frank copula exhibiting lower and upper tail independence was taken into consideration as a benchmark. Employing Cramér–von Mises test, we attempted to address the following question: Are the lower tails of the MANA–THETA, MANA–BTC, and THETA–BTC pairs more dependent than their upper tails? We hypothesized that these pairs would tend to have lower tail dependence (
H3).
In addition, we proposed the use of heteroskedastic models (HMs) as statistical tools to capture the stylized facts of the return and volatility of each cryptocurrency. The HMs chosen included generalized autoregressive conditional heteroskedastic (GARCH), exponential GARCH (EGARCH), and Glosten–Jagannathan–Runkle GARCH (GJR-GARCH) models. The GARCH model was first introduced by
Engle (
1982) and then perfected by
Bollerslev (
1986). Meanwhile, the EGARCH and GJR-GARCH models were the developments of the standard GARCH model. The former overcame the nonnegativity of the GARCH model’s constant and coefficient terms (
Nelson 1991). Both of them allowed for leverage effects, i.e., the asymmetric responses of volatility to past negative and positive returns (
Glosten et al. 1993;
Nelson 1991). These HMs have been widely utilized for cryptocurrencies in the following instances: to forecast their volatility during bearish markets (
Kyriazis et al 2019), to observe their skewed returns (
Cerqueti et al 2020), to study common features of their returns (
Fung et al. 2021), and to analyze asymmetry in their volatility (
Apergis 2022;
Wajdi et al. 2020). In addition to HMs, we considered other predictive models employing bagging and boosting methods, i.e., ensemble learning-based models (ELs), that can generate better generalization ability in time series forecasting (
Khairalla 2022). More specifically, we selected three famous ELs to model the return and volatility of metaverse cryptocurrencies and Bitcoin. They included extreme gradient boosting (XGBoost), light gradient boosting machine (LightGBM), and categorical boosting (CatBoost). Many works have adopted these ELs, specifically for classification and regression tasks in engineering (
Bo et al. 2022;
Liu et al. 2022;
Mahmood and Ali 2022) and medical science (
Gao et al. 2020;
Wang et al. 2022b). XGBoost performs risk assessment better than other machine learning models (
Shi et al. 2022) and provides better accuracy than neural networks (
Abdikan et al. 2022). It also provides stability and preciseness compared to the classical support vector model (
Fan et al. 2018). Furthermore, XGBoost also provides the role of one of the comparable models with less time consumed (
Dong et al. 2018). Meanwhile, LightGBM has better prediction results than k-nearest neighbors, decision trees, and random forest, specifically for corporate finance risk (
Wang et al. 2022c). It also provides better accuracy in the stock selection model (
Li et al. 2022) and outperforms the classical machine learning models (
Ben Jabeur et al. 2021b;
Laifa et al. 2021). CatBoost exhibits effective improvement compared to other advanced approaches (
Ben Jabeur et al. 2021a), surpasses the accuracy of classical machine learning and artificial neural networks as a predictive model (
Dutta and Roy 2022;
Lu et al. 2022), and potentially increases accuracy as a hybrid model (
Bileki et al. 2022). However, implementing ELs for cryptocurrencies is still scarce, especially to extract their return and volatility. Thus, we attempted to apply the aforementioned ELs to model the return and volatility of the metaverse cryptocurrencies and Bitcoin and address the following question: Do ELs perform better than HMs in forecasting the volatility and aggregate risk measures for the metaverse cryptocurrencies and Bitcoin? Based on their superior performance mentioned above, we hypothesized that ELs would produce volatility and aggregate risk measure forecasts with higher accuracy (
H4).
The remainder of this paper is organized as follows.
Section 2 describes the data, the models, and the way to construct AggVaR, AggES, and AggM through copulas. In the same section, we provide the coverage probability calculation and backtesting procedures to confirm that our aggregate risk measure forecasts are accurate and valid.
Section 3 presents our findings and analyses regarding the modeling, forecasting, and validity. In
Section 4, we then provide our concluding remarks.
4. Conclusions
Metaverse links our digital and actual worlds due to rapid technological improvements. Some metaverses create not only a virtual environment, but also cryptocurrencies for NFT transactions inside their systems. In this study, we observed two specific metaverse cryptocurrencies from Decentraland (MANA) and Theta Network (THETA). We were interested in analyzing these two since Decentraland (MANA) operates the security system from the Theta Network (THETA), and they have a direct relationship. We also compared them with Bitcoin as a contribution to new literature, especially so as to conduct a portfolio analysis between the metaverse and conventional cryptocurrencies. Our main aim was to construct and forecast three risk measures (i.e., AggVaR, AggES, and AggM) for MANA–THETA, MANA–BTC, and THETA–BTC aggregates with heteroskedastic models (HMs) and ensemble learning-based models (ELs), by accounting for the dependence between their components.
In the first step, we modeled their return and volatility to understand the stylized facts in our datasets, since the volatility forecast plays a crucial role as the main component of aggregate risk forecasts. We found that the two metaverse cryptocurrencies were more volatile than Bitcoin with evidence of higher and more persistent volatility. We then revealed that ELs outperformed HMs when forecasting the volatility of each cryptocurrency. The dependence structure in each of the MANA–THETA, MANA–BTC, and THETA–BTC pairs was captured well using the Clayton copula, indicating the presence of lower tail dependence, as we observed in other financial assets. The risk measure forecasting results showed that the MANA–THETA aggregate possessed a higher risk than the MANA–BTC and THETA–BTC aggregates. This suggested that a portfolio would be safer if it involved Bitcoin, rather than having the two metaverse cryptocurrencies. In addition, we discovered that ELs exhibited better aggregate risk measure forecasting performances than HMs in the majority of cases. More specifically, the former models provided more accurate and more valid aggregate risk measure forecasts. The reason was that these forecasts had coverage probability values nearly equal to the significance level under consideration and satisfied unconditional coverage and independence properties.
Our empirical results provide recommendations helpful for investors, portfolio risk managers, and policy-makers. More specifically, investors and portfolio risk managers should adjust their investment strategies and portfolio allocation when extreme negative shocks occur. This is because extreme downturns in one cryptocurrency market tend to be followed by extreme downturns in other cryptocurrency markets. They may add Bitcoin, due to its more stable and less risky characteristics, to reduce the portfolio of metaverse cryptocurrencies. This may be an indication that Bitcoin has a safe-haven role for metaverse cryptocurrencies. Performing a statistical test to examine the role of Bitcoin or other safe-haven candidates for such a class of new cryptocurrencies is, thus, an important direction for future work. In addition, during extreme negative shocks, policy-makers should carefully monitor both the metaverse and conventional cryptocurrency markets and design appropriate decisions to prevent instability in these markets, which may trigger systemic risk. In future research, it is, thus, also important to quantitatively manage systemic risk possibly arising from these markets.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
